2023.8
编译
make install 去掉 folly
armv8-a+crc
arrow NEON
相关链接
https://blog.csdn.net/u011889952/article/details/118762819
这里面的方案二,我之前也是用的这个
https://blog.csdn.net/zzhongcy/article/details/105512565
参考的此博客
火焰图
https://blog.csdn.net/qq_43097201/article/details/125683217
https://blog.csdn.net/21aspnet/article/details/122256644
https://www.hikunpeng.com/document/detail/zh/kunpengbds/function/function.html
https://www.hikunpeng.com/document/detail/zh/kunpenggrf/tuningtip/kunpengtuning_12_0002.html#OmniRuntime
https://www.hikunpeng.com/document/detail/zh/kunpengbds/appAccelFeatures/sqlqueryaccelf/kunpengbds_omniruntime_20_0002.html
https://www.hikunpeng.com/document/detail/zh/kunpengboostkithistory/2200/bds/kunpengomnidata_20_0002.html
#腾讯云 文章
https://cloud.tencent.com/developer/article/1135965
#StarRocks
https://zhuanlan.zhihu.com/p/456520574
https://blog.csdn.net/weixin_35749796/article/details/129083732#京东 spark内核优化
https://developer.jdcloud.com/article/2344
#字节
https://zhuanlan.zhihu.com/p/157592720# 【麻省理工学院】MIT 6.S081 操作系统工程
https://www.bilibili.com/video/BV1Dy4y1m7ZE/?vd_source=883aee57c074fdece2b1cba2e009542b
# 哈工大 操作系统 李治军
https://www.bilibili.com/video/BV19r4y1b7Aw/?spm_id_from=333.337.search-card.all.click&vd_source=883aee57c074fdece2b1cba2e009542b
https://www.lanqiao.cn/courses/115/learning/#linux 源码
https://zhuanlan.zhihu.com/p/469193712
https://ke.qq.com/course/4032547?flowToken=1040236#term_id=104185168
https://space.bilibili.com/2459964/channel/collectiondetail?sid=1408252深入理解Linux虚拟内存管理#深入理解linux内核架构
https://github.com/zhiweifan/Professional-Linux-Kernel-Architecture.git#Operating Systems Design and Implementation, 3/E
https://book.douban.com/subject/1764254/#linux 0.12
https://zhuanlan.zhihu.com/p/344082401
https://space.bilibili.com/2459964/channel/collectiondetail?sid=1408252
https://github.com/yifengyou/linux-0.12
https://github.com/Kevin-Kevin/hit-operatingSystem#(哈工大)操作系统原理、实现与实践
https://github.com/EliasZuo/test2.git#unix v6
https://github.com/deyuhua/xv6-book-chinese#清华镜像
https://mirrors.tuna.tsinghua.edu.cn/gnu/metrics 采集
irate(node_disk_io_time_seconds_total[1m])
采集/proc/diskstats文件下的信息
日志
# ps -ef | grep 4226
root 4226 4217 5 14:47 ? 00:00:08 /usr/jdk64/current/bin/java -server -Xmx4096m -Djava.io.tmpdir=/data10/nm/usercache/root/appcache/application_1690958779805_0001/container_1690958779805_0001_01_000002/tmp -Dspark.driver.port=10951 -Dspark.yarn.app.container.log.dir=/data01/gluten_home/hadoop/logs/userlogs/application_1690958779805_0001/container_1690958779805_0001_01_000002 -XX:OnOutOfMemoryError=kill %p org.apache.spark.executor.YarnCoarseGrainedExecutorBackend --driver-url spark://CoarseGrainedScheduler@nma07-301-a-12-sev-tg225-02u03:10951 --executor-id 1 --hostname nma07-301-a-12-sev-tg225-02u03 --cores 24 --app-id application_1690958779805_0001 --resourceProfileId 0 --user-class-path file:/data10/nm/usercache/root/appcache/application_1690958779805_0001/container_1690958779805_0001_01_000002/__app__.jar
root 8274 51248 0 14:49 pts/4 00:00:00 grep --color=auto 4226# ll
total 4.0K
drwxr-xr-x 59 root root 4.0K Aug 2 15:33 blockmgr-c43711a4-5720-42b6-8979-8f0c4382847a
drwxr-xr-x 2 root root 10 Aug 2 14:47 gluten-279b0605-b14b-48bb-99bf-41bf1a999500
drwx------ 3 root root 63 Aug 2 14:47 spark-4bd32145-c445-4d9e-8739-e613af5f6fd8
shell 命令
pscp.pssh
pssh
$ cat /etc/os-release
(ARM)Shell_HDFS.sh
bin/spark-shell --master local[30] \--driver-memory 120g \--jars /home/op/spark-sql-perf_2.12-0.5.1-SNAPSHOT.jar#vanilla spark
./bin/spark-shell \--master local[30] \--driver-memory 30g \--conf spark.memory.offHeap.enabled=true \--conf spark.memory.offHeap.size=90g \--conf spark.serializer=org.apache.spark.serializer.KryoSerializer \--conf spark.kryoserializer.buffer.max=512m \--conf spark.sql.shuffle.partitions=60 \--conf spark.local.dir=/data01/gluten_home/tmp/http://10.37.90.2:18080/history/local-1687240040038Job 2 cancelled part of cancelled job group 5f7bc794-a8e8-44fd-b1b8-cf4fc076bfcf#vanilla
./bin/spark-shell \--master yarn \--driver-memory 20g \--executor-memory 4g \--executor-cores 8 \--conf spark.executor.instances=4 \--conf spark.executor.memoryOverhead=1g \--conf spark.memory.offHeap.enabled=true \--conf spark.memory.offHeap.size=18g \--conf spark.serializer=org.apache.spark.serializer.KryoSerializer \--conf spark.kryoserializer.buffer.max=512m \--conf spark.sql.shuffle.partitions=64 \--conf spark.local.dir=/data01/gluten_home/tmp/#result
http://10.37.90.2:18080/history/application_1687694342114_0038/SQL/#gluten
