并发相关面试题
巩固基础,砥砺前行 。
只有不断重复,才能做到超越自己。
能坚持把简单的事情做到极致,也是不容易的。
如何理解volatile关键字
在并发领域中,存在三大特性:原子性、有序性、可见性。volatile关键字用来修饰对象的属性,在并发环境下可以保证这个属性的可见性,对于加了volatile关键字的属性,在对这个属性进行修改时,会直接将CPU高级缓存中的数据写回到主内存,对这个变量的读取也会直接从主内存中读取,从而保证了可见性,底层是通过操作系统的内存屏障来实现的,由于使用了内存屏障,所以会禁止指令重排,所以同时也就保证了有序性,在很多并发场景下,如果用好volatile关键字可以很好的提高执行效率。
ReentrantLock中的公平锁和非公平锁的底层实现
首先不管是公平锁和非公平锁,它们的底层实现都会使用AQS来进行排队,它们的区别在于:线程在使用lock()方法加锁时,如果是公平锁,会先检查AQS队列中是否存在线程在排
队,如果有线程在排队,则当前线程也进行排队,如果是非公平锁,则不会去检查是否有线程在排队,而是直接竞争锁。
不管是公平锁还是非公平锁,一旦没竞争到锁,都会进行排队,当锁释放时,都是唤醒排在最前面的线程,所以非公平锁只是体现在了线程加锁阶段,而没有体现在线程被唤醒阶
段。
另外,ReentrantLock是可重入锁,不管是公平锁还是非公平锁都是可重入的。
Sychronized的偏向锁、轻量级锁、重量级锁
1.偏向锁:在锁对象的对象头中记录一下当前获取到该锁的线程ID,该线程下次如果又来获取该锁就可以直接获取到了
2.轻量级锁:由偏向锁升级而来,当一个线程获取到锁后,此时这把锁是偏向锁,此时如果有第二个线程来竞争锁,偏向锁就会升级为轻量级锁,
之所以叫轻量级锁,是为了和重量级锁区分开来,轻量级锁底层是通过自旋来实现的,并不会阻塞线程
3.如果自旋次数过多仍然没有获取到锁,则会升级为重量级锁,重量级锁会导致线程阻塞
4.自旋锁:自旋锁就是线程在获取锁的过程中,不会去阻塞线程,也就无所谓唤醒线程,阻塞和唤醒这两个步骤都是需要操作系统去进行的,比较消耗时间,自旋锁是线程通过CAS获取预期的一个标记,如果没有获取到,则继续循环获取,如果获取到了则表示获取到了锁,这个过程线程一直在运行中,相对而言没有使用太多的操作系统资源,比较轻量。
Sychronized和ReentrantLock的区别
- sychronized是一个关键字,ReentrantLock是一个类
2.sychronized会自动的加锁与释放锁,ReentrantLock需要程序员手动加锁与释放锁
3.sychronized的底层是JVM层面的锁,ReentrantLock是API层面的锁
4.sychronized是非公平锁,ReentrantLock可以选择公平锁或非公平锁
5.sychronized锁的是对象,锁信息保存在对象头中,ReentrantLock通过代码中int类型的state标识来标识锁的状态
6.sychronized底层有一个锁升级的过程
线程池的底层工作原理
线程池内部是通过队列+线程实现的,当我们利用线程池执行任务时:
1.如果此时线程池中的线程数量小于corePoolSize,即使线程池中的线程都处于空闲状态,也要创建新的线程来处理被添加的任务。
2.如果此时线程池中的线程数量等于corePoolSize,但是缓冲队列workQueue未满,那么任务被放入缓冲队列。
3.如果此时线程池中的线程数量大于等于corePoolSize,缓冲队列workQueue满,并且线程池中的数量小于maximumPoolsize,建新的线程来处理被添加的任务。
4.如果此时线程池中的线程数量大于corePoolSize,缓冲队列workQueue满,并且线程池中的数量等于maximumPoolSize,那么通过 handler所指
定的策略来处理此任务。
5.当线程池中的线程数量大于corePoolSize时,如果某线程空闲时间超过keepAliveTime,线程将被终止。这样,线程池可以动态的调整池中的线
程数
死锁编码和定位分析
package ttzz.juc.juc2;
/*** 第55讲 死锁编码和定位分析* 1.什么是死锁?* 指两个或者两个以上的进程在执行过程中,因争夺资源而造成的互相等待的现象,若无外力干预,他们将持续性的耗下去,* 如果系统资源充足,进程的资源请求都能得到满足,死锁出现的可能性低,否则就会因为争夺有限的资源而陷入死锁* 2. 造成死锁的原因:* 1)系统资源不足* 2)代码问题* 3)内存分配不合理*/
public class ThreadPool_55 {public static void main(String[] args) {String lockA = "lockA";String lockB = "lockB";new Thread(new LockThread(lockA,lockB),"ThreadAAA").start();new Thread(new LockThread(lockB,lockA),"ThreadBBB").start();/*** 查看进程* linux ps -ef|grep XXX ;ls -l* windows :jps -l 找到进程编号 ;jstack pid*/}
}
class LockThread implements Runnable{private String lockA;private String lockB;public LockThread(String lockA, String lockB) {super();this.lockA = lockA;this.lockB = lockB;}@Overridepublic void run() {synchronized (lockA) {System.out.println(Thread.currentThread().getName()+":占有锁:"+lockA+",尝试获得锁"+lockB);try {Thread.sleep(2000);} catch (InterruptedException e) {e.printStackTrace();}synchronized (lockB) {System.out.println(Thread.currentThread().getName()+":占有锁:"+lockB+",尝试获得锁"+lockA);}}}}Java 线程池
/*** 为啥使用线程池?线程池的优势是什么 ? 第46讲* 降低资源消耗:通过重复利用已经创建的线程降低线程创建和销毁造成的消耗;提高响应速度:当任务到达时,任务可以不需要等到线程创建就能执行;提高线程的可管理性:线程是稀缺资源,不能无限创建,否则会消耗系统资源、降低系统的稳定性,使用线程可以进行统一分配,调优和监控;* 线程池的三种常用方式?(一共有5中) 第47讲* 常用的三种:* Executors.newFixedThreadPool(nThreads)* 使用场景:执行长期任务,性能较好* 源码: public static ExecutorService newFixedThreadPool(int nThreads) {return new ThreadPoolExecutor(nThreads, nThreads,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>());}Executors.newSingleThreadExecutor()使用场景:单任务执行源码: public static ExecutorService newSingleThreadExecutor() {return new FinalizableDelegatedExecutorService(new ThreadPoolExecutor(1, 1,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>()));}Executors.newCachedThreadPool()使用场景:执行短期异步小程序或者负载较轻的服务器源码: public static ExecutorService newCachedThreadPool() {return new ThreadPoolExecutor(0, Integer.MAX_VALUE,60L, TimeUnit.SECONDS,new SynchronousQueue<Runnable>());}* 剩下的两种:* Executors.newScheduleThreadPool() 带有时间调度的线程池* Java8中推出的 Executors.newWorkStealingPool(int) 使用目前机器上可用的处理器作为它的并行级别* * * 第48讲(线程池7个参数简介) * ThreadPoolExecutor:底层实现 * 线程池几个重要参数介绍:* public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory) {this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,threadFactory, defaultHandler);}第49讲(线程池7个参数深入介绍) 