【Linux进阶之路】进程(上)
文章目录
- 前言
- 一、操作系统加载过程
- 二、进程
- 1.基本概念
- 2.基本信息
- ①运行并观察进程
- ②创建子进程
- ③僵尸与孤儿进程(父子进程衍生出来的问题)
- 1. 僵尸进程(Zombie状态)
- 2. 孤儿进程
- 3.基本状态
- ①操作系统的状态(统一)
- 1.运行态
- 2.阻塞态
- 3.挂起态
- ②Linux系统的状态(实际)
- 1.R状态
- 2.S状态
- 3.D状态
- 4.T状态
- 5.t状态
- 4.优先级
- ①查看优先级
- ②修改优先级
- 1.top
- 2.nice
- 3.renice
- ③基本结构
- 5.环境变量
- ①简单认识
- 1.PATH
- 2.HOME
- 3.SHELL
- ②常用的环境变量
- ③创建环境变量
- ④进程内使用环境变量
- 1.getenv
- 2.命令行参数
- 3.环境变量参数
- 总结
前言
回顾上文,操作系统是通过先描述再组织,进而管理软硬件资源的一款软件。那先组织再描述再组织的是什么呢?就是我们今天要讲的进程!
一、操作系统加载过程
操作系统是一款软件,那么它是如何加载到内存呢?其实,计算机在开机时早已做好准备,在你按下开机键的那一刻,BIOS(基本输入输出系统,英文: Basic Input Output System)芯片就开始启动,开始做准备工作,通电唤醒CPU,IO接口,内存等资源,有了CPU这一名大将,便可以接着加载硬件资源,比如:网卡,显卡,磁盘等。接着再找到操作系统的引导文件,借助引导文件,将操作系统从磁盘加载到内存中,接着操作系统就开始一顿乱杀。
- BIOS,是计算机的一个在CPU运行的可执行程序,说白了就是一个引子,加载基本资源,然后把操作系统带到内存当中,并让其管理软硬件资源的功能。
二、进程
1.基本概念
再来想一个问题,那我们的qq是如何运行的呢?学到现在我们应该都知道可执行程序,也就是一个可以执行的文件,一般都在磁盘当中,那点击它之后,便在计算机系统中运行了起来,这之间需经过什么过程么?
可执行程序的数据在磁盘当中,要想运行,首先需要加载到内存当中,因为磁盘的运行速度很慢只有1ms左右,而内存的运行速度在100ns左右,能更好的适配CPU中寄存器10ns左右的速度, 然后操作系统该如何管理加载到内存的数据呢?不可能直接管理一大堆数据吧?那么多的程序要运行,数据该多大?这样操作系统不得累死,为了操作系统管理方便,于是便将需要进行管理的属性信息组织到一块,统一进行管理,那操作系统管理的属性信息就叫做PCB(process control block),在Linux下叫做task_struct。以下我们统称为task_struct。
这是task_struct的源码:供参考。
struct task_struct {
volatile long state; //说明了该进程是否可以执行,还是可中断等信息
unsigned long flags; //Flage 是进程号,在调用fork()时给出
intsigpending; //进程上是否有待处理的信号
mm_segment_taddr_limit; //进程地址空间,区分内核进程与普通进程在内存存放的位置不同//0-0xBFFFFFFF foruser-thead//0-0xFFFFFFFF forkernel-thread
//调度标志,表示该进程是否需要重新调度,若非0,则当从内核态返回到用户态,会发生调度
volatilelong need_resched;
int lock_depth; //锁深度
longnice; //进程的基本时间片
//进程的调度策略,有三种,实时进程:SCHED_FIFO,SCHED_RR,分时进程:SCHED_OTHER
unsigned long policy;
struct mm_struct *mm; //进程内存管理信息
int processor;
//若进程不在任何CPU上运行, cpus_runnable 的值是0,否则是1这个值在运行队列被锁时更新
unsigned long cpus_runnable, cpus_allowed;
struct list_head run_list; //指向运行队列的指针
unsigned longsleep_time; //进程的睡眠时间
//用于将系统中所有的进程连成一个双向循环链表,其根是init_task
struct task_struct *next_task, *prev_task;
struct mm_struct *active_mm;
struct list_headlocal_pages; //指向本地页面
unsigned int allocation_order, nr_local_pages;
struct linux_binfmt *binfmt; //进程所运行的可执行文件的格式
int exit_code, exit_signal;
intpdeath_signal; //父进程终止是向子进程发送的信号
unsigned longpersonality;
//Linux可以运行由其他UNIX操作系统生成的符合iBCS2标准的程序
intdid_exec:1;
pid_tpid; //进程标识符,用来代表一个进程
pid_tpgrp; //进程组标识,表示进程所属的进程组
pid_t tty_old_pgrp; //进程控制终端所在的组标识
pid_tsession; //进程的会话标识
pid_t tgid;
intleader; //表示进程是否为会话主管
struct task_struct*p_opptr,*p_pptr,*p_cptr,*p_ysptr,*p_osptr;
struct list_head thread_group; //线程链表
struct task_struct*pidhash_next; //用于将进程链入HASH表
struct task_struct**pidhash_pprev;
wait_queue_head_t wait_chldexit; //供wait4()使用
struct completion*vfork_done; //供vfork()使用
unsigned long rt_priority; //实时优先级,用它计算实时进程调度时的weight值//it_real_value,it_real_incr用于REAL定时器,单位为jiffies,系统根据it_real_value
//设置定时器的第一个终止时间.在定时器到期时,向进程发送SIGALRM信号,同时根据
//it_real_incr重置终止时间,it_prof_value,it_prof_incr用于Profile定时器,单位为jiffies。
//当进程运行时,不管在何种状态下,每个tick都使it_prof_value值减一,当减到0时,向进程发送
//信号SIGPROF,并根据it_prof_incr重置时间.
//it_virt_value,it_virt_value用于Virtual定时器,单位为jiffies。当进程运行时,不管在何种
//状态下,每个tick都使it_virt_value值减一当减到0时,向进程发送信号SIGVTALRM,根据
//it_virt_incr重置初值。
unsigned long it_real_value, it_prof_value, it_virt_value;
unsigned long it_real_incr, it_prof_incr, it_virt_value;
struct timer_listreal_timer; //指向实时定时器的指针
struct tmstimes; //记录进程消耗的时间
unsigned longstart_time; //进程创建的时间
//记录进程在每个CPU上所消耗的用户态时间和核心态时间
longper_cpu_utime[NR_CPUS],per_cpu_stime[NR_CPUS];
//内存缺页和交换信息:
//min_flt, maj_flt累计进程的次缺页数(Copyon Write页和匿名页)和主缺页数(从映射文件或交换
//设备读入的页面数);nswap记录进程累计换出的页面数,即写到交换设备上的页面数。
//cmin_flt, cmaj_flt,cnswap记录本进程为祖先的所有子孙进程的累计次缺页数,主缺页数和换出页面数。
//在父进程回收终止的子进程时,父进程会将子进程的这些信息累计到自己结构的这些域中
unsignedlong min_flt, maj_flt, nswap, cmin_flt, cmaj_flt, cnswap;
int swappable:1; //表示进程的虚拟地址空间是否允许换出
//进程认证信息
//uid,gid为运行该进程的用户的用户标识符和组标识符,通常是进程创建者的uid,gid
//euid,egid为有效uid,gid
//fsuid,fsgid为文件系统uid,gid,这两个ID号通常与有效uid,gid相等,在检查对于文件
//系统的访问权限时使用他们。
//suid,sgid为备份uid,gid
uid_t uid,euid,suid,fsuid;
gid_t gid,egid,sgid,fsgid;
int ngroups; //记录进程在多少个用户组中
gid_t groups[NGROUPS]; //记录进程所在的组
//进程的权能,分别是有效位集合,继承位集合,允许位集合
kernel_cap_tcap_effective, cap_inheritable, cap_permitted;
int keep_capabilities:1;
struct user_struct *user;
struct rlimit rlim[RLIM_NLIMITS]; //与进程相关的资源限制信息
unsigned shortused_math; //是否使用FPU
charcomm[16]; //进程正在运行的可执行文件名//文件系统信息
int link_count, total_link_count;
//NULL if no tty进程所在的控制终端,如果不需要控制终端,则该指针为空
struct tty_struct*tty;
unsigned int locks;
//进程间通信信息
struct sem_undo*semundo; //进程在信号灯上的所有undo操作
struct sem_queue *semsleeping; //当进程因为信号灯操作而挂起时,他在该队列中记录等待的操作
//进程的CPU状态,切换时,要保存到停止进程的task_struct中
structthread_struct thread;//文件系统信息
struct fs_struct *fs;//打开文件信息
struct files_struct *files;//信号处理函数
spinlock_t sigmask_lock;
struct signal_struct *sig; //信号处理函数
sigset_t blocked; //进程当前要阻塞的信号,每个信号对应一位
struct sigpendingpending; //进程上是否有待处理的信号
unsigned long sas_ss_sp;
size_t sas_ss_size;
int (*notifier)(void *priv);
void *notifier_data;
sigset_t *notifier_mask;
u32 parent_exec_id;
u32 self_exec_id;spinlock_t alloc_lock;
void *journal_info;
};
像这样一个进程信息,操作系统并不会进行直接管理,而是将这样的进程放到指定的内存区域,然后自己弄个结构体指针,通过指针找到对应的进程即可。
那如果有很多的进程呢?我们可以从task_struct的源码中寻找答案:
//用于将系统中所有的进程连成一个双向循环链表,其根是init_task
struct task_struct *next_task, *prev_task;
图解:
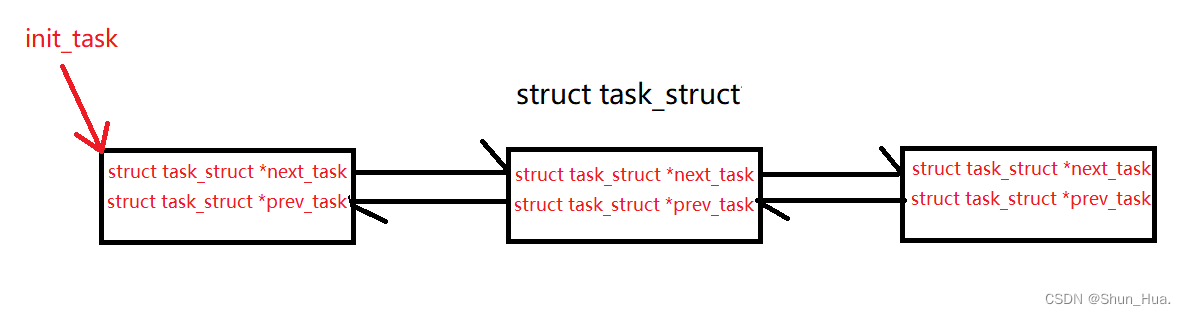
- 说明:这里的头尾相连省去了。
因此:操作系统的管理成本其实很低,只需要一个指针的大小,便可以管理所有存在内存中的task_struct。
那数据呢?有了task_struct你的信息和数据便也得到了管理,因为你的task_struct也会指向数据,方便对数据做更改和写入。
- 因此:进程 等于 task_struct数据结构对象 + 代码和数据。
2.基本信息
①运行并观察进程
在vim上编辑如下代码:

然后运行此代码:

此时再开一个窗口会话,查看此进程的信息。
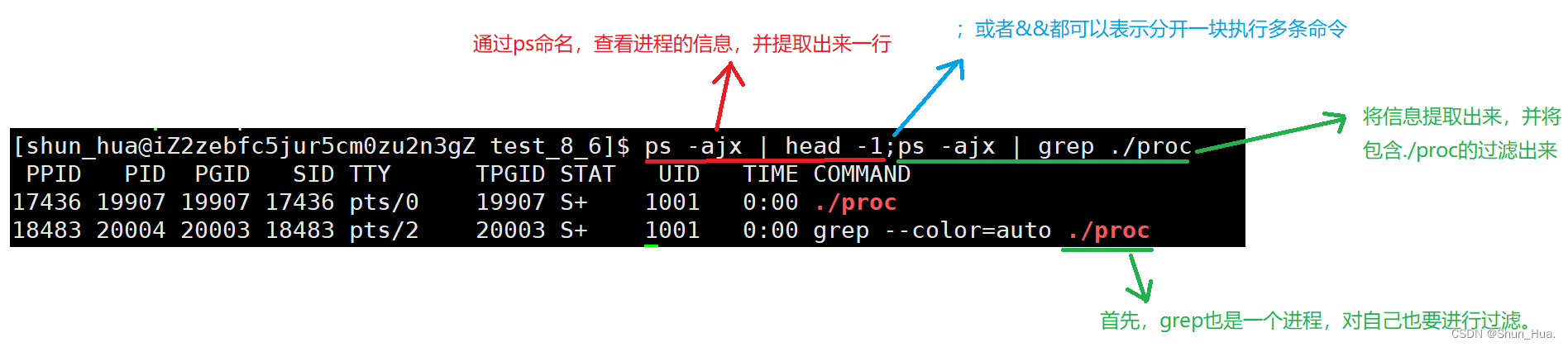
基本信息:

ps命令
ps ajx | less
- 可以通过上下翻来查看进程
ps aux --sort -pcpu | less
//将cpu占用资源进行排序
ps aux --sort -pmem | less
//将内存占用资源进行排序
- 查看进程的资源占用情况。
说明:一个进程只能有一个pid,一个可执行程序执行多次pid不同。
如何在进程里面查看pid与ppid呢?
介绍两个函数(系统调用接口):getpid() 与 getppid()
-
举例代码
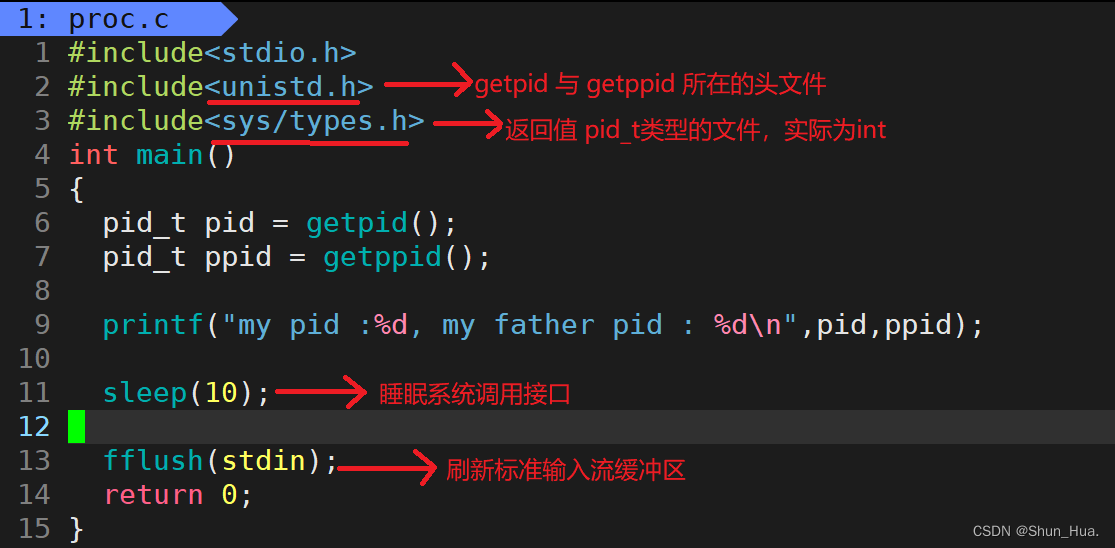
-
运行结果对比

