23.Netty源码之内置解码器
highlight: arduino-light
Netty内置的解码器
在前两节课我们介绍了 TCP 拆包/粘包的问题,以及如何使用 Netty 实现自定义协议的编解码。可以看到,网络通信的底层实现,Netty 都已经帮我们封装好了,我们只需要扩展 ChannelHandler 实现自定义的编解码逻辑即可。
更加人性化的是,Netty 提供了很多开箱即用的解码器,这些解码器基本覆盖了 TCP 拆包/粘包的通用解决方案。本节课我们将对 Netty 常用的解码器进行讲解,一起探索下它们有哪些用法和技巧。
在本节课开始之前,我们首先回顾一下 TCP 拆包/粘包的主流解决方案。并梳理出 Netty 对应的编码器类。
定长:FixedLengthFrameDecoder
固定长度解码器 FixedLengthFrameDecoder 非常简单,直接通过构造函数设置固定长度的大小 frameLength,无论接收方一次获取多大的数据,都会严格按照 frameLength 进行解码。如果累积读取到长度大小为 frameLength 的消息,那么解码器认为已经获取到了一个完整的消息。如果消息长度小于 frameLength,FixedLengthFrameDecoder 解码器会一直等后续数据包的到达,直至获得完整的消息。下面我们通过一个例子感受一下使用 Netty 实现固定长度解码是多么简单。
java package io.netty.example.decode; import io.netty.bootstrap.ServerBootstrap; import io.netty.buffer.ByteBuf; import io.netty.buffer.PooledByteBufAllocator; import io.netty.buffer.UnpooledByteBufAllocator; import io.netty.channel.*; import io.netty.channel.nio.NioEventLoopGroup; import io.netty.channel.socket.SocketChannel; import io.netty.channel.socket.nio.NioChannelOption; import io.netty.channel.socket.nio.NioServerSocketChannel; import io.netty.handler.codec.FixedLengthFrameDecoder; import io.netty.handler.logging.LogLevel; import io.netty.handler.logging.LoggingHandler; import io.netty.util.CharsetUtil; /** * Echoes back any received data from a client. */ public final class EchoServer { public static void main(String[] args) throws Exception { EventLoopGroup workerGroup = new NioEventLoopGroup(); EventLoopGroup bossGroup = new NioEventLoopGroup(); final EchoServerHandler serverHandler = new EchoServerHandler(); try { ServerBootstrap b = new ServerBootstrap(); b.group(bossGroup,workerGroup) //通过反射创建反射工厂类根据无参构造函数 反射生成实例 //将NioServerSocketChannel绑定到了bossGroup //NioServerSocketChannel接收到请求会创建SocketChannel放入workerGroup .channel(NioServerSocketChannel.class) //指的是SocketChannel .childOption(ChannelOption.SO_KEEPALIVE,true) //指的是SocketChannel .childOption(NioChannelOption.SO_KEEPALIVE,Boolean.TRUE) //默認不使用堆外内存 .childOption(ChannelOption.ALLOCATOR,PooledByteBufAllocator.DEFAULT) //false 不使用堆外内存 .childOption(ChannelOption.ALLOCATOR,new UnpooledByteBufAllocator(false)) // .handler(new LoggingHandler(LogLevel.INFO)) .childHandler(new ChannelInitializer<SocketChannel>() { @Override public void initChannel(SocketChannel ch) throws Exception { ChannelPipeline p = ch.pipeline(); // p.addLast(new LoggingHandler(LogLevel.INFO)); ch.pipeline().addLast(new FixedLengthFrameDecoder(10)); p.addLast(serverHandler); } }); ChannelFuture f = b.bind(8090).sync(); f.channel().closeFuture().sync(); } finally { workerGroup.shutdownGracefully(); } } } @ChannelHandler.Sharable class EchoServerHandler extends ChannelInboundHandlerAdapter { @Override public void channelRead(ChannelHandlerContext ctx, Object msg) { System.out.println("Receive client : [" + ((ByteBuf) msg).toString(CharsetUtil.UTF_8) + "]"); } }
java package io.netty.example.decode; import io.netty.bootstrap.Bootstrap; import io.netty.channel.*; import io.netty.channel.nio.NioEventLoopGroup; import io.netty.channel.socket.SocketChannel; import io.netty.channel.socket.nio.NioSocketChannel; import io.netty.handler.logging.LogLevel; import io.netty.handler.logging.LoggingHandler; public final class EchoClient { public static void main(String[] args) throws Exception { // Configure the client. EventLoopGroup group = new NioEventLoopGroup(); try { Bootstrap b = new Bootstrap(); b.group(group) .channel(NioSocketChannel.class) .option(ChannelOption.TCP_NODELAY, true) .handler(new ChannelInitializer<SocketChannel>() { @Override public void initChannel(SocketChannel ch) throws Exception { ChannelPipeline p = ch.pipeline(); // p.addLast(new LoggingHandler(LogLevel.INFO)); p.addLast(new EchoClientHandler()); } }); // Start the client. ChannelFuture f = b.connect("127.0.0.1", 8090).sync(); // Wait until the connection is closed. f.channel().closeFuture().sync(); } finally { // Shut down the event loop to terminate all threads. group.shutdownGracefully(); } } }
java package io.netty.example.decode; import io.netty.buffer.ByteBuf; import io.netty.buffer.Unpooled; import io.netty.channel.ChannelHandlerContext; import io.netty.channel.ChannelInboundHandlerAdapter; import java.util.concurrent.TimeUnit; /** * Handler implementation for the echo client. It initiates the ping-pong * traffic between the echo client and server by sending the first message to * the server. */ public class EchoClientHandler extends ChannelInboundHandlerAdapter { private final ByteBuf firstMessage; /** * Creates a client-side handler. */ //TODO 修改1234567890 看看10位数字 和 非10位数字的区别 public EchoClientHandler() { firstMessage = Unpooled.wrappedBuffer("1234567890".getBytes()); } @Override public void channelActive(ChannelHandlerContext ctx) { System.out.println("客户端发送消息" + firstMessage.toString()); ctx.writeAndFlush(firstMessage); } @Override public void channelRead(ChannelHandlerContext ctx, Object msg) { // ctx.write(msg); } @Override public void channelReadComplete(ChannelHandlerContext ctx) throws InterruptedException { TimeUnit.SECONDS.sleep(3); ctx.flush(); } @Override public void exceptionCaught(ChannelHandlerContext ctx, Throwable cause) { // cause.printStackTrace(); ctx.close(); } }
在上述服务端的代码中使用了固定 10 字节的解码器,并在解码之后通过 EchoServerHandler 打印结果。我们可以启动服务端,通过 telnet 命令像服务端发送数据,观察代码输出的结果。
java telnet localhost 8088 Trying ::1... Connected to localhost. Escape character is '^]'. 1234567890123 456789012
按10个字节一组进行解析注意有个换行符
服务端输出:
java Receive client : [1234567890] Receive client : [123 45678]
分隔:DelimiterBasedFrameDecoder
java public class DelimiterBasedFrameDecoder extends ByteToMessageDecoder { private final ByteBuf[] delimiters; private final int maxFrameLength; private final boolean stripDelimiter; private final boolean failFast; private boolean discardingTooLongFrame; private int tooLongFrameLength; /** Set only when decoding with "\n" and "\r\n" as the delimiter. */ private final LineBasedFrameDecoder lineBasedDecoder; /** * Creates a new instance. * * @param maxFrameLength the maximum length of the decoded frame. * A {@link TooLongFrameException} is thrown if * the length of the frame exceeds this value. * @param delimiter the delimiter */ public DelimiterBasedFrameDecoder(int maxFrameLength, ByteBuf delimiter) { this(maxFrameLength, true, delimiter); } /** * Creates a new instance. * * @param maxFrameLength the maximum length of the decoded frame. * A {@link TooLongFrameException} is thrown if * the length of the frame exceeds this value. * @param stripDelimiter whether the decoded frame should strip out the * delimiter or not * @param delimiter the delimiter */ public DelimiterBasedFrameDecoder( int maxFrameLength, boolean stripDelimiter, ByteBuf delimiter) { this(maxFrameLength, stripDelimiter, true, delimiter); } /** * Creates a new instance. * * @param maxFrameLength the maximum length of the decoded frame. * A {@link TooLongFrameException} is thrown if * the length of the frame exceeds this value. * @param stripDelimiter whether the decoded frame should strip out the * delimiter or not * @param failFast If <tt>true</tt>, a {@link TooLongFrameException} is * thrown as soon as the decoder notices the length of the * frame will exceed <tt>maxFrameLength</tt> regardless of * whether the entire frame has been read. * If <tt>false</tt>, a {@link TooLongFrameException} is * thrown after the entire frame that exceeds * <tt>maxFrameLength</tt> has been read. * @param delimiter the delimiter */ public DelimiterBasedFrameDecoder( int maxFrameLength, boolean stripDelimiter, boolean failFast, ByteBuf delimiter) { this(maxFrameLength, stripDelimiter, failFast, new ByteBuf[] { delimiter.slice(delimiter.readerIndex(), delimiter.readableBytes())}); } /** * Creates a new instance. * * @param maxFrameLength the maximum length of the decoded frame. * A {@link TooLongFrameException} is thrown if * the length of the frame exceeds this value. * @param delimiters the delimiters */ public DelimiterBasedFrameDecoder(int maxFrameLength, ByteBuf... delimiters) { this(maxFrameLength, true, delimiters); } /** * Creates a new instance. * * @param maxFrameLength the maximum length of the decoded frame. * A {@link TooLongFrameException} is thrown if * the length of the frame exceeds this value. * @param stripDelimiter whether the decoded frame should strip out the * delimiter or not * @param delimiters the delimiters */ public DelimiterBasedFrameDecoder( int maxFrameLength, boolean stripDelimiter, ByteBuf... delimiters) { this(maxFrameLength, stripDelimiter, true, delimiters); } /** * Creates a new instance. * * @param maxFrameLength the maximum length of the decoded frame. * A {@link TooLongFrameException} is thrown if * the length of the frame exceeds this value. * @param stripDelimiter whether the decoded frame should strip out the * delimiter or not * @param failFast If <tt>true</tt>, a {@link TooLongFrameException} is * thrown as soon as the decoder notices the length of the * frame will exceed <tt>maxFrameLength</tt> regardless of * whether the entire frame has been read. * If <tt>false</tt>, a {@link TooLongFrameException} is * thrown after the entire frame that exceeds * <tt>maxFrameLength</tt> has been read. * @param delimiters the delimiters */ public DelimiterBasedFrameDecoder( int maxFrameLength, boolean stripDelimiter, boolean failFast, ByteBuf... delimiters) { validateMaxFrameLength(maxFrameLength); if (delimiters == null) { throw new NullPointerException("delimiters"); } if (delimiters.length == 0) { throw new IllegalArgumentException("empty delimiters"); } if (isLineBased(delimiters) && !isSubclass()) { lineBasedDecoder = new LineBasedFrameDecoder(maxFrameLength, stripDelimiter, failFast); this.delimiters = null; } else { this.delimiters = new ByteBuf[delimiters.length]; for (int i = 0; i < delimiters.length; i ++) { ByteBuf d = delimiters[i]; validateDelimiter(d); this.delimiters[i] = d.slice(d.readerIndex(), d.readableBytes()); } lineBasedDecoder = null; } this.maxFrameLength = maxFrameLength; this.stripDelimiter = stripDelimiter; this.failFast = failFast; } /** Returns true if the delimiters are "\n" and "\r\n". */ private static boolean isLineBased(final ByteBuf[] delimiters) { if (delimiters.length != 2) { return false; } ByteBuf a = delimiters[0]; ByteBuf b = delimiters[1]; if (a.capacity() < b.capacity()) { a = delimiters[1]; b = delimiters[0]; } return a.capacity() == 2 && b.capacity() == 1 && a.getByte(0) == '\r' && a.getByte(1) == '\n' && b.getByte(0) == '\n'; } /** * Return {@code true} if the current instance is a subclass of DelimiterBasedFrameDecoder */ private boolean isSubclass() { return getClass() != DelimiterBasedFrameDecoder.class; } @Override protected final void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception { Object decoded = decode(ctx, in); if (decoded != null) { out.add(decoded); } } protected Object decode(ChannelHandlerContext ctx, ByteBuf buffer) throws Exception { if (lineBasedDecoder != null) { return lineBasedDecoder.decode(ctx, buffer); } // Try all delimiters and choose the delimiter which yields the shortest frame. int minFrameLength = Integer.MAX_VALUE; ByteBuf minDelim = null; for (ByteBuf delim: delimiters) { int frameLength = indexOf(buffer, delim); if (frameLength >= 0 && frameLength < minFrameLength) { minFrameLength = frameLength; minDelim = delim; } } if (minDelim != null) { int minDelimLength = minDelim.capacity(); ByteBuf frame; if (discardingTooLongFrame) { // We've just finished discarding a very large frame. // Go back to the initial state. discardingTooLongFrame = false; buffer.skipBytes(minFrameLength + minDelimLength); int tooLongFrameLength = this.tooLongFrameLength; this.tooLongFrameLength = 0; if (!failFast) { fail(tooLongFrameLength); } return null; } if (minFrameLength > maxFrameLength) { // Discard read frame. buffer.skipBytes(minFrameLength + minDelimLength); fail(minFrameLength); return null; } if (stripDelimiter) { frame = buffer.readRetainedSlice(minFrameLength); buffer.skipBytes(minDelimLength); } else { frame = buffer.readRetainedSlice(minFrameLength + minDelimLength); } return frame; } else { if (!discardingTooLongFrame) { if (buffer.readableBytes() > maxFrameLength) { // Discard the content of the buffer until a delimiter is found. tooLongFrameLength = buffer.readableBytes(); buffer.skipBytes(buffer.readableBytes()); discardingTooLongFrame = true; if (failFast) { fail(tooLongFrameLength); } } } else { // Still discarding the buffer since a delimiter is not found. tooLongFrameLength += buffer.readableBytes(); buffer.skipBytes(buffer.readableBytes()); } return null; } } }
使用特殊分隔符解码器 DelimiterBasedFrameDecoder 之前我们需要了解以下几个属性的作用。
- delimiters
delimiters 指定特殊分隔符,通过写入 ByteBuf 作为参数传入。delimiters 的类型是 ByteBuf 数组,所以我们可以同时指定多个分隔符,但是最终会选择长度最短的分隔符进行消息拆分。
例如接收方收到的数据为:
java +--------------+ | ABC\nDEF\r\n | +--------------+
如果指定的多个分隔符为 \n 和 \r\n,DelimiterBasedFrameDecoder 会退化成使用 LineBasedFrameDecoder 进行解析,那么会解码出两个消息。
java +-----+-----+ | ABC | DEF | +-----+-----+
如果指定的特定分隔符只有 \r\n,那么只会解码出一个消息:
java +----------+ | ABC\nDEF | +----------+
- maxLength
maxLength 是报文最大长度的限制。如果超过 maxLength 还没有检测到指定分隔符,将会抛出 TooLongFrameException。可以说 maxLength 是对程序在极端情况下的一种保护措施。
- failFast
failFast 与 maxLength 需要搭配使用,通过设置 failFast 可以控制抛出 TooLongFrameException 的时机,可以说 Netty 在细节上考虑得面面俱到。如果 failFast=true,那么在超出 maxLength 会立即抛出 TooLongFrameException,不再继续进行解码。如果 failFast=false,那么会等到解码出一个完整的消息后才会抛出 TooLongFrameException。
- stripDelimiter
stripDelimiter 的作用是判断解码后得到的消息是否去除分隔符。如果 stripDelimiter=false,特定分隔符为 \n,那么上述数据包解码出的结果为:
java +-------+---------+ | ABC\n | DEF\r\n | +-------+---------+
下面我们还是结合代码示例学习 DelimiterBasedFrameDecoder 的用法,依然以固定编码器小节中使用的代码为基础稍做改动,引入特殊分隔符解码器 DelimiterBasedFrameDecoder:
java package io.netty.example.decode; import io.netty.bootstrap.ServerBootstrap; import io.netty.buffer.ByteBuf; import io.netty.buffer.PooledByteBufAllocator; import io.netty.buffer.Unpooled; import io.netty.buffer.UnpooledByteBufAllocator; import io.netty.channel.*; import io.netty.channel.nio.NioEventLoopGroup; import io.netty.channel.socket.SocketChannel; import io.netty.channel.socket.nio.NioChannelOption; import io.netty.channel.socket.nio.NioServerSocketChannel; import io.netty.handler.codec.DelimiterBasedFrameDecoder; import io.netty.handler.codec.FixedLengthFrameDecoder; import io.netty.handler.logging.LogLevel; import io.netty.handler.logging.LoggingHandler; import io.netty.util.CharsetUtil; /** * Echoes back any received data from a client. */ public final class EchoServer { public static void main(String[] args) throws Exception { EventLoopGroup workerGroup = new NioEventLoopGroup(); EventLoopGroup bossGroup = new NioEventLoopGroup(); final EchoServerHandler serverHandler = new EchoServerHandler(); try { ServerBootstrap b = new ServerBootstrap(); b.group(bossGroup, workerGroup) //通过反射创建反射工厂类根据无参构造函数 反射生成实例 //将NioServerSocketChannel绑定到了bossGroup //NioServerSocketChannel接收到请求会创建SocketChannel放入workerGroup .channel(NioServerSocketChannel.class) //指的是SocketChannel .childOption(ChannelOption.SO_KEEPALIVE, true) //指的是SocketChannel .childOption(NioChannelOption.SO_KEEPALIVE, Boolean.TRUE) //默認不使用堆外内存 .childOption(ChannelOption.ALLOCATOR, PooledByteBufAllocator.DEFAULT) //false 不使用堆外内存 .childOption(ChannelOption.ALLOCATOR, new UnpooledByteBufAllocator(false)) // .handler(new LoggingHandler(LogLevel.INFO)) .childHandler(new ChannelInitializer<SocketChannel>() { @Override public void initChannel(SocketChannel ch) throws Exception { ChannelPipeline p = ch.pipeline(); // p.addLast(new LoggingHandler(LogLevel.INFO)); ByteBuf delimiter = Unpooled.copiedBuffer("&".getBytes()); ch.pipeline() //最大長度 超出最大长度是否立即抛出异常 是否除去分隔符 特殊分隔符 .addLast(new DelimiterBasedFrameDecoder(10, true, true, delimiter)); ch.pipeline() .addLast(new EchoServerHandler()); } }); ChannelFuture f = b.bind(8090).sync(); f.channel().closeFuture().sync(); } finally { workerGroup.shutdownGracefully(); } } } @ChannelHandler.Sharable class EchoServerHandler extends ChannelInboundHandlerAdapter { @Override public void channelRead(ChannelHandlerContext ctx, Object msg) { System.out.println("Receive client : [" + ((ByteBuf) msg).toString(CharsetUtil.UTF_8) + "]"); } }
package io.netty.example.decode; import io.netty.bootstrap.Bootstrap; import io.netty.channel.*; import io.netty.channel.nio.NioEventLoopGroup; import io.netty.channel.socket.SocketChannel; import io.netty.channel.socket.nio.NioSocketChannel; import io.netty.handler.logging.LogLevel; import io.netty.handler.logging.LoggingHandler; public final class EchoClient { public static void main(String[] args) throws Exception { // Configure the client. EventLoopGroup group = new NioEventLoopGroup(); try { Bootstrap b = new Bootstrap(); b.group(group) .channel(NioSocketChannel.class) .option(ChannelOption.TCP_NODELAY, true) .handler(new ChannelInitializer<SocketChannel>() { @Override public void initChannel(SocketChannel ch) throws Exception { ChannelPipeline p = ch.pipeline(); // p.addLast(new LoggingHandler(LogLevel.INFO)); p.addLast(new EchoClientHandler()); } }); // Start the client. ChannelFuture f = b.connect("127.0.0.1", 8090).sync(); // Wait until the connection is closed. f.channel().closeFuture().sync(); } finally { // Shut down the event loop to terminate all threads. group.shutdownGracefully(); } } }
