自然语言处理从入门到应用——LangChain:记忆(Memory)-[基础知识]
分类目录:《自然语言处理从入门到应用》总目录
默认情况下,链(Chains)和代理(Agents)是无状态的,这意味着它们将每个传入的查询视为独立的(底层的LLM和聊天模型也是如此)。在某些应用程序中(如:聊天机器人),记住先前的交互则非常重要。记忆(Memory)正是为此而设计的。 LangChain提供两种形式的记忆组件。首先,LangChain提供了用于管理和操作先前聊天消息的辅助工具,这些工具都被设计为模块化的使用方式。其次,LangChain提供了将这些工具轻松整合到链中的方法。
记忆涉及了在用户与语言模型的交互过程中保持状态的概念。用户与语言模型的交互被捕捉在ChatMessage的概念中,因此这涉及到对一系列聊天消息进行摄取、捕捉、转换和提取知识。有许多不同的方法可以实现这一点,每种方法都存在作为自己的记忆类型。通常情况下,对于每种类型的记忆,有两种使用记忆的方法。一种是独立的函数,从一系列消息中提取信息,另一种是在链中使用这种类型的记忆的方法。记忆可以返回多个信息(如:最近的 N N N条消息和所有先前消息的摘要),返回的信息可以是字符串或消息列表。在本文中,我们将介绍最简单形式的记忆:"缓冲"记忆。它只涉及保持先前所有消息的缓冲区。我们将展示如何在这里使用模块化的实用函数,然后展示它如何在链中使用(返回字符串和消息列表两种形式)。
聊天消息历史ChatMessageHistory
在大多数记忆模块的核心实用类之一是ChatMessageHistory类。这是一个超轻量级的包装器,提供了保存人类消息、AI 消息以及获取所有消息的便捷方法。如果我们在链外管理记忆,则可以直接使用此类。
from langchain.memory import ChatMessageHistoryhistory = ChatMessageHistory()
history.add_user_message("hi!")history.add_ai_message("whats up?")
history.messages[HumanMessage(content='hi!', additional_kwargs={}, example=False),AIMessage(content='whats up?', additional_kwargs={}, example=False)]
ConversationBufferMemory
现在我们展示如何在链中使用这个简单的概念。首先展示ConversationBufferMemory,它只是一个对ChatMessageHistory的包装器,用于提取消息到一个变量中。我们可以首先将其提取为一个字符串:
from langchain.memory import ConversationBufferMemorymemory = ConversationBufferMemory()
memory.chat_memory.add_user_message("hi!")
memory.chat_memory.add_ai_message("whats up?")
memory.load_memory_variables({})
输出:
{'history': 'Human: hi!\nAI: whats up?'}
我们还可以将历史记录作为消息列表获取:
memory = ConversationBufferMemory(return_messages=True)
memory.chat_memory.add_user_message("hi!")
memory.chat_memory.add_ai_message("whats up?")
memory.load_memory_variables({})
输出:
{'history': [HumanMessage(content='hi!', additional_kwargs={}, example=False),
AIMessage(content='whats up?', additional_kwargs={}, example=False)]}
在链中使用
最后,让我们看看如何在链中使用这个模块,其中我们设置了verbose=True以便查看提示。
from langchain.llms import OpenAI
from langchain.chains import ConversationChainllm = OpenAI(temperature=0)
conversation = ConversationChain(llm=llm, verbose=True, memory=ConversationBufferMemory()
)
conversation.predict(input="Hi there!")
日志输出:
> Entering new ConversationChain chain...
Prompt after formatting:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.Current conversation:Human: Hi there!
AI:> Finished chain.
输出:
" Hi there! It's nice to meet you. How can I help you today?"
输入:
conversation.predict(input="I'm doing well! Just having a conversation with an AI.")
日志输出:
> Entering new ConversationChain chain...
Prompt after formatting:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.Current conversation:
Human: Hi there!
AI: Hi there! It's nice to meet you. How can I help you today?
Human: I'm doing well! Just having a conversation with an AI.
AI: That's great! It's always nice to have a conversation with someone new. What would you like to talk about?
Human: Tell me about yourself.
AI:> Finished chain.
输出:
" Sure! I'm an AI created to help people with their everyday tasks. I'm programmed to understand natural language and provide helpful information. I'm also constantly learning and updating my knowledge base so I can provide more accurate and helpful answers."