可以看出是正确的pid与ppid -
看父进程到底是什么

补充小知识点:kill -9 【进程id】 可以杀掉进程。
那进程一般都存在哪呢?
在 Linux 下我们可以通过/proc(存的是内存级文件)目录中查看相关进程的信息,可以通过pid查看详细信息。
-
运行刚才我们写的代码:

-
通过pid查看进程的相关信息:
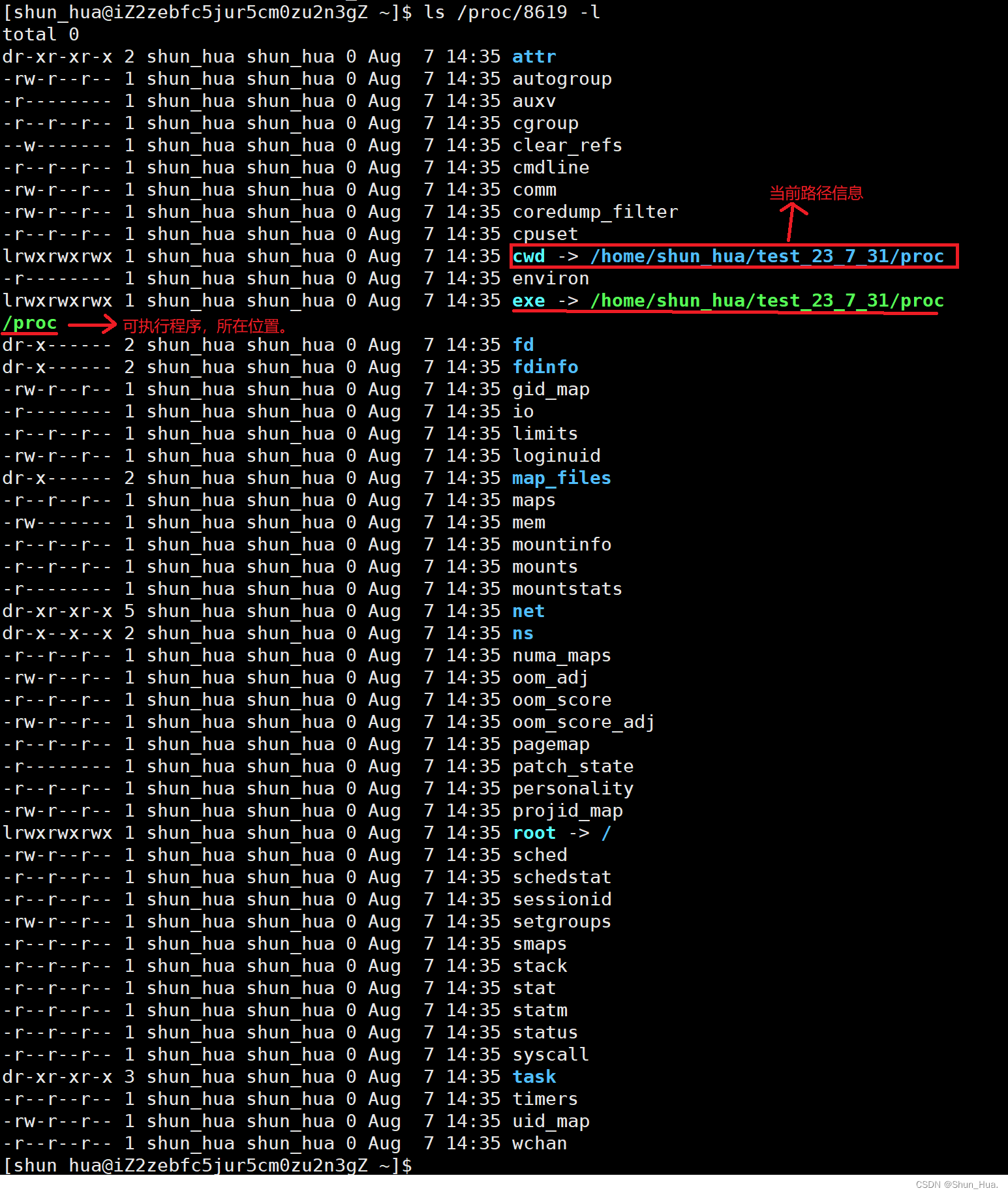
②创建子进程
-
函数:fork
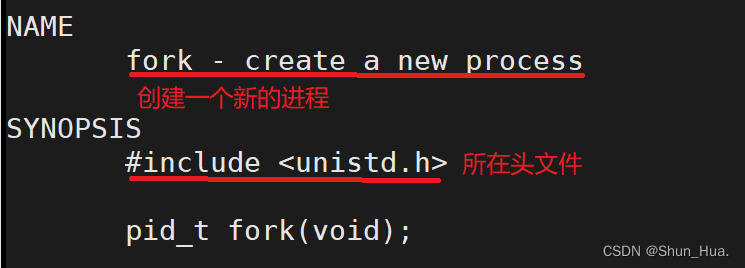
-
返回值

看返回值,可能会感到奇怪——为啥fork(创建成功)能返回两个不同返回值?子进程的代码和数据怎么办?
下面我们一个一个解释,首先父子进程的代码共享,画出图是这样的:
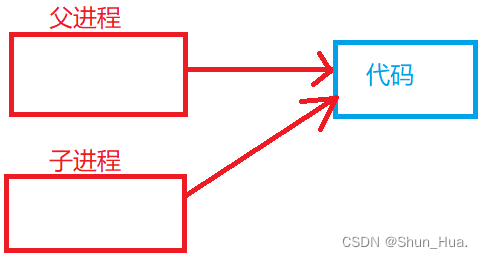
那为啥代码可以共享呢?因为代码不可以被修改!
其次我们再解释fork的原理,fork是一个函数。
其功能是完成子进程的task_struct创建,并对子进程的数据进行初始化,让子进程指向父进程的代码,在其返回时其实是父进程与子进程执行同一块代码,但其身份不同所以返回两个返回值,父进程接收子进程的pid是为了管理子进程。因为是父进程把子进程创建出来的!
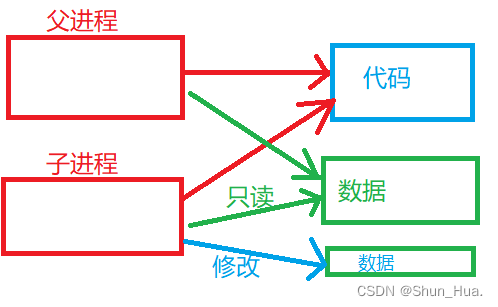
那数据是能够被修改的,总不可能使用同一块数据吧?是这样的。我们猜测是将数据拷贝出来一份给子进程使用,但是这样可能会导致资源浪费严重,万一子进程只修改一个数据呢?全部拷贝损耗有点大了!
还记得我们之前讲过一种技术吗?——写时拷贝(C++拷贝构造)。
当只进行访问时,我们使用同一块数据,但当对数据进行修改时,我们对数据再进行拷贝,这样极大地提升了对内存资源的使用效率。
