Python入门自学进阶-Web框架——39、redis、rabbitmq、git——2
RabbitMQ的exchange,即交换机有不同的类型:
1.direct Exchange(直接交换机)
匹配路由键,只有完全匹配消息才会被转发
2.Fanout Excange(扇出交换机)
将消息发送至所有的队列
3.Topic Exchange(主题交换机)
将路由按模式匹配,此时队列需要绑定要一个模式上。符号“#”匹配一个或多个词,符号“*”匹配不多不少一个词。因此“abc.#”能够匹配到“abc.def.ghi”,但是“abc.*” 只会匹配到“abc.def”。
4.Header Exchange
在绑定Exchange和Queue的时候指定一组键值对,header为键,根据请求消息中携带的header进行路由
RabbitMQ六种工作模式
六种模式分别为Hello world、Work queues(工作队列)、Publish/Subscribe(发布订阅)、Routing(路由)、Topics(主题)、RPC(远程调用),除了RPC模式外,其余的模式都是从简单的使用到更为灵活的使用,基本的代码框架都是差不多的,只是在不同的模式下达到的效果不同,它们各有各的特点,在实际使用中应该根据需求来选择具体的模式,而不是简单粗暴的选择最“高端”的模式。
1. Hello world模式(也叫simple (简单模式))
Hello world模式是最简单的一种模式,一个producer发送message,另一个consumer接收message。

2. Work queues模式(工作模式)
Work queues模式即工作队列模式,也称为Task queues模式(任务队列模式),这个模式的特点在于,同一个queue可以允许多个consumer从中获取massage,RabbitMQ默认会从queue中依次循环的给不同的consumer发送message。一个生产者生产信息,多个消费者进行消费,但是一条消息只能消费一次

3. Publish/Subscribe模式(发布订阅模式)相当于广播
相对于工作/任务模式中的一个message只能发送给一个consumer使用,发布订阅模式会将一个message同时发送给多个consumer使用,其实就是producer将message广播给所有的consumer。
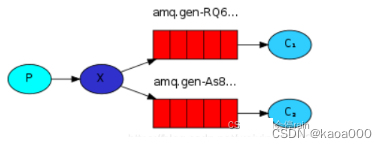
生产者首先投递消息到交换机,订阅了这个交换机的队列就会收到生产者投递的消息。
使用fanout交换机类型,传递到 exchange 的消息将会转发到所有与其绑定的 queue 上。
不需要指定 routing_key ,即使指定了也是无效。
需要提前将 exchange 和 queue 绑定,一个 exchange 可以绑定多个 queue,一个queue可以绑定多个exchange。
需要先启动 订阅者,此模式下的队列是 consumer 随机生成的,发布者 仅仅发布消息到 exchange ,由 exchange 转发消息至 queue。如果不先启动订阅者,则发布者发布的消息订阅者是无法事后接收到的。
发布者:
import pika # 链接mq需要pika模块
import jsonuser_info = pika.PlainCredentials('tester','test1234')
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.1.117',5672,'/',user_info))
channel = connection.channel()# 声明exchange,由exchange指定消息在哪个队列传递,如不存在,则创建。durable = True 代表exchange持久化存储,False 非持久化存储channel.exchange_declare(exchange='logs',exchange_type='fanout',)
for i in range(0,10):message = json.dumps({'消息ID':'1000%s'%i,},ensure_ascii=False)channel.basic_publish(exchange='logs',routing_key='',body=bytes(message,encoding='utf8'),)print(message)connection.close()接收者:
import pika
import jsonuser_info = pika.PlainCredentials('tester','test1234')
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.1.117',5672,'/',user_info))
channel = connection.channel()# 创建临时队列,队列名传空字符或不设置,将创建唯一的临时queue,consumer关闭后,队列自动删除
result = channel.queue_declare('',exclusive=True)
queue_name = result.method.queue
print("temp queue name:",queue_name)
channel.queue_bind(exchange='logs',queue=queue_name,)def callback(ch, method, properties, body):print("[x] Received %r" % str(body,encoding='utf8'))# 如果basic_consume中auto_ack为False,则这里要手动进行应答channel.basic_ack(delivery_tag=method.delivery_tag) # 手动应答print('手动应答队列中消息')channel.basic_consume(queue=queue_name, # 接收指定queue的消息on_message_callback=callback, # 设置收到消息的回调函数auto_ack=False) # 指定为True,表示消息接收到后自动给消息发送方回复确认,已收到消息,False表示不自动确认,需要在callback中手工确认print('[*] Waiting for message. To exit press CTRL+C')# 一直处于等待接收消息的状态,如果没收到消息就一直处于阻塞状态,收到消息就调用上面的回调函数
channel.start_consuming()
4. Routing模式(路由模式),相当于组播
路由模式中,exchange类型为direct,与发布订阅模式相似,但是不同之处在于,发布订阅模式将message不加区分广播给所有的绑定queue,但是路由模式中,允许queue在绑定exchange时,同时指定 routing_key ,exchange就只会发送message到与 routing_key 匹配的queue中,其他的所有message都将被丢弃。当然,也允许多个queue指定相同的 routing_key ,此时效果就相当于fanout类型的发布订阅模式了。

