尚硅谷大数据项目《在线教育之采集系统》笔记003
视频地址:尚硅谷大数据项目《在线教育之采集系统》_哔哩哔哩_bilibili
目录
P036
P037
P038
P039
P041
P042
P043
P044
P045
P046
P036
先启动zookeeper,在启动kafka,启动hadoop中的hdfs
node003启动flume,node001启动flume,node001启动mock.sh。

P037
数据漂移
数据传输流程:生成数据——>flume——>kafka——>flume——>hdfs。
hdfs落盘默认使用header头的默认时间戳timesamp,修改header头就能修改时间戳。
P038
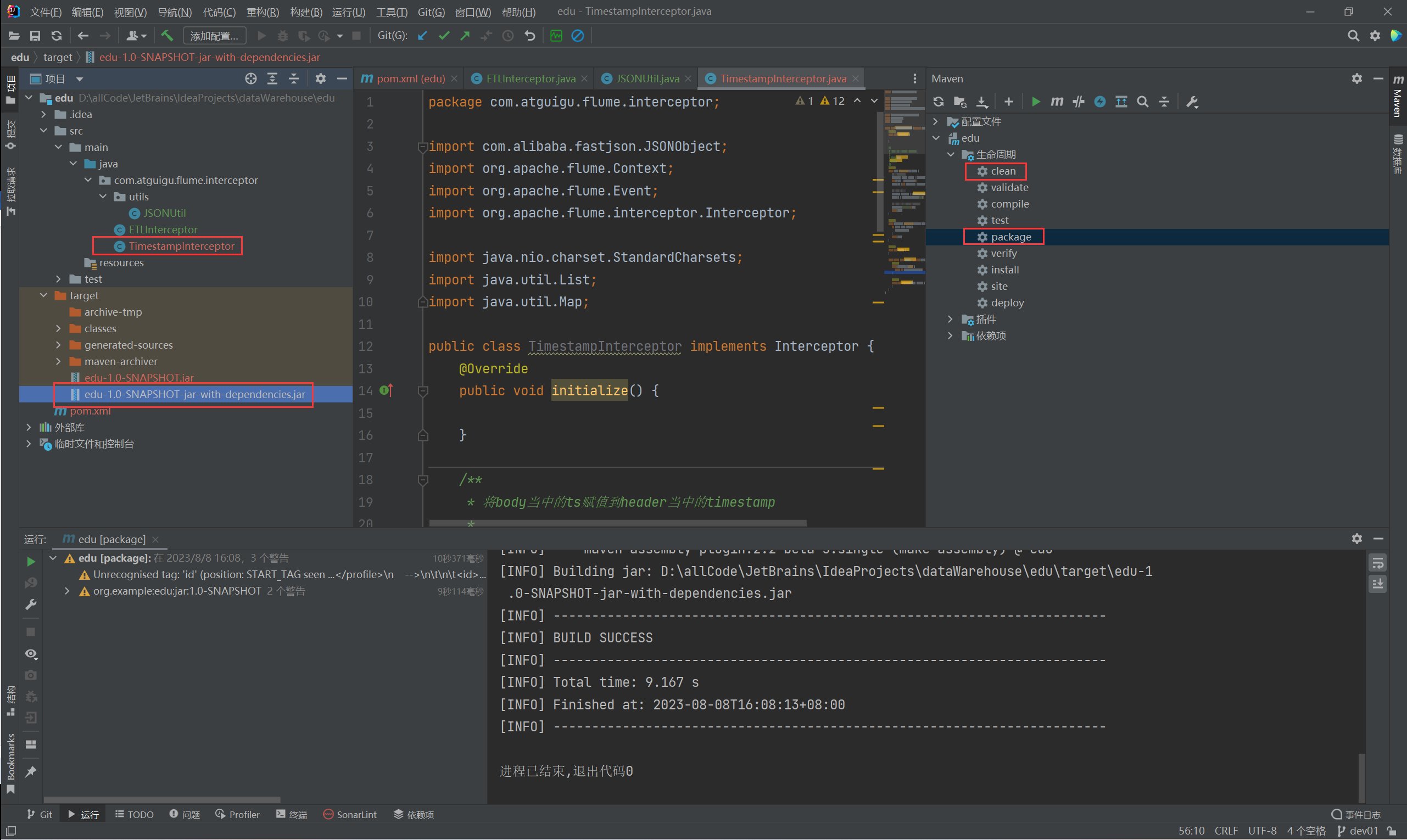
TimestampInterceptor:解决时间戳问题的拦截器。
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.atguigu.flume.interceptor.TimestampInterceptor$Builder

