机器学习实战4-数据预处理
文章目录
- 数据无量纲化
- preprocessing.MinMaxScaler(归一化)
- 导库
- 归一化
- 另一种写法
- 将归一化的结果逆转
- preprocessing.StandardScaler(标准化)
- 导库
- 实例化
- 查看属性
- 查看结果
- 逆标准化
- 缺失值
- impute.SimpleImputer
- 另一种填充写法
- 处理分类型特征:编码与哑变量
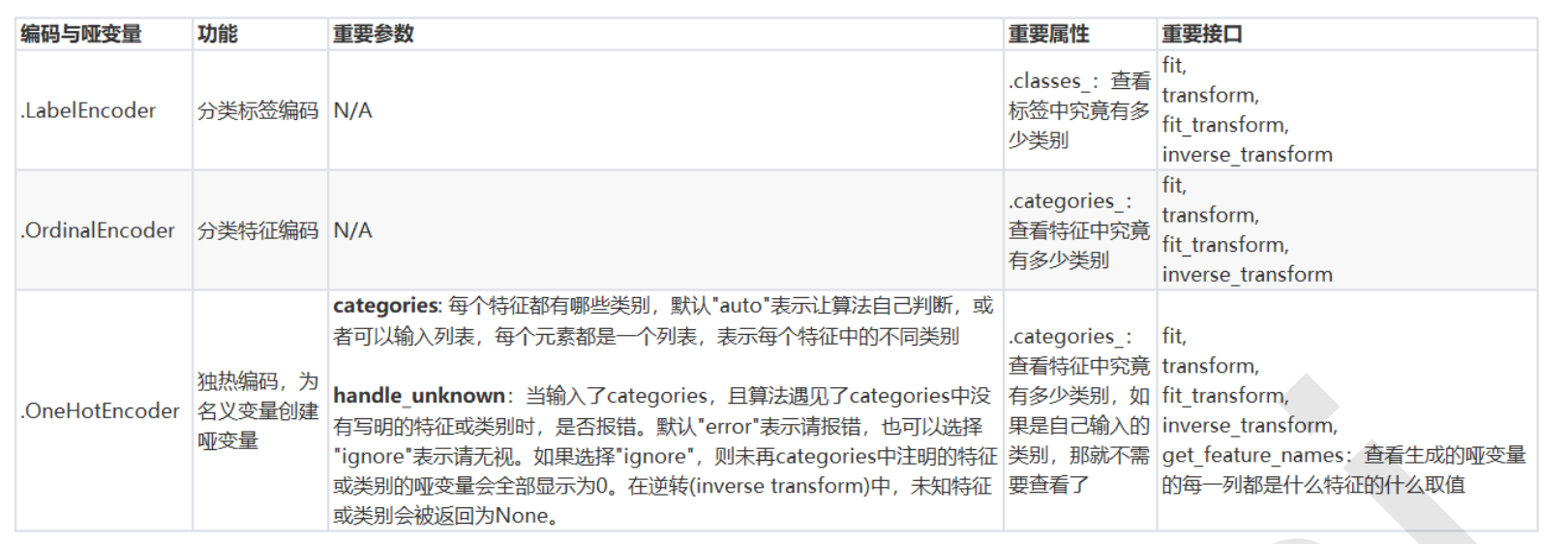
- preprocessing.LabelEncoder:标签专用,能够将分类转换为分类数值
- preprocessing.OrdinalEncoder:特征专用,能够将分类特征转换为分类数值
- preprocessing.OneHotEncoder:独热编码,创建哑变量
- 处理连续性特征:二值化与分段
- sklearn.preprocessing.Binarizer
- preprocessing.KBinsDiscretizer
数据无量纲化

preprocessing.MinMaxScaler(归一化)

导库
from sklearn.preprocessing import MinMaxScaler
data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]]
归一化
# 实现归一化
scaler = MinMaxScaler() #实例化
scaler = scaler.fit(data) #在这里本质是生成min(x), 和max(x)
result = scaler.transform(data) # 通过接口导出结果
result
另一种写法
scaler = MinMaxScaler() #实例化
result_ = scaler.fit_transform(data) # 训练和导出结果一步达成
result_


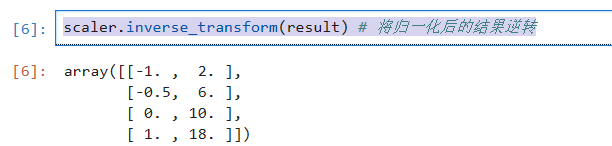
将归一化的结果逆转
scaler.inverse_transform(result) # 将归一化后的结果逆转

用numpy实现归一化
import numpy as np
X = np.array([[-1, 2], [-0.5, 6], [0, 10], [1, 18]])
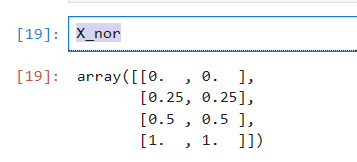
# 归一化
X_nor = (X - X.min(axis=0)) / (X.max(axis=0) - X.min(axis=0))
X_nor
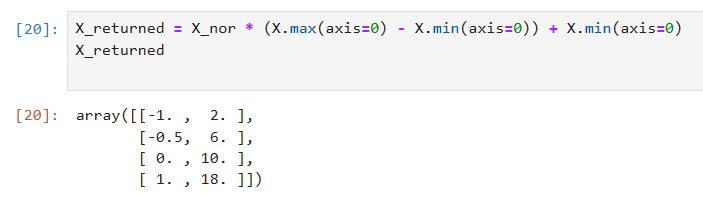
逆转
X_returned = X_nor * (X.max(axis=0) - X.min(axis=0)) + X.min(axis=0)
X_returned
preprocessing.StandardScaler(标准化)

