2.CUDA 编程手册中文版---编程模型
2.编程模型
更多精彩内容,请扫描下方二维码或者访问https://developer.nvidia.com/zh-cn/developer-program
来加入NVIDIA开发者计划

本章通过概述CUDA编程模型是如何在c++中公开的,来介绍CUDA的主要概念。
编程接口中给出了对 CUDA C++ 的广泛描述。
本章和下一章中使用的向量加法示例的完整代码可以在 vectorAddCUDA示例中找到。
2.1 内核
CUDA C++ 通过允许程序员定义称为Kernel的 C++ 函数来扩展 C++,当调用内核时,由 N 个不同的 CUDA 线程并行执行 N 次,而不是像常规 C++ 函数那样只执行一次。
使用 __global__ 声明说明符定义内核,并使用新的 <<<...>>> 执行配置语法指定内核调用的 CUDA 线程数(请参阅 C++语言扩展)。 每个执行内核的线程都有一个唯一的线程 ID,可以通过内置变量在内核中访问。
作为说明,以下示例代码使用内置变量 threadIdx 将两个大小为 N 的向量 A 和 B 相加,并将结果存储到向量 C 中:
// Kernel definition__global__ void VecAdd(float* A, float* B, float* C){int i = threadIdx.x;C[i] = A[i] + B[i];}int main(){...// Kernel invocation with N threadsVecAdd<<<1, N>>>(A, B, C);...}
这里,执行 VecAdd() 的 N 个线程中的每一个线程都会执行一个加法。
2.2 线程层次
为方便起见,threadIdx 是一个 3 分量向量,因此可以使用一维、二维或三维的线程索引来识别线程,形成一个一维、二维或三维的线程块,称为block。这提供了一种跨域的元素(例如向量、矩阵或体积)调用计算的方法。
线程的索引和它的线程 ID 以一种直接的方式相互关联:对于一维块,它们是相同的; 对于大小为(Dx, Dy)的二维块,索引为(x, y)的线程的线程ID为(x + yDx); 对于大小为 (Dx, Dy, Dz) 的三维块,索引为 (x, y, z) 的线程的线程 ID 为 (x + yDx + zDxDy)。
例如,下面的代码将两个大小为NxN的矩阵A和B相加,并将结果存储到矩阵C中:
// Kernel definition__global__ void MatAdd(float A[N][N], float B[N][N],float C[N][N]){int i = threadIdx.x;int j = threadIdx.y;C[i][j] = A[i][j] + B[i][j];}int main(){...// Kernel invocation with one block of N * N * 1 threadsint numBlocks = 1;dim3 threadsPerBlock(N, N);MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);...}
每个块的线程数量是有限制的,因为一个块的所有线程都应该驻留在同一个处理器核心上,并且必须共享该核心有限的内存资源。在当前的gpu上,一个线程块可能包含多达1024个线程。
但是,一个内核可以由多个形状相同的线程块执行,因此线程总数等于每个块的线程数乘以块数。
块被组织成一维、二维或三维的线程块网格(grid),如下图所示。网格中的线程块数量通常由正在处理的数据的大小决定,通常超过系统中的处理器数量。

<<<...>>> 语法中指定的每个块的线程数和每个网格的块数可以是 int或 dim3 类型。如上例所示,可以指定二维块或网格。
网格中的每个块都可以由一个一维、二维或三维的惟一索引标识,该索引可以通过内置的blockIdx变量在内核中访问。线程块的维度可以通过内置的blockDim变量在内核中访问。
扩展前面的MatAdd()示例来处理多个块,代码如下所示。
// Kernel definition__global__ void MatAdd(float A[N][N], float B[N][N],float C[N][N]){int i = blockIdx.x * blockDim.x + threadIdx.x;int j = blockIdx.y * blockDim.y + threadIdx.y;if (i < N && j < N)C[i][j] = A[i][j] + B[i][j];}int main(){...// Kernel invocationdim3 threadsPerBlock(16, 16);dim3 numBlocks(N / threadsPerBlock.x, N / threadsPerBlock.y);MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);...}
线程块大小为16x16(256个线程),尽管在本例中是任意更改的,但这是一种常见的选择。网格是用足够的块创建的,这样每个矩阵元素就有一个线程来处理。为简单起见,本例假设每个维度中每个网格的线程数可以被该维度中每个块的线程数整除,尽管事实并非如此。
程块需要独立执行:必须可以以任何顺序执行它们,并行或串行。这种独立性要求允许跨任意数量的内核以任意顺序调度线程块,如下图所示,使程序员能够编写随内核数量扩展的代码。

