Redis缓存设计
缓存能够有效地加速应用的读写速度,同时也可以降低后端负载,对日常应用的开发至关重要。但是将缓存加入应用架构后也会带来一些问题,本文将针对这些问题介绍缓存使用技巧和设计方案。
1缓存的收益和成本
下图左侧为客户端直接调用存储层的架构,右侧为比较典型的缓存层+存储层架构,下面分析一下缓存加入后带来的收益和成本。

收益如下:
加速读写:因为缓存通常都是全内存的(例如Redis、Memcache),而存储层通常读写性能不够强悍(例如MySQL),通过缓存的使用可以有效地加速读写,优化用户体验。
降低后端负载:帮助后端碱少访问量和复杂计算(例如很复杂的SQL语句),在很大程度降低了后端的负载。
成本如下:
数据不一致性:缓存层和存储层的数据存在着一定时间窗口的不一致性,时间窗口跟更新策略有关。
代码维护成本:加人缓存后,需要同时处理缓存层和存储层的逻辑,增大了开发者维护代码的成本。
运维成本:以Redis Cluster为例,加入后无形中增加了运维成本。
缓存的使用场景基本包含如下两种:
开销大的复杂计算:以MySQL为例子,--些复杂的操作或者计算(例如大量联表操作、一些分组计算),如果不加缓存,不但无法满足高并发量,同时也会给MySQL带来巨大的负担。
加速请求响应:即使查询单条后端数据足够快(例如select * from table where id=?),那么依然可以使用缓存,以Redis为例子,每秒可以完成数万次读写,并且提供的批量操作可以优化整个IO链的响应时间。
2缓存更新策略
缓存中的数据通常都是有生命周期的,需要在指定时间后被删除或更新,这样可以保证缓存空间在一个可控的范围。但是缓存中的数据会和数据源中的真实数据有一段时间窗口的不一致,需要利用某些策略进行更新。下面将分别从使用场景、一致性、开发人员开发维护成本三个方面介绍三种缓存的更新策略。
(1)LRU/LFU/FIFO算法剔除
使用场景。剔除算法通常用于缓存使用量超过了预设的最大值时候,如何对现有的数据进行剔除。例如Redis使用maxmemory-policy这个配置作为内存最大值后对于数据的剔除策略。
一致性。要清理哪些数据是由具体算法决定,开发人员只能决定使用哪种算法,所以数据的一致性是最差的。
维护成本。算法不需要开发人员自己来实现,通常只需要配置最大maxmemory和对应的策略即可。开发人员只需要知道每种算法的含义,选择适合自己的算法即可。
(2)超时剔除
使用场景。超时剔除通过给缓存数据设置过期时间,让其在过期时间后自动删除,例如Redis提供的expire命令。如果业务可以容忍一段时间内,缓存层数据和存储层数据不一致,那么可以为其设置过期时间。在数据过期后,再从真实数据源获取数据,重新放到缓存并设置过期时间。例如一个视频的描述信息,可以容忍几分钟内数据不一致,但是涉及交易方面的业务,后果可想而知。
一致性。一段时间窗口内(取决于过期时间长短)存在一致性问题,即缓存数据和真实数据源的数据不一致。
维护成本。维护成本不是很高,只需设置expire过期时间即可,当然前提是应用方允许这段时间可能发生的数据不一致。
(3)主动更新
使用场景。应用方对于数据的一致性要求高,需要在真实数据更新后,立即更新缓存数据。例如可以利用消息系统或者其他方式通知缓存更新。
一致性。一致性最高,但如果主动更新发生了问题,那么这条数据很可能很长时间不会更新,所以建议结合超时剔除一起使用效果会更好。
维护成本。维护成本会比较高,开发者需要自己来完成更新,并保证更新操作的正确性。
下表给出了缓存的三种常见更新策略的对比。

(4)最佳实践
有两个建议:
低一致性业务建议配置最大内存和淘汰策略的方式使用。
高一致性业务可以结合使用超时剔除和主动更新,这样即使主动更新出了问题,也能
保证数据过期时间后删除脏数据。
3缓存粒度控制
下图是很多项目关于缓存比较常用的选型,缓存层选用Redis,存储层选用MySQL。