package io.netty.example.decode; import io.netty.buffer.ByteBuf; import io.netty.buffer.Unpooled; import io.netty.channel.ChannelHandlerContext; import io.netty.channel.ChannelInboundHandlerAdapter; import java.util.concurrent.TimeUnit; /** * Handler implementation for the echo client. It initiates the ping-pong * traffic between the echo client and server by sending the first message to * the server. */ public class EchoClientHandler extends ChannelInboundHandlerAdapter { private final ByteBuf firstMessage; /** * Creates a client-side handler. */ //TODO 修改1234567890 看看10位数字 和 非10位数字的区别 public EchoClientHandler() { firstMessage = Unpooled.wrappedBuffer("1234567890".getBytes()); } @Override public void channelActive(ChannelHandlerContext ctx) { System.out.println("客户端发送消息" + firstMessage.toString()); ctx.writeAndFlush(firstMessage); } @Override public void channelRead(ChannelHandlerContext ctx, Object msg) { // ctx.write(msg); } @Override public void channelReadComplete(ChannelHandlerContext ctx) throws InterruptedException { TimeUnit.SECONDS.sleep(3); ctx.flush(); } @Override public void exceptionCaught(ChannelHandlerContext ctx, Throwable cause) { // cause.printStackTrace(); ctx.close(); } }
我们依然通过 telnet 模拟客户端发送数据,观察代码输出的结果,可以发现由于 maxLength 设置的只有 10,所以在解析到第三个消息时抛出异常。
客户端输入:
java telnet localhost 8088 Trying ::1... Connected to localhost. Escape character is '^]'. hello&world&1234567890ab
服务端输出:
java Receive client : [hello] Receive client : [world] 九月 25, 2020 8:46:01 下午 io.netty.channel.DefaultChannelPipeline onUnhandledInboundException 警告: An exceptionCaught() event was fired, and it reached at the tail of the pipeline. It usually means the last handler in the pipeline did not handle the exception. io.netty.handler.codec.TooLongFrameException: frame length exceeds 10: 13 - discarded at io.netty.handler.codec.DelimiterBasedFrameDecoder.fail(DelimiterBasedFrameDecoder.java:302) at io.netty.handler.codec.DelimiterBasedFrameDecoder.decode(DelimiterBasedFrameDecoder.java:268) at io.netty.handler.codec.DelimiterBasedFrameDecoder.decode(DelimiterBasedFrameDecoder.java:218)
长度域:LengthFieldBasedFrameDecoder
长度域解码器 LengthFieldBasedFrameDecoder 是解决 TCP 拆包/粘包问题最常用的解码器。 它基本上可以覆盖大部分基于长度拆包场景,开源消息中间件 RocketMQ 就是使用 LengthFieldBasedFrameDecoder 进行解码的。LengthFieldBasedFrameDecoder 相比 FixedLengthFrameDecoder 和 DelimiterBasedFrameDecoder 要复杂一些,接下来我们就一起学习下这个强大的解码器。
首先我们同样先了解 LengthFieldBasedFrameDecoder 中的几个重要属性,这里我主要把它们分为两个部分:长度域解码器特有属性以及与其他解码器(如特定分隔符解码器)的相似的属性。
- 长度域解码器特有属性
java // 长度字段的偏移量,也就是存放长度字段的位置 // 如 长度字段是0 那么长度字段放在了最前面 即 数据包的起始位置 private final int lengthFieldOffset; // 长度字段所占用的字节数 // 即长度字段占用数据包的字节数 private final int lengthFieldLength; /* * 消息长度的修正值,即根据 legnth + lengthAdjustment = 内容真正的长度 * * 在很多较为复杂一些的协议设计中,长度域不仅仅包含消息的长度,而且包含其他的数据,如版本号、数据类型、数据状态等,那么这时候我们需要使用 lengthAdjustment 进行修正。假如长度域的值为14, 其中content的长度是12 那lengthAdjustment = 12 - 14 =-2 * * lengthAdjustment = 解码前消息内容字段的起始位置 - 长度字段偏移量 -长度字段所占用的字节数 * lengthAdjustment = initialBytesToStrip - lengthFieldOffset -lengthFieldLength */ private final int lengthAdjustment; // 表示解码后需要跳过的初始字节数,也就是消息内容字段的起始位置。 private final int initialBytesToStrip; // 长度字段结束的偏移量,lengthFieldEndOffset = lengthFieldOffset + lengthFieldLength private final int lengthFieldEndOffset;
与固定长度解码器和特定分隔符解码器相似的属性
java private final int maxFrameLength; // 报文最大限制长度 private final boolean failFast; // 是否立即抛出 TooLongFrameException,与 maxFrameLength 搭配使用 private boolean discardingTooLongFrame; // 是否处于丢弃模式 private long tooLongFrameLength; // 需要丢弃的字节数 private long bytesToDiscard; // 累计丢弃的字节数
下面我们结合具体的示例来解释下每种参数的组合,其实在 Netty LengthFieldBasedFrameDecoder 源码的注释中已经描述得非常详细,一共给出了 7 个场景示例,理解了这些示例基本上可以真正掌握 LengthFieldBasedFrameDecoder 的参数用法。
示例 1:典型的基于消息长度 + 消息内容的解码。
java BEFORE DECODE (14 bytes) AFTER DECODE (14 bytes) +--------+----------------+ +--------+----------------+ | Length | Actual Content |----->| Length | Actual Content | | 12 | "HELLO, WORLD" | | 0x000C | "HELLO, WORLD" | +--------+----------------+ +--------+----------------+ 上述协议是最基本的格式,报文只包含消息长度 Length 和消息内容 Content 字段,其中 Length 为 16 进制表示,共占用 2 字节,Length 的值 0x000C 代表 Content 占用 12 字节。即要传输内容的字节数是12,该协议对应的解码器参数组合如下: lengthFieldOffset = 0,存放长度数据的起始位置, Length 字段就在报文的开始位置即0 lengthFieldLength = 2,长度字段所占用的字节数,协议设计的固定长度为2。 lengthAdjustment = 0 Length 字段只包含内容长度,不需要做任何修正。 initialBytesToStrip = 0 表示解码后需要跳过的初始字节数,也就是消息内容字段的起始位置。解码后14字节。表示内容就是12字节,我们可以先读2字节长度。再根据长度读取12字节的真正内容。
示例 2:解码结果需要截断。
java BEFORE DECODE (14 bytes) AFTER DECODE (12 bytes) +--------+----------------+ +----------------+ | Length | Actual Content |----->| Actual Content | | 12 | "HELLO, WORLD" | | "HELLO, WORLD" | +--------+----------------+ +----------------+ 示例 2 和示例 1 的区别在于解码后的结果只包含消息内容,其他的部分是不变的。其中 Length 为 16 进制表示,共占用 2 字节,Length 的值 0x000C 代表 Content 占用 12 字节。该协议对应的解码器参数组合如下: - lengthFieldOffset = 0,存放长度数据的起始位置,因为 Length 字段就在报文的开始位置。 - lengthFieldLength = 2,长度字段所占用的字节数,协议设计的固定长度。 - lengthAdjustment = 0 Length 字段只包含消息长度,不需要做任何修正。 - initialBytesToStrip = 2 表示需要跳过2字节才是真正的消息内容
示例 3:长度字段包含消息长度和消息内容所占的字节。
java BEFORE DECODE (14 bytes) AFTER DECODE (14 bytes) +--------+----------------+ +--------+----------------+ | Length | Actual Content |----->| Length | Actual Content | | 14 | "HELLO, WORLD" | | 0x000E | "HELLO, WORLD" | +--------+----------------+ +--------+----------------+ 与前两个示例不同的是,示例 3 的 Length 字段包含 Length 字段自身的固定长度以及 Content 字段所占用的字节数,Length 的值为 0x000E(2 + 12 = 14 字节),在 Length 字段值(14 字节)的基础上做 lengthAdjustment(-2)的修正,才能得到真实的 Content 字段长度,所以对应的解码器参数组合如下: lengthFieldOffset = 0,因为 Length 字段就在报文的开始位置。 lengthFieldLength = 2,协议设计的固定长度。 lengthAdjustment = -2,Actual Content是12,长度字段值为14,14 + (-2) =12 ,即需要减 2 才是拆包所需要的长度。 initialBytesToStrip = 0,解码后内容依然是 Length + Content,不需要跳过任何初始字节。解码前总长度14-解码后总长度14=0
示例 4:基于长度字段偏移的解码。
java BEFORE DECODE (17 bytes) AFTER DECODE (17 bytes) +----------+----------+----------------+ +----------+----------+------------- | Header| Length| Actual Content |-----> |Header | Length | Actual Content| | 2 | 12 | "HELLO, WORLD" | |0xCAFE | 0x00000C | "HELLO, WORLD"| +----------+----------+----------------+ +----------+----------+------------- 示例 4 中 Header 2字节, Length3字节,Length 字段不再是报文的起始位置,Length 字段的值为 0x00000C,表示 Content 字段占用 12 字节,该协议对应的解码器参数组合如下: - lengthFieldOffset = 2,需要跳过 Header 1 所占用的 2 字节,才是 Length 的起始位置。 - lengthFieldLength = 3,协议设计的固定长度。 - lengthAdjustment = 0,Length 字段只包含消息长度,不需要做任何修正。before和after一样 - initialBytesToStrip = 0,解码后内容依然是完整的报文,不需要跳过任何初始字节。
示例 5:长度字段与内容字段不再相邻。
java BEFORE DECODE (17 bytes) AFTER DECODE (17 bytes) +----------+----------+----------------+ +----------+----------+------------- | Length| Header| Actual Content |-----> |Length | Header | Actual Content | | 12 | 2 | "HELLO, WORLD" | |0x00000C| 0xCAFE | "HELLO, WORLD" | +----------+----------+----------------+ +----------+----------+------------- 示例 5 中的 Length 字段之后是 Header,Length 与 Content 字段不再相邻。Length 字段所表示的内容略过了 Header 1 字段,所以也需要通过 lengthAdjustment 修正才能得到 Header + Content 的内容。示例 5 所对应的解码器参数组合如下: lengthFieldOffset = 0,因为 Length 字段就在报文的开始位置。 lengthFieldLength = 3,协议设计的固定长度。 lengthAdjustment = 2 initialBytesToStrip = 0,解码后内容依然是完整的报文,不需要跳过任何初始字节。 解码前总长度17-解码后总长度17
示例 6:基于长度偏移和长度修正的解码。
java BEFORE DECODE (16 bytes) AFTER DECODE (13 bytes) +------+--------+------+----------------+ +------+----------------+ | HDR1 | Length | HDR2 | Actual Content |----->| HDR2 | Actual Content | | 1 | 12 | 1 | "HELLO, WORLD" | | 0xFE | "HELLO, WORLD" | +------+--------+------+----------------+ +------+----------------+ 示例 6 中 Length 字段前后分为别 HDR1 和 HDR2 字段,各占用 1 字节,所以既需要做长度字段的偏移,也需要做 lengthAdjustment 修正,具体修正的过程与 示例 5 类似。对应的解码器参数组合如下: - lengthFieldOffset = 1,需要跳过 HDR1 所占用的 1 字节,才是 Length 的起始位置。 - lengthFieldLength = 2,协议设计的固定长度。 - lengthAdjustment = 1,length: 12 + HDR2:1 =13 真正的内容长度13 - initialBytesToStrip = 3,解码后跳过 HDR1 和 Length 字段,共占用 3 字节。 解码前总长度16-解码后总长度13=3
示例 7:长度字段包含除 Content 外的多个其他字段。
java BEFORE DECODE (16 bytes) AFTER DECODE (13 bytes) +------+--------+------+----------------+ +------+----------------+ | HDR1 | Length | HDR2 | Actual Content |----->| HDR2 | Actual Content | | 1 | 16 | 3 | "HELLO, WORLD" | | 0xFE | "HELLO, WORLD" | +------+--------+------+----------------+ +------+----------------+ 示例 7 与 示例 6 的区别在于 Length 字段记录了整个报文的长度,包含 Length 自身所占字节2、HDR1占用字节1 、HDR2占用字节1 以及 Content 字段的长度12,解码器需要知道如何进行 lengthAdjustment 调整,才能得到 HDR2 和 Content 的内容。所以我们可以采用如下的解码器参数组合: - lengthFieldOffset = 1,需要跳过 HDR1 所占用的 1 字节,才是 Length 的起始位置。 - lengthFieldLength = 2,协议设计的固定长度。 - lengthAdjustment = -3,Actual Content 13 - 长度域的值16=-3 initialBytesToStrip = 3,解码前16 - 解码后 13 = 3
以上 7 种示例涵盖了 LengthFieldBasedFrameDecoder 大部分的使用场景,你是否学会了呢?最后留一个小任务,在上一节课程中我们设计了一个较为通用的协议,如下所示。如何使用长度域解码器 LengthFieldBasedFrameDecoder 完成该协议的解码呢?抓紧自己尝试下吧。
+---------------------------------------------------------------+ | 魔数 2byte | 协议版本号 1byte | 序列化算法 1byte | 报文类型 1byte | +---------------------------------------------------------------+ | 状态 1byte | 保留字段 4byte | 数据长度 4byte | +---------------------------------------------------------------+ | 数据内容 (长度不定) | +---------------------------------------------------------------+
编码需要使用LengthFieldPrepender
总结
本节课我们介绍了三种常用的解码器,从中我们可以体会到 Netty 在设计上的优雅,只需要调整参数就可以轻松实现各种功能。在健壮性上,Netty 也考虑得非常全面,很多边界情况 Netty 都贴心地增加了保护性措施。实现一个健壮的解码器并不容易,很可能因为一次解析错误就会导致解码器一直处理错乱的状态。如果你使用了基于长度编码的二进制协议,那么推荐你使用 LengthFieldBasedFrameDecoder,它已经可以满足实际项目中的大部分场景,基本不需要再自定义实现了。希望朋友们在项目开发中能够学以致用。
相关文章:

