二、 根据用户行为数据创建ALS模型并召回商品
二 根据用户行为数据创建ALS模型并召回商品
2.0 用户行为数据拆分
-
方便练习可以对数据做拆分处理
- pandas的数据分批读取 chunk 厚厚的一块 相当大的数量或部分
import pandas as pd reader = pd.read_csv('behavior_log.csv',chunksize=100,iterator=True) count = 0; for chunk in reader:count += 1if count ==1:chunk.to_csv('test4.csv',index = False)elif count>1 and count<1000:chunk.to_csv('test4.csv',index = False, mode = 'a',header = False)else:break pd.read_csv('test4.csv')
2.1 预处理behavior_log数据集
- 创建spark session
import os
# 配置spark driver和pyspark运行时,所使用的python解释器路径
PYSPARK_PYTHON = "/home/hadoop/miniconda3/envs/datapy365spark23/bin/python"
JAVA_HOME='/home/hadoop/app/jdk1.8.0_191'
# 当存在多个版本时,不指定很可能会导致出错
os.environ["PYSPARK_PYTHON"] = PYSPARK_PYTHON
os.environ["PYSPARK_DRIVER_PYTHON"] = PYSPARK_PYTHON
os.environ['JAVA_HOME']=JAVA_HOME
# spark配置信息
from pyspark import SparkConf
from pyspark.sql import SparkSessionSPARK_APP_NAME = "preprocessingBehaviorLog"
SPARK_URL = "spark://192.168.199.188:7077"conf = SparkConf() # 创建spark config对象
config = (("spark.app.name", SPARK_APP_NAME), # 设置启动的spark的app名称,没有提供,将随机产生一个名称("spark.executor.memory", "6g"), # 设置该app启动时占用的内存用量,默认1g("spark.master", SPARK_URL), # spark master的地址("spark.executor.cores", "4"), # 设置spark executor使用的CPU核心数# 以下三项配置,可以控制执行器数量
# ("spark.dynamicAllocation.enabled", True),
# ("spark.dynamicAllocation.initialExecutors", 1), # 1个执行器
# ("spark.shuffle.service.enabled", True)
# ('spark.sql.pivotMaxValues', '99999'), # 当需要pivot DF,且值很多时,需要修改,默认是10000
)
# 查看更详细配置及说明:https://spark.apache.org/docs/latest/configuration.htmlconf.setAll(config)# 利用config对象,创建spark session
spark = SparkSession.builder.config(conf=conf).getOrCreate()
- 从hdfs中加载csv文件为DataFrame
# 从hdfs加载CSV文件为DataFrame
df = spark.read.csv("hdfs://localhost:9000/datasets/behavior_log.csv", header=True)
df.show() # 查看dataframe,默认显示前20条
# 大致查看一下数据类型
df.printSchema() # 打印当前dataframe的结构
显示结果:
+------+----------+----+-----+------+
| user|time_stamp|btag| cate| brand|
+------+----------+----+-----+------+
|558157|1493741625| pv| 6250| 91286|
|558157|1493741626| pv| 6250| 91286|
|558157|1493741627| pv| 6250| 91286|
|728690|1493776998| pv|11800| 62353|
|332634|1493809895| pv| 1101|365477|
|857237|1493816945| pv| 1043|110616|
|619381|1493774638| pv| 385|428950|
|467042|1493772641| pv| 8237|301299|
|467042|1493772644| pv| 8237|301299|
|991528|1493780710| pv| 7270|274795|
|991528|1493780712| pv| 7270|274795|
|991528|1493780712| pv| 7270|274795|
|991528|1493780712| pv| 7270|274795|
|991528|1493780714| pv| 7270|274795|
|991528|1493780765| pv| 7270|274795|
|991528|1493780714| pv| 7270|274795|
|991528|1493780765| pv| 7270|274795|
|991528|1493780764| pv| 7270|274795|
|991528|1493780633| pv| 7270|274795|
|991528|1493780764| pv| 7270|274795|
+------+----------+----+-----+------+
only showing top 20 rowsroot|-- user: string (nullable = true)|-- time_stamp: string (nullable = true)|-- btag: string (nullable = true)|-- cate: string (nullable = true)|-- brand: string (nullable = true)
- 从hdfs加载数据为dataframe,并设置结构
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, LongType
# 构建结构对象
schema = StructType([StructField("userId", IntegerType()),StructField("timestamp", LongType()),StructField("btag", StringType()),StructField("cateId", IntegerType()),StructField("brandId", IntegerType())
])
# 从hdfs加载数据为dataframe,并设置结构
behavior_log_df = spark.read.csv("hdfs://localhost:8020/datasets/behavior_log.csv", header=True, schema=schema)
behavior_log_df.show()
behavior_log_df.count()
显示结果:
+------+----------+----+------+-------+
|userId| timestamp|btag|cateId|brandId|
+------+----------+----+------+-------+
|558157|1493741625| pv| 6250| 91286|
|558157|1493741626| pv| 6250| 91286|
|558157|1493741627| pv| 6250| 91286|
|728690|1493776998| pv| 11800| 62353|
|332634|1493809895| pv| 1101| 365477|
|857237|1493816945| pv| 1043| 110616|
|619381|1493774638| pv| 385| 428950|
|467042|1493772641| pv| 8237| 301299|
|467042|1493772644| pv| 8237| 301299|
|991528|1493780710| pv| 7270| 274795|
|991528|1493780712| pv| 7270| 274795|
|991528|1493780712| pv| 7270| 274795|
|991528|1493780712| pv| 7270| 274795|
|991528|1493780714| pv| 7270| 274795|
|991528|1493780765| pv| 7270| 274795|
|991528|1493780714| pv| 7270| 274795|
|991528|1493780765| pv| 7270| 274795|
|991528|1493780764| pv| 7270| 274795|
|991528|1493780633| pv| 7270| 274795|
|991528|1493780764| pv| 7270| 274795|
+------+----------+----+------+-------+
only showing top 20 rowsroot|-- userId: integer (nullable = true)|-- timestamp: long (nullable = true)|-- btag: string (nullable = true)|-- cateId: integer (nullable = true)|-- brandId: integer (nullable = true)
- 分析数据集字段的类型和格式
- 查看是否有空值
- 查看每列数据的类型
- 查看每列数据的类别情况
print("查看userId的数据情况:", behavior_log_df.groupBy("userId").count().count())
# 约113w用户
#注意:behavior_log_df.groupBy("userId").count() 返回的是一个dataframe,这里的count计算的是每一个分组的个数,但当前还没有进行计算
# 当调用df.count()时才开始进行计算,这里的count计算的是dataframe的条目数,也就是共有多少个分组
查看user的数据情况: 1136340
print("查看btag的数据情况:", behavior_log_df.groupBy("btag").count().collect()) # collect会把计算结果全部加载到内存,谨慎使用
# 只有四种类型数据:pv、fav、cart、buy
# 这里由于类型只有四个,所以直接使用collect,把数据全部加载出来
查看btag的数据情况: [Row(btag='buy', count=9115919), Row(btag='fav', count=9301837), Row(btag='cart', count=15946033), Row(btag='pv', count=688904345)]
print("查看cateId的数据情况:", behavior_log_df.groupBy("cateId").count().count())
# 约12968类别id
查看cateId的数据情况: 12968
print("查看brandId的数据情况:", behavior_log_df.groupBy("brandId").count().count())
# 约460561品牌id
查看brandId的数据情况: 460561
print("判断数据是否有空值:", behavior_log_df.count(), behavior_log_df.dropna().count())
# 约7亿条目723268134 723268134
# 本数据集无空值条目,可放心处理
判断数据是否有空值: 723268134 723268134
