生成式人工智能的潜在有害影响与未来之路(一)
这是本文的第1版,反映了截至2023年5月15日,Generative AI的已记载的和预期的危害。由于Generative AI的发展、使用和危害的快速变化,我们承认这是一篇内在的动态论文,未来会发生变化。
在本文中,我们使用一种标准格式来解释生成人工智能可能产生的危害的类型。每一节首先解释了生成人工智能带来的相关背景信息和潜在风险,然后强调了学者和监管机构为补救每一种伤害而采取的具体危害和干预措施。本文借鉴了人工智能危害的两个分类法来指导我们的分析:
1.Danielle Citron和Daniel Solove的隐私伤害类型论,包括身体伤害、经济伤害、名誉伤害、心理伤害、自主伤害、歧视伤害和关系伤害;
2.Joy Buolamwini的算法危害分类,包括机会的丧失、经济损失和社会污名化,包括自由的丧失、监督的加强、刻板印象的强化和其他权贵的危害。
这些分类法并不一定涵盖所有潜在的人工智能危害,我们使用这些分类法是为了帮助读者在不限制读者考虑的人工智能伤害的类型和多样性的情况下,将人工智能危害可视化和情境化。
-
引言
去年11月,OpenAI决定发布基于大型语言模型GPT-3的聊天机器人ChatGPT,这将人工智能工具推向了公众意识的前沿。在过去的六个月里,用于根据用户提示生成文本、图像、视频和音频的新人工智能工具大受欢迎。突然间,像“稳定扩散”、“幻觉”和“价值一致”这样的短语无处不在。每天都有关于生成人工智能的不同能力及其潜在危害的新故事出现,但没有任何明确的迹象表明接下来会发生什么或这些工具会产生什么影响。
尽管生成人工智能可能是新的,但其危害并非如此。多年来,人工智能学者一直在警告我们大型人工智能模型可能造成的问题。由于行业目标从研究和透明转向利润、不透明和权力集中,这些老问题更加严重。这些工具的广泛可用性和炒作导致了个人和大规模伤害的增加。人工智能复制了种族、性别和残疾歧视,这些危害不可避免地交织在本报告强调的每一个问题中。
OpenAI和其他公司决定将生成性人工智能技术快速集成到面向消费者的产品和服务中,这破坏了长期以来使人工智能开发透明和负责任的努力,使许多监管机构争相为其影响做好准备。很明显,生成型人工智能系统会显著放大个人隐私、民主和网络安全的风险。用OpenAI首席执行官的话来说,他确实有权不加速这项技术的发布,“我特别担心这些模型可能被用于广泛的错误信息……[和]攻击性网络攻击。”
这种在没有足够保障的情况下快速部署生成性人工智能系统的做法清楚地证明了自我监管已经失败。从企业到媒体和政府实体,数百个实体正在开发并寻求将这些未经测试的人工智能工具快速集成到广泛的系统中。如果从一开始就没有必要的公平、问责和透明度保护,这种快速推出将产生灾难性的结果。
我们正处于一个关键时刻,因为全球各地的政策制定者和行业都在关注人工智能带来的巨大风险和机遇。有机会让这项技术为人们服务。应要求公司展示其工作,明确人工智能何时使用,并在整个培训、开发和使用过程中提供知情同意。
公众关注的一个线索集中在人工智能的“生存”风险上,即机器人在工作、社交和最终接管人类的投机长期风险。州和联邦层面的一些立法者已经开始更认真地对待解决人工智能的问题-然而,他们的重点是否只是支持公司开发人工智能工具,并要求边际披露和透明度要求,还有待观察。制定明确的高风险使用禁令,解决虚假信息的容易传播问题,要求有意义和积极的披露以促进知情同意,并加强消费者保护机构,这些都是解决生成人工智能特有的危害和风险所必需的,教育立法者和公众,并提供一些减轻伤害的途径。
-Ben Winters,高级法律顾问
加强级别的信息操纵
-
背景和风险
免费和低成本的生成人工智能工具的广泛可用性促进了大量文本、图像、语音和视频内容的传播。人工智能系统创建的大部分内容可能是良性的,或者可能对特定受众有益,但这些系统也会助长极其有害的内容的传播。例如,生成人工智能工具可以也将被用于传播虚假、误导、偏见、煽动性或危险的内容。随着生成性人工智能工具变得越来越复杂,制作这些内容将更快、更便宜、更容易,而现有的有害内容可以作为制作更多内容的基础。在本节中,我们考虑了人工智能工具会煽动的五类有害内容:诈骗、虚假信息、错误信息,网络安全威胁,以及点击诱饵和监控广告。尽管我们区分了虚假信息(有目的地传播虚假信息)和错误信息(目的性较低的虚假信息传播或创建),但人工智能生成内容的传播将模糊使用人工智能生成的内容而未经事先编辑或事实核查的各方的界限。使用人工智能生成的输出而未进行尽职调查的实体应与生成该输出的实体共同对其造成的伤害负责。
| 案例研究–2024年大选 使用GPT-4和随后的大型语言模型的产品可以创建快速而独特的听起来像人类的“脚本”,这些脚本可以通过文本、电子邮件、打印或通过人工智能语音生成器与人工智能视频生成器相结合来分发。这些人工智能生成的脚本可以用来劝阻或恐吓选民,或传播有关投票或选举的错误信息。例如,2022年,至少有五个州的选民收到了带有故意错误投票信息的短信。近年来,这种类型的选举错误信息已经很常见,但生成的人工智能工具将增强不良行为者快速传播可信选举错误信息的能力。 国会必须制定立法,防止通过虚假或误导性信息以及虚假的支持声明蓄意恐吓、威慑或干扰选民。 |
诈骗
诈骗电话、短信和电子邮件早已失控,在许多方面伤害了公众。仅在2021年,就有280万消费者向联邦贸易委员会提交了欺诈报告,声称损失超过23亿美元,近140万消费者提交了身份盗窃报告。生成人工智能可以使用人工智能生成的文本、语音和视频加速这些各种骗局的创建、个性化和可信度。人工智能语音生成也可以用来模仿亲人的声音,打电话立即请求经济援助以获得保释、法律帮助或赎金。
根据EPIC和国家消费者法律中心2022年的一份报告,在2020-21年6月期间,美国电话每月有超过10亿个诈骗机器人,导致近300亿美元的消费者损失,其中最常见的是针对老年人、残疾人和负债者等弱势群体,并且经常使用自动语音说话——由ChatGPT等文本生成器生成的脚本,旨在假装自己是权威人士,以恐吓消费者汇款。2022年,估计消费者损失增加到395亿美元,联邦贸易委员会报告称,仅诈骗短信就损失了3.26亿美元。
自动拨号器、自动短信、自动电子邮件和邮件器,再加上销售号码或电子邮件地址列表的数据代理,使实体能够同时发送大量信息。同样的数据代理可以出售作为潜在目标的人的名单,以及关于他们的心理健康状况、宗教信仰或性取向的“见解”。数据代理被允许对个人使用的针对性程度加剧了人工智能造成的伤害。
文本生成服务还增加了网络钓鱼诈骗和不良行为者干预选举成功的可能性。这种情况已经发生了-在2021年的一项研究中,研究人员发现GPT-3生成的网络钓鱼电子邮件比人类生成的更有效。生成的人工智能可以帮助英语技能有限的人制作听起来自然准确的电子邮件,从而扩大潜在有效的欺诈者群体,以一种使检测骗局变得更加困难的方式。
虚假信息
不良行为者还可以使用生成性人工智能工具制作适应性强的内容,旨在支持竞选、政治议程或仇恨立场,并在许多平台上快速、廉价地传播这些信息。人工智能促成的虚假或误导性内容的快速传播也会对生成性人工智能产生周期性影响:例如,当大量虚假信息被注入数字生态系统,并通过强化学习方法对更具生成性的系统进行信息训练时,虚假或误导的输入可能会产生越来越不正确的输出。
使用生成性人工智能工具加速虚假信息的传播可能会助长影响公众舆论、骚扰特定个人或影响政治和选举的努力。虚假信息增多的影响可能是深远的,一旦传播就无法轻易反击;考虑到虚假信息给民主进程带来的风险,这一点尤其令人担忧。
错误信息
Bard或ChatGPT等生成文本的大型语言模型输出不准确的现象已经被广泛记录。即使没有撒谎或误导的意图,这些生成性人工智能工具也会产生有害的错误信息。人工智能生成的文本所遵循的精致且通常写得很好的风格,以及包含在真实事实中的做法,加剧了这种伤害,这可能会给虚假信息披上合法的外衣。例如,据《华盛顿邮报》报道,一名法学教授被列入人工智能生成的“性骚扰他人的法律学者名单”,即使不存在此类指控。正如普林斯顿大学教授阿文德·纳拉亚南在接受the Markup采访时所说:
