OceanBase X Flink 基于原生分布式数据库构建实时计算解决方案
摘要:本文整理自 OceanBase 架构师周跃跃,在 Flink Forward Asia 2022 实时湖仓专场的分享。本篇内容主要分为四个部分:
分布式数据库 OceanBase 关键技术解读
生态对接以及典型应用场景
OceanBase X Flink 在游戏行业实践
未来展望
点击查看原文视频 & 演讲PPT
一、分布式数据库 OceanBase 关键技术解读
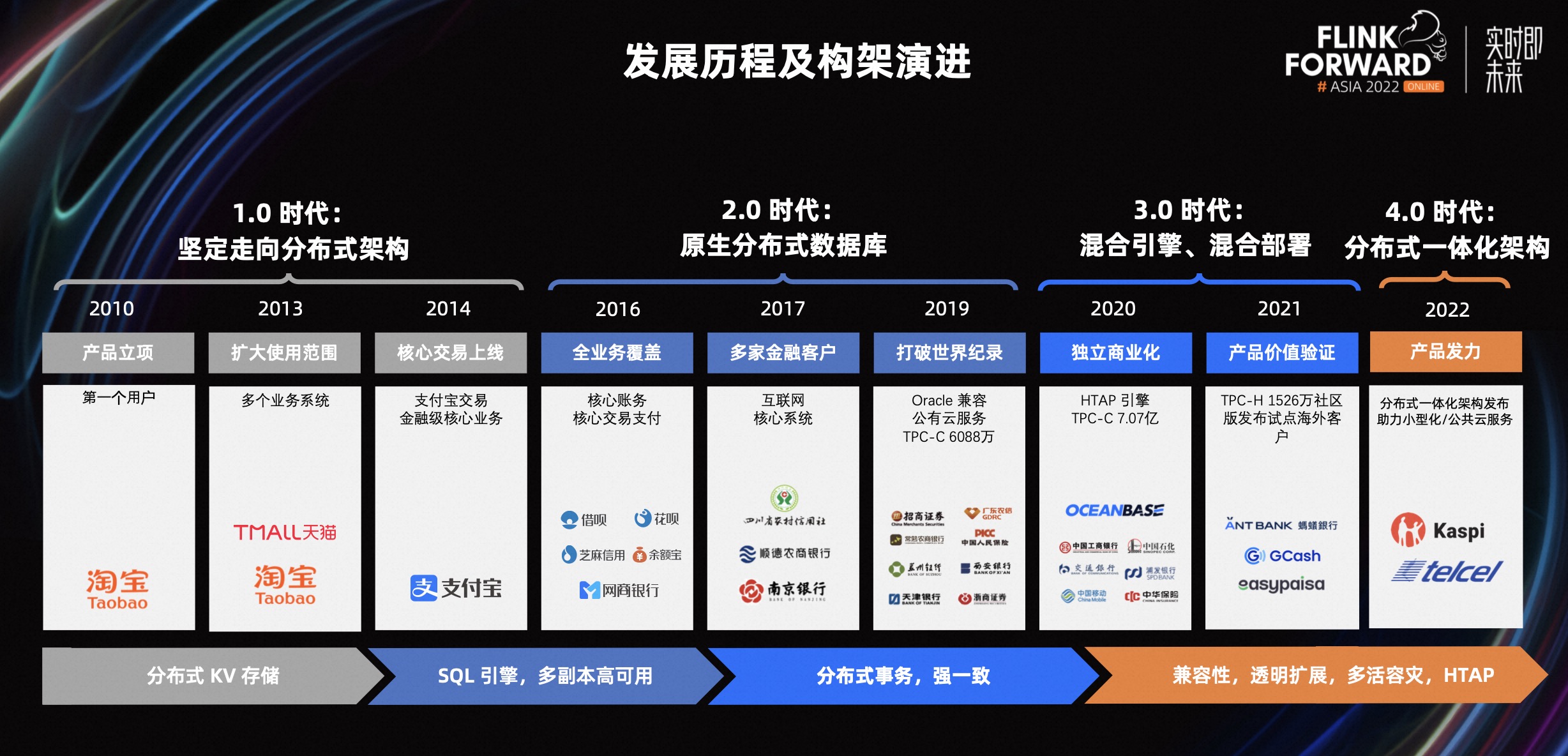
作为一款历经 12 年的纯自研国产分布式数据库,从产品立项到核心交易业务上线,OceanBase 从 1.0 时代坚定的走向分布式架构,产品在支付宝内部开始落地实践并支持核心业务。
随着产品能力进一步增强,OceanBase 2.0 时代从 KV 存储系统演变成具备分布式事务,以及多副本强一致性能力的原生分布式数据库,开始服务于外部企业客户,包括互联网、金融、证券等等行业。
在 3.0 时代,随着 HTAP 能力的完善,混合引擎以及混合部署方案吸引更多的海外企业客户使用。随着 4.0 版本的发布,OceanBase 提出单机分布式一体化架构,助力企业小型化和公有云服务。
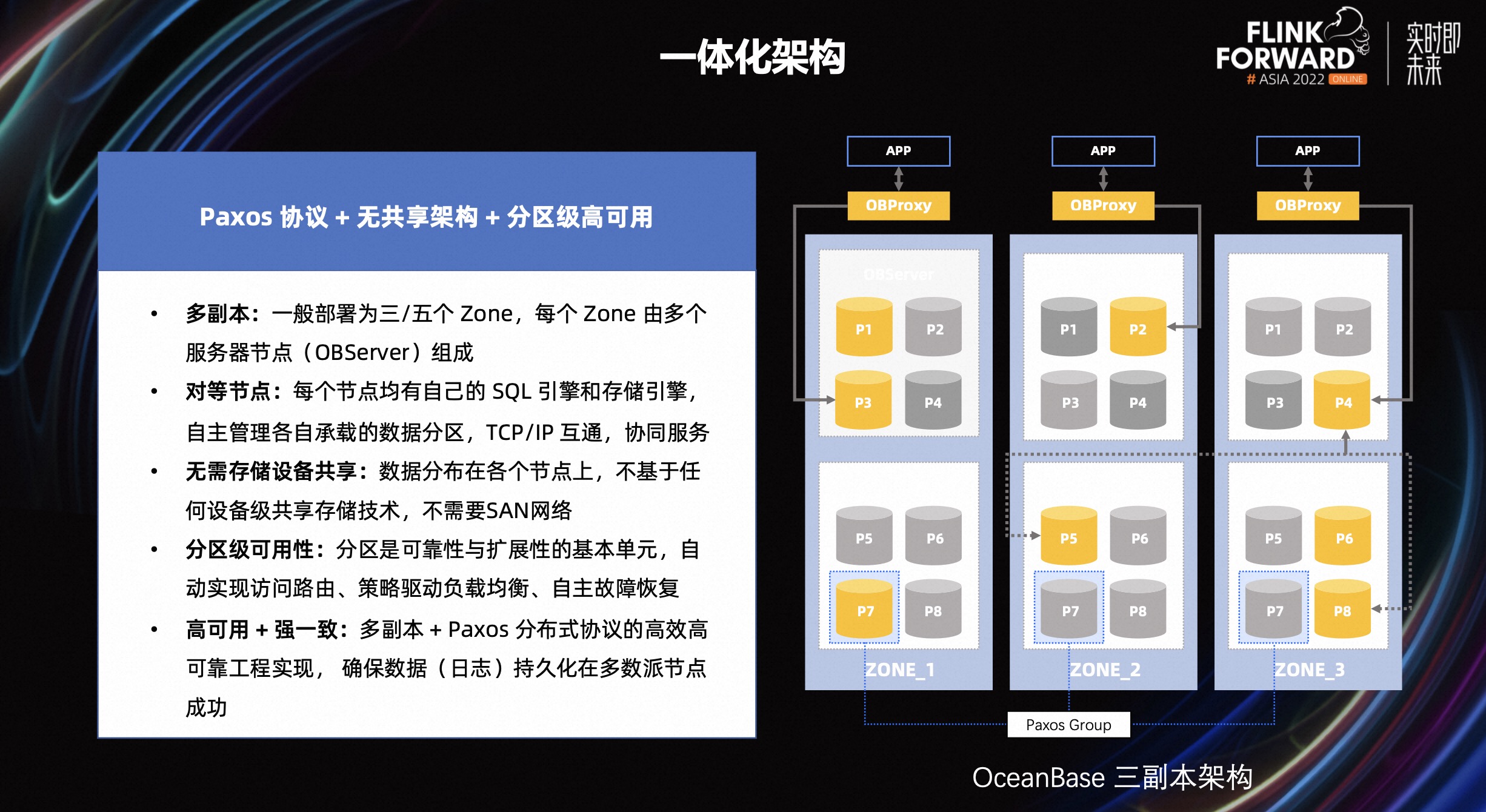
OceanBase 的一体化架构总结起来有三个关键字:Paxos 协议、无共享架构、分区级高可用。
