【Spark分布式内存计算框架——Spark SQL】12. External DataSource(下)rdbms 数据
6.7 rdbms 数据
回顾在SparkCore中读取MySQL表的数据通过JdbcRDD来读取的,在SparkSQL模块中提供对应接口,提供三种方式读取数据:
方式一:单分区模式

方式二:多分区模式,可以设置列的名称,作为分区字段及列的值范围和分区数目

方式三:高度自由分区模式,通过设置条件语句设置分区数据及各个分区数据范围

当加载读取RDBMS表的数据量不大时,可以直接使用单分区模式加载;当数据量很多时,考虑使用多分区及自由分区方式加载。
从RDBMS表中读取数据,需要设置连接数据库相关信息,基本属性选项如下:

范例演示:以MySQL数据库为例,加载订单表so数据,首先添加数据库驱动依赖包:
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.19</version>
</dependency>
完整演示代码如下:
import java.util.Properties
import org.apache.spark.sql.{DataFrame, SparkSession}
/**
* 使用SparkSession从RDBMS 表中读取数据,此处以MySQL数据库为例
*/
object SparkSQLMySQL {
def main(args: Array[String]): Unit = {
// 在SparkSQL中,程序的同一入口为SparkSession实例对象,构建采用是建造者模式
val spark: SparkSession = SparkSession.builder()
.master("local[4]")
.appName("SparkSQLMySQL")
.config("spark.sql.shuffle.partitions", "4")
.getOrCreate()
// 导入隐式转换
import spark.implicits._
// 连接数据库三要素信息
val url: String = "jdbc:mysql://node1.itcast.cn:3306/?serverTimezone=UTC&characterEncoding=ut
f8&useUnicode=true"
val table: String = "db_shop.so"
// 存储用户和密码等属性
val props: Properties = new Properties()
props.put("driver", "com.mysql.cj.jdbc.Driver")
props.put("user", "root")
props.put("password", "123456")
// TODO: 从MySQL数据库表:销售订单表 so
// def jdbc(url: String, table: String, properties: Properties): DataFrame
val sosDF: DataFrame = spark.read.jdbc(url, table, props)
println(s"Count = ${sosDF.count()}")
sosDF.printSchema()
sosDF.show(10, truncate = false)
// 关闭资源
spark.stop()
}
}
可以使用option方法设置连接数据库信息,而不使用Properties传递,代码如下:
// TODO: 使用option设置参数
val dataframe: DataFrame = spark.read
.format("jdbc")
.option("driver", "com.mysql.cj.jdbc.Driver")
.option("url", "jdbc:mysql://node1.itcast.cn:3306/?serverTimezone=UTC&characterEncoding=utf8&useUnicode=true")
.option("user", "root")
.option("password", "123456")
.option("dbtable", "db_shop.so")
.load()
dataframe.show(5, truncate = false)
6.8 hive 数据
Spark SQL模块从发展来说,从Apache Hive框架而来,发展历程:Hive(MapReduce)-> Shark (Hive on Spark) -> Spark SQL(SchemaRDD -> DataFrame -> Dataset),所以SparkSQL天然无缝集成Hive,可以加载Hive表数据进行分析。
官方文档:http://spark.apache.org/docs/2.4.5/sql-data-sources-hive-tables.html
spark-shell 集成 Hive
第一步、当编译Spark源码时,需要指定集成Hive,命令如下:

官方文档:http://spark.apache.org/docs/2.4.5/building-spark.html#building-with-hive-and-jdbc-support
第二步、SparkSQL集成Hive本质就是:读取Hive框架元数据MetaStore,此处启动Hive MetaStore服务即可。
-
Hive 元数据MetaStore读取方式:JDBC连接四要素和HiveMetaStore服务

