Towards Open World Object Detection【论文解析】
Towards Open World Object Detection
- 摘要
- 1 介绍
- 2 相关研究
- 3 开放世界目标检测
- 4 ORE:开放世界目标检测器
- 4.1 对比聚类
- 4.2 RPN自动标注未知类别
- 4.3 基于能量的未知标识
- 4.4 减少遗忘
- 5 实验
- 5.1开放世界评估协议
- 5.2 实现细节
- 5.3 开放世界目标检测结果
- 5.4 增量目标检测结果
- 6 讨论和分析
- 7 结论
- 补充材料
- A 变化FStore的队列大小
- B η的敏感性分析
- C. 在Lcont中变化边界值 (∆)
- D. 在方程4中变化温度(T)
- E.有关对比聚类的更多详细信息
- F 进一步的实现细节
- G 增量目标检测的相关工作
- H 时间和存储费用
- I 基于Softmax的未知识别
- J 定性结果
- K 讨论关于失败的案例
摘要
人类在环境中有一种自然本能,即识别未知的物体实例。对于这些未知实例的内在好奇心有助于在相应的知识最终可得到时学习它们。这激发我们提出了一个新颖的计算机视觉问题,称为“开放世界目标检测”,其中模型的任务是:
- 无需明确监督就识别尚未引入为“未知”的物体。
- 当相应标签逐步接收时,逐步学习这些已识别的未知类别,而不会遗忘先前学习的类别。
我们对问题进行了规定,引入了强大的评估协议,并提供了一种新颖的解决方案,称为ORE:开放世界目标检测器,它基于对比聚类和基于能量的未知识别。我们的实验评估和消融研究分析了ORE在实现开放世界目标方面的效力。作为有趣的副产品,我们发现识别和描述未知实例有助于减少增量式目标检测中的混淆,在这种情况下,我们在没有额外方法论努力的情况下实现了最先进的性能。
我们希望我们的工作能吸引更多关于这个新识别但至关重要的研究方向的进一步研究。
1 介绍
深度学习在目标检测研究中加速了进展[14, 54, 19, 31, 52],其中模型的任务是在图像中识别和定位物体。所有现有的方法都基于一个强烈的假设,即在训练阶段可以获得所有要检测的类别。然而,当我们放松这个假设时,出现了两个具有挑战性的情况:
- 测试图像可能包含来自未知类别的物体,应该将其分类为未知。
- 当关于这些已识别未知类别的信息(标签)变得可用时,模型应该能够逐步学习新的类别。
发展心理学的研究[41, 36]发现,识别自己不知道的东西是激发好奇心的关键。这种好奇心激发了对学习新事物的渴望[9, 16]。这激励我们提出了一个新的问题,即模型应该能够将未知对象的实例标识为未知,并随后在训练数据逐步到达时学习识别它们,以统一的方式解决这个问题。我们将这个问题设置称为“开放世界目标检测”。
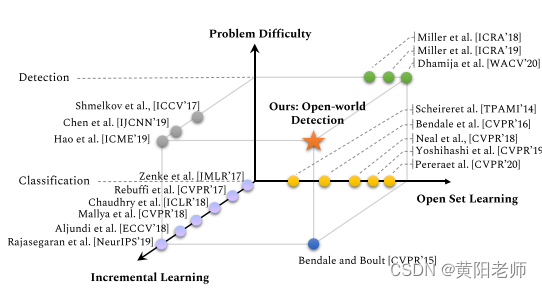
图1:开放世界目标检测(▲)是一个迄今为止尚未被正式定义和解决的新问题。尽管与开放集和开放世界分类相关,但开放世界目标检测提供了独特的挑战,一旦解决,将提高目标检测器的实用性。
标准视觉数据集(例如Pascal VOC [10]和MS-COCO [32])中注释的类别数量非常有限(分别为20和80),而在开放世界中存在无限数量的类别。将未知识别为未知对象需要强大的泛化能力。Scheirer等人[57]将其形式化为开放集分类问题。因此,各种方法(使用1对多SVM和深度学习模型)已经被制定来解决这个具有挑战性的设置。Bendale等人[3]将开放集扩展为开放世界分类设置,通过额外更新图像分类器来识别已识别的新未知类别。有趣的是,正如图1所示,开放世界目标检测尚未被探索,这归因于问题设置的复杂性。
开放集和开放世界图像分类的进展不能直接适用于开放集和开放世界目标检测,因为问题设置存在一个根本性的区别:目标检测器被训练用于将未知对象检测为背景。许多未知类的实例已经与已知对象一起引入到目标检测器中。由于它们没有标签,这些未知实例在训练检测模型时会被显式地学习为背景。Dhamija等人发现,即使有了这种额外的训练信号,现有的最先进目标检测器会产生误报检测,其中未知对象最终被错误地分类为已知类之一,通常概率非常高。Miller等人[43]提出使用dropout采样来获得目标检测预测的不确定性估计。这是开放集目标检测文献中唯一经过同行评审的研究工作。我们提出的开放世界目标检测更进一步,一旦检测到未知类并且一个“预言家”为所有未知类中感兴趣的对象提供标签,我们会逐步学习这些新类别。据我们所知,这在文献中尚未尝试过。
开放世界目标检测设置比现有的封闭世界、静态学习设置更加自然。在现实世界中,新类别的数量、类型和配置是多样且动态变化的。假设在推断时所期望的所有类别都在训练过程中已经出现是幼稚的。在机器人、自动驾驶汽车、植物表型学、医疗保健和监控等实际应用中,无法在内部训练过程中完全了解在推断时会出现的所有类别。