- pivot透视操作,把某列里的字段值转换成行并进行聚合运算(pyspark.sql.GroupedData.pivot)
- 如果透视的字段中的不同属性值超过10000个,则需要设置spark.sql.pivotMaxValues,否则计算过程中会出现错误。文档介绍。
# 统计每个用户对各类商品的pv、fav、cart、buy数量
cate_count_df = behavior_log_df.groupBy(behavior_log_df.userId, behavior_log_df.cateId).pivot("btag",["pv","fav","cart","buy"]).count()
cate_count_df.printSchema() # 此时还没有开始计算
显示效果:
root|-- userId: integer (nullable = true)|-- cateId: integer (nullable = true)|-- pv: long (nullable = true)|-- fav: long (nullable = true)|-- cart: long (nullable = true)|-- buy: long (nullable = true)
- 统计每个用户对各个品牌的pv、fav、cart、buy数量并保存结果
# 统计每个用户对各个品牌的pv、fav、cart、buy数量
brand_count_df = behavior_log_df.groupBy(behavior_log_df.userId, behavior_log_df.brandId).pivot("btag",["pv","fav","cart","buy"]).count()
# brand_count_df.show() # 同上
# 113w * 46w
# 由于运算时间比较长,所以这里先将结果存储起来,供后续其他操作使用
# 写入数据时才开始计算
cate_count_df.write.csv("hdfs://localhost:9000/preprocessing_dataset/cate_count.csv", header=True)
brand_count_df.write.csv("hdfs://localhost:9000/preprocessing_dataset/brand_count.csv", header=True)
2.2 根据用户对类目偏好打分训练ALS模型
- 根据您统计的次数 + 打分规则 ==> 偏好打分数据集 ==> ALS模型
# spark ml的模型训练是基于内存的,如果数据过大,内存空间小,迭代次数过多的化,可能会造成内存溢出,报错
# 设置Checkpoint的话,会把所有数据落盘,这样如果异常退出,下次重启后,可以接着上次的训练节点继续运行
# 但该方法其实指标不治本,因为无法防止内存溢出,所以还是会报错
# 如果数据量大,应考虑的是增加内存、或限制迭代次数和训练数据量级等
spark.sparkContext.setCheckpointDir("hdfs://localhost:8020/checkPoint/")
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, LongType, FloatType# 构建结构对象
schema = StructType([StructField("userId", IntegerType()),StructField("cateId", IntegerType()),StructField("pv", IntegerType()),StructField("fav", IntegerType()),StructField("cart", IntegerType()),StructField("buy", IntegerType())
])# 从hdfs加载CSV文件
cate_count_df = spark.read.csv("hdfs://localhost:9000/preprocessing_dataset/cate_count.csv", header=True, schema=schema)
cate_count_df.printSchema()
cate_count_df.first() # 第一行数据
显示结果:
root|-- userId: integer (nullable = true)|-- cateId: integer (nullable = true)|-- pv: integer (nullable = true)|-- fav: integer (nullable = true)|-- cart: integer (nullable = true)|-- buy: integer (nullable = true)Row(userId=1061650, cateId=4520, pv=2326, fav=None, cart=53, buy=None)
- 处理每一行数据:r表示row对象
def process_row(r):# 处理每一行数据:r表示row对象# 偏好评分规则:# m: 用户对应的行为次数# 该偏好权重比例,次数上限仅供参考,具体数值应根据产品业务场景权衡# pv: if m<=20: score=0.2*m; else score=4# fav: if m<=20: score=0.4*m; else score=8# cart: if m<=20: score=0.6*m; else score=12# buy: if m<=20: score=1*m; else score=20# 注意这里要全部设为浮点数,spark运算时对类型比较敏感,要保持数据类型都一致pv_count = r.pv if r.pv else 0.0fav_count = r.fav if r.fav else 0.0cart_count = r.cart if r.cart else 0.0buy_count = r.buy if r.buy else 0.0pv_score = 0.2*pv_count if pv_count<=20 else 4.0fav_score = 0.4*fav_count if fav_count<=20 else 8.0cart_score = 0.6*cart_count if cart_count<=20 else 12.0buy_score = 1.0*buy_count if buy_count<=20 else 20.0rating = pv_score + fav_score + cart_score + buy_score# 返回用户ID、分类ID、用户对分类的偏好打分return r.userId, r.cateId, rating
- 返回一个PythonRDD类型
# 返回一个PythonRDD类型,此时还没开始计算
cate_count_df.rdd.map(process_row).toDF(["userId", "cateId", "rating"])
显示结果:
DataFrame[userId: bigint, cateId: bigint, rating: double]
- 用户对商品类别的打分数据
# 用户对商品类别的打分数据
# map返回的结果是rdd类型,需要调用toDF方法转换为Dataframe
cate_rating_df = cate_count_df.rdd.map(process_row).toDF(["userId", "cateId", "rating"])
# 注意:toDF不是每个rdd都有的方法,仅局限于此处的rdd
# 可通过该方法获得 user-cate-matrix
# 但由于cateId字段过多,这里运算量比很大,机器内存要求很高才能执行,否则无法完成任务
# 请谨慎使用# 但好在我们训练ALS模型时,不需要转换为user-cate-matrix,所以这里可以不用运行
# cate_rating_df.groupBy("userId").povit("cateId").min("rating")
# 用户对类别的偏好打分数据
cate_rating_df
显示结果:
DataFrame[userId: bigint, cateId: bigint, rating: double]
- 通常如果USER-ITEM打分数据应该是通过一下方式进行处理转换为USER-ITEM-MATRIX
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4dF4oXj6-1691649134814)(/img/CF%E4%BB%8B%E7%BB%8D.png)]
但这里我们将使用的Spark的ALS模型进行CF推荐,因此注意这里数据输入不需要提前转换为矩阵,直接是 USER-ITEM-RATE的数据
-
基于Spark的ALS隐因子模型进行CF评分预测
-
ALS的意思是交替最小二乘法(Alternating Least Squares),是Spark2.*中加入的进行基于模型的协同过滤(model-based CF)的推荐系统算法。
同SVD,它也是一种矩阵分解技术,对数据进行降维处理。
-
详细使用方法:pyspark.ml.recommendation.ALS
-
注意:由于数据量巨大,因此这里也不考虑基于内存的CF算法
参考:为什么Spark中只有ALS
-
# 使用pyspark中的ALS矩阵分解方法实现CF评分预测
# 文档地址:https://spark.apache.org/docs/2.2.2/api/python/pyspark.ml.html?highlight=vectors#module-pyspark.ml.recommendation
from pyspark.ml.recommendation import ALS # ml:dataframe, mllib:rdd# 利用打分数据,训练ALS模型
als = ALS(userCol='userId', itemCol='cateId', ratingCol='rating', checkpointInterval=5)# 此处训练时间较长
model = als.fit(cate_rating_df)
- 模型训练好后,调用方法进行使用,具体API查看
# model.recommendForAllUsers(N) 给所有用户推荐TOP-N个物品
ret = model.recommendForAllUsers(3)
# 由于是给所有用户进行推荐,此处运算时间也较长
ret.show()
# 推荐结果存放在recommendations列中,
ret.select("recommendations").show()
显示结果:
+------+--------------------+
|userId| recommendations|
+------+--------------------+
| 148|[[3347, 12.547271...|
| 463|[[1610, 9.250818]...|
| 471|[[1610, 10.246621...|
| 496|[[1610, 5.162216]...|
| 833|[[5607, 9.065482]...|
| 1088|[[104, 6.886987],...|
| 1238|[[5631, 14.51981]...|
| 1342|[[5720, 10.89842]...|
| 1580|[[5731, 8.466453]...|
| 1591|[[1610, 12.835257...|
| 1645|[[1610, 11.968531...|
| 1829|[[1610, 17.576496...|
| 1959|[[1610, 8.353473]...|
| 2122|[[1610, 12.652732...|
| 2142|[[1610, 12.48068]...|
| 2366|[[1610, 11.904813...|
| 2659|[[5607, 11.699315...|
| 2866|[[1610, 7.752719]...|
| 3175|[[3347, 2.3429515...|
| 3749|[[1610, 3.641833]...|
+------+--------------------+
only showing top 20 rows+--------------------+
| recommendations|
+--------------------+
|[[3347, 12.547271...|
|[[1610, 9.250818]...|
|[[1610, 10.246621...|
|[[1610, 5.162216]...|