块内的线程可以通过一些共享内存共享数据并通过同步它们的执行来协调内存访问来进行协作。 更准确地说,可以通过调用 __syncthreads()内部函数来指定内核中的同步点; __syncthreads() 充当屏障,块中的所有线程必须等待,然后才能继续。 Shared Memory 给出了一个使用共享内存的例子。 除了__syncthreads()之外,Cooperative Groups API 还提供了一组丰富的线程同步示例。
为了高效协作,共享内存是每个处理器内核附近的低延迟内存(很像 L1 缓存),并且 __syncthreads() 是轻量级的。
2.3 存储单元层次
CUDA 线程可以在执行期间从多个内存空间访问数据,如下图所示。每个线程都有私有的本地内存。每个线程块都具有对该块的所有线程可见的共享内存,并且具有与该块相同的生命周期。 所有线程都可以访问相同的全局内存。

还有两个额外的只读内存空间可供所有线程访问:常量和纹理内存空间。全局、常量和纹理内存空间针对不同的内存使用进行了优化(请参阅设备内存访问)。纹理内存还为某些特定数据格式提供不同的寻址模式以及数据过滤(请参阅纹理和表面内存)。
全局、常量和纹理内存空间在同一应用程序的内核启动中是持久的。
2.4 异构编程
如下图所示,CUDA 编程模型假定 CUDA 线程在物理独立的设备上执行,该设备作为运行 C++ 程序的主机的协处理器运行。例如,当内核在 GPU 上执行而 C++ 程序的其余部分在 CPU 上执行时,就是这种情况。