保存消息记录
我们可能经常需要保存消息,并在以后使用时加载它们。我们可以通过将消息首先转换为普通的Python字典来轻松实现此操作,然后将其保存(如:保存为JSON格式),然后再加载。以下是一个示例:
import json
from langchain.memory import ChatMessageHistory
from langchain.schema import messages_from_dict, messages_to_dicthistory = ChatMessageHistory()history.add_user_message("hi!")history.add_ai_message("whats up?")
dicts = messages_to_dict(history.messages)
dicts
输出:
[{'type': 'human','data': {'content': 'hi!', 'additional_kwargs': {}, 'example': False}},{'type': 'ai','data': {'content': 'whats up?', 'additional_kwargs': {}, 'example': False}}]
输入:
new_messages = messages_from_dict(dicts)
new_messages
输出:
[HumanMessage(content='hi!', additional_kwargs={}, example=False),AIMessage(content='whats up?', additional_kwargs={}, example=False)]
参考文献:
[1] LangChain官方网站:https://www.langchain.com/
[2] LangChain 🦜️🔗 中文网,跟着LangChain一起学LLM/GPT开发:https://www.langchain.com.cn/
[3] LangChain中文网 - LangChain 是一个用于开发由语言模型驱动的应用程序的框架:http://www.cnlangchain.com/
相关文章:
-[基础知识])
自然语言处理从入门到应用——LangChain:记忆(Memory)-[基础知识]
分类目录:《自然语言处理从入门到应用》总目录 默认情况下,链(Chains)和代理(Agents)是无状态的,这意味着它们将每个传入的查询视为独立的(底层的LLM和聊天模型也是如此)…...
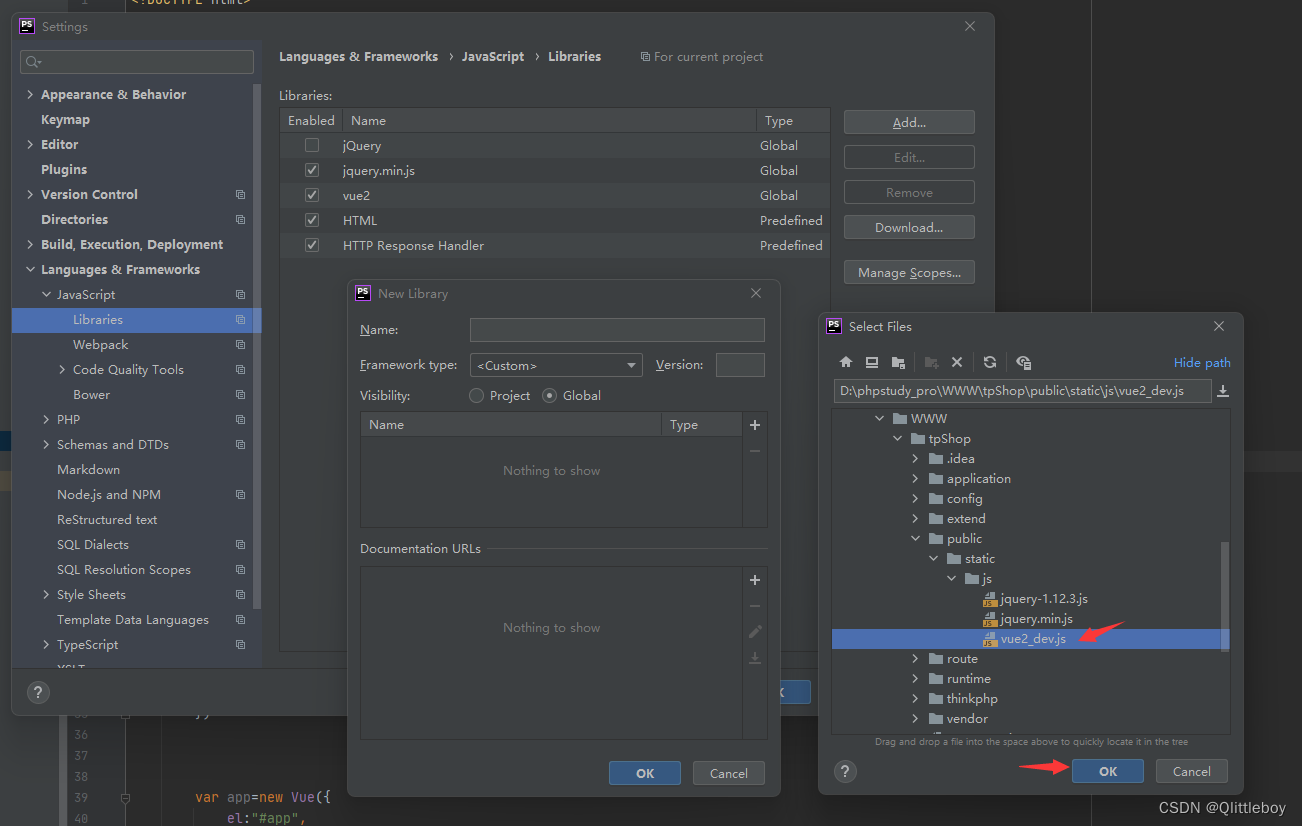
phpstorm添加vue 标签属性绑定提示和提示vue的方法提示
v-text v-html v-once v-if v-show v-else v-for v-on v-bind v-model v-ref v-el v-pre v-cloak v-on:click v-on:keyup.enter v-on:keyup click change input number debounce transition :is :class把上面这些文字粘贴到点击右下角放大按钮 后的文本框里,然后保存…...

