【变形金刚01】attention和transformer所有信息

图1.来源:Arseny Togulev在Unsplash上的照片
一、说明
这是一篇 长文 ,几乎讨论了人们需要了解的有关注意力机制的所有信息,包括自我注意、查询、键、值、多头注意力、屏蔽多头注意力和转换器,包括有关 BERT 和 GPT 的一些细节。因此,我将本文分为两部分。在本文中,我将介绍所有注意力块,在下一个故事中,我将深入探讨变压器网络架构。
二、RNN背景知识提要
- RNN 面临的挑战以及转换器模型如何帮助克服这些挑战
- 注意力机制
2.1 自我注意
2.2 查询、键和值
2.3 注意力的神经网络表示
2.4 多头注意力
3. 变形金刚(下篇继续)
2.1 介绍
注意力机制于2014年首次用于计算机视觉,试图理解神经网络在进行预测时正在查看的内容。这是尝试理解卷积神经网络(CNN)输出的第一步。2015年,注意力首先用于对齐机器翻译中的自然语言处理(NLP)。最后,在2017年,注意力机制被用于Transformer网络中的语言建模。此后,变压器已经超越了递归神经网络(RNN)的预测精度,成为NLP任务的最新技术。
2.2 . RNN 的挑战以及转换器模型如何帮助克服这些挑战
1.1 RNN 问题 1 — 遇到长期依赖问题。RNN 不适用于长文本文档。
变压器解决方案 — 变压器网络几乎只使用注意力块。注意力有助于在序列的任何部分之间建立连接,因此长期依赖不再是问题。对于变压器,长期依赖性与任何其他短程依赖性具有相同的可能性。
1.2. RNN 问题 2 — 遭受梯度消失和梯度爆炸。
变压器解决方案 — 几乎没有梯度消失或爆炸问题。在变压器网络中,整个序列是同时训练的,并且在此基础上仅添加几层。因此,梯度消失或爆炸很少成为问题。
1.3. RNN 问题 3 — RNN 需要更大的训练步骤才能达到局部/全局最小值。RNN可以可视化为一个非常深的展开网络。网络的大小取决于序列的长度。这产生了许多参数,并且这些参数中的大多数是相互关联的。因此,优化需要更长的训练时间和很多步骤。
变压器解决方案 — 比 RNN 需要更少的训练步骤。
1.4. RNN 问题 4 — RNN 不允许并行计算。GPU 有助于实现并行计算。但是RNN作为序列模型工作,也就是说,网络中的所有计算都是按顺序进行的,不能并行化。
变压器解决方案 — 变压器网络中没有重复出现,允许并行计算。因此,每一步都可以并行进行计算。
三. 注意力机制
3.1 自我注意
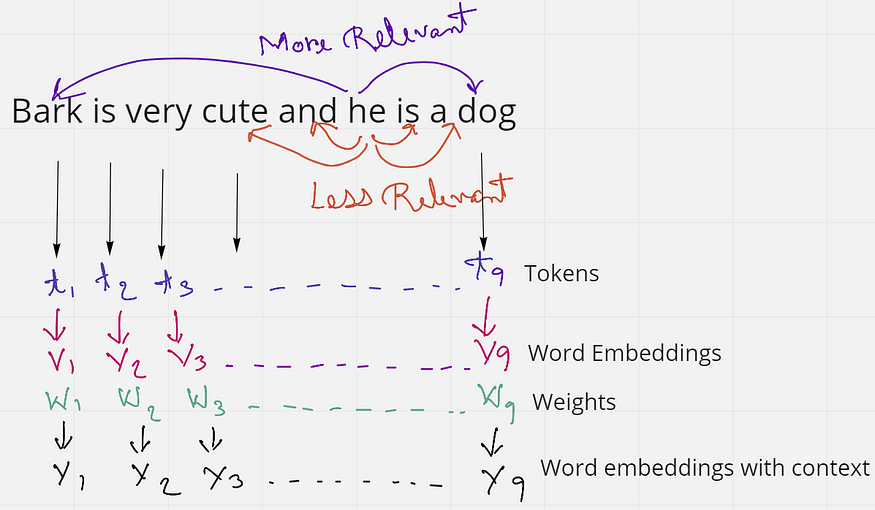
图2.解释自我注意的示例(来源:作者创建的图片)
考虑一下这句话——“吠叫很可爱,他是一只狗”。这句话有9个单词或标记。如果我们只考虑句子中的“他”这个词,我们会发现“和”是“是两个非常接近它的词。但这些词并没有给“他”这个词任何上下文。相反,“吠叫”和“狗”这两个词与句子中的“他”更相关。由此,我们了解到接近并不总是相关的,但上下文在句子中更相关。
当这个句子被馈送到计算机时,它将每个单词视为一个标记t,并且每个标记都有一个单词嵌入V。但是这些词嵌入没有上下文。因此,我们的想法是应用某种权重或相似性来获得最终的单词嵌入Y,它比初始嵌入V具有更多的上下文。
在嵌入空间中,相似的单词看起来更靠近或具有相似的嵌入。比如“国王”这个词会更与“女王”和“皇室”这个词相关,而不是与“斑马”这个词相关。同样,“斑马”与“马”和“条纹”的关系比与“情感”一词的关系更大。要了解有关嵌入空间的更多信息,请访问Andrew Ng(NLP和单词嵌入)的视频。
因此,直觉上,如果“国王”一词出现在句子的开头,而“女王”一词出现在句子的末尾,它们应该相互提供更好的上下文。我们使用这个想法来找到权重向量 W,通过将单词嵌入相乘(点积)以获得更多的上下文。所以,在句子中,Bark非常可爱,他是一只狗,而不是按原样使用单词嵌入,我们将每个单词的嵌入相乘。图 3 应该能更好地说明这一点。