例如现在需要将MySQL的用户信息使用Redis缓存,可以执行如下操作:
从MySQL获取用户信息:
select * from user where id={id}
将用户信息缓存到Redis中:
set user: {id} ' select * from user where id={id} '
假设用户表有100个列,需要缓存到什么维度呢?
缓存全部列:
set user:{id} ' select * from user where id={id} '
缓存部分重要列:
set user:{id} 'select {importantColumn1},{important Column2} ... { importantColumnN}
from user where id={id} '
上述这个问题就是缓存粒度问题,究竟是缓存全部属性还是只缓存部分重要属性呢?下面将从通用性、空间占用、代码维护三个角度进行说明。
通用性。缓存全部数据比部分数据更加通用,但从实际经验看,很长时间内应用只需要几个重要的属性。
空间占用。缓存全部数据要比部分数据占用更多的空间,可能存在以下问题:
全部数据会造成内存的浪费。
全部数据可能每次传输产生的网络流量会比较大,耗时相对较大,在极端情况下会阻塞网络。
全部数据的序列化和反序列化的CPU开销更大。
代码维护。全部数据的优势更加明显,而部分数据一旦要加新字段需要修改业务代码,而且修改后通常还需要刷新缓存数据。
下表给出缓存全部数据和部分数据在通用性、空间占用、代码维护上的对比。

缓存粒度问题是一个容易被忽视的问题,如果使用不当,可能会造成很多无用空间的浪费,网络带宽的浪费,代码通用性较差等情况,需要综合数据通用性、空间占用比、代码维护性三点进行取舍。
4穿透优化
缓存穿透是指查询一个根本不存在的数据,缓存层和存储层都不会命中,通常出于容错的考虑,如果从存储层查不到数据则不写人缓存层,如下图所示整个过程分为如下3步:
(1)缓存层不命中。
(2)存储层不命中,不将空结果写回缓存。
(3)返回空结果。

缓存穿透将导致不存在的数据每次请求都要到存储层去查询,失去了缓存保护后端存储的意义。
缓存穿透问题可能会使后端存储负载加大,由于很多后端存储不具备高并发性,甚至可能造成后端存储宕掉。通常可以在程序中分别统计总调用数、缓存层命中数、存储层命中数,如果发现大量存储层空命中,可能就是出现了缓存穿透问题。
造成缓存穿透的基本原因有两个。第一,自身业务代码或者数据出现问题,第二,一些恶意攻击、爬虫等造成大量空命中。下面我们来看一下如何解决缓存穿透问题。
(1)缓存空对象
如下图所示,当第2步存储层不命中后,仍然将空对象保留到缓存层中,之后再访问这个数据将会从缓存中获取,这样就保护了后端数据源。

缓存空对象会有两个问题:第一,空值做了缓存,意味着缓存层中存了更多的键,需要更多的内存空间(如果是攻击,问题更严重),比较有效的方法是针对这类数据设置一个较短的过期时间,让其自动剔除。第二,缓存层和存储层的数据会有一段时间窗口的不一致,可能会对业务有一定影响。例如过期时间设置为5分钟,如果此时存储层添加了这个数据,那此段时间就会出现缓存层和存储层数据的不一致,此时可以利用消息系统或者其他方式清除掉缓存层中的空对象。
下面给出了缓存空对象的实现代码:
String get (String key) {//从缓存中获取数据String cacheValue = cache.get(key);//缓存为空if (StringUtils.isBlank (cacheValue)){//从存储中获取String storageValue = storage.get(key);cache.set(key, storageValue);//如果存储数据为空,需要设置一个过期时间(300秒)if (storageValue == null) {cache.expire(key,60 * 5);}return storageValue;} else {//缓存非空return cacheValue;}
(2)布隆过滤器拦截
如下图所示,在访问缓存层和存储层之前,将存在的key用布隆过滤器提前保存起来,做第一层拦截。例如:一个推荐系统有4亿个用户id,每个小时算法工程师会根据每个用户之前历史行为计算出推荐数据放到存储层中,但是最新的用户由于没有历史行为,就会发生缓存穿透的行为,为此可以将所有推荐数据的用户做成布隆过滤器。如果布隆过滤器认为该用户id不存在,那么就不会访问存储层,在一定程度保护了存储层。

