SpringCloud实用篇5——elasticsearch基础
目录
- 1.初识elasticsearch
- 1.1 了解ES
- 1.1.1 elasticsearch的作用
- 1.1.2 ELK技术栈
- 1.1.3 elasticsearch和lucene
- 1.1.4 总结
- 1.2.倒排索引
- 1.2.1.正向索引
- 1.2.2.倒排索引
- 1.2.3.正向和倒排
- 1.3 es的一些概念
- 1.3.1 文档和字段
- 1.3.2 索引和映射
- 1.3.3 mysql与elasticsearch
- 1.4 部署单点elasticsearch
- 1.4.1 创建网络
- 1.4.2 加载镜像
- 1.4.3 运行
- 1.5 部署kibana
- 1.5.1 部署
- 1.5.2 DevTools
- 1.6 分词器
- 1.6.1 在线安装ik插件(较慢)
- 1.6.2 离线安装ik插件(推荐)
- 1.6.3 ik分词器-拓展词库
- 1.6.4 停用词词典
- 1.6.5 总结
- 1.7 部署es集群
- 2 索引库操作
- 2.0 "_cat"集群命令
- 2.1.mapping映射属性
- 2.2 索引库的CRUD
- 2.2.1 创建索引库和映射
- 2.2.2 查询索引库
- 2.2.3 修改索引库
- 2.2.4 删除索引库
- 2.2.5 总结
- 3 文档操作
- 3.1 新增文档
- 3.2 查询文档
- 3.3 删除文档
- 3.4 修改文档
- 3.4.1 全量修改
- 3.4.2 增量修改
- 3.5 总结
- 4.RestAPI
- 4.0.导入Demo工程
- 4.0.1 导入数据
- 4.0.2 导入项目
- 4.0.3 mapping映射分析
- 4.0.4 初始化RestClient
- 4.1 创建索引库
- 4.1.1 代码解读
- 4.1.2 完整示例
- 4.2 删除索引库
- 4.3 判断索引库是否存在
- 4.4 总结
- 5.RestClient操作文档
- 5.1 新增文档
- 5.1.1 索引库实体类
- 5.1.2 语法说明
- 5.1.3 完整代码
- 5.2 查询文档
- 5.2.1 语法说明
- 5.2.2 完整代码
- 5.3 删除文档
- 5.4 修改文档
- 5.4.1.语法说明
- 5.4.2 完整代码
- 5.5 批量导入文档
- 5.5.1 语法说明
- 5.5.2 完整代码
- 5.6 小结
1.初识elasticsearch
1.1 了解ES
1.1.1 elasticsearch的作用
elasticsearch是一款非常强大的开源搜索引擎,具备非常多强大功能,可以帮助我们从海量数据中快速找到需要的内容
例如:
- 在GitHub搜索代码
- 在电商网站搜索商品
- 在百度搜索答案
- 在打车软件搜索附近的车
1.1.2 ELK技术栈
- elasticsearch结合kibana、Logstash、Beats,也就是elastic stack(ELK)。被广泛应用在日志数据分析、实时监控等领域
- elasticsearch是elastic stack的核心,负责存储、搜索、分析数据。
1.1.3 elasticsearch和lucene
elasticsearch底层是基于lucene来实现的。
Lucene是一个Java语言的搜索引擎类库,是Apache公司的顶级项目,由DougCutting于1999年研发。官网地址:https://lucene.apache.org/ 。

elasticsearch的发展历史:
- 2004年Shay Banon基于Lucene开发了Compass
- 2010年Shay Banon 重写了Compass,取名为Elasticsearch。

1.1.4 总结
什么是elasticsearch?
- 一个开源的分布式搜索引擎,可以用来实现搜索、日志统计、分析、系统监控等功能
什么是elastic stack(ELK)?
- 是以elasticsearch为核心的技术栈,包括beats、Logstash、kibana、elasticsearch
什么是Lucene?
- 是Apache的开源搜索引擎类库,提供了搜索引擎的核心API
1.2.倒排索引
倒排索引的概念是基于MySQL这样的正向索引而言的。
1.2.1.正向索引
什么是正向索引呢?例如给下表(tb_goods)中的id创建索引:
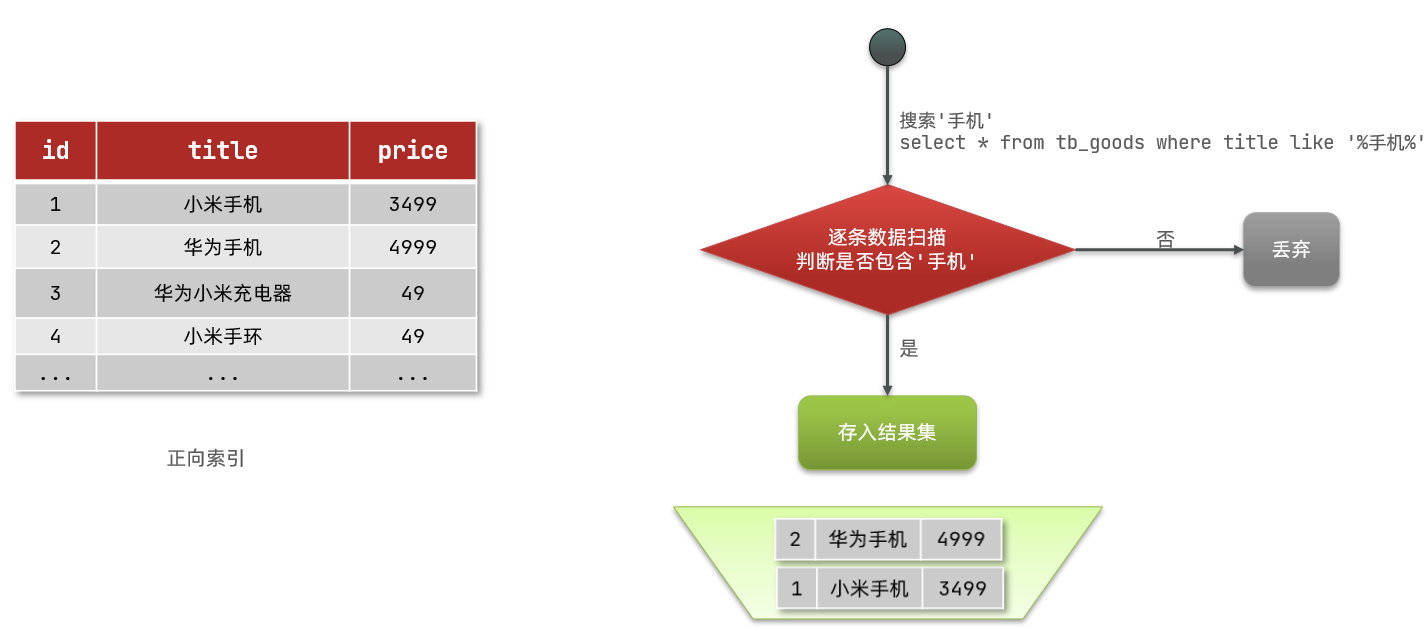
如果是根据id查询,那么直接走索引,查询速度非常快。但如果是基于title做模糊查询,只能是逐行扫描数据,流程如下:
1)用户搜索数据,条件是title符合"%手机%"
2)逐行获取数据,比如id为1的数据
3)判断数据中的title是否符合用户搜索条件
4)如果符合则放入结果集,不符合则丢弃。回到步骤1
逐行扫描,也就是全表扫描,随着数据量增加,其查询效率也会越来越低。当数据量达到数百万时,就是一场灾难。
1.2.2.倒排索引
倒排索引中有两个非常重要的概念:
- 文档(
Document):用来搜索的数据,其中的每一条数据就是一个文档。例如一个网页、一个商品信息 - 词条(
Term):对文档数据或用户搜索数据,利用某种算法分词,得到的具备含义的词语就是词条。例如:我是中国人,就可以分为:我、是、中国人、中国、国人这样的几个词条
创建倒排索引是对正向索引的一种特殊处理,流程如下:
- 将每一个文档的数据利用算法分词,得到一个个词条
- 创建表,每行数据包括词条、词条所在文档id、位置等信息
- 因为词条唯一性,可以给词条创建索引,例如hash表结构索引
如图:

倒排索引的搜索流程如下(以搜索"华为手机"为例):
1)用户输入条件"华为手机"进行搜索。
2)对用户输入内容分词,得到词条:华为、手机。
3)拿着词条在倒排索引中查找,可以得到包含词条的文档id:1、2、3。
4)拿着文档id到正向索引中查找具体文档。
如图:
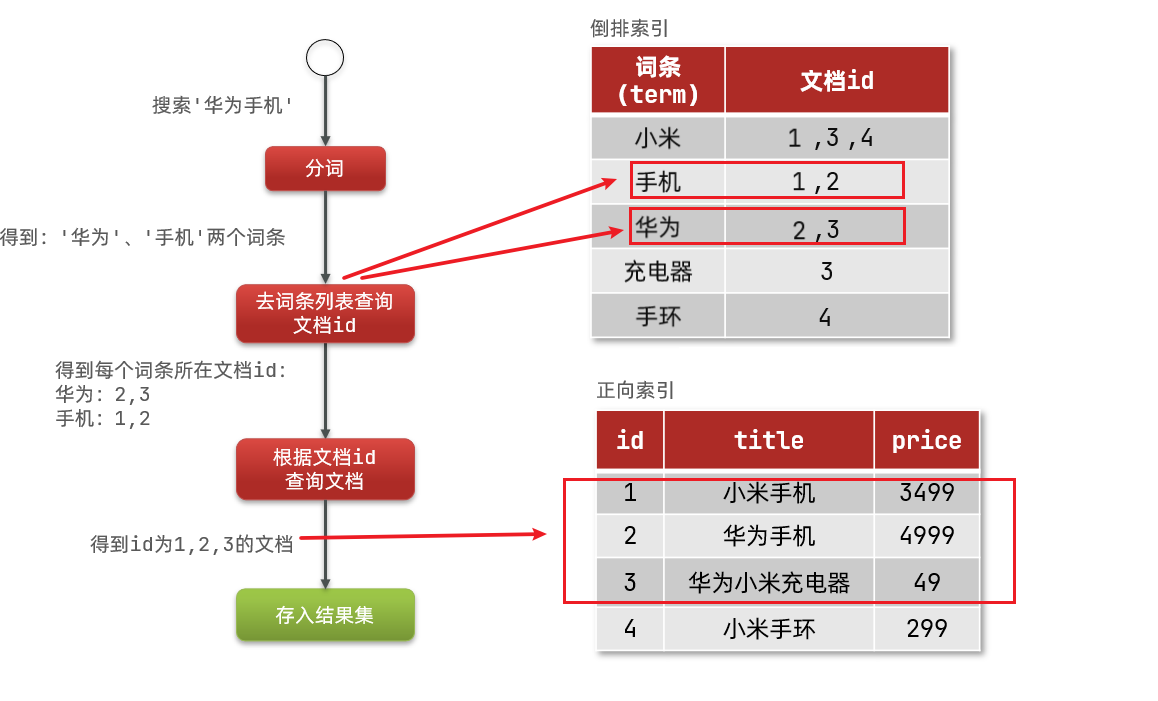
虽然要先查询倒排索引,再查询正向索引,但是无论是词条、还是文档id都建立了索引,查询速度非常快!无需全表扫描。
1.2.3.正向和倒排
那么为什么一个叫做正向索引,一个叫做倒排索引呢?
-
正向索引是最传统的,根据id索引的方式。但根据词条查询时,必须先逐条获取每个文档,然后判断文档中是否包含所需要的词条,是根据文档找词条的过程。
-
倒排索引则相反,是先找到用户要搜索的词条,根据词条得到保护词条的文档的id,然后根据id获取文档。是根据词条找文档的过程。
是不是恰好反过来了?
那么两者方式的优缺点是什么呢?
正向索引:
- 优点:
- 可以给多个字段创建索引
- 根据索引字段搜索、排序速度非常快
- 缺点:
- 根据非索引字段,或者索引字段中的部分词条查找时,只能全表扫描。
倒排索引:
- 优点:
- 根据词条搜索、模糊搜索时,速度非常快
- 缺点:
- 只能给词条创建索引,而不是字段
- 无法根据字段做排序
1.3 es的一些概念
elasticsearch中有很多独有的概念,与mysql中略有差别,但也有相似之处。
1.3.1 文档和字段
elasticsearch是面向文档(Document) 存储的,可以是数据库中的一条商品数据,一个订单信息。文档数据会被序列化为json格式后存储在elasticsearch中:

而Json文档中往往包含很多的字段(Field),类似于数据库中的列。
1.3.2 索引和映射
索引(Index),就是相同类型的文档的集合。
例如:
- 所有用户文档,就可以组织在一起,称为用户的索引;
- 所有商品的文档,可以组织在一起,称为商品的索引;
- 所有订单的文档,可以组织在一起,称为订单的索引;

因此,我们可以把索引当做是数据库中的表。
数据库的表会有约束信息,用来定义表的结构、字段的名称、类型等信息。因此,索引库中就有映射(mapping),是索引中文档的字段约束信息,类似表的结构约束。
1.3.3 mysql与elasticsearch
我们统一的把mysql与elasticsearch的概念做一下对比:
| MySQL | Elasticsearch | 说明 |
|---|---|---|
| Table | Index | 索引(index),就是文档的集合,类似数据库的表(table) |
| Row | Document | 文档(Document),就是一条条的数据,类似数据库中的行(Row),文档都是JSON格式 |
| Column | Field | 字段(Field),就是JSON文档中的字段,类似数据库中的列(Column) |
| Schema | Mapping | Mapping(映射)是索引中文档的约束,例如字段类型约束。类似数据库的表结构(Schema) |
| SQL | DSL | DSL是elasticsearch提供的JSON风格的请求语句,用来操作elasticsearch,实现CRUD |
是不是说,我们学习了elasticsearch就不再需要mysql了呢?
并不是如此,两者各自有自己的擅长支出:
-
Mysql:擅长事务类型操作,可以确保数据的安全和一致性
-
Elasticsearch:擅长海量数据的搜索、分析、计算
因此在企业中,往往是两者结合使用:
- 对安全性要求较高的写操作,使用mysql实现
- 对查询性能要求较高的搜索需求,使用elasticsearch实现
- 两者再基于某种方式,实现数据的同步,保证一致性

1.4 部署单点elasticsearch
1.4.1 创建网络
因为我们还需要部署kibana容器,因此需要让es和kibana容器互联。这里先创建一个网络:
docker network create es-net
1.4.2 加载镜像
我们采用elasticsearch的7.12.1版本的镜像,这个镜像体积非常大,接近1G。不建议大家自己pull。
利用课前资料提供了镜像的tar包,将其上传到虚拟机中,然后运行命令加载即可:docker load -i es.tar,同理还有kibana的tar包也需要这样做。
1.4.3 运行
运行docker命令,部署单点es:
docker run -d \--name es \-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \-e "discovery.type=single-node" \-v es-data:/usr/share/elasticsearch/data \-v es-plugins:/usr/share/elasticsearch/plugins \--privileged \--network es-net \-p 9200:9200 \-p 9300:9300 \
elasticsearch:7.12.1
命令解释:
-e "cluster.name=es-docker-cluster":设置集群名称-e "http.host=0.0.0.0":监听的地址,可以外网访问-e "ES_JAVA_OPTS=-Xms512m -Xmx512m":内存大小-e "discovery.type=single-node":非集群模式-v es-data:/usr/share/elasticsearch/data:挂载逻辑卷,绑定es的数据目录-v es-logs:/usr/share/elasticsearch/logs:挂载逻辑卷,绑定es的日志目录-v es-plugins:/usr/share/elasticsearch/plugins:挂载逻辑卷,绑定es的插件目录--privileged:授予逻辑卷访问权--network es-net:加入一个名为es-net的网络中-p 9200:9200:端口映射配置
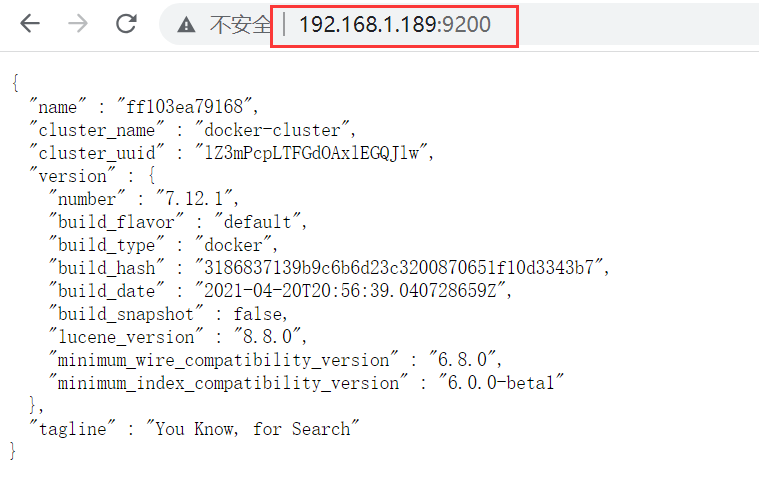
在浏览器中输入:http://192.168.150.101:9200 即可看到elasticsearch的响应结果:
1.5 部署kibana
kibana可以给我们提供一个elasticsearch的可视化界面,便于我们学习。
1.5.1 部署
运行docker命令,部署kibana
docker run -d \
--name kibana \
-e ELASTICSEARCH_HOSTS=http://es:9200 \
--network=es-net \
-p 5601:5601 \
kibana:7.12.1
--network es-net:加入一个名为es-net的网络中,与elasticsearch在同一个网络中-e ELASTICSEARCH_HOSTS=http://es:9200":设置elasticsearch的地址,因为kibana已经与elasticsearch在一个网络,因此可以用容器名直接访问elasticsearch-p 5601:5601:端口映射配置
kibana启动一般比较慢,需要多等待一会,可以通过命令:
docker logs -f kibana
查看运行日志,当查看到下面的日志,说明成功:
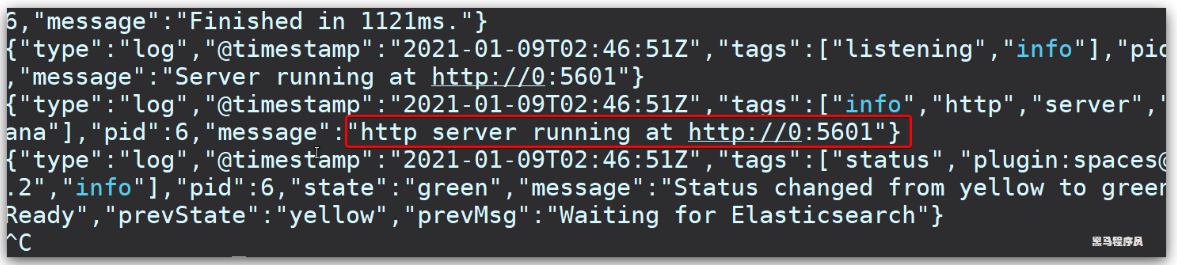
此时,在浏览器输入地址访问:http://192.168.150.101:5601,即可看到结果
1.5.2 DevTools
kibana中提供了一个DevTools界面:

这个界面中可以编写DSL来操作elasticsearch。并且对DSL语句有自动补全功能。
1.6 分词器
es在创建倒排索引时需要对文档分词;在搜索时,需要对用户输入内容分词。但默认的分词规则对中文处理并不友好。
我们在kibana的DevTools中测试:
POST /_analyze
{"analyzer": "standard","text": "黑马程序员学习java太棒了!"
}
语法说明:
- POST:请求方式
- /_analyze:请求路径,这里省略了http://192.168.150.101:9200,有kibana帮我们补充
- 请求参数,json风格:
- analyzer:分词器类型,这里是默认的standard分词器
- text:要分词的内容
可以看到是一个字一个字分的,这并不是我们想要的。
因此我们需要处理中文分词,一般会使用IK分词器。https://github.com/medcl/elasticsearch-analysis-ik
1.6.1 在线安装ik插件(较慢)
# 进入容器内部
docker exec -it elasticsearch /bin/bash# 在线下载并安装
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.1/elasticsearch-analysis-ik-7.12.1.zip#退出
exit
#重启容器
docker restart elasticsearch
1.6.2 离线安装ik插件(推荐)
- 查看数据卷目录
安装插件需要知道elasticsearch的plugins目录位置,而我们用了数据卷挂载,因此需要查看elasticsearch的数据卷目录,通过下面命令查看: docker volume inspect es-plugins
显示结果:

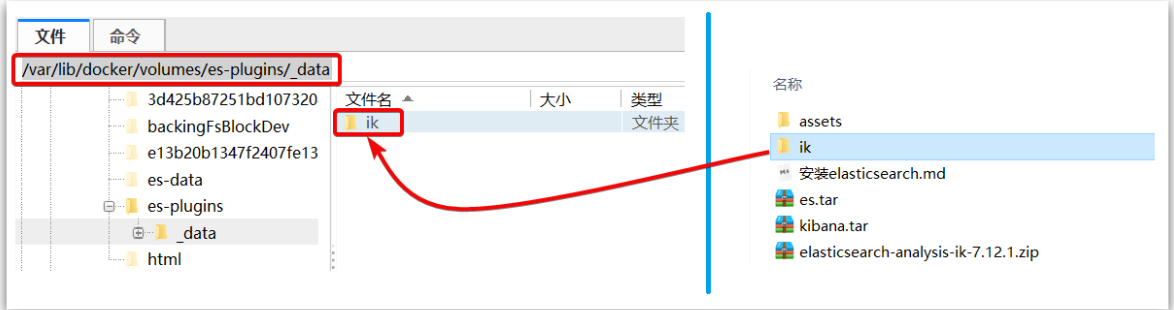
说明plugins目录被挂载到了:/var/lib/docker/volumes/es-plugins/_data 这个目录中。
- 解压缩分词器安装包
下面我们需要把课前资料中的ik分词器解压缩,重命名为ik
- 上传到es容器的插件数据卷中
也就是/var/lib/docker/volumes/es-plugins/_data :
- 重启容器
# 4、重启容器
docker restart es
# 查看es日志
docker logs -f es
- 测试:
IK分词器包含两种模式:
-
ik_smart:最少切分,粗粒度 -
ik_max_word:最细切分,细粒度
GET /_analyze
{"analyzer": "ik_max_word","text": "黑马程序员学习java太棒了"
}
结果:
{"tokens" : [{"token" : "黑马","start_offset" : 0,"end_offset" : 2,"type" : "CN_WORD","position" : 0},{"token" : "程序员","start_offset" : 2,"end_offset" : 5,"type" : "CN_WORD","position" : 1},{"token" : "程序","start_offset" : 2,"end_offset" : 4,"type" : "CN_WORD","position" : 2},{"token" : "员","start_offset" : 4,"end_offset" : 5,"type" : "CN_CHAR","position" : 3},{"token" : "学习","start_offset" : 5,"end_offset" : 7,"type" : "CN_WORD","position" : 4},{"token" : "java","start_offset" : 7,"end_offset" : 11,"type" : "ENGLISH","position" : 5},{"token" : "太棒了","start_offset" : 11,"end_offset" : 14,"type" : "CN_WORD","position" : 6},{"token" : "太棒","start_offset" : 11,"end_offset" : 13,"type" : "CN_WORD","position" : 7},{"token" : "了","start_offset" : 13,"end_offset" : 14,"type" : "CN_CHAR","position" : 8}]
}
1.6.3 ik分词器-拓展词库
随着互联网的发展,“造词运动”也越发的频繁。出现了很多新的词语,在原有的词汇列表中并不存在。比如:“奥力给”,“传智播客” 等。
所以我们的词汇也需要不断的更新,IK分词器提供了扩展词汇的功能。
要拓展ik分词器的词库,只需要修改一个ik分词器目录中的config目录中的IkAnalyzer.cfg.xml文件
1)打开IK分词器config目录:
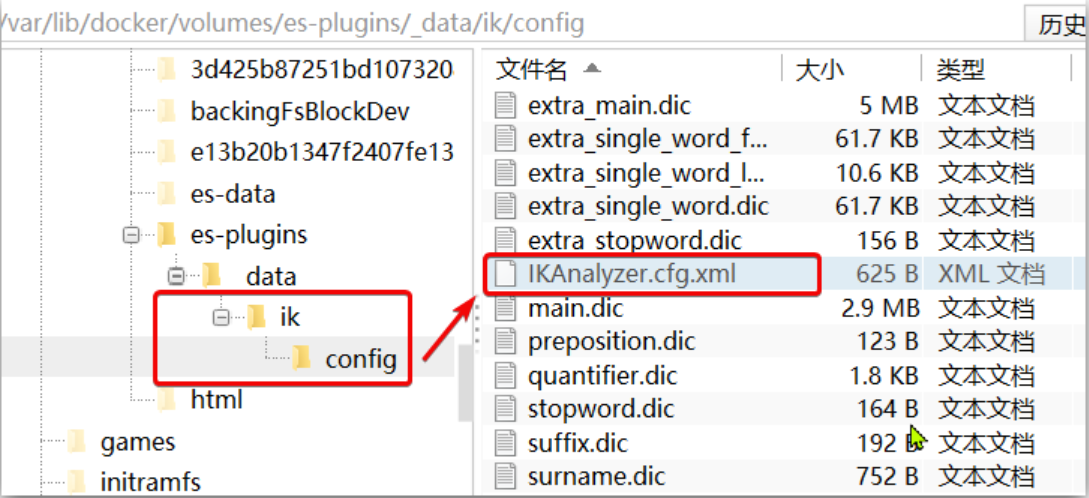
2)在IKAnalyzer.cfg.xml配置文件内容添加:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties><comment>IK Analyzer 扩展配置</comment><!--用户可以在这里配置自己的扩展字典 *** 添加扩展词典--><entry key="ext_dict">ext.dic</entry>
</properties>
3)新建一个 ext.dic,可以参考config目录下复制一个配置文件进行修改
传智播客
奥力给
4)重启elasticsearch
docker restart es# 查看 日志
docker logs -f elasticsearch
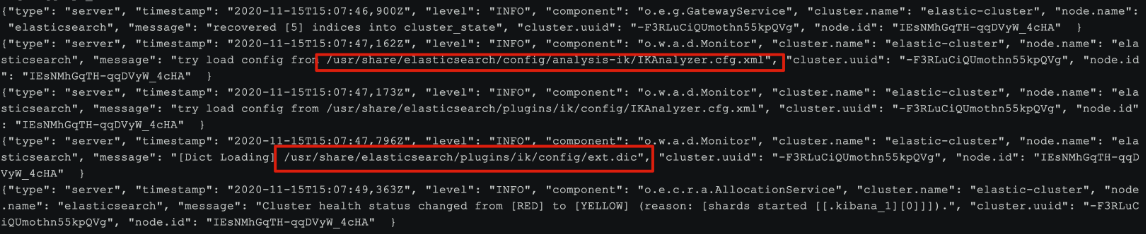
日志中已经成功加载ext.dic配置文件
5)测试效果:
GET /_analyze
{"analyzer": "ik_max_word","text": "传智播客Java就业超过90%,奥力给!"
}
注意:当前文件的编码必须是 UTF-8 格式,严禁使用Windows记事本编辑
1.6.4 停用词词典
-
在互联网项目中,在网络间传输的速度很快,所以很多语言是不允许在网络上传递的,如:关于宗教、政治等敏感词语,那么我们在搜索时也应该忽略当前词汇。也有些词语无意义如的、地、嗯等
-
IK分词器也提供了强大的停用词功能,让我们在索引时就直接忽略当前的停用词汇表中的内容。
1)IKAnalyzer.cfg.xml配置文件内容添加:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties><comment>IK Analyzer 扩展配置</comment><!--用户可以在这里配置自己的扩展字典--><entry key="ext_dict">ext.dic</entry><!--用户可以在这里配置自己的扩展停止词字典 *** 添加停用词词典--><entry key="ext_stopwords">stopword.dic</entry>
</properties>
3)在 stopword.dic 添加停用词
的
地
啊
4)重启elasticsearch
# 重启服务
docker restart elasticsearch
docker restart kibana# 查看 日志
docker logs -f elasticsearch
日志中已经成功加载stopword.dic配置文件
5)测试效果:
GET /_analyze
{"analyzer": "ik_max_word","text": "传智播客的Java就业率超过95%,奥力给!"
}
注意:当前文件的编码必须是 UTF-8 格式,严禁使用Windows记事本编辑
1.6.5 总结
分词器的作用是什么?
- 创建倒排索引时对文档分词
- 用户搜索时,对输入的内容分词
IK分词器有几种模式?
- ik_smart:智能切分,粗粒度
- ik_max_word:最细切分,细粒度
IK分词器如何拓展词条?如何停用词条?
- 利用config目录的IkAnalyzer.cfg.xml文件添加拓展词典和停用词典
- 在词典中添加拓展词条或者停用词条
1.7 部署es集群
部署es集群可以直接使用docker-compose来完成,不过要求你的Linux虚拟机至少有4G的内存空间
首先编写一个docker-compose文件,内容如下:
version: '2.2'
services:es01:image: docker.elastic.co/elasticsearch/elasticsearch:7.12.1container_name: es01environment:- node.name=es01- cluster.name=es-docker-cluster- discovery.seed_hosts=es02,es03- cluster.initial_master_nodes=es01,es02,es03- bootstrap.memory_lock=true- "ES_JAVA_OPTS=-Xms512m -Xmx512m"ulimits:memlock:soft: -1hard: -1volumes:- data01:/usr/share/elasticsearch/dataports:- 9200:9200networks:- elastices02:image: docker.elastic.co/elasticsearch/elasticsearch:7.12.1container_name: es02environment:- node.name=es02- cluster.name=es-docker-cluster- discovery.seed_hosts=es01,es03- cluster.initial_master_nodes=es01,es02,es03- bootstrap.memory_lock=true- "ES_JAVA_OPTS=-Xms512m -Xmx512m"ulimits:memlock:soft: -1hard: -1volumes:- data02:/usr/share/elasticsearch/datanetworks:- elastices03:image: docker.elastic.co/elasticsearch/elasticsearch:7.12.1container_name: es03environment:- node.name=es03- cluster.name=es-docker-cluster- discovery.seed_hosts=es01,es02- cluster.initial_master_nodes=es01,es02,es03- bootstrap.memory_lock=true- "ES_JAVA_OPTS=-Xms512m -Xmx512m"ulimits:memlock:soft: -1hard: -1volumes:- data03:/usr/share/elasticsearch/datanetworks:- elasticvolumes:data01:driver: localdata02:driver: localdata03:driver: localnetworks:elastic:driver: bridge
Run docker-compose to bring up the cluster:docker-compose up
2 索引库操作
索引库就类似数据库表,mapping映射就类似表的结构。
我们要向es中存储数据,必须先创建“库”和“表”。
2.0 "_cat"集群命令
GET /_cat/nodes
#查看所有节点。集群中会用到GET /_cat/health
#查看es健康状况GET /_cat/master
#查看主节点GET /_cat/indices
#查看所有索引 ,等价于mysql数据库的show databases;
2.1.mapping映射属性
mapping是对索引库中文档的约束,常见的mapping属性包括:
-
type:字段数据类型,常见的简单类型有:
- 字符串:text(可分词的文本)、keyword(精确值,例如:品牌、国家、ip地址)
- 数值:long、integer、short、byte、double、float、
- 布尔:boolean
- 日期:date
- 对象:object
-
index:是否创建索引,默认为true
-
analyzer:使用哪种分词器,注意只有text类型可以设置分词器,
-
properties:该字段的子字段
es的数组类型:es数组类型不用特别定义,支持每个字段有多个值,效果就相当于数组。例如索引库里"score":{“type”:“integer”},文档可以"score":[1,2,3,4,5]
例如下面的json文档:
{"age": 21,"weight": 52.1,"isMarried": false,"info": "黑马程序员Java讲师","email": "zy@itcast.cn","score": [99.1, 99.5, 98.9],"name": {"firstName": "云","lastName": "赵"}
}
对应的每个字段映射(mapping):
- age:类型为 integer;参与搜索,因此需要index为true;无需分词器
- weight:类型为float;参与搜索,因此需要index为true;无需分词器
- isMarried:类型为boolean;参与搜索,因此需要index为true;无需分词器
- info:类型为字符串,需要分词,因此是text;参与搜索,因此需要index为true;分词器可以用ik_smart
- email:类型为字符串,但是不需要分词,因此是keyword;不参与搜索,因此需要index为false;无需分词器
- score:虽然是数组,但是我们只看元素的类型,类型为float;参与搜索,因此需要index为true;无需分词器
- name:类型为object,需要定义多个子属性
- name.firstName;类型为字符串,但是不需要分词,因此是keyword;参与搜索,因此需要index为true;无需分词器
- name.lastName;类型为字符串,但是不需要分词,因此是keyword;参与搜索,因此需要index为true;无需分词器
nested类型解决数组的扁平化处理
问题:es数组的扁平化处理:es存储对象数组时,它会将数组扁平化,也就是说将对象数组的每个属性抽取出来,作为一个数组。因此会出现查询紊乱的问题。
示例:下面user字段是对象数组类型,因为数组扁平化处理,下面结果跟期望查询结果不符:
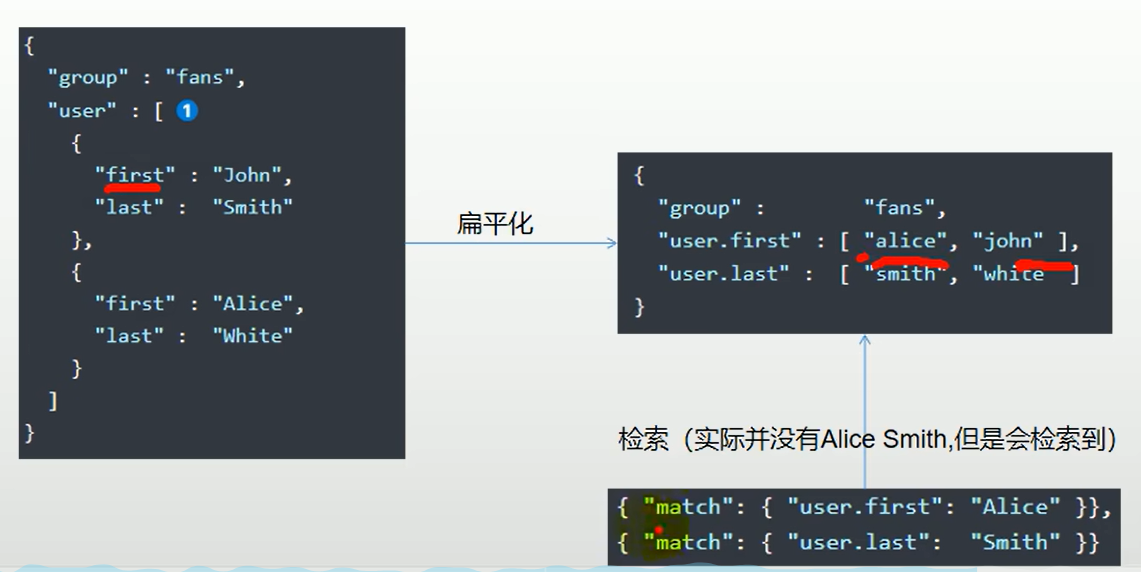
解决办法:使用nested子类类型:

2.2 索引库的CRUD
这里我们统一使用Kibana编写DSL的方式来演示。
2.2.1 创建索引库和映射
基本语法:
- 请求方式:PUT
- 请求路径:/索引库名,可以自定义
- 请求参数:mapping映射
ES中通过Restful请求操作索引库、文档。请求内容用DSL语句来表示。创建索引库和mapping的DSL语法格式如下:
PUT /索引库名称
{"mappings": {"properties": {"字段名":{"type": "text","analyzer": "ik_smart"},"字段名2":{"type": "keyword","index": "false"},"字段名3":{"properties": {"子字段": {"type": "keyword"}}},// ...略}}
}
示例:
PUT /heima
{"mappings": {"properties": {"info":{"type": "text","analyzer": "ik_smart"},"email":{"type": "keyword","index": "falsae"},"name":{"properties": {"firstName": {"type": "keyword"}}},// ... 略}}
}
2.2.2 查询索引库
基本语法:
-
请求方式:GET
-
请求路径:/索引库名
-
请求参数:无
格式:
GET /索引库名
示例:
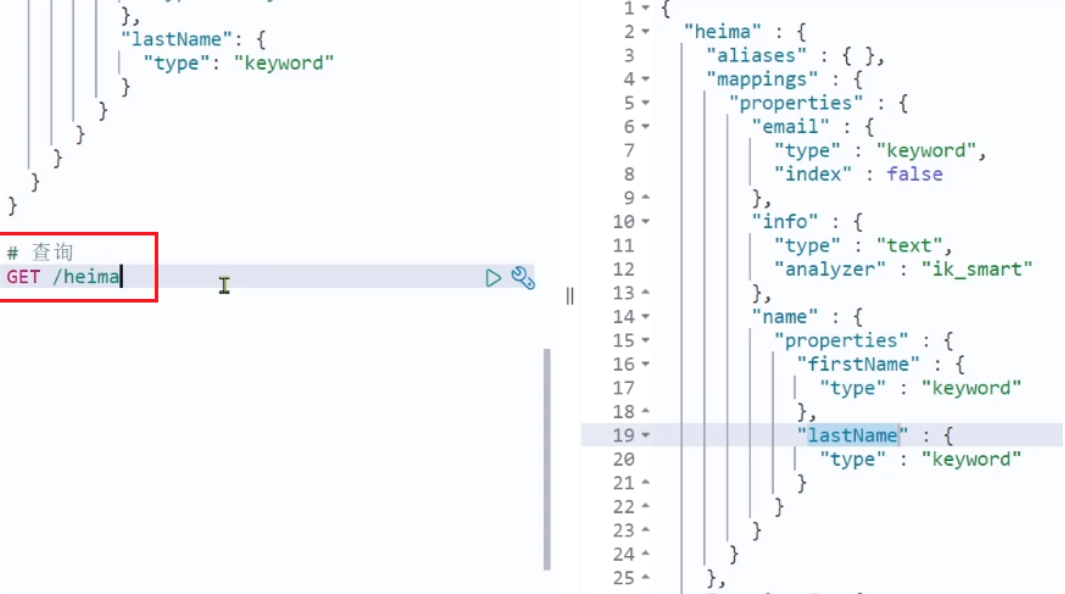
2.2.3 修改索引库
倒排索引结构虽然不复杂,但是一旦数据结构改变(比如改变了分词器),就需要重新创建倒排索引,这简直是灾难。因此索引库一旦创建,无法修改mapping。
虽然无法修改mapping中已有的字段,但是却允许添加新的字段到mapping中,因为不会对倒排索引产生影响。
修改只能追加新字段,不能修改原索引
语法说明:
PUT /索引库名/_mapping
{"properties": {"新字段名":{"type": "integer"}}
}
示例:

注意:
- 修改只能追加新字段,不能修改原索引
- 注意区分修改和新增,两者都是put,但修改路径最后面有个/_mapping,json最外圈没有"mappings":{}
2.2.4 删除索引库
语法:
-
请求方式:DELETE
-
请求路径:/索引库名
-
请求参数:无
格式:
DELETE /索引库名
在kibana中测试:

2.2.5 总结
索引库操作有哪些?
- 创建索引库:PUT /索引库名
- 查询索引库:GET /索引库名
- 删除索引库:DELETE /索引库名
- 添加字段:PUT /索引库名/_mapping
3 文档操作
3.1 新增文档
语法:
POST /索引库名/_doc/文档id
{"字段1": "值1","字段2": "值2","字段3": {"子属性1": "值3","子属性2": "值4"},// ...
}
示例:
POST /heima/_doc/1
{"info": "黑马程序员Java讲师","email": "zy@itcast.cn","name": {"firstName": "云","lastName": "赵"}
}
响应:

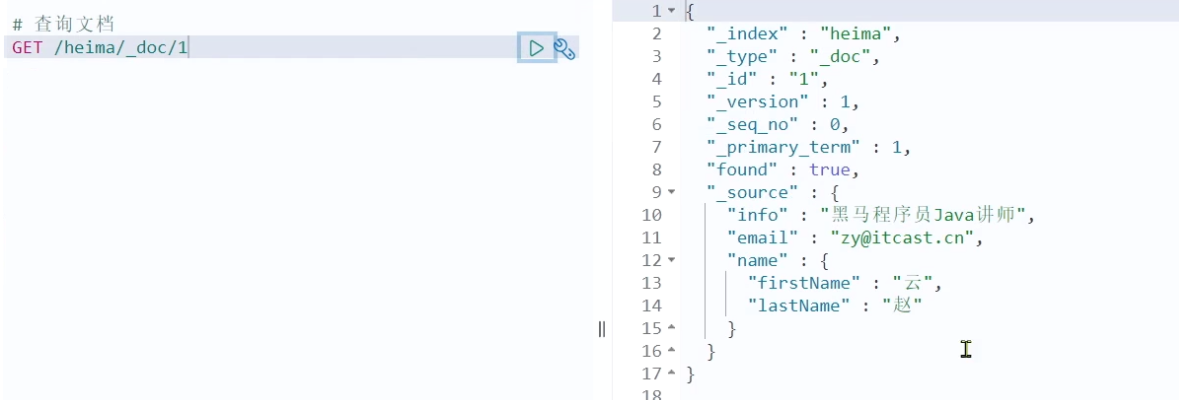
3.2 查询文档
根据rest风格,新增是post,查询应该是get,不过查询一般都需要条件,这里我们把文档id带上。
语法:
GET /{索引库名称}/_doc/{id}
通过kibana查看数据:
GET /heima/_doc/1
查看结果:
3.3 删除文档
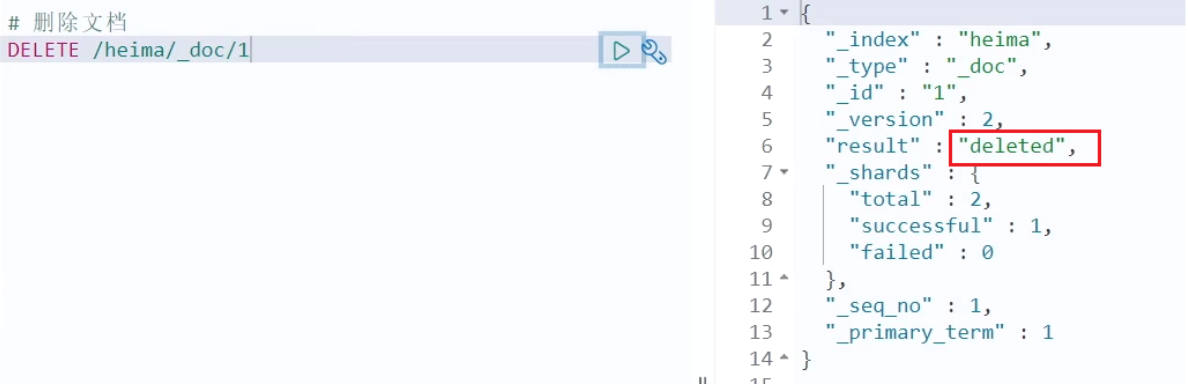
删除使用DELETE请求,同样,需要根据id进行删除:
语法:
DELETE /{索引库名}/_doc/id值
示例:
# 根据id删除数据
DELETE /heima/_doc/1
结果:
3.4 修改文档
修改有两种方式:
- 全量修改:直接覆盖原来的文档
- 增量修改:修改文档中的部分字段
3.4.1 全量修改
全量修改是覆盖原来的文档,其本质是:
- 根据指定的id删除文档
- 新增一个相同id的文档
注意:如果根据id删除时,id不存在,第二步的新增也会执行,也就从修改变成了新增操作了。
语法:
PUT /{索引库名}/_doc/文档id
{"字段1": "值1","字段2": "值2",// ... 略
}
示例:
PUT /heima/_doc/1
{"info": "黑马程序员高级Java讲师","email": "zy@itcast.cn","name": {"firstName": "云","lastName": "赵"}
}
3.4.2 增量修改
增量修改是只修改指定id匹配的文档中的部分字段。
语法:
POST /{索引库名}/_update/文档id
{"doc": {"字段名": "新的值",}
}
示例:
POST /heima/_update/1
{"doc": {"email": "ZhaoYun@itcast.cn"}
}
3.5 总结
文档操作有哪些?
- 创建文档:POST /{索引库名}/_doc/文档id { json文档 }
- 查询文档:GET /{索引库名}/_doc/文档id
- 删除文档:DELETE /{索引库名}/_doc/文档id
- 修改文档:
- 全量修改:PUT /{索引库名}/_doc/文档id { json文档 }
- 增量修改:POST /{索引库名}/_update/文档id { “doc”: {字段}}
4.RestAPI
-
ES官方提供了各种不同语言的客户端,用来操作ES。这些客户端的本质就是组装DSL语句,通过http请求发送给ES。官方文档地址:https://www.elastic.co/guide/en/elasticsearch/client/index.html
-
其中的Java Rest Client又包括两种:
- Java Low Level Rest Client
- Java High Level Rest Client