默认情况下,数据被存储多份,即多副本概念。副本之间通过 Paxos 协议保证数据强一致性。通过多副本+Paxos 协议,保证数据库系统的高可用性。
系统中每个 OBServer 节点,同时具备计算和存储能力。整个系统没有单点瓶颈,可多点读写。在集群扩容和缩容时,数据以分区为基本单元进行迁移,自动实现负载均衡。
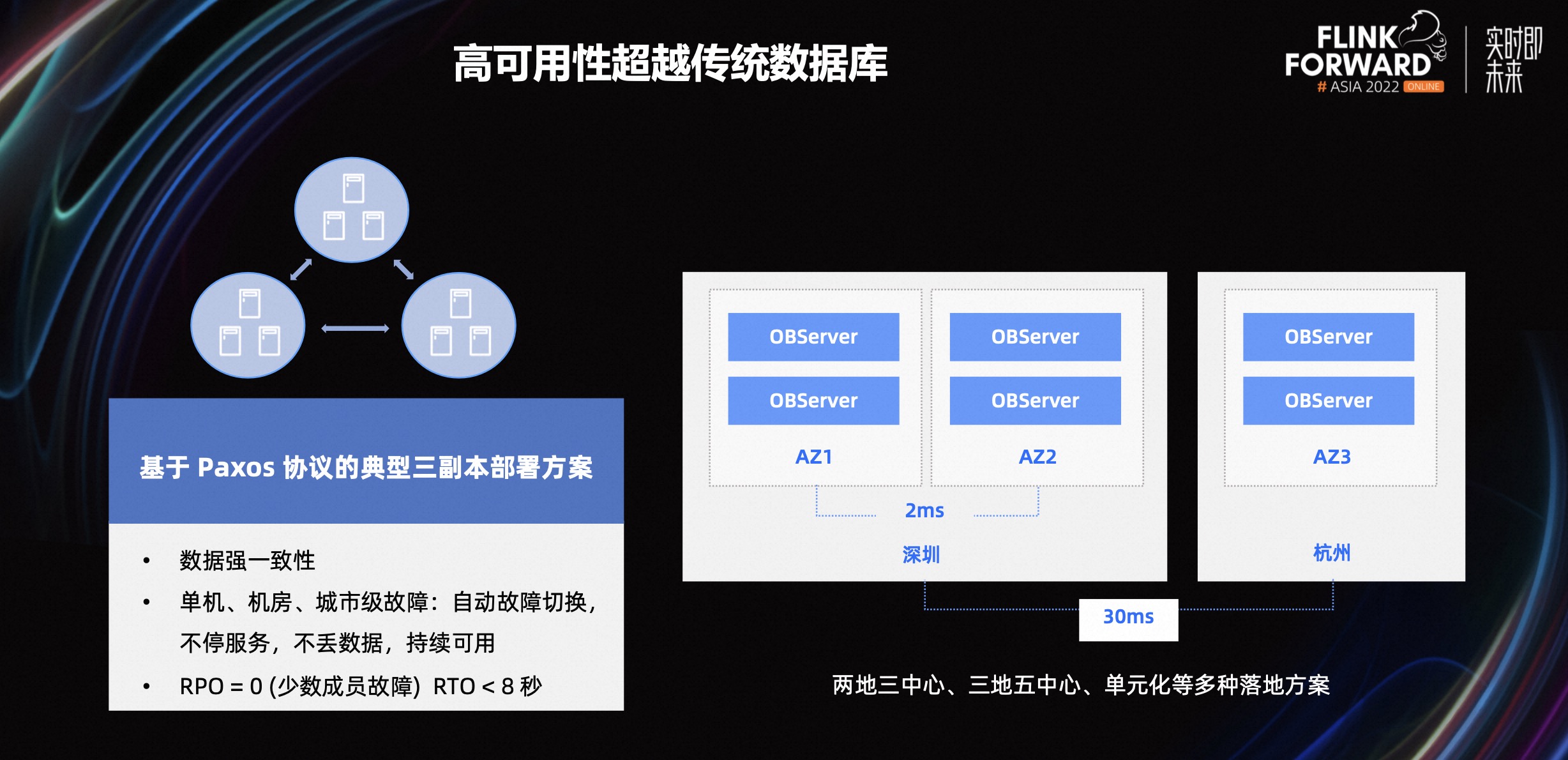
作为承担企业命脉的系统,数据库的高可用性对企业至关重要。OceanBase 基于 Paxos 协议的典型三副本部署方案,保证在单机、机房、城市出现故障时,数据不丢,服务不停。
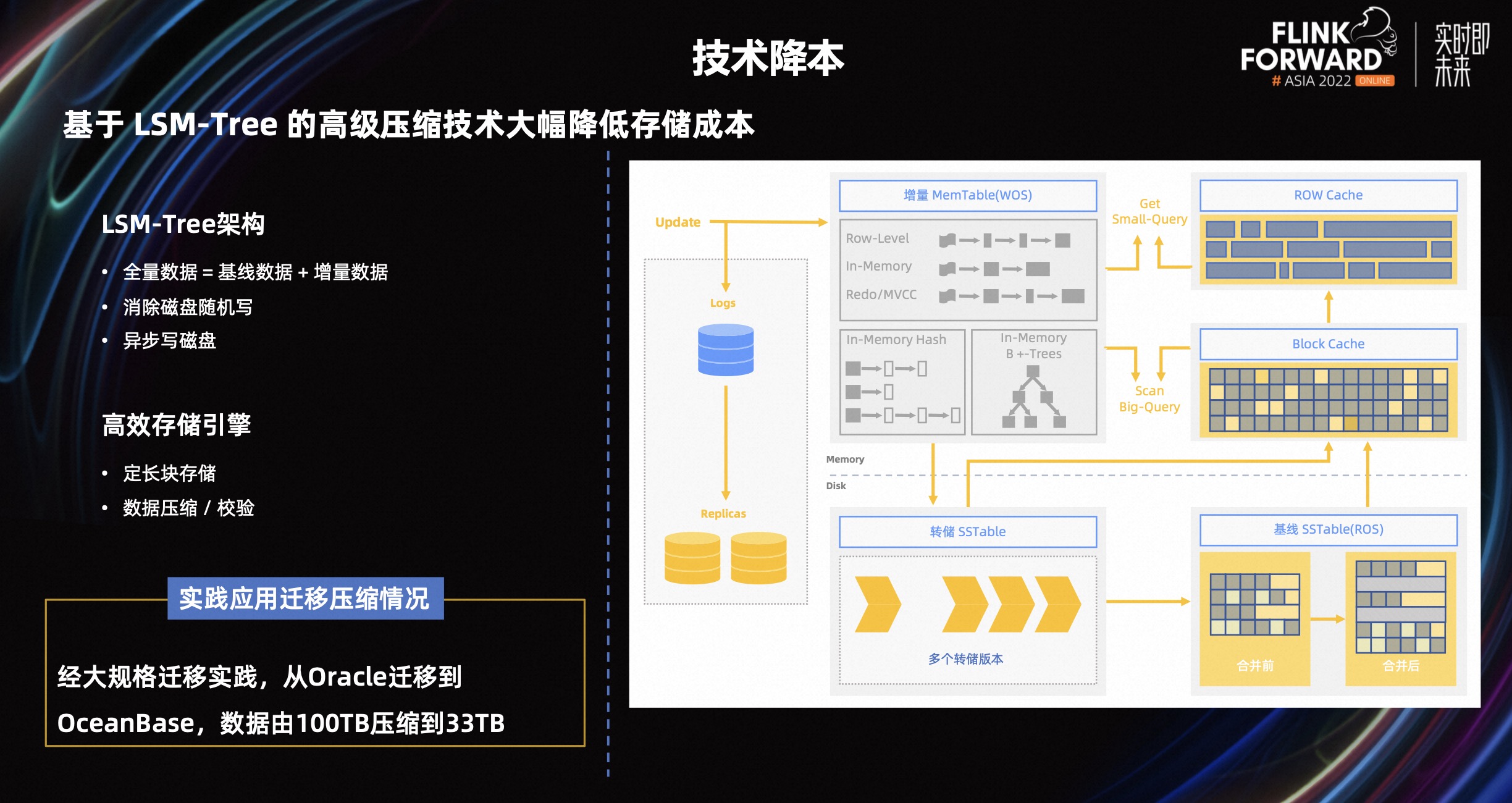
降本增效是企业永恒的话题,那么如何通过技术手段,降低硬件成本是每一个企业都关注的问题。数据在写入 OceanBase 时,首先写入内存里面,当满足条件或者触发设定的阈值时,数据会被刷新到磁盘上。
因此,在 OceanBase 中全量数据由磁盘的基线数据和内存的增量数据组成,所以有时候 OceanBase 也被叫做准内存数据库。在数据压缩方面,OceanBase 使用的 LSM tree 数据结构,在每一层有对应的压缩算法,此类压缩称为通用压缩。
在通用压缩的基础上,OceanBase 自研了一套对数据库进行行列混存编码的压缩方法(encoding),会进一步对数据进行压缩。存储空间在通用压缩的基础上,进一步降低。在同等条件下,相比 Oracle,OceanBase 存储成本仅为前者 1/3 左右。
