7.6 通俗易懂解读残差网络ResNet 手撕ResNet
一.举例通俗解释ResNet思想
假设你正在学习如何骑自行车,并且想要骑到一个遥远的目的地。你可以选择直接骑到目的地,也可以选择在途中设置几个“中转站”,每个中转站都会告诉你如何朝着目的地前进。
在传统的神经网络中,就好比只能选择直接骑到目的地。当你的目的地很远时,可能会出现骑不到目的地的情况,因为网络在训练过程中无法有效地传递信息,导致梯度消失或梯度爆炸。
而ResNet则是在途中设置多个**“残差块”作为中转站**。每个残差块相当于一个中转站。
二.ResNet网络结构

假设f(x)是最终求得的函数。ResNet把函数拆成了f(x) = x + g(x).

传统网络相当于直接达到目的地,就是直接求f(x)。
ResNet是先到达一个中转站,即先求得g(x),再求g(x) + x 得到f(x)。同时可以推出g(x) = f(x) - x。
三.用实际的数举例子:
假设要求的f(x) = 5x^2 + 3x +2
ResNet先求得 g(x) = f(x) - x = 5x^2 + 2x +2 ,然后将g(x) 与x相加,最终得到f(x)=g(x) + x = 5x^2 + 3x +2
四.为什么ResNet非要设计成先求一个中转的函数g(x),然后再加上x呢?
4.1 解决网络加深,效果变差的问题
假如输入的x已经是最好的结果,如果加深网络效果会变差,即把最好的结果x输入到新一层的网络g(x)中,效果会变差。
那么我们直接令g(x)=0,相当于舍弃掉影响最优结果的网络块。最终得到的f(x) = 0 +x,保留了最优结果x。
从反向传播的角度来说,解决梯度消失和梯度爆炸的问题

