LLM - Transformer LLaMA2 结构分析与 LoRA 详解
目录
一.引言
二.图说 LLM
1.Transformer 结构
◆ Input、Output Embedding
◆ PositionEmbedding
◆ Multi-Head-Attention
◆ ADD & Norm
◆ Feed Forward
◆ Linear & Softmax
2.不同 LLM 结构
◆ Encoder-Only
◆ Encoder-Decoder
◆ Decoder-Only
3.LLaMA-2 结构
◆ Input Embedding
◆ RMSNorm
◆ RoPE
◆ Attention
◆ SwiGLU
◆ MLP
三.数说 LoRA
1.LLaMA-2 7B 原始参数
2.LLaMA-2 7B LoRA 参数
3.Peft Add LoRA Adapter
◆ LoraModel
◆ add_adapter
◆ _find_and_replace
◆ mark_only_lora_as_trainable
◆ Linear
◆ update_layer
◆ reset_lora_parameters
四.总结
一.引言
大模型进行 Lora 微调时,需要指定 lora_target,以 LLama2 为例,官方指出可以使用下述层:
--lora_target 'q_proj,v_proj,k_proj,o_proj,gate_proj,down_proj,up_proj'看过 Transformer 的同学对 Q/K/V 肯定不陌生,但是 gate、up、down 又是什么鬼;还有 Lora 指定不同 lora_target 时可训练参数会调整,具体每个地方增加了多少参数也没搞明白。结合上述问题,博主本文对 Transformer、LLaMA-2 以及 LoRA 的一些基础知识进行分享~
二.图说 LLM
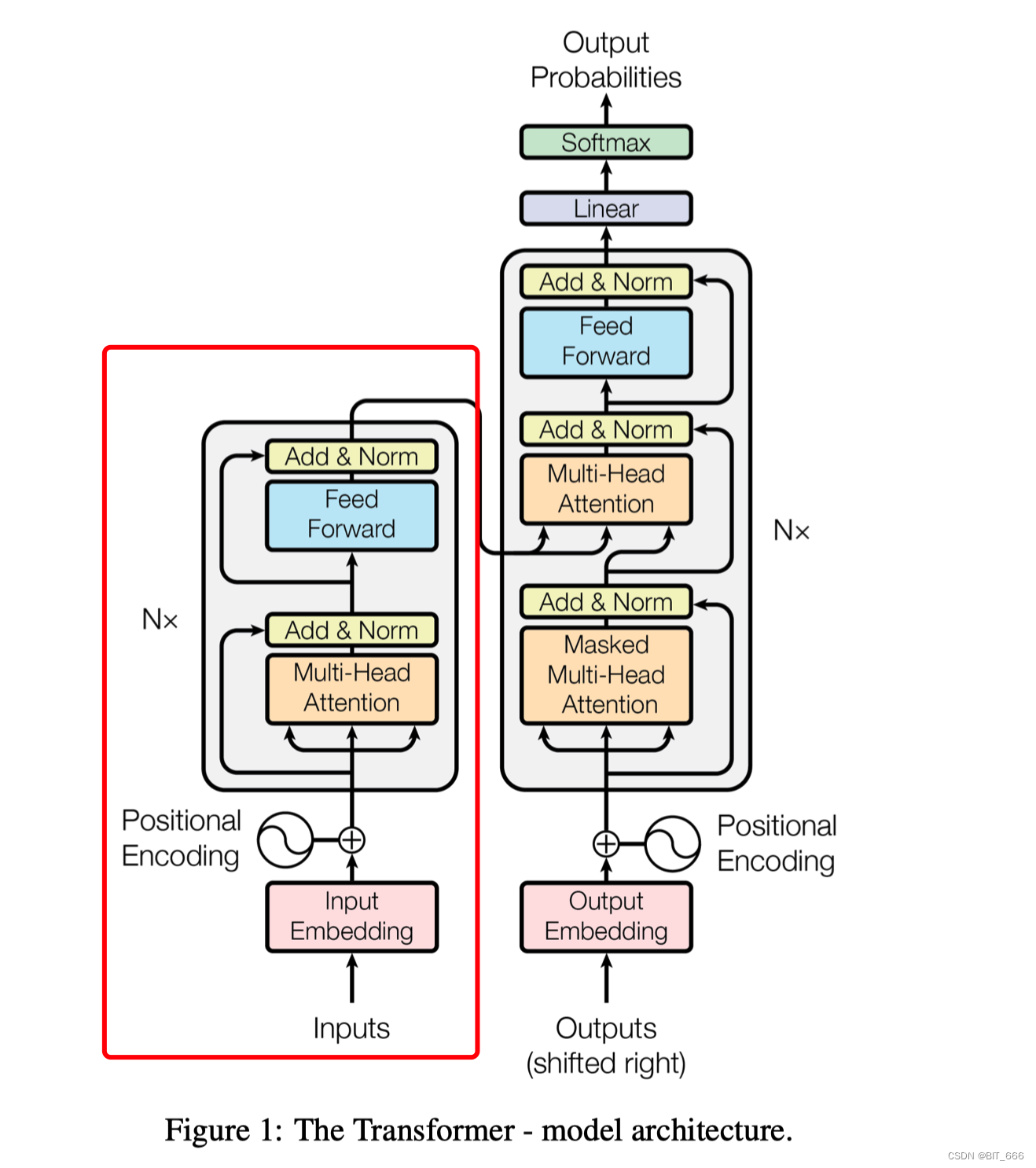
1.Transformer 结构

左侧为多个 Encoder Block 叠加,右侧为多个 Decoder Block 叠加,二者合在一起为整体的 Transformer 结构。关于 Transformer 这里简单介绍其各个结构,更具体的详解会在文末给出参考链接,大家可以深入学习。
◆ Input、Output Embedding

