ElasticSearch:项目实战(1)
es环境搭建参考:ElasticSearch:环境搭建步骤_Success___的博客-CSDN博客
需求:
-
用户输入关键可搜索文章列表
-
关键词高亮显示
-
文章列表展示与home展示一样,当用户点击某一篇文章,可查看文章详情
思路:
为了加快检索的效率,在查询的时候不会直接从数据库中查询文章,需要在elasticsearch中进行高速检索。

1、使用postman往虚拟机es中创建索引和映射
put请求 : http://192.168.200.130:9200/app_info_article
{"mappings":{"properties":{"id":{"type":"long"},"publishTime":{"type":"date"},"layout":{"type":"integer"},"images":{"type":"keyword","index": false},"staticUrl":{"type":"keyword","index": false},"authorId": {"type": "long"},"authorName": {"type": "text"},"title":{"type":"text","analyzer":"ik_smart"},"content":{"type":"text","analyzer":"ik_smart"}}}
} 下图为例添加成功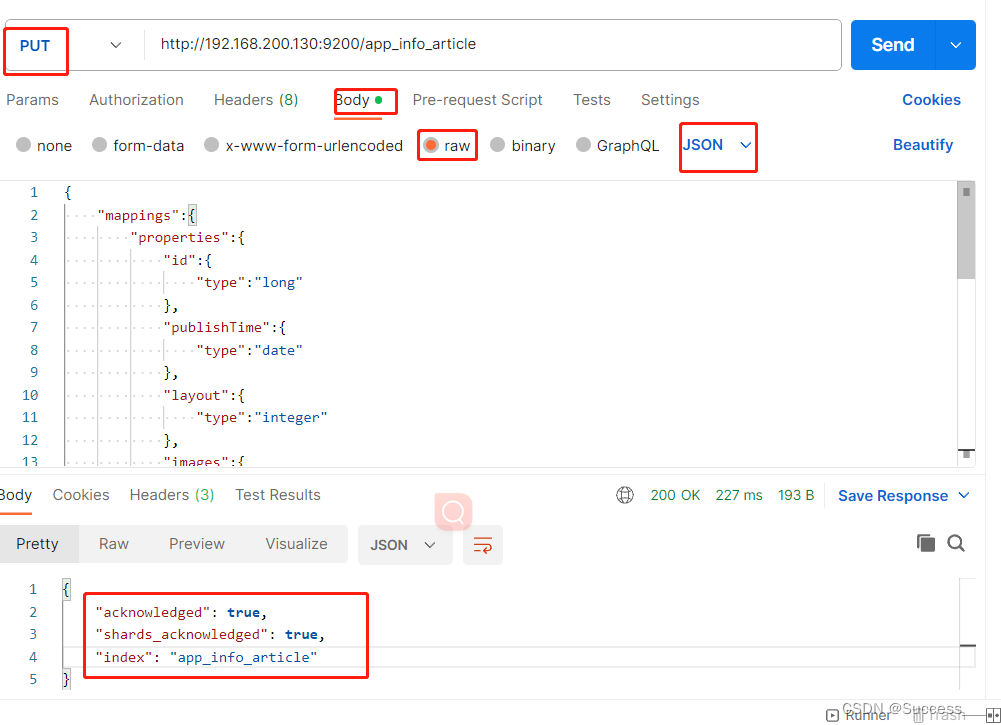
GET请求查询映射:http://192.168.200.130:9200/app_info_article
DELETE请求,删除索引及映射:http://192.168.200.130:9200/app_info_article
GET请求,查询所有文档:http://192.168.200.130:9200/app_info_article/_search
2、将数据从数据库导入到ES索引库中
①创建es-init工程,pom文件如下
<dependencies><!-- 引入依赖模块 --><dependency><groupId>com.heima</groupId><artifactId>heima-leadnews-common</artifactId></dependency><!-- Spring boot starter --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><exclusions><exclusion><groupId>org.junit.vintage</groupId><artifactId>junit-vintage-engine</artifactId></exclusion></exclusions></dependency><!--elasticsearch--><dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId><version>7.4.0</version></dependency><dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-client</artifactId><version>7.4.0</version></dependency><dependency><groupId>org.elasticsearch</groupId><artifactId>elasticsearch</artifactId><!-- web项目可以不排除下面的依赖 --><exclusions><exclusion><groupId>com.google.guava</groupId><artifactId>guava</artifactId></exclusion><exclusion><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-core</artifactId></exclusion><exclusion><groupId>com.fasterxml.jackson.dataformat</groupId><artifactId>jackson-dataformat-smile</artifactId></exclusion><exclusion><groupId>com.fasterxml.jackson.dataformat</groupId><artifactId>jackson-dataformat-yaml</artifactId></exclusion><exclusion><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-databind</artifactId></exclusion><exclusion><groupId>com.fasterxml.jackson.dataformat</groupId><artifactId>jackson-dataformat-cbor</artifactId></exclusion></exclusions><version>7.4.0</version></dependency><dependency><groupId>org.jsoup</groupId><artifactId>jsoup</artifactId><version>1.15.4</version></dependency></dependencies>②配置application.yml文件
server:port: 9999
spring:application:name: es-articledatasource:driver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://localhost:3306/leadnews_article?useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTCusername: rootpassword: 1234
# 设置Mapper接口所对应的XML文件位置,如果你在Mapper接口中有自定义方法,需要进行该配置
mybatis-plus:mapper-locations: classpath*:mapper/*.xml# 设置别名包扫描路径,通过该属性可以给包中的类注册别名type-aliases-package: com.heima.model.common.article.model.po#自定义elasticsearch连接配置
