中文版开源Llama 2同时有了语言、多模态大模型,完全可商用
可以说,AI 初创公司 LinkSoul.Al 的这些开源项目让海外开源大模型在国内的普及和推广速度与国际几乎保持了一致。
7 月 19 日,Meta 终于发布了免费可商用版本 Llama 2,让开源大模型领域的格局发生了巨大变化。
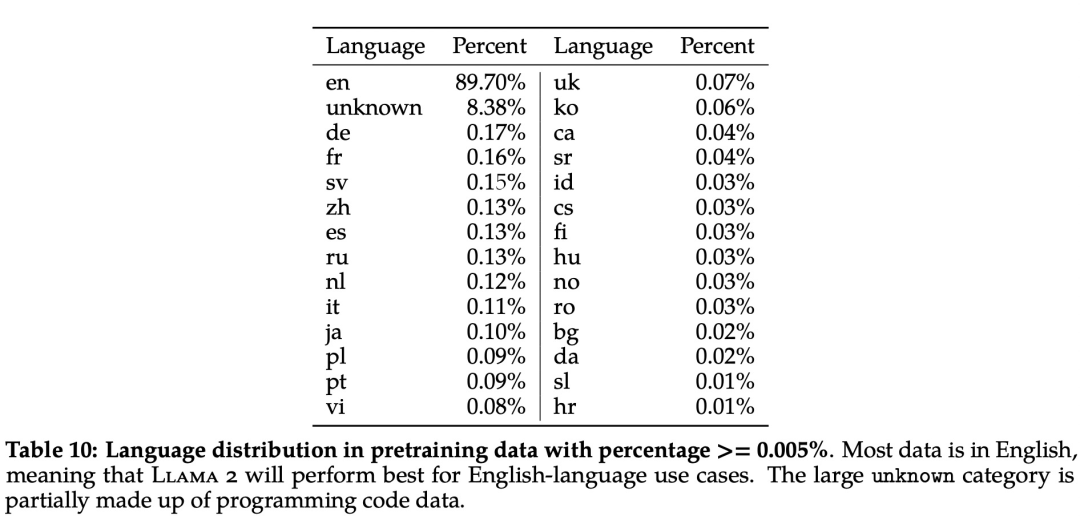
Llama 2 模型系列包含 70 亿、130 亿和 700 亿三种参数变体,相比上一代的训练数据增加了 40%,在包括推理、编码、精通性和知识测试等许多外部基准测试中展示出了优越的表现,且支持多个语种。
美中不足的是,Llama 2 语料库仍以英文(89.7%)为主,而中文仅占据了其中的 0.13%。这导致 Llama 2 很难完成流畅、有深度的中文对话。
中文版 Llama2 开源大模型创下社区「首个」
好消息是,在 Meta Al 开源 Llama 2 模型的次日,开源社区首个能下载、能运行的开源中文 LLaMA2 模型就出现了。该模型名为「Chinese Llama 2 7B」,由国内 AI 初创公司 LinkSoul.Al 推出。

仅仅两周时间,该项目在 Hugging Face 上收获过万次下载,并在 GitHub 上获得了 1200 Stars。
据项目介绍,Chinese-Llama-2-7b 开源的内容包括完全可商用的中文版 Llama2 模型及中英文 SFT 数据集,输入格式严格遵循 llama-2-chat 格式,兼容适配所有针对原版 llama-2-chat 模型的优化。
项目地址:
https://github.com/LinkSoul-AI/Chinese-Llama-2-7b