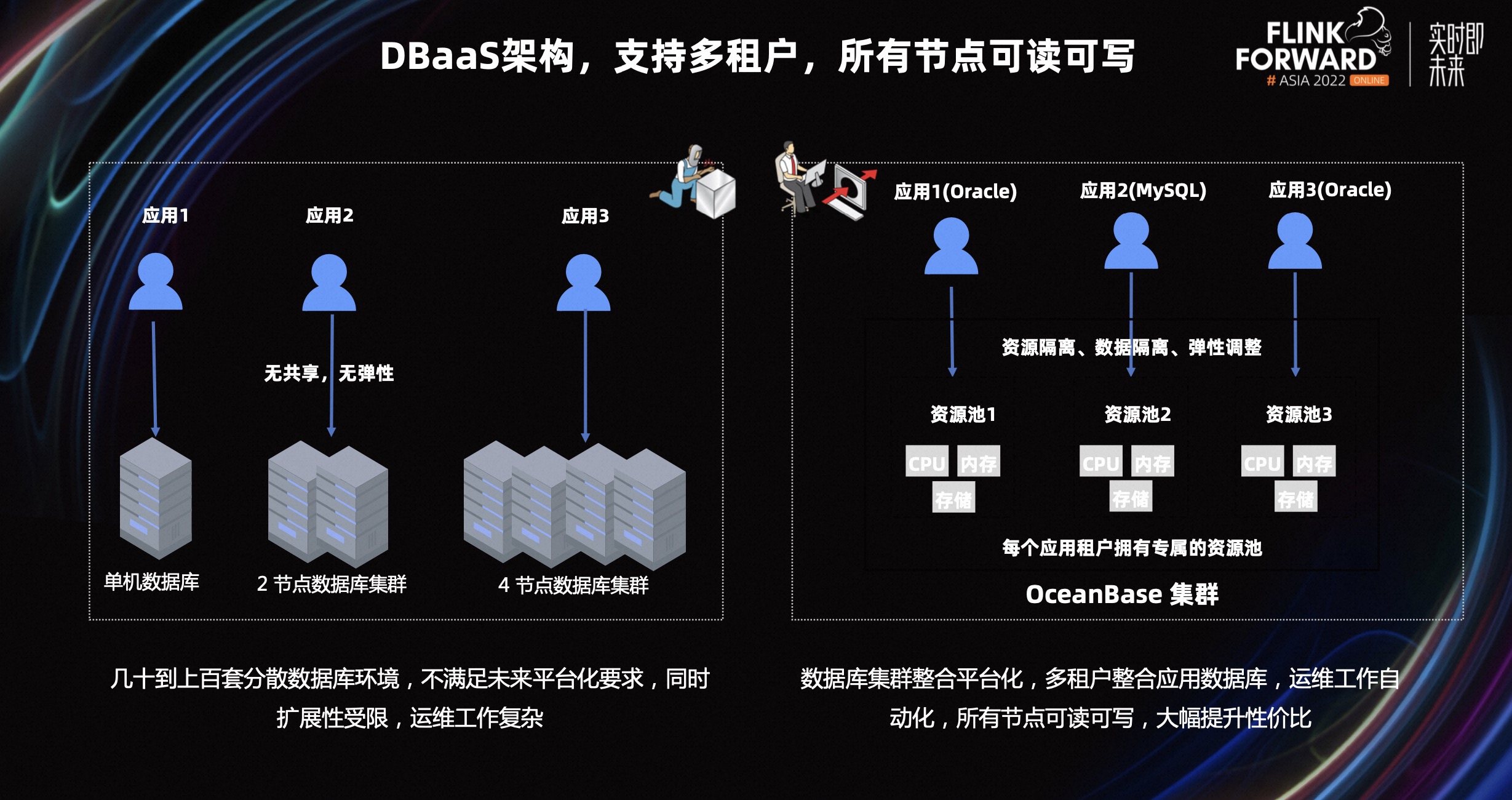
在传统数据库方案里,比如最常使用的 MySQl 数据库,一般将多个业务拆分到多个数据库上面。进行物理隔离。避免单个业务异常,影响到整个业务系统。随着业务的快速增长,运维人员需要运维和管理多套环境,成本较高。
在 OceanBase 里面,在资源充足的情况下,只需要新建租户即可接入新业务,业务之间做到资源隔离和数据独立。租户之间的资源隔离方案,保证一套环境可承载多套业务,运维人员工作量大大减少。
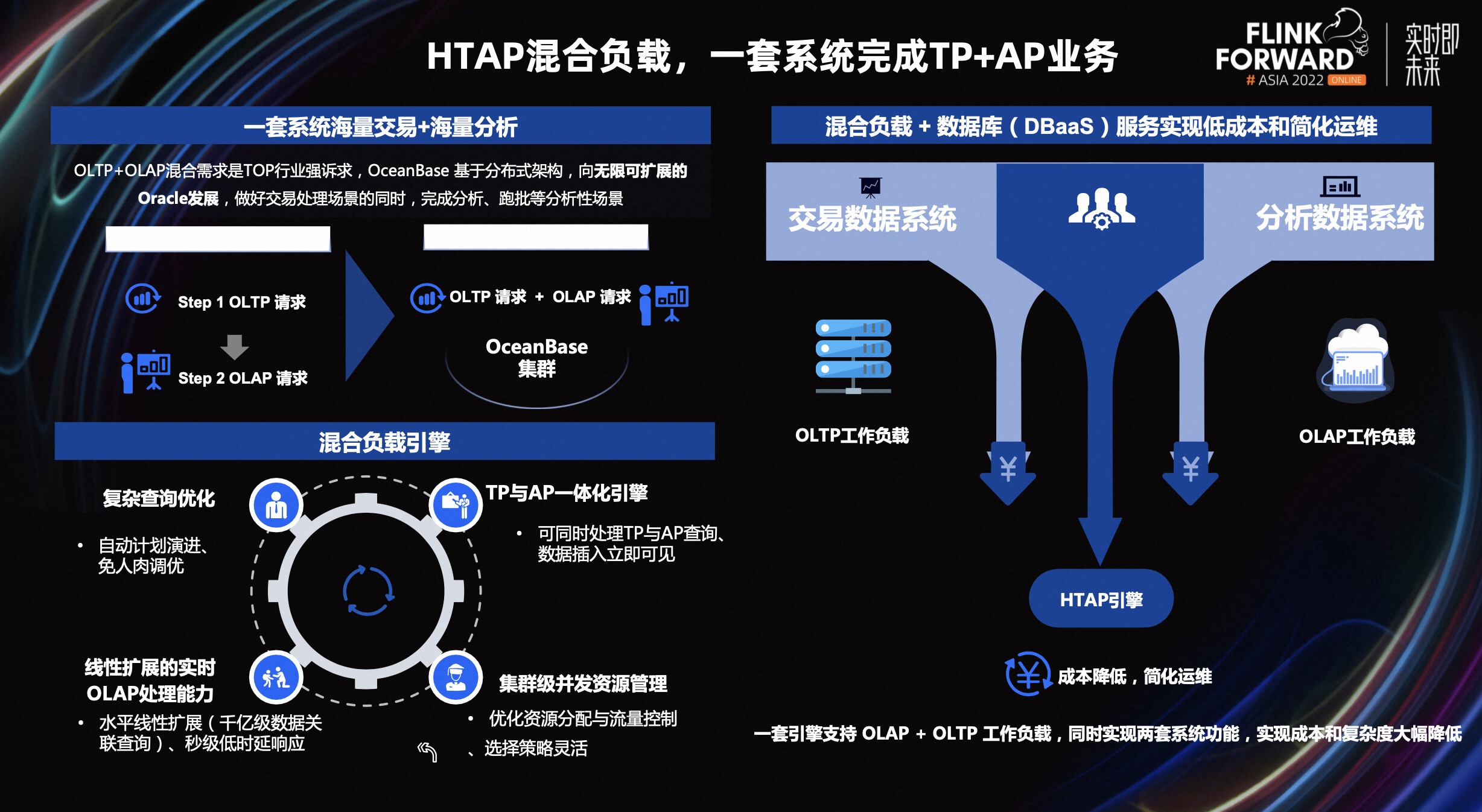
HTAP 是近几年不断被提及的一个话题,那么 HTAP 是不是一个伪命题?其实 HTAP 并不是凭空出现,现实是用户有真实的业务需求、实际的场景。
在之前的方案里,TP 业务产生的数据通过工具,同步到一些分析型产品里,进行数据分析、跑批等任务。这样涉及到多个系统拼接,以及多份数据流转和存储。
当前,大家共识的 HTAP 也是 OB 认为的 HTAP:即在做好 TP 的同时,兼顾和提升分析能力。在这个概念里,有两个核心的点,即一份数据和一套系统。数据在一个系统里处理即可,不需要再次进行同步和流转。
OceanBase 除了一套 SQL 引擎满足 TP 和 AP 需求,又可以根据用户的读写分离需求,通过多副本类型和弱一致性,灵活的实现各种读写分离策略,保证原有业务不做变动,改造成本为 0,即可满足用户需求。

