【数据结构】二叉树常见题目
文章目录
- 前言
- 二叉树概念
- 满二叉树
- 完全二叉树
- 二叉搜索树(二叉排序树)
- 平衡⼆叉搜索树
- 存储⽅式
- 二叉树OJ
- 二叉树创建字符串
- 二叉树的分层遍历1
- 二叉树的分层遍历2
- 给定一个二叉树, 找到该树中两个指定节点的最近公共祖先
- 二叉树搜索树转换成排序双向链表
- 二叉树展开为链表
- 根据一棵树的前序遍历与中序遍历构造二叉树
- 根据一棵树的中序遍历与后序遍历构造二叉树
- 二叉树的前序遍历 非递归迭代实现
- 二叉树中序遍历 非递归迭代实现
- 二叉树的后序遍历 非递归迭代实现
- 单值二叉树
- 检查两棵树是否相同
- 对称二叉树
- 另一棵树的子树
- 二叉树的遍历-清华408机试
- 翻转二叉树
- 求二叉树某个节点的后继节点
- 升级版(通用版)
- 判断二叉搜索树
- 判断平衡二叉树
- 判断满二叉树
- 判断完全二叉树
- 前序遍历构造二叉搜索树
- 相等子树的数量
- 恢复二叉搜索树
- 层序遍历系列题目
- 二叉树的右视图
- 二叉树的层平均值
- N叉树的层序遍历
- 在每个树行中找最大值
- 填充每个节点的下一个右侧节点指针
前言
此乃本人自用版本,用于复习回顾! 所以部分题目不会有过大详细的解析,不懂的可以评论!笔者将竭力为你解答
二叉树概念
满二叉树
满⼆叉树:如果⼀棵⼆叉树只有度为0的结点和度为2的结点,并且度为0的结点在同⼀层上,则这棵⼆叉树为满⼆叉树
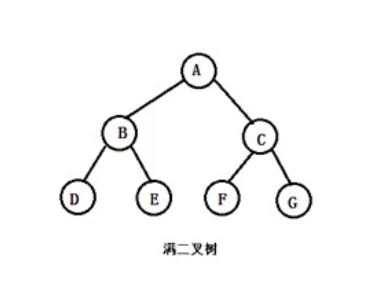
高度为h的满二叉树,共有2^h -1个节点
完全二叉树
完全⼆叉树的定义如下:在完全⼆叉树中,除了最底层节点可能没填满外,其余每层节点数都达到最⼤值,并且最下⾯⼀层的节点都集中在该层最左边的若⼲位置。
完全二叉树的高度为h,则在第h层:包含 1~ 2^h -1个节点
完全二叉树的判断:
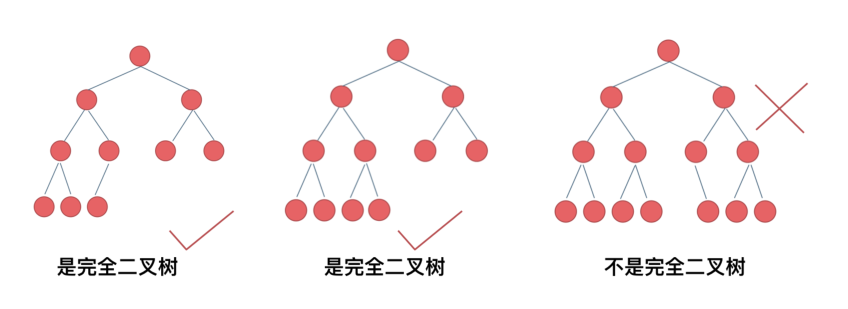
最后一层必须从左到右依次变满,如果不连续,就不符合完全二叉树
优先级队列其实是⼀个堆,堆就是⼀棵完全⼆叉树,同时保证⽗⼦节点的顺序关系
二叉搜索树(二叉排序树)
⼆叉搜索树是⼀个有序树
- 若它的左⼦树不空,则左⼦树上所有结点的值均⼩于它的根结点的值;
- 若它的右⼦树不空,则右⼦树上所有结点的值均⼤于它的根结点的值;
- 它的左、右⼦树也分别为⼆叉排序树
平衡⼆叉搜索树
平衡⼆叉搜索树:⼜被称为AVL树
且具有以下性质:它是⼀棵空树或 它的左右两个⼦树的⾼度差的绝对值不超过1,并且左右两个⼦树都是⼀棵平衡⼆叉树
最后⼀棵树不是平衡⼆叉树,因为它的左右两个⼦树的⾼度差的绝对值超过了1
注意:C++中map、set、multimap,multiset的底层实现都是平衡⼆叉搜索树,所以map、set的增删操作
时间时间复杂度是log n 而:unordered_map底层实现是哈希表
存储⽅式
⼆叉树可以链式存储,也可以顺序存储
链式存储⽅式就⽤指针, 顺序存储的⽅式就是⽤数组
顺序存储:
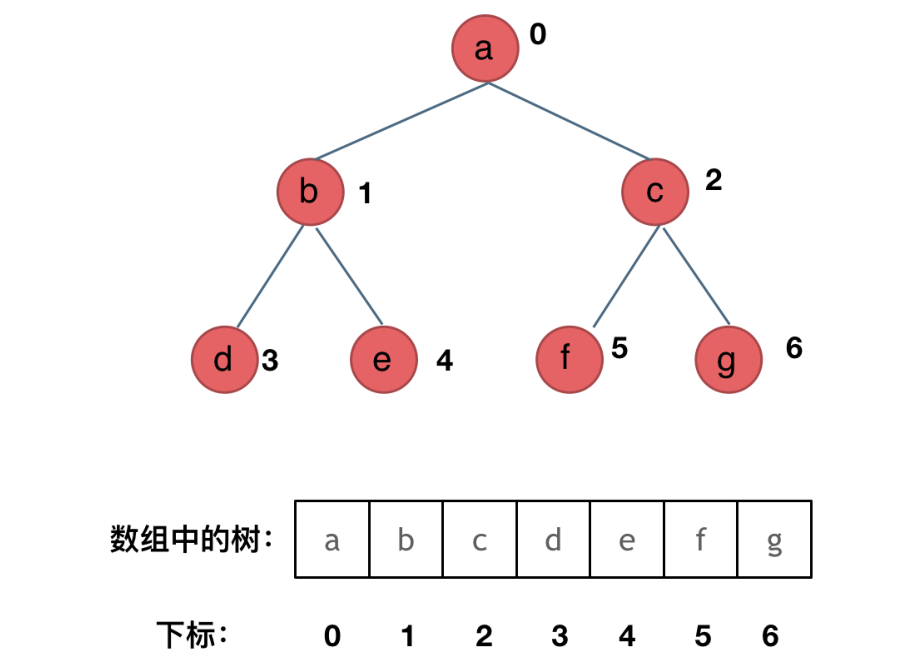
其中我们也可以发现下标的规律:
- parent = (child-1)/2
- left_child = parent*2+1
- right_child = parent*2+2
链式存储:
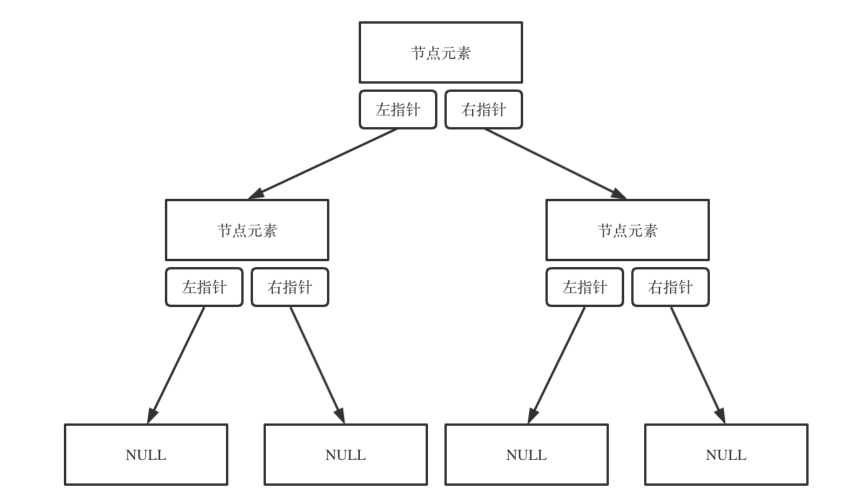
我们通常使用的是链式存储
二叉树OJ
二叉树创建字符串
给你二叉树的根节点 root ,请你采用前序遍历的方式,将二叉树转化为一个由括号和整数组成的字符串,返回构造出的字符串,空节点使用一对空括号对 “()” 表示,转化后需要省略所有不影响字符串与原始二叉树之间的一对一映射关系的空括号对,
https://leetcode-cn.com/problems/construct-string-from-binary-tree/
前序遍历的方式, 先处理根节点:
左树怎么处理? 右树怎么处理? 什么时候需要加括号!
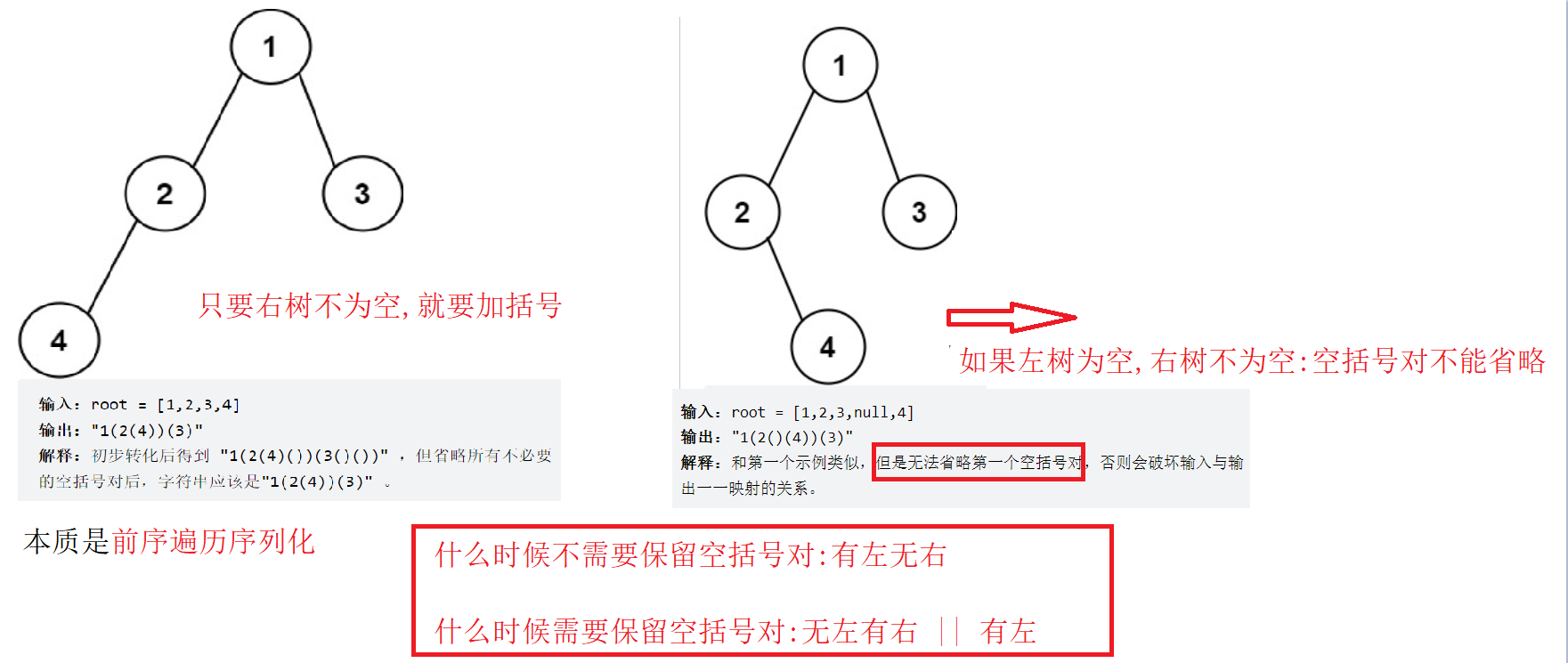
构建左树的括号的时候,如果左树存在 或者 左树不存在,右树存在,那么此时序列化这个左树需要加括号
//左树是否需要加括号:有左 || 无左有右 -> 就需要加括号
if(root->left || root->right)
{ans += '(';_tree2str(root->left,ans);ans += ')';
}
构建右树的括号的时候:如果右树存在就需要加
if(root->right)
{ans += '(';_tree2str(root->right,ans);ans += ')';
}
err:
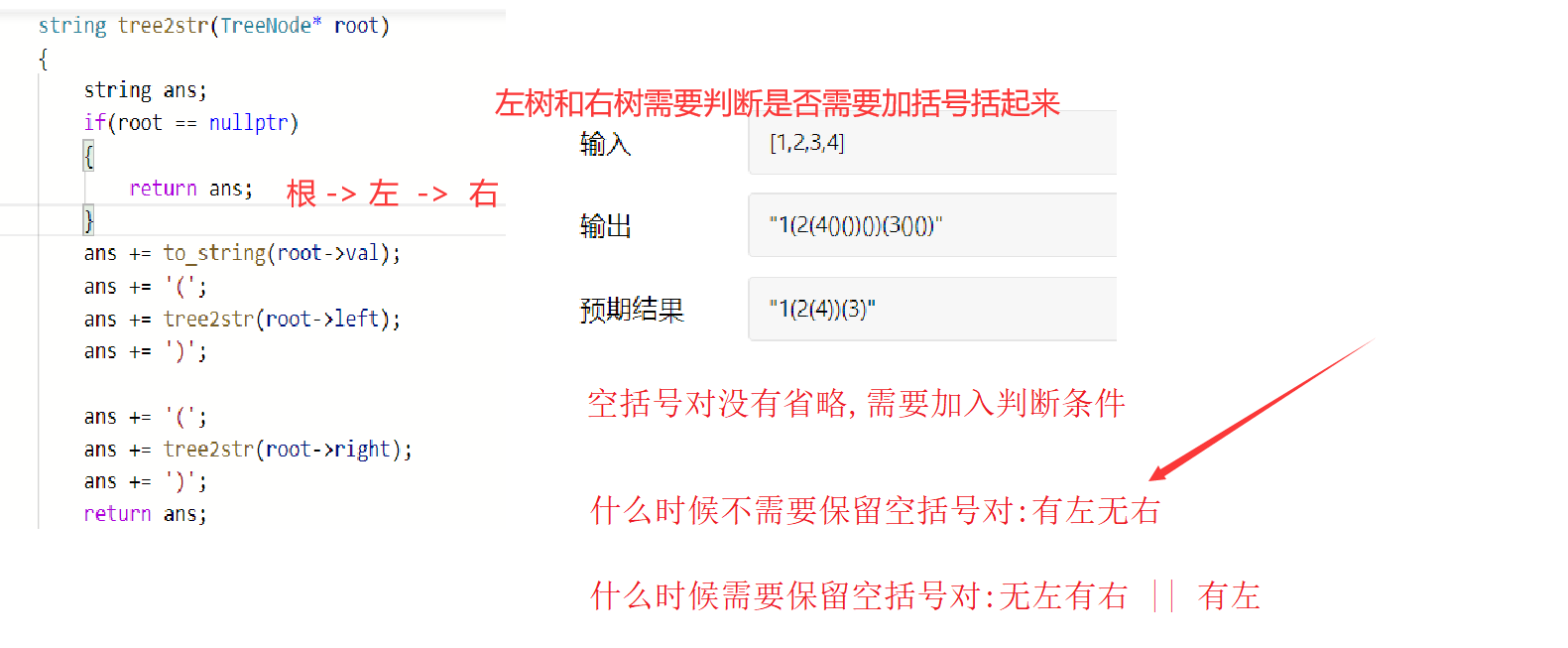
方法1:
class Solution {public:string tree2str(TreeNode* root){string ans;if(root == nullptr){return ans;}ans += to_string(root->val);//有左 || 无左有右 -> 就需要加括号//root->left || root->right就可以代表上面的描述if(root->left || root->right){ans += '(';ans += tree2str(root->left);ans += ')';}//右树只要不为空就加括号,否则不处理右树if(root->right){ans += '(';ans += tree2str(root->right);ans += ')';}return ans;}
};
缺点: 每一次返回都是传值返回, 由于返回的ans是临时变量,不能使用引用返回, 所以是深拷贝
优化:写子函数,传引用作为参数,减少拷贝
class Solution {public:void _tree2str(TreeNode* root,string& ans){if(root == nullptr){return ;}//前序遍历序列化,需要判断是否需要加括号ans += to_string(root->val);//左树是否需要加括号:有左 || 无左有右 -> 就需要加括号if(root->left || root->right){ans += '(';_tree2str(root->left,ans);ans += ')';}//判断右树是否需要加括号->右树不为空,就需要加if(root->right){ans += '(';_tree2str(root->right,ans);ans += ')'; }}string tree2str(TreeNode* root) {string ans;_tree2str(root,ans);return ans;}
};
二叉树的分层遍历1
https://leetcode-cn.com/problems/binary-tree-level-order-traversal/
 d
d
class Solution {public:vector<vector<int>> levelOrder(TreeNode* root) {vector<vector<int>> vv;if(root == nullptr){return vv;//返回空容器}queue<TreeNode* >q;//用于层序遍历的容器q.push(root);//先把根节点入队列while(!q.empty()){int size = q.size();//这一层有多少个节点vector<int> v;for(int i =0;i<size;i++){//对这一层的节点做处理TreeNode* node = q.front();q.pop();v.push_back(node->val);//左右孩子不为空,就进队列if(node->left){q.push(node->left);}if(node->right){q.push(node->right);}}//把这一层的结果放到容器中vv.push_back(v);}return vv;}
};
二叉树的分层遍历2
https://leetcode-cn.com/problems/binary-tree-level-order-traversal-ii/
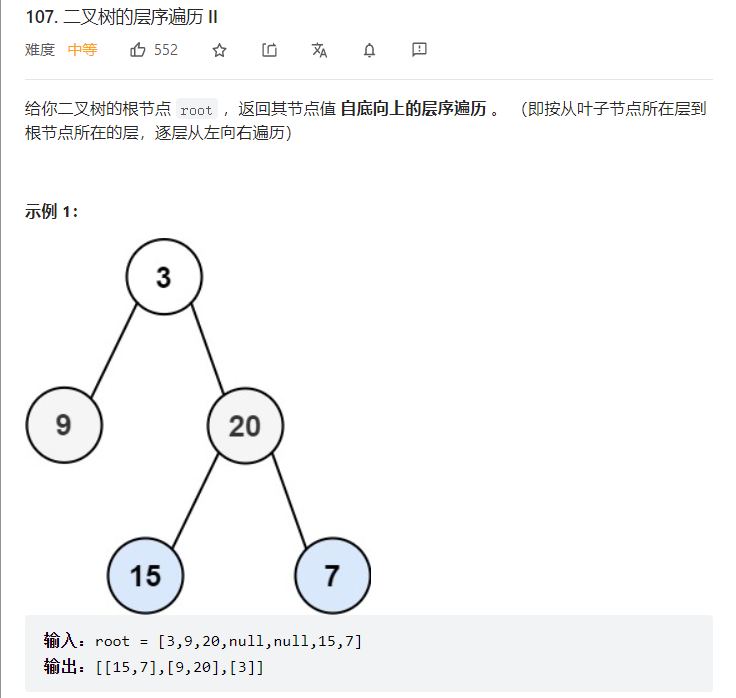
此题和上面的区别就是,这个是自底向上存放结果,而上一题是自顶向下存放结果,
所以我们处理的方法是:先得到自顶向下的结果,然后翻转容器,得到的就是自底向上的结果
class Solution {
public:vector<vector<int>> levelOrderBottom(TreeNode* root) {vector<vector<int>> vv;if(root == nullptr){return vv;//返回空容器}queue<TreeNode* >q;//用于层序遍历的容器q.push(root);//先把根节点入队列while(!q.empty()){int size = q.size();//这一层有多少个节点vector<int> v;for(int i =0;i<size;i++){//对这一层的节点做处理TreeNode* node = q.front();q.pop();v.push_back(node->val);//左右孩子不为空,就进队列if(node->left){q.push(node->left);}if(node->right){q.push(node->right);}}//把这一层的结果放到容器中vv.push_back(v);}reverse(vv.begin(),vv.end());return vv;}
};
给定一个二叉树, 找到该树中两个指定节点的最近公共祖先
https://leetcode-cn.com/problems/lowest-common-ancestor-of-a-binary-tree/
什么叫公共祖先: 沿着自己的路径往上走,最坏就走到根节点, 二者的交点就是祖先
情况分析:该类题目的常见类型:
1.如果是三叉链
即左右孩子指针 + 父亲节点指针
此时可以转化为链表相交问题:
- 两个节点不断往上走到根节点位置,统计二者的长度,然后长链表先走差距步,然后二者再一起走,当二者相遇就是祖先

