【人工智能前沿弄潮】——生成式AI系列:Diffusers学习(1)了解Pipeline 、模型和scheduler
Diffusers旨在成为一个用户友好且灵活的工具箱,用于构建针对您的用例量身定制的扩散系统。工具箱的核心是模型和scheduler。虽然DiffusionPipeline为了方便起见将这些组件捆绑在一起,但您也可以拆分管道并单独使用模型和scheduler来创建新的扩散系统。
在本教程中,您将学习如何使用模型和scheduler来组装用于推理的扩散系统,从基本管道开始,然后发展到稳定扩散管道。
1、解构Diffusion Model基本Pipeline
Pipeline是运行模型进行推理的一种快速简便的方法,生成图像需要不超过四行代码:
from diffusers import DDPMPipelineddpm = DDPMPipeline.from_pretrained("google/ddpm-cat-256").to("cuda")
image = ddpm(num_inference_steps=25).images[0]
image
这非常容易,但是Pipeline是怎么做到的呢?让我们分解Pipeline,看看发生了什么。
在上面的示例中,管道包含一个UNet2DModel模型和一个DDPMScheduler。
Pipeline通过获取所需输出大小的随机噪声并将其多次传递到模型中来对图像进行去噪。在每个时间步,模型预测噪声残余,scheduler使用它来预测噪声较小的图像。Pipeline重复此过程,直到到达指定数量的推理步骤的末尾。
要分别使用模型和scheduler重新创建Pipeline,让我们编写自己的去噪过程。