“Sayash Kapoor和我称之为胡说生成器,其他人也一样。我们的意思不是规范性的,而是相对精确的。我们的意思是,它被训练来产生看似合理的文本。它非常善于说服人,但它没有经过训练来产生真实的陈述。它通常会产生真实的陈述,作为似是而非和有说服力的副作用,但这不是目标。”
人工智能生成的内容还涉及一个更广泛的法律问题:我们对所见所闻的信任。随着人工智能生成的媒体变得越来越普遍,我们被诱骗相信虚构的东西是真实的或真实的东西是虚构的情况也会越来越普遍。当个人不再信任信息,新信息的生成速度超过了检查准确性的速度时,他们该怎么办?像维基百科这样的信息源可能会被人工智能生成的虚假内容淹没。在有针对性的情况下,这可能是有害的,因为这会导致目标在假设他们所爱的人处于危机中的情况下采取行动。
安全
上述网络钓鱼问题也构成了安全威胁。尽管聊天机器人(目前)还不能从头开始开发自己的新型恶意软件,但黑客很快可能会利用像ChatGPT这样的大型语言模型的编码能力来创建恶意软件,然后可以对其进行细微调整,以达到最大的覆盖范围和效果,从而使更多的新手黑客成为严重的安全风险。事实上,安全专业人士已经注意到,黑客已经在讨论如何使用ChatGPT安装恶意软件并从目标中提取信息。
一代又一代的人工智能工具很可能开始从反复暴露在恶意软件中学习,并能够开发出更新颖、更不可预测的恶意软件,从而逃避常见安全系统的检测。
点击诱饵与监控广告生态系统
除了错误信息和虚假信息,生成人工智能还可以用来创建点击诱饵标题和文章,操纵用户如何浏览互联网和应用程序。例如,生成人工智能被用来创建完整的文章,无论它们的真实性、语法或缺乏常识,以推动搜索引擎优化,并创建更多用户可以点击的网页。这些机制试图以牺牲真相为代价,最大限度地提高点击量和参与度,从而降低用户在此过程中的体验。生成型人工智能继续以更快的速度传播错误信息,制造最大化浏览量和破坏消费者自主权的头条新闻,从而助长这一有害循环。
危害
- 经济损失:成功的诈骗和恶意软件可能会通过勒索、欺骗或获取金融账户,导致受害者直接经济损失。这也可能对信贷产生长期影响。
- 声誉/关系/社会污名化:虚假信息和虚假信息会产生和传播关于个人的虚假或有害信息,从而损害他们在社区中的声誉,潜在损害他们的个人和职业关系,并影响他们的尊严。
- 心理-情绪困扰:虚假信息和错误信息可能会造成严重的情绪伤害,因为个人会应对传播的虚假信息的影响。此外,如果许多人是骗局的受害者,他们可能会感到被操纵或被用于点击诱饵和监控广告,他们将面临耻辱和尴尬。
- 心理障碍:虚假或误导性信息和点击诱饵的涌入使个人难以在网上进行日常活动。
- 自主性:错误信息和虚假信息的传播使个人越来越难以做出正确的知情选择,而监控广告的操纵性使选择问题更加复杂。
- 歧视:骗局、虚假信息、错误信息、恶意软件和点击诱饵都利用“标记”的漏洞,包括某些弱势群体和类别(老年人、移民等)的成员身份。
示例
- 人们使用人工智能向学校等公共场所发出虚假炸弹威胁。
- 人工智能语音发生器被用来给人们的亲人打电话,让他们相信他们的家人在监狱里,急需保释金和法律援助。
- 反数字仇恨中心测试了谷歌的巴德聊天机器人,看看他们是否会复制100种常见的阴谋论,包括否认大屠杀,并称桑迪胡克的大规模儿童谋杀悲剧是利用“危机演员”上演的。巴德在100次中有78次在没有上下文或披露的情况下,根据这些谎言发表了文本。
- Vice记者在互联网上广泛发现了未经编辑的人工智能垃圾邮件。
- 科技新闻网站CNET暂停使用人工智能,并对其发布的77篇使用人工智能工具撰写的报道中的41篇进行了更正。人工智能撰写的文章旨在增加谷歌搜索的浏览量,以增加广告收入,其中包含不准确和误导性的信息。
- 同样,据报道,Buzzfeed发布了人工智能写作内容,即旅行指南,目的是吸引不同目的地的搜索流量。结果的质量被一致认为是无用和无益的。
干预措施
- 颁布一项法律,将恐吓、欺骗或故意误导某人有关选举或候选人的信息定为非法(无论手段如何),如《欺诈行为和选民恐吓预防法》。
- 通过《美国数据隐私保护法案》。ADPPA将个人信息的收集和使用限制在合理必要的范围内,并与收集信息的目的相称。这样的限制将限制用于对用户进行简介的个人信息,使其成为广告、网络钓鱼和其他骗局的目标。ADPPA还将限制使用个人数据来训练可以操纵用户的生成人工智能系统。
- 颁布联邦贸易委员会商业监督规则,制定数据最小化标准,禁止断章取义地二次使用个人信息,这同样会阻止使用为无关目的收集的个人信息训练生成性人工智能系统。
骚扰、冒充和勒索
背景和风险
生成人工智能技术最早的一些使用或误用是deepfakes:使用机器学习算法创建的逼真图像或视频,将某人描绘成他们没有说或做的事情,通常是将一个人的肖像替换为相似的另一个人。deepfakes和其他人工智能生成的内容可以用来促进或加剧在整个报告中列出的许多危害,但本节侧重于一个子集:故意、有针对性地虐待个人。人工智能生成的图像和视频为不良行为者提供了几种模仿、骚扰、羞辱、剥削和勒索他人的方式。例如,深度伪造的视频可以显示受害者赞扬他们厌恶的事业,或者从事露骨的性行为或其他羞辱行为。这些图像和视频也可能在互联网上迅速传播,使受害者、执法部门和其他相关方很难或不可能识别创作者,并确保删除有害的deepfakes。
不幸的是,许多有针对性的deepfakes的受害者没有追索权,而那些寻求追索权的人往往被迫自己识别和面对肇事者。
合成媒体的危害早于人工智能和机器学习。早在20世纪90年代,商业照片编辑软件就允许用户在照片中更改外观或交换人脸。然而,现代deepfakes和其他人工智能生成的合成内容可以追溯到谷歌2015年发布的TensorFlow,这是一款用于构建机器学习模型的开源工具,以及2017年使用这种工具创建的深度伪造的病毒传播。为了创建这些早期的深度伪造,其中许多涉及将名人的脸放在色情电影演员的身体上——创作者必须使用TensorFlow等工具构建一个机器学习模型(通常是生成对抗性网络或GAN),在各种图像、视频或音频文件上训练它,然后指示模型将特定人的特征或声音映射到另一个人的身体上。Midtravel和Runway等新的生成人工智能服务的发布消除了这些技术障碍,使任何人都可以通过提供一些关键图像、源视频甚至文本条目来快速创建人工智能生成的内容。
从本质上讲,使用人工智能生成的内容来模仿、骚扰、羞辱、剥削或勒索个人或组织,通常与使用其他方法没有什么不同。deepfake危害的受害者仍可能求助于现有的欺诈、冒充、勒索和网络跟踪的刑事和民事补救措施以纠正对生成人工智能工具的恶意使用。然而,生成性人工智能提出了新的法律问题,并以新的方式加剧了伤害,使受害者和监管机构都无法利用现有的法律途径来补救伤害。例如,对死者的深度假冒——一种被称为“幽灵机器人”的现象——不仅可能涉及诽谤法,而且可能会在死者的亲人中造成情感困扰,而虚假的文本引用可能不会。这些新的法律问题大致分为三类:涉及恶意的问题;涉及隐私和同意的问题;以及涉及可信度的问题。
| 案例研究–让一名记者噤声 2018年4月,印度调查记者拉纳·阿尤布收到了莫迪政府内部消息人士的电子邮件。一段她从事性行为的视频在网上疯传,导致了公众的羞辱和那些想诋毁她的作品的人的批评。但那是假的。阿尤布的肖像被使用早期的深度伪造技术插入到一个色情视频中。随着公众监督的加强,她的家庭地址和手机信息被泄露,导致死亡和强奸威胁。这段早期的视频被传播是为了骚扰、羞辱和排斥一位直言不讳的政府批评者——几个月来,它取得了成功。 |
恶意
