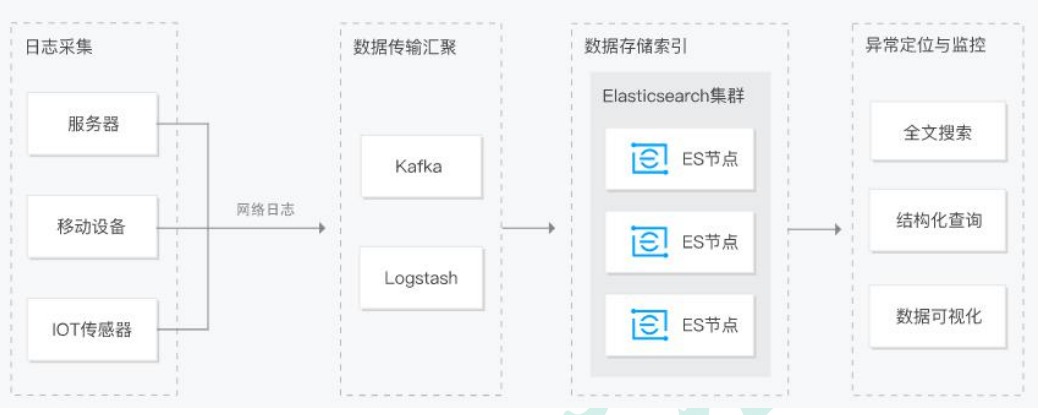
ElasticSearch详细操作
ElasticSearch搜索引擎详细操作以及概念
文章目录
- ElasticSearch搜索引擎详细操作以及概念
- 1、_cat节点操作
- 1.1、GET/_cat/nodes:查看所有节点
- 1.2、GET/_cat/health:查看es健康状况
- 1.3_、_GET/_cat/master:查看主节点
- 1.4、GET/_cat/indices:查看所有索引
- 2、索引一个文档(保存)
- 2.1 PUT请求添加文档
- 2.2 POST请求添加文档
- 3、查询文档
- 4、更新文档
- 5、删除操作
- 5.1删除文档
- 5.2删除索引
- 6、bulk 批量 操作API
- 7、复杂实例
- 8、样本数据测试
- 9、进阶检索
- 9.1、uri+检索参数
- 9.2、uri+请求体
- 10、 Query DSL
- 10.1、基本语法格式
- 10.2 返回部分字段
- 10.3 match - 匹配查询
- 10.3.1 、基本类型(非字符串),精确匹配
- 10.3.2 、字符串,全文检索
- 10.3.3 、字符串,多个单词(分词+全文检索)
- 10.3.4、match_phrase【短语匹配】
- 10.3.5、multi_match【多字段匹配】
- 10.4、bool【复合查询】
- 10.5、filter【结果过滤】
- 10.6、Term-精确匹配
- 10.7、aggregations(执行聚合)
- 10.8、Mapping
- 10.8.1 Mapping概念
- 10.8.2、创建映射
- 10.8.3、添加新的字段映射
- 10.8.4、更新映射
- 10.8.5、数据迁移
- 10.9、新版本改变
- 11、分词
- 11.1、安装ik分词器
- 11.2、测试ik分词器
- 11.2.1、使用默认分词器
- 11.2.2、使用分词器smart
- 11.2.3、使用分词器ik_max_word
- 11.3、安装nginx
- 11.4、自定义ik分词器词库
- 12、Elasticsearch-Rest-Client
- 13、SpringBoot整合
- 13.1、引入依赖
- 13.2、配置
- 13.3、使用
如果想了解基础概念和安装可以参考我的另一篇文章
ElasticSearch基础概念和安装
1、_cat节点操作
_cat命令用来查看节点信息,如下
1.1、GET/_cat/nodes:查看所有节点
127.0.0.1 58 95 0 0.03 0.07 0.08 dilm * 6f3e5d796c52
1.2、GET/_cat/health:查看es健康状况
1691239183 12:39:43 elasticsearch green 1 1 3 3 0 0 0 0 - 100.0%
1.3_、_GET/_cat/master:查看主节点
kkJtLv8bTgW3m7LcaNsw-g 127.0.0.1 127.0.0.1 6f3e5d796c52
1.4、GET/_cat/indices:查看所有索引
这个命令相当于mysql的show databases
green open .kibana_task_manager_1 3GwJZOIQQAmf9t8f3-JopQ 1 0 2 0 38.2kb 38.2kb
green open .apm-agent-configuration 9LnnUcgnQ_-3dM3qfxOTmg 1 0 0 0 283b 283b
green open .kibana_1 QP3CKMY_R12e6lV7XTjN5A 1 0 5 0 18.3kb 18.3kb
2、索引一个文档(保存)
2.1 PUT请求添加文档
保存一个数据,保存在哪个索引的哪个类型下。必须指定id,不能不带id。
请求:
PUT/customer/external/1;在customer索引下的external类型下保存1号数据为
{
“name”:“JohnDoe”
}
响应:
{"_index": "customer","_type": "external","_id": "1","_version": 1,"result": "created", 第一次创建叫新建,后面是updated"_shards": {"total": 2,"successful": 1,"failed": 0},"_seq_no": 0,"_primary_term": 1
}
2.2 POST请求添加文档
post请求,指定用哪个唯一标识 ,而且同一id发送多次是更新操作,版本号增加。如果不指定id就是永远的新增操作。
请求:
POST/customer/external/1;在customer索引下的external类型下保存1号数据为
{
“name”:“JohnDoe”
}
响应:
{"_index": "customer","_type": "external","_id": "1","_version": 1,"result": "created", 第一次创建叫新建,后面是updated"_shards": {"total": 2,"successful": 1,"failed": 0},"_seq_no": 0,"_primary_term": 1
}
3、查询文档
url: /customer/external/1
请求方式:GET
响应结果:
{"_index": "customer","_type": "external","_id": "1","_version": 2,"_seq_no": 1, 乐观锁,并发控制字段,每次更新就会+1"_primary_term": 1, 同上,主分片重新分片,如重启就会变化"found": true,"_source": {"name": "zmz" source才是我们自己保存的内容}
}
乐观锁操作的话,更新携带 ?if_seq_no=0&if_primary_term=1,两个请求一样的话只有一个会成功,另一个会409异常。
4、更新文档
url: POST customer/external/1/_update
{ "doc":{ 如果添加了_update 就需要添加"doc""name": "John Doew" }
}
不同:
带_update 对比元数据如果一样就不进行任何操作,版本号不会增加。
看场景;
- 对于大并发更新,不带 update;
- 对于大并发查询偶尔更新,带 update;对比更新,重新计算分配规则。
更新同时增加属性,加了/_update 就得加“doc”
POST customer/external/1/_update
{
“doc”: { “name”: “Jane Doe”, “age”: 20 }
}
5、删除操作
5.1删除文档
DELETE customer/external/1
响应结果
{"_index": "customer","_type": "external","_id": "2","_version": 3,"result": "deleted", 这里为deleted"_shards": {"total": 2,"successful": 1,"failed": 0},"_seq_no": 7,"_primary_term": 1
}
删除后再次查询的结果为
{"_index": "customer","_type": "external","_id": "2","found": false
}
5.2删除索引
DELETE customer
响应结果:
{"acknowledged": true
}
删除后查询结果为:
{"error": {"root_cause": [{"type": "index_not_found_exception","reason": "no such index [customer]","resource.type": "index_expression","resource.id": "customer","index_uuid": "_na_","index": "customer"}],"type": "index_not_found_exception","reason": "no such index [customer]","resource.type": "index_expression","resource.id": "customer","index_uuid": "_na_","index": "customer"},"status": 404
}
6、bulk 批量 操作API
POST customer/external/_bulk
注意下面是两行,两个文档,不是json格式,用kibana操作
POST customer/external/_bulk
