大数据第二阶段测试
大数据第二阶段测试
一、简答题
参考答案一
-上游和下游可以实现解耦,上游不需要关心下游的处理逻辑,下游不需要关心上游的数据源。
-上游和下游可以并行处理,提高整体处理效率。
-可以实现数据的分发和负载均衡,提高系统的稳定性和可扩展性。
参考答案二
- 可以很方便地将多个数据源的数据汇聚到一起,然后发送到下游的存储/计算系统中。
- 可以很容易地在 Flume agent 之间传递 event,实现更复杂的拓扑结构。
- 可以通过 Source、Channel、Sink 的灵活组合,实现不同的采集需求。
- 可以在 Flume 层面对数据流进行过滤、聚合等处理,减少下游系统的压力。
参考答案三
1. 可靠性:使用上下游架构可以确保数据完整性和可靠性。当下游发生故障时,上游存储器不会被耗尽,可以保证数据不会丢失。
2. 灵活性:使用上下游架构可以轻松地添加或移除采集器,而不必担心数据传输的安全性和一致性。
3. 提高性能:使用上下游架构可以更好地利用网络资源,同时可以对数据进行负载平衡,从而提高整个数据采集系统的性能。
4. 易于管理:使用上下游架构可以将数据采集器和数据存储器进行分离,从而轻松地对系统进行管理和维护。
参考答案一
-内存 Channel:适合数据量较小、实时性要求高的场景。
-文件 Channel:适合数据量较大、可靠性要求高的场景。
-JDBC Channel:适合将数据实时写入数据库的场景。
-MemoryMapped Channel:适合数据量大且需要持久化的场景。
参考答案二
- 存储容量和可扩展性
- 性能,包括吞吐量和事件写入/读取延迟
- 可靠性
- 持久化需求
- 多 Agent 情况下是否支持事务
参考答案三
常用的Channel有两种,一种是Memory Channel,另一种是File Channel
Channel type 选择memory时Channel的性能最好,但是如果Flume进程意外挂掉可能会丢失数据。可以通过修改channel的参数,比如capacity,transactioncapacity等参数。 type选择file时Channel的容错性更好,但是性能上会比memory channel差。 使用file Channel时dataDirs配置多个不同盘下的目录可以提高性能。
参考答案一
-使用可靠性 Channel,如文件 Channel,保证数据在传输过程中的可靠性。
-设置合适的事务超时时间,防止数据传输过程中出现长时间的等待。
-配置合适的重试策略,如设置重试次数和重试间隔时间。
参考答案二
- 使用时间戳插件TimestampInterceptor在Flume事件头中插入时间戳
- 使用Taildir Source读取新增文件,根据文件名判断时间
- 使用自定义Interceptor根据内容解析时间戳
参考答案三
不用系统本地的时间戳,用我们数据产生时本身的时间戳**,在拦截器里面把数据自己的时间戳设置到头部,然后在flume的conf拉取文件中,定义拦截器,然后把useLocalTimeStamp改成false
参考答案一
-使用 DataX 的增量采集方式,如配置增量字段和增量查询条件。
-根据增量字段的值,判断是否需要采集该条数据。
-保存增量字段的最大值,下次采集时使用该值作为查询条件。
参考答案二
- 利用参数 incrementalRead 开启增量读模式
- 在 增量检测阶段,根据用户配置的 增量键,扫描目的表与增量状态表,过滤已存在的数据
- 在 增量同步阶段,使用增量键将源端新的数据同步到目的端
- 更新 增量状态表,保存增量键的状态
参考答案三
在JSON文件使用where条件过滤
参考答案一
-使用 Hive 的 JSON SerDe,将 JSON 数据直接存储到 Hive 表中。
-使用 Spark 的 DataFrame API,将 JSON 数据转换为 DataFrame,并存储到 Hive 或其他数据源中。
-使用 Flume 将 JSON 数据采集到 Hadoop/HDFS 中,然后使用 Hive 或 Spark 进行处理和存储。
参考答案二
- 直接Load: 使用JsonSerDe解析Json,直接Load到Hive表中。
- 预处理:使用Spark、MapReduce 等进行Json解析,处理为结构化数据后再Load到hive。
- 使用Hive JSON函数:使用get_json_object、json_tuple等函数解析json。
参考答案三
1. Spark解析:通过Spark程序解析Json文件再写入Hive表中
2. getJsonObject():将整个Json看作一个字段先存入Hive表中,再通过Hive自带的函数(getJsonObject)解析再写入另一张表
3. JsonSerDe:通过Hive兼容的Json解析器直接将Json数据解析到一张表中。hive3.x自带JsonSerDe
参考答案一
-行转列:使用 Hive 的 Lateral View 和集合函数,如 explode、posexplode,将一行数据拆分为多行,每行包含一列。
-列转行:使用 Hive 的 Unpivot 操作,将多列数据合并为一列,可以使用 Lateral View 和 UDTF 函数实现。
参考答案二
- 列转行:使用 lateral view explode() 函数。
- 行转列:使用 pivot 进行,需要指定转列的字段、输出列名、聚合函数。
参考答案三
行转列:侧视图+explode函数
列转行:COLLECT_SET() 和 COLLECT_LIST() 可以将多行数据转成一行数据,区别就是 LIST 的元素可重复而 SET 的元素是去重的。
参考答案一
-在创建表时,可以通过指定字段的数据类型来设置数据格式,如 INT、STRING、DECIMAL、TIMESTAMP 等。
-可以使用 Hive 的 SerDe(序列化和反序列化)来自定义数据格式,如 CSV、JSON、Avro 等。
参考答案二
- 创建表时使用STORED AS指定存储格式,如STORED AS ORC
- 创建表时使用ROW FORMAT 指定行格式,如ROW FORMAT DELIMITED
- 创建分区时使用FILEFORMAT指定分区文件格式