类比于银行网点办理业务corePoolSize:线程池中常驻核心线程池maximumPoolSize:线程池中能够容纳同时执行最大线程数,该值必须大于等于1keepAliveTime:多余线程的最大存活时间unit:keepAliveTime的单位workQueue:任务队列,被提交但尚未被执行的任务threadFactory:生成线程池中工作线程的线程工厂,一般使用默认即可handler:拒绝策略,表示当任务队列满并且工作线程大于等于线程池的最大线程数时,对即将到来的线程的拒绝策略第50讲(线程池底层工作原理)线程池具体工作流程:在创建线程后,等待提交过来的任务请求当调用execute()/submit()方法添加一个请求任务时,线程池会做出以下判断:如果正在运行的线程数量小于corePoolSize,会立刻创建线程运行该任务如果正在运行的线程数量大于等于corePoolSize,会将该任务放入阻塞队列中如果队列也满但是正在运行的线程数量小于maximumPoolSize,线程池会进行拓展,将线程池中的线程数拓展到最大线程数(并立即运行)如果队列满并且运行的线程数量大于等于maximumPoolSize,那么线程池会启动相应的拒绝策略来拒绝相应的任务请求当一个线程完成任务时,它会从队列中取下一个任务来执行当一个线程空闲时间超过给定的keepAliveTime时,线程会做出判断:如果当前运行线程大于corePoolSize,那么该线程将会被停止。也就是说,当线程池的所有任务都完成之后,它会收缩到corePoolSize的大小**/package ttzz.juc.juc2;import java.util.concurrent.BlockingQueue;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.SynchronousQueue;
import java.util.concurrent.ThreadFactory;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
public class ThreadPool_46_47_48_49_50 {public static void main(String[] args) {//测试线程池中的线程数达到核心线程,并且阻塞队列中也满了,//但是未达到最大线程数时的逻辑处理ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(2, 5, 100L, TimeUnit.SECONDS, new LinkedBlockingQueue<>(3));try {for (int i = 1; i <= 6; i++) {final int num = i;threadPoolExecutor.execute(new Runnable() {@Overridepublic void run() {System.out.println(Thread.currentThread().getName()+":"+num);try {TimeUnit.SECONDS.sleep(4);} catch (InterruptedException e) {e.printStackTrace();}}});}} finally {threadPoolExecutor.shutdown();}}/*** 测试各种线程池*/public static void testThreadPool() {
// ExecutorService executorService = Executors.newFixedThreadPool(5);ExecutorService executorService = Executors.newSingleThreadExecutor();
// ExecutorService executorService = Executors.newCachedThreadPool();try {for (int i = 0; i < 10; i++) {executorService.execute(new Runnable() {@Overridepublic void run() {System.out.println(Thread.currentThread().getName()+"处理业务");}});}} catch (Exception e) {}finally {executorService.shutdown();}}
}/*** 第51讲(线程池的四种拒绝策略理论介绍)* * 线程池的拒绝策略 第51讲(线程池的四种拒绝策略理论介绍)* 1. 什么是线程池的拒绝策略?* 等待队列满了,再也容不下新的任务,同时线程池达到了最大线程,无法继续为新任务服务了。* 这个时候,就需要使用拒绝策略机制合理的处理这个问题* 2. jdk内置的四种拒绝策略 RejectedExecutionHandler* AbortPolicy(默认):直接抛出RejectedExecutionException 异常 阻止系统正常运行* CallerRunsPolicy:调用者运行的一种机制,该策略既不会抛弃任务,也不会抛出异常,* 而是将某些任务回退到调用者DiscardOldestPolicy:抛弃队列中等待最久的任务,然后把当前任务加入到队列中尝试再次提交当前任务DiscardPolicy:直接丢弃任务,不予任何处理也不抛出异常。如果任务允许丢失,那么该策略是最好的方案第52讲(线程池实际中使用那种线程池??) * 3. 线程池实际中使用那种线程池?* 一个都不用,生产上只用我们自定义的线程池* jdk已经提供了现成的,你为啥不用呢 ?* 并发处理阿里巴巴手册中有说明* 4. 并发处理阿里巴巴手册* 1)获取单例对象需要保证线程安全,其中的方法也要保证线程安全* 资源驱动类,工具类、单例工厂都许需要注意* 2)创建线程或者线程池时指定有意义的线程的名称,方便出错排查* 3)线程资源必须通过线程池提供,不允许在应用中自行显示的创建线程* 使用线程池的好处是减少在创建和销毁线程上的时间以及系统资源的开销,解决资源不足的问题* 如果不适用线程池,有可能造成系统创建大量同类线程而导致消耗完内存或者 过度切换的问题* 4)线程池不允许使用Executors去创建,而是通过ThreadPoolExecutor的方式,这样处理方式让* 写的同学更加名且线程池的运行规则,规避资源耗尽的风险* Executors返回的线程池对象弊端如下:* FixedThreadPool和SingleThreadExecutor 允许的请求队列长度最大时Integer.maxValue,可能会堆积大量请求导致oom* CachedThreadPool和ScheduleThreadPool 允许的请求队列长度最大时Integer.maxValue,可能创建大量线程导致oom* 第53讲(线程池的手写改造和拒绝策略)* * 第54讲(线程池配置合理线程)* 合理配置线程池,你是如何考虑的?* 按照业务分为两种,其次要熟悉自己的硬件配置或者服务器配置,* 1)CPU密集型* //获取cpu的核心数System.out.println(Runtime.getRuntime().availableProcessors());CPU密集型 的意思时给业务需要大量的运算,而没有阻塞,cpu一致全速运行cpu密集任务只有在真正的多喝cpu上才可能得到加速(通过多线程)而在单核cpu上(悲剧),无论你开几个模拟的多线程该任务都不可能得到加速,因为cpu中的运算能力就哪些CPU密集型任务配置尽可能减少线程数量一般的公式:CPU核心数+1个线程的线程池* 2)IO密集型* A: 由于IO密集型任务并不是一直在执行任务,则应配置尽可能多的线程,入CPU核心数*2* B: IO密集型,即该任务需要大量的阻塞,* 在单线程上运行io密集型的任务会浪费大量的cpu运算能力,浪费在等待上* 所以io密集型任务需要使用多线程可以大大加速线程运行,及时在单核cpu上,这种加速主要是利用了被* 浪费掉的阻塞时间* io密集型是,大部分线程都阻塞,所以需要多配置线程数* 参考公式:cpu核心数/(1-阻塞系数 )阻塞系数在0.8-0.9之间* 比如8核cpu: 8 / (1-0.9) = 80个核心数 */
package ttzz.juc.juc2;import java.util.concurrent.Executors;
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;import org.omg.SendingContext.RunTime;