在这样的实际部署中,一个更加自然和现实的期望是,目标检测算法能够自信地将未知对象预测为未知,并准确地将已知对象分类到相应的类别中。随着对已识别未知类别的更多信息逐渐变得可用,系统应能将它们逐步纳入到现有的知识库中。这将定义一个智能目标检测系统,而我们的工作是为实现这一目标而努力。
我们提出的方法致力于解决开放世界目标检测的挑战,旨在创建更加健壮、灵活的检测系统,以应对现实世界场景中的不确定性和复杂性。
我们的工作的主要贡献如下:
• 我们引入了一种新颖的问题设置,即开放世界目标检测,更加贴近真实世界的情况。
• 我们开发了一种新颖的方法,称为ORE,基于对比聚类、对未知对象感知的提议网络和基于能量的未知对象识别,以解决开放世界检测的挑战。
• 我们引入了一个全面的实验设置,有助于衡量目标检测器的开放世界特性,并将ORE与竞争性基准方法在该设置下进行了对比评估。
• 作为一个有趣的副产品,我们提出的方法在增量式目标检测方面实现了最先进的性能,尽管它的主要设计目标并非如此。
2 相关研究
开集分类 开放集设置考虑通过训练集获取的知识是不完整的,因此在测试过程中可能会遇到新的未知类别。Scheirer等人[58]在一对多的设置中开发了开放集分类器,以平衡性能和标记样本与已知训练样本之间的风险(称为开放空间风险)。随后的研究[23, 59]将开放集框架扩展为多类分类器设置,并使用概率模型来考虑未知类别情况下分类器置信度的逐渐减弱。
Bendale和Boult [4]在深度网络的特征空间中识别未知样本,并使用Weibull分布来估计集合风险(称为OpenMax分类器)。[13]提出了OpenMax的生成版本,通过合成新的类别图像来实现。Liu等人[35]考虑了长尾识别的情况,其中主要类、少数类和未知类共存。他们开发了一个度量学习框架来识别未知类别。在类似的思路下,一些专门的方法针对检测分布之外的样本[30]或新奇性[48]。最近,自监督学习[46]和带有重构的无监督学习[65]已被用于开放集识别。然而,尽管这些方法可以识别未知样本,但它们不能在多个训练阶段中以增量方式动态更新自己。此外,我们基于能量的未知检测方法以前还没有被探索过。
开放世界分类 [3]首次提出了图像识别的开放世界设置。与静态分类器在固定的一组类别上训练不同,他们提出了一个更加灵活的设置,其中已知类别和未知类别都共存。该模型可以识别这两种类型的对象,并在为未知类别提供新标签时自适应地改进自己。他们的方法通过重新校准类别概率以平衡开放空间风险,将最近类均值分类器扩展到在开放世界环境中运行。
[47]研究了开放世界人脸身份学习,而[64]提出使用已知类别的示例集与新样本进行匹配,如果与所有先前已知类别的匹配度较低,则拒绝该样本。然而,他们没有在图像分类基准上进行测试,而是研究了电子商务应用中的产品分类。
开放集目标检测 : Dhamija等[8]正式研究了开放集设置对流行的目标检测器的影响。他们注意到,尽管检测器明确地使用背景类[55, 14, 33]进行训练和/或应用一对多分类器来对每个类建模[15, 31],但现有的目标检测器通常会将未知类别与已知类别高置信度地分类。一系列专门的研究[43, 42, 17]专注于开发目标检测器的(空间和语义)不确定性度量,以拒绝未知类别。例如,[43, 42]在SSD检测器中使用蒙特卡洛Dropout [12]采样来获得不确定性估计。然而,这些方法不能在动态世界中逐步地调整其知识。
3 开放世界目标检测
让我们在本节中形式化定义开放世界目标检测。在任意时刻t,我们将已知的目标类别集合定义为Kt = {1, 2, …, C} ⊂ N+,其中N+表示正整数集。为了真实地模拟现实世界的动态性,我们还假设存在一组未知的类别U = {C + 1, …},可能在推断过程中遇到。已知的目标类别Kt被假定在数据集Dt = {Xt,Yt}中标记,其中X和Y分别表示输入图像和标签。输入图像集合包含M个训练图像,Xt = {I1, . . . , IM},每个图像的关联目标标签形成标签集合Yt = {Y1, . . . ,YM}。每个Yi = {y1, y2, …, yK}编码一组K个目标实例及其类别标签和位置,即yk = [lk, xk, yk, wk, hk],其中lk ∈ Kt,xk, yk, wk, hk分别表示边界框的中心坐标、宽度和高度。
开放世界目标检测设置考虑了一个目标检测模型MC,该模型被训练以检测所有先前遇到的C个目标类别。重要的是,模型MC能够识别属于任何已知的C个类别的测试实例,并且还可以通过将其分类为未知(用标签0表示)来识别新的或未见过的类别实例。然后,未知实例集合Ut可以传递给人类用户,用户可以识别出n个感兴趣的新类别(在可能很多未知类别中),并提供它们的训练样本。学习器逐步添加n个新类别并更新自身,以产生更新后的模型MC+n,而无需从头开始对整个数据集重新进行训练。已知的类别集合也会更新为Kt+1 = Kt + {C + 1, . . . , C + n}。这个周期在目标检测器的使用期间持续进行,它通过新的知识自适应地更新自身。该问题设置在图2的顶部行中进行了说明。