参考答案三
直接在字段后面添加数据类型就行了
比如:name string
参考答案一
-内部表:数据存储在 Hive 的默认位置,删除表时会同时删除数据。适合管理不频繁的临时数据。
-外部表:数据存储在外部目录中,删除表时不会删除数据。适合对外部数据进行管理和查询。
参考答案二
- 临时表用内部表,数据会在删除表时删除。
- 业务事实表等需要hive管理生命周期的使用内部表。
- 对外统一提供数据访问的表使用外部表,数据存放在外部位置。
- 需作为其他系统数据源的using外部表,prevent drop data
参考答案三
内部表的创建,不用加external关键字,创建成功后在hdfs上面能够看见,如果删除内部表,连同他的原始文件也会被删除,危,所以一般在自己的库中使用内部表,或者在小组内使用。即创建 Hive内部表时,数据将真实存在于表所在的目录内,删除内部表时,物理数据和文件也一并删除。默认创建的是内部表。
外部表的创建需要加上external关键字,创建之后在hdfs上面看不见,其管理仅仅只是在逻辑和语法意义上的,即新建表仅仅是指向一个外部目录而已。同样,删除时也并不物理删除外部目录,而仅仅是将引用和定义删除。
参考答案一
-数据抽取:从数据源中读取数据,可以使用 Spark 的 DataFrame、RDD、Streaming 等 API。
-数据清洗:对数据进行过滤、转换、去重等操作,可以使用 Spark 的转换操作和自定义函数。
-数据转换:将数据格式转换为目标格式,如将结构化数据转换为 JSON 或 Parquet 格式。
-数据加载:将处理后的数据写入到目标数据源,如 Hive、HDFS、关系型数据库等。
参考答案二
- 数据抽取:从数据源读取数据,封装为DataFrame
- 数据转换:对DataFrame进行各种转换,清洗、补全、修改数据
- 数据加载:将处理后的数据写入目标存储系统
实现方式是通过Spark SQL,Dataframe API进行业务转换,最后写入存储系统。
参考答案三
1. 清洗过滤
- 去除json数据体中的废弃字段(前端开发人员在埋点设计方案变更后遗留的无用字段)
- 过滤掉json格式不正确的
- 过滤掉日志中缺少关键字段(deviceid/properties/eventid/sessionid 缺任何一个都不行)的记录!
- 过滤掉日志中不符合时间段的记录
- 对于web端日志,过滤爬虫请求数据
2. 数据规范处理
- 数据口径统一
- Boolean字段,在数据中有使用1/0/-1标识的,也有使用true/false表示的,统一为Y/N/U
- 字符串类型字段,在数据中有 空串 ,有 null值 ,统一为null值
- 日期格式统一, 2020/9/2 2020-9-2 2020-09-02 20200902 都统一成 yyyy-MM-dd
- 小数类型,统一成decimal
- 字符串,统一成string
- 时间戳,统一成bigint
3. Session分割
-判断前后时间戳的间隔是否超过了三十分钟,超过了之后就需要进行分割,重新赋予sessionid
4. 地理位置转换
-用的是GeoHash,把经纬度信息转成字符串编码
-还有一种是IP地址转换
5. ID_MAPPING(全局用户标识生成)
6. 标记新老访客
-设置一个全局guid,每天记录最大的全局id,第二天新增的guid就是新用户
参考答案一
-使用 OLAP(联机分析处理)工具,如 Kylin、ClickHouse、Presto 等,可以对大规模数据进行多维分析。
-使用数据仓库和数据集市,通过事实表和维度表的关联,使用 SQL 进行多维分析查询。
-使用数据可视化工具,如 Tableau、Power BI 等,将数据以可视化的方式展示出来,进行多维分析。
参考答案二
- OLAP多维立方:使用OLAP工具构建多维Cube,进行多维分析。
- Hive多维分析:在Hive中建立Fact和Dimension表,使用Cube、Rollup、Grouping Sets实现多维聚合。
- Spark SQL pivoting: 使用grouping sets、rollup、cube实现多维聚合。
参考答案三
略
参考答案一
-Map 算子是对 RDD/DataFrame/Dataset 中的每个元素进行单独的操作,可以对每个元素应用一个函数。
-MapPartition 算子是对 RDD/DataFrame/Dataset 中的每个分区进行操作,可以对每个分区应用一个函数。
-MapPartition 比 Map 算子效率更高,因为它减少了函数调用的开销。但是需要注意,MapPartition 算子可能会导致内存溢出,因为它处理的是整个分区的数据。
参考答案二
- Map 对RDD每个分区的数据应用转换函数。MapPartition对每个分区作为整体应用转换函数。
- Map 针对RDD的每个元素进行转换,函数输入是单个元素。MapPartition以分区为单位,输入是迭代器。
- Map任务数和RDD分区数相同。MapPartition任务数等于RDD分区数。
参考答案三
两者的主要区别是作用对象不一样:map的输入变换函数是应用于RDD中每个元素,而mapPartitions的输入函数是应用于每个分区
参考答案一
-漏斗分析模型用于分析用户在一个流程中的转化情况,可以发现流程中的瓶颈和优化点。
-计算思路:统计每个步骤的用户数量,然后计算每个步骤之间的转化率。可以使用 SQL 或编程语言实现。
参考答案二
漏斗分析可以衡量用户从进入网站特定页面到达成交的转换率,识别转化路径中的堵点。
其计算思路是:
- 根据事件时间顺序,识别用户访问的各个页面
- 计算相邻页面之间的用户流失率
- 按照流失率高低找出转化路径的漏斗
参考答案三
漏斗分析模型可以通过把具体的业务线中的步骤量化,计算每个步骤的转化率,找到这条业务线的薄弱环节,精准打击,提高用户的转化率。
参考答案一
数仓一般分为原始层、清洗层、集市层和报表层。
-原始层:存储原始数据,不做任何处理。
-清洗层:对原始数据进行清洗、过滤、去重等操作。
-集市层:对清洗后的数据进行加工和整合,构建维度模型。
-报表层:根据业务需求进行数据汇总、统计和可视化。
