MySQL慢查询分析和性能优化
1 背景
我们的业务服务随着功能规模扩大,用户量扩增,流量的不断的增长,经常会遇到一个问题,就是数据存储服务响应变慢。
导致数据库服务变慢的诱因很多,而RD最重要的工作之一就是找到问题并解决问题。
下面以MySQL为例子,我们从几个角度分析可能产生原因,并讨论解决的方案。
2 定位慢查询的原因并优化
2.1 慢查询的分析
开启SlowLog,默认是关闭的,由参数slow_query_log决定,在MySQL命令终端中输入下面的命令:
# 是否开启,这边为开启,默认情况下是off
setglobal slow_query_log=on;# 设置慢查询阈值,单位是 s,默认为10s,这边的意思是查询耗时超过0.5s,便会记录到慢查询日志里面
setglobal long_query_time=0.5;# 确定慢查询日志的文件名和路径
mysql>showglobal variables like'slow_query_log_file';
+---------------------+-------------------------------------------------------+| Variable_name |Value|+---------------------+-------------------------------------------------------+| slow_query_log_file |/usr/local/mysql/data/MacintoshdeMacBook-Pro-slow.log |+---------------------+-------------------------------------------------------+1rowinset (0.00 sec)# 检查慢查询的详细指标,可以看到下面 slow_query_log =ON,long_query_time =0.5 ,都是因为我们调整过的
mysql>showglobal variables like'%quer%';
+----------------------------------------+-------------------------------------------------------+| Variable_name |Value|+----------------------------------------+-------------------------------------------------------+| binlog_rows_query_log_events | OFF || ft_query_expansion_limit |20|| have_query_cache |NO|| log_queries_not_using_indexes | OFF || log_throttle_queries_not_using_indexes |0|| long_query_time |0.500000|| query_alloc_block_size |8192|| query_prealloc_size |8192|| slow_query_log |ON|| slow_query_log_file |/usr/local/mysql/data/MacintoshdeMacBook-Pro-slow.log |+----------------------------------------+-------------------------------------------------------+10rowsinset (0.01 sec)
配置好之后,就会按照阈值默认把慢查询日志收集下来,可以到对应的目录下分析具体的慢请求原因。
2.2 使用Explain进行查询语句分析
2.2.1 分析过程举例
很多时候我们在评审RD同学代码和SQL脚本的时候,上下文和使用环境不了解,不能做出很准确的判断。
这时候使用Explain分析SQL的执行计划就显得非常有用,拿到具体环境中Run一下就能看出很多问题。