4 ORE:开放世界目标检测器
成功的开放世界目标检测方法应该能够在没有明确监督的情况下识别未知实例,并且在这些已识别的新实例的标签被呈现给模型进行知识更新时,不会忘记先前的实例(而无需从头开始重新训练)。我们提出了一种名为ORE的解决方案,以统一的方式解决了这两个挑战。
神经网络是通用的函数逼近器[22],通过一系列隐藏层学习输入与输出之间的映射关系。在这些隐藏层中学习到的潜在表示直接控制着每个函数的实现方式。我们假设,在目标检测的潜在空间中学习明确的类别区分能够产生两种效果。首先,它有助于模型识别未知实例的特征表示与其他已知实例的差异,从而帮助将未知实例识别为新奇。其次,它促使在潜在空间中学习新类别实例的特征表示,而不会与先前的类别重叠,从而有助于增量学习而不会遗忘。帮助我们实现这一点的关键组件是我们提出的潜在空间中的对比聚类,我们在第4.1节中详细阐述了这一点。
为了通过对比聚类来最优地聚类未知实例,我们需要对未知实例进行监督。手动注释可能是无限的未知类别中的一个小子集是不可行的。为了解决这个问题,我们提出了一种基于区域提议网络[54]的自动标注机制,以伪标签方式标记未知实例,详见第4.2节。自动标记的未知实例在潜在空间中的固有分离有助于我们的基于能量的分类头部区分已知和未知实例。正如在第4.3节中所阐述的那样,我们发现未知实例的Helmholtz自由能较高。
图2展示了ORE的高层架构概述。我们选择Faster R-CNN [54]作为基础检测器,因为Dhamija等人发现与一阶RetinaNet检测器[31]和基于目标性的YOLO检测器[52]相比,它在开放集性能方面表现更好。Faster R-CNN [54]是一个两阶段的目标检测器。在第一阶段,一个与类别无关的区域提议网络(RPN)从共享的骨干网络生成的特征图中提议可能包含目标的区域。第二阶段对每个提议区域的边界框坐标进行分类和调整。感兴趣区域(RoI)头部的残差块生成的特征进行对比聚类。RPN和分类头部分别适应于自动标注和识别未知对象。我们在以下各小节中对这些一致的组成部分进行解释。
4.1 对比聚类
在潜在空间中的类别分离是一种理想的特征,对于开放世界的方法来识别未知类别是非常重要的。一种自然的方式是将其建模为一个对比聚类问题,其中同一类别的实例被迫保持靠近,而不同类别的实例则被推开。这种方式有助于在潜在空间中形成明确的类别边界,使得不同类别之间的距离较大,而同一类别内的距离较小。这样,当新的未知类别出现时,它们在潜在空间中会有与已知类别区分开的位置,从而可以更容易地被识别为未知。
通过对比聚类,可以将潜在空间中的实例分组成更清晰的类别,使得开放世界目标检测方法能够更准确地识别未知类别,并更好地应对在测试时可能出现的新类别。这有助于提高模型的适应性和泛化能力。
对于每个已知类别 i ∈ Kt,我们维护一个原型向量 pi。假设 fc ∈ Rd 是由目标检测器的中间层生成的特征向量,表示属于类别 c 的物体。我们定义对比损失如下:
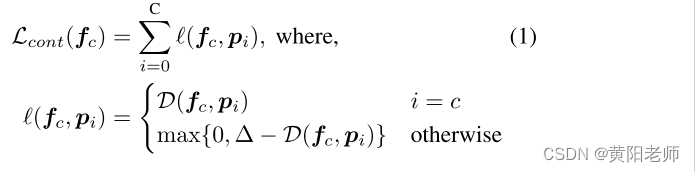
其中 D 是任何距离函数,而 ∆ 定义了相似物品和不相似物品之间的接近程度。最小化这个损失将确保在潜在空间中实现所需的类别分离。
每个类别对应的特征向量的均值用于创建类别原型的集合:P = {p0 · · · pC}。维护每个原型向量是ORE的一个关键组成部分。由于整个网络是端到端训练的,类别原型也应随着成分特征的逐渐变化而逐渐演变(由于随机梯度下降在每次迭代中通过小步骤更新权重)。我们为每个类别维护一个固定长度的队列 qi,用于存储相应的特征。特征存储 Fstore = {q0 · · · qC} 在相应的队列中存储类别特定的特征。这是一种可扩展的方法,用于跟踪特征向量随着训练如何演化,因为存储的特征向量数量受限于 C × Q,其中 Q 是队列的最大大小。
算法1提供了在计算聚类损失时如何管理类别原型的概述。我们只在完成一定数量的burn-in迭代(Ib)之后开始计算损失。这允许初始特征嵌入成熟,以编码类别信息。从那时起,我们使用公式1计算聚类损失。每隔Ip次迭代,会计算一组新的类别原型Pnew(第8行)。然后,通过使用动量参数η对现有原型P和Pnew进行加权更新原型P。这使得类别原型能够逐渐演化,并保持先前的上下文。计算得到的聚类损失添加到标准检测损失中,并进行反向传播,以端到端地学习网络。
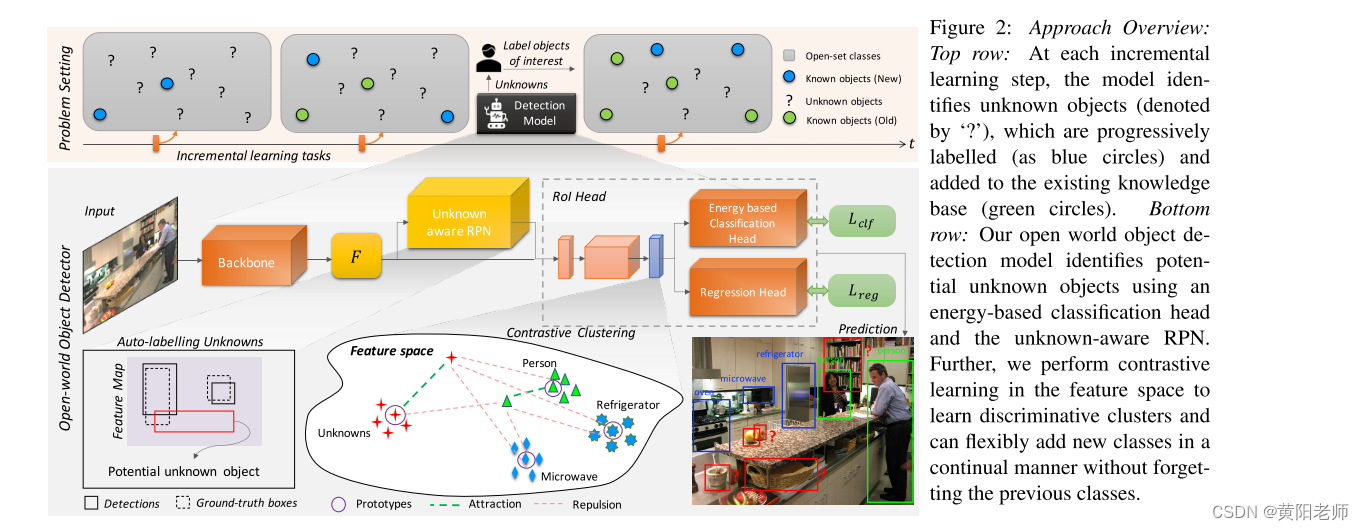 图 2: 方法概述:
图 2: 方法概述:
顶部行:在每个增量学习步骤中,模型会识别未知对象(用“?”表示),这些对象逐渐被标记为蓝色圆圈,并添加到现有的知识库中(绿色圆圈)。
底部行:我们的开放世界目标检测模型使用基于能量的分类头和未知感知的RPN来识别潜在的未知对象。此外,我们在特征空间中进行对比学习,以学习有区别的聚类,可以灵活地以连续的方式添加新的类别,而不会遗忘先前的类别。