23.Netty源码之内置解码器
highlight: arduino-light Netty内置的解码器 在前两节课我们介绍了 TCP 拆包/粘包的问题,以及如何使用 Netty 实现自定义协议的编解码。可以看到,网络通信的底层实现,Netty 都已经帮我们封装好了,我们只需要扩展 ChannelHandler …...
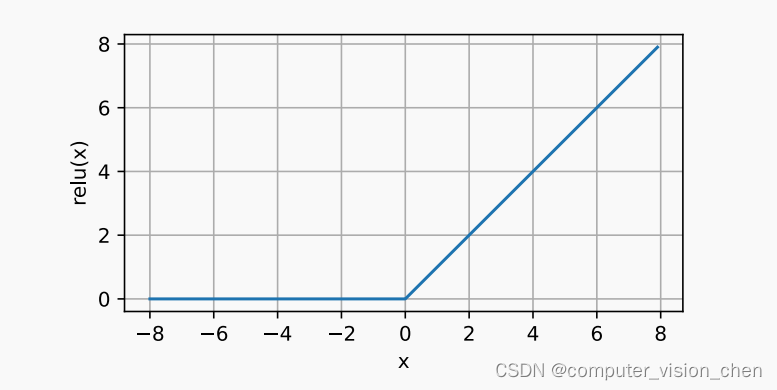
sigmoid ReLU 等激活函数总结
sigmoid ReLU sigoid和ReLU对比 1.sigmoid有梯度消失问题:当sigmoid的输出非常接近0或者1时,区域的梯度几乎为0,而ReLU在正区间的梯度总为1。如果Sigmoid没有正确初始化,它可能在正区间得到几乎为0的梯度。使模型无法有效训练。 …...