举个例子:
模拟一个千万级别的雇员表,我们在没有做索引的字段上做一下查询看看,在500W数据中查询一个名叫LsHfFJA的员工,消耗 2.239S ,获取到一条id为4582071的数据。
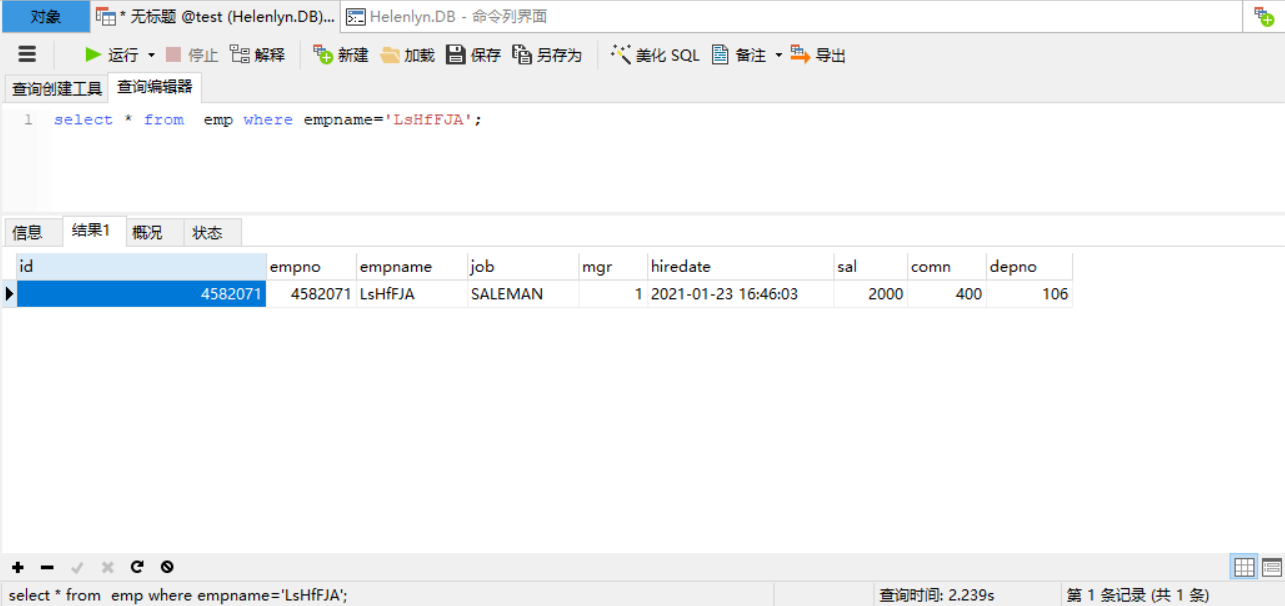
再看看他的执行计划,扫描了4952492 条数据才找到该行数据:
mysql> explain select*from emp where empname='LsHfFJA';
+----+-------------+-------+------+---------------+------+---------+------+---------+-------------+| id | select_type |table| type | possible_keys | key | key_len |ref|rows| Extra |+----+-------------+-------+------+---------------+------+---------+------+---------+-------------+|1| SIMPLE | emp |ALL|NULL|NULL|NULL|NULL|4952492|Usingwhere|+----+-------------+-------+------+---------------+------+---------+------+---------+-------------+1rowinset这就是无索引或者索引不合理的结果,这个时候我们就可以根据实际情况进行查询优化了。
2.2.2 Explain需要关注的指标
比较核心要关注的字段一般有 select_type、type、possible_keys、key、rows、Extra等
我们来一个个说明:
select_type:代表表示查询中每个select子句的类型,是简单查询还是联合查询还是子查询,一目了然。咱们上面的例子是SIMPLE,代表简单查询,其他枚举参考下列表格:
select_type的值 | 解释 |
SIMPLE | 简单查询(不使用关联查询或子查询) |
PRIMARY | 如果包含关联查询或者子查询,则最外层的查询部分标记primary |
UNION | 联合查询(UNION)中第二个及后面的查询 |
DEPENDENT UNION | UNION中的第二个或后面的SELECT语句,取决于外面的查询 |
UNION RESULT | UNION的结果,union语句中第二个select开始后面所有select |
SUBQUERY | 字查询中的第一个擦讯 |
DEPENDENT SUBQUERY | 子查询中的第一个查询,并且依赖外部查询 |
DERIVED | 派生表的SELECT, FROM子句的子查询 |
MATERIALIZED | 被物化的子查询 |
UNCACHEABLE SUBQUERY | 一个子查询的结果不能被缓存,必须重新评估外链接的第一行 |
type:表示MySQL在表中查找所需数据的方式,也称“访问类型”,咱们上面的例子是All,代表全表扫描,是非常差的模式,其他枚举参考下列表格:
type的值 | 解释 |
system | 查询对象表只有一行数据,且只能用于MyISAM和Memory引擎的表,这是最好的情况 |
const | 基于主键或唯一索引查询,最多返回一条结果 |
eq_ref | 类似ref,区别就在使用的索引是唯一索引,对于每个索引键值,表中只有一条记录匹配,简单来说,就是多表连接中使用primary key或者 unique key作为关联条件 |
ref | 表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值 |
fulltext | 全文检索 |
ref_or_null | 表连接类型是ref,但进行扫描的索引列中可能包含NULL值 |
index_merge | 利用多个索引 |
unique_subquery | 子查询中使用唯一索引 |
index_subquery | 子查询中使用普通索引 |
