Flink-串讲面试题
1. 概念
有状态的流式计算框架
可以处理源源不断的实时数据,数据以event为单位,就是一条数据。
2. 开发流程
先获取执行环境env,然后添加source数据源,转换成datastream,然后使用各种算子进行计算,使用sink算子指定输出的目的地,最后调用execute方法执行。
3. flink运行模式
- standalone
- yarn
- k8s
4. flink部署模式(yarn)
- session
- 先启动集群,再提交job到集群
- per-job
- 一个job启动一个集群
- aplication
- 一个job启动一个集群
per-job和application区别:
- 提交代码位置不一样,单作业模式的main方法在客户端执行,应用模式的main方法在JobManager执行
应用模式是生产上主要提交模式,单作业模式和应用模式都是一个job启动一个集群,所以可以做到资源隔离,而会话模式是多个job分享一个集群,适合小作业共享。
5. 运行时架构
- Client
- 解析代码,提交作业
-
JobManager
-
管理节点,任务切分分配
-
dispatcher:将job传递给Jobmaster
-
resourManager:申请资源
-
JobMaster:切分任务
-
Checkpointcoordinator:向数据源注入barrier
-
-
TaskManager
-
执行任务计算
-
资源最小单位slot ,算子就是我们task任务
-
6. 基本概念
6.1.task和subtask区别?
一个算子(map,filter,flatmap)就是一个task
算子并行子任务就是subtask
6.2 task和slot的关系
一个task的子任务不能在一个slot中执行
一个slot中可以执行不同算子的subtask
6.3 并行度的优先级
算子 > 全局env > 提交命令行 > 配置文件
6.4 算子链路的合并
多个subtask组成一个大的subtask
条件:
- 前后算子的并行度一致
- forward(数据分区规则)
- subtask必须在一个共享槽(.slotSharingGroup("default"), 在一个slot槽中执行)
算子合并优点和缺点 ?
- 优点
- 节省数据传输IO
- 缺点
- 如果有subtask计算逻辑复杂会有抢占资源问题
如何禁用算子链?
env.disableOperatorChaining()
如何设置不同的共享槽?
.slotSharingGroup("aa")
6.5 流图转化
| 产生 | 发送 | 做了什么事情 | |
|---|---|---|---|
| StreamGraph | Client | Client | 代码解析 |
| JobGraph | Client | JM | 算子链的合并 |
| ExecutionGraph | JM | TM | 并行子任务显示 |
| 物理执行图 |
6.6 per-job模式提交作业流程
- 客户端提交代码,解析参数 生成StreamGraph
- 由StreamGraph生成jobGraph,主要是做了算子链合并
- 封装参数 提交给集群yarn 的RM
- yarn找一个NM,启动JM
- 启动dispatcher,RM,Jobmaster,生成executionGraph
- 向JM的RM申请资源,然后去找Yarn的RM申请资源,创建TM启动slot
- 注册slot,分配任务
7. API
7.1 source
kafkasource(算子状态,保存offset)
7.2 transform
- 单流:map,flatmap,filter
- keyby :sum, min, max ,reduce
