【Explain详解与索引优化最佳实践】
摘要
explain命令是查看MySQL查询优化器如何执行查询的主要方法,可以很好的分析SQL语句的执行情况。每当遇到执行慢(在业务角度)的SQL,都可以使用explain检查SQL的执行情况,并根据explain的结果相应的去调优SQL等。
要使用explain,只需在查询中的select前加上explain关键字。它会返回一行或多行信息,显示出执行计划中的每一部分和执行的次序。在查询中每个表在输出中占一行,如果查询是两个表的联接,那么输出中将有两行,因此如果一个表与自己联接,输出中也会有两行。表的含义在这里是一个很泛的含义:可以是一个子查询、一个union结果等。
Mysql安装文档参考:https://blog.csdn.net/yougoule/article/details/56680952
Explain工具介绍
使用EXPLAIN关键字可以模拟优化器执行SQL语句,分析你的查询语句或是结构的性能瓶颈,在 select 语句之前增加 explain 关键字,MySQL 会在查询上设置一个标记,执行查询会返回执行计划的信息,而不是执行这条SQL
注意:如果 from 中包含子查询,仍会执行该子查询,将结果放入临时表中
Explain分析示例
参考官方文档:https://dev.mysql.com/doc/refman/5.7/en/explain-output.html
示例表:
DROP TABLE IF EXISTS `actor`;
CREATE TABLE `actor` (`id` int(11) NOT NULL,`name` varchar(45) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,`update_time` datetime NULL DEFAULT NULL,PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;INSERT INTO `actor` VALUES (1, 'a', '0000-00-00 00:00:00');
INSERT INTO `actor` VALUES (2, 'b', '0000-00-00 00:00:00');
INSERT INTO `actor` VALUES (3, 'c', '0000-00-00 00:00:00');DROP TABLE IF EXISTS `film`;
CREATE TABLE `film` (`id` int(11) NOT NULL AUTO_INCREMENT,`name` varchar(10) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,PRIMARY KEY (`id`) USING BTREE,INDEX `idx_name`(`name`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 4 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;INSERT INTO `film` VALUES (3, 'film0');
INSERT INTO `film` VALUES (1, 'film1');
INSERT INTO `film` VALUES (2, 'film2');DROP TABLE IF EXISTS `film_actor`;
CREATE TABLE `film_actor` (`id` int(11) NOT NULL,`film_id` int(11) NOT NULL,`actor_id` int(11) NOT NULL,`remark` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,PRIMARY KEY (`id`) USING BTREE,INDEX `idx_film_actor_id`(`film_id`, `actor_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;INSERT INTO `film_actor` VALUES (1, 1, 1, NULL);
INSERT INTO `film_actor` VALUES (2, 1, 2, NULL);
INSERT INTO `film_actor` VALUES (3, 2, 1, NULL);
explain select * from actor;

在查询中的每个表会输出一行,如果有两个表通过 join 连接查询,那么会输出两行
explain 两个变种
1)explain extended:会在 explain 的基础上额外提供一些查询优化的信息。紧随其后通过 show warnings命令可以得到优化后的查询语句,从而看出优化器优化了什么。额外还有 filtered 列,是一个半分比的值,rows * filtered/100 可以估算出将要和 explain 中前一个表进行连接的行数(前一个表指 explain 中的id值比当前表id值小的表)。
explain extended select * from film where id = 1;

show warnings;