参考答案二
- ODS层:操作数据存储层,用于存放原始数据。
- DWD层:数据仓库存放层,对ODS层数据进行清洗、去重复、校验等处理。
- DWS层:数据集市层,对DWD层数据进行汇总、加工生成分析数据集。
- ADS层:应用数据存储层,存放生成报表及模型分析所需的数据集。
参考答案三
-原始数据层ODS:这一层主要是原始数据,尽量让数据保持他本来的样子。这里的数据可以是离线和准实时接入的数据,包括行为数据和业务数据
-数据明细层DWD:对ODS层的数据进行一定的清洗和主题汇总
-数据服务层DWS:对应各个业务主题的宽表
-数据应用层ADS:是对应各个不同业务的具体的表
参考答案一
-可以使用 Hive 的变量(Variable)来传递参数,如使用 ${var_name} 的方式引用变量。
-在执行 HiveSQL 之前,可以使用 SET var_name=value 的方式设置变量的值。
参考答案二
- 使用变量 substitute 参数
- 使用 --hivevar 定义参数,SQL中使用 ${hivevar:name}引用
- 设置参数配置文件,SQL中使用 ${hivedvar:name} 引用
参考答案三
--hivevar | 传参数 ,专门提供给用户自定义变量 |
|---|---|
--hiveconf | ①传参数;②覆盖 hive-site.xml中配置的hive全局变量 |
在hivesql中使用${}取值
参考答案一
-DolphinScheduler 会根据任务的重试策略进行重试,直到达到最大重试次数。
-如果任务重试失败,则会将任务状态设置为失败,触发后续的失败处理流程。
-失败处理流程可以根据配置进行自定义,如发送通知、触发报警、记录日志等。
参考答案二
- 发送钉钉、邮件通知相关负责人
- 检查日志,分析失败原因,如资源不足、业务数据问题等
- 重试任务执行或修复失败原因后手动触发重试
- 如果非系统问题,需要更新任务方案,重新发布上线
参考答案三
1. 确认任务调度失败的原因,并进行问题排查。这可能包括检查日志文件、查看错误信息等。
2. 解决问题并重新启动任务调度程序。这可能需要修复代码、更新配置文件或重新安装软件包。
3. 确认任务调度是否成功重新启动,并观察系统处理各个阶段的时间。经过一段时间后,如果任务仍然失败,则需要考虑其他解决方案。
4. 如果以上步骤无法解决问题,则需要评估当前的系统配置和资源,并确定是否需要调整或增加系统资源。这可以包括增加内存、增加处理器数量或添加额外的存储空间。
5. 最后,应该考虑优化程序,并确保它能够应对未来可能出现的任何问题。这可能包括调整代码、重新设计任务调度过程或升级硬件设备。
参考答案一
-使用合适的索引,可以加快查询的速度。
-对查询语句进行优化,如使用合适的连接方式、减少子查询的使用、优化 WHERE 条件等。
-对数据表进行分区、分桶,可以提高查询性能。
-使用合适的缓存机制,如使用 Redis 缓存查询结果。
-使用合适的硬件设备,如使用 SSD 替代传统的机械硬盘。
参考答案二
- 使用explain分析执行计划,针对问题进行优化
- 加入索引,提高查询速度
- SQL改写,简化查询逻辑
- 参数调优,合理配置内存、并发等参数
- 使用分区、分桶改善数据存取
- 使用视频、序列等提升查询性能
参考答案三
1. 避免使用select * 进行全表查询
2. 用union all代替union,排重的过程需要遍历、排序和比较,它更耗时,更消耗cpu资源。
3. 小表驱动大表
4. 批量操作,避免去频繁的连接数据库
5. 多用limit进行数据展示限制
6. 连表时尽量避免产生笛卡尔积
7. 在进行某些聚合操作的时候,可以提前对数据进行筛选
二、编码题
1.(1)求每个月的每个省份的每个店铺销售额(单个订单的销售额= Quantity *Unit_price)
SELECT SUBSTRING(Order_datetime, 1, 6) AS Month, s.Province_name, s.Store_name, SUM(o.Quantity * o.Unit_price) AS Sales
FROM Order_detail o
JOIN Dim_store s ON o.Store_id = s.Store_id
GROUP BY Month, s.Province_name, s.Store_name;
(2)求每个月每个产品的销售额及其在当月销售额的占比
WITH MonthlySales AS (SELECT SUBSTRING(Order_datetime, 1, 6) AS Month, SUM(Quantity * Unit_price) AS TotalSales FROM Order_detail GROUP BY Month), ProductSales AS (SELECT SUBSTRING(Order_datetime, 1, 6) AS Month, Product_name, SUM(Quantity * Unit_price) AS Sales FROM Order_detail GROUP BY Month, Product_name)SELECT p.Month, p.Product_name, p.Sales, p.Sales/m.TotalSales AS SalesRatio
FROM ProductSales p
JOIN MonthlySales m ON p.Month = m.Month;
(3)求每个月的销售额及其环比(销售额环比=(本销售额-上月销售额)/(上月销售额))
WITH MonthlySales AS (SELECT SUBSTRING(Order_datetime, 1, 6) AS Month, SUM(Quantity * Unit_price) AS Sales FROM Order_detail GROUP BY Month)SELECT Month, Sales, (Sales - LAG(Sales) OVER (ORDER BY Month))/LAG(Sales) OVER (ORDER BY Month) AS MoM
FROM MonthlySales;
