【博客686】k8s informer list-watch机制中的re-list与resync
k8s informer的re-list与resync
1、informer的list-watch机制
client-go中的reflector模块首先会list apiserver获取某个资源的全量信息,然后根据list到的resourceversion来watch资源的增量信息。且希望使用client-go编写的控制器组件在与apiserver发生连接异常时,尽量的re-watch资源而不是re-list
2、re-list的场景:
场景一:very short watch
reflector与api建立watch连接,但apiserver关闭了连接,则会重新re-list
这意味着 apiserver 接受了监视请求,但立即终止了连接,如果您偶尔看到它,则表明存在暂时性错误,并不值得警惕。如果您反复看到它,则意味着 apiserver(或 etcd)有问题。
I0728 11:32:06.170821 67483 streamwatcher.go:114] Unexpected EOF during watch stream event decoding: unexpected EOF I0728 11:32:06.171062 67483 reflector.go:391] k8s.io/client-go/informers/factory.go:134: Watch close - *v1.Deployment total 0 items received W0728 11:32:06.187394 67483 reflector.go:302] k8s.io/client-go/informers/factory.go:134: watch of *v1.Deployment ended with: very short watch: k8s.io/client-go/informers/factory.go:134: Unexpected watch close - watch lasted less than a second and no items received
场景二:401 Gone
为什么跟etcd不会一直记录历史版本有关:参考:bookmark机制
reflector与api建立watch连接,但是出现watch的相关事件丢失时(etcd不会一直记录历史版本),api返回401 Gone,reflector提示too old resource version并重新re-list
I0728 14:40:58.807670 71423 reflector.go:300] k8s.io/client-go/informers/factory.go:134: watch of *v1.Deployment ended with: too old resource version: 332167941 (332223202) I0728 14:40:59.808153 71423 reflector.go:159] Listing and watching *v1.Deployment from k8s.io/client-go/informers/factory.go:134 I0728 14:41:00.300695 71423 reflector.go:312] reflector list resourceVersion: 332226582
3、resync场景:
// k8s.io/client-go/tools/cache/delta_fifo.go
// 重新同步一次 Indexer 缓存数据到 Delta FIFO 队列中
func (f *DeltaFIFO) Resync() error {f.lock.Lock()defer f.lock.Unlock()if f.knownObjects == nil {return nil}// 遍历 indexer 中的 key,传入 syncKeyLocked 中处理keys := f.knownObjects.ListKeys()for _, k := range keys {if err := f.syncKeyLocked(k); err != nil {return err}}return nil
}func (f *DeltaFIFO) syncKeyLocked(key string) error {obj, exists, err := f.knownObjects.GetByKey(key)if err != nil {klog.Errorf("Unexpected error %v during lookup of key %v, unable to queue object for sync", err, key)return nil} else if !exists {klog.Infof("Key %v does not exist in known objects store, unable to queue object for sync", key)return nil}// 如果发现 FIFO 队列中已经有相同 key 的 event 进来了,说明该资源对象有了新的 event,// 在 Indexer 中旧的缓存应该失效,因此不做 Resync 处理直接返回 nilid, err := f.KeyOf(obj)if err != nil {return KeyError{obj, err}}if len(f.items[id]) > 0 {return nil}// 重新放入 FIFO 队列中if err := f.queueActionLocked(Sync, obj); err != nil {return fmt.Errorf("couldn't queue object: %v", err)}return nil
}
为什么需要 Resync 机制呢?因为在处理 SharedInformer 事件回调时,可能存在处理失败的情况,定时的 Resync 让这些处理失败的事件有了重新处理的机会。
那么经过 Resync 重新放入 Delta FIFO 队列的事件,和直接从 apiserver 中 watch 得到的事件处理起来有什么不一样呢?
// k8s.io/client-go/tools/cache/shared_informer.go
func (s *sharedIndexInformer) HandleDeltas(obj interface{}) error {s.blockDeltas.Lock()defer s.blockDeltas.Unlock()// from oldest to newestfor _, d := range obj.(Deltas) {// 判断事件类型,看事件是通过新增、更新、替换、删除还是 Resync 重新同步产生的switch d.Type {case Sync, Replaced, Added, Updated:s.cacheMutationDetector.AddObject(d.Object)if old, exists, err := s.indexer.Get(d.Object); err == nil && exists {if err := s.indexer.Update(d.Object); err != nil {return err}isSync := falseswitch {case d.Type == Sync:// 如果是通过 Resync 重新同步得到的事件则做个标记isSync = truecase d.Type == Replaced:...}// 如果是通过 Resync 重新同步得到的事件,则触发 onUpdate 回调s.processor.distribute(updateNotification{oldObj: old, newObj: d.Object}, isSync)} else {if err := s.indexer.Add(d.Object); err != nil {return err}s.processor.distribute(addNotification{newObj: d.Object}, false)}case Deleted:if err := s.indexer.Delete(d.Object); err != nil {return err}s.processor.distribute(deleteNotification{oldObj: d.Object}, false)}}return nil