2)explain partitions:相比 explain 多了个 partitions 字段,如果查询是基于分区表的话,会显示查询将访问的分区。
explain中的列
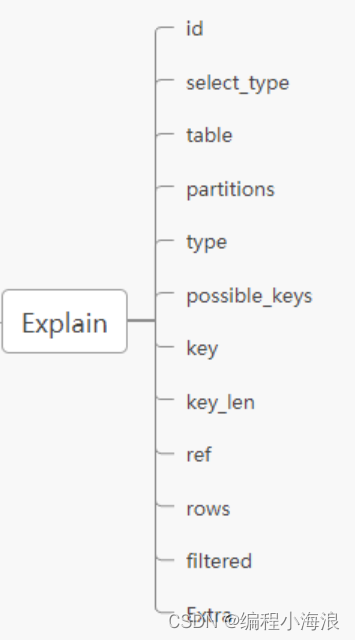
id:标识符
select_type:表示查询的类型
table:输出结果集的表
partitions:匹配的分区
type:表示表的连接类型
possible_keys:表示查询时,可能使用的索引
key:表示实际使用的索引
key_len:索引字段的长度
ref:列与索引的比较
rows:扫描出的行数(估算的行数)
filtered:按表条件过滤的行百分比
Extra:执行情况的描述和说明
接下来我们将展示 explain 中每个列的信息。
- id列
id列的编号是 select 的序列号,有几个 select 就有几个id,并且id的顺序是按 select 出现的顺序增长的。
id列越大执行优先级越高,id相同则从上往下执行,id为NULL最后执行。 - select_type列
select_type 表示对应行是简单还是复杂的查询。
1)simple:简单查询。查询不包含子查询和union
1 mysql> explain select * from film where id = 2;
2)primary:复杂查询中最外层的 select
3)subquery:包含在 select 中的子查询(不在 from 子句中)
4)derived:包含在 from 子句中的子查询。MySQL会将结果存放在一个临时表中,也称为派生表(derived的英文含义)
用这个例子来了解 primary、subquery 和 derived 类型
1 mysql> set session optimizer_switch=‘derived_merge=off’; #关闭mysql5.7新特性对衍生表的合并优化
2 mysql> explain select (select 1 from actor where id = 1) from (select * from film
where id = 1) der;
1 mysql> set session optimizer_switch=‘derived_merge=on’; #还原默认配置
5)union:在 union 中的第二个和随后的 select
1 mysql> explain select 1 union all select 1; - table列
这一列表示 explain 的一行正在访问哪个表。
当 from 子句中有子查询时,table列是格式,表示当前查询依赖 id=N 的查询,于是先执行id=N 的查询。
当有 union 时,UNION RESULT 的 table 列的值为<union1,2>,1和2表示参与 union 的 select 行id。 - partitions
官方定义为The matching partitions(匹配的分区),该字段看table所在的分区, 值为NULL表示表未被分区. - type列
这一列表示关联类型或访问类型,即MySQL决定如何查找表中的行,查找数据行记录的大概范围。
性能依次从最优到最差分别为:system > const > eq_ref > ref > range > index > ALL
一般来说,得保证查询达到range级别,最好达到ref
NULL:mysql能够在优化阶段分解查询语句,在执行阶段用不着再访问表或索引。例如:在索引列中选取最小
值,可以单独查找索引来完成,不需要在执行时访问表
1 mysql> explain select min(id) from film;
const, system:mysql能对查询的某部分进行优化并将其转化成一个常量(可以看show warnings 的结果)。
用于 primary key 或 unique key 的所有列与常数比较时,所以表最多有一个匹配行,读取1次,速度比较快。
system是const的特例,表里只有一条元组匹配时为system
1 mysql> explain extended select * from (select * from film where id = 1) tmp;
1 mysql> show warnings;
eq_ref:primary key 或 unique key 索引的所有部分被连接使用 ,最多只会返回一条符合条件的记录。这可能
是在 const 之外最好的联接类型了,简单的 select 查询不会出现这种 type。
explain select * from film_actor left join film on film_actor.film_id = fi
lm.id;
ref:相比 eq_ref,不使用唯一索引,而是使用普通索引或者唯一性索引的部分前缀,索引要和某个值相比较,
可能会找到多个符合条件的行。
简单 select 查询,name是普通索引(非唯一索引)
explain select * from film where name = 'film1';
2.关联表查询,idx_film_actor_id是film_id和actor_id的联合索引,这里使用到了film_actor的左边前缀film_id
部分。
explain select film_id from film left join film_actor on film.id = film_ac
tor.film_id;
range:范围扫描通常出现在 in(), between ,> ,<, >= 等操作中。使用一个索引来检索给定范围的行。
explain select * from actor where id > 1;
index:扫描全索引就能拿到结果,一般是扫描某个二级索引,这种扫描不会从索引树根节点开始快速查找,而是直接对二级索引的叶子节点遍历和扫描,速度还是比较慢的,这种查询一般为使用覆盖索引,二级索引一般比较小,所以这种通常比ALL快一些。
explain select * from film;
ALL:即全表扫描,扫描你的聚簇索引的所有叶子节点。通常情况下这需要增加索引来进行优化了。
explain select * from actor;
- possible_keys列
这一列显示查询可能使用哪些索引来查找。
explain 时可能出现 possible_keys 有列,而 key 显示 NULL 的情况,这种情况是因为表中数据不多,mysql认为索引对此查询帮助不大,选择了全表查询。
如果该列是NULL,则没有相关的索引。在这种情况下,可以通过检查 where 子句看是否可以创造一个适当的索引来提高查询性能,然后用 explain 查看效果。 - key列
这一列显示mysql实际采用哪个索引来优化对该表的访问。
如果没有使用索引,则该列是 NULL。如果想强制mysql使用或忽视possible_keys列中的索引,在查询中使用force index、ignore index。 - key_len列
这一列显示了mysql在索引里使用的字节数,通过这个值可以算出具体使用了索引中的哪些列。
举例来说,film_actor的联合索引 idx_film_actor_id 由 film_id 和 actor_id 两个int列组成,并且每个int是4字节。通过结果中的key_len=4可推断出查询使用了第一个列:film_id列来执行索引查找。
explain select * from film_actor where film_id = 2;
key_len计算规则如下:
字符串,char(n)和varchar(n),5.0.3以后版本中,n均代表字符数,而不是字节数,如果是utf-8,一个数字或字母占1个字节,一个汉字占3个字节
char(n):如果存汉字长度就是 3n 字节
varchar(n):如果存汉字则长度是 3n + 2 字节,加的2字节用来存储字符串长
度,因为varchar是变长字符串
数值类型
tinyint:1字节
smallint:2字节
int:4字节
bigint:8字节
时间类型
date:3字节
timestamp:4字节
datetime:8字节
如果字段允许为 NULL,需要1字节记录是否为 NULL
索引最大长度是768字节,当字符串过长时,mysql会做一个类似左前缀索引的处理,将前半部分的字符提取出来做索引。
9. ref列
这一列显示了在key列记录的索引中,表查找值所用到的列或常量,常见的有:const(常量),字段名(例:film.id)
10. rows列
根据表统计信息及索引选用情况大致估算出找到所需记录所要读取的行数. 当然该值越小越好。这一列是mysql估计要读取并检测的行数,注意这个不是结果集里的行数。
11. filtered
百分比值, 表示存储引擎返回的数据经过滤后, 剩下多少满足查询条件记录数量的比例。
12. Extra列
这一列展示的是额外信息。常见的重要值如下:
1)Using index:使用覆盖索引
覆盖索引定义:mysql执行计划explain结果里的key有使用索引,如果select后面查询的字段都可以从这个索引
的树中获取,这种情况一般可以说是用到了覆盖索引,extra里一般都有using index;覆盖索引一般针对的是辅
助索引,整个查询结果只通过辅助索引就能拿到结果,不需要通过辅助索引树找到主键,再通过主键去主键索引
树里获取其它字段值
explain select film_id from film_actor where film_id = 1;
2)Using where:使用 where 语句来处理结果,并且查询的列未被索引覆盖
explain select * from actor where name = 'a';
3)Using index condition:查询的列不完全被索引覆盖,where条件中是一个前导列的范围;
explain select * from film_actor where film_id > 1;
4)Using temporary:mysql需要创建一张临时表来处理查询。出现这种情况一般是要进行优化的,首先是想
到用索引来优化。
actor.name没有索引,此时创建了张临时表来distinct
explain select distinct name from actor;
film.name建立了idx_name索引,此时查询时extra是using index,没有用临时表
explain select distinct name from film;
5)Using filesort:将用外部排序而不是索引排序,数据较小时从内存排序,否则需要在磁盘完成排序。这种
情况下一般也是要考虑使用索引来优化的。
actor.name未创建索引,会浏览actor整个表,保存排序关键字name和对应的id,然后排序name并检索行记录
explain select * from actor order by name;
film.name建立了idx_name索引,此时查询时extra是using index
explain select * from film order by name;
6)Select tables optimized away:使用某些聚合函数(比如 max、min)来访问存在索引的某个字段是
explain select min(id) from film;
总结
explain包含的信息十分的丰富, 主要关注以下几个字段信息.
- id: select子句或表执行顺序, id相同, 从上到下执行, id不同, id值越大, 执行优先级越高.
- type: type主要取值及其表示sql的好坏程度(由好到差排序):system > const > eq_ref > ref > range > index > ALL. 保证range, 最好到ref.
- type:实际被使用的索引列.
- key:关联的字段, 常量等值查询, 显示为const, 如果为连接查询, 显示关联的字段.
- Extra: 额外信息, 使用优先级using index > using filesort > using temporary
相关文章:
【Explain详解与索引优化最佳实践】
摘要 explain命令是查看MySQL查询优化器如何执行查询的主要方法,可以很好的分析SQL语句的执行情况。每当遇到执行慢(在业务角度)的SQL,都可以使用explain检查SQL的执行情况,并根据explain的结果相应的去调优SQL等。 …...
【树和二叉树】数据结构二叉树和树的概念认识
前言:在之前,我们已经把栈和队列的相关概念以及实现的方法进行了学习,今天我们将认识一个新的知识“树”!!! 目录1.树概念及结构1.1树的概念1.2树的结构1.3树的相关概念1.4 树的表示1.5 树在实际中的运用&a…...