- 侧输出流
- 物理分流算子:shuffle,forwawrd,rebalance(默认),rescale
- union(类型要求一致) connect(可以不一致)
7.3 sink
kafkasink,dorissink, jdbcsink, filesink
7.4 join
- API
- windowjoin
- interval join :两条实时流去根据范围关联,如果一些迟到特别久的数据关联不上
- SQL
- 常规join(比如left join ,支持回撤流)
- lookupjoin:读取外部系统数据,可以缓存, 适用于数据量小,而且基本不变化的表(比如字典表)
- interval join
- window tvf函数 :累积函数,滚动,滑动
8. 时间语义
- 事件时间:业务数据推动,获取数据中时间戳,推进时间
- 处理时间:获取操作系统时间
- 摄入时间:数据进入到flink集群的系统时间
- 共同点
- 时间不能倒退,单调递增
- 区分
- (处理时间)速度稳定,不能停滞
- (事件时间)速度不稳定,可能会停滞
9. WaterMark
9.1 你对watermakr的理解
逻辑时钟,单调递增,解决乱序迟到问题
9.2 水位线传递
- 一对多:广播水位线
- 多对一:取最小
- 多对多:先广播,再取最小
场景题:上游算子发生数据倾斜,某一个subtask没有数据,水位线无法抬升怎么办?
解决办法:
调用withIdleness()方法,如果某一个subtask没有数据,超过了空闲等待时间,那么放弃使用这个subtask的水位线。
9.3 迟到数据问题如何解决?
- 设置乱序时间:针对于迟到时间短的数据
- 窗口延迟关闭:迟到中级
- 侧输出流:迟到特别长
9.4 水位线注入规则
当前最大时间戳 - 乱序时间 - 1ms
10. 窗口
概念:无界流切分为有界流, 集合中是一个个的桶
10.1 分类
- 滑动
- 滚动
- 会话:按照时间间隔划分窗口
10.2 四大组成
- assigner:分配器
- trigger :触发窗口计算
- evictor:驱逐器,清除窗口数据
- 聚合逻辑:增量聚合, 全量聚合(reduce aggregate)
场景问题:表的字段有mid timestamp price ,要求算当前累积GMV, 5分钟输出一次
解决方案:
- 第1种方案:windowtvf函数 Cumulate Windows
- 第2种方案:用滚动窗口 1天 ,实现ContinuousEventTimeTrigger,自定义每5分钟输出一次
10.3 核心概念
划分(数据属于哪个窗口)
开一个5s滚动窗口 数据是3s 会落到哪个窗口:0-5 3-8
结论:窗口的向下取整
timestamp - (timestamp - offset) % windowSize
生命周期
创建:属于窗口第一条数据到来
销毁:事件时间 >= 窗口长度 +允许迟到时间
左闭右开
endtime -1ms
10.4 设置乱序时间 和窗口延迟关闭时间 有什么区别?
5s滚动窗口 乱序时间设置2s 销毁时间5s (7s数据过来时候,时间推进到5s)
5s滚动窗口 窗口延迟关闭2s 销毁时间7s (7s数据过来时候,时间推进到7s)
结论:
设置乱序时间,并不会影响窗口销毁时间,影响时间推进规则,窗口延迟关闭时间影响窗口的关闭时间。
举个栗子:
10s滚动窗口,设置乱序时间5s,窗口延迟关闭时间5s
窗口销毁:水位线15s时候销毁, 数据携带20s及以上过来触发窗口销毁
11. 状态
概念:用户定义的一些变量
状态数据是交由Flink托管的,考虑程序数据的恢复
11.1 分类
- 算子状态:每个subtask
- list:恢复状态时候轮询
- unionlist:广播