- 加载模型和scheduler:
from diffusers import DDPMScheduler, UNet2DModelscheduler = DDPMScheduler.from_pretrained("google/ddpm-cat-256")
model = UNet2DModel.from_pretrained("google/ddpm-cat-256").to("cuda")
- 设置运行去噪过程的时间步数:
scheduler.set_timesteps(50)
- 设置scheduler时间步长会创建一个张量,其中包含均匀间隔的元素,在本例中为50。每个元素对应于模型对图像进行去噪的时间步长。稍后创建去噪循环时,您将迭代此张量以对图像进行去噪:
scheduler.timesteps
tensor([980, 960, 940, 920, 900, 880, 860, 840, 820, 800, 780, 760, 740, 720,700, 680, 660, 640, 620, 600, 580, 560, 540, 520, 500, 480, 460, 440,420, 400, 380, 360, 340, 320, 300, 280, 260, 240, 220, 200, 180, 160,140, 120, 100, 80, 60, 40, 20, 0])
- 创建一些与所需输出形状相同的随机噪声:
import torchsample_size = model.config.sample_size
noise = torch.randn((1, 3, sample_size, sample_size)).to("cuda")
- 现在编写一个循环来迭代时间步长。在每个时间步长,模型都会进行UNet2DModel.forward() 传递并返回带噪声的残差。scheduler的 step()方法接受带噪声的残差、时间步长和输入,并预测前一个时间步长的图像。该输出成为去噪循环中模型的下一个输入,它会重复,直到到达时间步长数组的末尾。
input = noisefor t in scheduler.timesteps:with torch.no_grad():noisy_residual = model(input, t).sampleprevious_noisy_sample = scheduler.step(noisy_residual, t, input).prev_sampleinput = previous_noisy_sample
这是整个去噪过程,您可以使用相同的模式来编写任何扩散系统。
- 最后一步是将去噪输出转换为图像:
from PIL import Image
import numpy as npimage = (input / 2 + 0.5).clamp(0, 1)
image = image.cpu().permute(0, 2, 3, 1).numpy()[0]
image = Image.fromarray((image * 255).round().astype("uint8"))
image
在下一节中,您将测试您的技能,并分解更复杂的稳定扩散Pipeline。步骤或多或少是一样的。您将初始化必要的组件,并设置时间步数来创建时间步数数组。时间步数数组用于去噪循环,对于该数组中的每个元素,模型预测噪声较小的图像。去噪循环在时间步上迭代,在每个时间步上,它输出一个嘈杂的残差,scheduler使用它来预测前一个时间步上噪声较小的图像。重复此过程,直到到达时间步长数组的末尾。 我们来试试看吧!
2、解构Stable Diffusion pipeline
Stable Diffusion是一种文本到图像的潜在扩散模型。它被称为潜在扩散模型,因为它使用图像的低维表示而不是实际的像素空间,这使得它的内存效率更高。编码器将图像压缩成更小的表示,解码器将压缩的表示转换回图像。对于文本到图像模型,您需要一个标记器和一个编码器来生成文本嵌入。从前面的例子中,您已经知道您需要一个UNet模型和一个Scheduler。
如您所见,这已经比仅包含UNet模型的DDPM管道更复杂。Stable Diffusion模型有三个独立的预训练模型。
💡 阅读 How does Stable Diffusion work?了解有关VAE、UNet和文本编码器模型的更多详细信息。
现在您知道Stable Diffusion pipeline需要什么了,使用from_pretrained()方法加载所有这些组件。您可以在预训练的runwayml/stable-diffusion-v1-5checkpoint中找到它们,每个组件都存储在单独的子文件夹中:
from PIL import Image
import torch
from transformers import CLIPTextModel, CLIPTokenizer
from diffusers import AutoencoderKL, UNet2DConditionModel, PNDMSchedulervae = AutoencoderKL.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="vae")
tokenizer = CLIPTokenizer.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="tokenizer")
text_encoder = CLIPTextModel.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="text_encoder")
unet = UNet2DConditionModel.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="unet")
代替默认的PNDMScheduler,将其换成UniPCMultistepScheduler,看看插入不同的Scheduler有多容易:
from diffusers import UniPCMultistepSchedulerscheduler = UniPCMultistepScheduler.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="scheduler")
为了加快推理速度,请将模型移动到GPU,因为与调度程序不同,它们具有可训练的权重:
torch_device = "cuda"
vae.to(torch_device)