4.2 RPN自动标注未知类别
在使用公式1计算聚类损失时,我们将输入特征向量fc与原型向量进行对比,其中包括未知对象的原型(c ∈ {0, 1, …, C},其中0表示未知类)。这将要求未知对象实例被标记为未知的真实类别,然而这在实践中并不可行,因为重新注释已经在大规模标注的数据集中的每个图像实例的工作是非常艰巨的。
作为替代方案,我们建议自动将图像中的一些物体标记为潜在的未知对象。为此,我们依赖于区域建议网络(RPN)是类不可知的事实。给定一个输入图像,RPN会为前景和背景实例生成一组边界框预测,以及相应的物体性分数。我们将那些具有高物体性分数但与地面真实对象不重叠的建议标记为潜在的未知对象。简而言之,我们选择由物体性分数排序的前k个背景区域建议,作为未知对象。这个看似简单的启发式方法在第5节中展示出了良好的性能。
4.3 基于能量的未知标识
给定潜在空间F中的特征(f ∈ F)及其对应的标签l ∈ L,我们试图学习一个能量函数E(F, L)。我们的表述基于能量模型(EBMs)[27],该模型通过一个输出标量(E(f) : Rd → R)来估计观察变量F和可能的输出变量L之间的兼容性。EBMs将低能量值分配给分布内的数据,反之亦然,这激发了我们使用能量度量来判断样本是否来自未知类别。具体而言,我们使用Helmholtz自由能公式,将L中所有值的能量结合起来,以此来衡量样本是否来自未知类别。
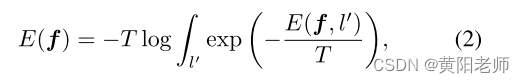
其中T是温度参数。在softmax层之后,网络输出与类特定能量值的Gibbs分布之间存在简单的关系[34]。可以将其表述为:
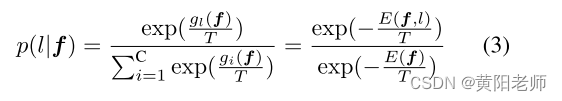
其中p(l|f)是标签l的概率密度,gl(f)是分类头g(.)的第l个分类逻辑。利用这种对应关系,我们可以将我们的分类模型的自由能定义为:
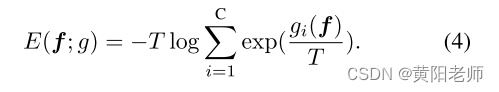
上述方程为我们提供了一种将标准 Faster R-CNN [54] 的分类头转换为能量函数的自然方法。由于我们在潜空间中强制进行的明确分离,我们在已知类别数据点和未知数据点的能量水平之间看到了明显的分离,如图3所示。鉴于这种趋势,我们用一组偏移的Weibull分布来建模已知和未知能量值ξkn(f)和ξunk(f)的能量分布。当与伽马分布、指数分布和正态分布进行比较时,发现这些分布非常适合一个小的保留验证集(包含已知和未知实例)的能量数据。通过学习的分布,可以将预测标记为未知,如果ξkn(f) < ξunk(f)。
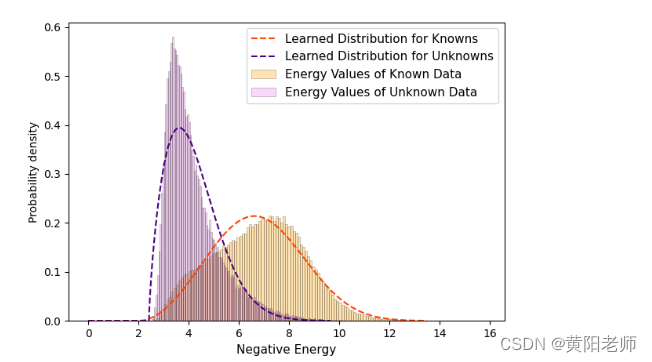
图3:如上所示,已知和未知数据点的能量值呈现出明显的分离。我们在每个数据点上拟合了一个Weibull分布,并将其用于识别未知的已知和未知样本,如第4.3节所述。
4.4 减少遗忘
在识别出未知类别之后,开放世界检测器的一个重要要求是在提供了某些感兴趣的未知类别的标记示例时能够学习新的类别。重要的是,在这个阶段不会存在用于以前任务的训练数据,因为从头开始重新训练不是一个可行的解决方案。仅使用新的类别实例进行训练会导致对先前类别的灾难性遗忘[40, 11]。我们注意到已经开发了许多涉及的方法来缓解这种遗忘,包括基于参数正则化[2, 24, 29, 66]、示范性回放[6, 51, 37, 5]、动态扩展网络[39, 60, 56]和元学习[50, 25]等方法。
我们基于最近的研究成果[49, 26, 62]进行了进一步的探索,比较了示范性回放与其他更复杂解决方案的重要性。具体而言,Prabhu等人[49]回顾了复杂的持续学习方法取得的进展,并展示了在增量学习中,一种贪婪的示范性选择策略在回放方面始终比现有的最先进方法表现出更大的优势。Knoblauch等人[26]为回放方法的非必要性提供了理论上的证明。他们证明了最优的持续学习器解决了一个NP难的问题,并且需要无限的内存。Wang等人[62]在相关的少样本目标检测设置中发现,存储少量示范性样本并进行回放在提高效果方面是有效的。这使得我们能够采用相对简单的方法来缓解遗忘问题,即我们存储一组平衡的示范性样本,并在每次增量步骤后在这些样本上进行微调。在每个阶段,我们确保示范性样本集中至少包含每个类的Nex个实例。
5 实验
我们提出了一个综合的评估方案,以研究开放世界目标检测器在识别未知类别、检测已知类别以及在为一些未知类别提供标签时逐步学习新类别方面的性能。
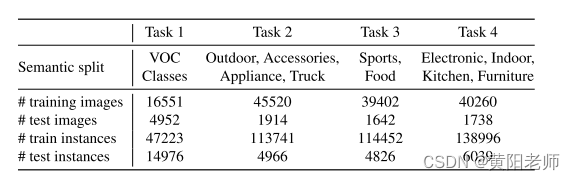
表格1:该表格显示了提议的开放世界评估协议中的任务组成。展示了每个任务的语义以及在不同划分下的图像数量和实例(物体)数量。
5.1开放世界评估协议
数据划分:我们将类别分组为一组任务T = {T1,…,Tt,…}。在时间点t引入系统的所有特定任务的类别。在学习Tt时,将所有{ Tτ:τ<t}的类别视为已知,将{ Tτ:τ>t}视为未知。对于此协议的具体实例化,我们考虑了来自Pascal VOC [10]和MS-COCO [32]的类别。我们将所有的VOC类别和数据分为第一个任务T1。将MS-COCO [32]的其余60个类别分成三个连续的任务,其中包含语义漂移(见表1)。与上述来自Pascal VOC和MS-COCO训练集的图像相对应的所有图像构成了训练数据。对于评估,我们使用Pascal VOC测试集和MS-COCO验证集。每个任务的训练数据中保留了1,000张图像用于验证。数据划分和代码可在https://github.com/JosephKJ/OWOD找到。
评估指标:由于未知对象很容易被误认为是已知对象,我们使用“Wilderness Impact”(WI)指标[8]来明确地描述这种行为。
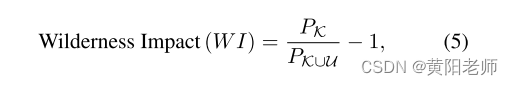
