【黑马头条之app端文章搜索ES-MongoDB】
本笔记内容为黑马头条项目的app端文章搜索部分
目录
一、今日内容介绍
1、App端搜索-效果图
2、今日内容
二、搭建ElasticSearch环境
1、拉取镜像
2、创建容器
3、配置中文分词器 ik
4、使用postman测试
三、app端文章搜索
1、需求分析
2、思路分析
3、创建索引和映射
4、数据初始化到索引库
5、文章搜索功能实现
6、文章自动审核构建索引
四、app端搜索-搜索记录
1、需求分析
2、数据存储说明
3、MongoDB安装及集成
4、保存搜索记录
5、加载搜索记录列表
6、删除搜索记录
五、app端搜索-关键字联想词
1、需求分析
2、搜索词-数据来源
3、功能实现
一、今日内容介绍
1、App端搜索-效果图
2、今日内容
文章搜索
ElasticSearch环境搭建
索引库创建
文章搜索多条件复合查询
索引数据同步
搜索历史记录
Mongodb环境搭建
异步保存搜索历史
查看搜索历史列表
删除搜索历史
联想词查询
联想词的来源
联想词功能实现
二、搭建ElasticSearch环境
1、拉取镜像
docker pull elasticsearch:7.4.02、创建容器
docker run -id --name elasticsearch -d --restart=always -p 9200:9200 -p 9300:9300 -v /usr/share/elasticsearch/plugins:/usr/share/elasticsearch/plugins -e "discovery.type=single-node" elasticsearch:7.4.03、配置中文分词器 ik
因为在创建elasticsearch容器的时候,映射了目录,所以可以在宿主机上进行配置ik中文分词器
在去选择ik分词器的时候,需要与elasticsearch的版本好对应上
把资料中的elasticsearch-analysis-ik-7.4.0.zip上传到服务器上,放到对应目录(plugins)解压
#切换目录
cd /usr/share/elasticsearch/plugins
#新建目录
mkdir analysis-ik
cd analysis-ik
#root根目录中拷贝文件
mv elasticsearch-analysis-ik-7.4.0.zip /usr/share/elasticsearch/plugins/analysis-ik
#解压文件
cd /usr/share/elasticsearch/plugins/analysis-ik
unzip elasticsearch-analysis-ik-7.4.0.zip4、使用postman测试

三、app端文章搜索
1、需求分析
-
用户输入关键可搜索文章列表
-
关键词高亮显示
-
文章列表展示与home展示一样,当用户点击某一篇文章,可查看文章详情
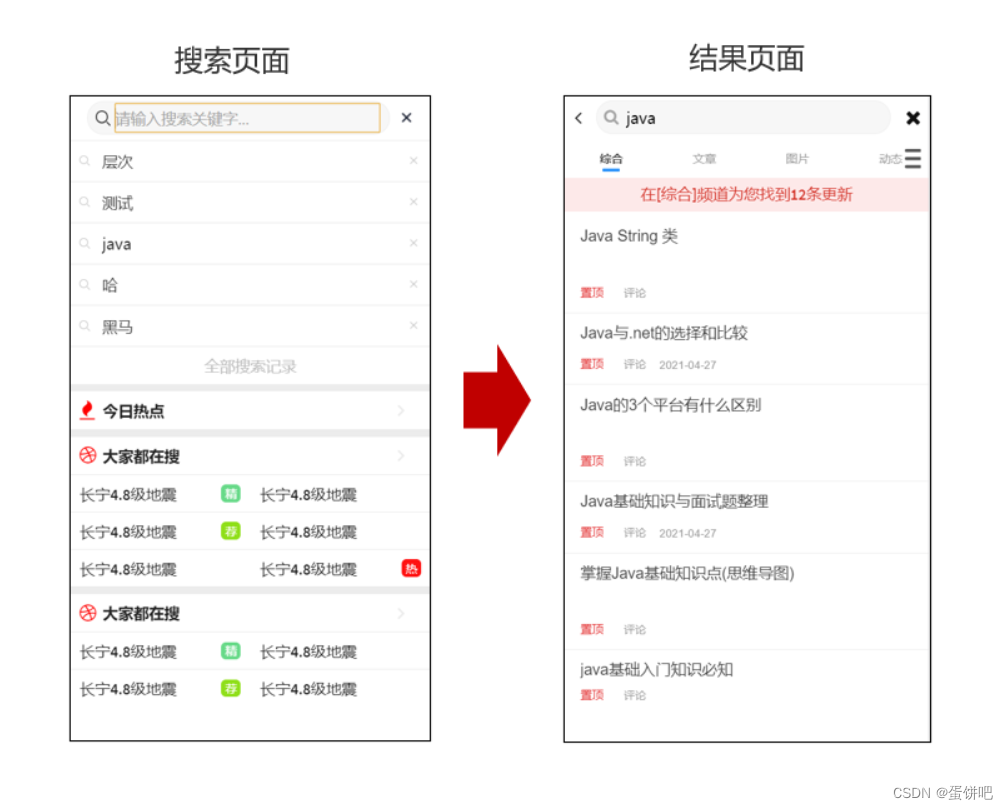
2、思路分析
为了加快检索的效率,在查询的时候不会直接从数据库中查询文章,需要在elasticsearch中进行高速检索。

3、创建索引和映射
使用postman添加映射
put请求 : http://192.168.200.130:9200/app_info_article
{"mappings":{"properties":{"id":{"type":"long"},"publishTime":{"type":"date"},"layout":{"type":"integer"},"images":{"type":"keyword","index": false},"staticUrl":{"type":"keyword","index": false},"authorId": {"type": "long"},"authorName": {"type": "text"},"title":{"type":"text","analyzer":"ik_smart"},"content":{"type":"text","analyzer":"ik_smart"}}}
}4、数据初始化到索引库
1.导入es-init到heima-leadnews-test工程下
2.查询所有的文章信息,批量导入到es索引库中
package com.heima.es;import com.alibaba.fastjson.JSON;
import com.heima.es.mapper.ApArticleMapper;
import com.heima.es.pojo.SearchArticleVo;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.xcontent.XContentType;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;import java.util.List;@SpringBootTest
@RunWith(SpringRunner.class)
public class ApArticleTest {@Autowiredprivate ApArticleMapper apArticleMapper;@Autowiredprivate RestHighLevelClient restHighLevelClient;/*** 注意:数据量的导入,如果数据量过大,需要分页导入* @throws Exception*/@Testpublic void init() throws Exception {//1.查询所有符合条件的文章数据List<SearchArticleVo> searchArticleVos = apArticleMapper.loadArticleList();//2.批量导入到es索引库BulkRequest bulkRequest = new BulkRequest("app_info_article");for (SearchArticleVo searchArticleVo : searchArticleVos) {IndexRequest indexRequest = new IndexRequest().id(searchArticleVo.getId().toString()).source(JSON.toJSONString(searchArticleVo), XContentType.JSON);//批量添加数据bulkRequest.add(indexRequest);}restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);}}3.测试
postman查询所有的es中数据 GET请求: http://192.168.200.130:9200/app_info_article/_search