text_encoder.to(torch_device)
unet.to(torch_device)
2.1 创建文本嵌入
下一步是标记文本以生成embedding。文本用于调节UNet模型并将扩散过程引导到类似于输入提示符的东西。
💡注: guidance_scale参数决定了在生成图像时应该给prompt多少权重。
如果您想生成其他内容,请随意选择您喜欢的任何prompt!
prompt = ["a photograph of an astronaut riding a horse"]
height = 512 # default height of Stable Diffusion
width = 512 # default width of Stable Diffusion
num_inference_steps = 25 # Number of denoising steps
guidance_scale = 7.5 # Scale for classifier-free guidance
generator = torch.manual_seed(0) # Seed generator to create the inital latent noise
batch_size = len(prompt)
标记文本并从提示生成embeddings :
text_input = tokenizer(prompt, padding="max_length", max_length=tokenizer.model_max_length, truncation=True, return_tensors="pt"
)with torch.no_grad():text_embeddings = text_encoder(text_input.input_ids.to(torch_device))[0]
您还需要生成**无条件文本embeddings **,它们是填充标记的embeddings 。这些需要具有与条件text_embeddings相同的形状(batch_size和seq_length):
max_length = text_input.input_ids.shape[-1]
uncond_input = tokenizer([""] * batch_size, padding="max_length", max_length=max_length, return_tensors="pt")
uncond_embeddings = text_encoder(uncond_input.input_ids.to(torch_device))[0]
让我们将条件和无条件嵌入连接到一个批处理中,以避免进行两次前向传递:
text_embeddings = torch.cat([uncond_embeddings, text_embeddings])
2.2 制造随机噪音
接下来,生成一些初始随机噪声作为扩散过程的起点。这是图像的潜在表示(latent representation),它将逐渐去噪。在这一点上,潜在图像小于最终图像尺寸,但没关系,因为模型稍后会将其转换为最终的512x512图像尺寸。
💡注: 高度和宽度除以8,因为vae模型有3个下采样层。您可以通过运行以下命令来检查:
2 ** (len(vae.config.block_out_channels) - 1) == 8
latents = torch.randn((batch_size, unet.in_channels, height // 8, width // 8),generator=generator,
)
latents = latents.to(torch_device)
2.3 去噪图像
首先使用**初始噪声分布sigma(噪声标度值)**缩放输入,这是改进scheduler(如UniPCMultistepScheduler)所必需的:
latents = latents * scheduler.init_noise_sigma
最后一步是创建去噪循环,将潜在的纯噪声逐步转换为提示所描述的图像。记住,去噪循环需要做三件事:
- 设置在去噪期间使用的scheduler的时间步长。
- 迭代时间步长。
- 在每个时间步,调用UNet模型来预测噪声残余并将其传递给scheduler以计算先前的噪声样本。
from tqdm.auto import tqdmscheduler.set_timesteps(num_inference_steps)for t in tqdm(scheduler.timesteps):# 如果我们正在进行无分类器引导以避免进行两次前向传递,则扩展latents。latent_model_input = torch.cat([latents] * 2)latent_model_input = scheduler.scale_model_input(latent_model_input, timestep=t)# 预测噪声残余with torch.no_grad():noise_pred = unet(latent_model_input, t, encoder_hidden_states=text_embeddings).sample# 执行guidancenoise_pred_uncond, noise_pred_text = noise_pred.chunk(2)noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)# 计算先前的噪声样本x_t->x_t-1latents = scheduler.step(noise_pred, t, latents).prev_sample
2.4 解码图像
最后一步是使用vae将潜在表示解码为图像并获得带有样本的解码输出:
# 用vae缩放和解码图像latents
latents = 1 / 0.18215 * latents
with torch.no_grad():image = vae.decode(latents).sample
最后,将图像转换为PIL. Image以查看您生成的图像!
image = (image / 2 + 0.5).clamp(0, 1)
image = image.detach().cpu().permute(0, 2, 3, 1).numpy()
images = (image * 255).round().astype("uint8")
pil_images = [Image.fromarray(image) for image in images]
pil_images[0]