## 1、定义组件
a1.sources = r1
a1.channels = c1
a1.sinks = k1## 2、配置sources
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.kafka.bootstrap.servers = node001:9092,node002:9092,node003:9092
a1.sources.r1.kafka.consumer.group.id = topic_log
a1.sources.r1.kafka.topics = topic_log
a1.sources.r1.batchSize = 1000
a1.sources.r1.batchDurationMillis = 1000
a1.sources.r1.useFlumeEventFormat = falsea1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.atguigu.flume.interceptor.TimestampInterceptor$Builder## 3、配置channels
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /opt/module/flume/flume-1.9.0/checkpoint/behavior1
a1.channels.c1.useDualCheckpoints = false
a1.channels.c1.dataDirs = /opt/module/flume/flume-1.9.0/data/behavior1/
a1.channels.c1.capacity = 1000000
a1.channels.c1.maxFileSize = 2146435071
a1.channels.c1.keep-alive = 3## 4、配置sinks
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /origin_data/edu/log/edu_log/%Y-%m-%d
a1.sinks.k1.hdfs.filePrefix = log
a1.sinks.k1.hdfs.round = false## 控制输出文件是原生文件。
a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k1.hdfs.codeC = gzipa1.sinks.k1.hdfs.rollInterval = 10
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0## 5、组装 拼装
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
[atguigu@node002 ~]$ kafka-console-consumer.sh --bootstrap-server node001:9092 --topic topic_log
P039
/home/atguigu/bin
-----------------------------------------------------------
#! /bin/bashcase $1 in
"start") {echo " --------消费flume启动-------"ssh node003 "nohup /opt/module/flume/flume-1.9.0/bin/flume-ng agent -n a1 -c /opt/module/flume/flume-1.9.0/conf/ -f /opt/module/flume/flume-1.9.0/job/kafka_to_hdfs_log.conf >/dev/null 2>&1 &"
};;
"stop") {echo " --------消费flume关闭-------"ssh node003 "ps -ef | grep kafka_to_hdfs_log | grep -v grep | awk '{print \$2}' | xargs -n1 kill -9"
};;
esac
P041
P042
本项目中,全量同步采用DataX,增量同步采用Maxwell。
P043
- https://github.com/alibaba/DataX
- https://github.com/alibaba/DataX/blob/master/introduction.md
P044
[atguigu@node001 datax]$ cd /opt/module/datax/
[atguigu@node001 datax]$ python bin/datax.py -r mysqlreader -w hdfswriterDataX (DATAX-OPENSOURCE-3.0), From Alibaba !
Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.Please refer to the mysqlreader document:https://github.com/alibaba/DataX/blob/master/mysqlreader/doc/mysqlreader.md Please refer to the hdfswriter document:https://github.com/alibaba/DataX/blob/master/hdfswriter/doc/hdfswriter.md Please save the following configuration as a json file and usepython {DATAX_HOME}/bin/datax.py {JSON_FILE_NAME}.json
to run the job.{"job": {"content": [{"reader": {"name": "mysqlreader", "parameter": {"column": [], "connection": [{"jdbcUrl": [], "table": []}], "password": "", "username": "", "where": ""}}, "writer": {"name": "hdfswriter", "parameter": {"column": [], "compress": "", "defaultFS": "", "fieldDelimiter": "", "fileName": "", "fileType": "", "path": "", "writeMode": ""}}}], "setting": {"speed": {"channel": ""}}}
}
[atguigu@node001 datax]$ P045
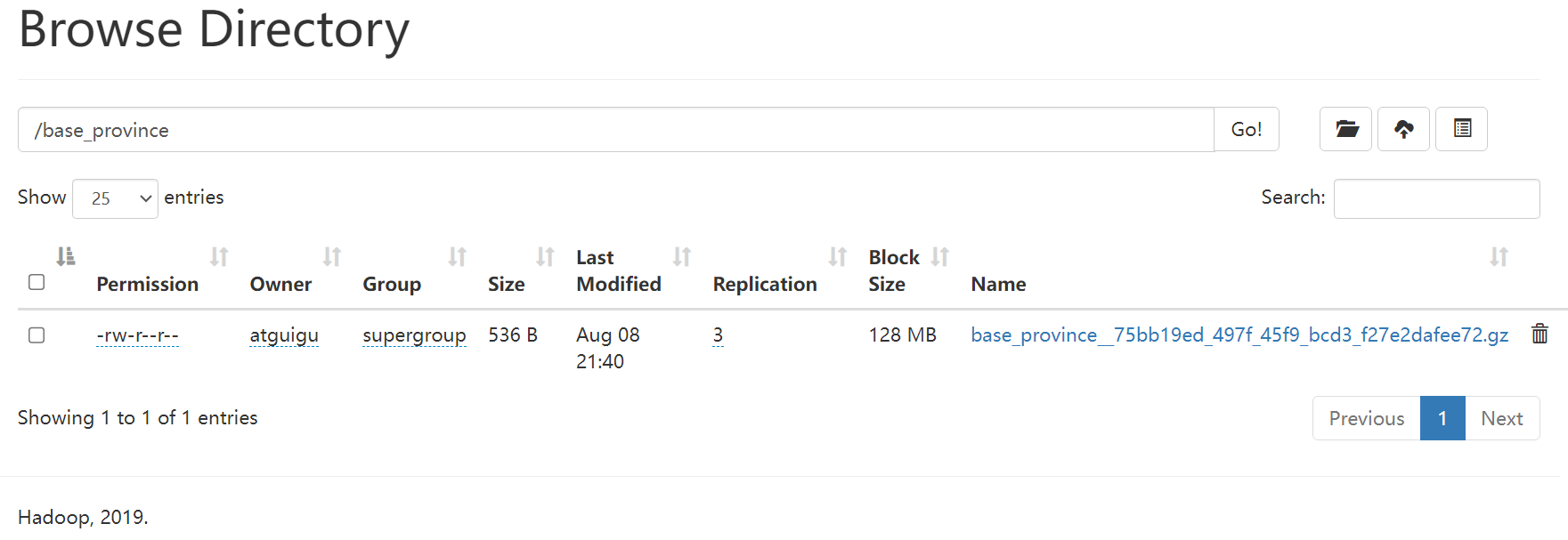
/opt/module/datax/job/base_province.json{"job": {"content": [{"reader": {"name": "mysqlreader","parameter": {"column": ["id","name","region_id","area_code","iso_code","iso_3166_2"],"where": "id>=3","connection": [{"jdbcUrl": ["jdbc:mysql://node001:3306/edu2077"],"table": ["base_province"]}],"password": "000000","splitPk": "","username": "root"}},"writer": {"name": "hdfswriter","parameter": {"column": [{"name": "id","type": "bigint"},{"name": "name","type": "string"},{"name": "region_id","type": "string"},{"name": "area_code","type": "string"},{"name": "iso_code","type": "string"},{"name": "iso_3166_2","type": "string"}],"compress": "gzip","defaultFS": "hdfs://node001:8020","fieldDelimiter": "\t","fileName": "base_province","fileType": "text","path": "/base_province","writeMode": "append"}}}],"setting": {"speed": {"channel": 1}}}