作为分布式数据库,扩展性是最重要的一个能力,在 OceanBase 的一体化架构下,集群节点对等,每个节点都具备计算和存储能力,同时可在线进行扩容和缩容。每个节点都可以进行读写,理论上,集群的性能随着节点的扩容线性增长。

在前不久,OceanBase 发布 4.0 版本,推出单机分布式一体化架构。分布式架构更多应用在数据体量和规模大的业务场景,在这些场景下更能发挥分布式优势。
对于业务数据体量不够大,或者当前数据体量不大的企业用户,分布式方案对资源的要求过高,所以不太合适中小型业务体量的场景。与此同时,单机或者轻量的架构,更适合这类业务。单机一体化架构方案,在使用单机的同时,随着未来数据规模增长之后,又可以将单机变为分布式架构,充分契合业务发展需求。
二、生态对接以及典型应用场景
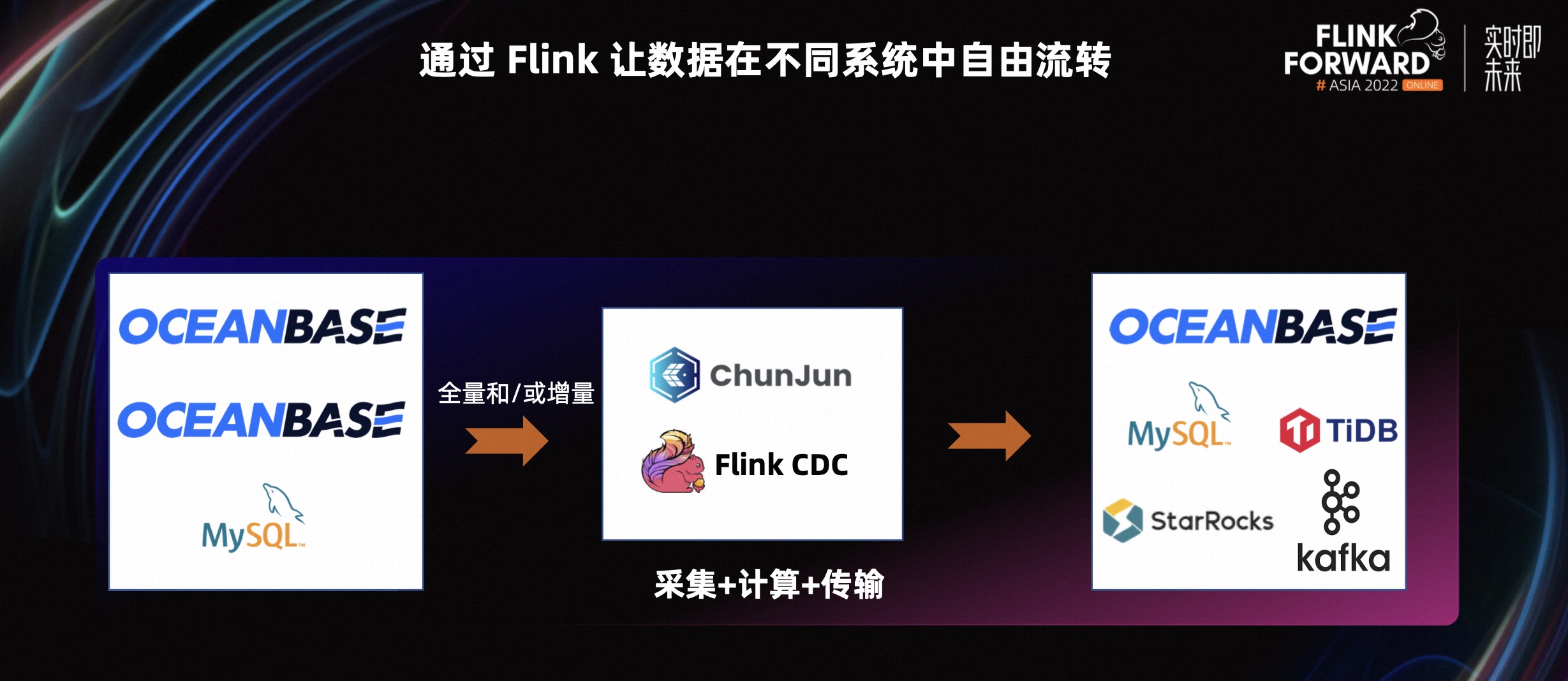
Flink 作为实时分析领域的代表性产品,被很多 OceanBasse 社区用户使用并在实时数仓业务场景使用。根据社区用户需求,我们对接和适配了 Flink 以及其周边生态工具,比如 ChunJun 等。
用户通过 Flink 以及相应生态工具,让数据可以在不同系统中自由流转。比如将上游的源端 MySQL 或者 OceanBase 数据,同步到下游 OceanBase、Kafka 等目标端。
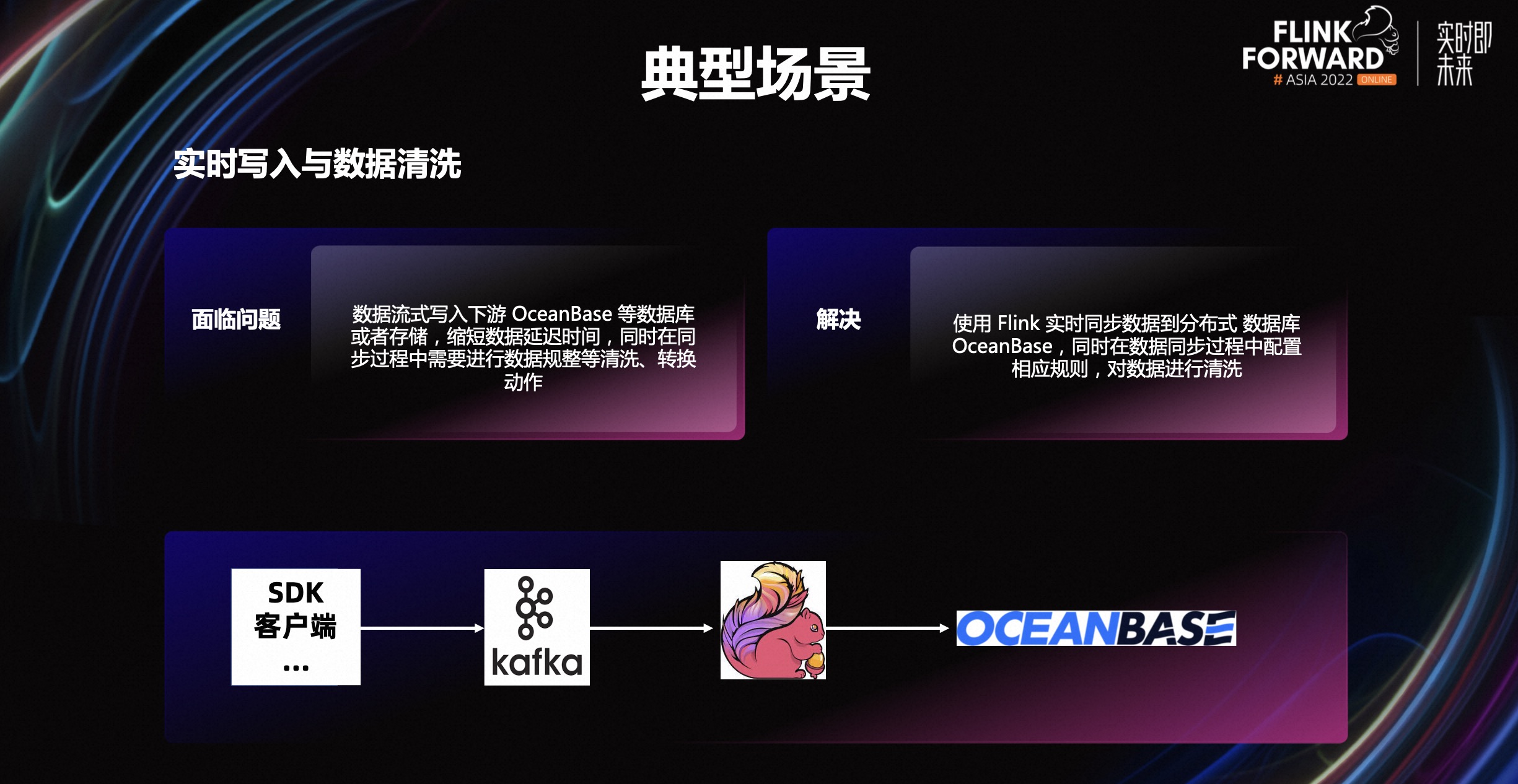
在 OceanBase 社区里,很多用户使用 OceanBase+Flink 来解决生产遇到的实际问题,典型的应用场景包括:
场景一,数据实时写入与数据清洗,这也是使用最多的一个场景。数据在流式写入到下游时,不仅仅要保证写入的实时性,同样可能存在数据格式的清洗、转换等问题,因此通过 Flink 可以实现数据的实时写入到下游数据库比如 OceanBase 等,同时在写入过程中可以进行数据清洗等动作。