}
从上面对 Delta FIFO 的队列处理源码可看出,如果是从 Resync 重新同步到 Delta FIFO 队列的事件,会分发到 updateNotification 中触发 onUpdate 的回调
Resync 机制的引入,定时将 Indexer 缓存事件重新同步到 Delta FIFO 队列中,在处理 SharedInformer 事件回调时,让处理失败的事件得到重新处理。并且通过入队前判断 FIFO 队列中是否已经有了更新版本的 event,来决定是否丢弃 Indexer 缓存不进行 Resync 入队。在处理 Delta FIFO 队列中的 Resync 的事件数据时,触发 onUpdate 回调来让事件重新处理。
4、Reflector.lastSyncResourceVersion 是哪个资源的 resourceVersion
一个resourceVersion怎么对应多种资源呢?其实是一个informer对应一个Reflector,一个informer本来就是对应一种资源的,然后每一类resourceVersion是不断递增的,比如:informer watch了pod,那么informer对应的Reflector的resourceVersion是对应k8s etcd里pod这一类资源的resourceVersion。因此是一类资源使用一个resourceVersion
list-watch example:
https://codeburst.io/kubernetes-watches-by-example-bc1edfb2f83
5、注意点
-
1、resync不是re-list,resync不需要访问apiserver
-
2、resync 是重放 informer 中的 obj 到 DeltaFIFO 队列中,触发 handler 再次处理 obj。
目的是防止有些 handler 处理失败了而缺乏重试的机会。特别是,需要修改外部系统的状态的时候,需要做一些补偿的时候。
比如说,根据 networkpolicy刷新 node 上的 iptables。
iptables 有可能会被其他进程或者管理员意外修改,有 resync 的话,才有机会定期修正。
这也说明,回调函数的实现需要保证幂等性。对于 OnUpdate 函数而言,有可能会拿到完全一样的两个 Obj,实现 OnUpdate 时要考虑到。 -
3、re-list 是指 reflector 重新调用 kube-apiserver 全量同步所有 obj。但目前(v1.20)没有显式配置 re-list 周期的参数。
list 的时机一般是在程序第一次启动,或者 watch 有错误,才会 re-list。
-
4、resync 是一个水平触发的模式
水平触发是只要处于某个状态,就会一直通知。比如在这里,对象已经在缓存里,会触发不止一次回调函数。
-
5、process 函数怎么区分从 DeltaFIFO 里拿到的 obj 是新的还是重放的呢?
根据 obj 的 key(namespace/name)从 index 里拿到旧的 obj,和新出队的 obj 比较 resource revision,这两个 resource revision 如果一样,就是重放的,如果不一样,就是从 kube-apiserver 拿到的新的。因为 resource revision 只有在 etcd 才能更新。 index 作为客户端缓存,这个值是不变的。
-
6、sharedInformer 如何实现 Resync
把需要 resync(resync 的周期到了) 的 listeners 数组复制一份到 syncingListeners,在 distribute 中,
会调用 syncingListeners 的 add 函数,触发 syncingListeners 上的回调函数
6、resync要注意的问题:
-
1、如何配置resync的周期?
func NewSharedIndexInformer(lw ListerWatcher, exampleObject runtime.Object, defaultEventHandlerResyncPeriod time.Duration, indexers Indexers)
第三个参数 defaultEventHandlerResyncPeriod 就指定多久 resync 一次。如果为0,则不 resync。
AddEventHandlerWithResyncPeriod也可以给单独的 handler 定义 resync period,否则默认和 informer 的是一样的。
-
2、配置resync周期间隔太小会有什么问题
此时会以比较高的频率促使事件重新入队进行reconcile,造成controller的压力过大
-
3、resync用于解决什么问题,resync 多久一次比较合适?或者需不需要 resync?
根据具体业务场景来,根据外部状态是不是稳定的、是否需要做这个补偿来决定的,举例:假设controller是一个LB controller
当watch到了service创建,然后调用LB api去创建一个对应的LB,然后如果此时这个对应的LB由于某种bug被删除了,此时service就不通了,
那么此时状态不一致了,集群里有这个service,LB那边没有对应的LB,并且由于bug被删除了,而不是删除service而触发LB删除的,此时service是没有变化的,
也就不会出发reconcile了。假设我们reconcile里有逻辑是判断如果service没有对应的LB就创建,那么此时reconcile不会被出发,那也就没有被执行了。
此时如果有resync,定时将indexer里的对象,也就是缓存的对象来一次update事件的入队,进行后续出队触发reconcile,那我们就会发现service对应的LB没了,
进而进行创建。也就是本质上resync是防止业务层的bug。且resync将indexer的对象重入队,里面的service不是所有service,而是创建了LB的service,因为我们
只会watch我们关心的资源,前提是代码里添加的对象写的是有LB字段的service因为这些操作都是异步的 合理的sync可以提高事件消费的容错性。Resync 机制的引入,定时将 Indexer 缓存事件重新同步到 Delta FIFO 队列中,在处理 SharedInformer 事件回调时,让处理失败的事件得到重新处理。并且通过入队前判断 FIFO 队列中是否已经有了更新版本的 event,来决定是否丢弃 Indexer 缓存不进行 Resync 入队。在处理 Delta FIFO 队列中的 Resync 的事件数据时,触发 onUpdate 回调来让事件重新处理。
7、这个issue讨论里面有Programming Kubernetes相关讨论内容:
https://github.com/cloudnativeto/sig-kubernetes/issues/11
相关文章:

【博客686】k8s informer list-watch机制中的re-list与resync
k8s informer的re-list与resync 1、informer的list-watch机制 client-go中的reflector模块首先会list apiserver获取某个资源的全量信息,然后根据list到的resourceversion来watch资源的增量信息。且希望使用client-go编写的控制器组件在与apiserver发生连接异常时&…...
【Spring专题】Spring底层核心原理解析
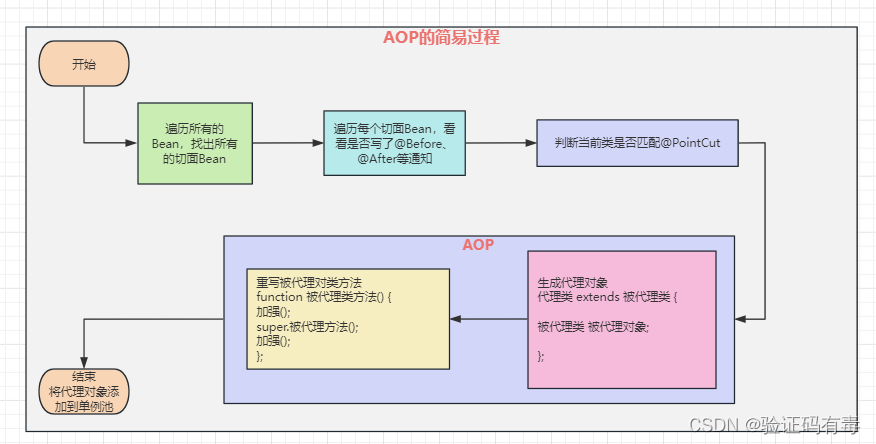
目录 前言阅读导航前置知识Q1:你能描述一下JVM对象创建过程吗?Q2:Spring的特性是什么?前置知识总结 课程内容一、Spring容器的启动二、一般流程推测2.1 扫描2.2 IOC2.3 AOP 2.4 小结三、【扫描】过程简单推测四、【IOC】过程简单推…...

