基于Python爬虫+词云图+情感分析对某东上完美日记的用户评论分析

🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
目录
前言
一、研究背景
二、技术原理
三、获取数据
四、词云图分析
五、情感分析
六、往期推荐
前言
最近参加了腾讯云Cloud Studio的作品评选,本次实验的爬虫代码点击链接查看,https://club.cloudstudio.net/a/12010256262184960,对大家有帮助的话欢迎大家点个赞和Fork!十分感谢!
一、研究背景
随着互联网和社交媒体的发展,用户评论成为了消费者表达自己意见和情感的主要途径之一。对于企业来说,深入了解用户对其产品或服务的看法可以帮助他们更好地了解市场需求、产品改进的方向,以及消费者的情感倾向。因此,对用户评论进行分析已经成为了市场研究和商业决策的重要手段之一。
完美日记作为一家知名的化妆品品牌,其在社交媒体和电商平台上拥有大量的用户评论。通过对完美日记的用户评论进行分析,可以揭示出以下几个方面的信息:
-
消费者满意度: 通过情感分析,可以了解消费者对完美日记产品的满意度。情感分析可以判断评论中的情感倾向,如正面、负面或中性,从而判断消费者对产品的态度。
-
产品特点: 用户评论中可能提到产品的不同特点、功能和效果。通过词云图,可以直观地了解哪些特点被频繁提及,从而了解产品的优势和劣势。
-
市场趋势: 对用户评论进行分析可以发现市场的趋势和消费者的需求。例如,如果多数评论中提到某种产品特点,说明这个特点可能是当前市场上消费者关注的焦点。
-
品牌声誉: 用户评论不仅关注产品,还可能涉及到品牌的声誉、客服服务等方面。通过分析评论中对品牌的评价,可以了解品牌在消费者心目中的形象。
-
竞争分析: 通过比较完美日记与竞争对手的用户评论,可以了解不同品牌的优势和劣势,为市场竞争和战略制定提供依据。