场景二:打宽数据流。多表 join 以及和维度表、事实表关联是最常见的一个场景。在上图中,业务数据源会不断的生成一个数据流,和 OceanBase 里面的维表做 join 操作,打宽数据流,生成一个大宽表。最终,将数据写入到一个结果集中,并存储在数据库系统里,比如 OceanBase 等。
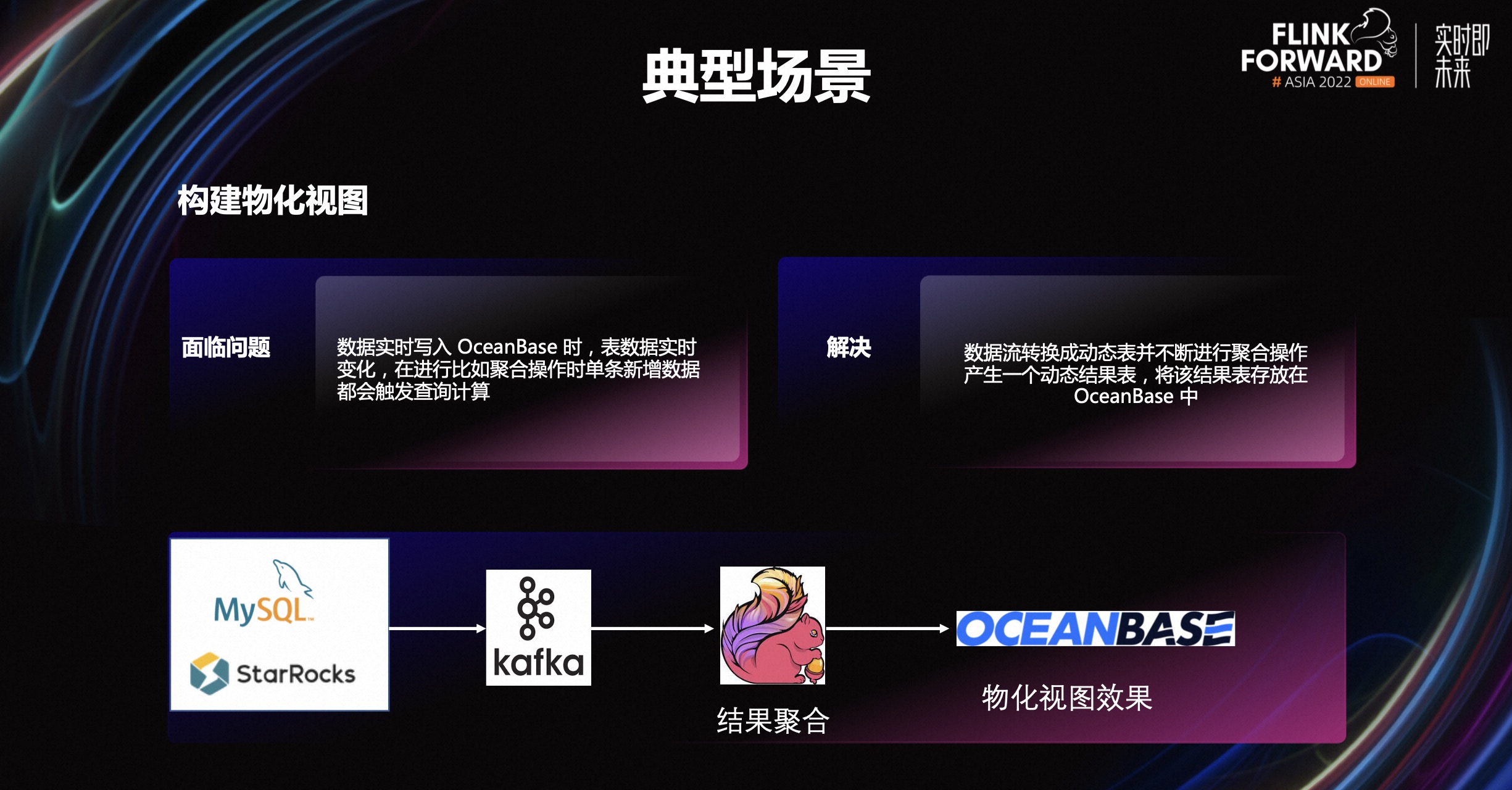
场景三:构建物化视图。当业务数据源源不断的写入到 OceanBase 时,表中的数据不断变化。此时,进行一些查询操作,比如聚合查询时,单条新增的数据会触发查询计算。当查询涉及到的数据规模大且数据频繁更新时,会出现查询性能不理想的情况。
使用 Flink 之后,将数据流转换成动态表,并不断进行聚合操作。将产生的结果集存放在下游,比如 OceanBase 等。用户只需要查询该结果集,即可拿到需要的数据,不需要每次进行聚合操作,性能提升非常明显。