其中,PK表示在已知类别上评估模型的精度,PK∪U表示在已知和未知类别上评估模型的精度,测量在召回率水平R(在所有实验中为0.8)处。理想情况下,WI应该较小,因为在测试集中添加未知对象时精度不应下降。除了WI,我们还使用“Absolute Open-Set Error”(A-OSE)[43]来报告将未知对象错误地分类为任何已知类别的数量。WI和A-OSE都隐含地衡量了模型处理未知对象的有效性。
为了在存在新标记类别的情况下量化模型的增量学习能力,我们在IoU阈值为0.5的情况下测量平均精度(mAP),这与现有文献[61, 45]一致。
5.2 实现细节
ORE使用了标准的Faster R-CNN [54]目标检测器,其主干网络是ResNet-50 [20]。为了处理分类头中可变数量的类别,采用了增量分类方法 [50, 25, 6, 37],假设了最大类别数量的上限,并且修改了损失函数,只考虑感兴趣的类别。这是通过将未见类别的分类logits设置为一个大的负值(v),从而使它们对softmax的贡献变得微不足道(e^-v → 0)来实现的。这样做可以确保在计算分类损失时,只有已知类别的贡献被考虑。
2048维的特征向量来自于RoI Head中的最后一个残差块,用于进行对比聚类。对比损失(在公式1中定义)添加到标准的Faster R-CNN分类和定位损失中,并进行联合优化。在学习任务Ti时,只会对Ti中的类别进行标记。在测试任务Ti时,之前引入的所有类别都会与Ti中的类别一起进行标记,并且未来任务中的所有类别都会被标记为“未知”。对于样本回放,我们经验性地选择了Nex = 50。在第6节中,我们对样本内存的大小进行了敏感性分析。更多的实现细节可以在补充材料中找到。
5.3 开放世界目标检测结果
表格2显示了ORE在提出的开放世界评估协议上与Faster R-CNN的比较情况。一个“Oracle”检测器在任何时候都可以访问所有已知和未知标签,并作为参考。在学习每个任务后,使用WI和A-OSE指标来量化未知实例与任何已知类别之间的混淆情况。我们可以看到,由于对未知的明确建模,ORE具有显著较低的WI和A-OSE得分。当在任务2中逐步标记未知类别时,我们可以看到基线检测器在已知类别集上的性能(通过mAP量化)从56.16%显著下降到4.076%。所提议的平衡微调能够将以前的类别性能恢复到可观的水平(51.09%),但代价是WI和A-OSE的增加,而ORE能够实现两个目标:检测已知类别并全面减少未知的影响。当添加任务3类别时,也出现了类似的趋势。由于没有任何未知的实况数据,无法测量任务4的WI和A-OSE得分。我们在图4和补充部分中报告了定性结果,以及失败案例分析。我们在第6节和补充部分进行了广泛的敏感性分析。
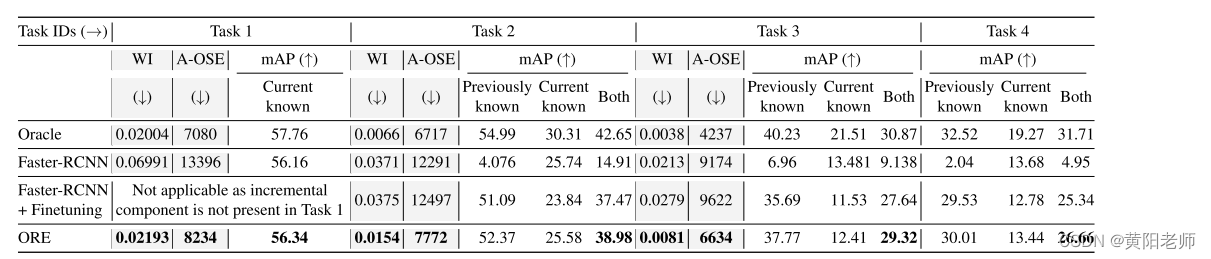
表格2:在这里,我们展示了ORE在开放世界目标检测上的表现。野外影响(WI)和平均开放集误差(A-OSE)量化了ORE如何处理未知类别(灰色背景),而均值平均精度(mAP)衡量了其检测已知类别的效果(白色背景)。我们可以看到,ORE在所有指标上始终优于基于Faster R-CNN的基线。请参阅第5.3节,了解有关评估指标的更详细分析和解释。
5.4 增量目标检测结果
我们发现ORE能够独特地建模未知对象的能力带来了一个有趣的结果:它在增量目标检测(iOD)任务中表现得非常出色(见表3)。这是因为ORE减少了将未知对象错误地分类为已知对象的混淆,从而使检测器能够逐步学习真正的前景对象。我们使用了在iOD领域中使用的标准协议[61, 45]来评估ORE,在该协议中,来自Pascal VOC 2007 [10]的类别组(10、5和最后一个类别)通过对其余类别进行训练的检测器进行了逐步学习。值得注意的是,ORE完全按照第4节中介绍的方法使用,没有任何更改。我们剔除了对比聚类(CC)和基于能量的未知识别(EBUI),发现它导致了比标准ORE更低的性能。
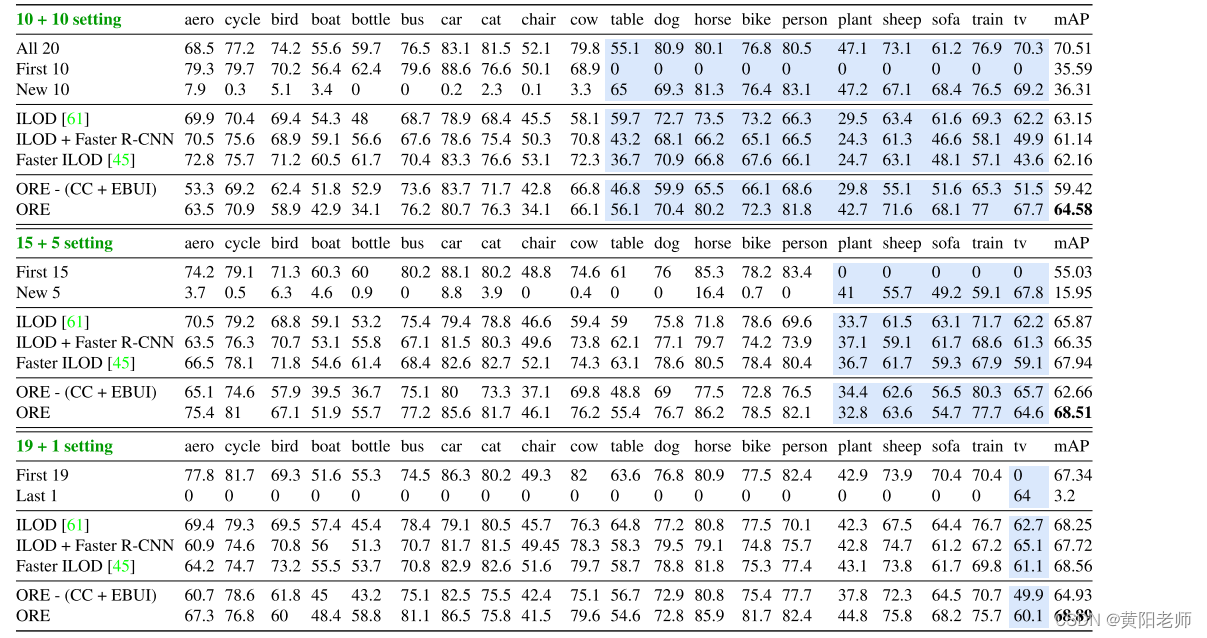
表3:我们在三种不同的设置下将ORE与最先进的增量目标检测器进行了比较。分别向在10、15和19个类别上进行训练的检测器引入了来自Pascal VOC 2007 [10]数据集的10、5和最后一个类别(显示在蓝色背景中)。ORE在所有设置中都能够表现出色,而无需进行任何方法上的改变。详细信息请参见第5.4节。
6 讨论和分析
6.1 剔除ORE组成部分:为了研究ORE中每个组成部分的贡献,我们进行了仔细的剔除实验(表4)。我们考虑引入Task 1到模型的情况。自动标注方法(称为ALU)与基于能量的未知类别识别(EBUI)结合在一起的效果更好(第5行)比分开使用它们中的任何一个效果更好(第3行和第4行)。在此配置中添加对比聚类(CC)获得了最佳的未知类别处理性能(第7行),以WI和A-OSE进行衡量。在未知类别的识别方面,没有严重的已知类别检测性能下降(以mAP指标衡量)。在第6行中,我们可以看出EBUI是一个关键组件,其缺失会增加WI和A-OSE分数。因此,ORE中的每个组件都在未知类别识别方面发挥了关键作用。
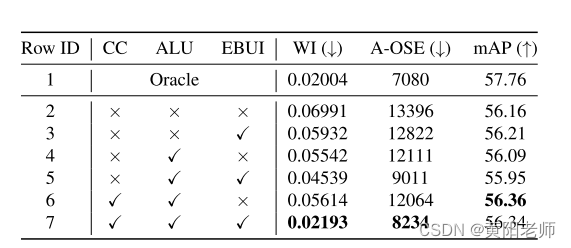
表4:我们仔细地剔除了ORE的每个组成部分。CC,ALU和EBUI分别指的是“对比聚类”,“未知类别的自动标注”和“基于能量的未知类别识别”。详细信息请参见第6.1节。
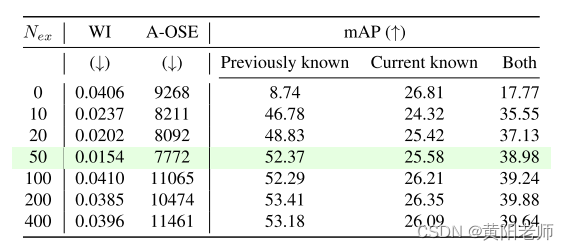
表5:该表显示了敏感性分析结果。将Nex增加到一个较大的值会损害对未知类别的性能,而保留一小组图像对于减轻遗忘是至关重要的(绿色中的最佳行)。
6.2 对示例记忆大小进行敏感性分析:我们的平衡微调策略需要存储至少每个类别Nex个实例的示例图像。在学习任务2时,我们改变Nex的值,并在表5中报告结果。我们发现,即使每个类别只有最少10个实例,平衡微调策略也非常有效地提高了先前已知类别的准确性。然而,我们发现将Nex增加到很大的值并不会有所帮助,同时会对未知类别的处理产生不利影响(从WI和A-OSE得分可以看出)。因此,通过验证,我们在所有实验中将Nex设置为50,这是一个在已知和未知类别上平衡性能的最佳点。

