01-Spark环境部署
1 Spark的部署方式介绍
Spark部署模式分为Local模式(本地模式)和集群模式(集群模式又分为Standalone模式、Yarn模式和Mesos模式)
1.1 Local模式
Local模式常用于本地开发程序与测试,如在idea中
1.2 Standalone模式
Standalone模式被称为集群单机模式。Spark与Hadoop1.0版本有点类似,Spark本身自带了完整的资源调度管理服务(但这不是它的强项,因为Spark主要是一个计算框架),可以独立部署到集群中,无须依赖任何其他的资源管理系统,在该模式下,Spark集群架构为主从模式,即一台Master节点与多台Slave节点,Slave节点启动的进程名称为Worker,此时集群会存在单点故障。(单点故障可利用Spark HA 与zookeeper解决)
这种模式下, Driver 和 Worker 是启动在节点上的进程,运行在JVM 中的进程
- Driver 与集群节点之间有频繁的通信。
- Driver 负责任务(task)的分发和结果的回收 即任务的调度。如果task的计算结果非常大就不要回收了。会造成OOM
- Worker 是 Standalone 资源调度框架里面资源管理的从节点,也是JVM进程
- 管理每个节点中的资源状态,启动进程,执行Task任务
- Master 是 Standalone 资源调度框架里面资源管理的主节点,也是JVM进程
- 管理所有资源状态
简单来说:
Master类似于 yarn的 RM,Driver类似于 yarn的 AM(ApplicationMaster),Slaves类似于 yarn的 NM
Worker、Master是常驻进程、Driver是当有任务来时才会启动
1.3 Yarn模式
Yarn模式被称为 Spark on Yarn 模式,即把Spark作为一个客户端,将作业提交给Yarn服务,由于在生产环境中,很多时候要与Hadoop使用同一个集群,因此采用Yarn来管理资源调度,可以有效提高资源利用率
Yarn模式又分为Yarn Cluster模式、Yarn Client模式
- Yarn Cluster:用于生产环境,所以的资源调度和计算都在集群上运行
- Yarn Client:用于交互、调试环境
若要基于 yarn 来进行资源调度,必须实现 ApplicationMaster 接口,Spark 实现了这个接口,所以可以基于 Yarn 来进行资源调度
1.4 Mesos模式
Mesos模式被称为 Spark on Mesos 模式,Mesos与Yarn同样是一款资源调度管理系统,可以为Spark提供服务,由于Spark与Mesos存在密切的关系,因此在设计Spark框架时充分考虑到了对Mesos的集成,但如果同时运行Hadoop和Spark,从兼容性的角度来看,Spark on Yarn是更好的选择。
1.5 小结
Spark作为一个数据处理框架和计算引擎,被设计在所有常见的集群环境中运行, 在国内工作中主流的环境为Yarn,不过逐渐容器式环境也慢慢流行起来。接下来,我们就分别看看不同环境下Spark的运行
2 Spark环境部署
2.1 Local模式
Local模式,就是不需要其他任何节点资源就可以在本地执行Spark代码的环境,一般用于教学,调试,演示等
这种模式最为简单,解压即用不需要进入任何配置
1)将压缩包上传至Linux并解压到指定目录
[nhk@kk01 opt]$ tar -zxvf spark-3.2.0-bin-hadoop3.2-scala2.13.tgz -C /opt/software/
[nhk@kk01 opt]$ cd /opt/software/
[nhk@kk01 software]$ mv spark-3.2.0-bin-hadoop3.2-scala2.13 spark-local
2)配置文件spark-env.sh
[nhk@kk01 conf]$ pwd
/opt/software/spark-local/conf
[nhk@kk01 conf]$ cp spark-env.sh.template spark-env.sh
[nhk@kk01 conf]$ vim spark-env.sh
# 添加如下配置JAVA_HOME=/opt/software/jdk1.8.0_152
SCALA_HOME=/opt/software/scala-2.13.5HADOOP_CONF_DIR=/opt/software/hadoop-3.1.3/etc/hadoop
3)启动spark shell
命令
spark-shell -master local | local[k]| local[*] # 建议 k>= 2
其中k表示启动线程数目(CPU Core核数)
| Value | |
|---|---|
| local | Runs Spark locally with one worker thread. There will be no multiple threads running in parallel |
| local[k] | Runs Spark locally with k number of threads.( K is ideally the number of cores in your machine.) |
| local[*] | Runs Spark locally with a number of worker threads that equals the number of logical cores in your machine. |
# 进入解压缩后的路径,执行如下指令
[nhk@kk01 software]$ cd spark-local/
[nhk@kk01 spark-local]$ bin/spark-shell
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Welcome to____ __/ __/__ ___ _____/ /___\ \/ _ \/ _ `/ __/ '_//___/ .__/\_,_/_/ /_/\_\ version 3.2.0/_/Using Scala version 2.13.5 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_152)
Type in expressions to have them evaluated.