5、文章搜索功能实现
1.搭建搜索微服务
①导入 heima-leadnews-search

②在heima-leadnews-service的pom中添加依赖
<!--elasticsearch-->
<dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId><version>7.4.0</version>
</dependency>
<dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-client</artifactId><version>7.4.0</version>
</dependency>
<dependency><groupId>org.elasticsearch</groupId><artifactId>elasticsearch</artifactId><version>7.4.0</version>
</dependency>③nacos配置中心leadnews-search
spring:autoconfigure:exclude: org.springframework.boot.autoconfigure.jdbc.DataSourceAutoConfiguration
elasticsearch:host: 192.168.200.130port: 92002.搜索接口定义
package com.heima.search.controller.v1;import com.heima.model.common.dtos.ResponseResult;
import com.heima.model.search.dtos.UserSearchDto;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;import java.io.IOException;@RestController
@RequestMapping("/api/v1/article/search")
public class ArticleSearchController {@PostMapping("/search")public ResponseResult search(@RequestBody UserSearchDto dto) throws IOException {return null;}
}
UserSearchDto
package com.heima.model.search.dtos;import lombok.Data;import java.util.Date;@Data
public class UserSearchDto {/*** 搜索关键字*/String searchWords;/*** 当前页*/int pageNum;/*** 分页条数*/int pageSize;/*** 最小时间*/Date minBehotTime;public int getFromIndex(){if(this.pageNum<1)return 0;if(this.pageSize<1) this.pageSize = 10;return this.pageSize * (pageNum-1);}
}3.业务层实现
创建业务层接口:ApArticleSearchService
package com.heima.search.service;import com.heima.model.search.dtos.UserSearchDto;
import com.heima.model.common.dtos.ResponseResult;import java.io.IOException;public interface ArticleSearchService {/**ES文章分页搜索@return*/ResponseResult search(UserSearchDto userSearchDto) throws IOException;
}实现类:
package com.heima.search.service.impl;import com.alibaba.fastjson.JSON;
import com.heima.model.common.dtos.ResponseResult;
import com.heima.model.common.enums.AppHttpCodeEnum;
import com.heima.model.search.dtos.UserSearchDto;
import com.heima.model.user.pojos.ApUser;
import com.heima.search.service.ArticleSearchService;
import com.heima.utils.thread.AppThreadLocalUtil;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.lang3.StringUtils;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.text.Text;
import org.elasticsearch.index.query.*;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder;
import org.elasticsearch.search.sort.SortOrder;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;@Service
@Slf4j
public class ArticleSearchServiceImpl implements ArticleSearchService {@Autowiredprivate RestHighLevelClient restHighLevelClient;/*** es文章分页检索** @param dto* @return*/@Overridepublic ResponseResult search(UserSearchDto dto) throws IOException {//1.检查参数if(dto == null || StringUtils.isBlank(dto.getSearchWords())){return ResponseResult.errorResult(AppHttpCodeEnum.PARAM_INVALID);}//2.设置查询条件SearchRequest searchRequest = new SearchRequest("app_info_article");SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();//布尔查询BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();//关键字的分词之后查询QueryStringQueryBuilder queryStringQueryBuilder = QueryBuilders.queryStringQuery(dto.getSearchWords()).field("title").field("content").defaultOperator(Operator.OR);boolQueryBuilder.must(queryStringQueryBuilder);//查询小于mindate的数据RangeQueryBuilder rangeQueryBuilder = QueryBuilders.rangeQuery("publishTime").lt(dto.getMinBehotTime().getTime());boolQueryBuilder.filter(rangeQueryBuilder);//分页查询searchSourceBuilder.from(0);searchSourceBuilder.size(dto.getPageSize());//按照发布时间倒序查询searchSourceBuilder.sort("publishTime", SortOrder.DESC);//设置高亮 titleHighlightBuilder highlightBuilder = new HighlightBuilder();highlightBuilder.field("title");highlightBuilder.preTags("<font style='color: red; font-size: inherit;'>");highlightBuilder.postTags("</font>");searchSourceBuilder.highlighter(highlightBuilder);searchSourceBuilder.query(boolQueryBuilder);searchRequest.source(searchSourceBuilder);SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);//3.结果封装返回List<Map> list = new ArrayList<>();SearchHit[] hits = searchResponse.getHits().getHits();for (SearchHit hit : hits) {String json = hit.getSourceAsString();Map map = JSON.parseObject(json, Map.class);//处理高亮if(hit.getHighlightFields() != null && hit.getHighlightFields().size() > 0){Text[] titles = hit.getHighlightFields().get("title").getFragments();String title = StringUtils.join(titles);//高亮标题map.put("h_title",title);}else {//原始标题map.put("h_title",map.get("title"));}list.add(map);}return ResponseResult.okResult(list);}
}4.控制层实现
新建控制器ArticleSearchController
package com.heima.search.controller.v1;import com.heima.model.common.dtos.ResponseResult;
import com.heima.model.search.dtos.UserSearchDto;
import com.heima.search.service.ArticleSearchService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;import java.io.IOException;@RestController
@RequestMapping("/api/v1/article/search")
public class ArticleSearchController {@Autowiredprivate ArticleSearchService articleSearchService;@PostMapping("/search")public ResponseResult search(@RequestBody UserSearchDto dto) throws IOException {return articleSearchService.search(dto);}
}5.测试
需要在app的网关中添加搜索微服务的路由配置
#搜索微服务
- id: leadnews-searchuri: lb://leadnews-searchpredicates:- Path=/search/**filters:- StripPrefix= 1启动项目进行测试,至少要启动文章微服务,用户微服务,搜索微服务,app网关微服务,app前端工程
6、文章自动审核构建索引
1.思路分析

2.文章微服务发送消息
①把SearchArticleVo放到model工程下
package com.heima.model.search.vos;import lombok.Data;import java.util.Date;@Data
public class SearchArticleVo {// 文章idprivate Long id;// 文章标题private String title;// 文章发布时间private Date publishTime;// 文章布局private Integer layout;// 封面private String images;// 作者idprivate Long authorId;// 作者名词private String authorName;//静态urlprivate String staticUrl;//文章内容private String content;}②文章微服务的ArticleFreemarkerService中的buildArticleToMinIO方法中收集数据并发送消息
完整代码如下:
package com.heima.article.service.impl;import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONArray;
import com.baomidou.mybatisplus.core.toolkit.Wrappers;
import com.heima.article.mapper.ApArticleContentMapper;
import com.heima.article.service.ApArticleService;
import com.heima.article.service.ArticleFreemarkerService;
import com.heima.common.constants.ArticleConstants;
import com.heima.file.service.FileStorageService;
import com.heima.model.article.pojos.ApArticle;
import com.heima.model.search.vos.SearchArticleVo;
import freemarker.template.Configuration;
import freemarker.template.Template;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.lang3.StringUtils;
import org.springframework.beans.BeanUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.scheduling.annotation.Async;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;import java.io.ByteArrayInputStream;
import java.io.InputStream;
import java.io.StringWriter;
import java.util.HashMap;
import java.util.Map;@Service
@Slf4j
@Transactional
public class ArticleFreemarkerServiceImpl implements ArticleFreemarkerService {@Autowiredprivate ApArticleContentMapper apArticleContentMapper;@Autowiredprivate Configuration configuration;@Autowiredprivate FileStorageService fileStorageService;@Autowiredprivate ApArticleService apArticleService;/*** 生成静态文件上传到minIO中* @param apArticle* @param content*/@Async@Overridepublic void buildArticleToMinIO(ApArticle apArticle, String content) {//已知文章的id//4.1 获取文章内容if(StringUtils.isNotBlank(content)){//4.2 文章内容通过freemarker生成html文件Template template = null;StringWriter out = new StringWriter();try {template = configuration.getTemplate("article.ftl");//数据模型Map<String,Object> contentDataModel = new HashMap<>();contentDataModel.put("content", JSONArray.parseArray(content));//合成template.process(contentDataModel,out);} catch (Exception e) {e.printStackTrace();}//4.3 把html文件上传到minio中InputStream in = new ByteArrayInputStream(out.toString().getBytes());String path = fileStorageService.uploadHtmlFile("", apArticle.getId() + ".html", in);//4.4 修改ap_article表,保存static_url字段apArticleService.update(Wrappers.<ApArticle>lambdaUpdate().eq(ApArticle::getId,apArticle.getId()).set(ApArticle::getStaticUrl,path));//发送消息,创建索引createArticleESIndex(apArticle,content,path);}}@Autowiredprivate KafkaTemplate<String,String> kafkaTemplate;/*** 送消息,创建索引* @param apArticle* @param content* @param path*/private void createArticleESIndex(ApArticle apArticle, String content, String path) {SearchArticleVo vo = new SearchArticleVo();BeanUtils.copyProperties(apArticle,vo);vo.setContent(content);vo.setStaticUrl(path);kafkaTemplate.send(ArticleConstants.ARTICLE_ES_SYNC_TOPIC, JSON.toJSONString(vo));}}在ArticleConstants类中添加新的常量,完整代码如下
package com.heima.common.constants;public class ArticleConstants {public static final Short LOADTYPE_LOAD_MORE = 1;public static final Short LOADTYPE_LOAD_NEW = 2;public static final String DEFAULT_TAG = "__all__";public static final String ARTICLE_ES_SYNC_TOPIC = "article.es.sync.topic";public static final Integer HOT_ARTICLE_LIKE_WEIGHT = 3;public static final Integer HOT_ARTICLE_COMMENT_WEIGHT = 5;public static final Integer HOT_ARTICLE_COLLECTION_WEIGHT = 8;public static final String HOT_ARTICLE_FIRST_PAGE = "hot_article_first_page_";
}③文章微服务集成kafka发送消息
在文章微服务的nacos的配置中心添加如下配置
kafka:bootstrap-servers: 192.168.200.130:9092producer:retries: 10key-serializer: org.apache.kafka.common.serialization.StringSerializervalue-serializer: org.apache.kafka.common.serialization.StringSerializer3.搜索微服务创建索引
①搜索微服务中添加kafka的配置,nacos配置如下
spring:kafka:bootstrap-servers: 192.168.200.130:9092consumer:group-id: ${spring.application.name}key-deserializer: org.apache.kafka.common.serialization.StringDeserializervalue-deserializer: org.apache.kafka.common.serialization.StringDeserializer②定义监听接收消息,保存索引数据
package com.heima.search.listener;import com.alibaba.fastjson.JSON;
import com.heima.common.constants.ArticleConstants;
import com.heima.model.search.vos.SearchArticleVo;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.lang3.StringUtils;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.xcontent.XContentType;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;import java.io.IOException;@Component
@Slf4j
public class SyncArticleListener {@Autowiredprivate RestHighLevelClient restHighLevelClient;@KafkaListener(topics = ArticleConstants.ARTICLE_ES_SYNC_TOPIC)public void onMessage(String message){if(StringUtils.isNotBlank(message)){log.info("SyncArticleListener,message={}",message);SearchArticleVo searchArticleVo = JSON.parseObject(message, SearchArticleVo.class);IndexRequest indexRequest = new IndexRequest("app_info_article");indexRequest.id(searchArticleVo.getId().toString());indexRequest.source(message, XContentType.JSON);try {restHighLevelClient.index(indexRequest, RequestOptions.DEFAULT);} catch (IOException e) {e.printStackTrace();log.error("sync es error={}",e);}}}
}四、app端搜索-搜索记录
1、需求分析