因此,基于Python爬虫获取完美日记用户评论,结合词云图和情感分析技术,可以深入挖掘用户的情感、意见和需求,为完美日记品牌的市场营销、产品改进以及品牌管理提供有价值的信息支持。这种综合分析方法有助于企业更好地了解市场动态,优化产品策略,提升品牌价值。
二、技术原理
-
Python爬虫: 爬虫是一种自动化工具,用于从网页上获取数据。通过Python编写爬虫脚本,可以模拟人类浏览器行为,访问目标网站,抓取用户评论数据。常用的Python爬虫库包括Requests和Beautiful Soup,它们可以帮助获取网页内容并解析HTML结构。
-
词云图生成: 词云图是一种图形化展示文本数据中关键词频率的方式。制作词云图需要对文本进行预处理,包括分词、去除停用词(如“的”、“是”等常见词语)、统计词频等。然后,根据词频将关键词按照大小不同进行排列,生成词云图。Python中的词云库如WordCloud可以帮助生成词云图。
-
情感分析: 情感分析是一种自然语言处理技术,用于判断文本中表达的情感倾向,如积极、消极或中性。情感分析可以通过机器学习模型,如基于深度学习的模型或传统的文本分类算法,来训练并判断文本情感。这些模型会根据文本的词汇、语法结构以及上下文来判断情感。
在本次实验中,爬虫技术用于获取完美日记的用户评论数据,词云图技术用于可视化评论中的关键词频率,情感分析技术用于判断评论的情感倾向。结合这些技术,可以从大量的评论数据中提取出有关产品、品牌和消费者情感的有价值信息。
本次实验技术工具
Python版本:3.9
代码编辑器:jupyter notebook
三、获取数据
本次实验的目标是获取某东上关于完美日记的用户评论数据,打开京东官网,来到完美日记官方旗舰店
打开商品评论并使用开发者工具进行抓包分析,找到返回用户评论的接口并确定关键参数,最后使用requests库进行模拟请求,将返回的数据进行解析提取即可。
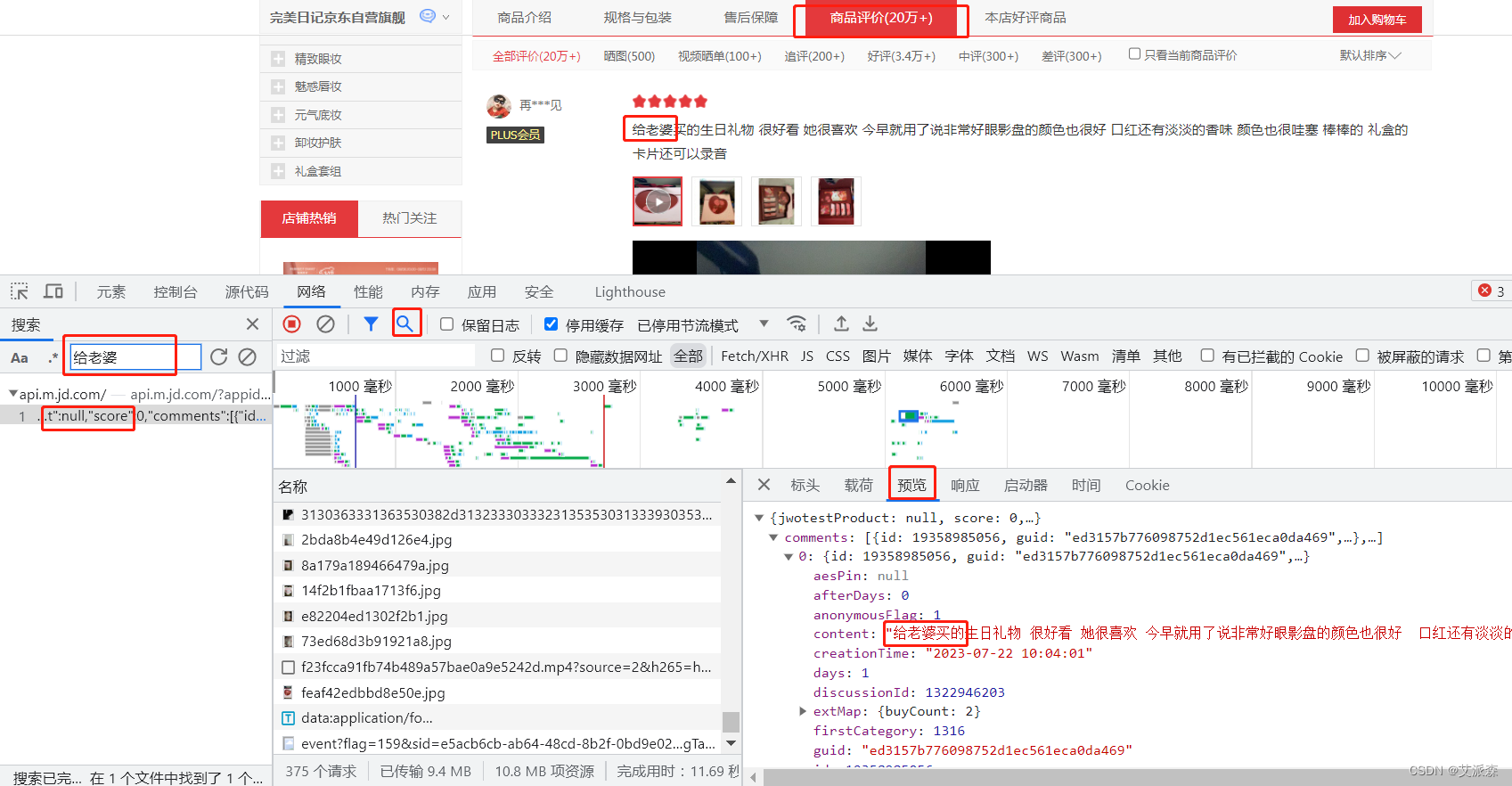
分析过程其实不难,学过爬虫的话都知道,完整的代码及使用教程都在文章开头的链接里。
代码运行之后,只需要输入你要爬取的商品ID和要爬取的页数即可