2.如果是搜索树:
a.如果一个值比当前root节点的值小,一个值比当前root节点的值大 ->我就是最近公共祖先
b.如果两个值都比当前root节点的值小 -> 去左树递归查找
c.如果两个值都比当前root节点的值大-> 去右树递归查找

3.普通的二叉树
相比搜索二叉树,此时不能使用值的大小去判断在左树还是右树!此时要整棵树查找
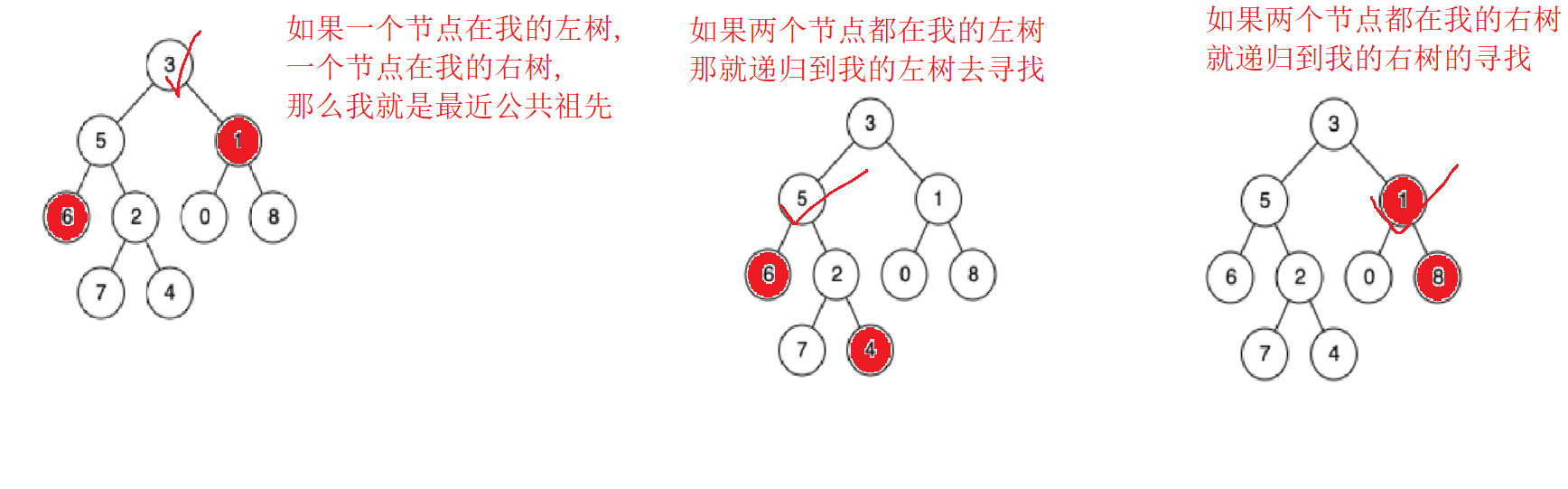