}
2023-08-08 21:40:16.749 [job-0] INFO JobContainer -
任务启动时刻 : 2023-08-08 21:39:59
任务结束时刻 : 2023-08-08 21:40:16
任务总计耗时 : 17s
任务平均流量 : 66B/s
记录写入速度 : 3rec/s
读出记录总数 : 32
读写失败总数 : 0[atguigu@node001 datax]$ hadoop fs -cat /base_province/base_province__75bb19ed_497f_45f9_bcd3_f27e2dafee72.gz | zcat
2023-08-08 21:42:28,250 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
3 山西 1 140000 CN-14 CN-SX
4 内蒙古 1 150000 CN-15 CN-NM
5 河北 1 130000 CN-13 CN-HE
6 上海 2 310000 CN-31 CN-SH
7 江苏 2 320000 CN-32 CN-JS
8 浙江 2 330000 CN-33 CN-ZJ
9 安徽 2 340000 CN-34 CN-AH
10 福建 2 350000 CN-35 CN-FJ
11 江西 2 360000 CN-36 CN-JX
12 山东 2 370000 CN-37 CN-SD
13 重庆 6 500000 CN-50 CN-CQ
14 台湾 2 710000 CN-71 CN-TW
15 黑龙江 3 230000 CN-23 CN-HL
16 吉林 3 220000 CN-22 CN-JL
17 辽宁 3 210000 CN-21 CN-LN
18 陕西 7 610000 CN-61 CN-SN
19 甘肃 7 620000 CN-62 CN-GS
20 青海 7 630000 CN-63 CN-QH
21 宁夏 7 640000 CN-64 CN-NX
22 新疆 7 650000 CN-65 CN-XJ
23 河南 4 410000 CN-41 CN-HA
24 湖北 4 420000 CN-42 CN-HB
25 湖南 4 430000 CN-43 CN-HN
26 广东 5 440000 CN-44 CN-GD
27 广西 5 450000 CN-45 CN-GX
28 海南 5 460000 CN-46 CN-HI
29 香港 5 810000 CN-91 CN-HK
30 澳门 5 820000 CN-92 CN-MO
31 四川 6 510000 CN-51 CN-SC
32 贵州 6 520000 CN-52 CN-GZ
33 云南 6 530000 CN-53 CN-YN
34 西藏 6 540000 CN-54 CN-XZ
[atguigu@node001 datax]$
P046
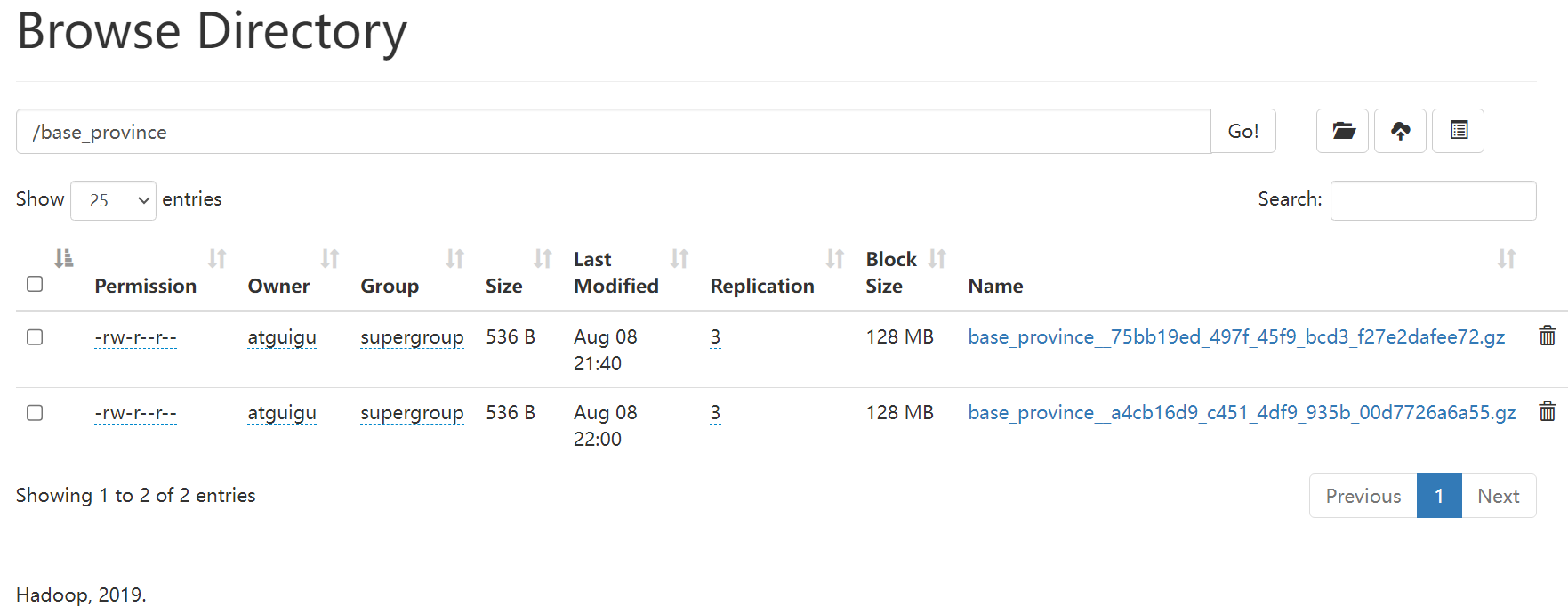
/opt/module/datax/job/base_province_sql.json{"job": {"content": [{"reader": {"name": "mysqlreader","parameter": {"connection": [{"jdbcUrl": ["jdbc:mysql://hadoop102:3306/edu2077"],"querySql": ["select id,name,region_id,area_code,iso_code,iso_3166_2 from base_province where id>=3"]}],"password": "000000","username": "root"}},"writer": {"name": "hdfswriter","parameter": {"column": [{"name": "id","type": "bigint"},{"name": "name","type": "string"},{"name": "region_id","type": "string"},{"name": "area_code","type": "string"},{"name": "iso_code","type": "string"},{"name": "iso_3166_2","type": "string"}],"compress": "gzip","defaultFS": "hdfs://hadoop102:8020","fieldDelimiter": "\t","fileName": "base_province","fileType": "text","path": "/base_province","writeMode": "append"}}}],"setting": {"speed": {"channel": 1}}}
}[atguigu@node001 datax]$ bin/datax.py job/base_province_sql.json2023-08-08 22:00:47.596 [job-0] INFO JobContainer - PerfTrace not enable!
2023-08-08 22:00:47.597 [job-0] INFO StandAloneJobContainerCommunicator - Total 32 records, 667 bytes | Speed 66B/s, 3 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.001s | All Task WaitReaderTime 0.000s | Percentage 100.00%
2023-08-08 22:00:47.600 [job-0] INFO JobContainer -
任务启动时刻 : 2023-08-08 22:00:33
任务结束时刻 : 2023-08-08 22:00:47
任务总计耗时 : 14s
任务平均流量 : 66B/s
记录写入速度 : 3rec/s
读出记录总数 : 32
读写失败总数 : 0[atguigu@node001 datax]$ 相关文章:
尚硅谷大数据项目《在线教育之采集系统》笔记003
视频地址:尚硅谷大数据项目《在线教育之采集系统》_哔哩哔哩_bilibili 目录 P036 P037 P038 P039 P041 P042 P043 P044 P045 P046 P036 先启动zookeeper,在启动kafka,启动hadoop中的hdfs node003启动flume,node001启动f…...
刷题指南 —— 第七弹)
PAT(Advanced Level)刷题指南 —— 第七弹
一、1012 The Best Rank 1. 问题重述 排序问题,原题叙述比较清晰,按照A > C > M > E四种排序的最高名次以及对应的排序方式输出。 2. Sample Input 5 6 310101 98 85 88 310102 70 95 88 310103 82 87 94<...