图3.查找权重并获得最终嵌入(来源:作者创建的图像)
如图 3 所示,我们首先通过将第一个单词的初始嵌入乘以(点积)与句子中所有其他单词的嵌入来找到权重。这些权重(W11 到 W19)也归一化为总和为 1。接下来,将这些权重乘以句子中所有单词的初始嵌入。
W11 V1 + W12 V2 + ....W19 V9 = Y1
W11 到 W19 都是具有第一个单词 V1 上下文的权重。因此,当我们将这些权重乘以每个单词时,我们实际上是在将所有其他单词重新加权到第一个单词。因此,从某种意义上说,“吠叫”这个词现在更倾向于“狗”和“可爱”这两个词,而不是紧随其后的词。这在某种程度上提供了一些背景。
对所有单词重复此操作,以便每个单词从句子中的其他单词中获得一些上下文。
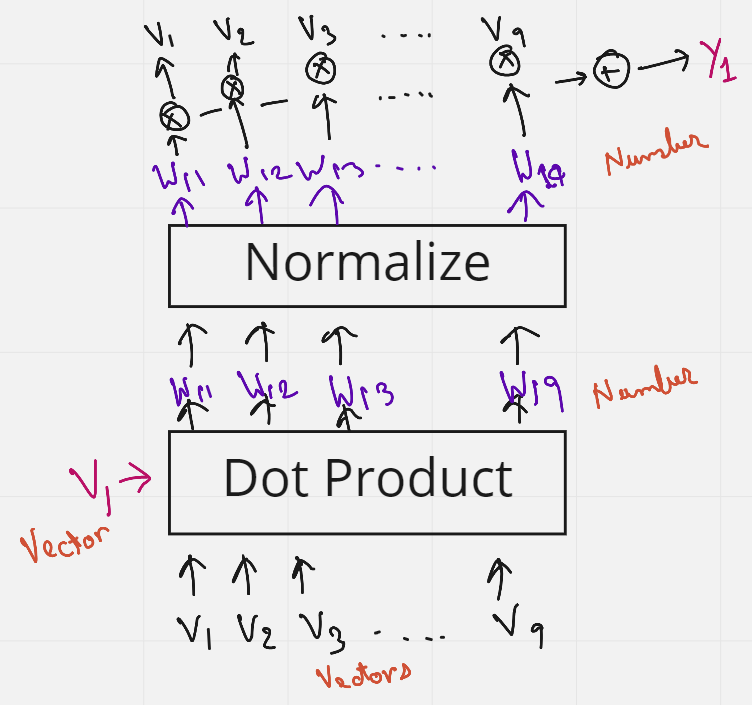
图4.上述步骤的图形表示(来源:作者创建的图像)
图4使用图形图更好地理解了获得Y1的上述步骤。
有趣的是,没有训练权重,单词的顺序或接近度彼此没有影响。此外,该过程不依赖于句子的长度,也就是说,句子中更多或更少的单词无关紧要。这种为句子中的单词添加一些上下文的方法称为自我注意。
3.2 查询、键和值
自我注意的问题在于没有任何东西被训练。但也许如果我们添加一些可训练的参数,网络就可以学习一些模式,从而提供更好的上下文。此可训练参数可以是训练其值的矩阵。因此,引入了查询、键和值的概念。
让我们再考虑一下前面的一句话——“吠叫很可爱,他是一只狗”。在自我注意的图 4 中,我们看到初始词嵌入 (V) 使用了 3 次。1st作为句子中第一个单词嵌入和所有其他单词(包括其自身,2nd)之间的点积以获得权重,然后再次将它们(第3次)乘以权重,以获得带有上下文的最终嵌入。这 3 个出现的 V 可以替换为三个术语查询、键和值。
假设我们想使所有单词与第一个单词 V1 相似。然后,我们将 V1 作为查询词发送。然后,这个查询词将对句子中的所有单词(V1 到 V9)做一个点积——这些就是键。因此,查询和键的组合为我们提供了权重。然后将这些权重再次与充当值的所有单词(V1 到 V9)相乘。我们有它,查询,键和值。如果您仍然有一些疑问,图 5 应该能够清除它们。
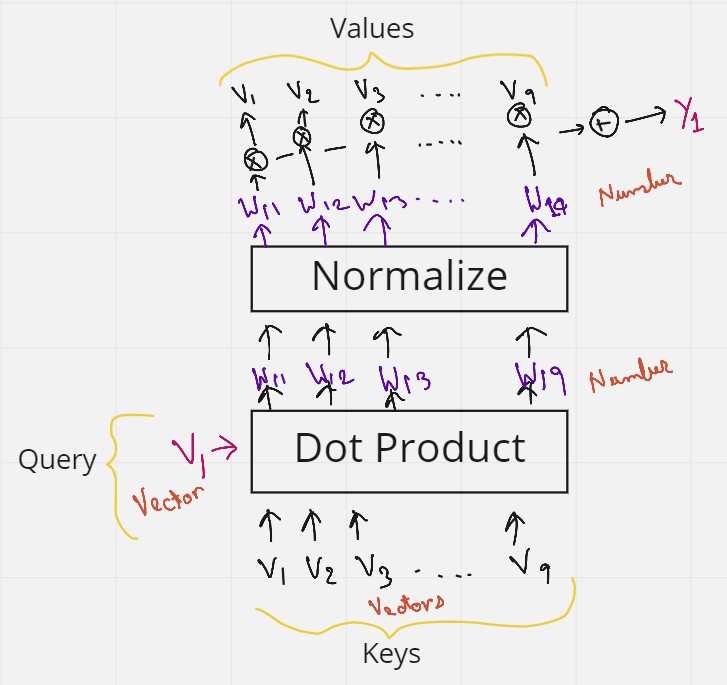
图5.表示查询、键和值(来源:作者创建的图像)
但是等等,我们还没有添加任何可以训练的矩阵。这很简单。我们知道,如果将 1 x k 形向量乘以 k x k 形矩阵,我们得到一个 1 x k 形向量作为输出。记住这一点,让我们将每个键从 V1 乘以 V10 到 V1(每个形状为 6 x k),并乘以形状为 k x k 的矩阵 Mk(键矩阵)。类似地,查询向量乘以矩阵 Mq(查询矩阵),值向量乘以值矩阵 Mv。这些矩阵 Mk、Mq 和 Mv 中的所有值现在都可以由神经网络训练,并且比仅仅使用自我注意提供更好的上下文。同样,为了更好地理解,图 <> 显示了我刚才解释的内容的图形表示。
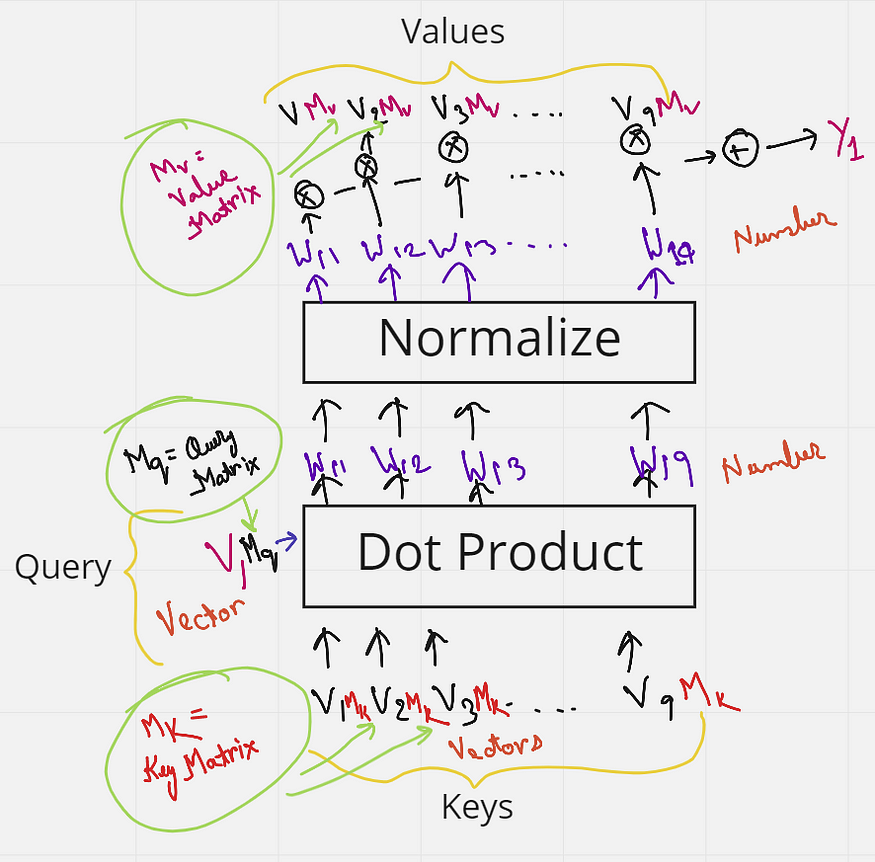
图6.键矩阵、查询矩阵和值矩阵(来源:作者创建的图像)
现在我们知道了键、查询和值的直觉,让我们看看数据库分析以及注意力背后的官方步骤和公式。
让我们通过查看数据库的示例来尝试理解注意力机制。因此,在数据库中,如果我们想根据查询 q 和键 k i 检索某个值 vi,可以执行一些操作,其中我们可以使用查询来识别对应于某个值的键。注意力可以被认为是与此数据库技术类似的过程,但以更概率的方式。下图对此进行了演示。
图 7 显示了在数据库中检索数据的步骤。假设我们将一个查询发送到数据库中,一些操作会找出数据库中哪个键与查询最相似。找到密钥后,它将发送与该密钥对应的值作为输出。在图中,该操作发现查询与键 5 最相似,因此为我们提供了值 5 作为输出。