public class ThreadPool_51_52_53_54 {public static void main(String[] args) {//获取cpu的核心数System.out.println(Runtime.getRuntime().availableProcessors());ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(2,5, 1L,TimeUnit.SECONDS,new LinkedBlockingQueue<>(3),Executors.defaultThreadFactory(),
// new ThreadPoolExecutor.AbortPolicy());
// new ThreadPoolExecutor.CallerRunsPolicy());new ThreadPoolExecutor.DiscardOldestPolicy());
// new ThreadPoolExecutor.DiscardPolicy());/*** 最大线程数= 最大线程数+队列长度 * * AbortPolicy:超过 最大线程数 报异常* Exception in thread "main" pool-1-thread-1办理业务pool-1-thread-3办理业务pool-1-thread-2办理业务pool-1-thread-4办理业务pool-1-thread-2办理业务pool-1-thread-5办理业务pool-1-thread-3办理业务pool-1-thread-1办理业务java.util.concurrent.RejectedExecutionException: Task ttzz.juc.test2.ThreadPool_51$1@55f96302 rejected from java.util.concurrent.ThreadPoolExecutor@3d4eac69[Running, pool size = 5, active threads = 0, queued tasks = 0, completed tasks = 8]at java.util.concurrent.ThreadPoolExecutor$AbortPolicy.rejectedExecution(ThreadPoolExecutor.java:2047)at java.util.concurrent.ThreadPoolExecutor.reject(ThreadPoolExecutor.java:823)at java.util.concurrent.ThreadPoolExecutor.execute(ThreadPoolExecutor.java:1369)at ttzz.juc.test2.ThreadPool_51.main(ThreadPool_51.java:79)* CallerRunsPolicy:超过 最大线程数 ,回退给调用者* pool-1-thread-1办理业务main办理业务pool-1-thread-2办理业务pool-1-thread-4办理业务pool-1-thread-3办理业务pool-1-thread-4办理业务pool-1-thread-2办理业务pool-1-thread-1办理业务pool-1-thread-5办理业务DiscardOldestPolicy:超过 最大线程数 ,抛弃队列中等待最久的任务,然后把当前任务加入到队列中尝试再次提交当前任务 pool-1-thread-1办理业务pool-1-thread-4办理业务pool-1-thread-5办理业务pool-1-thread-3办理业务pool-1-thread-2办理业务pool-1-thread-5办理业务pool-1-thread-4办理业务pool-1-thread-1办理业务DiscardPolicy: 超过 最大线程数 ,直接丢弃任务,不予任何处理也不抛出异常。如果任务允许丢失,那么该策略是最好的方案pool-1-thread-2办理业务pool-1-thread-4办理业务pool-1-thread-3办理业务pool-1-thread-1办理业务pool-1-thread-3办理业务pool-1-thread-5办理业务pool-1-thread-2办理业务pool-1-thread-4办理业务*/try {// 最大线程数= 最大线程数+队列长度 for (int i = 1; i <=9; i++) {final int num = i;threadPoolExecutor.execute(new Runnable() {@Overridepublic void run() {System.out.println(Thread.currentThread().getName()+"办理业务");
// try {
// TimeUnit.SECONDS.sleep(4);
// } catch (InterruptedException e) {
// e.printStackTrace();
// }}});}} finally {threadPoolExecutor.shutdown();}}
}请谈谈你对volatile的理解
volatile 是java提供的轻量级的同步机制
保证可见性
不保证原子性
禁止指令重排(有序性)
指令重排:在计算机执行程序时,为了题号新能,编译器和处理器常常会对指令做重排。一般分为一下三种:
原代码-》编译器优化的重排-》指令并行的重排-》内存系统的重排-》最终执行的指令
单线程环境里面保证程序最终执行结果和代码顺序执行结果一致
处理器在进行重排序时必须考虑指令之间的数据依赖性
多线程环境中线程交替执行,优于编译器优化重排的存在。两个线程中使用的
变量能够保证一致性是无法确定的,结果无法预测
volatile 实现禁止指令重排,从而避免多线程环境下程序出阿信乱序执行的现象
先了解一个概念,内存屏障,Merray Barries,是一个内存指令。他有两个作用:一个是保证操作的执行顺序,
另一个是保证某些变量的内存可见性(利用该特性实现了volatile的内存可见性)。由于编译器和处理器都能执行指令重排
优化,如果在指令中插入一条memory barries则会告诉编译器和cpu,不管什么指令都不能和这条memory barries指令重排。
也就是说通过插入内存屏障禁止在内存屏障前后的指令执行重排序优化,内存屏障的另一个作用则是强制刷出各种cpu的缓存数据。
因此任何cpu上的线程都能读取到这些数据的最新版本。
对volatile变量进行写操作时,会在操作后加入一条store屏障指令,将工作内存中的共享变量值刷新到主内存中;
对volatile变量进行写读操作时,会在读操作前加一条load指令,从从主内存中读取共享变量
lock和unlock数量 对程序代码的影响
结论:
当lock.lock()数量 > lock.unlock():程序一直运行
当lock.lock()数量 < lock.unlock():抛出java.lang.IllegalMonitorStateException异常
public class Lock_25 {public static void main(String[] args) {demo11 d = new demo11();for (int i = 0; i < 10; i++) {new Thread(new Runnable() {@Overridepublic void run() {try {d.PP();} catch (InterruptedException e) {e.printStackTrace();}}},"生产者").start();new Thread(new Runnable() {@Overridepublic void run() {try {d.CC();} catch (InterruptedException e) {e.printStackTrace();}}},"消费者").start();}}
}class demo11{private Lock lock = new ReentrantLock();private Condition condition = lock.newCondition();private Integer num = 0;public void PP() throws InterruptedException {lock.lock();try {while(num!=0) {condition.await();}num++;System.out.println("生产者:"+num);condition.signal();} finally {lock.unlock();}}public void CC() throws InterruptedException {//lock.lock(); 少一个程序报错//lock.lock(); 多一个程序一直运行try {while(num==0) {condition.await();}num--;Thread.sleep(200);System.out.println("消费者:"+num);condition.signal();} finally {lock.unlock();}}
}
BlockingQueue 的继承
public interface BlockingQueue extends Queue