2、数据存储说明
用户的搜索记录,需要给每一个用户都保存一份,数据量较大,要求加载速度快,通常这样的数据存储到mongodb更合适,不建议直接存储到关系型数据库中
3、MongoDB安装及集成
1.安装MongoDB
拉取镜像
docker pull mongo创建容器
docker run -di --name mongo-service --restart=always -p 27017:27017 -v ~/data/mongodata:/data mongo2.导入资料中的mongo-demo项目到heima-leadnews-test中
其中有三项配置比较关键:
第一:mongo依赖
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-mongodb</artifactId>
</dependency>第二:mongo配置
server:port: 9998
spring:data:mongodb:host: 192.168.200.130port: 27017database: leadnews-history第三:映射
package com.itheima.mongo.pojo;import lombok.Data;
import org.springframework.data.mongodb.core.mapping.Document;import java.io.Serializable;
import java.util.Date;/*** <p>* 联想词表* </p>** @author itheima*/
@Data
@Document("ap_associate_words")
public class ApAssociateWords implements Serializable {private static final long serialVersionUID = 1L;private String id;/*** 联想词*/private String associateWords;/*** 创建时间*/private Date createdTime;}3.核心方法
package com.itheima.mongo.test;import com.itheima.mongo.MongoApplication;
import com.itheima.mongo.pojo.ApAssociateWords;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.domain.Sort;
import org.springframework.data.mongodb.core.MongoTemplate;
import org.springframework.data.mongodb.core.query.Criteria;
import org.springframework.data.mongodb.core.query.Query;
import org.springframework.test.context.junit4.SpringRunner;import java.util.Date;
import java.util.List;@SpringBootTest(classes = MongoApplication.class)
@RunWith(SpringRunner.class)
public class MongoTest {@Autowiredprivate MongoTemplate mongoTemplate;//保存@Testpublic void saveTest(){/*for (int i = 0; i < 10; i++) {ApAssociateWords apAssociateWords = new ApAssociateWords();apAssociateWords.setAssociateWords("黑马头条");apAssociateWords.setCreatedTime(new Date());mongoTemplate.save(apAssociateWords);}*/ApAssociateWords apAssociateWords = new ApAssociateWords();apAssociateWords.setAssociateWords("黑马直播");apAssociateWords.setCreatedTime(new Date());mongoTemplate.save(apAssociateWords);}//查询一个@Testpublic void saveFindOne(){ApAssociateWords apAssociateWords = mongoTemplate.findById("60bd973eb0c1d430a71a7928", ApAssociateWords.class);System.out.println(apAssociateWords);}//条件查询@Testpublic void testQuery(){Query query = Query.query(Criteria.where("associateWords").is("黑马头条")).with(Sort.by(Sort.Direction.DESC,"createdTime"));List<ApAssociateWords> apAssociateWordsList = mongoTemplate.find(query, ApAssociateWords.class);System.out.println(apAssociateWordsList);}@Testpublic void testDel(){mongoTemplate.remove(Query.query(Criteria.where("associateWords").is("黑马头条")),ApAssociateWords.class);}
}4、保存搜索记录
1.实现思路
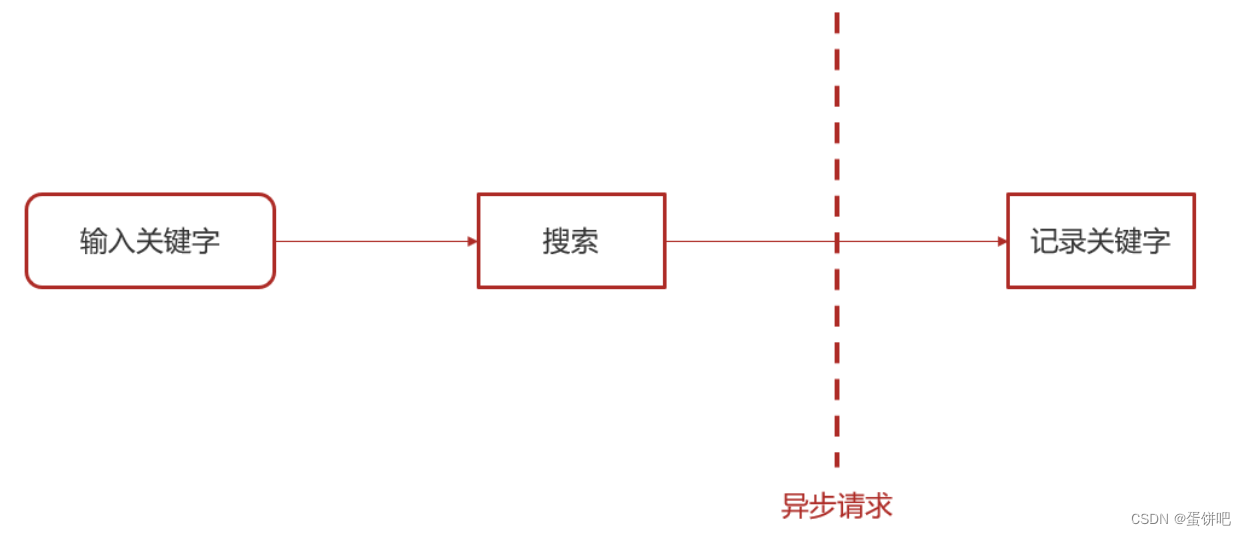
用户输入关键字进行搜索的异步记录关键字
用户搜索记录对应的集合,对应实体类:
package com.heima.search.pojos;import lombok.Data;
import org.springframework.data.mongodb.core.mapping.Document;import java.io.Serializable;
import java.util.Date;/*** <p>* APP用户搜索信息表* </p>* @author itheima*/
@Data
@Document("ap_user_search")
public class ApUserSearch implements Serializable {private static final long serialVersionUID = 1L;/*** 主键*/private String id;/*** 用户ID*/private Integer userId;/*** 搜索词*/private String keyword;/*** 创建时间*/private Date createdTime;}2.实现步骤
①搜索微服务集成mongodb
pom依赖
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-mongodb</artifactId>
</dependency>nacos配置
spring:data:mongodb:host: 192.168.200.130port: 27017database: leadnews-history在当天资料中找到对应的实体类拷贝到搜索微服务下
package com.heima.search.pojos;import lombok.Data;
import org.springframework.data.mongodb.core.mapping.Document;import java.io.Serializable;
import java.util.Date;/*** <p>* APP用户搜索信息表* </p>* @author itheima*/
@Data
@Document("ap_user_search")
public class ApUserSearch implements Serializable {private static final long serialVersionUID = 1L;/*** 主键*/private String id;/*** 用户ID*/private Integer userId;/*** 搜索词*/private String keyword;/*** 创建时间*/private Date createdTime;}package com.heima.search.pojos;import lombok.Data;
import org.springframework.data.mongodb.core.mapping.Document;import java.io.Serializable;
import java.util.Date;/*** <p>* 联想词表* </p>** @author itheima*/
@Data
@Document("ap_associate_words")
public class ApAssociateWords implements Serializable {private static final long serialVersionUID = 1L;private String id;/*** 联想词*/private String associateWords;/*** 创建时间*/private Date createdTime;}②创建ApUserSearchService新增insert方法
public interface ApUserSearchService {/*** 保存用户搜索历史记录* @param keyword* @param userId*/public void insert(String keyword,Integer userId);
}实现类:
@Service
@Slf4j
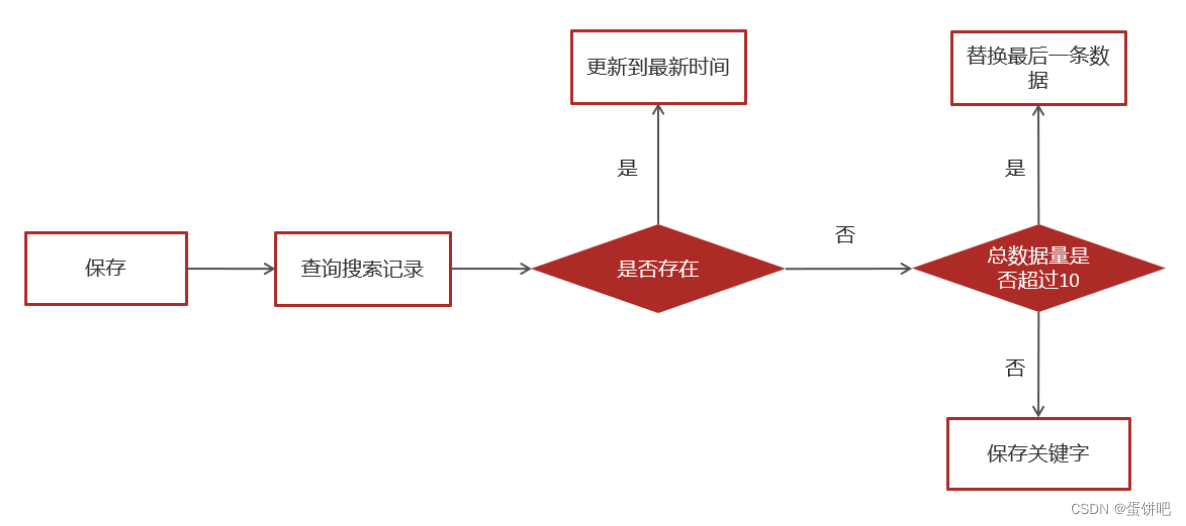
public class ApUserSearchServiceImpl implements ApUserSearchService {@Autowiredprivate MongoTemplate mongoTemplate;/*** 保存用户搜索历史记录* @param keyword* @param userId*/@Override@Asyncpublic void insert(String keyword, Integer userId) {//1.查询当前用户的搜索关键词Query query = Query.query(Criteria.where("userId").is(userId).and("keyword").is(keyword));ApUserSearch apUserSearch = mongoTemplate.findOne(query, ApUserSearch.class);//2.存在 更新创建时间if(apUserSearch != null){apUserSearch.setCreatedTime(new Date());mongoTemplate.save(apUserSearch);return;}//3.不存在,判断当前历史记录总数量是否超过10apUserSearch = new ApUserSearch();apUserSearch.setUserId(userId);apUserSearch.setKeyword(keyword);apUserSearch.setCreatedTime(new Date());Query query1 = Query.query(Criteria.where("userId").is(userId));query1.with(Sort.by(Sort.Direction.DESC,"createdTime"));List<ApUserSearch> apUserSearchList = mongoTemplate.find(query1, ApUserSearch.class);if(apUserSearchList == null || apUserSearchList.size() < 10){mongoTemplate.save(apUserSearch);}else {ApUserSearch lastUserSearch = apUserSearchList.get(apUserSearchList.size() - 1);mongoTemplate.findAndReplace(Query.query(Criteria.where("id").is(lastUserSearch.getId())),apUserSearch);}}