相关文章:
【人工智能前沿弄潮】——生成式AI系列:Diffusers学习(1)了解Pipeline 、模型和scheduler
Diffusers旨在成为一个用户友好且灵活的工具箱,用于构建针对您的用例量身定制的扩散系统。工具箱的核心是模型和scheduler。虽然DiffusionPipeline为了方便起见将这些组件捆绑在一起,但您也可以拆分管道并单独使用模型和scheduler来创建新的扩散系统。 …...

TypeScript 非空断言
TypeScript 非空断言 发布于 2020-04-08 15:20:15 17.5K0 举报 一、非空断言有啥用 介绍非空断言前,先来看个示例: function sayHello(name: string | undefined) {let sname: string name; // Error } 对于以上代码,TypeScript 编译器…...

Python编程——谈谈函数的定义、调用与传入参数
作者:Insist-- 个人主页:insist--个人主页 本文专栏:Python专栏 专栏介绍:本专栏为免费专栏,并且会持续更新python基础知识,欢迎各位订阅关注。 目录 一、理解函数 二、函数的定义 1、语法 2、定义一个…...
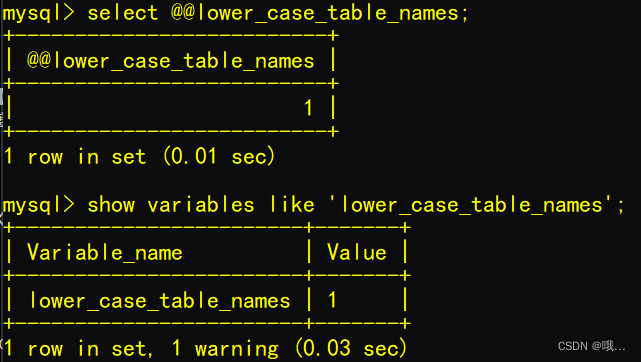
在Ubuntu中使用Docker启动MySQL8的天坑
写在前面 简介: lower_case_table_names 是mysql设置大小写是否敏感的一个参数。 1.参数说明: lower_case_table_names0 表名存储为给定的大小和比较是区分大小写的 lower_case_table_names 1 表名存储在磁盘是小写的,但是比较的时候是不区…...