|[[5607, 9.065482]...|
|[[104, 6.886987],...|
|[[5631, 14.51981]...|
|[[5720, 10.89842]...|
|[[5731, 8.466453]...|
|[[1610, 12.835257...|
|[[1610, 11.968531...|
|[[1610, 17.576496...|
|[[1610, 8.353473]...|
|[[1610, 12.652732...|
|[[1610, 12.48068]...|
|[[1610, 11.904813...|
|[[5607, 11.699315...|
|[[1610, 7.752719]...|
|[[3347, 2.3429515...|
|[[1610, 3.641833]...|
+--------------------+
only showing top 20 rows
- model.recommendForUserSubset 给部分用户推荐TOP-N个物品
# 注意:recommendForUserSubset API,2.2.2版本中无法使用
dataset = spark.createDataFrame([[1],[2],[3]])
dataset = dataset.withColumnRenamed("_1", "userId")
ret = model.recommendForUserSubset(dataset, 3)# 只给部分用推荐,运算时间短
ret.show()
ret.collect() # 注意: collect会将所有数据加载到内存,慎用
显示结果:
+------+--------------------+
|userId| recommendations|
+------+--------------------+
| 1|[[1610, 25.4989],...|
| 3|[[5607, 13.665942...|
| 2|[[5579, 5.9051886...|
+------+--------------------+[Row(userId=1, recommendations=[Row(cateId=1610, rating=25.498899459838867), Row(cateId=5737, rating=24.901548385620117), Row(cateId=3347, rating=20.736785888671875)]),Row(userId=3, recommendations=[Row(cateId=5607, rating=13.665942192077637), Row(cateId=1610, rating=11.770171165466309), Row(cateId=3347, rating=10.35690689086914)]),Row(userId=2, recommendations=[Row(cateId=5579, rating=5.90518856048584), Row(cateId=2447, rating=5.624575138092041), Row(cateId=5690, rating=5.2555742263793945)])]
- transform中提供userId和cateId可以对打分进行预测,利用打分结果排序后
# transform中提供userId和cateId可以对打分进行预测,利用打分结果排序后,同样可以实现TOP-N的推荐
model.transform
# 将模型进行存储
model.save("hdfs://localhost:8020/models/userCateRatingALSModel.obj")
# 测试存储的模型
from pyspark.ml.recommendation import ALSModel
# 从hdfs加载之前存储的模型
als_model = ALSModel.load("hdfs://localhost:8020/models/userCateRatingALSModel.obj")
# model.recommendForAllUsers(N) 给用户推荐TOP-N个物品
result = als_model.recommendForAllUsers(3)
result.show()
显示结果:
+------+--------------------+
|userId| recommendations|
+------+--------------------+
| 148|[[3347, 12.547271...|
| 463|[[1610, 9.250818]...|
| 471|[[1610, 10.246621...|
| 496|[[1610, 5.162216]...|
| 833|[[5607, 9.065482]...|
| 1088|[[104, 6.886987],...|
| 1238|[[5631, 14.51981]...|
| 1342|[[5720, 10.89842]...|
| 1580|[[5731, 8.466453]...|
| 1591|[[1610, 12.835257...|
| 1645|[[1610, 11.968531...|
| 1829|[[1610, 17.576496...|
| 1959|[[1610, 8.353473]...|
| 2122|[[1610, 12.652732...|
| 2142|[[1610, 12.48068]...|
| 2366|[[1610, 11.904813...|
| 2659|[[5607, 11.699315...|
| 2866|[[1610, 7.752719]...|
| 3175|[[3347, 2.3429515...|
| 3749|[[1610, 3.641833]...|
+------+--------------------+
only showing top 20 rows
- 召回到redis
import redis
host = "192.168.19.8"
port = 6379
# 召回到redis
def recall_cate_by_cf(partition):# 建立redis 连接池pool = redis.ConnectionPool(host=host, port=port)# 建立redis客户端client = redis.Redis(connection_pool=pool)for row in partition:client.hset("recall_cate", row.userId, [i.cateId for i in row.recommendations])
# 对每个分片的数据进行处理 #mapPartition Transformation map
# foreachPartition Action操作 foreachRDD
result.foreachPartition(recall_cate_by_cf)# 注意:这里这是召回的是用户最感兴趣的n个类别
# 总的条目数,查看redis中总的条目数是否一致
result.count()
显示结果:
1136340
2.3 根据用户对品牌偏好打分训练ALS模型
from pyspark.sql.types import StructType, StructField, StringType, IntegerTypeschema = StructType([StructField("userId", IntegerType()),StructField("brandId", IntegerType()),StructField("pv", IntegerType()),StructField("fav", IntegerType()),StructField("cart", IntegerType()),StructField("buy", IntegerType())
])
# 从hdfs加载预处理好的品牌的统计数据
brand_count_df = spark.read.csv("hdfs://localhost:8020/preprocessing_dataset/brand_count.csv", header=True, schema=schema)
# brand_count_df.show()
def process_row(r):# 处理每一行数据:r表示row对象# 偏好评分规则:# m: 用户对应的行为次数# 该偏好权重比例,次数上限仅供参考,具体数值应根据产品业务场景权衡# pv: if m<=20: score=0.2*m; else score=4# fav: if m<=20: score=0.4*m; else score=8# cart: if m<=20: score=0.6*m; else score=12# buy: if m<=20: score=1*m; else score=20# 注意这里要全部设为浮点数,spark运算时对类型比较敏感,要保持数据类型都一致pv_count = r.pv if r.pv else 0.0fav_count = r.fav if r.fav else 0.0cart_count = r.cart if r.cart else 0.0buy_count = r.buy if r.buy else 0.0pv_score = 0.2*pv_count if pv_count<=20 else 4.0fav_score = 0.4*fav_count if fav_count<=20 else 8.0cart_score = 0.6*cart_count if cart_count<=20 else 12.0buy_score = 1.0*buy_count if buy_count<=20 else 20.0rating = pv_score + fav_score + cart_score + buy_score# 返回用户ID、品牌ID、用户对品牌的偏好打分return r.userId, r.brandId, rating
# 用户对品牌的打分数据
brand_rating_df = brand_count_df.rdd.map(process_row).toDF(["userId", "brandId", "rating"])
# brand_rating_df.show()
-
基于Spark的ALS隐因子模型进行CF评分预测
-
ALS的意思是交替最小二乘法(Alternating Least Squares),是Spark中进行基于模型的协同过滤(model-based CF)的推荐系统算法,也是目前Spark内唯一一个推荐算法。
同SVD,它也是一种矩阵分解技术,但理论上,ALS在海量数据的处理上要优于SVD。
更多了解:pyspark.ml.recommendation.ALS
注意:由于数据量巨大,因此这里不考虑基于内存的CF算法
参考:为什么Spark中只有ALS
-
-
使用pyspark中的ALS矩阵分解方法实现CF评分预测
# 使用pyspark中的ALS矩阵分解方法实现CF评分预测
# 文档地址:https://spark.apache.org/docs/latest/api/python/pyspark.ml.html?highlight=vectors#module-pyspark.ml.recommendation
from pyspark.ml.recommendation import ALSals = ALS(userCol='userId', itemCol='brandId', ratingCol='rating', checkpointInterval=2)
# 利用打分数据,训练ALS模型
# 此处训练时间较长
model = als.fit(brand_rating_df)
# model.recommendForAllUsers(N) 给用户推荐TOP-N个物品
model.recommendForAllUsers(3).show()
# 将模型进行存储
model.save("hdfs://localhost:9000/models/userBrandRatingModel.obj")
# 测试存储的模型
from pyspark.ml.recommendation import ALSModel
# 从hdfs加载模型
my_model = ALSModel.load("hdfs://localhost:9000/models/userBrandRatingModel.obj")
my_model
# model.recommendForAllUsers(N) 给用户推荐TOP-N个物品
my_model.recommendForAllUsers(3).first()
相关文章:

二、 根据用户行为数据创建ALS模型并召回商品
二 根据用户行为数据创建ALS模型并召回商品 2.0 用户行为数据拆分 方便练习可以对数据做拆分处理 pandas的数据分批读取 chunk 厚厚的一块 相当大的数量或部分 import pandas as pd reader pd.read_csv(behavior_log.csv,chunksize100,iteratorTrue) count 0; for chunk in …...
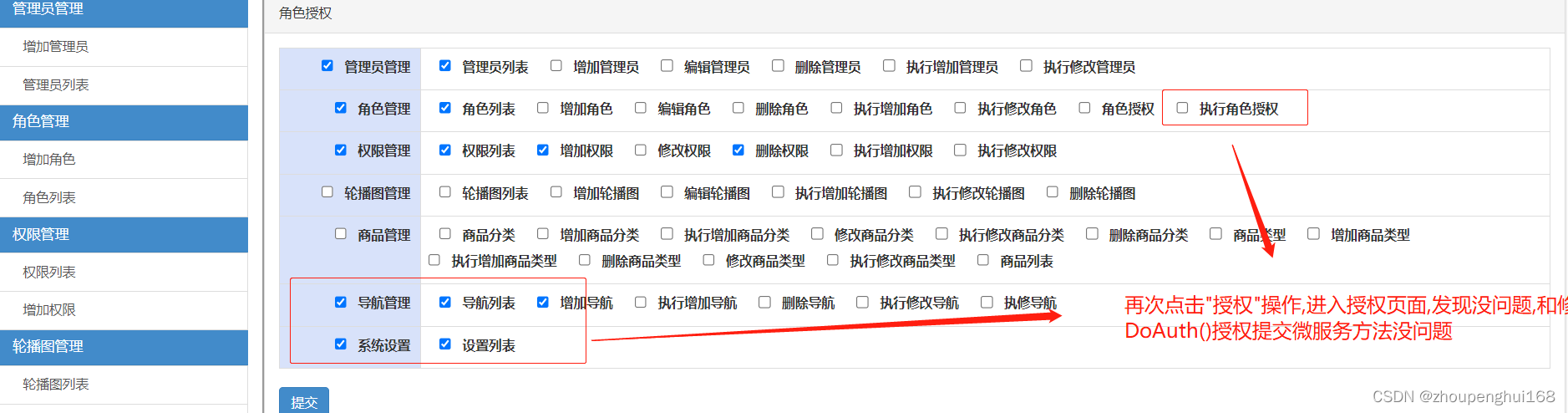
[golang gin框架] 45.Gin商城项目-微服务实战之后台Rbac微服务之角色权限关联
角色和权限的关联关系在前面文章中有讲解,见[golang gin框架] 14.Gin 商城项目-RBAC管理之角色和权限关联,角色授权,在这里通过微服务来实现角色对权限的授权操作,这里要实现的有两个功能,一个是进入授权,另一个是,授权提交操作,页面如下: 一.实现后台权限管理Rbac之角色权限关…...
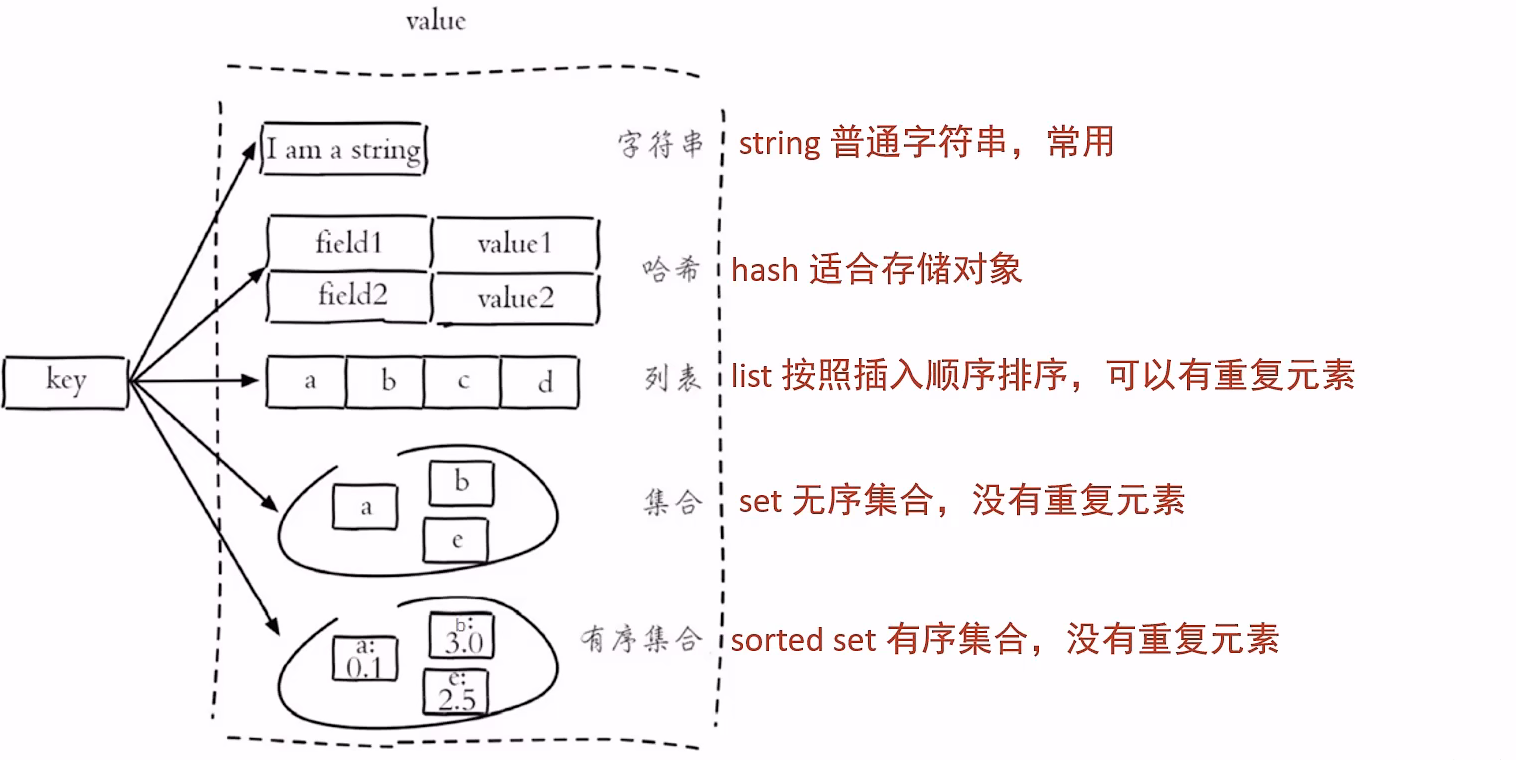
Redis中的数据类型
Redis中的数据类型 Redis存储的是key-value结构的数据,其中key是字符串类型,value有5种常用的数据类型: 字符串string哈希hash列表list集合set有序集合sorted set...
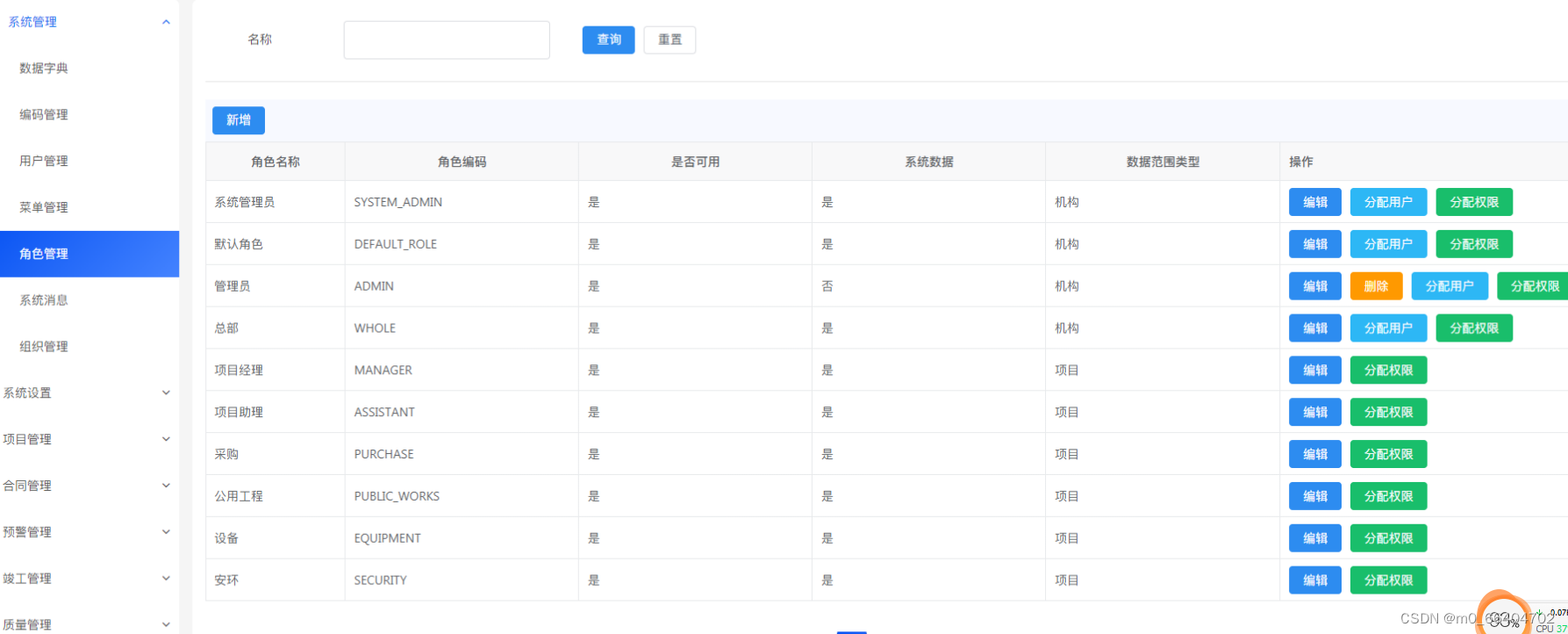
java spring cloud 企业工程管理系统源码+二次开发+定制化服务 em
Java版工程项目管理系统 Spring CloudSpring BootMybatisVueElementUI前后端分离 功能清单如下: 首页 工作台:待办工作、消息通知、预警信息,点击可进入相应的列表 项目进度图表:选择(总体或单个)项目显…...
Java程序猿搬砖笔记(十五)
文章目录 在Java中将类作为参数传递(泛型)IDEA快捷键:查看该方法调用了哪些方法、被哪些方法调用快捷键:ctrlalth IDEA快捷键:快速从controller跳转到serviceImplIDEA快捷键:实现接口的方法IDEA 快捷键:快速包裹代码ID…...