range | 只检索给定范围的行,使用一个索引来选择行 |
index | Full Index Scan,index与ALL区别为index类型只遍历索引树 |
ALL | Full Table Scan, MySQL将遍历全表以找到匹配的行 |
possible_keys:应该或建议使用的索引
表示MySQL能使用哪个索引在表中找到记录,查询涉及到的字段上若存在索引,则该索引将被列出,但不一定被查询使用。这个趋向于指导性作用。
key:实际使用的索引,没有的情况下为NULL
显示MySQL在查询中实际使用的索引,若没有使用索引,显示为NULL
rows:预估扫描了了多少行,咱们上面的例子 4952492 ,非常不合理。
表示MySQL根据表统计信息及索引选用情况,估算的找到所需的记录所需要读取的行数。基本表现为实际扫描过的行数。
3 一些使用上的规范
3.1 分析是否有不合理的查询
★ 以下是我们团队的准入规范,也是CodeReview 标准。
尽量避免使用select *,join语句使用select * 可能导致只需要访问索引即可完成的查询需要回表取数。
一种是可能取出很多不需要的数据,对于宽表来说,这是灾难;一种是尽可能避免回表,因为取一些根本不需要的数据而回表导致性能低下,是很不合算。
严禁使用select * from t_name,不加任何where条件,道理一样,这样会变成全表全字段扫描。
MySQL中的text类型字段存储:
不与其他普通字段存放在一起,因为读取效率低,也会影响其他轻量字段存取效率。大宽表、大字段表,整体性能也不好。
如果不需要text类型字段,又使用了select *,会让该执行消耗大量io,效率也很低下
在取出字段上可以使用相关函数,但应尽可能避免出现 now() , rand() , sysdate() 等不确定结果的函数,在Where条件中的过滤条件字段上严禁使用任何函数,包括数据类型转换函数。大量的计算和转换会造成效率低下,这个在索引那边也描述过了。
分页查询语句全部都需要带有排序条件 , 否则很容易引起乱序
用in()/union替换or,效率会好一些,并注意in的个数小于300
严禁使用%前缀进行模糊前缀查询。
-- 如下,这种查询会导致扫描表:select a,b,c from t_name where a like'%name';
-- 可以使用%模糊后缀查询如:select a,b from t_name where a like'name%';尽量避免使用子查询,可以把子查询优化为join操作,通常子查询在in子句中,且子查询中为简单SQL(不包含union、group by、order by、limit从句)时,才可以把子查询转化为关联查询进行优化。子查询性能差的原因:
子查询的结果集无法使用索引,通常子查询的结果集会被存储到临时表中,不论是内存临时表还是磁盘临时表都不会存在索引,所以查询性能会受到一定的影响;
特别是对于返回结果集比较大的子查询,其对查询性能的影响也就越大;
由于子查询会产生大量的临时表也没有索引,所以会消耗过多的CPU和IO资源,产生大量的慢查询。
在多表join中,尽量选取结果集较小的表作为驱动表,来join其他表。
分页查询,当limit起点较高时,可先用过滤条件进行过滤,如下。原理参考这篇
-- 如 select a,b,c from t1 limit 10000,20;
-- 优化为:select a,b,c from t1 where id>10000 limit 20;3.2 检查是否有不合理的索引使用
建议参考笔者这篇《构建高性能索引(策略篇)》,比较完整
索引区分度(> 0.2)
索引必须创建在索引选择性(区分度)较高的列上,选择性的计算方式为:
selecttivity = count(distinct c_name)/count(*) ; 如果区分度结果小于0.2,则不建议在此列上创建索引,否则大概率会拖慢SQL执行
遵循最左前缀,将索引区分度最高的放在左边
对于确定需要组成组合索引的多个字段,设计时建议将选择性高的字段靠前放。使用时,组合索引的首字段,必须在where条件中,且需要按照最左前缀规则去匹配。