}3.参考自媒体相关微服务,在搜索微服务中获取当前登录的用户
Util类
package com.heima.utils.thread;import com.heima.model.user.pojos.ApUser;
import com.heima.model.wemedia.pojos.WmUser;/*** Description: new java files header..** @author zhangzuhao* @version 1.0* @date 2023/7/18 15:56*/public class AppThreadLocalUtil {private final static ThreadLocal<ApUser> WM_USER_THREAD_LOCAL = new ThreadLocal<>();//存入线程中public static void setUser(ApUser apUser){WM_USER_THREAD_LOCAL.set(apUser);}//获取线程数据public static ApUser getUser(){return WM_USER_THREAD_LOCAL.get();}//清理数据public static void clear(){WM_USER_THREAD_LOCAL.remove();}
}interceptor
package com.heima.search.interceptor;import com.heima.model.user.pojos.ApUser;
import com.heima.model.wemedia.pojos.WmUser;
import com.heima.utils.thread.AppThreadLocalUtil;
import com.heima.utils.thread.WmThreadLocalUtil;
import org.springframework.web.servlet.HandlerInterceptor;
import org.springframework.web.servlet.ModelAndView;import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;/*** Description: new java files header..** @author zhangzuhao* @version 1.0* @date 2023/8/7 16:54*/public class AppTokenInterceptor implements HandlerInterceptor {@Overridepublic boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {String userId = request.getHeader("userId");if (userId!=null){ApUser apUser = new ApUser();apUser.setId(Integer.valueOf(userId));AppThreadLocalUtil.setUser(apUser);}return true;}@Overridepublic void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {AppThreadLocalUtil.clear();}
}
config
package com.heima.search.config;import com.heima.search.interceptor.AppTokenInterceptor;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.servlet.config.annotation.InterceptorRegistry;
import org.springframework.web.servlet.config.annotation.WebMvcConfigurer;/*** Description: new java files header..** @author zhangzuhao* @version 1.0* @date 2023/7/18 16:06*/@Configuration
public class WebMvcConfig implements WebMvcConfigurer {@Overridepublic void addInterceptors(InterceptorRegistry registry) {registry.addInterceptor(new AppTokenInterceptor()).addPathPatterns("/**");}
}
4.在ArticleSearchService的search方法中调用保存历史记录
完整代码如下:
package com.heima.search.service.impl;import com.alibaba.fastjson.JSON;
import com.heima.model.common.dtos.ResponseResult;
import com.heima.model.common.enums.AppHttpCodeEnum;
import com.heima.model.search.dtos.UserSearchDto;
import com.heima.model.user.pojos.ApUser;
import com.heima.search.service.ApUserSearchService;
import com.heima.search.service.ArticleSearchService;
import com.heima.utils.thread.AppThreadLocalUtil;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.lang3.StringUtils;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.text.Text;
import org.elasticsearch.index.query.*;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder;
import org.elasticsearch.search.sort.SortOrder;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;@Service
@Slf4j
public class ArticleSearchServiceImpl implements ArticleSearchService {@Autowiredprivate RestHighLevelClient restHighLevelClient;@Autowiredprivate ApUserSearchService apUserSearchService;/*** es文章分页检索** @param dto* @return*/@Overridepublic ResponseResult search(UserSearchDto dto) throws IOException {//1.检查参数if(dto == null || StringUtils.isBlank(dto.getSearchWords())){return ResponseResult.errorResult(AppHttpCodeEnum.PARAM_INVALID);}ApUser user = AppThreadLocalUtil.getUser();//异步调用 保存搜索记录if(user != null && dto.getFromIndex() == 0){apUserSearchService.insert(dto.getSearchWords(), user.getId());}//2.设置查询条件SearchRequest searchRequest = new SearchRequest("app_info_article");SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();//布尔查询BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();//关键字的分词之后查询QueryStringQueryBuilder queryStringQueryBuilder = QueryBuilders.queryStringQuery(dto.getSearchWords()).field("title").field("content").defaultOperator(Operator.OR);boolQueryBuilder.must(queryStringQueryBuilder);//查询小于mindate的数据RangeQueryBuilder rangeQueryBuilder = QueryBuilders.rangeQuery("publishTime").lt(dto.getMinBehotTime().getTime());boolQueryBuilder.filter(rangeQueryBuilder);//分页查询searchSourceBuilder.from(0);searchSourceBuilder.size(dto.getPageSize());//按照发布时间倒序查询searchSourceBuilder.sort("publishTime", SortOrder.DESC);//设置高亮 titleHighlightBuilder highlightBuilder = new HighlightBuilder();highlightBuilder.field("title");highlightBuilder.preTags("<font style='color: red; font-size: inherit;'>");highlightBuilder.postTags("</font>");searchSourceBuilder.highlighter(highlightBuilder);searchSourceBuilder.query(boolQueryBuilder);searchRequest.source(searchSourceBuilder);SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);//3.结果封装返回List<Map> list = new ArrayList<>();SearchHit[] hits = searchResponse.getHits().getHits();for (SearchHit hit : hits) {String json = hit.getSourceAsString();Map map = JSON.parseObject(json, Map.class);//处理高亮if(hit.getHighlightFields() != null && hit.getHighlightFields().size() > 0){Text[] titles = hit.getHighlightFields().get("title").getFragments();String title = StringUtils.join(titles);//高亮标题map.put("h_title",title);}else {//原始标题map.put("h_title",map.get("title"));}list.add(map);}return ResponseResult.okResult(list);}
}5.保存历史记录中开启异步调用,添加注解@Async