线程池的拒绝策略

并发编程–Java中的原子操作类
在Java JDK1.5以后,在java.util.concurrent.atomic包,在这个包中提供了一种简单、新能高效的、线程安全的更新一个变量的方式。
Atomic类中提供了13个类,4中数据类型的原子更新方式:原子更新基本类型、原子更新数组、原子更新引用、原子更新属性。
原子更新基本类型类
AtomicBoolean、AtomicInteger、AtomicLong ,他们提供的方法基本一样。
以AtomicInteger为例,提供的API如下:
int addAndGet(int value)将value和原子类中的值相加,返回相加之和的结果。boolean compareAndSet(int except,int update)int getAndIncrement() 将原子类中的值+1,注意:返回的是自增前的值void lazySet(int value) 有延迟作用int getAndSet(int value)
其中,compareAndSet使用的是unsafe类中的cas,比较并交换。
原子更新数组
AtomicIntegerArray、AtomicIongArray、AtomicRefrenceArray
int addAndGet(int i,int value)i表示数组下标
boolean compareAndSet(int i,int except,int update)
原子更新引用类型
AtomicRefrence 原子更新引用类型
AtomicRefrenceFieldUpdater 更新引用类型中里的字段
AtomicMakableReference 带有标记的引用类型。
原子更新字段类
AtomicIntegerFiledUpdater 更新对象中的Integer类型
AtomicLongFiledUpdater 更新对象中的Long类型
AtomicStampedUpdater 带有版本号的引用类型,可以有效解决ABA问题。
想要更新字段类需要两步:1.因为原子更新字段类都是抽象类,妹子使用的时候需要使用静态方法newUpdater()构建一个更新器,并需要设置想要更新的类和属性 2.更新类的属性必须使用public volatite修饰符。
import java.util.concurrent.atomic.AtomicIntegerFieldUpdater;public class TestCase {private static AtomicIntegerFieldUpdater<User> atomicIntegerFieldUpdater= AtomicIntegerFieldUpdater.newUpdater(User.class, "age");public static void main(String[] args) {User u = new User("name1",10);System.out.println(u.getAge());System.out.println(atomicIntegerFieldUpdater.getAndIncrement(u));//getAndIncrement返回的是更新前的数值System.out.println(atomicIntegerFieldUpdater.get(u));}public static class User{private String name;public volatile int age;public User(String name, int age) {super();this.name = name;this.age = age;}public String getName() {return name;}public void setName(String name) {this.name = name;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}}
}
并发编程 聊聊ConcurrentHashMap
ConcurrentHashMap 是线程安全 高效的HashMap,聊聊它是如何保证安全的同时实现高效操作的?
为什么使用它?
并发编程中HashMap可能导致死循环,使用HashTable效率低下,所以就是用ConcurrentHashMap喽。
死循环的HashMap
效率底下的HashTable?
HashTable同期使用synchoronized来保证线程安全,但是在线程竞争激烈的请款下HashTable效率低,因为当一个线程访问HashTable的同步方法时,其他线程也访问HashTable的同步方法时,会进入到阻塞或者轮训状态。竞争越激烈效率越低下。
ConcurrentHashMap的锁分段技术可以有效的提升并发访问效率
HashTable容器在竞争激烈的并发环境下表现出来的效率低下的原因是所有访问HashTable的线程都必须竞争同一把锁,加入容器中有多把锁,每一把锁用于锁容器中的一部分数据,那么当多线程访问容器里不同的数据时,线程间就不存在锁竞争。从而有效提高线程并发访问效率,这就是ConcurrentHashMap所使用的的锁分段技术。首先将数据分成一段一段地存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中的一段数据时,其他段的数据也可能被其他线程访问。
ConcurrentHashMap的结构
ConcurrentHashMap是有segment数组和HashEntry数组结构构成的,segment是一种可重入锁(ReentrantLock),在ConcurrentHashMap中扮演锁的角色;HashEntry则是用于存储键值对数据,一个ConcurrentHashMap里包含一个segment数组。segment数组的结构和hashmap类似,是一种数组和链表结构。一个segment里包含一个HashEntry数组,每个HashEntry是一个链表结构的元素,每个segment守护着一个HashEntry数组里的元素,当对HashEntry数组的元素修改时,必须首先获得segment锁。
ConcurrentHashMap的初始化
ConcurrentHashMap初始化方法时通过initCapacity、loadFactory、concurrencyLevel等几个参数来初始化segment数组、偏移量segmentShift、段掩码segmentMask和每个segment里的HashEntry数组来实现。
ConcurrentHashMap的操作
get 、 put、size
get操作:get操作简单高效。先经过一次散列,然后在使用得到的散列值 通过散列 定位到segment,在通过散列算法定位到元素。
get操作高效 在于整个过程中不许要加锁,除非读到的值是空才会加锁重读。ConcurrentHashMap的get方法为啥不加锁?她的get方法里需要使用共享变量多需要定义成volatile类型,用于作用当前segment大小的count字段和使用存储值得hashentry的value。定义成为valatile的变量,能够在各个线程之间保持可见性,能被多线程同事督导,并且保证不会读取到过期值,但是只能被单线程写(一种特殊的情况可以被多线程写,就是写入的值不依赖于原值),在get操作里只需要读不需要写共享变量count和value。所以不需要加锁。之所以不会不会读到过期的数据,是因为java内存模型中的happen berfre原则,对volatile字段的写入操作先于读取操作。
put操作:put方法需要对共享变量进行写入操作,所以为了线程安全,在操作共享变量时需要加锁。put方法首先定位到segment,然后在segment数组进行insert操作,insert操作需要经过两个步骤,第一需要对segment素组里的hashentry数组做判断,是否需要扩容,第二定位添加元素的位置,让后insert到hashentry数组中。
判断是否需要扩容,segment里的hashentry数组是否超过容量,如果超过,则扩容。hashmap的扩容方式是先insert,然后在判断。
如何扩容:首先创建一个容量是当前容量的2倍的数组,然后将原来数组里的元素进行散列后insert到新数组中。为了高效,ConcurrentHashMap不会对所有的segment数组惊喜扩容,仅仅对segment进行扩容。
size操作:统计ConcurrentHashMap里的元素的。统计每个segment中的count值,相加,这种方式存在一个问题,就是在计算的时候,获取的count不是最新值,有可能在计算时有可能对数组的元素进行操作。就会导致统计不准。最安全的方法就是在统计的时候,对所有segment的操作进行锁住。但是这种方式低效。它是如何做的呢?它是使用先累加,然后再判断的方式。在累加count操作过程中,之间累加过得count变化几率小,所以ConcurrentHashMap的做法就是先尝试2次通过不给segment加锁的方式来统计各个segment的大小。如果统计过程中count发生了变化,则在采用加锁的方式来统计所有的元素。如何判断在统计时容器中的元素发生改变,使用modcount,在put、remove、clean方法操作元素前都会将变量modcount+1,在比较不加锁的两次modcount数值是否相同,就知道segment数组中的元素是否发生过改变。