flask----内置信号的使用/django的信号/ flask-script/sqlalchemy介绍和快速使用/sqlalchemy介绍和快速使用
信号 内置信号的使用 # 第一步:写一个函数 def test(app, **kwargs):print(app)print(type(kwargs))# 请求地址是根路径,才记录日志,其它都不记录print(kwargs[context][request].path)if kwargs[context][request].path /:print(记录日志…...
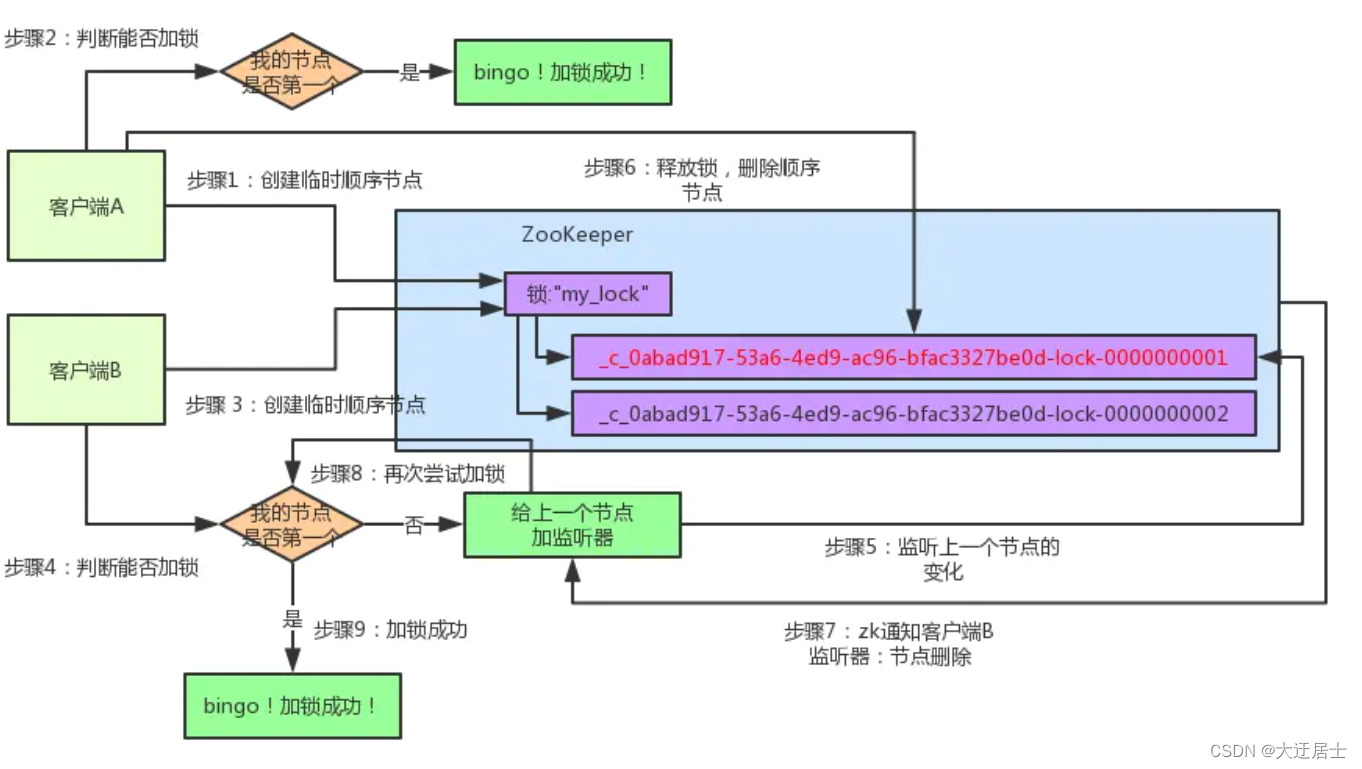
Zookeeper 面试题
一、ZooKeeper 基础题 1.1、Zookeeper 的典型应用场景 Zookeeper 是一个典型的发布/订阅模式的分布式数据管理与协调框架,开发人员可以使用它来进行分布式数据的发布和订阅。 通过对 Zookeeper 中丰富的数据节点进行交叉使用,配合 Watcher 事件通知机…...
ELK 企业级日志分析系统(二)
目录 ELK Kiabana 部署(在 Node1 节点上操作) 1.安装 Kiabana 2.设置 Kibana 的主配置文件 3.启动 Kibana 服务 4.验证 Kibana 5.将 Apache 服务器的日志(访问的、错误的&#x…...