出于网络安全考虑,印度启用本土操作系统”玛雅“取代Windows
据《印度教徒报》报道,印度将放弃微软系统,选择新的操作系统和端点检测与保护系统。 备受期待的 "玛雅操作系统 "将很快用于印度国防部的数字领域,而新的端点检测和保护系统 "Chakravyuh "也将一起面世。 不过…...
和tf.broadcast())
tensotflow中tf.title()和tf.broadcast()
tf.tile() 和 tf.broadcast_to() 都是 TensorFlow 中用于张量复制的函数,但它们的实现方式和使用场景略有不同。 tf.tile() 函数的定义如下: tf.tile(input, multiples, nameNone) 其中,input 表示要复制的张量,multiples 表示…...
想要延长Macbook寿命?这六个保养技巧你必须get!
Mac作为我们工作生活的伙伴,重要性不需要多说。但在使用的过程中,我们总会因不当操作导致Mac出现各种问题。 要想它长久的陪伴,平时的维护与保养自然不能少,Mac的保养很重要的两点就是硬件保养和电脑系统保养,硬件保养…...
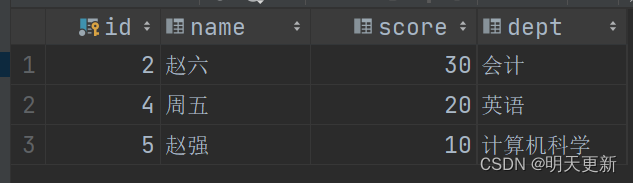
mysql基础之触发器的简单使用
1.建立学生信息表 -- 触发器 -- 建立学生信息表 create table s1(id int unsigned auto_increment,name varchar(30),score tinyint unsigned,dept varchar(50),primary key(id) );2.建立学生补考信息表 -- 建立学生补考信息表 create table s2 like s1;3.建立触发器…...