{"index":{"_id":"1"}}
{"name": "John Doe" }
{"index":{"_id":"2"}}
{"name": "Jane Doe" }
响应结果
#! Deprecation: [types removal] Specifying types in bulk requests is deprecated.
{"took" : 11,"errors" : false,"items" : [ 每个数据会独立统计它的结果{"index" : {"_index" : "customer","_type" : "external","_id" : "1","_version" : 2,"result" : "updated","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 1,"_primary_term" : 1,"status" : 200}},{"index" : {"_index" : "customer","_type" : "external","_id" : "2","_version" : 1,"result" : "created","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 2,"_primary_term" : 1,"status" : 201}}]
}7、复杂实例
POST /_bulk
{ "delete": { "_index": "website", "_type": "blog", "_id": "123" }}
{ "create": { "_index": "website", "_type": "blog", "_id": "123" }}
{ "title": "My first blog post" }
{ "index": { "_index": "website", "_type": "blog" }}
{ "title": "My second blog post" }
{ "update": { "_index": "website", "_type": "blog", "_id": "123"} }
{ "doc" : {"title" : "My updated blog post"} }
响应结果:
#! Deprecation: [types removal] Specifying types in bulk requests is deprecated.
{"took" : 135, 花费了135毫秒"errors" : false, 没有出现任何错误"items" : [{"delete" : { 删除操作"_index" : "website","_type" : "blog","_id" : "123","_version" : 1,"result" : "not_found","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 0,"_primary_term" : 1,"status" : 404 404是因为没有这个记录}},{"create" : {"_index" : "website","_type" : "blog","_id" : "123","_version" : 2,"result" : "created","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 1,"_primary_term" : 1,"status" : 201 201 创建成功}},{"index" : {"_index" : "website","_type" : "blog","_id" : "Fz4FxokBKApesxsABSSJ","_version" : 1,"result" : "created","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 2,"_primary_term" : 1,"status" : 201 201创建成功}},{"update" : {"_index" : "website","_type" : "blog","_id" : "123","_version" : 3,"result" : "updated","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 3,"_primary_term" : 1,"status" : 200 更新成功}}]
}bulk API 以此按顺序执行所有的 action(动作)。如果一个单个的动作因任何原因而失败, 它将继续处理它后面剩余的动作。当 bulk API 返回时,它将提供每个动作的状态(与发送 的顺序相同),所以您可以检查是否一个指定的动作是不是失败了.
8、样本数据测试
准备了一份顾客银行账户信息的虚构的 JSON 文档样本。每个文档都有下列的 schema (模式):
es官方测试数据地址:测试数据地址
POST /bank/account/_bulk
测试数据
9、进阶检索
ES 支持两种基本方式检索 :
9.1、uri+检索参数
GET bank/_search 检索 bank 下所有信息,包括 type 和 docs
GET bank/_search?q=*&sort=account_number:asc 请求参数方式检索
q=* 查询所有 查询所有的话就不存在最大得分
响应结果:(默认返回10条这里省略了)
{"took" : 1, Elasticsearch 执行搜索的时间(毫秒) "timed_out" : false, 告诉我们搜索是否超时 "_shards" : { 告诉我们多少个分片被搜索了,以及统计了成功/失败的搜索分片 "total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : { 搜索结果 "total" : {"value" : 1000, 总共检索出来1000条记录"relation" : "eq" 检索关系是相等},"max_score" : 1.0, 最高得分"hits" : [ 实际的搜索结果数组(默认为前 10 的文档) {"_index" : "bank", 索引"_type" : "account", 类型"_id" : "1", 唯一id"_score" : 1.0, 相关性得分"_source" : {"account_number" : 1,"balance" : 39225,"firstname" : "Amber","lastname" : "Duke","age" : 32,"gender" : "M","address" : "880 Holmes Lane","employer" : "Pyrami","email" : "amberduke@pyrami.com","city" : "Brogan","state" : "IL"}}}]}
}9.2、uri+请求体
GET bank/_search
{"query": {"match_all": {} 匹配所有,有条件就写条件,没有就是大括号},"sort": [{"account_number": { 账号降序搜索"order": "desc"}}]
}
HTTP 客户端工具(POSTMAN),get 请求不能携带请求体,我们变为 post 也是一样的 我们 POST 一个 JSON 风格的查询请求体到 _search API。 需要了解,一旦搜索的结果被返回,Elasticsearch 就完成了这次请求,并且不会维护任何 服务端的资源或者结果的 cursor(游标)
10、 Query DSL
10.1、基本语法格式
Elasticsearch 提供了一个可以执行查询的 Json 风格的 DSL(domain-specific language 领域特 定语言)。这个被称为 Query DSL。该查询语言非常全面,并且刚开始的时候感觉有点复杂, 真正学好它的方法是从一些基础的示例开始的。
- 一个查询语句 的典型结构
{ QUERY_NAME: { ARGUMENT: VALUE, ARGUMENT: VALUE,... } }
GET bank/_search
{ "query": {"match_all": {}},"from": 0, "size": 5, "sort": [ { "account_number": { "order": "desc" } } ]}
query 定义如何查询
- match_all 查询类型【代表查询所有的所有】,es 中可以在 query 中组合非常多的查询类型完成复杂查询 。
- 除了 query 参数之外,我们也可以传递其它的参数以改变查询结果。如 sort,size