Linux版本 centOS 7,java连接mysql
在Linux下 使用java 访问数据库 , java 1.7版本, mysql 8.0.33版本, 连接驱动 mysql-connector-java-5.1.49.jar 代码如下: import java.sql.Connection; import java.sql.DriverManager; import java.sql.ResultSet; import ja…...
开发工具IDEA的下载与初步使用【各种快捷键的设置,使你的开发事半功倍】
🥳🥳Welcome Huihuis Code World ! !🥳🥳 接下来看看由辉辉所写的关于IDEA的相关操作吧 目录 🥳🥳Welcome Huihuis Code World ! !🥳🥳 一.IDEA的简介以及优势 二.IDEA的下载 1.下…...
,效果秒杀CBAM和CA等 | 即插即用系列)
YoloV5/YoloV7优化:感受野注意力卷积运算(RFAConv),效果秒杀CBAM和CA等 | 即插即用系列
💡💡💡本文改进:感受野注意力卷积运算(RFAConv),解决卷积块注意力模块(CBAM)和协调注意力模块(CA)只关注空间特征,不能完全解决卷积核参数共享的问题 RFAConv| 亲测在多个数据集能够实现大幅涨点,有的数据集达到3个点以上 💡💡💡Yolov5/Yolov7魔术师…...

freeswitch的mod_xml_curl模块动态获取configuration
概述 freeswitch是一款简单好用的VOIP开源软交换平台。 mod_xml_curl模块支持从web服务获取xml配置,本文介绍如何动态获取acl配置。 环境 centos:CentOS release 7.0 (Final)或以上版本 freeswitch:v1.6.20 GCC:4.8.5 web…...