RabbitMQ 消息队列
文章目录 🍰有几个原因可以解释为什么要选择 RabbitMQ:🥩mq之间的对比🌽RabbitMQ vs Apache Kafka🌽RabbitMQ vs ActiveMQ🌽RabbitMQ vs RocketMQ🌽RabbitMQ vs Redis 🥩linux docke…...
PHP实现在线进制转换器,10进制,2、4、8、16、32进制转换
1.接口文档 2.laravel实现代码 /*** 进制转换计算器* return \Illuminate\Http\JsonResponse*/public function binaryConvertCal(){$ten $this->request(ten);$two $this->request(two);$four $this->request(four);$eight $this->request(eight);$sixteen …...

报错 | Spring报错详解
Spring报错详解 一、前言二、报错提示三、分层解读1.最下面一层Caused by2.上一层Caused by3.最上层Caused by 四、总结五、解决方案 一、前言 本文主要是记录在初次学习Spring时遇到报错后的解读以及解决方案 二、报错提示 三、分层解读 遇到报错的时候,我们需要…...

PHP最简单自定义自己的框架数据库封装调用(五)
1、实现效果调用实现数据增删改查封装 2、index.php 入口定义数据库账号密码 <?php//定义当前请求模块 define("MODULE",index);//定义数据库 define(DB_HOST,localhost);//数据库地址 define(DB_DATABASE,aaa);//数据库 define(DB_USER,root);//数据库账号 def…...