- from+size 限定,完成分页功能
- sort 排序,多字段排序,会在前序字段相等时后续字段内部排序,否则以前序为准
10.2 返回部分字段
GET bank/_search
{"query": {"match_all": {}},"from": 0,"size": 5,"_source": [ 只查询age和balance"age", "balance"]
}
10.3 match - 匹配查询
10.3.1 、基本类型(非字符串),精确匹配
match 返回 account_number=20 的.匹配age,height等推荐用term。
GET bank/_search
{"query": {"match": {"account_number": "20"}}
}
10.3.2 、字符串,全文检索
最终查询出 address 中包含 mill 单词的所有记录 ,match 当搜索字符串类型的时候,会进行全文检索,并且每条记录有相关性得分,并根据评分进行排序
GET bank/_search
{"query": {"match": {"address": "mill"}}
}
10.3.3 、字符串,多个单词(分词+全文检索)
最终查询出 address 中包含 mill 或者 road 或者 mill road 的所有记录,并给出相关性得分
GET bank/_search
{"query": {"match": {"address": "mill road"}}
}
10.3.4、match_phrase【短语匹配】
将需要匹配的值当成一个整体单词**(不分词)**进行检索 ,查出 address 中包含 mill road 的所有记录,并给出相关性得分 。
GET bank/_search
{"query": {"match_phrase": {"address": "mill road"}}
}
10.3.5、multi_match【多字段匹配】
查询出state 或者 address中 包含 mill单词的数据
GET bank/_search
{"query": {"multi_match": {"query": "mill","fields": ["state","address"]}}
}
10.4、bool【复合查询】
bool 用来做复合查询: 复合语句可以合并任何 其它查询语句,包括复合语句,了解这一点是很重要的。这就意味着复合语句之间可以互相嵌套,可以表达非常复杂的逻辑。
GET bank/_search
{"query": {"bool": {"must": [ 可以组合条件,必须达到 must 列举的所有条件 {"match": {"address": "mill"}},{"match": {"gender": "M"}}],#should 应该达到 should 列举的条件(也可不匹配,只是应该),如果达到会增加相关文档的评分,并不会改变查询的结果。如果 query 中只有 should 且只有一种匹配规则,那么 should 的条件就会被作为默认匹配条件而去改变查询结果"should": [ {"match": {"address": "lane"}}],"must_not": [ 可以组合条件,必须不匹配列举的所有条件 {"match": {"email": "baluba.com"}}]}}
}
10.5、filter【结果过滤】
并不是所有的查询都需要产生分数(上面的must,should都会产生相关性得分),特别是那些仅用于 “filtering”(过滤)的文档。为了不计算分数 Elasticsearch 会自动检查场景并且优化查询的执行。
GET bank/_search
{"query": {"bool": {"must": [{"match": {"address": "mill"}}],"filter": { 加上后就不会有相关性得分,每个得分都是0,直接过滤"range": { 查询余额区间在10000到2000之间的"balance": { "gte": 10000,"lte": 20000}}}}}
}
10.6、Term-精确匹配
和 match 一样。匹配某个属性的值。全文检索字段用 match,其他非 text 字段匹配用term。精确的,比如age,height等用term,会分词全文检索的就用match。
GET bank/_search
{"query": {"bool": {"must": [{"term": {"age": {"value": "28"}}},{"match": {"address": "990 Mill Road"}}]}}
}
10.7、aggregations(执行聚合)
聚合提供了从数据中分组和提取数据的能力。最简单的聚合方法大致等于 SQL GROUP BY 和 SQL 聚合函数。在 Elasticsearch 中,您有执行搜索返回 hits(命中结果),并且同时返 回聚合结果,把一个响应中所有hits(命中结果)分隔开的能力。这是非常强大且有效的, 您可以执行查询和多个聚合,并且在一次使用中得到各自的(任何一个的)返回结果,使用 一次简洁和简化的 API 来避免网络往返。
“aggs”就是用来聚合的函数
搜索 address 中包含mill 的所有人的年龄分布以及平均年龄,但不显示这些人的详情。
GET bank/_search
{"query": {"match": {"address": "mill"}},"aggs": { 聚合函数"group_by_state": { 执行聚合后起的名字"terms": { 查询聚合有多少种可能(比如不同年龄的人分别有多少人),求分布"field": "age" “field” 字段}},"avg_age": { 执行聚合后起的名字"avg": { "field": "age"}}},"size": 0
}响应结果:
{"took" : 20,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 4, 命中记录"relation" : "eq" },"max_score" : null,"hits" : [ ]},"aggregations" : { 聚合结果"avg_age" : {"value" : 34.0 平均年龄34},"group_by_state" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [ 三钟不同年龄段的人数{"key" : 38,"doc_count" : 2},{"key" : 28,"doc_count" : 1},{"key" : 32,"doc_count" : 1}]}}
}复杂:
按照年龄聚合,并且请求这些年龄段的这些人的平均薪资(套娃,在聚合的里面再次聚合)
GET bank/account/_search
{"query": {"match_all": {}},"aggs": {"age_avg": {"terms": {"field": "age","size": 1000},"aggs": { 在里面进行子聚合 求出每个年龄段的人数和平均薪资"banlances_avg": {"avg": {"field": "balance"}}}}},"size": 1000
}
复杂:查出所有年龄分布,并且这些年龄段中 M 的平均薪资和 F 的平均薪资以及这个年龄
段的总体平均薪资
GET bank/account/_search
{"query": {"match_all": {}},"aggs": {"age_agg": {"terms": {"field": "age","size": 100},"aggs": {"gender_agg": {"terms": {"field": "gender.keyword", 这里的性别被定义为了文本类型,所以得用keyword转为关键词"size": 100},"aggs": {"balance_avg": { “M”和“F”分别有多少人,平均薪资有多少"avg": {"field": "balance"}}}},"balance_avg": { 全年龄段得平均薪资是多少"avg": {"field": "balance" }}}}},"size": 1000
}
10.8、Mapping
10.8.1 Mapping概念
Mapping(映射) Mapping是用来定义一个文档(document),以及它所包含的属性(field)是如何存储和索引的。比如,使用 mapping 来定义:
-
哪些字符串属性应该被看做全文本属性(full text fields)。
-
哪些属性包含数字,日期或者地理位置。
-
文档中的所有属性是否都能被索引(_all 配置)。
-
日期的格式。
-
自定义映射规则来执行动态添加属性。
查看 mapping 信息:(可以看到当前数据的索引对应的类型)
字段类型