(4)求每个月比较其上个月的新增用户量及其留存率(新增用户定义:上月未产生购买行为且本月产生了购买行为的用户 留存用户:定义为上月产生过购买行为的人,留存率=本月留存用户数量/上月产生过购买用户数量)
WITH UserPurchases AS (SELECT User_id, SUBSTRING(Order_datetime, 1, 6) AS Month FROM Order_detail GROUP BY User_id, Month), NewUsers AS (SELECT Month, COUNT(User_id) AS NewUsers FROM (SELECT User_id, Month, LAG(Month) OVER (PARTITION BY User_id ORDER BY Month) AS PrevMonth FROM UserPurchases) WHERE PrevMonth IS NULL OR Month - PrevMonth > 1 GROUP BY Month), RetainedUsers AS (SELECT Month, COUNT(User_id) AS RetainedUsers FROM (SELECT User_id, Month, LAG(Month) OVER (PARTITION BY User_id ORDER BY Month) AS PrevMonth FROM UserPurchases) WHERE Month - PrevMonth = 1 GROUP BY Month)SELECT n.Month, n.NewUsers, r.RetainedUsers, r.RetainedUsers/LAG(r.RetainedUsers) OVER (ORDER BY n.Month) AS RetentionRate
FROM NewUsers n
JOIN RetainedUsers r ON n.Month = r.Month;
SELECT name, SUM(CASE `subject` WHEN 'Chinese' THEN score ELSE 0 END) as 'Chinese', SUM(CASE `subject` WHEN 'Math' THEN score ELSE 0 END) as 'Math', SUM(CASE `subject` WHEN 'English' THEN score ELSE 0 END) as 'English', SUM(score) as 'Score'
FROM score
GROUP BY name
3.建表语句:
CREATE TABLE student (sid INT PRIMARY KEY,sname VARCHAR(50),sage INT,ssex VARCHAR(10)
);CREATE TABLE teacher (tid INT PRIMARY KEY,tname VARCHAR(50)
);
CREATE TABLE sc (sid INT,cid INT,score INT,PRIMARY KEY (sid, cid),FOREIGN KEY (sid) REFERENCES student(sid),FOREIGN KEY (cid) REFERENCES course(cid)
);CREATE TABLE course (cid INT PRIMARY KEY,cname VARCHAR(50),tid INT,FOREIGN KEY (tid) REFERENCES teacher(tid)
);
(1)查询平均成绩大于 60 分的同学的学号和平均成绩、总成绩
select sid, avg(score), sum(score)
from sc
group by sid
having avg(score) > 60;
(2)查询所有课程的选课学生数、平均成绩。
SELECT cid, COUNT(DISTINCT sid),AVG(score)
FROM sc
GROUP BY cid;
(3)查询同时学过“张三”,“李四”二位老师所教课的同学的学号,姓名
select s.sid,s.sname
from student sjoin sc on s.sid = sc.sidjoin course on sc.cid = course.cidjoin teacher t on course.tid = t.tid
where t.tname in ('张三', '李四');
(4)统计每个学生平均成绩的各个分段的人数:[100-85],[85-70],[70-60],[0-60]
SELECT a.cid,b.cname,sum(CASE WHEN a.score < 60 THEN 1 ELSE 0 END) '[0-60]',sum(CASE WHEN a.score >= 60 AND a.score < 70 THEN 1 ELSE 0 END) '[61-70]',sum(CASE WHEN a.score >= 70 AND a.score < 85 THEN 1 ELSE 0 END) '[71-85]',sum(CASE WHEN a.score >= 85 THEN 1 ELSE 0 END) '[86-100]'
FROM sc AS aJOIN course AS b ON a.cid = b.cid
GROUP BY a.cid;
该查询语句使用JOIN操作将学生表(student)、成绩表(sc)和课程表(course)连接起来,
然后计算每个学生的平均成绩,并将平均成绩分为四个分段,并统计每个分段的人数。
最后,使用GROUP BY子句按照学生号(sid)和学生姓名(sname)对结果进行分组。
sum(CASE WHEN a.score >= 60 AND a.score < 70 THEN 1 ELSE 0 END) ‘[61-70]’,
解释:它首先判断成绩是否在[60, 70)区间内,如果是,则返回1,否则返回0。然后,使用SUM函数将所有符合条件的学生的值相加,得到这个区间内学生的数量。最后,使用AS关键字将这个数量的列命名为’[61-70]'。
相关文章:

大数据第二阶段测试
大数据第二阶段测试 一、简答题 Flume 采集使用上下游的好处是什么? 参考答案一 -上游和下游可以实现解耦,上游不需要关心下游的处理逻辑,下游不需要关心上游的数据源。 -上游和下游可以并行处理,提高整体处理效率。 -可以实现…...
06 为什么需要多线程;多线程的优缺点;程序 进程 线程之间的关系;进程和线程之间的区别
为什么需要多线程 CPU、内存、IO之间的性能差异巨大多核心CPU的发展线程的本质是增加一个可以执行代码工人 多线程的优点 多个执行流,并行执行。(多个工人,干不一样的活) 多线程的缺点 上下文切换慢,切换上下文典型值…...

datax-web报错收集
在查看datax时发现日志出现了如上错误,因为项目是部署在本地linux虚拟机上的,使用的是nat网络地址转换,不知道为什么虚拟机的端口号发生了变化,导致数据库根本连接不进去,更新linux虚拟机的ip地址就好...
YOLO相关原理(文件结构、视频检测等)
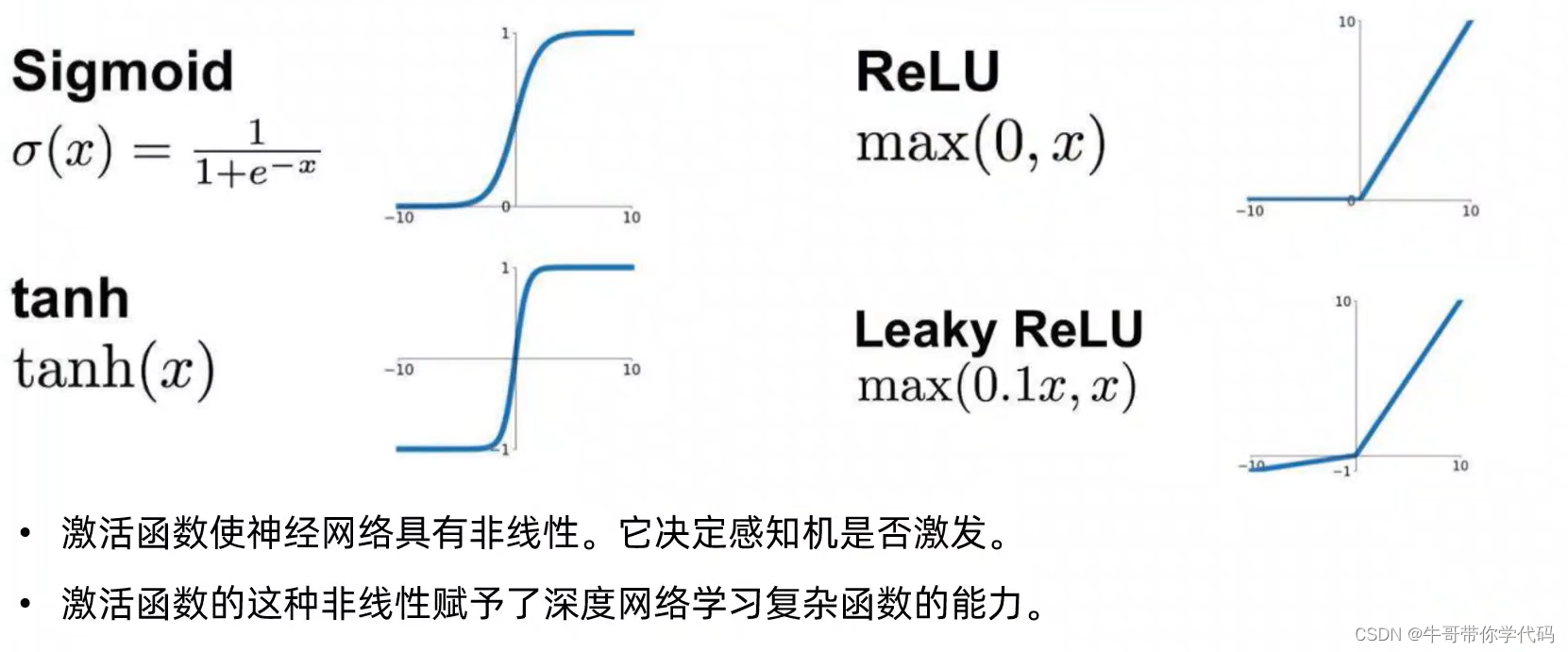
超参数进化(hyperparameter evolution) 超参数进化是一种使用了genetic algorithm(GA)遗传算法进行超参数优化的一种方法。 YOLOv5的文件结构 images文件夹内的文件和labels中的文件存在一一对应关系 激活函数:非线性处理单元 activation f…...