Type :help for more information.
23/04/13 07:08:48 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Spark context Web UI available at http://kk01:4040
Spark context available as 'sc' (master = local[*], app id = local-1681384129891).
Spark session available as 'spark'.scala>
3)输入网址进入web ui监控页面访问
http://kk01:4040
注意:
这里的kk01是在hosts文件配置了ip地址映射,如果没有,默认填写ip
4)退出Local本地模式
两种方式:
1、直接按ctrl+c 或 ctrl+d
2、输入Scala指令
:quit
5)提交应用
[nhk@kk01 spark-local]$ bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[2] \
./examples/jars/spark-examples_2.13-3.2.0.jar \
10# --class 表示要执行的程序的主类(可以可以根据我们自己编写的程序做出相应修改)
# --master local[2] 部署模式,默认为本地模式,数字表示分配的虚拟cpu核数量
# spark-examples_2.13-3.2.0.jar 运行的应用类所在的jar包(实际使用时可设定为我们自己打的jar报)
# 数字10表示程序的入口参数,用于设定当前应用的任务数量
2.2 Standalone模式
真实工作中还是要将应用提交到对应的集群中去执行,这里我们来看看只使用Spark自身节点运行的集群模式,也就是我们所谓的独立部署(Standalone)模式。
Spark的 Standalone 模式体现了经典的master-slave模式
注意:
搭建集群之前需要确认 jdk版本为8
0)集群规划
| kk01 | kk02 | kk03 |
|---|---|---|
| Worker Master | Worker | Worker |
1)将压缩包上传至Linux并解压到指定目录
[nhk@kk01 opt]$ tar -zxvf spark-3.2.0-bin-hadoop3.2-scala2.13.tgz -C /opt/software/
[nhk@kk01 opt]$ cd /opt/software/
[nhk@kk01 software]$ mv spark-3.2.0-bin-hadoop3.2-scala2.13 spark-standalone
2)修改配置文件
- 进入spark-standalone/conf目录,修改workers.template文件名为workes(保守做法可以选择复制)
[nhk@kk01 software]$ cd spark-standalone/conf/
[nhk@kk01 conf]$ cp workers.template workers
- 修改workes文件,添加worker节点
[nhk@kk01 conf]$ vim workers
# 将文件内容替换为如下kk01
kk02
kk03
- 修改spark-env.sh.template文件名为spark-env.sh (保守做法可以选择复制)
[nhk@kk01 conf]$ cd /opt/software/spark-standalone/conf/
[nhk@kk01 conf]$ cp spark-env.sh.template spark-env.sh
- 修改spark-env.sh文件,添加JAVA_HOME环境变量和集群对应的master节点
[nhk@kk01 conf]$ vim spark-env.sh
# 在文件末尾添加如下内容# 配置 jdk 环境
export JAVA_HOME=/opt/software/jdk1.8.0_152
# 配置 Master 的 IP 端口
export SPARK_MASTER_HOST=kk01
export SPARK_MASTER_PORT=7077# 注意:7077端口,相当于kk01内部通信的8020端口(此处的端口需要确认自己的Hadoop)
3)分发spark-standalone目录
# 使用scp或rsync分发,scp或rsync区别在于 scp是完全拷贝 rsync只对差异文件进行拷贝# 由于是第一次配置standalone模式,因此这里使用scp
[nhk@kk01 software]$ scp -r /opt/software/spark-standalone/ kk02:/opt/software/spark-standalone/
[nhk@kk01 software]$ scp -r /opt/software/spark-standalone/ kk03:/opt/software/spark-standalone/# 如果定义了分发脚本 xsync ,则使用自定义脚本
[nhk@kk01 software]$ xsync spark-standalone
4)启动集群
[nhk@kk01 spark-standalone]$ sbin/start-all.sh
5)查看服务器进程
[nhk@kk01 spark-standalone]$ jps