这种方法适用于数据命中不高、数据相对固定、实时性低(通常是数据集较大)的应用场景,代码维护较为复杂,但是缓存空间占用少。
(3)两种方案对比
前面介绍了缓存穿透问题的两种解决方法(实际上这个问题是一个开放问题,有很多解决方法),下面通过下表从适用场景和维护成本两个方面对两种方案进行分析。

5雪崩优化
下图描述了什么是缓存雪崩:由于缓存层承载着大量请求,有效地保护了存储层,但是如果缓存层由于某些原因不能提供服务,于是所有的请求都会达到存储层,存储层的调用量会暴增,造成存储层也会级联宕机的情况。

预防和解决缓存雪崩问题,可以从以下三个方面进行着手。
(1)保证缓存层服务高可用性。和飞机都有多个引擎一样,如果缓存层设计成高可用的,即使个别节点、个别机器、甚至是机房宕掉,依然可以提供服务,例如Redis Sentinel和Redis Cluster都实现了高可用。
(2)依赖隔离组件为后端限流并降级。无论是缓存层还是存储层都会有出错的概率,可以将它们视同为资源。作为并发量较大的系统,假如有一个资源不可用,可能会造成线程全部阻塞(hang)在这个资源上,造成整个系统不可用。降级机制在高并发系统中是非常普遍的:比如推荐服务中,如果个性化推荐服务不可用,可以降级补充热点数据,不至于造成前端页面是开天窗。在实际项目中,我们需要对重要的资源(例如Redis、MySQL、HBase、外部接口)都进行隔离,让每种资源都单独运行在自己的线程池中,即使个别资源出现了问题,对其他服务没有影响。但是线程池如何管理,比如如何关闭资源池、开启资源池、资源池阀值管理,这些做起来还是相当复杂的。
(3)提前演练。在项目上线前,演练缓存层宕掉后,应用以及后端的负载情况以及可能出现的问题,在此基础上做一些预案设定。
6热点key重建优化
开发人员使用“缓存+过期时间”的策略既可以加速数据读写,又保证数据的定期更新,这种模式基本能够满足绝大部分需求。但是有两个问题如果同时出现,可能就会对应用造成致命的危害:
当前key是一个热点key (例如一个热门的娱乐新闻),并发量非常大。
重建缓存不能在短时间完成,可能是一个复杂计算,例如复杂的SQL、多次IO、多个依赖等。
在缓存失效的瞬间,有大量线程来重建缓存,造成后端负载加大,甚至可能会让应用崩溃。
要解决这个问题也不是很复杂,但是不能为了解决这个问题给系统带来更多的麻烦,所以需要制定如下目标:
减少重建缓存的次数。
数据尽可能一致。
较少的潜在危险。
--互斥锁(mutex key)
此方法只允许一个线程重建缓存,其他线程等待重建缓存的线程执行完,重新从缓存获取数据即可,整个过程如下图所示。
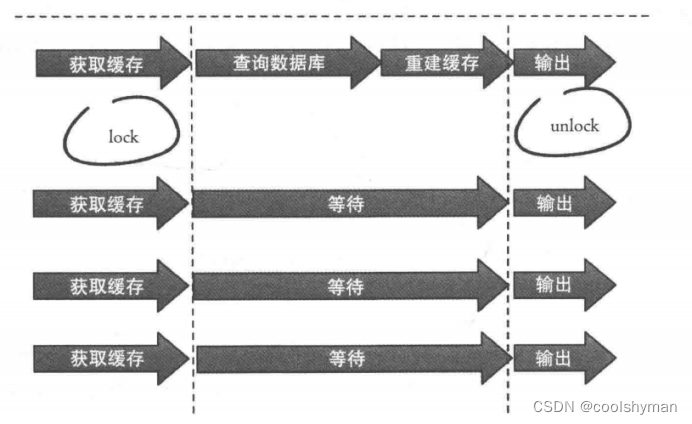
下面代码使用Redis的setnx命令实现上述功能:
String get(String key) {//从Redis中获取数据String value = redis.get(key);//如果value为空,则开始重构缓存if (value == null) {//只允许一个线程重构缓存,使用nx,并设置过期时间exString mutexKey = "mutext:key:" + key; if (redis.set(mutexKey,"1","ex 180","nx")) {//从数据源获取数据value = db.get(key);//回写Redis,并设置过期时间redis.setex(key, timeout, value);//删除key_mutexredis.delete(mutexKey);}//其他线程休息50毫秒后重试else {Thread.sleep(50);get(key);}}return value;
}
(1)从Redis获取数据,如果值不为空,则直接返回值;否则执行下面的(2.1)和(2.2)步骤。
(2.1)如果set (nx和ex)结果为true,说明此时没有其他线程重建缓存,那么当前线程执行缓存构建逻辑。
(2.2)如果set (nx和ex)结果为false,说明此时已经有其他线程正在执行构建缓存的工作,那么当前线程将休息指定时间(例如这里是50毫秒,取决于构建缓存的速度)后,重新执行函数,直到获取到数据。
--永远不过期
“永远不过期”包含两层意思:
从缓存层面来看,确实没有设置过期时间,所以不会出现热点key过期后产生的问题,也就是“物理”不过期。
从功能层面来看,为每个value设置一个逻辑过期时间,当发现超过逻辑过期时间后,会使用单独的线程去构建缓存。
整个过程如下图所示。
从实战看,此方法有效杜绝了热点key产生的问题,但唯一不足的就是重构缓存期间,会出现数据不一致的情况,这取决于应用方是否容忍这种不一致。