并发编程-Java内存模型基础介绍
并发编程需要处理的两个关键问题,下船之间如何通信及县城之间如何同步。这里的现场是指并发执行的活动实体。通信是指线程之间以何种机制来交换信息,在命令式编程中。现场之间的通信机制有两种,共享内存和消息传递。
在共享内存的并发模型里,线程之间共享程序的公共状态。通过读写内存中的公共状态进行隐式通信。在消息传递的并发模型里。线程之间没有公共状态,线程之间必须通过发送消息来显示通信。
同步是指程序中用于控制不同线程将操作发生相对顺序的机制。在共享内存并发模型里,同步是显示进行的,程序员必须想是指定某个方法或某段代码。需要在县城之间互斥进行。在消息传递的并发模型里,由于消息的发送,必须在消息的接收之前,因此同步是隐式也是进行的。
Java的并发采用的是共享内存模型,Java线程之间的通信总是隐式进行,整个通信过程对程序员完全透明。如果编写多线程程序的Java程序员不理解隐式进行的线程之间通信的工作机制。很可能会遇到各种奇怪的内存可见性问题。
Java并发编程基础知识回顾
为什么要使用多线程
- 更多的处理器核心
- 更快的响应时间
- 更好的编程模型
Java为多线程编程提供了良好、考究并且一致的编程模型,使开发人员能够更加专注于问 题的解决,即为所遇到的问题建立合适的模型,而不是绞尽脑汁地考虑如何将其多线程化。一 旦开发人员建立好了模型,稍做修改总是能够方便地映射到Java提供的多线程编程模型上
线程优先级
在Java线程中,通过一个整型成员变量priority来控制优先级,优先级的范围从1~10,在线 程构建的时候可以通过setPriority(int)方法来修改优先级,默认优先级是5,优先级高的线程分 配时间片的数量要多于优先级低的线程。设置线程优先级时,针对频繁阻塞(休眠或者I/O操 作)的线程需要设置较高优先级,而偏重计算(需要较多CPU时间或者偏运算)的线程则设置较 低的优先级,确保处理器不会被独占。在不同的JVM以及操作系统上,线程规划会存在差异, 有些操作系统甚至会忽略对线程优先级的设定
public class Priority {private static volatile boolean notStart = true;private static volatile boolean notEnd = true;public static void main(String[] args) throws Exception { List<Job> jobs = new ArrayList<Job>(); for (int i = 0; i < 10; i++) { int priority = i < 5 ? Thread.MIN_PRIORITY : Thread.MAX_PRIORITY; Job job = new Job(priority); jobs.add(job); Thread thread = new Thread(job, "Thread:" + i); thread.setPriority(priority); thread.start(); }notStart = false; TimeUnit.SECONDS.sleep(10); notEnd = false; for (Job job : jobs) { System.out.println("Job Priority : " + job.priority + ", Count : " + job.jobCount); } }static class Job implements Runnable {private int priority;private long jobCount;public Job(int priority) {this.priority = priority;}public void run() {while (notStart) {Thread.yield();}while (notEnd) {Thread.yield();jobCount++;}}}
}
运行结果
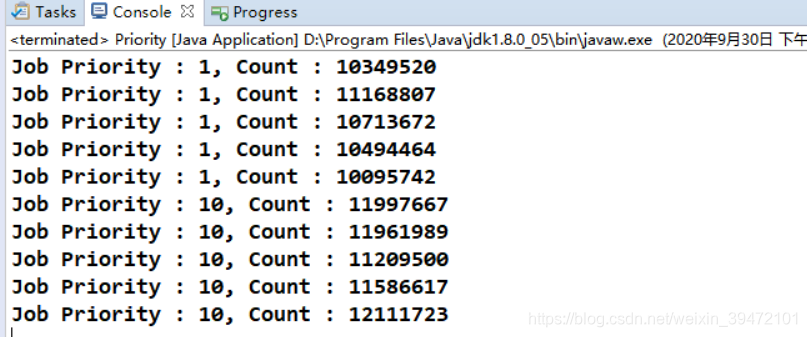
从输出可以看到线程优先级没有生效,优先级1和优先级10的Job计数的结果非常相近, 没有明显差距。这表示程序正确性不能依赖线程的优先级高低。
注意:线程优先级不能作为程序正确性的依赖,因为操作系统可以完全不用理会Java 线程对于优先级的设定。
什么是线程的上下文切换?
多线程执行是cpu抢占时间片的方式执行。多线程创建并切换到另一个线程的过程,称之为线程的上下文切换
如何减少上下文切换
减少上下文切换的方法有无锁并发编程、CAS算法、使用最少线程和使用协程。
- 无锁并发编程。多线程竞争锁时,会引起上下文切换,所以多线程处理数据时,可以用一 些办法来避免使用锁,如将数据的ID按照Hash算法取模分段,不同的线程处理不同段的数据。
- CAS算法。Java的Atomic包使用CAS算法来更新数据,而不需要加锁。
- 使用最少线程。避免创建不需要的线程,比如任务很少,但是创建了很多线程来处理,这 样会造成大量线程都处于等待状态
- 协程:在单线程里实现多任务的调度,并在单线程里维持多个任务间的切换
Java 之线程死锁简介
死锁代码
package aa.testcase;public class DeadLockDemo {private static String A = "A";private static String B = "B";public static void main(String[] args) {Thread t1 = new Thread(new Runnable() {@Overridepublic void run() {synchronized (A) {try {Thread.currentThread().sleep(2000);} catch (Exception e) {e.printStackTrace();}//synchronized (B) {System.out.println("BBBBBBBBBBBBb");}}}}) ;Thread t2 = new Thread(new Runnable() {@Overridepublic void run() {synchronized (B) {synchronized (A) {System.out.println("AAAAAAAA");}}}}) ;t1.start();t2.start();}
}死锁出现之后,后续的代码就不能正常执行。
如何避免死锁呢?(☺️嘻嘻)
- 避免一个线程同时获取多个锁。
- 避免一个线程在锁内同时占用多个资源,尽量保证每个锁只占用一个资源
- 尝试使用定时锁,使用lock.tryLock(timeout)来替代使用内部锁机制。
- 对于数据库锁,加锁和解锁必须在一个数据库连接里,否则会出现解锁失败的情况。
资源限制的挑战
什么是资源限制?
资源限制是指在进行并发编程时,程序的执行速度受限于计算机硬件资源或软件资源。例如服务器宽带只有两兆每秒。某个资源的下载速度是一兆每秒系统启动十个线程下载资源,下载速度不会是10m/s,所以在进行并发编程时要考虑这些资源的限制,硬件资源限制带有框带着的上传下载速度。磁盘读写速度和CPU的处理速度,软件资源限制,有数据库的链接书和socket链接数等
资源限制引发的问题
在并发编程中间代码执行速度加快的原则,事件代码中,创新执行的部分变成并发执行。倒是如果监保段了创新的代码并发执行,因为受限于资源。仍然在创新执行,这时,程序不仅不会加快执行,反而会更忙,因为增加了上下文切换和资源调度的时间。例如,之前看到一个程序使用多线程在办公网络并发下载和处理数据时,导致CPU利用率达百分之百,几个小时都不能运行完成任务。后来修改成当现场一个小时就执行完成了。
如何解决资源限制的问题?
对于硬件资源的限制,可以考虑使用集群并行执行程序,既然当地的资源有限,那么就让程序在多台机器上运行。比如使用ODPS,还都破获自己搭建的服务器集群。不同的机械处理的不同的数据。可以通过数据id%机器数。计算得到一个机器编号,然后由对应编号的机器处理这笔数据。对于软件资源的限制,可以考虑使用资源池间资源复用,比如使用链接指尖数据库和socket链接复用。或者再调用对方我把service接口获取数据时只建立一个链接。
在资源限制情况下进行并发编
如何在资源限制的情况下让程序执行的更快,方法就是根据不同的资源调整。程序的并发度,例如下载文件上去一那两个资源,宽带和硬盘读写速度。有数据库操作时涉及数据库链接数,如果烧烤语句执行非常快而现成的。数量比数据库链接数大很多。则某些线程会被阻塞,等待数据库链接。
相关文章:
并发相关面试题
巩固基础,砥砺前行 。 只有不断重复,才能做到超越自己。 能坚持把简单的事情做到极致,也是不容易的。 如何理解volatile关键字 在并发领域中,存在三大特性:原子性、有序性、可见性。volatile关键字用来修饰对象的属性…...
Hadoop+Python+Django+Mysql热门旅游景点数据分析系统的设计与实现(包含设计报告)
系统阐述的是使用热门旅游景点数据分析系统的设计与实现,对于Python、B/S结构、MySql进行了较为深入的学习与应用。主要针对系统的设计,描述,实现和分析与测试方面来表明开发的过程。开发中使用了 django框架和MySql数据库技术搭建系统的整体…...