elasticsearch:host: 192.168.200.130port: 9200
③在工程config中创建配置类ElasticSearchConfig用来操作es
package com.heima.es.config;import lombok.Getter;
import lombok.Setter;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;@Getter
@Setter
@Configuration
@ConfigurationProperties(prefix = "elasticsearch")
public class ElasticSearchConfig {private String host;private int port;@Beanpublic RestHighLevelClient client(){return new RestHighLevelClient(RestClient.builder(new HttpHost(host,port,"http")));}
}
④在工程pojo中创建实体类SearchArticleVo
需要存储到es索引库中的字段
package com.heima.es.pojo;import lombok.Data;
import java.util.Date;@Data
public class SearchArticleVo {// 文章idprivate Long id;// 文章标题private String title;// 文章发布时间private Date publishTime;// 文章布局private Integer layout;// 封面private String images;// 作者idprivate Long authorId;// 作者名词private String authorName;//静态urlprivate String staticUrl;//文章内容private String content;}⑤在工程mapper中创建方法用来查询对应的数据库字段
package com.heima.es.mapper;import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.heima.es.pojo.SearchArticleVo;
import com.heima.model.common.article.model.po.ApArticle;
import org.apache.ibatis.annotations.Mapper;import java.util.List;@Mapper
public interface ApArticleMapper extends BaseMapper<ApArticle> {List<SearchArticleVo> loadArticleList();}
⑥创建mapper.xml动态sql文件
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.heima.es.mapper.ApArticleMapper"><resultMap id="resultMap" type="com.heima.es.pojo.SearchArticleVo"><id column="id" property="id"/><result column="title" property="title"/><result column="author_id" property="authorId"/><result column="author_name" property="authorName"/><result column="layout" property="layout"/><result column="images" property="images"/><result column="publish_time" property="publishTime"/><result column="static_url" property="staticUrl"/><result column="content" property="content"/></resultMap><select id="loadArticleList" resultMap="resultMap">SELECTaa.*, aacon.contentFROM`ap_article` aa,ap_article_config aac,ap_article_content aaconWHEREaa.id = aac.article_idAND aa.id = aacon.article_idAND aac.is_delete != 1AND aac.is_down != 1</select></mapper>⑦创建test类并执行数据导入代码
package com.heima.es;import com.alibaba.fastjson.JSON;
import com.heima.es.mapper.ApArticleMapper;
import com.heima.es.pojo.SearchArticleVo;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.xcontent.XContentType;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;import java.util.List;@SpringBootTest
@RunWith(SpringRunner.class)