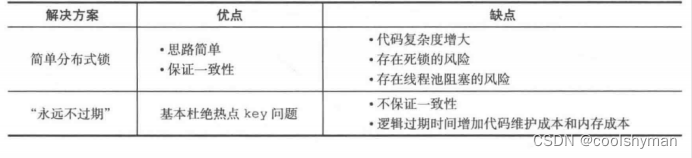
作为一个并发量较大的应用,在使用缓存时有三个目标:第一,加快用户访问速度,提高用户体验。第二,降低后端负载,减少潜在的风险,保证系统平稳。第三,保证数据“尽可能”及时更新。下面将按照这三个维度对上述两种解决方案进行分析。
互斥锁(mutex key):这种方案思路比较简单,但是存在一定的隐患,如果构建缓存过程出现问题或者时间较长,可能会存在死锁和线程池阻塞的风险,但是这种方法能够较好地降低后端存储负载,并在一致性上做得比较好。
“永远不过期”:这种方案由于没有设置真正的过期时间,实际上已经不存在热点key产生的一系列危害,但是会存在数据不一致的情况,同时代码复杂度会增大。
两种解决方法对比如下表所示。
总结:
(1)缓存的使用带来的收益是能够加速读写,降低后端存储负载。
(2)缓存的使用带来的成本是缓存和存储数据不一致性,代码维护成本增大,架构复杂
度增大。
(3)比较推荐的缓存更新策略是结合剔除、超时、主动更新三种方案共同完成。
(4)穿透问题:使用缓存空对象和布隆过滤器来解决,注意它们各自的使用场景和局
限性。
(5)无底洞问题:分布式缓存中,有更多的机器不保证有更高的性能。有四种批量操作
方式:串行命令、串行I0、并行IO、hash_tag。
(6)雪崩问题:缓存层高可用、客户端降级、提前演练是解决雪崩问题的重要方法。
(7)热点key问题:斥锁、“永远不过期”能够在一定程度上解决热点key问题,开发人员在使用时要了解它们各自的使用成本。
相关文章:
Redis缓存设计