生成人工智能伤害、羞辱或性化他人的一个常见恶意使用案例涉及生成非感官性图像或视频的深度伪造。这些性deepfakes是deepfake技术最早、最常见的例子之一,引起了媒体的广泛关注。然而,许多现有的非色情法律将责任限制在发布内容意图造成伤害的情况下。生成人工智能的一些恶意使用无疑达到了这一门槛,但许多深度造假创作者可能并不打算伤害性深度造假的主题;相反,他们可能会创建并传播deepfake,而不希望受试者看到或受到内容的影响。
| deepfakes是如何制作的 创建deepfake的标准方法使用机器学习模型来检测参考帧或视频中的关键点,称为“驱动视频”,然后将目标个人的照片映射到“使用关键点将源照片绘制到每一帧上。例如,可以训练机器学习模型来检测视频中一个人脸上的几个点,然后根据这些关键点将来源照片映射到视频中的一张脸上。然后可以编辑生成的照片或深度假照片,以去除可能揭示深度假照片不真实性的微小伪影。 |
意图要求也渗透到适用于恶意使用生成性人工智能的其他刑法中。例如,联邦网络跟踪法规《美国法典》第18卷第2261A节仅适用于“意图杀害、伤害、骚扰、恐吓或监视[具有类似意图]的人”。“像《加利福尼亚州刑法典》第528.5条这样的州冒充法规同样将执法限制在那些“以伤害、恐吓、威胁或诈骗他人为目的”冒充他人的人。使用生成人工智能恐吓、骚扰、诈骗或勒索他人可能属于这些刑事法规,但为了个人享受或娱乐而制造有害或性的deepfakes可能不会。
最后,由于许多在线平台的一个现代功能:用户匿名性,预测深度伪造创作者的意图变得更加困难。当受害者意识到一个恶意的deepfake在网上传播时,就像2018年记者拉纳·阿尤布所发生的那样,即使不是不可能,也很难找到原始创作者提起诉讼或刑事指控。
隐私和同意
即使人工智能生成的有针对性的伤害的受害者成功地识别出一个有恶意的deepfake创作者,他们也可能很难纠正许多伤害,因为生成的图像或视频不是受害者,而是一个使用多个来源的合成图像或视频来创建可信但虚构的场景。从本质上讲,这些人工智能生成的图像和视频规避了隐私和同意的传统概念:因为它们依赖于公共图像和视频,就像发布在社交媒体网站上的图像或视频一样,所以通常不依赖任何私人信息。人工智能生成内容的这一特征排除了某些传统的隐私侵权行为,包括侵入隔离和公开私人事实,这明确依赖于公开或侵犯私人事实。其他隐私侵权行为,包括虚假曝光,表现更好,因为它们只需要原告证明创作者知道或鲁莽地无视一个理性的人是否会发现人工智能生成的内容非常令人反感。尽管如此,这些主张也面临着一个困难的法律障碍:第一修正案。
Midtravel和Runway等新人工智能工具的生成性使它们处于言论自由保护和深度伪造受害者隐私保护之间的艰难十字路口。许多人工智能生成的照片和视频以可能受到第一修正案保护的方式转换原始材料或包含新内容,但它们可能看起来是受害者在尴尬、性或其他不良情况下的真实镜头。言论自由、隐私和同意之间的紧张关系给个人和名人、政治家等公众人物带来了新的、棘手的法律问题。
考虑同意的问题。许多对个人有害的人工智能描述都使用受害者在网上发布的公共来源的照片。受害者可能不同意生成人工智能工具为他们制作的虚构但可信的照片和视频,但现有的法律主张可能无法提供这些受害者所期望的补救措施。尽管公示权最初保护的是个人的隐私和尊严,例如,一些现代法院将注意力集中在受害者对其身份的经济利益上,即名人对其公共形象的经济利益,这些法院和类似的国家拨款法可能无法提供受害者在面对非感官深度伪造时所期望的简单的法律补救措施;他们可能期望受害者除了未经同意外,还会表现出一些经济或身体伤害,或者他们可能期望deepfake的创建者从经济上受益。这些法律和司法解释的制定并没有考虑到生成性人工智能,这意味着即使是本应易于补救的人工智能伤害也可能变得复杂、昂贵,并使受害者感到困惑。当然,恶意deepfakes和其他人工智能生成内容的受害者仍然可以提出其他几项法律索赔,例如诽谤或疏忽造成情绪困扰,但新人工智能工具的生成性表明,即使是这些索赔也可能面临法律障碍。生成人工智能的新颖性和可扩展性可能会成为恶意deepfakes受害者的障碍,即使他们的潜在法律主张很强。
诽谤是生成型人工智能使法律索赔更具挑战性的又一个例子。虽然只要描述是虚假的并伤害了受害者,私人可能会追究诽谤性深度伪造的创作者的责任,但名人和政客等公众人物必须克服更高的第一修正案障碍才能获得赔偿。在纽约时报公司诉。
例如,苏利文最高法院裁定,公众人物必须证明被告发布诽谤性材料时带有实际恶意,换句话说,“明知其为虚假,或不顾其是否为虚假”。在《骗子杂志》(Hustler Magazine)《股份有限公司诉Falwell案中,最高法院采用了同样的标准来驳回故意造成精神痛苦的指控。然而,在这些案件中采用的实际恶意标准是基于一个合理谨慎的人可以做些什么来调查和揭露他们收到的信息的真实性的假设而制定的。随着生成性人工智能工具变得越来越复杂,个人和新闻机构只会越来越难判断某些东西是真实的还是由人工智能生成的,这实际上增加了公众人物必须克服的障碍,以弥补诽谤性深度伪造造成的伤害。
重要的是,生成人工智能的恶意使用会影响到每个人——个人和公众人物。法律中个人和公众人物之间的区别远未明确,个人和公众人士都成功地克服了上文讨论的第一修正案、隐私和同意障碍。这些案件及其所涉及的法律测试只是强调了当某人使用生成人工智能冒充时可能不成立的法律假设,骚扰、诽谤或以其他方式伤害他人的法律假设可能会为纠正和延续人工智能造成的伤害设置障碍。尽管许多传统的法律补救措施可能仍然适用于恶意deepfakes和其他生成人工智能危害的受害者,但生成人工智能提出的新的法律问题,以及公开可用的生成人工智能工具可能产生的潜在大量违规行为,无疑将使这些法律补救措施更难寻求,在实践中也不那么有效。
可信度
当Deepfakes被传播给那些认为它们是真实的观众时,它们会给受试者带来真正的社会伤害。即使deepfake被揭穿,它也会对其他人如何看待deepfakes的主题产生持续的负面影响。人工智能生成的内容的可信度也会削弱受害者寻求法律补救的能力。生成人工智能和deepfakes的激增破坏了关于法律事实调查和证据验证如何发生的核心假设。目前,验证法庭证据的门槛并不是特别高。索赔人必须证明的是,一个合理的陪审员可以发现有利于真实性或身份验证,在此之后,真实性的确定由陪审团决定。此外,许多法院对deepfakes破坏的听觉和视觉证据的真实性采取了假设。例如,一些法院承认视频认证的“沉默证人”理论,其中录音的存在说明了证据的真实性,而无需人类证人的观察。其他法院则认为从新闻档案或政府数据库中获取的证据是真实的,这两者都可能容易受到deepfakes的攻击。随着人工智能生成的内容变得越来越普遍和可信,法院和监管机构都需要识别和采用方法来确定图像和视频是否真实,并重新考虑对审判中提交的证据的真实性和价值的法律假设。
危害
- 物理:在某些情况下,受害者似乎有某些行为的可信深度伪造可能会使他们面临身体伤害和暴力的风险,例如,在公开的性行为会让家庭蒙羞的文化中,或者在同性关系非法的文化中。
- 经济/经济损失:传播人工智能生成的色情假图像和视频,或涉及热点政治或社会话题,可能导致受害者失业,并难以找到未来的工作。
- 名誉/关系/社会污名化:例如,如果deepfakes让其他人相信受害者在欺骗伴侣或与未成年人进行非法行为,受害者在社区中的地位、亲密和职业关系以及尊严都可能受到严重损害或破坏。
- 心理上:这些袭击的受害者往往感到受到严重侵犯,可能会感到绝望,担心自己的生活被摧毁。
- 自主性/机会丧失:Deepfakes已经被武器化,故意让记者、活动家和其他弱势群体噤声,如果被广泛相信,可能会导致机会丧失和生活环境的改变。这也可能对民主和社会变革构成威胁。
- 自主性/歧视:Deepfakes很容易成为针对属于边缘化群体的本已脆弱的个人或使个人看起来属于边缘化人群的工具——它们也可能强化对性工作和性工作者的负面态度。
示例
- 欧盟警察部队发布官方警告称,使用ChatGPT和其他生成人工智能工具的“严重”犯罪虐待行为正在出现并愈演愈烈。
- 一名Twitch流媒体人制作了另一名Twich流媒体人的Deepfake色情作品,将她的脸强加在色情作品上,并假装是她。