使用Redis来实现点赞功能的基本思路
使用Redis来实现点赞功能是一种高效的选择,因为Redis是一个内存数据库,适用于处理高并发的数据操作。以下是一个基本的点赞功能在Redis中的设计示例: 假设我们有一个文章或帖子,用户可以对其进行点赞,取消点赞&#x…...
【黑马头条之app端文章搜索ES-MongoDB】
本笔记内容为黑马头条项目的app端文章搜索部分 目录 一、今日内容介绍 1、App端搜索-效果图 2、今日内容 二、搭建ElasticSearch环境 1、拉取镜像 2、创建容器 3、配置中文分词器 ik 4、使用postman测试 三、app端文章搜索 1、需求分析 2、思路分析 3、创建索引和…...

Nginx安装以及LVS-DR集群搭建
Nginx安装 1.环境准备 yum insatall -y make gcc gcc-c pcre-devel #pcre-devel -- pcre库 #安装openssl-devel yum install -y openssl-devel 2.tar安装包 3.解压软件包并创建软连接 tar -xf nginx-1.22.0.tar.gz -C /usr/local/ ln -s /usr/local/nginx-1.22.0/ /usr/local…...
后端开发9.商品类型模块
概述 简介 商品类型我设计的复杂了点,设计了多级类型 效果图 数据库设计...