目前,普通用户可以在线体验「Chinese Llama-2 7B Chat」。
试用地址:
https://huggingface.co/spaces/LinkSoul/Chinese-Llama-2-7b
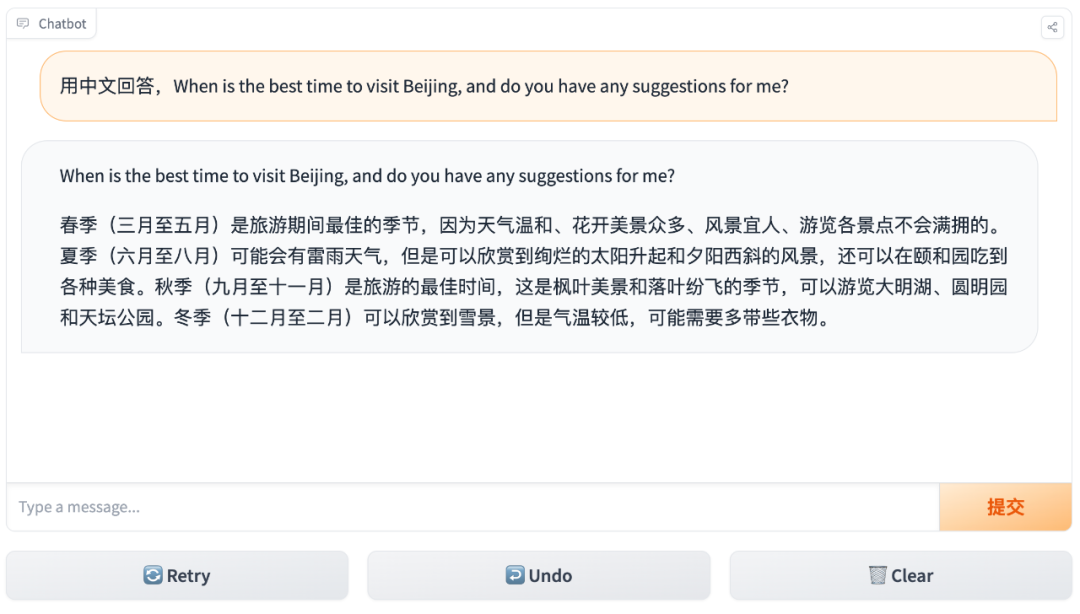
比如你能够以英文提问,并让它用中文回答:
或者直接中文对话,它也能以中文实现准确、流畅的回答:
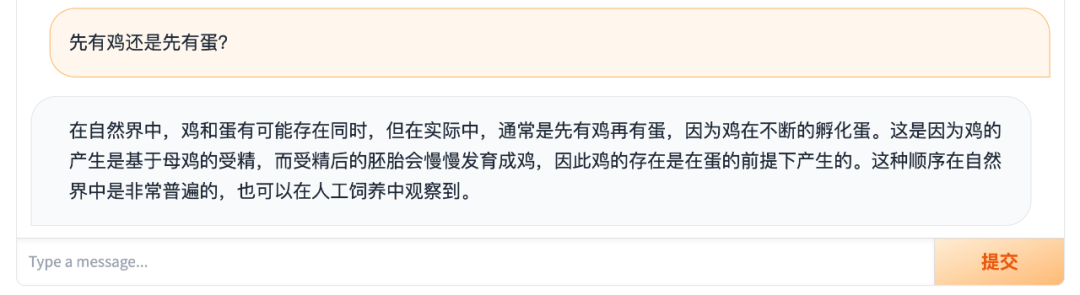
主打的就是一个中英文灵活切换:

有人已上手,表示运行良好:
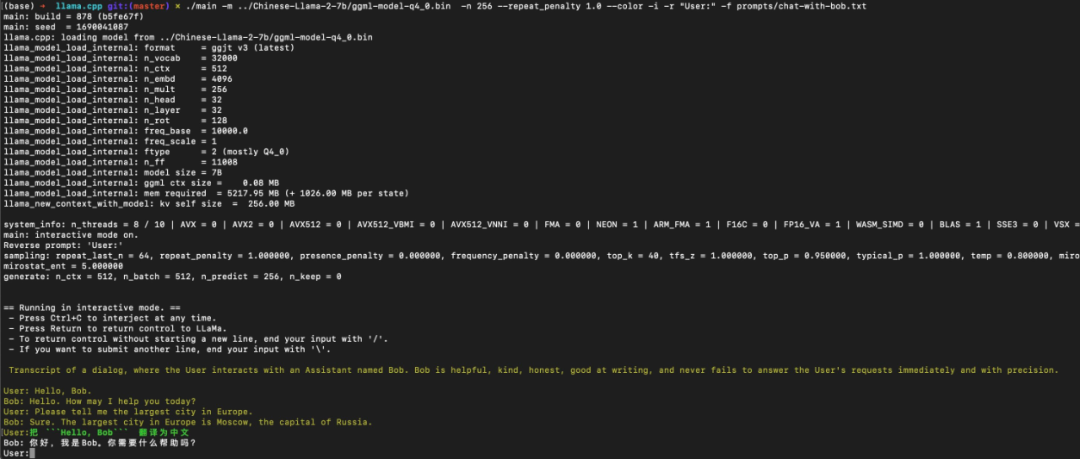
图源:https://twitter.com/roya10x7/status/1682781475458957315?s=20
语言模型之外,继续开源两个中文多模态大模型
在推出首个开源 Llama2 中文语言大模型之后,LinkSoul.AI 团队将目光投向了目前全球尚外于发展初期的语音文本多模态大模型和图文大模型,并再次率先开源了相关的模型,提供国内开发者免费下载、自由商用。
本次开源的两个中文多模态大模型,包括如下:
-
由 LinkSoul.Al 团队牵头,北京智源人工智能研究院、北京大学、零一万物等国内头部顶尖人工智能团队通力合作的第一个支持中英双语、语音到文本的多模态开源对话模型 (LLaSM)
-
第一个基于 Llama 2 的支持中英文双语视觉到文本的多模态模型 (Chinese-LLaVA)
两个模型都基于 Apache-2.0 协议开源,完全可商用。
LinkSoul.Al 开发团队负责人史业民表示,「放眼全球,目前如何让『模型听世界、看世界』仍然没有可靠的开源模型可用。我们希望能够尽微薄之力,让中国大模型生态距离国际领先标准再近一些。」
语音到文本多模态开源对话模型 (LLaSM)
LinkSoul.AI 开源了可商用的中英文双语语音 - 语言助手 LLaSM 以及中英文语音 SFT 数据集 LLaSM-Audio-Instructions。LLaSM 是首个支持中英文语音 - 文本多模态对话的开源可商用对话模型。
相较以往的传统方案,LLaSM 能够通过便捷的语音输入的交互方式,大幅改善过往以文本为输入的大模型的使用体验,同时有效避免基于 ASR 解决方案的繁琐流程以及可能引入的错误。