-
启动Hive MetaStore 服务,脚本【metastore-start.sh】内容如下:
#!/bin/sh
HIVE_HOME=/export/server/hive
## 启动服务的时间
DATE_STR=`/bin/date '+%Y%m%d%H%M%S'`
# 日志文件名称(包含存储路径)
HIVE_SERVER2_LOG=${HIVE_HOME}/hivemetastore-${DATE_STR}.log
## 启动服务
/usr/bin/nohup ${HIVE_HOME}/bin/hive --service metastore > ${HIVE_SERVER2_LOG} 2>&1 &
第三步、连接HiveMetaStore服务配置文件hive-site.xml,放于【$SPARK_HOME/conf】目录
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hive.metastore.uris</name>
<value>thrift://node1.itcast.cn:9083</value>
</property>
</configuration>
将hive-site.xml配置发送到集群中所有Spark按照配置目录,此时任意机器启动应用都可以访问Hive表数据。
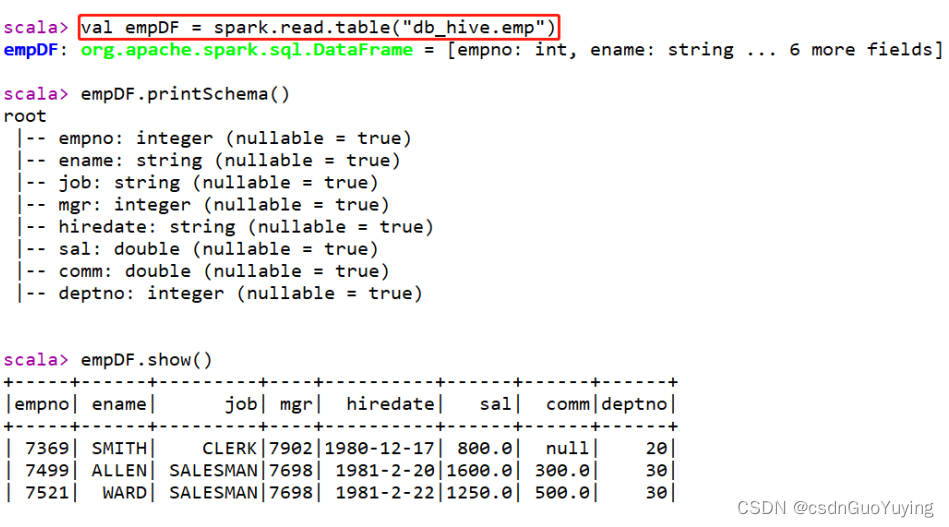
第四步、案例演示,读取Hive中db_hive.emp表数据,分析数据
-
其一、读取表的数据,使用DSL分析
-
其二、直接编写SQL语句
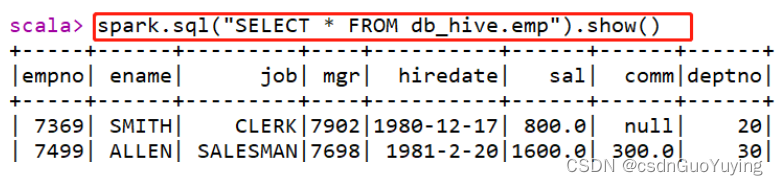
复杂SQL分析语句执行:
spark.sql("select e.ename, e.sal, d.dname from db_hive.emp e join db_hive.dept d on e.deptno = d.dept
no").show()
IDEA 集成 Hive
在IDEA中开发应用,集成Hive,读取表的数据进行分析,构建SparkSession时需要设置HiveMetaStore服务器地址及集成Hive选项,首先添加MAVEN依赖包:
<!-- Spark SQL 与 Hive 集成 依赖 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
范例演示代码如下:
import org.apache.spark.sql.SparkSession
/**
* SparkSQL集成Hive,读取Hive表的数据进行分析
*/
object SparkSQLHive {
def main(args: Array[String]): Unit = {
// TODO: 构建SparkSession实例对象
val spark: SparkSession = SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[4]")
.config("spark.sql.shuffle.partitions", "4")
// 指定Hive MetaStore服务地址
.config("hive.metastore.uris", "thrift://node1.itcast.cn:9083")
// TODO: 表示集成Hive,读取Hive表的数据
.enableHiveSupport()
.getOrCreate()
// 导入隐式转换
import spark.implicits._
// 导入函数库
import org.apache.spark.sql.functions._
// TODO: 读取Hive表的数据
spark.sql(
"""
|SELECT deptno, ROUND(AVG(sal), 2) AS avg_sal FROM db_hive.emp GROUP BY deptno
""".stripMargin)
.show(10, truncate = false)
println("===========================================================")
import org.apache.spark.sql.functions._
spark.read
.table("db_hive.emp")
.groupBy($"deptno")
.agg(round(avg($"sal"), 2).alias("avg_sal"))
.show(10, truncate = false)
// 应用结束,关闭资源
spark.stop()
}
}
运行程序结果如下:

相关文章:
【Spark分布式内存计算框架——Spark SQL】12. External DataSource(下)rdbms 数据
6.7 rdbms 数据 回顾在SparkCore中读取MySQL表的数据通过JdbcRDD来读取的,在SparkSQL模块中提供对应接口,提供三种方式读取数据: 方式一:单分区模式 方式二:多分区模式,可以设置列的名称,作为…...

【React】React入门--更改状态、属性、表单的非受控组件和受控组件
🎀个人主页:努力学习前端知识的小羊 感谢你们的支持:收藏🎄 点赞🍬 加关注🪐 文章目录setState属性(props)属性vs状态非受控组件受控组件setState this.state是纯js对象,在vue中,dat…...
0216-0218复习:继承
目录 继承 一、基本介绍 二、示意图 三、基本语法 四、入门案例 父类 子类1 子类2 main方法 五、继承细节 第一条 第二条 第三条 第四条 编辑 第五条 第六条 第七条 第八条 第九条 第十条 六、继承本质 七、练习题 第三题 继承 一、基本介绍 继承可以…...
【数据库】HNU数据库系统期末考试复习重点
前言 今天刚结束考试,考的范围基本没有超过这套重点内容,觉得整理的这份资料还算比较有用,遂睡前整理了下分享给大家,希望能帮到要准备数据库期末又时间紧张的学弟学妹~ 文章参考: 1.课程老师发《数据库期末考试复习…...

SCI论文写作常见连词及适用情况
And:用于连接同类或相似的词、短语或句子,表达并列关系。Moreover:用于连接两个相似或相关的想法,表达附加的信息或思想。Furthermore:用于连接两个相似或相关的想法,表达更进一步的信息或思想。In additio…...
Spring中的数据校验--进阶
分组校验 场景描述 在实际开发中经常会遇到这种情况:添加用户时,id是由后端生成的,不需要校验id是否为空,但是修改用户时就需要校验id是否为空。如果在接收参数的User实体类的id属性上添加NotNull,显然无法实现。这时…...
多种方法解决谷歌(chrome)、edge、火狐等浏览器F12打不开调试页面或调试模式(面板)的问题。
文章目录1. 文章引言2. 解决问题3. 解决该问题的其他方法1. 文章引言 不论是前端开发者,还是后端开发者,我们在调试web项目时,偶尔弹出相关错误。 此时,我们需要打开浏览器的调试模式,如下图所示: 通过浏…...

默认生成的接口实现方法体的问题
随着集成开发环境越来越强大,编程开发工作也变得越来越高效,很多的代码都不需要逐字输入,可以利用代码生成和自动补全来辅助开发。但是这样的便利也可能引起一些疏忽,本文就Java开发中默认生成的接口实现方法来谈谈以前遇到的问题…...