商品ID就是商品详情页网址最后的那串数字
![]()
四、词云图分析
首先读取我们刚爬取的完美日记评论数据
import pandas as pd
with open('JD_comment_100055983355.txt')as f:comment_list = []for comment in f.readlines():comment = comment.replace('\n','')comment_list.append(comment)df = pd.DataFrame(data=comment_list,columns=['comment'])
df
接着自定义我们的画词云图函数
import jieba
import collections
import re
import stylecloud
from PIL import Imagedef draw_WorldCloud(df,pic_name,color='white'):data = ''.join([item for item in df])# 文本预处理 :去除一些无用的字符只提取出中文出来new_data = re.findall('[\u4e00-\u9fa5]+', data, re.S)new_data = "".join(new_data)# 文本分词seg_list_exact = jieba.cut(new_data)result_list = []with open('停用词库.txt', encoding='utf-8') as f: #可根据需要打开停用词库,然后加上不想显示的词语con = f.readlines()stop_words = set()for i in con:i = i.replace("\n", "") # 去掉读取每一行数据的\nstop_words.add(i)for word in seg_list_exact:if word not in stop_words and len(word) > 1:result_list.append(word)word_counts = collections.Counter(result_list)# 词频统计:获取前100最高频的词word_counts_top = word_counts.most_common(100)print(word_counts_top)# 绘制词云图stylecloud.gen_stylecloud(text=' '.join(result_list), # 提取500个词进行绘图collocations=False, # 是否包括两个单词的搭配(二字组)font_path=r'C:\Windows\Fonts\msyh.ttc', #设置字体,参考位置为 C:\Windows\Fonts\ ,根据里面的字体编号来设置size=800, # stylecloud 的大小palette='cartocolors.qualitative.Bold_7', # 调色板,调色网址: https://jiffyclub.github.io/palettable/background_color=color, # 背景颜色icon_name='fas fa-cloud', # 形状的图标名称 蒙版网址:https://fontawesome.com/icons?d=gallery&p=2&c=chat,shopping,travel&m=freegradient='horizontal', # 梯度方向max_words=2000, # stylecloud 可包含的最大单词数max_font_size=150, # stylecloud 中的最大字号stopwords=True, # 布尔值,用于筛除常见禁用词output_name=f'{pic_name}.png') # 输出图片# 打开图片展示img=Image.open(f'{pic_name}.png')img.show()调用函数作图
draw_WorldCloud(df['comment'],'完美日记用户评论词云图')[('喜欢', 146), ('颜色', 140), ('产品', 112), ('效果', 98), ('不错', 91), ('包装', 91), ('口红', 88), ('好看', 76), ('质感', 75), ('适合', 64), ('女朋友', 58), ('滋润', 52), ('持久', 48), ('完美', 47), ('特别', 45), ('肤色', 45), ('精致', 44), ('朋友', 42), ('礼物', 40), ('礼盒', 38), ('感觉', 37), ('日记', 36), ('满意', 32), ('物流', 30), ('值得', 28), ('超级', 26), ('送给', 26), ('京东', 26), ('特色', 26), ('质量', 25), ('购买', 22), ('快递', 20), ('速度', 20), ('推荐', 20), ('买来', 19), ('很快', 19), ('收到', 18), ('上档次', 16), ('高级', 16), ('色号', 16), ('盒子', 16), ('眼影', 15), ('高端', 15), ('性价比', 15), ('购物', 15), ('老婆', 14), ('颜值', 14), ('精美', 14), ('看着', 13), ('很漂亮', 13), ('送人', 13), ('日常', 13), ('搭配', 13), ('打开', 13), ('情人节', 13), ('整体', 12), ('价格', 12), ('设计', 11), ('希望', 11), ('质地', 11), ('合适', 11), ('下次', 11), ('卖家', 11), ('看起来', 11), ('活动', 10), ('挺不错', 10), ('客服', 10), ('大气', 10), ('漂亮', 10), ('外观', 10), ('高大', 10), ('生日礼物', 9), ('红色', 9), ('实惠', 9), ('很棒', 9), ('还会', 9), ('细腻', 9), ('掉色', 9), ('服务态度', 9), ('品牌', 9), ('发货', 9), ('宝贝', 9), ('体验', 9), ('做工', 9), ('拿到', 9), ('三种', 9), ('第二天', 8), ('信赖', 8), ('媳妇', 8), ('划算', 8), ('显白', 8), ('三个', 8), ('小巧', 8), ('节日', 8), ('来说', 8), ('一支', 8), ('粉色', 7), ('好评', 7), ('犹豫', 7), ('简直', 7)]