生产者生产消息投递到direct交换机中,扇出交换机会根据消息携带的routing Key匹配相应的队列
生产者:
import pika # 链接mq需要pika模块
import sysuser_info = pika.PlainCredentials('tester','test1234')
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.1.117',5672,'/',user_info))
channel = connection.channel()channel.exchange_declare(exchange='direct-logs',exchange_type='direct', # 类型为directdurable = True,)severity = sys.argv[1] if len(sys.argv)>1 else 'info' # 定义消息严重级别
message = ''.join(sys.argv[2:]) or 'Hello World!'channel.basic_publish(exchange='direct-logs',routing_key=severity, # 把消息发送到一组队列,这一组队列按routing_key分组body=message)
print(" [x] Sent %r:%r" % (severity,message))
connection.close()消费者:
import pika
import sysuser_info = pika.PlainCredentials('tester','test1234')
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.1.117',5672,'/',user_info))
channel = connection.channel()# 创建临时队列,队列名传空字符或不设置,将创建唯一的临时queue,consumer关闭后,队列自动删除
result = channel.queue_declare('',exclusive=True)
queue_name = result.method.queueseverities = sys.argv[1:] # 可以输入多个级别
if not severities:sys.stderr.write("Usage: %s [info] [warning] [error]\n" % sys.argv[0])sys.exit(1)for severity in severities: # 循环绑定routing_keychannel.queue_bind(exchange='direct-logs',queue=queue_name,routing_key=severity,)def callback(ch, method, properties, body):print("[x] Received %r" % body)# 如果basic_consume中auto_ack为False,则这里要手动进行应答channel.basic_ack(delivery_tag=method.delivery_tag) # 手动应答print('手动应答队列中消息')channel.basic_consume(queue=queue_name, # 接收指定queue的消息on_message_callback=callback, # 设置收到消息的回调函数auto_ack=False) # 指定为True,表示消息接收到后自动给消息发送方回复确认,已收到消息,False表示不自动确认,需要在callback中手工确认channel.start_consuming()运行结果:
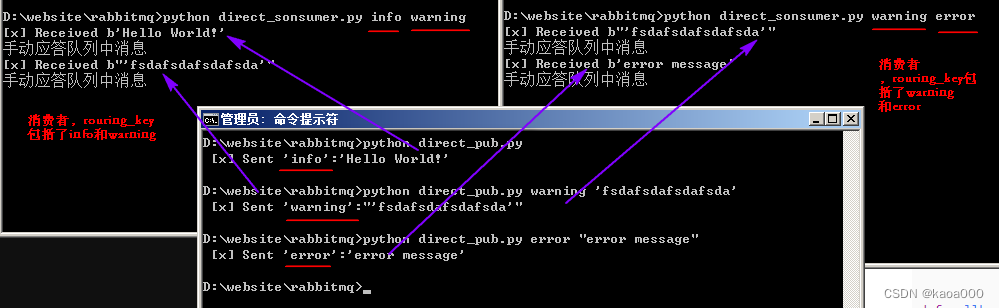
5. Topics模式(主题模式)
主题模式的exchange类型为topic,相较于路由模式,主题模式更加灵活,区别就在于它的routing_key可以带通配符 * (匹配一个单词)和 # (匹配0个或多个单词),每个单词以点号分隔,但注意,routing_key的总大小不能超过255个字节。
如果一个message同时匹配了多个queue中的routing_key,那这几个queue都会收到这个message,如果一个message同时匹配了一个queue中的多个routing_key,那这个queue也只会接收一次这条message,如果一个message没有匹配上任何routing_key,那么这个message将被丢弃。
如果routing_key定义为 # (就只有这一个通配符),那么这个queue将接收所有message,就像exchange类型为fanout的发布订阅模式一样,如果routing_key两个通配符都没有使用,那么这个queue将会接收固定routing_key的message,就像exchange类型为direct的路由模式一样。
producer端:从代码上讲,producer的代码与路由模式没什么区别,只不过在routing_key的传值上需要注意与想要发送到的queue进行匹配。