【OJ】十级龙王间的决斗
📚Description: 在《驯龙高手2》,最精彩的高潮出现在两只阿尔法决斗的时候。 驯龙高手中的十星龙王又称喷冰龙,有且只有两只,是最大型的龙,所有其他龙都要膜拜它(当然,幼龙除外)&…...

java 自定义注解
文章目录前言Annotation包自定义注解自定义注解示例参考文章:java 自定义注解 用处_java注解和自定义注解的简单使用参考文章:java中自定义注解的作用和写法前言 在使用Spring Boot的时候,大量使用注解的语法去替代XML配置文件,十…...

产品经理知识体系:2.如何进行商业需求分析?
商业需求分析 思考 笔记 用户细分: 核心用户、用户分级 用户关系: 如何维护用户关系、维护等成本 关系和商业模式的整合 核心价值: 解决什么问题,满足什么需求,最终带给用户什么价值 渠道通道: 如何触达…...

EditPlus正则表达式替换字符串详解
正则表达式是一个查询的字符串,它包含一般的字符和一些特殊的字符,特殊字符可以扩展查找字符串的能力,正则表达式在查找和替换字符串的作用不可忽视,它能很好提高工作效率。EditPlus的查找,替换,文件中查找…...

Go基础-环境安装
文章目录1 Go?Golang?2 下载Go3 windows安装4 测试是否成功1 Go?Golang? Go也称为Golang,是Google开发的一个开源的编译型的静态语言。 Golang的主要关注点是高可用、高并发和高扩展性,Go语言定位是系统级编程语言,对web程序具有很好的支…...

《NFL橄榄球》:纽约巨人·橄榄1号位
纽约巨人(New York Giants)是美国全国橄榄球联盟在新泽西州东卢瑟福的一支球队。巨人是在1925年作为五个成员之一加入国家美式橄榄球联盟。 在2018年时,球队市值为33亿美元,在世界前50名球队中并列第8名,同时在NFL高居…...