- 一位TikTok用户公开谈论了她在互联网上分享的数字创作的裸照。这些照片被用来威胁和勒索她。
- 视频游戏配音演员的声音被拿走,并被用来训练人工智能,在他们不知情或不同意的情况下,用他们的声音骚扰和暴露他们的信息。
干预措施
- 技术解决方案包括深度伪造检测软件和为人工智能生成的内容添加水印的方法。这些解决方案可能有助于受害者、法院和监管机构识别人工智能生成的内容,但这些解决方案的有效性完全取决于技术专家和负责任的人工智能行为者开发创新检测和认证工具的速度,而非恶意人工智能开发者开发新的、更难检测的人工智能工具的速度。
- 尽管生成人工智能工具具有新颖的功能及其带来的法律挑战,但许多长期存在的法律工具仍可能适用。例如,利用受版权保护的内容(可能包括受害者自己拍摄的照片)的deepfakes可能容易受到传统版权索赔的影响。根据人工智能生成内容的具体情况,受害者还可能求助于各种侵权索赔,如诽谤、虚假陈述、故意施加情绪困扰以及盗用姓名和肖像。为了规避识别匿名创作者的挑战,受害者可能会起诉托管和传播恶意人工智能生成内容的在线平台,如果这些平台(包括Midtravel和Runway等人工智能工具的提供商)对这些内容的有害或非法性做出了重大贡献,可能适用于涉及人工智能生成内容恶意传播的索赔。
- 一些监管干预措施可能会进一步保护深度伪造和其他恶意使用生成人工智能的受害者。虽然对深度伪造或生成人工智能工具的全面禁令可能会违反第一修正案,根据版权法或隐私侵权扩大索赔范围,将不顾内容对受害者的影响而对受害者进行的虚构描述包括在内,这将大大有助于弥补恶意使用生成人工智能造成的伤害。刑事法规也可以更新或辅之以捕捉上述问题的法定语言,包括降低要求某人对非感官的、人工智能生成的对他人的性描述负责的意图的语言。鉴于识别可信的deepfakes和验证证据的困难,《联邦证据规则》可能会受益于更高的验证标准,以对抗可能的deepfakes。最后,恶意deepfakes和其他为商业目的创建的人工智能生成内容可能会受到联邦贸易委员会和州检察长办公室等行政机构的监管,理由是它们不公平且具有欺骗性。
聚焦:第230条规定
《通信体面法》第230条规定,交互式计算机服务的提供商不得“被视为”第三方提供的信息的发布者或发言人,如果这起诉讼与第三方提供的内容有任何关系,公司就要求获得第230条的豁免权。近年来,法院已经开始限制第230条的适用范围,相反,法院发现,只有在责任的基础是传播公司在制造不当信息方面没有发挥任何作用的情况下,公司才能要求第230条豁免。
生成人工智能工具没有获得全面豁免:一些评论家将生成人工智能第230条的辩论定义为要么全有要么全无的决定,一些人宣称生成人工智能软件获得第230条豁免,另一些人则宣称它们没有。但法官在最近的重大法院裁决中拒绝以如此广泛的方式适用第230条。相反,法院在逐个索赔的基础上适用第230条。因此,公司是否会获得第230条的保护将取决于所争议的具体事实和法律义务,而不仅仅是他们是否部署了生成人工智能工具。
第230条不应适用于某些索赔,如产品责任索赔,因为它们不将公司视为信息的发布者或发言人:过去,法院对第230条的适用非常广泛,主要是将该条款解读为,只要一家公司涉嫌非法活动涉及传播第三方信息,就将其视为出版商或发言人。法院已经开始反悔这一点,并认识到第230条并不能保护公司免受针对其自身不造成伤害的义务的索赔。因此,关于生成型人工智能公司在服务设计、信息收集、使用或披露以及内容创建方面违反了其自身职责的索赔不应被第230条禁止。
例如,生成型人工智能公司将很难利用第230条来逃避产品责任索赔,例如疏忽设计或未能至少在第九巡回法院发出警告,法院现在承认,此类索赔不是基于第三方信息造成的伤害,而是基于一家公司违反了其设计不会对消费者造成不合理伤害风险的产品的义务,以及披露个人信息,因为这些法律规定公司有义务尊重第三方的隐私利益。
当工具完全负责创建内容时,生成型人工智能公司将无法获得第230条的保护:生成型人工智慧公司可能会面临关于其工具生成的信息的几种不同类型的索赔。第230条为公司提供了基于另一方提供的信息的法律索赔保护,另一方是第230条行话中的“信息内容提供商”。信息内容提供商被定义为“对提供给公司的信息的创建或开发负有全部或部分责任的任何个人或实体”。因此,如果生成型人工智能公司本身是有争议信息的信息内容提供商,且公司“对信息的创建或开发负有全部或部分责任”,则该公司不受第230条的保护。
当生成性人工智能工具被指控创建了新的有害内容时,例如当它“产生幻觉”或编造了不在其训练数据中的信息时,法律索赔不基于第三方信息,第230条不应适用。例如,当生成人工智能工具编造关于个人的虚假和损害声誉的信息时,生成人工智能公司将不受第230条的保护,例如诽谤或虚假信息,因为该公司而不是任何第三方负责创建虚假和损害名誉的信息,这是法律索赔的基础。
当生成型人工智能公司对不当内容做出重大贡献时,它们将不会得到第230条的保护:在某些情况下,生成型人工智慧公司会试图辩称,有争议的输出来源于第三方,无论是作为用户输入还是培训数据。在这种情况下,法院必须确定该公司是否部分创建或开发了信息。主要的测试是公司是否对信息的不当性做出了重大贡献。重大贡献可能包括更改或汇总第三方信息以使其违反法律,要求或鼓励第三方输入违反法律的信息,或以其他方式导致违法。
当用户要求生成人工智能工具创建错误信息或深度伪造时,或者当工具使用训练数据创建有害内容时,该工具会将输入转换为有害内容,部署该工具的公司不应使用第230条来避免责任。用户输入有害信息的请求,深度伪造目标的照片或视频本身并不有害,也不足以创建有害内容。毕竟,这就是用户使用生成人工智能来创建内容的原因。这些投入本身也不太可能足以构成针对生成型人工智能公司的索赔的法律依据。在这种情况下,部署生成性人工智能工具的公司通过将不能构成责任基础的信息转化为可以构成责任依据的信息,对不当信息做出了重大贡献。
另一方面,如果用户要求生成人工智能工具简单地重复用户在该工具中输入的诽谤性声明,或重复来自其他来源的有害信息,则该工具可能不会对伤害造成实质性影响,因此可能受益于第230条的保护。
第230条不应成为追究公司对生成人工智能工具造成的伤害的障碍。任何新的法规或索赔都应说明生成人工智能公司的义务以及生成有害内容对工具本身造成的伤害。
目前尚不清楚被窃取的培训数据是否是“由”第三方“提供的”信息:为了获得第230条的保护,公司必须证明构成责任基础的信息是“由第三方提供的”。关于信息何时由第三方“提供”的问题,几乎没有先例。“提供”信息可能意味着提供信息或将其提供给他人。但目前还不清楚第三方是否打算仅仅通过让互联网上的普通观众看到他们的信息,就可以将他们的信息提供给生成的人工智能工具。事实上,在许多情况下,情况显然恰恰相反。
互联网公司和第三方信息提供商之间的关系对于确定第三方是否提供信息至关重要。第230条最初设想的服务类型包括直接向该服务提供信息的用户,例如作为启发第230.72条的案件基础的Prodigy留言板,第三方不直接提供信息的搜索引擎和其他类型的服务也被发现享有第230条的一些保护,但即使是这些公司也让第三方对其信息是否在其服务上发布或重新发布以及在多大程度上发布拥有一定的控制权。例如,网站可以告诉谷歌的搜索引擎爬虫不要索引他们的页面,但没有有效的手段阻止人工智能公司抓取他们的网站。第三方对其信息在生成人工智能工具中的使用缺乏控制,以及[隐私部分]中描述的类似考虑,可能会动摇法院,使其无法认定被窃取的数据是“由”第三方“提供的”。
相关文章:
)
生成式人工智能的潜在有害影响与未来之路(一)
这是本文的第1版,反映了截至2023年5月15日,Generative AI的已记载的和预期的危害。由于Generative AI的发展、使用和危害的快速变化,我们承认这是一篇内在的动态论文,未来会发生变化。 在本文中,我们使用一种标准格式…...