public class ApArticleTest {@Autowiredprivate ApArticleMapper apArticleMapper;@Autowiredprivate RestHighLevelClient restHighLevelClient;/*** 注意:数据量的导入,如果数据量过大,需要分页导入* @throws Exception*/@Testpublic void init() throws Exception {/*查询符合条件的文章数据*/List<SearchArticleVo> searchArticleVos = apArticleMapper.loadArticleList();/*批量导入es数据*///索引库名称BulkRequest bulkRequest = new BulkRequest("app_info_article");for (SearchArticleVo searchArticleVo : searchArticleVos) {IndexRequest indexRequest =new IndexRequest().id(searchArticleVo.getId().toString()).source(JSON.toJSONString(searchArticleVo), XContentType.JSON);bulkRequest.add(indexRequest);}restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);}}⑧使用postman请求查看数据
导入成功
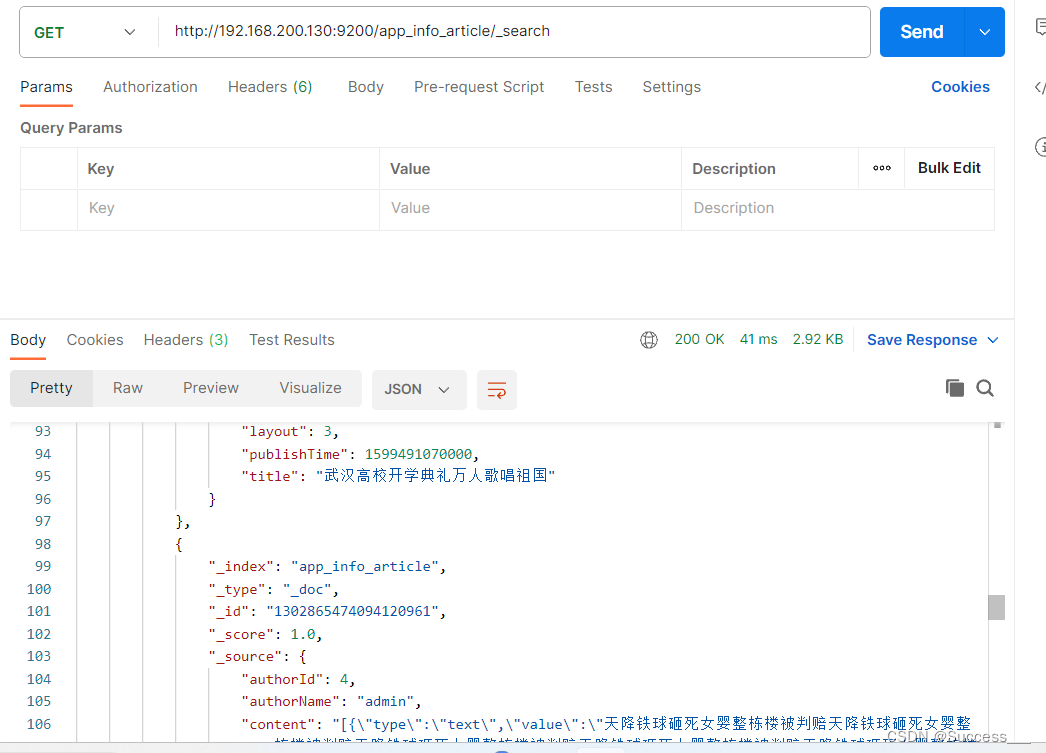
3、文章搜索功能实现
①创建heima-leadnews-search搜索工程
pom文件内容如下
<!--elasticsearch--><dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId><version>7.4.0</version></dependency><dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-client</artifactId><version>7.4.0</version></dependency><dependency><groupId>org.elasticsearch</groupId><artifactId>elasticsearch</artifactId><!-- web项目可以不排除下面的依赖 --><exclusions><exclusion><groupId>com.google.guava</groupId><artifactId>guava</artifactId></exclusion><exclusion><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-core</artifactId></exclusion><exclusion><groupId>com.fasterxml.jackson.dataformat</groupId><artifactId>jackson-dataformat-smile</artifactId></exclusion><exclusion><groupId>com.fasterxml.jackson.dataformat</groupId><artifactId>jackson-dataformat-yaml</artifactId></exclusion><exclusion><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-databind</artifactId></exclusion><exclusion><groupId>com.fasterxml.jackson.dataformat</groupId><artifactId>jackson-dataformat-cbor</artifactId></exclusion></exclusions><version>7.4.0</version></dependency>
②配置nacos
server:port: 51804
spring:application:name: leadnews-searchcloud:nacos:discovery:server-addr: 192.168.200.130:8848config:server-addr: 192.168.200.130:8848file-extension: yml③nacos中配置elasticsearch
spring:autoconfigure:exclude: org.springframework.boot.autoconfigure.jdbc.DataSourceAutoConfiguration
elasticsearch:host: 192.168.200.130port: 9200④创建controller
package com.heima.search.controller.v1;import com.heima.model.common.dtos.ResponseResult;
import com.heima.model.common.search.UserSearchDto;
import com.heima.search.service.ArticleSearchService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;import java.io.IOException;@RestController
@RequestMapping("/api/v1/article/search")
public class ArticleSearchController {@AutowiredArticleSearchService articleSearchService;@PostMapping("/search")public ResponseResult search(@RequestBody UserSearchDto dto) throws IOException {return articleSearchService.search(dto);}}
⑤实现service层
package com.heima.search.service.impl;import com.alibaba.cloud.commons.lang.StringUtils;
import com.alibaba.fastjson.JSON;
import com.heima.model.common.dtos.ResponseResult;
import com.heima.model.common.enums.AppHttpCodeEnum;
import com.heima.model.common.search.UserSearchDto;