CUDA 编程模型还假设主机(host)和设备(device)都在 DRAM 中维护自己独立的内存空间,分别称为主机内存和设备内存。因此,程序通过调用 CUDA 运行时(在编程接口中描述)来管理内核可见的全局、常量和纹理内存空间。这包括设备内存分配和释放以及主机和设备内存之间的数据传输。
统一内存提供托管内存来桥接主机和设备内存空间。托管内存可从系统中的所有 CPU 和 GPU 访问,作为具有公共地址空间的单个连贯内存映像。此功能可实现设备内存的超额订阅,并且无需在主机和设备上显式镜像数据,从而大大简化了移植应用程序的任务。有关统一内存的介绍,请参阅统一内存编程。
注:串行代码在主机(host)上执行,并行代码在设备(device)上执行。
2.5 异步SIMT编程模型
在 CUDA 编程模型中,线程是进行计算或内存操作的最低抽象级别。 从基于 NVIDIA Ampere GPU 架构的设备开始,CUDA 编程模型通过异步编程模型为内存操作提供加速。 异步编程模型定义了与 CUDA 线程相关的异步操作的行为。
异步编程模型为 CUDA 线程之间的同步定义了异步屏障的行为。 该模型还解释并定义了如何使用 cuda::memcpy_async 在GPU计算时从全局内存中异步移动数据。
2.5.1 异步操作
异步操作定义为由CUDA线程发起的操作,并且与其他线程一样异步执行。在结构良好的程序中,一个或多个CUDA线程与异步操作同步。发起异步操作的CUDA线程不需要在同步线程中.
这样的异步线程(as-if 线程)总是与发起异步操作的 CUDA 线程相关联。异步操作使用同步对象来同步操作的完成。这样的同步对象可以由用户显式管理(例如,cuda::memcpy_async)或在库中隐式管理(例如cooperative_groups::memcpy_async)。
同步对象可以是 cuda::barrier 或 cuda::pipeline。这些对象在Asynchronous
Barrier 和 Asynchronous Data Copies using cuda::pipeline.中进行了详细说明。这些同步对象可以在不同的线程范围内使用。作用域定义了一组线程,这些线程可以使用同步对象与异步操作进行同步。下表定义了CUDA C++中可用的线程作用域,以及可以与每个线程同步的线程。
| Thread Scope | Description |
|---|---|
| cuda::thread_scope::thread_scope_thread | Only the CUDA thread which initiated |
| asynchronous operations synchronizes. | |
| cuda::thread_scope::thread_scope_block | All or any CUDA threads within the |
| same thread block as the initiating thread synchronizes. | |
| cuda::thread_scope::thread_scope_device | All or any CUDA threads in the same |
| GPU device as the initiating thread synchronizes. | |
| cuda::thread_scope::thread_scope_system | All or any CUDA or CPU threads in the |
| same system as the initiating thread synchronizes. |
这些线程作用域是在CUDA标准c++库中作为标准c++的扩展实现的。
2.6 Compute Capability