CANdelaStudio 使用介绍
CANdela Studio使用_哔哩哔哩_bilibili 一.CANdelaStudio使用tips 1.开始菜单打开软件,避免软件字体是德文的 2.打开软件之后,用“Open”打开.cdd或者.cddt文件,不要双击文件打开,这样容易报错 3.查看软件版本信息 4.只有Admin版…...
锚框【动手学深度学习】
生成多个锚框 假设输入图像高为h,宽为w,我们以图像每个像素为中心生成不同形状的锚框,缩放比 s∈(0,1],宽高比为r>0。那么锚框的宽度和高度分别为和。当中心位置给定时, 已知宽和高的锚框是确定的。缩放比为锚框高与图像高的比值,然后得到一个正方形锚框面积。 …...
Qt扫盲-Qt Model/View 理论总结 [上篇]
Qt Model/View 理论总结 [上篇] 一、概述1.model / view 架构2. Model3. View4. Delegate5. 排序6. 快捷类 二、使用model/view1. Qt包含两种 model2. 在现有 model 中使用 view 三、Model 类1. 基本概念1.model 索引2. 行和列2. item 的父 item3. Item roles4. 总结 2. 使用mo…...
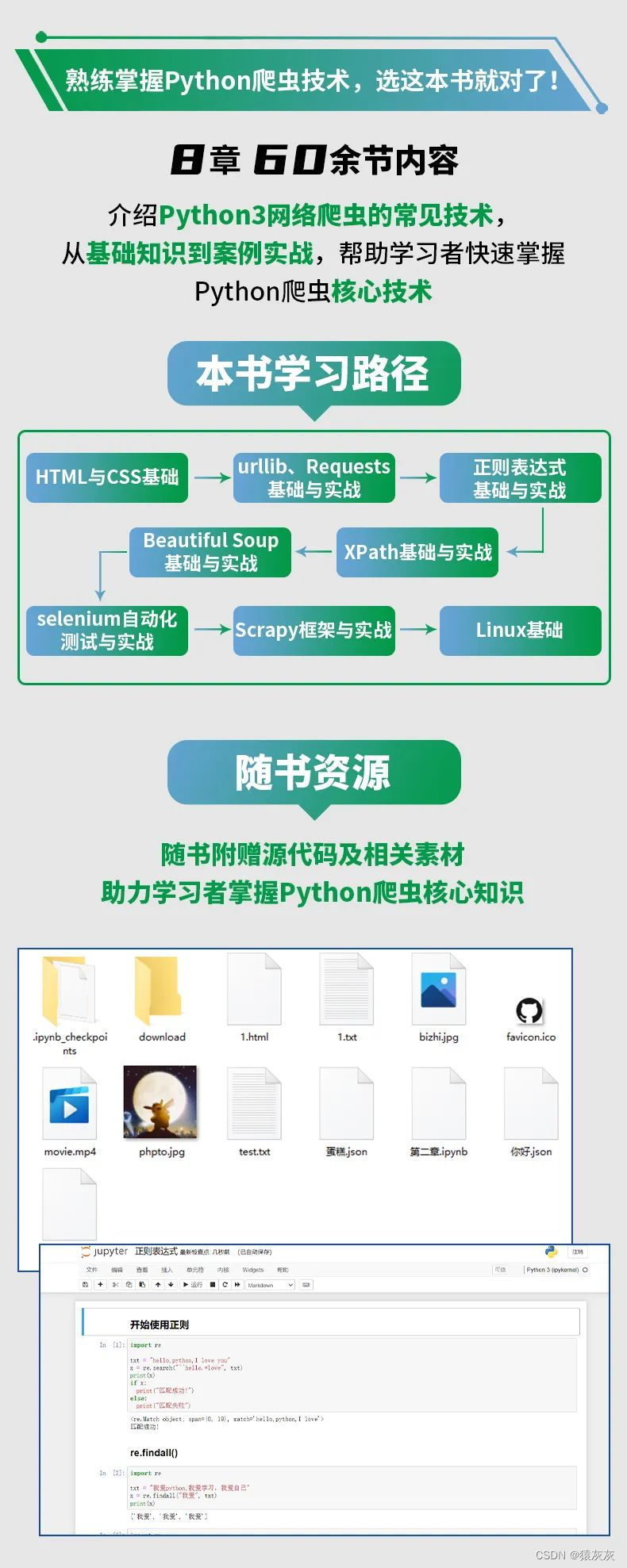
【猿灰灰赠书活动 - 01期】- 【Python网络爬虫入门到实战】
说明:博文为大家争取福利,与机械工业出版社合作进行送书活动 图书:《Python网络爬虫入门到实战》 一、好书推荐 图书介绍 本书介绍了Python3网络爬虫的常见技术。首先介绍了网页的基础知识,然后介绍了urllib、Requests请求库以及X…...
小兔鲜项目 uniapp (1)
目录 项目架构 uni-app小兔鲜儿电商项目架构 小兔鲜儿电商课程安排 创建uni-app项目 1.通过HBuilderX创建 2.通过命令行创建 pages.json和tabBar案例 uni-app和原生小程序开发区别 用VS Code开发uni-app项目 拉取小兔鲜儿项目模板代码 基础架构–引入uni-ui组件库 操…...