合宙Air724UG LuatOS-Air script lib API--sys
sys Table of Contents sys sys.restart sys.wait(ms) sys.waitUntil(id, ms) sys.waitUntilExt(id, ms) sys.taskInit(fun, …) sys.init(mode, lprfnc) sys.timerStop(val, …) sys.timerStopAll(fnc) sys.timerStart(fnc, ms, …) sys.timerLoopStart(fnc, ms, …) sys.time…...
MySQL建表和增添改查
1.创建一个名为mydb的数据库 mysql> show database mydb; 查询 mysql> show database mydb; 2.创建一个学生信息表 mysql> create table mydb.student_informtion( -> student_id int UNSIGNED NOT NULL PRIMARY KEY, //非空(不允许为空࿰…...
@Transactional 注解下,事务失效的七种场景
此文章为笔记,为阅读其他文章的感受、补充、记录、练习、汇总,非原创,感谢每个知识分享者。 文章目录 1、异常被捕获后没有抛出2、抛出非运行时异常3、方法内部直接调用4、新开启一个线程5、注解到private方法上6、数据库本身不支持7、事务传…...
chrome V3 插件开发 基础
目录 准备popup通信popup 发消息给 backgroundpopup 发消息给 content长期连接 如何页面上添加一个按钮?tabs.onUpdatedcontent-script.jsinject.js 右键菜单chrome.contextMenus举个例子添加关于报错(cannot create item with duplicate id XXX…...
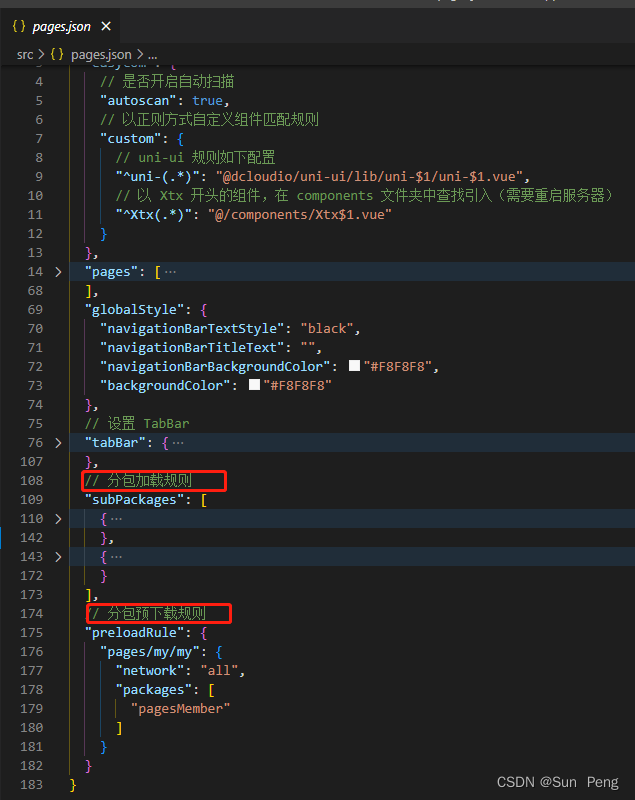
【uniapp】uniapp自动导入自定义组件和设置分包:
文章目录 一、自动导入自定义组件:二、设置分包和预加载: 一、自动导入自定义组件: 【Volar 官网】https://github.com/vuejs/language-tools 二、设置分包和预加载: 【官方文档】https://uniapp.dcloud.net.cn/collocation…...