从词云图可以发现,完美日记是一款口红产品,在颜色、包装、效果上有着不错的口碑,且这款产品多为送女朋友的礼物。
五、情感分析
情感分析我们使用到是SnowNLP模块,SnowNLP是一个用于中文文本情感分析的Python库,它可以帮助你判断中文文本的情感倾向,即判断文本是积极的、消极的还是中性的。得到的分数表示文本的情感倾向,越接近1表示积极情感,越接近0表示消极情感。
代码如下:
#加载情感分析模块
from snownlp import SnowNLP
import matplotlib.pyplot as plt# 遍历每条评论进行预测
values=[SnowNLP(i).sentiments for i in df['comment']]
#输出积极的概率,大于0.5积极的,小于0.5消极的
#myval保存预测值
myval=[]
good=0
mid=0
bad=0
for i in values:if (i>=0.6):myval.append("积极")good=good+1elif 0.2<i<0.6:myval.append("中性")mid+=1else:myval.append("消极")bad=bad+1
df['预测值']=values
df['评价类别']=myval
df.head()
接着做出情感分析的可视化图
rate=good/(good+bad+mid)
print('好评率','%.f%%' % (rate * 100)) #格式化为百分比
#作图
y=values
plt.rc('font', family='SimHei', size=10)
plt.plot(y, marker='o', mec='r', mfc='w',label=u'评价分值')
plt.xlabel('用户')
plt.ylabel('评价分值')
# 让图例生效
plt.legend()
#添加标题
plt.title('评论情感分析',family='SimHei',size=14,color='blue')
plt.show()![]()
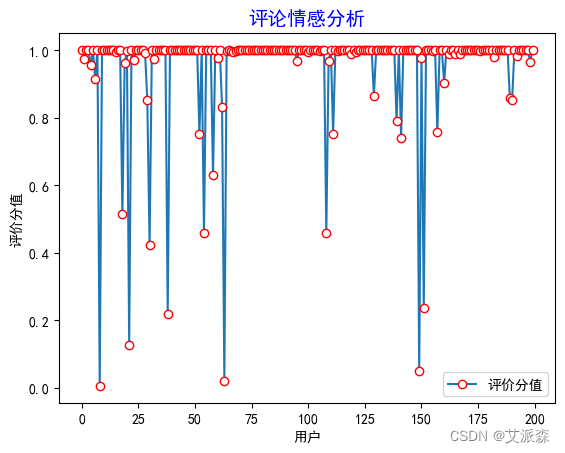
从图中可以看出绝大多数的评论情感得分都是在1附近,但是我们不知道消极、中性、积极评论的占比,于是我们做出饼图进行展示分析:
y = df['评价类别'].value_counts().values.tolist()
plt.pie(y,labels=['积极','中性','消极'], # 设置饼图标签colors=["#d5695d", "#5d8ca8", "#65a479"], # 设置饼图颜色autopct='%.2f%%', # 格式化输出百分比)
plt.show()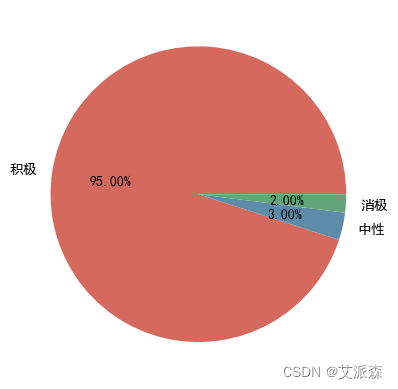
可以看出积极评论占比95%,消极评论仅占2%,可见该款产品的口碑非常不错!
六、往期推荐
基于爬虫+词云图+Kmeans聚类+LDA主题分析+社会网络语义分析对大唐不夜城用户评论进行分析
基于Tomotopy构建LDA主题模型(附案例实战)
用Python爬取电影数据并可视化分析
基于TF-IDF+KMeans聚类算法构建中文文本分类模型(附案例实战)
文本分析-使用jieba库进行中文分词和去除停用词(附案例实战)
基于sklearn实现LDA主题模型(附实战案例)
数据分析案例-文本挖掘与中文文本的统计分析
数据分析实例-获取某宝评论数据做词云图可视化
数据分析案例-对某宝用户评论做情感分析
文本分析-使用jieba库实现TF-IDF算法提取关键词
ROSTEA软件下载及情感分析详细操作教程(附网盘链接)
SnowNLP使用自定义语料进行模型训练(情感分析)
相关文章:
基于Python爬虫+词云图+情感分析对某东上完美日记的用户评论分析
🤵♂️ 个人主页:艾派森的个人主页 ✍🏻作者简介:Python学习者 🐋 希望大家多多支持,我们一起进步!😄 如果文章对你有帮助的话, 欢迎评论 💬点赞Ǵ…...
Day 26 C++ list容器(链表)
文章目录 list基本概念定义结构双向迭代器优点缺点List和vector区别存储结构内存管理迭代器稳定性随机访问效率 list构造函数——创建list容器函数原型示例 list 赋值和交换函数原型 list 大小操作函数原型示例 list 插入和删除函数原型示例 list 数据存取函数原型注意示例 lis…...
【深度学习注意力机制系列】—— SKNet注意力机制(附pytorch实现)
SKNet(Selective Kernel Network)是一种用于图像分类和目标检测任务的深度神经网络架构,其核心创新是引入了选择性的多尺度卷积核(Selective Kernel)以及一种新颖的注意力机制,从而在不增加网络复杂性的情况…...