项目地址:https://github.com/LinkSoul-AI/LLaSM
数据集: https://huggingface.co/datasets/LinkSoul/LLaSM-Audio-Instructions
下面是 LLaSM 的一个语音 - 文本对话示例。

LLaSM 也有相应的文献介绍。

模型、代码和数据地址:
https://huggingface.co/spaces/LinkSoul/LLaSM
图像到文本多模态开源对话模型 (Chinese LLaVA)
LinkSoul.AI 开源了可商用的中英文双语视觉 - 语言助手 Chinese-LLaVA 以及中英文视觉 SFT 数据集 Chinese-LLaVA-Vision-Instructions,支持中英文视觉 - 文本多模态对话的开源可商用对话模型。

项目地址:https://github.com/LinkSoul-AI/Chinese-LLaVA
数据集: https://huggingface.co/datasets/LinkSoul/Chinese-LLaVA-Vision-Instructions
下面是 Chinese LLaVA 的一个视觉 - 文本对话示例。
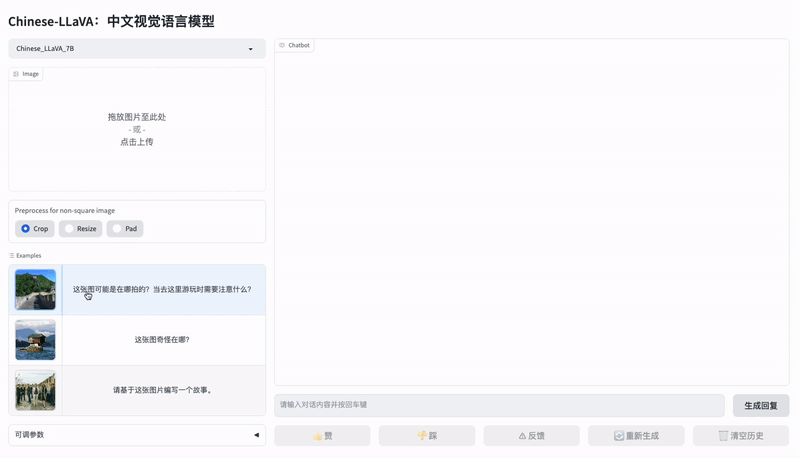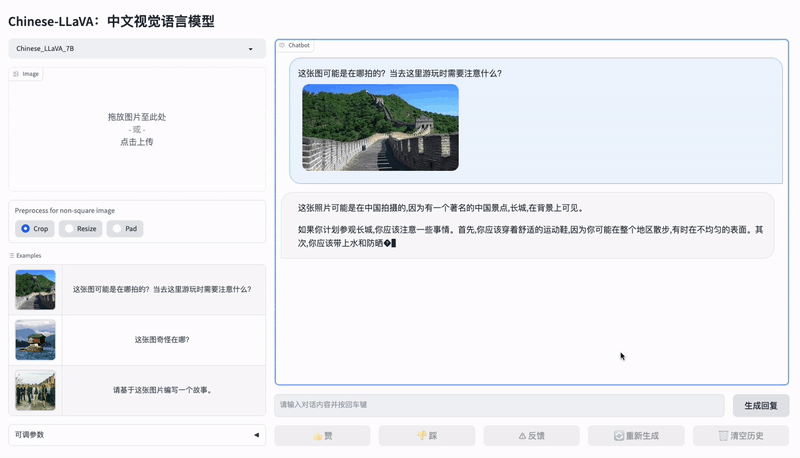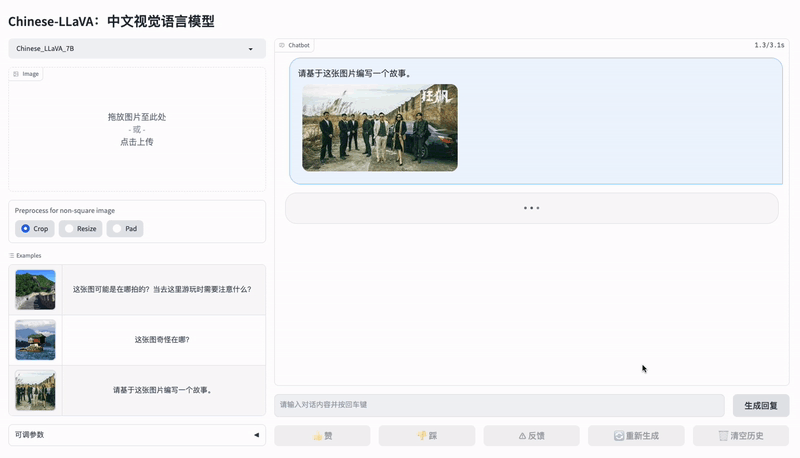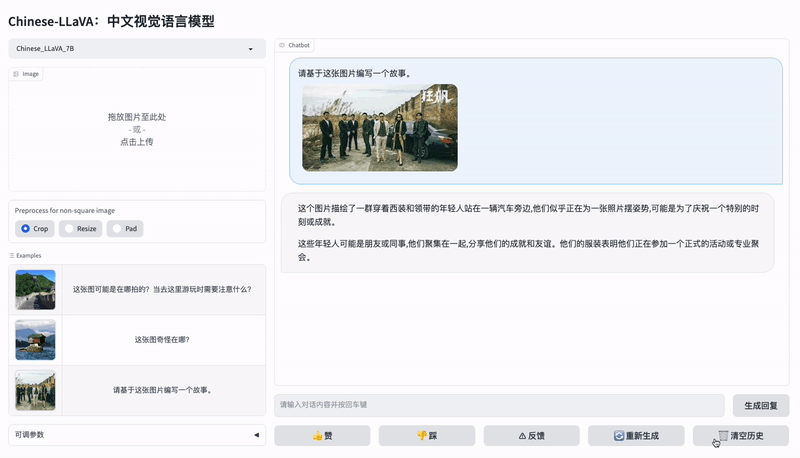
模型、代码和数据地址:
https://huggingface.co/spaces/LinkSoul/Chinese-LLaVa
多模态模型统一架构解读
大语言模型在很多方面展现了强大的能力,也在一定程度上让人们看到了实现通用人工智能(AGI)的希望。多模态模型提供了不同模态之间信息交互的渠道,使得视觉信息、语音信息等能和文本语义信息互为补充,让大语言模型能听到世界、看到世界,从而向 GI 又前进一步。
因此,训练多模态模型的重点是如何融合互补不同模态间的信息,并充分利用现有大语言模型能力。LinkSoul.AI 开源的语音 - 语言多模态模型和视觉 - 语言多模态模型统一采用下图所示框架。
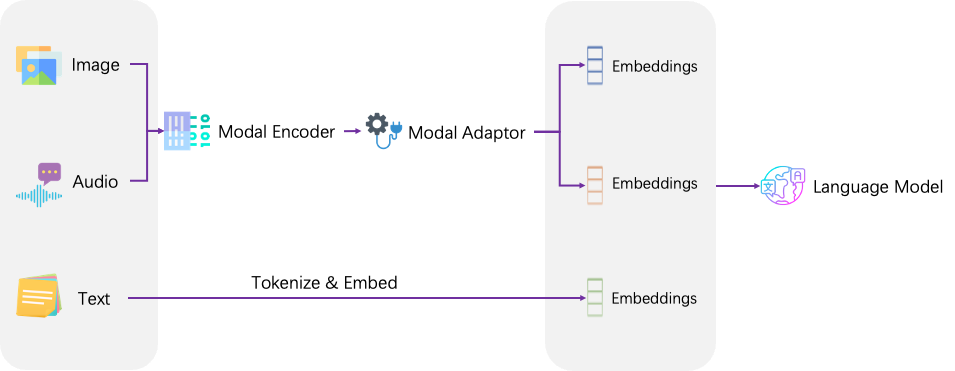
首先通过模态编码器编码不同模态数据特征,紧接着在多模态特征对齐的预训练阶段学习模态适配器(Adaptor),将不同模态的输入特征与大语言模型对齐。