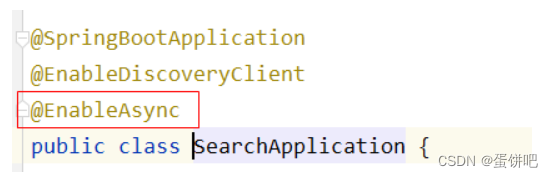
6.在搜索微服务引导类上开启异步调用
7.测试,搜索后查看结果
5、加载搜索记录列表
1.思路分析
按照当前用户,按照时间倒序查询
| 说明 | |
|---|---|
| 接口路径 | /api/v1/history/load |
| 请求方式 | POST |
| 参数 | 无 |
| 响应结果 | ResponseResult |
2.接口定义
/*** <p>* APP用户搜索信息表 前端控制器* </p>** @author itheima*/
@Slf4j
@RestController
@RequestMapping("/api/v1/history")
public class ApUserSearchController{@PostMapping("/load")@Overridepublic ResponseResult findUserSearch() {return null;}}3.mapper
已定义
4.业务层
在ApUserSearchService中新增方法
/**查询搜索历史@return*/
ResponseResult findUserSearch();实现方法
/*** 查询搜索历史** @return*/
@Override
public ResponseResult findUserSearch() {//获取当前用户ApUser user = AppThreadLocalUtil.getUser();if(user == null){return ResponseResult.errorResult(AppHttpCodeEnum.NEED_LOGIN);}//根据用户查询数据,按照时间倒序List<ApUserSearch> apUserSearches = mongoTemplate.find(Query.query(Criteria.where("userId").is(user.getId())).with(Sort.by(Sort.Direction.DESC, "createdTime")), ApUserSearch.class);return ResponseResult.okResult(apUserSearches);
}5.控制器
/*** <p>* APP用户搜索信息表 前端控制器* </p>* @author itheima*/
@Slf4j
@RestController
@RequestMapping("/api/v1/history")
public class ApUserSearchController{@Autowiredprivate ApUserSearchService apUserSearchService;@PostMapping("/load")public ResponseResult findUserSearch() {return apUserSearchService.findUserSearch();}}6.测试
打开app的搜索页面,可以查看搜索记录列表
6、删除搜索记录
1.思路分析
按照搜索历史id删除
| 说明 | |
|---|---|
| 接口路径 | /api/v1/history/del |
| 请求方式 | POST |
| 参数 | HistorySearchDto |
| 响应结果 | ResponseResult |
2.接口定义
在ApUserSearchController接口新增方法
@PostMapping("/del")
public ResponseResult delUserSearch(@RequestBody HistorySearchDto historySearchDto) {return null;
}HistorySearchDto
@Data
public class HistorySearchDto {/*** 接收搜索历史记录id*/String id;
}3.业务层
在ApUserSearchService中新增方法
/**删除搜索历史@param historySearchDto@return*/
ResponseResult delUserSearch(HistorySearchDto historySearchDto);实现方法
/*** 删除历史记录** @param dto* @return*/
@Override
public ResponseResult delUserSearch(HistorySearchDto dto) {//1.检查参数if(dto.getId() == null){return ResponseResult.errorResult(AppHttpCodeEnum.PARAM_INVALID);}//2.判断是否登录ApUser user = AppThreadLocalUtil.getUser();if(user == null){return ResponseResult.errorResult(AppHttpCodeEnum.NEED_LOGIN);}//3.删除mongoTemplate.remove(Query.query(Criteria.where("userId").is(user.getId()).and("id").is(dto.getId())),ApUserSearch.class);return ResponseResult.okResult(AppHttpCodeEnum.SUCCESS);
}4.控制器
修改ApUserSearchController,补全方法
@PostMapping("/del")
public ResponseResult delUserSearch(@RequestBody HistorySearchDto historySearchDto) {return apUserSearchService.delUserSearch(historySearchDto);
}5.测试
打开app可以删除搜索记录
五、app端搜索-关键字联想词
1、需求分析
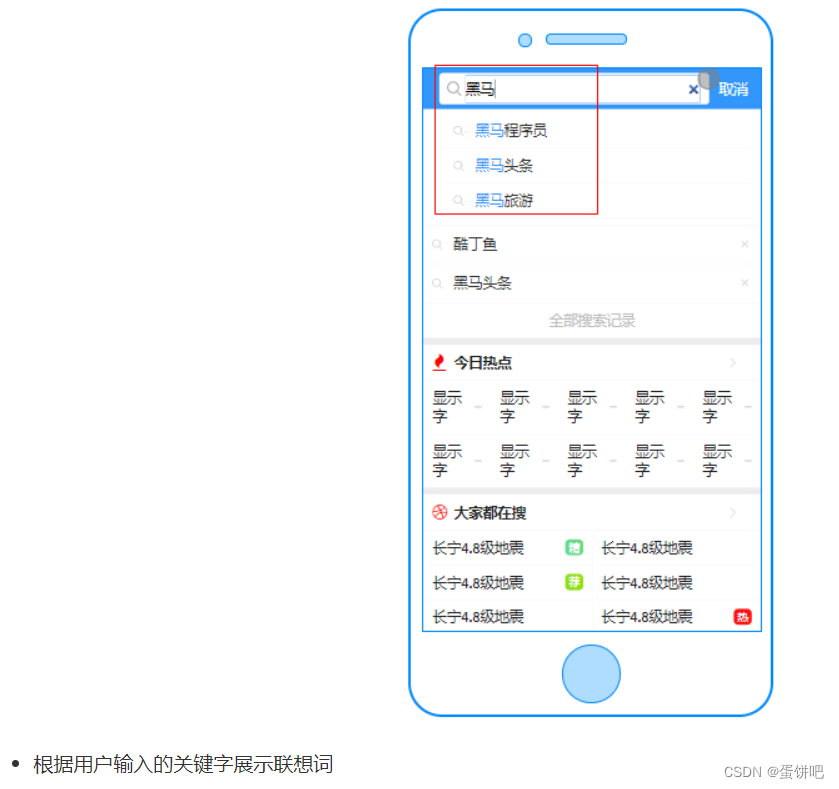
对应实体类
package com.heima.search.pojos;import lombok.Data;
import org.springframework.data.mongodb.core.mapping.Document;import java.io.Serializable;
import java.util.Date;/*** <p>* 联想词表* </p>** @author itheima*/
@Data
@Document("ap_associate_words")
public class ApAssociateWords implements Serializable {private static final long serialVersionUID = 1L;private String id;/*** 联想词*/private String associateWords;/*** 创建时间*/private Date createdTime;}2、搜索词-数据来源
通常是网上搜索频率比较高的一些词,通常在企业中有两部分来源:
第一:自己维护搜索词
通过分析用户搜索频率较高的词,按照排名作为搜索词
第二:第三方获取
关键词规划师(百度)、5118、爱站网
3、功能实现
1.接口定义
| 说明 | |
|---|---|
| 接口路径 | /api/v1/associate/search |
| 请求方式 | POST |
| 参数 | UserSearchDto |
| 响应结果 | ResponseResult |
新建接口
package com.heima.search.controller.v1;import com.heima.model.common.dtos.ResponseResult;
import com.heima.model.search.dtos.UserSearchDto;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;@RestController
@RequestMapping("/api/v1/associate")
public class ApAssociateWordsController {@PostMapping("/search")public ResponseResult search(@RequestBody UserSearchDto userSearchDto) {return null;}
}
2.业务层
新建联想词业务层接口
package com.heima.search.service;import com.heima.model.common.dtos.ResponseResult;
import com.heima.model.search.dtos.UserSearchDto;/*** <p>* 联想词表 服务类* </p>** @author itheima*/
public interface ApAssociateWordsService {/**联想词@param userSearchDto@return*/ResponseResult findAssociate(UserSearchDto userSearchDto);}实现类
package com.heima.search.service.impl;import com.heima.model.common.dtos.ResponseResult;
import com.heima.model.common.enums.AppHttpCodeEnum;
import com.heima.model.search.dtos.UserSearchDto;
import com.heima.search.pojos.ApAssociateWords;
import com.heima.search.service.ApAssociateWordsService;
import org.apache.commons.lang3.StringUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.mongodb.core.MongoTemplate;
import org.springframework.data.mongodb.core.query.Criteria;
import org.springframework.data.mongodb.core.query.Query;
import org.springframework.stereotype.Service;import java.util.List;/*** @Description:* @Version: V1.0*/
@Service
public class ApAssociateWordsServiceImpl implements ApAssociateWordsService {@AutowiredMongoTemplate mongoTemplate;/*** 联想词* @param userSearchDto* @return*/@Overridepublic ResponseResult findAssociate(UserSearchDto userSearchDto) {//1 参数检查if(userSearchDto == null || StringUtils.isBlank(userSearchDto.getSearchWords())){return ResponseResult.errorResult(AppHttpCodeEnum.PARAM_INVALID);}//分页检查if (userSearchDto.getPageSize() > 20) {userSearchDto.setPageSize(20);}//3 执行查询 模糊查询Query query = Query.query(Criteria.where("associateWords").regex(".*?\\" + userSearchDto.getSearchWords() + ".*"));query.limit(userSearchDto.getPageSize());List<ApAssociateWords> wordsList = mongoTemplate.find(query, ApAssociateWords.class);return ResponseResult.okResult(wordsList);}
}3.控制器
新建联想词控制器
package com.heima.search.controller.v1;import com.heima.model.common.dtos.ResponseResult;
import com.heima.model.search.dtos.UserSearchDto;
import com.heima.search.service.ApAssociateWordsService;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;/*** <p>* 联想词表 前端控制器* </p>* @author itheima*/
@Slf4j
@RestController
@RequestMapping("/api/v1/associate")
public class ApAssociateWordsController{@Autowiredprivate ApAssociateWordsService apAssociateWordsService;@PostMapping("/search")public ResponseResult findAssociate(@RequestBody UserSearchDto userSearchDto) {return apAssociateWordsService.findAssociate(userSearchDto);}
}4.测试
同样,打开前端联调测试效果
结束!
相关文章:
【黑马头条之app端文章搜索ES-MongoDB】
本笔记内容为黑马头条项目的app端文章搜索部分 目录 一、今日内容介绍 1、App端搜索-效果图 2、今日内容 二、搭建ElasticSearch环境 1、拉取镜像 2、创建容器 3、配置中文分词器 ik 4、使用postman测试 三、app端文章搜索 1、需求分析 2、思路分析 3、创建索引和…...