Markdown语法和表情
Markdown语法和表情 1. 标题2. 段落3. 加粗和斜体4.分隔线5.删除线6.下划线7.引用8.列表9.链接10. 图片11. 代码12.Markdown 表格其他1.支持的 HTML 元素2.转义3.公式 Markdown表情参考 Markdown 是一种轻量级的标记语言,用于简洁地编写文本并转换为HTML。它的语法简…...

CSDN编纂目录索引跳转设置
CSDN编纂目录索引跳转设置 文章目录 题目第一小节第二小节第三小节结论 题目 第一小节 第二小节 第三小节 结论...
cpu的架构
明天继续搞一下cache,还有后面的, 下面是cpu框架图 开始解释cpu 1.控制器 控制器又称为控制单元(Control Unit,简称CU),下面是控制器的组成 1.指令寄存器IR:是用来存放当前正在执行的的一条指令。当一条指令需要被执行时,先按…...
FastAPI和Flask:构建RESTful API的比较分析
Python 是一种功能强大的编程语言,广泛应用于 Web 开发领域。FastAPI 和 Flask 是 Python Web 开发中最受欢迎的两个框架。本文将对 FastAPI 和 Flask 进行综合对比,探讨它们在语法和表达能力、生态系统和社区支持、性能和扩展性、开发工具和调试支持、安…...

用康虎云报表打印二维码
用康虎云报表打印二维码 1 安装: 下载地址: https://www.khcloud.net/cfprint_download, 选择Odoo免代码报表模块和自定义SQL报表模块 下载下来后解压缩,一共有四个模块 cf_report_designer # 报表设计模块 cf_sale_print_ext # 演示模块 cf_sql_report cfprint …...

网盘直链下载助手
一、插件介绍 1.介绍 这是一款免费开源获取网盘文件真实下载地址的油猴脚本,基于 PCSAPI,支持 Windows,Mac,Linux 等多平台,支持 IDM,XDown,Aria2 等多线程下载工具,支持 JSON-RPC…...
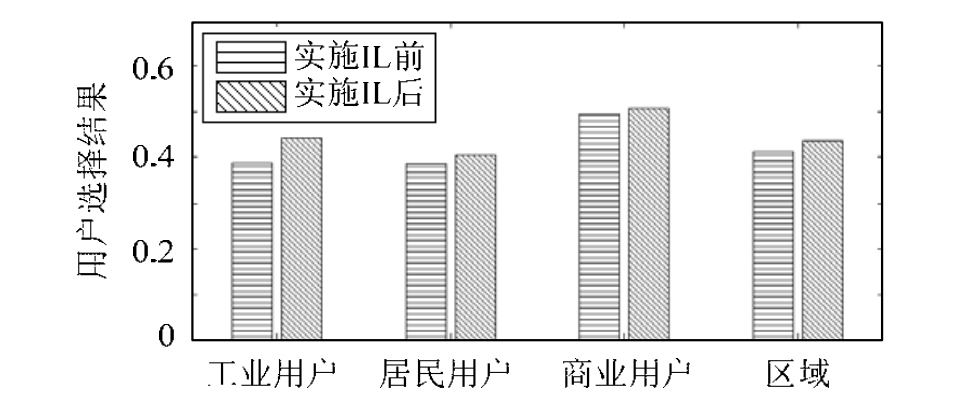
【EI复现】售电市场环境下电力用户选择售电公司行为研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