NLP 最基本的 Embedding 层,可以通过 Word2vec、Bert 等预训练方式获取 Token_Id 的 Embedding,也可以端到端训练得到,当我们输入原始文本后,Text 经过 Tokenizer 处理得到 Input_ids,Input_ids 再经过 Embedding 层就获得原始的词向量了。
◆ PositionEmbedding
![]()
除了原始的单词 Embeeding 外,Transformer 还引入了 position Embedding 表示单词在句子中的位置。实验表明,引入 Position Embedding 比不引入 Position Embedding 的效果更好,一般 PositionEmbedding 用于表示单词在句子中的绝对位置或相对位置。Position Embedding 维度与上面的单词 Embeeding 维度相同,可以训练也可以使用公式计算,Transformer 中采用了后者,计算公式为:
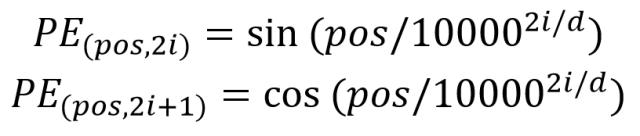
- pos 代表单词在句子中的位置
- d 标识 Position Embedding 的维度
- 2i、2i+1 标识偶数和奇数的维度
计算得到 PE 后与原 Embeeding 相加进入后续逻辑。
Tips:
这里奇数和偶数位置的编码方法使用了正弦 sin 和余弦 cos 的不同的函数。这里奇数位置和偶数位置的区别在于他们所应用的正弦和余弦函数的角频率,通过调整角频率,可以使得奇数和偶数位置的编码方式有所不同。通过调整角频率,可以使得奇数和偶数位置编码的值在编码空间呈现不同的变化模式。这样的设计旨在为相邻位置提供不同的位置编码,以增加模型对序列中位置信息的敏感度。
◆ Multi-Head-Attention
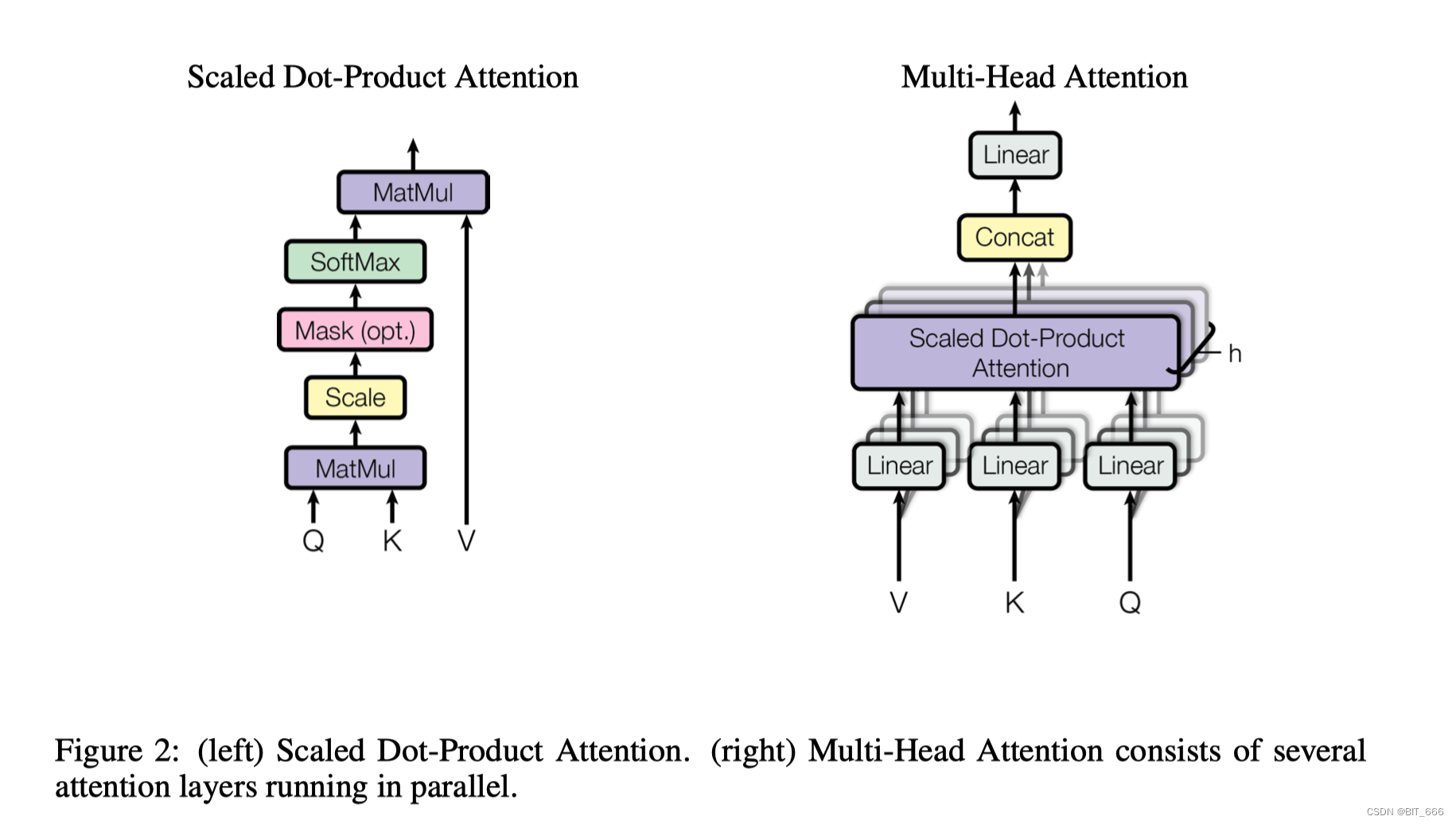
上图为 Multi-Head Attention [多头注意力] 结构,在计算的时候,会将 Embedding + Position Embeeding 相加的结果,分别经过 Q-Query-Linear、K-Key-Linear 和 V-Value-Linear 进行一次线性变换送入后续逻辑。
Scaled Dot-Product 负责将 Linear 转化的 Q/K/V 进行 Attention 计算,其中 Q/K MatMul 乘法后为了防止内积过大,会除以 进行 Scale 操作,最后通过 Softmax 归一化并与 Value 向量相乘得到最后的输出。
Multi-Head Attention 旨在学习向量不同特征空间的表现,所以 Multi-Head Attention 会有多个 Linear 和 Scaled Dot-Product,最终将多个 head 对应的 Attention 结果 Concat 再过一层 Linear 传到下一层作为 Input。
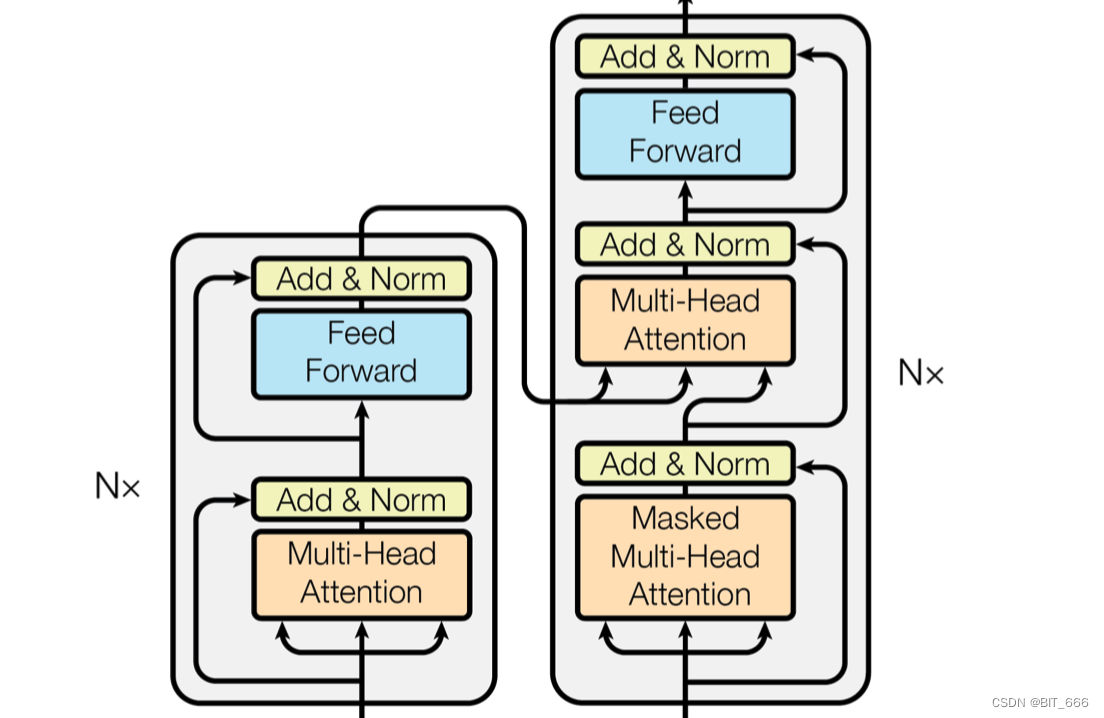
◆ ADD & Norm
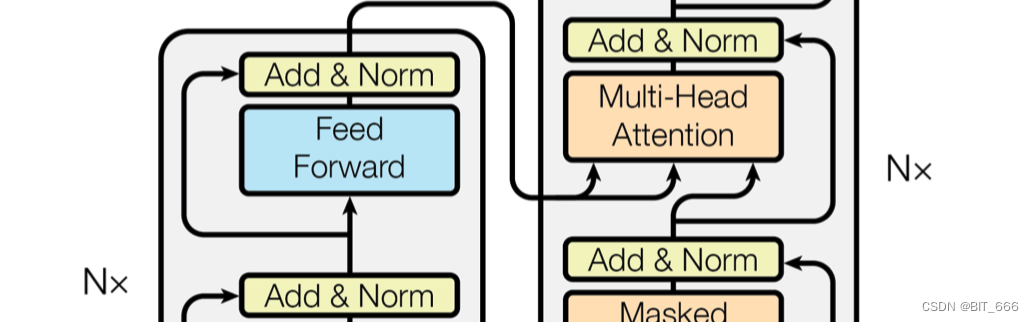
ADD & Norm 看字面意思就知道它是由 ADD 和 Norm 两个部分组成,其计算公式如下:

其中 X 代表上一步的输出,从图中可以看到 Feed Forward 和 Multi-Head Attention 都会输出到 ADD & Norm 层,这里结构与 RNN 的残差网络类似,将原始输入与上一步的输出相加。结果相加后通过 Norm 层就行归一化加速收敛。
◆ Feed Forward
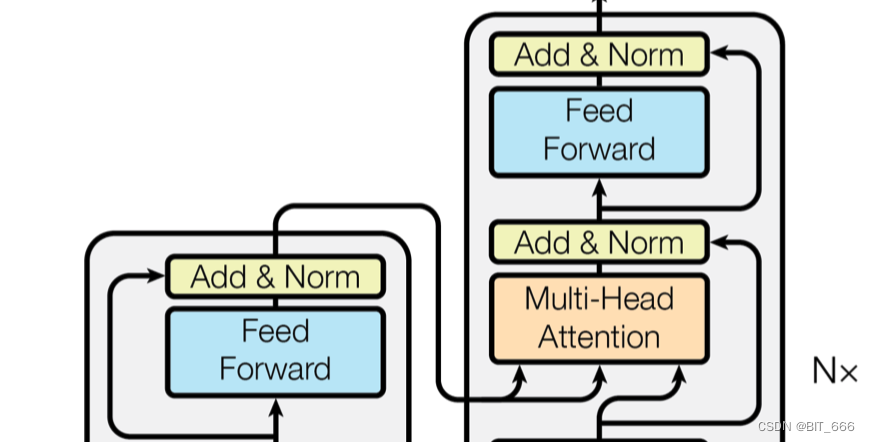
Feed Forward 层采用两层全连接,第一层为 Relu 第二层不使用激活函数。
![]()
◆ Linear & Softmax
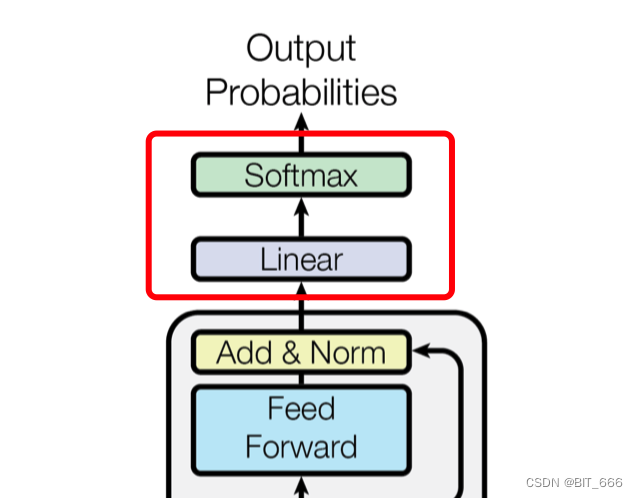
经过多层 Block 的堆叠,终于到达最终的 Linear 层,使用 LLM 我们常看到的 lm_head 就是一种 Linear,该层负责生成语言模型的输出。它是模型架构中的最后一层,用于将 Transformer 编码器的输出转化为预测下一个词或生成文本的概率分布。
具体来说,Linear 层会对编码器的输出进行线性变换,将其映射到与词汇表大小相同的向量空间。这样做的目的是为了预测下一个词的概率分布。通常,线性变换后的输出经过 softmax 函数处理,以获得归一化的概率分布,其中每个词的概率表示在给定前文条件下该词是下一个出现的可能性。
在训练阶段,可以使用交叉熵损失函数来比较模型输出的概率分布与实际的下一个词的标签,并通过反向传播更新模型参数。而在生成阶段,可以根据概率分布进行采样,以生成连贯的文本。
2.不同 LLM 结构
最新的大语言模型基本都是基于上述 Transformer 结构进行拓展:
◆ Encoder-Only
▲ 包含一个单独的编码器,没有显式的解码器部分。
▲ 主要用于 AutoEncoder 等任务,其主要学习数据的压缩标识
Encoder-Only 学习的压缩表示可以用于特征提取,数据降维等任务,具有较好的泛化能力。最常见的就是 Bert,这里所有输出 token 都能看到过去和未来的所有输入 Token,因此对于 NLU [Natural Language Understanding] 自然语言文本理解和分析的任务很友好。
Tips 常见的 NLU 任务如下:
- 语句分类 [Sentence Classification] 根据给定文本判断其标签,如情感分类、垃圾邮件分类
- 意图识别 [Intent Recognition] 识别用户输入表的的意图或目的,如天气、餐厅查询
- 实体识别 [Named Entity Recognition] 从文本中识别标注实体,如人名、地点识别
- 信息抽取 [Infomation Extraction] 从文本中提取特定含义信息,如从新闻提取摘要
- 关系抽取 [Relation Extraction] 识别本文与实体的关系,如 "Apple" 与 "Steve Jobs" 的关系
- 问答系统 [Question Answering] 为给定问题找到答案,如阅读理解,知识库问答。
这些任务旨在让计算机能够理解和处理自然语言文本,从而支持各种应用场景,如智能助手、虚拟客服、搜索引擎等。NLU 任务的目标是将自然语言转化为结构化的表示形式,以便计算机能够更好地理解和响应用户的需求。
◆ Encoder-Decoder
▲ 由一个编码器和一个解码器组成,常用于序列到序列(Sequence-to-Sequence)任务,如机器翻译、语音识别等。
▲ 编码器将输入序列编码为固定长度的向量,解码器从该向量生成输出序列。
Encoder-Decoder 适用于需要输入和输出之间存在复杂映射的任务,能够处理变长序列,并且可以用于翻译、生成等多种任务。GLM、T5、Bart 都已普遍应用。
◆ Decoder-Only
Decoder-Only 相比前两个分支明显枝繁叶茂,硕果累累,最出名的就算是 GPT 家族了。
▲ 只包含解码器部分,没有显式的编码器。通常用于条件生成任务,其中给定一些条件信息,模型通过解码器生成相应的输出。
▲ 与 Encoder 相比二者 Multi-Head Attention 相差一个 MASK,会导致前文无法使用后文未知的消息,第二个 Multi-Head Attention 则与 Encoder 相似。
实际应用中,Decoder-Only 适用于从条件信息中生成输出的任务,例如图像描述生成,文本生成。常见的 chat 模型就基于 Decoder-Only。
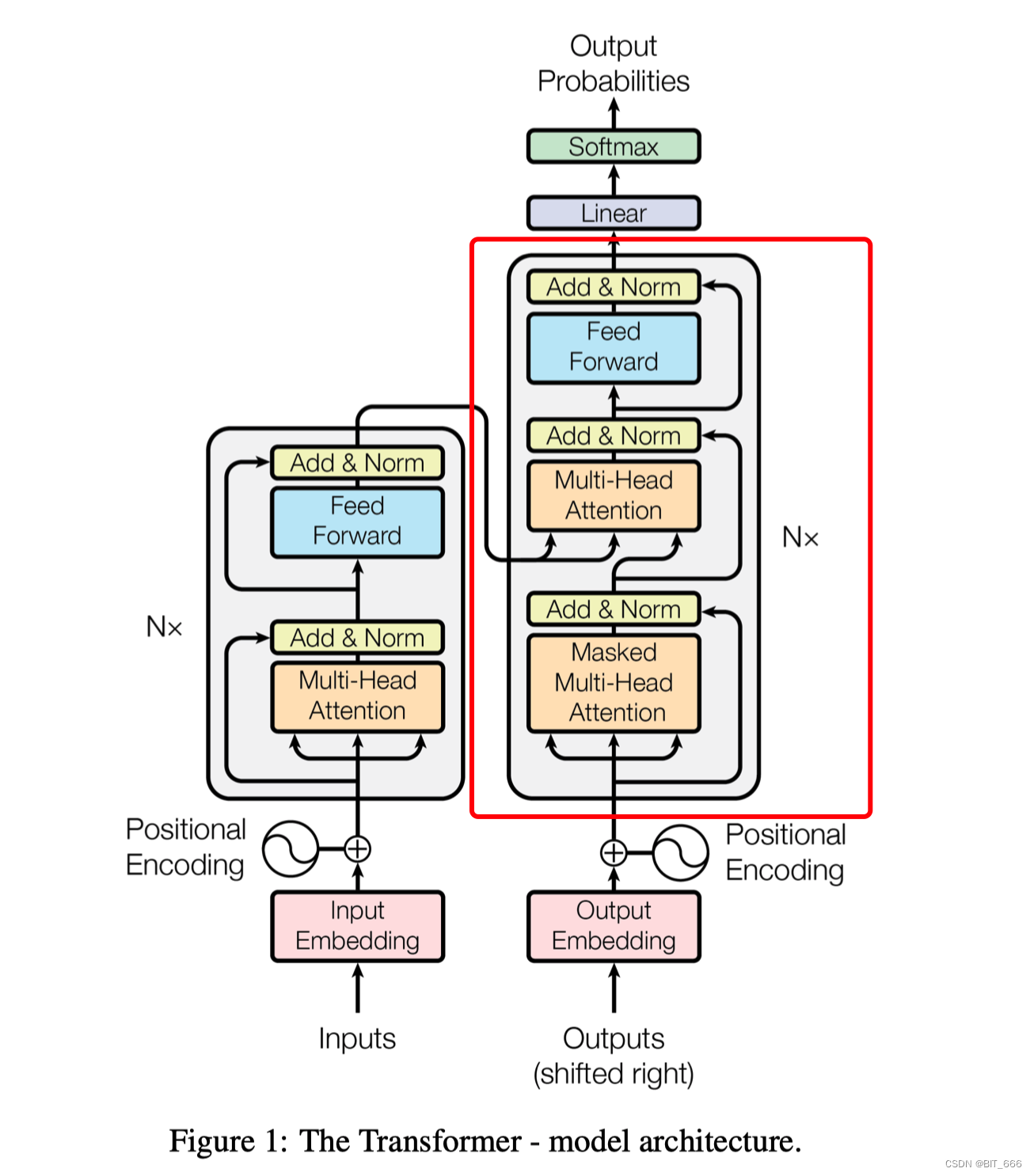
3.LLaMA-2 结构

LLaMA-2 采用 Decoder-Only 的架构,由 Attention 和 MLP 层堆叠而成,Lora 微调 LLaMA-2 时这些 target 对应的结构也能在图中找出了。
--lora_target 'q_proj,v_proj,k_proj,o_proj,gate_proj,down_proj,up_proj'与传统 Transformer 结构相比,其主要做了如下修改:
▲ RMSNorm - 传统结构 Norm 放在 Att 后,这里将 Norm 前置
▲ RoPE 编码 - 更换了 Position Embedding 的编码方式
▲ MLP 层更新 - 增加了 UP 和 Donw 的线性层并使用 SiLU 激活
与 LLaMA-1 相比,其增加了一倍 Context Length 达到 4096,使其处理长文本能力更强:

◆ Input Embedding
这里与常规 transformer 的输入层逻辑一致。
◆ RMSNorm

Bert、GPT 常用的均值方差归一化 LayerNorm 为:
RMS 意为 root mean square 均方根,用于衡量一组数值的平均值大小:
RMSNorm 发现 LayerNorm 的取消中心偏移即 Mean(x) 效果激活不变且可以提高计算效率,最终公式为:
LLaMA-2 在 Embedding 和 Attention Output 后都引入了 RMSNorm。
◆ RoPE