图7.数据库中的值检索过程(来源:作者创建的图像)
注意力机制是一种模仿这种检索过程的神经架构。
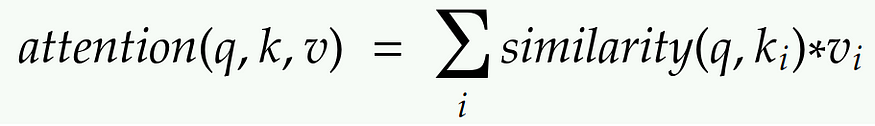
- 注意力机制测量查询 q 和每个键值 k i 之间的相似性。
- 此相似性为每个键值返回一个权重。
- 最后,它生成一个输出,该输出是我们数据库中所有值的加权组合。
从某种意义上说,数据库检索和注意力之间的唯一区别是,在数据库检索中,我们只得到一个值作为输入,但在这里我们得到一个值的加权组合。在注意力机制中,如果查询与键 1 和键 4 最相似,那么这两个键将获得最多的权重,输出将是值 1 和值 4 的组合。
图 8 显示了从查询、键和值获取最终注意力值所需的步骤。下面将详细解释每个步骤。(键值 k 是向量,相似性值 S 是标量,权重值 (softmax) 值 a 是标量,值 V 是向量)
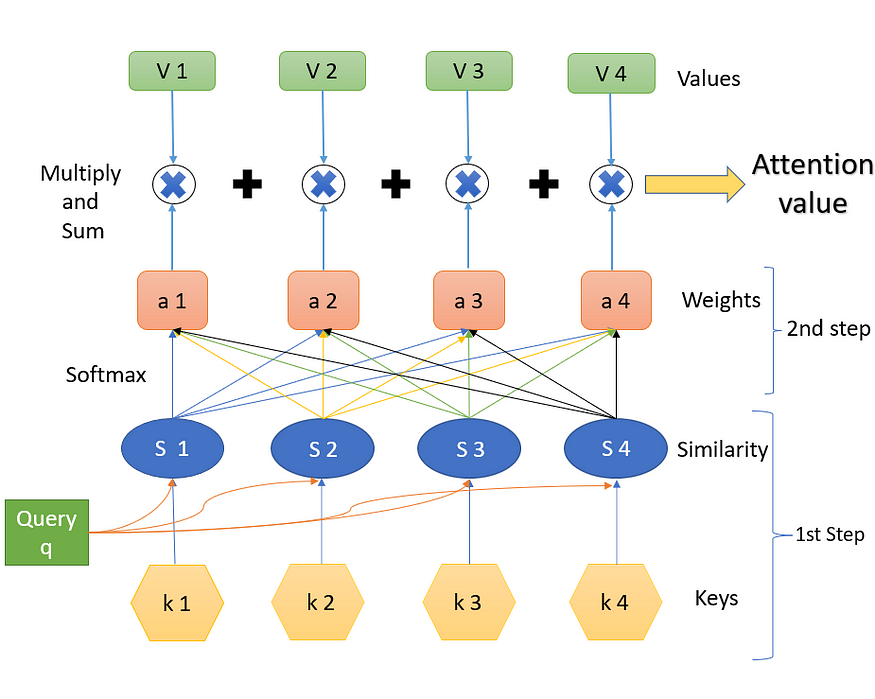
图8.获得注意力值的步骤(来源:作者创建的图像)
第 1 步。
步骤 1 包含键和查询以及相应的相似性度量。查询 q 会影响相似性。我们拥有的是查询和键,并计算相似性。相似性是查询 q 和键 k 的某些函数。查询和键都是一些嵌入向量。相似性 S 可以使用各种方法计算,如图 9 所示。