2480 Master
2695 Jps
2586 Worker[nhk@kk02 ~]$ jps
2497 Jps
2414 Worker[nhk@kk03 ~]$ jps
2416 Worker
2499 Jps
6)查看Master资源监控Web UI界面
http://kk01:8080
注意:
kk01这里默认是填写服务器ip,但是我们在hosts文件里映射了ip,因此填主机名也可以
7)提交应用(client模式)
[root@kk01 spark-standalone]# bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://kk01:7077 \
./examples/jars/spark-examples_2.13-3.2.0.jar \
10# --class 表示要执行的程序的主类(可以可以根据我们自己编写的程序做出相应修改)
# --master spark://kk01:7077 独立部署模式,连接到Spark集群
# spark-examples_2.13-3.2.0.jar 运行的应用类所在的jar包
# 数字10表示程序的入口参数,用于设定当前应用的任务数量
-
执行任务时,会产生多个Java进程
CoarseGrainedExecutorBackend 执行节点进程
SparkSumbit 提交节点进程
[nhk@kk01 ~]$ jps 2611 DataNode 3027 ResourceManager 3171 NodeManager 3687 Master 3783 Worker 2473 NameNode 3581 JobHistoryServer 4205 Jps 3998 SparkSubmit -
执行任务时,默认采用服务器集群节点的总核数,每个节点内存1024M。
任务执行流程
- client 模式提交任务后,会在客户端启动 Driver进程
- Driver 回向 Master 申请启动 Application 启动的资源
- 资源申请成功,Driver 端将 task 分发到worker 端执行,启动 executor进程(任务的分发)
- Worker 端(executor进程) 将task 执行结果返回到 Driver 端(任务结果的回收)
提交参数说明
在提交应用中,一般会同时一些提交参数
bin/spark-submit \
--class <main-class>
--master <master-url> \
... # other options
<application-jar> \
[application-arguments]
| 参数 | 解释 | 可选值举例 |
|---|---|---|
| –class | Spark程序中包含主函数的类 | |
| –master | Spark程序运行的模式(环境) | 模式:local[*]、spark://linux1:7077、Yarn |
| –executor-memory 1G | 指定每个executor可用内存为1G (这里越大计算能力越强) | |
| –total-executor-cores 2 | 指定所有executor使用的cpu核数为2个 | |
| –executor-cores | 指定每个executor使用的cpu核数 | |
| application-jar | 打包好的应用jar,包含依赖。 这个URL在集群中全局可见。 比如hdfs:// 共享存储系统。 如果是file://path,那么所有的节点的path都包含同样的jar | |
| application-arguments | 传给main()方法的参数 |
总结:
**client模式适用于测试调试程序。**Driver进程是在客户端启动的,这里的客户端指的是提交应用程序的当前节点。在Driver端可以看到 task执行的情况
**生成环境中不能使用client模式。**因为:假设要提交100个application 到集群运行,Driver每次都会在 client端启动,那么就会导致客户端100网卡流量暴增的问题。
8)提交应用(cluster模式)
[nhk@kk01 spark-standalone]$ bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://kk01:7077 \
--deploy-mode cluster \
./examples/jars/spark-examples_2.13-3.2.0.jar \
10
2.3 standalone配置历史服务器
由于spark-shell停止掉后,集群监控kk01:4040页面就看不到历史任务的运行情况,所以开发时都配置历史服务器记录任务运行情况。(说白点,就是Driver节点停止了)
1)修改spark-defaults.conf.template文件名为spark-defaults.conf
[nhk@kk01 conf]$ cd /opt/software/spark-standalone/conf/
[nhk@kk01 conf]$ cp spark-defaults.conf.template spark-defaults.conf
2)修改spark-default.conf文件,配置日志存储路径
[nhk@kk01 conf]$ vim spark-defaults.conf