通达信收费接口查询可申购新股c++源码分享
有很多股民在做股票交易时为了实现盈利会借助第三三方炒股工具帮助自己,那么通达信收费接口就是人们常用到的,今天小编来分享一下通达信收费接口查询可申购新股c源码: std::cout << " 查询可申购新股: category 12 \n"; c…...
。)
【C#设计模式】创建型设计模式 (单例,工厂)。
c# 创建型设计模式 1.单例设计模式c# 单例JS 单例(ES6)c# 扩展方法c# 如果窗体非单例(tips:窗口可以容器化)2.工厂设计模式JS 简单工厂(ES6)C# 简单工厂C# params关键词(自定义参数个数)JS 手写JQuery(委托,工厂方式隐藏细节)JS ...四种用法C# 偷懒工厂1.单例设计模式 …...
Ubuntu 22.04 LTS 入门安装配置优化、开发软件安装一条龙
Ubuntu 22.04 LTS 入门安装配置&优化、开发软件安装 例行前言 最近在抉择手上空余的笔记本(X220 i7-2620M,Sk Hynix ddr3 8G*2 ,Samsung MINISATA 256G)拿来运行什么系统比较好,早年间我或许还会去继续使用Win…...
第五十章 动态规划——数位DP模型
第五十章 动态规划——数位DP模型一、什么是数位DP数位DP的识别数位DP的思路二、例题1、AcWing 1083. Windy数(数位DP)2、AcWing 1082. 数字游戏(数位DP)3、AcWing 1081. 度的数量(数位DP)一、什么是数位DP…...
02- pandas 数据库 (机器学习)
pandas 数据库重点: pandas 的主要数据结构: Series (一维数据)与 DataFrame (二维数据)。 pd.DataFrame(data np.random.randint(0,151,size (5,3)), # 生成pandas数据 index [Danial,Brandon,softpo,Ella,Cindy], # 行索引 …...