导库
from sklearn.preprocessing import StandardScaler
data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]]
实例化
scaler = StandardScaler() # 实例化
scaler.fit(data) # 本质是生成均值和方差
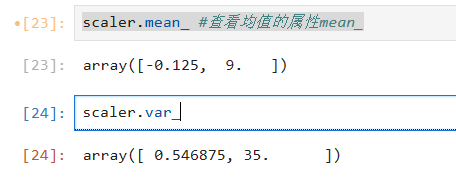
查看属性
scaler.mean_ #查看均值的属性mean_
scaler.var_ # 查看方差的属性var_
查看结果
x_std = scaler.fit_transform(data)
x_std


逆标准化
return_x = scaler.inverse_transform(x_std)
return_x


关于如何选择这两种无量纲化的方式要具体问题具体分析,但是我们一般在机器学习算法中选择标准化,这就好比我们能让他符合标准正态分布为什么不呢?而且MinMaxScaler对异常值很敏感,如果有一个很大的值会把其他值压缩到一个很小的区间内
缺失值

impute.SimpleImputer

导库
import pandas as pd
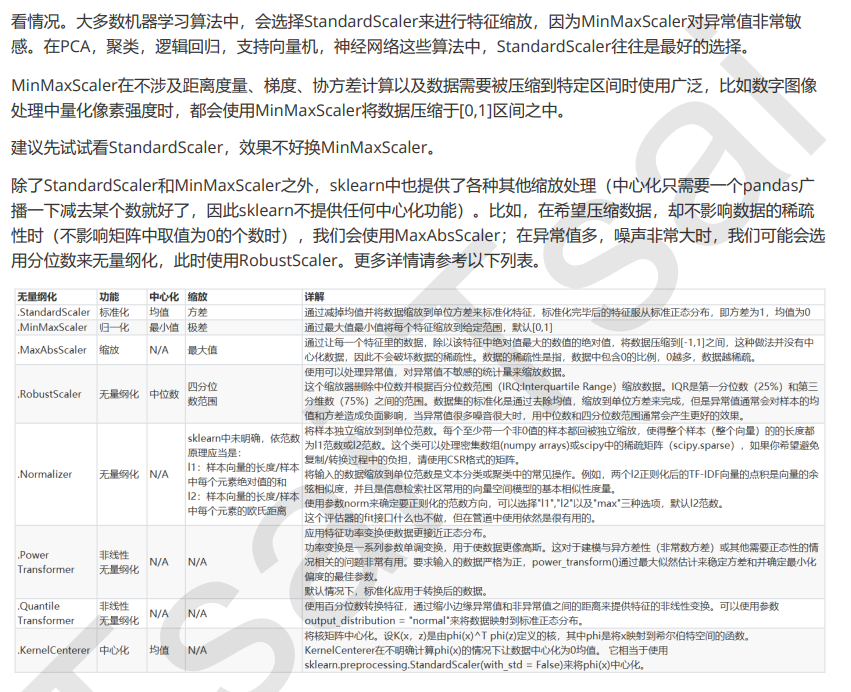
data = pd.read_csv(r"C:\Users\cxy\OneDrive\桌面\【机器学习】菜菜的sklearn课堂(1-12全课)\03数据预处理和特征工程\Narrativedata.csv",index_col=0 # 告诉python第0列是索引不是属性)
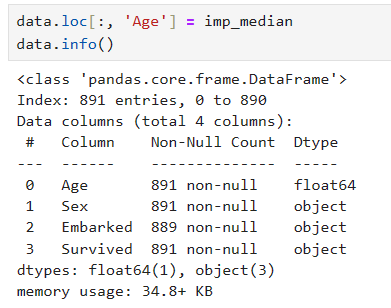
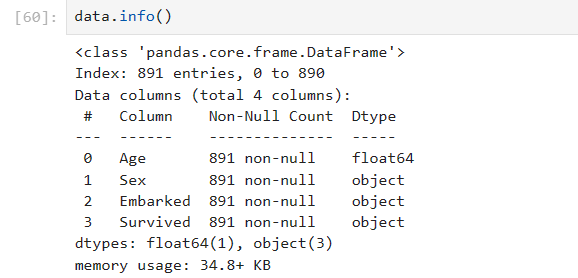
data.info()
提取出我们要填补的列
Age = data.loc[:, 'Age'].values.reshape(-1, 1) # reshape()能够将数据升维的方法
建模
from sklearn.impute import SimpleImputer
imp_mean = SimpleImputer() #实例化默认均值填补
imp_median = SimpleImputer(strategy='median') # 用中位数填补
imp_0 = SimpleImputer(strategy='constant', fill_value=0) # 用0填补
imp_mean = imp_mean.fit_transform(Age)
imp_median = imp_median.fit_transform(Age)
imp_0 = imp_0.fit_transform(Age)
用均值填补的结果
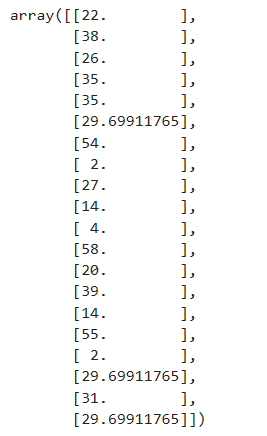
用中位数填补的结果