# 在文件末尾加入如下内容spark.eventLog.enabled true
spark.eventLog.dir hdfs://kk01:8020/spark-history
注意:
需要启动hadoop集群,HDFS上的spark-history 目录需要提前存在。
3)在创建HDFS上的spark-history 目录
[nhk@kk01 conf]$ start-dfs.sh # Hadoop配置了环境变量,脚本全局可用
[nhk@kk01 conf]$ hadoop fs -mkdir /spark-history
4)修改spark-env.sh文件, 添加日志配置
[nhk@kk01 conf]$ pwd
/opt/software/spark-standalone/conf
[nhk@kk01 conf]$ vim spark-env.sh # 在文件中添加如下内容
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://kk01:8020/spark-history
-Dspark.history.retainedApplications=30"# 参数说明
# 参数1含义:WEB UI访问的端口号为18080
# 参数2含义:指定历史服务器日志存储路径
# 参数3含义:指定保存Application历史记录的个数,如果超过这个值,旧的应用程序信息将被删除,这个是内存中的应用数,而不是页面上显示的应用数
5)分发配置文件
# 使用rsync命名更新差异文件 # 因为我们只更改了conf目录下的文件,因此只分发conf目录即可
[nhk@kk01 spark-standalone]$ rsync -av /opt/software/spark-standalone/conf/ kk02:/opt/software/spark-standalone/conf/[nhk@kk01 spark-standalone]$ rsync -av /opt/software/spark-standalone/conf/ kk02:/opt/software/spark-standalone/conf/# 参数说明
# -a 归档拷贝
# -v 显示拷贝过程
6)重新启动集群和历史服务
# 先确保hdfs集群、spark集群关闭
[nhk@kk01 spark-standalone]$ stop-dfs.sh
[nhk@kk01 spark-standalone]$ sbin/stop-all.sh # 重启
[nhk@kk01 spark-standalone]$ start-dfs.sh
[nhk@kk01 spark-standalone]$ sbin/start-all.sh
[nhk@kk01 spark-standalone]$ sbin/start-history-server.sh
7)查看进程
[nhk@kk01 spark-standalone]$ jps
5921 Master
6052 Worker
5558 DataNode
5371 NameNode
6235 Jps
6174 HistoryServer
8)重新执行任务
[nhk@kk01 spark-standalone]$ bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://kk01:7077 \
./examples/jars/spark-examples_2.13-3.2.0.jar \
10
9)查看历史服务
确保历史服务可用
http://kk01:18080/
2.4 standalone配置高可用(HA)基于Zookeeper
当前集群中的Master节点只有一个,所以会存在单点故障问题。所以为了解决单点故障问题,需要在集群中配置多个Master节点,一旦处于活动状态的Master发生故障时,由备用Master提供服务,保证作业可以继续执行。这里的高可用一般采用Zookeeper设置
集群规划
kk01 Worker ZooKeeper Masterkk02 Worker ZooKeeper Masterkk03 Worker ZooKeeper
1)停止集群(可选)
在确保hdfs集群、spark集群停止的情况下,才开始配置HA
[nhk@kk01 spark-standalone]$ sbin/stop-all.sh
[nhk@kk01 spark-standalone]$ stop-dfs.sh 2)启动Zookeeper集群
[nhk@kk01 spark-standalone]$ zkServer.sh start
[nhk@kk02 ~]$ zkServer.sh start
[nhk@kk03 ~]$ zkServer.sh start# 也可以使用自定义脚本启动集群(如果你定义了的话)
[nhk@kk01 spark-standalone]$ xzk.sh start
3)修改spark-env.sh文件添加如下配置
[nhk@kk01 conf]$ pwd
/opt/software/spark-standalone/conf
[nhk@kk01 conf]$ vim spark-env.sh注释如下内容:
#SPARK_MASTER_HOST=kk01
#SPARK_MASTER_PORT=7077添加如下内容:
#Master监控页面默认访问端口为8080,但是可能会和Zookeeper冲突,所以改成8989,也可以自定义,访问UI监控页面时请注意