然后在端到端的有监督微调(SFT)阶段使用不同模态的指令数据集对模态适配器和大语言模型进行微调。在有监督微调阶段,同时使用跨模态(cross-modal)指令数据和仅文本(text-only)指令数据进行多任务训练。LinkSoul.AI 团队认为多任务训练有助于避免模型产生模态依赖和偏见,并且可以自然地用一个模型实现多种模态。
LinkSoul.AI 团队接下来的工作会把语音 - 视觉 - 文本进一步融合,让大语言模型同时支持语音和视觉模态。
预训练阶段
预训练阶段将模态编码器和大语言模型参数都冻结,使用跨模态的语音 / 视觉 - 文本对进行 Adaptor 的训练,优化目标为对输入的指令(instructions)生成相应的回复(responses)。
具体来讲,对于语音模态,采用 Whisper 作为特征编码器,冻结 Whisper [5] 并提取音频输入的特征。使用公开的中英文自动语音识别(ASR)数据集 Aishell [1]、 LibriSpeech [2]、Magicdata [3] 和 Primewords [4]。
对每个数据样本(audio、text_label)依据对应语言随机从预训练语音指令表(见第三节数据部分)中选取一个指令,组成(audio,instruct,text_label)格式的数据,并在训练过程中预测 text_label。
对于视觉模态,采用 CLIP [6] 作为图片特征提取器,并使用 mBART [8] 对 LLaVA [7] 开源的视觉预训练数据进行翻译汉化,生成中文图片文本对。在预训练阶段同时使用中英文数据进行训练,从而让模型更好的支持中文。
有监督微调
预训练阶段将不同模态的特征和大语言模型对齐,有监督微调阶段则仅冻结模态编码器权重,将模态适配器和大语言模型参数打开,使用跨模态指令数据进行微调。
针对目前几乎没有公开语音多模态指令数据这一问题,基于公开数据集 WizardLM [9]、ShareGPT [10]、GPT-4-LLM [11] 构造语音 - 文本多模态指令数据集 LLaSM-Audio-Instructions。以语音输入作为指令,并预测对应的文本输出。
对于视觉模态,同样先通过 mBART [8] 对 LLaVA [7] 开源的视觉指令数据集进行翻译汉化,生成中文的视觉指令数据集,然后类似地进行训练。
数据集
模态转换预训练数据集
先来看 Audio。语音多模态预训练数据集采用公开中英文自动语音识别(ASR)数据集 Aishell [1]、LibriSpeech [2]、Magicdata [3] 和 Primewords [4]。
同时构造如下指令集,对每个(audio、text_label)样本依据对应语言随机选择一条指令构造数据样本(instruction、audio、text_label)。