设备的Compute Capability由版本号表示,有时也称其“SM版本”。该版本号标识GPU硬件支持的特性,并由应用程序在运行时使用,以确定当前GPU上可用的硬件特性和指令。
Compute Capability包括一个主要版本号X和一个次要版本号Y,用X.Y表示
主版本号相同的设备具有相同的核心架构。设备的主要修订号是8,为NVIDIA Ampere GPU的体系结构的基础上,7基于Volta设备架构,6设备基于Pascal架构,5设备基于Maxwell架构,3基于Kepler架构的设备,2设备基于Fermi架构,1是基于Tesla架构的设备。
次要修订号对应于对核心架构的增量改进,可能包括新特性。
Turing是计算能力7.5的设备架构,是基于Volta架构的增量更新。
CUDA-Enabled GPUs 列出了所有支持 CUDA 的设备及其计算能力。Compute Capabilities给出了每个计算能力的技术规格。
注意:特定GPU的计算能力版本不应与CUDA版本(如CUDA 7.5、CUDA 8、CUDA
9)混淆,CUDA版本指的是CUDA软件平台的版本。CUDA平台被应用开发人员用来创建运行在许多代GPU架构上的应用程序,包括未来尚未发明的GPU架构。尽管CUDA平台的新版本通常会通过支持新的GPU架构的计算能力版本来增加对该架构的本地支持,但CUDA平台的新版本通常也会包含软件功能。
从CUDA 7.0和CUDA 9.0开始,不再支持Tesla和Fermi架构。
相关文章:
2.CUDA 编程手册中文版---编程模型
2.编程模型 更多精彩内容,请扫描下方二维码或者访问https://developer.nvidia.com/zh-cn/developer-program 来加入NVIDIA开发者计划 本章通过概述CUDA编程模型是如何在c中公开的,来介绍CUDA的主要概念。 编程接口中给出了对 CUDA C 的广泛描述。 本章…...
Claude 2、ChatGPT、Google Bard优劣势比较
Claude 2: 优势:Claude 2能够一次性处理多达10万个tokens(约7.5万个单词)。 tokens数量反映了模型可以处理的文本长度和上下文数量。tokens越多,模型理解语义的能力就越强)。它在法律、数学和编码等多个…...
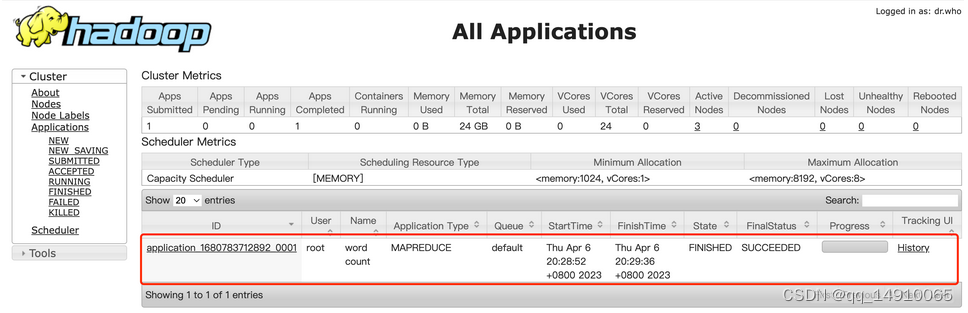
Docker安装Hadoop分布式集群
一、准备环境 docker search hadoop docker pull sequenceiq/hadoop-docker docker images二、Hadoop集群搭建 1. 运行hadoop102容器 docker run --name hadoop102 -d -h hadoop102 -p 9870:9870 -p 19888:19888 -v /opt/data/hadoop:/opt/data/hadoop sequenceiq/hadoop-do…...
文盘 Rust -- tokio 绑定 cpu 实践
tokio 是 rust 生态中流行的异步运行时框架。在实际生产中我们如果希望 tokio 应用程序与特定的 cpu core 绑定该怎么处理呢?这次我们来聊聊这个话题。 首先我们先写一段简单的多任务程序。 use tokio::runtime; pub fn main() {let rt runtime::Builder::new_mu…...
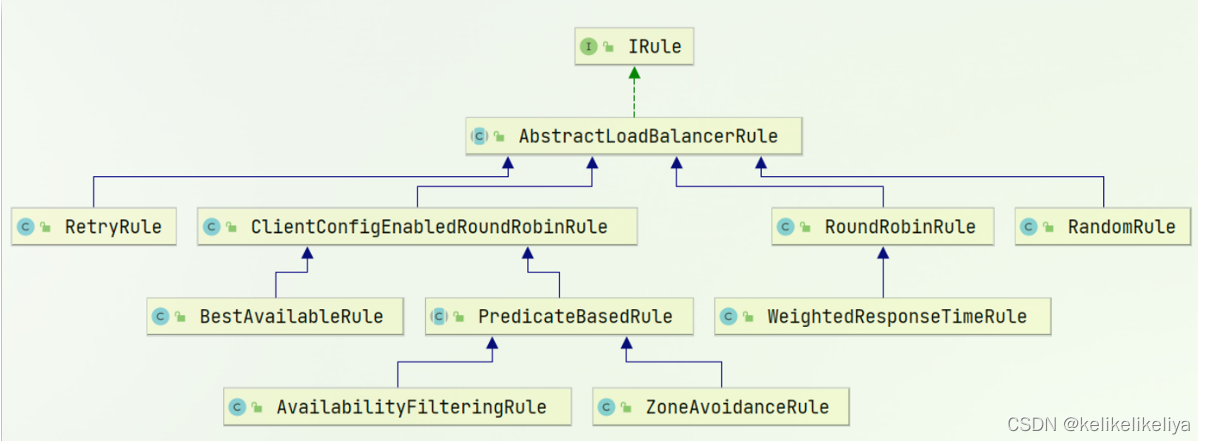
微服务Ribbon-负载均衡策略和饥饿加载
目录 一、负载均衡策略 1.1 负载均衡策略介绍 1.2 自定义负载均衡策略 二、饥饿加载 (笔记整理自bilibili黑马程序员课程) 一、负载均衡策略 1.1 负载均衡策略介绍 负载均衡的规则都定义在IRule接口中,而IRule有很多不同的实现类&…...