盛弘电气2021秋招笔试题
笔试时间:2020.09.16,60分钟 宣讲会后直接笔试,若通过会有两轮面试,7-15 天出结果。 题型:简答题8道,每题5分,共40分。编程题4道,每题15分,共60分。 公司介绍:公司现阶段主要产品为充电桩,专注于电力电子技术控制电能,交直流变换。 薪资待遇:本科8-15K,研究生…...

Poco框架(跨平台自动化测试框架)
Poco基于UI控件搜索原理 ,适用于Android、iOS原生和各种主流的游戏引擎应用。 中文官方文档:欢迎使用Poco (ポコ) UI自动化框架 — poco 1.0 文档 参考文档: Poco介绍 - Airtest Project Docs 环境准备 安装库:pip install po…...

使用RANSAC算法在点云中拟合原始3D形状:pyRANSAC-3D的介绍和应用
随机样本共识(RANSAC)是一种强大的算法,用于从数据集中估计数学模型的参数,特别是在数据包含大量异常值时。在3D计算机视觉中,RANSAC常用于从点云数据中拟合原始形状,例如平面、长方体和圆柱体。本文将介绍一个名为pyRANSAC-3D的开源库,它提供了RANSAC算法的Python实现,…...

【Hot 100 刷题计划】 LeetCode 2. 两数相加 | C++ 分支迭代法
LeetCode 2. 两数相加 📌 题目描述 题目级别:中等 给你两个 非空 的链表,表示两个非负的整数。它们每位数字都是按照 逆序 的方式存储的,并且每个节点只能存储 一位 数字。 请你将两个数相加,并以相同形式返回一个表示…...

解锁Axure RP中文界面:专业设计师的效率革命
解锁Axure RP中文界面:专业设计师的效率革命 【免费下载链接】axure-cn Chinese language file for Axure RP. Axure RP 简体中文语言包。支持 Axure 11、10、9。不定期更新。 项目地址: https://gitcode.com/gh_mirrors/ax/axure-cn 当语言成为原型设计流程…...

RAID卡电池坏了先别慌:手把手教你排查缓存策略降级与数据安全应急处理流程
RAID卡电池故障应急指南:从性能诊断到安全恢复的全流程解析 凌晨三点,数据中心告警系统突然响起刺耳的蜂鸣声。值班工程师小李揉了揉惺忪的睡眼,发现十几台关键业务服务器的磁盘写入延迟曲线全部呈现断崖式下跌。这种性能骤降往往意味着RAID卡…...

VideoDownloadHelper:如何用浏览器插件轻松下载网络视频
VideoDownloadHelper:如何用浏览器插件轻松下载网络视频 【免费下载链接】VideoDownloadHelper Chrome Extension to Help Download Video for Some Video Sites. 项目地址: https://gitcode.com/gh_mirrors/vi/VideoDownloadHelper 作为一名技术爱好者&…...

如何免费获得7款专业级思源宋体:设计师必备的完整字体包指南 [特殊字符]
如何免费获得7款专业级思源宋体:设计师必备的完整字体包指南 🎨 【免费下载链接】source-han-serif-ttf Source Han Serif TTF 项目地址: https://gitcode.com/gh_mirrors/so/source-han-serif-ttf 还在为中文设计项目寻找高质量字体而烦恼吗&…...

八大网盘直链解析工具:告别限速,轻松获取真实下载地址
八大网盘直链解析工具:告别限速,轻松获取真实下载地址 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动…...

Semtech AirLink 5G RedCap路由器工业应用解析
1. Semtech AirLink RX400/EX400 5G RedCap路由器深度解析工业物联网领域最近迎来了一对重量级选手——Semtech最新发布的AirLink RX400和EX400 5G RedCap路由器。作为长期跟踪工业通信设备的技术从业者,我第一时间研究了这两款产品的技术细节和应用场景。不同于市面…...
)
别再死记硬背漏洞了!用bWAPP靶场在Windows 10上实战SQL注入与XSS(保姆级环境搭建)
从零构建实战型Web安全实验室:bWAPP靶场深度攻防指南 当你在网络安全书籍上看到"SQL注入"或"XSS"这些术语时,是否感觉它们就像天书般难以理解?纸上谈兵的安全知识往往让人昏昏欲睡,而真正的技能提升来自于亲手…...

5分钟学会:本地化视频字幕提取神器,87种语言一键转换SRT
5分钟学会:本地化视频字幕提取神器,87种语言一键转换SRT 【免费下载链接】video-subtitle-extractor 视频硬字幕提取,生成srt文件。无需申请第三方API,本地实现文本识别。基于深度学习的视频字幕提取框架,包含字幕区域…...

Dripsy进阶技巧:如何实现动态主题切换和深色模式
Dripsy进阶技巧:如何实现动态主题切换和深色模式 【免费下载链接】dripsy 🍷 Responsive, unstyled UI primitives for React Native Web. 项目地址: https://gitcode.com/gh_mirrors/dr/dripsy Dripsy是一个为React Native和Web开发的响应式、无…...