学Qt想系统的学习,看哪本书?
Qt 是一个跨平台应用开发框架(framework),它是用 C语言写的一套类库。使用 Qt 能为 桌面计算机、服务器、移动设备甚至单片机开发各种应用(application),特别是图形用户界面 (graphical user in…...
)
2023年网络安全比赛--跨站脚本攻击②中职组(超详细)
一、竞赛时间 180分钟 共计3小时 二、竞赛阶段 1.访问服务器网站目录1,根据页面信息完成条件,将获取到弹框信息作为flag提交; 2.访问服务器网站目录2,根据页面信息完成条件,将获取到弹框信息作为flag提交; 3.访问服务器网站目录3,根据页面信息完成条件,将获取到弹框信息…...

网络安全实验室4.注入关
4.注入关 1.最简单的SQL注入 url:http://lab1.xseclab.com/sqli2_3265b4852c13383560327d1c31550b60/index.php 查看源代码,登录名为admin 最简单的SQL注入,登录名写入一个常规的注入语句: admin’ or ‘1’1 密码随便填,验证…...

领域搜索算法之经典The Lin-Kernighan algorithm
领域搜索算法之经典The Lin-Kernighan algorithmThe Lin-Kernighan algorithm关于算法性能提升的约束参考文献领域搜索算法是TSP问题中的三大经典搜索算法之一,另外两种分别是回路构造算法和组合算法。 而这篇文章要介绍的The Lin-Kernighan algorithm属于领域搜索算…...

深度学习基础-机器学习基本原理
本文大部分内容参考《深度学习》书籍,从中抽取重要的知识点,并对部分概念和原理加以自己的总结,适合当作原书的补充资料阅读,也可当作快速阅览机器学习原理基础知识的参考资料。 前言 深度学习是机器学习的一个特定分支。我们要想…...