spring框架自带的http工具RestTemplate用法
1. RestTemplate是什么? RestTemplate是由Spring框架提供的一个可用于应用中调用rest服务的类它简化了与http服务的通信方式。 RestTemplate是一个执行HTTP请求的同步阻塞式工具类,它仅仅只是在 HTTP 客户端库(例如 JDK HttpURLConnection&a…...
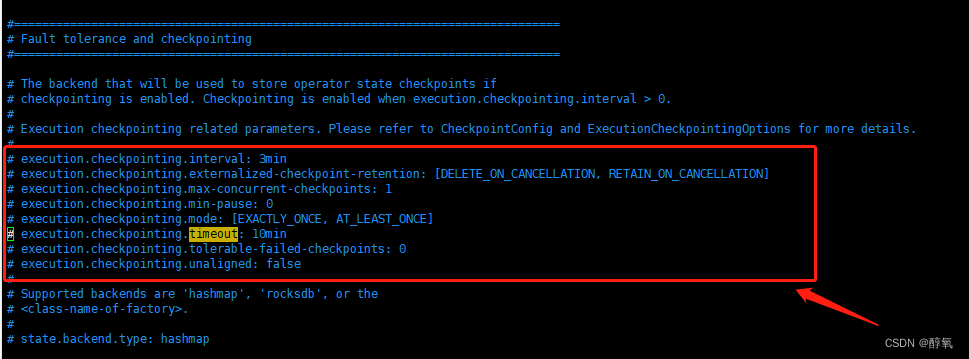
【flink】Checkpoint expired before completing.
使用flink同步数据出现错误Checkpoint expired before completing. 11:32:34,455 WARN org.apache.flink.runtime.checkpoint.CheckpointFailureManager [Checkpoint Timer] - Failed to trigger or complete checkpoint 4 for job 1b1d41031ea45d15bdb3324004c2d749. (2 con…...
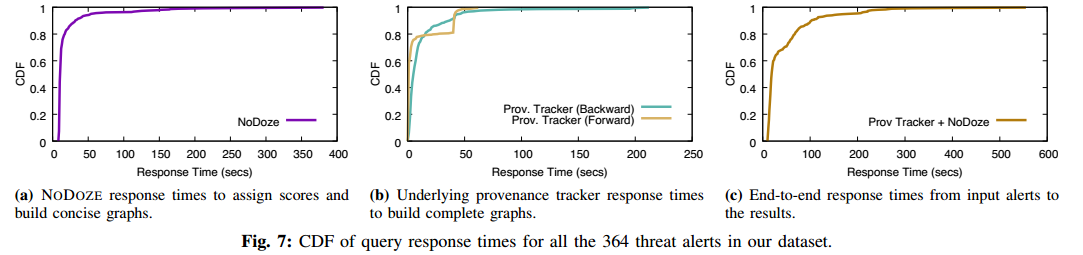
【论文阅读】NoDoze:使用自动来源分类对抗威胁警报疲劳(NDSS-2019)
NODOZE: Combatting Threat Alert Fatigue with Automated Provenance Triage 伊利诺伊大学芝加哥分校 Hassan W U, Guo S, Li D, et al. Nodoze: Combatting threat alert fatigue with automated provenance triage[C]//network and distributed systems security symposium.…...

【ARM64 常见汇编指令学习 16 -- ARM64 SMC 指令】
文章目录 ARMv8 同步异常同步异常指令SMC TYPE 上篇文章:ARM64 常见汇编指令学习 15 – ARM64 标志位的学习 下篇文章:ARM64 常见汇编指令学习 17 – ARM64 BFI 指令 ARMv8 同步异常 在ARMv8架构中,同步异常主要包括以下几种: Un…...
uprobe trace多线程mutex等待耗时
问题背景环境 ubuntu2204 服务器支持debugfs uprobe,为了提升应用程序的性能,需要量化不同参数下多线程主程序等待在mutex上的耗时区别 linux document中对uprobe events的说明如下 uprobetracer.rst - Documentation/trace/uprobetracer.rst - Linux…...
)
Linux 和 MacOS 中的 profile 文件详解(一)
什么是 profile 文件? profile 文件是 Linux、MacOS 等(unix、类 unix 系统)系统中的一种配置文件,主要用于设置系统和用户的环境变量。 在 shell 中,可以通过执行 profile 文件来设置用户的环境变量。shell 有两种运…...

不用技术代码,如何制作成绩查询系统?
为了解决学校无力承担传统学生考试成绩查询平台的高昂费用,老师们可以考虑使用易查分这样的工具来免费制作一个学生考试成绩查询平台。易查分是一种简单易用的在线成绩查询系统,可以帮助老师们快速创建一个个性化的学生考试成绩查询平台。 使用易查分制作…...
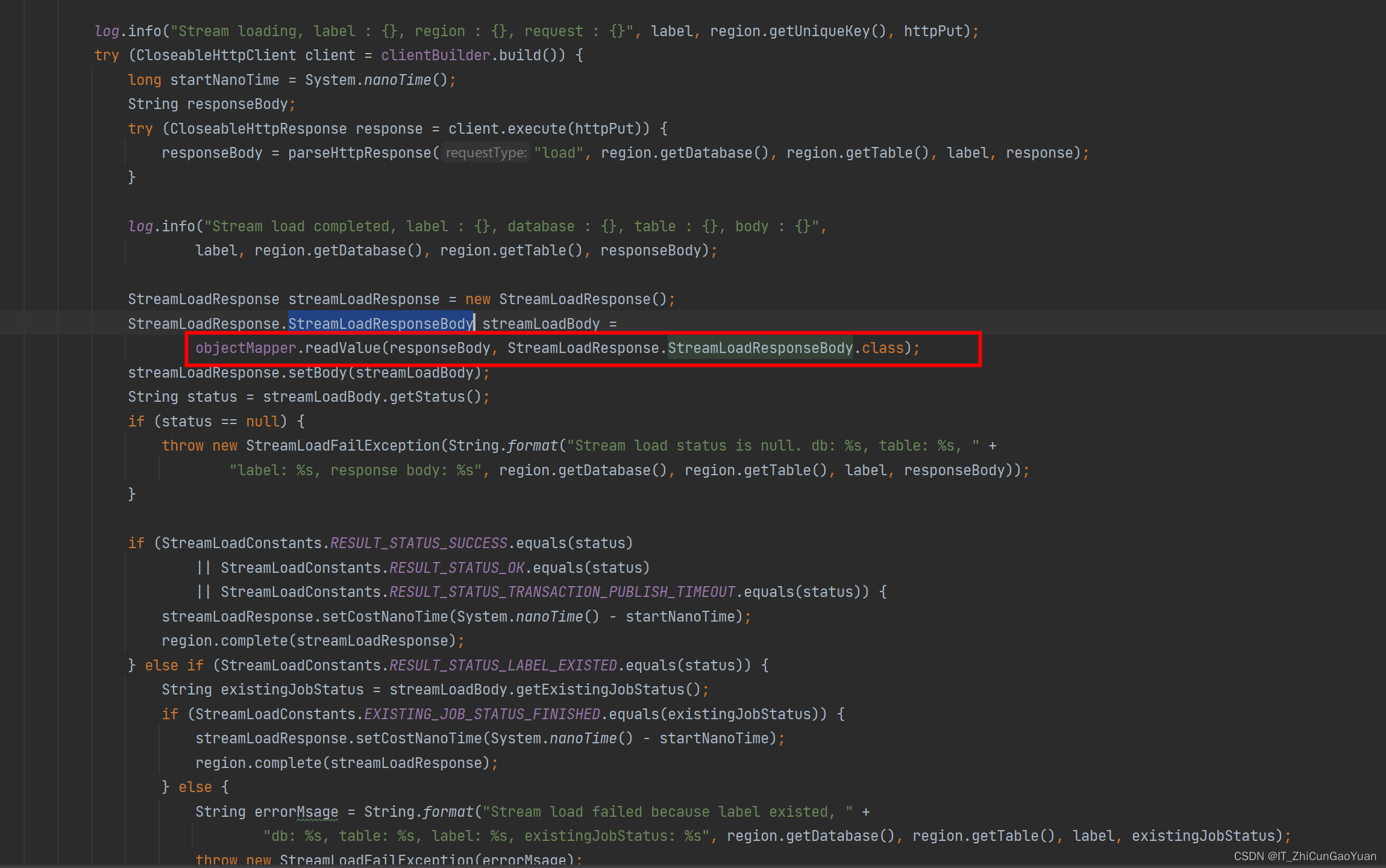
flinksql sink to sr often fail because of nullpoint
flinksql or DS sink to starrocks often fail because of nullpoint flink sql 和 flink ds sink starrocks 经常报NullpointException重新编译代码 并上传到flink 集群 验证,有效 flink sql 和 flink ds sink starrocks 经常报NullpointException 使用flink-sta…...