./bin/spark-shell \--master yarn \--driver-memory 20g \--executor-memory 4g \--executor-cores 8 \--conf spark.executor.instances=4 \--conf spark.executor.memoryOverhead=1g \--conf spark.memory.offHeap.enabled=true \--conf spark.memory.offHeap.size=18g \--conf spark.serializer=org.apache.spark.serializer.KryoSerializer \--conf spark.kryoserializer.buffer.max=512m \--conf spark.sql.shuffle.partitions=64 \--conf spark.local.dir=/data01/gluten_home/tmp/ \--conf spark.plugins=io.glutenproject.GlutenPlugin \--conf spark.gluten.sql.columnar.backend.lib=velox \--conf spark.gluten.loadLibFromJar=false \--conf spark.shuffle.manager=org.apache.spark.shuffle.sort.ColumnarShuffleManager \--conf spark.driver.extraClassPath=/data01/gluten_home/gluten/package/target/gluten-velox-bundle-spark3.2_2.12-ctyunos_2.0.1-0.5.0-SNAPSHOT.jar \--conf spark.executor.extraClassPath=/data01/gluten_home/gluten/package/target/gluten-velox-bundle-spark3.2_2.12-ctyunos_2.0.1-0.5.0-SNAPSHOT.jar \--conf spark.gluten.memory.offHeap.size.in.bytes=19327352832 \--conf spark.gluten.memory.task.offHeap.size.in.bytes=2415919104 \--conf spark.gluten.sql.columnar.logicalJoinOptimizeEnable=true \--conf spark.gluten.sql.columnar.logicalJoinOptimizationLevel=19 \--conf spark.gluten.sql.columnar.physicalJoinOptimizeEnable=true \--conf spark.gluten.sql.columnar.physicalJoinOptimizationLevel=18 \--conf spark.executorEnv.LIBHDFS3_CONF="/data01/gluten_home/hadoop/etc/hadoop/hdfs-site.xml"// eventlog
http://10.37.90.2:18080/history/application_1687694342114_0007/SQL/// eventlog
http://10.37.90.2:18080/history/application_1687694342114_0040/SQL/#0801
#gluten
./bin/spark-shell \--master yarn \--driver-memory 20g \--executor-memory 4g \--executor-cores 8 \--conf spark.executor.instances=4 \--conf spark.executor.memoryOverhead=1g \--conf spark.memory.offHeap.enabled=true \--conf spark.memory.offHeap.size=18g \--conf spark.serializer=org.apache.spark.serializer.KryoSerializer \--conf spark.kryoserializer.buffer.max=512m \--conf spark.sql.shuffle.partitions=64 \--conf spark.local.dir=/data01/gluten_home/tmp/,/data02/tmp/,/data03/tmp/,/data04/tmp/,/data05/tmp/,/data06/tmp/,/data07/tmp/,/data08/tmp/,/data09/tmp/,/data10/tmp/ \--conf spark.plugins=io.glutenproject.GlutenPlugin \--conf spark.gluten.sql.columnar.backend.lib=velox \--conf spark.gluten.loadLibFromJar=false \--conf spark.shuffle.manager=org.apache.spark.shuffle.sort.ColumnarShuffleManager \--conf spark.driver.extraClassPath=/data01/gluten_home/gluten/package/target/gluten-velox-bundle-spark3.2_2.12-ctyunos_2.0.1-0.5.0-SNAPSHOT.jar \--conf spark.executor.extraClassPath=/data01/gluten_home/gluten/package/target/gluten-velox-bundle-spark3.2_2.12-ctyunos_2.0.1-0.5.0-SNAPSHOT.jar \--conf spark.gluten.memory.offHeap.size.in.bytes=19327352832 \--conf spark.gluten.memory.task.offHeap.size.in.bytes=2415919104 \--conf spark.gluten.sql.columnar.logicalJoinOptimizeEnable=true \--conf spark.gluten.sql.columnar.logicalJoinOptimizationLevel=19 \--conf spark.gluten.sql.columnar.physicalJoinOptimizeEnable=true \--conf spark.gluten.sql.columnar.physicalJoinOptimizationLevel=18 \--conf spark.executorEnv.LIBHDFS3_CONF="/data01/gluten_home/hadoop/etc/hadoop/hdfs-site.xml"mkdir /data02/tmp/
mkdir /data03/tmp/
mkdir /data04/tmp/
mkdir /data05/tmp/
mkdir /data06/tmp/
mkdir /data07/tmp/
mkdir /data08/tmp/
mkdir /data09/tmp/
mkdir /data10/tmp/mkdir /data01/nm/
mkdir /data02/nm/
mkdir /data03/nm/
mkdir /data04/nm/
mkdir /data05/nm/
mkdir /data06/nm/
mkdir /data07/nm/
mkdir /data08/nm/
mkdir /data09/nm/
mkdir /data10/nm//data01/nm/,/data02/nm/,/data03/nm/,/data04/nm/,/data05/nm/,/data06/nm/,/data07/nm/,/data08/nm/,/data09/nm/,/data10/nm/<property><name>yarn.nodemanager.local-dirs</name><value>/data01/nm/,/data02/nm/,/data03/nm/,/data04/nm/,/data05/nm/,/data06/nm/,/data07/nm/,/data08/nm/,/data09/nm/,/data10/nm/</value></property>#0802 spark
./bin/spark-shell \--master yarn \--driver-memory 20g \--executor-memory 4g \--executor-cores 24 \--conf spark.executor.instances=4 \--conf spark.executor.memoryOverhead=1g \--conf spark.memory.offHeap.enabled=true \--conf spark.memory.offHeap.size=18g \--conf spark.serializer=org.apache.spark.serializer.KryoSerializer \--conf spark.kryoserializer.buffer.max=512m \--conf spark.sql.shuffle.partitions=64 \--conf spark.local.dir=/data01/gluten_home/tmp/,/data02/tmp/,/data03/tmp/,/data04/tmp/,/data05/tmp/,/data06/tmp/,/data07/tmp/,/data08/tmp/,/data09/tmp/,/data10/tmp/#0802 gluiten
./bin/spark-shell \--master yarn \--driver-memory 20g \--executor-memory 4g \--executor-cores 24 \--conf spark.executor.instances=4 \--conf spark.executor.memoryOverhead=1g \--conf spark.memory.offHeap.enabled=true \--conf spark.memory.offHeap.size=18g \--conf spark.serializer=org.apache.spark.serializer.KryoSerializer \--conf spark.kryoserializer.buffer.max=512m \--conf spark.sql.shuffle.partitions=64 \--conf spark.local.dir=/data01/gluten_home/tmp/,/data02/tmp/,/data03/tmp/,/data04/tmp/,/data05/tmp/,/data06/tmp/,/data07/tmp/,/data08/tmp/,/data09/tmp/,/data10/tmp/ \--conf spark.plugins=io.glutenproject.GlutenPlugin \--conf spark.gluten.sql.columnar.backend.lib=velox \--conf spark.gluten.loadLibFromJar=false \--conf spark.shuffle.manager=org.apache.spark.shuffle.sort.ColumnarShuffleManager \--conf spark.driver.extraClassPath=/data01/gluten_home/gluten/package/target/gluten-velox-bundle-spark3.2_2.12-ctyunos_2.0.1-0.5.0-SNAPSHOT.jar \--conf spark.executor.extraClassPath=/data01/gluten_home/gluten/package/target/gluten-velox-bundle-spark3.2_2.12-ctyunos_2.0.1-0.5.0-SNAPSHOT.jar \--conf spark.gluten.memory.offHeap.size.in.bytes=19327352832 \--conf spark.gluten.memory.task.offHeap.size.in.bytes=2415919104 \--conf spark.gluten.sql.columnar.logicalJoinOptimizeEnable=true \--conf spark.gluten.sql.columnar.logicalJoinOptimizationLevel=19 \--conf spark.gluten.sql.columnar.physicalJoinOptimizeEnable=true \--conf spark.gluten.sql.columnar.physicalJoinOptimizationLevel=18 \--conf spark.executorEnv.LIBHDFS3_CONF="/data01/gluten_home/hadoop/etc/hadoop/hdfs-site.xml"集群