对于 Q-Query、K-Key 第 m 个位置的向量 q,通过下述方法得到 Position Embedding:
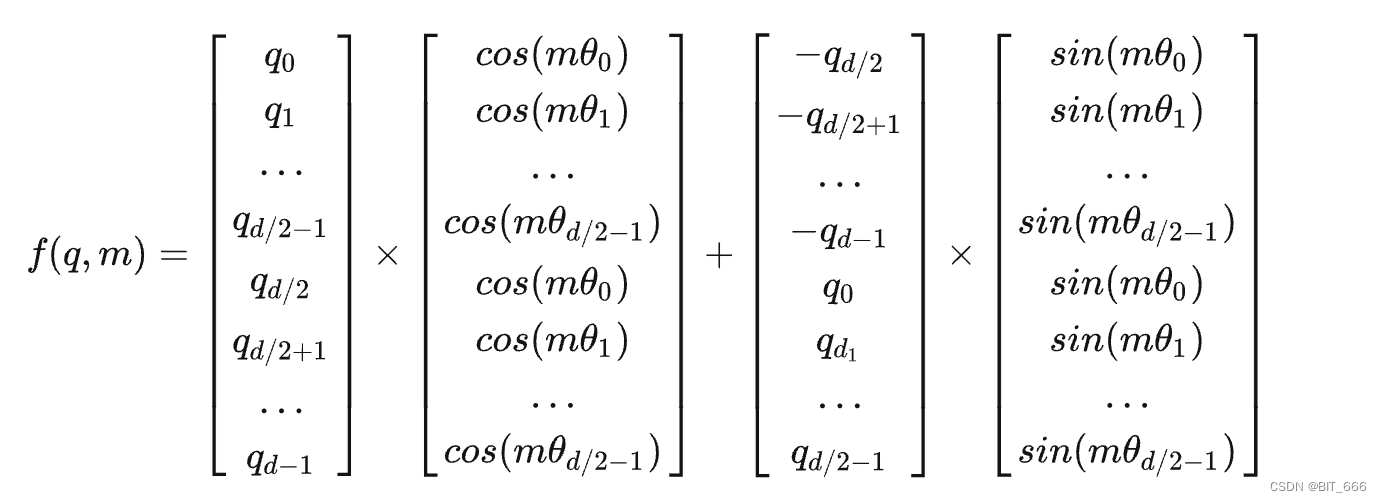
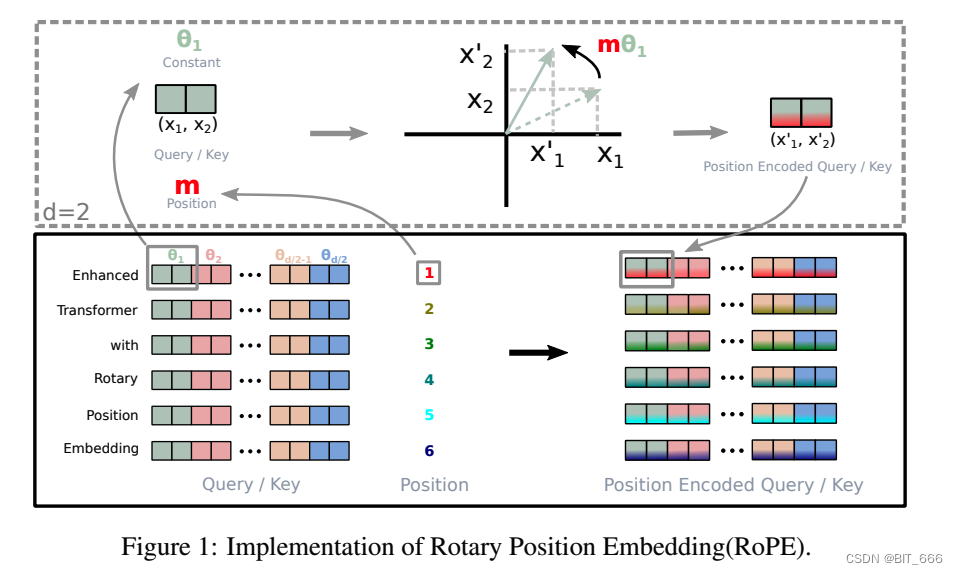
d 为 Embedding 的维度,θ 为预设的非零常数,RoPE 旋转位置嵌入的实现过程如下图:
◆ Attention
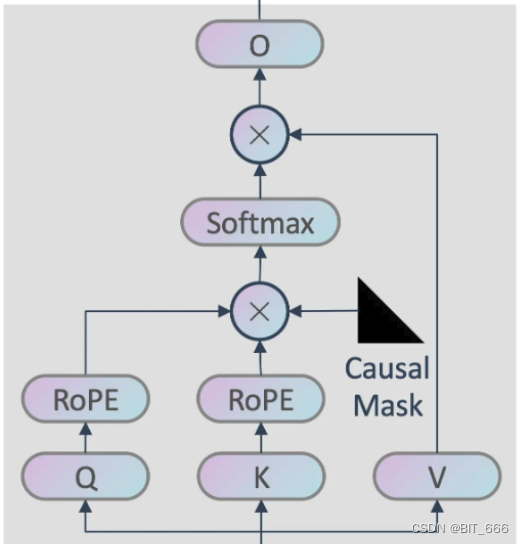
Attention 部分的 QKV 与先前相似,除了引入 RoPE 旋转位置嵌入外,还引入了 Causal Mask:
Causal Mask 的引入使得前文无法获得下文的知识,例如 'I love eating lunch' 中 love 只能获得 'I' 和 'love' 的信息。剩下就是常规的 Attention 与 Softmax 操作,最后的 o 代表 Output,其参数维度与 Q/K/V 的 Linear 相同。
◆ SwiGLU
SwiGLU 又称 SiLU,与 GeGLU 相比用 Swish 替代了 GeLU:

其中 ⓧ 代表逐元素乘法,Swish 公式为:
其中 σ 代表 sigmoid 函数,其示意图如下:
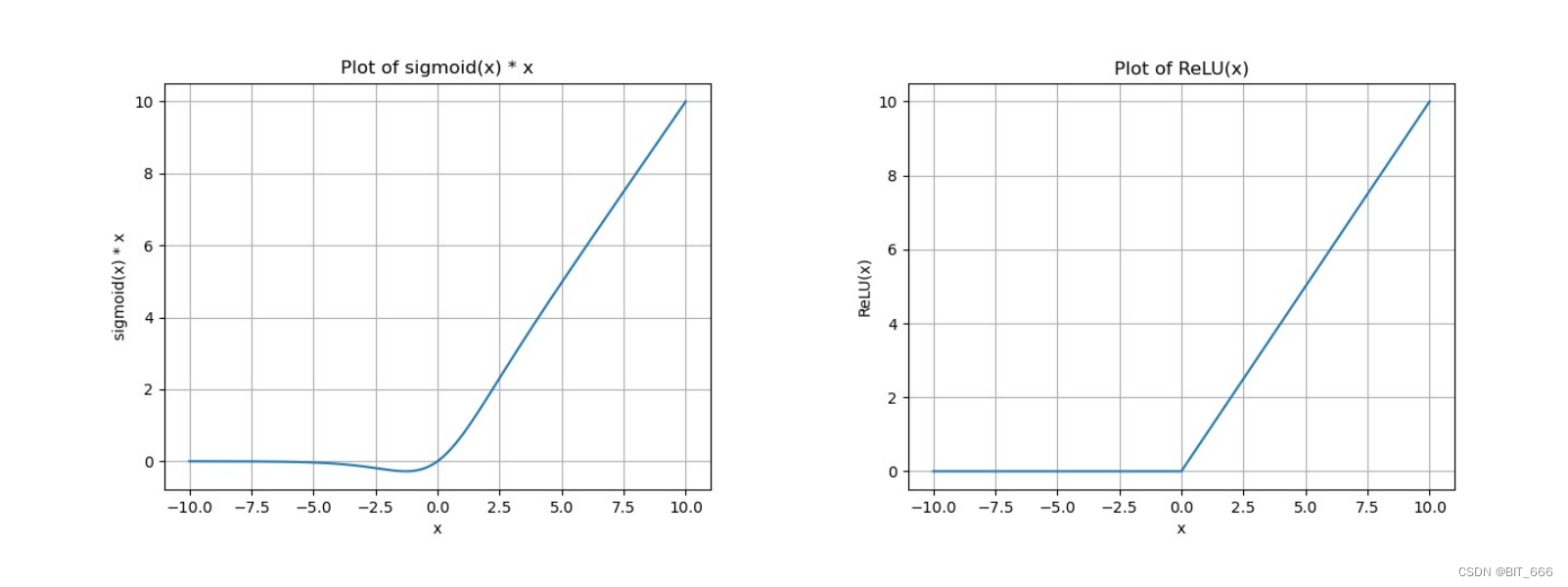
从图像可以看出 SiLU 更像是 ReLU 的平滑版本。
◆ MLP

这里 MLP 的表达式为:
其中 up、down 与 gate 是三个维度相同的 Linear 层。
三.数说 LoRA
1.LLaMA-2 7B 原始参数
model = AutoModelForCausalLM.from_pretrained(base_model,config=config,torch_dtype=torch.float16,low_cpu_mem_usage=True,trust_remote_code=True,revision='main')model_vocab_size = model.get_input_embeddings().weight.size(0)tokenzier_vocab_size = len(tokenizer)print(model.get_input_embeddings().weight.size())print(f"Vocab of the base model: {model_vocab_size}")print(f"Vocab of the tokenizer: {tokenzier_vocab_size}")for name,param in model.named_parameters():print(name, param.numel(), param.requires_grad)这里我们直接加载 LLaMA-2 7B 模型,看看每一层参数的情况:
model.embed_tokens.weight 131072000 True
model.layers.0.self_attn.q_proj.weight 16777216 True
model.layers.0.self_attn.k_proj.weight 16777216 True
model.layers.0.self_attn.v_proj.weight 16777216 True
model.layers.0.self_attn.o_proj.weight 16777216 True
model.layers.0.mlp.gate_proj.weight 45088768 True
model.layers.0.mlp.down_proj.weight 45088768 True
model.layers.0.mlp.up_proj.weight 45088768 True
model.layers.0.input_layernorm.weight 4096 True
model.layers.0.post_attention_layernorm.weight 4096 True...
model.layers.31.self_attn.q_proj.weight 16777216 True
model.layers.31.self_attn.k_proj.weight 16777216 True
model.layers.31.self_attn.v_proj.weight 16777216 True
model.layers.31.self_attn.o_proj.weight 16777216 True
model.layers.31.mlp.gate_proj.weight 45088768 True
model.layers.31.mlp.down_proj.weight 45088768 True
model.layers.31.mlp.up_proj.weight 45088768 True
model.layers.31.input_layernorm.weight 4096 True
model.layers.31.post_attention_layernorm.weight 4096 True
model.norm.weight 4096 True
lm_head.weight 131072000 True这里可以看到 LLaMA-2 7B 共堆叠了 32 个 Block,其中有我们 lora_target 熟悉的层:
--lora_target 'q_proj,v_proj,k_proj,o_proj,gate_proj,down_proj,up_proj'通过上面 LLaMA-2 结构的分析,相信这几个层在哪我们起码已经知道了,下面看看每一个 Block 的参数量:

前面已经介绍了 LLaMA-2 将 Context Length 扩展至 4096,这里 layernorm 参数量为 4096,一个单独 Block 的参数量为 2 亿左右。再看下整体的参数量:
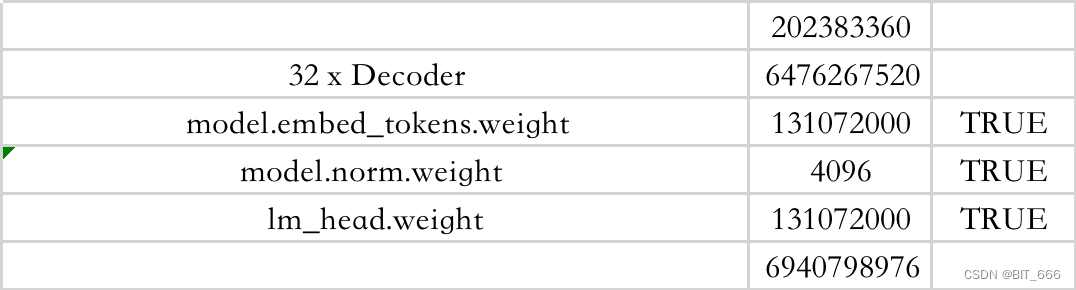
这里打印得到的 Token 数为 32000,32000 * 4096 = 131072000 与 Input Embedding 和 lm_head 层的参数可以匹配。32 个 Decoder 再加上 Norm 和最后的 lm_head,总参数 6.94B ≈ 7B。
2.LLaMA-2 7B LoRA 参数
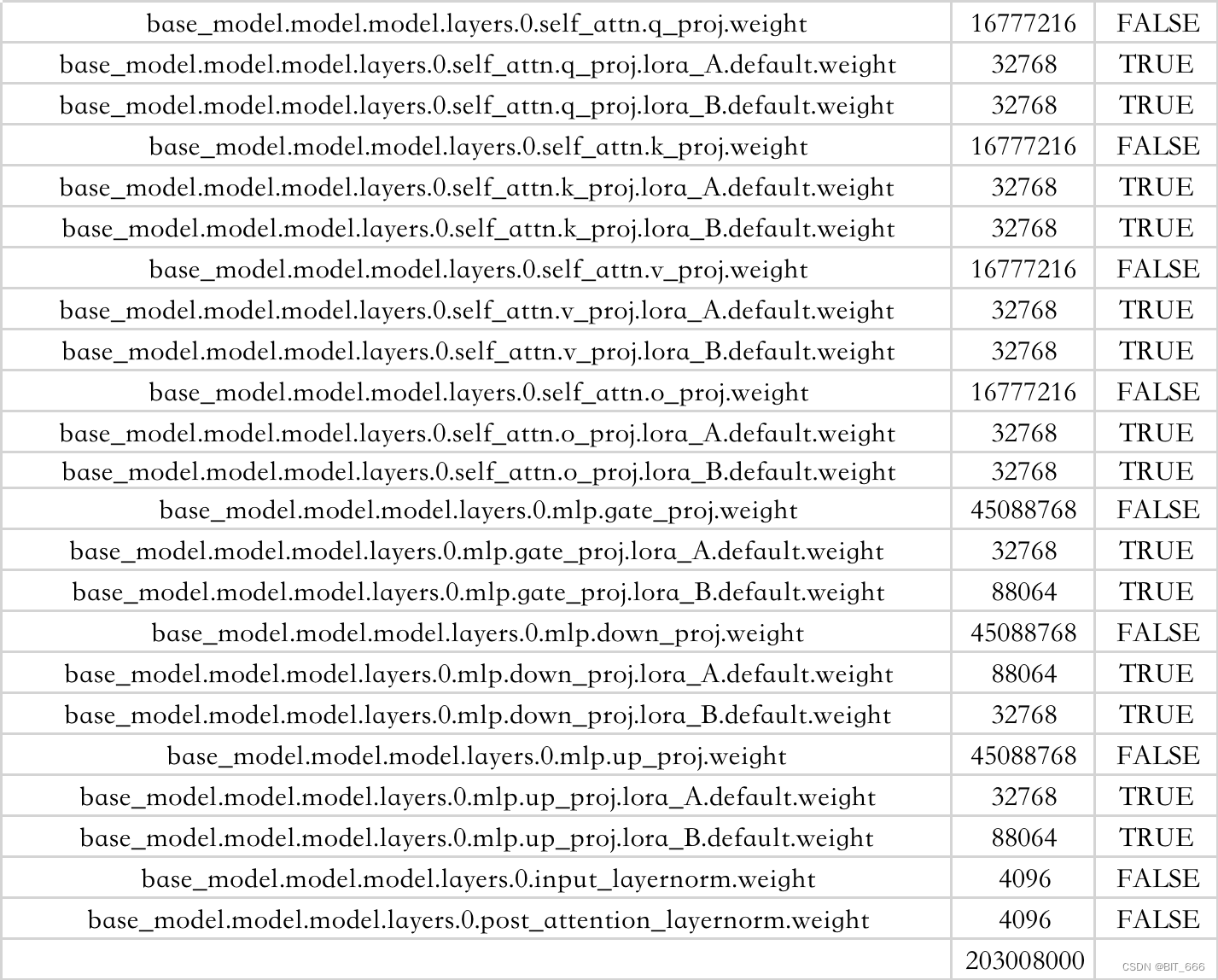
lora_config = LoraConfig(task_type=TaskType.CAUSAL_LM,inference_mode=False,r=8,lora_alpha=32,lora_dropout=0.1,target_modules=["q_proj","v_proj","k_proj","o_proj","gate_proj","down_proj","up_proj"])model = get_peft_model(model, lora_config)for name,param in model.named_parameters():print(name, param.numel(), param.requires_grad)增加 LoraConfig 结合 peft 获取 LoRA 后的模型,这里秩 r = 8,再看下每层的情况:
base_model.model.model.embed_tokens.weight 131072000 False
base_model.model.model.layers.0.self_attn.q_proj.weight 16777216 False
base_model.model.model.layers.0.self_attn.q_proj.lora_A.default.weight 32768 True
base_model.model.model.layers.0.self_attn.q_proj.lora_B.default.weight 32768 True
base_model.model.model.layers.0.self_attn.k_proj.weight 16777216 False
base_model.model.model.layers.0.self_attn.k_proj.lora_A.default.weight 32768 True
base_model.model.model.layers.0.self_attn.k_proj.lora_B.default.weight 32768 True
base_model.model.model.layers.0.self_attn.v_proj.weight 16777216 False
base_model.model.model.layers.0.self_attn.v_proj.lora_A.default.weight 32768 True
base_model.model.model.layers.0.self_attn.v_proj.lora_B.default.weight 32768 True
base_model.model.model.layers.0.self_attn.o_proj.weight 16777216 False
base_model.model.model.layers.0.self_attn.o_proj.lora_A.default.weight 32768 True
base_model.model.model.layers.0.self_attn.o_proj.lora_B.default.weight 32768 True
base_model.model.model.layers.0.mlp.gate_proj.weight 45088768 False
base_model.model.model.layers.0.mlp.gate_proj.lora_A.default.weight 32768 True
base_model.model.model.layers.0.mlp.gate_proj.lora_B.default.weight 88064 True
base_model.model.model.layers.0.mlp.down_proj.weight 45088768 False
base_model.model.model.layers.0.mlp.down_proj.lora_A.default.weight 88064 True
base_model.model.model.layers.0.mlp.down_proj.lora_B.default.weight 32768 True
base_model.model.model.layers.0.mlp.up_proj.weight 45088768 False
base_model.model.model.layers.0.mlp.up_proj.lora_A.default.weight 32768 True
base_model.model.model.layers.0.mlp.up_proj.lora_B.default.weight 88064 True
base_model.model.model.layers.0.input_layernorm.weight 4096 False
base_model.model.model.layers.0.post_attention_layernorm.weight 4096 False...
base_model.model.model.norm.weight 4096 False
base_model.model.lm_head.weight 131072000 False依旧是 32 个 Decoder 的堆叠,可以看到在我们制定的 target_model 上都增加了对应的 LoRA weight,由于我们的 Context Length x r = 4096 x 8 = 32768 可得矩阵 A 的维度,通过 lora_B 的 88604 维度也可以反推出,88604 / 8 = 11008 矩阵 B 的维度 8 x 11008,不过看原图中 LoRA 的维度是属于 ,这里有一点疑问,大家可以提供下思路:

单个 Decoder 参数量:
参数量为 2 亿,可以看到 r = 8 较低时,整体训练的参数量占比很低,我们计算下 r = 8 时全部可训练参数的占比:

624640 * 32 [32 个 Decoder 的 Lora 参数量] / (6940798976 [LLaMA-2 7B 总参数量] + 624640 * 32) = 0.002871583154398789,只占总参数比的 0.287%,所以一直都说 LoRA 可以有效减少参数训练量。同理,根据上面的 API 和算法,我们可以计算不同秩 r 对应的可选参数量并打印:

3.Peft Add LoRA Adapter
代码版本为 peft==0.4.0,类位置为:src/peft/tuners/lora.py
◆ LoraModel
class LoraModel(torch.nn.Module):"""Creates Low Rank Adapter (Lora) model from a pretrained transformers model."""def __init__(self, model, config, adapter_name):super().__init__()self.model = modelself.forward = self.model.forwardself.peft_config = configself.add_adapter(adapter_name, self.peft_config[adapter_name])# transformers models have a .config attribute, whose presence is assumed later onif not hasattr(self, "config"):self.config = {"model_type": "custom"}LoraModel 初始化除了获取原始的基模型和 peft_config 外,执行了 add_adapter 添加 LoRA 层的逻辑,下面我们看下 add_adapter 方法主要实现什么功能。
◆ add_adapter
def add_adapter(self, adapter_name, config=None):if config is not None:model_config = getattr(self.model, "config", {"model_type": "custom"})if hasattr(model_config, "to_dict"):model_config = model_config.to_dict()config = self._prepare_lora_config(config, model_config)self.peft_config[adapter_name] = configself._find_and_replace(adapter_name)if len(self.peft_config) > 1 and self.peft_config[adapter_name].bias != "none":raise ValueError("LoraModel supports only 1 adapter with bias. When using multiple adapters, set bias to 'none' for all adapters.")mark_only_lora_as_trainable(self.model, self.peft_config[adapter_name].bias)if self.peft_config[adapter_name].inference_mode:_freeze_adapter(self.model, adapter_name)这里 config 配置部分我们先忽略,主要注意这两行:
_find_and_replace -> 寻找并替换
mark_only_lora_as_trainable -> 标记 lora 层可训
◆ _find_and_replace
def _find_and_replace(self, adapter_name):lora_config = self.peft_config[adapter_name]self._check_quantization_dependency()is_target_modules_in_base_model = False# 获取模型内层的 Namekey_list = [key for key, _ in self.model.named_modules()]for key in key_list:# 检查是否为 lora_target 指定的 layerif not self._check_target_module_exists(lora_config, key):continueis_target_modules_in_base_model = Trueparent, target, target_name = _get_submodules(self.model, key)if isinstance(target, LoraLayer) and isinstance(target, torch.nn.Conv2d):...elif isinstance(target, LoraLayer) and isinstance(target, torch.nn.Embedding):...elif isinstance(target, LoraLayer):...# Conv2D、Embedding 和 loraLayer 的情况忽略# 因为我们这里是为 Base Model 增加 LoRA Layer,所以进入 else 逻辑else:new_module = self._create_new_module(lora_config, adapter_name, target)self._replace_module(parent, target_name, new_module, target)if not is_target_modules_in_base_model:raise ValueError(f"Target modules {lora_config.target_modules} not found in the base model. "f"Please check the target modules and try again.")这里先用 model.named_modules 获取 Base Model 全部层的 name,例如 layers.x.mlp.up_proj,随后遍历每一个 name 是否属于 lora_target 所指范畴,随后根据 lora_config 调用_create_new_module 获取新的 Lora Adapter,最后执行 _replace_module。如果 target_modules 不存在于 base_model,会抛出异常。例如我们将 Baichuan 的 'W_pack' 传给 LLaMA-2 就会抛出该异常。
▲ _create_new_module
根据 in_features 和 out_features 与 bias 构建 Linear 层。
new_module = Linear(adapter_name, in_features, out_features, bias=bias, **kwargs)
▲ _replace_module
将 old_model 的 weight 和 bias 赋值到 new_model,并 to_device 将 new_model 分配到 old_model 对应的 device 上。
def _replace_module(self, parent_module, child_name, new_module, old_module):setattr(parent_module, child_name, new_module)new_module.weight = old_module.weightif hasattr(old_module, "bias"):if old_module.bias is not None:new_module.bias = old_module.biasif getattr(old_module, "state", None) is not None:new_module.state = old_module.statenew_module.to(old_module.weight.device)# dispatch to correct devicefor name, module in new_module.named_modules():if "lora_" in name:module.to(old_module.weight.device)if "ranknum" in name:module.to(old_module.weight.device)◆ mark_only_lora_as_trainable
# had to adapt it for `lora_only` to work
def mark_only_lora_as_trainable(model: nn.Module, bias: str = "none") -> None:for n, p in model.named_parameters():if "lora_" not in n:p.requires_grad = Falseif bias == "none":returnelif bias == "all":for n, p in model.named_parameters():if "bias" in n:p.requires_grad = Trueelif bias == "lora_only":for m in model.modules():if isinstance(m, LoraLayer) and hasattr(m, "bias") and m.bias is not None:m.bias.requires_grad = Trueelse:raise NotImplementedError判断 lora_ 是否在 param_name 中,随后决定是否训练。
◆ Linear
class Linear(nn.Linear, LoraLayer):# Lora implemented in a dense layerdef __init__(self,adapter_name: str,in_features: int,out_features: int,r: int = 0,lora_alpha: int = 1,lora_dropout: float = 0.0,fan_in_fan_out: bool = False, # Set this to True if the layer to replace stores weight like (fan_in, fan_out)is_target_conv_1d_layer: bool = False,**kwargs,):init_lora_weights = kwargs.pop("init_lora_weights", True)nn.Linear.__init__(self, in_features, out_features, **kwargs)LoraLayer.__init__(self, in_features=in_features, out_features=out_features)# Freezing the pre-trained weight matrix 原始 weight Freezingself.weight.requires_grad = Falseself.fan_in_fan_out = fan_in_fan_outif fan_in_fan_out:self.weight.data = self.weight.data.T# 初始化 LoRA 参数并更新 LoRA-A LoRA-Bnn.Linear.reset_parameters(self)self.update_layer(adapter_name, r, lora_alpha, lora_dropout, init_lora_weights)self.active_adapter = adapter_nameself.is_target_conv_1d_layer = is_target_conv_1d_layer上面 _create_new_module 方法根据 fan_in、fan_out 创建了 Linear,这里 Linear 也是 Lora 类中实现的,继承了 nn.linear,主要关注 update_layer 方法。
◆ update_layer
def update_layer(self, adapter_name, r, lora_alpha, lora_dropout, init_lora_weights):self.r[adapter_name] = rself.lora_alpha[adapter_name] = lora_alphaif lora_dropout > 0.0:lora_dropout_layer = nn.Dropout(p=lora_dropout)else:lora_dropout_layer = nn.Identity()self.lora_dropout.update(nn.ModuleDict({adapter_name: lora_dropout_layer}))# Actual trainable parametersif r > 0:self.lora_A.update(nn.ModuleDict({adapter_name: nn.Linear(self.in_features, r, bias=False)}))self.lora_B.update(nn.ModuleDict({adapter_name: nn.Linear(r, self.out_features, bias=False)}))self.scaling[adapter_name] = lora_alpha / rif init_lora_weights:self.reset_lora_parameters(adapter_name)self.to(self.weight.device)首先根据 lora_config 定义 lora_alpha 和 lora_dropout_ratio,如果 r > 0 则 update lora_A 和 lora_B,scaling 层根据 lora_alpha 和 r 计算,最后 reset_lora_parameters。
◆ reset_lora_parameters
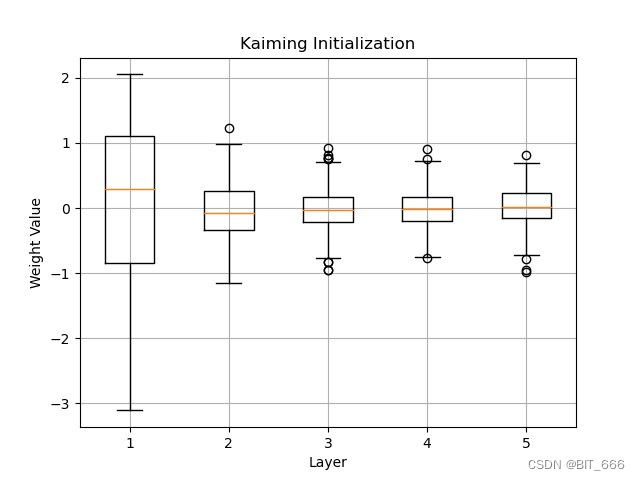
def reset_lora_parameters(self, adapter_name):if adapter_name in self.lora_A.keys():# initialize A the same way as the default for nn.Linear and B to zeronn.init.kaiming_uniform_(self.lora_A[adapter_name].weight, a=math.sqrt(5))nn.init.zeros_(self.lora_B[adapter_name].weight)if adapter_name in self.lora_embedding_A.keys():# initialize a the same way as the default for nn.linear and b to zeronn.init.zeros_(self.lora_embedding_A[adapter_name])nn.init.normal_(self.lora_embedding_B[adapter_name])这里 lora_A 采用 Kaiming 初始化,这是一种常用的神经网络权重初始化方法,旨在有效地初始化深度神经网络,lora_B 采用零初始化。不过 lora_A 这里与原文的正态分布初始化有所不同。
四.总结
这里整理了 Transformer 、LLM 和 LoRA 的一些基础知识,结合最后 LoRA 的参数量与代码,我们可以很轻松的得到可训的参数与参数量,同时也可以在 LoRA 的时候增加更多自定义的功能。
!!! 最后特别感谢下面大佬们的输出:
Transformer: Transformer模型详解(图解最完整版) - 知乎
LLaMA V1/2: LLaMA v1/2模型结构总览 - 知乎
LLM 基座: [Transformer 101系列] 初探LLM基座模型 - 知乎
GLU: https://arxiv.org/pdf/2002.05202.pdf
LLaMA 2: https://arxiv.org/pdf/2307.09288.pdf
RoPE: https://arxiv.org/pdf/2104.09864.pdf
Peft: GitHub - huggingface/peft at v0.4.0
LoRA: 大模型训练——PEFT与LORA介绍_常鸿宇的博客-CSDN博客
相关文章:
LLM - Transformer LLaMA2 结构分析与 LoRA 详解
目录 一.引言 二.图说 LLM 1.Transformer 结构 ◆ Input、Output Embedding ◆ PositionEmbedding ◆ Multi-Head-Attention ◆ ADD & Norm ◆ Feed Forward ◆ Linear & Softmax 2.不同 LLM 结构 ◆ Encoder-Only ◆ Encoder-Decoder ◆ Decoder-Only …...