对y=F(x)+x求偏导发现会出现画圈的地方,梯度消失是累积的乘积中出现接近0的数,影响梯度的结果,梯度爆炸是累积乘积,结果出现指数级增长。多了画圈地方的+操作,就打破了累乘,结果不容易出现梯度消失与爆炸。
五.代码实现
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
import time
class Residual(nn.Module):def __init__(self,input_channels,num_channels,use_1x1conv=False,strides=1):super().__init__()self.conv1 = nn.Conv2d(input_channels,num_channels,kernel_size=3,padding=1,stride=strides)self.conv2 = nn.Conv2d(num_channels,num_channels,kernel_size=3,padding=1)if use_1x1conv: # 使用1x1卷积核控制输出通道数self.conv3 = nn.Conv2d(input_channels,num_channels,kernel_size=1,stride=strides)else:self.conv3 = Noneself.bn1 = nn.BatchNorm2d(num_channels)self.bn2 = nn.BatchNorm2d(num_channels)def forward(self,X):Y = F.relu(self.bn1(self.conv1(X)))Y = self.bn2(self.conv2(Y))if self.conv3: # 用1x1卷积将x通道与形状 调整的与 f(x)-x一致X = self.conv3(X)# 不用1x1调整通道时直接 y+X = = f(x)-X + XY += Xreturn F.relu(Y)
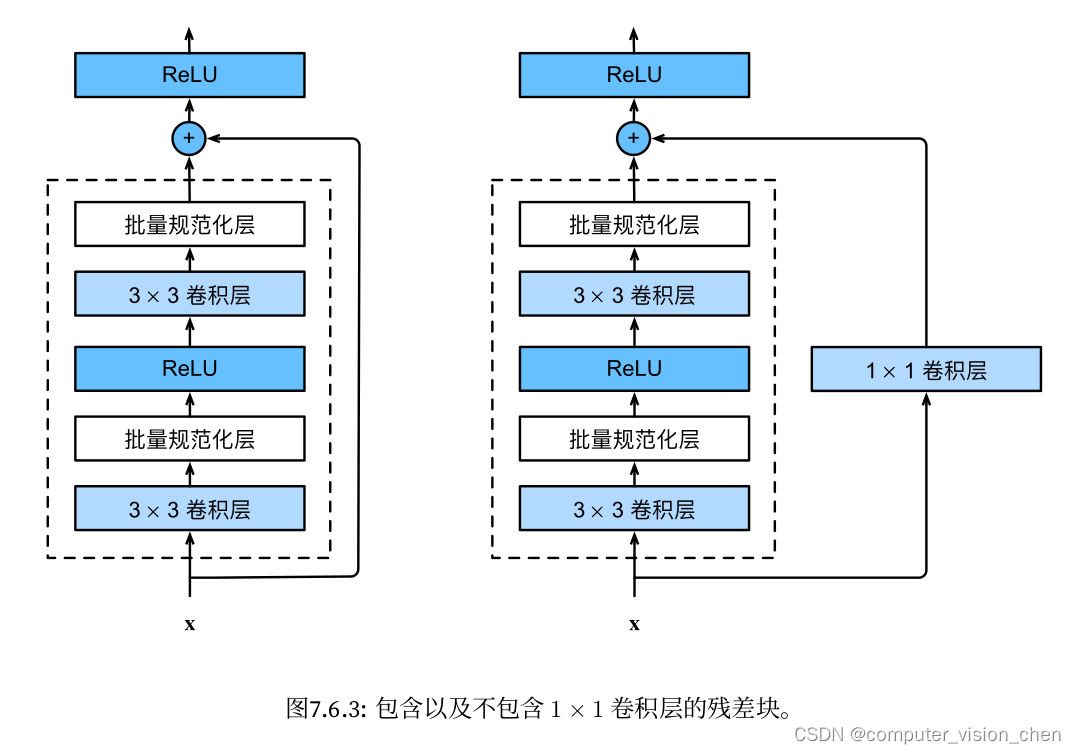
包含以及不包含 1 × 1 卷积层的残差块
此代码生成两种类型的网络:一种是当use_1x1conv=False时,应用ReLU非线性函数之前,
将输入添加到输出。另一种是当use_1x1conv=True时,添加通过1 × 1卷积调整通道和分辨率。
blk = Residual(input_channels=3,num_channels=3)
X = torch.rand(4, 3, 6, 6)
Y = blk(X)
Y.shape
torch.Size([4, 3, 6, 6])
# 使用1x1卷积控制通道数,使用strides=2减半输出的高和宽,num_channels是输出的通道数
blk = Residual(input_channels=3,num_channels=6, use_1x1conv=True, strides=2)
blk(X).shape
torch.Size([4, 6, 3, 3])
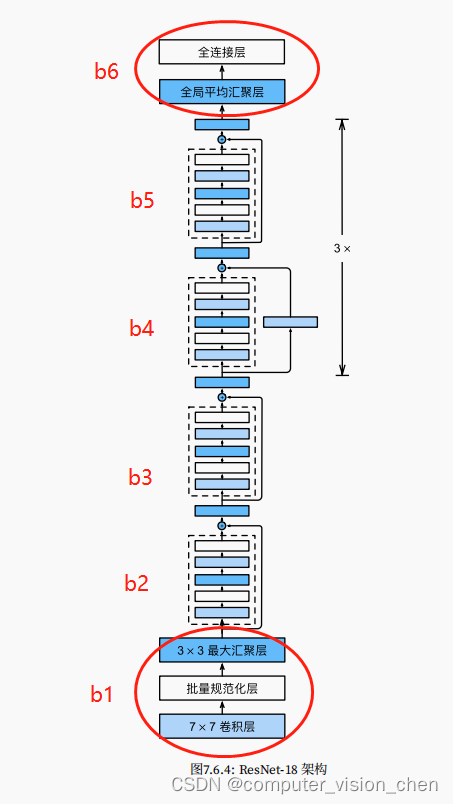
ResNet模型架构
#ResNet模型
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
# 残差块
def resnet_block(input_channels, num_channels, num_residuals,first_block=False):blk = []for i in range(num_residuals):if i == 0 and not first_block:blk.append(Residual(input_channels, num_channels,use_1x1conv=True, strides=2))else:blk.append(Residual(num_channels, num_channels))return blk
# 接着在ResNet加入所有残差块,这里每个模块使用2个残差块。
b2 = nn.Sequential(*resnet_block(64, 64, 2, first_block=True))
b3 = nn.Sequential(*resnet_block(64, 128, 2))
b4 = nn.Sequential(*resnet_block(128, 256, 2))
b5 = nn.Sequential(*resnet_block(256, 512, 2))
# 最后,与GoogLeNet一样,在ResNet中加入全局平均汇聚层,以及全连接层输出。
# 每个模块有4个卷积层(不包括恒等映射的1 × 1卷积层)。加上第一个7 × 7卷积层和最后一个全连接层,共有18层。因此,这种模型通常被称为ResNet-18。
net = nn.Sequential(b1, b2, b3, b4, b5,nn.AdaptiveAvgPool2d((1,1)),nn.Flatten(), nn.Linear(512, 10))
# 观察一下ResNet中不同模块的输入形状是如何变化的。在之前所有架构中,分辨率降低,通道数量增加,直到全局平均汇聚层聚集所有特征。
X = torch.rand(size=(1, 1, 224, 224))
for layer in net:X = layer(X)print(layer.__class__.__name__,'output shape:\t', X.shape)