export LIBHDFS3_CONF="/usr/local/hadoop-3.3.3/etc/hadoop/hdfs-site.xml"./bin/spark-shell \--master local[30] \--driver-memory 50g \--executor-memory 4g \--executor-cores 8 \--conf spark.executor.instances=24 \--conf spark.executor.memoryOverhead=1g \--conf spark.memory.offHeap.enabled=true \--conf spark.memory.offHeap.size=18g \--conf spark.serializer=org.apache.spark.serializer.KryoSerializer \--conf spark.kryoserializer.buffer.max=512m \--conf spark.sql.shuffle.partitions=384 \--conf spark.plugins=io.glutenproject.GlutenPlugin \--conf spark.gluten.sql.columnar.backend.lib=velox \--conf spark.gluten.loadLibFromJar=true \--conf spark.shuffle.manager=org.apache.spark.shuffle.sort.ColumnarShuffleManager \--conf spark.gluten.memory.offHeap.size.in.bytes=19327352832 \--conf spark.gluten.memory.task.offHeap.size.in.bytes=2415919104 \--conf spark.gluten.sql.columnar.logicalJoinOptimizeEnable=true \--conf spark.gluten.sql.columnar.logicalJoinOptimizationLevel=19 \--conf spark.gluten.sql.columnar.physicalJoinOptimizeEnable=true \--conf spark.gluten.sql.columnar.physicalJoinOptimizationLevel=18 \--conf spark.executorEnv.LIBHDFS3_CONF="/usr/local/hadoop-3.3.3/etc/hadoop/hdfs-site.xml" \--jars /home/op/0719/gluten-velox-bundle-spark3.2_2.12-centos_7-1.1.0-SNAPSHOT.jar,/home/op/0719/gluten-thirdparty-lib-centos-7.jar#yarn, 未通过./bin/spark-shell \--master yarn --deploy-mode client \--driver-memory 50g \--executor-memory 4g \--executor-cores 8 \--conf spark.executor.instances=24 \--conf spark.executor.memoryOverhead=1g \--conf spark.memory.offHeap.enabled=true \--conf spark.memory.offHeap.size=18g \--conf spark.serializer=org.apache.spark.serializer.KryoSerializer \--conf spark.kryoserializer.buffer.max=512m \--conf spark.sql.shuffle.partitions=384 \--conf spark.plugins=io.glutenproject.GlutenPlugin \--conf spark.gluten.sql.columnar.backend.lib=velox \--conf spark.gluten.loadLibFromJar=true \--conf spark.shuffle.manager=org.apache.spark.shuffle.sort.ColumnarShuffleManager \--conf spark.driver.extraClassPath=/home/op/0719/gluten-velox-bundle-spark3.2_2.12-centos_7-1.1.0-SNAPSHOT.jar \--conf spark.executor.extraClassPath=/home/op/0719/gluten-velox-bundle-spark3.2_2.12-centos_7-1.1.0-SNAPSHOT.jar \--conf spark.gluten.memory.offHeap.size.in.bytes=19327352832 \--conf spark.gluten.memory.task.offHeap.size.in.bytes=2415919104 \--conf spark.gluten.sql.columnar.logicalJoinOptimizeEnable=true \--conf spark.gluten.sql.columnar.logicalJoinOptimizationLevel=19 \--conf spark.gluten.sql.columnar.physicalJoinOptimizeEnable=true \--conf spark.gluten.sql.columnar.physicalJoinOptimizationLevel=18 \--conf spark.executorEnv.LIBHDFS3_CONF="/usr/local/hadoop-3.3.3/etc/hadoop/hdfs-site.xml" \--jars /home/op/0719/gluten-velox-bundle-spark3.2_2.12-centos_7-1.1.0-SNAPSHOT.jar,/home/op/0719/gluten-thirdparty-lib-centos-7.jar./bin/spark-shell \--master yarn --deploy-mode client \--driver-memory 50g \--executor-memory 4g \--executor-cores 8 \--conf spark.executor.instances=24 \--conf spark.executor.memoryOverhead=1g \--conf spark.memory.offHeap.enabled=true \--conf spark.memory.offHeap.size=18g \--conf spark.serializer=org.apache.spark.serializer.KryoSerializer \--conf spark.kryoserializer.buffer.max=512m \--conf spark.sql.shuffle.partitions=384 \--conf spark.plugins=io.glutenproject.GlutenPlugin \--conf spark.gluten.sql.columnar.backend.lib=velox \--conf spark.gluten.loadLibFromJar=true \--conf spark.shuffle.manager=org.apache.spark.shuffle.sort.ColumnarShuffleManager \--conf spark.driver.extraClassPath=/home/op/0719/gluten-velox-bundle-spark3.2_2.12-centos_7-1.1.0-SNAPSHOT.jar \--conf spark.executor.extraClassPath=/home/op/0719/gluten-velox-bundle-spark3.2_2.12-centos_7-1.1.0-SNAPSHOT.jar \--conf spark.gluten.memory.offHeap.size.in.bytes=19327352832 \--conf spark.gluten.memory.task.offHeap.size.in.bytes=2415919104 \--conf spark.gluten.sql.columnar.logicalJoinOptimizeEnable=true \--conf spark.gluten.sql.columnar.logicalJoinOptimizationLevel=19 \--conf spark.gluten.sql.columnar.physicalJoinOptimizeEnable=true \--conf spark.gluten.sql.columnar.physicalJoinOptimizationLevel=18 \--conf spark.executorEnv.LIBHDFS3_CONF="/usr/local/hadoop-3.3.3/etc/hadoop/hdfs-site.xml" \--jars /home/op/0719/gluten-velox-bundle-spark3.2_2.12-centos_7-1.1.0-SNAPSHOT.jar,/home/op/0719/gluten-thirdparty-lib-centos-7.jar \--conf spark.sql.files.maxPartitionBytes=2g \--conf spark.gluten.sql.columnar.backend.velox.memoryCapRatio=0.75相关文章:

2023.8
编译 make install 去掉 folly armv8-acrc arrow NEON 相关链接 https://blog.csdn.net/u011889952/article/details/118762819 这里面的方案二,我之前也是用的这个 https://blog.csdn.net/zzhongcy/article/details/105512565 参考的此博客 火焰图 https://b…...
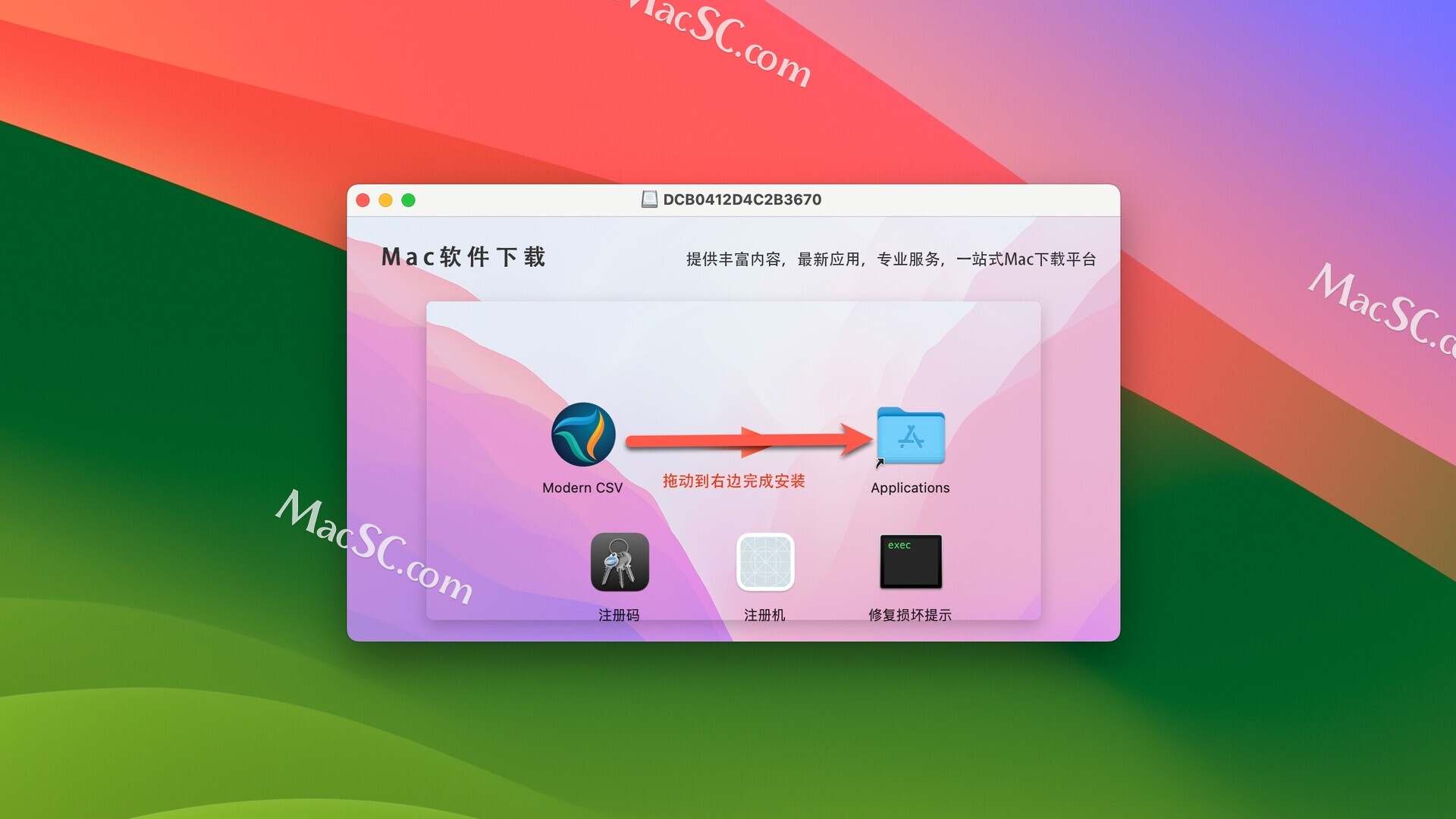
CSV文件编辑器——Modern CSV for mac
Modern CSV for Mac是一款功能强大、操作简单的CSV文件编辑器,适用于Mac用户快速、高效地处理和管理CSV文件。Modern CSV具有直观的用户界面,可以轻松导入、编辑和导出CSV文件。它支持各种功能,包括排序、过滤、查找和替换,使您能…...
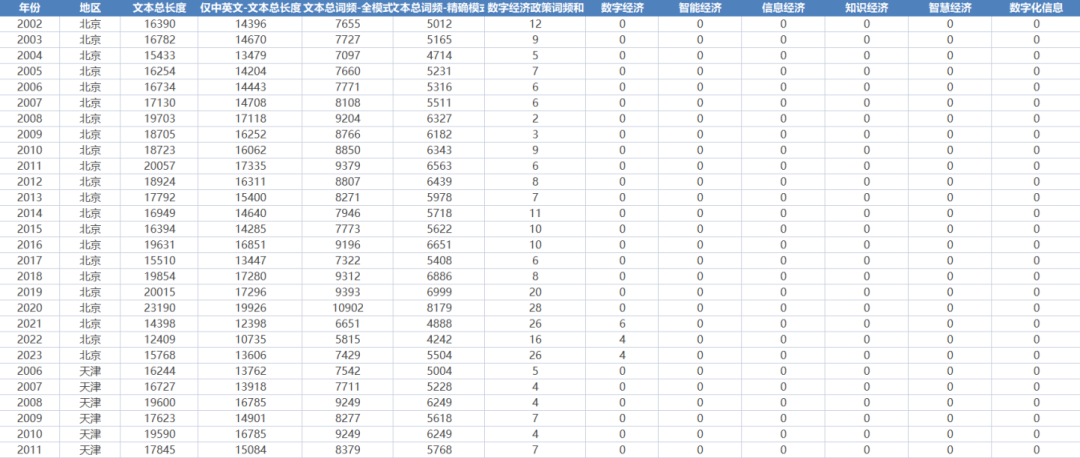
全国各地区数字经济工具变量-文本词频统计(2002-2023年)
数据简介:本数据使用全国各省工作报告,对其中数字经济相关的词汇进行词频统计,从而构建数字经济相关的工具变量。凭借数字经济政策供给与数字经济发展水平的相关系数的显著性作为二者匹配程度的划分依据,一定程度上规避了数字经济…...