uni-app 运行时报错“本应用使用HBuilderX x.x.x 或对应的cli版本编译,而手机端SDK版本是x.x.x。不匹配的版本可能造成应用异常”
uni-app 运行时报错“本应用使用HBuilderX x.x.x 或对应的cli版本编译,而手机端SDK版本是x.x.x。不匹配的版本可能造成应用异常” 出现原因 手机端SDK版本和HBuilderX版本不一致。 解决办法 方法一 项目根目录下找到 manifest.json 配置文件,选择源码…...
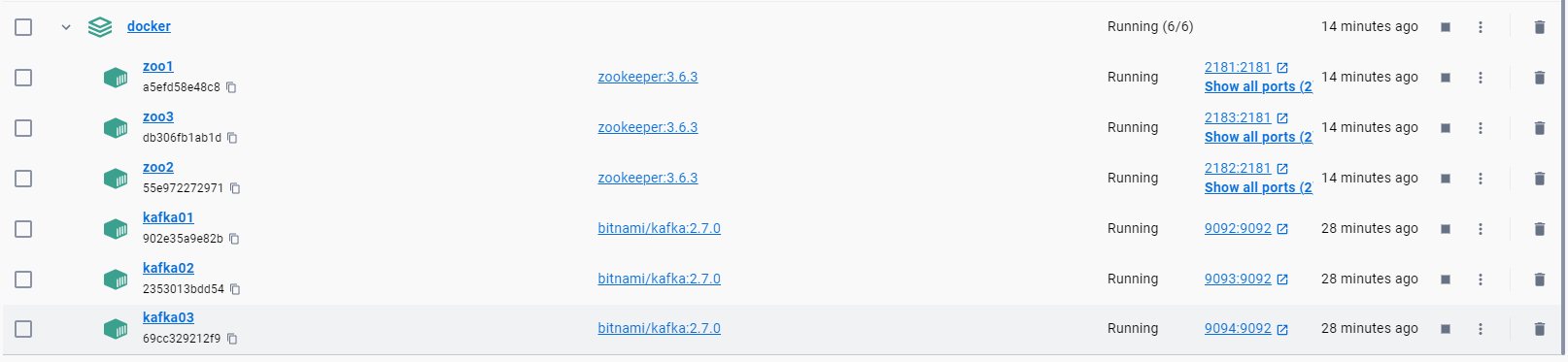
Windows使用docker desktop 安装kafka、zookeeper集群
docker-compose安装zookeeper集群 参考文章:http://t.csdn.cn/TtTYI https://blog.csdn.net/u010416101/article/details/122803105?spm1001.2014.3001.5501 准备工作: 在开始新建集群之前,新建好文件夹,用来挂载kafka、z…...