lightdb23.3 表名与包名不能重复
LightDB 表名与包名不能重复 从 LightDB 23.3 版本开始表名和包名不能重复,与 oracle 一致。原先已已支持包名和schema名不能重复。 背景 在之前版本在同一schema 下可以创建相同名字的表和包。这会导致在存储过程中使用%type指定变量类型时,如果存在…...

Oracle 开发篇+Java通过HiKariCP访问Oracle数据库
标签:HikariCP、数据库连接池、JDBC连接池、释义:HikariCP 是一个高性能的 JDBC 连接池组件,号称性能最好的后起之秀,是一个基于BoneCP做了不少的改进和优化的高性能JDBC连接池。 ★ Java代码 import java.sql.Connection; impor…...
进销存管理系统(小杨国贸)springboot采购仓库财务java jsp源代码mysql
本项目为前几天收费帮学妹做的一个项目,Java EE JSP项目,在工作环境中基本使用不到,但是很多学校把这个当作编程入门的项目来做,故分享出本项目供初学者参考。 一、项目描述 进销存管理系统(小杨国贸)spri…...
)
指针初阶(2)
文章目录 5. 指针和数组6. 二级指针7. 指针数组 附: 5. 指针和数组 指针变量:指针变量就是指针变量,不是数组,指针变量的大小是4/8个字节,专门是用来存放地址的。 数组:数组就是数组,不是指针&a…...
基于Gradio的GPT聊天程序
网上很多别人写的,要用账号也不放心。就自己写了一个基于gradio的聊天界面,部署后可以本地运行。 特点: 可以用openai的,也可以用api2d,其他api可以自己测试一下。使用了langchain的库 可以更改模型,会的…...