- 键控状态:每个key去维护的状态
- value map list reduce aggregate
11.2 状态后端
| 本地 | 远端 | |
|---|---|---|
| hashmap | TM堆内存 | hdfs |
| rocksdb | rocksdb | hdfs |
使用场景:rocksdb存储数据量级别比hashmap大
11.3 状态后端场景选择
企业中大状态场景选用的rocksdb ,大状态场景优化
举个例子:
用户新老访客修复 1000w用户 1k ≈ 10G
rocksdb支持:增量检查点 、 本地恢复 、预定义选项
11.4 TTL
状态的过期时间是由哪个类设置的:
StateTttlConfig
12. 容错机制
12.1 端到端一致性 (kafka flink kafka)
源头:offset可重发
Flink:checkpoint
sink:事务(2pc 预写日志) 幂等
12.2 checkpoint流程
- JM的checkpoint协调器发送命令startcheckpint开始
- 定期向数据源注入barrier (特殊事件,不会跳过数据向下游发送)
- barrier随数据流过每个subtask
- barrier到每个算子,将本地状态快照到hdfs文件系统,快照完之后acks应答(barrier之前的数据已经进入kafka,预提交)
- JM中协调器收到所有算子的acks,标志所有快照做完,向算子分发消息
- 正式提交kafka
12.3 barrier
- 精确一次性
- barrier对齐:等待所有barrier到来,快照,等待的时候将数据缓存不处理
- 1.11版本,barrier不对齐,状态数据和缓存数据同时快照
- 至少一次
- barrier对齐:等待所有barrier到来,快照,数据直接向下游传递,不阻塞在缓存中
- 问题:出现意外恢复,状态中有重复数据问题
12.4 savepoint 和checkpoint区别
- checkpoint:自动帮我做
- savepoint手动:配置文件指定savepoint的路径,取消任务触发保存点停止
场景:程序升级 (算子增加,算子减少)
增加uid
13. FlinkSql
Flinksql如何转化成底层的api?
使用calcite解析语法树
sql转化 ast语法树 逻辑执行 物理执行 底层api执行
14. Flink生产经验
14.1 提交任务脚本
bin/flink run
-d 后台运行
-D 并行度 5
-D JM内存 1~4 G
-D TM内存 4~8 G
-D TM的slot个数 3(1~4)
-c 主类
./jar包
如果并行设置为5个,slot个数设置为3个,那么会启动2个TM
14.2 TM内存模型
- JVM
- 元空间
- 执行开销
- FLink内存
- 堆内:框架内存,task计算内存(分配,剩余内存)
- 堆外:框架内存,task计算内存(0) 网络内存(组件之间交互,算子缓存区) 托管内存(状态数据)
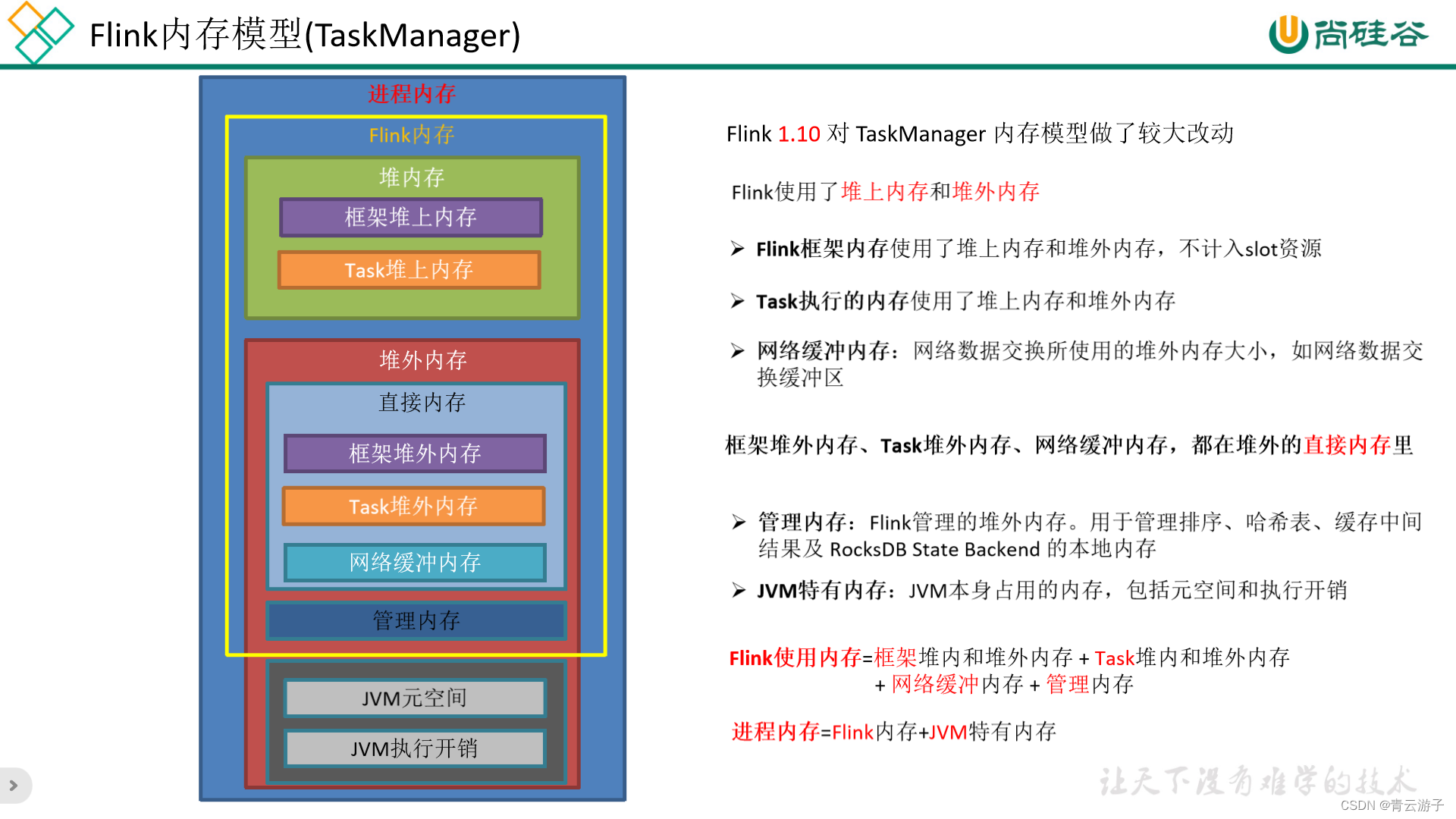
14.3 Flink部署多少台机器
FLink充当客户端, ds的worker节点都需要部署
如果是streampark:需要部署一台
15. Flink和sparkstreaming区别 /Flink优点
| Flink | sparkstreaming | |
|---|---|---|
| 模型 | 流式 | 微批次 |
| 时间 | 丰富 | 处理时间 |
| 乱序 | 解决 | 不能解决 |
| 窗口 | 多灵活 | 窗口长度必须是批次整数倍 |
| 容错机制 | 有 | 没有 |
| 状态 | 有 | 没有 |