Spring Boot 配置多数据源【最简单的方式】
Druid连接池 Spring Boot 配置多数据源【最简单的方式】 文章目录 Druid连接池 Spring Boot 配置多数据源【最简单的方式】 0.前言1.基础介绍2.步骤2.1. 引入依赖2.2. 配置文件2.3. 核心源码Druid数据源创建器Druid配置项 DruidConfig 3.示例项目3.1. pom3.1.1. 依赖版本定义3.…...

1、Java简介+DOS命令+编译运行+一个简单的Java程序
Java类型: JavaSE 标准版:以前称为J2SE JavaEE 企业版:包括技术有:Servlet、Jsp,以前称为J2EE JavaME 微型版:以前称为J2ME Java应用: Android平台应用。 大数据平台开发:Hadoo…...

Linux 文件与目录管理,Linux 文件内容查看
目录 Linux 文件与目录管理 处理目录的常用命令 ls (列出目录) mv (移动文件与目录,或修改名称)...
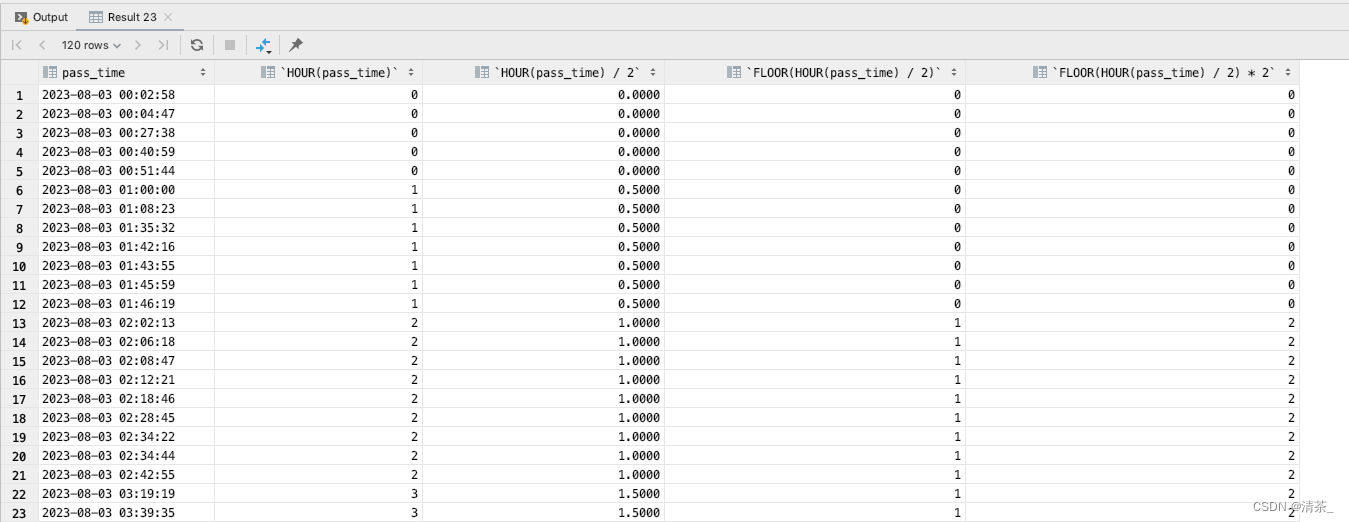
Mysql按小时进行分组统计数据
目录 前言 按1小时分组统计 按2小时分组统计 按X小时分组统计 前言 统计数据时这种是最常见的需求场景,今天写需求时发现按2小时进行分组统计也特别简单,特此记录下。 按1小时分组统计 sql: select hour(pass_time) …...

springboot3日志配置
简介 Spring 使用commons-logging作为内部日志,但是底层日志实现是开放的,可以对接其他日志框架 spring5以及以后common-logging被spring直接自己写了 支持jul, log4j2,logback,springBoot提供了默认的控制台输出配置,也可以配置…...

7款轻量级平面图设计软件推荐
平面图设计的痕迹体现在日常生活的方方面面,如路边传单、杂志、产品包装袋或手机开屏海报等,平面设计软件层出不穷。Photoshop是大多数平面图设计初学者的入门软件,但随着设计师需求的不断提高,平面图设计软件Photoshop逐渐显示出…...
SpringCloud实用篇5——elasticsearch基础
目录 1.初识elasticsearch1.1 了解ES1.1.1 elasticsearch的作用1.1.2 ELK技术栈1.1.3 elasticsearch和lucene1.1.4 总结 1.2.倒排索引1.2.1.正向索引1.2.2.倒排索引1.2.3.正向和倒排 1.3 es的一些概念1.3.1 文档和字段1.3.2 索引和映射1.3.3 mysql与elasticsearch 1.4 部署单点…...
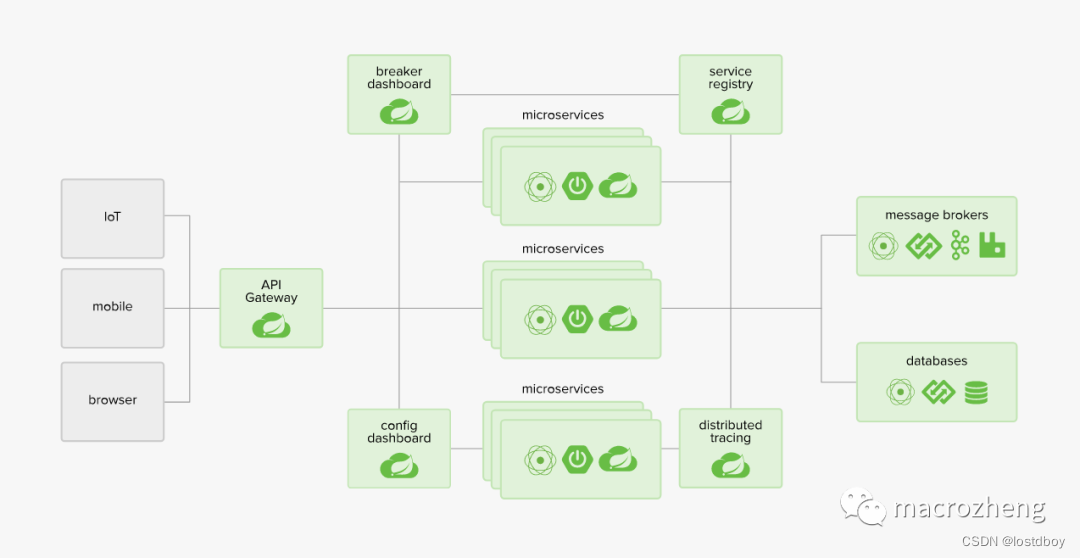
SpringCloud整体架构概览
什么是SpringCloud 目标 协调任何服务,简化分布式系统开发。 简介 构建分布式系统不应该是复杂的,SpringCloud对常见的分布式系统模式提供了简单易用的编程模型,帮助开发者构建弹性、可靠、协调的应用程序。SpringCloud是在SpringBoot的基…...