MacOS安装RabbitMQ
官网地址: RabbitMQ: easy to use, flexible messaging and streaming — RabbitMQ 一、brew安装 brew update #更新一下homebrew brew install rabbitmq #安装rabbitMQ 安装结果: > Caveats > rabbitmq Management Plugin enabled by defa…...
关于selenium 元素定位的浅度解析
一、By类单一属性定位 元素名称 描述 Webdriver API id id属性 driver.find_element(By.ID, "id属性值") name name属性 driver.find_element(By.NAME, "name属性值") class_name class属性 driver.find_element(By.CLASS_NAME, "class_na…...

狐猬编程:货运
玩具厂生产了一批玩具需要运往美国销售。该批玩具根据大小,已经将其打包装在不同的包装盒里用以运输。该批玩具包装盒共有六个型号,分别1*1*h、2*2*h、3*3*h、4*4*h、5*5*h、6*6*h的包装盒。由于疫情的影响,运输价格十分昂贵,海运…...
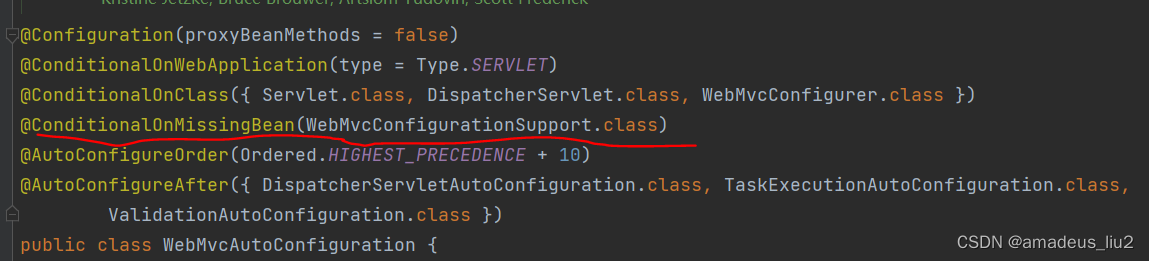
SpringBoot复习:(34)@EnableWebMvc注解为什么让@WebMvcAutoconfiguration失效?
它导入了DelegatingWebMvcConfiguration 它会把容器中的类型为WebMvcConfigurer的bean注入到类型为WebMvcConfigurerComposite的成员变量configurers中。 可以看到它继承了WebMvcConfigurerSupport类 而WebMvcConfigureAutoConfiguration类定义如下 可以看到一个Conditional…...