Python3.x String内置函数大全
文章目录 总结一下Python3.x字符串的常用系统函数,总共分为8类1. 大小写字母转换类的函数str.capitalize()str.title()str.lower()str.upper()str.swapcase() 2. 统计类的函数str.count(str1, beg 0,endlen(string)) 3. 匹配类的函数str.endswith(suffix, beg0, end…...

Go异常处理机制panic和recover
recover 使用panic抛出异常后, 将立即停止当前函数的执行并运行所有被defer的函数,然后将panic抛向上一层,直至程序crash。但是也可以使用被defer的recover函数来捕获异常阻止程序的崩溃,recover只有被defer后才是有意义的。 func main() { p…...
QMainwindow窗口
QMainwindow窗口 菜单栏在二级菜单中输入中文的方法给菜单栏添加相应的动作使用QMenu类的API方法添加菜单项分隔符也是QAction类 工具栏状态栏停靠窗口 菜单栏 只能有一个, 位于窗口的最上方 关于顶级菜单可以直接在UI窗口中双击, 直接输入文本信息即可, 对应子菜单项也可以通…...

P5735 【深基7.例1】距离函数
题目描述 给出平面坐标上不在一条直线上三个点坐标 ( x 1 , y 1 ) , ( x 2 , y 2 ) , ( x 3 , y 3 ) (x_1,y_1),(x_2,y_2),(x_3,y_3) (x1,y1),(x2,y2),(x3,y3),坐标值是实数,且绝对值不超过 100.00,求围成的三角形周长。保留两…...
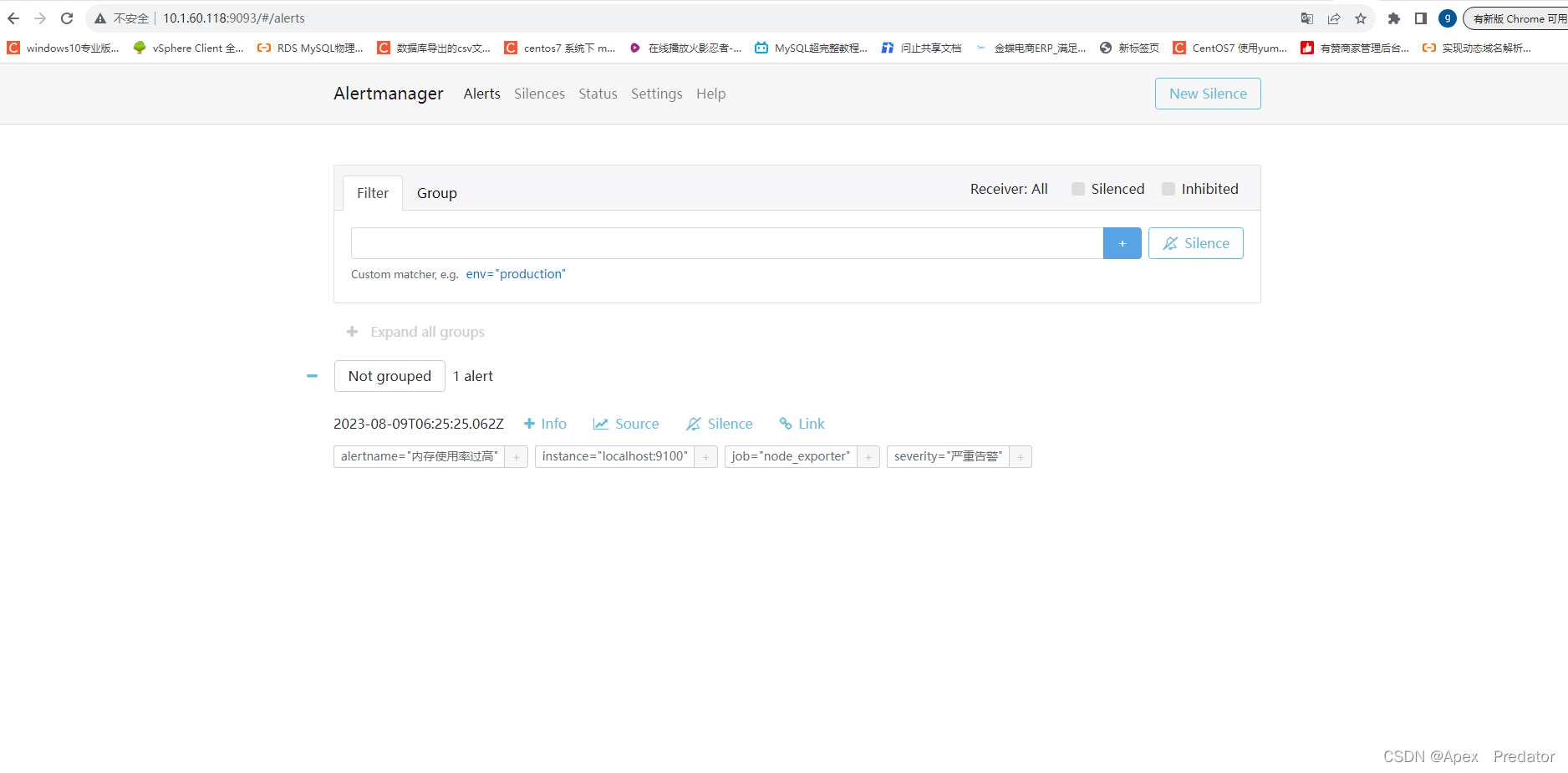
prometheus告警发送组件部署
一、前言 要实现Prometheus的告警发送需要通过alertmanager组件,当prometheus触发告警策略时,会将告警信息发送给alertmanager,然后alertmanager根据配置的策略发送到邮件或者钉钉中,发送到钉钉需要安装额外的prometheus-webhook…...