用0填补的结果

在实际中我们会直接把那两个缺失的数据直接删除
# 使用众数填补空缺值
Embarked = data.loc[:, 'Embarked'].values.reshape(-1, 1) # reshape()能够将数据升维的方法
imp_mode = SimpleImputer(strategy='most_frequent')
imp_mode = imp_mode.fit_transform(Embarked)
data.loc[:, "Embarked"] = imp_mode
另一种填充写法
导库
import pandas as pd
data_ = pd.read_csv(r"C:\Users\cxy\OneDrive\桌面\【机器学习】菜菜的sklearn课堂(1-12全课)\03数据预处理和特征工程\Narrativedata.csv",index_col=0 # 告诉python第0列是索引不是属性)
data_.head()
填补
data_.loc[:, 'Age'] = data_.loc[:, 'Age'].fillna(data_.loc[:, 'Age'].median()) # fillna()在DataFrame里面直接进行填补
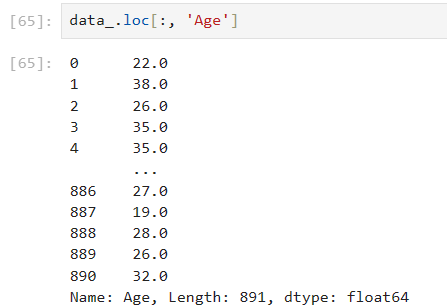
删除缺失值
data_.dropna(axis=0, inplace=True)
#axis=0表示删除所有有缺失值的行。inplace表示覆盖原数据,即在原数据上进行修改,当inplace = False时,表示会产生一个复制的数据
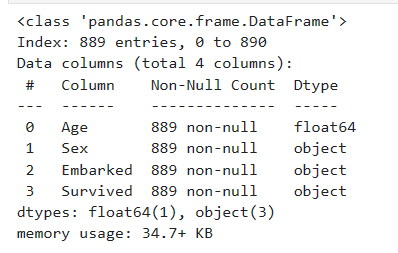
处理分类型特征:编码与哑变量

preprocessing.LabelEncoder:标签专用,能够将分类转换为分类数值
from sklearn.preprocessing import LabelEncoder
y = data.iloc[:, -1] # 要输入的时标签不是特征矩阵,允许一维
le = LabelEncoder()
le = le.fit_transform(y)
data.iloc[:,-1] = label
preprocessing.OrdinalEncoder:特征专用,能够将分类特征转换为分类数值
from sklearn.preprocessing import OrdinalEncoder
data_ = data.copy()
OrdinalEncoder().fit(data.iloc[:, 1:-1]).categories_
data.iloc[:, 1:-1] = OrdinalEncoder().fit_transform(data.iloc[:, 1:-1])
data.head()
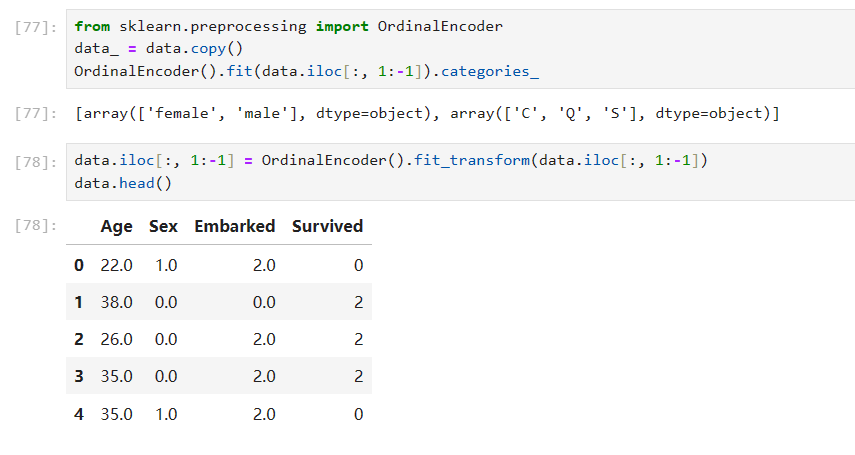
preprocessing.OneHotEncoder:独热编码,创建哑变量


from sklearn.preprocessing import OneHotEncoder
X = data.iloc[:1:-1]
result = OneHotEncoder(categories='auto').fit_transform(X).toarray() # 使用autopython会自己帮我们确定这个参数应该填什么
result



我们如何把我们新生成的哑变量放回去?
先将哑变量直接连在表的右边
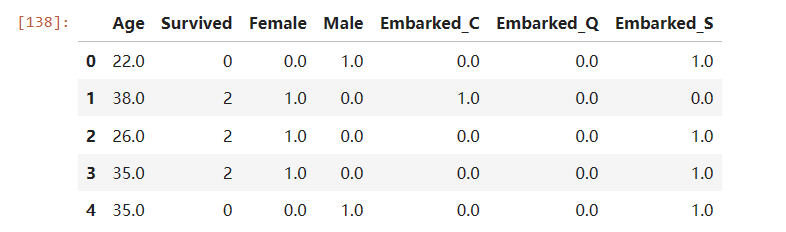
newdata = pd.concat([data, pd.DataFrame(result)], axis=1)
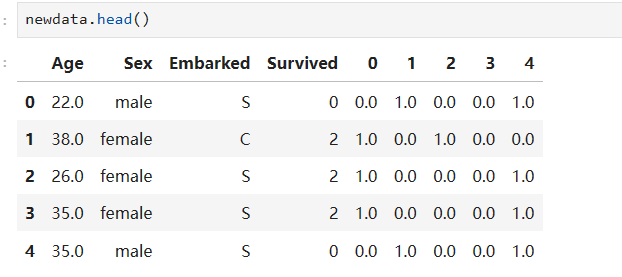
将不需要的列删除
newdata.drop(["Sex", "Embarked"], axis=1, inplace=True)
newdata.columns = ["Age", "Survived", "Female", "Male", "Embarked_C", "Embarked_Q", "Embarked_S"]
newdata.head()