从计算到人类知识:ChatGPT与智能演化
引 言 智能是自然界演化出来的结果,而人工智能则是人类创造的产物。随着人工智能的不断进步,尤其是近期ChatGPT的开放,我们发现人工智能的智能水平似乎已经达到了非常高的水平。然而,对于自然界中生物来说很简单的行为࿰…...
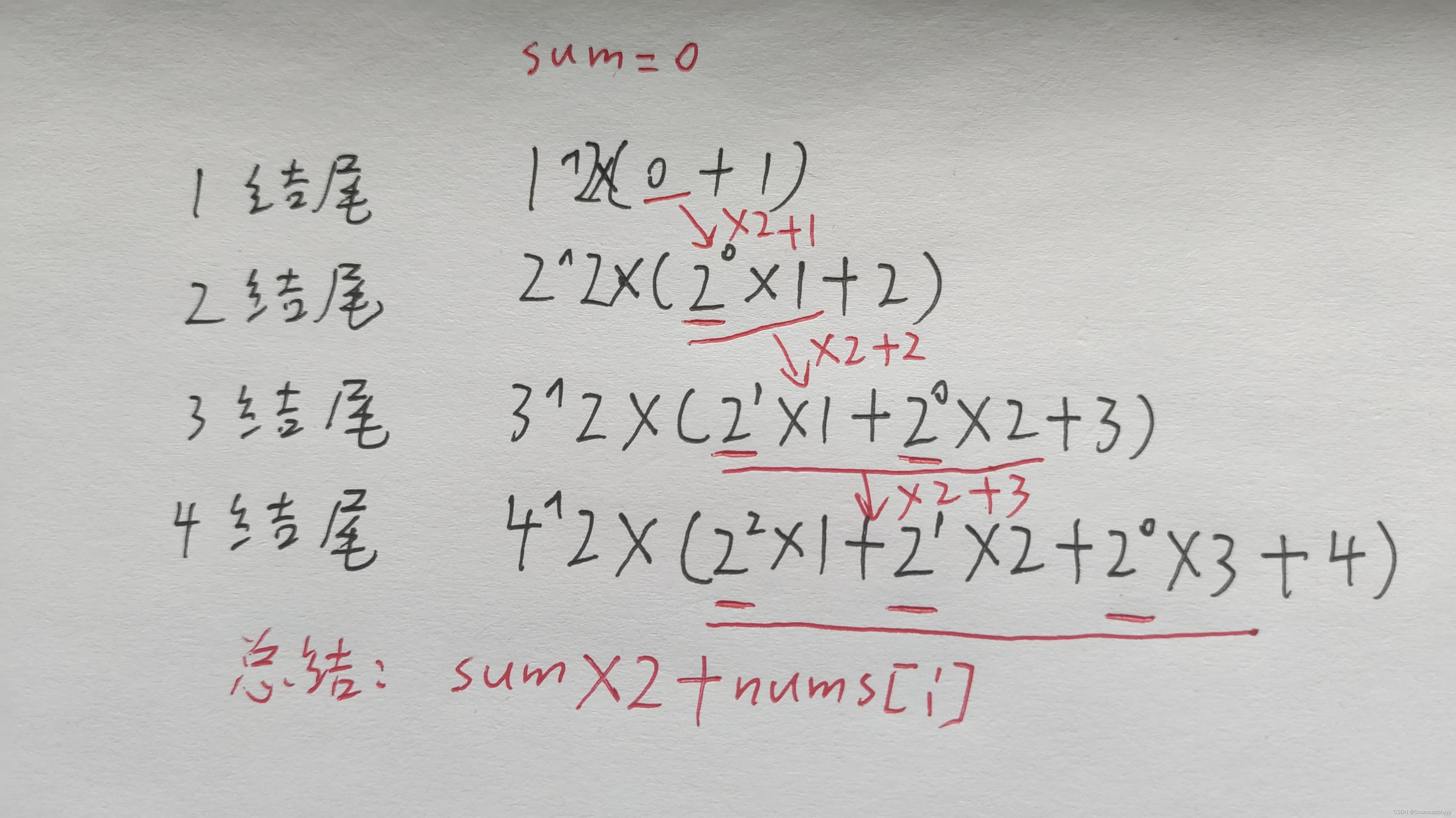
Leetcode每日一题:2681. 英雄的力量(2023.8.1 C++)
目录 2681. 英雄的力量 题目描述: 实现代码与解析: 数学规律 原理思路: 2681. 英雄的力量 题目描述: 给你一个下标从 0 开始的整数数组 nums ,它表示英雄的能力值。如果我们选出一部分英雄,这组英雄的…...