我们学习的是Java HighLevel Rest Client客户端API
4.0.导入Demo工程
4.0.1 导入数据
首先导入课前资料提供的数据库数据:tb_hotel.sql文件
数据结构如下:
CREATE TABLE `tb_hotel` (`id` bigint(20) NOT NULL COMMENT '酒店id',`name` varchar(255) NOT NULL COMMENT '酒店名称;例:7天酒店',`address` varchar(255) NOT NULL COMMENT '酒店地址;例:航头路',`price` int(10) NOT NULL COMMENT '酒店价格;例:329',`score` int(2) NOT NULL COMMENT '酒店评分;例:45,就是4.5分',`brand` varchar(32) NOT NULL COMMENT '酒店品牌;例:如家',`city` varchar(32) NOT NULL COMMENT '所在城市;例:上海',`star_name` varchar(16) DEFAULT NULL COMMENT '酒店星级,从低到高分别是:1星到5星,1钻到5钻',`business` varchar(255) DEFAULT NULL COMMENT '商圈;例:虹桥',`latitude` varchar(32) NOT NULL COMMENT '纬度;例:31.2497',`longitude` varchar(32) NOT NULL COMMENT '经度;例:120.3925',`pic` varchar(255) DEFAULT NULL COMMENT '酒店图片;例:/img/1.jpg',PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
4.0.2 导入项目
然后导入课前资料提供的项目:hotel-demo
项目结构如图:
4.0.3 mapping映射分析
创建索引库,最关键的是mapping映射,而mapping映射要考虑的信息包括:
- 字段名
- 字段数据类型
- 是否参与搜索
- 是否需要分词
- 如果分词,分词器是什么?
其中:
- 字段名、字段数据类型,可以参考数据表结构的名称和类型
- 是否参与搜索要分析业务来判断,例如图片地址,就无需参与搜索
- 是否分词呢要看内容,内容如果是一个整体就无需分词,反之则要分词
- 分词器,我们可以统一使用ik_max_word
来看下酒店数据的索引库结构:
PUT /hotel
{"mappings": {"properties": {"id": {"type": "keyword"},"name":{"type": "text","analyzer": "ik_max_word","copy_to": "all"},"address":{"type": "keyword","index": false},"price":{"type": "integer"},"score":{"type": "integer"},"brand":{"type": "keyword","copy_to": "all"},"city":{"type": "keyword","copy_to": "all"},"starName":{"type": "keyword"},"business":{"type": "keyword"},"location":{"type": "geo_point"},"pic":{"type": "keyword","index": false},"all":{"type": "text","analyzer": "ik_max_word"}}}
}
几个特殊字段说明:
- location:地理坐标,里面包含精度、纬度
- all:一个组合字段,其目的是将多字段的值 利用copy_to合并,提供给用户搜索
地理坐标说明:

copy_to说明:

4.0.4 初始化RestClient
在elasticsearch提供的API中,与elasticsearch一切交互都封装在一个名为RestHighLevelClient的类中,必须先完成这个对象的初始化,建立与elasticsearch的连接。
分为三步:
1)引入es的RestHighLevelClient依赖:
<dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId>
</dependency>
2)因为SpringBoot默认的ES版本是7.6.2,所以我们需要覆盖默认的ES版本:
<properties><java.version>1.8</java.version><elasticsearch.version>7.12.1</elasticsearch.version>
</properties>
3)初始化RestHighLevelClient:
初始化的代码如下:
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(HttpHost.create("http://192.168.150.101:9200")
));
这里为了单元测试方便,我们创建一个测试类HotelIndexTest,然后将初始化的代码编写在@BeforeEach方法中:
package cn.itcast.hotel;import org.apache.http.HttpHost;
import org.elasticsearch.client.RestHighLevelClient;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;import java.io.IOException;public class HotelIndexTest {private RestHighLevelClient client;@Testvoid testInit(){System.out.println(client);}@BeforeEachvoid setUp() {this.client = new RestHighLevelClient(RestClient.builder(HttpHost.create("http://192.168.150.101:9200")));}@AfterEachvoid tearDown() throws IOException {this.client.close();}
}
执行结果:

4.1 创建索引库
4.1.1 代码解读
创建索引库的API如下:

代码分为三步:
- 1)创建Request对象。因为是创建索引库的操作,因此Request是CreateIndexRequest。
- 2)添加请求参数,其实就是DSL的JSON参数部分。因为json字符串很长,这里是定义了静态字符串常量MAPPING_TEMPLATE,让代码看起来更加优雅。
- 3)发送请求,**client.indices()**方法的返回值是IndicesClient类型,封装了所有与索引库操作有关的方法。
4.1.2 完整示例
在hotel-demo的cn.itcast.hotel.constants包下,创建一个类,定义mapping映射的JSON字符串常量:
package cn.itcast.hotel.constants;public class HotelConstants {public static final String MAPPING_TEMPLATE = "{\n" +" \"mappings\": {\n" +" \"properties\": {\n" +" \"id\": {\n" +" \"type\": \"keyword\"\n" +" },\n" +" \"name\":{\n" +" \"type\": \"text\",\n" +" \"analyzer\": \"ik_max_word\",\n" +" \"copy_to\": \"all\"\n" +" },\n" +" \"address\":{\n" +" \"type\": \"keyword\",\n" +" \"index\": false\n" +" },\n" +" \"price\":{\n" +" \"type\": \"integer\"\n" +" },\n" +" \"score\":{\n" +" \"type\": \"integer\"\n" +" },\n" +" \"brand\":{\n" +" \"type\": \"keyword\",\n" +" \"copy_to\": \"all\"\n" +" },\n" +" \"city\":{\n" +" \"type\": \"keyword\",\n" +" \"copy_to\": \"all\"\n" +" },\n" +" \"starName\":{\n" +" \"type\": \"keyword\"\n" +" },\n" +" \"business\":{\n" +" \"type\": \"keyword\"\n" +" },\n" +" \"location\":{\n" +" \"type\": \"geo_point\"\n" +" },\n" +" \"pic\":{\n" +" \"type\": \"keyword\",\n" +" \"index\": false\n" +" },\n" +" \"all\":{\n" +" \"type\": \"text\",\n" +" \"analyzer\": \"ik_max_word\"\n" +" }\n" +" }\n" +" }\n" +"}";
}
在hotel-demo中的HotelIndexTest测试类中,编写单元测试,实现创建索引:
@Test
void createHotelIndex() throws IOException {// 1.创建Request对象CreateIndexRequest request = new CreateIndexRequest("hotel");// 2.准备请求的参数:DSL语句request.source(MAPPING_TEMPLATE, XContentType.JSON);// 3.发送请求client.indices().create(request, RequestOptions.DEFAULT);
}
4.2 删除索引库
删除索引库的DSL语句非常简单:
DELETE /hotel
与创建索引库相比:
- 请求方式从PUT变为DELTE
- 请求路径不变
- 无请求参数
所以代码的差异,注意体现在Request对象上。依然是三步走:
- 1)创建Request对象。这次是DeleteIndexRequest对象
- 2)准备参数。这里是无参
- 3)发送请求。改用delete方法
在hotel-demo中的HotelIndexTest测试类中,编写单元测试,实现删除索引:
@Test
void testDeleteHotelIndex() throws IOException {// 1.创建Request对象DeleteIndexRequest request = new DeleteIndexRequest("hotel");// 2.发送请求client.indices().delete(request, RequestOptions.DEFAULT);
}
4.3 判断索引库是否存在
判断索引库是否存在,本质就是查询,对应的DSL是:
GET /hotel
因此与删除的Java代码流程是类似的。依然是三步走:
- 1)创建Request对象。这次是GetIndexRequest对象
- 2)准备参数。这里是无参
- 3)发送请求。改用exists方法
@Test
void testExistsHotelIndex() throws IOException {// 1.创建Request对象GetIndexRequest request = new GetIndexRequest("hotel");// 2.发送请求boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);// 3.输出System.err.println(exists ? "索引库已经存在!" : "索引库不存在!");
}
4.4 总结
JavaRestClient操作elasticsearch的流程基本类似。核心是client.indices()方法来获取索引库的操作对象。
索引库操作的基本步骤:
- 初始化RestHighLevelClient
- 创建XxxIndexRequest。XXX是Create、Get、Delete
- 准备DSL( Create时需要,其它是无参)
- 发送请求。调用RestHighLevelClient#indices().xxx()方法,xxx是create、exists、delete
5.RestClient操作文档
为了与索引库操作分离,我们再次参加一个测试类,做两件事情:
- 初始化RestHighLevelClient
- 我们的酒店数据在数据库,需要利用IHotelService去查询,所以注入这个接口
package cn.itcast.hotel;import cn.itcast.hotel.pojo.Hotel;
import cn.itcast.hotel.service.IHotelService;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;import java.io.IOException;
import java.util.List;@SpringBootTest
public class HotelDocumentTest {@Autowiredprivate IHotelService hotelService;private RestHighLevelClient client;@BeforeEachvoid setUp() {this.client = new RestHighLevelClient(RestClient.builder(HttpHost.create("http://192.168.150.101:9200")));}@AfterEachvoid tearDown() throws IOException {this.client.close();}
}5.1 新增文档
我们要将数据库的酒店数据查询出来,写入elasticsearch中。
5.1.1 索引库实体类
数据库查询后的结果是一个Hotel类型的对象。结构如下:
@Data
@TableName("tb_hotel")
public class Hotel {@TableId(type = IdType.INPUT)private Long id;private String name;private String address;private Integer price;private Integer score;private String brand;private String city;private String starName;private String business;private String longitude;private String latitude;private String pic;
}
与我们的索引库结构存在差异:
- longitude和latitude需要合并为location
因此,我们需要定义一个新的类型HotelDoc,与索引库结构吻合:
package cn.itcast.hotel.pojo;import lombok.Data;
import lombok.NoArgsConstructor;@Data
@NoArgsConstructor
public class HotelDoc {private Long id;private String name;private String address;private Integer price;private Integer score;private String brand;private String city;private String starName;private String business;private String location;private String pic;public HotelDoc(Hotel hotel) {this.id = hotel.getId();this.name = hotel.getName();this.address = hotel.getAddress();this.price = hotel.getPrice();this.score = hotel.getScore();this.brand = hotel.getBrand();this.city = hotel.getCity();this.starName = hotel.getStarName();this.business = hotel.getBusiness();this.location = hotel.getLatitude() + ", " + hotel.getLongitude();this.pic = hotel.getPic();}
}5.1.2 语法说明
新增文档的DSL语句如下:
POST /{索引库名}/_doc/1
{"name": "Jack","age": 21
}
对应的java代码如图:

可以看到与创建索引库类似,同样是三步走:
- 1)创建Request对象
- 2)准备请求参数,也就是DSL中的JSON文档
- 3)发送请求
变化的地方在于,这里直接使用client.xxx()的API,不再需要client.indices()了。
5.1.3 完整代码
我们导入酒店数据,基本流程一致,但是需要考虑几点变化:
- 酒店数据来自于数据库,我们需要先查询出来,得到hotel对象
- hotel对象需要转为HotelDoc对象
- HotelDoc需要序列化为json格式
因此,代码整体步骤如下:
- 1)根据id查询酒店数据Hotel
- 2)将Hotel封装为HotelDoc
- 3)将HotelDoc序列化为JSON
- 4)创建IndexRequest,指定索引库名和id
- 5)准备请求参数,也就是JSON文档
- 6)发送请求
在hotel-demo的HotelDocumentTest测试类中,编写单元测试:
@Test
void testAddDocument() throws IOException {// 1.根据id查询酒店数据Hotel hotel = hotelService.getById(61083L);// 2.转换为文档类型HotelDoc hotelDoc = new HotelDoc(hotel);// 3.将HotelDoc转jsonString json = JSON.toJSONString(hotelDoc);// 1.准备Request对象IndexRequest request = new IndexRequest("hotel").id(hotelDoc.getId().toString());// 2.准备Json文档request.source(json, XContentType.JSON);// 3.发送请求client.index(request, RequestOptions.DEFAULT);
}
5.2 查询文档
5.2.1 语法说明
查询的DSL语句如下:
GET /hotel/_doc/{id}
非常简单,因此代码大概分两步:
- 准备Request对象
- 发送请求
不过查询的目的是得到结果,解析为HotelDoc,因此难点是结果的解析。完整代码如下:

可以看到,结果是一个JSON,其中文档放在一个_source属性中,因此解析就是拿到_source,反序列化为Java对象即可。
与之前类似,也是三步走:
- 1)准备Request对象。这次是查询,所以是GetRequest
- 2)发送请求,得到结果。因为是查询,这里调用client.get()方法
- 3)解析结果,就是对JSON做反序列化
5.2.2 完整代码
在hotel-demo的HotelDocumentTest测试类中,编写单元测试:
@Test
void testGetDocumentById() throws IOException {// 1.准备RequestGetRequest request = new GetRequest("hotel", "61082");// 2.发送请求,得到响应GetResponse response = client.get(request, RequestOptions.DEFAULT);// 3.解析响应结果String json = response.getSourceAsString();HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);System.out.println(hotelDoc);
}
5.3 删除文档
删除的DSL为是这样的:
DELETE /hotel/_doc/{id}
与查询相比,仅仅是请求方式从DELETE变成GET,可以想象Java代码应该依然是三步走:
- 1)准备Request对象,因为是删除,这次是DeleteRequest对象。要指定索引库名和id
- 2)准备参数,无参
- 3)发送请求。因为是删除,所以是client.delete()方法
在hotel-demo的HotelDocumentTest测试类中,编写单元测试:
@Test
void testDeleteDocument() throws IOException {// 1.准备RequestDeleteRequest request = new DeleteRequest("hotel", "61083");// 2.发送请求client.delete(request, RequestOptions.DEFAULT);
}
5.4 修改文档
5.4.1.语法说明
修改我们讲过两种方式:
- 全量修改:本质是先根据id删除,再新增
- 增量修改:修改文档中的指定字段值
在RestClient的API中,全量修改与新增的API完全一致,判断依据是ID:
- 如果新增时,ID已经存在,则修改
- 如果新增时,ID不存在,则新增
这里不再赘述,我们主要关注增量修改。
代码示例如图:

与之前类似,也是三步走:
- 1)准备Request对象。这次是修改,所以是UpdateRequest
- 2)准备参数。也就是JSON文档,里面包含要修改的字段
- 3)更新文档。这里调用client.update()方法
5.4.2 完整代码
在hotel-demo的HotelDocumentTest测试类中,编写单元测试:
@Test
void testUpdateDocument() throws IOException {// 1.准备RequestUpdateRequest request = new UpdateRequest("hotel", "61083");// 2.准备请求参数request.doc("price", "952","starName", "四钻");// 3.发送请求client.update(request, RequestOptions.DEFAULT);
}
5.5 批量导入文档
案例需求:利用BulkRequest批量将数据库数据导入到索引库中。
步骤如下:
-
利用mybatis-plus查询酒店数据
-
将查询到的酒店数据(Hotel)转换为文档类型数据(HotelDoc)
-
利用JavaRestClient中的BulkRequest批处理,实现批量新增文档
5.5.1 语法说明
批量处理BulkRequest,其本质就是将多个普通的CRUD请求组合在一起发送。
其中提供了一个add方法,用来添加其他请求:
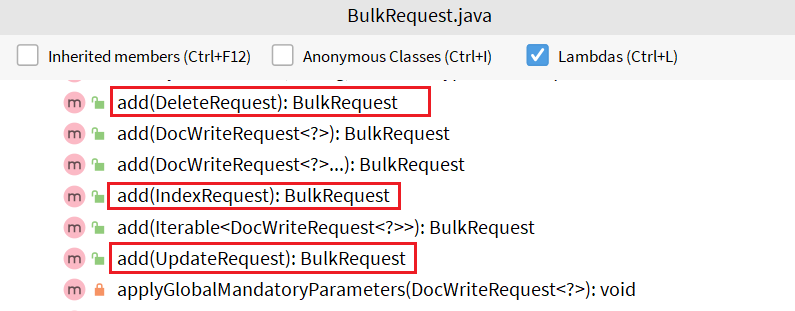
可以看到,能添加的请求包括:
- IndexRequest,也就是新增
- UpdateRequest,也就是修改
- DeleteRequest,也就是删除
因此Bulk中添加了多个IndexRequest,就是批量新增功能了。示例:
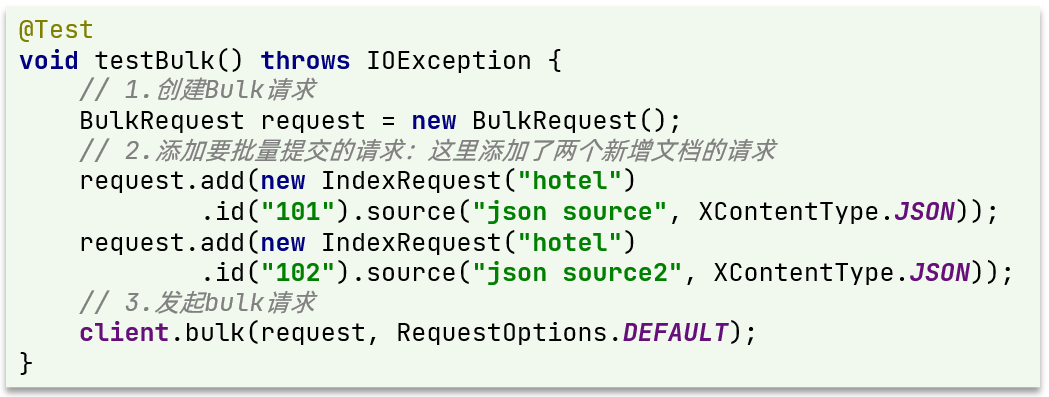
其实还是三步走:
- 1)创建Request对象。这里是BulkRequest
- 2)准备参数。批处理的参数,就是其它Request对象,这里就是多个IndexRequest
- 3)发起请求。这里是批处理,调用的方法为client.bulk()方法
我们在导入酒店数据时,将上述代码改造成for循环处理即可。
5.5.2 完整代码
在hotel-demo的HotelDocumentTest测试类中,编写单元测试:
@Test
void testBulkRequest() throws IOException {// 批量查询酒店数据List<Hotel> hotels = hotelService.list();// 1.创建RequestBulkRequest request = new BulkRequest();// 2.准备参数,添加多个新增的Requestfor (Hotel hotel : hotels) {// 2.1.转换为文档类型HotelDocHotelDoc hotelDoc = new HotelDoc(hotel);// 2.2.创建新增文档的Request对象request.add(new IndexRequest("hotel").id(hotelDoc.getId().toString()).source(JSON.toJSONString(hotelDoc), XContentType.JSON));}// 3.发送请求client.bulk(request, RequestOptions.DEFAULT);
}
5.6 小结
文档操作的基本步骤:
- 初始化RestHighLevelClient
- 创建XxxRequest。XXX是Index、Get、Update、Delete、Bulk
- 准备参数(Index、Update、Bulk时需要)
- 发送请求。调用RestHighLevelClient#.xxx()方法,xxx是index、get、update、delete、bulk
- 解析结果(Get时需要)
相关文章:
SpringCloud实用篇5——elasticsearch基础
目录 1.初识elasticsearch1.1 了解ES1.1.1 elasticsearch的作用1.1.2 ELK技术栈1.1.3 elasticsearch和lucene1.1.4 总结 1.2.倒排索引1.2.1.正向索引1.2.2.倒排索引1.2.3.正向和倒排 1.3 es的一些概念1.3.1 文档和字段1.3.2 索引和映射1.3.3 mysql与elasticsearch 1.4 部署单点…...
SpringCloud整体架构概览
什么是SpringCloud 目标 协调任何服务,简化分布式系统开发。 简介 构建分布式系统不应该是复杂的,SpringCloud对常见的分布式系统模式提供了简单易用的编程模型,帮助开发者构建弹性、可靠、协调的应用程序。SpringCloud是在SpringBoot的基…...