import com.heima.search.service.ArticleSearchService;
import lombok.extern.slf4j.Slf4j;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.text.Text;
import org.elasticsearch.index.query.*;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder;
import org.elasticsearch.search.sort.SortOrder;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;@Service
@Slf4j
public class ArticleSearchServiceImpl implements ArticleSearchService {@AutowiredRestHighLevelClient restHighLevelClient;/*文章搜索*/@Overridepublic ResponseResult search(UserSearchDto dto) throws IOException {//参数校验System.out.println(dto);//1.检查参数if(dto == null || StringUtils.isBlank(dto.getSearchWords())){return ResponseResult.errorResult(AppHttpCodeEnum.PARAM_INVALID);}//2.设置查询条件SearchRequest searchRequest = new SearchRequest("app_info_article");SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();//布尔查询BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();//关键字的分词之后查询QueryStringQueryBuilder queryStringQueryBuilder = QueryBuilders.queryStringQuery(dto.getSearchWords()).field("title").field("content").defaultOperator(Operator.OR);boolQueryBuilder.must(queryStringQueryBuilder);//查询小于mindate的数据
// RangeQueryBuilder rangeQueryBuilder = QueryBuilders.rangeQuery("publishTime").lt(dto.getMinBehotTime().getTime());
// boolQueryBuilder.filter(rangeQueryBuilder);//分页查询searchSourceBuilder.from(0);searchSourceBuilder.size(dto.getPageSize());//按照发布时间倒序查询searchSourceBuilder.sort("publishTime", SortOrder.DESC);//设置高亮 titleHighlightBuilder highlightBuilder = new HighlightBuilder();highlightBuilder.field("title");highlightBuilder.preTags("<font style='color: red; font-size: inherit;'>");highlightBuilder.postTags("</font>");searchSourceBuilder.highlighter(highlightBuilder);searchSourceBuilder.query(boolQueryBuilder);searchRequest.source(searchSourceBuilder);SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);//3.结果封装返回List<Map> list = new ArrayList<>();SearchHit[] hits = searchResponse.getHits().getHits();for (SearchHit hit : hits) {String json = hit.getSourceAsString();Map map = JSON.parseObject(json, Map.class);//处理高亮if(hit.getHighlightFields() != null && hit.getHighlightFields().size() > 0){Text[] titles = hit.getHighlightFields().get("title").getFragments();String title = org.apache.commons.lang.StringUtils.join(titles);//高亮标题map.put("h_title",title);}else {//原始标题map.put("h_title",map.get("title"));}list.add(map);}System.out.println(list);return ResponseResult.okResult(list);}}
⑥在gateway网关中配置当前项目
#搜索微服务- id: leadnews-searchuri: lb://leadnews-searchpredicates:- Path=/search/**filters:- StripPrefix= 1⑦启动项目并测试
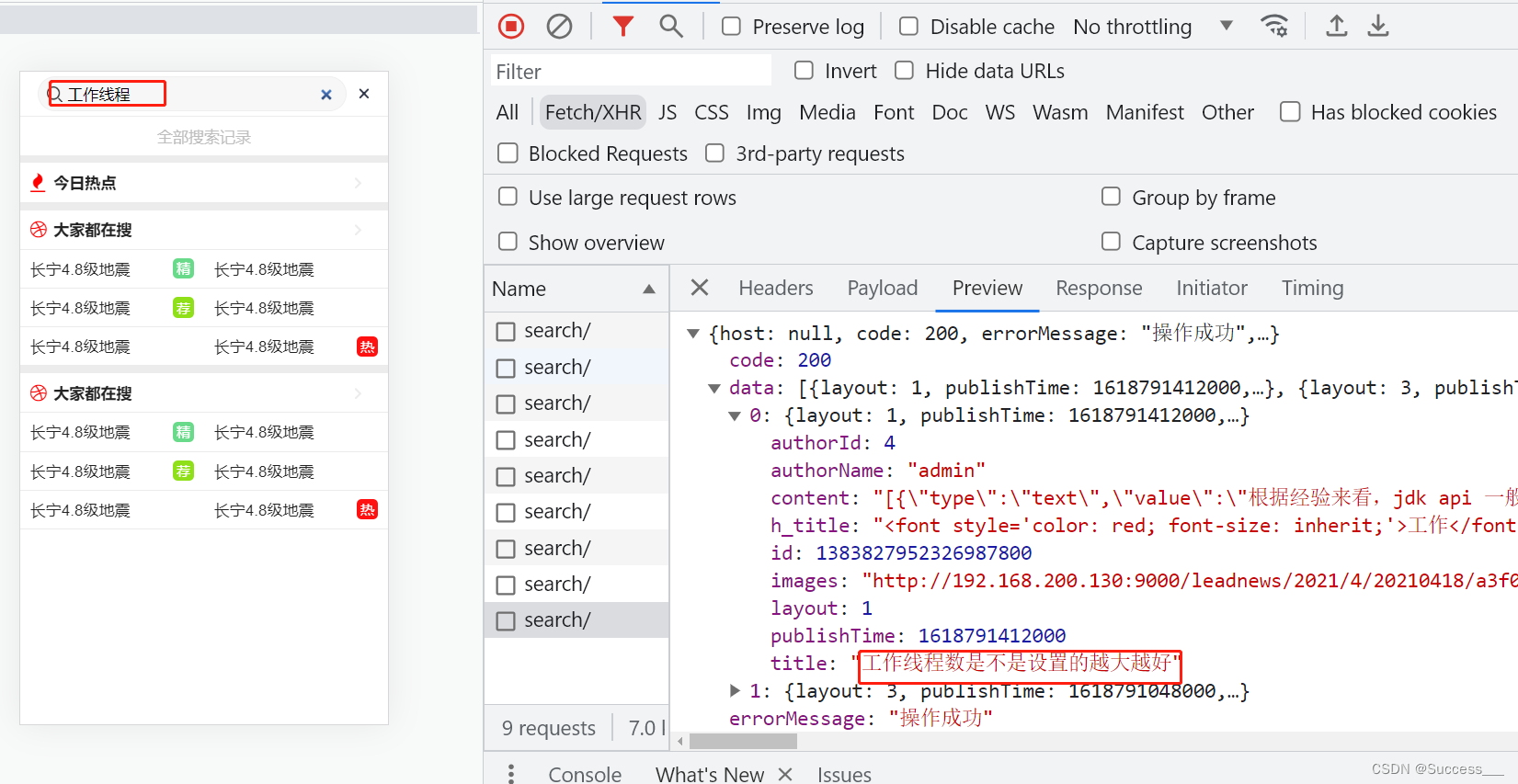
下一篇:ElasticSearch:项目实战(2)
相关文章:
ElasticSearch:项目实战(1)
es环境搭建参考:ElasticSearch:环境搭建步骤_Success___的博客-CSDN博客 需求: 用户输入关键可搜索文章列表 关键词高亮显示 文章列表展示与home展示一样,当用户点击某一篇文章,可查看文章详情 思路: …...