处理连续性特征:二值化与分段
sklearn.preprocessing.Binarizer

from sklearn.preprocessing import Binarizer
X = data_2.iloc[:,0].values.reshape(-1,1)
transformer = Binarizer(threshold=30).fit_transform(X)
preprocessing.KBinsDiscretizer

from sklearn.preprocessing import KBinsDiscretizer
X = data.iloc[:, 0].values.reshape(-1, 1)
est = KBinsDiscretizer(n_bins=3, encode='ordinal', strategy='uniform')
est.fit_transform(X)
相关文章:
机器学习实战4-数据预处理
文章目录 数据无量纲化preprocessing.MinMaxScaler(归一化)导库归一化另一种写法将归一化的结果逆转 preprocessing.StandardScaler(标准化)导库实例化查看属性查看结果逆标准化 缺失值impute.SimpleImputer另一种填充写法 处理分类型特征:编…...
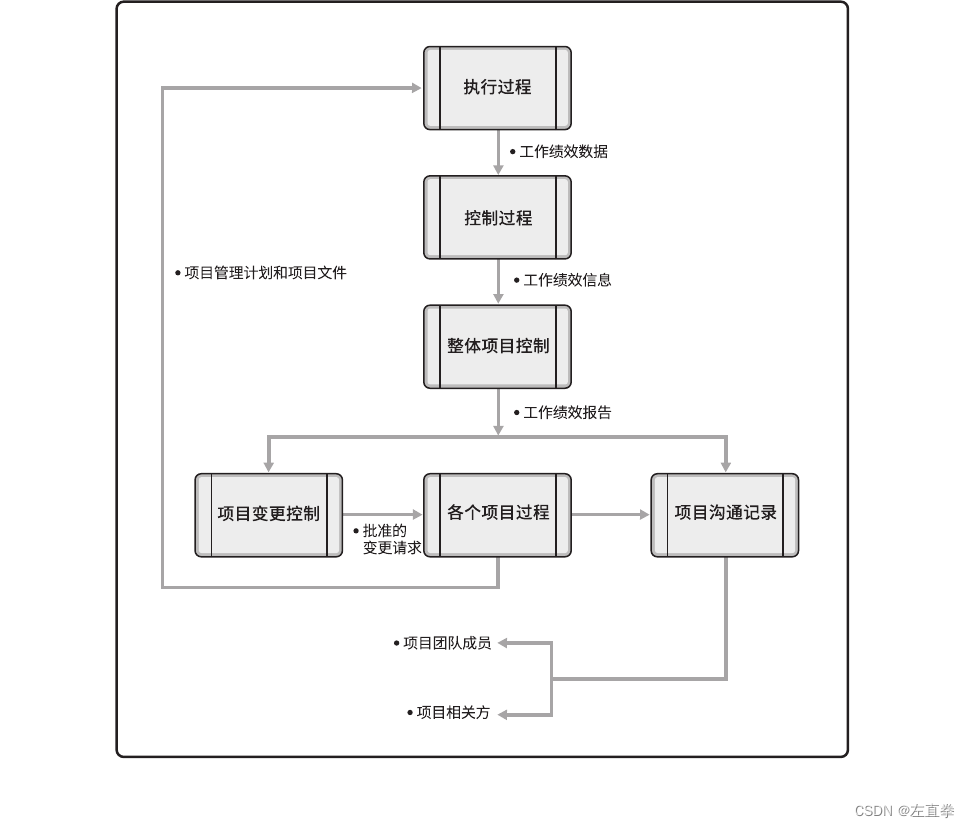
项目管理师基础之项目管理计划和项目文件
项目管理过程中,会使用并产生两大类文件:项目管理计划和项目文件。内容一般如下: 整个项目生命周期需要收集、分析和转化大量的数据。从各个过程收集项目数据,并在项目团队内共享。在各个过程中所收集的数据经过结合相关背景的分…...
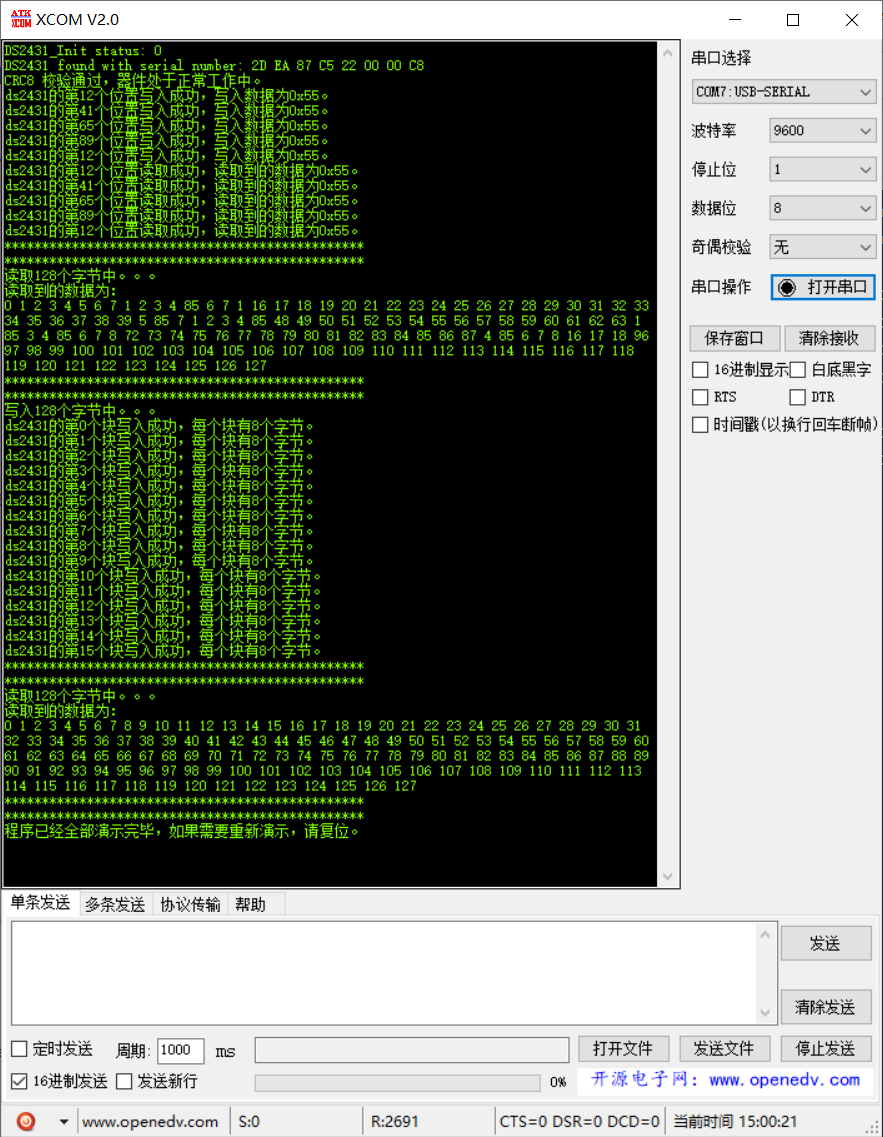
【单片机】DS2431,STM32,EEPROM读取与写入
芯片介绍: https://qq742971636.blog.csdn.net/article/details/132164189 接线 串口结果: 部分代码: #include "sys.h" #include "DS2431.h"unsigned char serialNb[8]; unsigned char write_data[128]; unsigned cha…...
(std::basic_stringbuf)(一))
c++11 标准模板(STL)(std::basic_stringbuf)(一)
定义于头文件 <sstream> template< class CharT, class Traits std::char_traits<CharT>, class Allocator std::allocator<CharT> > class basic_stringbuf : public std::basic_streambuf<CharT, Traits> std::basic_stringbuf…...