16. Flink的Interval Join的实现原理?Join不上的怎么办?
底层调用的是keyby + connect ,处理逻辑:
(1)判断是否迟到(迟到就不处理了,直接return)
(2)每条流都存了一个Map类型的状态(key是时间戳,value是List存数据)
(3)任一条流,来了一条数据,遍历对方的map状态,能匹配上就发往join方法
(4)使用定时器,超过有效时间范围,会删除对应Map中的数据(不是clear,是remove)
Interval join不会处理join不上的数据,如果需要没join上的数据,可以用 coGroup+join算子实现,或者直接使用flinksql里的left join或right join语法。
17. Flink的keyby怎么实现的分区?分区、分组的区别是什么?
分组和分区在 Flink 中具有不同的含义和作用:
分区:分区(Partitioning)是将数据流划分为多个子集,这些子集可以在不同的任务实例上进行处理,以实现数据的并行处理。
数据具体去往哪个分区,是通过指定的 key 值先进行一次 hash 再进行一次 murmurHash,通过上述计算得到的值再与并行度进行相应的计算得到。
分组:分组(Grouping)是将具有相同键值的数据元素归类到一起,以便进行后续操作(如聚合、窗口计算等)。key 值相同的数据将进入同一个分组中。
注意:数据如果具有相同的 key 将一定去往同一个分组和分区,但是同一分区中的数据不一定属于同一组。
相关文章:
Flink-串讲面试题
1. 概念 有状态的流式计算框架 可以处理源源不断的实时数据,数据以event为单位,就是一条数据。 2. 开发流程 先获取执行环境env,然后添加source数据源,转换成datastream,然后使用各种算子进行计算,使用s…...
如何培养对技术的热爱
这篇博文主要针对计算机专业相关的同学,对于理工科专业的同学有一定的借鉴意义,对于其他专业的同学,还请自行取舍。 背景 初学计算机,可能并不是每个人都能对其产生兴趣,更不要说从其中获得快乐。对于如何培养兴趣&a…...
Vue响应式数据的原理
在 vue2 的响应式中,存在着添加属性、删除属性、以及通过下标修改数组,但页面不会自动更新的问题。而这些问题在 vue3 中都得以解决。 vue3 采用了 proxy 代理,用于拦截对象中任意属性的变化,包括:属性的读写、属性的…...
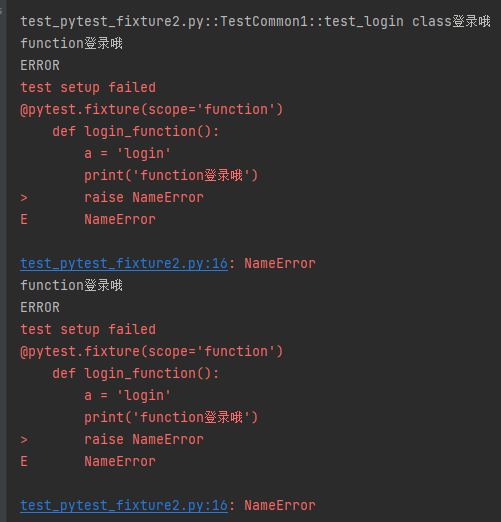
pytest fixture 用于teardown工作
fixture通过scope参数控制setup级别,setup作为用例之前前的操作,用例执行完之后那肯定也有teardown操作。这里用到fixture的teardown操作并不是独立的函数,用yield关键字呼唤teardown操作。 举个例子: 输出: 说明&…...
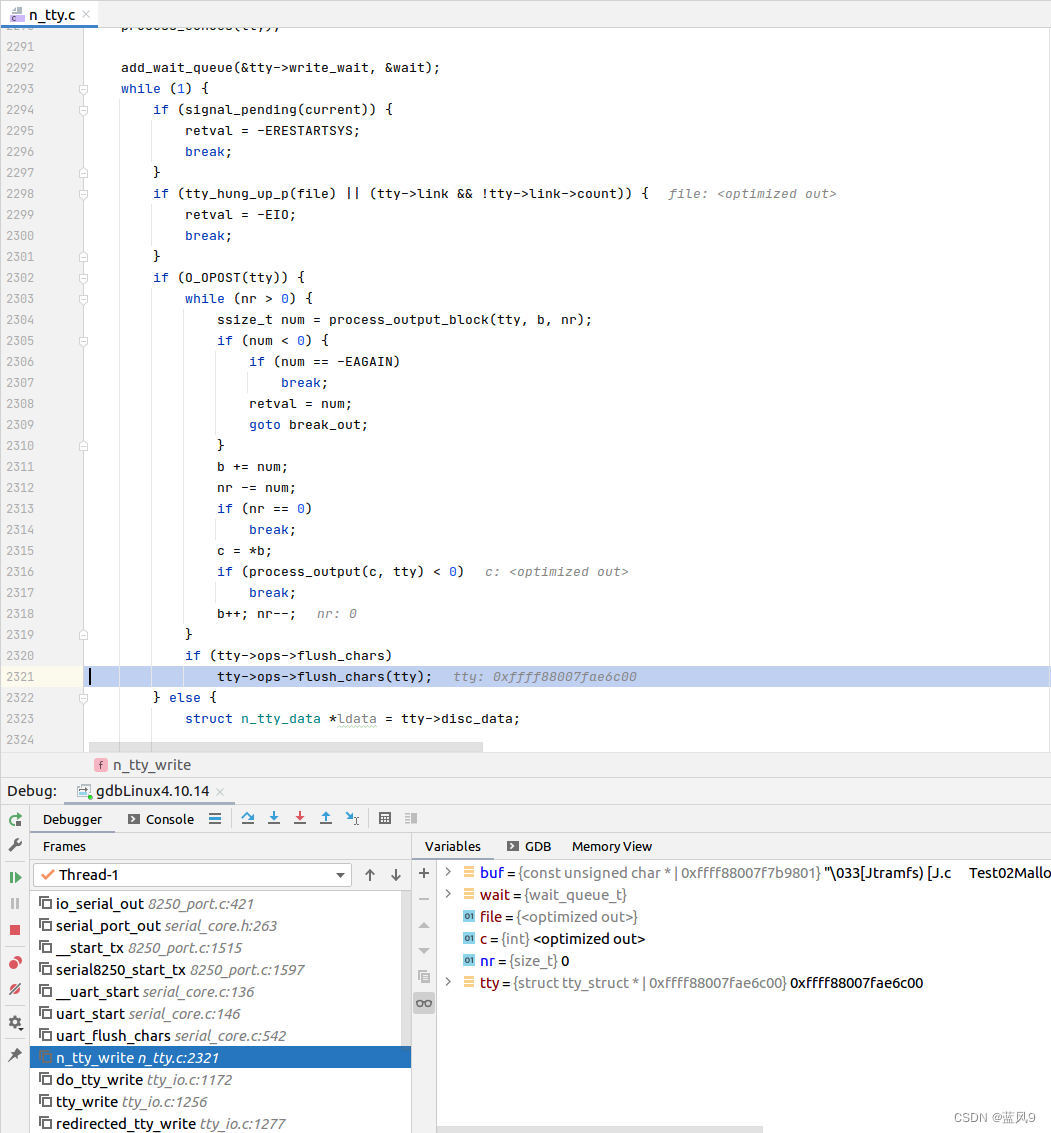
39 printf 的输出到设备层的调试
前言 在前面 printf 的调试 我们只是调试到了 glibc 调用系统调用, 封装了参数 stdout, 带输出的字符缓冲, 以及待输出字符长度 然后内核这边 只是到了 write 的系统调用, 并未向下细看 我们这里 稍微向下 细追一下, 看看 到达设备层面 这里是怎么具体的 impl 的 测试用例…...
)
数字普惠金融、数字创新与经济增长—基于省级面板数据的实证考察(2011-2021年)
参照陈啸(2023)的做法,本对来自经济问题《数字普惠金融、数字创新与经济增长——基于省级面板数据的实证考察》一文中的基准回归部分进行复刻。数字普惠金融、数字创新已经成为驱动经济高质量发展的关键。利用省级面板数据,构建固…...