前端技术搭建五子棋游戏(内含源码)
The sand accumulates to form a pagoda ✨ 写在前面✨ 功能介绍✨ 页面搭建✨ 样式设置✨ 逻辑部分 ✨ 写在前面 上周我们实通过前端基础实现了拼图游戏,今天还是继续按照我们原定的节奏来带领大家完成一个五子棋游戏,功能也比较简单简单,也…...
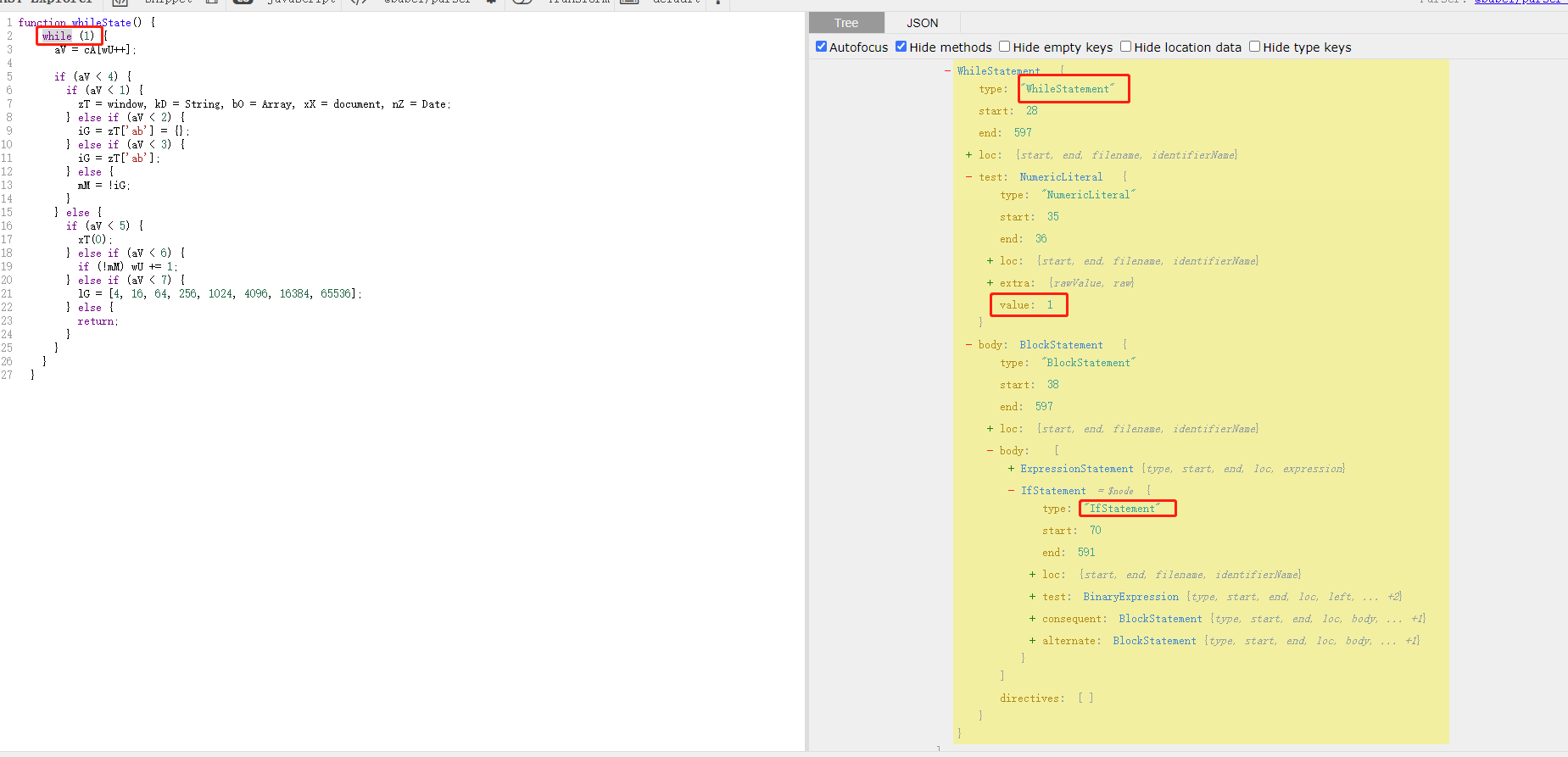
AST入门与实战(三):if节点转switch节点(瑞数5)
原文地址:https://zhuoyue360.com/jsnx/110.html 1. 期望 这是一个瑞数5代解混淆的案例,我们本章节需要做的是把if节点的内容转换成switch-case内容.以此来熟悉AST对JS混淆的对抗. 原始代码: function whileState() {while (1) {aV cA[wU];if (aV < 4) {if (…...
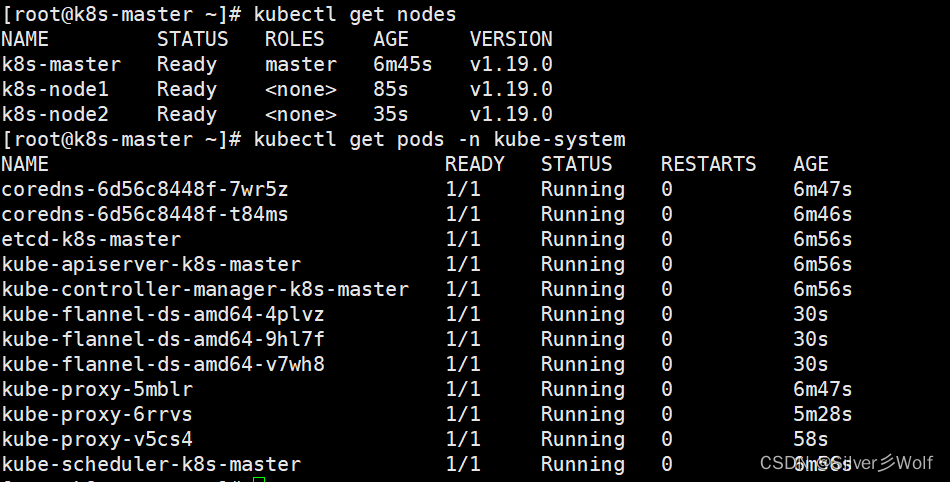
小白到运维工程师自学之路 第七十一集 (kubernetes网络设置)
一、概述 Master 节点NotReady 的原因就是因为没有使用任何的网络插件,此时Node 和Master的连接还不正常。目前最流行的Kubernetes 网络插件有Flannel、Calico、Canal、Weave 这里选择使用flannel。 二、安装flannel 1、master下载kube-flannel.yml,所…...
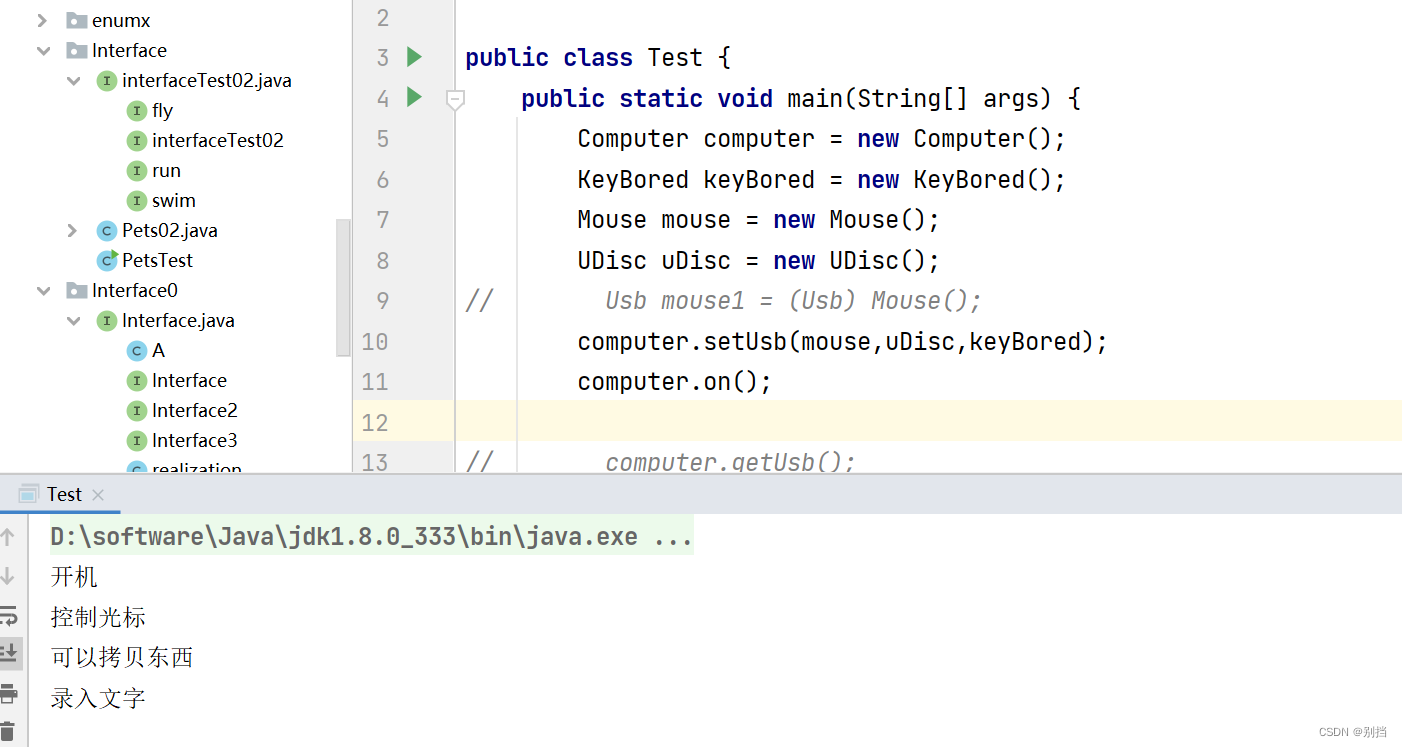
day17 enum abstract interface 枚举 抽象 接口
一、枚举 enum 枚举本来的面目 创建Season类, 所有类都默认继承Object,写不写都一样 声明属性 :季节的名字、 季节的描述, 因为枚举的对象是看的见的客观事物, 想让它的属性不可修改 使用 final修饰表示最终的 &am…...

c刷题(二)
目录 加减混合运算 计算n的k次方 计算非负整数各位之和 字符串逆序 双指针 递归 矩阵计算 矩阵转置 加减混合运算 题目:计算1 / 1 - 1 / 2 1 / 3 - 1 / 4 1 / 5 …… 1 / 99 - 1 / 100 的值,打印出结果。 一般情况我们可以写个循环然后在用条…...
)
【leetcode】15. 三数之和(medium)
给你一个整数数组 nums ,判断是否存在三元组 [nums[i], nums[j], nums[k]] 满足 i ! j、i ! k 且 j ! k ,同时还满足 nums[i] nums[j] nums[k] 0 。请 你返回所有和为 0 且不重复的三元组。 注意:答案中不可以包含重复的三元组。 这题真…...