深入解析Spring Boot的核心特性与示例代码
系列文章目录 文章目录 系列文章目录前言一、自动配置(Auto-Configuration)二、起步依赖(Starter Dependencies)三、命令行界面(CLI)四、微服务支持五、内嵌Web服务器六、配置文件管理七、简化的日志配置八、健康检查与监控九、注解驱动开发十、外部化配置总结前言 Spri…...

什么是Java中的观察者模式?
Java中的观察者模式是一种设计模式,它允许一个对象在状态发生改变时通知它的所有观察者。这种模式在许多情况下都非常有用,例如在用户界面中,当用户与界面交互时,可能需要通知其他对象。 下面是一个简单的Java代码示例࿰…...

无涯教程-Perl - endhostent函数
描述 此函数告诉系统您不再希望使用gethostent从hosts文件读取条目。 语法 以下是此函数的简单语法- endhostent返回值 此函数不返回任何值。 例 以下是显示其基本用法的示例代码- #!/usr/bin/perlwhile( ($name, $aliases, $addrtype, $length, addrs)gethostent() ) …...

Vue2使用easyplayer
说一下easyplayer在vue2中的使用,vue3中没测试,估计应该差不多,大家可自行验证。 安装: pnpm i easydarwin/easyplayer 组件封装 习惯性将其封装为单独的组件 <template><div class"EasyPlayer"><e…...
Map映射学习
一、Map的遍历 创建Map集合 Map<String, Integer> map new HashMap<>();添加元素 map.put("java", 99);map.put("c", 88);map.put("c", 93);map.put("python", 96);map.put("Go", 88); 遍历方法: …...