此时是第三种 普通二叉树的情况:
方法1:
设计一个子函数Find:用于查找x这个节点在不在
对要查找的两个节点的情况分析:
如果其中一个节点是当前根节点,最近公共祖先就是当前节点
如果两个节点不在root这棵树的同一侧:当前root节点就是二者的最近公共祖先
如果两个节点都在root的右树:去root的右树寻找
如果两个节点都在root的左数:去root的左树查找
为了方便,可以设计4个变量分别标志p和q是否在左树/右树
子函数Find:
//查找x这个节点是否在这棵树
bool Find(TreeNode* root,TreeNode* x)
{//root为空树if(root == nullptr) return false;//root就是x节点if(root == x) return true;//去左树和右树查找//任意一棵树找到就说明x在这棵树,所以用的是||的逻辑return Find(root->left,x) || Find(root->right,x);
}
主函数:
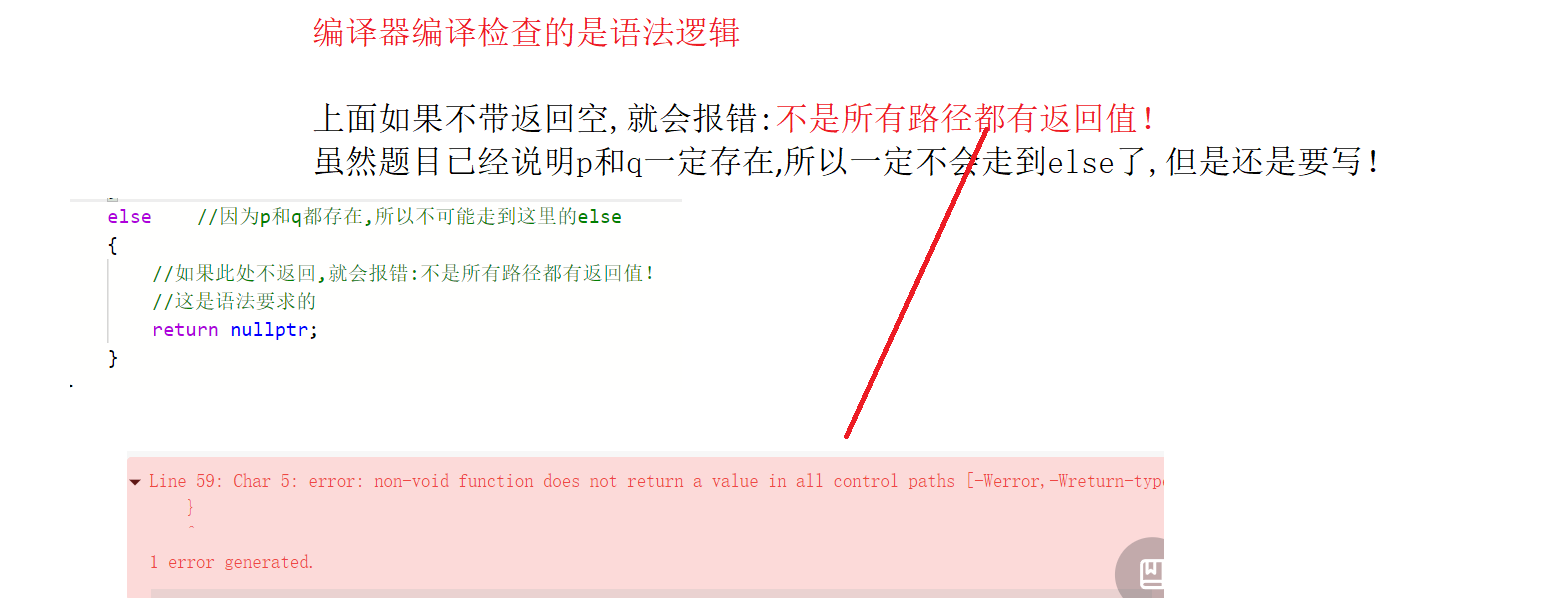
注意返回值的问题:
时间复杂度:O(N^2)
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q)
{//root为空树if(root == nullptr) return nullptr;//如果其中一个节点是当前根节点,最近公共祖先就是当前节点if(root == p || root == q){return root;}//定义4个变量标志p和q在root的哪一侧bool pInLeft,pInRight,qInLeft,qInRight;//如果p/q在左树了就不可能在右树pInLeft = Find(root->left,p);//调用子函数查找p是否在root的左树pInRight = !pInLeft;qInLeft = Find(root->left,q);//调用子函数查找q是否在root的左树qInRight = !qInLeft;//对p和q的情况分析//1.两个节点不在同一侧:根节点就是祖先if((pInLeft&&qInRight) || (pInRight&&qInLeft)){return root;}//2.两个节点都在左树->去左树找else if(pInLeft&&qInLeft){return lowestCommonAncestor(root->left,p,q);}//3.两个节点都在右树->去右树找else if(pInRight&&qInRight){return lowestCommonAncestor(root->right,p,q);}else //因为p和q都存在,所以不可能走到这里的else{//如果此处不返回,就会报错:不是所有路径都有返回值!//这是语法要求的return nullptr;}
}
方法2:分别求出从根节点到p和q的路径,再找两个路径的交点
这里可以选择把路径加入到栈中,注意栈中最好存放节点指针,如果存的是节点的值,如果存在树中存在相同的值,就会出错(虽然这题说了节点的值不重复)
FindPath函数:把从根节点到x的路径加入到容器中,
注意:要排除节点->回溯 时间复杂度:O(N)
子函数FindPath:查找x节点,并保存沿途的路径节点 返回值为bool类型,用于标志是否发现节点x
不管三七二十一,先把当前节点放到路径容器中
0.如果当前节点为空 ->返回false
1.如果当前节点就是x ->返回true
否则:
2.去左树查找,找到了就返回true,否则就是false
3.去右树查找,找到了就返回true,否则就是false
4.如果走到这一步,说明在当前节点的这颗子树不可能找到x节点,(说明该节点不是从根节点到x节点的路径中的一个节点) 把这个节点从就容器中去掉,然后返回false
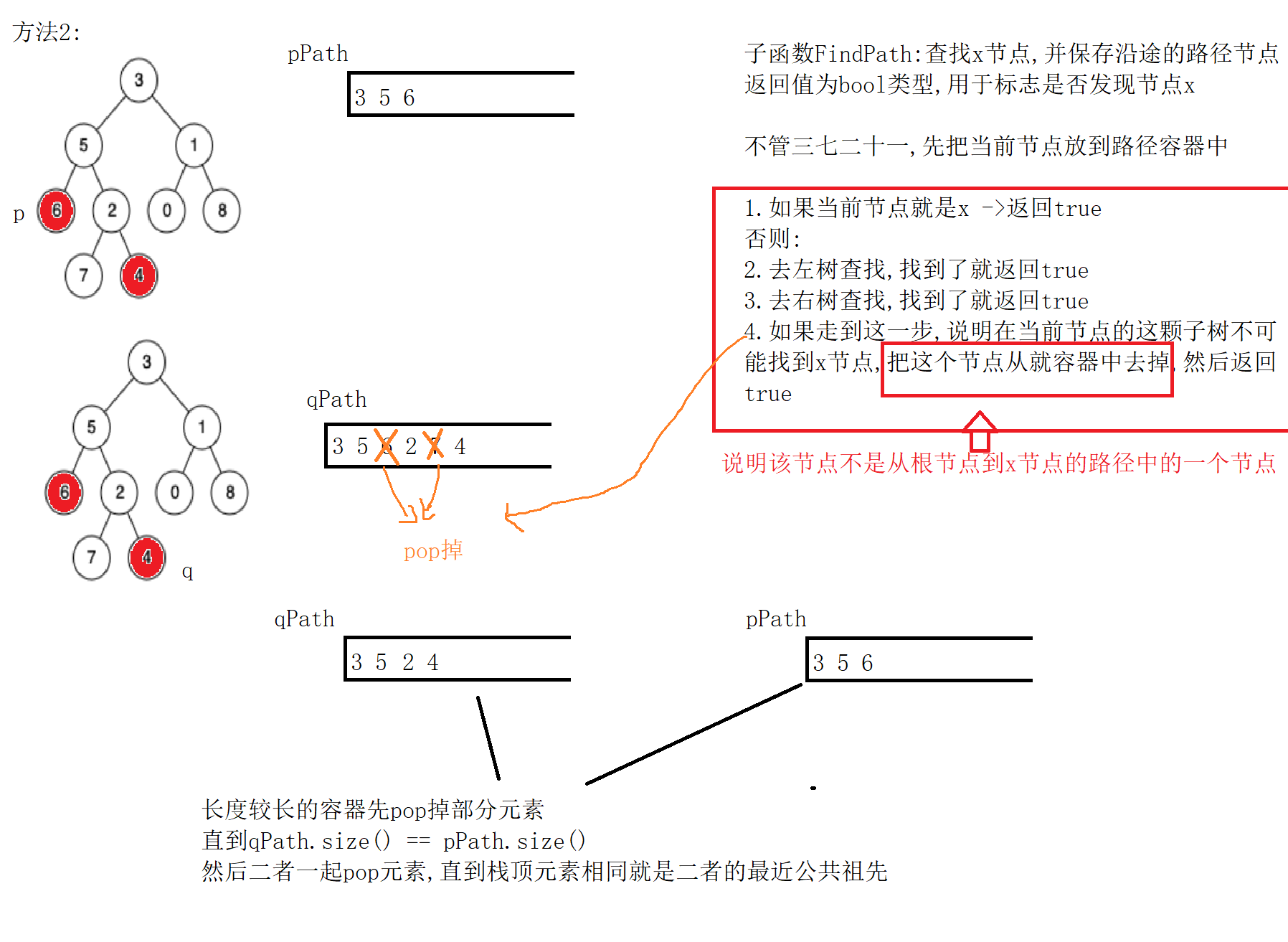
- 上述第四步应该是返回false!!!手误
// 返回bool类型是为了判断是否发现x,发现了就不需要往下找了
//因为要修改path容器的内容,所以要传引用
bool FindPath(TreeNode* root,TreeNode* x,stack<TreeNode*>& path)
{//当前节点为空 ->返回falseif(root == nullptr) return false;path.push(root);//先把当前节点放到路径中//当前节点就是x节点->返回trueif(root == x) return true;//如果root不是x -> 去当前节点的左树和右树找x,并保存沿途的路径if(FindPath(root->left,x,path)){//在当前节点的左树中找到x了,返回truereturn true;}if(FindPath(root->right,x,path)){//在当前节点的右树找到x,返回truereturn true;}//走到这里,说明当前节点的左树和右树都没有找到x节点->把当前节点在路径中去掉,返回falsepath.pop();return false;
}
主函数:
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q)
{stack<TreeNode*> pPath,qPath;//分别保存到p和q的路径FindPath(root,p,pPath);//得到到p节点的路径,保存到pPathFindPath(root,q,qPath);//得到到q节点的路径,保存到qPath//长的路径容器先走差距步while(qPath.size() != pPath.size()){if(qPath.size() > pPath.size()){qPath.pop();}else{pPath.pop();}}//此时二者得路径长度相同,一起出数据//当二者栈顶元素相同,就是祖先while(qPath.top() != pPath.top()){qPath.pop();pPath.pop();}return qPath.top();
}
方法3:二叉树递归套路
class Solution {
public:struct Info{bool isFindQ;//是否发现qbool isFindP;//是否发现pTreeNode* ans;//记录q和p的公共祖先答案Info(bool isQ, bool isP,TreeNode* an){isFindP = isP;isFindQ = isQ;ans = an;}};Info process(TreeNode* x,TreeNode* p,TreeNode* q){if(x == nullptr){return Info(false,false,nullptr);//设置空信息}Info leftInfo = process(x->left,p,q);Info rightInfo = process(x->right,p,q);//处理x这棵树的信息bool isFindQ = leftInfo.isFindQ || rightInfo.isFindQ || x == q;bool isFindP = leftInfo.isFindP || rightInfo.isFindP || x == p;TreeNode* ans = nullptr;//是否在左树/右树发现答案if(leftInfo.ans != nullptr){ans = leftInfo.ans; }else if(rightInfo.ans != nullptr){ans = rightInfo.ans;}else{//此时走到这,说明没有找到答案//如果在x这棵树即发现了p也发现了q,说明x这个节点就是答案if(isFindP&&isFindQ){ans = x;}}//返回这棵树的信息return Info(isFindQ,isFindP,ans);}TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {return process(root,p,q).ans;}
};
二叉树搜索树转换成排序双向链表

https://www.nowcoder.com/practice/947f6eb80d944a84850b0538bf0ec3a5?tpId=13&&tqId=11179&rp=1&ru=/activity/oj&qru=/ta/coding-interviews/question-ranking
方法1:容器作弊法 走一遍中序遍历,把节点的指针放到容器中,然后遍历链接前后两个节点
特殊点:第一个节点的left链接空 最后一个节点的right链接空
class Solution {
public:vector<TreeNode*> v;//存放节点指针//中序遍历void _inOrder(TreeNode* root){if(root == nullptr) return ;_inOrder(root->left);v.push_back(root);_inOrder(root->right);}TreeNode* Convert(TreeNode* pRootOfTree) {if(pRootOfTree == nullptr) return nullptr;_inOrder(pRootOfTree);//先走一边中序遍历//二叉树的左孩子指针 -> prev 右孩子指针 -> next//第一个节点的prev置为空TreeNode* head = v[0];TreeNode* cur = head;cur->left = nullptr;TreeNode* next = nullptr;for(int i = 0;i<v.size()-1;i++){cur = v[i];next = v[i+1];//cur next前后链接cur ->right = next;next -> left = cur;}//最后一个节点的next置为空v[v.size()-1] -> right = nullptr;return head;}
};
方法2:递归走中序遍历
思想:让每个节点的left指向上一个遍历的节点,让每个节点的right指向下一个遍历的节点
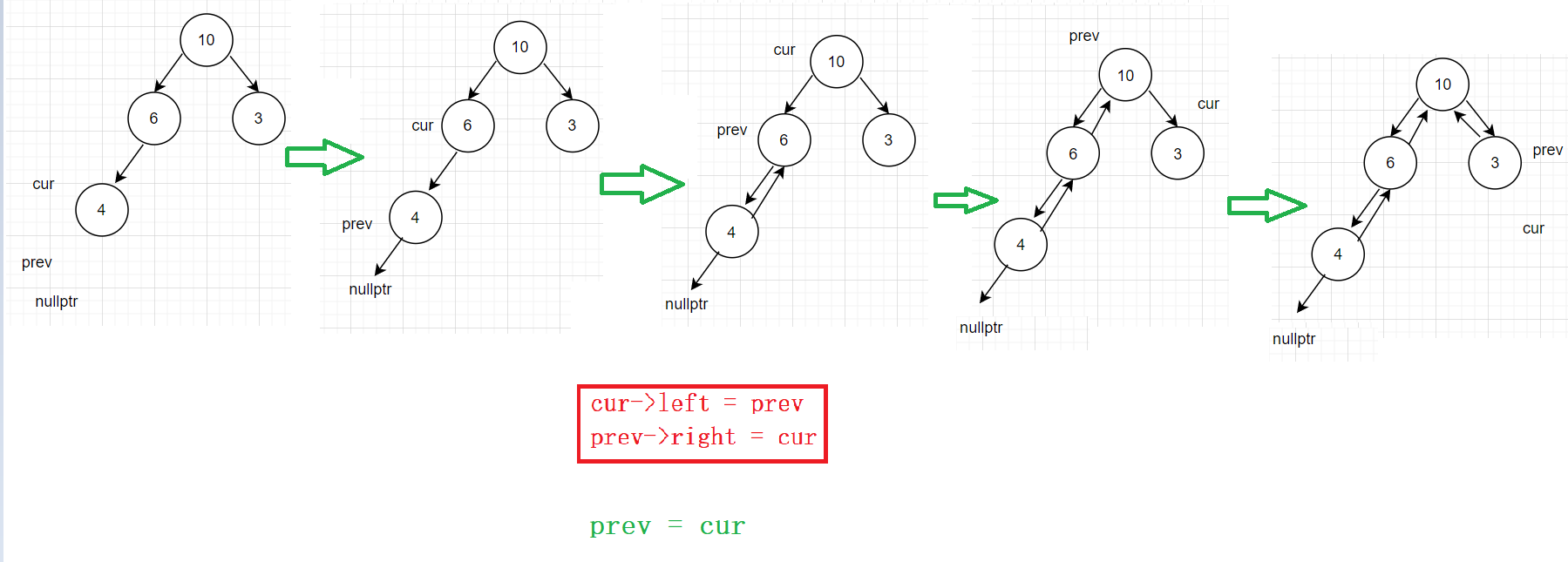
定义两个指针:一个prev 一个 cur,其中cur记录当前中序遍历时到达的节点,prev记录上一次中序遍历时到达的节点
当我们遍历到cur的时候,我们不知道下一个节点是谁,但是我们可以明确知道,prev的下一个节点是cur,cur的上一个节点是prev 即我们可以知道: 此时left是指向前一个指针,right是指向下一个的指针
cur->left = prev
prev->right = cur
注意:由于prev要记录上一次中序遍历的节点,即prev只能存在一个,并非每个栈帧都有一个prev,所以传参的时候,prev要传引用 第一次的时候,prev是nullptr
class Solution {
public://prev传的时引用!!!void InOrderConvert(TreeNode* cur ,TreeNode*& prev){if(cur == nullptr) return ;//中序遍历InOrderConvert(cur->left,prev);//cur和prev链接cur->left = prev;//注意第一次的时候prev时空,所以要判断一下if(prev != nullptr){prev ->right = cur;}prev = cur;//此时的cur就成了上一次中序遍历的节点InOrderConvert(cur->right,prev);}TreeNode* Convert(TreeNode* pRootOfTree){if(pRootOfTree == nullptr){return nullptr;}TreeNode* prev = nullptr;//prev初始化为空InOrderConvert(pRootOfTree,prev);//调用子函数进行处理//先找到原来根节点的位置,然后往前找,找到链表的头TreeNode* head = pRootOfTree;while(head->left){head = head->left;}return head;}
};
二叉树展开为链表
给你二叉树的根结点 root ,请你将它展开为一个单链表:
- 展开后的单链表应该同样使用 TreeNode ,其中 right 子指针指向链表中下一个结点,而左子指针始终为 null
- 展开后的单链表应该与二叉树 先序遍历 顺序相同
https://leetcode-cn.com/problems/flatten-binary-tree-to-linked-list/
方法1:因为展开后的单链表应该与二叉树 先序遍历 顺序相同,所以可以先走一遍前序遍历,把节点存到容器中,然后进行链接
- 注意:left指针要置空,前一个节点的right指针链接下一个节点
- 注意:最后一个节点的left和right指针都置为空
class Solution {
public:vector<TreeNode*> v;void preOrder(TreeNode* root){if(root == nullptr ) return ;v.push_back(root);preOrder(root->left);preOrder(root->right);}void flatten(TreeNode* root) {if(root == nullptr) return ;preOrder(root);//遍历容器进行链接for(int i =0;i<v.size()-1;i++ ){v[i]->right = v[i+1];v[i]->left = nullptr;}v[v.size()-1]->right = nullptr;v[v.size()-1]->left = nullptr;}
};
方法2:递归
为了将两个树节点进行链接操作,通常希望它们是前驱和后继的关系