场景四:数据二次加工。随着分布式方案的普及,企业利用分布式数据库的扩展性将大数据场景里的原生数据存储在数据库里,比如各种指标数据。
当需要将原生数据的指标进行二次加工时,借助 Flink 的实时同步能力,在同步过程中对指标数据进行再次加工,并将加工之后的数据回写至 OceanBase,供业务使用。同时加工之后的数据,又可以作为源端再次进行加工,使用非常灵活。
三、OceanBase X Flink 在游戏行业实践

随着企业越来越重视数据价值,因此数据的新鲜度至关重要,企业需要能够实时观测到数据的变化。比如在快递流转中,企业需要实时掌握从用户下单到用户签收整个流程的快递运转情况,及时发现在每一个环节可能出现的问题以及快速解决,提升运营效率,提高用户体验。
在流量黄金时间段,企业决策者需要时刻关注热点广告位情况,及时调整广告投放,最大发挥广告位价值。
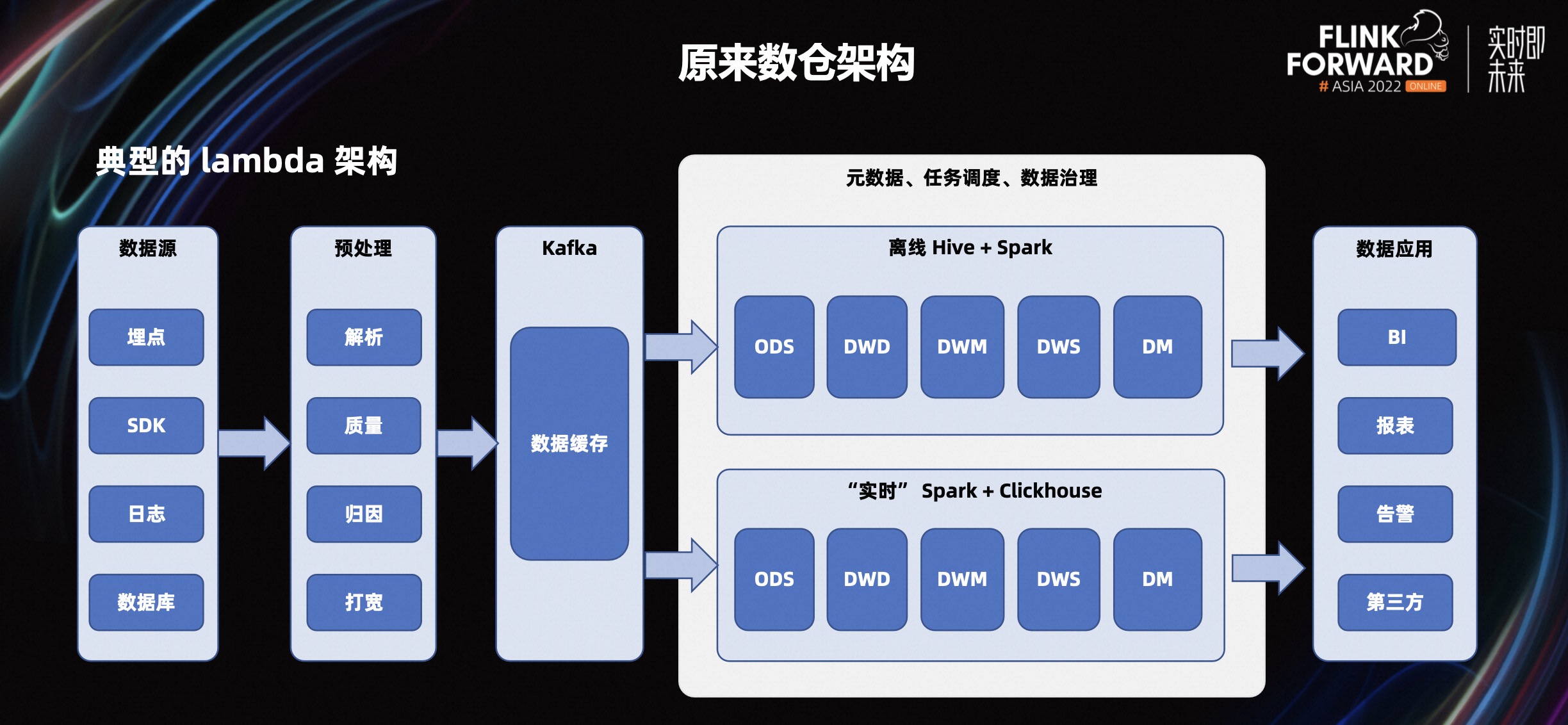
在大数据实时数仓领域,数仓为企业的决策制定过程,提供数据支持的战略,Lambda 架构是较早的数仓解决方案,使用流处理和批处理两种架构,进行数据处理。某游戏公司数仓架构如图所示:离线处理交给 Hive,实时分析由 Click House 完成。
Hive 是基于 Hadoop 的数据仓库工具,可对存储在 HDFS 的数据集进行数据整理、特殊查询和分析处理。Spark 是一个基于内存分析计算的开源的集群计算系统,目的是让数据分析更加快速,Hive+Spark 两者优势互补。而 Spark+Click House 则是通过 Spark 微批写入到 Click House 里面,发挥 Click House 的分析能力。
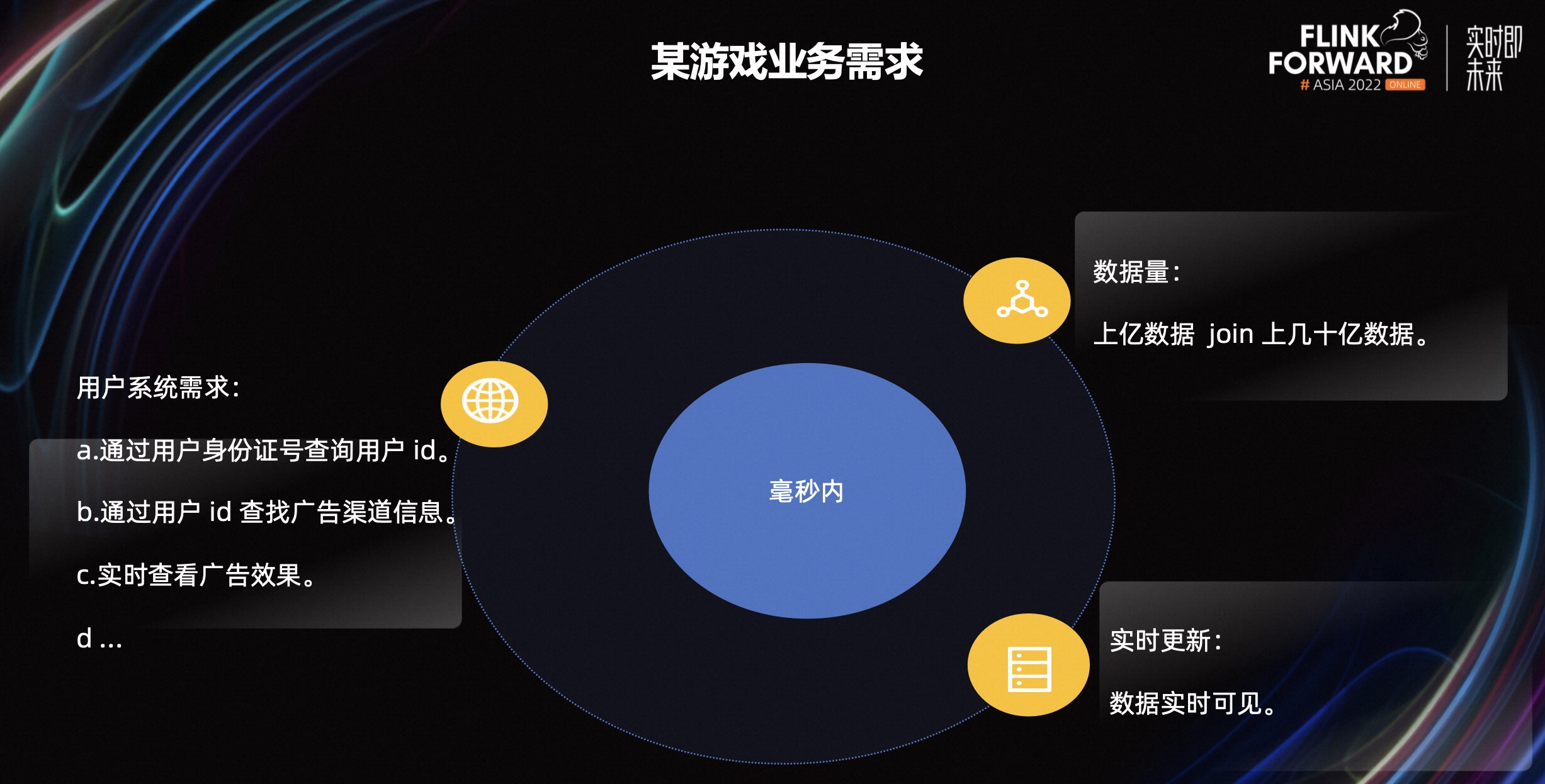
在游戏行业有以下三个典型场景:
-
场景一:通过身份证号查询用户 ID。当用户注册时,系统需要通过身份证号信息,去各个平台查询是否已经有注册信息或者多个 ID。如果已有注册信息,则提醒用户登陆。
-
场景二:通过用户 ID 查看广告渠道。当用户注册后,第三方渠道商需要得到是否正确归因的回调,比如从该渠道注册的用户,是不是被黑掉。
-
场景三:实时广告效果查看。游戏主播在推广游戏时,需要实时看到游戏的点击,下载,安装,注册,创建角色,渠道等等这些指标信息的数据。对应到业务层面,涉及到 7 张表的关联操作。
在场景一和二里,使用 Click House 分析需要 66s;在场景三里,Hive 方案里完成查询需要二十多分钟。