【每日一题Day292】LC1572矩阵对角线元素的和 模拟
矩阵对角线元素的和【LC1572】](https://leetcode.cn/problems/matrix-diagonal-sum/) 思路 简单模拟,主对角线的元素横纵坐标相等,副对角线的元素横纵坐标相加为n-1,注意避免重复计算 实现 class Solution {public int diagonalSum(int[][]…...
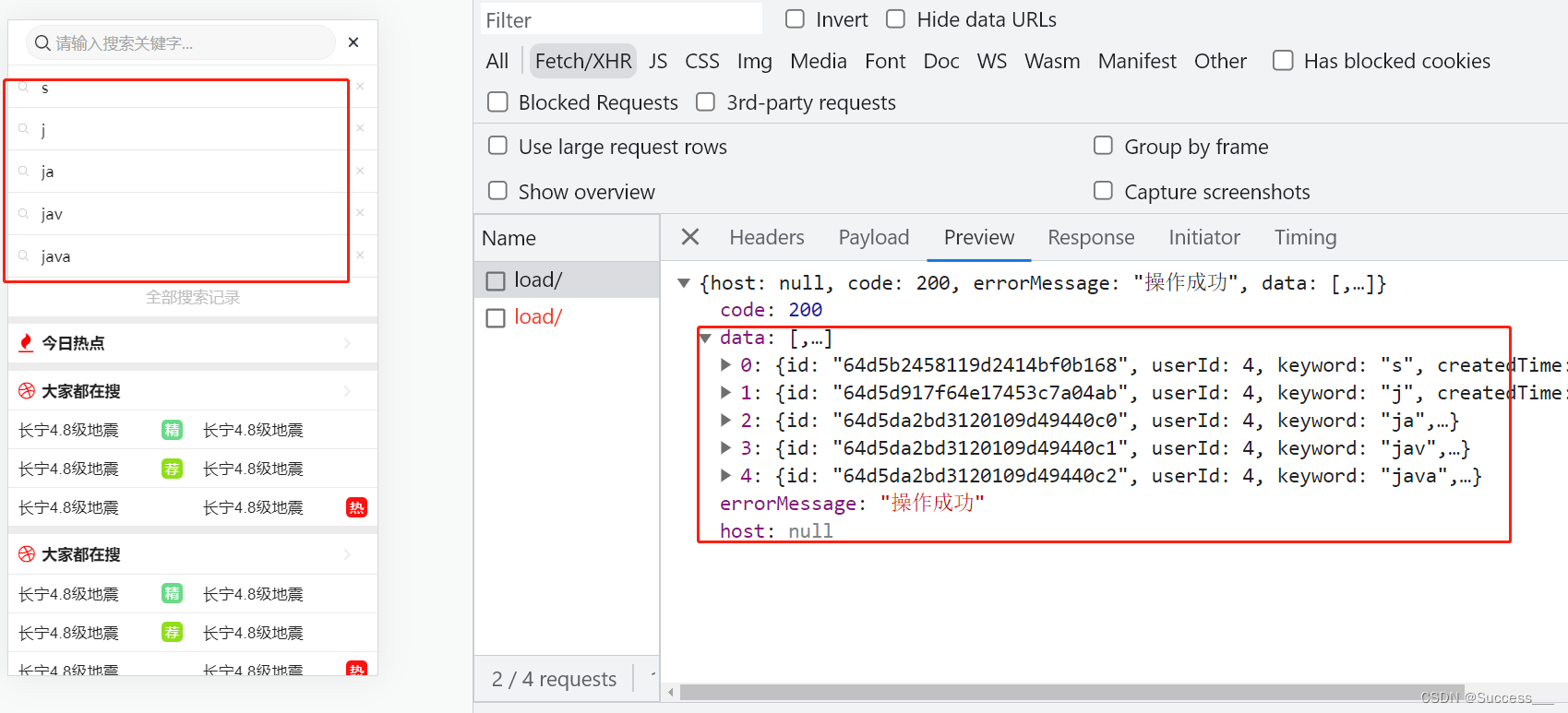
Mongodb:业务应用(2)
需求: 1、获取保存到mongodb库中的搜索记录列表 2、实现删除搜索记录接口 保存搜索记录数据参考上篇Mongodb:业务应用(1)_Success___的博客-CSDN博客 获取记录列表 1、创建controller package com.heima.search.controller.v1;…...

DSO学习笔记
最近在学习DSO系列的代码,整理记录一下 DOS代码流程 TODO DSO跑kitti数据集 参考高翔大佬的LDSO中LDSO/examples/run_dso_kitti.cc,由于kitti数据集木有光度参数标定文件,其实最重要的就是相机内参文件camera.txt按照格式来就行了ÿ…...
中实现右上角及右下角数字显示】)
【Windows 常用工具系列 5 -- 如何在网页(CSDN)中实现右上角及右下角数字显示】
文章目录 网页右上角/右下角标号写法 网页右上角/右下角标号写法 在网页撰写文章时经常遇到需要平方的写法,比如书写 X 的 2次方, 可以通过下面方法完成: <sup>x</sup> : x 上移到右上角;<sub>x</sub> : x 下移到右下角。 实…...

sql注入--报错注入
常用的简单测试语句和注释符号说明 sql语句的注释符号,是sq注入语句的关键点:常用 # 和 -- 1、# 和 --(有个空格)表示注释,可以使它们后面的语句不被执行。在url中,如果是get请求也就是我们在浏览器地址栏…...

Nginx常用功能
Nginx 介绍 Nginx 是开源、高性能、高可靠的 Web 和反向代理服务器,而且支持热部署,几乎可以做到 7 * 24 小时不间断运行,即使运行几个月也不需要重新启动,还能在不间断服务的情况下对软件版本进行热更新。性能是 Nginx 最重要的…...

