(2)原神角色数据分析-2
功能一:
得到某个属性的全部角色,将其封装在class中
"""各元素角色信息:一对多"""
from pandas import DataFrame, Series
import pandas as pd
import numpy as npclass FindType:# 自动执行,将传入参数赋值给私有属性self.Attributedef __init__(self, attribute):self.Attribute = attributedef find_type(self):role_things = pd.read_excel("C:/Users/YHT/Desktop/项目/原神各属性角色信息.xlsx", header=0, index_col=0)# 补全role_things = role_things.fillna(axis=0, method="ffill")# 按照"属性"这一列的信息,将所有数据重新分组,得到一个字典things_list = role_things.groupby("属性").groupsreturn role_things.loc[things_list[self.Attribute]]
功能二:
定向查找某个角色信息,传入参数为该角色的名称
"""查找对应角色:一对一"""
from pandas import DataFrame, Series
import pandas as pd
import numpy as npclass FindRole:def __init__(self, role_name):self.role_name = role_namedef findrole(self):role_things = pd.read_excel("C:/Users/YHT/Desktop/项目/原神各属性角色信息.xlsx", header=0, index_col=0)# 将属性所包含的nan,进行填充role_things = role_things.fillna(axis=0, method="ffill")print(role_things)print()all_name = role_things["角色"]print(all_name)num = 0for x in all_name:if x == self.role_name:return_role = role_things.loc[:, "角色":]print(return_role.iloc[num])Attribute = return_role.iloc[num]["属性"]Name = return_role.iloc[num]["角色"]Hp = return_role.iloc[num]["生命值"]Def = return_role.iloc[num]["防御力"]Atk = return_role.iloc[num]["攻击力"]Break = return_role.iloc[num]["突破加成"]print(Name, Attribute, Hp, Def, Atk, Break)num += 1
功能三:
设置对应参数,筛选角色
比如,要找出生命值高于10000,防御力高于270,攻击力高于300的角色
"""设置限制参数,查找对应角色:多对多"""
from pandas import DataFrame, Series
import pandas as pd
import numpy as npclass Num:def __init__(self, Hp, Def, Atk):self.Hp = Hpself.Def = Defself.Atk = Atkdef num(self):role_things = pd.read_excel("C:/Users/YHT/Desktop/项目/原神各属性角色信息.xlsx", header=0, index_col=0)role_things = role_things.fillna(axis=0, method="ffill")if self.Hp is None:if self.Def is None:if self.Atk is None:print(role_things)else:return_things = role_things.loc[role_things["攻击力"] > self.Atk]print(return_things)else:if self.Atk is None:return_things = role_things.loc[role_things["防御力"] > self.Def]print(return_things)else:return_things = role_things.loc[(role_things["防御力"] > self.Def) & (role_things["攻击力"] > self.Atk)]print(return_things)else:if self.Def is None:if self.Atk is None:return_things = role_things.loc[role_things["生命值"] > self.Hp]print(return_things)else:return_things = role_things.loc[(role_things["生命值"] > self.Hp) & (role_things["攻击力"] > self.Atk)]print(return_things)else:if self.Atk is None:return_things = role_things.loc[(role_things["生命值"] > self.Hp) & (role_things["防御力"] > self.Def)]print(return_things)else:return_things = role_things.loc[(role_things["生命值"] > self.Hp) & (role_things["防御力"] > self.Def) & (role_things["攻击力"] > self.Atk)]print(return_things)
功能四:
按照某一参数,将角色顺序重新排列
例如,按照生命值大小,将所有角色重新排列
"""按照某一参数重新排序:一对多"""
from pandas import DataFrame, Series
import pandas as pd
import numpy as npclass Sort:def __init__(self, input_x):self.input_x = input_xdef sort(self):type_bool = Truerole_things = pd.read_excel("C:/Users/YHT/Desktop/项目/原神各属性角色信息.xlsx", header=0, index_col=0)role_things = role_things.fillna(axis=0, method="ffill")return_things = role_things.sort_values(by=self.input_x, ascending=type_bool, axis=0)print(return_things)
相关文章:
原神角色数据分析-2)
(2)原神角色数据分析-2
功能一: 得到某个属性的全部角色,将其封装在class中 """各元素角色信息:一对多""" from pandas import DataFrame, Series import pandas as pd import numpy as npclass FindType:# 自动执行,将…...

138. 复制带随机指针的链表
138. 复制带随机指针的链表 题目-中等难度示例1. 题目-中等难度 给你一个长度为 n 的链表,每个节点包含一个额外增加的随机指针 random ,该指针可以指向链表中的任何节点或空节点。 构造这个链表的 深拷贝。 深拷贝应该正好由 n 个 全新 节点组成&…...