表 1:英文简单指令集

表 2:中文简单指令集
然后是 Vision。对于视觉模态,采用 LLaVA [7] 开源的视觉预训练数据,通过 mBART [8] 翻译进行汉化,生成中文图片文本对,以提升模型的中文能力。
指令微调数据集
同样先来看 Audio。在构建音频数据集的过程中,首先仔细过滤所有对话数据,通过删除那些不适合发声的对话,包括代码、符号、URL 和其他不可读的文本。然后,为确保数据质量,每轮对话中聊天机器人的答案再次被过滤,那些不包含有价值信息的内容将被丢弃。最后,使用 Microsoft Azure [12] 语音合成 API 来生成语音数据。
然后是 Vision。对于视觉模态,采用 LLaVA [7] 开源的视觉指令数据集,通过 mBART [8] 进行汉化,生成中文多模态指令数据,使得模型能够具有中文视觉指令执行能力。
为了便于开源社区快速感受多模态大模型的能力,以及共同推进多模态大模型的研究进展,训练用到的数据在项目中开源,并提供 Hugging Face 仓库下载。
对于 LinkSoul.AI 团队而言,这两个开源可商用的多模态大模型不仅为大模型生态带来了语音和视觉多模态能力,也在大模型多语言方面做出了贡献。
此外在商用场景上,该团队推出的模型都允许完全免费商用,这对于国内个人开发者和初创公司也具有非凡的价值。
参考文献:
[1] Aishell: https://www.openslr.org/33/
[2] LibriSpeech: https://huggingface.co/datasets/librispeech_asr
[3] Magicdata: https://openslr.org/68/
[4] Primewords: https://openslr.org/47/
[5] Whisper: https://huggingface.co/openai/whisper-large-v2
[6] CLIP: https://huggingface.co/openai/clip-vit-large-patch14
[7] LLaVA: https://llava-vl.github.io/
[8] mBART: https://arxiv.org/pdf/2001.08210.pdf, https://huggingface.co/facebook/mbart-large-50-one-to-many-mmt
[9] WizardLM: https://github.com/nlpxucan/WizardLM
[10] ShareGPT: https://sharegpt.com/
[11] GPT-4-LLM: https://arxiv.org/abs/2304.03277
[12] Microsoft Azure 语音合成 API:https://azure.microsoft.com/en-us/products/ai-services/ai-speech
相关文章:
中文版开源Llama 2同时有了语言、多模态大模型,完全可商用
可以说,AI 初创公司 LinkSoul.Al 的这些开源项目让海外开源大模型在国内的普及和推广速度与国际几乎保持了一致。 7 月 19 日,Meta 终于发布了免费可商用版本 Llama 2,让开源大模型领域的格局发生了巨大变化。 Llama 2 模型系列包含 70 亿、…...
JavaScript、TypeScript、ES5、ES6之间的联系和区别
ECMAScript: 一个由 ECMA International 进行标准化,TC39 委员会进行监督的语言。通常用于指代标准本身。JavaScript: ECMAScript 标准的各种实现的最常用称呼。这个术语并不局限于某个特定版本的 ECMAScript 规范,并且可能被用于…...
RCNA——单臂路由
一,实验背景 之前的VLAN实现的很多都是相同部门互相访问,不同部门无法访问。不过这次整来了一个路由器,领导说大部分的部门虽说有保密信息需要互相隔离,但是这些部门和其它部门也应该互相连通以方便工作交流。因此要配置新的环境&…...

leetcode做题笔记69
给你一个非负整数 x ,计算并返回 x 的 算术平方根 。 由于返回类型是整数,结果只保留 整数部分 ,小数部分将被 舍去 。 注意:不允许使用任何内置指数函数和算符,例如 pow(x, 0.5) 或者 x ** 0.5 。 思路一ÿ…...
!)
CentOS根分区扩容实战(非LVM)!
在虚拟化平台(如KVM,ESXI)中,将虚拟机的磁盘大小扩展到所需的大小。这将增加虚拟机的磁盘空间。 在虚拟机中,使用以下命令查看可用的磁盘和分区信息: sudo fdisk -l确定要扩展的根分区的设备名称(如 /dev/…...
uniapp 微信小程序 分包
1、manifest.json内添加如图所示: "optimization" : {"subPackages" : true },2、在与pages同级上创建各个分包的文件夹 把需要分包的文件对应移入分包文件夹内 3、page.json内修改分包文件的路径 比如: {"path" : &qu…...

Redis_安装、启动以及基本命令
2.Redis安装 2.1前置处理环境 VMware安装安装centOS的linux操作系统xshellxftp 2.2 配置虚拟机网络 按ctrlaltf2 切换到命令行 cd (/)目录 修改/etc/sysconfig/network-scripts/ifcfg-ens3 vi 命令 按insert表示插入 按ctrlesc退出修改状态 :wq 写入并退出 此文件必须保持一…...

IPv4编址及子网划分
IPv4编址及子网划分 一、IPv4地址概述1.1、IPv4报文结构1.2、IPv4地址分类1.2.1、A类1.2.2、B类1.2.3、C类1.2.4、D类1.2.5、E类 1.3、私有IP地址1.4、特殊地址 二、子网划分2.1、子网掩码2.2、VLSM 可变长的子网掩码2.3、子网划分2.4、子网划分示例2.4.1、子网划分案例 —— A…...
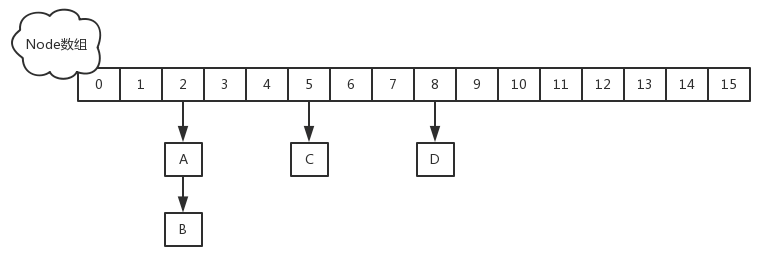
HashMap 二十一问
1:HashMap 的数据结构? A:哈希表结构(链表散列:数组链表)实现,结合数组和链表的优点。当链表长度超过 8 时,链表转换为红黑树。transient Node<K,V>[] table; 2:…...
什么是Selenium?使用Selenium进行自动化测试
什么是 Selenium? Selenium 是一种开源工具,用于在 Web 浏览器上执行自动化测试(使用任何 Web 浏览器进行 Web 应用程序测试)。 等等,先别激动,让我再次重申一下,Selenium 仅可以测试We…...