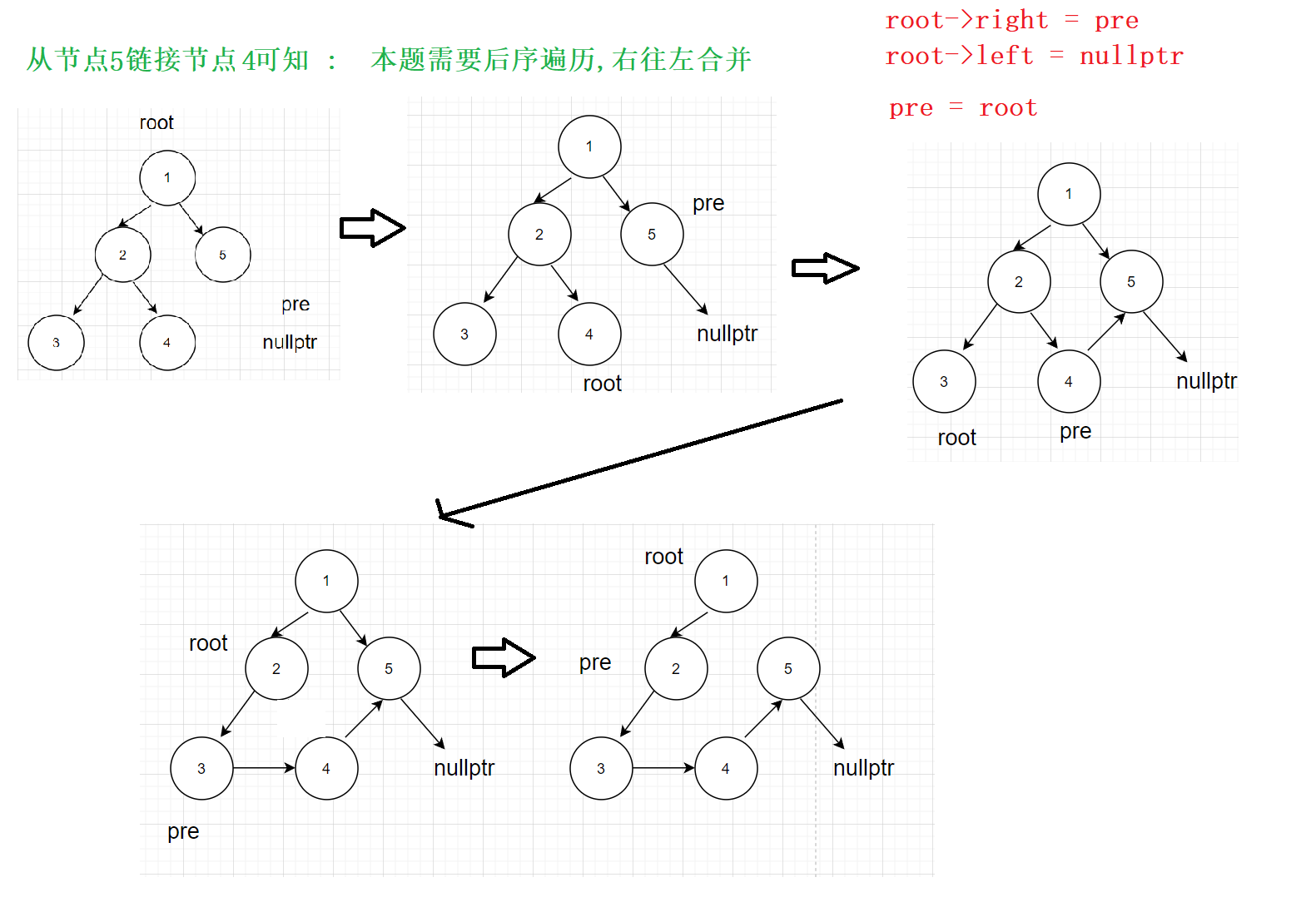
此时这棵树,按右 左 根的顺序得到的结果为:5 4 3 2 1 然后pre:上一个遍历到的节点,root:当前节点
class Solution {
public:TreeNode* pre = nullptr;//记录前一个节点void flatten(TreeNode* root){if (root && (root->left || root->right)) {//先右后左的后序遍历flatten(root->right);flatten(root->left);//进行链接root->right = pre;//将前驱结点作为当前结点的右孩子root->left = nullptr;//当前结点的左孩子置空pre = root; //更新前驱结点}}
};
根据一棵树的前序遍历与中序遍历构造二叉树
https://leetcode-cn.com/problems/construct-binary-tree-from-preorder-and-inorder-traversal/

方法1:根据每一棵子树的元素个数划分左树和右树
class Solution {
public://闭区间TreeNode* _buildTree(vector<int> preorder,int preStart,int preEnd,vector<int> order,int orStart,int orEnd){//如果某一个区间不符合,直接返回空if(preStart>preEnd || orStart > orEnd){return nullptr;}//根节点的位置就是前序数组区间的的第一个位置TreeNode* head = new TreeNode(preorder[preStart]);//在中序数组中找到根节点的位置for(int i = orStart;i<=orEnd;i++){if(order[i] == head->val){//构建左树和右树//中序数组中,此时i位置就是根节点在中序数组的位置:左树范围:[orStart,i-1] 根节点:i 右树范围:[i+1,orEnd]//根据左子树个数一样的原则,可以得知,前序遍历中,根节点位置为preStart位置,所以左树的范围是[preStart+1,x] x-(preStart+1)+1 = i-1-orStart+1 -> x = preStart+i-orStarthead->left = _buildTree(preorder,preStart+1,preStart+i-orStart,order,orStart,i-1);head->right =_buildTree(preorder,preStart+i-orStart+1,preEnd,order,i+1,orEnd);break;}}return head;//最后返回头节点}TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder) {//如果其中一个数组为空 || 两个数组的元素个数不同if(preorder.size() != inorder.size() || preorder.empty() || inorder.empty()){return nullptr;}return _buildTree(preorder,0,preorder.size()-1,inorder,0,inorder.size()-1);}
};
方法2:前序确定根,中序区间分割左右子树

定义一个变量prei标志当前前序数组的位置,确定根位置,然后prei++指向前序数组中下一个根节点的位置,为下一棵子树做准备,然后划分当前节点的左右子树
由于prei的位置是每一层都使用同一个变量往下递归,即函数栈帧中只存在一个prei,所以要传引用
class Solution {
public://前序确定根,中序区间分割左右子树//传5个参数:前序和中序数组 前序中的根位置 中序区间的首尾(闭区间)//注意:prei要传引用,因为每一层递归的prei都是对同一个prei进行修改TreeNode* _buildTree(vector<int>& preorder,vector<int>& inorder,int& prei,int inbegin,int inend){if(inbegin>inend){return nullptr;//区间不存在,返回空树 }TreeNode* root = new TreeNode(preorder[prei]);//前序确定根//在中序数组中找到根位置,划分左右区间int rooti = inbegin;while(rooti<=inend){if(inorder[rooti] == root->val){break;}else{rooti++;}}++prei;//指向前序数组中下一个根节点的位置,为下一棵子树做准备//划分当前节点的左右子树//[inbegin,rooti-1] rooti [rooti+1,inend]root->left = _buildTree(preorder,inorder,prei,inbegin,rooti-1);root->right = _buildTree(preorder,inorder,prei,rooti+1,inend);//返回根位置return root;}TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder) {if(preorder.size() != inorder.size() || preorder.empty() ||inorder.empty()){return nullptr;}int prei = 0;return _buildTree(preorder,inorder,prei,0,inorder.size()-1);}
};
根据一棵树的中序遍历与后序遍历构造二叉树
https://leetcode-cn.com/problems/construct-binary-tree-from-inorder-and-postorder-traversal/
和上面前序和中序构建树的方法基本一致!
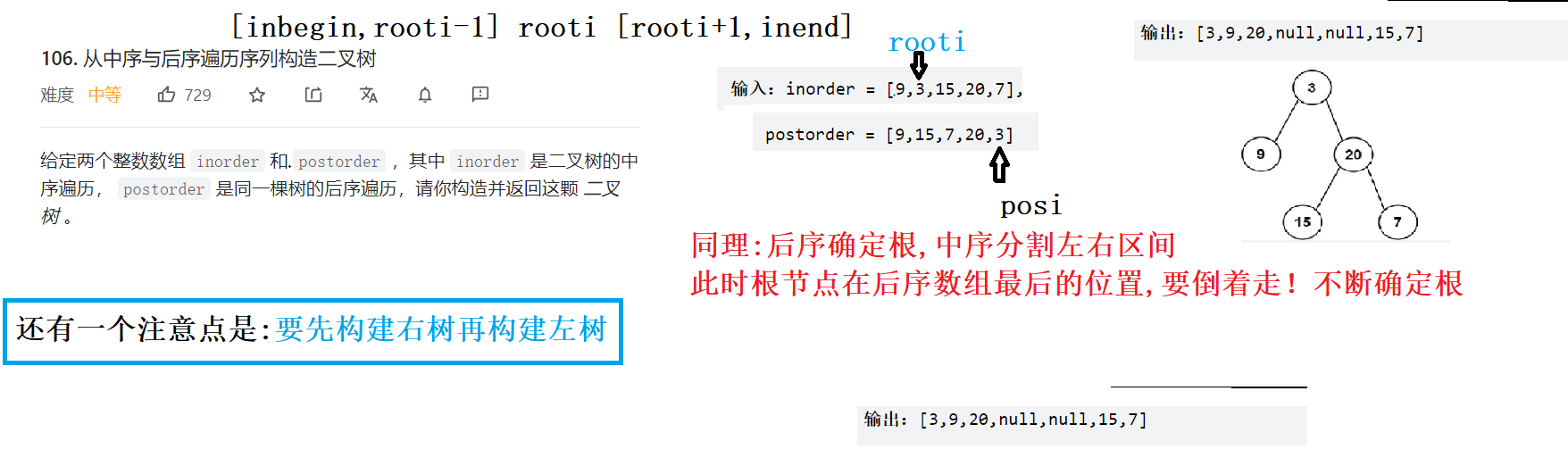
前序和中序: 前序确定根,中序分割左右区间, 由于前序的访问顺序是:根左右,所以根在前面的位置,所以prei从前序数组的第一个元素0下标位置开始往后走确定每棵子树的根
- 构造树的时候,先构建左树再构造右树
中序和后序: 后序确定根,中序分割左右区间, 由于后序的访问顺序是:左右根,所以根在后面的位置,所以posi从后序数组最后一个元素posorder.size()-1位置开始往前走确定每棵子树的根
- 构造树的时候,先构建右树再构造左树
相同点:
由于prei/posi的位置是每一层都使用同一个变量往下递归,即函数栈帧中只存在一个prei/posi,所以要传引用
class Solution {
public:TreeNode* _buildTree(vector<int>& inorder, vector<int>& postorder,int& posi,int inbegin,int inend){if(inbegin>inend){return nullptr;//区间不存在,返回空树}TreeNode* root = new TreeNode(postorder[posi]);//后序确定根位置//在中序中找到根节点位置int rooti = inbegin;while(rooti<= inend){if(inorder[rooti] == root->val){break;}else{rooti++;}}--posi;//指向后序数组中前一个根节点的位置,为下一棵子树做准备//划分当前节点的左右子树//[inbegin,rooti-1] rooti [rooti+1,inend]//注意:要先构建右树!!再构建左树root->right = _buildTree(inorder,postorder,posi,rooti+1,inend);root->left = _buildTree(inorder,postorder,posi,inbegin,rooti-1);//返回头节点位置return root;} TreeNode* buildTree(vector<int>& inorder, vector<int>& postorder) {if(inorder.size() != postorder.size() ||inorder.empty() || postorder.empty()){return nullptr;}int posi = postorder.size()-1;//根在后面 return _buildTree(inorder,postorder,posi,0,inorder.size()-1);}
};
二叉树的前序遍历 非递归迭代实现
https://leetcode-cn.com/problems/binary-tree-preorder-traversal/
class Solution {
public://子函数处理,只有容器要传引用,因为要对容器的内容做修改void _preorderTraversal(TreeNode* root,vector<int>& v){if(root == nullptr){return ;}v.push_back(root->val);//把根节点放到容器中_preorderTraversal(root->left,v);//递归处理左树_preorderTraversal(root->right,v);//递归处理右树}vector<int> preorderTraversal(TreeNode* root) {vector<int> v;_preorderTraversal(root,v);return v;}
};
**方法2:**访问顺序:根 左 右
一棵树的访问分为:
- 1.访问左路节点,并且左路节点进栈
- 2.出栈顶元素,去它的右子树, 转化为子问题
class Solution {
public:vector<int> preorderTraversal(TreeNode* root) {vector<int> v;if(root == nullptr) return v;stack<TreeNode*> st;TreeNode* cur = root;//循环结束条件:cur为空&&栈为空,说明所有节点都处理完了while(cur !=nullptr || !st.empty()){//循环每走一次迭代,都表示在访问一棵子树的开始//1.访问左路节点,左路节点进栈while(cur){v.push_back(cur->val);st.push(cur);cur = cur->left;}//2.栈里面左路节点的右子树没有访问,去右树访问TreeNode* top = st.top();st.pop();//3.以子树的方式访问当前栈顶节点右子树cur = top->right;}return v;}
};
二叉树中序遍历 非递归迭代实现
https://leetcode-cn.com/problems/binary-tree-inorder-traversal/
class Solution {
public://子函数处理,只有容器要传引用,因为要对容器的内容做修改void _inorderTraversal(TreeNode* root,vector<int>& v){if(root == nullptr){return ;}_inorderTraversal(root->left,v);//递归处理左树v.push_back(root->val);//把根节点放到容器中_inorderTraversal(root->right,v);//递归处理右树}vector<int> inorderTraversal(TreeNode* root){vector<int> v;_inorderTraversal(root,v);return v;}
};
方法2:访问顺序:左 根 右
什么时候能访问当前节点?
先把cur的所有左子树进栈,当我们把节点从栈里面取出来,然后就可以访问当前栈顶节点,然后再去它的右子树
右子树也是一样的递归子问题!
class Solution {
public:vector<int> inorderTraversal(TreeNode* root) {vector<int> v;if(root == nullptr) return v;stack<TreeNode*> st;TreeNode* cur = root;//循环结束条件:cur为空&&栈为空,说明所有节点都处理完了while(cur !=nullptr || !st.empty()){//1.先把左路节点全部进栈while(cur){st.push(cur);cur = cur->left;}//2.访问当前栈顶节点,然后再去访问它的右子树TreeNode* top = st.top();v.push_back(top->val);st.pop();//3.以子树的方式访问当前栈顶节点右子树cur = top->right;}return v;}
};
二叉树的后序遍历 非递归迭代实现
https://leetcode-cn.com/problems/binary-tree-postorder-traversal/
class Solution {
public://子函数处理,只有容器要传引用,因为要对容器的内容做修改void _postorderTraversal(TreeNode* root,vector<int>& v){if(root == nullptr){return ;}_postorderTraversal(root->left,v);//递归处理左树_postorderTraversal(root->right,v);//递归处理右树v.push_back(root->val);//把根节点放到容器中}vector<int> postorderTraversal(TreeNode* root){vector<int> v;_postorderTraversal(root,v);return v;}
};
方法2:访问顺序:左 右 根
什么时候能访问当前节点?
当前节点的右树已经访问过了,就可以访问当前节点
- prev:表示上一个访问的节点, 每访问一个节点,就把当前节点给prev
注意:如果我的右树已经访问过了,那上一个访问的节点一定是我自己右树的根节点
class Solution {
public:vector<int> postorderTraversal(TreeNode* root) {vector<int> v;if(root == nullptr) return v;stack<TreeNode*> st;TreeNode* cur = root;TreeNode* prev = nullptr;//循环结束条件:cur为空&&栈为空,说明所有节点都处理完了while(cur !=nullptr || !st.empty()){//1.先把左路节点全部进栈while(cur){st.push(cur);cur = cur->left;}TreeNode* top = st.top();//如果top的右子树已经访问过了,就可以访问top//ps:如果我的右子树为空,或者上一轮访问的节点就是我的右孩子节点,//就说明我的右子树已经访问过了,现在可以访问我//否则就以子树的方式访问当前栈顶节点右子树if(top->right == nullptr || top->right == prev){v.push_back(top->val);prev = top;//更新上一个访问的节点st.pop();}else{cur = top->right;}}return v;}
};
总结:
前序的顺序是:根 左 右
所以我们在把所有左路节点进栈的时候,就可以直接访问当前节点**(把当前节点保存容器中)**
当我们把当前节点的所有左路节点都进栈之后,弹出当前栈顶节点,去当前栈顶节点的右子树以相同的子问题方式进行处理
中序的顺序是: 左 根 右
- 先把当前节点的所有左路节点进栈
- 访问当前栈顶节点 (把当前节点保存容器中)
- 去当前栈顶节点的右子树以子问题的方式进行处理
后序的顺序是: 左 右 根
-
先把当前节点的所有左路节点进栈
-
如果当前栈顶节点的右子树已经访问过了 或者当前节点的右子树为空 ,我们才可以访问当前栈顶节点
-
如果判断是否访问过呢?
- 我们定义了一个变量prev标志了上一次访问的节点,如果当前节点的右孩子就是prev,说明右子树已经访问过了,
-
否则:去当前栈顶节点的右子树以子问题的方式进行处理
-
单值二叉树
https://leetcode.cn/problems/univalued-binary-tree/submissions/
先判断根的左右子树的值是否和根的值一致,如果一致,则去递归判断左右子树是否是单值二叉树
bool isUnivalTree(struct TreeNode* root)
{//空树是单值二叉树if(root == NULL) return true;//判断左子树的值是否和根的值一致//要判断左子树是否存在//不相等,直接返回falseif(root->left && root->left->val != root->val)return false;if(root->right && root->right->val != root->val)return false;//如果左子树,右子树的值和根结点的值一致,左子树和右子树还要作为根继续往下递归//要保证左右子树都是单值二叉树,所以用&&return isUnivalTree(root->left) && isUnivalTree(root->right);
}
检查两棵树是否相同
https://leetcode.cn/problems/same-tree/
- 如果两棵树都是空树:返回true
- 如果其中一个是空树,另外一个不是空树->返回false
- 如果根结点的值不一样->返回false
- 递归q和p的左子树和右子树 判断是否是相同的树
- 若二者的左右子树都相同才返回true
- 使用的是
&&操作符
class Solution {
public:bool isSameTree(TreeNode* p, TreeNode* q) {if(!p && !q) return true;if(!p || !q) return false;if(p->val != q->val) return false;return isSameTree(p->left,q->left) && isSameTree(p->right,q->right);}
};
对称二叉树
https://leetcode.cn/problems/symmetric-tree/
//判断是否是相同的树
bool _isSymmetricTree(struct TreeNode* root1,struct TreeNode* root2)
{//如果两棵树都为NULL->相同if(root1 == NULL && root2 == NULL){return true;}//其中一棵树为空,另一棵树不为空,说明不相同//如果两棵树都是相同的,在上面判断就返回了if(root1== NULL || root2 == NULL){return false;}//如果根的值不相同->不是相同的树if(root1->val != root2->val){return false;}//递归判断是否是相同的树//二者都要是相同的树,结果才是相同的树 ->所以使用&&return _isSymmetricTree(root1->left,root2->right) //root1的左子树和root2的右子树比较 && _isSymmetricTree(root1->right,root2->left); //root1的右子树和root2的左子树比较
}bool isSymmetric(struct TreeNode* root)
{//空树是对称二叉树if(root == NULL){return true;}//用子函数判断左右子树是否是对称的return _isSymmetricTree(root->left,root->right);
}
另一棵树的子树
https://leetcode.cn/problems/subtree-of-another-tree/