控制renderQueue解决NGUI与Unity3D物体渲染顺序问题
NGUI与Unity3D物体渲染顺序问题,做过UI的各位应该都遇到过。主要指的是UI与Unity制作的特效、3D人物等一同显示时的层次问题。 由于UI与特效等都是以transparent方式渲染,而Unity与NGUI在管理同是透明物体的render queue时实际上互相没有感知࿰…...

概率论与数理统计:第二、三章:一维~n维随机变量及其分布
文章目录 Ch2. 一维随机变量及其分布1.一维随机变量1.随机变量2.分布函数 F ( x ) F(x) F(x)(1)定义(2)分布函数的性质 (充要条件)(3)分布函数的应用——求概率3.最大最小值函数 2.一维离散型随机变量及其概率分布(分布律)3.一维连续型随机变量及其概率分布(概率密度)4.一般类型…...

BOLT- 识别和优化热门的基本块
在BOLT中,识别和优化热门的基本块之所以关键,是因为BOLT的主要目标是优化程序以更好地利用硬件特性,特别是指令缓存(ICache)。以下是BOLT如何识别和优化热门基本块的流程: 收集性能数据: BOLT开始的时候并不…...
:函数详解)
Golang 中的 time 包详解(四):函数详解
在日常开发过程中,会频繁遇到对时间进行操作的场景,使用 Golang 中的 time 包可以很方便地实现对时间的相关操作。接下来的几篇文章会详细讲解 time 包,本文讲解一下 time 包中的函数。 func Now() Time 返回当前的系统时间。 package mai…...