生产者生产消息投递到topic交换机中,上面是完全匹配路由键,而主题模式是模糊匹配,只要有合适规则的路由就会投递给消费者。
生产者:
import pika # 链接mq需要pika模块
import sysuser_info = pika.PlainCredentials('tester','test1234')
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.1.117',5672,'/',user_info))
channel = connection.channel()channel.exchange_declare(exchange='topic-logs',exchange_type='topic', # 类型为directdurable = True,)routing_key = sys.argv[1] if len(sys.argv)>1 else 'anonymous.info' # 定义消息严重级别message = ''.join(sys.argv[2:]) or 'Hello World!'channel.basic_publish(exchange='topic-logs',routing_key=routing_key, # 把消息发送到一组队列,这一组队列按routing_key分组body=message)
print(" [x] Sent %r:%r" % (routing_key,message))
connection.close()消费者:
import pika
import sysuser_info = pika.PlainCredentials('tester','test1234')
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.1.117',5672,'/',user_info))
channel = connection.channel()channel.exchange_declare(exchange='topic-logs',exchange_type='topic',durable=True,)# 创建临时队列,队列名传空字符或不设置,将创建唯一的临时queue,consumer关闭后,队列自动删除
result = channel.queue_declare('',exclusive=True)
queue_name = result.method.queuebinding_keys = sys.argv[1:] # 可以输入多个级别
if not binding_keys:sys.stderr.write("Usage: %s [binding_key]...\n" % sys.argv[0])sys.exit(1)for binding_key in binding_keys: # 循环绑定routing_keychannel.queue_bind(exchange='topic-logs',queue=queue_name,routing_key=binding_key,)def callback(ch, method, properties, body):print("[x] Received %r" % body)# 如果basic_consume中auto_ack为False,则这里要手动进行应答channel.basic_ack(delivery_tag=method.delivery_tag) # 手动应答print('手动应答队列中消息')channel.basic_consume(queue=queue_name, # 接收指定queue的消息on_message_callback=callback, # 设置收到消息的回调函数auto_ack=False) # 指定为True,表示消息接收到后自动给消息发送方回复确认,已收到消息,False表示不自动确认,需要在callback中手工确认print('[*] Waiting for message. To exit press CTRL+C')
channel.start_consuming()运行结果:可以使用*,#等进行过滤