图9.计算相似性的方法(Souce:作者创建的图像)
相似性可以是查询和键的简单点积。它可以是缩放点积,其中q和k的点积除以每个键的维数d的平方根。 这是查找相似性最常用的两种技术。
通常,使用权重矩阵 W 将查询投影到新空间中,然后使用键 k 创建点积。内核方法也可以用作相似性。
第 2 步。
第 2 步是查找权重 a。这是使用“SoftMax”完成的。公式如下所示。(exp 是指数级的)
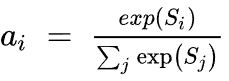
相似性像完全连接的层一样与权重相连。
第 3 步。
步骤 3 是 softmax (a) 的结果与相应值 (V) 的加权组合。a 的第一个值乘以 V 的第一个值,然后与 a 的第 1 个值与值 V 的第 2 个值的乘积相加,依此类推。我们获得的最终输出是所需的结果注意力值。
![]()
三个步骤的摘要:
W在查询 q 和键 k 的帮助下,我们获得注意值,它是值 V 的加权和/线性组合,权重来自查询和键之间的某种相似性。
3.3 注意力的神经网络表示

图 10.注意力块的神经网络表示(来源:作者创建的图像)
图 10 显示了注意力块的神经网络表示。词嵌入首先传递到一些线性层中。这些线性层没有“偏差”项,因此只不过是矩阵乘法。其中一个层表示为“键”,另一个表示为“查询”,最后一个层表示为“值”。如果在键和查询之间执行矩阵乘法,然后进行规范化,我们将得到权重。然后将这些权重乘以值并相加,得到最终的注意力向量。这个块现在可以在神经网络中使用,被称为注意力块。可以添加多个这样的注意力块以提供更多上下文。最好的部分是,我们可以获得梯度反向传播来更新注意力块(键、查询、值的权重)。
3.4 多头注意力
为了克服使用单头注意力的一些陷阱,使用了多头注意力。让我们回到那句话——“吠叫很可爱,他是一只狗”。在这里,如果我们使用“狗”这个词,从语法上我们理解“吠叫”、“可爱”和“他”应该与“狗”这个词有某种意义或相关性。这些话说,狗的名字叫树皮,是公狗,是一只可爱的狗。仅凭一种注意力机制未必能正确识别出这三个词与“狗”相关,我们可以说,这里用“狗”这个词来表示这三个词更好。这减少了一个注意力查找所有重要单词的负担,也增加了轻松找到更多相关单词的机会。
因此,让我们添加更多的线性层作为键、查询和值。这些线性层是并行训练的,并且彼此具有独立的权重。所以现在,每个值、键和查询都为我们提供了三个输出,而不是一个。这 3 个键和查询现在提供三种不同的权重。然后用矩阵乘以这三个值,得到三个倍数输出。这三个注意力块最终连接起来,给出一个最终的注意力输出。此表示如图 11 所示。
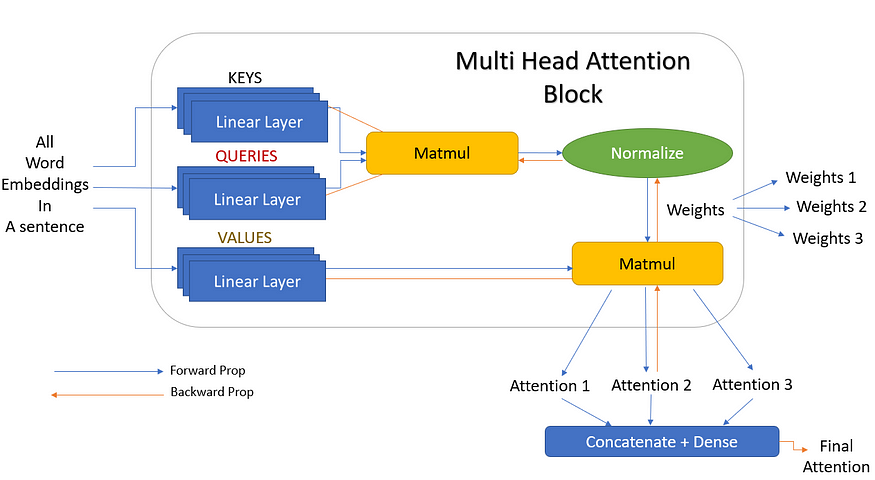
图 11.具有3个线性层的多头注意力(来源:作者创建的图像)
但 3 只是我们选择的随机数。在实际场景中,这些可以是任意数量的线性层,这些层称为头部(h)。也就是说,可以有 h 个线性层,给出 h 个注意力输出,然后将其连接在一起。这正是它被称为多头注意力(多头)的原因。图 11 的简化版本,但头部数量为 h 如图 12 所示。