11 | 苹果十年财报分析
在本文中,我们将对苹果公司的财务报告进行深入分析,关注其销售收入、利润情况以及关键产品线的表现。我们将研究财报中的数据,挖掘背后的商业策略和市场动态,以便更好地了解苹果公司在不同市场环境下的业绩表现。通过对财报数据的解读和分析,我们将探讨苹果公司在竞争激烈…...

Zookeeper与Redis 对比
1. 为什么使用分布式锁? 使用分布式锁的目的,是为了保证同一时间只有一个 JVM 进程可以对共享资源进行操作。 根据锁的用途可以细分为以下两类: 1、 允许多个客户端操作共享资源,我们称为共享锁。 这种锁的一般是对共享资源具有幂…...
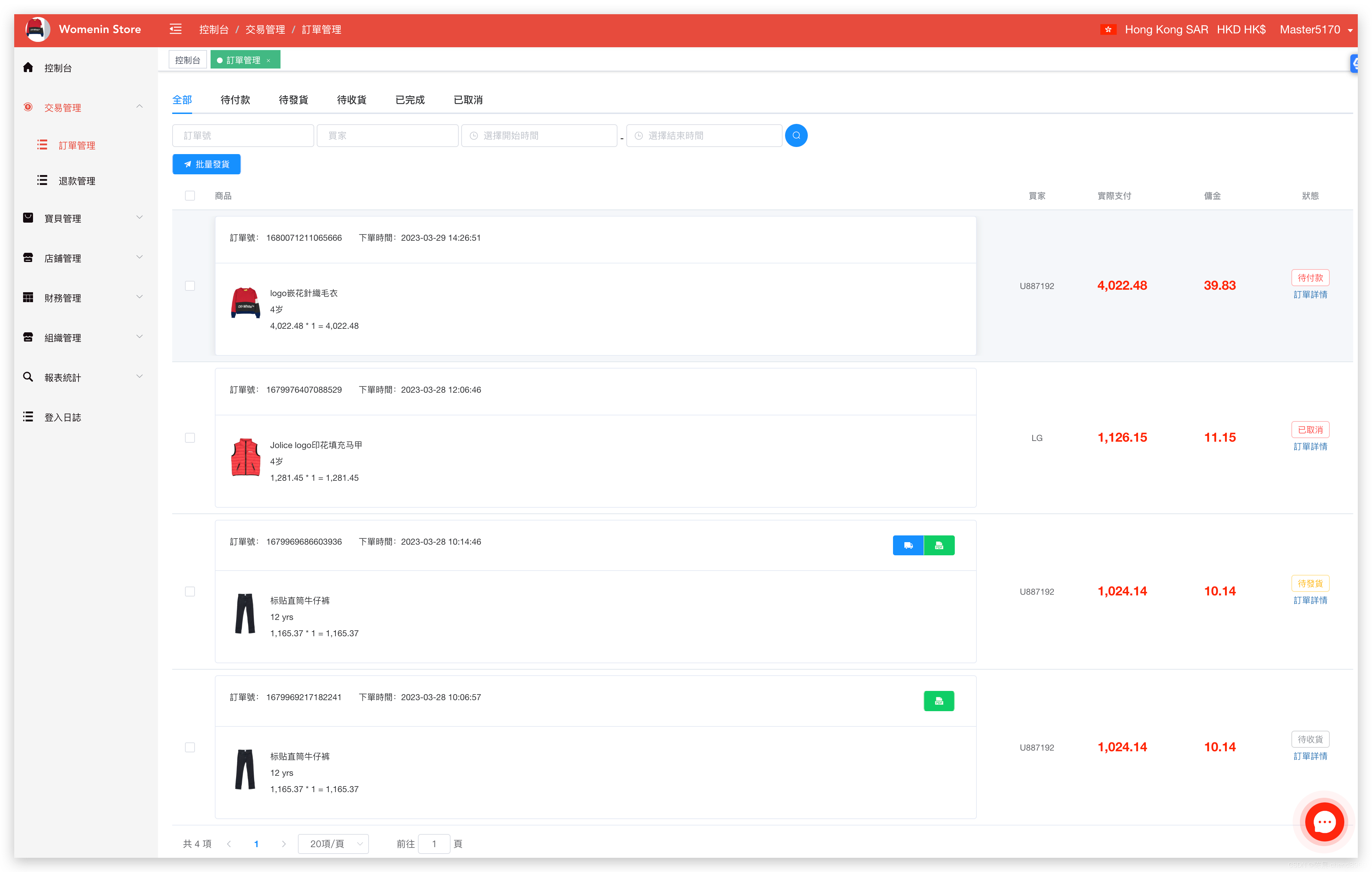
跨境商城服务平台搭建与开发(金融服务+税务管理)
随着全球电子商务的快速发展,跨境贸易已经成为一种新的商业趋势。在这个背景下,搭建一个跨境商城服务平台,提供金融服务、税务管理等一系列服务,可以极大地促进跨境贸易的发展。本文将详细阐述跨境商城服务平台搭建与开发的步骤。…...

docker配置文件
/etc/docker/daemon.json 文件作用 /etc/docker/daemon.json 文件是 Docker 配置文件,用于配置 Docker 守护进程的行为和参数。Docker 守护进程是负责管理和运行 Docker 容器的后台进程,通过修改 daemon.json 文件,可以对 Docker 守护进程进…...