结合业务测试和架构特点,当前面临的挑战主要有以下四个方面:
- 实时性不够。在 Hive 架构下,数据从导入到可见需要 30 分钟,而 ClickHouse 也需要一分钟。
- 一致性不足。相信用过 Lambda 架构的人都知道 ClickHouse 和 Hive 的数据经常“打架”,二者计算出来的数据不一致。需要在计算上做去重处理,但即使重复处理完,仍然有数据不一致的问题,导致 ClickHouse 的数据只能用于实时数据的查看,Hive 数据则会用于最终数据使用。
- 可维护性复杂。在业务使用中,需要开发两套代码对接 Hive 和 ClickHouse 架构。
- 查询性能不理想。在以上介绍的三个场景里,场景一和二在 ClickHouse 里面需要秒级甚至分钟级才能出结果,场景三需要十几分钟。
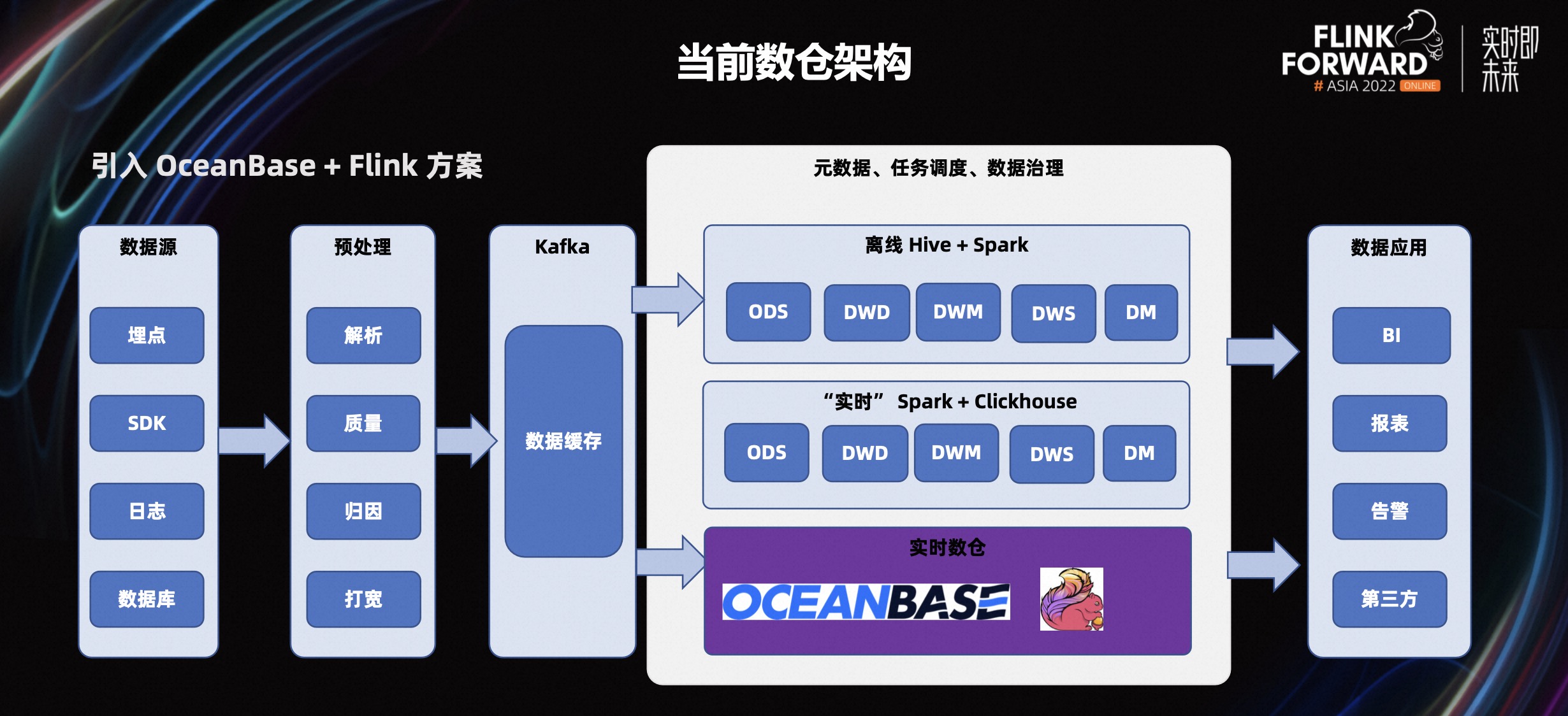
引入 OceanBase+Flink 方案之后,数据通过 Flink 实时写入到 OB,同时进行数据清洗,规整数据格式。在场景一和场景二中,在毫秒级就能返回结果。在场景三里面 1.5 秒就可以看到广告效果,性能提升非常明显。

新方案收益同样非常明显,相比之前的架构,性能从分钟级到秒级甚至于毫秒级,同时组件更少,架构上更轻量。一套方案即可满足一些业务的实时性要求,维护成本低,业务改造成本小。
四、未来展望

在 OceanBase 和 Flink 方案实际落地中,我们发现还可以对 Flink 做一些优化,主要有以下三个方面:
- 在性能方面。当前 Flink 是单线程读取数据快照。未来,会将快照切成多个数据片同时并发读,提升性能,
- 在一致性方面。原有设计中为了保证数据不丢,会先启动增量读再启动快照读。在进行 ETL 操作时,可能存在数据冗余问题。新设计中,可以对快照+增量数据读进行优化,实现一致性读取。
- 在兼容性方面。当前 Flink 适配 OceanBase 的 connector 5.1 版本。随着 OceanBase 兼容 mysql 8.0,未来同样需要 Flink 适配 8.0 connector。
随着 OceanBase+Flink 被广泛的应用于生产环境,未来我们将与 Flink 以及周边生态工具不断进行适配并完善该方案,更好的服务企业用户。
点击查看原文视频 & 演讲PPT
相关文章:
OceanBase X Flink 基于原生分布式数据库构建实时计算解决方案
摘要:本文整理自 OceanBase 架构师周跃跃,在 Flink Forward Asia 2022 实时湖仓专场的分享。本篇内容主要分为四个部分: 分布式数据库 OceanBase 关键技术解读 生态对接以及典型应用场景 OceanBase X Flink 在游戏行业实践 未来展望 点击…...

600V EasyPIM™ IGBT模块FB30R06W1E3、FB20R06W1E3B11、FB20R06W1E3降低了系统成本和损耗,可满足高能效要求。
EasyPIM™ IGBT模块是一种三相输入整流器PIM IGBT模块,采用TRENCHSTOP™ IGBT7、发射器控制7二极管和NTC/PressFIT技术。该模块具有增强的dv/dt可控性、改进的FWD软度、优化的开关损耗以及8μs短路稳定性。EasyPIM(功率集成模块)外形非常小巧…...
form 表单恢复初始数据
写表单的时候,想做到,某个操作时,表单恢复初始数据 this.$options.data().form form 是表单的对象 <template><div><el-dialog title"提示" :visible.sync"dialogVisible"><el-form :model"…...

MySQL—索引
这里写目录标题 索引是什么? 索引优缺点?MySQL索引类型索引底层实现? 为什么使用B树, 而不是B树, BST, AVL, 红黑树等等?什么是聚簇索引和非聚簇索引?非聚簇索引一定会回表吗?什么是联合索引?为什么需要注意联合索引中的字段顺序?什么是最左前缀原则?什么是前缀索引?…...

Android图形-合成与显示-概论
目录 引言 概念与理解 SurfaceFlinger Surface HWC Fence: Gralloc: DisplayDevice 引言 Activity是Android的主要UI相关组件。通过View的相关类和接口实现,在WMS的管理下,进行窗口和控件的测量,布局和绘制&am…...

Swift 5 数组如何获取集合的索引和对应的元素值
Swift 5 数组如何获取集合的索引和对应的元素值 在Swift 5中,你可以使用enumerated()方法来获取集合的索引和对应的元素值。这个方法会返回一个包含索引和元素的元组数组。以下是使用enumerated()方法来获取一个数组的索引和元素的示例: let array [1…...

计算 Nginx 日志的PV和UV
计算 Nginx 日志的 PV(页面浏览量)和 UV(独立访客数),你需要使用一些工具和技术。 PV(页面浏览量)是指网站的所有页面被访问的总次数,而 UV(独立访客数)则是指…...

Spring中常用的注解
1.声明Bean的注解(标注在类上) Component:表示普通的组件,也可泛指下面三种组件。Controller:控制层。Service:业务逻辑层。Repository:数据访问层。 2.Bean的生命周期的注解 Scope表示设置Spring是如何创建Bean的…...

Plugin 插件
Plugin 插件 插件是 webpack 的支柱功能。插件目的在于解决 loader 无法实现的其他事。Webpack 提供很多开箱即用的插件。 常用插件 clean-webpack-plugin 自动清理输出目录 html-webpack-plugin 自动生成使用 bundle.js 的 HTML copy-webpack-plugin 拷贝文件到输出目…...