缓存能够有效地加速应用的读写速度,同时也可以降低后端负载,对日常应用的开发至关重要。但是将缓存加入应用架构后也会带来一些问题,本文将针对这些问题介绍缓存使用技巧和设计方案。 1缓存的收益和成本 下图左侧为客户端直接调用存储层的架…...
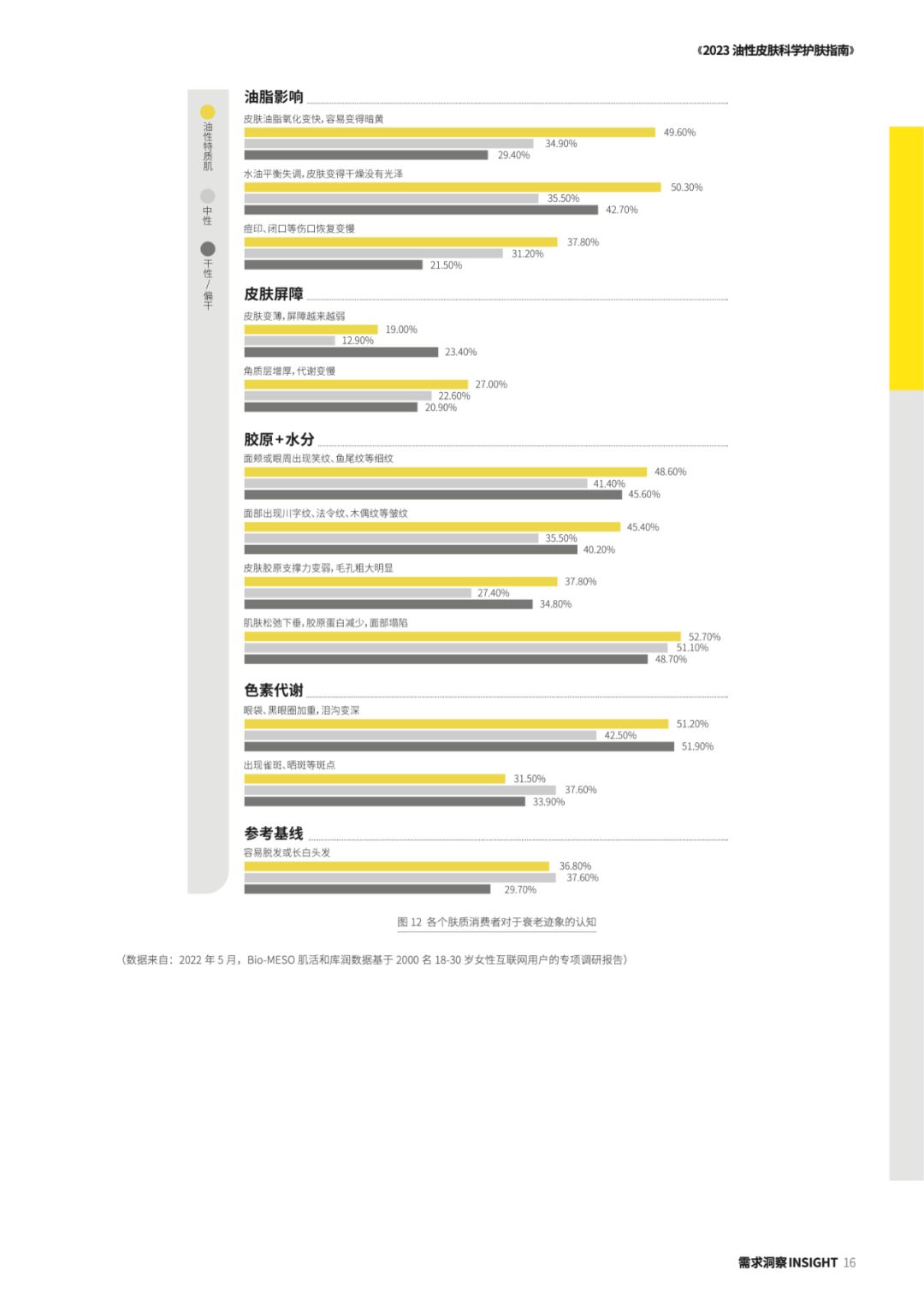
华熙生物肌活:2023年版Bio-MESO肌活油性皮肤科学护肤指南
关于报告的所有内容,公众【营销人星球】获取下载查看 核心观点 以悦己和尝鲜为消费动机的他们,已迅速崛起成为护肤行业的焦点人群。而在新生代护肤议题中,“油性皮肤护理”已经成为一个至关重要的子集。今天,中国新生代人口数量…...
mysql索引介绍
索引可以提升查询速度,会影响where查询,以及order by排序。MySQL索引类型如下: 从索引存储结构划分:B Tree索引、Hash索引、全文索引 从应用层次划分:主键索引、唯一索引、单值索引、复合索引 从索引键值类型划分&am…...
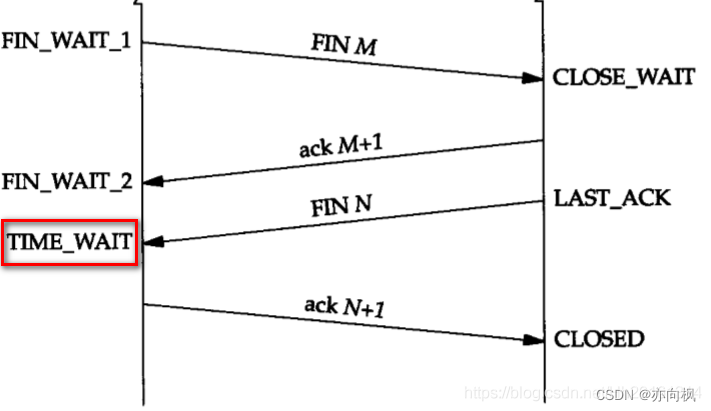
说一下什么是tcp的2MSL,为什么客户端在 TIME-WAIT 状态必须等待 2MSL 的时间?
1.TCP之2MSL 1.1 MSL MSL:Maximum Segment Lifetime报文段最大生存时间,它是任何报文段被丢弃前在网络内的最长时间 1.2为什么存在MSL TCP报文段以IP数据报在网络内传输,而IP数据报则有限制其生存时间的TTL字段,并且TTL的限制是基于跳数 1.3…...