正确理解和计算索引字段的区分度,文中有计算规则,区分度高的索引,可以快速得定位数据,区分度太低,无法有效的利用索引,可能需要扫描大量数据页,和不使用索引没什么差别。
禁止使用外键,可以在程序级别来约束完整性
varchar、text类型字段如果需要创建索引,必须使用前缀索引。
前缀索引计算公式如下,calcul_len 是数字,长度为1 ~ c_name字段的最长值,可以逐一比较,对比区分度最高的出来
正确理解和计算前缀索引的字段长度,文中有判断规则,合适的长度要保证高的区分度和最恰当的索引存储容量,只有达到最佳状态,才是保证高效率的索引。
selectcount(distinctleft(`c_name`,calcul_len))/count(*) from t_name;单张表的索引数量理论上应控制在5个以内。经常有大批量插入、更新操作表,应尽量少建索引,索引建立的原则理论上是多读少写的场景。
ORDER BY,GROUP BY,DISTINCT的字段需要添加在索引的后面,形成覆盖索引
联合索引注意最左匹配原则:查询时必须按照从左到右的顺序匹配,MySQL会一直向右匹配索引直到遇到范围查询(>、<、between、like)然后停止匹配。如:
-- 如果建立(depno,empname,job)顺序的索引,job是用不到索引的。
depno=1and empname>''and job=1应需而取策略,查询记录的时候,不要一上来就使用*,只取需要的数据,可能的话尽量只利用索引覆盖,可以减少回表操作,提升效率。
正确判断是否使用联合索引,应避免索引下推(IPC),减少回表操作,提升效率。
避免索引失效的原则:禁止对索引字段使用函数、运算符操作,会使索引失效。这是实际上就是需要保证索引所对应字段的”干净度“。
避免非必要的类型转换,字符串字段使用数值进行比较的时候会导致索引无效。
模糊查询'%value%'会使索引无效,变为全表扫描,因为无法判断扫描的区间,但是'value%'是可以有效利用索引。
索引覆盖排序字段,这样可以减少排序步骤,提升查询效率
尽量的扩展索引,非必要不新建索引。比如表中已经有a的索引,现在要加(a,b)的索引,那么只需要修改原来的索引即可。
举例子:比如一个品牌表,建立的的索引如下,一个主键索引,一个唯一索引
PRIMARYKEY (`id`),
UNIQUEKEY `uni_brand_define` (`app_id`,`define_id`)实际场景中,建议代码交叉评审,当你同事业务代码中的检索语句如下的时候,应建议调整:
select brand_id,brand_name from ds_brand_system where status=? and define_id=? and app_id=?建议改成如下:
select brand_id,brand_name from ds_brand_system where app_id=? and define_id=? and status=?虽然说 MySQL的查询优化器会根据实际索引情况进行顺序优化,所以这边不做强制。但是同等条件下还是按照顺序进行排列,比较清晰,并且节省查询优化器的处理。
4 总结
这边仅仅是从查询语句的角度进行分析,实际上缓存服务变慢的可能性很多,不仅仅是慢查询怎么分析(Slow Log、Explain命令)。还应该全面的分析原因,并给出处理方案,如 分析SQL脚本合理性、建立索引或优化索引、读写分离、垂直+水平分区)、多读少写/冷数据 做缓存、优化数据库的锁竞争、数据库配置调优、硬件资源升级 等等,后面几篇我们慢慢说。
相关文章:
MySQL慢查询分析和性能优化
1 背景我们的业务服务随着功能规模扩大,用户量扩增,流量的不断的增长,经常会遇到一个问题,就是数据存储服务响应变慢。导致数据库服务变慢的诱因很多,而RD最重要的工作之一就是找到问题并解决问题。下面以MySQL为例子&…...
C++学习笔记(四)
组合、继承。委托(类与类之间的关系) 复合 queue类里有一个deque,那么他们的关系叫做复合。右上角的图表明复合的概念。上图的特例表明,queue中的功能都是通过调用c进行实现(adapter)。 复合关系下的构造和…...