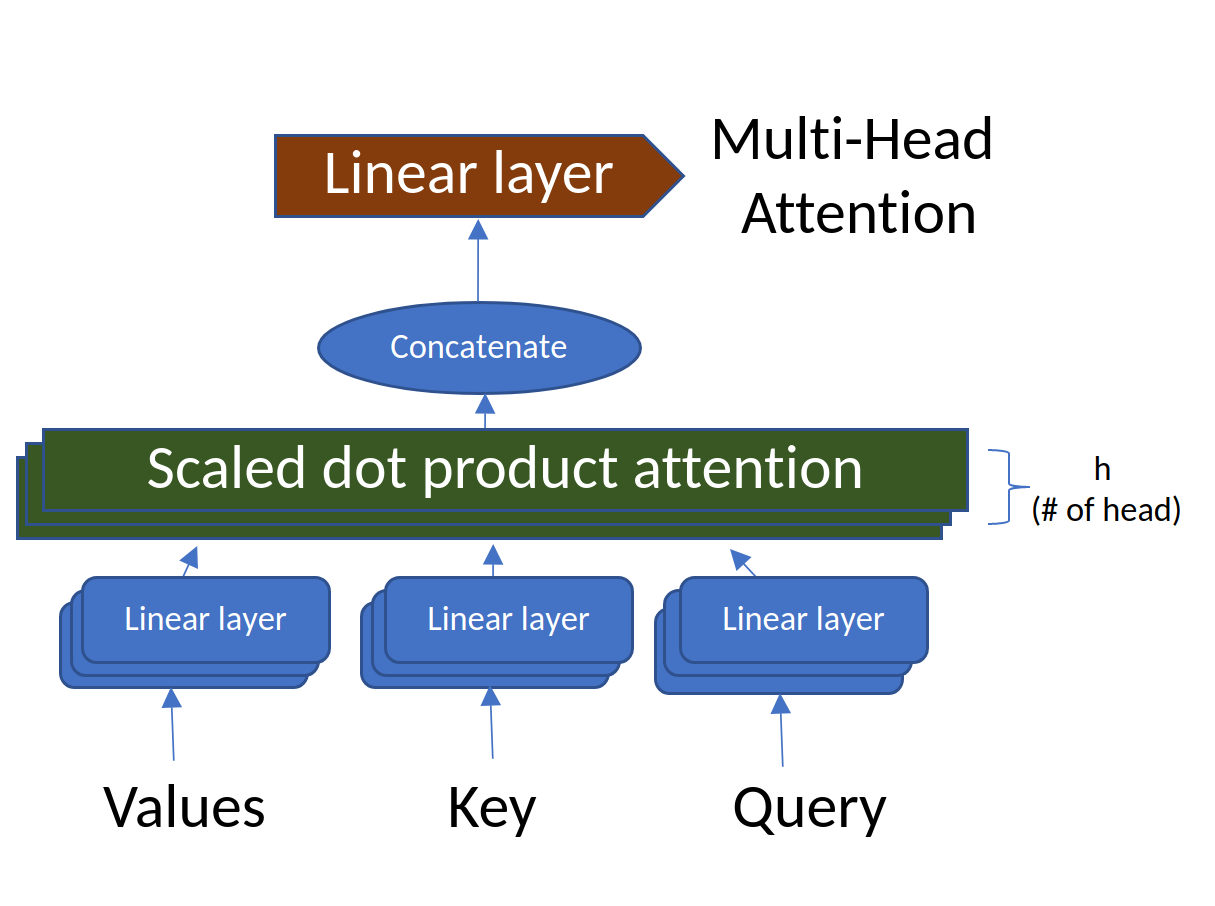
图 12.具有“h”层的多头注意力(来源:作者创建的图片)
N由于我们了解了注意力、查询、键、值和多头注意力背后的机制和思想,我们已经涵盖了变压器网络的所有重要构建块。在下一个故事中,我将讨论所有这些块如何堆叠在一起形成变压器网络,并讨论一些基于变压器的网络,例如BERT和GPT。
四、引用:
2017. 注意力就是你所需要的一切。第31届神经信息处理系统国际会议论文集(NIPS'17)。Curran Associates Inc.,Red Hook,NY,USA,6000–6010。
相关文章:
【变形金刚01】attention和transformer所有信息
图1.来源:Arseny Togulev在Unsplash上的照片 一、说明 这是一篇 长文 ,几乎讨论了人们需要了解的有关注意力机制的所有信息,包括自我注意、查询、键、值、多头注意力、屏蔽多头注意力和转换器,包括有关 BERT 和 GPT 的一些细节。因…...
面试热题(路径总和II)
给你二叉树的根节点 root 和一个整数目标和 targetSum ,找出所有 从根节点到叶子节点 路径总和等于给定目标和的路径。 叶子节点 是指没有子节点的节点。 在这里给大家提供两种方法进行思考,第一种方法是递归,第二种方式使用回溯的方式进行爆…...

测试 tensorflow 1.x 的一个demo 01
tensorflow 1.0的示例代码 demo_01.py import tensorflow as tf import os os.environ[TF_CPP_MIN_LOG_LEVEL]2def tf114_demo():a 3b 4c a bprint("a b in py ",c)a_t tf.constant(3)b_t tf.constant(4)c_t a_t b_tprint("TensorFlow add a_t b_t &…...

达蒙DM数据库使用经验
DM表/字段注释 注:dm数据库无法在建表的同时为字段名添加注释 //为表添加注释 comment on table 库名.表名 is 表注释; //为表字段添加注释 comment on column 库名.表名.列名 is 列注释;DM查询错误:无效的表或视图 1,确认表一定存在 2&am…...
Redis—集群
目录标题 主从复制第一次同步命令传播分担主服务器压力增量复制总结面试题什么是Redis主从复制Redis主从复制的原理Redis主从复制的优点Redis主从复制的缺点Redis主从复制的配置步骤Redis主从复制的同步策略主从节点是长还是短连接判断某个节点是否正常工作主从复制架构中&…...
【C语言】数据在内存中的存储详解
文章目录 一、什么是数据类型二、类型的基本归类三、 整型在内存中的存储1.原码、反码、补码2.大小端(1)什么是大小端(2)为什么会有大小端 四、浮点型在内存中的存储1. 浮点数存储规则 五、练习1.2.3.4.5.6.7. 一、什么是数据类型 我们可以把数据类型想象为一个矩形盒子&#x…...