之 “ 异常处理”)
【学习】若依源码(前后端分离版)之 “ 异常处理”
大型纪录片:学习若依源码(前后端分离版)之 “ 异常处理” 前言1、统一返回实体定义2、定义登录异常定义3、基于ControllerAdvice注解的Controller层的全局异常统一处理4、测试访问请求结语 前言 通常一个web框架中,有大量需要处理…...
天花板级,Python接口自动化测试-接口关联封装调用(实例)
目录:导读 前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜) 前言 流程相关的接口&a…...
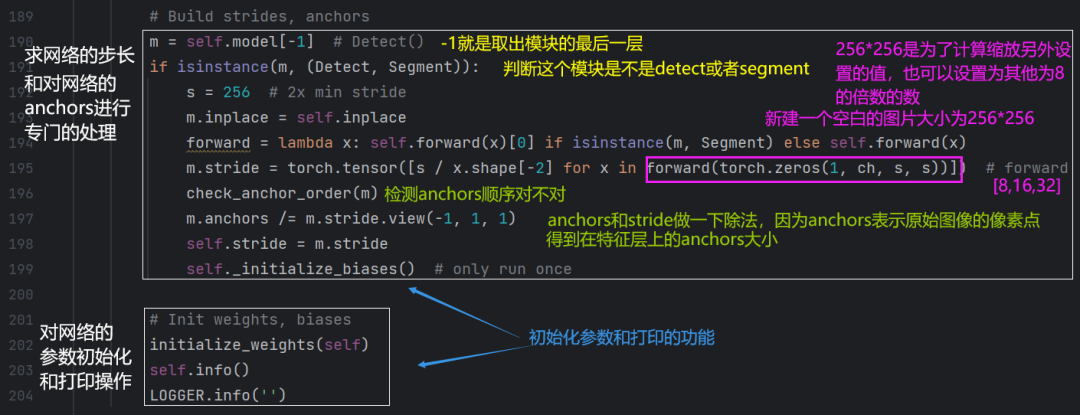
yolov5代码解读之yolo.py【网络结构】
这个文件阿对于做模型修改、模型创新有很好大好处。 首先加载一些python库和模块: 如果要执行这段代码,直接在终端输入python yolo.py. yolov5的模型定义和网络搭建都用到了model这个类(也就是以下图片展示的东西):(以前代码没…...
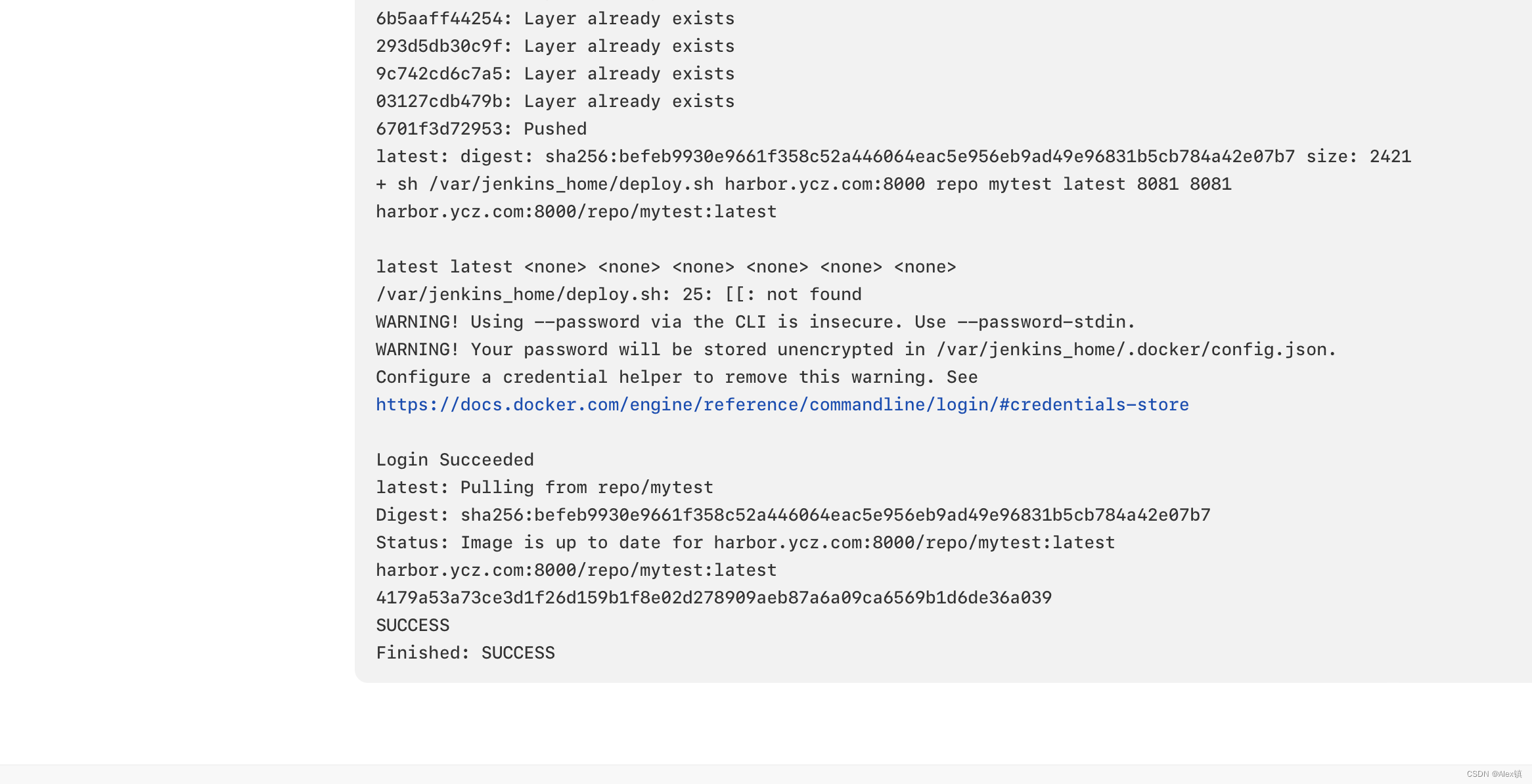
Docker之jenkins部署harbor在harbor中完成部署
Docker之jenkins部署harbor在harbor中完成部署 1、harbor作用 Harbor允许用户用命令行工具对容器镜像及其他Artifact进行推送和拉取,并提供了图形管理界面帮助用户查阅和删除这些Artifact。在Harbor 2.0版本中,除容器镜像外,Harbor对符合OCI…...