【css】属性选择器
有些场景中需要在相同元素中获取具有特定属性的元素,比如同为input,type属性有text、button,可以通过属性选择器设置text和button的不同样式。 代码: <style> input[typetext] {width: 150px;display: block;margin-bottom…...
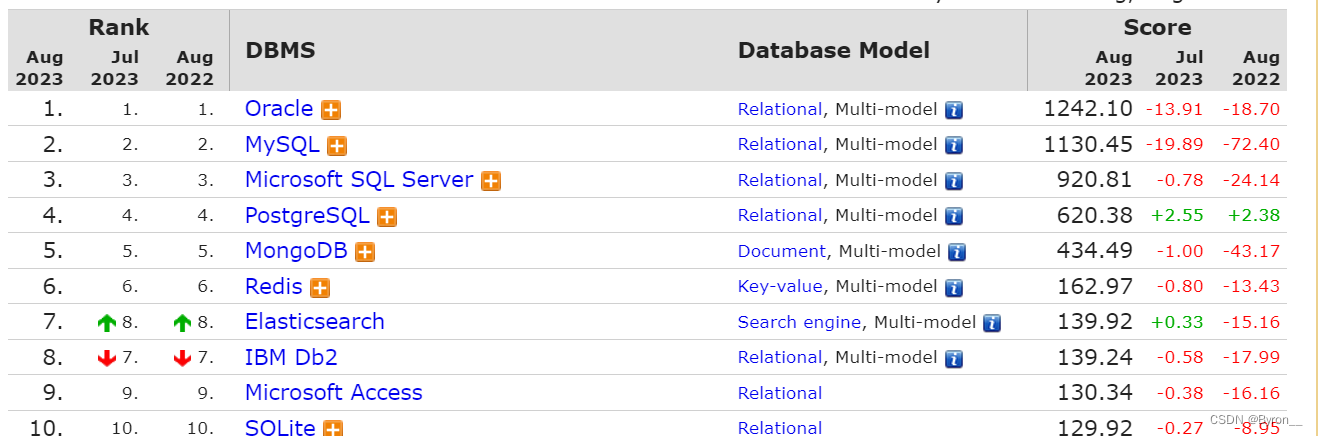
Redis_概述
1.redis概述 1.1 简介 截止到2021年12月 数据库排名https://db-engines.com/en/ranking redis(Remote Dictionary Server) 一个开源的key-value存储系统它支持存储的Value类型:包括String(字符串),list(链表),set(集合),zset(sorted set 有序集合),hash(哈希类型…...
)
【从零学习python 】16. Python字符串的format方法(一)
文章目录 字符串的format方法1. 概念:2. 字段名2.1 简单字段名2.1.1 省略字段名2.1.2 数字字段名2.1.3 变量字段名2.1.4 简单字段名的混合使用2.1.5 使用元组和字典传参 进阶案例 字符串的format方法 1. 概念: str.format() 方法通过字符串中的大括号{}来识别替换字段 replac…...

python re 模块 正则表达式
一、正则表达式基本符号 ^ 表示匹配字符串的开始位置 (例外 用在中括号中[ ] 时,可以理解为取反,表示不匹配括号中字符串)$ 表示匹配字符串的结束位置* 表示匹配 零次到多次(记忆方法:符号是星星,天上的星星可以是无数个也可以看不到&#x…...

c#设计模式-创建型模式 之 单例模式
目录 前言: 优点: 缺点: 饿汉式(静态变量方式) 懒汉式(线程不安全) 懒汉式(双重检查锁定) 推荐方式Lazy 总结: 前言: 这种模式涉及到一个单一的类&a…...
场:郑州轻工业大学))
K-01BFS(2023河南萌新联赛第(五)场:郑州轻工业大学)
链接:登录—专业IT笔试面试备考平台_牛客网 来源:牛客网 思路: 直接枚举这个图中的拐点 这个拐点是经过左右平移到上下平移或者上下平移到左右平移 假设这个点事左到右后然后再从下到上 左到右就相当于走了个最长上升子序列࿰…...
CSP复习每日一题(四)
树的重心 给定一颗树,树中包含 n n n 个结点(编号 1 ∼ n 1∼n 1∼n)和 n − 1 n−1 n−1条无向边。请你找到树的重心,并输出将重心删除后,剩余各个连通块中点数的最大值。 重心定义: 重心是指树中的一…...
dubbo之整合SpringBoot
目录 zookeeper安装 1.拉取ZooKeeper镜像 2.新建文件夹 3.挂载本地文件夹并启动服务 4.查看容器 5.进入容器(zookeeper) Dubbo Admin安装 1.下载dubbo-admin 2.zip包解压 3.修改配置文件 4.打包项目 5.启动jar 6.访问 构建项目 api模块 1.创建…...
UE 5 GAS 在项目中处理AttributeSet相关
这一篇文章是个人的实战经验记录,如果对基础性的内容不了解的,可以看我前面一篇文章对基础的概念以及内容的讲解。 设置AttributeSet 使用GAS之前,首先需要设置参数集AS,这个是用于同步的一些参数,至于如何设置GAS&a…...
JDBC数据库连接
目录 引言 一,基本概念 二,常用操作步骤 三,连接操作 引言 JDBC(Java DataBase Connectivity,java数据库连接)是一种用于执行SQL语句的Java API,可以为多种 关系数据库提供统一访问,它由一组用Java语言编写的类和接口…...

gitee分支合并
合并dev分支到master(合并到主分支) git checkout master git merge dev //这里的dev表示你的分支名称 git push //推送到远程仓库 效果如下图 不报错就表示推送成功了,希望能帮助各位小伙伴...

Python小白入门:文件、异常处理和json格式存储数据
这里写自定义目录标题 所用资料 一、从文件中读取数据1.1 读取整个文件1.2 文件路径1.3 逐行读取1.4 创建一个包含文件各行内容的列表1.5 使用文件的内容1.6 包含一百万位的大型文件1.7 圆周率值中包含你的生日吗练习题 二、写入文件2.1 写入空文件2.2 写入多行2.3 附加到文件练…...
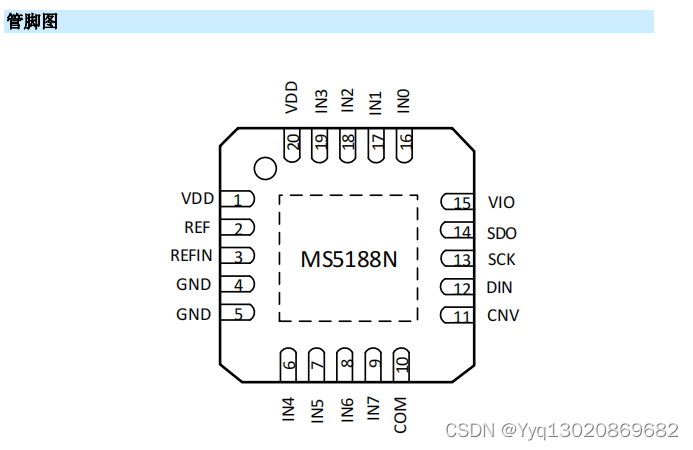
16bit、8 通道、500kSPS、 SAR 型 ADC——MS5188N
MS5188N 是 8 通道、 16bit 、电荷再分配逐次逼近型模数 转换器,采用单电源供电。 MS5188N 拥有多通道、低功耗数据采集系统所需的所有 组成部分,包括:无失码的真 16 位 SAR ADC ;用于将输入配 置为单端输入࿰…...
让你的Windows任务栏焕然一新:TranslucentTB透明化美化全攻略
让你的Windows任务栏焕然一新:TranslucentTB透明化美化全攻略 【免费下载链接】TranslucentTB A lightweight utility that makes the Windows taskbar translucent/transparent. 项目地址: https://gitcode.com/gh_mirrors/tr/TranslucentTB 你是否厌倦了Wi…...

AI 写论文哪个软件最好?2026 实测:虎贲等考 AI 凭真文献 + 真图表 + 全流程实证,稳坐毕业论文首选
每到毕业季,“AI 写论文哪个软件最好” 成为无数本硕博学生最纠结的问题。市面上 AI 写作工具看似丰富,却普遍存在虚构文献、无实证图表、AI 痕迹重、功能碎片化、不合规五大硬伤,轻则反复返修,重则触碰学术诚信红线。 经过对当前…...

国内免费玩转ClaudeCode
Claude Code 是 Anthropic 公司推出的强大 AI 编程助手,通过命令行(CLI)提供代码生成、解释、调试和重构等能力。要在国内免费使用,核心在于解决网络访问和 API 调用问题。以下是一套清晰、可操作的“三步走”方案,结合…...

政府如何实现区域科技资源的高效整合与共享?
观点作者:科易网-国家科技成果转化(厦门)示范基地 现状概述:成效与短板 近年来,我国区域科技创新体系建设取得显著成效,各地政府陆续建设了一批科技平台,覆盖了政策发布、项目申报、成果展示等…...

本地部署OpenAI TTS:开源项目openai-edge-tts实战指南
1. 项目概述:当TTS遇见边缘计算最近在折腾一个智能语音项目,需要把文本实时转换成听起来很自然的语音。市面上成熟的云端TTS服务不少,但一涉及到实时性要求高、数据隐私敏感或者网络不稳定的场景,云端方案就显得有些力不从心了。要…...

【故障定位】基于粒子群优化算法的故障定位及故障区段研究【IEEE33节点】附Matlab代码
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、建模仿真、程序设计、完整代码获取、论文复现及科研仿真。🍎 往期回顾关注个人主页:Matlab科研工作室👇 关注我领取海量matlab电子书和…...

让任天堂控制器在Windows上重获新生的双剑合璧方案
让任天堂控制器在Windows上重获新生的双剑合璧方案 【免费下载链接】WiinUPro 项目地址: https://gitcode.com/gh_mirrors/wi/WiinUPro 你是否曾经为手中的Wii、Wii U或Switch控制器无法在Windows电脑上使用而感到遗憾?那些设计精良、手感出色的任天堂控制器…...

TVHeadend终极指南:从零开始构建你的专属电视流媒体服务器
TVHeadend终极指南:从零开始构建你的专属电视流媒体服务器 【免费下载链接】tvheadend Tvheadend is the leading TV streaming server for Linux with ATSC, DVB-C/C2, DVB-S/S2, DVB-T/T2, IPTV, SAT>IP and unix pipe input sources 项目地址: https://gitc…...

软件因果图管理中的根因分析者
在软件开发和运维过程中,因果图管理是一种用于识别和解决复杂问题的有效方法。而根因分析者(Root Cause Analyst)则是这一过程中的核心角色,他们通过系统化的方法追溯问题的源头,确保类似问题不再发生。随着软件系统规…...

Qwerty Learner终极指南:如何通过打字练习高效记忆英语单词
Qwerty Learner终极指南:如何通过打字练习高效记忆英语单词 【免费下载链接】qwerty-learner 为键盘工作者设计的单词记忆与英语肌肉记忆锻炼软件 / Words learning and English muscle memory training software designed for keyboard workers 项目地址: https:…...