Windows中redis怎么设置密码
设置密码有两种方式,用过第一种可以 1. 命令行设置密码。 运行cmd切换到redis根目录,先启动服务端 >redis-server.exe 另开一个cmd切换到redis根目录,启动客户端 >redis-cli.exe -h 127.0.0.1 -p 6379 客户端使用config get requ…...

租赁OLED透明屏:打造独特商业体验的智慧选择
近年来,OLED透明屏技术在商业领域中迅速崛起,其高透明度和卓越的图像质量为商家创造了全新的展示方式。 租赁OLED透明屏作为一种智慧选择,不仅能提升品牌形象和吸引力,还能创造与众不同的视觉体验。 对此,尼伽将和大…...
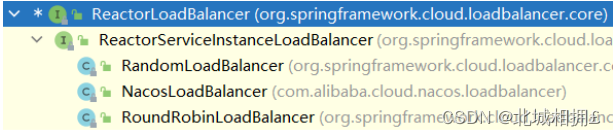
Nacos服务治理—负载均衡
引入负载均衡 在消费方引入负载均衡机制,同时简化获取服务提供者信息的流程 Spring Cloud引入组件LoadBalance实现负载均衡 添加依赖 <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web<…...
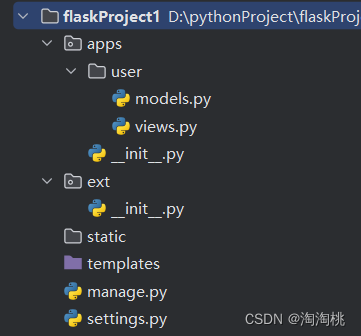
flask-----初始项目架构
1.初始的项目目录 -apps 包 ------存放app -user文件夹 -------就是一个app -models.py --------存放表模型 -views.py -------存放主代码 -ext包 -init.py -------实例化db对象 -manage.py -----运行项目的入口 -setting.py -----配置文件 2.各文件内容 manage…...
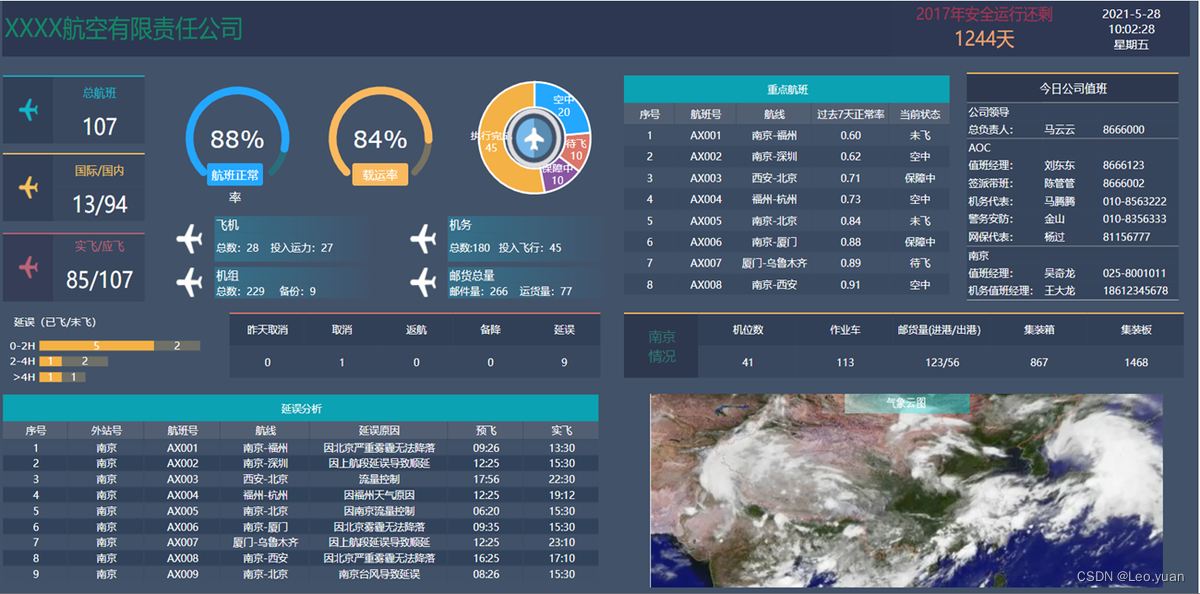
揭秘史上最全可视化大屏模板,00后亲测好用到离谱,效率加速99%
前几天老陈公司刚入职的一个00后,昨天被领导叫到办公室怒批了一个小时,我在外面都能听到领导的怒吼声,直接骂他是个垃圾,屁用没有,学都白上了。一个180的大高个小伙,直接被骂到痛哭流涕,走出办公…...