更新spring boot jar包中的BOOT-INF/lib目录下的jar包
更新spring-boot jar包中的BOOT-INF/lib目录下的jar包 场景 需要更新lib目录下某个jar包的配置文件 失败的解决方法 用解压软件依次打开spring-boot jar包(设为a.jar)、BOOT-INF/lib目录下的jar包(设为b.jar),然后修改…...
纯前端 -- html转pdf插件总结
一、html2canvasjsPDF(文字会被截断): 将HTML元素呈现给添加到PDF中的画布对象,不能仅使用jsPDF,需要html2canvas或rasterizeHTML html2canvasjsPDF的具体使用链接 二、html2pdf(内容显示不全文字会被截断…...

数据结构和算法基础
巩固基础,砥砺前行 。 只有不断重复,才能做到超越自己。 能坚持把简单的事情做到极致,也是不容易的。 数据结构和算法 程序 数据结构算法 数据结构是算法的基础 问题1:字符串匹配问题。str1 是否完全包含 str2 1)暴…...

JS二维数组转化为对象
将二维数组转化为对象的形式 转之前的数据: 转之后: const entries new Map([[foo, bar],[baz, 42],[beginNode, 202212151048010054],[beginNode, 202212151048447710],]); console.log(entries)const obj Object.fromEntries(entries);console.lo…...

通过 EPOLL 解决客户端同时连接多服务器的问题
项目需求是 程序上 同时配置了多个服务端 设备 每隔一段时间需要 比如1分钟 连一下服务器看下是否连通 并将结果上报给平台 原来是用线程池来做的 具体大概就是 定时器到了之后 遍历设备列表 找到设备之后 通过 socket连接 发送一个指令 等待服务器返回 用来检查是…...

JavaScript数据结构【进阶】
注:最后有面试挑战,看看自己掌握了吗 文章目录 使用 splice() 添加元素使用 slice() 复制数组元素使用展开运算符复制数组使用展开运算符合并数组使用 indexOf() 检查元素是否存在使用 for 循环遍历数组中的全部元素创建复杂的多维数组将键值对添加到对象…...