(el-switch)操作(不使用 ts):Element-plus 中 Switch 将默认值修改为 “true“ 与 “false“(字符串)来控制开关
Ⅰ、Element-plus 提供的 Switch 开关组件与想要目标情况的对比: 1、Element-plus 提供 Switch 组件情况: 其一、Element-ui 自提供的 Switch 代码情况为(示例的代码): // Element-plus 自提供的代码: // 此时是使用了 ts 语言环…...

AI绘画网站都有哪些比较好用?
人工智能绘画网站是一种利用人工智能技术进行图像处理和创作的网站。这些绘画网站通常可以帮助艺术家以人工智能绘画的形式快速生成有趣、美丽和独特的绘画作品。无论你是专业的艺术家还是对人工智能绘画感兴趣的普通人,人工智能绘画网站都可以为你提供新的创作灵感…...

Android应用开发(35)SufaceView基本用法
Android应用开发学习笔记——目录索引 参考Android官网:https://developer.android.com/reference/android/view/SurfaceView 一、SurfaceView简介 SurfaceView派生自View,提供嵌入视图层次结构内部的专用绘图表面,SurfaceView可以在主线程之…...

原生JS手写扫雷小游戏
场景 实现一个完整的扫雷游戏需要一些复杂的逻辑和界面交互。我将为你提供一个简化版的扫雷游戏示例,帮助你入门。请注意,这只是一个基本示例,你可以根据自己的需求进行扩展和改进。 思路 创建游戏板(Grid)࿱…...
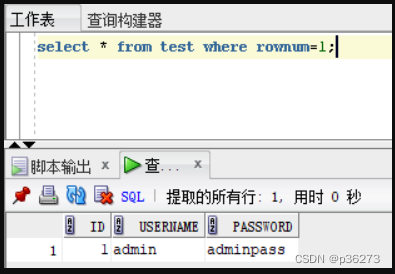
网络安全进阶学习第十五课——Oracle SQL注入
文章目录 一、Oracle数据库介绍二、Oracle和MySQL的语法差异:三、Oracle的数据库结构四、Oracle的重点系统表五、Oracle权限分类1、系统权限2、实体权限3、管理角色 六、oracle常用信息查询方法七、联合查询注入1、order by 猜字段数量2、查数据库版本和用户名3、查…...

线程池死循环系统卡住
案例: 同一个线程池。 首先核心线程数是8,我一次提交了 > 8个主任务,然后主任务又各自开启了几个子任务。 所以子任务没有核心线程来跑,只能放进阻塞队列等。 但主任务又等待子任务的结果,不释放占用线程ÿ…...
多用户微商城多端智慧生态电商系统搭建
多用户微商城多端智慧生态电商系统的搭建步骤如下: 系统规划:在搭建多用户微商城多端智慧生态电商系统之前,需要进行系统规划。包括确定系统的目标、功能、架构、技术选型、开发流程等方面。市场调研:进行市场调研,了…...
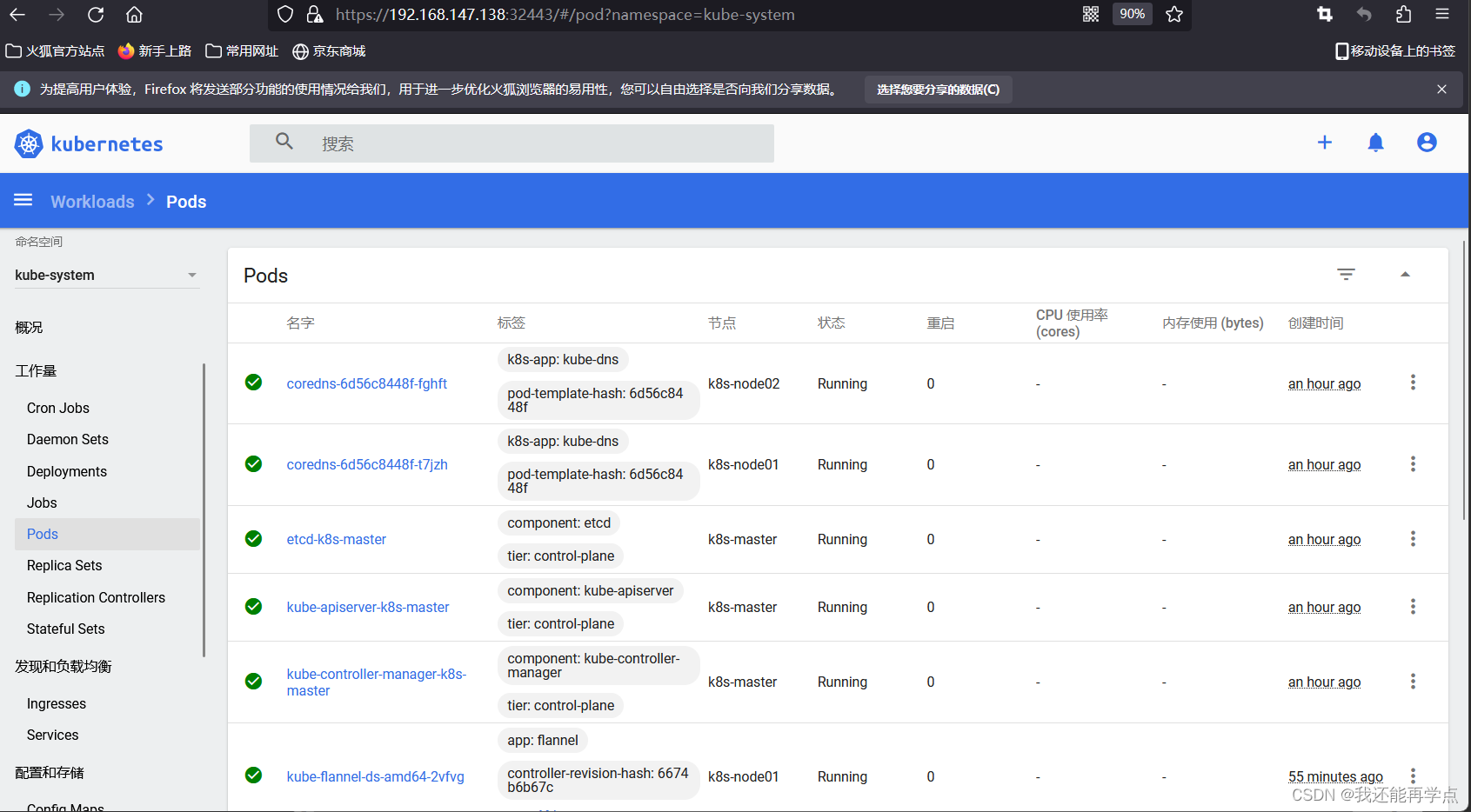
基于Kubeadm部署k8s集群:下篇
继续上篇内容 目录 7、安装flannel 8、节点管理命令 三、安装Dashboard UI 1、部署Dashboard 2、开放端口设置 3、权限配置 7、安装flannel Master 节点NotReady 的原因就是因为没有使用任何的网络插件,此时Node 和Master的连接还不正常。目前最流行的Kuber…...

【Python matplotlib】鼠标右键移动画布
在 Matplotlib 中,鼠标右键移动画布的功能通常是通过设置交互模式来实现的,例如使用 mpl_connect 方法。以下是一个示例代码,展示如何在 Matplotlib 中使用 mpl_connect 方法来实现鼠标右键移动画布的功能: import numpy as np …...

Sleuth+Zipkin服务链路追踪
微服务架构是一个分布式架构,它按业务划分服务单元。一个分布式系统往往有很多个服务单元。由于服务单元数量众多,业务的复杂性,如果出现了错误和异常,很难去定位。主要体现在,一个请求可能需要调用很多个服务…...

100G光模块的应用案例分析:电信、云计算和大数据领域
100G光模块是一种高速光模块,由于其高速率和低延迟的特性,在电信、云计算和大数据领域得到了广泛的应用。在本文中,我们将深入探讨100G光模块在这三个领域的应用案例。 一、电信领域 在电信领域,100G光模块被广泛用于构建高速通…...
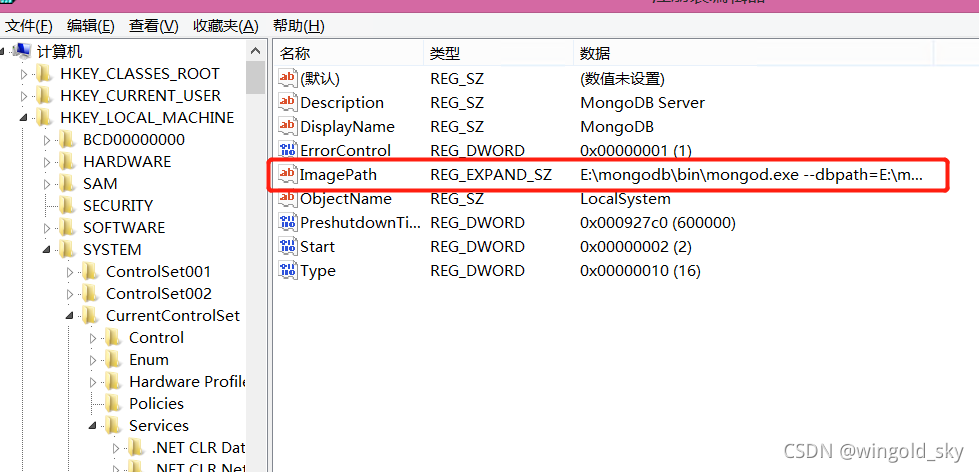
MongoDB安装和配置
一、MongoDB安装和配置 1、进入官网下载你所需要的安装版本,点击直通官网 Step1:进入官网后,将看到如下界面,点击上方导航栏Products,找到Community Server Step2:选择自己需要的版本、系统和压缩方式 2、下…...
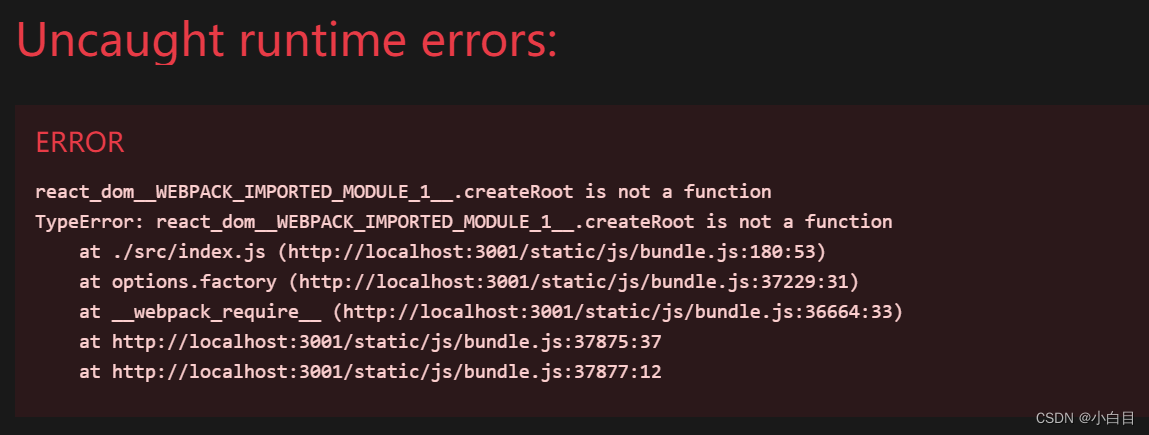
解决createRoot is not a function
报错: 出现的原因:在于把react18使用的vite构建,在开发中因react版本太高与其他库不兼容,而在降级的时候,出现以上dom渲染出现报错。 解决:将 src/index.j文件改成如下 import React from react; import…...
、背景色设置】)
【Windows 常用工具系列 6 -- CSDN字体格式(字体、颜色、大小)、背景色设置】
文章目录 背景字体大小设置字体颜色设置字体类型背景色 背景 Markdown是一种轻量级标记语言,它的目标是实现“易读易写”。创立于2004年,由约翰格鲁伯(John Gruber)和亚伦斯沃茨(Aaron Swartz)共同设计。 …...