【Express.js】express-validator
express-validator express.js 集成 express-validator进行数据校验 在最初的时候,对于请求的数据校验,我们是自定义一个中间件,然后在里面通过最原生的方式检验。在本节,我们将尝试用一种更优雅的方式进行数据校验。 准备工作…...
沁恒ch32V208处理器开发(三)GPIO控制
目录 GPIO功能概述 CH32V2x 微控制器的GPIO 口可以配置成多种输入或输出模式,内置可关闭的上拉或下拉电阻,可以配置成推挽或开漏功能。GPIO 口还可以复用成其他功能。端口的每个引脚都可以配置成以下的多种模式之一: 1 浮空输入 2 上拉输入…...

Jenkins 中 shell 脚本执行失败却不自行退出
Jenkins 中 执行 shell 脚本时,有时候 shell 执行失败了,或者判断结果是错误的,但是 Jenkins 执行完成后确提示成功 success 。 此时,可以通过条件判断来解决这个问题,让 Jenkins 强制退出并提示执行失败 failed 。 …...

2021年12月 C/C++(一级)真题解析#中国电子学会#全国青少年软件编程等级考试
第1题:输出整数部分 输入一个双精度浮点数f, 输出其整数部分。 时间限制:1000 内存限制:65536 输入 一个双精度浮点数f(0 < f < 100000000)。 输出 一个整数,表示浮点数的整数部分。 样例输入 3.8889 样例输出 3 下面是一个使用C语言编写的输出双精度浮点数整数部分…...
)
别再让Electron应用开机自启弹窗烦你了!一个环境变量判断搞定(附Windows/Mac/Linux全平台代码)
优雅解决Electron应用开机自启弹窗问题的全平台方案 每次开机时那个突兀的命令行提示框"To run a local app..."是否让你和用户都感到困扰?作为Electron开发者,我们常常忽略开发环境与生产环境的差异配置,导致用户体验出现裂痕。本…...

不是世界太乱,而是咱们的心缺了一套“防守准绳”
《斯多葛式人生管理罗盘》 发刊词 —— (0/24) 那天深夜快十二点了,我正站在阳台上给君子兰浇水。 手机突然震了一下。我瞄了一眼,是个老同事发来的。这哥们儿以前跟我在一个省中心项目上并肩熬过几个通宵,典型的“能扛事”的硬汉。他刚从干了十二年的大厂出来,整个部门被…...

ADS瞬态仿真实操:从数据手册参数到共射放大器波形,一步步验证你的设计
ADS瞬态仿真实战:从2N2222参数到共射放大器波形验证 在硬件设计领域,理论计算与仿真验证如同车之两轮,缺一不可。当我们翻开一本经典的模拟电路教材,共射放大器总是作为第一个实战案例出现——它简单到足以用一支三极管搭建&…...

USB隔离
USB设备与主机之间常常因为接地电位差产生地环路电流,轻则导致数据传输不稳定、丢包误码,重则可能损坏昂贵的测试仪器。为了解决这个问题,设计了一款基于数字隔离技术的4路USB隔离电路,实现了信号与电源的双重隔离,同时…...

GPTeam多智能体框架:构建AI协作团队的技术实践
1. 项目概述:当AI学会“组队”与“协作”最近在AI应用开发圈里,一个名为“GPTeam”的开源项目引起了我的注意。它不是一个单一的AI模型,而是一个模拟人类团队协作的“多智能体”框架。简单来说,GPTeam让你可以创建多个拥有不同角色…...

QtCreator+CMake+Ninja:跨平台C++开发环境高效搭建指南
1. 为什么选择QtCreatorCMakeNinja组合? 如果你正在开发跨平台的C应用程序,那么QtCreatorCMakeNinja这个组合绝对值得一试。作为一个长期使用这套工具链的开发者,我发现它完美解决了传统构建方式中的几个痛点:编译速度慢、配置复杂…...

基于前缀树的 Harness 快速指令匹配
万亿级指令毫秒级命中:基于前缀树的Harness自动化测试指令匹配系统从原理到落地全指南 关键词 前缀树(Trie)、Harness自动化平台、指令模糊匹配、DevOps性能优化、参数自动提取、多租户规则隔离、毫秒级响应 摘要 在云原生DevOps普及的今天,Harness作为主流的自动化交付…...

2026年电脑录屏软件推荐:6款神器总有一款适合你
每次想录个教程、游戏高光时刻,或是线上会议,却找不到好用的录屏工具?别急!这里整理了6款超实用的电脑录屏软件,从系统自带工具到专业软件,总有一款适合你。Xbox Game Bar:游戏玩家的首选如果你…...

3分钟掌握跨平台资源下载神器:res-downloader完整使用指南
3分钟掌握跨平台资源下载神器:res-downloader完整使用指南 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader 还在为…...

成都有做多智能体开发的公司吗?大厂平台和本地服务商怎么选
如果你最近在看多智能体(Multi-Agent)项目,会发现市场上讲这件事的公司很多,放到现在的市场里,大致可以分成两类。一类是全国性的大厂平台。 比如阿里云百炼、百度智能云千帆、华为云 AgentArts、腾讯云 ADP࿰…...