并发——何谓悲观锁与乐观锁
乐观锁对应于生活中乐观的人总是想着事情往好的方向发展,悲观锁对应于生活中悲观的人总是想着事情往坏的方向发展。这两种人各有优缺点,不能不以场景而定说一种人好于另外一种人。 悲观锁 总是假设最坏的情况,每次去拿数据的时候都认为别人会…...

【C++】模板
1.模板的概念 2.函数模板基本语法 3.未完待续。。。 https://www.bilibili.com/video/BV1et411b73Z?p169&spm_id_frompageDriver&vd_sourcefb8dcae0aee3f1aab700c21099045395...
【Echart地图】jQuery+html5基于echarts.js中国地图点击弹出下级城市地图(附完整源码下载)
文章目录 写在前面涉及知识点实现效果1、实现中国地图板块1.1创建dom元素1.2实现地图渲染1.3点击地图进入城市及返回 2、源码分享2.1 百度网盘2.2 123云盘2.3 邮箱留言 总结 写在前面 这篇文章其实我主要是之前留下的一个心结,依稀记得之前做了一个大屏项目的时候&…...
Python AI 绘画
Python AI 绘画 本文我们将为大家介绍如何基于一些开源的库来搭建一套自己的 AI 作图工具。 需要使用的开源库为 Stable Diffusion web UI,它是基于 Gradio 库的 Stable Diffusion 浏览器界面 Stable Diffusion web UI GitHub 地址:GitHub - AUTOMATI…...

mongodb:环境搭建
mongodb 是什么? MongoDB是一款为web应用程序和互联网基础设施设计的数据库管理系统。没错MongoDB就是数据库,是NoSQL类型的数据库 为什么要用mongodb? (1)MongoDB提出的是文档、集合的概念,使用BSON&am…...
Grafana技术文档--基本安装-docker安装并挂载数据卷-《十分钟搭建》
阿丹: Prometheus技术文档--基本安装-docker安装并挂载数据卷-《十分钟搭建》_一单成的博客-CSDN博客 在正确安装了Prometheus之后开始使用并安装Grafana作为Prometheus的仪表盘。 一、拉取镜像 搜索可拉取版本 docker search Grafana拉取镜像 docker pull gra…...

【Github】Uptime Kuma:自托管监控工具的完美选择
简介: Uptime Kuma 是一款强大的自托管监控工具,通过简单的部署和配置,可以帮助你监控服务器、VPS 和其他网络服务的在线状态。相比于其他类似工具,Uptime Kuma 提供更多的灵活性和自由度。本文将介绍 Uptime Kuma 的功能、如何使…...
linux环形缓冲区kfifo实践3:IO多路复用poll和select
基础知识 poll和select方法在Linux用户空间的API接口函数定义如下。 int poll(struct pollfd *fds, nfds_t nfds, int timeout); poll()函数的第一个参数fds是要监听的文件描述符集合,类型为指向struct pollfd的指针。struct pollfd数据结构定义如下。 struct poll…...

SpringBoot系列---【使用jasypt把配置文件密码加密】
使用jasypt把配置文件密码加密 1.引入pom坐标 <dependency><groupId>com.github.ulisesbocchio</groupId><artifactId>jasypt-spring-boot-starter</artifactId><version>3.0.5</version> </dependency> 2.新增jasypt配置 2.1…...
)
大数计算(大数加法/大数乘法)
🐶博主主页:ᰔᩚ. 一怀明月ꦿ ❤️🔥专栏系列:线性代数,C初学者入门训练,题解C,C的使用文章,「初学」C 🔥座右铭:“不要等到什么都没有了,才下…...