【前端 | CSS】5种经典布局
页面布局是样式开发的第一步,也是 CSS 最重要的功能之一。 常用的页面布局,其实就那么几个。下面我会介绍5个经典布局,只要掌握了它们,就能应对绝大多数常规页面。 这几个布局都是自适应的,自动适配桌面设备和移动设备…...

腾讯云宣布VPC网络架构重磅升级,可毫秒级感知网络故障并实现自愈
8月11日,腾讯云宣布VPC(Virtual Private Cloud,云私有网络)架构重磅升级。新架构采用多项腾讯核心自研技术,能够支撑用户构建业界最大 300万节点超大规模单VPC网络,并将转发性能最大提升至业界领先的200Gbp…...
vue 路由页面跳转
从index.vue跳转到data.vue index.vue <el-table-column label"客户数" align"center" :show-overflow-tooltip"true"><template slot-scope"scope"><router-link :to"/system/enterprise-data/index/ scope.ro…...

Vue toRefs:在Vue中不失去响应式的情况下解构属性
Vue toRefs:在Vue中不失去响应式的情况下解构属性 文章目录 Vue toRefs:在Vue中不失去响应式的情况下解构属性什么是响应式?解构Props的挑战使用toRefs保持响应式结论 在Vue开发中,我们经常会在组件之间传递数据。这时候ÿ…...

自定义element-plus的弹框样式
项目中弹框使用频繁,需要统一样式风格,此组件可以自定义弹框的头部样式和内容 一、文件结构如下: 二、自定义myDialog组件 需求: 1.自定义弹框头部背景样式和文字 2.自定义弹框内容 3.基本业务流程框架 components/myDialog/index.vue完整代码: &…...

Linux:iptables防火墙
目录 绪论 1、防火墙 1.1 保护范围 1.2 网络协议划分 1.3 协议:tcp 1.4 四表 1.5 五链 1.6 iptables的规则 1.7 匹配顺序 流入本机:prerouting ------->iuput---------->用户进程(httpd服务)------请求--------响应--------->数据要返…...

MongoDB文档-进阶使用-spring-boot整合使用MongoDB---MongoTemplate完成增删改查
传送门: MongoDB文档--基本概念_一单成的博客-CSDN博客 MongoDB文档--基本安装-linux安装(mongodb环境搭建)-docker安装(挂载数据卷)-以及详细版本对比_一单成的博客-CSDN博客 MongoDB文档--基本安装-linux安装&…...
)
设计模式十四:责任链模式(Chain of Responsibility Pattern)
责任链模式(Chain of Responsibility Pattern)是一种行为设计模式,它允许你将请求沿着处理者链进行传递,直到有一个处理者能够处理该请求。 在责任链模式中,多个处理者对象被连接成一个链。当接收到一个请求时…...