Mysql数据库之单表查询
目录 一、练习时先导入数据如下: 二、查询验证导入是否成功 三、单表查询 四、where和having的区别 一、练习时先导入数据如下: 素材: 表名:worker-- 表中字段均为中文,比如 部门号 工资 职工号 参加工作 等 CRE…...

macos搭建appium-iOS自动化测试环境
目录 准备工作 安装必需的软件 安装appium 安装XCode 下载WDA工程 配置WDA工程 搭建appiumwda自动化环境 第一步:启动通过xcodebuild命令启动wda服务 分享一下如何在mac电脑上搭建一个完整的appium自动化测试环境 准备工作 前期需要准备的设备和账号&…...
日常工具 之 一些 / 方便好用 / 免费 / 在线 / 工具整理
日常工具 之 一些 / 方便好用 / 免费 / 在线 / 工具整理 目录 日常工具 之 一些 / 方便好用 / 免费 / 在线 / 工具整理 1、在线Json ,可以在线进行json 格式验证,解析转义等操作 2、Gif动图分解,在线把 gif 图分解成一张张单图 3、在线P…...
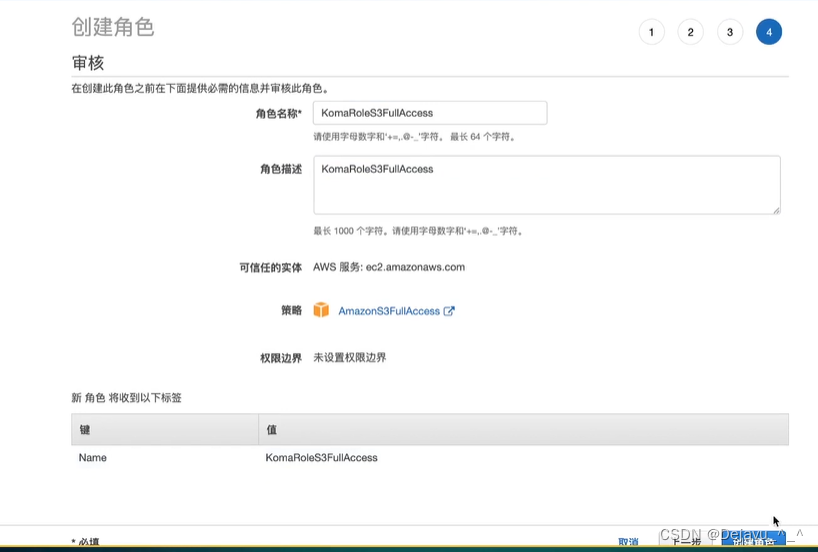
AWS 中文入门开发教学 50- S3 - 网关终端节点 - 私有网络访问S3的捷径
知识点 通过设置网关终端节点,使私有网段中的EC2也可以访问到S3服务官网 https://docs.aws.amazon.com/zh_cn/codeartifact/latest/ug/create-s3-gateway-endpoint.html 实战演习 通过网关访问S3 看图说话"> 实战步骤 创建一个可以访问S3的角色 KomaRoleS3FullAcc…...

windows使用/服务(13)戴尔电脑怎么设置通电自动开机
戴尔pc机器通电自启动 1、将主机显示器键盘鼠标连接好后,按主机电源键开机 2、在开机过程中按键盘"F12",进入如下界面,选择“BIOS SETUP” 3、选择“Power Management” 4、选择“AC Recovery”,点选“Power On”,点击“…...
Leetcode每日一题:1289. 下降路径最小和 II(2023.8.10 C++)
目录 1289. 下降路径最小和 II 题目描述: 实现代码与解析: 动态规划 原理思路: 1289. 下降路径最小和 II 题目描述: 给你一个 n x n 整数矩阵 grid ,请你返回 非零偏移下降路径 数字和的最小值。 非零偏移下降路…...
Node.js |(一)Node.js简介及计算机基础 | 尚硅谷2023版Node.js零基础视频教程
学习视频:尚硅谷2023版Node.js零基础视频教程,nodejs新手到高手 文章目录 📚关于Node.js🐇为什么要学Node.js🐇Node.js是什么🐇Node.js的作用🐇Node.js下载安装🐇命令行工具…...

Canal+Kafka实现Mysql数据同步
Canal介绍 canal [kənl],译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费 canal可以用来监控数据库数据的变化,从而获得新增数据,或者修改的数据。 canal是应阿里巴巴存在杭…...