php中nts和ts
PHP语言解析器:官方提供了2种类型的版本,线程安全(TS)版和非线程安全(NTS)版 TS: TS(Thread-Safety)即线程安全,多线程访问时,采用了加锁机制,当一个线程访问该类的某个数据时进行数据加锁保护,其他线程不能同时进行访…...
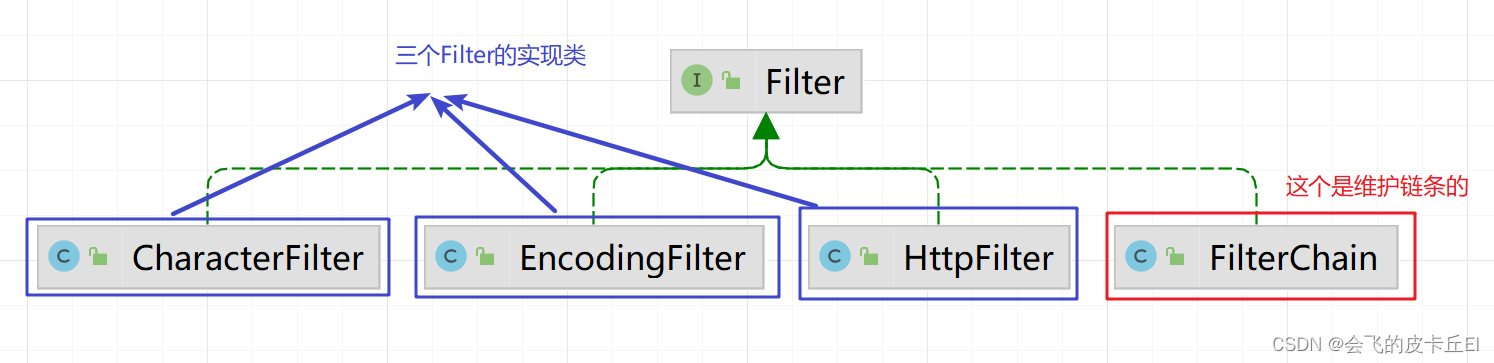
设计模式之责任链模式【Java实现】
责任链(Chain of Resposibility) 模式 概念 责任链(chain of Resposibility) 模式:为了避免请求发送者与多个请求处理者耦合在一起,于是将所有请求的处理者 通过前一对象记住其下一个对象的引用而连成一条…...

Android 12.0 系统systemui状态栏下拉左滑显示通知栏右滑显示控制中心模块的流程分析
1.前言 在android12.0的系统rom定制化开发中,在系统原生systemui进行自定义下拉状态栏布局的定制的时候,需要在systemui下拉状态栏下滑的时候,根据下滑坐标来 判断当前是滑出通知栏还是滑出控制中心模块,所以就需要根据屏幕宽度,来区分x坐标值为多少是左滑出通知栏或者右…...
服务器安装JDK
三种方法 方法一: 方法二: 首先登录到Oracle官网下载JDK JDK上传到服务器中,记住文件上传的位置是在哪里(我放的位置在/www/java),然后看下面指示进行安装 方法三: 首先登录到Oracle官网下载…...

cpu查询
1.mpstat查看系统cpu状况 mpstat 1 1或者mpstat -P ALL查看每个cpu使用状态,(用户态cpu是用来,内核态cpu使用率,等待IO使用率) 2.vmstat 可以查看系统运行任务数(正在cpu运行进程和就绪队列进程࿰…...

【muduo】关于自动增长的缓冲区
目录 为什么需要缓冲区自动增长的缓冲区buffer数据结构buffer类 写详细比较费时间,就简单总结下。 总结自Linux 多线程服务端编程:使用 muduo C 网络库 Muduo网络编程: IO-multiplexnon-blocking 为什么需要缓冲区 Non-blocking IO 的核心…...
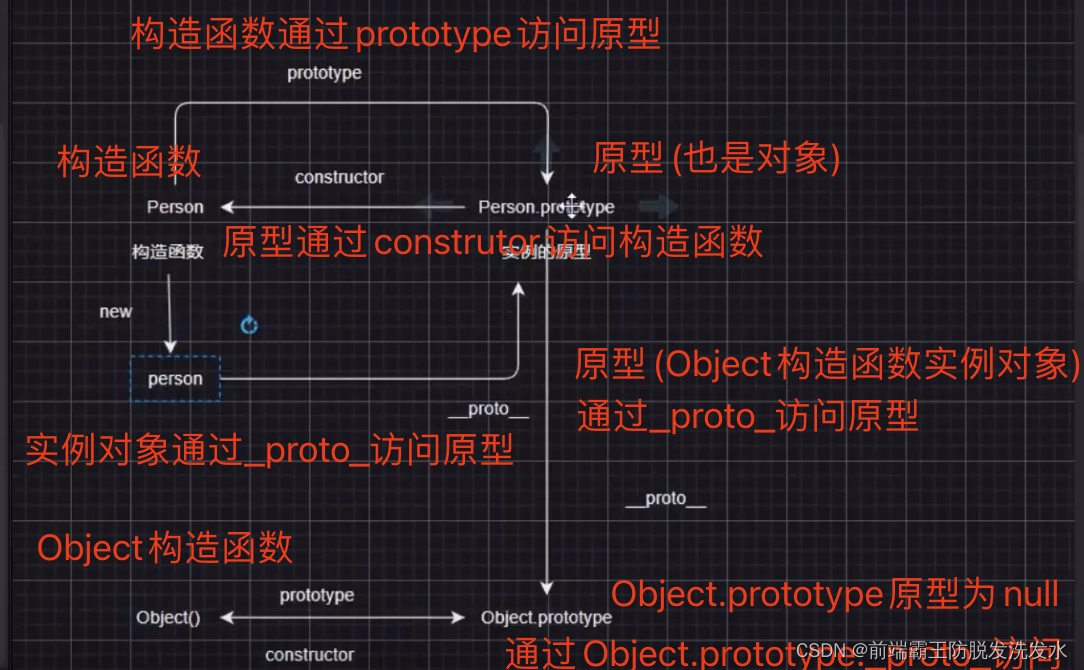
原型和原型链理解
这个图大概能概括原型和原型链的关系 1.对象都是通过 _proto_ 访问原型 2.原型都是通过constructor 访问构造函数 3.原型是构造函数的 prototype 4.原型也是对象实例 也是通过 _proto_ 访问原型(Object.prototype) 5.Object.prototype的原型通过 _proto_ 访问 为null 那么…...