React 实现文件分片上传和下载
React 实现文件分片上传和下载 在开发中,文件的上传和下载是常见的需求。然而,当面对大型文件时,直接的上传和下载方式可能会遇到一些问题,比如网络传输不稳定、文件过大导致传输时间过长等等。为了解决这些问题,我们…...

2023.8.13
atcoder_abc\AtCoder Beginner Contest 310\E_NAND_repeatedly //题意:给定一个n长度的01串,计算f(l,r)(l<r,l在1~n,r在1~n)的和,f的计算(ai,a(i1))运算,有0就为1,11为0 //若f(l,r)1,则f(l,r-1)为0或sr为0,即只取决于上一位的情况和当前位ÿ…...

kvm not all arguments converted during string
kylin virt-manager 远程镜像制作问题记录(not all arguments ) 项目场景: 服务器端安装的OS版本:Kylin-Server-10-SP1-Release-Build20-20210518-arm64-2021-05-18 客户端安装的OS版本:Kylin-Server-10-SP1-Release-Build20-20210518-x86_…...

JVM 基础
巩固基础,砥砺前行 。 只有不断重复,才能做到超越自己。 能坚持把简单的事情做到极致,也是不容易的。 JVM 类加载机制 JVM 类加载机制分为五个部分:加载,验证,准备,解析,初始化&am…...

智谷星图赵俊:让人才和区块链产业“双向奔赴”丨对话MVP
区块链产业需要什么样的人才?赵俊很有发言权。 赵俊是北京智谷星图科技有限公司的技术总监,也是FISCO BCOS官方认证讲师。他2017年接触区块链,随后选择人才培育领域深耕。“为区块链行业引进更多人才这件事很有价值,跟我的职业理…...
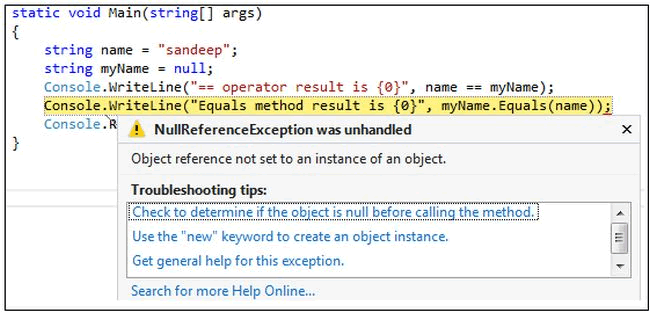
C# Equals()方法报错:NullReferenceException was unhandled
下面是一个C# Equals()方法的例子,执行时报错了 static void Main(string[] args) {string name "sandeep";string myName null;Console.WriteLine(" operator result is {0}", name myName);Console.WriteLine("Equals method result…...
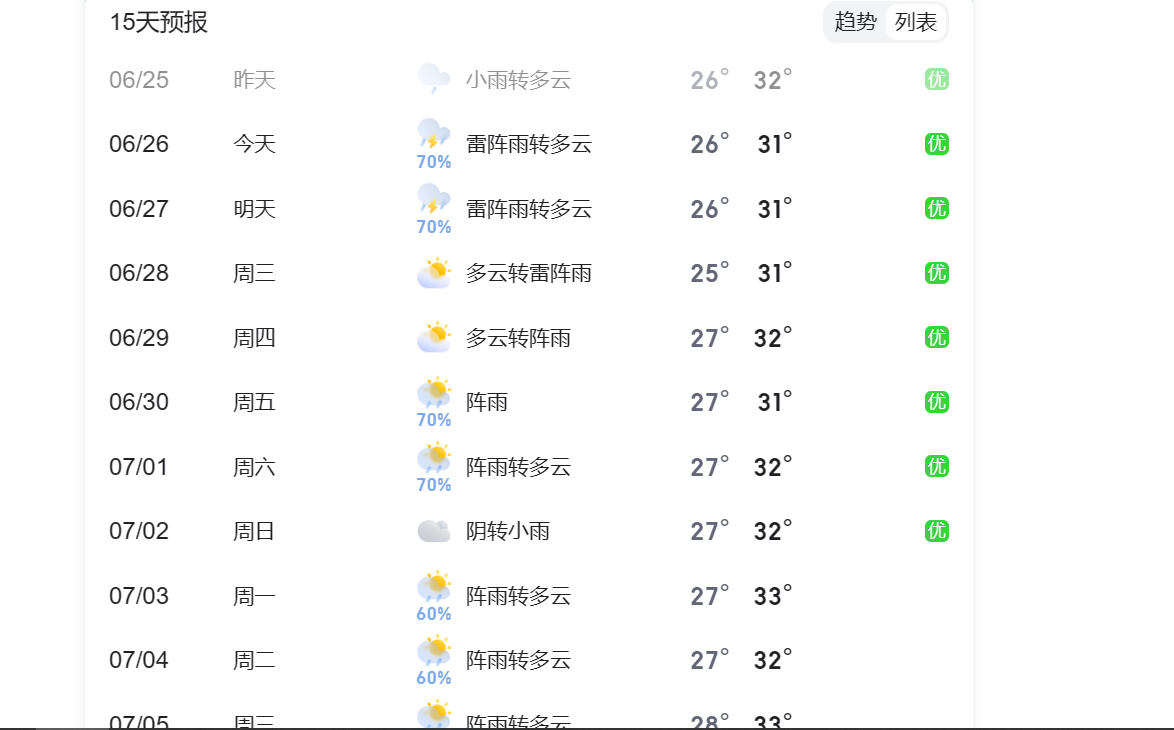
Linux下C语言调用libcurl库获取天气预报信息
一、概述 当前文章介绍如何在Linux(Ubuntu)下使用C语言调用libcurl库获取天气预报的方法。通过HTTP GET请求访问百度天气API,并解析返回的JSON数据,可以获取指定城市未来7天的天气预报信息。 二、设计思路 【1】使用libcurl库进…...