【4】深度学习之Pytorch——如何使用张量处理时间序列数据集(共享自行车数据集)
表格数据 表格中的每一行都独立于其他行,他们的顺序页没有任何关系。并且,没有提供有关行之前和行之后的列编码信息。 表格类型的数据是指通过表格的形式表示的数据,它以行和列的方式组织数据。表格中的每一行代表一个数据项,每…...

mulesoft MCIA 破釜沉舟备考 2023.02.10.01
mulesoft MCIA 破釜沉舟备考 2023.02.10.01 1. What is a defining charcateristic of an integration-Platform-as-a-Service(iPaaS)?2. An application deployed to a runtime fabric environment with two cluster replicas is designed to periodically trigger of flow f…...

干货 | PCB拼板,那几条很讲究的规则!
拼板指的是将一张张小的PCB板让厂家直接给拼做成一整块。一、为什么要拼板呢,也就是说拼板的好处是什么?1.为了满足生产的需求。有些PCB板太小,不满足做夹具的要求,所以需要拼在一起进行生产。2.提高SMT贴片的焊接效率。只需要过一…...

笔试题-2023-思远半导体-数字IC设计【纯净题目版】
回到首页:2023 数字IC设计秋招复盘——数十家公司笔试题、面试实录 推荐内容:数字IC设计学习比较实用的资料推荐 题目背景 笔试时间:2022.08.20应聘岗位:数字IC设计工程师笔试时长:90min笔试平台:牛客网题目类型:填空题(2道),不定项选择题(3道),单选题(2道),问…...
canvas根据坐标点位画图形-canvas拖拽编辑单个图形形状
首先在选中图形的时候需要用鼠标右击来弹出选择框,实现第一个编辑节点功能 在components文件夹下新建右键菜单 RightMenu文件: <template><div v-show"show" class"right-menu" :style"top:this.ypx;left:this.xpx…...

JavaEE 初阶 — 确认应答机制
文章目录确认应答机制(安全机制)1 什么是后发先至问题1 如何解决后发先至问题确认应答机制(安全机制) 确认应答 是实现可靠传输的最核心机制。 这里指的 可靠传输 不是说 100% 可以把消息发给接收方,而是尽力而为&…...
0207 事件
事件监听事件监听版本事件类型事件概念事件在编程时系统内发生的动作或者发生的事情例子点击按钮鼠标经过拖拽鼠标事件监听(注册事件,绑定事件)让程序员检测是否有事件产生,一旦有事件触发,就立即调用一个函数做出响应…...

SpringBoot整合Swagger
目录 一、swagger介绍 二、springboot集成swagger 1、创建一个springboot-web项目 2、导入相关依赖 3、编写一个Hellow工程 4、配置swagger --->config 5、启动springboot工程 6、配置swagger信息 7、配置swagger扫描接口 8、如何设置Swagger在生产环境中使用&…...

20230210英语学习
Why Do So Many Cats Have White ‘Socks’ on Their Paws? 为什么好多猫咪脚上都“穿着白袜子”? If you see a house cat, the odds are high that it will have white paws, a look that many owners affectionately call "socks."But socks are rar…...

【图像处理OpenCV(C++版)】——4.5 全局直方图均衡化
前言: 😊😊😊欢迎来到本博客😊😊😊 🌟🌟🌟 本专栏主要结合OpenCV和C来实现一些基本的图像处理算法并详细解释各参数含义,适用于平时学习、工作快…...

2022年API安全研究报告
目录 导读 2022年API安全风险概况 2022年平均每月遭受攻击的API数量超21万...
【内网安全-横向移动】基于SMB协议-PsExec
目录 一、SMB协议 1、简述: 2、工具: 二、PsExec 1、简述: 2、使用: 1、常用参数: 2、情况: 3、插件 三、PsExec(impacket) 1、简述: 1、impacket࿱…...

whistle 一个神奇的前端调试工具(抓包\代理工具)
在进行前端开发过程中,我们常常需要对一些接口进行处理,以及当后端接口没有弄好需要我们mock一些假数据,针对这些场景,我们就可以使用whistle 来解决。首先,我们要知道能满足我们需求的工具有很多,例如&…...
node.js下载和vite项目创建以及可能遇到的错误
目录 一、node.js的下载 1、去官网下载 节点.js (nodejs.org) 2、下载过程 第一步: 第二步: 第三步: 第四步: 第五步: 二、vite项目的创建(使用的工具是Hbuilder x) 第一步: 出现报错…...

如何使用python画一个爱心
1 问题 如何使用python画一个爱心。 2 方法 桌面新建一个文本文档,文件后缀改为.py,输入相关代码ctrls保存,关闭,最后双击运行。 代码清单 1 from turtle import * def curvemove(): for i in range(200): right(1) …...

1 Flutter UI Container和 Text 和图片组件
一 Text 组件Text 文本组件的一些属性如下body: const Text("this is leonardo fibonacci",// 文本对齐的方式textAlign: TextAlign.center,// 文本方向textDirection: TextDirection.rtl,// 字体显示最大的行数maxLines: 2,// 文字超出屏幕之后的显示方式 ellipsi…...