CSS:弹性盒子模型详解(用法 + 例子 + 效果)
目录 弹性盒子模型flex-direction 排列方式 主轴方向换行排序控制子元素缩放比例缩放是如何实现的? 控制子元素的对其方式justify-content 横向 对齐方式align-items 纵向 对齐方式 align-content 多行 对齐方式 弹性盒子模型 flex-direction 排列方式 主轴方向 f…...
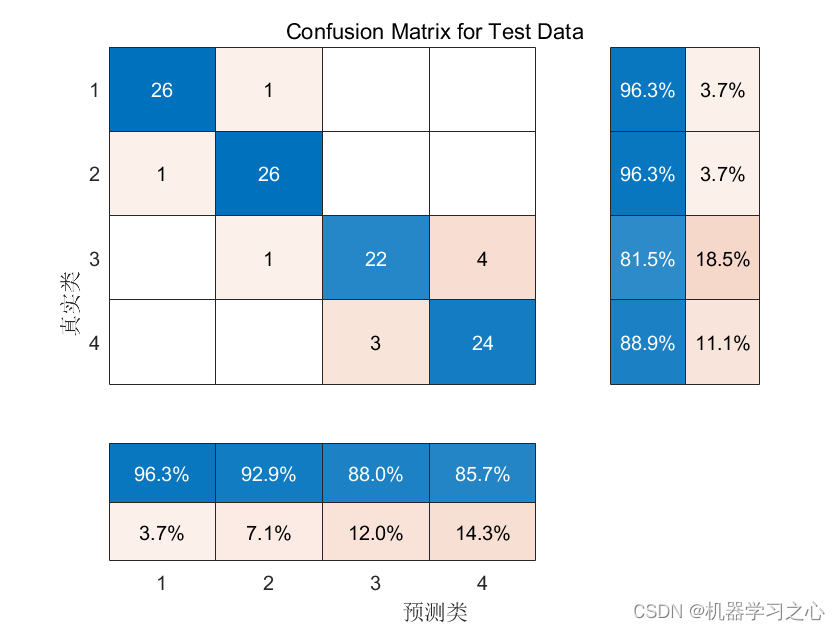
分类预测 | Matlab实现基于MIC-BP最大互信息系数数据特征选择算法结合BP神经网络的数据分类预测
分类预测 | Matlab实现基于MIC-BP最大互信息系数数据特征选择算法结合BP神经网络的数据分类预测 目录 分类预测 | Matlab实现基于MIC-BP最大互信息系数数据特征选择算法结合BP神经网络的数据分类预测效果一览基本介绍研究内容程序设计参考资料 效果一览 基本介绍 Matlab实现基于…...

拜读苏神-1-深度学习+文本情感分类
一、闲聊神经网络与深度学习 参考链接:https://www.kexue.fm/archives/3331 分类模型本质上是在做拟合——模型其实就是一个函数(或者一簇函数),里边有一些待定的参数,根据已有的数据,确定损失函数&#x…...

【uniapp 小程序开发语法篇】资源引入 | 语法介绍 | UTS 语法支持(链接格式)
博主:_LJaXi Or 東方幻想郷 专栏: uni-app | 小程序开发 开发工具:HBuilderX 小程序开发语法篇 引用组件easycom Js文件引入NPM支持 Css文件引入静态资源引入css 引入静态资源如何引入字体图标?css 引入字体图标示例nvue 引入字体…...