C语言操作符详解 一针见血!
目录算数操作符移位操作符位操作符赋值操作符单目操作符关系操作符逻辑操作符条件操作符逗号表达式下标引用、函数调用和结构成员表达式求值11.1 隐式类型转换算数操作符💭 注意/ 除法 --得到的是商% 取模(取余)--得到的是余数如果除法操作符…...
前端面试题汇总
一:JavaScript 1、闭包是什么?利弊?如何解决弊端? 闭包是什么:JS中内层函数可以访问外层函数的变量,外层函数无法操作内存函数的变量的特性。我们把这个特性称作闭包。 闭包的好处: 隔离作用…...

以数据驱动管理场景,低代码助力转型下一站
数据驱动 数据驱动,是通过移动互联网或者其他的相关软件为手段采集海量的数据,将数据进行组织形成信息,之后对相关的信息讲行整合和提炼,在数据的基础上经过训练和拟合形成自动化的决策模型,简单来说,就是…...

2023年全国数据治理DAMA-CDGA/CDGP考试报名到弘博创新
弘博创新是DAMA中国授权的数据治理人才培养基地,贴合市场需求定制教学体系,采用行业资深名师授课,理论与实践案例相结合,快速全面提升个人/企业数据治理专业知识与实践经验,通过考试还能获得数据专业领域证书。 DAMA认…...

流程控制之循环
文章目录五、流程控制之循环5.1 步进循环语句for5.1.1 带列表的for循环语句5.1.2 不带列表的for循环语句5.1.3 类C风格的for循环语句5.2 while循环语句5.2.1 while循环读取文件5.2.2 while循环语句示例5.3 until循环语句5.4 select循环语句5.5 嵌套循环5.4 利用break和continue…...
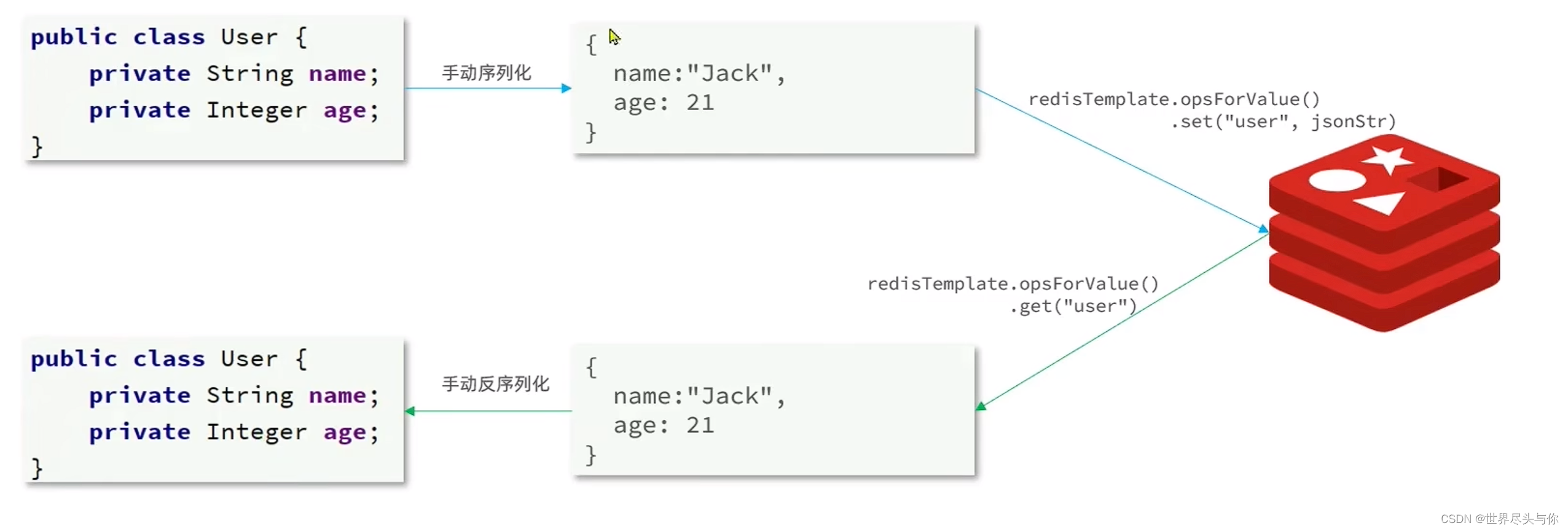
SpringDataRedis快速入门
SpringDataRedis快速入门1.SpringDataRedis简介2.RedisTemplate快速入门3.RedisSerializer4.StringRedisTemplate1.SpringDataRedis简介 SpringData是Spring中数据操作的模块,包含对各种数据库的集成,其中对Redis的集成模块就叫做SpringDataRedis Spri…...