bool isSameTree(struct TreeNode* p,struct TreeNode* q)
{// 两棵树都是空树 ->相同if(p==NULL && q == NULL){return true;}//其中一个为空树,另一个不为空->不是相同树if(p == NULL || q == NULL){return false;}//根的值不同->不是相同树if(p->val != q->val){return false;}//递归判断p和q的左子树和右子树是否相等//二者都相同,一整棵树才是相同return isSameTree(p->left,q->left) && isSameTree(p->right,q->right);
}bool isSubtree(struct TreeNode* root, struct TreeNode* subRoot)
{//subroot不可能为NULL,如果root为空,说明不是相同的树if(root == NULL){return false;}//root和subroot两棵树完全相同if(isSameTree(root,subRoot)){return true;}//以左子树和右子树为根,递归下去找和subRoot相同的树// 用 || 一个为true 就说明找到了return isSubtree(root->left,subRoot) || isSubtree(root->right,subRoot);
}
最坏情况: 每个子树都要比较,且都要比较到最后一个结点 O(N^2)
二叉树的遍历-清华408机试
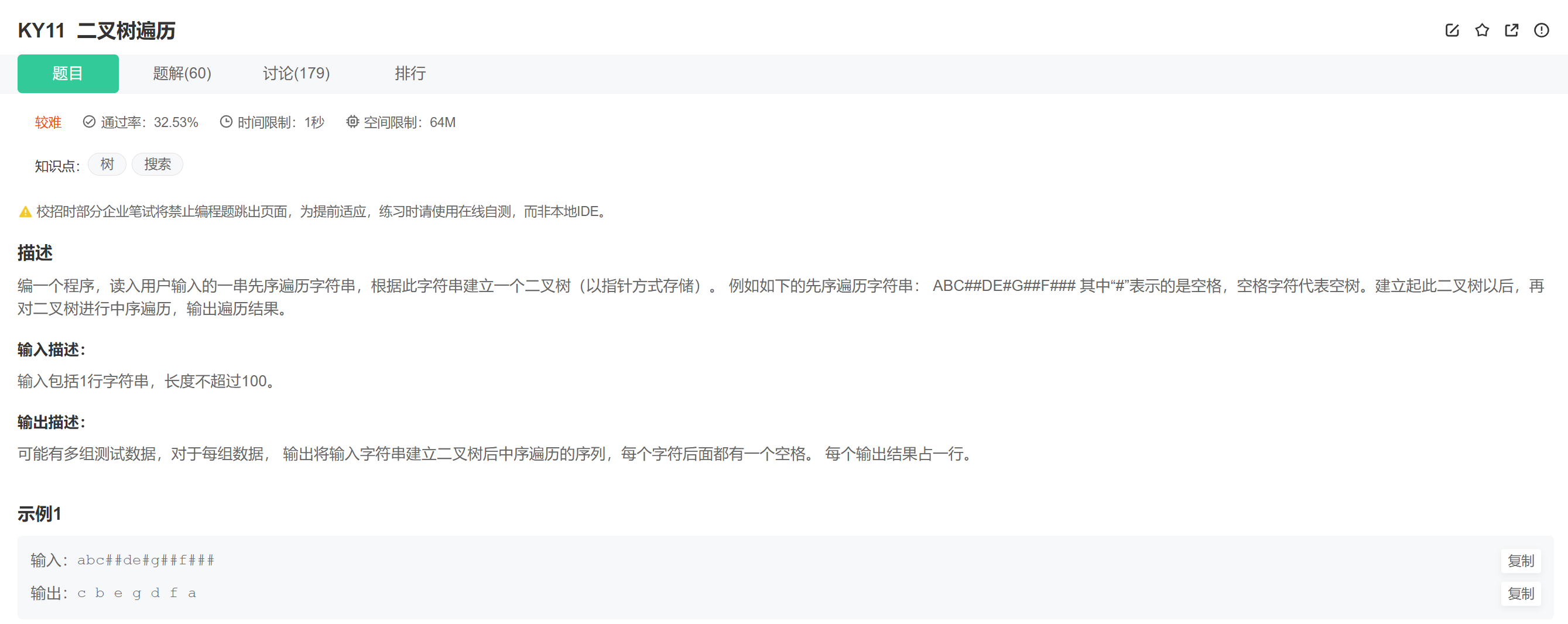
#include <iostream>
using namespace std;struct TreeNode
{TreeNode(char v = '0') :left(nullptr),right(nullptr),val(v){}TreeNode* left;TreeNode* right;char val;
};
TreeNode* CreateTree(string& str,int& index)
{if(str[index] == '#') {index++; //注意:此时 需要让index往后走!!!return nullptr;}TreeNode* root = new TreeNode(str[index]);index++;root->left = CreateTree(str,index);root->right = CreateTree(str,index);return root;
}
void InOrder(TreeNode* root)
{if(!root) return;InOrder(root->left);cout <<root->val <<" ";InOrder(root->right);
}
int main()
{string str;while(cin >>str){int index = 0;TreeNode* root = CreateTree(str,index);InOrder(root);//中序遍历}return 0;
}
翻转二叉树
https://leetcode.cn/problems/invert-binary-tree/
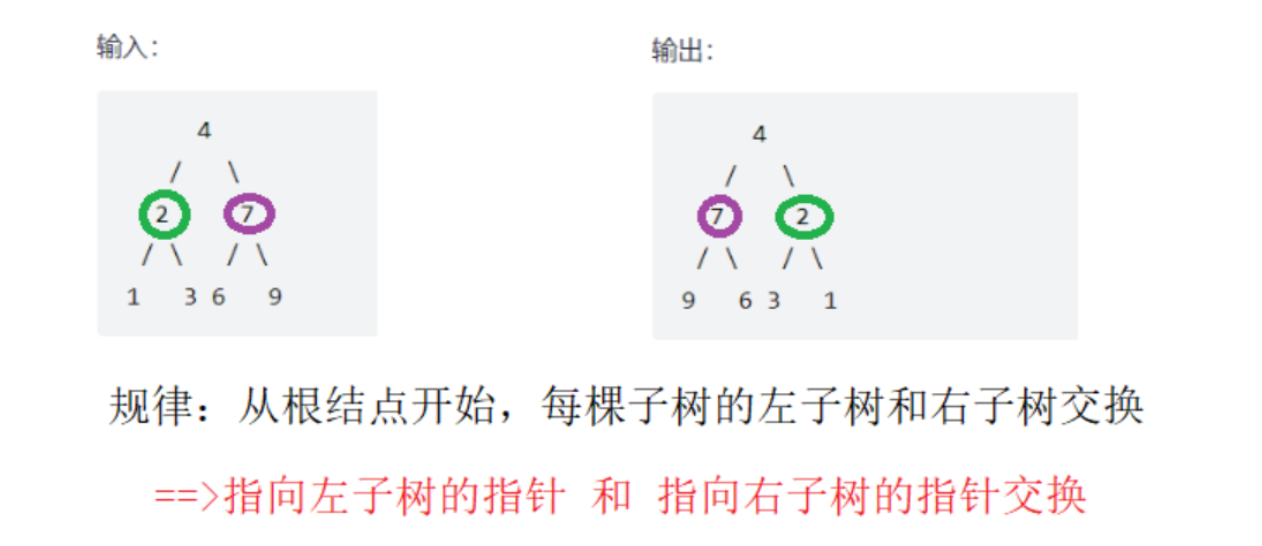
class Solution {
public:TreeNode* invertTree(TreeNode* root) {if(!root) return root;swap(root->left,root->right);invertTree(root->left);invertTree(root->right);return root;}
};
求二叉树某个节点的后继节点
https://leetcode.cn/problems/successor-lcci/