PIC单片机配置字的设置
PIC单片机配置字的设置 PIC系列单片机,其芯片内部大都设置有一个特殊的程序存储单元,地址根据不同的单片机而定,此存储单元用来由单片机用户自由配置或定义单片机内部的一些功能电路单元的性能选项,所以被称之为系统配置字。目前PIC单片机系统配置字的方法有两种,一种是利…...
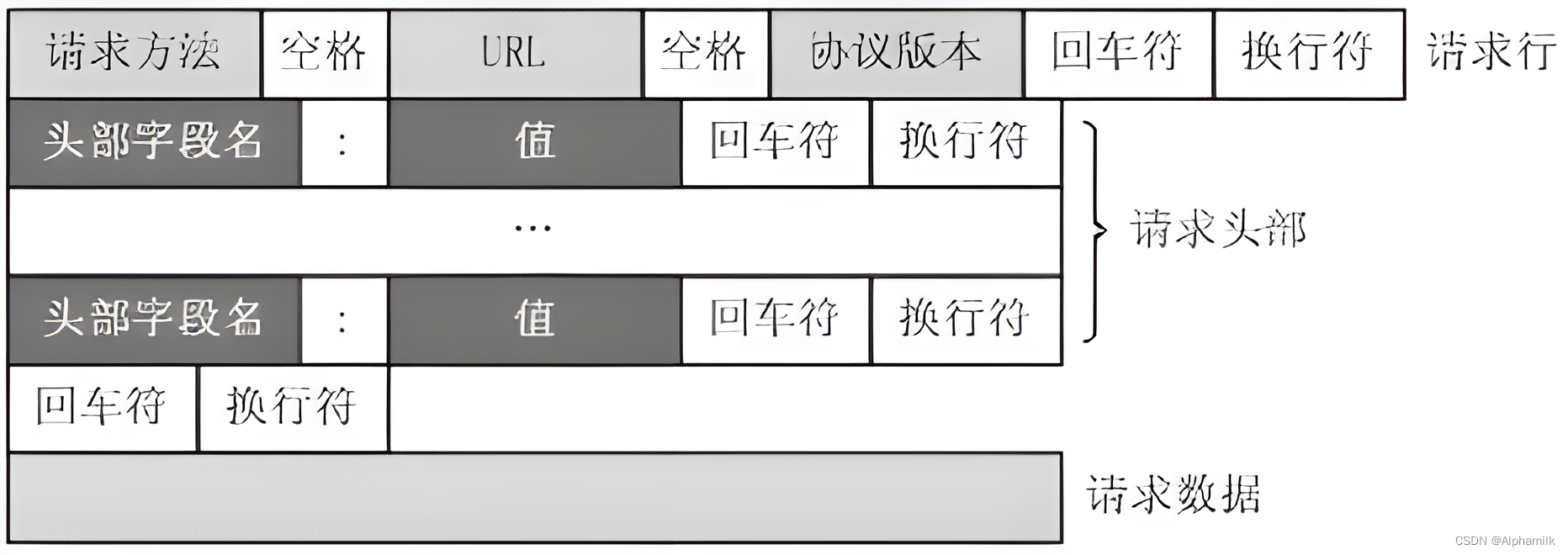
JavaWeb-Servlet服务连接器(一)
目录 1.Servlet生命周期 2.Servlet的配置 3.Servlet的常用方法 4.Servlet体系结构 5.HTTP请求报文 6.HTTP响应报文 1.Servlet生命周期 Servlet(Server Applet)是Java Servlet的简称。其主要的功能是交互式地浏览和修改数据,生成一些动态…...

新华三超融合态势感知标准版
产品概述: H3C SecCenter CSAP-XS 超融合态势感知一体机产品集合了态势感知和安全流量分析探针设备能无需复杂配置;态势感知平台具备强大的安全分析和可视化呈现功能;同时具备远程专家会诊功能,通过云端协同实现外部安全服务资源的…...
13.2-Mcal Port配置)
AutoSAR系列讲解(深入篇)13.2-Mcal Port配置
目录 一、配置界面 二、通用配置 1、ConfigVariant 2、PortSafety 3、PortGeneral 三、Port配置集合...
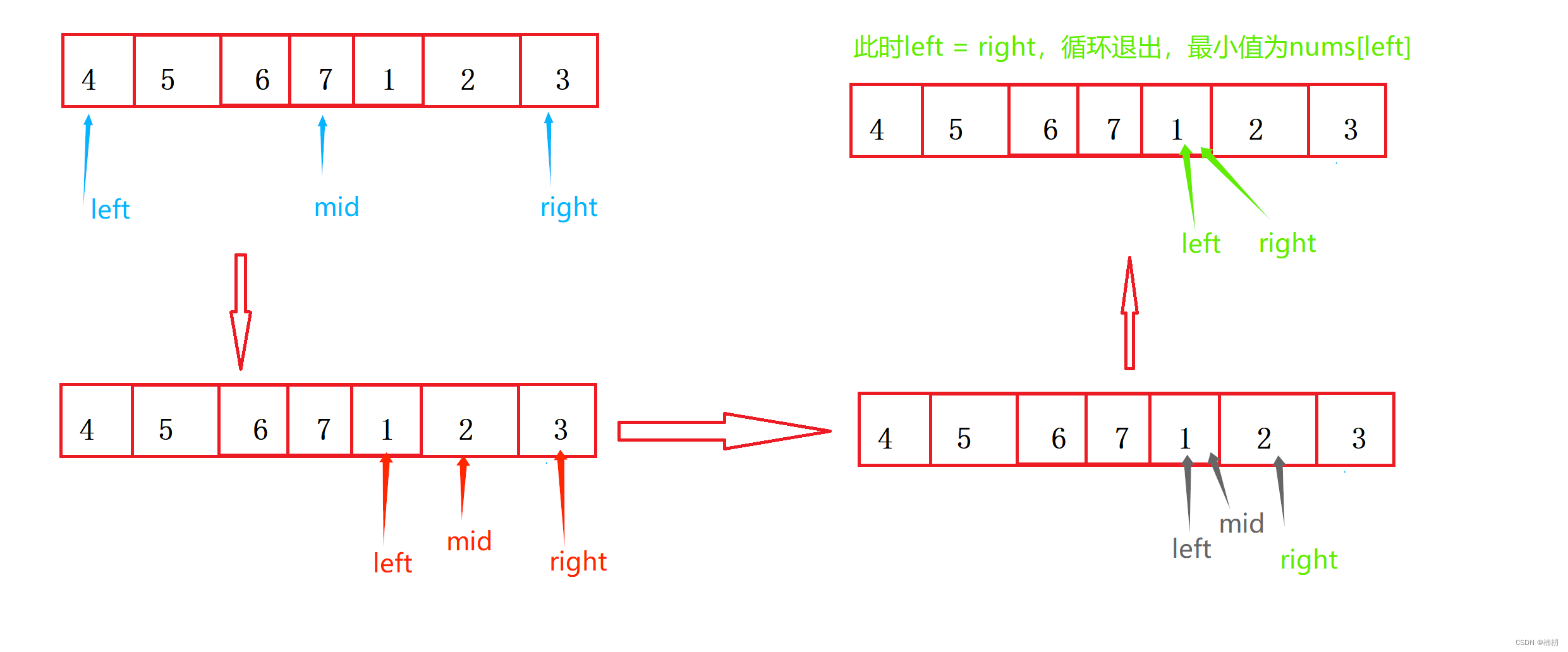
Java旋转数组中的最小数字(图文详解版)
目录 1.题目描述 2.题解 分析 具体实现 方法一(遍历): 方法二(排序): 方法三(二分查找): 1.题目描述 有一个长度为 n 的非降序数组,比如[1,2,3,4,5]&a…...