# 库中的函数没有取最优的准确率,自己实现一个
def train_ch6(net, train_iter, test_iter, num_epochs, lr, device):"""Train a model with a GPU (defined in Chapter 6).Defined in :numref:`sec_lenet`"""def init_weights(m):if type(m) == nn.Linear or type(m) == nn.Conv2d:nn.init.xavier_uniform_(m.weight)net.apply(init_weights)print('training on', device)net.to(device)optimizer = torch.optim.SGD(net.parameters(), lr=lr)loss = nn.CrossEntropyLoss()animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],legend=['train loss', 'train acc', 'test acc'])timer, num_batches = d2l.Timer(), len(train_iter)best_test_acc = 0for epoch in range(num_epochs):# Sum of training loss, sum of training accuracy, no. of examplesmetric = d2l.Accumulator(3)net.train()for i, (X, y) in enumerate(train_iter):timer.start()optimizer.zero_grad()X, y = X.to(device), y.to(device)y_hat = net(X)l = loss(y_hat, y)l.backward()optimizer.step()with torch.no_grad():metric.add(l * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0])timer.stop()train_l = metric[0] / metric[2]train_acc = metric[1] / metric[2]if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:animator.add(epoch + (i + 1) / num_batches,(train_l, train_acc, None))test_acc = d2l.evaluate_accuracy_gpu(net, test_iter)if test_acc>best_test_acc:best_test_acc = test_accanimator.add(epoch + 1, (None, None, test_acc))print(f'loss {train_l:.3f}, train acc {train_acc:.3f}, 'f'test acc {test_acc:.3f}, best test acc {best_test_acc:.3f}')# 取的好像是平均准备率print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec 'f'on {str(device)}')
'''训练并打印训练耗时'''
'''开始计时'''
start_time = time.time()lr, num_epochs, batch_size = 0.05, 10, 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=96)
# 使用自己的训练函数
train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())'''计时结束'''
end_time = time.time()
run_time = end_time - start_time
# 将输出的秒数保留两位小数
if int(run_time)<60:print(f'{round(run_time,2)}s')
else:print(f'{round(run_time/60,2)}minutes')
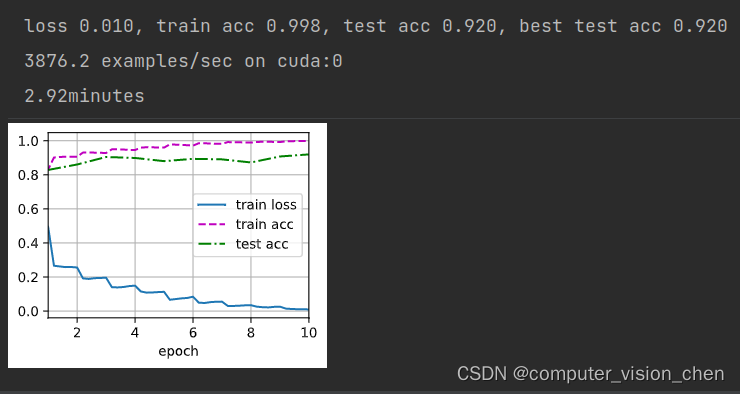
牛逼!比之前所有的模型准确率都高。
参考文章与视频
三分钟说明白ResNet ,关于它的设计、原理、推导及优点
https://www.bilibili.com/video/BV1cM4y117ob/?spm_id_from=333.337.search-card.all.click&vd_source=ebc47f36e62b223817b8e0edff181613
ResNet详解——通俗易懂版
https://blog.csdn.net/sunny_yeah_/article/details/89430124
相关文章:
7.6 通俗易懂解读残差网络ResNet 手撕ResNet
一.举例通俗解释ResNet思想 假设你正在学习如何骑自行车,并且想要骑到一个遥远的目的地。你可以选择直接骑到目的地,也可以选择在途中设置几个“中转站”,每个中转站都会告诉你如何朝着目的地前进。 在传统的神经网络中,就好比只…...