批量将CSV文件转换为TXT文件
要批量将CSV文件转换为TXT文件,可以按照以下步骤进行操作: 1. 导入所需的Python库:首先,您需要导入csv库来读取CSV文件。 import csv 2. 定义文件路径和输出文件夹: input_folder "your_input_folder_path&q…...

vite跨域配置踩坑,postman链接后端接口正常,但是前端就是不能正常访问
问题一:怎么都链接不了后端地址 根据以下配置,发现怎么都链接不了后端地址,proxy对了呀。 仔细看,才发现host有问题 // 本地运行配置,及反向代理配置server: {host: 0,0,0,0,port: 80,// cors: true, // 默认启用并允…...
模式)
Java设计模式-抽象工厂(Abstract Factory)模式
说明 抽象工厂(Abstract Factory)模式是一种工厂模式。用一个接口类中的不同方法创建不同的产品。 为了便于理解,先打个比方: 将老虎、狮子、猴子比作三个抽象产品的接口类,也就是有3个产品等级。 老虎又分动物园的…...

Hive加密,PostgreSQL解密还原
当前公司数据平台使用的处理架构,由Hive进行大数据处理,然后将应用数据同步到PostgreSQL中做各类外围应用。由于部分数据涉及敏感信息,必须在Hive进行加密,然后在PG使用时再进行单个数据解密,并监控应用的数据调用事情…...
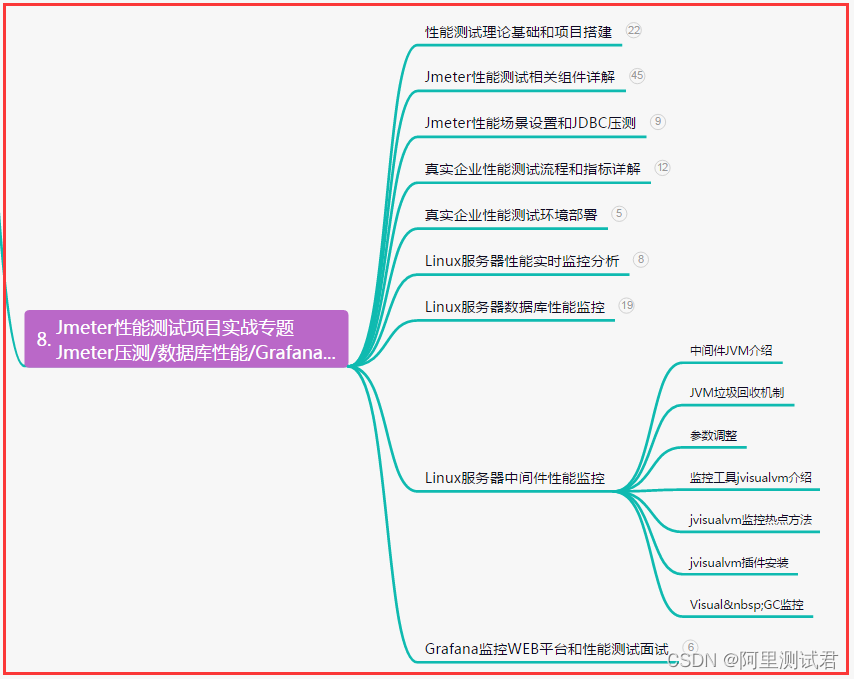
2023年测试岗,接口测试面试题汇总+答案,拿捏面试官...
目录:导读 前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜) 前言 1、你们公司的接口…...

C# --- Case Study
C# --- Case Study C# — Mongo数据库事务的应用 C# — 如何解析Json文件并注入MongoDB C# — MongoDB如何安全的替换Collection...
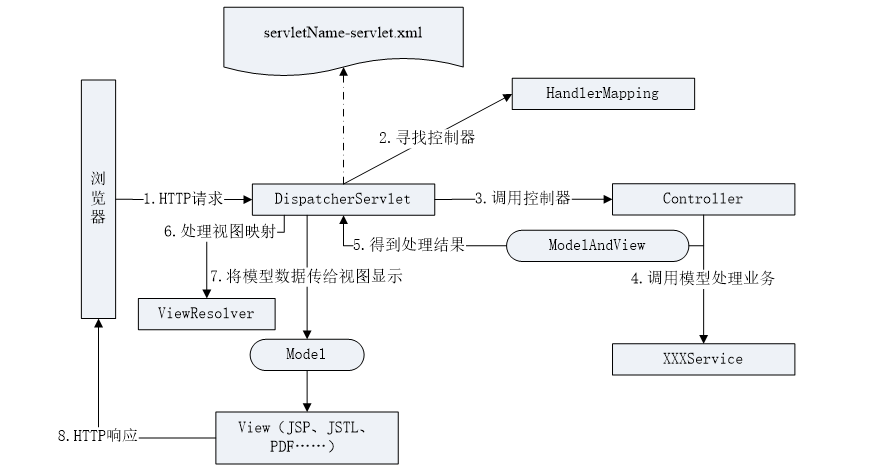
3.1 Spring MVC概述
1. MVC概念 MVC是一种编程思想,它将应用分为模型(Model)、视图(View)、控制器(Controller)三个层次,这三部分以最低的耦合进行协同工作,从而提高应用的可扩展性及可维护…...

Towards Open World Object Detection【论文解析】
Towards Open World Object Detection 摘要1 介绍2 相关研究3 开放世界目标检测4 ORE:开放世界目标检测器4.1 对比聚类4.2 RPN自动标注未知类别4.3 基于能量的未知标识4.4 减少遗忘 5 实验5.1开放世界评估协议5.2 实现细节5.3 开放世界目标检测结果5.4 增量目标检测结果 6 讨论…...
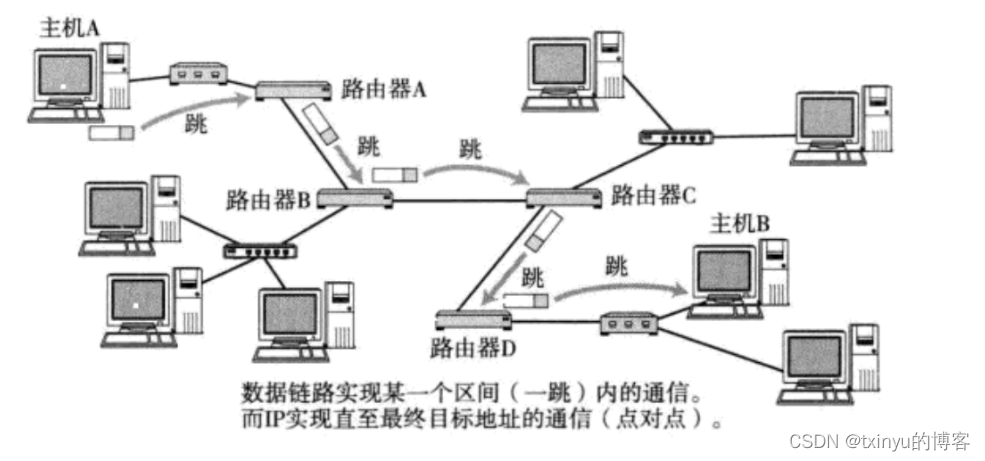
IP协议
目录 网络层 理解路由选择 IP协议 IP首部 IP分片原理 IP校验和原理 网段划分 IP地址数量限制 私有和公网IP地址 路由 什么是IP地址,IP地址有什么特征?IP地址和MAC地址有什么区别和联系? IP报文由IP头部和IP数据两个部分组成&#…...
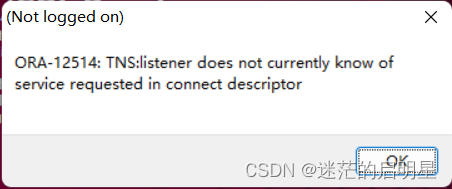
使用sqlplus连接oracle,提示ORA-01034和ORA-27101
具体内容如下 PL/SQL Developer 处 登录时 终端处 登录时 ERROR: ORA-01034: ORACLE not available ORA-27101: shared memory realm does not exist Process ID: 0 Session ID: 0 Serial number: 0 解决方法是执行以下命令 sqlplus /nolog conn / as sysdba startup …...