6. RPC模式
RPC远程调用(Remote Procedure Call)模式其实就是使用消息队列处理请求的一种方式,通常请求接收到后会立即执行且多个请求是并行执行的,如果一次性来了太多请求,达到了服务端处理请求的瓶颈就会影响性能,但是如果使用消息队列的方式,最大的一点好处是可以不用立即处理请求,而是将请求放入消息队列,服务端只需要根据自己的状态从消息队列中获取并处理请求即可。
producer端:RPC模式的客户端(producer)需要使用到两个queue,一个用于发送request消息(此queue通常在服务端声明和创建),一个用于接收response消息。另外需要特别注意的一点是,需要为每个request消息指定一个uuid(correlation_id属性,类似请求id),用于识别返回的response消息是否属于对应的request。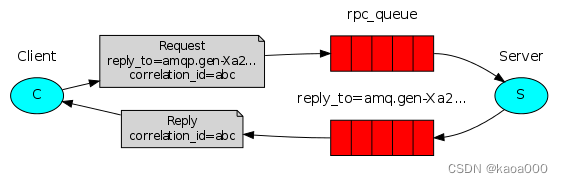
客户端client:
import pika
import uuidclass FibonacciRpcClient(object):def __init__(self):self.connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.1.117', 5672, '/', pika.PlainCredentials('tester','test1234')))self.channel = self.connection.channel()result = self.channel.queue_declare('',exclusive=True) # 随机生成一个临时的唯一的queueself.callback_queue = result.method.queue # 这个临时唯一queue的名字# 注意,这个临时queue不是用于发送消息的,是用于接收消息的,这个queue名字,# 会传给server端,server端用这个Queue发送消息,也就是客户端指定了服务器端要使用的queueself.channel.basic_consume(on_message_callback=self.on_response,auto_ack=False,queue=self.callback_queue,) # 这是客户端发送完请求后,接收服务器端返回消息的配置,注意queue就是上面生成的临时queuedef on_response(self,ch,method,props,body):if self.corr_id == props.correlation_id:self.response = bodych.basic_ack(delivery_tag=method.delivery_tag)print("手动应答成功")def call(self,n):self.response = Noneself.corr_id = str(uuid.uuid4())self.channel.basic_publish(exchange='',routing_key='rpc_queue',properties=pika.BasicProperties(reply_to=self.callback_queue,correlation_id=self.corr_id,# 这个参数是用来标识本次请求,如果客户端发送多个请求,每个请求有不同的uuid,以此进行区分,类似cookie),body=str(n))while self.response is None:self.connection.process_data_events() # 以非阻塞的方式去检查有没有新消息,return int(self.response)fibonacci_rpc = FibonacciRpcClient()print("[x] Requesting fib(7)")
response = fibonacci_rpc.call(7)
print("[.] Got %r" % response)服务器端server:
import pikauser_info = pika.PlainCredentials('tester','test1234')
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.1.117',5672,'/',user_info,))channel = connection.channel()channel.queue_declare(queue='rpc_queue')def fib(n):if n == 0:return 0elif n == 1:return 1else:return fib(n-1) + fib(n-2)def on_request(ch,method,props,body):n = int(body)print("[.] fib(%s)" % n)response = fib(n)ch.basic_publish(exchange='',routing_key=props.reply_to,properties=pika.BasicProperties(correlation_id=props.correlation_id),body=str(response))ch.basic_ack(delivery_tag=method.delivery_tag)channel.basic_qos(prefetch_count=1)
channel.basic_consume(on_message_callback=on_request, queue='rpc_queue')print("[x] Awaiting RPC requests")
channel.start_consuming()要注意的是,作为RPC模式,client端一开始是消息发送方,即发布者,server端是消费者,当server端收到消息后,经过处理,要将处理结果再返回给client端,此时,server端就是发布者,client端就是消费者,并且server端发布时使用的queue是client端指定的,即client端生成的临时queue。
correlation_id主要是为了在异步处理中,客户端发送多个请求,服务器端返回的响应因处理速度不同,可能响应的顺序也不同,为了区分不同的请求的响应,使用此标志。
相关文章:
Python入门自学进阶-Web框架——39、redis、rabbitmq、git——2
RabbitMQ的exchange,即交换机有不同的类型: 1.direct Exchange(直接交换机) 匹配路由键,只有完全匹配消息才会被转发 2.Fanout Excange(扇出交换机) 将消息发送至所有的队列 3.Topic Exchange(主题交换机) 将路由按模…...
了解IL汇编跳转语句
il代码, .assembly extern mscorlib {}.assembly Test{.ver 1:0:1:0}.module test.exe.method static void main() cil managed{.maxstack 5.entrypointldstr "Enter First Number"call void [mscorlib]System.Console::WriteLine (string)call string …...
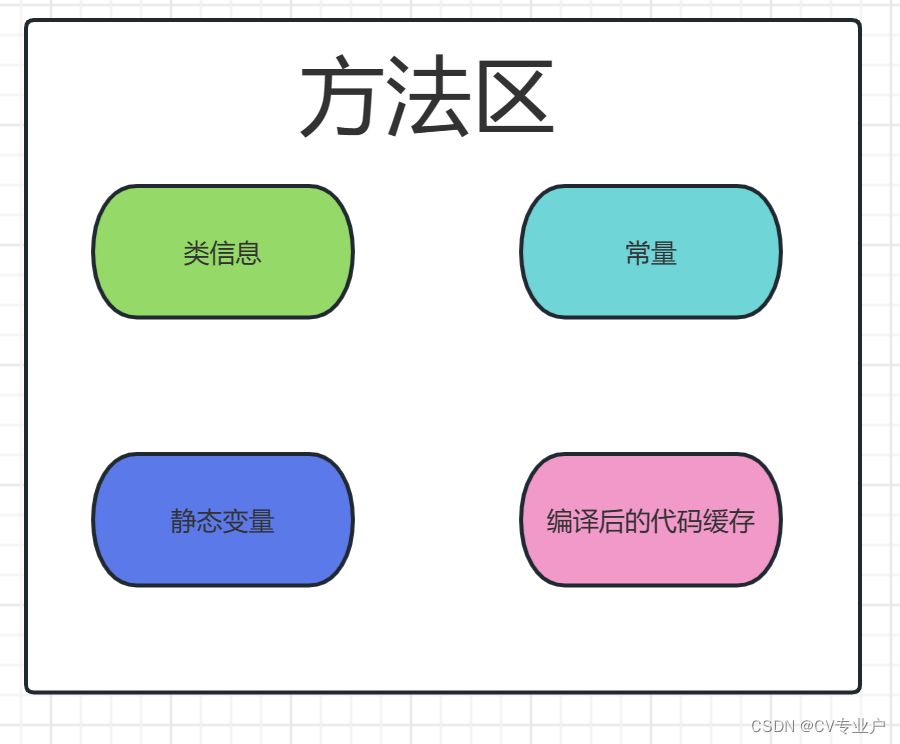
JVM运行时五大数据区域详解
前言: java虚拟机再执行Java程序的时候把它所拥有的内存区域划分了若干个数据区域。这些区域有着不同的功能,各司其职。这些区域不但功能不同,创建、销毁时间也不同。有些区域为线程私有,如:每个线程都有自己的程序计数…...