6.3 与开放集检测器的比较:当检测器在封闭集数据(在Pascal VOC 2007上进行训练和测试)和开放集数据(测试集包含来自MS-COCO的相同数量的未知图像)上进行评估时的mAP值有助于衡量检测器如何处理未知实例。理想情况下,不应该出现性能下降。我们将ORE与最近由Miller等人提出的开放集检测器进行比较[43]。从表6中可以看出,ORE的性能下降要比[43]低得多,这归因于对未知实例的有效建模。
6.4 聚类损失和 t-SNE [38] 可视化:我们通过可视化对比度聚类损失(方程1)在任务1训练过程中形成的聚类质量来评估。在图5(a)中,我们看到了良好形成的聚类。图例中的每个数字对应于任务1中引入的20个类别。标签20表示未知类。重要的是,我们看到未知实例也被聚类,这增强了在对比度聚类中使用的自动标记的未知实例的质量。在图5(b)中,我们绘制了训练迭代次数与对比度聚类损失之间的关系,我们可以看到损失逐渐减小,表明收敛良好。

图4:ORE在任务1上训练后的预测。“大象”、“苹果”、“香蕉”、“斑马”和“长颈鹿”尚未被引入模型,因此被成功分类为“未知”。该方法错误地将“长颈鹿”中的一个分类为“马”,显示了ORE的局限性。
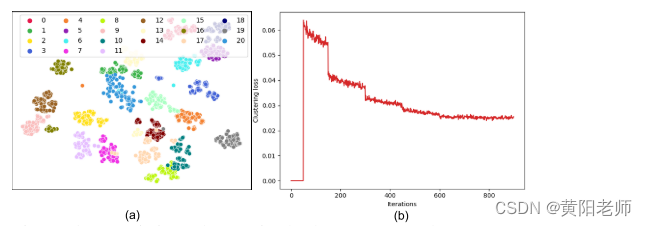
图5:(a)潜在空间中的不同簇。(b)我们的对比损失,这确保了这样的聚类稳定收敛。
7 结论
充满活力的目标检测社区在标准数据集上将性能基准推进了很大的幅度。这些数据集和评估协议的闭集性质阻碍了进一步的进展。我们引入了开放世界目标检测,其中目标检测器能够将未知对象标记为未知,并在模型逐渐暴露于新标签时逐渐学习未知对象。我们的主要创新包括用于未知检测的基于能量的分类器,以及用于开放世界学习的对比度聚类方法。我们希望我们的工作将在这个重要而开放的方向上引发进一步的研究。
补充材料
在这份补充材料中,我们提供了在主要论文中由于篇幅限制无法包含的额外细节,包括实验分析、实现细节、讨论和结果,这些细节有助于深入理解所提出的开放世界目标检测方法。我们将讨论以下内容:
• 对特征存储队列大小、动量参数η、聚类损失中的边界∆以及能量计算中的温度参数的敏感性分析。
• 对对比聚类的更多详细说明。
• 更具体的实现细节。
• 关于失败案例的讨论。
• 增量目标检测领域的相关工作。
• ORE的一些定性结果。
A 变化FStore的队列大小
在第4.1节中,我们解释了如何使用类别特定的队列qi来存储特征向量,这些特征向量用于计算类别原型。一个名为Q的超参数控制每个qi的大小。在学习任务1时,我们变化Q的值,并在表7中报告了结果。我们观察到在不同的Q值实验中,性能相对类似。这可以归因于原型一旦定义,就会定期通过新观察到的特征进行更新,从而有效地演化自己。因此,用于计算这些原型(P和Pnew)的实际特征数量并不是非常重要。我们在所有实验中使用Q = 20。
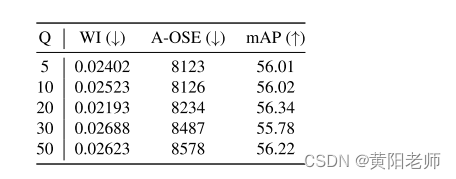
表7:我们发现,改变用于计算类原型的特征数量不会对性能产生巨大影响。
B η的敏感性分析
动量参数η控制类别原型的更新速度,如算法1所述。较大的η值意味着新计算的原型对当前类别原型的影响较小。从表8中我们可以得知,在原型更新较慢(η值较大)时,性能会有所提升。这个结果是直观的,因为缓慢地改变聚类中心有助于稳定对比学习。
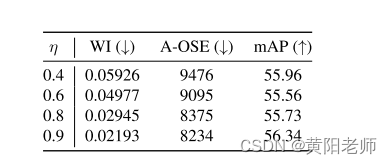
表8:我们可以看到较高的η值会获得更好的性能,这意味着逐渐演化的类别原型会改善对比聚类。
C. 在Lcont中变化边界值 (∆)
边界参数∆是对比聚类损失Lcont(方程1)中的一个参数,它定义了输入特征向量应该与不同类别原型在潜在空间中保持的最小距离。如表9所示,当学习第一个任务时,增加边界参数会提高已知类别的性能,并改善未知类别的处理方式。这可能意味着在潜在空间中具有更大的分离对ORE是有益的。
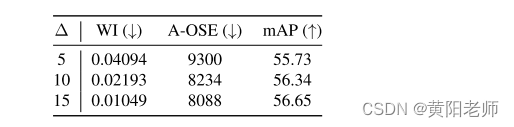
表9:增加边界参数∆会提高已知和未知类别的性能,与我们的假设一致,即在潜在空间中的分离对ORE是有益的。
D. 在方程4中变化温度(T)
我们在所有实验中将方程4中的温度参数(T)固定为1。将能量稍微加大到T = 2会在一定程度上改善未知识别的性能,然而进一步增加会导致性能下降,如表10所示。
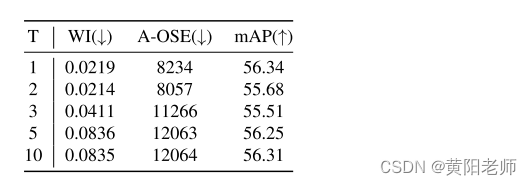
表10:温度参数在T = 1和T = 2之间有一个良好的取值范围,可以获得最佳性能。
E.有关对比聚类的更多详细信息
使用对比聚类在潜在空间中实现分离的动机有两个方面:1)它使模型能够将未知实例与已知实例分开聚类,从而提高未知实例的识别能力;2)它确保每个类的实例与其他类实例分开,减轻遗忘问题。
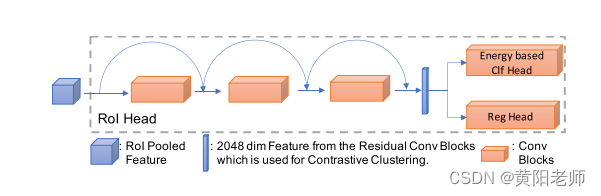
图6:RoI头架构,显示用于对比聚类的2048维特征向量。
从RoI头的残差块中出来的2048维特征向量(图6)进行了对比聚类。对比损失添加到Faster R-CNN损失中,整个网络端到端地进行训练。因此,在Faster R-CNN流水线中在RoI头之前和包括RoI头中的残差块之前的所有部分都会得到来自对比聚类损失的梯度更新。
F 进一步的实现细节
我们在拥有8个Nvidia V100 GPU的服务器上进行了实验,每个GPU的有效批处理大小为8。我们使用了随机梯度下降(SGD)优化算法,学习率为0.01。每个任务训练了8个epoch,大约相当于50,000次迭代。特征存储队列的大小设置为20。
聚类过程在前1000次迭代之后启动,每隔3000次迭代更新一次聚类原型,使用动量参数0.99。我们采用欧几里得距离作为方程1中的距离函数(D)。对于对比聚类损失,边界(∆)设置为10。
在RPN中自动标记未知实例时,我们选择了根据其物体性分数排序的前1个背景提议。用于能量基分类头部的温度参数设置为1。
我们的代码使用PyTorch [44]和Detectron 2 [63]框架进行了实现。此外,我们还使用了Reliability库 [53] 来对能量分布进行建模。为了促进可重复研究,我们已经公开发布了所有的代码,您可以在以下链接找到:https://github.com/JosephKJ/OWOD。
G 增量目标检测的相关工作
类增量式目标检测(iOD)设置考虑了随时间逐步观察类别的情况,学习者必须在不从头开始对旧类别进行重新训练的情况下进行适应。目前的方法[61, 28, 18, 7] 使用知识蒸馏[21]作为正则化措施,以在训练新类别时避免忘记旧类别的信息。具体而言,Shmelkov等人[61]将Fast R-CNN用于增量学习,通过从先前阶段模型中提取分类和回归输出来蒸馏模型输出。除了蒸馏模型输出外,Chen等人[7]和Li等人[28]还蒸馏了中间的网络特征。Hao等人[18]在Faster R-CNN的基础上,使用学生-教师框架进行RPN的自适应。Acharya等人[1]提出了一种用于在线检测的重放机制。最近,Peng等人[45]将自适应蒸馏技术引入了Faster R-CNN中,他们的方法是iOD领域中的最新状态。然而,这些方法在开放世界环境中无法工作,而开放世界是本文的重点,它们也无法识别未知对象。
H 时间和存储费用
ORE的训练和推断比标准的Faster R-CNN多花费了0.1349秒/迭代和0.009秒/迭代。维护FStore的存储开销是微不足道的,而示例内存(对于Nex = 50)大约占用了34 MB的空间。
I 基于Softmax的未知识别
我们修改了未知对象识别的标准为max(softmax(logits)) < t。对于t = {0.3, 0.5, 0.7},A-OSE、WI和mAP(平均值和标准差)分别为11815 ± 352.13、0.0436 ± 0.009和55.22 ± 0.02。这相对于ORE来说效果较差。
J 定性结果
我们在图中显示了ORE的定性结果。8图13.我们看到,ORE是能够识别各种未知的实例,并逐步学习他们,使用建议的对比聚类和基于能量的未知识别方法。所有这些图像中的子图(a)示出了识别的未知实例沿着检测器已知的其它实例。对应的子图(b)示出了在递增地添加新类别之后来自相同检测器的检测。
K 讨论关于失败的案例
物体的遮挡和拥挤是我们的方法趋于混淆的情况(外部存储、随身听和包未被检测为未知的)。11、13)。困难的观点(如背面)也会导致一些错误分类(图中长颈鹿→马)。4、12)。我们还注意到,检测与较大已知对象共存的小未知对象是困难的。由于ORE是在这个方向上的第一次努力,我们希望这些发现的缺点将成为进一步研究的基础。