GET bank/_mapping 查询银行下面的每一个字段的类型
{"bank" : {"mappings" : {"properties" : { 属性包含每一个字段的类型"account_number" : { 比如account_number是long类型的"type" : "long"},"address" : {"type" : "text", address是text类型的,就会进行全文检索,会进行分词"fields" : {"keyword" : { 子属性,如果用address.keyword子属性就会进行精确匹配查询"type" : "keyword","ignore_above" : 256}}},"age" : {"type" : "long"},"balance" : {"type" : "long"},"city" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}},"email" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}},"employer" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}},"firstname" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}},"gender" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}},"lastname" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}},"state" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}}}}}
}10.8.2、创建映射
1、创建索引并指定映射
PUT /my-index
{"mappings": {"properties": {"age": {"type": "integer" },"email": {"type": "keyword"},"name": {"type": "text"}}}
}
10.8.3、添加新的字段映射
PUT /my-index/_mapping
{"properties": {"employee-id": {"type": "keyword","index": false}}
}
10.8.4、更新映射
对于已经存在的映射字段,我们不能更新。更新必须创建新的索引进行数据迁移。
10.8.5、数据迁移
1、把之前的索引的映射查出来,重新创建一个新的索引。然后再使用下面的方式迁移
POST _reindex
POST _reindex [固定写法]
{ "source": { "index": "twitter" },"dest": { "index": "new_twitter" } }
2、将旧索引的type下的数据进行迁移到新的索引
POST _reindex
{"source": {"index": "twitter", 老的索引"type": "tweet" 索引下的类型},"dest": {"index": "tweets" 目标迁移的索引}
}
10.9、新版本改变
- Es7 及以上移除了 type 的概念。
- 关系型数据库中两个数据表示是独立的,即使他们里面有相同名称的列也不影响使用, 但 ES 中不是这样的。elasticsearch 是基于 Lucene 开发的搜索引擎,而 ES 中不同 type 下名称相同的 filed 最终在 Lucene 中的处理方式是一样的。 两个不同 type 下的两个 user_name,在 ES 同一个索引下其实被认为是同一个 filed, 你必须在两个不同的 type 中定义相同的 filed 映射。否则,不同 type 中的相同字段 名称就会在处理中出现冲突的情况,导致 Lucene 处理效率下降。 去掉 type 就是为了提高 ES 处理数据的效率。
- Elasticsearch 7.x URL 中的 type 参数为可选。比如,索引一个文档不再要求提供文档类型。
- Elasticsearch 8.x 不再支持 URL 中的 type 参数。
解决:
1)、将索引从多类型迁移到单类型,每种类型(前面提到的type,类似于表)文档一个独立索引
2)、将已存在的索引下的类型数据,全部迁移到指定位置即可。详见数据迁移
11、分词
一个 tokenizer(分词器)接收一个字符流,将之分割为独立的 tokens(词元,通常是独立 的单词),然后输出 tokens 流。 例如,whitespace tokenizer 默认分词器遇到空白字符时分割文本。它会将文本 “Quick brown fox!” 分割 为 [Quick, brown, fox!]。 该 tokenizer(分词器)还负责记录各个 term(词条)的顺序或 position 位置(用于 phrase 短 语和 word proximity 词近邻查询),以及 term(词条)所代表的原始 word(单词)的 start (起始)和 end(结束)的 character offsets(字符偏移量)(用于高亮显示搜索的内容)。 Elasticsearch 提供了很多内置的分词器,可以用来构建 custom analyzers(自定义分词器)。
11.1、安装ik分词器
注意:不能用默认 elasticsearch-plugin install xxx.zip 进行自动安装
分词器 对应 es 版本安装
- 安装wget
yum install wget
这里再docker安装es的时候已经把es的安装目录挂在在了我的根目录的mydata下面了
cd /
cd mydata
cd elasticsearch
# 进入elasticsearch的plugins目录下面
cd plugins
#然后使用wget安装对应es版本的ik分词器到plugins下面(这里用wget太慢了,我从外网下载上传进去,外网路径https://github.com/medcl/elasticsearch-analysis-ik/releases/tag/v7.4.2)
wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.4.2/elasticsearch-anal ysis-ik-7.4.2.zip
#解压并删除压缩包unzip elasticsearch-analysis-ik-7.4.2.zip -d analysis-ikrm -rf elasticsearch-analysis-ik-7.4.2.zip#修改文件权限chmod -R 777 analysis-ik
#进入elasticsearch容器内部
docker ps
docker exec -it 6f3e /bin/bash
#可以发现容器内部的plugins下面也已经有了安装好的ik分词器,检查安装的pluginselasticsearch-plugin list#退出容器exit;#重启esdocker restart elasticsearch#刷新自己的kibana就可以使用分词器了
11.2、测试ik分词器
11.2.1、使用默认分词器
POST _analyze
{"text": "我是中国人"
}
响应结果:
{"tokens" : [{"token" : "我","start_offset" : 0,"end_offset" : 1,"type" : "<IDEOGRAPHIC>","position" : 0},{"token" : "是","start_offset" : 1,"end_offset" : 2,"type" : "<IDEOGRAPHIC>","position" : 1},{"token" : "中","start_offset" : 2,"end_offset" : 3,"type" : "<IDEOGRAPHIC>","position" : 2},{"token" : "国","start_offset" : 3,"end_offset" : 4,"type" : "<IDEOGRAPHIC>","position" : 3},{"token" : "人","start_offset" : 4,"end_offset" : 5,"type" : "<IDEOGRAPHIC>","position" : 4}]
}
11.2.2、使用分词器smart
POST _analyze
{"analyzer": "ik_smart","text": "我是中国人"
}
响应结果:
{"tokens" : [{"token" : "我","start_offset" : 0,"end_offset" : 1,"type" : "CN_CHAR","position" : 0},{"token" : "是","start_offset" : 1,"end_offset" : 2,"type" : "CN_CHAR","position" : 1},{"token" : "中国人","start_offset" : 2,"end_offset" : 5,"type" : "CN_WORD","position" : 2}]
}
11.2.3、使用分词器ik_max_word
POST _analyze
{"analyzer": "ik_max_word","text": "我是中国人"
}
响应结果:
{"tokens" : [{"token" : "我","start_offset" : 0,"end_offset" : 1,"type" : "CN_CHAR","position" : 0},{"token" : "是","start_offset" : 1,"end_offset" : 2,"type" : "CN_CHAR","position" : 1},{"token" : "中国人","start_offset" : 2,"end_offset" : 5,"type" : "CN_WORD","position" : 2},{"token" : "中国","start_offset" : 2,"end_offset" : 4,"type" : "CN_WORD","position" : 3},{"token" : "国人","start_offset" : 3,"end_offset" : 5,"type" : "CN_WORD","position" : 4}]
}
能够看出不同的分词器,分词有明显的区别,所以以后定义一个索引不能再使用默 认的 mapping 了,要手工建立 mapping, 因为要选择分词器。
11.3、安装nginx
可以先查看内存够不够 free-m 命令
#切换到/mydata目录下
Cd /
cd mydata
#创建nginx目录
mkdir nginx
#启动安装nginx(这个只是为了复制里面的配置文件,并不是要装的版本)
docker run -p 80:80 --name nginx -d nginx:1.10
#将容器内的配置文件拷贝到当前目录:
docker container cp nginx:/etc/nginx .
#停掉删除nginx
docker stop nginx
docker rm nginx
#到mydata下面给nginx重命名为conf
mv nginx conf
#重新创建nginx目录,并把conf移动到nginx目录下面
mkdir nginx
mv conf nginx/
#创建新的 nginx;执行以下命令docker run -p 80:80 --name nginx \-v /mydata/nginx/html:/usr/share/nginx/html \-v /mydata/nginx/logs:/var/log/nginx \-v /mydata/nginx/conf:/etc/nginx \-d nginx:1.10#查看nginx状态
docker ps
#访问nginx端口80会发现403是因为没有任何页面
cd html/
vi index.html
输入
<h1>hello nginx</h1>
#创建自定义词库txt
mkdir es
cd es
vi zmz.txt
输入需要识别的名词
比如
蔡徐坤
鸡你太美
#重新刷新页面
#开机自启
docker udpate nginx --restart=always
11.4、自定义ik分词器词库
cd /mydata/elasticsearch/plugins/analysis-ik/config/
#修改ik配置
vi IKAnalyzer.cfg.xml
----------------------------如下--------------------------------<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment> <!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict"></entry> <!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry> <!--用户可以在这里配置远程扩展字典 -->
<entry key="remote_ext_dict">http://yourip/es/zmz.txt</entry>
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>------------------------------------------------------------------
#重启es
docker restart elasticsearch#还可以设置开机自启
docker udpate elasticsearch --restart=always
更新完成后,es 只会对新增的数据用新词分词。历史数据是不会重新分词的。如果想要历 史数据重新分词。需要执行:
POST my_index/_update_by_query?conflicts=proceed
12、Elasticsearch-Rest-Client
9300:TCP
- spring-data-elasticsearch:transport-api.jar;