中序遍历中,这个结点的下一个结点就是它的后继结点 注意:最后一个结点没有后继结点
方法1:直接中序遍历,找出x的后一个节点
时间复杂度分析: 弄出中序遍历的顺序: O(N) 再次遍历查找x的下一个节点:O(N) ->整体:O(N)
空间复杂度:O(N)
void InOrder(TreeNode* node,vector<TreeNode*>& v)
{if(!node) return;InOrder(node->left,v);v.push_back(node);InOrder(node->right,v);
}
TreeNode* inorderSuccessor(TreeNode* root, TreeNode* p) {vector<TreeNode*> v;InOrder(root,v);for(int i = 0;i<v.size()-1;i++)if(v[i] == p) return v[i+1];return nullptr;
}
方法2:由于这里是 二叉搜索树,所以可以根据其性质来实现。 要找到p的下一个节点,本质上就是找到第一个比p->val的值大的节点
递归版本:
class Solution {
public:TreeNode* inorderSuccessor(TreeNode* root, TreeNode* p) {//我们要找的是第一个大于p->val的节点, 所以遇到第一个大于p->val的即可返回if(root == nullptr) return nullptr;TreeNode* res = inorderSuccessor(root->left,p); //在左树有没有找到答案if(res!=nullptr) return res;if(root->val > p->val)return root;return inorderSuccessor(root->right,p);}
};
不能将if(root->val > p->val)的判断放在前面,因为可能root确实大于p的值,但他并不是p的后继节点!应该先到root的左树去找,然后再看看root是否符合,然后再去root的右树找
非递归版本
class Solution {
public:TreeNode* inorderSuccessor(TreeNode* root, TreeNode* p){if(root == nullptr) return nullptr;//找到中序遍历中第一个值大于p->val的节点//非递归中序遍历stack<TreeNode*> st;TreeNode* cur = root;TreeNode* ans = nullptr;//记录答案while(!st.empty() || cur !=nullptr){//先把左路节点全部入栈while(cur){st.push(cur);cur = cur->left;}TreeNode* top = st.top();st.pop();//比较值是否大于p->valif(top->val > p->val){ans = top;break;}//去右树访问cur = top->right;}return ans;}
};
升级版(通用版)
现在多了一个指向parent的指针,但是如果题目当中没有给出根节点,只给出了一个node节点,找它的后继节点,而没有给整棵树的头节点,所以我们不能弄出中序遍历的结果,所以方法1不可行
-
多了一个指向parent的指针,可以优化到O(k) k是这个结点距离它的后继结点的真实距离
-
case1:如果node有右树
- node的后继结点是中序遍历 node的下一个结点。假如node有右树,则它的后继结点是 node右树的最左孩子
- 中序遍历结果: 左 根 右 这里的node节点相当于根 的位置,下一个位置就是其右树(下一个根位置)的最左孩子
-
case2:node没有右树
- 从node结点开始往上走,如果发现是此时结点是父亲的右孩子就往上走,不断往上走
- 直到某一时刻,该结点是他父亲的左孩子. 则node的后继结点就是该结点的父亲结点
子函数:获取当前节点的最左节点:
TreeNode* getLeftMost(TreeNode* node)
{if (node == nullptr){return nullptr;}//找最左节点->即到达某个位置之后->left 为空,则此时这个node节点就是最左节点while (node->left!=nullptr) {node = node->left;//一直往左走}return node;
}
TreeNode* getSuccessorNode(TreeNode* node)
{//空节点 ->返回空if (node == nullptr){return node;}TreeNode* parent = node->parent;//case1:有右树 -> 去找它右树的最左节点if (node->right != nullptr){return getLeftMost(node->right);//去右树找,所以参数是:node->right}else//case2:没有右树:{//从node结点开始往上走, 如果发现是此时结点是父亲的右孩子就往上走, 不断往上走//父亲结点不能为空 && 当前节点是其父亲节点右孩子 ->往上走while (parent && parent->right == node){//往上走node = parent;//node来到父亲的位置parent = node->parent;//找到此时node节点的夫父节点位置}}//只有else情况下,会跳出循环,此时://case1:当前节点node是其父亲节点parent的左孩子,返回parent结点//case2:父亲结点为空//返回此时的父亲结点位置return parent;
}
判断二叉搜索树
https://leetcode.cn/problems/validate-binary-search-tree/description/

方法1:中序遍历判断前一个值和当前值的关系,前一个值要<当前值
class Solution {public:bool isValidBST(TreeNode* root) {if(!root) return true;stack<TreeNode*> st;TreeNode* cur = root;TreeNode* prev = nullptr;while(cur != nullptr || !st.empty()){while(cur){st.push(cur);cur = cur->left;}TreeNode* top = st.top();st.pop();//判断前一个的值是否是>=当前值,如果是,那么就不是BSTif(prev != nullptr) if(prev->val >= top->val) //有重复值也不是BSTreturn false;prev = top;//记录前一个的值cur = top->right;}//符合要求return true;}
};
判断平衡二叉树
https://leetcode.cn/problems/balanced-binary-tree/description/