SPARK_MASTER_WEBUI_PORT=8989export SPARK_DAEMON_JAVA_OPTS="
-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=kk01,kk02,kk03
-Dspark.deploy.zookeeper.dir=/spark"
参考配置文件如下
export JAVA_HOME=/opt/software/jdk1.8.0_152
#SPARK_MASTER_HOST=kk01
#SPARK_MASTER_PORT=7077export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://kk01:8020/spark-history
-Dspark.history.retainedApplications=30"#Master监控页面默认访问端口为8080,但是可能会和Zookeeper冲突,所以改成8989,也可以自定义,访问UI监控页面时请注意
SPARK_MASTER_WEBUI_PORT=8989export SPARK_DAEMON_JAVA_OPTS="
-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=kk01,kk02,kk03
-Dspark.deploy.zookeeper.dir=/spark"4)分发配置文件
[nhk@kk01 conf]$ rsync -av /opt/software/spark-standalone/conf/ kk02:/opt/software/spark-standalone/conf/[nhk@kk01 conf]$ rsync -av /opt/software/spark-standalone/conf/ kk03:/opt/software/spark-standalone/conf/
5)启动集群
启动spark集群前先启动hdfs集群,确定历史服务器正常,当然也需要确保zookeeper集群正常启动
[nhk@kk01 conf]$ start-dfs.sh # 启动hdfs集群[nhk@kk01 spark-standalone]$ pwd
/opt/software/spark-standalone
[nhk@kk01 spark-standalone]$ sbin/start-all.sh [nhk@kk01 spark-standalone]$ sbin/start-history-server.sh # 启动历史服务进程
6) 启动kk02的单独Master节点,此时kk02节点Master状态处于备用状态
[nhk@kk02 ~]$ cd /opt/software/spark-standalone/
[nhk@kk02 spark-standalone]$ sbin/start-master.sh
7)查看进程
[nhk@kk01 spark-standalone]$ jps
7697 NameNode
8385 Worker
8504 Jps
7289 QuorumPeerMain
8250 Master
7884 DataNode
6174 HistoryServer # 历史服务器进程[nhk@kk02 spark-standalone]$ jps
4546 DataNode
4315 QuorumPeerMain
5003 Jps
4909 Master # 备份master
4798 Worker[nhk@kk03 ~]$ jps
4688 SecondaryNameNode
4256 Worker
4347 Jps
3884 QuorumPeerMain
4111 DataNodes
8)提交应用到高可用集群
[nhk@kk01 spark-standalone]$ bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://kk01:7077,kk02:7077 \
./examples/jars/spark-examples_2.13-3.2.0.jar \
10
9)查看kk01的Master 资源监控Web UI
http://kk01:8989/
发现状态为 Status: ALIVE
10)手动停止kk01的Master资源监控进程
[nhk@kk01 spark-standalone]$ jps
7697 NameNode
8385 Worker
7289 QuorumPeerMain
8250 Master
7884 DataNode
6174 HistoryServer
8910 Jps
[nhk@kk01 spark-standalone]$ kill -9 8250
11) 查看kk02的Master 资源监控Web UI,稍等一段时间后,kk02节点的Master状态提升为活动状态
http://kk02:8989/
状态变化
Status:STANDBY ====> Status: ALIVE
2.5 Yarn模式
独立部署(Standalone)模式由Spark自身提供计算资源,无需其他框架提供资源。这种方式降低了和其他第三方资源框架的耦合性,独立性非常强。但是你也要记住,**Spark主要是计算框架,而不是资源调度框架,所以本身提供的资源调度并不是它的强项,所以还是和其他专业的资源调度框架集成会更靠谱一些。**所以接下来我们来学习在强大的Yarn环境下Spark是如何工作的(其实是因为在国内工作中,Yarn使用的非常多)。
注意:
Spark on Yarn 不需要单独开启spark相关的进程
Spark On Yarn的本质
- Master 角色由YARN的 ResourceManager 担任
- Worker 角色由YARN的 NodeManager 担任
- Driver 角色运行在YARN容器内 或 提交任务的客户端进程中
- 真正干活的Executor运行在YARN提供的容器内
1)上传并解压缩文件
将spark-3.2.0-bin-hadoop3.2-scala2.13.tgz文件上传到linux并解压缩,放置在指定位置。
[nhk@kk01 ~]$ cd /opt/software/
[nhk@kk01 software]$ rz[nhk@kk01 software]$ tar -zxvf spark-3.2.0-bin-hadoop3.2-scala2.13.tgz -C /opt/software/
2)重命名
[nhk@kk01 software]$ mv spark-3.2.0-bin-hadoop3.2-scala2.13/ spark-yarn
3)修改配置文件yarn-site.xml
修改hadoop配置文件/opt/software/hadoop-3.1.3/etc/hadoop/yarn-site.xml
修改这个配置文件的原因是因为:
[nhk@kk01 hadoop]$ pwd
/opt/software/hadoop-3.1.3/etc/hadoop
[nhk@kk01 hadoop]$ vim yarn-site.xml
# 添加如下内容<!-- 是否将对容器实施物理内存限制 生产中可产生改配置-->
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property><name>yarn.nodemanager.pmem-check-enabled</name><value>true</value>
</property><!-- 是否将对容器实施虚拟内存限制 生产中可产生改配置-->
<property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value>
</property><!-- 开启日志聚集-->
<property><name>yarn.log-aggregation-enable</name><value>true</value>
</property>
<!-- 设置yarn历史服务器地址-->
<property><name>yarn.log.server.url</name><value>http://kk01:19888/jobhistory/logs</value>
</property><property><name>yarn.nodemanager.remote-app-log-dir</name><value>/tmp/logs</value>
</property>
<!-- 历史日志保存的时间 7天-->
<property><name>yarn.log-aggregation.retain-seconds</name><value>604800</value>
</property>
4)同步修改的文件至所有服务器
[nhk@kk01 hadoop]$ rsync -av /opt/software/hadoop-3.1.3/etc/hadoop/ kk02:/opt/software/hadoop-3.1.3/etc/hadoop/[nhk@kk01 hadoop]$ rsync -av /opt/software/hadoop-3.1.3/etc/hadoop/ kk03:/opt/software/hadoop-3.1.3/etc/hadoop/
5) 修改conf/spark-env.sh
当Spark Application连接到yarn集群上运行时,需要设置环境变量HADOOP_CONF_DIR指向Hadoop配置目录,以获取集群信息
在 $SPARK_HOME/conf/spark-env.sh 文件中
修改conf/spark-env.sh,添加 JAVA_HOME和YARN_CONF_DIR配置
[nhk@kk01 hadoop]$ cd /opt/software/spark-yarn/conf/
[nhk@kk01 conf]$ cp spark-env.sh.template spark-env.sh
[nhk@kk01 conf]$ vim spark-env.sh
# 添加如下内容export JAVA_HOME=/opt/software/jdk1.8.0_152HADOOP_CONF_DIR=/opt/software/hadoop-3.1.3/etc/hadoop
# 下面这个也可以不配,因为和上面一样
YARN_CONF_DIR=/opt/software/hadoop-3.1.3/etc/hadoop
6)启动HDFS集群、YARN集群
# 我们配置过Hadoop环境变量,因此可以直接使用脚本一键启动
[nhk@kk01 conf]$ start-dfs.sh
[nhk@kk01 conf]$ start-yarn.sh
7)提交应用(cluster模式)
[nhk@kk01 spark-yarn]$ pwd
/opt/software/spark-yarn
[nhk@kk01 spark-yarn]$ bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