2023/02/18 ES6数组的解读
1 扩展运算符 扩展运算符(spread)是三个点(…). 它好比 rest 参数的逆运算,将一个数组转为用逗号分隔的参数序列. console.log(...[1, 2, 3]) // 1 2 3console.log(1, ...[2, 3, 4], 5) // 1 2 3 4 5该运算符主要用于…...
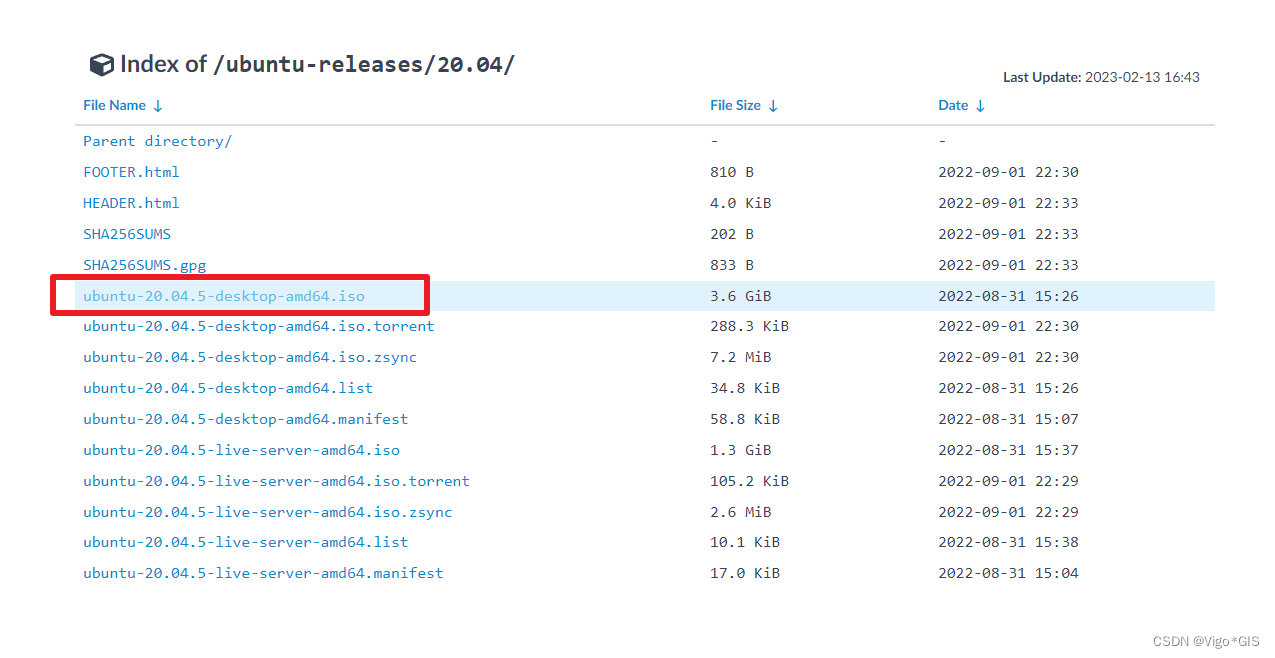
Ubuntu 20 安装包下载(清华镜像)
Ubuntu 20 安装包下载在国内推荐使用清华大学镜像 清华镜像地址:https://mirrors.tuna.tsinghua.edu.cn/ 在搜索框中输入Ubuntu,然后点击Ubuntu -release,这里面有近几年的Ubuntu镜像 点击你想下载的版本,我选择的是20.0413点击…...
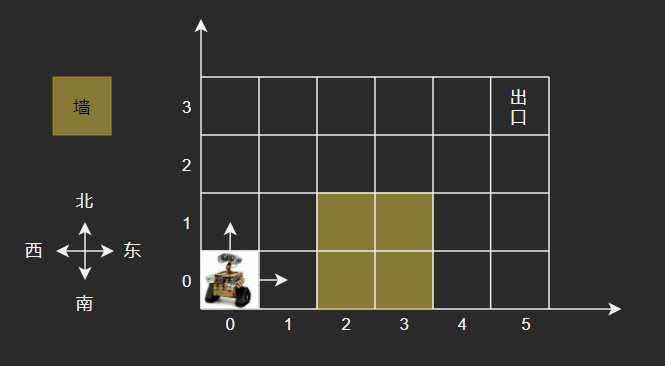
华为OD机试 - 机器人走迷宫(JS)
机器人走迷宫 题目 房间有X*Y的方格组成,例如下图为6*4的大小。每一个放个以坐标(x,y)描述。 机器人固定从方格(0,0)出发,只能向东或者向北前进, 出口固定为房间的最东北角,如下图的方格(5,3)。 用例保证机器人可以从入口走到出…...

字节二面:10Wqps超高流量系统,如何设计?
超高流量系统设计思路 前言 在40岁老架构师 尼恩的**读者交流群(50)**中,大流量、高并发的面试题是一个非常、非常高频的交流话题。最近,有小伙伴面试字节时,遇到一个面试题: 10Wqps超高流量系统,该如何设计…...
基于springboot+html汽车维修系统汽车维修系统的设计与实现
基于springboothtml汽车维修系统汽车维修系统的设计与实现 ✌全网粉丝20W,csdn特邀作者、博客专家、CSDN新星计划导师、java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取项目下载方式…...

营销狂人杜国楹的两大顶级思维
“营销狂人”小罐茶 杜国楹两大顶级思维 1.一定要有【参照物思维】 2.一定要有【终局思维】 趣讲大白话:大牛的思考就是不同 *********** 杜国楹对茶行业思考 1.参照咖啡、酒的发展路径 2.中国茶工业化,品牌化是唯一壮大之路 3.龙头企业必须全品 没有参照物思维就没…...