Nginx安装以及LVS-DR集群搭建
Nginx安装 1.环境准备 yum insatall -y make gcc gcc-c pcre-devel #pcre-devel -- pcre库 #安装openssl-devel yum install -y openssl-devel 2.tar安装包 3.解压软件包并创建软连接 tar -xf nginx-1.22.0.tar.gz -C /usr/local/ ln -s /usr/local/nginx-1.22.0/ /usr/local…...
后端开发9.商品类型模块
概述 简介 商品类型我设计的复杂了点,设计了多级类型 效果图 数据库设计...

spring框架自带的http工具RestTemplate用法
1. RestTemplate是什么? RestTemplate是由Spring框架提供的一个可用于应用中调用rest服务的类它简化了与http服务的通信方式。 RestTemplate是一个执行HTTP请求的同步阻塞式工具类,它仅仅只是在 HTTP 客户端库(例如 JDK HttpURLConnection&a…...
【flink】Checkpoint expired before completing.
使用flink同步数据出现错误Checkpoint expired before completing. 11:32:34,455 WARN org.apache.flink.runtime.checkpoint.CheckpointFailureManager [Checkpoint Timer] - Failed to trigger or complete checkpoint 4 for job 1b1d41031ea45d15bdb3324004c2d749. (2 con…...
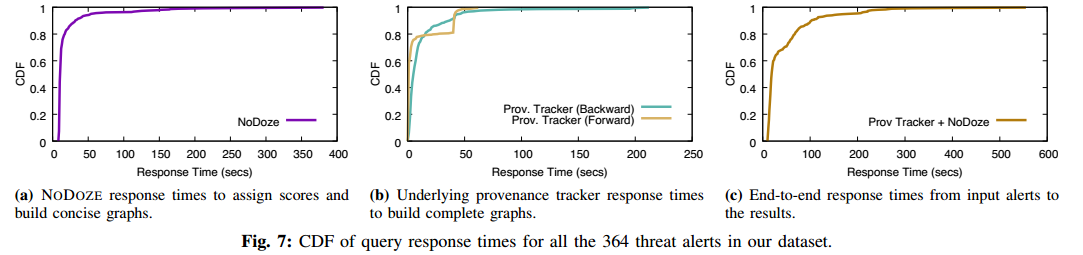
【论文阅读】NoDoze:使用自动来源分类对抗威胁警报疲劳(NDSS-2019)
NODOZE: Combatting Threat Alert Fatigue with Automated Provenance Triage 伊利诺伊大学芝加哥分校 Hassan W U, Guo S, Li D, et al. Nodoze: Combatting threat alert fatigue with automated provenance triage[C]//network and distributed systems security symposium.…...

【ARM64 常见汇编指令学习 16 -- ARM64 SMC 指令】
文章目录 ARMv8 同步异常同步异常指令SMC TYPE 上篇文章:ARM64 常见汇编指令学习 15 – ARM64 标志位的学习 下篇文章:ARM64 常见汇编指令学习 17 – ARM64 BFI 指令 ARMv8 同步异常 在ARMv8架构中,同步异常主要包括以下几种: Un…...
uprobe trace多线程mutex等待耗时
问题背景环境 ubuntu2204 服务器支持debugfs uprobe,为了提升应用程序的性能,需要量化不同参数下多线程主程序等待在mutex上的耗时区别 linux document中对uprobe events的说明如下 uprobetracer.rst - Documentation/trace/uprobetracer.rst - Linux…...
)
Linux 和 MacOS 中的 profile 文件详解(一)
什么是 profile 文件? profile 文件是 Linux、MacOS 等(unix、类 unix 系统)系统中的一种配置文件,主要用于设置系统和用户的环境变量。 在 shell 中,可以通过执行 profile 文件来设置用户的环境变量。shell 有两种运…...

不用技术代码,如何制作成绩查询系统?
为了解决学校无力承担传统学生考试成绩查询平台的高昂费用,老师们可以考虑使用易查分这样的工具来免费制作一个学生考试成绩查询平台。易查分是一种简单易用的在线成绩查询系统,可以帮助老师们快速创建一个个性化的学生考试成绩查询平台。 使用易查分制作…...
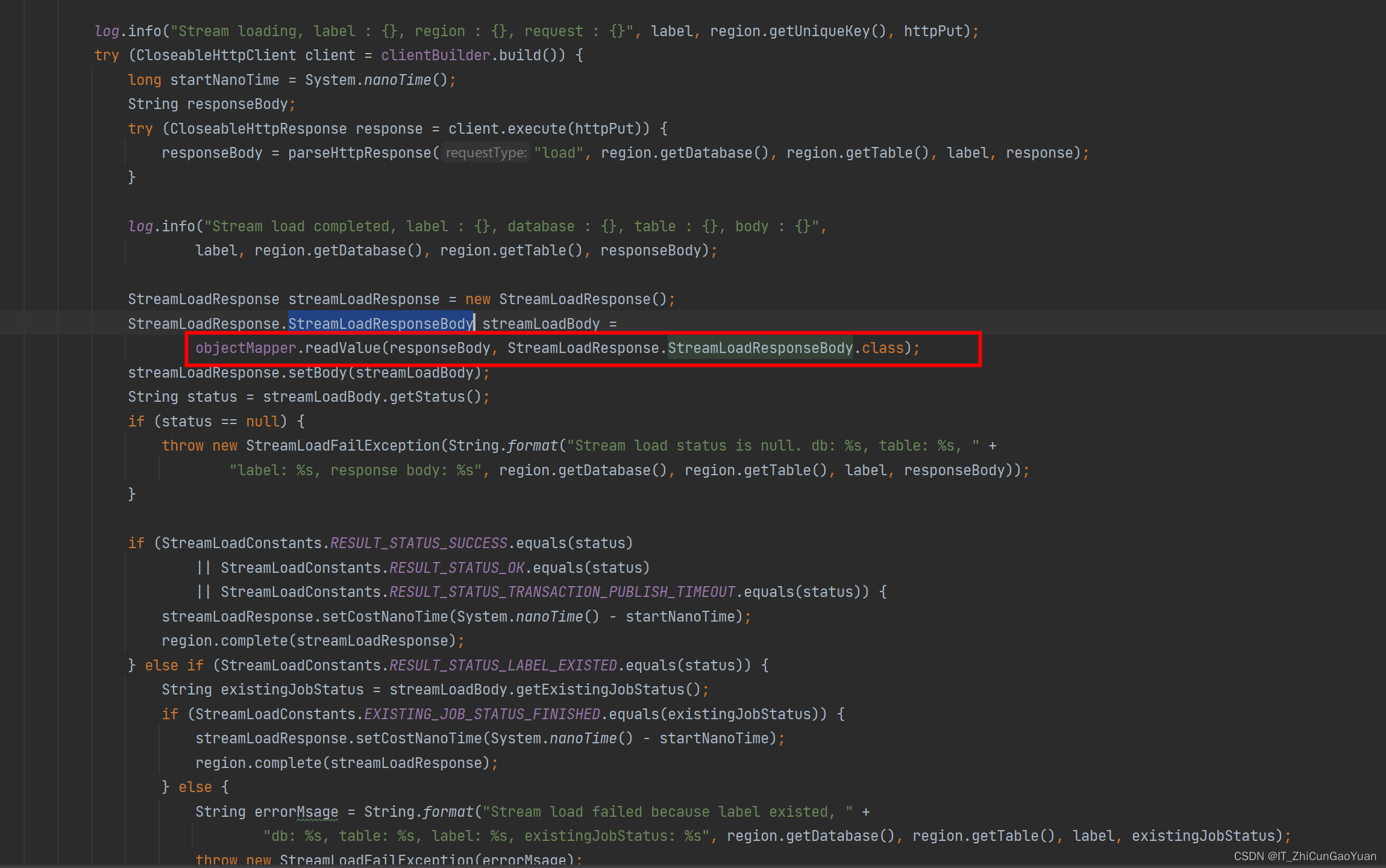
flinksql sink to sr often fail because of nullpoint
flinksql or DS sink to starrocks often fail because of nullpoint flink sql 和 flink ds sink starrocks 经常报NullpointException重新编译代码 并上传到flink 集群 验证,有效 flink sql 和 flink ds sink starrocks 经常报NullpointException 使用flink-sta…...