nginx基于主机和用户访问控制以及缓存简单例子
一.基于主机访问控制 1.修改nginx.conf文件 2.到其他主机上测试 (1)191主机 (2)180主机 二.基于用户访问控制 1.修改nginx.conf文件 2.使用hpasswd为用户创建密码文件,并指定到刚才指定的密码文件webck 3.测试…...
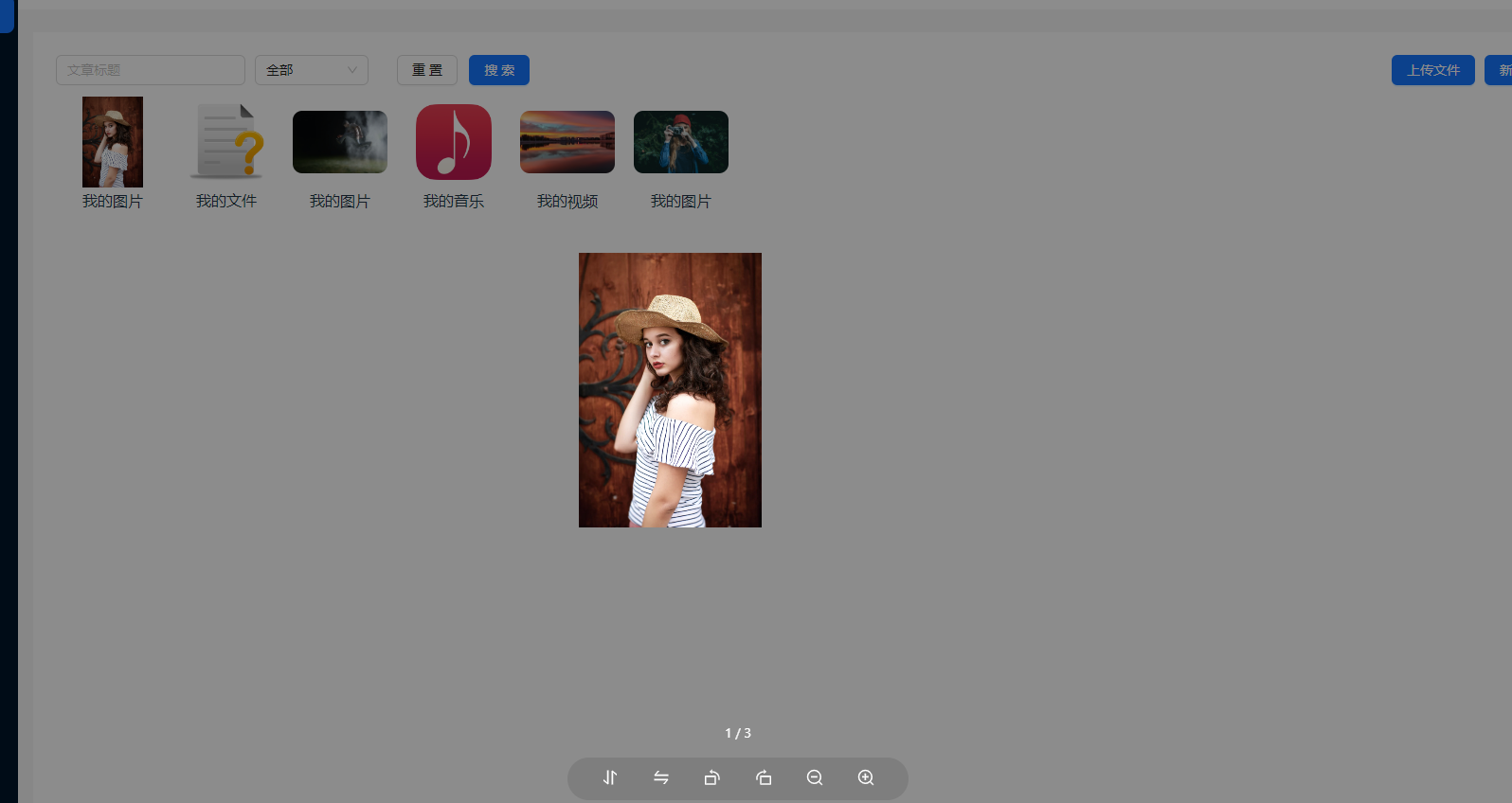
React使用antd的图片预览组件,点击哪个图片就预览哪个的设置
使用了官方推荐的相册模式的预览,但是点击预览之后,每次都是从图片列表的第一张开始预览,而不是点击哪张就从哪张开始预览: 所以这里我就封装了一下,对初始化预览的列表进行了逻辑处理: 当点击开始预览的…...