Vuex 使用教程
Vuex 各子模块的内部结构及作用 这是vuex的内部代码结构,所有的子模块都是一样的 state:存放数据状态; action:指派 mutation ; mutation:修改state里面的状态; getter:侧重于对数据…...

springboot启动you will need to add ‘org.slf4j‘ to prefer-application-packages异常解决
摘自个人印象笔记2020-09-12内容:[https://app.yinxiang.com/fx/6c3c7d9d-d5e5-4e5b-b2a1-33d6f29c48a7](https://app.yinxiang.com/fx/6c3c7d9d-d5e5-4e5b-b2a1-33d6f29c48a7) 启动异常: Caused by: java.lang.IllegalArgumentException: LoggerFactory…...

云原生核心原则和特征
云原生(Cloud Native)是一种软件开发和部署方法论,旨在充分利用云计算的优势来构建和管理应用程序。云原生应用程序是专为在云环境中设计、构建和运行的应用程序。 以下是云原生的一些核心原则和特征: 微服务架构:云…...
【ElasticSearch入门】
目录 1.ElasticSearch的简介 2.用数据库实现搜素的功能 3.ES的核心概念 3.1 NRT(Near Realtime)近实时 3.2 cluster集群,ES是一个分布式的系统 3.3 Node节点,就是集群中的一台服务器 3.4 index 索引(索引库) 3.5 type类型 3.6 doc…...