达梦数据库:Error updating database. Cause: dm.jdbc.driver.DMException: 数据未找到
异常:Error updating database. Cause: dm.jdbc.driver.DMException: 数据未找到 在使用达梦数据库批量插入或更新数据时,给我报了一个从来没有遇到过的错误,当时我给的一批数据就只有那么几条数据插入不进去,检查了语法和数据类…...

电脑怎么查看连接过的WIFI密码(测试环境win11,win10也能用)
电脑怎么查看连接过的WIFI密码 方法一:适用于正在连接的WIFI密码的查看 打开设置 点击“网络和Internet”,在下面找到“高级网络设置”点进去 在下面找到 “更多网络适配器选项” 点进去 找到 WLAN ,然后双击它 5.然后点击“无线属性” 6.…...

处理数据部分必备代码
1、读取数据出现UTF-8错误 encoding"gbk"2、进行时间系列的平均,并将平均后的数据转化为时间格式 data.index pd.to_datetime(data.index) data data.groupby(data.index.to_period(H)).mean() data.index data.index.to_timestamp() df[hour] df.i…...

layui 集成 ztree异步加载
首先,layui环境搭建,ztree环境引入 ztree的js和css都要引入,我这里暂时用的是core包> 静态,一句话就够了 <!-- 左侧菜单树形组件 --><div class"layui-col-md3"><div class"layui-footer "…...
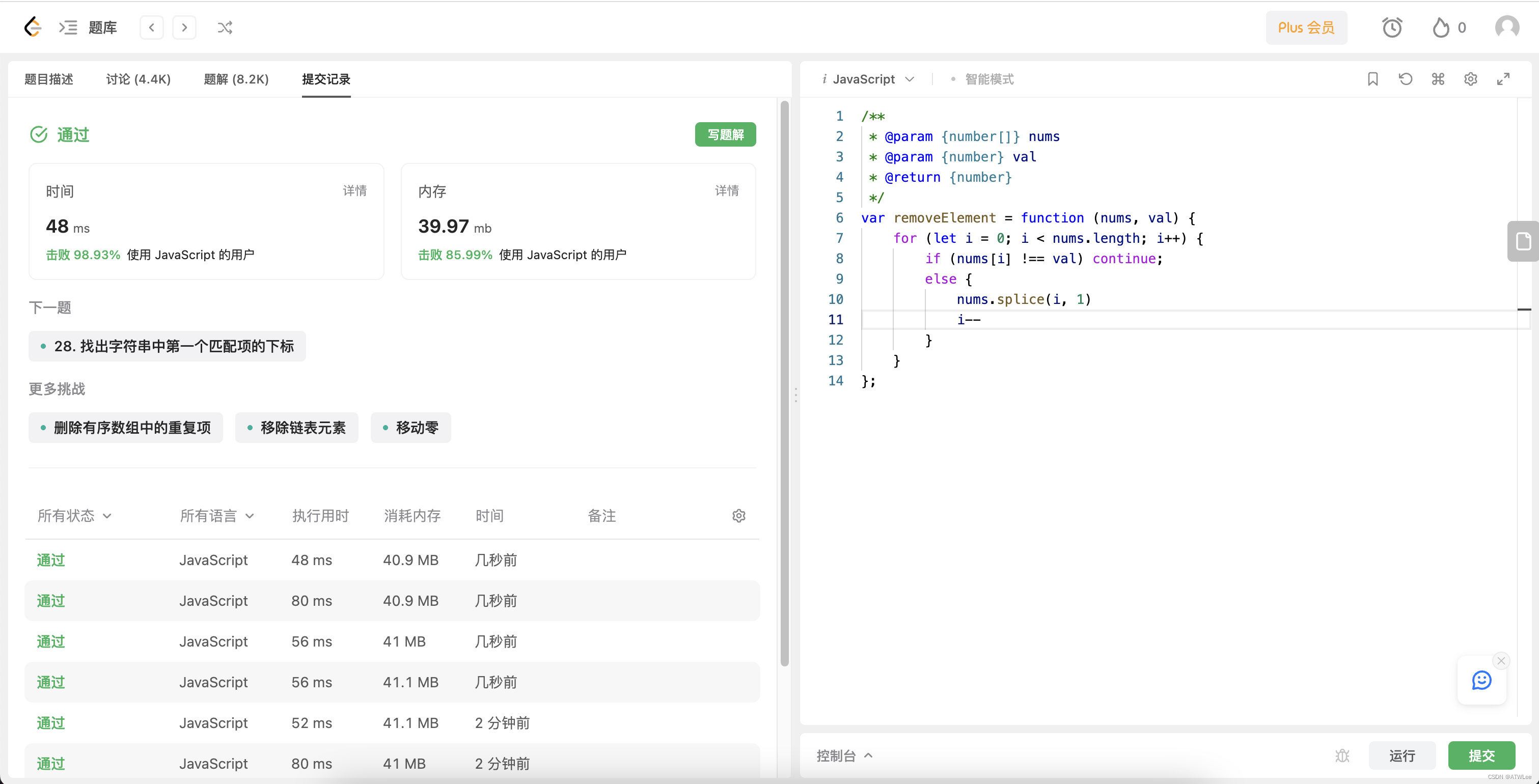
LeetCode面向运气之Javascript—第27题-移除元素-98.93%
LeetCode第27题-移除元素 题目要求 一个数组nums和一个值val,你需要原地移除所有数值等于val的元素,并返回移除后数组的新长度 举例 输入:nums [3,2,2,3], val 3 输出:2, nums [2,2] 输入:nums [0,1,2,2,3,0,4,2…...
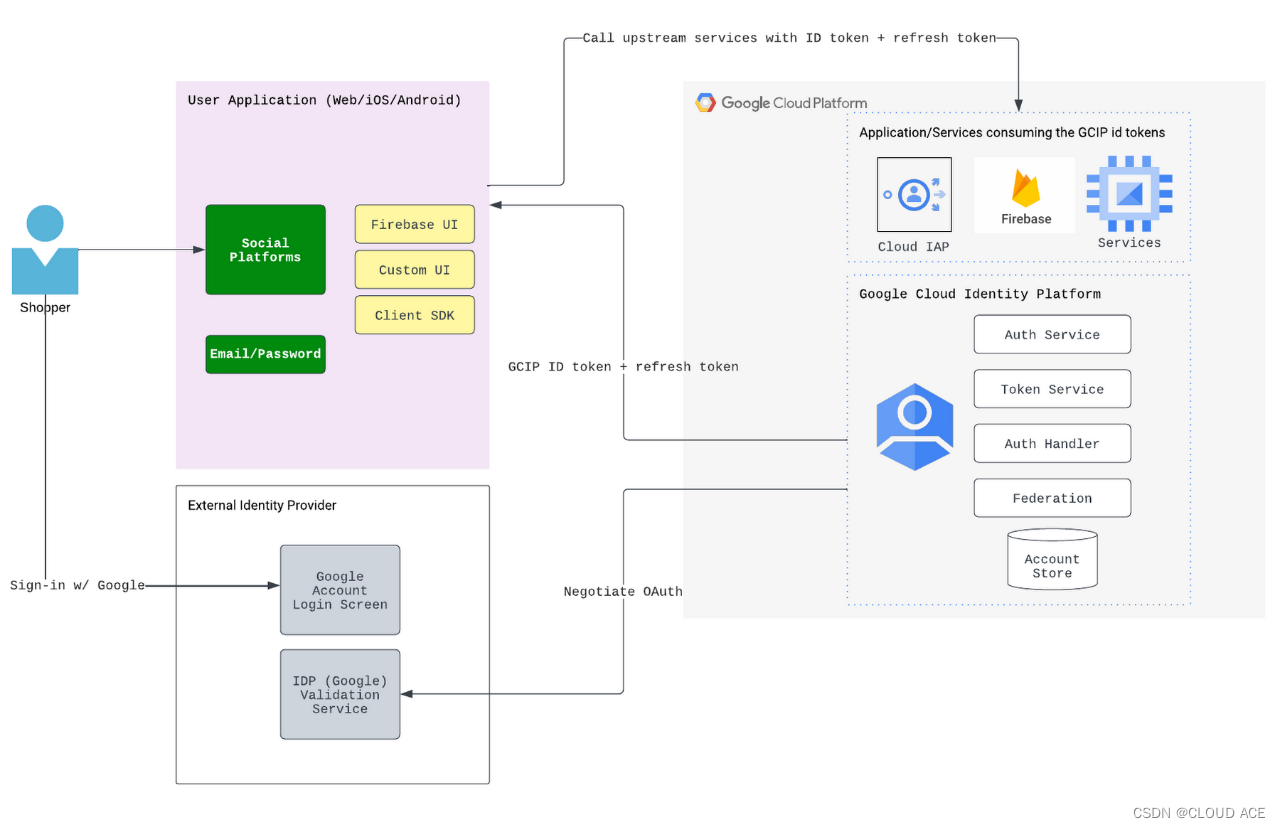
谷歌云 | 电子商务 | 如何更好地管理客户身份以支持最佳的用户体验
【本文由Cloud Ace整理发布。Cloud Ace是谷歌云全球战略合作伙伴,拥有 300 多名工程师,也是谷歌最高级别合作伙伴,多次获得 Google Cloud 合作伙伴奖。作为谷歌托管服务商,我们提供谷歌云、谷歌地图、谷歌办公套件、谷歌云认证培训…...
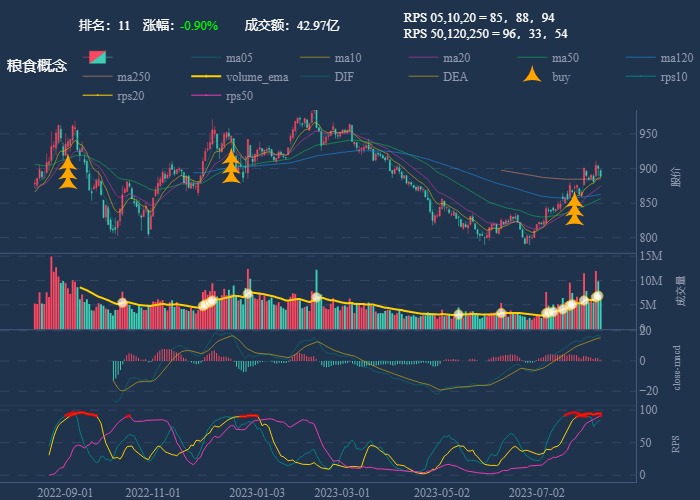
行业追踪,2023-08-09
自动复盘 2023-08-09 凡所有相,皆是虚妄。若见诸相非相,即见如来。 k 线图是最好的老师,每天持续发布板块的rps排名,追踪板块,板块来开仓,板块去清仓,丢弃自以为是的想法,板块去留让…...