jQuery编程学习3(jQuery 其他方法: jQuery 拷贝对象、 jQuery 多库共存、jQuery 插件)
目录 jQuery 其他方法 1. jQuery 拷贝对象 $.extend()方法 2. jQuery 多库共存 问题概述: 客观需求: jQuery 解决方案:(两种方式) 3. jQuery 插件 jQuery 插件常用的网站: jQuery 插件使用步骤&…...
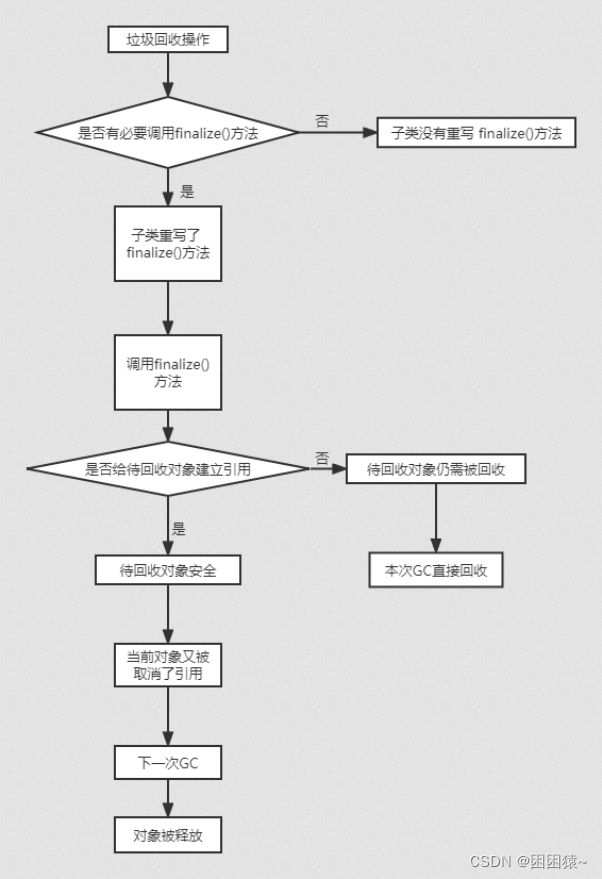
jvm——垃圾回收机制(GC)详解
开始之前有几个GC的基本问题 什么是GC? GC 是 garbage collection 的缩写,意思是垃圾回收——把内存(特别是堆内存)中不再使用的空间释放掉;清理不再使用的对象。 为什么要GC? 堆内存是各个线程共享的空间…...

计算机组成原理-笔记-第七章
目录 七、第七章——输入输出系统 1、IO设备与IO控制方式 (1)控制方式(查询,中断,DMA) (2)通道控制 (3)IO系统 (4)总结 2、外设…...
【Linux】网络基础2
文章目录 网络基础21. 应用层1.1 协议1.2 HTTP 协议1.2.1 URL1.2.2 urlencode和urldecode1.2.3 HTTP协议格式1.2.4 HTTP的方法1.2.5 HTTP的状态码1.2.6 HTTP 常见的header1.2.7 最简单的HTTP服务器 2. 传输层2.1 端口号2.1.1 端口号范围划分2.1.2 认识知名端口号2.1.3 netstat2…...
-三维簇状柱形图(3D Clustered Bar Chart))
可视化绘图技巧100篇进阶篇(四)-三维簇状柱形图(3D Clustered Bar Chart)
目录 前言 适用场景 图例 柱形图 一、柱形图的特点 二、柱形图的类型...

架构设计第八讲:架构 - 理解架构的模式2 (重点)
架构设计第八讲:架构 - 理解架构的模式2 (重点) 本文是架构设计第8讲:架构 - 理解架构的模式2,整理自朱晔的互联网架构实践心得, 他是结合了 微软给出的云架构的一些模式的基础上加入他自己的理解来总结互联网架构中具体的一些模式。我在此基…...

Java中的Maven Shade插件是什么?
Maven Shade插件是一个非常有用的Maven插件,它可以帮助你在构建项目时打包所有依赖项,并将其打包到一个单独的JAR文件中。这对于在构建过程中使用多个依赖项的项目非常有用,因为它可以让你避免在每个依赖项中都包含所有依赖项,从而…...

ffmpeg的bpp是什么?
例如: AV_PIX_FMT_YUV420P, ///< planar YUV 4:2:0, 12bpp, (1 Cr & Cb sample per 2x2 Y samples) AV_PIX_FMT_YUYV422, ///< packed YUV 4:2:2, 16bpp, Y0 Cb Y1 Cr AV_PIX_FMT_RGB24, ///< packed RGB 8:8:8, 24bpp, RGBRGB... AV_PIX_FMT_BGR24, …...

【C# 基础精讲】类和对象的概念
在面向对象编程(Object-Oriented Programming,OOP)中,类和对象是两个核心概念,用于描述和实现现实世界中的实体和关系。OOP 是一种编程范式,通过将数据和操作封装为对象来组织和管理代码,使得代…...