flutter开发实战-WidgetsBinding监听页面前台后台退出状态
flutter开发实战-WidgetsBinding监听页面前台后台退出状态 在开发过程中,经常监听页面前台后台退出状态,这里用到了WidgetsBinding 一、WidgetsBinding是什么? WidgetsBinding是Flutter中最重要的Binding之一,它提供了与Widget…...

父进程等待子进程退出 / 僵尸进程孤儿进程
Q:父进程为什么要等待子进程退出? A:回顾创建子进程的目的,就是让子进程去处理一些事情,那么“事情干完了没有”这件事,父进程需要知道并收集子进程的退出状态。子进程的退出状态如果不被收集,…...
【LeetCode 75】第二十六题(394)字符串解码
目录 题目: 示例: 分析: 代码运行结果: 题目: 示例: 分析: 给我们字符串,让我们解码,那么该怎么解码呢,被括号【】包裹起来的字符串需要扩展成括号左边第…...

UNIX网络编程——TCP协议API 基础demo服务器代码
目录 一.TCP客户端API 1.创建套接字 2.connect连接服务器编辑 3.send发送信息 4.recv接受信息 5.close 二.TCP服务器API 1.socket创建tcp套接字(监听套接字) 2.bind给服务器套接字绑定port,ip地址信息 3.listen监听并创建连接队列 4.accept提取客户端的连接 5.send,r…...