排序的介绍
排序算法介绍 排序是计算机内经常进行的一种操作,其目的是将一组“无序”的记录序列调整为“有序”的记录序列 粗暴理解 将杂乱无章的数据元素,通过一定的方法按照关键字顺序排列的过程叫做排序 排序分内部排序和外部排序,若整个排序过程不需…...

appuploader使用教程
转载:appuploader使用教程 目录 问题解决秘籍 登录失败 don’t have access,提示没权限或同意协议 上传后在app管理中心找不到版本提交 不是等待上传状态 提示已经上传过包 上传提示tcpPort or udpPorts错误 上传提示已经有进程在上传 保存上传专用密码提示…...
企业权限管理(七)-权限操作
1. 数据库与表结构 1.1 用户表 1.1.1 用户表信息描述 users 1.1.2 sql语句 CREATE TABLE users( id varchar2(32) default SYS_GUID() PRIMARY KEY, email VARCHAR2(50) UNIQUE NOT NULL, username VARCHAR2(50), PASSWORD VARCHAR2(50), phoneNum VARCHAR2(20), STATUS INT )…...
【深度学习笔记】TensorFlow 常用函数
TensorFlow 提供了一些机器学习中常用的数学函数,并封装在 Module 中,例如 tf.nn Module 提供了神经网络常用的基本运算,tf.math Module 则提供了机器学习中常用的数学函数。本文主要介绍 TensorFlow 深度学习中几个常用函数的定义与用法&…...
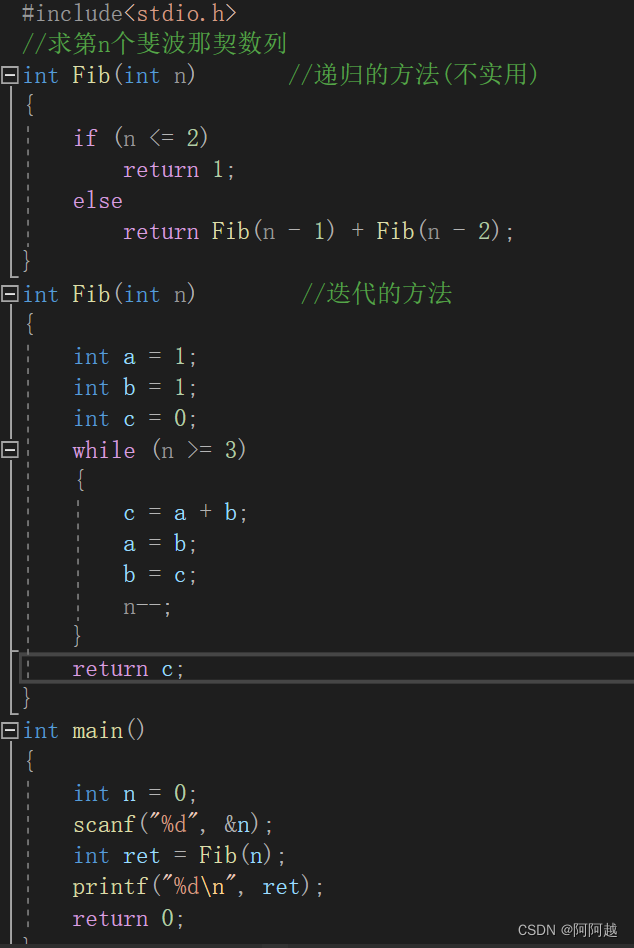
函数的递归与迭代
递归经典问题:(自行尝试) 1、汉诺塔问题 2、青蛙跳台阶问题 练习1、 练习2、...
win10 + VS2022 安装opencv C++
最近需要用到C opencv,看了很多帖子都需要自己编译opencv源码。为避免源码编译,可以使用VS来配置opencv C。下面是主要过程: 目录 1. 从官网下载 opencv - Get Started - OpenCV 2. 点击这个exe文件进行安装 3. 配置环境变量 4. VS中的项…...

nginx反向代理及负载均衡的实现
目录 1.nginx反向代理 2.nginx负载均衡 3.nginx反向代理及负载均衡实现 nginx反向代理 4台主机都需要的操作: 两台服务器操作: 两台主机服务器进行测试; nginx负载均衡配置 4.nginx配置其他参数 多虚拟机访问 后端服务器日志中需要…...