解决“先commit再pull”造成的git冲突
一、问题场景 在分支上修改了代码然后commit(没有push),此时再git pull,拉下了别人的修改,但是报错无法merge 二、解决步骤 1.在idea下方工具栏选择git -> log,可以看到版本变化链表,右键…...
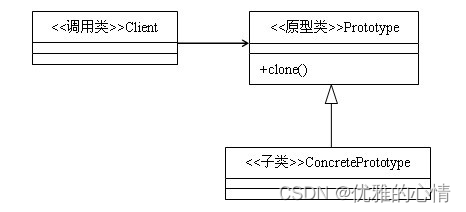
JAVA设计模式----原型设计模式
文章目录 一、简介二、实现方式三、原型模式的注意事项浅拷贝与深拷贝浅拷贝深拷贝一、简介 定义:用原型实例指定创建对象的种类,并通过拷贝这些原型创建新的对象。 类型:创建类模式 类图: 原型模式主要用于对象的复制,它的核心是就是类图中的原型类Prototype。Protot…...

树·c++
树(Tree) 是一种非线性的数据结构,它由若干个 节点(Node) 组成,并通过 边(Edge) 相互连接。树的结构类似于现实中的树,其中 根节点(Root Node) 位…...
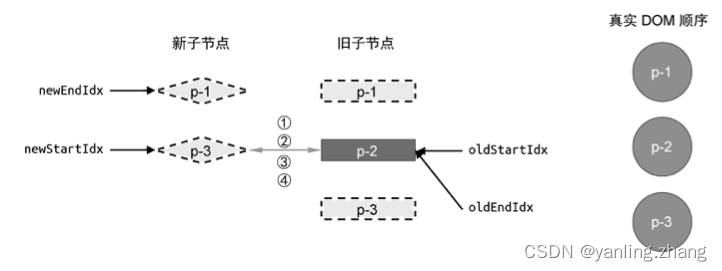
vuejs 设计与实现 - 双端diff算法
我们介绍了简单 Diff 算法的实现原理。简单 Diff 算法利用虚拟节点的 key 属性,尽可能地复用 DOM元素,并通过移动 DOM的方式来完成更新,从而减少不断地创建和销毁 DOM 元素带来的性能开销。但是,简单 Diff 算法仍然存在很多缺陷&a…...

RISC-V在快速发展的处理器生态系统中找到立足点
原文:RISC-V Finds Its Foothold in a Rapidly Evolving Processor Ecosystem 作者:Agam Shah 转载自:https://thenewstack.io/risc-v-finds-its-foothold-in-a-rapidly-evolving-processor-ecosystem/ 以下是正文 But the open source pr…...

面试题02
这里写目录标题 主存储器和CPU之间增加Cache的目的是?判断一个char变量c1是否为小写字母循环链表顺序存储的线性表,访问结点和增加删除结点的时间复杂度请列举你所知道的c/c++ 语言中引入性能开销或阻碍编译优化的语言特性,并尝试说明对应的解决办法请列举CPU cache对编程开…...
第六章 SpringBoot注解 @ConditionalOnBean
满足条件的则进行组件的注入 Configuration(proxyBeanMethods true) //告诉SpringBoot这是一个配置类 配置文件 ConditionalOnBean(name "tom") public class MyConfig {Bean("tom")public Pet tom(){return new Pet("tomPet");}/*** 外部无论…...
MySQL8的下载与安装-MySQL8知识详解
本文的内容是mysql8的下载与安装。主要讲的是两点:从官方网站下载MySQL8安装和从集成环境安装MySQL8。 一、从官方网站下载MySQL8.0安装 MySQL8.0官方下载地址是:(见图) 官方正式版的最新版本是8.0.34,也推出了创新版…...