包管理工具详解npm 、 yarn 、 cnpm 、 npx 、 pnpm(2023)
1、包管理工具npm (1)包管理工具npm: Node Package Manager,也就是Node包管理器;但是目前已经不仅仅是Node包管理器了,在前端项目中我们也在使用它来管理依赖的包;比如vue、vue-router、vuex、…...

Terraform 系列-批量创建资源时如何根据某个字段判断是否创建
系列文章 Terraform 系列文章Grafana 系列文章 概述 前文 Grafana 系列 - Grafana Terraform Provider 基础 介绍了使用 Grafana Terraform Provider 创建 Datasource. 这几天碰到这么一个现实需求: 使用 Terraform 批量创建日志数据源时, 有的数据源类型是 El…...

Android侧滑栏(一)可缩放可一起移动的侧滑栏
在实际的各类App开发中,经常会需要做一个左侧的侧滑栏,类似于QQ这种。 今天这篇文章总结下自己在开发中遇到的这类可以跟随移动且可以缩放的侧滑栏。 一、实现原理 使用 HorizontalScrollView 实现一个水平方向的可滑动的View,左布局为侧滑…...
简单程度与自负是否相关?探索STM32的学习价值
事实上,无论STM32是否简单并不重要,更重要的是我们能通过学习STM32获得什么。通过STM32,我们可以学习到许多知识:如果我们制作一个键盘或鼠标,我们可以学习USB协议。如果我们制作一个联网设备,我们需要学习…...
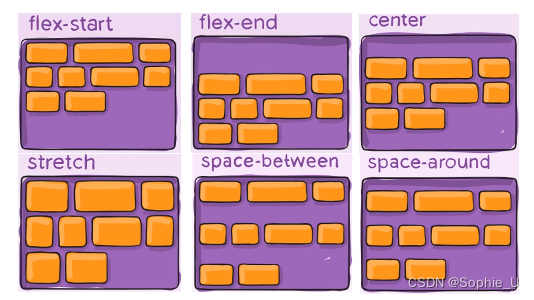
第二章:CSS基础进阶-part3:弹性例子布局
文章目录 Flex盒模型二、常见属性2.1 flex属性2.2 justify-content2.3 flex-wrap2.4 flex-flow2.5 align-items2.6 父容器-align-content Flex盒模型 1、普通盒模型 2、弹性盒布局 使用弹性盒布局能让容器的宽度跟随浏览器窗口的变化而变换 二、常见属性 2.1 flex属性 2.2 …...