“深入解析JVM:Java虚拟机原理和内部结构“
标题:深入解析JVM:Java虚拟机原理和内部结构 摘要:本文将深入解析JVM(Java虚拟机)的原理和内部结构。我们将从JVM的基础概念开始,逐步介绍其组成部分,包括类加载器、运行时数据区、字节码解释器…...
 返回的list不能add,remove)
Arrays.asList() 返回的list不能add,remove
一.Arrays.asList() 返回的list不能add,remove Arrays.asList()返回的是List,而且是一个定长的List,所以不能转换为ArrayList,只能转换为AbstractList 原因在于asList()方法返回的是某个数组的列表形式,返回的列表只是数组的另一个视图,而数组本身并没…...
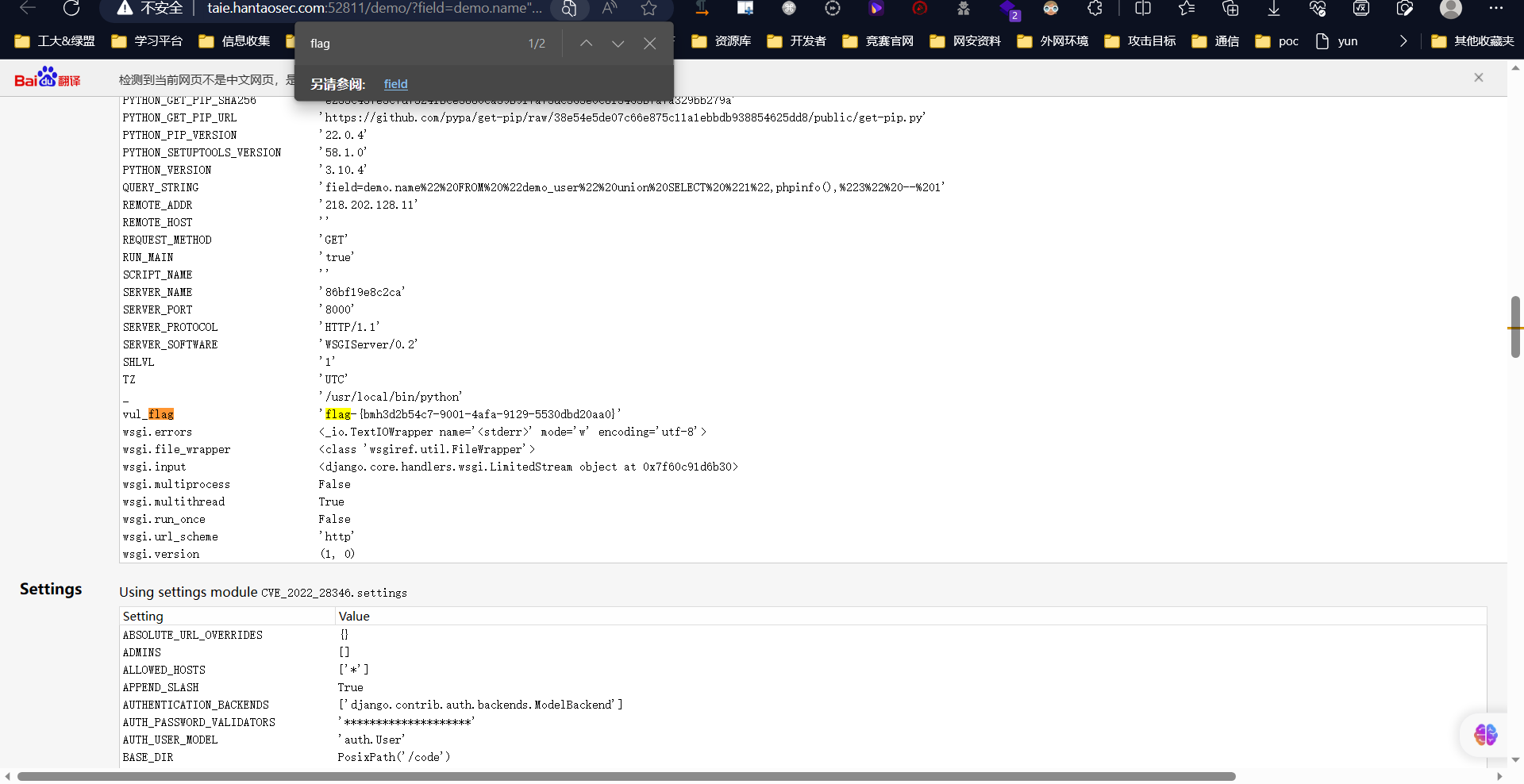
命令执行漏洞
1、命令执行漏洞 1.1、简介 Django是用Python开发的一个免费开源的Web结构,几乎包括了Web使用方方面面,能够用于快速建立高性能、文雅的网站,Diango提供了许多网站后台开发常常用到的模块,使开发者可以专注于业务部分。 1.2、漏…...