安装Jenkins
一、什么是Jenkins Jenkins是一个开源软件项目,是基于Java开发的。我们可以利用Jenkins来实现持续集成的功能。 因为Jenkins是基于Java开发的,所以在安装Jenkins之前首先需要安装Java的JDK。 二、安装Jenkins 在Windows平台上面安装Jenkins共有两种方式…...

大运空瓶行动,绘就生态文明画卷
随着成都第31届世界大学生夏季运动会赛事的成功举办,为了倡导节约水资源、绿色大运,在此之前成都电视2台《城视民生》栏目面向全市发起“大运空瓶行动”的倡议,呼吁市民杜绝水资源浪费,喝完瓶中水,并鼓励市民积极参与到…...
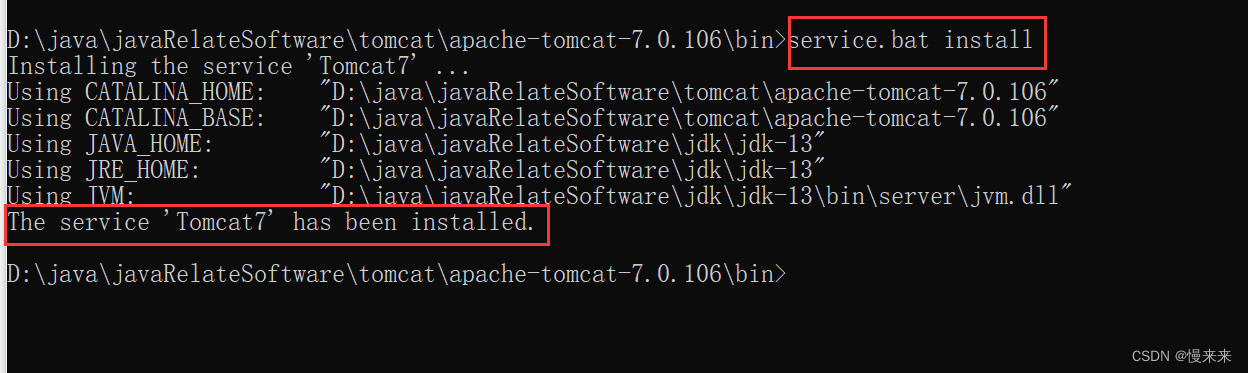
tomcat7.exe 启动闪退解决
标题tomcat7.exe 启动闪退解决 双击tomcat7.exe启动,但是出现闪退问题,无法启动tomcat 解决: 1.解决 tomcat7.exe 启动闪退解决 第一步:双击打开tomcat7w.exe 文件 如果出现 “指定的服务未安装。 Unable to open the service ‘…...

java修改jar包中的配置文件
方法一 !!!除了以上的方式,其实也可以通过 vim 命令直接修改 jar 包配置文件的内容,然后直接保存即可,不过这种方法必须保证服务器上已经安装了 zip 和 unzip 命令。 方法二 首先需要找出你的配置文件在…...