函数与方法有区别?
有区别,当然是有区别。 不管是java、rust还是go,他们都是不一样的。 先看定义: 函数(Function) 是一段独立的代码块,用于执行特定的任务。函数可以被多次调用,并且可以接受参数和返回结果。在G…...
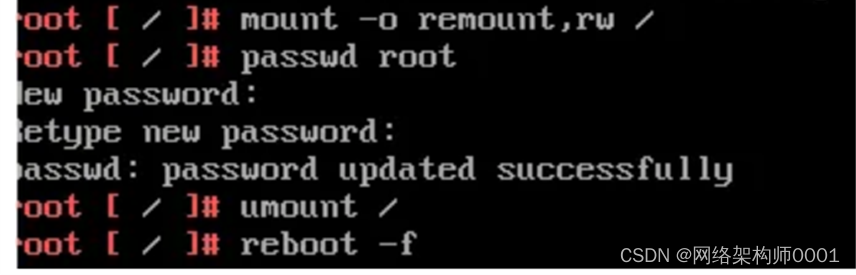
VMware vCenter忘记密码操作,和Linus原理一致
mount -o remount,rw / passwd root ## 修改 root 密码要选择对应账户## 输入新密码,再输入一次新密码 umount / ## 卸载根文件系统 reboot -f ## 重新引导 vCenter...
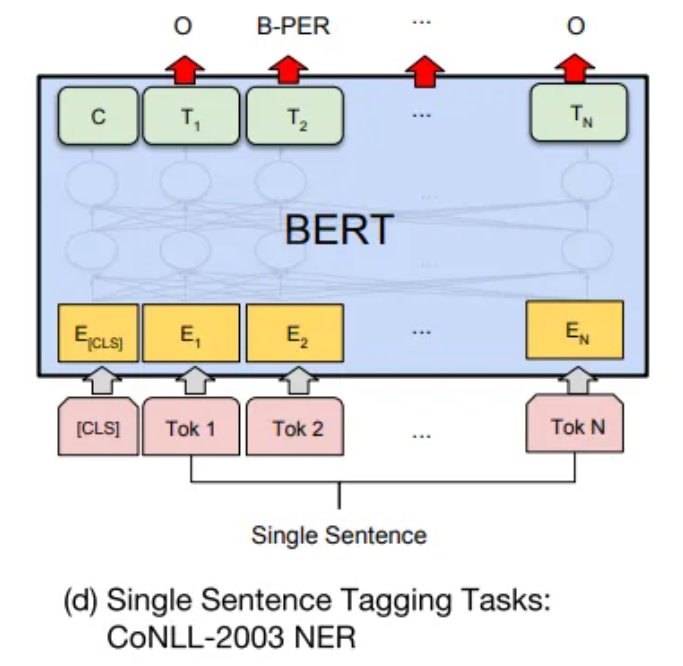
Bert详细学习及代码实现详解
BERT概述 BERT的全称是Bidirectional Encoder Representation from Transformers,即双向Transformer的Encoder,因为decoder是不能获要预测的信息的。在大型语料库(Wikipedia BookCorpus)上训练一个大型模型(12 层到 …...
Vue [Day7] 综合案例
核心概念回顾 state:提供数据 getters:提供与state相关的计算属性 mutations:提供方法,用于修改state actions:存放异步操作 modules:存模块 功能分析 https://www.npmjs.com/package/json-server#ge…...
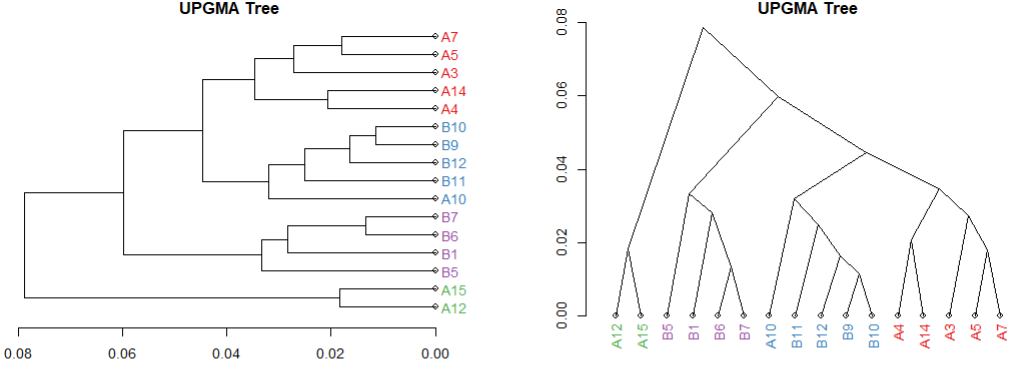
基于R做宏基因组的进化树ClusterTree分析
写在前面 同上一篇的PCoA分析,这个也是基于公司结果基础上的再次分析,重新挑选样本,在公司结果提供的csv结果表上进行删减,本地重新分析作图 步骤 表格预处理 在公司给的ClusterTree的原始表格数据里选取要保留的样本…...
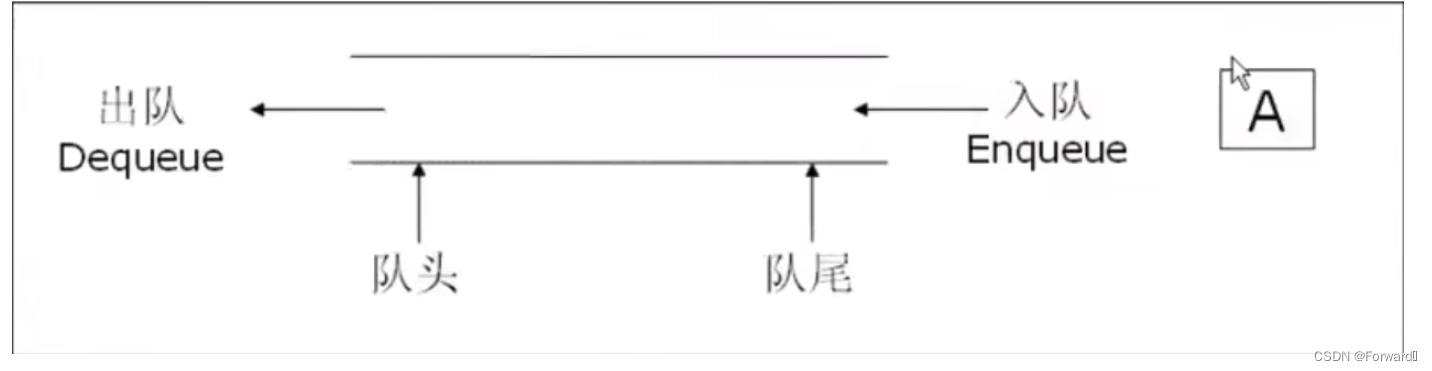
栈和队列修炼指南(基本操作+OJ练习)
栈和队列修炼指南 1. 栈 1. 1 概念及结构 栈:是一种特殊的线性表,其只允许在固定的一端进行插入和删除元素的操作。进行数据插入和删除操作的一端称为栈顶,另一端为栈底。 栈中的数据元素遵守后进先出原则(LIFO)原则 压栈:栈的…...