Hive 中 sort by 和 order by 的区别
文章目录 数据量大小区别作用范围 在 Hive 中, SORT BY 和 ORDER BY 都用于对查询结果进行排序,但它们在实现方式和适用场景上有一些区别。 数据量大小区别 SORT BY: SORT BY 用于在 Hive 中对查询结果进行排序,它的主要特点是在…...

网络资源利用最大化:爬虫带宽优化解决方案
大家好,作为一名专业的爬虫程序员,我们都知道在爬取大量数据的过程中,网络带宽是一个十分宝贵的资源。如果我们不合理地利用网络带宽,可能会导致爬虫任务的效率低下或者不稳定。今天,我将和大家分享一些优化爬虫带宽利…...

STDF - 基于 Svelte 和 Tailwind CSS 打造的移动 web UI 组件库,Svelte 生态里不可多得的优秀项目
Svelte 是一个新兴的前端框架,组件库不多,今天介绍一款 Svelte 移动端的组件库。 关于 STDF STDF 是一个移动端的 UI 组件库,主要用来开发移动端 web 应用。和我之前介绍的很多 Vue 组件库不一样,STDF 是基于近来新晋 js 框架 S…...
C语言一些有趣的冷门知识
文章目录 概要1.访问数组元素的方法运行结果 2.中括号的特殊用法运行结果 3.大括号的特殊用法运行结果 4.sizeof的用法运行结果 5.渐进运算符运行结果 小结 概要 本文章只是介绍一些有趣的C语言知识,纯属娱乐。这里所有的演示代码我是使用的编译器是Visual Studio …...

Oracle数据库审计
1.什么是审计 审计是用来监控和记录用户的数据库操作的 2.审计级别 语句审计权限审计对象审计 3.查看审计功能是否开启: show parameter audit;相关参数: audit_file_destOS中审计信息存放位置audit_sys_operations默认值为FALSE,即不审…...

Node.js新手在哪儿找小项目练手?
前言 可以参考一下下面的nodejs相关的项目,希望对你的学习有所帮助,废话少说,让我们直接进入正题>> 1、 NodeBB Star: 13.3k 一个基于Node.js的现代化社区论坛软件,具有快速、可扩展、易于使用和灵活的特点。它支持多种数…...
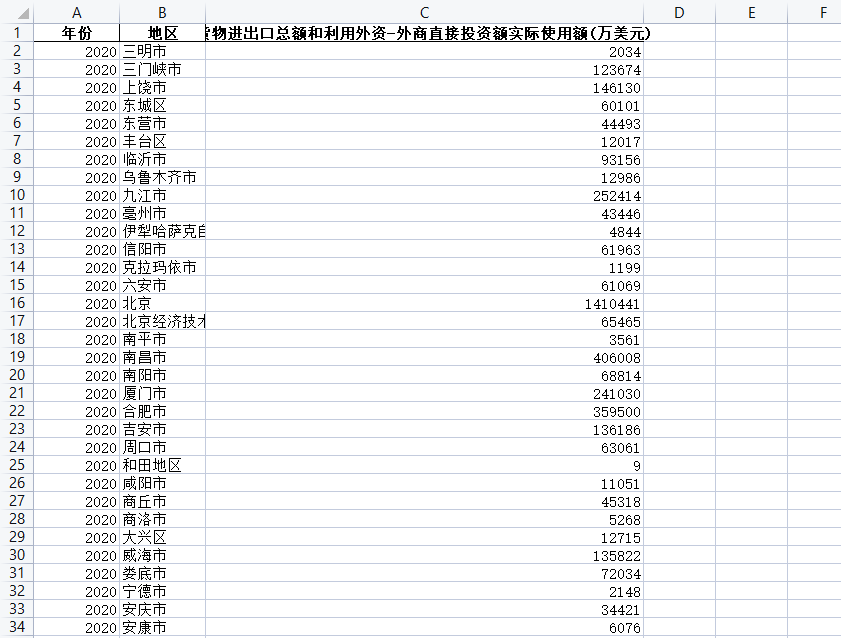
全国各城市-货物进出口总额和利用外资-外商直接投资额实际使用额(1999-2020年)
最新数据显示,全国各城市外商直接投资额实际使用额在过去一年中呈现了稳步增长的趋势。这一数据为研究者提供了对中国外商投资活动的全面了解,并对未来投资趋势和政策制定提供了重要参考。 首先,这一数据反映了中国各城市作为外商投资的热门目…...