CAPL - XML和TestModule结合实现测试项可选
目录 目的:是否想实现如下面的功能呢? 一、.can和.cin文件中函数开发...

Latex安装与环境配置(TeXlive、TeXstudio与VS code的安装)编译器+编辑器与学习应用
TeXlive 配置Tex排版系统需要安装编译器+编辑器。TeX 的源代码是后缀为 .tex 的纯文本文件。使用任意纯文本编辑器,都可以修改 .tex 文件:包括 Windows 自带的记事本程序,也包括专为 TeX 设计的编辑器(TeXworks, TeXmaker, TeXstudio, WinEdt 等),还包括一些通用的文本编…...
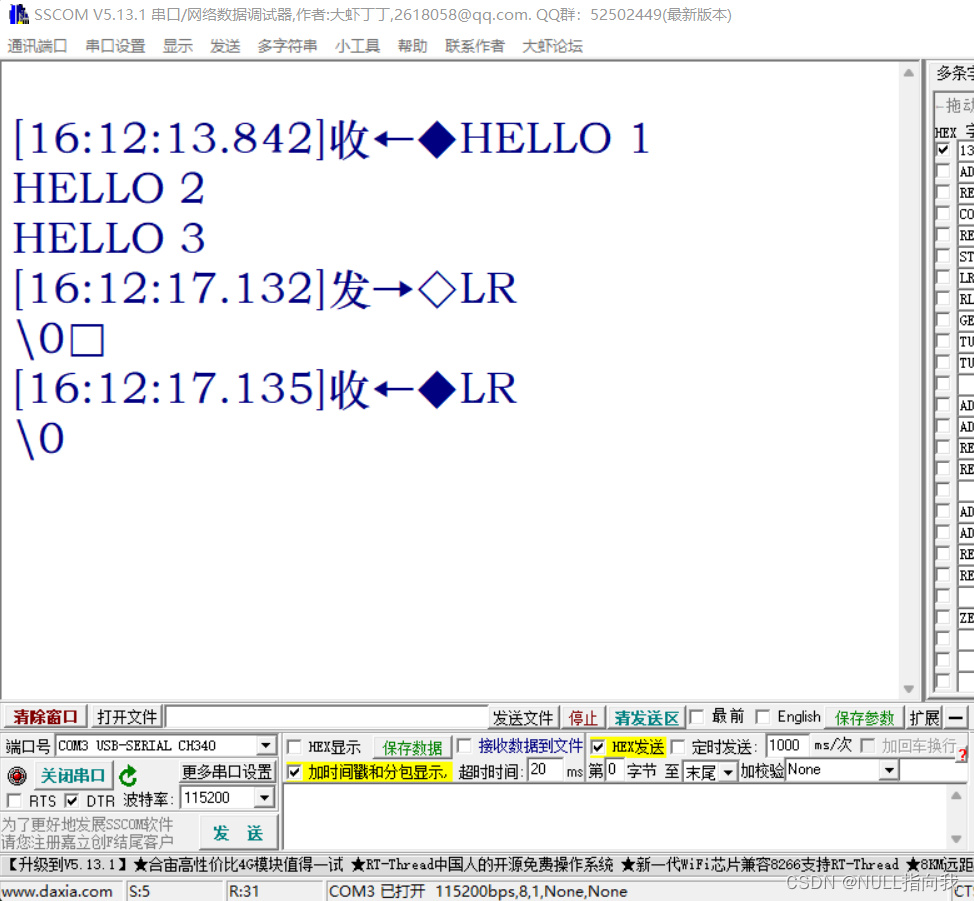
STM32 F103C8T6学习笔记3:串口配置—串口收发—自定义Printf函数
今日学习使用STM32 C8T6的串口,我们在经过学习笔记2的总结归纳可知,STM32 C8T6最小系统板上有三路串口,如下图: 今日我们就着手学习如何配置开通这些串口进行收发,这里不讲串口通信概念与基础,可以自行网上…...

python中字符串内建函数篇4
一、ljust() 语法:str.ljust(width,[fillchar]) 参数说明: width – 指定字符串长度。 fillchar – 填充字符,默认为空格。 返回值:返回一个原字符串左对齐,并使用空格填充至长度 width 的新字符串。如果指定的长度小于原字符串…...

并发下如何使用redis存储列表数据
1、问题 今天在工作中遇到一个问题,需要查询表A,需要根据每天所处小时所在时段,返回不同的记录给前端展示,如0-2时是在昨日0到2时生成的记录,而2-4时则是在昨日2-4时生成的记录,每条记录有一个唯一的id。表…...

Leecode螺旋矩阵 II59
59.螺旋矩阵II 题目建议: 本题关键还是在转圈的逻辑,在二分搜索中提到的区间定义,在这里又用上了。 题目链接:力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台 文章讲解:代码随想录 视频…...

echarts 横向柱状图
<template><div ref"chart" style"height: 100%"></div> </template><script> import * as echarts from "echarts"; var cate ["质量通病1", "质量通病2", "质量通病3", "质…...

Vue3 —— to 全家桶及源码学习
该文章是在学习 小满vue3 课程的随堂记录示例均采用 <script setup>,且包含 typescript 的基础用法 前言 本篇主要学习几个 api 及相关源码: toReftoRefstoRaw 一、toRef toRef(reactiveObj, key) 接收两个参数,第一个是 响应式对象…...
 ansible-kubeadm在线安装高可以用集群())
(第三篇) ansible-kubeadm在线安装高可以用集群()
ansible可以安装的KS8版本如下: 请按照此博客中的内容操作后,才可以通过下面的命令查询到版本。 [rootk8s-master01 ~]# yum list kubectl --showduplicates | sort -r kubectl.x86_64 1.20.0-0 kubern…...