SQL | 注释
2-注释 2.1-单行注释 select prod_name -- 这是一条行内注释 from products; 使用两个连字符(-- ) 放在行内,两个连字符后的内容即为注释内容。 # 这是一条注释 select prod_name from products; 这种注释方式可能有些数据库不支持,所以使用前应该…...

oi知识表+NOIP提高组算法及算法思想总结
算法及算法思想总结 │ By lib │ ├暴力 ├模拟 ├递归及递推:数位统计类 ├构造 ▼├排序算法 │ ├冒泡排序 │ ├选择排序 │ ├计数排序 │ ├基数排序 │ ├插入排序 │ ├归并排序 │ ├快速排序 │…...
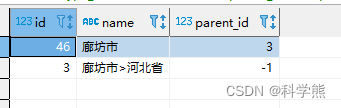
【mysql】实现递归查询
mysql实现递归查询的方法:首先创建表,并初始化数据;然后向下递归,利用find_in_set()函数和group_concat()函数、with recursive实现递归查询。 mysql实现递归查询的方法: 1、创建表 DROP TABLE IF EXISTS t_areainf…...

JUC并发编程之原子类
目录 1. 什么是原子操作 1.1 原子类的作用 1.2 原子类的常见操作 原子类的使用注意事项 并发编程是现代计算机应用中不可或缺的一部分,而在并发编程中,处理共享资源的并发访问是一个重要的问题。为了避免多线程访问共享资源时出现竞态条件࿰…...

测试设计中隐藏的边界有哪些?
概述:边界值分析是测试设计一个稳定的部分,但是对黑盒测试人员来讲有时候边界并不是那么明显。这些不明显的边界被称作隐藏的边界。本文提供几个隐藏的边界的例子,还有一些以让隐藏边界显露来设计测试计划的要点方法。 使用边界值分析和等价…...

领航优配:暑期旅游市场热度持续攀升,相关公司业绩有望持续释放
到发稿,海看股份涨停,中广天择、探路者、众信旅行等涨幅居前。 8月8日,在线旅行板块震动上涨,到发稿,海看股份涨停,中广天择、探路者、众信旅行等涨幅居前。 今年以来,国内旅行商场逐渐恢复。文…...

基于 CentOS 7 构建 LVS-DR 集群 及 配置nginx负载均衡
一、构建LVS-DR集群 1、主机规划 Node01:PC Node02:LVS Node03、Node04:Webserver 2、部署环境 2.1 在Node02上配置 2.1.1 安装ipvsadm管理软件按 [rootlocalhost ~]# yum install -y ipvsadm 2.1.2 配置VIP [rootlocalhost ~]# if…...

docker搭建在线Markdown服务器
1.安装docker 2.编写docker-compose.yml version: "3" services:database:image: postgres:11.6-alpineenvironment:- POSTGRES_USERcodimd- POSTGRES_PASSWORDchange_password- POSTGRES_DBcodimdvolumes:- "database-data:/var/lib/postgresql/data"re…...

打靶练习:WestWild 1.1(一个简单但不失优雅的Ubuntu靶机)
主机发现和nmap信息收集 //主机发现 sudo nmap -sn 192.168.226.0/24 //扫描整个C段//端口扫描//初步扫描 sudo nmap -sT --min-rate 10000 -p- 192.168.226.131 -oA nmapscan/ports //用TCP的三次握手,以速率10000扫描1-65535端口,扫描结果以全格式…...
【2.3】Java微服务:sentinel服务哨兵
✅作者简介:大家好,我是 Meteors., 向往着更加简洁高效的代码写法与编程方式,持续分享Java技术内容。 🍎个人主页:Meteors.的博客 💞当前专栏:Java微服务 ✨特色专栏: 知识分享 &…...

【C++】开源:abseil-cpp基础组件库配置使用
😏★,:.☆( ̄▽ ̄)/$:.★ 😏 这篇文章主要介绍abseil-cpp基础组件库配置使用。 无专精则不能成,无涉猎则不能通。——梁启超 欢迎来到我的博客,一起学习,共同进步。 喜欢的朋友可以关注一下&#…...
【GPT-3 】创建能写博客的AI工具
一、说明 如何使用OpenAI API,GPT-3和Python创建AI博客写作工具。 在本教程中,我们将从 OpenAI API 中断的地方继续,并创建我们自己的 AI 版权工具,我们可以使用它使用 GPT-3 人工智能 (AI) API 创建独特的…...
[保研/考研机试] KY35 最简真分数 北京大学复试上机题 C++实现
题目链接: 最简真分数https://www.nowcoder.com/share/jump/437195121691719749588 描述 给出n个正整数,任取两个数分别作为分子和分母组成最简真分数,编程求共有几个这样的组合。 输入描述: 每组包含n(n<600&…...
)
用OpenMMLab全家桶做项目?先收好这份mmcv/mmdet版本兼容性自查清单(附最新PyTorch 2.0+适配指南)
OpenMMLab全栈开发实战:版本兼容性矩阵与工程化环境管理指南 在计算机视觉项目的实际开发中,环境配置往往成为第一个"拦路虎"。我曾参与过一个跨团队协作的工业质检项目,团队中三位工程师分别使用不同版本的mmdetection开发模块&a…...