【深度学习MOT videos detect】Detect to Track and Track to Detect
论文:https://arxiv.org/abs/1710.03958 代码:https://github.com/feichtenhofer/Detect-Track 文章目录 Abstract1. Introduction2. Related work后面翻译略 Abstract 近期用于在视频中高精度检测和跟踪目标类别的方法越来越复杂,每年都变得…...
关于Neo4j的使用及其基本命令
关于Neo4j的使用 文章目录 关于Neo4j的使用1、启动方式2、创建新节点,节点内有属性3、创建关系4、查询节点5、查询关系6、删除两个节点的关系7、删除节点8、删除某个标签的全部关系9、某个节点添加属性10、删除节点某个属性 1、启动方式 进入bin目录: …...

【笔记】树状数组
【笔记】树状数组 目录 简介引入1. 直接暴力2. 维护前缀和数组总结 定义前置知识: lowbit \operatorname{lowbit} lowbit 操作区间的表示方法操作单点修改前缀和查询任意区间查询 例题1: 单点修改,区间查询例题2: 区间修改,单点查询例题3:…...
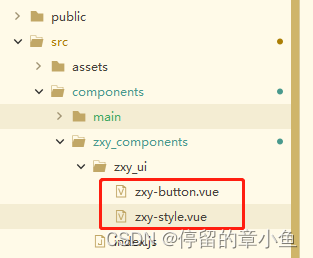
vue全局组件自动注册直接使用,无需单独先引用注册再使用
目录结构: 本案例是在根目录下components文件夹测试的,文件位置项目内任意,确保在main.js挂载路径正确即可 1、新建文件夹(名字随意)zxy_components (放自己组件的地方) 2、在zxy_components文件夹下 !新建…...