带着问题学习分布式系统
写在前面 听过很多道理,却依然过不好这一生。 看过很多关于学习的技巧、方法,却没应用到自己的学习中。 随着年纪变大,记忆力越来越差,整块的时间也越来越少,于是,越来越希望能够更高效的学习。学习是一种习…...
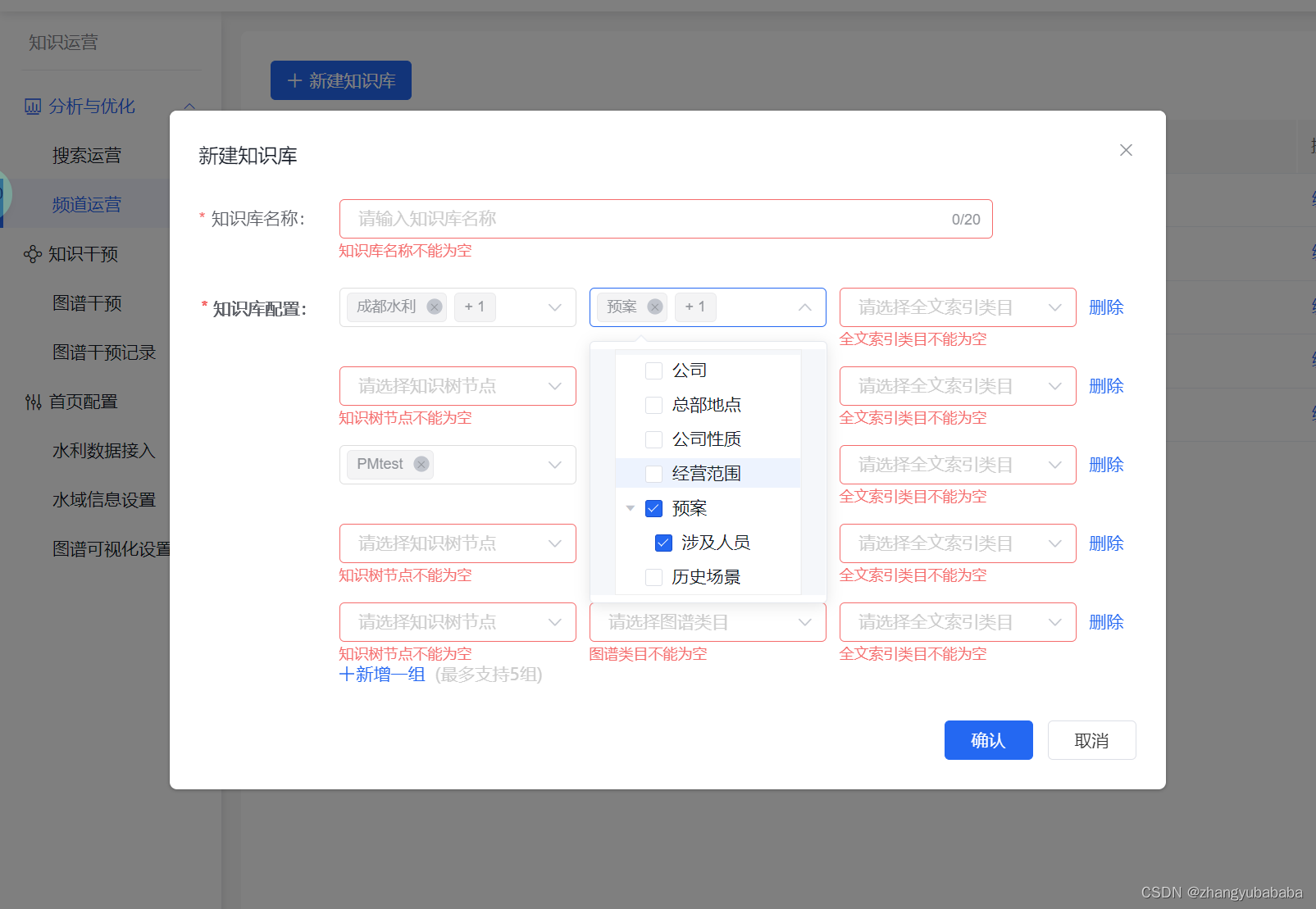
element vue2 动态添加 select+tree
难点在 1 添加一组一组的渲染 是往数组里push对象 循环的;但是要注意对象的结构! 因为这涉及到编辑完成后,表单提交时候的 校验! 是校验每一个select tree里边 是否勾选 2 是在后期做编辑回显的时候 保证后端返回的值 是渲染到 select中的tr…...

MySQL Linux自建环境备份至远端服务器自定义保留天数
环境准备 linux下安装mysql请看 Linux环境安装单节点mysql8.0.16 系统版本: CentOS 7 软件版本: mysql8.0.16 备份策略与实现方法 此次备份依赖mysql自带命令mysqldump与linux下crontab命令(定时任务) mysqldump mysqldump客户实用程序执行 逻辑备份,产生一组能够被执行…...
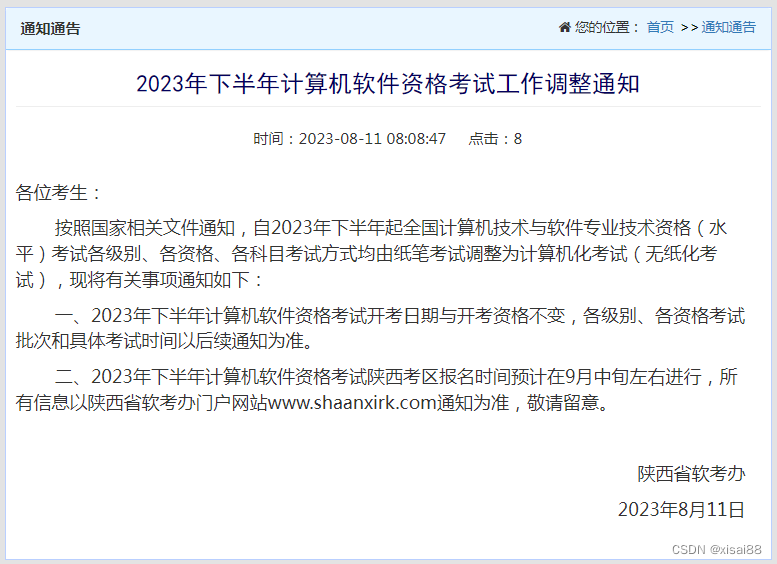
2023下半年软考改成机考,对考生有哪些影响?
软考改革成无纸化考试已经实锤。根据陕西软考办官网的消息,从2023年11月起,软考的所有科目都将改为机器考试形式。详情请参阅: 那么软考考试改为机考后,对我们会有哪些影响呢?我来简单概括一下。 1、复习的方法可以根…...

QCraft 于北京 2026 年中国国际汽车展览会重磅发布物理 AI 模型及 500+ TOPS 智能驾驶解决方案
QPilot MAX 500 TOPS 城市导航解决方案基于世界模型与强化学习框架构建,性能表现达行业领先水准,其 AEB 误触发率远低于行业平均水平 全球自动驾驶领域领先企业 QCraft 今日在 2026 年北京国际汽车展览会(Auto China 2026)开幕活…...

【收藏备用】2026年金三银四春招|AI岗位暴涨12倍,程序员/小白靠大模型逆袭指南
“金三银四”春招大战已全面打响,2026年职场招聘市场被AI技术彻底激活!AI相关岗位同比暴涨12倍,平均月薪突破6万,顶级岗位月薪直逼13.7万,这场席卷全行业的AI人才争夺战,早已进入白热化阶段。对于程序员、A…...

2026 AI搜索优化必备,免费GEO监测工具实测
摘要随着生成式AI搜索的普及,GEO(Generative Engine Optimization,生成式引擎优化)已成为企业数字营销的重要技术方向。本文对当前国内外主流的5款GEO优化工具进行了技术评测。评测维度包括功能完整性、AI模型支持、诊断能力和性价…...

OpenClaw 实时语音功能分析
OpenClaw 实时语音功能分析 核心架构 OpenClaw 的实时语音功能采用分层架构设计,主要由以下模块组成: 1. 实时语音桥接系统 (RealtimeVoiceBridge) realtime-voice/ 目录下的核心实现 提供 RealtimeVoiceBridge 接口,支持创建和管理语音会话 关键类型:RealtimeVoiceBrid…...

物流快递查询工具
一个专业的快递查询工具,支持单个查询和批量查询功能,为个人和企业提供便捷的物流查询服务。 功能特性 前台用户端 - **首页**:品牌介绍、核心功能、价格套餐、免费试用入口、登录/注册 - **单个快递查询页**:手动输单号、自动识别快递公司、实时轨迹 - **批量快递查询…...

2026最权威的六大AI论文工具横评
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 要降低AIGC检测率,其核心就存在于消除机器生成所具备的规律性特征之中。其一&…...

CAST模型:流程性视频检索的时序一致性解决方案
1. CAST模型技术解析:重新定义流程性视频检索在当今视频内容爆炸式增长的时代,视频检索技术的重要性与日俱增。传统视频检索系统主要依赖全局视频-文本对齐,通过将视频片段和文本查询映射到共享嵌入空间来实现跨模态匹配。这种方法虽然简单有…...

终极Viper配置管理指南:5步自动生成专业配置文档
终极Viper配置管理指南:5步自动生成专业配置文档 【免费下载链接】viper Go configuration with fangs 项目地址: https://gitcode.com/gh_mirrors/vi/viper Viper是Go语言生态中功能强大的配置管理工具,被广泛应用于各类Go项目中处理配置需求。本…...

vue2+element-UI上传图片封装
针对上传组件进行封装,在页面直接引用即可,上传到minio文件服务器: 可以预览,重新上传,只读模式,可以传入展示缩略图尺寸,传入上传校验尺寸 <template><div><div v-if"read…...

基于LLM与OpenClaw的AI智能体架构实践:构建自动化学生助理
1. 项目概述:一个能主动思考的AI学生助理如果你是一名学生,或者曾经是,你一定对那种被各种作业、实验报告和项目截止日期追着跑的感觉深有体会。日历上密密麻麻的标记,稍不留神就可能错过一个重要的提交时间。传统的待办事项应用需…...