【Hello Linux】 Linux基础命令(持续更新中)
作者:小萌新 专栏:Linux 作者简介:大二学生 希望能和大家一起进步! 本篇博客简介:介绍Linux的基础命令 Linux基础命令ls指令lsls -als -dls -ils -sls -lls -nls -Fls -rls -tls -Rls -1总结思维导图pwd指令whoami指令…...
记录一下slf4j2打印一直不成功
整理一个之前的老项目问题,发现日志一直打印不出来,本地启动发现了第一个问题日志如下:此处可发现,jar包冲突问题,去掉冲突的jar包即可,此处不做过多赘述。然后发现了重新启动项目,发现jar包冲突…...

零代码构建HomeKit运动检测系统:Adafruit IO与itsaSNAP实战指南
1. 项目概述:零代码构建HomeKit运动检测系统想给家里的走廊、储物间或者车库入口加个自动感应灯,但又不想折腾复杂的编程和服务器搭建?或者,你手头有一些非HomeKit原生设备,希望通过苹果的“家庭”App进行统一管理&…...

大模型涌现能力:从原理到工程实践的激发与评测方法
1. 项目概述:从“玄学”到“可操作”的涌现能力拆解最近和几个做模型训练和评测的朋友聊天,话题总绕不开“涌现能力”。这个词现在火得不行,但聊深了发现,大家对这个概念的理解其实挺割裂的。有人说它是大模型“开窍”的瞬间&…...

揭秘开源驾驶辅助系统openpilot:如何用代码重新定义汽车智能化体验
揭秘开源驾驶辅助系统openpilot:如何用代码重新定义汽车智能化体验 【免费下载链接】openpilot openpilot is an operating system for robotics. Currently, it upgrades the driver assistance system on 300 supported cars. 项目地址: https://gitcode.com/Gi…...
)
从CuteCom到代码:手把手教你用I.MX6ULL实现串口双向通信(附完整工程)
从CuteCom到代码:手把手教你用I.MX6ULL实现串口双向通信 在嵌入式开发中,串口通信是最基础也最关键的调试手段之一。无论是简单的日志输出,还是复杂的数据交互,串口都扮演着不可或缺的角色。本文将带你从零开始,在I.MX…...

2026届学术党必备的降重复率神器实际效果
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 人工智能技术飞速发展着,学术研究和论文创作领域迎来了深刻变革,维普…...

学校AIGC检测标准差异解读:不同高校AI率标准对比2026年如何针对性免费处理完整指南
学校AIGC检测标准差异解读:不同高校AI率标准对比2026年如何针对性免费处理完整指南 同一段文字,不同平台检测AI率相差20%以上。这不是玄学,有原因可解释。 关于高校AIGC检测标准差异解读,理解了背后逻辑,很多「奇怪现…...

好用的昆明线上经营推广哪家好选
在数字化浪潮席卷的当下,昆明的企业和商家们越来越意识到线上经营推广的重要性。选择一家靠谱的线上经营推广公司,能够让企业在激烈的市场竞争中脱颖而出。那么,在昆明众多的推广公司中,哪家才是比较好的选择呢?今天&a…...

泰米尔文TTS项目上线倒计时:ElevenLabs API v2.4.1强制启用新语音编码协议,旧集成方案将于2024年9月30日失效
更多请点击: https://intelliparadigm.com 第一章:泰米尔文TTS项目上线倒计时:ElevenLabs API v2.4.1强制启用新语音编码协议,旧集成方案将于2024年9月30日失效 ElevenLabs 已于 2024 年 7 月 15 日正式发布 API v2.4.1ÿ…...

如何快速上手专业3D点云标注工具:完整入门指南
如何快速上手专业3D点云标注工具:完整入门指南 【免费下载链接】labelCloud A lightweight tool for labeling 3D bounding boxes in point clouds. 项目地址: https://gitcode.com/gh_mirrors/la/labelCloud 在自动驾驶、机器人视觉和三维重建等领域&#x…...

STM32 HAL库设计解析:从GPIO到外设的面向对象编程实践
1. 项目概述:从寄存器操作到HAL API的思维跃迁如果你是从标准外设库(SPL)或者更早的寄存器直接操作时代过来的STM32开发者,第一次接触HAL库时,可能会觉得有点“绕”。为什么一个简单的引脚翻转,不再是对GPI…...