Android 13 Hotseat定制化修改——005 hotseat图标禁止形成文件夹
目录 一.背景 二.方案 一.背景 由于需求是需要自定义修改Hotseat,所以此篇文章是记录如何自定义修改hotseat的,应该可以覆盖大部分场景,修改点有修改hotseat布局方向,hotseat图标数量,hotseat图标大小,hotseat布局位置,hotseat图标禁止形成文件夹,hotseat图标禁止移动…...
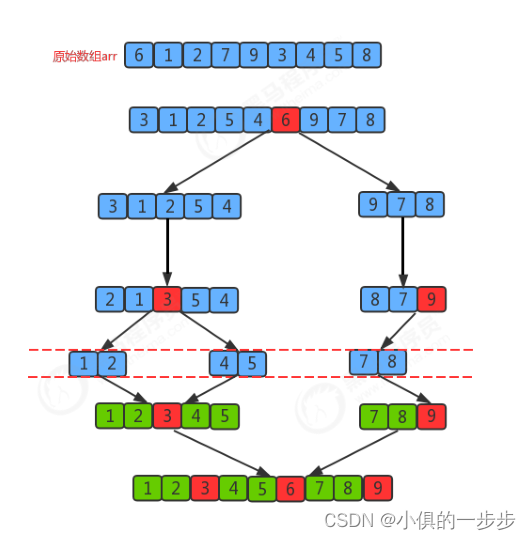
插入、希尔、归并、快速排序(java实现)
目录 插入排序 希尔排序 归并排序 快速排序 插入排序 排序原理: 1.把所有元素分为两组,第一组是有序已经排好的,第二组是乱序未排序。 2.将未排序一组的第一个元素作为插入元素,倒序与有序组比较。 3.在有序组中找到比插入…...
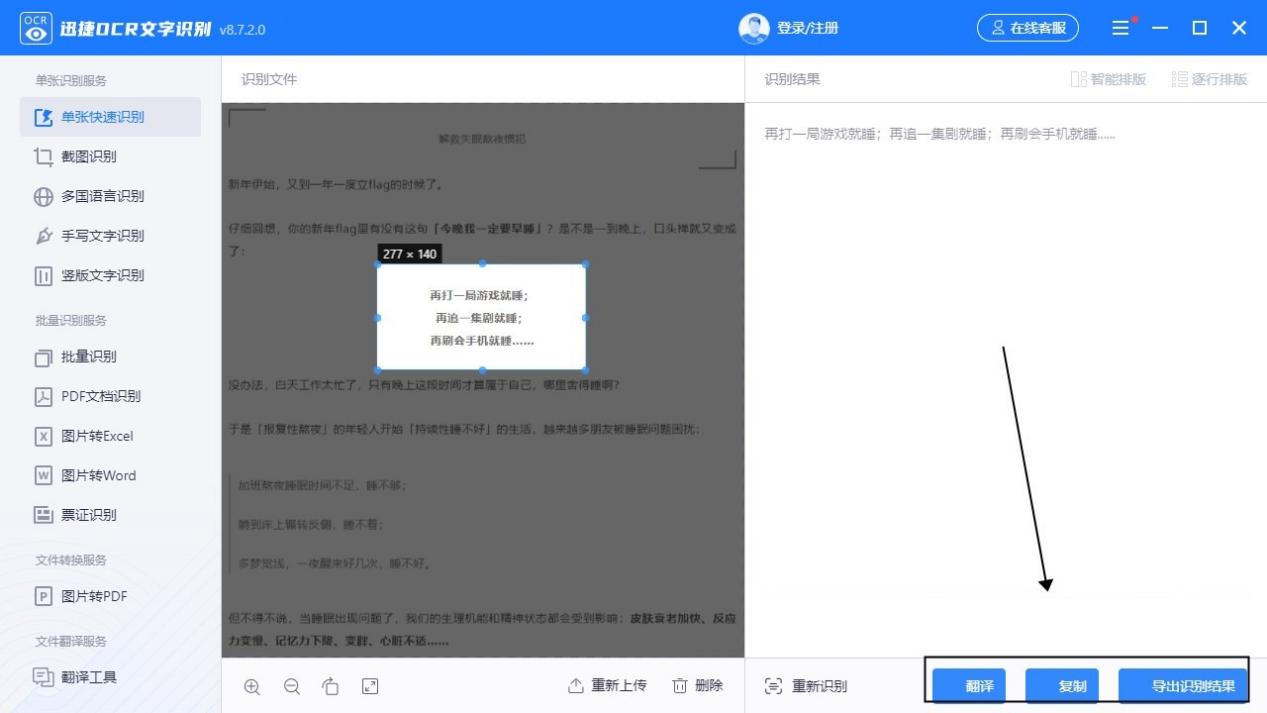
怎么把图片表格转换成word表格?几个步骤达成
在处理文档时,图片表格的转换是一个常见的需求。而手动输入表格是非常耗时的,因此,使用文本识别软件来自动转换图片表格可以大大提高工作效率。在本文中,我们将介绍如何使用OCR文字识别技术来将图片表格转换为Word表格。 OCR文字识…...
多线程与高并发--------阻塞队列
四、阻塞队列 一、基础概念 1.1 生产者消费者概念 生产者消费者是设计模式的一种。让生产者和消费者基于一个容器来解决强耦合问题。 生产者 消费者彼此之间不会直接通讯的,而是通过一个容器(队列)进行通讯。 所以生产者生产完数据后扔到…...