TLS协议
目录 什么是TLS协议? TLS的基本流程? 两种密钥交换算法? 基于ECDHE密钥交换算法的TLS握手过程? 基于RSA密钥交换算法的TLS握手过程? 基于RSA的握手和基于ECDHE的握手有什么区别? 什么是前向保密&…...
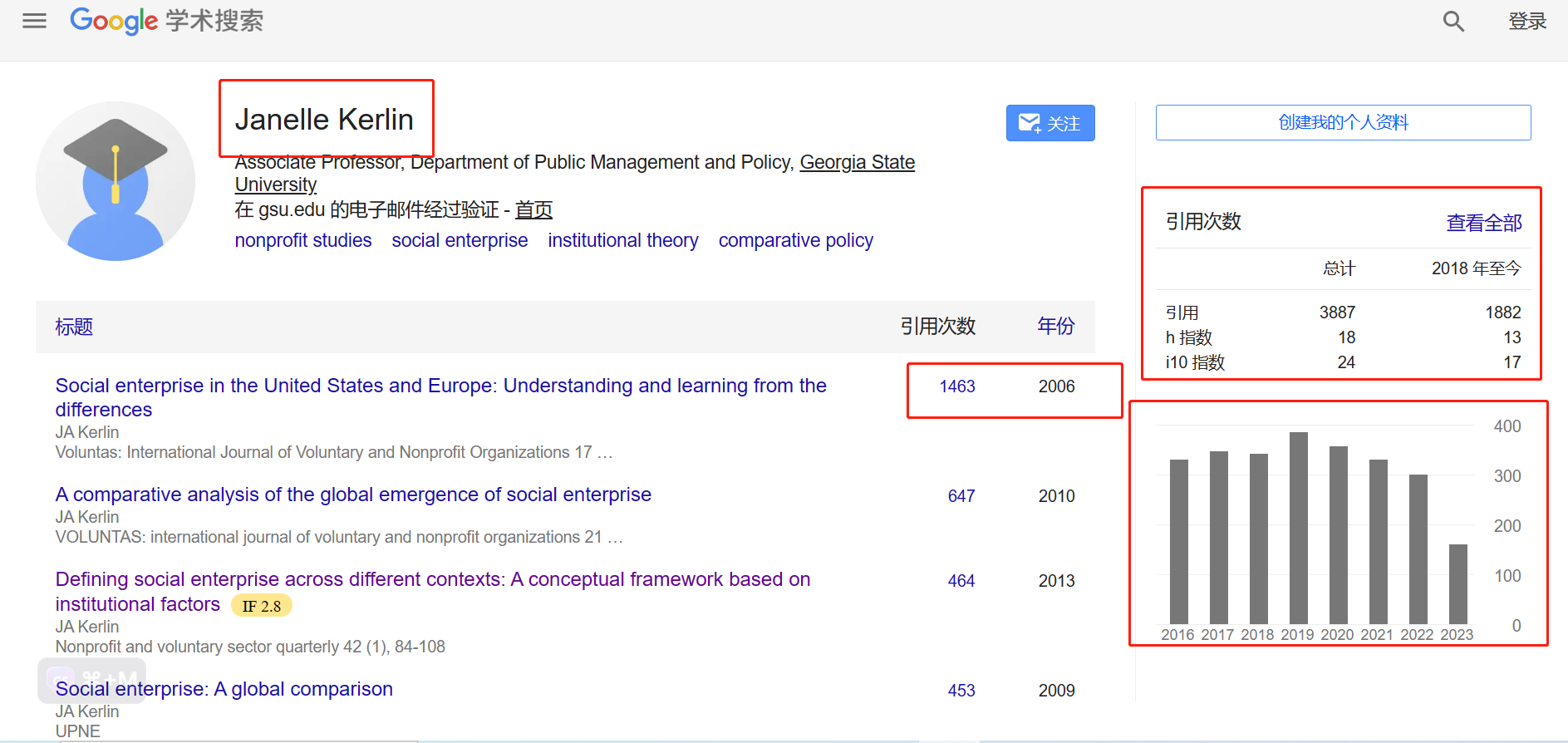
Academic Inquiry|国外文献查找
一个失去了男子气概的人总有很多忧虑,这样就可以分散注意力,而不必为那件特别的羞耻而苦恼不堪。 ——《狂野之夜》〔美〕乔伊斯卡罗尔欧茨著 樊维娜译 许多研究者在进行研究的时候,都会查找对应主体的国内外引用文献,而大多得出的…...
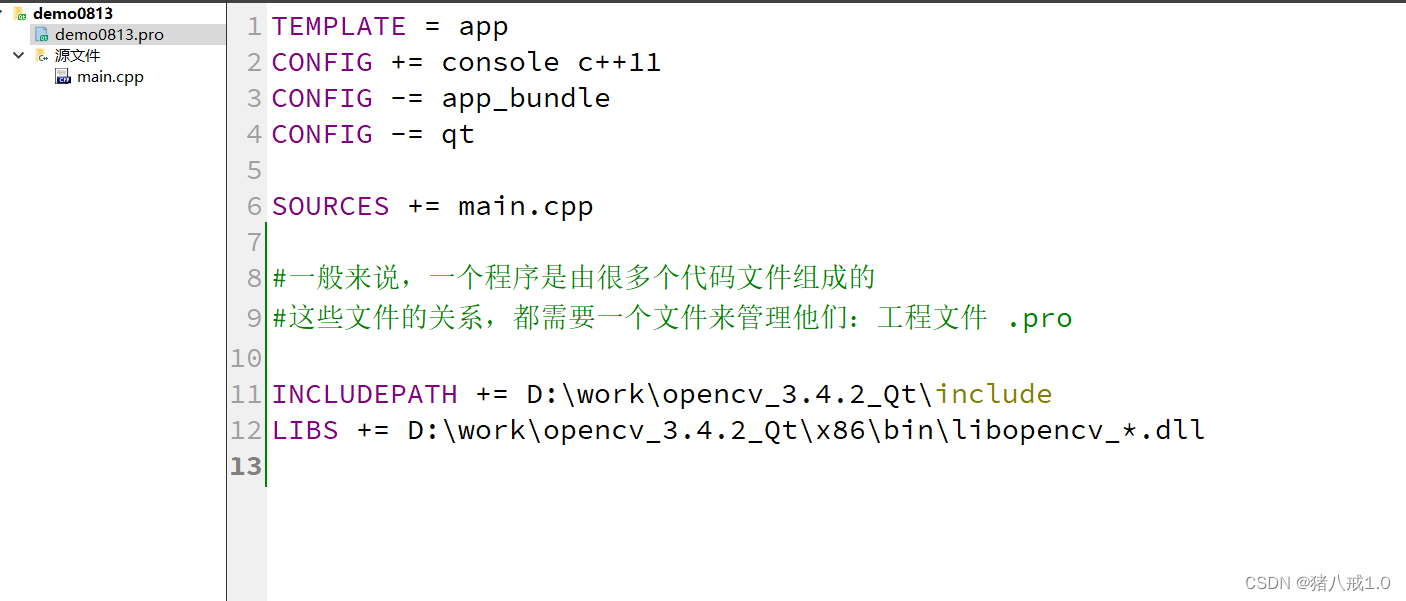
opencv图片灰度二值化
INCLUDEPATH D:\work\opencv_3.4.2_Qt\include LIBS D:\work\opencv_3.4.2_Qt\x86\bin\libopencv_*.dll #include <iostream> #include<opencv2/opencv.hpp> //引入头文件using namespace cv; //命名空间 using namespace std;//opencv这个机器视…...