Structure needs cleaning fsimage文件系统损坏修复
最近清除数据的时候发现有些文件无法rm [rootnode101 application_1691504014432_0002]# rm -rf ls:* [rootnode101 application_1691504014432_0002]# ls ls: 无法访问flink-dist-cache-8f72398e-9254-42d4-a14d-a0def99b493d: Structure needs cleaning以下操作可能会删除文件…...
MATLAB|信号处理的Simulink搭建与研究
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
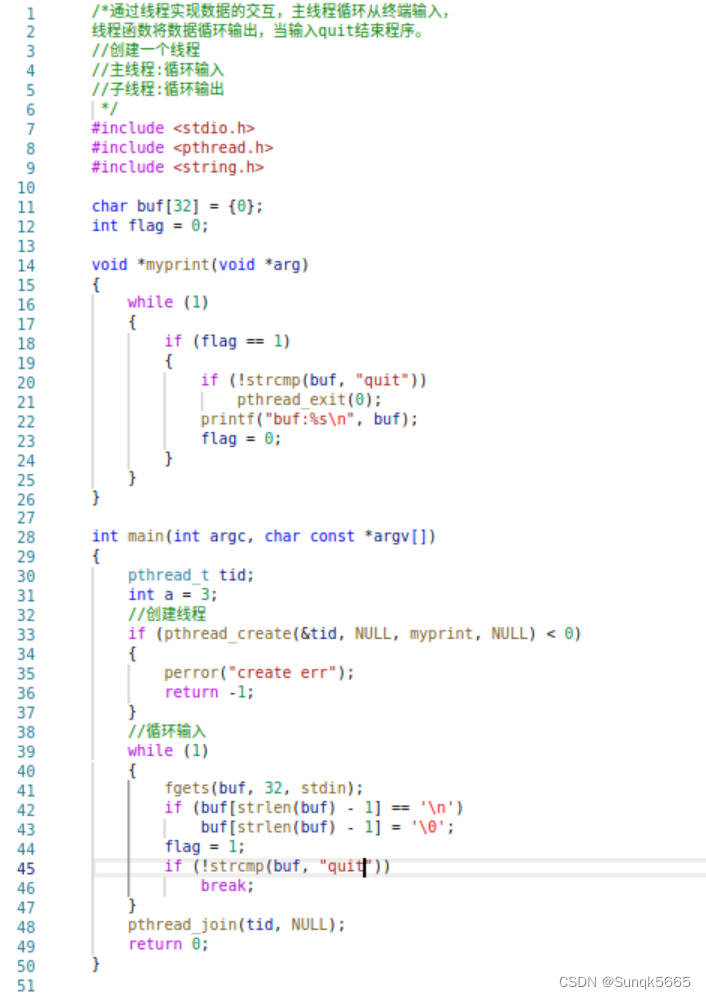
LinuxC编程——线程
目录 一、概念二、进程与线程的区别⭐⭐⭐三、线程资源四、函数接口4.1 线程创建4.2 线程退出4.3 线程回收4.3.1 阻塞回收4.3.2 非阻塞回收 4.4 pthread_create之传参4.5 练习 一、概念 是一个轻量级的进程,为了提高系统的性能引入线程。 进程与线程都参与cpu的统一…...
的实例)
使用fetch调用fastapi接口(post)的实例
前端代码 //定义函数 async function sendRequest(data) {let myurl"http://127.0.0.1:8848/get_student_info"const response await fetch(myurl, {method: POST,mode: cors, // 执行跨域请求headers: {Content-Type: application/json, },body: JSON.st…...
探索规律:Python地图数据可视化艺术
文章目录 一 基础地图使用二 国内疫情可视化图表2.1 实现步骤2.2 完整代码2.3 运行结果 一 基础地图使用 使用 Pyecharts 构建地图可视化也是很简单的。Pyecharts 支持多种地图类型,包括普通地图、热力图、散点地图等。以下是一个构建简单地图的示例,以…...

Django-------自定义命令
每次在启动Django服务之前,我们都会在终端运行python manage.py xxx的管理命令。其实我们还可以自定义管理命令,这对于执行独立的脚本或任务非常有用,比如清除缓存、导出用户邮件清单或发送邮件等等。 自定义的管理命令不仅可以通过manage.p…...

【Linux】在浏览器输入网址后发生了什么事情?
在浏览器输入网址后发生了什么事情? 1.域名解析2.建立TCP连接3.发出HTTP请求4.响应请求5.TCP断开连接6.解析资源和布局渲染 其实我们在浏览器输入网址后,发生了如下的事情 1.域名解析 由于计算机是无法识别我们输入的地址的,那么就需要将当前…...
推荐两本书《JavaRoadmap》、《JustCC》
《JavaRoadmap》 前言 本书的受众 如果你是一名有开发经验的程序员,对 Java 语言语法也有所了解,但是却一直觉得自己没有入门,那么希望这本书能帮你打通 Java 语言的任督二脉。 本书的定位 它不是一本大而全的书,而是一本打通、…...

使用基于jvm-sandbox的对三层嵌套类型的改造
使用基于jvm-sandbox的对三层嵌套类型的改造 问题背景 先简单介绍下基于jvm-sandbox的imock工具,是Java方法级别的mock,操作就是监听指定方法,返回指定的mock内容。 jvm-sandbox 利用字节码操作和自定义类加载器的技术,将原始方法…...

[HDLBits] Mt2015 q4b
Circuit B can be described by the following simulation waveform: Implement this circuit. module top_module ( input x, input y, output z );//001 100 010 111assign z(xy); endmodule...

C++:堆排序
堆排序 输入一个长度为n的整数数列,从小到大输出前m小的数 输入格式 第一行包含整数n和m 第二行包含n个整数,表示整数数列 输出格式 共一行,包含m个整数,表示整数数列中前m小的数 数据范围 1 ≤ m ≤ n ≤ 1 0 5 1\le m\le …...

案例速递|手机摄像头模组底壳检测
东莞市沃德普自动化科技有限公司 www.wordop.com 检测背景: 在手机摄像头模组的精密制造流程中,模组底壳是镜头、CMOS传感器、VCM马达的核心承载与定位基准,其表面质量直接决定模组的装配精度、光学性能与长期使用可靠性。 检测需求&#x…...

如何高效管理全面战争MOD?虎符台Legion Seal终极指南
如何高效管理全面战争MOD?虎符台Legion Seal终极指南 【免费下载链接】legion-seal 虎符台/Legion Seal,全面战争游戏MOD管理器,技术栈:Tauri 2 Vue TailwindCSS 项目地址: https://gitcode.com/zeyl/legion-seal 前言&a…...

AudioLM-PyTorch代码深度解析:架构设计、模块实现与扩展方法
AudioLM-PyTorch代码深度解析:架构设计、模块实现与扩展方法 【免费下载链接】audiolm-pytorch Implementation of AudioLM, a SOTA Language Modeling Approach to Audio Generation out of Google Research, in Pytorch 项目地址: https://gitcode.com/gh_mirro…...

化工园区智慧巡检平台
化工园区智慧巡检平台概述化工园区智慧巡检平台通过物联网、大数据、人工智能等技术,实现巡检流程数字化、智能化,提升安全性和效率。平台通常涵盖设备监控、隐患识别、数据分析、应急响应等功能,助力园区管理降本增效。核心功能模块实时监控…...

终极指南:如何快速安装Koikatu HF Patch完整增强补丁
终极指南:如何快速安装Koikatu HF Patch完整增强补丁 【免费下载链接】KK-HF_Patch Automatically translate, uncensor and update Koikatu! and Koikatsu Party! 项目地址: https://gitcode.com/gh_mirrors/kk/KK-HF_Patch 还在为Koikatu和Koikatsu Party游…...

为什么你的低代码表单在高并发下崩了?——基于TPS 3800+的真实压测日志,还原PHP-FPM+Redis缓存穿透链路
第一章:低代码表单的核心架构与PHP实现边界低代码表单系统并非“无代码”,而是将表单建模、渲染、校验、数据绑定与后端集成等能力抽象为可配置层,其核心架构通常由元数据驱动引擎、可视化设计器、动态渲染器、规则执行器及服务适配器五部分构…...

foss_photo_libraries移动端功能详解:从自动上传到多平台支持的终极指南
foss_photo_libraries移动端功能详解:从自动上传到多平台支持的终极指南 【免费下载链接】foss_photo_libraries Free and Open Source Photo Libraries 项目地址: https://gitcode.com/gh_mirrors/fo/foss_photo_libraries 在当今移动优先的时代,…...

Z-Image-Turbo镜像实战指南:Xinference多模型管理+Gradio多Tab界面配置
Z-Image-Turbo镜像实战指南:Xinference多模型管理Gradio多Tab界面配置 1. 快速了解Z-Image-Turbo镜像 今天给大家介绍一个特别实用的AI镜像——Z-Image-Turbo,这是一个基于Xinference框架的多模型管理平台,专门用于生成高质量的人物图像。如…...

3分钟快速上手:免费城通网盘解析器终极指南
3分钟快速上手:免费城通网盘解析器终极指南 【免费下载链接】ctfileGet 获取城通网盘一次性直连地址 项目地址: https://gitcode.com/gh_mirrors/ct/ctfileGet 还在为城通网盘下载慢、广告多而烦恼吗?城通网盘解析器正是解决这些问题的利器&#…...

Clawdbot对接Qwen3:32B全流程:从Ollama部署到Web聊天界面
Clawdbot对接Qwen3:32B全流程:从Ollama部署到Web聊天界面 1. 项目概述与核心价值 你是否正在寻找一种简单高效的方式,将强大的Qwen3:32B大模型集成到你的工作流程中?本指南将带你完成从Ollama模型部署到Clawdbot Web聊天界面搭建的全过程&a…...