- springboot 版本不同, transport-api.jar 不同,不能适配 es 版本
- 7.x 已经不建议使用,8 以后就要废弃
9200:HTTP
-
JestClient:非官方,更新慢
-
RestTemplate:模拟发 HTTP 请求,ES 很多操作需要自己封装,麻烦
-
HttpClient:同上
Elasticsearch-Rest-Client:官方 RestClient,封装了 ES 操作,API 层次分明,上手简单
最终选择 Elasticsearch-Rest-Client(elasticsearch-rest-high-level-client)
https://www.elastic.co/guide/en/elasticsearch/client/java-rest/current/java-rest-high.html
13、SpringBoot整合
13.1、引入依赖
<dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId><version>7.6.2</version></dependency>
13.2、配置
@Configuration
public class GulimallElasticSearchConfig {// @Bean// public RestHighLevelClient esRestClient(){// RestHighLevelClient client = new RestHighLevelClient(// RestClient.builder(new HttpHost("172.20.10.11", 9200, "http")));// return client;// }public static final RequestOptions COMMON_OPTIONS;static {RequestOptions.Builder builder = RequestOptions.DEFAULT.toBuilder();// builder.addHeader("Authorization", "Bearer " + TOKEN);// builder.setHttpAsyncResponseConsumerFactory(// new HttpAsyncResponseConsumerFactory// .HeapBufferedResponseConsumerFactory(30 * 1024 * 1024 * 1024));COMMON_OPTIONS = builder.build();}@Beanpublic RestHighLevelClient esRestClient(){RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("172.20.10.11", 9200, "http")));return client;}}
13.3、使用
参照官方文档:
package com.xunqi.gulimall.search;import com.alibaba.fastjson.JSON;
import com.xunqi.gulimall.search.config.GulimallElasticSearchConfig;
import lombok.Data;
import lombok.Getter;
import lombok.Setter;
import lombok.ToString;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.xcontent.XContentType;
import org.elasticsearch.index.query.QueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.aggregations.AggregationBuilders;
import org.elasticsearch.search.aggregations.Aggregations;
import org.elasticsearch.search.aggregations.bucket.terms.Terms;
import org.elasticsearch.search.aggregations.bucket.terms.TermsAggregationBuilder;
import org.elasticsearch.search.aggregations.metrics.Avg;
import org.elasticsearch.search.aggregations.metrics.AvgAggregationBuilder;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;import javax.annotation.Resource;
import java.io.IOException;@RunWith(SpringRunner.class)
@SpringBootTest
public class GulimallSearchApplicationTests {@Resourceprivate RestHighLevelClient client;@ToString@Datastatic class Account {private int account_number;private int balance;private String firstname;private String lastname;private int age;private String gender;private String address;private String employer;private String email;private String city;private String state;}/*** 复杂检索:在bank中搜索address中包含mill的所有人的年龄分布以及平均年龄,平均薪资** @throws IOException*/@Testpublic void searchData() throws IOException {//1. 创建检索请求SearchRequest searchRequest = new SearchRequest();//1.1)指定索引searchRequest.indices("bank");//1.2)构造检索条件SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();sourceBuilder.query(QueryBuilders.matchQuery("address", "Mill"));//1.2.1)按照年龄分布进行聚合TermsAggregationBuilder ageAgg = AggregationBuilders.terms("ageAgg").field("age").size(10);sourceBuilder.aggregation(ageAgg);//1.2.2)计算平均年龄AvgAggregationBuilder ageAvg = AggregationBuilders.avg("ageAvg").field("age");sourceBuilder.aggregation(ageAvg);//1.2.3)计算平均薪资AvgAggregationBuilder balanceAvg = AggregationBuilders.avg("balanceAvg").field("balance");sourceBuilder.aggregation(balanceAvg);System.out.println("检索条件:" + sourceBuilder);searchRequest.source(sourceBuilder);//2. 执行检索SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);System.out.println("检索结果:" + searchResponse);//3. 将检索结果封装为BeanSearchHits hits = searchResponse.getHits();SearchHit[] searchHits = hits.getHits();for (SearchHit searchHit : searchHits) {String sourceAsString = searchHit.getSourceAsString();Account account = JSON.parseObject(sourceAsString, Account.class);System.out.println(account);}//4. 获取聚合信息Aggregations aggregations = searchResponse.getAggregations();Terms ageAgg1 = aggregations.get("ageAgg");for (Terms.Bucket bucket : ageAgg1.getBuckets()) {String keyAsString = bucket.getKeyAsString();System.out.println("年龄:" + keyAsString + " ==> " + bucket.getDocCount());}Avg ageAvg1 = aggregations.get("ageAvg");System.out.println("平均年龄:" + ageAvg1.getValue());Avg balanceAvg1 = aggregations.get("balanceAvg");System.out.println("平均薪资:" + balanceAvg1.getValue());}/*** @throws IOException*/@Testpublic void searchState() throws IOException {//1. 创建检索请求SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();// sourceBuilder.query(QueryBuilders.termQuery("city", "Nicholson"));// sourceBuilder.from(0);// sourceBuilder.size(5);// sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));QueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("state", "AK");// .fuzziness(Fuzziness.AUTO)// .prefixLength(3)// .maxExpansions(10);sourceBuilder.query(matchQueryBuilder);SearchRequest searchRequest = new SearchRequest();searchRequest.indices("bank");searchRequest.source(sourceBuilder);//2. 执行检索SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);System.out.println(searchResponse);}/*** 测试ES数据* 更新也可以*/@Testpublic void indexData() throws IOException {IndexRequest indexRequest = new IndexRequest("users");indexRequest.id("1"); //数据的id// indexRequest.source("userName","zhangsan","age",18,"gender","男");User user = new User();user.setUserName("zhangsan");user.setAge(18);user.setGender("男");String jsonString = JSON.toJSONString(user);indexRequest.source(jsonString, XContentType.JSON); //要保存的内容//执行操作IndexResponse index = client.index(indexRequest, GulimallElasticSearchConfig.COMMON_OPTIONS);//提取有用的响应数据System.out.println(index);}@Getter@Setterclass User {private String userName;private String gender;private Integer age;}@Testpublic void contextLoads() {System.out.println(client);}
}
至此,elasticsearch就可以使用了!!!
相关文章:
ElasticSearch详细操作
ElasticSearch搜索引擎详细操作以及概念 文章目录 ElasticSearch搜索引擎详细操作以及概念 1、_cat节点操作1.1、GET/_cat/nodes:查看所有节点1.2、GET/_cat/health:查看es健康状况1.3_、_GET/_cat/master:查看主节点1.4、GET/_cat/indices&a…...
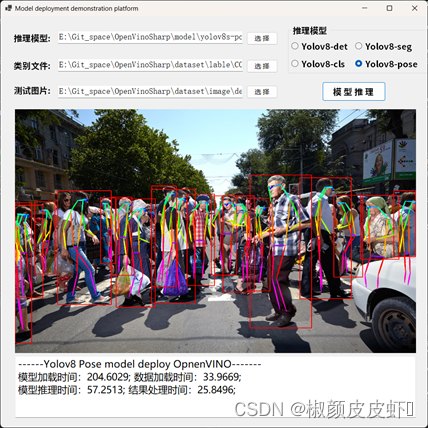
【OpenVINOSharp】 基于C#和OpenVINO2023.0部署Yolov8全系列模型
基于C#和OpenVINO2023.0部署Yolov8全系列模型 1 项目简介1.1 OpenVINOTM 2 OpenVinoSharp2.1 OpenVINOTM 2023.0安装配置2.2 C 动态链接库2.3 C#构建Core推理类2.4 NuGet安装OpenVinoSharp 3 获取和转换Yolov8模型3.1 安装ultralytics3.2 导出yolov8模型3.3 安装OpenVINOTM Pyt…...