flutter开发实战-颜色Color与16进制转换
flutter开发实战-颜色Color与16进制转换 一、颜色Color与16进制转换 代码如下 import dart:ui; class ColorUtil {/// 十六进制颜色,/// hex, 十六进制值,例如:0xffffff,/// alpha, 透明度 [0.0,1.0]static Color hexColor(int hex, {doub…...
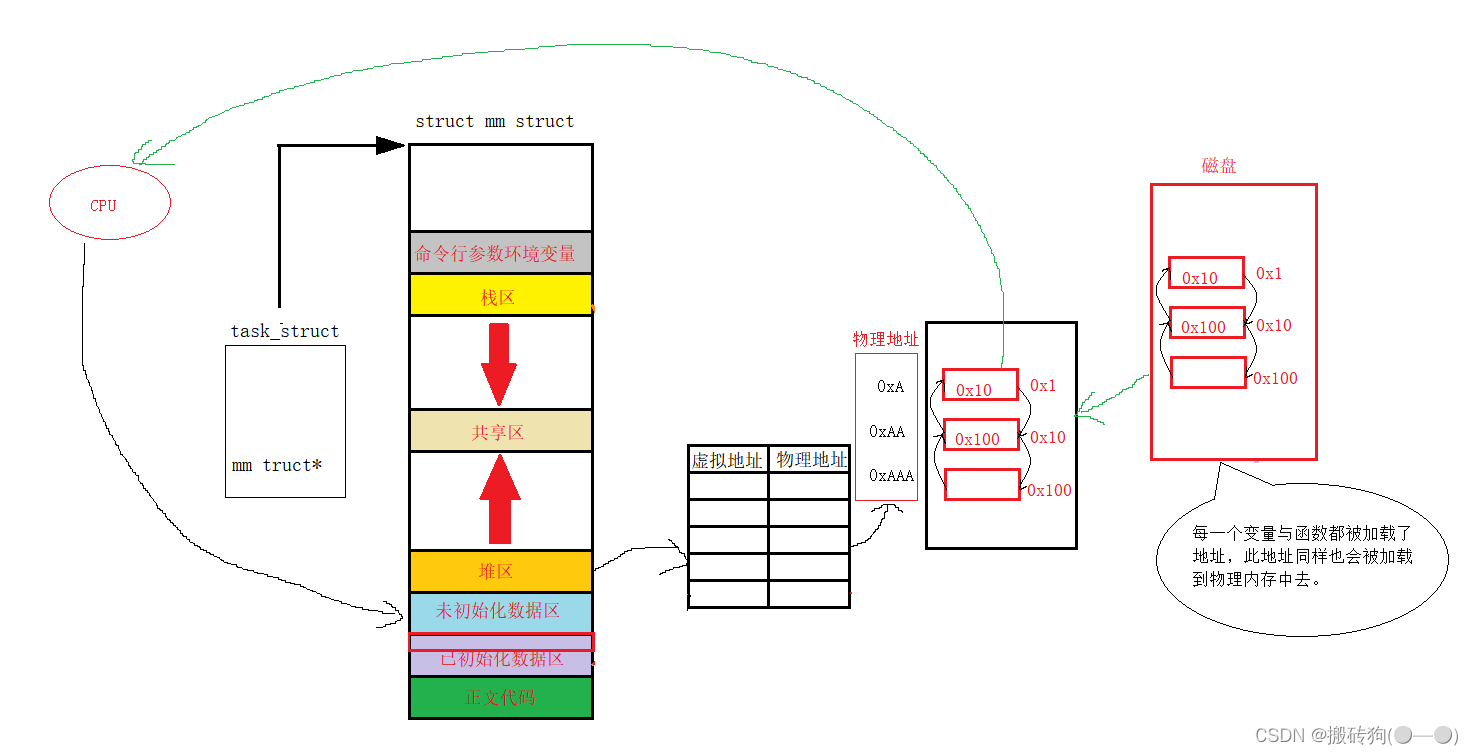
Linux(进程地址空间)
进程地址空间 程序地址空间进程地址空间 程序地址空间 在Linux环境下,我们可以对上述程序空间地址进行验证: 运行程序,可以看到,我们就可以很好看出程序的地址空间的排布了: 进程地址空间 严格来说,我们…...