[保研/考研机试] KY163 素数判定 哈尔滨工业大学复试上机题 C++实现
题目链接: 素数判定https://www.nowcoder.com/share/jump/437195121691718831561 描述 给定一个数n,要求判断其是否为素数(0,1,负数都是非素数)。 输入描述: 测试数据有多组,每组输入一个数…...
)
iOS_crash文件的获取及符号化(解析)
文章目录 1. 使用 symbolicatecrash 解析 .ips 文件:2. 使用 CrashSymbolicator.py 解析 ips 文件3. 使用 atos 解析 crash 文件4. Helps4.1 .ips 文件获取4.2 .crash 文件获取4.3 获取 .dSYM 和 .app 文件4.4 使用 dwarfdump 查询 uuid 5. Tips6. 总结 1. 使用 sym…...
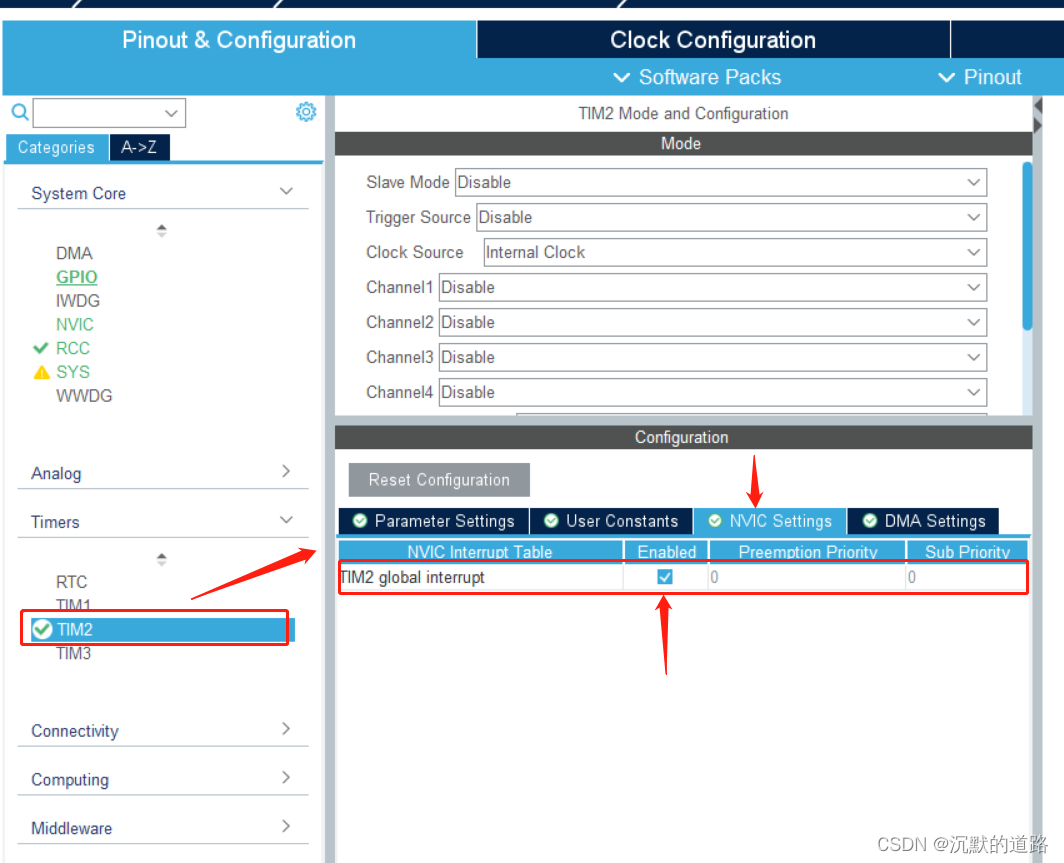
STM32定时器TIM控制
一、CubeMX的设置 1、新建工程,进行基本配置 2、配置定时器TIM2 1)定时器计算公式:(以下两条公式相同) Tout ((ARR1) * PSC1)) / Tclk TimeOut ((Prescaler 1) * (Period 1)) / TimeClockFren Tout TimeOut&…...
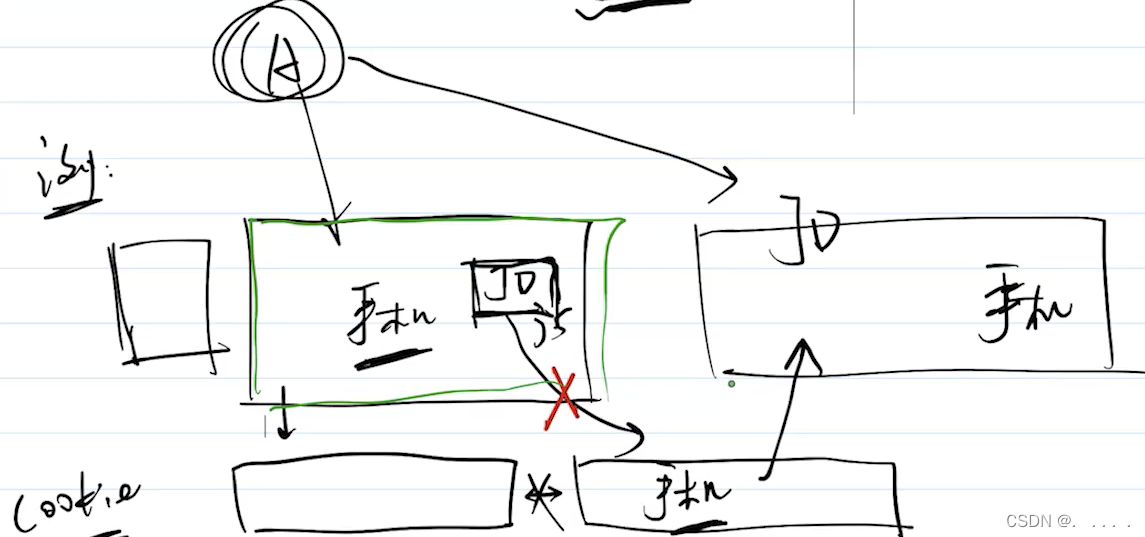
网络请求中,token和cookie有什么区别
HTTP无状态,每次请求都要携带cookie,以帮助识别用户身份; 服务端也可以向客户端set-cookie,cookie大小限制为4kb; cookie默认有跨域限制,不跨域共享和传递,例如: 现代浏览器开始禁…...