121. 买卖股票的最佳时机
题目描述 给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。 你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获取的最大利润。 返回你可以从这笔交易中获取的…...
 LTO(Link-Time Optimization))
FDO(Feedback-Driven Optimization) LTO(Link-Time Optimization)
反馈驱动优化(Feedback-Driven Optimization,FDO)和链接时优化(Link-Time Optimization,LTO)是两种重要的编译器优化技术。下面我们详细介绍这两种技术: 反馈驱动优化 (FDO): FDO 是…...

低成本无刷高速吹风机单片机方案
高速吹风机的转速一般是普通吹风机的5倍左右。一般来说,吹风机的电机转速一般为2-3万转/分钟,而高速吹风机的电机转速一般为10万转/分钟左右。高转速增加了高风速。一般来说,吹风机的风力只有12-17米/秒,而高速吹风机的风力可以达…...

使用Python爬取某查查APP端(Appium自动化篇)
1. 写在前面 某查查网站反爬虫风控还是较强的,之后会分别介绍一下PC端协议、APP端自动化、APP端接口协议三种采集方案。这里主要介绍APP端的自动化方式,APP端自动化方式需要登陆账号,协议的话需要签名授权(自动化经测试没有太多限…...

vue3实现组件可拖拽 vuedraggable
npm i -S vuedraggablenext 中文文档,里面有完整代码案例,值得一看 vue.draggable vue3 版本在工作台中的应用场景 - itxst.com...