Tomcat部署SpringBoot项目
1.修改打包方式 pom.xml 里 加上 <packaging>war</packaging>2.移除内嵌的Tomcat <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-tomcat</artifactId><scope>provided</scope…...

Oracle笔记--dblink
概述 1、database link是定义一个数据库到另一个数据库的路径的对象,database link允许你查询远程表及执行远程程序。在任何分布式环境里,database都是必要的。另外要注意的是database link是单向的连接。 2、在创建database link的时候,Ora…...

Mapbox加载天地图CGCS2000矢量瓦片地图
1.背景 最近在做天地图的项目,要基于MapBox添加CGCS2000矢量切片数据,但是 Mapbox 只支持web 墨卡托(3857)坐标系的数据。Github有专业用户修改了mapbox-gl的相关代码,支持CGCS2000的切片数据加载,并且修改…...

day3 STM32 GPIO口介绍
GPIO接口简介 通用输入输出接口GPIO是嵌入式系统、单片机开发过程最常用的接口,用户可以通过编程灵活的对接口进行控制,实现对电路板上LED、数码管、按键等常用设备控制驱动,也可以作为串口的数据收发管脚,或AD的接口等复用功能使…...

FigmaCN技术解析:本地化方案如何实现设计效率优化
FigmaCN技术解析:本地化方案如何实现设计效率优化 【免费下载链接】figmaCN 中文 Figma 插件,设计师人工翻译校验 项目地址: https://gitcode.com/gh_mirrors/fi/figmaCN 中文设计师在使用Figma时,常因界面语言障碍导致操作效率降低30…...
)
GTE-Pro语义引擎效果展示:跨年度文档语义关联(2023制度→2024执行细则)
GTE-Pro语义引擎效果展示:跨年度文档语义关联(2023制度→2024执行细则) 今天想和大家分享一个特别有意思的案例,也是我们团队最近用GTE-Pro语义引擎解决的一个实际问题。 想象一下这个场景:你是一家公司的员工&#…...

Windows系统清理完全指南:使用WindowsCleaner高效解决C盘爆红问题
Windows系统清理完全指南:使用WindowsCleaner高效解决C盘爆红问题 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 你是否经常遇到Windows系统C盘空间不…...

企业级 Agent 治理平台:公司用数字帮手的必备管家
个人用智能体这个数字帮手,自己教、自己用,出点小问题也就影响自己;但公司里用,几十上百个智能体一起跑,要是没人管,麻烦事就多了:有的智能体可能随便翻公司的敏感数据,有的学会的好…...

隐式神经表示在计算机视觉中的5个关键应用:图像超分辨率到3D场景重建
隐式神经表示在计算机视觉中的5个关键应用:图像超分辨率到3D场景重建 【免费下载链接】awesome-implicit-representations A curated list of resources on implicit neural representations. 项目地址: https://gitcode.com/gh_mirrors/aw/awesome-implicit-repr…...

解锁本科论文「无痛通关」密码:Paperxie 毕业论文功能全维度拆解,从选题到定稿一步到位
paperxie-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AIPPThttps://www.paperxie.cn/ai/dissertationhttps://www.paperxie.cn/ai/dissertation 引言:毕业季的「论文困局」,AI 正在打破僵局 每年毕业季,「写论文」几乎是所有…...

STM32CubeMX+Keil5+ESP8266:基于HAL库的物联网设备快速联网实战
1. 环境准备与工具链搭建 第一次接触STM32ESP8266组合开发时,我花了整整两天时间才把开发环境理顺。现在回想起来,其实只需要三个核心工具:STM32CubeMX、Keil MDK-ARM和串口调试助手。建议使用Keil5版本,它对HAL库的支持最稳定。我…...

逻辑漏洞与信息工具实战博客
在网络安全的学习路径中,我们常常会经历从 CTF 赛题练手到真实 SRC 漏洞挖掘的进阶过程。近期的「逻辑漏洞深挖与信息工具赋能」实战课上,我们从经典 CTF 真题出发,拆解 PHP 反序列化的底层逻辑,再到实战的信息收集工具与 SRC 漏洞…...

MySQL数据库高级特性:
MySQL数据库高级特性:创建测试表:create database jx character set utf8use jx;my> desc users;主键:特性:唯一标识的一条记录不能有重复值一个表有一个主键可以是单列或多列的组合自动定义为NOT NULL作用:&#x…...

三步快速完成Windows和Office永久激活:KMS_VL_ALL_AIO完整指南
三步快速完成Windows和Office永久激活:KMS_VL_ALL_AIO完整指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 你是否曾经因为Windows或Office的激活问题而烦恼?当系统弹…...