class Solution {
public://求二叉树的高度int TreeHeight(TreeNode* root){if(!root) return 0;return 1 + max(TreeHeight(root->left),TreeHeight(root->right));}bool isBalanced(TreeNode* root) {if(!root) return true;int leftTreeHeight = TreeHeight(root->left);int rightTreeHeight = TreeHeight(root->right);//左树和右树的高度不超过1 && 左树和右树都是平衡二叉树return abs(leftTreeHeight - rightTreeHeight) <= 1 && isBalanced(root->left) && isBalanced(root->right);}
};
判断满二叉树
满二叉树:假设树的高度为h,那么整棵树的节点个数为2^h -1 ,每一层的节点个数都是满的
方法1:节点个数是否满足 2^高度 -1
// 计算二叉树的节点个数
int getNodeCount(TreeNode* root) {if (root == nullptr) {return 0;}return 1 + getNodeCount(root->left) + getNodeCount(root->right);
}// 判断一棵树是否是满二叉树
bool isFullBinaryTree(TreeNode* root) {if (root == nullptr) {return true;}int height = 0;TreeNode* current = root;while (current) { //求二叉树的高度height++;current = current->left;}int nodeCount = getNodeCount(root);return nodeCount == (1 << height) - 1;//判断节点个数是否是2^h - 1
}
方法2:层序遍历,判断每一层的节点个数是否为2^(层数 -1),最上面为第1层
// 判断一棵树是否是满二叉树
bool isFullBinaryTree(TreeNode* root) {if (root == nullptr) {return true;}std::queue<TreeNode*> q;q.push(root);int level = 1; // 第一层int expectedNodeCount = 1; // 第一层的预期节点个数while (!q.empty()) {int currentLevelNodeCount = q.size();if (currentLevelNodeCount != expectedNodeCount) {return false;}for (int i = 0; i < currentLevelNodeCount; ++i) {TreeNode* current = q.front();q.pop();if (current->left) {q.push(current->left);}if (current->right) {q.push(current->right);}}level++;expectedNodeCount = std::pow(2, level - 1);}return true;
}
判断完全二叉树
方法1:
层序遍历,对每一个节点进行判断,得到它的左右孩子,定义一个变量表示**:是否遇到过左右孩子不双全的节点**
当第一次碰到了左右孩子不双全的情况:
- 如果后序又遇到了左右孩子不双全的情况 && 当前的节点不是叶子节点 ->不是完全二叉树
- 如果有右孩子,但是没有左孩子->说明不是完全二叉树
//判断是否是完全二叉树
bool isCBT(TreeNode* head)
{//空树是完全二叉树if (head == nullptr)return true;queue<TreeNode*> q;//存放节点的队列q.push(head);//先把头节点放到队列中bool leaf = false;//标志是否遇到过左右孩子不双全的节点while (!q.empty()){TreeNode* node = q.front();//得到此时队头节点q.pop();//弹出队头节点//得到node的左孩子和右孩子TreeNode* left = node->left;TreeNode* right = node->right;//进行判断是否是完全二叉树//如果已经遇到过左右孩子不双全的节点 && 当前的节点不是叶子节点 ->不是完全二叉树if (leaf && (!left || !right))return false;//如果有右孩子, 但是没有左孩子->说明不是完全二叉树if (right && !left)return false;//层序遍历 如果左右孩子不为空,就放到队列中if (node->left)q.push(node->left);if (node->right)q.push(node->right);//如果第一次遇到左右孩子不双全 把leaf置为空,后序节点都应该要是叶子节点才是完全二叉树if (!left || !right)leaf = true;}//如果层序遍历没有判断出不满足完全二叉树的情况 -> 说明是完全二叉树return true;
}
方法2:
完全二叉树和非完全二叉树的区别:
- 完全二叉树的非空结点是连续的
- 非完全二叉树的非空结点是不连续的
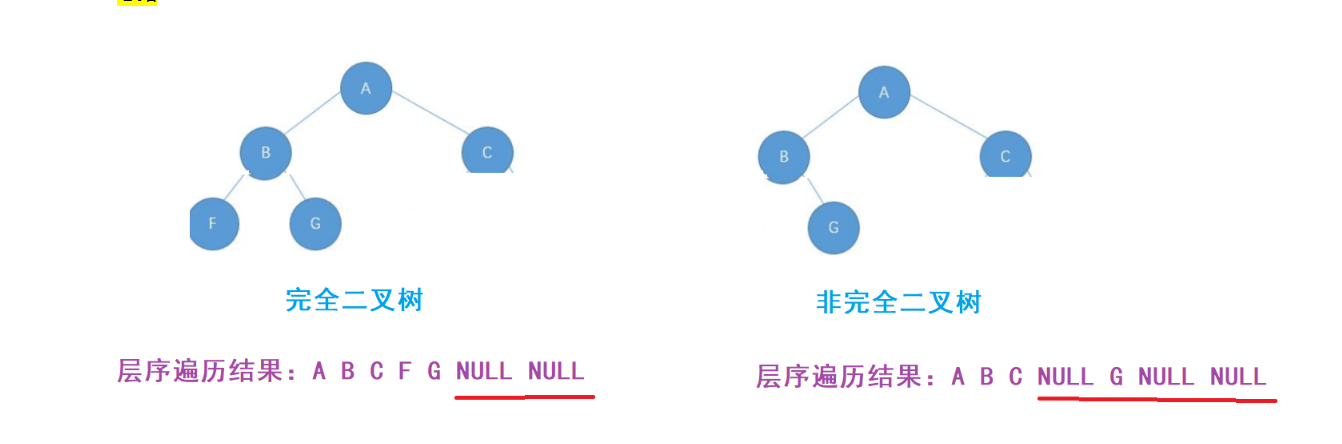
方法:使用层序遍历,当遇到空指针跳出循环,检查后面的元素,如果后面有一个结点不是空,说明不是完全二叉树,如果后面的元素全部都是空指针->就是完全二叉树
//判断是否是完全二叉树
bool BinaryTreeComplete(BTNode* root)
{//空树是完全二叉树if (root == NULL)return true;//层序遍历 遇到空结点则跳出queue<TreeNode*> q;q.push(root);while (!QueueEmpty(&q)){TreeNode* front = q.front();q.pop();//如果遇到空了,就可以跳出,比较后面的结点if (front == NULL){break;}//否则把左孩子和右孩子带进来,空结点也要带进队列else{q.push(front->left);q.push(front->right);}}//遇到空指针了,break/队列为空跳出,判断后面的元素//1.剩下的全是空,则是完全二叉树//2.剩下的存在非空,说明不是完全二叉树while (!QueueEmpty(&q)){TreeNode* front = q.front();q.pop();//如果有一个不为空->不是完全二叉树,返回falseif (front !=NULL )return false;}//如果全部都为空,while跳出循环return true;
}
前序遍历构造二叉搜索树
https://leetcode.cn/problems/construct-binary-search-tree-from-preorder-traversal/
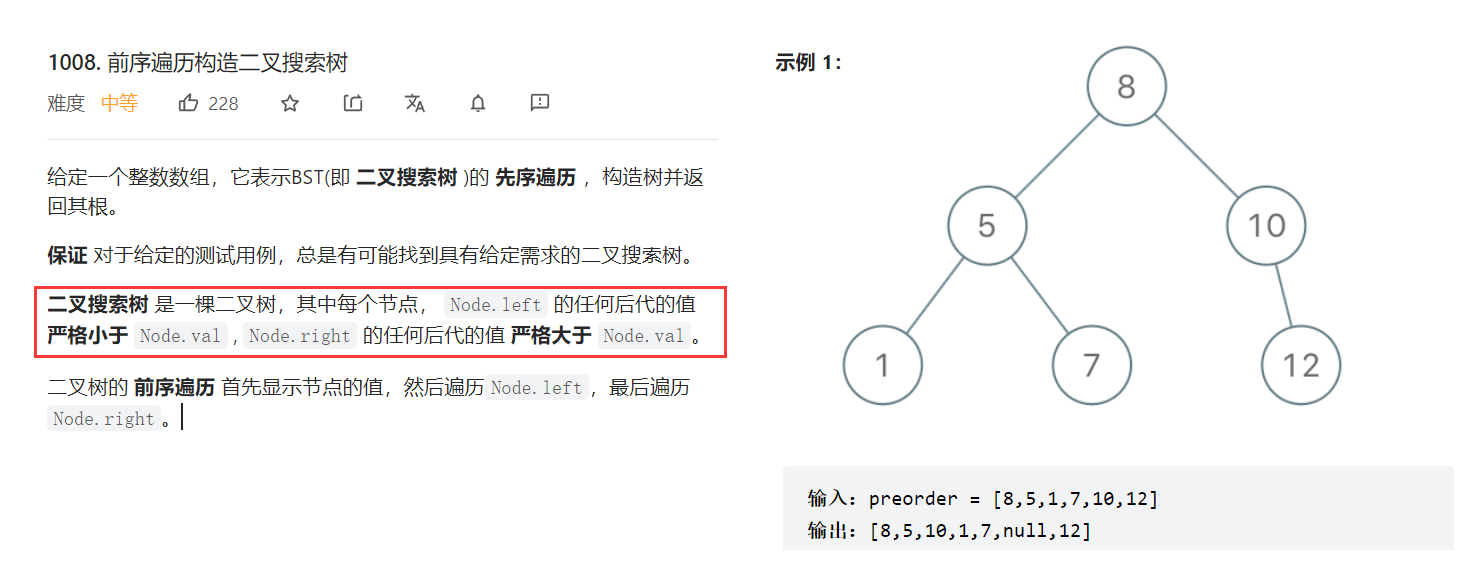
定义一个process函数, 左右:[L,R]范围是先序遍历的结果,把这棵树构建好返回头节点
- L位置的就是头节点,只要比L位置小的都是左树,比L位置大的都是右树
- 所以可以遍历[L+1,R]范围,找到第一个比L大的位置记为firstBig
- 左树的范围就是:[L+1,firstBig-1] 右树的范围是:[firstBig,R] 这棵树的根节点位置 :L
注意2 左树和右树可能是空树! 如果L>R 应该返回空树
class Solution {
public:TreeNode* CreateTree(vector<int>& preorder,int preLeft,int preRight){//无效范围, 应该返回空树if(preLeft > preRight) return nullptr;int FirstBigIndex = preLeft;//找第一个值大于pre[L]的位置for(;FirstBigIndex<=preRight;FirstBigIndex++){if(preorder[FirstBigIndex] > preorder[preLeft])break;}//preLeft 左树: [preLeft+1,FirstBigIndex-1] 右树: [FirstBigIndex,preRight]TreeNode* root = new TreeNode(preorder[preLeft]);root->left = CreateTree(preorder,preLeft+1,FirstBigIndex-1);root->right = CreateTree(preorder,FirstBigIndex,preRight);return root;}TreeNode* bstFromPreorder(vector<int>& preorder) {if(preorder.size() == 0) return nullptr;return CreateTree(preorder,0,preorder.size()-1);}
};
时间复杂度: 因为要遍历[L,R]范围找第一个值大于pre[L]的位置,最坏情况,单支二叉树 O(N^2)
相等子树的数量
如果一个节点X,它左树结构和右树结构完全一样,那么我们说以X为头的树是相等树,给定一棵二叉树的头节点head,返回head整棵树上有多少棵相等子树
子函数:判断两棵树是否相同
//判断两棵树是否相同
bool SameTree(TreeNode* head1, TreeNode* head2)
{if (head1 == nullptr ^ head2 == nullptr)//含义就是:一个为空树一个不为空, 返回falsereturn false;if (head1 == nullptr && head2 == nullptr)return true;// 两棵树都不为空//比较值&&比较二者的左树和右树是否都相同return head1->val == head2->val && SameTree(head1->left, head2->left) && SameTree(head2->right, head2->right);
}
当前head整棵树上有多少棵相等子树 = 左树上有多少棵相等子树 + 右树上有多少棵相等子树 + 整棵树是不是相等子树
int SameNumber(TreeNode* head)
{if (head == nullptr)return 0;int leftNumber = SameNumber(head->left);//左树上有多少个相同子树int rightNumber = SameNumber(head->right);//右树上有多少个相同子树int headNumber = SameTree(head->left, head->right) ? 1 : 0;//当前树的左树结构和右树结构相同就+1return leftNumber + rightNumber + headNumber;
}
恢复二叉搜索树
https://leetcode.cn/problems/recover-binary-search-tree/description/
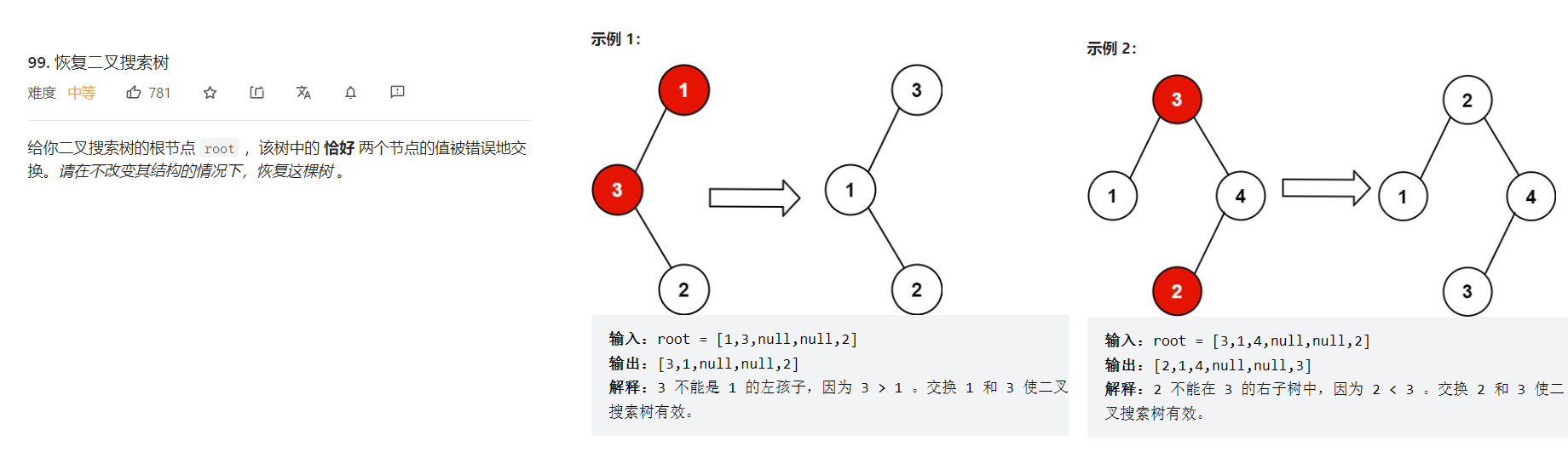
做法1:中序遍历,把树里面的值存入数组,然后对数组排序,之后再次中序遍历树,依次把数组里面的值存到树里面
做法2:只需要清楚找错误节点的标准
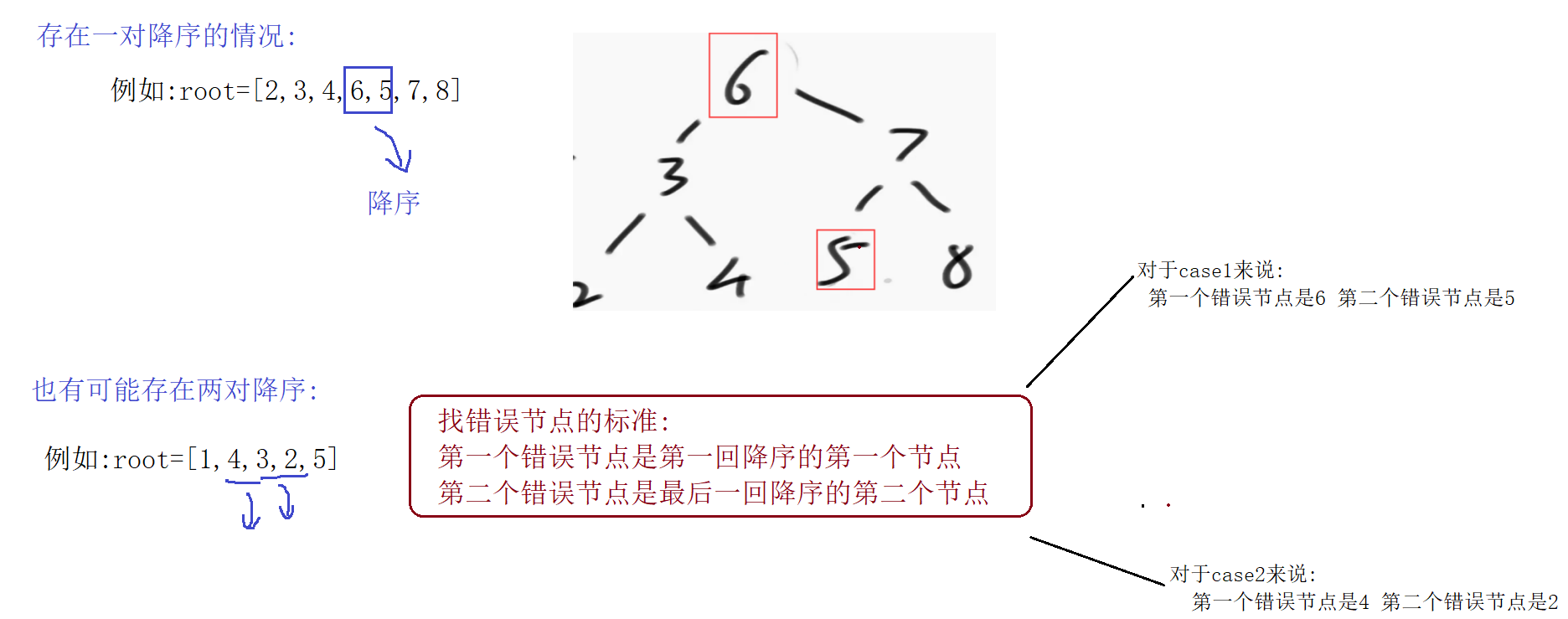
第一个错误节点是第一回降序的第一个节点 第二个错误节点是最后一回降序的第二个节点
步骤:
1)因为可能存在两次/一次降序,所以我们要定义一个变量flag记录当前是第几次降序
2)定义两个变量记录错误节点
3)因为要前后节点的值进行比较,所以再定义一个变量pre,记录前一个节点
4)走一遍中序遍历
-
如果发现上一个节点的值 > 当前节点的值 ,并且当前是第一回降序
- 第一个错误节点是第一回降序的第一个节点,第二个错误节点是最后一回降序的第二个节点
-
如果是第二回出现降序的情况,此时就需要修改第二个错误节点
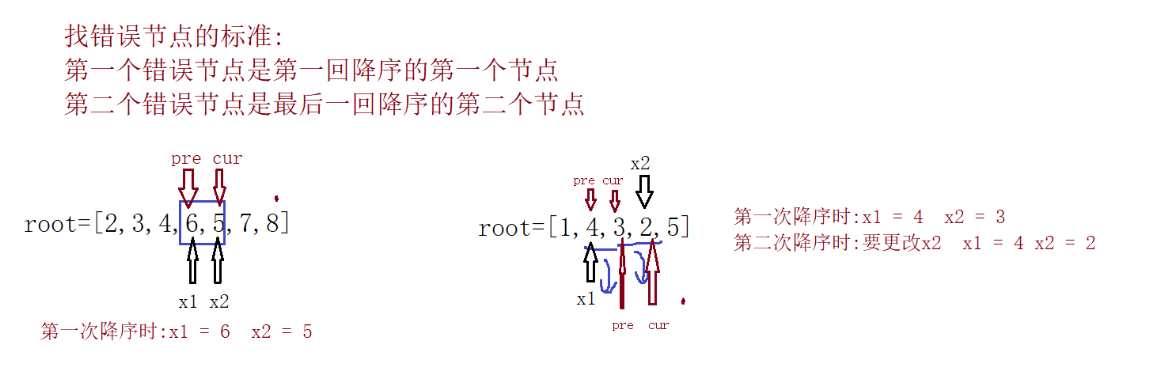
空间复杂度:O(H) 其中 H 为二叉搜索树的高度 (递归的空间消耗)
class Solution {public:TreeNode* x1= nullptr;//记录第一个错误节点TreeNode* x2= nullptr;//记录第二个错误节点TreeNode* pre = nullptr;//记录上一个节点int flag = 0;//记录当前是第几次降序//中序遍历void inOrder(TreeNode* cur){if(cur == nullptr) return ;inOrder(cur->left);//前后比较 第一次遍历的时候,pre为空if(pre!=nullptr && pre->val > cur->val){flag++;if(flag == 1){x1 = pre;x2 = cur;}else //flag == 2x2 = cur;}pre = cur;inOrder(cur->right);}void recoverTree(TreeNode* root) {inOrder(root);if(x1 && x2)swap(x1->val,x2->val);}
};
优化:并不需要定义变量flag记录当前是第几次降序,只要再次进入pre->val > cur->val, 发现x1不为空了,说明当前就是第二次降序了
void inOrder(TreeNode* cur)
{if(cur == nullptr) return ;inOrder(cur->left);//前后比较if(pre!=nullptr && pre->val > cur->val){if(x1 ==nullptr) x1 = pre; //记录第一个错误节点x2 = cur;//不管是1次/2次降序, 第二个错误节点都能记录正确}pre = cur;inOrder(cur->right);
}
层序遍历系列题目
层序遍历⼀个⼆叉树:就是从左到右⼀层⼀层的去遍历⼆叉树,需要借⽤⼀个辅助数据结构即队列来实现,队列先进先出,符合⼀层⼀层遍历的逻辑
二叉树的右视图
https://leetcode.cn/problems/binary-tree-right-side-view/
class Solution {
public:vector<int> rightSideView(TreeNode* root) {if(root == nullptr) return {};vector<int> ans;queue<TreeNode*> q;q.push(root);while(!q.empty()){int size = q.size();for(int i = 0;i<size;i++){TreeNode* front = q.front();q.pop();if(i == size - 1) //当前层最后一个节点==>右视图能看到的节点ans.push_back(front->val);//处理当前节点的左右孩子if(front->left) q.push(front->left);if(front->right) q.push(front->right);}}return ans;}
};
二叉树的层平均值
https://leetcode.cn/problems/average-of-levels-in-binary-tree/

class Solution {
public:vector<double> averageOfLevels(TreeNode* root) {if(root == nullptr) return {};vector<double> ans;queue<TreeNode*> q;q.push(root);while(!q.empty()){int size = q.size();double sum = 0;//每一层下来,重新置为0,注意:不能为int,要定义为double类型!!!for(int i = 0;i<size;i++){TreeNode* front = q.front();q.pop();sum += front->val;//累加当前层节点的值//处理当前节点的左右孩子if(front->left) q.push(front->left);if(front->right) q.push(front->right);}ans.push_back(sum / size); //当前层节点的累加值 / 当前层节点个数}return ans;}
};
N叉树的层序遍历
https://leetcode.cn/problems/n-ary-tree-level-order-traversal/