gradio常用组件
gradio常用组件 1.gradio程序启动2.写入html相关代码3.文本框4. 回车触发事件5.选择按钮框6.下拉框7.点击按钮8.清空按钮9.监听组件10.输出流11.template 1.gradio程序启动 import gradio as gr def tab():pass with gr.Blocks() as ui:gr.Markdown("# <center>&am…...
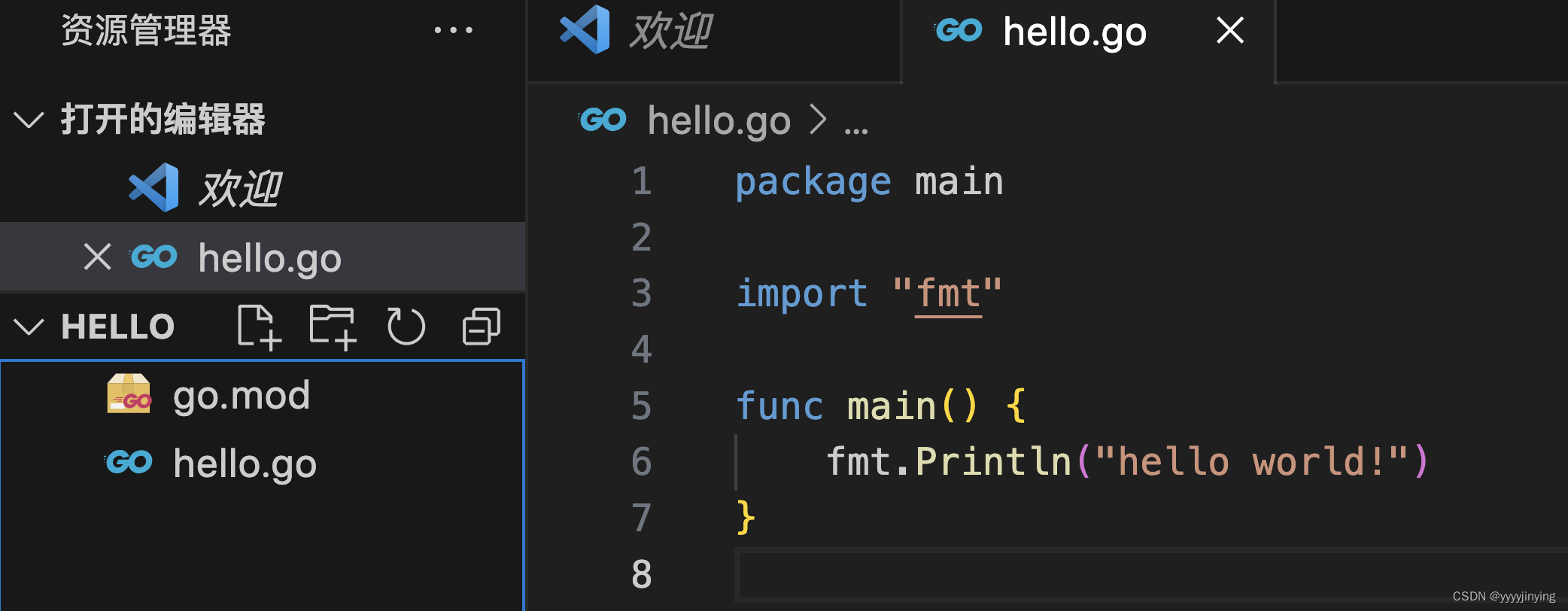
vcode开发go
配置环境变量 go env -w GO111MODULEon go env -w GOPROXYhttps://goproxy.cn,direct 创建文件夹 mkdir hello cd hello go mod help go mod help 初始化一个项目 go mod init hello 获取第三方包 go get github.com/shopspring/decimal 将依赖包下载到本地 go mod …...

聊城大学823软件工程考研
1.什么是软件工程?它目标和内容是什么? 软件工程就是用科学的知识和技术原理来定义,开发,维护软件的一门学科。 软件工程目标:付出较低开发成本;达到要求的功能;取得较好的性能;开发的软件易于移植&…...
Spring Initailizr--快速入门--SpringBoot的选择
😀前言 本篇博文是关于IDEA使用Spring Initializer快速创建Spring Boot项目的说明,希望能够帮助到您😊 🏠个人主页:晨犀主页 🧑个人简介:大家好,我是晨犀,希望我的文章可…...

大数据课程I1——Kafka的概述
文章作者邮箱:yugongshiye@sina.cn 地址:广东惠州 ▲ 本章节目的 ⚪ 了解Kafka的概念; ⚪ 掌握Kafka的配置与启动; 一、简介 1. 基本概念 Apache kafka 是一个分布式数据流平台。可以从如下几个层面来理解: 1. 我们可以向Kafka发布数据以及从Kafka订阅…...

视图簇 se54 sm34 se54
今天演练了一下 维护视图到视图簇的过程。 se11建表,建表之后 【使用程序】→【表维护生成器】 se54 新建视图簇 对象结构 选中其中一行 字段附属 PS:以上每一行都要设置过去 , 设置完成了 激活 sm34展示...

风丘科技将亮相 EVM ASIA 2023
风丘科技将首次亮相 EVM ASIA 2023 WINDHILL will debut EVM ASIA 2023 ——可持续移动的未来 —The Future of SUSTAINABLE Mobility EVM ASIA 2023是亚太地区电气化的国际性展会,专注于新能源汽车、充电技术及汽车零件制造等。展会致力于促进包括充电站、交通…...

腾讯云服务器S6、SA3、S5、SA2等CVM实例介绍
腾讯云服务器CVM实例标准型S6、SA3、S5、SA2等多款实例降价,最高幅度达40%,标准型S6云服务器是新一代云服务器,SA3和SA2是AMD处理器,标准型S5是次新一代的云服务器,如下图: 腾讯云服务器CVM降价 标准型S6&a…...