Javaweb_xml
文章目录 1.xml是什么?2.xml的用途 1.xml是什么? xml 是可扩展的标记性语言 2.xml的用途 1、用来保存数据,而且这些数据具有自我描述性 2、它还可以做为项目或者模块的配置文件 3、还可以做为网络传输数据的格式(现在 JSON 为主…...
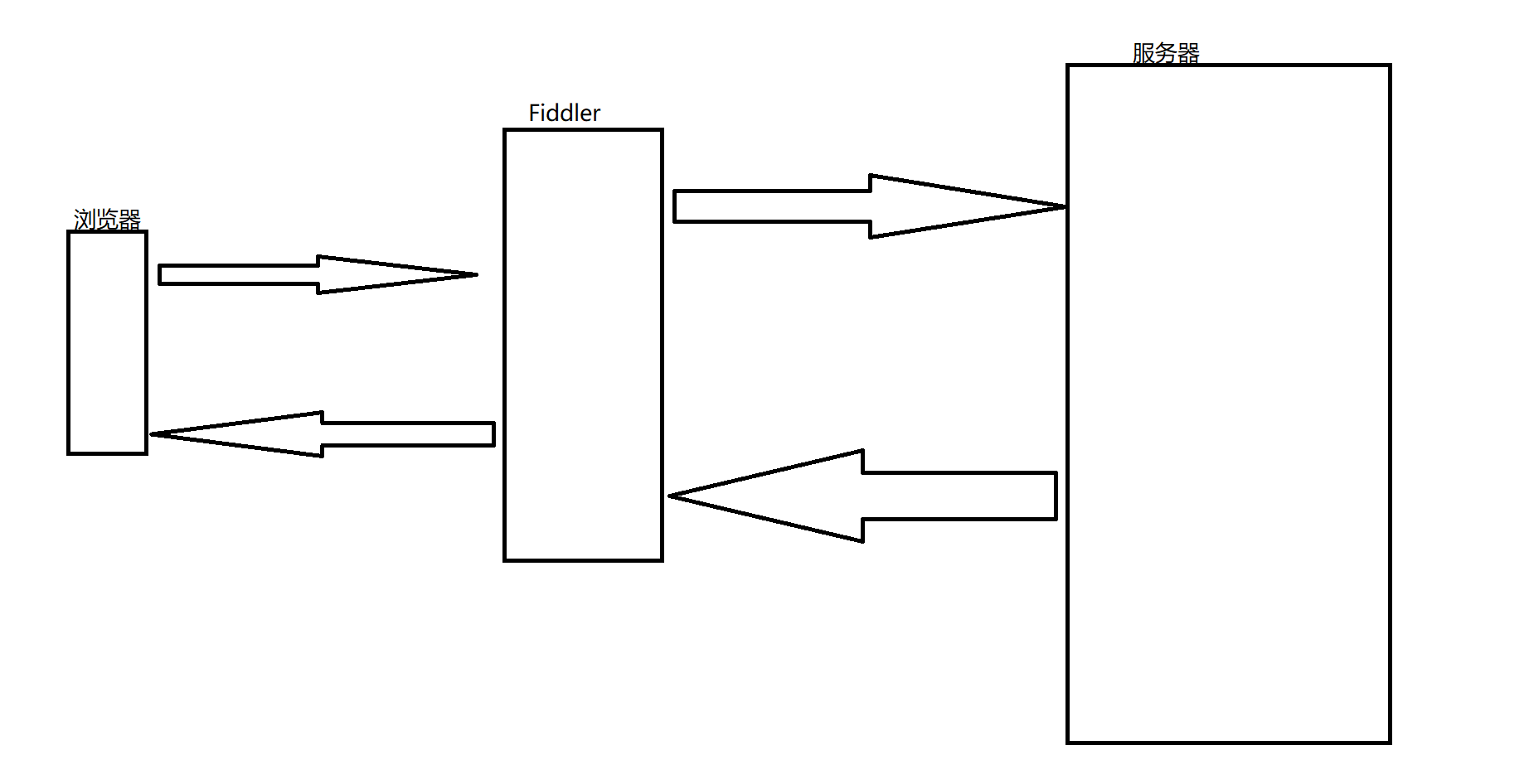
http相关知识点
文章目录 长链接http周边会话保持方案1方案2 基本工具postmanFiddlerFiddler的原理 长链接 一张网页实际上可能会有多种元素组成,这也就说明了网页需要多次的http请求。可由于http是基于TCP的,而TCP创建链接是有代价的,因此频繁的创建链接会…...

【SA8295P 源码分析】68 - Android 侧用户层 输入子系统获取 /dev/input/event0 节点数据 代码流程分析
【SA8295P 源码分析】68 - Android 侧用户层 输入子系统获取 /dev/input/event0 节点数据 代码流程分析 一、EventHub.cpp 监听 /dev/input/event0 节点流程二、EventHub.cpp 读取 /dev/input/event0 节点数据流程系列文章汇总见:《【SA8295P 源码分析】00 - 系列文章链接汇总…...
)
走出迷宫(多组输入bfs)
链接:登录—专业IT笔试面试备考平台_牛客网 来源:牛客网 题目描述 小明现在在玩一个游戏,游戏来到了教学关卡,迷宫是一个N*M的矩阵。 小明的起点在地图中用“S”来表示,终点用“E”来表示,障碍物用“#…...

Linux系统编程-终端、进程组、会话
一、终端的概念 在UNIX系统中,用户通过终端登录系统后得到一个Shell进程,这个终端成为Shell进程的控制终端(Controlling Terminal),进程中,控制终端是保存在PCB中的信息,而fork会复制PCB中的信息…...