K8s部署
K8s部署 一、实验架构 二进制搭建 Kubernetes v1.20 -单master节点部署k8s集群master01:192.168.111.10 kube-apiserver kube-controller-manager kube-scheduler etcd k8s集群master02:192.168.111.20k8s集群node01:192.168.111.20 kubele…...

OpenClaw个人知识库:Qwen3-14b_int4_awq自动标注与关联文档
OpenClaw个人知识库:Qwen3-14b_int4_awq自动标注与关联文档 1. 为什么需要自动化知识管理 作为一个长期与技术文档打交道的开发者,我发现自己电脑里的资料库越来越臃肿。每次新增一篇技术文章或研究论文,都需要手动打标签、写摘要、建立关联…...

打破信息壁垒:Bypass Paywalls Chrome Clean的技术实现与伦理边界
打破信息壁垒:Bypass Paywalls Chrome Clean的技术实现与伦理边界 核心痛点:数字时代的知识获取困境 独立创作者的内容付费墙困境 🖋️ 独立科技作者李明在撰写行业分析报告时,需要参考多家商业媒体的深度报道。然而,每…...

全球首发 | 「AI智能库」正式官宣,智库智能重新定义仓库!
智库智能 江苏智库智能科技有限公司创立于2017年,是全球托盘仓储机器人领航者,专注于托盘仓储机器人的研发设计和生产交付,拥有机器人本体、业务系统、核心算法、交付系统等全价值链研发能力。公司已推出多款托盘仓储机器人及智能仓储软件…...

SQL查询语句--EXISTS子查询
EXISTS子查询的逻辑是先查询外层数据,再逐行进行EXISTS子查询。外层查询出的每条记录都执行一EXISTS子查询,EXISTS子查询为TRUE则保留当前记录,为FALSE则不保留。例如:需求:查询选择了课程号C_id为1的学生学号和姓名。…...

CKKS 同态加密数学基础推导昧
背景 StreamJsonRpc 是微软官方维护的用于 .NET 和 TypeScript 的 JSON-RPC 通信库,以其强大的类型安全、自动代理生成和成熟的异常处理机制著称。在 HagiCode 项目中,为了通过 ACP (Agent Communication Protocol) 与外部 AI 工具(如 iflow …...

为什么顶尖金融科技公司集体弃用React转向Blazor?——2026真实项目ROI对比:开发效率↑41%,首屏加载↓68%,运维成本↓53%
第一章:为什么顶尖金融科技公司集体弃用React转向Blazor?——2026真实项目ROI对比:开发效率↑41%,首屏加载↓68%,运维成本↓53%过去两年,高盛、摩根士丹利、PayPal风控平台与新加坡星展银行核心交易看板等1…...

Arduboy光线投射渲染库:8位MCU上的实时3D引擎
1. ArduboyRaycast 库概述ArduboyRaycast 是一个专为 Arduboy 平台设计的轻量级光线投射(Raycasting)渲染库,面向资源极度受限的 8-bit AVR 微控制器(ATmega32U4,16MHz,2.5KB RAM,32KB Flash&am…...

GEO 科普指南
GEO 科普指南 什么是 GEO? GEO(Generative Engine Optimization) 即「生成式引擎优化」,是针对 AI 搜索引擎(如 ChatGPT、Claude、Perplexity 等)进行内容优化的新兴策略。 简单来说:SEO 是让 G…...

Servlet-JAVA【笔记】
JAVA_WEBTomcattomcat工作流程servlet的生命周期ServletConfigServletContextHttpServletRequestHttpServletResponse前端提交的数据和请求域里的数据的区别?应用域和请求域的区别?如何做到两个servlet之间交流/共享数据?请求转发和重定向区别…...

3步解决浏览器Markdown阅读难题:从乱码到专业渲染的蜕变之路
3步解决浏览器Markdown阅读难题:从乱码到专业渲染的蜕变之路 【免费下载链接】markdown-viewer Markdown Viewer / Browser Extension 项目地址: https://gitcode.com/gh_mirrors/ma/markdown-viewer 你是否遇到过这样的窘境:在浏览器中打开本地M…...