(el-switch)操作(不使用 ts):Element-plus 中 Switch 将默认值修改为 “true“ 与 “false“(字符串)来控制开关
Ⅰ、Element-plus 提供的 Switch 开关组件与想要目标情况的对比: 1、Element-plus 提供 Switch 组件情况: 其一、Element-ui 自提供的 Switch 代码情况为(示例的代码): // Element-plus 自提供的代码: // 此时是使用了 ts 语言环…...

AI绘画网站都有哪些比较好用?
人工智能绘画网站是一种利用人工智能技术进行图像处理和创作的网站。这些绘画网站通常可以帮助艺术家以人工智能绘画的形式快速生成有趣、美丽和独特的绘画作品。无论你是专业的艺术家还是对人工智能绘画感兴趣的普通人,人工智能绘画网站都可以为你提供新的创作灵感…...

Android应用开发(35)SufaceView基本用法
Android应用开发学习笔记——目录索引 参考Android官网:https://developer.android.com/reference/android/view/SurfaceView 一、SurfaceView简介 SurfaceView派生自View,提供嵌入视图层次结构内部的专用绘图表面,SurfaceView可以在主线程之…...

原生JS手写扫雷小游戏
场景 实现一个完整的扫雷游戏需要一些复杂的逻辑和界面交互。我将为你提供一个简化版的扫雷游戏示例,帮助你入门。请注意,这只是一个基本示例,你可以根据自己的需求进行扩展和改进。 思路 创建游戏板(Grid)࿱…...
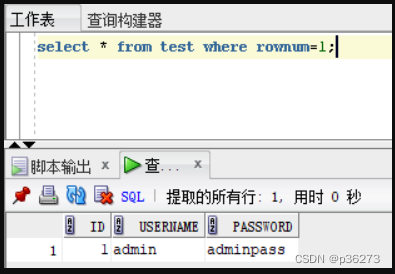
网络安全进阶学习第十五课——Oracle SQL注入
文章目录 一、Oracle数据库介绍二、Oracle和MySQL的语法差异:三、Oracle的数据库结构四、Oracle的重点系统表五、Oracle权限分类1、系统权限2、实体权限3、管理角色 六、oracle常用信息查询方法七、联合查询注入1、order by 猜字段数量2、查数据库版本和用户名3、查…...

线程池死循环系统卡住
案例: 同一个线程池。 首先核心线程数是8,我一次提交了 > 8个主任务,然后主任务又各自开启了几个子任务。 所以子任务没有核心线程来跑,只能放进阻塞队列等。 但主任务又等待子任务的结果,不释放占用线程ÿ…...