【HarmonyOS】@ohos.request 上传下载的那些事儿
【关键字】 ohos.request、上传下载 【写在前面】 在进行HarmonyOS应用开发时,可能需要进行上传或下载文件功能开发,本文章主要进行上传下载相关功能介绍和一些注意事项及FAQ。 【上传开发步骤】 步骤1:上传下载接口需要申请ohos.permis…...
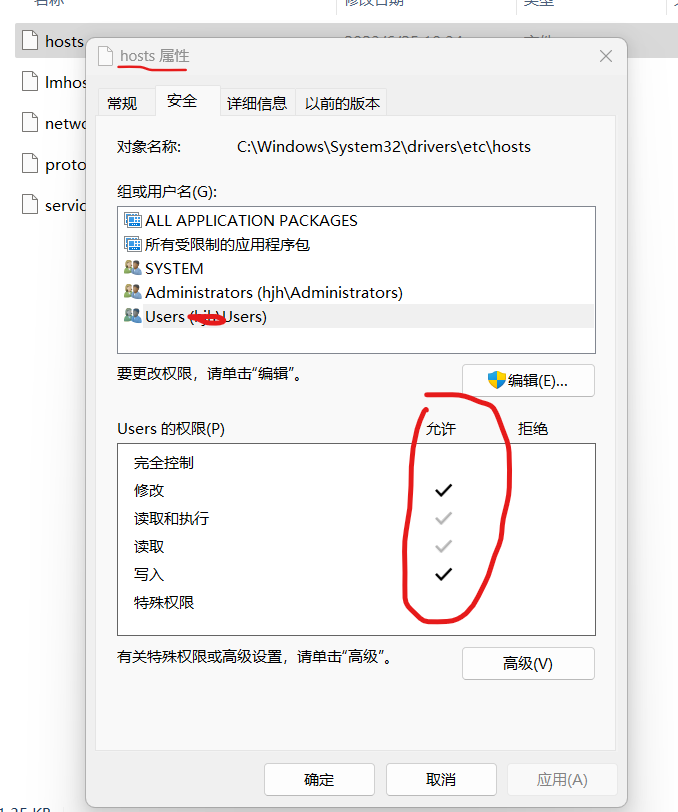
github版面混乱加载不出的解决办法
最近出现打开github 界面加载不成功,网页访问乱码,打开chrome的检查发现 github的github.githubassets.com 拒绝访问, 解法: 1.先打开hosts文件所在的目录C:\Windows\System32\drivers\etc 2.右键点击hosts文件-选择用记事本或者…...
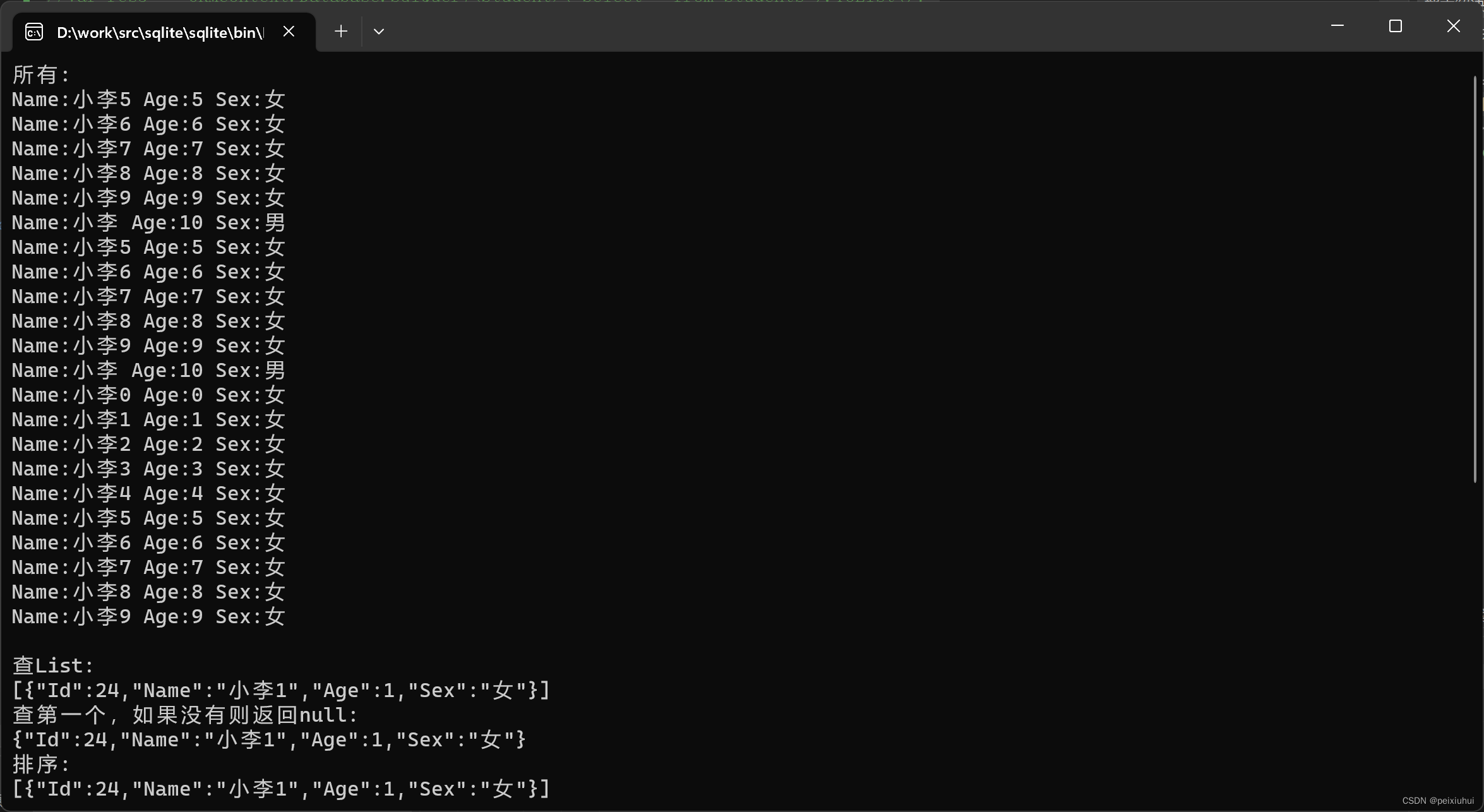
dotNet 之数据库sqlite
Sqlite3是个特别好的本地数据库,体积小,无需安装,是写小控制台程序最佳数据库。NET Core是同样也是.NET 未来的方向。 **硬件支持型号 点击 查看 硬件支持 详情** DTU701 产品详情 DTU702 产品详情 DTU801 产品详情 DTU802 产品详情 D…...