Linux部分文件操作记录
问题描述 多级文件夹下,有多个同名文件,以及其他无关文件,为了减轻体量,遍历目录,只保留对应文件 首先open terminal here find . -type f \( ! -name algo_imu.bin -a ! -name post_gnss_only_error.log -a ! -name…...
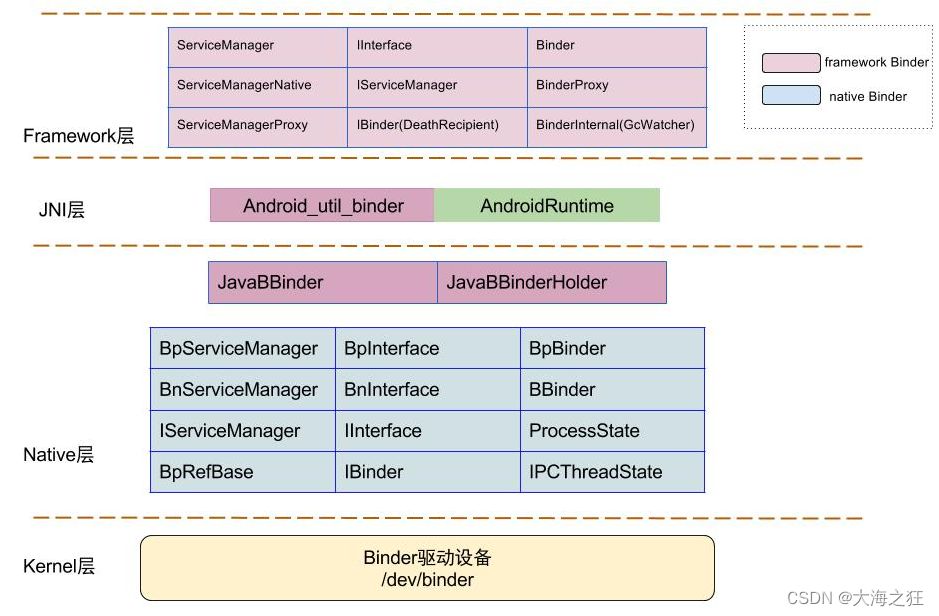
Android系统-进程-Binder2-Java层
引言: 对于Android系统,一般是从java层到native层,再到kernel驱动层,形成一个完整的软件架构。Android系统中的Binder IPC通信机制的整体架构,从java层到底层驱动层是怎么样的一个架构和原理的呢? 概念与…...
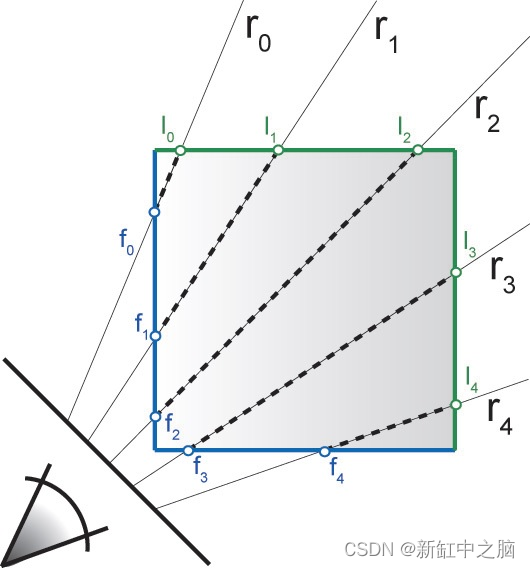
体渲染原理及WebGL实现【Volume Rendering】
体渲染(Volume Rendering)是NeRF神经场辐射AI模型的基础,与传统渲染使用三角形来显示 3D 图形不同,体渲染使用其他方法,例如体积光线投射 (Volume Ray Casting)。本文介绍体渲染的原理并提供Three.js实现代码ÿ…...

如何快速永久保存微信聊天记录:WeChatMsg免费工具终极指南
如何快速永久保存微信聊天记录:WeChatMsg免费工具终极指南 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/W…...

这4个本科专业稀缺又不“卷”,就业率几乎100%,很多家长都忽视了
收藏!网络安全专业就业率逼近100%,2026年最被低估的黄金赛道,小白必学! 文章介绍2026年就业前景好的四大冷门专业,其中网络安全作为国家一级学科,因政企和基础设施需求指数级增长,就业率接近100…...
用不对,你的系统可能随时崩溃)
FreeRTOS临界区避坑指南:taskENTER_CRITICAL()用不对,你的系统可能随时崩溃
FreeRTOS临界区避坑指南:taskENTER_CRITICAL()用不对,你的系统可能随时崩溃 调试嵌入式系统时最令人抓狂的瞬间,往往是那些看似毫无规律的随机崩溃——比如某个传感器数据偶尔错位、系统突然卡死、或是中断服务程序莫名丢失事件。上周我就遇到…...
)
告别啸叫与发热!手把手教你搞定DC-DC电源PCB布局(附Buck电路实战避坑清单)
告别啸叫与发热!手把手教你搞定DC-DC电源PCB布局(附Buck电路实战避坑清单) 在硬件工程师的日常工作中,DC-DC电源模块的设计总是让人又爱又恨。高效的电源转换性能背后,往往隐藏着各种"暗坑"——莫名其妙的啸…...

BGP邻居建不起来?从Open报文到Keepalive,一份完整的排错检查清单
BGP邻居建立故障排查实战指南:从报文解析到命令集 凌晨三点,数据中心告警面板突然亮起——"BGP邻居状态异常"。作为网络运维工程师,这种场景再熟悉不过。BGP作为互联网的"邮政系统",其邻居关系的稳定性直接决…...

Lenovo Legion Toolkit:拯救者笔记本的终极性能控制中心
Lenovo Legion Toolkit:拯救者笔记本的终极性能控制中心 【免费下载链接】LenovoLegionToolkit Lightweight Lenovo Vantage and Hotkeys replacement for Lenovo Legion laptops. 项目地址: https://gitcode.com/gh_mirrors/le/LenovoLegionToolkit 想要完全…...

Bootcamp性能优化技巧:10个提升社交网络响应速度的方法
Bootcamp性能优化技巧:10个提升社交网络响应速度的方法 【免费下载链接】bootcamp An enterprise social network 项目地址: https://gitcode.com/gh_mirrors/bo/bootcamp Bootcamp作为企业社交网络平台,随着用户规模增长和数据量增加,…...

VM如何将扩展容量减小
原来:由于硬盘磁盘容量拓展时候分配了300GB,导致虚拟机内部未分配内存161GB。现在:硬盘磁盘容量拓展缩减至144GB,虚拟机内部保留一些未分配内存为E盘扩容。那么如何将过多的未分配内存进行缩减呢:1.找到vmdk文件目录&a…...

Magpie v0.12.1:让Windows窗口缩放体验焕然一新的秘密武器
Magpie v0.12.1:让Windows窗口缩放体验焕然一新的秘密武器 【免费下载链接】Magpie A general-purpose window upscaler for Windows 10/11. 项目地址: https://gitcode.com/gh_mirrors/mag/Magpie 还在为Windows系统下窗口放大后画面模糊、游戏拉伸失真、办…...

WSL2安装配置与优化:在Windows上流畅运行忍者像素绘卷:天界画坊
WSL2安装配置与优化:在Windows上流畅运行忍者像素绘卷:天界画坊 1. 前言:为什么选择WSL2 如果你是一名Windows平台的开发者或游戏爱好者,想要体验《忍者像素绘卷:天界画坊》这款Linux原生游戏,WSL2(Windo…...