前端-NVM,Node.js版本管理
NVM(Node Version Manager)是一个用于管理Node.js版本的工具,主要用于前端开发中。它允许开发者同时安装和切换不同版本的Node.js,以满足不同项目对Node.js版本的需求。 使用NVM可以带来以下几个好处: 多版本管理&…...

React - useEffect函数的理解和使用
文章目录 一,useEffect描述二,它的执行时机三,useEffect分情况使用1,不写第二个参数 说明监测所有state,其中一个变化就会触发此函数2,第二个参数如果是[]空数组,说明谁也不监测3,第…...

python模块 — 加解密模块rsa,cryptography
一、密码学 1、密码学介绍 密码学(Cryptography)是研究信息的保密性、完整性和验证性的科学和实践。它涉及到加密算法、解密算法、密钥管理、数字签名、身份验证等内容。 密码学中的主要概念包括: 1. 加密算法:加密算法用于将…...
)
【C++】速识模板(template<class T>)
一、引言 在我们学习C时,常会用到函数重载。而函数重载,通常会需要我们编写较为重复的代码,这就显得臃肿,且效率低下。 重载的函数仅仅只是类型不同,代码的复用率比较低,只要有新类型出现时,就…...

腾讯云10万日活服务器配置怎么选?费用多少?
日活10万的小程序或APP使用腾讯云服务器配置怎么选?腾讯云10万人服务器配置多少钱一年?可以选择腾讯云4核8G12M轻量应用服务器或8核16G18M服务器,云服务器CVM的话可以选择标准型S5实例,腾讯云服务器网来详细说下腾讯云日活10万服务…...

FPGA数据流处理小技巧:深度解读Shift Register IP核的‘额外周期’坑与可变延时实战
FPGA数据流处理实战:揭秘Shift Register IP核的延时陷阱与动态配置技巧 在图像处理流水线中,我们常常需要对像素数据进行精确的时序对齐。上周调试一个实时边缘检测系统时,发现经过移位寄存器处理后的Sobel算子计算结果总是比预期晚一个周期出…...

Midscene.js终极性能调优:如何将自动化脚本速度提升85%
Midscene.js终极性能调优:如何将自动化脚本速度提升85% 【免费下载链接】midscene AI-powered, vision-driven UI automation for every platform. 项目地址: https://gitcode.com/GitHub_Trending/mid/midscene Midscene.js作为一款先进的AI驱动跨平台自动化…...

江科大STM32实战笔记精讲『上篇』
1. STM32入门实战基础 STM32作为嵌入式开发领域的明星产品,其强大的性能和丰富的外设资源使其成为工程师的首选。对于初学者来说,掌握STM32的核心外设配置是迈向嵌入式开发的第一步。本部分将重点介绍STM32最小系统搭建和开发环境配置。 要构建一个完整的…...

探索Nintendo Switch游戏备份神器:nxdumptool深度解析与实战指南
探索Nintendo Switch游戏备份神器:nxdumptool深度解析与实战指南 【免费下载链接】nxdumptool Generates XCI/NSP/HFS0/ExeFS/RomFS/Certificate/Ticket dumps from Nintendo Switch gamecards and installed SD/eMMC titles. 项目地址: https://gitcode.com/gh_m…...

【新手必备】2026年OpenClaw/Hermes Agent京东云10分钟保姆级集成流程
【新手必备】2026年OpenClaw/Hermes Agent京东云10分钟保姆级集成流程。OpenClaw(前身为Clawdbot/Moltbot)作为开源、本地优先的AI助理框架,凭借724小时在线响应、多任务自动化执行、跨平台协同等核心能力,成为个人办公与轻量团队…...

音乐解密工具终极指南:打破音乐格式壁垒,重获音频自由
音乐解密工具终极指南:打破音乐格式壁垒,重获音频自由 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目…...
)
保姆级教程:用Protege 5.5.0从零构建你的第一个知识图谱(附实战案例文件)
从零开始用Protege构建知识图谱:手把手实战指南 第一次打开Protege时,满屏的专业术语和复杂界面确实容易让人望而却步。但别担心,本文将带你像拼乐高一样,一步步搭建出你的第一个知识图谱。我们以"中国古代文人关系网"…...

全能资源网站:咖喱君的资源库
分享一个涵盖学习、软件、影音、AI 等全场景资源的免费宝藏网站,帮你一站式解决绝大多数资源需求。——咖喱君的资源库(https://link3.cc/galijun)...

从一次线上故障复盘:深度解析AutoSar WDGM如何守护你的ECU核心任务链
从一次线上故障复盘:深度解析AutoSar WDGM如何守护你的ECU核心任务链 在汽车电子控制单元(ECU)开发中,功能安全始终是悬在工程师头顶的达摩克利斯之剑。去年我们团队遭遇了一次典型的线上故障:某个关键SWC任务链因执行…...

终极Windows激活方案:KMS_VL_ALL_AIO智能激活脚本完全解析
终极Windows激活方案:KMS_VL_ALL_AIO智能激活脚本完全解析 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统激活而烦恼吗?每次重装系统后面对"需要…...