图7:只在任务1上训练的ORE成功地将一个风筝定位为未知对象,如子图(a)所示,而在学习了任务3中的关于风筝的信息后,它逐步学习如何同时检测风筝和飞机,如子图(b)所示。

图8:子图(a)是ORE在学习了任务2后产生的结果。由于任务3中的类别,如苹果和橙子,尚未引入,ORE将其识别并正确标记为未知。在学习了任务3后,这些实例在子图(b)中被正确标记。仍然存在一个未被识别的类别实例,ORE成功将其检测为未知。

图9:在任务4的一部分中,时钟类最终被学习(在子图(b)中),最初被标识为未知(在子图(a)中)。ORE展示了开放世界检测器的真正特征,它能够逐步学习已识别的未知类别。

图10:牙刷和书是作为任务4的一部分引入的室内物体。在子图(a)中,经过任务3训练的检测器将牙刷识别为未知对象,并最终在任务4中学会了识别它,在子图(b)中仍然可以识别人。

图11:在学习任务1后,桌子上的笔记本电脑旁边的几件物品被识别为未知物体。在任务4中引入了笔记本电脑、书和鼠标,因此之后被检测到。然而,从未引入过的外部存储设备和随身听(两者都是未知物体)最初被识别为未知,但在学习了任务4后未被检测到,这是ORE的失败案例之一。

图12:被识别为未知的手提箱最终在任务2中被学习,与此同时还出现了误报的椅子检测。

图13:在这个高度混杂的场景中,在学习任务2后,未知的时钟实例被识别出来,但定位效果不佳。在学习任务4后,ORE检测到了时钟,并减少了对汽车和自行车的误报检测。然而,红色的手提箱在学习任何任务后都没有被标记,因此是一个失败的案例。
相关文章:
Towards Open World Object Detection【论文解析】
Towards Open World Object Detection 摘要1 介绍2 相关研究3 开放世界目标检测4 ORE:开放世界目标检测器4.1 对比聚类4.2 RPN自动标注未知类别4.3 基于能量的未知标识4.4 减少遗忘 5 实验5.1开放世界评估协议5.2 实现细节5.3 开放世界目标检测结果5.4 增量目标检测结果 6 讨论…...
IP协议
目录 网络层 理解路由选择 IP协议 IP首部 IP分片原理 IP校验和原理 网段划分 IP地址数量限制 私有和公网IP地址 路由 什么是IP地址,IP地址有什么特征?IP地址和MAC地址有什么区别和联系? IP报文由IP头部和IP数据两个部分组成&#…...
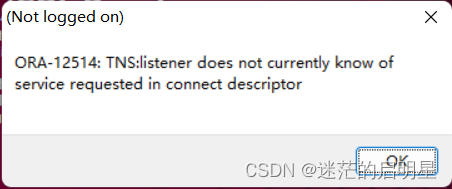
使用sqlplus连接oracle,提示ORA-01034和ORA-27101
具体内容如下 PL/SQL Developer 处 登录时 终端处 登录时 ERROR: ORA-01034: ORACLE not available ORA-27101: shared memory realm does not exist Process ID: 0 Session ID: 0 Serial number: 0 解决方法是执行以下命令 sqlplus /nolog conn / as sysdba startup …...

TLS协议
目录 什么是TLS协议? TLS的基本流程? 两种密钥交换算法? 基于ECDHE密钥交换算法的TLS握手过程? 基于RSA密钥交换算法的TLS握手过程? 基于RSA的握手和基于ECDHE的握手有什么区别? 什么是前向保密&…...
Academic Inquiry|国外文献查找
一个失去了男子气概的人总有很多忧虑,这样就可以分散注意力,而不必为那件特别的羞耻而苦恼不堪。 ——《狂野之夜》〔美〕乔伊斯卡罗尔欧茨著 樊维娜译 许多研究者在进行研究的时候,都会查找对应主体的国内外引用文献,而大多得出的…...
opencv图片灰度二值化
INCLUDEPATH D:\work\opencv_3.4.2_Qt\include LIBS D:\work\opencv_3.4.2_Qt\x86\bin\libopencv_*.dll #include <iostream> #include<opencv2/opencv.hpp> //引入头文件using namespace cv; //命名空间 using namespace std;//opencv这个机器视…...

短肥网络的 RTT 敏感性
周二下班路上发了一则朋友圈: 长肥管道的特征和问题谈得够多了,但这里谈的是短肥管道,因为下面趋势,短肥管道才是未来大势: 云计算致使数据中心网络快速发展,而数据中心网络时延短,带宽大。CD…...
Nonebot实战之编写插件1
前言 应粉丝群内粉丝要求,我也决定写一个Nonebot插件编写教程,从0开始教学。有些不对的地方也欢迎大家指正,修改。 开始 准备 合适的代码编辑器一定的python基础懂得提问的方式 代码编辑器 代码编辑器有很多种选择,比如 vsc…...
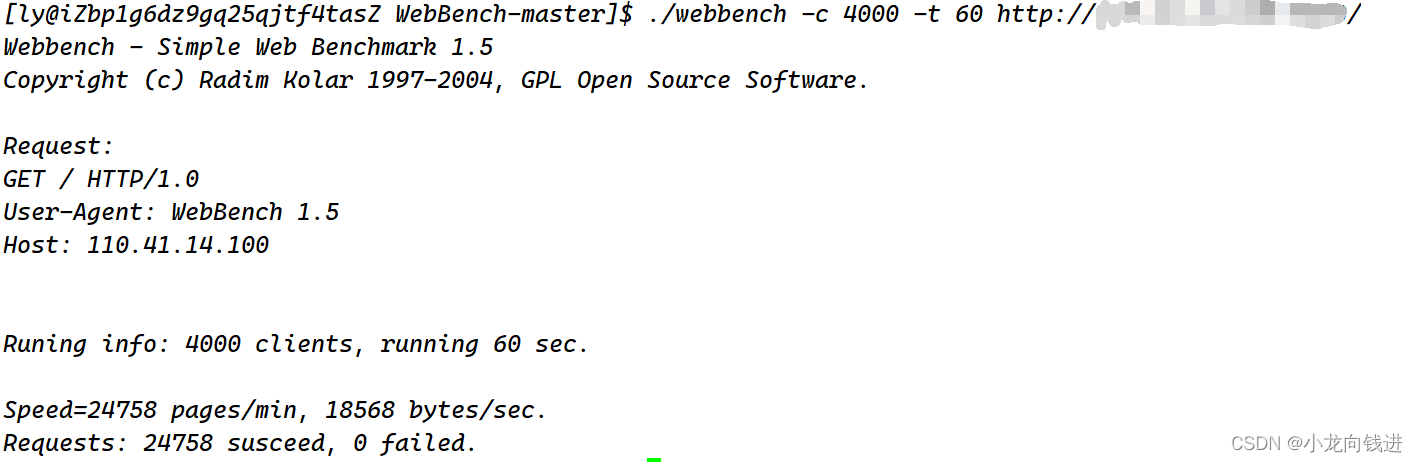
Linux-C++开发项目:基于主从Reactor模式的高性能并发服务器
目录 1.项目介绍2.1项目部署2.2安装版本较高的编译器 2.项目开发过程2.1网络库模块开发2.1.1简单日志宏的实现2.1.2Buffer模块实现2.1.3Socket模块实现2.1.4Channel模块实现2.1.5Poller模块实现2.1.6TimerWheel模块实现2.1.7EventLoop模块实现2.1.8整合测试12.1.9LoopThread模块…...