MySQL 的执行计划 explain 详解
目录 什么是执行计划 执行计划的内容 select子句的类型 访问类型 索引的存在形式...
2023年网络安全比赛--Web综合渗透测试中职组(超详细)
一、竞赛时间 180分钟 共计3小时 二、竞赛阶段 1.通过URL访问http://靶机IP/1,对该页面进行渗透测试,将完成后返回的结果内容作为FLAG值提交; 2.通过URL访问http://靶机IP/2,对该页面进行渗透测试,将完成后返回的结果内容作为FLAG值提交; 3.通过URL访问http://靶机IP/3,对…...

如何快速搭建AI聊天前端:SillyTavern完整教程与角色扮演系统指南
如何快速搭建AI聊天前端:SillyTavern完整教程与角色扮演系统指南 【免费下载链接】SillyTavern LLM Frontend for Power Users. 项目地址: https://gitcode.com/GitHub_Trending/si/SillyTavern 想象一下,你能够与任何AI角色进行沉浸式对话&#…...

音频变压器关键参数深度解析:Z值与最大电流的工程实践
音频变压器关键参数深度解析:Z值与最大电流的工程实践引言在专业音频系统、高保真音响以及工业信号隔离场景中,音频变压器始终扮演着不可替代的角色。它的核心使命是在保持信号完整性的同时,完成阻抗匹配、地环路隔离和信号平衡转换三大任务。…...

WPF中OxyPlot不同图表的使用
在 WPF 中使用 OxyPlot 实现不同图表,核心在于创建和配置PlotModel对象,并将其绑定到PlotView控件上进行显示。通过向PlotModel中添加不同类型的Series(数据系列),即可轻松实现折线图、柱状图、饼图、散点图等多种图表…...

RAD-NeRF:面向实时人像合成的神经辐射场高效架构
1. 项目概述:当NeRF遇上实时人像,RAD-NeRF到底在解决什么问题?我第一次看到“Efficient NeRFs for Real-Time Portrait Synthesis (RAD-NeRF)”这个标题时,手边正调试一个跑在RTX 4090上的标准NeRF模型——单帧渲染耗时23秒&#…...
)
斐讯K3从梅林‘变砖’到官复原职:一个手残党的硬核救砖全记录(附TTL/编程器操作避坑点)
斐讯K3救砖实战:从梅林固件崩溃到完美恢复的完整指南 1. 当路由器变成"砖头":一个普通用户的崩溃瞬间 那是一个普通的周末下午,我正兴冲冲地准备给我的斐讯K3刷上梅林固件,幻想着能获得更强大的功能和更稳定的性能。按照…...

Flair NLP框架:从入门到精通的7步完整学习指南 [特殊字符]
Flair NLP框架:从入门到精通的7步完整学习指南 🚀 【免费下载链接】flair A very simple framework for state-of-the-art Natural Language Processing (NLP) 项目地址: https://gitcode.com/gh_mirrors/fl/flair Flair是一个简单而强大的自然语…...

知识竞赛软件高可用架构解析:主备切换与故障自愈如何保障业务连续
🏗️ 知识竞赛软件的高可用架构主备切换与故障自愈之道📌 引言在数字化竞赛时代,一场线上知识竞赛的参与者可能遍布全国,任何系统中断都可能导致活动失败、体验受损。因此,构建一个具备高可用性的知识竞赛平台…...

从零手写CNN:理解卷积网络的生物学原理与工程逻辑
1. 项目概述:从人眼到机器之眼,一次真实的视觉理解之旅你有没有盯着一张照片发过呆?比如朋友刚发来的旅行照——蓝天、雪山、一只歪头的雪豹。你几乎是一瞬间就认出了“雪豹”,甚至能判断它“在看镜头”“毛很厚”“可能刚睡醒”。…...

终极指南:3分钟学会在Windows电脑上安装安卓应用
终极指南:3分钟学会在Windows电脑上安装安卓应用 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾经想过在Windows电脑上直接运行手机应用ÿ…...

从U盘到移动硬盘:深入拆解USB存储设备里的BOT和UASP协议栈
从U盘到移动硬盘:深入拆解USB存储设备里的BOT和UASP协议栈 当你将一块移动固态硬盘插入电脑的USB 3.2接口,期待每秒上千兆字节的传输速度时,是否想过这背后隐藏着怎样的协议魔法?在USB存储设备的世界里,BOT(…...