此时的节点定义:
class Node {
public:int val;vector<Node*> children;Node() {}Node(int _val) {val = _val;}Node(int _val, vector<Node*> _children) {val = _val;children = _children;}
};
class Solution {
public:typedef Node TreeNode;vector<vector<int>> levelOrder(Node* root) {if(root == nullptr) return {};vector<vector<int>> ans;queue<TreeNode*> q;q.push(root);while(!q.empty()){int size = q.size();vector<int> v;//保存当前层的节点值for(int i = 0;i<size;i++){TreeNode* front = q.front();q.pop();v.push_back(front->val);//此时当前节点的孩子是一个 vector<Node*> children;//只要不为空,就放到队列当中for(auto node:front->children){if(node != nullptr) q.push(node);}}ans.push_back(v);}return ans;}
};
在每个树行中找最大值
https://leetcode.cn/problems/find-largest-value-in-each-tree-row/
class Solution {
public:vector<int> largestValues(TreeNode* root) {if(root == nullptr) return {};vector<int> ans;queue<TreeNode*> q;q.push(root);while(!q.empty()){int size = q.size();int maxVal = INT_MIN;//保存当前层节点的最大值,先定义为系统最小值for(int i = 0;i<size;i++){TreeNode* front = q.front();q.pop();maxVal = max(front->val,maxVal);//处理当前节点的左右孩子if(front->left) q.push(front->left);if(front->right) q.push(front->right);}ans.push_back(maxVal); }return ans;}
};
填充每个节点的下一个右侧节点指针
https://leetcode.cn/problems/populating-next-right-pointers-in-each-node/

class Solution {
public:typedef Node TreeNode;Node* connect(Node* root) {if(root == nullptr) return root;queue<TreeNode*> q;q.push(root);while(!q.empty()){int size = q.size();TreeNode* prev = nullptr;//记录上一个节点for(int i = 0;i<size;i++){TreeNode* front = q.front();q.pop();if(i != 0) //当前层的第一个节点不需要处理{prev->next = front;//当前层上一个节点连接当前节点}prev = front;//处理当前节点的左右孩子if(front->left) q.push(front->left);if(front->right) q.push(front->right);}}return root;}
};
相关文章:
【数据结构】二叉树常见题目
文章目录 前言二叉树概念满二叉树完全二叉树二叉搜索树(二叉排序树)平衡⼆叉搜索树存储⽅式 二叉树OJ二叉树创建字符串二叉树的分层遍历1二叉树的分层遍历2给定一个二叉树, 找到该树中两个指定节点的最近公共祖先二叉树搜索树转换成排序双向链表二叉树展开为链表根据一棵树的前…...

树莓派使用 ENC28J60
前言 一些老的、Mini 的 ARM 开发板上没有预留网口,这样在调试升级内核或应用程序时很不方便。纵使有串口下载工具,但其速度也是慢地捉急。这种情况下,使用其它接口来扩展出一个网口无疑是一个比较好的方法。 ENC28J60 就是一个使用 SPI 接口…...

跟我学C++中级篇——模板友元的应用
一、友元 友元在以前分析过,而且一般编程是不推荐使用友元的,原因是友元破坏了类的封装性。但凡事总有例外,在某些情况下,用友元还是比较方便的,那么该用还得用,不能因噎废食。普通的友元,各种…...

软件测试基础篇——MySQL
MySQL 1、数据库技术概述 数据库database:存放和管理各种数据的仓库,操作的对象主要是【数据data】,科学的组织和存储数据,高效的获取和处理数据SQL:结构化查询语言,专为**关系型数据库而建立的操作语言&…...

FreeRTOS(二值信号量)
资料来源于硬件家园:资料汇总 - FreeRTOS实时操作系统课程(多任务管理) 目录 一、信号量的概念 1、信号量的基本概念 2、信号量的分类 二、二值信号量的定义与应用 1、二值信号量的定义 2、二值信号量的应用 三、二值信号量的运作机制 1、FreeRTOS任务间二值…...
)
leetcode面试题:动物收容所(考查对队列的理解和运用)
题目: 有家动物收容所只收容狗与猫,且严格遵守“先进先出”的原则。在收养该收容所的动物时,收养人只能收养所有动物中“最老”(由其进入收容所的时间长短而定)的动物,或者可以挑选猫或狗(同时…...

【Linux命令行与Shell脚本编程】第十八章 文本处理与编辑器基础
Linux命令行与Shell脚本编程 第十八章 文本处理与编辑器基础 文章目录 Linux命令行与Shell脚本编程第十八章 文本处理与编辑器基础 文本处理与编辑器基础8.1.文本处理8.1.1.sed编辑器8.1.1.1.在命令行中定义编辑器命令8.1.1.2.在命令行中使用多个编辑器命令8.1.1.3.从文件中读…...
2023牛客暑期多校训练营7
Beautiful Sequence 贪心,二进制,构造 Cyperation 模拟 ,数学 We Love Strings 分块,二进制枚举,二进制容斥dp Writing Books 签到 根据相邻两个异或值B,因为前小于等于后,故从高到低遍历B的每一…...
centos7升级glibc2.28
1 概述 centos7自带的glibc对于某些软件是太旧的,决定将glibc升级至2.28。 2 安装过程 2.1 下载glibc源码 mkdir -p /opt/third-party && cd /opt/third-party wget http://ftp.gnu.org/gnu/glibc/glibc-2.28.tar.gz tar -xf glibc-2.28.tar.gz cd glibc…...
腾讯云香港服务器租用_2核2G20M_2核4G30M
腾讯云香港服务器租用费用表,目前中国香港地域轻量应用服务器可选配置2核2G20M、2核2G30M、2核4G30M,操作系统可选Windows和Linux,不只是香港云服务器,新加坡、硅谷、法兰克福和东京服务器均有活动,腾讯云服务器网分享…...

十三、ESP32PS2摇杆(ADC)
1. 运行效果 在上下左右操作PS2摇杆的时候,会检测到数据 2. 滑动电阻...
网络安全的相关知识点
网络安全威胁类型: 1.窃听:广播式网络系统。 2.假冒 3.重放:重复一份报文或者报文的一部分,以便产生一个被授权的效果。 4.流量分析 5.数据完整性破坏 6.拒绝服务 7.资源的非授权使用 8.陷门和特洛伊木马:木马病毒有客…...
:牛客在线编程06 递归/回溯)
算法练习(6):牛客在线编程06 递归/回溯
package jz.bm;import java.io.PushbackInputStream; import java.lang.reflect.Array; import java.util.ArrayList; import java.util.Arrays;public class bm6 {/*** BM55 没有重复项数字的全排列*/ArrayList<ArrayList<Integer>> res new ArrayList<>()…...
图像局部二值化处理实例)
C#使用OpenCv(OpenCVSharp)图像局部二值化处理实例
本文实例演示C#语言中如何使用OpenCv(OpenCVSharp)对图像进行局部二值化处理。 目录 图像二值化原理 局部二值化 自适应阈值 实例 效果...

MySQL多表关联查询
目录 1. inner join: 2. left join: 3. right join: 4.自连接 5.交叉连接: 6、联合查询 7、子查询 1. inner join: 代表选择的是两个表的交差部分。 内连接就是表间的主键与外键相连,只取得键值一致…...

flutter开发实战-CustomClipper裁剪长图帧动画效果
flutter开发实战-CustomClipper裁剪长图帧动画效果 在开发过程中,经常遇到帧动画的每一帧图显示在超长图上,需要处理这种帧动画效果。我这里使用的是CustomClipper 一、CustomClipper CustomClipper继承于Listenable abstract class CustomClipper e…...

CSS 中的优先级规则是怎样的?
聚沙成塔每天进步一点点 ⭐ 专栏简介⭐内联样式(Inline Styles)⭐ID 选择器(ID Selectors)⭐类选择器、属性选择器和伪类选择器(Class, Attribute, and Pseudo-class Selectors)⭐元素选择器和伪元素选择器…...

概率图模型(Probabilistic Graphical Model,PGM)
概率图模型(Probabilistic Graphical Model,PGM),是一种用图结构来描述多元随机变量之间条件独立性的概率模型。它可以用来表示复杂的概率分布,进行有效的推理和学习,以及解决各种实际问题,如图…...

Oracle 知识篇+会话级全局临时表在不同连接模式中的表现
标签:会话级临时表、全局临时表、幻读释义:Oracle 全局临时表又叫GTT ★ 结论 ✔ 专用服务器模式:不同应用会话只能访问自己的数据 ✔ 共享服务器模式:不同应用会话只能访问自己的数据 ✔ 数据库驻留连接池模式:不同应…...
MySQL 数据库文件的导入导出
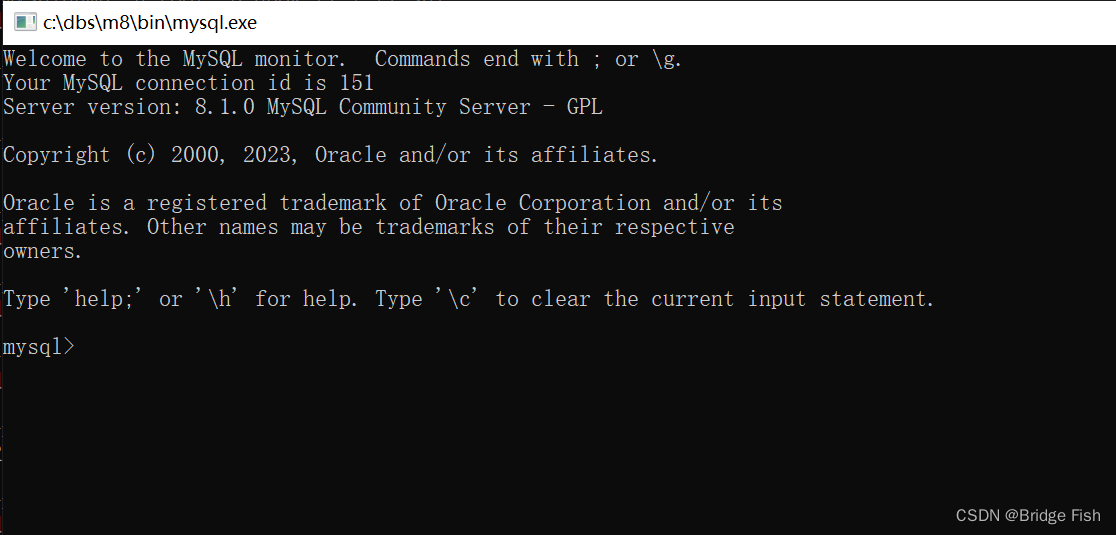
目录 数据库的导出 导出整个数据库 导出数据库中的数据表 导出数据库结构 导出数据库中表的表结构 导出多个数据库 导出所有数据库 数据库的导入 数据库的导出 mysqldump -h IP地址 -P 端口 -u 用户名 -p 数据库名 > 导出的文件名 用管理员权限打开cmd进入MySQL的bi…...

LeagueAkari英雄联盟工具包:3大核心功能提升你的游戏体验
LeagueAkari英雄联盟工具包:3大核心功能提升你的游戏体验 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit LeagueAkari是一款基于LC…...

GHelper完整指南:3分钟掌握华硕笔记本轻量控制工具,彻底告别臃肿系统
GHelper完整指南:3分钟掌握华硕笔记本轻量控制工具,彻底告别臃肿系统 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephy…...

获取淘宝商品详情item_get_pro参数说明
item_get_pro-获得淘宝商品详情高级版taobao.item_get_pro公共参数名称类型必须描述keyString是调用key(必须以GET方式拼接在URL中)secretString是调用密钥api_nameString是API接口名称(包括在请求地址中)[item_search,item_get,i…...
)
别再只会用OpenCV的resize了!手把手教你用NumPy实现图像缩放(Nearest/Bilinear/Bicubic/Lanczos对比)
从零实现图像缩放:四种插值算法的NumPy实战指南 当你第一次调用cv2.resize()时,是否好奇过这个黑盒子内部究竟发生了什么?图像缩放远不止是简单的像素复制或删除,背后隐藏着数学与艺术的完美结合。本文将带你用NumPy亲手实现四种…...

MetaboAnalystR 4.0:从原始质谱数据到生物学洞察的完整代谢组学分析实战
MetaboAnalystR 4.0:从原始质谱数据到生物学洞察的完整代谢组学分析实战 【免费下载链接】MetaboAnalystR R package for MetaboAnalyst 项目地址: https://gitcode.com/gh_mirrors/me/MetaboAnalystR 代谢组学研究常常让研究人员感到头疼:原始LC…...

抖音无水印下载器终极指南:一站式高效批量下载解决方案
抖音无水印下载器终极指南:一站式高效批量下载解决方案 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback supp…...

Rust的trait对象大小限制与dynTrait在类型擦除中的内存布局影响
Rust作为一门强调零成本抽象的现代系统编程语言,其trait对象与动态分发机制一直是开发者关注的焦点。特别是当使用dyn Trait进行类型擦除时,trait对象的大小限制与内存布局会直接影响程序的性能与设计模式。理解这些底层机制不仅能帮助开发者规避常见陷阱…...

Z-Image-GGUF提示词入门:‘主体+风格+光照+质量’四步法详解
Z-Image-GGUF提示词入门:‘主体风格光照质量’四步法详解 你是不是也遇到过这种情况:看到别人用AI生成的图片惊艳无比,自己上手一试,出来的却总是不尽人意?要么是画面模糊,要么是风格跑偏,要么…...
)
手把手教你用Cadence仿真验证Charge Pump的current mismatch与deviation(以65nm PDK为例)
手把手教你用Cadence仿真验证Charge Pump的current mismatch与deviation(以65nm PDK为例) 电荷泵(Charge Pump)作为锁相环(PLL)中的关键模块,其电流匹配性能直接影响整个系统的相位噪声和杂散水…...

Applite:3步告别终端命令,用图形界面轻松管理macOS应用
Applite:3步告别终端命令,用图形界面轻松管理macOS应用 【免费下载链接】Applite User-friendly GUI macOS application for Homebrew Casks 项目地址: https://gitcode.com/gh_mirrors/ap/Applite 还在为繁琐的终端命令而头疼吗?macO…...