【Linux的开胃小菜】Linux系统安装后初始化配置操作
我们刚接手一台刚安装好服务器系统之后,可以对系统进行一些基础优化: 常规设定: centos: 1.关闭 iptables 2.关闭 selinux 3.设定 ChronyUbuntu: 4. /etc/security/limits.conf 5. /etc/sysctl.conf1.首先使用国内阿里云的yum源(…...

Java批量下载书籍图片并保存为PDF的方法
背景 因为经常出差火车上没网、不方便电子书阅读器批注,需要从某网站上批量下载多本书籍的图片并自动打包成PDF文件。 分析 1、尝试获得图片地址,发现F12被禁 解决方法:使用Chrome浏览器,点击右上角三个点呼出菜单,…...

flutter 创建lib
在根目录下创建 packages 文件夹创建lib (flutter create --templatepackage xxx)需要在pubspec.yaml中的根目录下添加 publish_to: ‘none’ # 如果你想发布到pub.dev,请删除这一行配置 lib_rock_utils:path: packages/lib_rock_utils...
深度剖析堆栈指针
为什么打印root的值与&root->value的值是一样的呢 测试结果: *号一个变量到底取出来的是什么? 以前我写过一句话,就是说,如果看到一个*变量,那就是直逼这个变量所保存的内存地址,然后取出里面保存的…...

C++笔记之静态成员函数的使用场景
C笔记之静态成员函数的使用场景 C静态成员函数的核心特点是不与特定类实例相关,可通过类名直接调用,用于执行与类相关的操作而无需创建类对象。其主要用途是在类级别上共享功能,管理全局状态或提供工具函数。 code review! 文章目录 C笔记之…...

Nginx的优化和防盗链
一、Nginx的优化 1、隐藏版本号 curl -I http://192.168.79.28 #查看信息(版本号等)方法一:修改配置文件 vim /usr/local/nginx/conf/nginx.conf vim /usr/local/nginx/conf/nginx.conf http {include mime.types;default_type ap…...

第二十次CCF计算机软件能力认证
数学专场 第一题:称检测点查询 解题思路:计算欧几里得距离 #include<iostream> #include<vector> #include<algorithm>using namespace std;typedef pair<int , int> PII; int n , x , y; vector<PII>v;int main() {ci…...

一篇文章带你了解Java发送邮件:使用JavaMail API发送电子邮件的注意事项、发送附件等
Java发送邮件:使用JavaMail API发送电子邮件 作者:Stevedash 发表于:2023年8月13日 15点48分 来源:Java 发送邮件 | 菜鸟教程 (runoob.com) 电子邮件在现代通信中扮演着至关重要的角色,而在Java编程中,…...

kubernetes的日志
1、日志在哪里 kubelet组件,systemd方式部署,journalctl -u kubelet 查看 其他组件,pod方式部署,kubectl logs 查看 容器运行时将日志写入 /var/log/pods 系统日志,/var/log/message 2、查看服务日志 #首先检查服…...

设计HTML5文本
网页文本内容丰富、形式多样,通过不同的版式显示在页面中,为用户提供最直接、最丰富的信息。HTML5新增了很多文本标签,它们都有特殊的语义,正确使用这些标签,可以让网页文本更严谨、更符合语义。 1、通用文本 1.1、标…...
msvcr120.dll丢失怎样修复?总结三个dll修复方法
当我遇到msvcr120.dll丢失的问题时,我感到有些困惑和焦虑。因为这个问题会导致我无法运行依赖这个文件的应用程序。msvcr120.dll是运行时库文件的一部分,为应用程序提供了必要的运行时支持。它的丢失会导致应用程序无法正常运行,这让我意识到…...

我的Qt实践:融合QTabWidget与AdvancedDocking,打造可定制的Ribbon界面框架【开源分享】
1. 从零开始构建Ribbon界面框架 第一次接触Ribbon界面是在使用Office 2007时,那种将功能按逻辑分组、通过标签页切换的设计让我眼前一亮。后来做Qt开发时,发现很多企业级应用也需要类似的界面风格。经过多次尝试,我发现用QTabWidget配合QSS样…...

解决 Git 报错:fatal: refusing to merge unrelated histories
最近我在同步一个深度学习课程代码库时,因为误删了本地的 .git 文件夹,遭遇了一个经典的 Git 报错。本文将复盘这次错误的解决过程。 1. 事故现场:误删 .git 引发的惨案 事情的起因是我不小心删除了项目根目录下的 .git 文件夹。为了挽救&a…...

【LLM转型三周年纪念——Harness agent 理解】成为每个读者的独家记忆,从第一性原则出发,一文打穿你的AI幻觉,
前言 本文动机是从CV到NLP的三年 LLM转型的历程,趁着harness agent 热度 ,主观视角下对当前一些事情的理解观点,希望对读者有所启发和帮助,并且我也将我的观点和新发布的opus4.7 进行了一波讨论,这也是我决定发出来的…...

银行数据中心基础设施建设与运维管理【2.1】
4. 4. 2 常用设备 UPS 系统中, 常用的设备和装置包括 UPS 输入配电柜、 UPS 主机、 UPS 输出配电柜和电池等。 1. UPS 输入配电柜 UPS 输入配电柜是为 UPS 主机提供交流配电的电器装置, 如图 4⁃38 所示。 图 4⁃38 UPS 输入配电柜 由于在上游的低压配电柜内已经有 UPS 系…...

ComfyUI动画制作终极实战指南:MTB Nodes全功能深度解析
ComfyUI动画制作终极实战指南:MTB Nodes全功能深度解析 【免费下载链接】comfy_mtb Animation oriented nodes pack for ComfyUI 项目地址: https://gitcode.com/gh_mirrors/co/comfy_mtb 在数字内容创作领域,动画制作、人脸处理和帧插值技术正成…...

Abaqus响应谱分析避坑指南:如何用模态动态法验证发动机悬置冲击结果?
Abaqus响应谱分析实战:模态动态法验证发动机悬置冲击结果的三大关键步骤 汽车发动机悬置系统的冲击仿真一直是CAE工程师的痛点领域。当你在凌晨三点盯着屏幕上两组截然不同的仿真结果时——响应谱法给出的峰值应力比模态动态法高出40%,该相信哪个&#x…...

ES-Client架构解析:轻量级Elasticsearch客户端的实现原理与深度集成
ES-Client架构解析:轻量级Elasticsearch客户端的实现原理与深度集成 【免费下载链接】es-client elasticsearch客户端,issue请前往码云:https://gitee.com/qiaoshengda/es-client 项目地址: https://gitcode.com/gh_mirrors/es/es-client …...

新手避坑指南:用RK3576开发板点亮MIPI-DSI屏幕,从接线到配置的完整流程
RK3576开发板实战:MIPI-DSI屏幕连接与配置避坑手册 第一次拿到RK3576开发板和MIPI-DSI屏幕时,那种既兴奋又忐忑的心情我至今记忆犹新。作为嵌入式开发的新手,面对密密麻麻的接口和陌生的术语,最担心的莫过于一个不小心就把几千块的…...

3个核心挑战:PvZ Toolkit如何解决植物大战僵尸修改难题
3个核心挑战:PvZ Toolkit如何解决植物大战僵尸修改难题 【免费下载链接】pvztoolkit 植物大战僵尸 PC 版综合修改器 项目地址: https://gitcode.com/gh_mirrors/pv/pvztoolkit 植物大战僵尸作为经典的塔防游戏,其PC版本拥有庞大的玩家社区。然而&…...

5步掌握GHelper:彻底解决华硕笔记本臃肿问题的终极方案
5步掌握GHelper:彻底解决华硕笔记本臃肿问题的终极方案 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, Flow, TUF, Strix, S…...