使用kickstart和anaconda自动化安装centos系统
使用kickstart和anaconda自动化安装centos系统 使用kickstart和anaconda自动化安装centos系统 anaconda 介绍 kickstart 介绍 实验过程 前提 1.已经安装好至少两台centos系统 2.需要实现自动安装的系统的光盘镜像 3.已安装的系统之间可以通讯(比如处于VMware中的NAT网络的…...
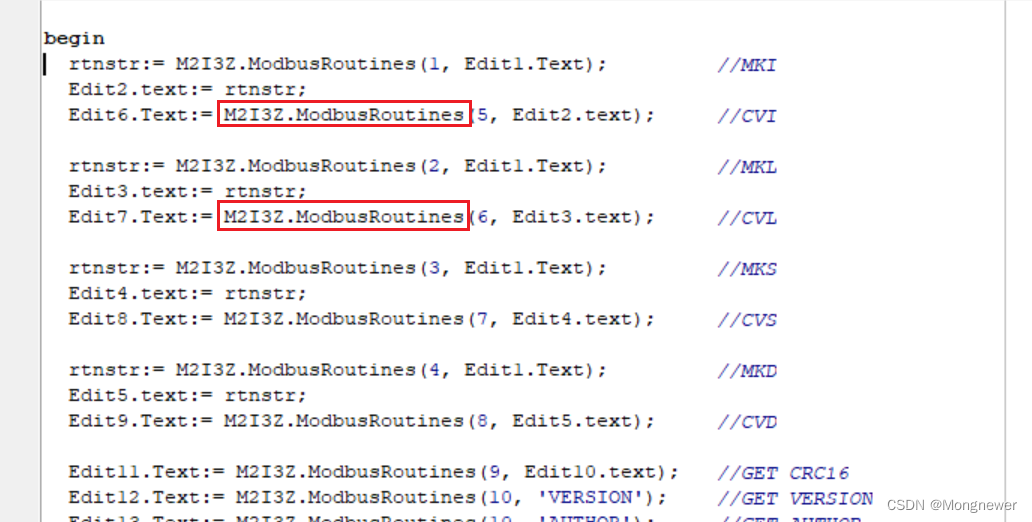
Delphi7通过VB6之COM对象调用PowerBASIC写的DLL功能
Delphi7通过VB6之COM对象调用PowerBASIC写的DLL功能。标题挺长,其实目标很简单,就是在Delphi7中使用PowerBASIC的MKI/CVI, MKS/CVS, MKD/CVD,并顺便加入CRC16检验函数,再进行16进制高低字节调整,方便在VB6、Delphi、La…...

中电金信:ChatGPT一夜爆火,知识图谱何以应战?
随着ChatGPT的爆火出圈 人工智能再次迎来发展小高潮 那么作为此前搜索领域的主流技术 知识图谱前路又将如何呢? 事实上,ChatGPT也并非“万能”,作为黑箱模型,ChatGPT很难验证生成的知识是否准确。并且ChatGPT是通过概率模型执行推…...

单细胞分类和预测任务
对于分类和预测任务,在生物信息学领域有一些常用的方法和工具可以使用。以下是一些常见的方法和工具: 1. 机器学习方法: 包括支持向量机(Support Vector Machine,SVM)、随机森林(Random Forest…...

那些年的Webview开发经验记录
获取网站视频真实链接 直接上工具类 直接调用即可,这个工具类会返回加载的网页中所有的链接,至于对链接怎么处理就是你们自己的事了, 亲测至今我所遇到的所有视频,它都可以捕获到其链接 import android.app.Activity; import an…...

HaoMD:基于Tauri 2与AI的下一代高性能Markdown编辑器深度解析
1. 项目概述:为什么我们需要另一个Markdown编辑器? 如果你和我一样,是个常年与文字、代码和文档打交道的人,那么你的电脑里大概率已经躺了好几个Markdown编辑器:可能是轻量级的Typora,功能强大的VS Code&a…...

告别万年历芯片!用STM32的RTC和备份寄存器做个带事件记录的简易数据日志器
基于STM32 RTC与备份寄存器的轻量级数据日志器设计实战 在物联网边缘设备开发中,数据记录功能往往面临三大挑战:实时时间戳精度、掉电数据保存和有限硬件资源之间的矛盾。传统方案依赖外部RTC芯片加Flash存储的组合,不仅增加BOM成本ÿ…...
|SpringBoot后端 + Vue前端一体化项目)
Java开发的ERP管理系统(含SQL脚本+完整源码)|SpringBoot后端 + Vue前端一体化项目
温馨提示:文末有联系方式项目技术架构说明 本ERP管理系统采用主流企业级技术栈构建:后端基于SpringBoot框架,使用Java语言开发,具备高稳定性与可扩展性;前端采用Vue.js实现响应式交互界面,前后端分离设计&a…...
超导量子电路中的约瑟夫森效应与Transmon设计
1. 约瑟夫森效应的物理本质与数学描述 约瑟夫森效应是超导量子电路中最核心的量子现象之一,它揭示了超导体中库珀对隧穿的量子力学本质。1962年,Brian Josephson在理论上预言了这一现象,随后被实验证实。这个效应从根本上改变了我们对超导电子…...

摩尔线程 × 上海AI实验室|基于S5000和KernelSwift实现DeepSeek-V4核心算子Day-0适配
今日,DeepSeek-V4预览版正式发布并开源。摩尔线程携手上海 AI 实验室 DeepLink 团队,通过大模型驱动的智能算子迁移系统 KernelSwift,率先在旗舰级AI训推一体智算卡 MTT S5000 上完成了核心算子的Day-0适配。目前算子通过率已超80%࿰…...

别再死记硬背了!用STM32CubeMX实战配置GPIO的推挽、开漏、上拉、下拉
STM32CubeMX实战:GPIO模式配置全解析与项目应用 第一次接触STM32的GPIO配置时,我被各种专业术语搞得晕头转向——推挽输出、开漏输出、上拉输入、下拉输入...这些概念在数据手册上冷冰冰地排列着,直到我真正用STM32CubeMX动手配置了一个LED闪…...
)
别再硬编码密码了!Android Gradle打包时,如何安全地管理签名密钥(附keystore.properties配置)
Android应用签名密钥安全管理的进阶实践 在Android应用开发中,签名密钥是应用身份的唯一标识,也是应用商店验证开发者身份的重要凭证。然而,很多开发者仍然习惯在build.gradle文件中直接硬编码这些敏感信息,这种做法不仅存在安全隐…...

RH850 F1开发避坑指南:选项字节配置不当,我的程序怎么都烧不进去?
RH850 F1开发实战:选项字节配置陷阱与看门狗调试全解析 第一次将编译好的程序烧录进RH850 F1系列MCU时,我盯着纹丝不动的调试器界面,后背渗出一层冷汗——JTAG接口毫无反应,仿佛芯片成了一块砖头。这种场景对许多从STM32转向瑞萨平…...

零信任架构下的AI内存安全系统设计与实践
1. MemTrust:零信任架构下的AI内存系统革命 在AI技术快速发展的今天,内存系统正成为支撑智能代理协作与个性化服务的核心基础设施。作为一名长期关注AI系统架构的研究者,我见证了从早期简单的对话记忆到如今复杂的多模态上下文管理的演进过程…...

AI代码生成工具评测:Copilot vs. CodeWhisperer实战对比
AI代码生成工具对测试工作的范式影响在软件测试领域,技术栈的演进从未停歇。从自动化测试框架的普及,到DevOps与持续集成/持续交付(CI/CD)的深度融合,测试从业者始终站在技术变革的前沿。如今,以GitHub Cop…...