达梦数据库:Error updating database. Cause: dm.jdbc.driver.DMException: 数据未找到
异常:Error updating database. Cause: dm.jdbc.driver.DMException: 数据未找到 在使用达梦数据库批量插入或更新数据时,给我报了一个从来没有遇到过的错误,当时我给的一批数据就只有那么几条数据插入不进去,检查了语法和数据类…...

电脑怎么查看连接过的WIFI密码(测试环境win11,win10也能用)
电脑怎么查看连接过的WIFI密码 方法一:适用于正在连接的WIFI密码的查看 打开设置 点击“网络和Internet”,在下面找到“高级网络设置”点进去 在下面找到 “更多网络适配器选项” 点进去 找到 WLAN ,然后双击它 5.然后点击“无线属性” 6.…...
)
Tomcat8跑JSP页面报错ClassNotFound?可能是你的JSTL配置少了这一步(附jstl-1.2.jar正确用法)
Tomcat8部署JSP应用时JSTL配置全解析:从ClassNotFound到完美运行 最近在技术社区看到不少开发者反馈,在Tomcat8环境下部署JSP应用时频繁遇到ClassNotFoundException或NoClassDefFoundError,特别是与JSTL相关的错误。这类问题看似简单…...

自动驾驶/机器人定位必知:ECEF、ENU、UTM坐标系到底该怎么选?一篇讲清应用场景
自动驾驶与机器人定位:ECEF、ENU、UTM坐标系工程选型指南 当你在深夜调试一台自动驾驶车辆的定位模块时,突然发现GPS数据在ENU坐标系下表现良好,但切换到UTM后却出现了微妙的偏移——这种场景对机器人算法工程师来说再熟悉不过。坐标系选择不…...

深度解析:Win11Debloat的Windows系统优化完整实践
深度解析:Win11Debloat的Windows系统优化完整实践 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter and custom…...

5个必知技巧:rgthree-comfy如何让你的ComfyUI工作流更智能高效?
5个必知技巧:rgthree-comfy如何让你的ComfyUI工作流更智能高效? 【免费下载链接】rgthree-comfy Making ComfyUI more comfortable! 项目地址: https://gitcode.com/gh_mirrors/rg/rgthree-comfy 你是否曾在使用ComfyUI时感到工作流程杂乱无章&am…...

ERNIE-4.5-0.3B-PT实战:vLLM高效部署,Chainlit打造可视化对话界面
ERNIE-4.5-0.3B-PT实战:vLLM高效部署,Chainlit打造可视化对话界面 1. 项目概述与核心价值 在当今AI技术快速发展的背景下,如何在本地环境中高效部署和调用大语言模型成为许多开发者的实际需求。本文将详细介绍如何使用vLLM框架部署ERNIE-4.…...

5分钟完成Android Studio中文界面配置:AndroidStudioChineseLanguagePack终极操作指南
5分钟完成Android Studio中文界面配置:AndroidStudioChineseLanguagePack终极操作指南 【免费下载链接】AndroidStudioChineseLanguagePack AndroidStudio中文插件(官方修改版本) 项目地址: https://gitcode.com/gh_mirrors/an/AndroidStudioChineseLa…...

JCSprout事务管理终极指南:声明式与编程式事务对比分析
JCSprout事务管理终极指南:声明式与编程式事务对比分析 【免费下载链接】JCSprout 👨🎓 Java Core Sprout : basic, concurrent, algorithm 项目地址: https://gitcode.com/gh_mirrors/jc/JCSprout JCSprout作为Java核心知识的学习…...

2026年最新B站视频下载教程:3分钟掌握BiliTools跨平台下载神器
2026年最新B站视频下载教程:3分钟掌握BiliTools跨平台下载神器 【免费下载链接】BiliTools A cross-platform bilibili toolbox. 跨平台哔哩哔哩工具箱,支持下载视频、番剧等等各类资源 项目地址: https://gitcode.com/GitHub_Trending/bilit/BiliTool…...

【功能安全C++生死线】:3个未加volatile的变量,如何让某风电主控系统在-40℃下静默失效?
更多请点击: https://intelliparadigm.com 第一章:【功能安全C生死线】:3个未加volatile的变量,如何让某风电主控系统在-40℃下静默失效? 在风电主控系统的功能安全认证(IEC 61508 SIL3 / ISO 26262 ASIL…...

【YOLOv11】063、YOLOv11与神经架构搜索:用NAS自动寻找最优结构
从一次失败的调参说起 上周在部署YOLOv11到边缘设备时遇到性能瓶颈:模型在Jetson Orin上跑不到实时帧率。手动调整了卷积核尺寸、通道数、注意力模块位置,折腾两天,精度掉了3个点,速度却只提升5%。这种“盲人摸象”式的结构优化让我开始重新审视:为什么不让算法自己寻找最…...