Stable Diffusion教程(9) - AI视频转动漫
配套抖音视频教程:https://v.douyin.com/UfTcrcJ/ 安装mov2mov插件 打开webui点击扩展->从网址安装输入地址,然后点击安装 https://github.com/Scholar01/sd-webui-mov2mov 最后重启webui 下载模型 从国内liblib AI 模型站下载模型 LiblibAI哩…...
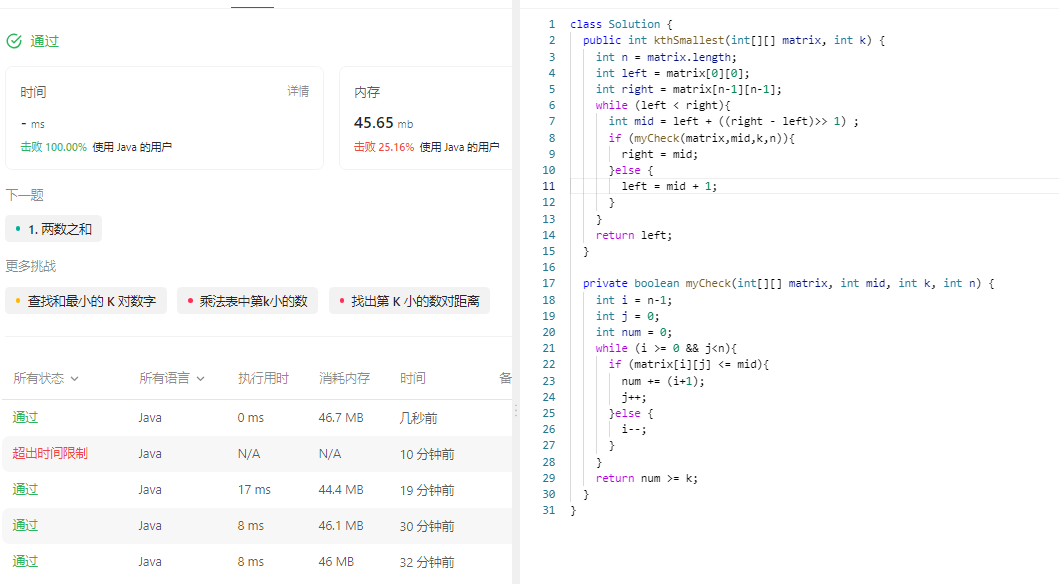
378. 有序矩阵中第 K 小的元素
378. 有序矩阵中第 K 小的元素 原题链接:完成情况:解题思路:参考代码:__378有序矩阵中第K小的元素__直接排序__378有序矩阵中第K小的元素__归并排序__378有序矩阵中第K小的元素__二分查找 原题链接: 378. 有序矩阵中…...
)
商品首页(sass+git本地初始化)
目录 安装sass/sass-loader 首页(vue-setup) 使用git本地提交 同步远程git库 安装sass/sass-loader #安装sass npm i sass -D#安装sass-loader npm i sass-loader10.1.1 -D 首页(vue-setup) <template><view class"u-wrap"><!-- 轮播图 --><…...
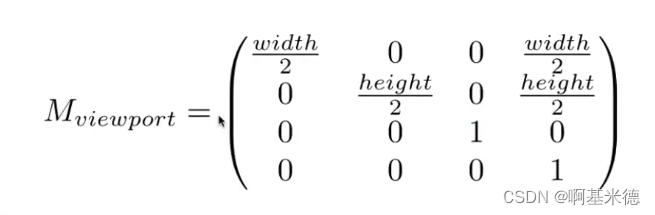
Games101学习笔记 - MVP矩阵
MV矩阵(模型视图变换) 目的,把摄像机通过变换移动的世界坐标远点,并且朝向与Z轴的负方向相同。这个变换就是模型试图变换。 因为移动了相机,如果想保持正确的渲染的话,那么对应的物体需要要和相机保持相对…...
从零开始搭建个人博客网站(hexo框架)
1.工具及环境搭建 1)注册GitHub并且新建一个repositories 2)下载node.js以及Git 下载链接: 检验安装是否成功: 【注】:MacOS自带Git,可以直接在终端输入git --version进行检验 3)新建一个…...
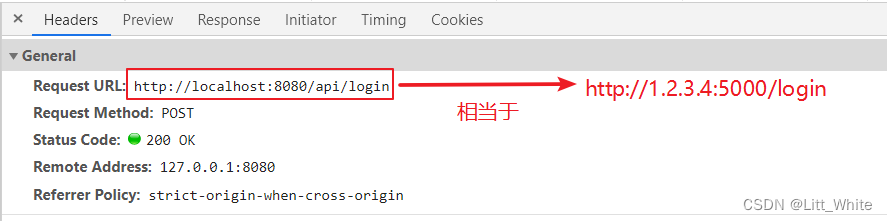
vue的proxy代理详解
一、proxy常用参数说明 module.exports {publicPath: "/",devServer: {proxy: {"/api": {// 代理名称 凡是使用/api开头的地址都是用此代理target: "http://1.2.3.4:5000/", // 需要代理访问的api地址changeOrigin: true, // 允许跨域请求pa…...

计算机网络 ARP协议 IP地址简述
ARP只能在一个链路或一段网络上使用...

如何轻松管理6款二次元游戏模组:XXMI启动器完整指南
如何轻松管理6款二次元游戏模组:XXMI启动器完整指南 【免费下载链接】XXMI-Launcher Modding platform for GI, HSR, WW and ZZZ 项目地址: https://gitcode.com/gh_mirrors/xx/XXMI-Launcher 还在为管理多个游戏的模组而烦恼吗?每次玩不同的二次…...

WAS Node Suite图像批量处理终极指南:5种高效解决Load Image Batch节点异常的实战方案
WAS Node Suite图像批量处理终极指南:5种高效解决Load Image Batch节点异常的实战方案 【免费下载链接】was-node-suite-comfyui An extensive node suite for ComfyUI with over 210 new nodes 项目地址: https://gitcode.com/gh_mirrors/wa/was-node-suite-comf…...
)
别再只盯着论文了!手把手教你用PyTorch复现3个经典医学图像融合模型(附完整代码)
从理论到实践:PyTorch复现医学图像融合模型的实战指南 医学图像融合技术正逐渐成为临床诊断和科研分析的重要工具。不同于单纯的理论探讨或论文整理,本文将带您深入三个经典模型的代码实现细节,让抽象的网络结构变得触手可及。无论您是刚入门…...
)
从‘模糊’到‘精确’:手把手教你用频域分析搞定高斯滤波参数(附MATLAB/Python对比)
从频域视角解密高斯滤波:用频谱分析精准调参的实战指南 第一次接触高斯滤波时,你可能和我一样困惑——为什么调整那个叫"标准差"的σ参数,图像就会变得模糊?空域中那个神秘的钟形卷积核,到底是如何影响像素的…...

破茧成蝶:2026全栈技术趋势全景——TypeScript、Rust、AI Agent、云原生与边缘计算的深度融合
引言:站在时代交汇点的全栈工程师 2026年,我们正站在一个前所未有的技术奇点之上。过去五年,技术浪潮以前所未有的速度和深度重塑了软件开发的每一个环节。从前端到后端,从云端到设备边缘,从人工编码到AI自主执行&…...

【OpenCV 实战】LBP 统计直方图:从纹理特征到图像识别的关键一步
1. 为什么LBP统计直方图是图像识别的秘密武器? 第一次接触LBP(局部二值模式)时,我盯着那些黑白相间的纹理图看了半天——这不就是把像素点变成01编码吗?直到把统计直方图加进去,才发现这个组合简直是纹理识…...

WebCord Chrome扩展支持:实验性功能的完整使用手册
WebCord Chrome扩展支持:实验性功能的完整使用手册 【免费下载链接】WebCord A Discord and SpaceBar :electron:-based client implemented without Discord API. 项目地址: https://gitcode.com/gh_mirrors/we/WebCord WebCord是一款基于Electron构建的Dis…...

把 ABAP CDS 看透,DDL 与 DCL 如何一起撑起语义数据模型
今天把这张图放在旁边看,很多原本容易混在一起的概念,一下子就清楚了。左边是 DDL,右边是 DCL,上面两个蓝色框像是入口,下面两大片留白反而很有意思,它提醒我们,ABAP CDS 不是一条单纯的查询语法,而是一套把数据模型、语义信息、访问控制同时装进同一个设计面里的语言体…...

Hexo 博客无法复制 Markdown 本地图片?我写了一个插件
不知道现在大家写博客、文章还多不多,我一直在用 Obsidian Markdown 写文章,然后用 Hexo 生成静态站点发布到 GitHub Pages,绑定到域名 xiaoming.io。 几年前我写过一篇文章,分享我是怎么构建笔记和博客系统的。 构建自己的笔记…...

学Simulink——基于Simulink的轴向磁通电机多物理场耦合仿真
目录 手把手教你学Simulink——基于Simulink的轴向磁通电机多物理场耦合仿真 摘要 一、背景与挑战 1.1 为什么轴向磁通电机的仿真让人“头秃”? 1.2 核心痛点与设计目标 二、系统架构与核心控制推导 2.1 整体架构:跨越维度的“降阶打击” 2.2 核心数学推…...