robotframework+selenium 进行webui页面自动化测试
robotframework其实就是一个自动化的框架,想要进行什么样的自动化测试,就需要在这框架上添加相应的库文件,而用于webui页面自动化测试的就是selenium库. 关于robotframework框架的搭建我这里就不说了,今天就给大家根据一个登录的实…...

手机突然无法获取ip地址
在日常生活中,我们对手机的依赖越来越大,尤其是在联网方面。然而,有时候我们可能会遇到手机无法获取IP地址的问题,这给我们的正常使用带来了很多不便。当我们的手机无法获得IP地址时,我们将无法连接到互联网或局域网&a…...

C++——关于命名空间
写c项目时,大家常用到的一句话就是: using namespace std; 怎么具体解析这句话呢? 命名冲突: 在c语言中,我们有变量的命名规范,如果一个变量名或者函数名和某个库里面自带的库函数或者某个关键字重名&…...
怎么进行流程图制作?用这个工具制作很方便
怎么进行流程图制作?流程图是一种非常有用的工具,可以帮助我们更好地理解和展示各种复杂的业务流程和工作流程。它可以将复杂的过程简化为易于理解的图形和文本,使得人们更容易理解和跟踪整个流程。因此,制作流程图是在日常工作中…...

【ChatGPT 指令大全】怎么使用ChatGPT来辅助学习英语
在当今全球化的社会中,英语已成为一门世界性的语言,掌握良好的英语技能对个人和职业发展至关重要。而借助人工智能的力量,ChatGPT为学习者提供了一个有价值的工具,可以在学习过程中提供即时的帮助和反馈。在本文中,我们…...

Ubuntu20配置仅主机网络
Ubuntu20配置仅主机网络,使虚拟机与物理机网络联通且配置固定IP 进入终端:vim /etc/netplan/01-network-manager-all.yaml 修改为: network:ethernets:enp0s8:addresses: [192.168.138.108/24]dhcp4: false optional: truegateway4: 192.…...

调整奇数偶数顺序
调整数组使奇数全部都位于偶数前面。 题目: 输入一个整数数组,实现一个函数,来调整该数组中数字的顺序使得数组中所有的奇数位于数组的前半部分,所有偶数位于数组的后半部分。 思路: 1. 给定两个下标left和right&#…...

日志的规范
确定日志级别: 确保你的系统有一个明确的日志级别策略。通常,日志级别包括DEBUG,INFO,WARN,ERROR和FATAL。DEBUG级别的日志记录所有详细信息,适用于开发和调试环境。INFO级别的日志记录常规操作信息&#x…...
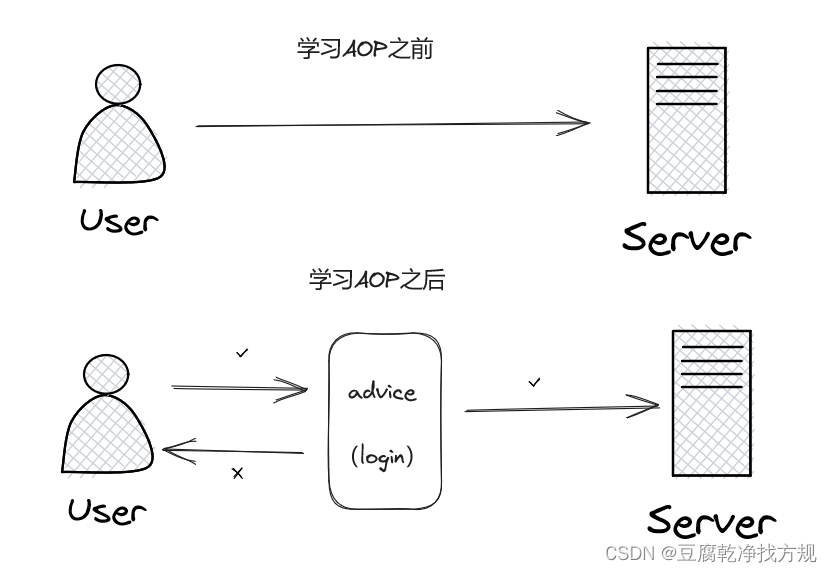
Spring AOP(AOP概念,组成成分,实现,原理)
目录 1. 什么是Spring AOP? 2. 为什么要用AOP? 3. AOP该怎么学习? 3.1 AOP的组成 (1)切面(Aspect) (2)连接点(join point) (3&a…...