./examples/jars/spark-examples_2.13-3.2.0.jar \
10# 或者[nhk@kk01 spark-yarn]$ pwd
/opt/software/spark-yarn
[nhk@kk01 spark-yarn]$ bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn-cluster \
./examples/jars/spark-examples_2.13-3.2.0.jar \
10
查看http://kk01:8088页面,查看历史页面,查看任务调度情况,点击History,查看历史页面
yarn client 任务执行流程
- 客户端提交一个 Application,在客户端会启动一个 Driver进程
- 应用程序启动后会向 RM(ResourceMananger)(相当于 standalone模式下的master进程)发送请求,启动AM(ApplicationMaster)
- RM收到请求,随机选择一台 NM(NodeManager)启动AM。这里的NM相当于standalone中的Worker进程
- AM启动后,会向 RM 请求一批 container资源,用于启动Executor
- RM会找到一批 NM(包含container)返回给AM,用于启动Executor
- AM 会向 NM发送命令启动 Executor
- Executor启动后,会方向注册给 Driver,Driver发送 task 到 Executor ,执行情况和结果返回给Driver端
总结:
yarn-client模式同样是适用于测试,因为Driver 运行在本地,Driver会与yarn集群中的Executor 进行大量的通信,提交的 application 过多同样会造成客户机网卡流量的大量增加
ApplicationMaster(executorLauncher)在次模式中的作用:
- 为当前的 Application 申请资源
- 给 NodeManager 发送消息启动 Executor
注意:ApplicationMaster 在此模式下有 launchExecutor和申请资源的功能,没有作业调度的功能
2.6 Yarn配置历史服务器
配置了 historyServer,停止程序后,可以在web ui 中 Completed Application 对应的 ApplicationID 中能查看history
1)spark-defaults.conf
修改spark-defaults.conf.template 文件名为 spark-defaults.conf
[nhk@kk01 spark-yarn]$ cd conf/
[nhk@kk01 conf]$ pwd
/opt/software/spark-yarn/conf
[nhk@kk01 conf]$ cp spark-defaults.conf.template spark-defaults.conf
2)修改spark-default.conf文件**,配置日志存储路径**
[nhk@kk01 conf]$ vim spark-defaults.conf
# 在文件末尾加入如下内容# 开启记录事件日志的功能
spark.eventLog.enabled true
# 设置事件日志存储的路径
spark.eventLog.dir hdfs://kk01:8020/spark-history
spark.history.fs.logDirectory hdfs://kk01:8020/spark-history # 日志优化选项,压缩日志
spark.eventLog.compress true
注意:
需要启动hadoop集群,HDFS上的spark-history 目录需要提前存在。
3)在创建HDFS上的directory目录
[nhk@kk01 conf]$ start-dfs.sh # Hadoop配置了环境变量,脚本全局可用
[nhk@kk01 conf]$ hadoop fs -mkdir /spark-history
4)修改spark-env.sh文件, 添加日志配置
[nhk@kk01 conf]$ pwd
/opt/software/spark-yarn/conf
[nhk@kk01 conf]$ vim spark-env.sh # 在文件中添加如下内容
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://kk01:8020/spark-history
-Dspark.history.retainedApplications=30"# 参数说明
# 参数1含义:WEB UI访问的端口号为18080
# 参数2含义:指定历史服务器日志存储路径
# 参数3含义:指定保存Application历史记录的个数,如果超过这个值,旧的应用程序信息将被删除,这个是内存中的应用数,而不是页面上显示的应用数
5)修改spark-defaults.conf配置SparkHistoryServer
[nhk@kk01 conf]$ vim spark-defaults.conf
# 添加如下配置spark.yarn.historyServer.address=kk01:18080
spark.history.ui.port=18080
6)启动历史服务器
[nhk@kk01 conf]$ cd ..