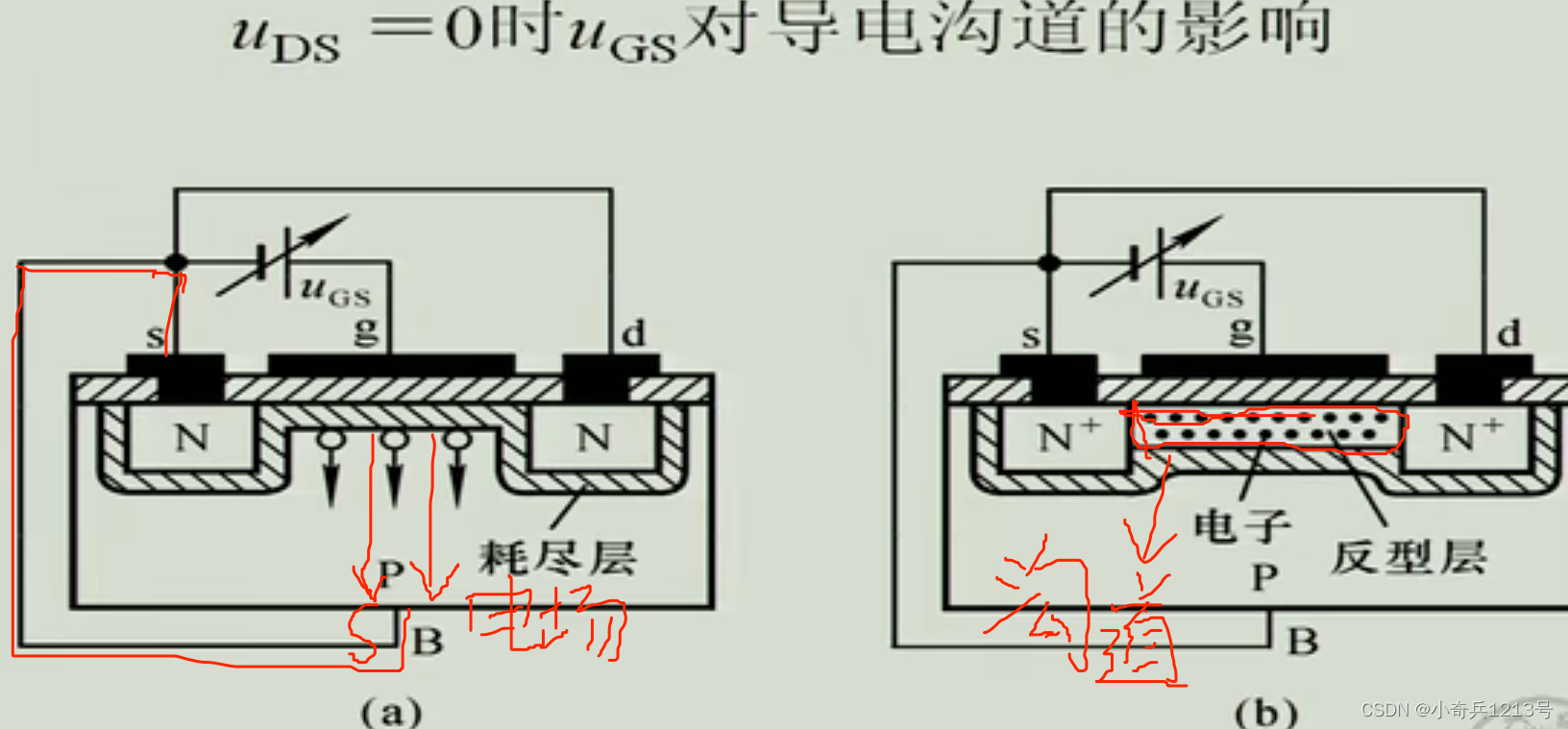
半导体器件||的学习
电子管的介绍: 到底什么是电子管(真空管)? - 知乎 芯片破壁者(一):从电子管到晶体管“奇迹”寻踪 - 知乎 晶体管: 什么是晶体管?它有什么作用? - 知乎 改…...
jenkins流水线
1.拉取代码 https://gitee.com/Wjc_project/yygh-parent.git2、项目编译 mvn clean package -Dmaven.test.skiptrue ls hospital-manage/target3、构建镜像 ls hospital-manage/target docker build -t hospital-manage:latest -f hospital-manage/Dockerfile ./hospital-ma…...
视频监控汇聚EasyCVR平台WebRTC流地址无法播放的原因排查
开源EasyDarwin视频监控TSINGSEE青犀视频平台EasyCVR能在复杂的网络环境中,将分散的各类视频资源进行统一汇聚、整合、集中管理,在视频监控播放上,TSINGSEE青犀视频安防监控汇聚平台可支持1、4、9、16个画面窗口播放,可同时播放多…...
NOSQL——redis的安装,配置与简单操作
目录 一、缓存的相关知识 1)缓存的概念 2)系统缓存 buffer与cache: 3)缓存保存位置及分层结构 DNS缓存 应用层缓存 数据层缓存 分布式缓存服务: 数据库: 硬件缓存 二、关系型数据与非关系型数据…...