接收迭代器begin函数的返回值为什么只能是复制
思考:代码为什么编译报错#include <iostream> #include <vector> #include <algorithm>vector<string> v4 {"null", "null", "null", "null", "null"}; fill_n(v4.begin(), 2, "h…...
** 已)
**发散创新:服务端渲染实战优化——从基础到高性能架构设计**在现代前端开发中,**服务端渲染(SSR)** 已
发散创新:服务端渲染实战优化——从基础到高性能架构设计 在现代前端开发中,服务端渲染(SSR) 已成为提升 SEO 和首屏加载速度的关键技术。尤其是在 Vue.js 和 React 生态中,SSR 不再是“可选项”,而是构建企…...

HoYo-Glyphs:米哈游游戏字体库终极指南,11款开源架空文字字体让你的创作瞬间拥有游戏世界氛围
HoYo-Glyphs:米哈游游戏字体库终极指南,11款开源架空文字字体让你的创作瞬间拥有游戏世界氛围 【免费下载链接】HoYo-Glyphs Constructed scripts by HoYoverse 米哈游的架空文字 项目地址: https://gitcode.com/gh_mirrors/ho/HoYo-Glyphs 你是否…...

突破信息壁垒:Bypass Paywalls Clean的非典型应用指南
突破信息壁垒:Bypass Paywalls Clean的非典型应用指南 在信息自由日益受到限制的数字时代,内容解锁工具成为知识获取的重要桥梁。Bypass Paywalls Clean作为一款开源浏览器扩展,以其轻量高效的特性,为用户提供了突破付费内容限制的…...

分割函数 UF_MODL_split_body 的用法代码
#include <uf_modl.h> #include <uf_obj.h> double corner_pt[3]{0,0,0}; //定位极点 char * edge_len[3]{"5","10","15"}; //大小(x,y,z) tag_t blk_tag; UF_MODL_create_block1(UF_N…...

C++ 入门学习经验 02—— 新手最容易遇到的几个问题以及如何解决
大家好啊!这里是阳阳的博客,一个正在努力学习技术的大学生。上一篇和大家聊了刚接触 C 时的环境搭建、学习路径和心态问题,收到了很多同学的共鸣。所以今天这第二篇,我想继续沿着新手学习时的路线,来和大家聊聊刚学 C …...

【数据库系统】数据库系统概论——第十二章 数据库管理系统
第十二章 数据库管理系统 文章目录 第十二章 数据库管理系统 12.1数据库管理系统的基本功能 12.2数据库管理系统的系统结构 12.2.1数据库管理系统的层次结构 12.2.2关系数据库管理系统的运行过程示例 12.3语言处理层 12.3.1语言处理层的任务和工作步骤 12.3.2解释方法 12.3.3预…...

[特殊字符] 第88课:目标和
想系统提升编程能力、查看更完整的学习路线,欢迎访问 AI Compass:https://github.com/tingaicompass/AI-Compass 仓库持续更新刷题题解、Python 基础和 AI 实战内容,适合想高效进阶的你。 📖 第88课:目标和 模块:动态规划 | 难度:…...

Glide:Android图片加载的瑞士军刀,真的有这么神?
Glide:Android图片加载的瑞士军刀,真的有这么神? Glide 是什么,为何选择它 在 Android 开发的世界里,图片加载是一个绕不开的重要环节。想象一下,在一个社交类 APP 中,用户的头像、发布的照片&a…...

从报告看懂安全隐患,提升防护能力
渗透测试报告不仅是“漏洞清单”,更是企业提升安全防护能力的“行动指南”。很多企业拿到报告后,只关注漏洞数量,却不知道如何解读隐患、落地整改,最终导致测试流于形式,安全风险依然存在。下面通俗拆解,教…...