ANIMATEDIFF PRO企业落地实践:中小工作室AI视频内容生产提效方案
ANIMATEDIFF PRO企业落地实践:中小工作室AI视频内容生产提效方案 1. 项目概述:电影级AI视频渲染工作站 ANIMATEDIFF PRO是一款专为中小型创意工作室打造的高性能AI视频生成平台。基于先进的AnimateDiff架构和Realistic Vision V5.1模型构建,…...

为什么你的MCP插件在Staging通不过却在Prod崩盘?揭秘环境差异导致的3层依赖漂移真相
更多请点击: https://intelliparadigm.com 第一章:VS Code MCP 插件生态搭建手册 MCP(Model Context Protocol)是新兴的 AI 工具链通信标准,VS Code 通过官方 MCP 客户端插件可无缝对接各类本地大模型服务。本章聚焦于…...

C语言学习笔记 - 17.C编程预备计算机专业知识 - 数据类型
一、数据类型的核心意义编程的第一步是将数据存储到计算机中(如图书管理系统的图书信息、人事管理系统的人员关系)。为了高效存储和处理不同类型的数据,需对数据进行分类,这就是"数据类型"的核心作用。数学中数据分为整…...

嵌入式事件驱动框架zeptoclaw:轻量级任务调度与协作式编程实践
1. 项目概述:一个为嵌入式与边缘计算而生的轻量级控制框架最近在折腾一些嵌入式项目,尤其是基于ESP32、树莓派Pico这类资源受限的MCU(微控制器)时,我总在寻找一个既轻量又灵活的控制框架。传统的实时操作系统ÿ…...

避坑指南:Qt QML地图开发中QtLocation插件加载失败、坐标偏移及手势冲突的解决方案
Qt QML地图开发避坑实战:插件加载、坐标偏移与手势冲突的深度解决方案 当你在Qt QML项目中集成地图功能时,可能会遇到三个令人头疼的问题:QtLocation插件加载失败、地图坐标显示偏移,以及多个手势处理器之间的冲突。这些问题往往…...

TensorRT-LLM与Triton部署AI编程助手实战
1. 基于TensorRT-LLM和Triton的AI编程助手部署指南在当今软件开发领域,AI编程助手正迅速成为开发者日常工作的标配工具。根据行业预测,到2025年,80%的产品开发生命周期将使用生成式AI进行代码编写。本文将手把手教你如何利用NVIDIA TensorRT-…...

Kafka集群管理新选择:深度体验Kafka-UI,对比CMAK/Offset Explorer谁更香?
Kafka集群管理工具横向评测:Kafka-UI与主流方案的深度对比 在分布式消息系统的运维实践中,可视化工具的选择往往决定了团队的管理效率。当命令行操作无法满足日常监控、故障排查和配置管理需求时,一个得心应手的Kafka管理界面就成了技术团队…...

终极指南:如何让Intro.js用户引导完全符合WCAG无障碍标准
终极指南:如何让Intro.js用户引导完全符合WCAG无障碍标准 【免费下载链接】intro.js Lightweight, user-friendly onboarding tour library 项目地址: https://gitcode.com/gh_mirrors/in/intro.js 在当今数字化时代,网站和应用程序的无障碍性已成…...

【20年IDE生态专家实测】:Copilot Next 工作流配置面试通关路径图——含YAML Schema校验、权限沙箱、Telemetry埋点3大权威验证项
更多请点击: https://intelliparadigm.com 第一章:VS Code Copilot Next 自动化工作流配置面试全景概览 VS Code Copilot Next 并非独立产品,而是微软在 VS Code 1.90 版本中深度集成的 AI 编程增强套件,融合 GitHub Copilot Cha…...

PCB制造工艺优化与质量控制关键技术解析
1. PCB制造的核心挑战与应对策略印刷电路板(PCB)作为现代电子产品的核心载体,其制造质量直接影响最终产品的性能和可靠性。在实际生产线上,一块裸板要经历20多道工序才能成为功能完整的电路板。这个过程中,工艺工程师面临的最大挑战是如何在保…...