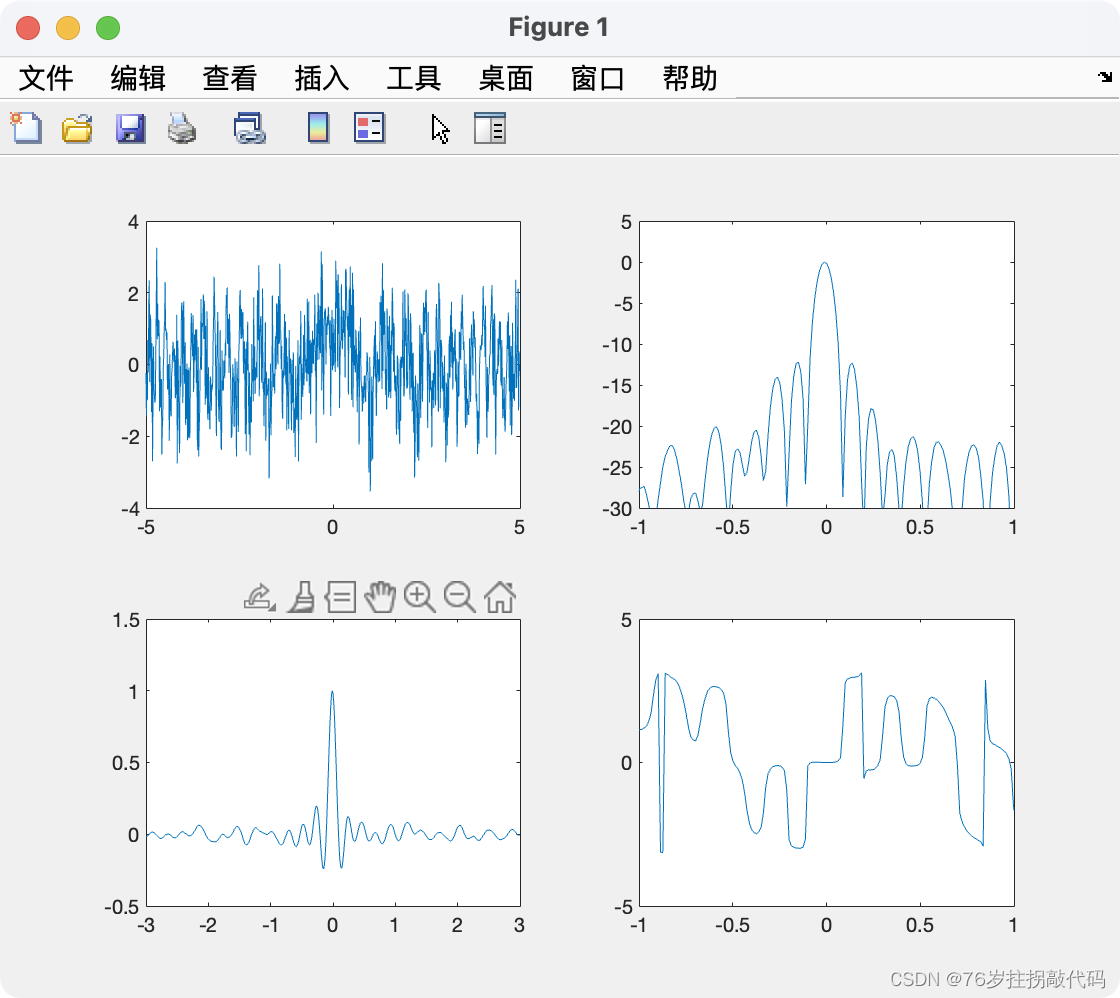
《合成孔径雷达成像算法与实现》Figure3.7
代码复现如下: clc clear all close all%参数设置 TBP 100; %时间带宽积 T 10e-6; %脉冲持续时间%参数计算 B TBP/T; …...
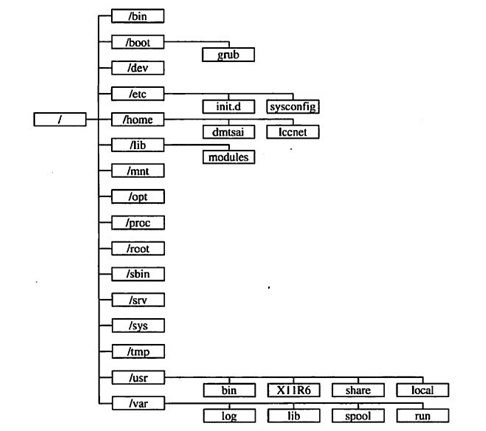
Linux 目录结构
初学Linux,首先需要弄清Linux 标准目录结构 / root --- 启动Linux时使用的一些核心文件。如操作系统内核、引导程序Grub等。home --- 存储普通用户的个人文件 ftp --- 用户所有服务httpdsambauser1user2bin --- 系统启动时需要的执行文件(二进制&#x…...