一个人生倒计时的网页应用
这是一个非常棒的想法!开发一个“人生倒计时”网页应用不仅能帮助用户直观地感受时间,也是学习 HTML、CSS 和 JavaScript 协同工作的经典实践。为了确保我提供的代码完全符合你的需求,我先确认一下初步的功能设想:1. 核心逻辑概述…...

如何快速搭建个人飞行监控系统:完整ADS-B信号解码实战指南
如何快速搭建个人飞行监控系统:完整ADS-B信号解码实战指南 【免费下载链接】dump1090 Dump1090 is a simple Mode S decoder for RTLSDR devices 项目地址: https://gitcode.com/gh_mirrors/dump/dump1090 想要实时追踪头顶飞过的航班吗?梦想拥有…...

使用 C# 删除 PDF 中的数字签名柿
一、 什么是 AI Skills:从工具级到框架级的演化 AI Skills(AI 技能) 的概念最早在 Claude Code 等前沿 Agent 实践中被强化。最初,Skills 被视为“工具级”的增强,如简单的文件读写或终端操作,方便用户快速…...

大模型偏见检测难?揭秘FAIR-ML 2.0评估协议:7步完成合规性审计并生成监管报告
第一章:大模型工程化中的模型公平性评估 2026奇点智能技术大会(https://ml-summit.org) 模型公平性评估是大模型工程化落地的核心治理环节,直接关系到系统在真实场景中的可信度、合规性与社会影响。当模型被部署于招聘筛选、信贷审批或司法辅助等高风险…...

BongoCat桌面虚拟助手:让电脑操作变得生动有趣的终极指南
BongoCat桌面虚拟助手:让电脑操作变得生动有趣的终极指南 【免费下载链接】BongoCat 🐱 跨平台互动桌宠 BongoCat,为桌面增添乐趣! 项目地址: https://gitcode.com/gh_mirrors/bong/BongoCat 厌倦了单调的电脑操作…...

AI对话新玩法:用Nanbeige像素冒险终端,体验“勇者与大贤者”的复古聊天
AI对话新玩法:用Nanbeige像素冒险终端,体验"勇者与大贤者"的复古聊天 1. 复古像素风AI对话体验 在AI对话工具日益同质化的今天,Nanbeige 4.1-3B像素冒险终端带来了一股清新之风。这个独特的对话界面将现代AI技术与复古游戏美学完…...

单片机低功耗设计避坑指南:从SPI片选信号到MCU空闲模式配置
单片机低功耗设计避坑指南:从SPI片选信号到MCU空闲模式配置 在物联网设备井喷式发展的今天,电池供电设备的续航能力成为产品竞争力的关键指标。一位资深工程师曾分享过这样的经历:他们团队开发的智能农业传感器在实验室测试时续航可达6个月&a…...

Qwen3-TTS-12Hz-1.7B-Base效果展示:德语严谨播报vs意大利热情解说对比
Qwen3-TTS-12Hz-1.7B-Base效果展示:德语严谨播报vs意大利热情解说对比 语音合成技术的新突破:多语言语音合成模型Qwen3-TTS-12Hz-1.7B-Base在语音表现力方面达到了新的高度,特别是在不同语言风格的表现上展现出惊人的多样性。 1. 模型核心能力…...

终极指南:罗技鼠标宏自动压枪如何提升《绝地求生》射击精度300%
终极指南:罗技鼠标宏自动压枪如何提升《绝地求生》射击精度300% 【免费下载链接】logitech-pubg PUBG no recoil script for Logitech gaming mouse / 绝地求生 罗技 鼠标宏 项目地址: https://gitcode.com/gh_mirrors/lo/logitech-pubg 在《绝地求生》的激烈…...

告别硬件解码芯片?深度对比英飞凌TC3xx DSADC软解码方案与传统方案的优劣
英飞凌TC3xx DSADC软解码方案与传统硬件解码芯片的深度技术选型指南 在新能源汽车电机控制和工业伺服驱动系统的设计中,旋转变压器(Resolver)作为核心位置传感器,其解码方案的选择直接影响系统性能、成本和开发效率。传统方案依赖…...