如何快速提升Obsidian笔记体验:AnuPpuccin主题完整指南
如何快速提升Obsidian笔记体验:AnuPpuccin主题完整指南 【免费下载链接】AnuPpuccin Personal theme for Obsidian 项目地址: https://gitcode.com/gh_mirrors/an/AnuPpuccin 还在为单调的Obsidian界面而烦恼吗?想让你的笔记软件既美观又实用吗&a…...

从Crustocean/conch看轻量级工作流编排:DAG原理与Python实现
1. 项目概述:从“Crustocean/conch”看现代数据管道编排的演进最近在梳理团队的数据处理流程时,我又一次被那些错综复杂的脚本、定时任务和手动依赖检查搞得焦头烂额。这让我想起了几年前第一次接触“Crustocean/conch”这个项目时的情景。当时ÿ…...

容器化自动化数据抓取平台OpenClaw-Compose部署与实战指南
1. 项目概述:一个容器化的开源自动化抓取与处理平台最近在折腾一个自动化数据抓取和处理的项目,发现了一个挺有意思的GitHub仓库:alexleach/openclaw-compose。乍一看标题,你可能会觉得这又是一个普通的Docker Compose编排文件集合…...

iOS 17-26越狱终极指南:5个安全解锁iPhone隐藏功能的专业方法
iOS 17-26越狱终极指南:5个安全解锁iPhone隐藏功能的专业方法 【免费下载链接】Jailbreak iOS 26.4 - 26, 17 - 17.7.5 & iOS 18 - 18.7.3 Jailbreak Tools, Cydia/Sileo/Zebra Tweaks & Jailbreak News Updates || AI Jailbreak Finder 👇 项…...

从网站点击到疾病预测:泊松回归模型在5个真实业务场景下的应用拆解与避坑指南
从网站点击到疾病预测:泊松回归模型在5个真实业务场景下的应用拆解与避坑指南 在数据驱动的商业决策中,计数型数据的分析往往被忽视。想象一下:电商平台每天需要决定发送多少条推送通知,客服中心要预测每小时可能接到的投诉电话数…...

Bluetooth 蓝牙协议详解
一、协议简介蓝牙(Bluetooth)短距离无线通信技术,主流分经典蓝牙与BLE 蓝牙 5.0/5.3(低功耗蓝牙),多用于近距离设备配对、数据透传、外设连接,消费电子与便携设备最常用。二、基础参数底层标准&…...
-virtual sequence实战:中断与异常场景构建)
I2C虚拟项目笔记(二)-virtual sequence实战:中断与异常场景构建
1. 为什么需要模拟中断与异常场景? 在实际的I2C总线通信中,各种异常情况时有发生。比如从设备突然掉电导致无应答(NACK),或者主设备在发送数据时遭遇干扰导致传输中断。这些场景如果不在验证阶段充分覆盖,…...

Python数据容器-元组
#元组-tuple# #数据不能被修改,只能查询# #索引访问和切片与列表类似# t1 (5,3,6,98,54,125,69,5,98)定义元组,t=(数据)# print(t1)# print(t1[5])125# t2 ()#空元组# #切片# print(t1[:7:2])5,6,54,69# #常用方法# t1 (5,3,6,98,54,125,6…...

从CenterFusion到车道线检测:聊聊DLAseg模型里可变形卷积的实战调优心得
从CenterFusion到车道线检测:DLAseg模型中可变形卷积的工程实践与调优策略 在自动驾驶和计算机视觉领域,特征提取网络的设计直接影响着感知系统的性能上限。Deep Layer Aggregation (DLA) 作为特征融合的经典方法,通过层级聚合机制实现了多尺…...

别再只会用L298N了!用STM32高级定时器玩转H桥双极模式,精准控制直流电机转速与刹车
从L298N到STM32高级定时器:H桥双极模式下的直流电机精准控制实战 在嵌入式开发领域,直流电机控制一直是经久不衰的话题。许多开发者入门时都会选择L298N这类现成驱动模块,它们简单易用,却隐藏着响应迟滞、效率低下和功能局限等问题…...