7天获英国名校邀请函|CSC青骨获批成功案例补记
Q老师要求2周内拿到邀请函且必须是世界排名前200名的高校。我们在第7天就获得了世界百强名校-英国兰卡斯特大学的邀请函,导师的研究方向完全契合,提前实现了Q老师的委托目标,使其顺利获批CSC青骨项目。特别提示:青骨项目国内派出院…...

ffmpeg ts列表合并为mp4
操作系统:ubuntu 注意事项: 1.ts文件顺序必须正确,也就是下一帧的dst和pst要比上一帧的大,否则会报错 2.codecpar->codec_tag要设置为0,否则报错Tag [27][0][0][0] incompatible with output codec id ‘27’ (avc1…...

LabelBee智能标注引擎:多模态数据标注的完整解决方案
LabelBee智能标注引擎:多模态数据标注的完整解决方案 【免费下载链接】labelbee LabelBee is an annotation Library 项目地址: https://gitcode.com/gh_mirrors/la/labelbee LabelBee是一个功能强大的开源数据标注工具库,专为机器学习项目提供高…...

ConvNeXt 系列改进:二次创新 ConvNeXt:结合 RepVGG 结构重参数化,训练多分支、推理单路
关键词:ConvNeXt RepVGG 结构重参数化 推理加速 模型部署 写在前面 2026年的视觉模型赛道呈现出一种有趣的“返璞归真”趋势——在Transformer狂飙数年之后,卷积网络正以全新的姿态回归。这其中,ConvNeXt无疑是纯卷积阵营中最耀眼的明星。从2022年Meta AI首次提出至今,…...
)
Windows11下VSCode配置C/C++开发环境避坑指南(附完整配置文件)
Windows 11下VSCode配置C/C开发环境全流程解析 最近在帮几位刚接触编程的朋友配置Windows 11下的C/C开发环境时,发现即便是照着教程一步步操作,也总会遇到各种"坑"。作为一个从Visual Studio转战VSCode的老码农,我深知配置过程中的…...
)
从编译到闪灯:用Keil5 MDK-ARM完成你的第一个STM32点灯程序(超详细避坑指南)
从零点亮STM32:Keil5 MDK-ARM实战指南与避坑全解析 当你第一次拿到STM32开发板时,最令人兴奋的莫过于让板载的LED灯按照你的指令闪烁。这不仅是一个简单的"Hello World",更是打开嵌入式世界大门的钥匙。本文将带你用Keil5 MDK-ARM完…...

MATLAB高阶谱分析工具箱全指南:cum3x/cum4x函数参数详解与避坑技巧
MATLAB高阶谱分析工具箱实战指南:从参数解析到工程避坑 在信号处理领域,高阶统计量分析正逐渐成为非高斯、非线性信号研究的利器。作为MATLAB用户,高阶谱分析工具箱(HOSA)中的cum3x、cum4x等函数为我们打开了这扇大门。但真正掌握这些工具的精…...
)
阿里滑块验证码x82y实战:手把手教你用Python搭建231.28版本补环境方案(附完整代码)
阿里滑块验证码x82y实战:Python补环境方案深度解析 最近在开发者社区中,关于验证码自动化的讨论热度持续攀升。特别是针对阿里系平台的滑块验证码,不少开发者都在寻找既稳定又高效的解决方案。今天我们就来深入探讨一种基于Python的补环境方案…...

从零开始:MySQL安装与IDEA数据库连接实战指南
1. MySQL安装全流程详解 第一次接触MySQL的开发者往往会被复杂的安装过程劝退,但其实只要跟着步骤一步步来,半小时内就能搞定。我经历过无数次安装失败后总结出这套"保姆级"教程,帮你避开所有坑点。 1.1 下载MySQL的正确姿势 打开M…...

番茄小说下载器终极指南:三步实现离线阅读自由
番茄小说下载器终极指南:三步实现离线阅读自由 【免费下载链接】Tomato-Novel-Downloader 番茄小说下载器不精简版 项目地址: https://gitcode.com/gh_mirrors/to/Tomato-Novel-Downloader 番茄小说下载器是一款基于Rust开发的开源工具,能够将在线…...

3步解决网盘下载烦恼:LinkSwift直链助手全解析
3步解决网盘下载烦恼:LinkSwift直链助手全解析 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云盘 / …...
LumiPixel Canvas Quest性能优化指南:针对低显存GPU的部署与推理技巧
LumiPixel Canvas Quest性能优化指南:针对低显存GPU的部署与推理技巧 1. 为什么需要专项优化? 如果你手头的GPU显存只有16GB或更少,直接运行LumiPixel Canvas Quest这类大型图像生成模型可能会遇到显存不足的问题。常见的情况包括ÿ…...