走近ChatGPT与类似产品:原理解析与比较
目录 1. 引言1.1 技术的进步与自然语言处理1.2 ChatGPT的崭新概念 2. ChatGPT: 一览众山小2.1 GPT-3.5架构简介2.2 ChatGPT的学习与训练2.3 文本生成的工作原理 3. 市场上类似产品调研3.1 对话式人工智能产品分类3.2 文心一言3.3 讯飞星火 4. 应用前景与局限性展望4.1 ChatGPT的…...

HarmonyOS SDK开放能力,服务鸿蒙生态建设,打造优质应用体验
华为开发者大会2023(HDC.Together)于8月4日至6日在东莞松山湖举行,在HarmonyOS端云开放能力技术分论坛上,华为为广大开发者们介绍了HarmonyOS SDK开放能力在基础开发架构、功能特性等方面的变化之处,通过将常见的通用能…...

数字经济对产业结构升级和创业增长的影响(2011-2021年)
参照刘翠花(2022)的做法,对来自中国人口科学《数字经济对产业结构升级和创业增长的影响》一文中的基准回归部分进行复刻。文章从理论层面分析数字经济发展对产业结构升级、创业增长的影响及其机理,并利用2011-2021年中国省级面板数…...
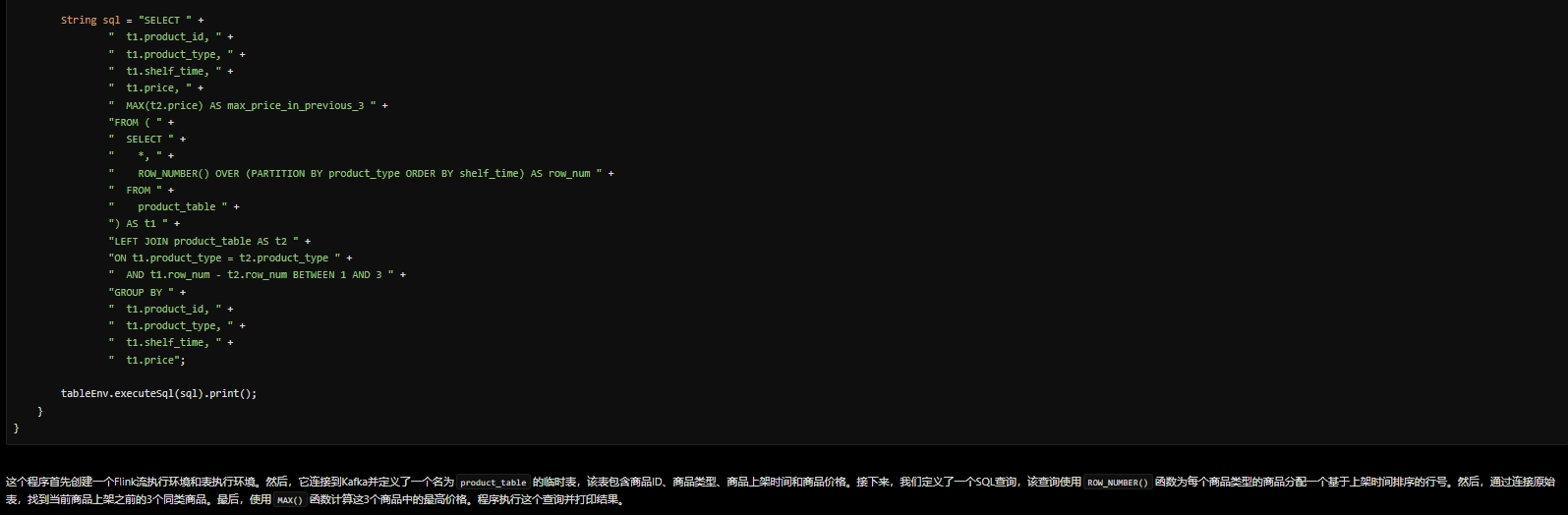
GPT-4助力数据分析:提升效率与洞察力的未来关键技术 | 京东云技术团队
摘要 随着大数据时代的到来,数据分析已经成为企业和组织的核心竞争力。然而,传统的数据分析方法往往无法满足日益增长的数据分析需求的数量和复杂性。在这种背景下,ChatGPT-4作为一种先进的自然语言处理技术,为数据分析带来了革命…...
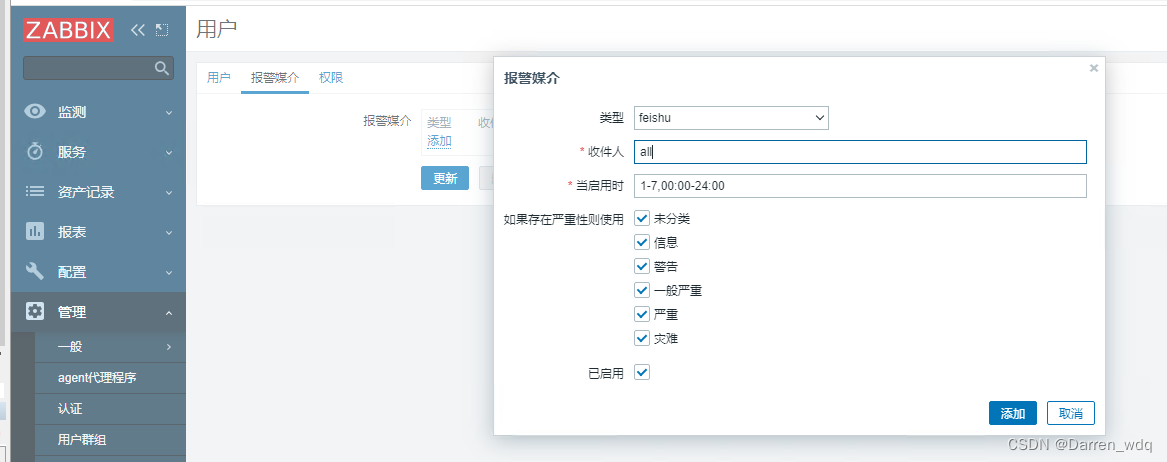
Zabbix6 对接飞书告警
文章目录 Zabbix对接飞书告警背景创建飞书群组Zabbix配置创建告警媒介类型创建动作用户关联飞书告警 Zabbix对接飞书告警 背景 运维 你看下他的进程是不是挂了,之前在9点28分有发消息的,这次没有发消息 哐哐哐的去看了一通,确实有个进程之前…...