那我们画出的完整的图应该是这样的:
-
再给出举例代码便于理解
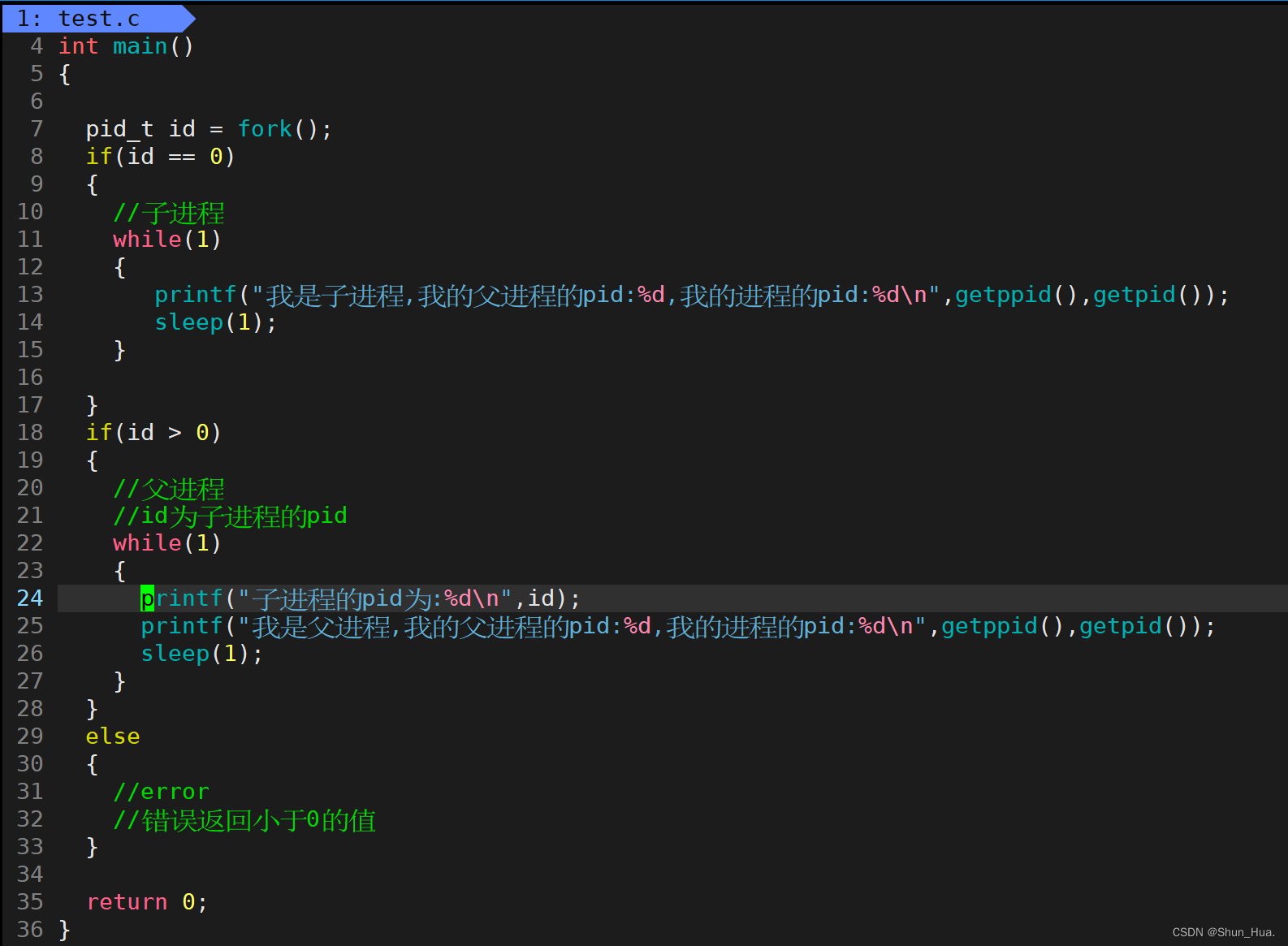
-
运行结果
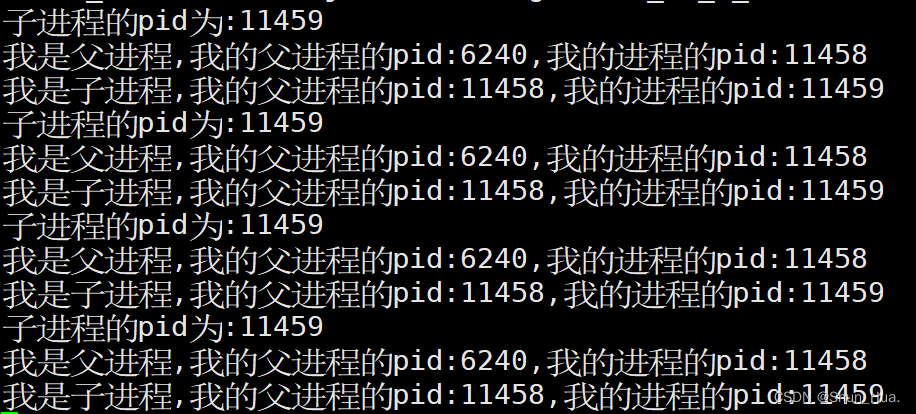
再来谈谈bash命令行,我们执行的命令一般都是bash的子进程,那bash里面是如何创建子进程的呢?肯定绕不过系统调用接口——fork。
总结一下:
父进程创建出子进程,并对子进程进行管理(fork对父进程返回子进程pid).父子进程代码共享。- 数据
当子进程进行只读时,共享,当子进程进行修改时会发生写时拷贝,从而进行修改拷贝之后的数据,因此数据可能共享,但共享部分的不同进程的访问权限不同!
③僵尸与孤儿进程(父子进程衍生出来的问题)
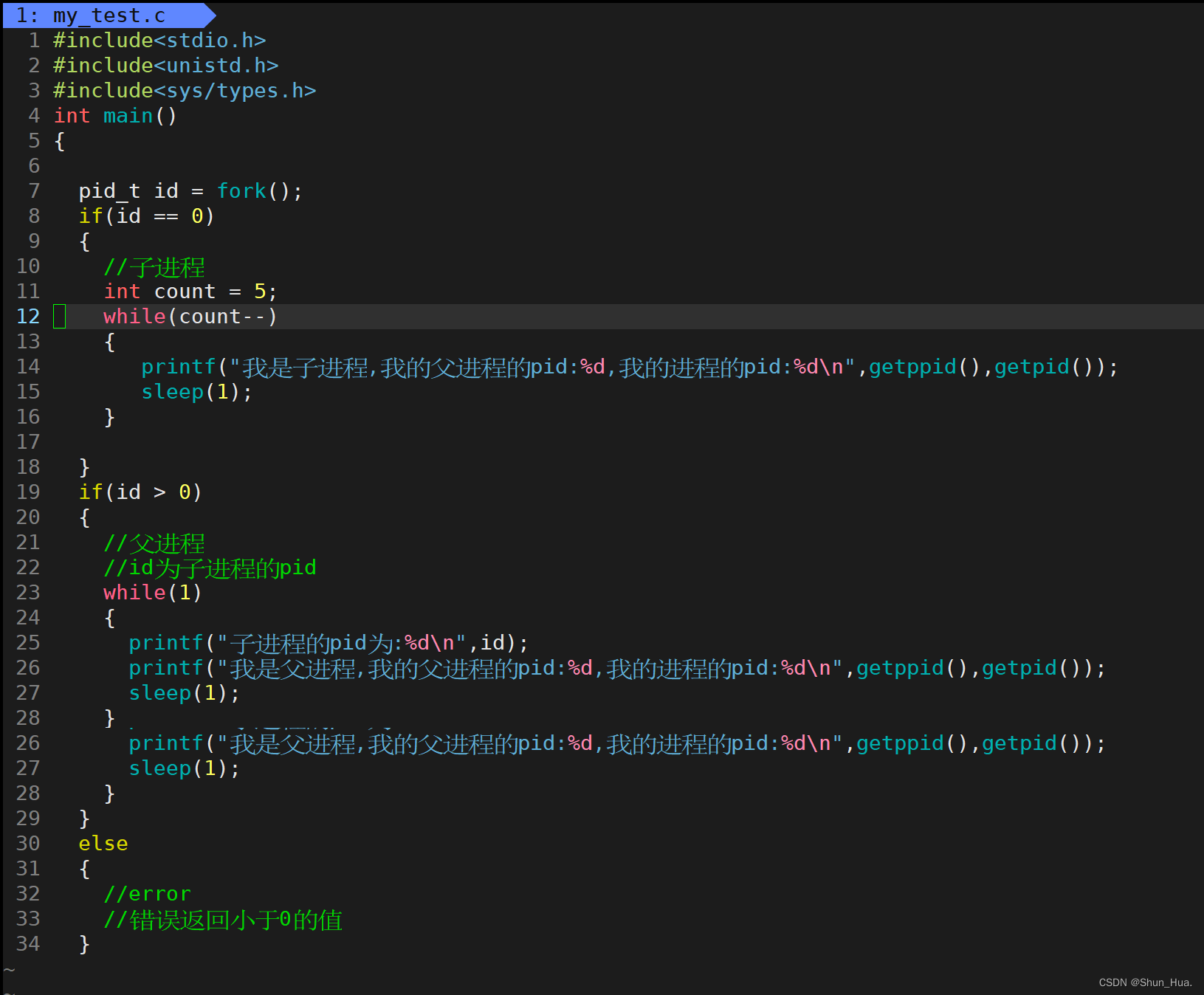
1. 僵尸进程(Zombie状态)
-
运行此代码:
-
不断用ps命名查看任务信息
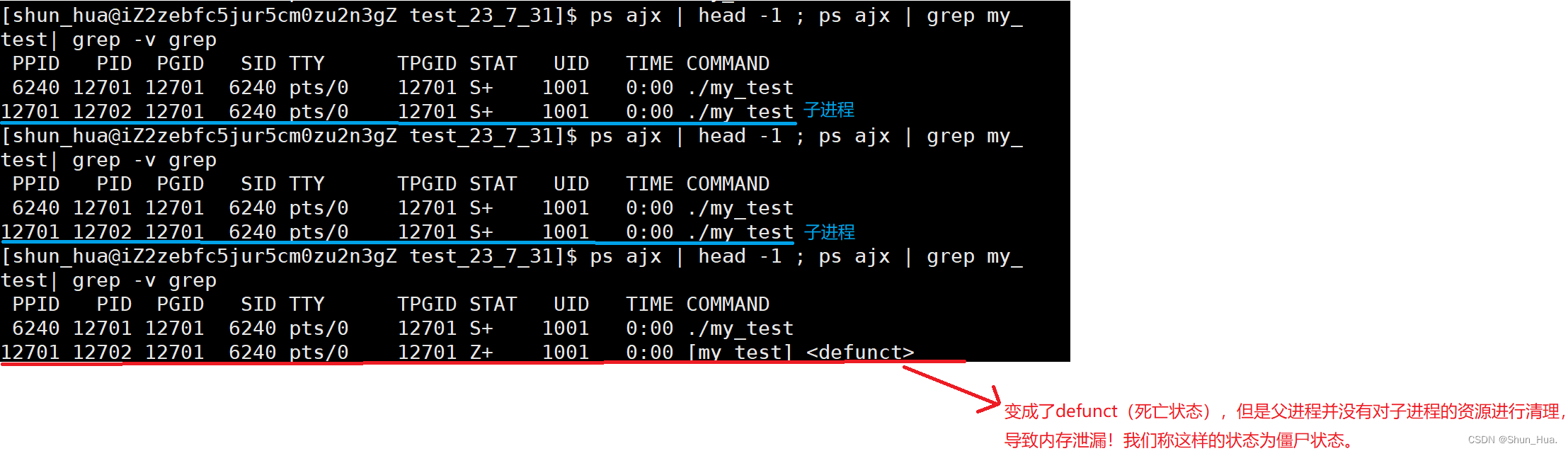
-
总结:形成此进程的原理很简单,子进程在运行结束时,应该交由父进程进行管理释放,但父进程由于在忙着自己的事情,因此父进程腾不出手将子进程进行释放。
-
解决方法:此时我们是不能进行kill命令,杀掉此进程的,因为此进程是僵尸进程,算死过一次了,鞭尸并不管用,而应该杀掉父进程,这样子进程的资源就交由操作系统(init进程)进行管理释放。
2. 孤儿进程
-
运行此代码:
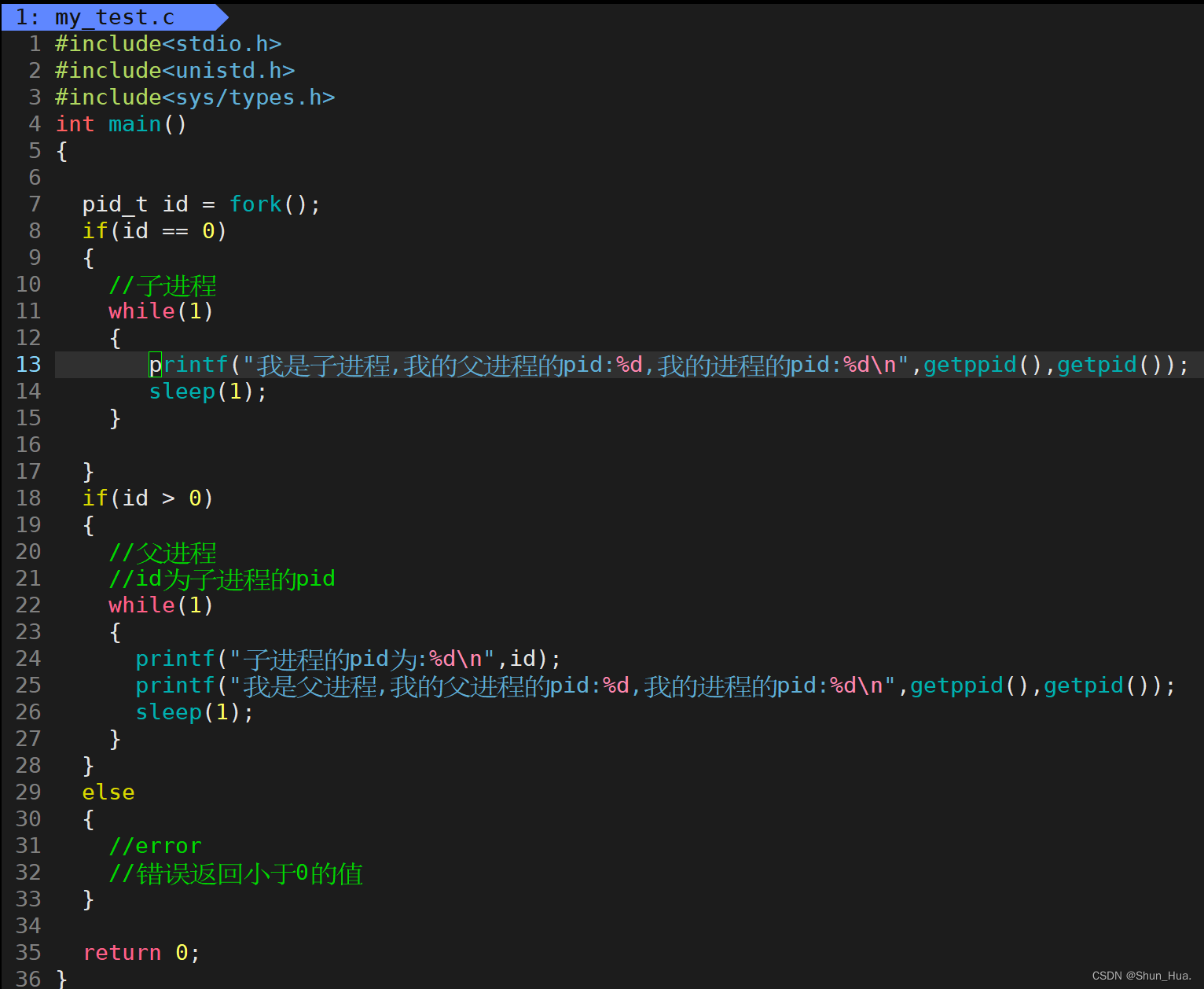
-
运行结果
此时我们用kill命令对父进程发送9号命令。 -
此时的运行结果:

可以看出子进程的父进程被干掉之后,变成了1号进程,那1号进程是谁呢? -
用ps命令进行查看

可见这个命令是操作系统的进程。
那为什么需要操作系统来管呢?它的爷爷进程管不了吗?这就需要考虑我们之前的原因是父进程把子进程创建出来的,那释放资源的信息是放在父进程中的,爷爷进程咋进行管理?是管不了的!因此释放资源的操作是由父进程进行管理,要么就是操作系统亲自进行管理。
那为啥这个进程叫孤儿进程呢?因为创建它的进程,被干掉了,就相当于世上唯一的亲人没了,只能被操作系统进行领养,成了孤儿,就叫做孤儿进程。
3.基本状态
①操作系统的状态(统一)
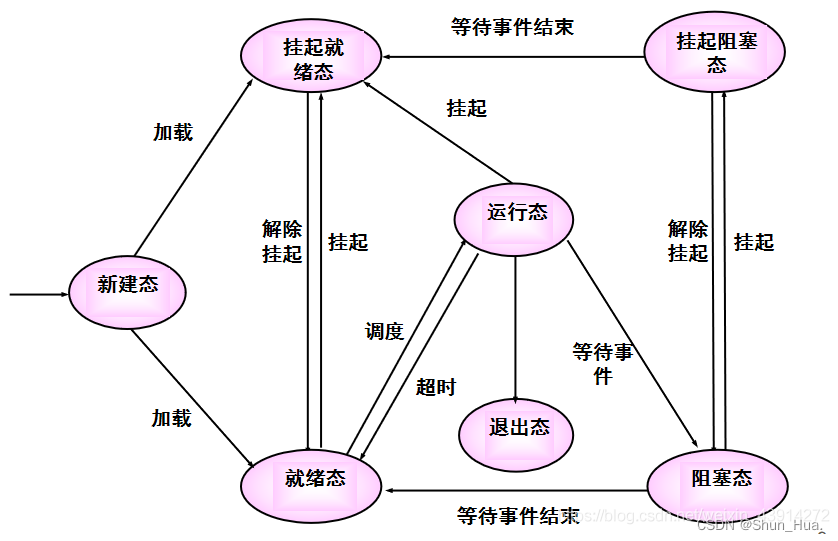
在网上我们可能会看到各种层出不穷的状态:
像这样的:
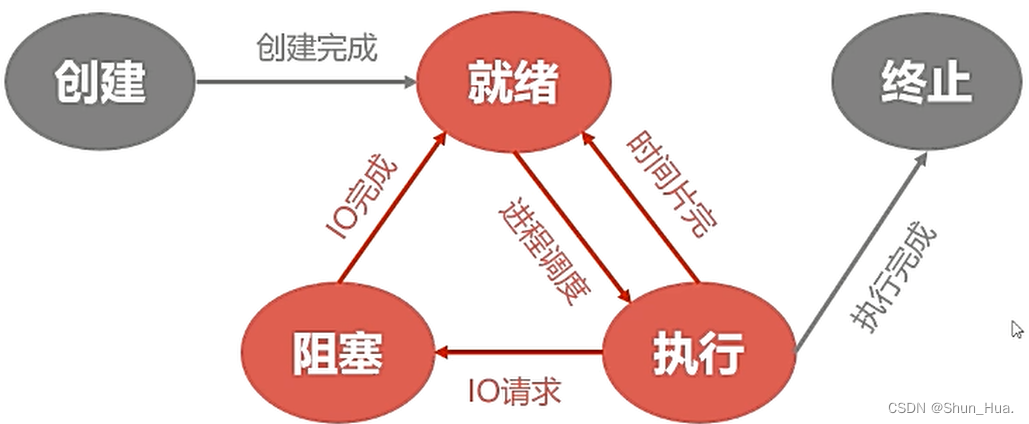
这样的:
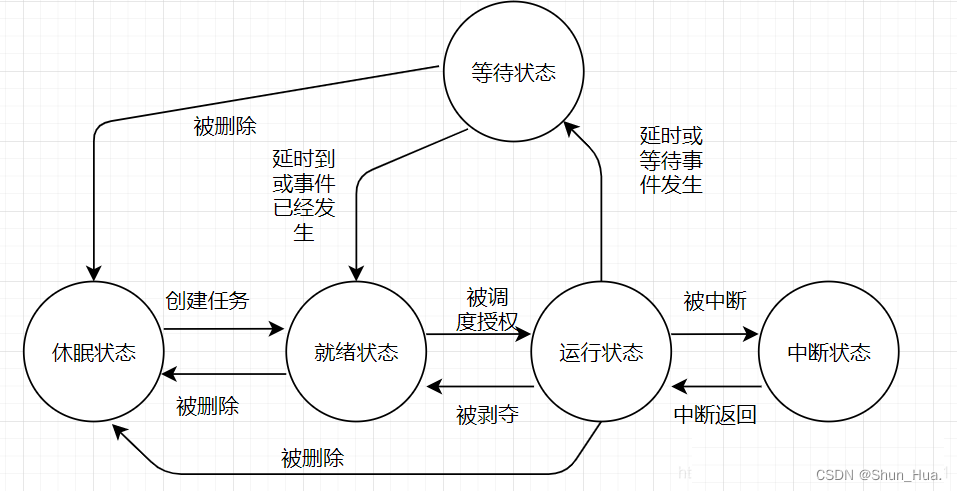
这样的:
还有很多,这一般都是教材上统一描述计算机系统的一些图解,但真正上我们用的并不多,下面我们从几个常用的状态来理解操作系统的状态~
1.运行态
毫无疑问,就是把进程放在CPU上跑,可是CPU又不是只跑一个进程,而是多个进程,因此操作系统该如何进行管理呢?
图解:
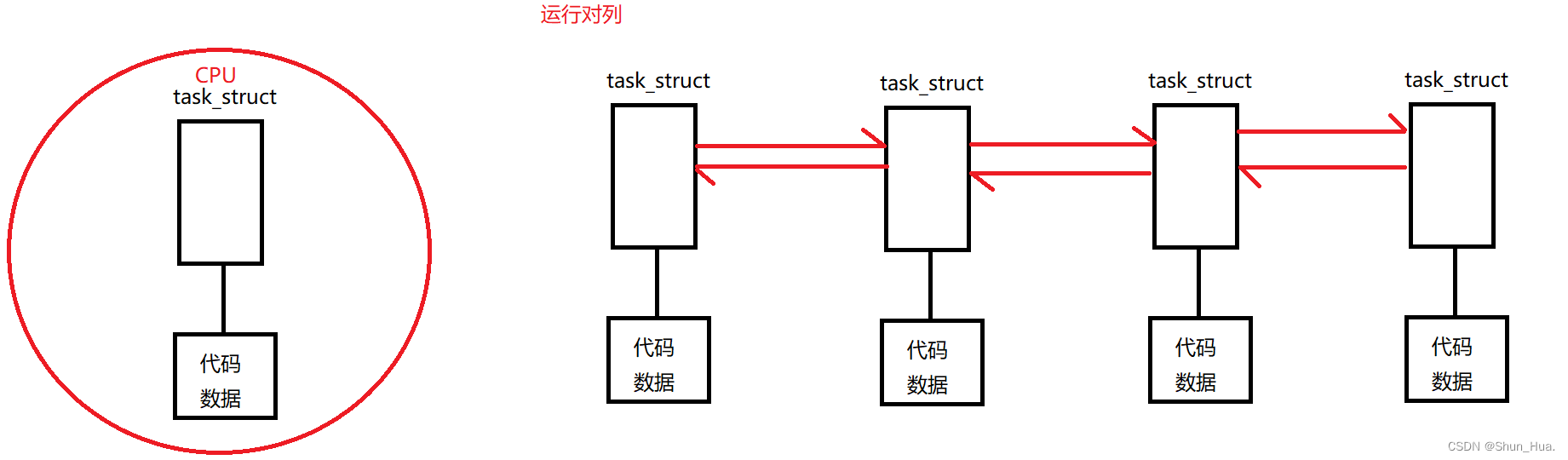
其实,每一个运行的进程,被放在了一个运行对列中排队,当该一个进程跑时,我们就把此进程放在CPU中跑,等跑一段时间再将此进程放下来换另一个对列,这个在CPU跑的时间段,我们称之为时间片。
听过函数栈帧的想必都知道,在计算机中代码的运行在底层都转换为了汇编指令的执行,一般都是使用的寄存器来执行这些指令,那我们常见的寄存器有哪些呢?
ebp:栈底寄存器
esp:栈顶寄存器
功能:维护当前正在使用的函数空间
eax:通用寄存器,保留临时数据,常用于返回值,也用于赋值。
ebx:通用寄存器,保留临时数据——通常是用于初始化用户栈
eip: 指令寄存器,保存当前指令的下一条指令的地址,确保上一条指令能够继续运行下去。
这里我再强调一下,eip,也叫程序计数器,称为pc指针,其作用我举个具体场景进行分析。
#include <stdio.h>
int Add(int x, int y)
{int z = 0;z = x + y;return z;
}
int main()
{int a = 3;int b = 5;int ret = 0;ret = Add(a, b);printf("%d\n", ret);return 0;
}调用函数的执行流:
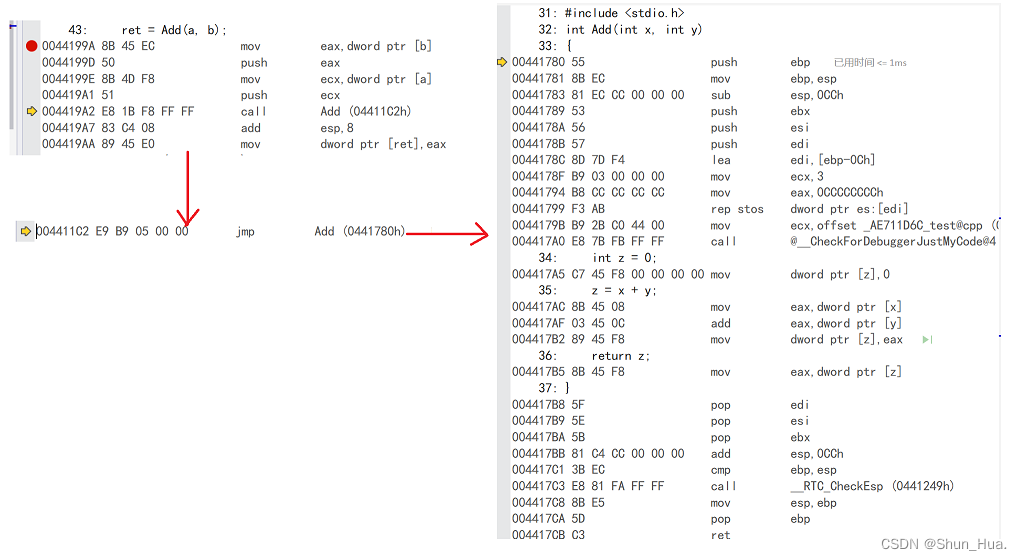
可以看出,我们在调用函数时,跳转到了函数地址处所在的代码段,执行函数的代码,但执行完了,怎么返回呢?其实涉及到两个操作,第一个就是在call地址时,就把call指令的下一条指令进行了压栈操作,第二个就是在pop时,当执行ret返回命令时,会把压栈的地址再压入eip程序指针中,确保能执行到下一条指令。
到此我们提出来一个问题:当程序执行到一半,时间片到了,这该怎办呢?
是执行信息打包让进程带走,还是让CPU默默承受这一切?肯定是打包带走了,CPU才屁大一点地方,都给占用了,那进程还跑不跑了?
- 因此:task_struct中必然有一处是记录程序运行的信息的,就是为了下次再次运行时,能够恢复运行信息。
说明:CPU是ns级别的,换算成s是10-9 次方,一般我们的进程放在CPU上运行10-6 次方秒,这已经足以让CPU做大量的工作,一般情况下,我们肉眼是观察不到计算机在轮流执行着进程,如果观察到了,那未免这个操作系统设计的也太挫了。
这里涉及到计算机的运行设置:
- 并行:简单来说就是
多个CPU跑多个程序。 - 并发:简单来说就是
一个CPU跑多个程序。
2.阻塞态
- 当你的程序需要硬件设备资源时,这时会陷入阻塞状态。
一张图带你理解操作系统如何管理硬件资源:
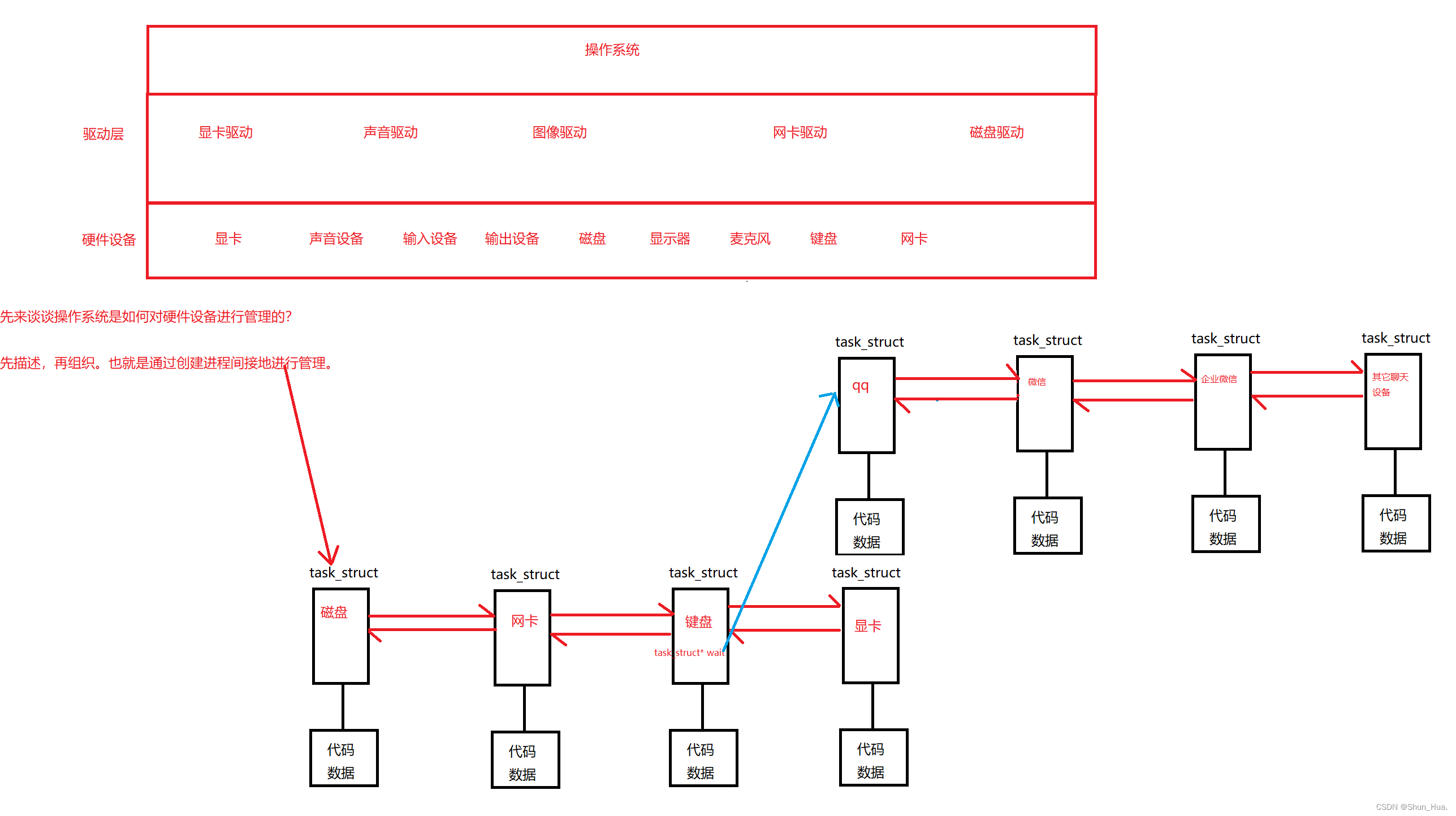
- 这时我们应该就差不多清楚,当计算机程序陷入等待计算机资源时,这时进程就为阻塞状态。
3.挂起态
这个状态主要是为了解决阻塞态,会导致浪费内存资源的问题, 因为在阻塞状态中,可能后面还会有一大堆的等待进程, 进程的代码和数据并没有多大的用处,甚至还会浪费系统资源,因此为了提高内存的使用效率,可以将还没排上队的进程的代码和数据先放在磁盘中,等到这个进程了,再从磁盘中读取出来,接着进行使用。
- 因此操作系统的真实状态应该是:阻塞+挂起
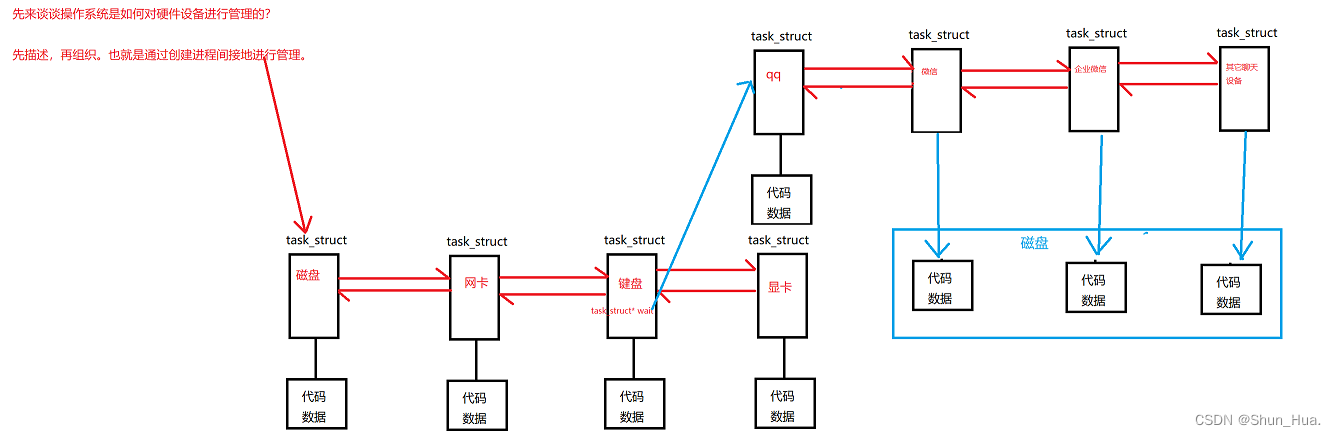
②Linux系统的状态(实际)
在前面,我们其实已经说明了两种状态:僵尸状态和孤儿状态。
1.R状态
示例代码:
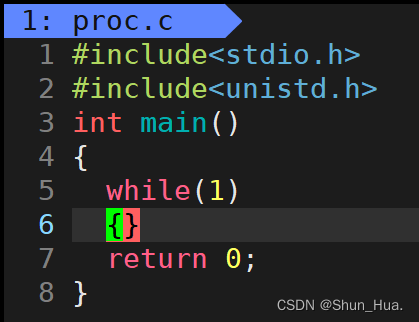
运行查看进程:

2.S状态
-
示例代码:
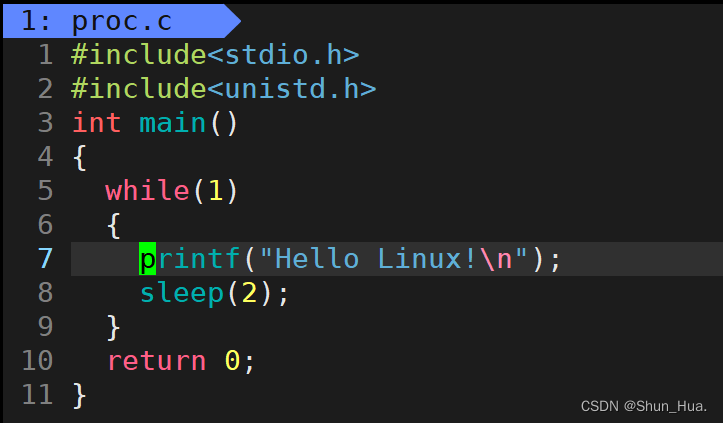
-
用ps命令查看进程信息

3.D状态
- 说明:无法提供场景进行实验,我们这里就详细解释一下。
-
D状态是一种比较深层次的睡眠状态,什么算比较深呢?也就是说操作系统都无法唤醒你,我们之前讲的S状态算是一种浅度睡眠,操作系统能进行杀死操作,而D状态操作系统是无法进行杀进程的,也就是说你给它发送kill -9 命令是不管用的!
-
为啥要这样做呢?因为当你在进行大量的磁盘写入状态时,你的进程是处于睡眠状态的,如果是浅度睡眠,也就是S状态,万一哪一天,系统资源不够,操作系统看你不顺眼,直接把你这个进程干掉了,你说你找谁说理去,操作系统只是在执行其应有的职责而已,这时为了解决这种问题,就有了D状态这一概念,在我写入磁盘文件不许操作系统的打扰,直到我写完了再说。
4.T状态
补充kill命令的几条信号:
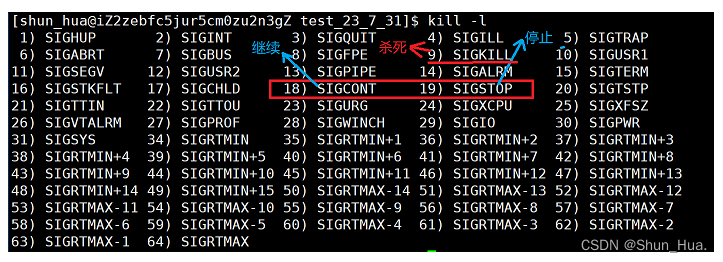
9号:杀死进程。18号:继续进程。19号:停止进程。
举例代码:

观察流程:
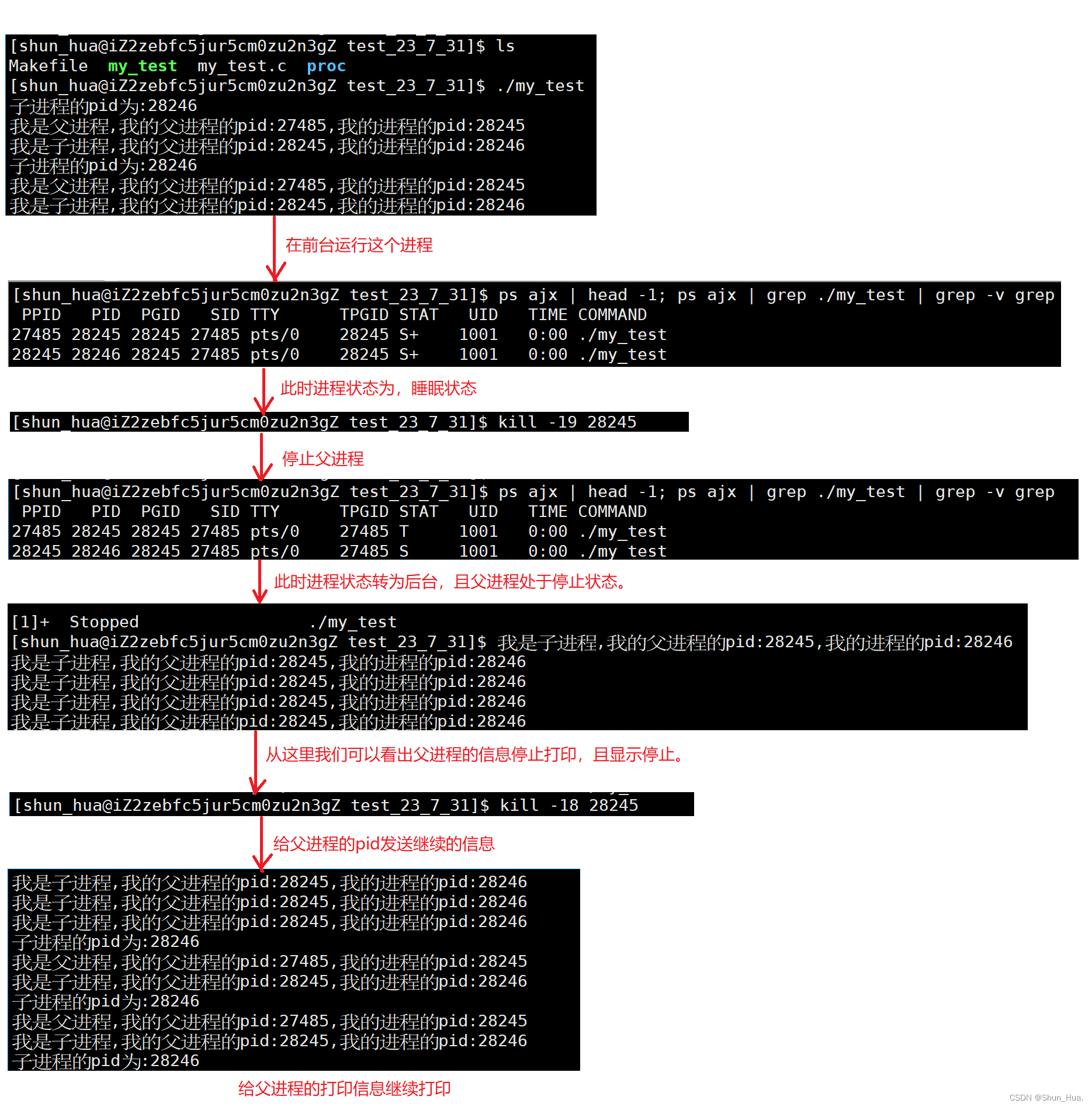
- 有同学就问了,这个状态有什么用呢?
其实实验已经告诉我们了,在你想要单独查看进程时你可以将其它进程停止,这样之间的关系(比如父子关系)没有打破,还能更好的查看你想要查看的进程。
5.t状态
-
全名:trace stop(追踪停止状态)
-
举例代码:
-
观察流程:
说明:还有一个X状态(dead状态),一般是无法看到的,因为经过上面的实验可以得出,进程结束之后会变成僵尸状态,等待父进程进行资源回收。
4.优先级
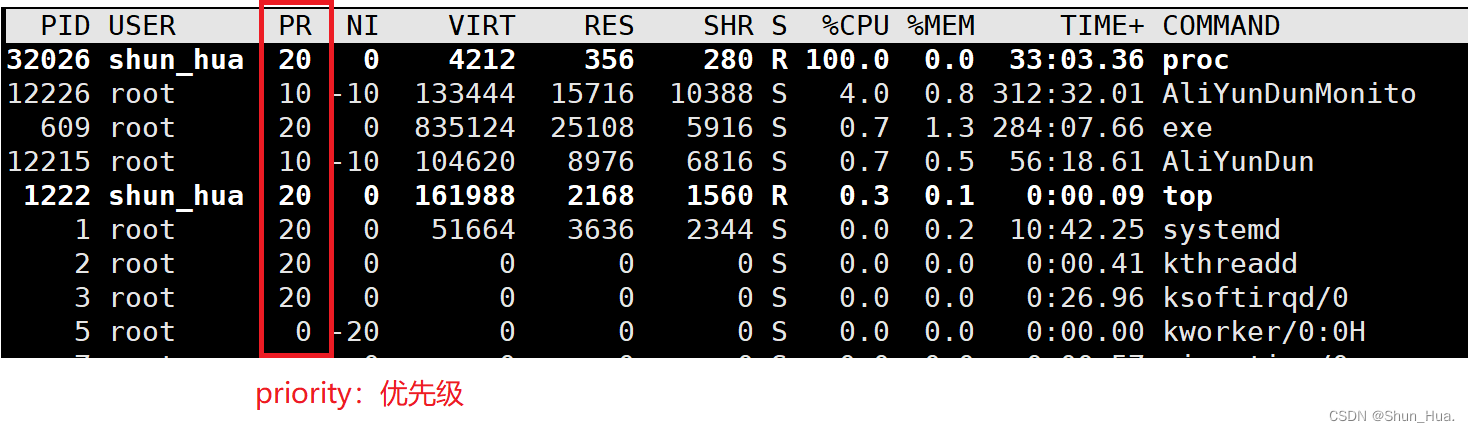
①查看优先级
在命令行输入:
ps len | grep 【进程】
可查看到进程的优先级

pri:优先级
也可以通过top命令查看进程:
②修改优先级
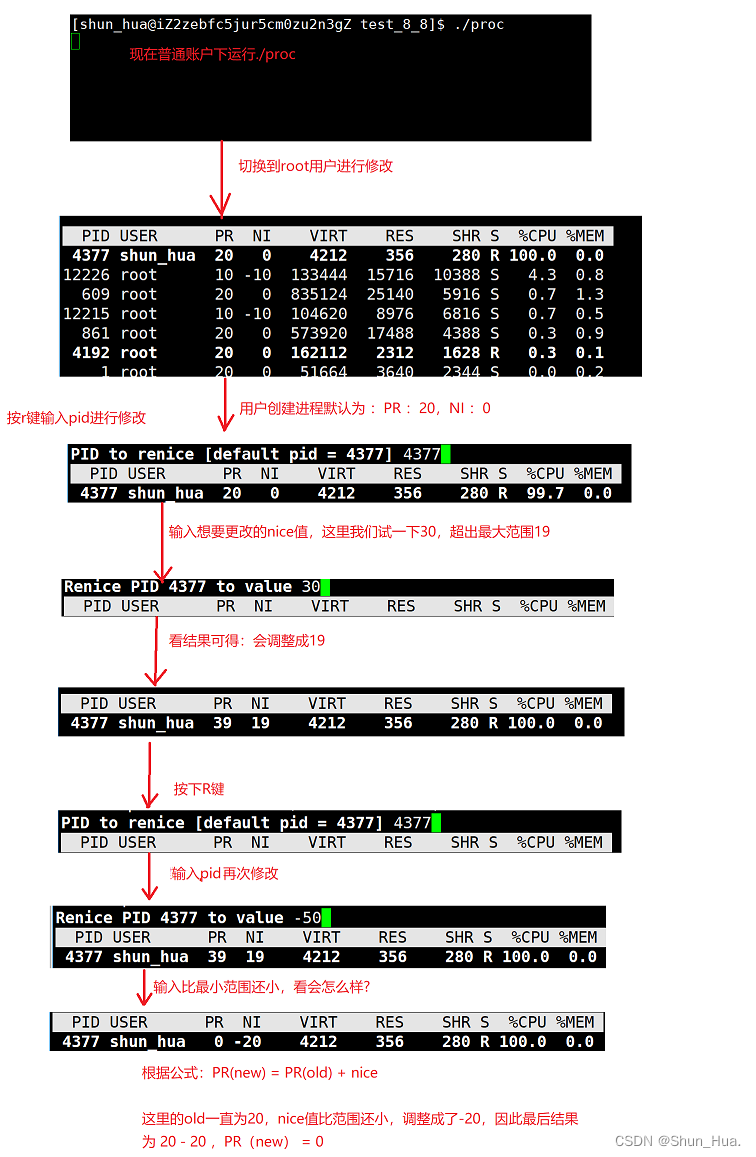
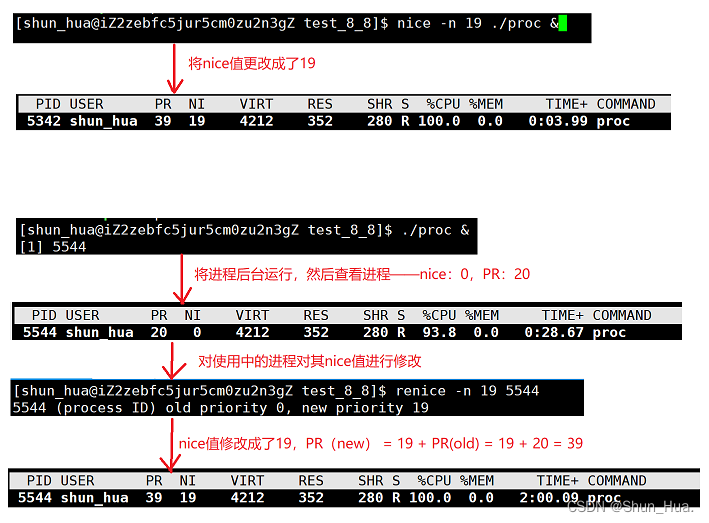
- 说明:pri(new)= pri(old) + nice
注意:nice值是可以修改的但是区间在[-20,19],pid(old)一经设置便不可以被直接修改。
原因:调度器为了公平分配资源,禁止随意大量高频次的修改pri,这样在一定程度上会导致进程的饥饿问题(也就是有的进程可能分配到不足的CPU的资源),进而严重上会导致程序瘫痪。
- pri修改优先级需要比较高的权限,因此普通用户只能nice往大了调,使优先级降低,root用户可以往大了也可以往小了进行调,不过范围还是再[-20,19]。
1.top
流程图:
2.nice
命令:
- 在运行开始前设置nice值
nice -n 【nice值】 【进程】
图解:

3.renice
命令:
- 在运行开始后设置renice
renice -n 【nice值】 【进程pid】
图解:
③基本结构
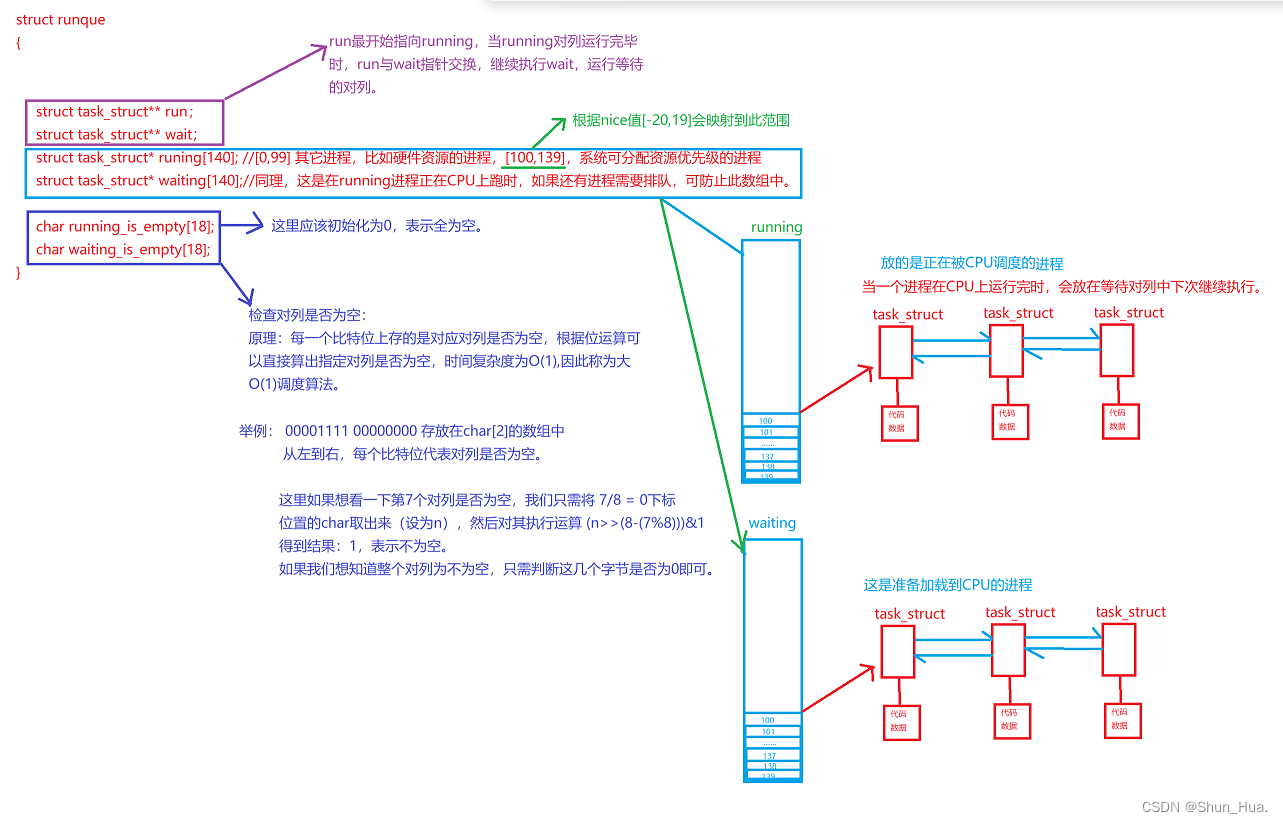
5.环境变量
- 环境变量是在加载过程中,系统自动配置的变量,具有全局属性。
①简单认识
1.PATH
- bash命令的默认查找路径。
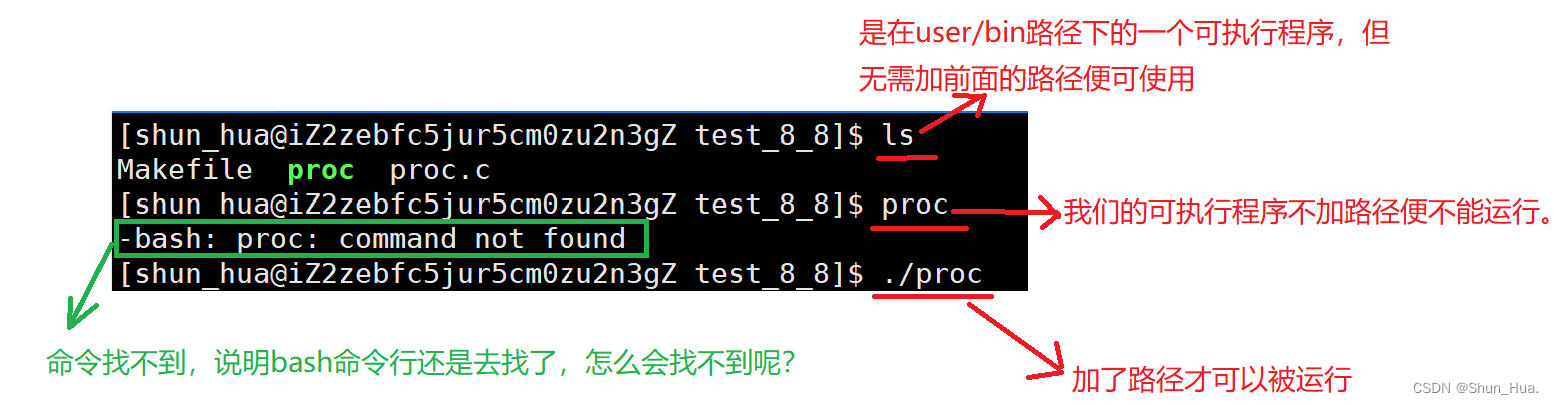
- 原因其实很简单,bash命令行的默认查找路径下没有当前路径。
如果要解决的话有两种办法,其一就是把可执行程序移到/user/bin路径下。
其二就是在默认路径上再加上我们的当前路径即可。
我们使用第二种方法:
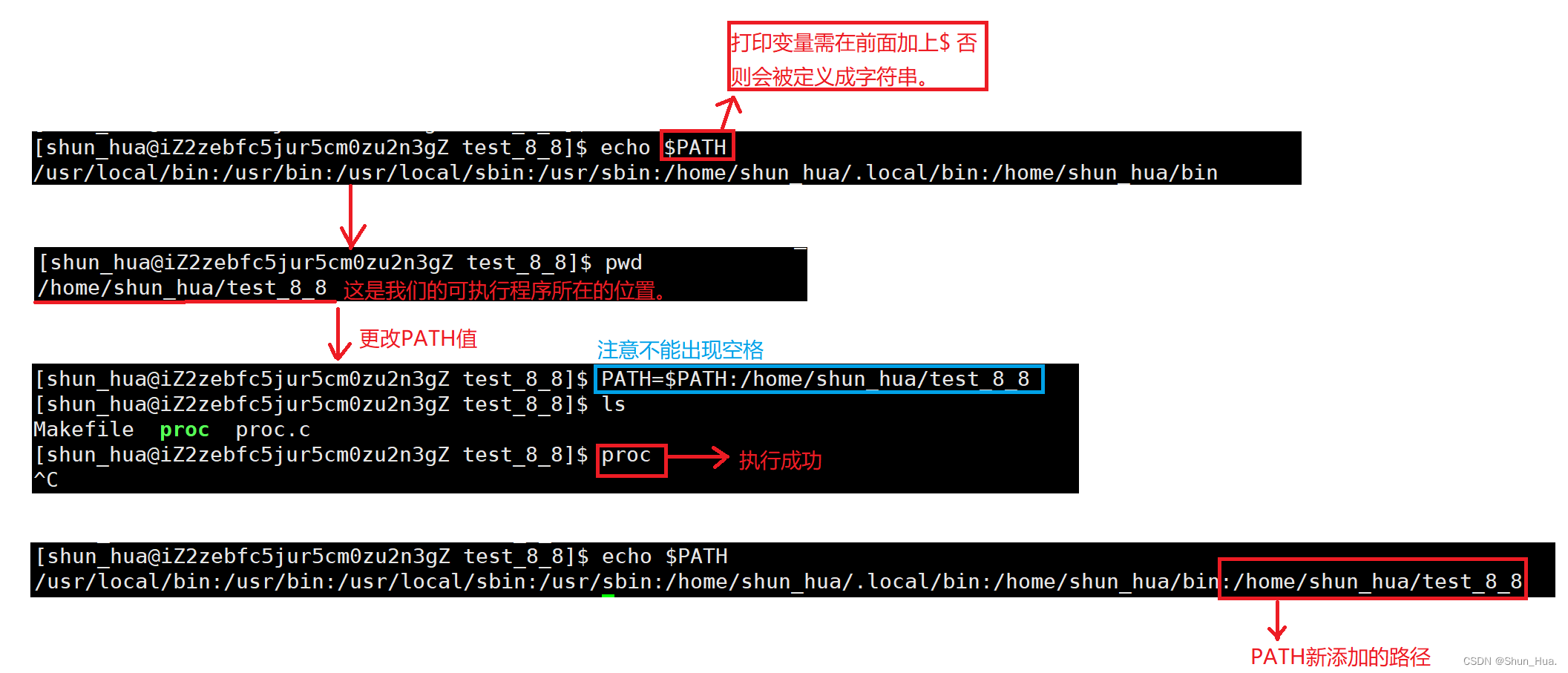
-
可以证明:bash是从PATH命令行中查找的命令。
-
那如果我们一不小心将PATH覆盖呢?
不用担心,因为PATH是内存级的变量,在启动xshell时,系统会默认将环境变量加载到内存中,如果你覆盖了,只需重启xshell即可。
2.HOME

- 可见打印出来的是家目录
3.SHELL

- 查看当前我们使用的shell命令行
②常用的环境变量
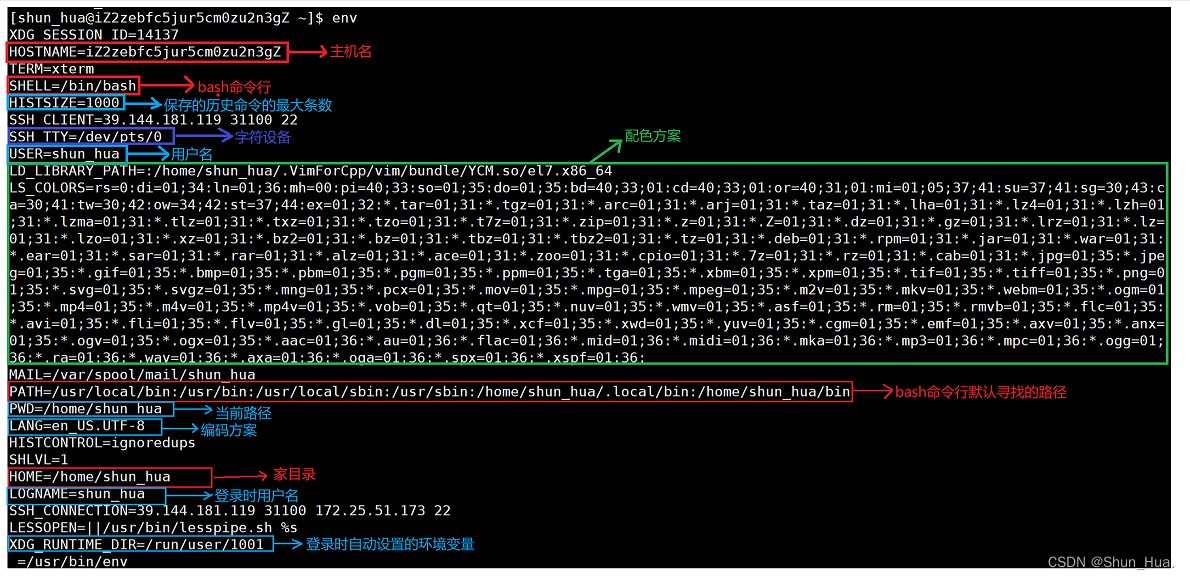
- env —— 查看所有的环境变量
③创建环境变量
- 命令
export 【变量=初始值】将变量设置为环境变量。
-
实验流程:

-
结果:我们最开始设置的变量并不是环境变量,而是本地变量,之后我们用export将本地变量导出才有了环境变量。
④进程内使用环境变量
1.getenv
-
参数:环境变量——char* 类型
-
返回值: char*

普通用户:

root用户:
-
因此:便可以根据环境变量识别不同的用户名,从而设置不同的权限。
2.命令行参数
这是main函数的前两个参数:
int main(int argv, char* argv[])
{return 0;
}- 顾名思义:就是打印出执行进程的命令
示例代码:
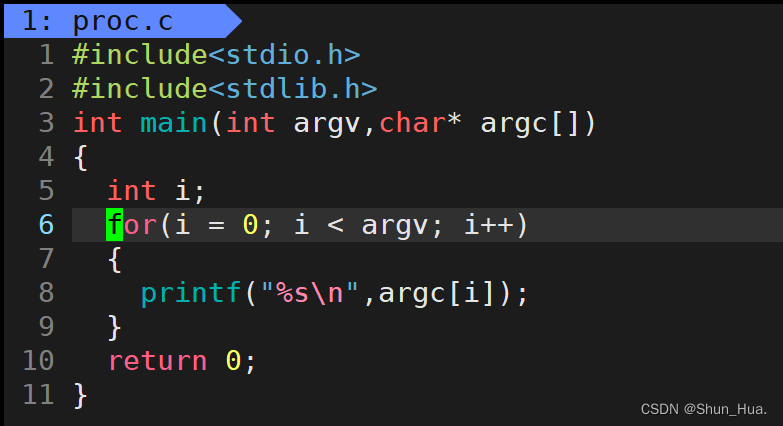
运行结果:

- 由此推出:argv是对传入的参数用空格进行分割,得到的字符串的个数。argc存放的就是分割过后的字符串。
- 引申出:可执行程序可以根据不同的选项从而实现不同的功能,这也是命令行的实现原理。
再来谈一下第二个参数的内存布局:
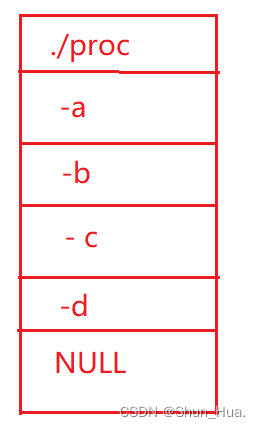
因此我们还可以这样进行使用:
int main(int argv, char* argv[])
{int i = 0;for(i = 0; argv[i]; i++){printf("%s\n",argv[i]);}return 0;
}
3.环境变量参数
除了命令行参数,还存在着一个环境变量参数:
int main(int argv, char* argv[], char* env[])
{return 0;
}
示例代码:
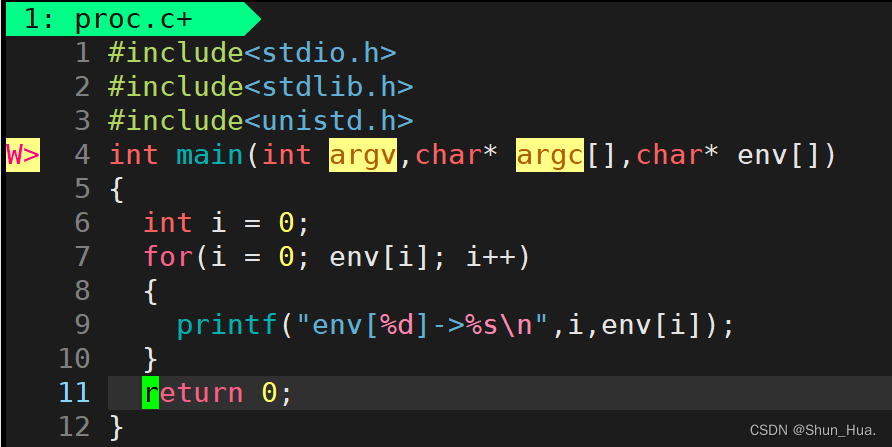
命令行流程图:
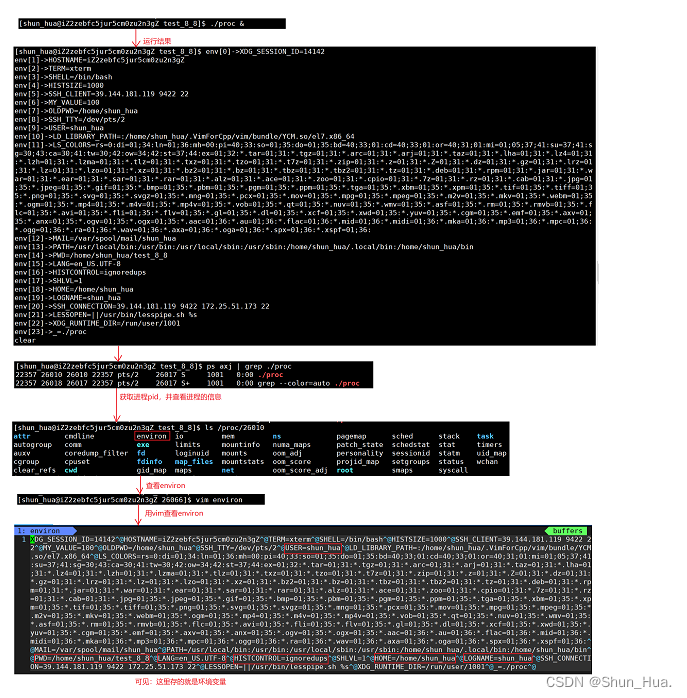
- 总结:环境变量是能够被直接从父进程中继承下来的,并在创建子进程时放在进程中的environ中。
- 补充:本地变量是不能够被继承的,因此在子进程中是无法看到的。
但是我们可能会对此命令产生疑问:

- 其原因在于执行此命令时,bash并没有创建子进程,而是bash内部直接进行处理了,因此是可以打印出此本地变量的。这也被称之为
内建命令。
这里再补充两点:
- 取消环境或者本地变量
unset 【变量】
- 打印本地变量与环境变量
set
总结
今天的分享就到这里了,如果觉得文章不错,点个赞鼓励一下吧!我们下篇文章再见!
相关文章:
【Linux进阶之路】进程(上)
文章目录 前言一、操作系统加载过程二、进程1.基本概念2.基本信息①运行并观察进程②创建子进程③僵尸与孤儿进程(父子进程衍生出来的问题)1. 僵尸进程(Zombie状态)2. 孤儿进程 3.基本状态①操作系统的状态(统一&#…...
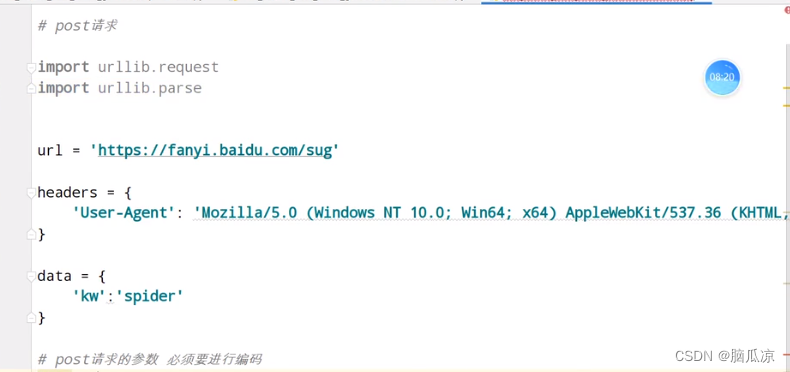
爬虫018_urllib库_cookie反爬_post请求百度翻译获取百分翻译内容_以及详细翻译内容---python工作笔记037
然后我们来看如何用urllib发送post请求,这里我们 用百度翻译为例 我们翻译一个spider,然后我们看请求,可以看到有很多 找到sug这个 可以看到这里的form data,就是post请求体中的内容 然后我们点击preview其实就是 返回的实际内容 然后请求方式用的post 然后我们把上面的信息…...