Android WebView简单应用:构建内嵌网页浏览功能
在现代移动应用开发中,内嵌网页浏览功能是许多应用程序的常见需求。Android平台提供了WebView组件,它允许开发者将网页内容嵌入到应用中,并提供了丰富的功能和定制选项。本文将介绍如何在Android应用中使用WebView组件,帮助您快速…...

并发——乐观锁常见的两种实现方式,乐观锁的缺点
文章目录 乐观锁常见的两种实现方式1. 版本号机制2. CAS算法 乐观锁的缺点1 ABA 问题2 循环时间长开销大3 只能保证一个共享变量的原子操作 乐观锁常见的两种实现方式 乐观锁一般会使用版本号机制或CAS算法实现。 1. 版本号机制 一般是在数据表中加上一个数据版本号version字段…...
Spring 事务管理
目录 1. 事务管理 1.1. Spring框架的事务支持模型的优势 1.1.1. 全局事务 1.1.2. 本地事务 1.1.3. Spring框架的一致化编程模型 1.2. 了解Spring框架的事务抽象(Transaction Abstraction) 1.2.1. Hibernate 事务设置 1.3. 用事务同步资源 1.3.1…...
unity修改单个3D物体的重力的大小该怎么处理呢?
在Unity中修改单个3D物体的重力大小可以通过以下步骤实现: 创建一个新的C#脚本来控制重力: 首先,创建一个新的C#脚本(例如:GravityModifier.cs)并将其附加到需要修改重力的3D物体上。在脚本中,…...

[Qt]FrameLessWindow实现调整大小、移动弹窗并具有Aero效果
说明 我们知道QWidget等设置了this->setWindowFlags(Qt::FramelessWindowHint);后无法移动和调整大小,但实际项目中是需要窗口能够调整大小的。所以以实现FrameLess弹窗调整大小及移动弹窗需求,并且在Windows 10上有Aero效果。 先看一下效果…...

【API生命周期看护】API日落
一、基本概念 在API的整个生命周期中,不可能是永远不变的。功能可能有变动、服务也可能有升级迭代,这个时候对外的能力入口:API自然也需要改变。 一般来说,API的变动是不可以引入兼容性问题的,也即不管做什么变动&am…...

PHP 使用ThinkPHP实现电子邮件发送示例
文章目录 首先我们需要设置我们的邮箱客户端授权,获取到授权码找到我们的邮箱设置去账号中找到这一堆服务,找到后开启smtp服务开启服务后管理服务 接下来需要去下载相应的第三方类库(我这里使用的是PHPMailer)在thinkPHP中封装一下邮件服务类实际调用效果…...
Leetcode-每日一题【剑指 Offer 18. 删除链表的节点】
题目 给定单向链表的头指针和一个要删除的节点的值,定义一个函数删除该节点。 返回删除后的链表的头节点。 注意:此题对比原题有改动 示例 1: 输入: head [4,5,1,9], val 5输出: [4,1,9]解释: 给定你链表中值为 5 的第二个节点,那么在调…...

[LINUX使用] top 命令的使用
COLUMNS150 LINES100 top 序号 是否为启动命令 命令模板 详解 1 no vh 帮助 2 yes -d 0.01 0.01秒的间隔刷新top输出 3 no c COMMAND列切换 4 yes -e [k | m | g | t | p] 以何种计量单位显示内存列 k-kb,m-mb,g-gb,t-t…...