Javascript异步编程的4种方法
你可能知道,Javascript语言的执行环境是"单线程"(single thread)。 所谓"单线程",就是指一次只能完成一件任务。如果有多个任务,就必须排队,前面一个任务完成,再执行后面一…...

番茄小说下载器:打造个人离线小说图书馆的终极解决方案
番茄小说下载器:打造个人离线小说图书馆的终极解决方案 【免费下载链接】Tomato-Novel-Downloader 番茄小说下载器不精简版 项目地址: https://gitcode.com/gh_mirrors/to/Tomato-Novel-Downloader 番茄小说下载器是一款专为番茄小说爱好者设计的强大开源工具…...

从房价预测到用户分群:CART回归树与分类树在真实业务场景下的应用避坑指南
从房价预测到用户分群:CART回归树与分类树实战避坑指南 在金融风控和电商推荐系统中,我们经常需要预测用户的贷款违约概率或对客户进行价值分层。去年为某银行优化信用卡审批系统时,我曾用CART分类树将用户逾期率预测准确率提升了23%…...

【50】软考软件设计师——【终章】50篇学习复盘与工程师之路|知识复盘+领证流程+进阶指引
摘要:本文是《软件设计师50讲通关|从零基础到工程师职称》专栏第50篇终章,也是整个专栏的收官与升华篇。全文围绕「备考闭环复盘+职业长期成长」双核心展开,完成三大使命:一是全专栏50篇知识体系结构化复盘,串联基础理论、算法、设计、机考、冲刺全模块,形成可视化知识地…...

3大核心技术揭秘:MAA如何实现明日方舟全自动化游戏体验
3大核心技术揭秘:MAA如何实现明日方舟全自动化游戏体验 【免费下载链接】MaaAssistantArknights 《明日方舟》小助手,全日常一键长草!| A one-click tool for the daily tasks of Arknights, supporting all clients. 项目地址: https://gi…...

REX-UniNLU与Typora文档智能分析
REX-UniNLU与Typora文档智能分析 1. 引言 在日常工作中,我们经常需要处理大量的Markdown文档。无论是技术文档、项目报告还是学习笔记,如何快速理解和分析这些文档内容一直是个挑战。传统的文档分析需要人工阅读和整理,费时费力且容易出错。…...

SQL插入数据时忽略错误行_使用错误日志表暂存失败条目
INSERT IGNORE 无法记录错误详情,因其静默忽略所有错误(包括主键冲突、字段超长、类型不匹配等),不触发错误日志、不返回具体错误码和消息,导致无法审计、重试或告警。MySQL INSERT IGNORE 为什么不能记录错误详情INSE…...

OpenAI发布GPT-5.4-Cyber:网络安全AI新利器
OpenAI周二正式发布了GPT-5.4-Cyber,这是其最新旗舰模型GPT-5.4的专属优化版本,针对网络安全防御场景进行了深度定制优化。此次发布正值竞争对手Anthropic推出前沿模型Mythos数日之后,再次点燃了AI安全领域的激烈竞争。 OpenAI Touts Wider A…...

2026便宜又好用的SCRM推荐
SCRM发展到今天,已经有相当多的选择。 1:销售类。主要提供销售型SCRM,比如尘锋、探马。 2:垂直类,比如专注一个行业的,比如电商行业,教育行业之类的。只做一个行业的垂直型SCRM。 3:…...

NVIDIA Profile Inspector终极指南:解锁显卡隐藏性能的免费工具
NVIDIA Profile Inspector终极指南:解锁显卡隐藏性能的免费工具 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector 还在为游戏卡顿、画面撕裂而烦恼吗?NVIDIA Profile Inspector是一…...

人工智能发展简史:关键节点与技术突破
文章目录 前言一、理论萌芽期(1943-1956):智能的火种悄然点燃1.1 1943年:人工神经元——智能的数学基石1.2 1950年:图灵测试——智能的评判标准1.3 1956年:达特茅斯会议——AI正式诞生 二、黄金时代与第一次…...