将商城项目放到docker-centos7中
1、docker pull centos:7 2、docker run -d -it --privileged 仓库名称/shopcentos:1.1 /usr/sbin/init 注意: /usr/sbin/init 必须加,否则没法使用systemctl启动mysql 3、安装mysql教程 安装msyql教程:https://blog.csdn.net/davice_li…...

C# Winform 自动获取 软件版本号
C# Winform如何自动获取版本号 方案一 缺点是不适配,clickones发布的版本 public static string GetVersion() {try {return System.Deployment.Application.ApplicationDeployment.CurrentDeployment.CurrentVersion.ToString();}catch{return System.Ref…...
)
为什么你的Dify知识库召回率低于62%?文档解析配置中被低估的7个语义锚点参数(附AB测试压测报告)
第一章:Dify知识库召回率失衡的根因诊断Dify知识库召回率失衡并非单一模块故障所致,而是语义理解、向量化策略与检索逻辑三者耦合失效的结果。典型表现为高相关文档未被召回(漏召),或低相关文档大量混入(误…...

SQLite JDBC 驱动:Java 生态中的原生数据库访问架构深度解析
SQLite JDBC 驱动:Java 生态中的原生数据库访问架构深度解析 【免费下载链接】sqlite-jdbc SQLite JDBC Driver 项目地址: https://gitcode.com/gh_mirrors/sq/sqlite-jdbc SQLite JDBC 驱动为 Java 应用提供了访问 SQLite 数据库的标准 JDBC 接口࿰…...

严肃面试官与搞笑程序员谢飞机:互联网大厂Java面试故事
严肃面试官与搞笑程序员谢飞机:互联网大厂Java面试故事 第一轮提问:基础打底 面试官:谢先生,我们先从基础问题开始吧。请问 HashMap 是线程安全的吗?为什么? 谢飞机:不是,因为它不是…...
)
保姆级教程:在Ubuntu 18.04上为ORB-SLAM2添加彩色点云地图(含PCL库避坑指南)
在Ubuntu 18.04上实现ORB-SLAM2彩色点云地图的全流程指南 当第一次看到ORB-SLAM2生成的稀疏特征点时,我意识到视觉SLAM的潜力远不止于此。直到成功运行彩色点云建图版本,那种从二维图像到三维稠密重建的震撼感,才真正让我理解了SLAM技术的魅力…...

5 款 AI 写论文哪个好?2026 实测:真文献 + 实图表,虎贲等考 AI 成毕业论文首选
毕业季选 AI 写论文工具,最纠结的莫过于 “5 款 AI 写论文哪个好”—— 通用 AI 文献造假、轻量工具功能残缺、专项平台适配不足,能同时满足真实文献、可溯源数据、学术规范图表、全流程写作的工具少之又少。经过对 5 款主流 AI 论文工具的深度实测&…...

Windows Cleaner终极指南:3分钟解决C盘爆红,让电脑重获新生!
Windows Cleaner终极指南:3分钟解决C盘爆红,让电脑重获新生! 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner "上周我的C盘…...

窗口管理革命:PinWin如何用一键置顶彻底改变你的多任务工作流
窗口管理革命:PinWin如何用一键置顶彻底改变你的多任务工作流 【免费下载链接】PinWin Pin any window to be always on top of the screen 项目地址: https://gitcode.com/gh_mirrors/pin/PinWin 你是否曾因频繁切换窗口而打断工作思路?是否在编…...

【含最新安装包】OpenClaw 2.6.4 环境搭建与一键部署全流程
OpenClaw(小龙虾)Windows 一键部署保姆级教程 | 10 分钟养出你的数字员工【点击下载最新安装包】 适配平台:Windows 10/11(64 位)|新手友好|全程可视化操作|无技术门槛 点击下方链…...

别再踩坑了!Windows 10/11上SQL Server 2019 Developer版保姆级安装与SSMS配置全流程
Windows 10/11上SQL Server 2019 Developer版零失败安装指南 第一次在Windows上安装SQL Server 2019 Developer版时,我遇到了各种奇怪的问题——安装程序卡在某个步骤、服务无法启动、SSMS连接失败...后来才发现,很多问题其实都有简单的预防措施。本文将…...

3分钟掌握网盘直链下载:告别限速的高效解决方案
3分钟掌握网盘直链下载:告别限速的高效解决方案 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云盘 /…...