【Nginx】Nginx网站服务
国外主流还是使用apache;国内现在主流是nginx(并发能力强,相对稳定) nginx:高新能、轻量级的web服务软件 特点: 1.稳定性高(没apache稳); 2.系统资源消耗比较低…...

go语言从0基础到安全项目开发实战
一.环境搭建并helloworld 搭建环境比较简单 1.1安装SDK 到以下链接下 Go下载 - Go语言中文网 - Golang中文社区 下载windows版本64位zip包 https://studygolang.com/dl/golang/go1.20.7.windows-amd64.zip 1.2配置环境变量 不配置的话就只能在bin目录下才能运行go命令 …...
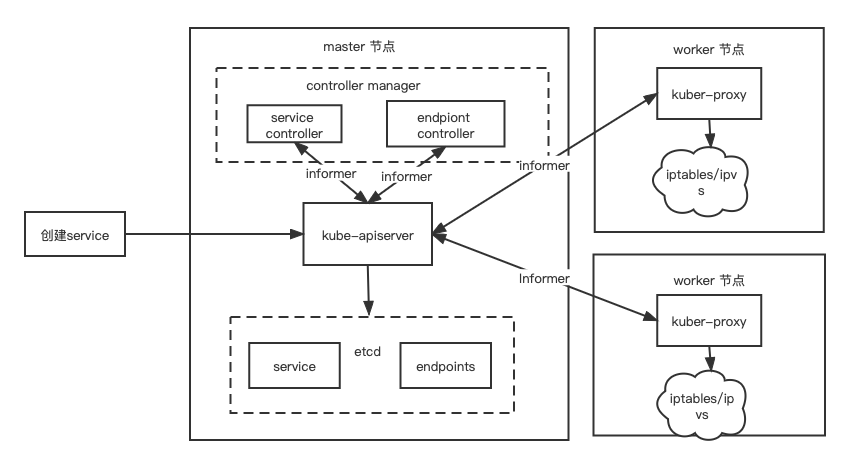
Kubernetes Service 工作原理
本文介绍了 Kubernetes Service 的概念、原理和具体使用。 作者:沈亚军 爱可生研发团队成员,负责公司 DMP 产品的后端开发,爱好太广,三天三夜都说不完,低调低调… 本文来源:原创投稿 爱可生开源社区出品&am…...

面部表情识别4:C++实现表情识别(含源码,可实时检测)
面部表情识别4:C实现表情识别(含源码,可实时检测) 目录 面部表情识别4:C实现表情识别(含源码,可实时检测) 1.面部表情识别方法 2.人脸检测方法 3.面部表情识别模型(Python) (1) 面部表情识别模型的训练…...
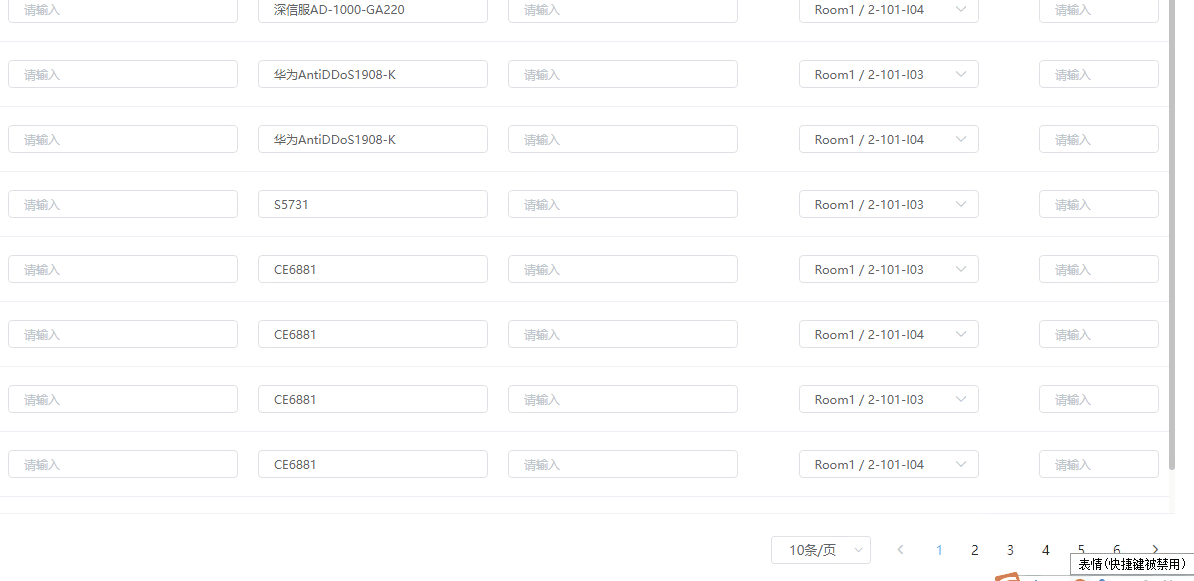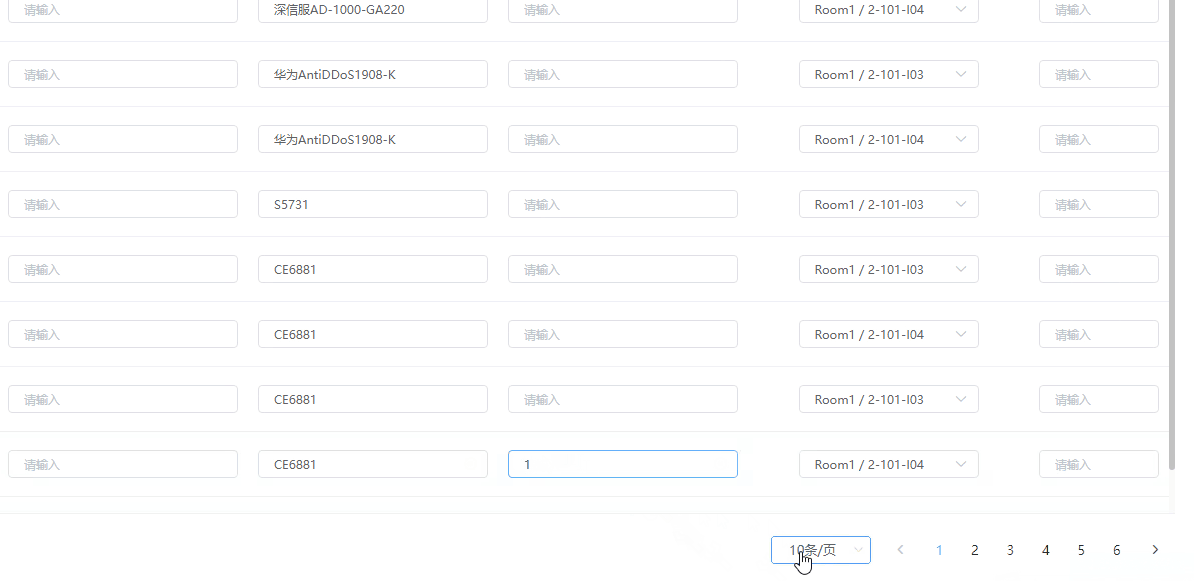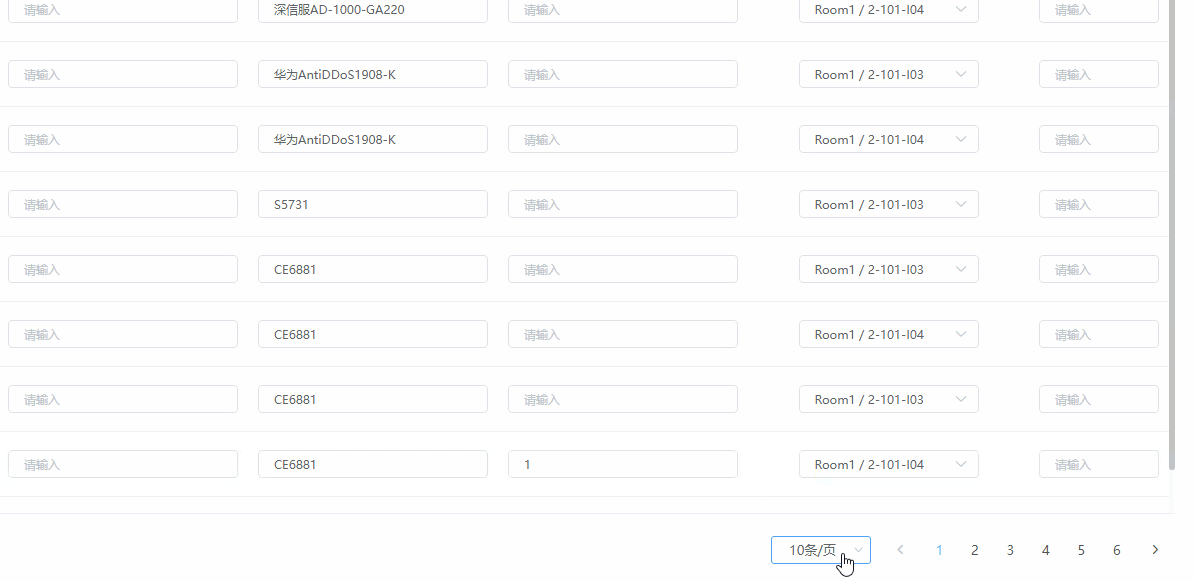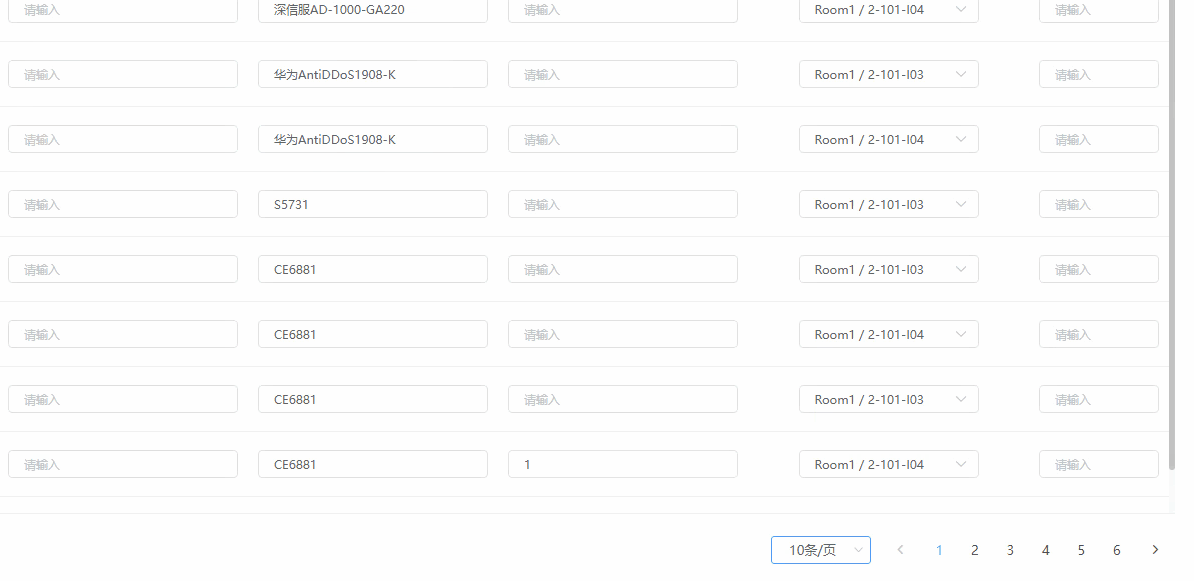
提升Element UI分页查询用户体验与交互:实现修改未保存提示
我实现的功能是在 element ui 的分页组件中进行分页查询时,如果当前有未保存的修改数据就提示用户,用户可以选择是否放弃未保存的数据。确认放弃就重新查询数据;选择不放弃,不重新查询,并且显示条数选择框保持原样&…...
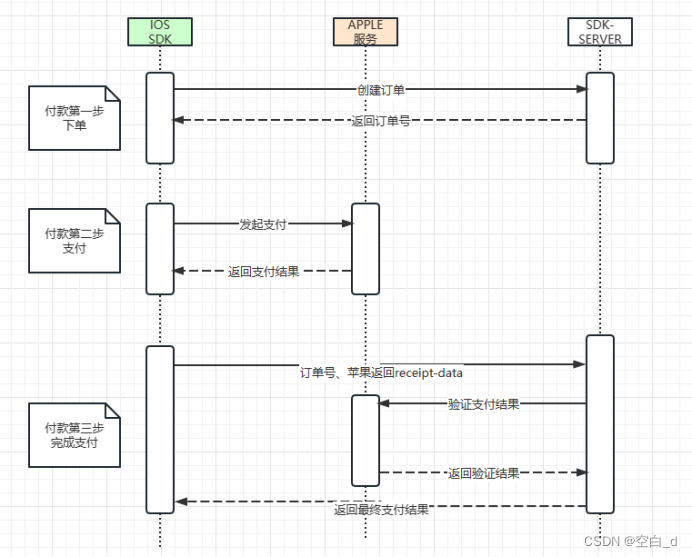
UML-时序图
目录 时序图 时序图构成: 对象: 消息: 生命线(激活): 活动条: 时序图举例: 时序图 时序图也叫顺序图、序列图. 时序图描述按照时间的先后顺序对象之间的动作过程,是由生命线和消息组成 时序图构成: 对象: 对象是类的实例,对象是通过类来创建的&…...
Seata - 入门笔记
1、事务 访问并可能更新数据库中数据库中各种数据线的一个程序执行单元 原子性:事务是一个不可分割的工作单位,一个事务要么都做要么都不做 一致性:必须是使数据库从一个一致性到另一个一致性的状态,中间状态不能被观察到 隔离…...