微信ipad实现批量添加联系人及批量分组
GEWE框架官方网站 geweapi.com 点击访问即可 搜索 小提示: 添加联系人必要接口搜索返回的V3 V4用于添加联系人 请求URL: http://域名地址/api/contacts/search 请求方式: POST 请求头: Content-Type:application/…...

Rust async-await 任务执行原理
Rust async/await 任务执行原理探秘 在现代高并发编程中,Rust的async/await语法凭借其高效、安全的特点成为开发者关注的焦点。它通过协作式多任务机制,在单线程内实现高吞吐量的异步操作。本文将深入剖析其任务执行原理,揭示其如何在不依赖…...

TrafficMonitor股票插件:Windows任务栏实时股票监控终极指南
TrafficMonitor股票插件:Windows任务栏实时股票监控终极指南 【免费下载链接】TrafficMonitorPlugins 用于TrafficMonitor的插件 项目地址: https://gitcode.com/gh_mirrors/tr/TrafficMonitorPlugins 想在Windows任务栏上实时监控股票行情,却不想…...
)
C++26反射让constexpr容器成为现实?揭秘编译期JSON Schema校验器的7层元编程架构(含完整Doxygen生成的反射依赖图)
更多请点击: https://intelliparadigm.com 第一章:C26反射核心机制与constexpr容器的范式突破 C26 将首次在标准中引入原生、零开销的编译期反射(std::reflect)设施,配合全面 constexpr 化的容器(如 std::…...

Nature综述核心要点速览:肿瘤标志物深度解析
一、中国癌症形势:挑战与积极变化并存依据《JAMA》最新发布的流行病学数据统计分析,中国癌症发展态势依旧严峻。在特定研究周期内,男性有11种癌症、女性有14种癌症的年龄调整患病率显著攀升。具体而言,男性癌症中,甲状…...

如何快速解包Godot游戏资源:终极PCK文件提取工具指南
如何快速解包Godot游戏资源:终极PCK文件提取工具指南 【免费下载链接】godot-unpacker godot .pck unpacker 项目地址: https://gitcode.com/gh_mirrors/go/godot-unpacker 如果你正在寻找一个高效、免费的Godot游戏资源解包工具,那么godot-unpac…...

3dsconv完整教程:5分钟学会3DS游戏格式转换的终极方案
3dsconv完整教程:5分钟学会3DS游戏格式转换的终极方案 【免费下载链接】3dsconv Python script to convert Nintendo 3DS CCI (".cci", ".3ds") files to the CIA format 项目地址: https://gitcode.com/gh_mirrors/3d/3dsconv 3dsconv是…...
到底怎么选?)
避坑指南:Halcon Variation_Model三种模式(standard/robust/direct)到底怎么选?
Halcon Variation_Model模式选型实战:从原理到避坑指南 在工业视觉检测领域,Variation_Model(差异模板)算子是处理轻微变形目标的利器,尤其在印刷品检测、包装缺陷识别等场景表现突出。但当开发者真正将其投入项目时&a…...

0-RTT详解和总结
0-RTT(Zero Round Trip Time,零往返时间)是一种优化网络连接的技术,允许客户端在未完成完整握手的情况下直接向服务器发送应用数据,从而消除握手阶段带来的往返延迟。该技术最早由 TLS 1.3 引入,后被 QUIC 协议继承并增强。以下从原理、实现、优缺点、安全性等维度进行系…...

LM文生图WebUI源码浅析:Gradio封装逻辑与参数映射关系
LM文生图WebUI源码浅析:Gradio封装逻辑与参数映射关系 1. 平台架构概述 LM文生图镜像基于Tongyi-MAI/Z-Image底座构建,采用Gradio框架封装Web界面,实现了从文本描述到高质量图像生成的完整流程。该系统特别适合角色设计、时尚人像等场景&am…...

SWE-agent状态环境钩子终极指南:智能监控与实时报告全攻略
SWE-agent状态环境钩子终极指南:智能监控与实时报告全攻略 【免费下载链接】SWE-agent SWE-agent takes a GitHub issue and tries to automatically fix it, using your LM of choice. It can also be employed for offensive cybersecurity or competitive coding…...