CSS如何规范化侧边栏的样式实现_基于BEM结构拆分侧边栏模块
侧边栏BEM命名推荐统一用sidebar为block名,如sidebar、sidebar__item;动画用max-height或transform替代height过渡;active状态需严格使用sidebar__item--active;隐藏/唤出宜用transformfixed避免重排。侧边栏容器的BEM命名是否必须…...
)
别再用FR4不行了!实测12G-SDI在普通PCB板材上的完整走线指南(附阻抗计算与AntiPad避坑)
突破认知:用普通FR4板材实现12G-SDI高速信号完整性的实战指南 在硬件设计领域,关于高速信号传输一直存在一个根深蒂固的误解——只有昂贵的专用高频板材才能胜任12G-SDI这类高速信号的需求。这种观念导致许多预算有限的中小企业、独立开发者和学生创客望…...

别再死记MobileNetV1结构了!用PyTorch手把手复现一遍,彻底搞懂Depthwise Separable Conv
从零实现MobileNetV1:用PyTorch拆解深度可分离卷积的奥秘 当你第一次听说MobileNetV1时,可能被它的轻量化特性所吸引——这个能在移动设备上流畅运行的神经网络,参数数量只有VGG16的1/32。但真正理解它的核心设计Depthwise Separable Convolu…...

Claude-Code-Workflow:基于AI的智能研发工作流引擎实战解析
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫“Claude-Code-Workflow”。光看名字,你可能会觉得这又是一个普通的代码生成工具,或者是一个简单的Claude API封装。但当我真正深入进去,把它的源码、文档和社区讨论…...
的底层原理与选择策略)
别再只加-fPIC了!深入理解静态库、共享库与位置无关代码(PIC)的底层原理与选择策略
深入解析静态库与共享库中的位置无关代码机制 在C/C开发中,我们经常遇到需要将静态库链接到共享库的情况,这时编译器可能会抛出"dangerous relocation: unsupported relocation"的错误。大多数开发者会条件反射地加上-fPIC选项重新编译&#x…...

Voxtral-4B-TTS-2603开源可部署:Mistral官方权重+社区Web封装完整溯源
Voxtral-4B-TTS-2603开源可部署:Mistral官方权重社区Web封装完整溯源 1. 平台介绍 Voxtral-4B-TTS-2603是Mistral发布的开源权重语音合成(TTS)模型,专为语音Agent等生产场景设计。这个模型支持多语言文本转语音功能,并提供多种预设音色选择…...

深度解析Blender glTF 2.0插件:3大核心模块架构设计与性能优化实战指南
深度解析Blender glTF 2.0插件:3大核心模块架构设计与性能优化实战指南 【免费下载链接】glTF-Blender-IO Blender glTF 2.0 importer and exporter 项目地址: https://gitcode.com/gh_mirrors/gl/glTF-Blender-IO Blender glTF 2.0插件是连接Blender与glTF …...

DeepTutor:基于智能体原生架构的个性化AI学习伴侣部署与实战指南
1. 项目概述:一个“原生智能体”驱动的个性化学习伴侣如果你正在寻找一个不仅仅是聊天机器人,而是一个能真正理解你的学习进度、拥有独立“人格”并能主动规划学习路径的AI导师,那么DeepTutor的出现,可能标志着一个新阶段的开始。…...

AI编程游戏化:Claude-Code-Game-Studios项目解析与实践
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫“Donchitos/Claude-Code-Game-Studios”。光看名字,你可能会觉得这是个游戏开发工作室的代码库,或者是什么大型游戏引擎。但点进去仔细研究后,我发现它的核心玩法其…...