springboot使用aop排除某些方法,更新从另外一张表,从另外一张表批量插入
AOP 在Spring Boot中使用AOP时,如果想要排除某些方法不被切面所影响,可以通过使用切面表达式中的!within关键字来实现。以下是一个示例: Aspect Component public class MyAspect {Before("execution(* com.example.service.*.*(..)) …...
:实现原理)
Go 语言面试题(二):实现原理
文章目录 Q1 init() 函数是什么时候执行的?Q2 Go 语言的局部变量分配在栈上还是堆上?Q3 2 个 interface 可以比较吗?Q4 两个 nil 可能不相等吗?Q5 简述 Go 语言GC(垃圾回收)的工作原理Q6 函数返回局部变量的指针是否安全ÿ…...
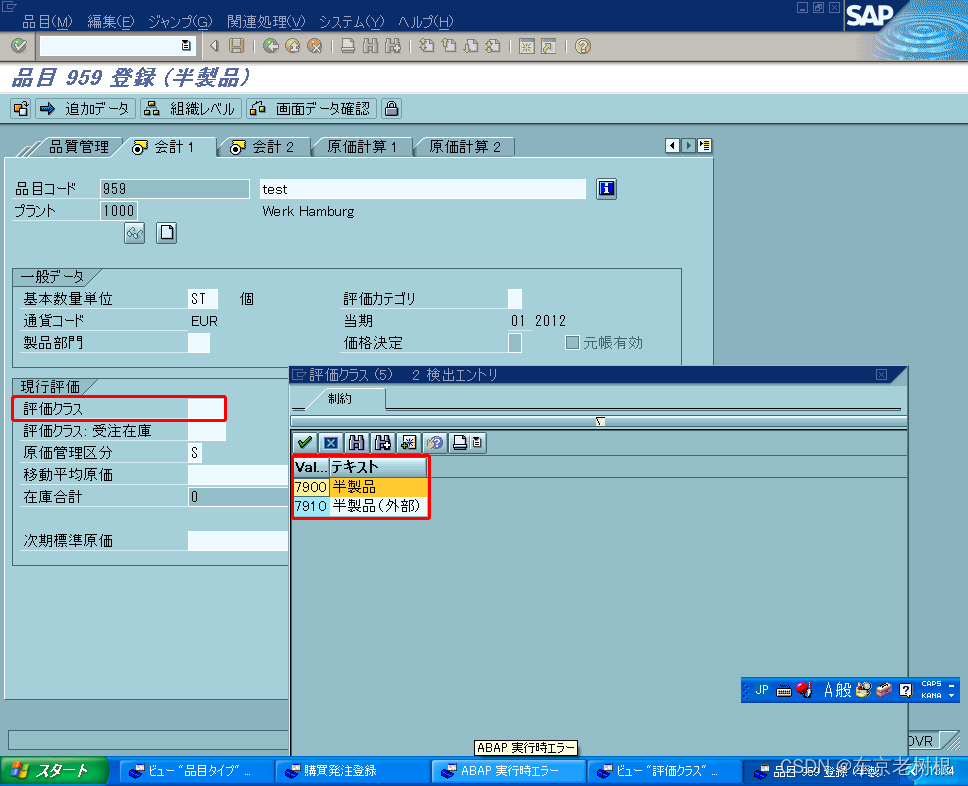
SAP MM学习笔记16-在库品目评价
在库品目评价是指评估物料。具体比如物料价格,数量,保管场所等发生变化的时候,判断是否发生了变化,要不要生成 FI票,用哪个FI科目来进行管理等内容就叫在库品目评价。 在库品目评价有很多层级,这里先讲3兄弟…...
Azure通过自动化账户实现对资源变更
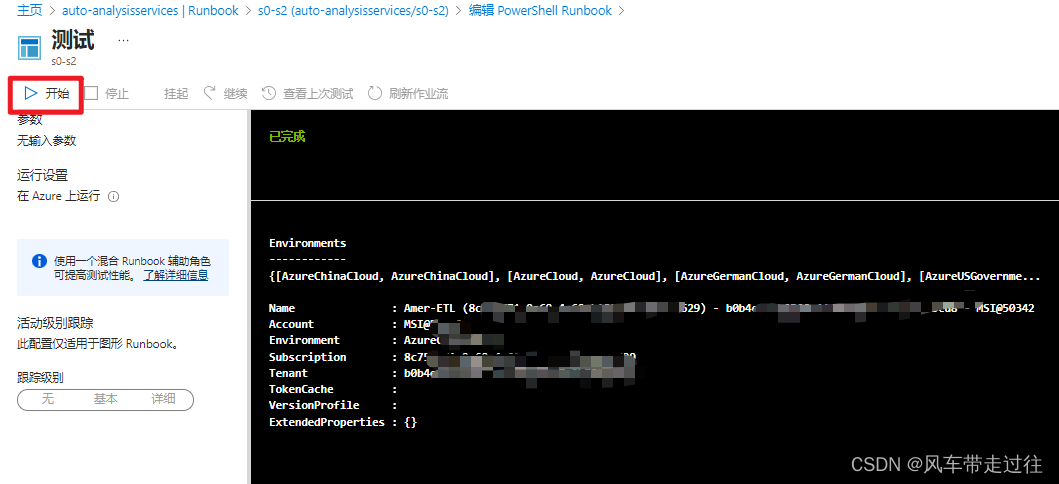
Azure通过自动化账户实现对资源变更 创建一个自动化账户第一种方式 添加凭据(有更改资源权限的账户,没有auth认证情况)创建一个Runbook,测试修改 AnalysisServices 定价层设置定时任务:开始定时任务: 第二种…...

使用luarocks安装cjson并使用cjson
1.luarocks安装 wget https://luarocks.org/releases/luarocks-3.3.1.tar.gz --no-check-certificatels -lrthtar -xvf luarocks-3.3.1.tar.gz mv luarocks-3.3.1 /usr/local/cd /usr/local/luarocks-3.3.1/./configure --prefix/usr/local/luarocks-3.3.1 vim /etc/profilePAT…...
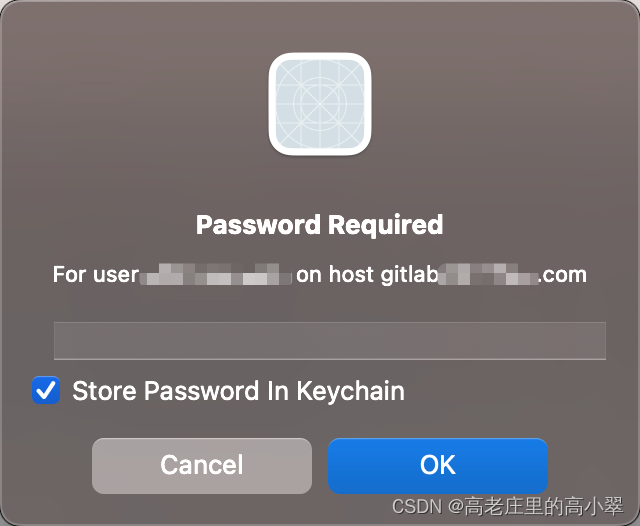
【已解决】mac端 sourceTree 解决remote: HTTP Basic: Access denied报错
又是在一次使用sourcetree拉取或者提交代码时候,遇到了sourcetree报错; 排查了一会,比如查看了SSH keys是否有问题、是否与sourcetree账户状态有问题等等,最终才发现并解决问题 原因: 因为之前公司要求企业gitlab中…...
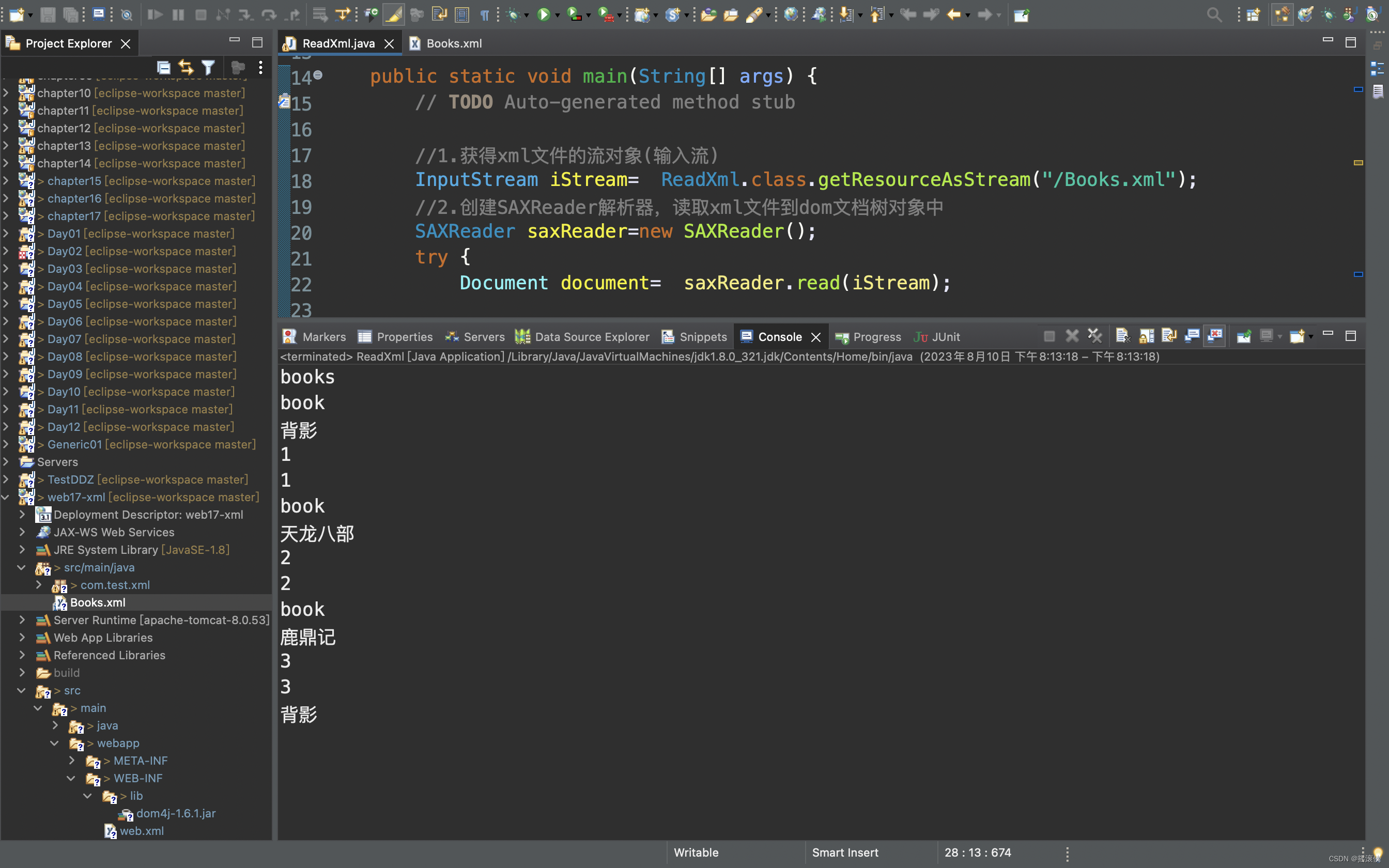
javaee dom4j读取xml文件
引入jar包 dom4j-1.6.1.jar 创建xml文件 <?xml version"1.0" encoding"UTF-8"?> <books><book id"1"><title ID"t1">背影</title><price>88</price><author>三毛</author>…...

各类背包问题
1、0-1背包问题 (1)用二维数组动态规划 #include<bits/stdc.h> using namespace std; int m,n; int w[50],c[50]; int dp[210][210]; int main() {cin>>m>>n;for(int i1;i<n;i){cin>>w[i]>>c[i];}for(int i1;i<n;…...

《练习100》91~95
题目91 # 自动生成字符串 # a [小马,小羊,小鹿] # b [草地上,电影院,家里] # c [看电影,听音乐,吃晚饭] # 随机生成三个0~2的数字,若是1,0,2 ,则输出: 小羊在草地上吃晚饭 import random a [小马,小羊,小鹿] b […...
3.6 Spring MVC文件上传
1. 文件上传到本地 实现方式 Spring MVC使用commons-fileupload实现文件上传,注意事项如下: l HTTP请求方法是POST。 l HTTP请求头的Content-Type是multipart/form-data。 SpringMVC配置 配置commons-fileupload插件的文件上传解析器CommonsMultip…...

# X11、Xlib、XFree86、Xorg、GTK、Qt、Gnome和KDE之间的关系
X11、Xlib、XFree86、Xorg、GTK、Qt、Gnome和KDE之间的关系 很多人对于他们是啥是傻傻分不清的,我做了个表格供大家参考。 摘抄: X11是X Window System Protocol, Version 11(RFC1013),是X server和X client之间的通…...

C++ 学习杂记06:std::unordered_map
概述std::unordered_map是C标准模板库(STL)中的一个关联容器,实现基于哈希表的键值对映射。自C11起成为标准库的一部分,位于 <unordered_map>头文件中。核心特性数据结构基于哈希表:使用散列函数将键映射到存储桶…...

MoveIt!避障实战:如何优化OctoMap质量,让你的机械臂在杂乱桌面也能精准抓取?
MoveIt!避障实战:优化OctoMap质量的五大核心策略 机械臂在杂乱桌面环境下的精准抓取,一直是工业自动化和服务机器人领域的痛点问题。上周在调试一台UR5机械臂时,我遇到了典型的"幽灵障碍物"现象——明明桌面上只有目标物体…...

Navicat重置工具:让数据库管理无限期免费使用的终极指南
Navicat重置工具:让数据库管理无限期免费使用的终极指南 【免费下载链接】navicat_reset_mac navicat mac版无限重置试用期脚本 Navicat Mac Version Unlimited Trial Reset Script 项目地址: https://gitcode.com/gh_mirrors/na/navicat_reset_mac 作为一名…...

如何用Zotero SciPDF插件一键获取科研文献PDF:终极免费解决方案
如何用Zotero SciPDF插件一键获取科研文献PDF:终极免费解决方案 【免费下载链接】zotero-scipdf Download PDF from Sci-Hub automatically For Zotero7 项目地址: https://gitcode.com/gh_mirrors/zo/zotero-scipdf 还在为下载学术论文PDF而头疼吗ÿ…...

告别重复刷图:E7Helper如何让你的《第七史诗》体验效率翻倍
告别重复刷图:E7Helper如何让你的《第七史诗》体验效率翻倍 【免费下载链接】e7Helper 【Epic Seven Auto Bot】第七史诗多功能覆盖脚本(刷书签🍃,挂讨伐、后记、祭坛✌️,挂JJC等📛,多服务器支持…...

ChatArena多智能体对话框架:从核心原理到实战应用
1. 项目概述:从零理解ChatArena,一个多智能体对话竞技场如果你对AI智能体(Agent)的开发、评测或者多智能体协作与竞争感兴趣,那么Farama Foundation旗下的ChatArena项目,绝对是一个值得你投入时间研究的“宝…...

MySQL索引设计有哪些原则?
MySQL索引的设计是数据库优化的重要一环,合理的索引可以显著提高查询性能。以下是一些常见的索引设计原则: 1. 选择适当的列进行索引 频繁用于查询的列:优先考虑那些在 WHERE、JOIN、ORDER BY 和 GROUP BY 子句中频繁出现的列。选择性高的列&…...

深度评测:GEO优化软件源代码如何赋能本地生活服务企业?爱搜索实战验证报告
在AI搜索浪潮席卷之下,企业信息能否被ChatGPT、DeepSeek、豆包等大模型精准识别并推荐,已成为决定获客流量的关键。传统SEO的规则正在被改写,一种名为GEO(生成式引擎优化)的新范式应运而生。本文将以本地生活服务行业为…...

AI Agent Harness Engineering 做测试:用例生成、回归与缺陷定位
AI Agent Harness Engineering 全栈测试指南:从用例自动生成到实时缺陷定位 副标题:整合 OpenAI GPT-4o/Claude 3.5 Sonnet Playwright Agent LangChain Harness CI/CD 构建企业级 AI 驱动测试中台第一部分:引言与基础 1.1 引人注目的标题…...
配置,省时避坑)
别再手动移植了!用STM32CubeIDE一键导入旧版CubeMX (.ioc)配置,省时避坑
STM32CubeIDE高效复用旧版配置:从.ioc文件一键重建工程的终极指南 面对那些躺在硬盘角落里的旧版STM32CubeMX工程文件,你是否经历过这样的困境:当需要基于已验证的稳定配置进行二次开发时,不得不手动重建所有时钟树、引脚分配和外…...