通过redis进行缓存分页,通过SCAN扫描进行缓存更新
问题:当我们要添加缓存时,如果我们用了PageHelper时,PageHelper只会对查询语句有效(使用到sql的查询),那么如果我们把查询到的数据都添加到缓存时,就会无法进行分页; 此时我们选择将…...

MySQL优化全攻略:索引、SQL与分库分表的最佳实践鸵
一、各自优势和对比 这是检索出来的数据,据说是根据第三方评测与企业数据,三款产品在代码生成质量上各有侧重: 产品 语言优势 场景亮点 核心差异 百度 Comate C核心代码质量第一;Python首生成率达92.3% SQL生成准确率提升35%&…...
)
周红伟:龙虾安装大全,这应该是最详细的 OpenClaw 安装手册了(附20+张图)
OpenClaw 是一个开源 AI 代理框架,由奥地利开发者 Peter Steinberger 创建,专注于构建自主 AI 代理,能够执行实际任务(如写代码、管理文件、浏览网页等),而非仅限于聊天。它从一个简单原型迅速演变为 GitHu…...
Pixel Language Portal 赋能网站开发:从需求到前端静态页面代码自动生成
Pixel Language Portal 赋能网站开发:从需求到前端静态页面代码自动生成 1. 效果惊艳的开场 想象一下这样的场景:你刚和客户开完需求会议,手上只有一份简单的网站描述文档。传统开发流程下,前端工程师需要至少1-2天才能完成静态…...

Python3.8镜像实战:3步创建独立环境,复现实验结果不再难
Python3.8镜像实战:3步创建独立环境,复现实验结果不再难 1. 为什么需要Python独立环境 在Python开发中,我们经常会遇到这样的问题:昨天还能正常运行的项目,今天突然报错了;在A电脑上跑通的代码࿰…...
)
第6章 6.1.2 数据呈现的艺术:sprintf格式化操作符深度解析(MATLAB入门课程)
1. 为什么数据需要格式化呈现? 第一次处理实验数据时,我直接把MATLAB工作区的变量值复制到论文里,结果被导师狠狠批评了一顿。那些密密麻麻的数字堆在一起,小数点位数参差不齐,有些科学计数法显示,有些又是…...

QTableWidget 表格组件腺
7.1 初识三维模型 7.1.1 三维模型的数据载体 随着计算机图形技术的发展,我们或多或少都会见过或者听说过三维模型。笔者始终记得小时候第一次在电视上看到三维动画《变形金刚:超能勇士》的震撼感受;而现在我们已经可以在手机上玩三维游戏《王…...

如何掌握IntelliJ Rust插件的Cargo项目结构:从入门到精通
如何掌握IntelliJ Rust插件的Cargo项目结构:从入门到精通 【免费下载链接】intellij-rust Rust plugin for the IntelliJ Platform 项目地址: https://gitcode.com/gh_mirrors/in/intellij-rust IntelliJ Rust插件是IntelliJ平台上的Rust开发工具,…...

GeoPort代码实现原理:Flask框架与iOS设备通信机制解析
GeoPort代码实现原理:Flask框架与iOS设备通信机制解析 【免费下载链接】GeoPort GeoPort: Your Location, Anywhere! The iOS location simulator 项目地址: https://gitcode.com/gh_mirrors/ge/GeoPort GeoPort作为一款强大的iOS位置模拟器,其核…...

实测Claude Opus 4.6:100万上下文,1人顶3人,这才是裁员潮的保命神器
作为深耕CSDN的技术博主,每天都能收到开发者的私信:“怕被裁,到底该怎么用AI提效?”“免费AI不好用,高级会员开通太麻烦”“Claude又更新了,跟不上节奏怎么办?”其实答案很简单:2026…...
]结构体)
Rust的#[repr(packed)]结构体
Rust语言中的#[repr(packed)]结构体是一个值得深入探讨的特性,它能够帮助开发者优化内存布局,特别适合对内存对齐有严格要求的场景。在嵌入式开发、网络协议解析等领域,精确控制结构体的内存排列至关重要。本文将带你了解#[repr(packed)]的独…...