Linux数据恢复实战:当extundelete失效后,我们还能用testdisk和dd做什么?
Linux数据恢复高阶指南:当extundelete失效时的专业抢救方案 误删重要数据是每位Linux运维人员都可能遭遇的噩梦。当常规恢复工具失效时,如何从底层进行专业级数据抢救?本文将带你深入探索ext4/XFS文件系统下的高阶恢复技巧,从原理…...

Maven工程中protobuf-maven-plugin的配置详解与实战
1. 为什么选择protobuf-maven-plugin 在Java项目中使用Protocol Buffers(简称protobuf)作为数据交换格式已经成为微服务架构中的常见做法。相比JSON和XML,protobuf具有更小的数据体积和更快的编解码速度,特别适合高并发场景。但在…...

电机减重一半,续航多半小时?拆解轴向磁通刷盘电机的省电逻辑
拿到这台YS-AFBL-120-20-24轴向磁通无刷刷盘电机,第一反应是:230W,5.8kg。同功率等级的传统径向电机方案,算上减速箱和皮带轮,整套驱动单元奔着10公斤往上去了。轴向方案等于直接砍掉了近一半的重量。重量减下去&#…...

矩阵求逆引理新解:从Woodbury恒等式到高效计算实践
1. 从通信到AI:Woodbury恒等式为何如此重要 第一次接触Woodbury恒等式是在研究生时期的通信系统课上。当时教授在黑板上写下这个公式时,我完全没意识到它会在后来的机器学习项目中成为我的"救命稻草"。这个看似复杂的公式,本质上解…...

Python的__annotations__:运行时类型注解访问
Python的__annotations__:运行时类型注解访问 在Python中,类型注解是一种强大的工具,它不仅能提升代码可读性,还能通过工具(如mypy)进行静态类型检查。注解的真正价值不仅限于开发阶段——Python还提供了_…...

低分辨率图像修复难题的终极解决方案:Upscayl深度技术解析
低分辨率图像修复难题的终极解决方案:Upscayl深度技术解析 【免费下载链接】upscayl 🆙 Upscayl - #1 Free and Open Source AI Image Upscaler for Linux, MacOS and Windows. 项目地址: https://gitcode.com/GitHub_Trending/up/upscayl 面对模…...
)
AGI不是“是否”,而是“谁先”:SITS2026圆桌首次公开全球TOP12机构AGI路线图对比(含训练成本曲线、对齐成熟度、安全冗余等级)
第一章:SITS2026圆桌:AGI何时到来 2026奇点智能技术大会(https://ml-summit.org) 圆桌共识与分歧焦点 在SITS2026主会场举行的“AGI何时到来”圆桌论坛中,来自DeepMind、Anthropic、中科院自动化所及OpenAI前核心架构师的六位专家展开激烈交…...

OpenIPC完整指南:5分钟掌握开源摄像头固件的终极改造方案 [特殊字符]
OpenIPC完整指南:5分钟掌握开源摄像头固件的终极改造方案 🚀 【免费下载链接】firmware Alternative IP Camera firmware from an open community 项目地址: https://gitcode.com/gh_mirrors/fir/firmware 还在为网络摄像头的封闭固件而烦恼吗&am…...

4步快速上手ComfyUI-WanVideoWrapper:AI视频生成的终极配置指南
4步快速上手ComfyUI-WanVideoWrapper:AI视频生成的终极配置指南 【免费下载链接】ComfyUI-WanVideoWrapper 项目地址: https://gitcode.com/GitHub_Trending/co/ComfyUI-WanVideoWrapper 想要在ComfyUI中实现专业级的AI视频生成?ComfyUI-WanVide…...

【JVM深度解析】第26篇:CAS、AQS与并发工具类原理
摘要 CAS(Compare-And-Swap)和 AQS(AbstractQueuedSynchronizer)是 Java 并发包的基石。CAS 通过硬件支持的原子指令实现无锁并发,AQS 通过模板模式封装了线程等待和唤醒的通用逻辑。本文深入解析 CAS 的底层实现&…...