ATF(TF-A)安全通告 TFV-9 (CVE-2022-23960)
ATF(TF-A)安全通告汇总 目录 一、ATF(TF-A)安全通告 TFV-9 (CVE-2022-23960) 二、CVE-2022-23960 一、ATF(TF-A)安全通告 TFV-9 (CVE-2022-23960) Title TF-A披露通过分支预测目标重用(branch prediction target reuse)引发的前瞻执行处理器漏洞 CV…...

docker实现Nginx
文章目录 1.docker 安装2.docker环境实现Nginx 1.docker 安装 1.使用环境为红帽8.1,添加源 yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo2.安装 yum install docker-ce docker-ce-cli containerd.io显示出错 Docker C…...
)
别再只会调库了!手把手教你用STM32的TIM8定时器精准控制SG90舵机(附完整代码)
深入理解STM32 TIM8定时器:从寄存器配置到SG90舵机精准控制实战 在嵌入式开发领域,直接调用HAL库函数虽然能快速实现功能,但真正理解底层硬件工作原理才能应对复杂场景。今天我们就以STM32的TIM8高级定时器为例,彻底拆解如何通过寄…...

用文言文和AI聊天省30%算力费用,这届年轻人的省钱思路太野了
昨天刷小红书的时候刷到个神操作,给我笑到喷饭:有个网友说他用GPT4的时候心疼额度,每次让AI写东西都叽里咕噜说一大段废话,额度哗哗掉,后来他突发奇想,用文言文跟AI聊天,结果同样的需求…...
)
别再只数朋友了!用NetworkX实战解读社交网络中的三种“核心”玩家(附完整代码)
社交网络中的关键角色识别:用NetworkX解锁三类核心玩家 在微信朋友圈里,总有几个"人脉王"能帮你联系到意想不到的资源;微博上总有些"信息枢纽"能让热点话题迅速发酵;而某些"活跃分子"则像社交网络的…...

Refined Now Playing:网易云音乐美化插件终极指南
Refined Now Playing:网易云音乐美化插件终极指南 【免费下载链接】refined-now-playing-netease 🎵 网易云音乐沉浸式播放界面、歌词动画 - BetterNCM 插件 项目地址: https://gitcode.com/gh_mirrors/re/refined-now-playing-netease Refined N…...

Tool.Net 3.0.0正式版发布:如何用MapApiRoute和AshxRoute特性玩转灵活API路由?
Tool.Net 3.0.0路由革命:MapApiRoute与AshxRoute的实战进阶指南 当ASP.NET Core开发者遇到需要为复杂业务系统设计多层级API路由时,传统配置方式往往显得力不从心。Tool.Net 3.0.0带来的MapApiRoute方法与AshxRoute特性组合,正在改变这一局面…...

从数据库查询到权限设计:聊聊集合与关系理论在真实开发中的隐形应用
从数据库查询到权限设计:集合与关系理论在真实开发中的隐形应用 当你在SQL中写下JOIN语句时,是否思考过背后隐藏的数学原理?设计RBAC权限系统时,有没有意识到自己正在运用离散数学中的等价类划分?集合与关系理论就像空…...

七段数码管显示数字0-9:从硬件原理到Verilog代码的保姆级解析
七段数码管显示数字0-9:从硬件原理到Verilog代码的保姆级解析 第一次接触七段数码管时,很多人会被它简单外表下的复杂逻辑所迷惑——为什么七个LED排列组合就能显示所有数字?共阴和共阳到底有什么区别?Verilog代码里那些神秘的二进…...

UABEA:下一代跨平台Unity资源编辑器完全指南
UABEA:下一代跨平台Unity资源编辑器完全指南 【免费下载链接】UABEA c# uabe for newer versions of unity 项目地址: https://gitcode.com/gh_mirrors/ua/UABEA 在当今游戏开发与模组制作领域,高效处理Unity资源包已成为开发者面临的核心挑战之一…...
)
别再瞎调了!用PSO粒子群算法自动优化模糊PID的5个关键参数(附Simulink模型避坑指南)
粒子群算法在模糊PID参数优化中的实战应用与避坑指南 引言:当传统调参遇上智能优化 记得第一次接触模糊PID控制器时,我被那些神秘的量化因子和比例因子折磨得够呛。连续三天守在电脑前,手动调整参数组合,每次仿真运行都要等待数小…...

如何彻底清理显卡驱动?Display Driver Uninstaller终极解决方案
如何彻底清理显卡驱动?Display Driver Uninstaller终极解决方案 【免费下载链接】display-drivers-uninstaller Display Driver Uninstaller (DDU) a driver removal utility / cleaner utility 项目地址: https://gitcode.com/gh_mirrors/di/display-drivers-uni…...