伪类和伪元素有何区别?
聚沙成塔每天进步一点点 ⭐ 专栏简介⭐ 伪类(Pseudo-class)⭐ 伪元素(Pseudo-element)⭐ 区别总结⭐ 写在最后 ⭐ 专栏简介 前端入门之旅:探索Web开发的奇妙世界 记得点击上方或者右侧链接订阅本专栏哦 几何带你启航前…...

自动测试框架airtest应用一:将XX读书书籍保存为PDF
一、Airtest的简介 Airtest是网易出品的一款基于图像识别和poco控件识别的一款UI自动化测试工具。Airtest的框架是网易团队自己开发的一个图像识别框架,这个框架的祖宗就是一种新颖的图形脚本语言Sikuli。Sikuli这个框架的原理是这样的,计算机用户不需要…...

ValueError:The following settings are not supported :{‘username‘: ‘neo4j“}
py2neo版本不同所导致的问题,下面我通过一段代码说明该问题。 import py2neoif py2neo.__version__ 4.3.0:graph Graph(http://localhost:7474, username config.neo4j_username, password config.neo4j_password) elif py2neo.__version__ 2021.2.3:graph G…...

AI专家助手:领域知识整合与复杂任务拆解实战
1. 项目概述:当AI助手成为你的专业顾问"ChatGPT as Your Expert Helper"这个标题直指当下最热门的AI应用场景——将大型语言模型转化为个人专属的专家级助手。作为一名长期跟踪AI技术落地的从业者,我见证过无数企业/个人尝试用AI提升效率的案例…...

5款机器学习模型可视化工具实战评测与应用指南
1. 机器学习模型可视化工具的价值与挑战在模型开发过程中,可视化工具就像给算法装上了X光机。三年前我参与一个金融风控项目时,曾花费两周时间调试一个准确率卡在89%的随机森林模型。直到使用了SHAP可视化工具,才发现某个特征的分箱方式导致模…...

【技术底稿 23】Ollama + Docker + Ubuntu 部署踩坑实录:网络通了,参数还在调
下午5点到晚上10点半,5个半小时。代码一行没改,全是环境、配置、默认参数的坑。 网络隔离、防火墙、Ollama默认监听127.0.0.1、Linux vs Windows差异——每一个都踩了一遍。 目前网络已通,向量模型的上下文问题还在调。 前置条件 操作系统&am…...

Hexo博客写好了却没人看?手把手教你用Vercel Analytics和SEO插件搞定流量
Hexo博客流量突围指南:Vercel Analytics与SEO实战手册 当你花了无数个深夜调试主题、打磨内容,却发现博客访问量始终徘徊在个位数时,那种挫败感我深有体会。作为同样从零起步的Hexo用户,我经历过每天刷新统计却只看到自己IP的尴尬…...

小米手表表盘设计终极指南:用Mi-Create打造你的专属表盘
小米手表表盘设计终极指南:用Mi-Create打造你的专属表盘 【免费下载链接】Mi-Create Unofficial watchface creator for Xiaomi wearables ~2021 and above 项目地址: https://gitcode.com/gh_mirrors/mi/Mi-Create 还在为小米手表找不到心仪的表盘而烦恼吗&…...

深入解析Merlin:基于Go与HTTP/2的现代C2框架设计与实战
1. 项目概述:一个用Go写的跨平台C2框架如果你在红队或者渗透测试领域摸爬滚打过一阵子,肯定对C2(Command & Control,命令与控制)框架不陌生。从老牌的Metasploit Meterpreter,到后来火热的Cobalt Strik…...

ARM RealView Debugger指令追踪技术详解与应用
1. ARM RealView Debugger中的指令追踪技术概述在嵌入式系统开发中,指令追踪(Instruction Trace)是最强大的调试手段之一。与传统的断点调试不同,指令追踪能够非侵入式地记录处理器的完整执行流程,这对实时系统调试、性能优化和异常诊断至关重…...

强化学习算法评估新范式:使用bsuite进行核心能力诊断与行为分析
1. 项目概述:从“玩具”到“基准”的认知升级如果你在强化学习(Reinforcement Learning, RL)领域摸爬滚打过一段时间,大概率会和我有同样的困惑:为什么论文里那些在Atari游戏上表现惊艳的算法,换到我自己的…...

VSCode多智能体协作开发:5个被90%开发者忽略的关键配置技巧
更多请点击: https://intelliparadigm.com 第一章:VSCode多智能体协作开发的核心概念与价值 什么是VSCode多智能体协作开发 VSCode多智能体协作开发是指在Visual Studio Code环境中,通过插件化架构集成多个具备特定能力的AI代理(…...

5分钟上手:英雄联盟国服换肤工具R3nzSkin完全指南
5分钟上手:英雄联盟国服换肤工具R3nzSkin完全指南 【免费下载链接】R3nzSkin-For-China-Server Skin changer for League of Legends (LOL) 项目地址: https://gitcode.com/gh_mirrors/r3/R3nzSkin-For-China-Server 你是否曾经羡慕别人拥有那些炫酷的限定皮…...