视图、存储过程、函数、触发器
1.视图 视图就是一张基于查询的虚拟表,里面定义的其实就是普通的SQL语句。如果一条复杂查询的SQL语句我们频繁的使用,就可以定义视图,方便操作。创建语法如下: CREATE VIEW <视图名> AS <SELECT语句> 2.存储过程 存…...

数学建模学习(10):遗传算法
遗传算法简介 • 遗传算法(Genetic Algorithms)是基于生物进化理论的原理发展起来的一种广为 应用的、高效的随机搜索与优化的方法。其主要特点是群体搜索策略和群体中个体之 间的信息交换,搜索不依赖于梯度信息。它是20世纪70年代初期由美国…...

持续测试流水线的瓶颈分析与优化
在软件研发效能与质量保障日益成为核心竞争力的今天,持续测试(Continuous Testing)作为DevOps和持续交付(Continuous Delivery)实践中的关键一环,其价值已无需赘言。它旨在通过自动化测试手段,在…...

DREAM模型:实现文本到图像的精准语义对齐
1. 项目背景与核心价值 去年在做一个文创IP设计项目时,我遇到了一个棘手问题:用常规扩散模型生成的图像总是和文本描述存在微妙的偏差。比如输入"戴着贝雷帽的柴犬在画向日葵",输出可能变成"戴草帽的秋田犬在看向日葵田"…...

2026年计算机科学论文降AI工具推荐:算法研究和软件工程部分降AI指南
2026年计算机科学论文降AI工具推荐:算法研究和软件工程部分降AI指南 帮同学选过降AI工具,综合价格、效果、保障来看,推荐嘎嘎降AI(www.aigcleaner.com)。 4.8元,达标率99.26%,计算机论文降AI的…...
)
C++(标签派发 Tag Dispatching)
一、什么是标签派发?🎯 核心概念标签派发(Tag Dispatching) 是C中一种编译期多态技术,它利用空结构体标签和函数重载,在编译时根据类型特征选择最优的实现路径。📊 为什么需要标签派发ÿ…...

激光雕刻新纪元:用LaserGRBL开启您的创意制造之旅
激光雕刻新纪元:用LaserGRBL开启您的创意制造之旅 【免费下载链接】LaserGRBL Laser optimized GUI for GRBL 项目地址: https://gitcode.com/gh_mirrors/la/LaserGRBL 想象一下,您刚刚完成了一个精美的设计,想要将它永久地雕刻在木头…...

APK Installer技术架构解析:Windows平台Android应用部署的创新实现
APK Installer技术架构解析:Windows平台Android应用部署的创新实现 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 在跨平台应用部署领域,Andro…...

抠图怎么抠?2026年最全工具对比+详细教程,一键搞定透明背景
前两天有个朋友问我,她要给产品拍照上架,但拍出来的背景乱七八糟,问我怎么抠图。我才意识到,虽然现在抠图工具多如牛毛,但真正好用、简单、不折腾的工具其实没几个。今天就来分享一下我用过的所有抠图方案,…...

ENACT基准:评估视觉语言模型在具身认知中的关键能力
1. 项目背景与核心价值 具身认知(Embodied Cognition)正成为AI领域的前沿方向,它强调智能体通过与环境的物理交互来发展认知能力。而视觉语言模型(VLMs)作为多模态AI的代表,如何评估其在具身场景中的世界建…...

Demo-ICL:提升多模态大模型视频理解能力的新方法
1. 项目背景与核心价值 视频理解一直是AI领域最具挑战性的任务之一。传统方法通常将视频拆解为帧序列进行处理,但这种方式难以捕捉视频中丰富的时空信息和语义关联。随着多模态大模型的兴起,如何让这些"通才"模型真正理解视频内容,…...

别再傻等画面了!海康/大华摄像头RTSP延迟高?试试这3个立竿见影的配置优化
海康/大华摄像头RTSP延迟优化实战指南 监控画面延迟3秒,关键事件发生时你还在看历史影像?这个问题困扰着无数安防工程师。上周某大型商超的防损案例就很典型——当值班人员通过监控发现货架商品被盗时,嫌疑人早已离开现场,3秒的延…...