CentOS 7查看磁盘空间
CentOS如何查看硬盘大小 CentOS是一种基于Linux的操作系统,主要用于服务器端应用。在服务器管理中,硬盘大小是一个非常重要的指标,查看硬盘大小可以帮助系统管理员有效地管理硬盘空间和避免硬盘满了的情况。 方法一:使用df命令 …...

基于PHP的轻量级博客typecho
本文完成于 5 月中旬,发布时未在最新版本上验证; 什么是 typecho ? Typecho 是一款基于 PHP 的博客软件,旨在成为世界上最强大的博客引擎。Typecho 在 GNU 通用公共许可证 2.0 下发布。支持多种数据库,原生支持 Markdo…...

VideoSrt:Windows平台免费视频字幕生成工具完整指南
VideoSrt:Windows平台免费视频字幕生成工具完整指南 【免费下载链接】video-srt-windows 这是一个可以识别视频语音自动生成字幕SRT文件的开源 Windows-GUI 软件工具。 项目地址: https://gitcode.com/gh_mirrors/vi/video-srt-windows 在当今视频内容爆炸的…...
)
别再手动算坐标了!用ROS tf2搞定机器人坐标系转换(附C++/Python代码对比)
别再手动算坐标了!用ROS tf2搞定机器人坐标系转换(附C/Python代码对比) 在机器人开发中,坐标系转换就像空气一样无处不在却又容易被忽视。想象一下,当激光雷达检测到前方1米处有个障碍物,这个"1米&quo…...
)
新手司机必看:直角转弯时,如何利用‘内轮差’原理避免剐蹭(附真实场景图解)
新手司机必看:直角转弯时,如何利用‘内轮差’原理避免剐蹭(附真实场景图解) 刚拿到驾照的小王最近遇到一件烦心事:在小区狭窄的直角转弯处,明明车头已经顺利通过,车身侧面却和路缘石来了个"…...
)
别再乱叠层了!四层、六层、八层PCB板分层实战指南(附Altium Designer设置要点)
多层PCB设计实战:从四层到八层的叠层策略与Altium Designer实现 在高速数字电路和射频系统设计中,PCB叠层结构的选择直接影响信号完整性、电源分配和电磁兼容性。许多工程师在面对四层、六层和八层板设计时,常常陷入"层数越多越好"…...

5步搞定MinGW-w64:在Windows上打造专业C/C++开发环境的终极指南
5步搞定MinGW-w64:在Windows上打造专业C/C开发环境的终极指南 【免费下载链接】mingw-w64 (Unofficial) Mirror of mingw-w64-code 项目地址: https://gitcode.com/gh_mirrors/mi/mingw-w64 你是否想在Windows系统上搭建一个功能完整、性能出色的C/C开发环境…...
Agent设计范式(3)Workflow / 状态机)
AI工程化设计(五)Agent设计范式(3)Workflow / 状态机
Workflow / 状态机:让 Agent 从“能跑”变成“可控运行”一、介绍1. 什么是 Workflow / 状态机在 Agent 设计中,Workflow / 状态机是一类非常“工程化”的范式。可以用一个直观的对比来理解:ReAct:边查边想Plan-and-Execute&#…...

JS Search 核心组件详解:索引策略、分词器与搜索算法的完美结合
JS Search 核心组件详解:索引策略、分词器与搜索算法的完美结合 【免费下载链接】js-search JS Search is an efficient, client-side search library for JavaScript and JSON objects 项目地址: https://gitcode.com/gh_mirrors/js/js-search JS Search 是…...

颠覆性视频生成革命:ComfyUI-FramePackWrapper如何将显存占用降低60%并重塑AI视频工作流
颠覆性视频生成革命:ComfyUI-FramePackWrapper如何将显存占用降低60%并重塑AI视频工作流 【免费下载链接】ComfyUI-FramePackWrapper 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-FramePackWrapper 在AI视频生成领域,开发者长期面临着…...

逆向工程深度实践:Cyberpunk 2077存档编辑器的架构解析与高级应用
逆向工程深度实践:Cyberpunk 2077存档编辑器的架构解析与高级应用 【免费下载链接】CyberpunkSaveEditor A tool to edit Cyberpunk 2077 sav.dat files 项目地址: https://gitcode.com/gh_mirrors/cy/CyberpunkSaveEditor CyberpunkSaveEditor是一款基于逆向…...

5分钟掌握Diff Checker:终极免费文本差异对比工具使用指南
5分钟掌握Diff Checker:终极免费文本差异对比工具使用指南 【免费下载链接】diff-checker Desktop application to compare text differences between two files (Windows, Mac, Linux) 项目地址: https://gitcode.com/gh_mirrors/di/diff-checker 还在为代码…...