[nhk@kk01 spark-yarn]$ sbin/start-history-server.sh
starting org.apache.spark.deploy.history.HistoryServer, logging to /opt/software/spark-yarn/logs/spark-nhk-org.apache.spark.deploy.history.HistoryServer-1-kk
01.out[nhk@kk01 spark-yarn]$ jps
2627 NameNode
2771 DataNode
3331 JobHistoryServer # 这个是Hadoop的历史服务器
4677 Jps
4605 HistoryServer # 这个是Spark的历史服务器
3134 NodeManager
7)重新提交应用(client模式)
[nhk@kk01 spark-yarn]$ bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
./examples/jars/spark-examples_2.13-3.2.0.jar \
10
8)Web页面查看日志
http://kk01:18080/
配置依赖Spark jar包(优化配置)
当Spark Application应用提交运行在YARN上时,默认情况下,每次提交应用都需要将Spark相关jar包上传到YARN集群上,为了节省提交时间和存储空间,将Spark相关jar包上传到HDFS目录,设置属性告知Spark Application应用
说明:
该项配置属于优化配置,可酌情考虑配置与否
上传Spark jar包前需要确保HDFS集群开启
# 在HDFS上创建目录,用于存放jar包
[nhk@kk01 ~]$ hadoop fs -mkdir sparkjars# 上传$SPARK_HOME/jars中所有的jar包
[nhk@kk01 ~]$ hadoop fs -put /opt/software/spark-yarn/jars/* /sparkjars
在$SPARK_HOME/conf/spark-defaults.conf文件增加spark 相关jar包存储在HDFS上的位置信息
[nhk@kk01 ~]$ vim /opt/software/spark-yarn/conf/spark-defaults.conf
# 添加如下配置spark.yarn.jars hdfs://kk01:8020/sparkjars/*
同步配置到所有节点
[nhk@kk01 ~]$ sudo /home/nhk/bin/xsync /opt/software/spark-yarn/
3 部署模式对比
| 模式 | Spark安装机器数 | 需启动的进程 | 所属者 | 应用场景 |
|---|---|---|---|---|
| Local | 1 | 无 | Spark | 测试 |
| Standalone | 3 | Master及Worker | Spark | 单独部署 |
| Yarn | 1 | Yarn及HDFS | Hadoop | 混合部署 |
4 常见端口号
-
Spark查看当前Spark-shell运行任务情况端口号:4040(计算)
-
Spark Master内部通信服务端口号:7077
-
Standalone模式下,Spark Master Web端口号:8080(资源)
-
Spark历史服务器端口号:18080
-
Hadoop YARN任务运行情况查看端口号:8088
相关文章:

01-Spark环境部署
1 Spark的部署方式介绍 Spark部署模式分为Local模式(本地模式)和集群模式(集群模式又分为Standalone模式、Yarn模式和Mesos模式) 1.1 Local模式 Local模式常用于本地开发程序与测试,如在idea中 1.2 Standalone模…...

HOT86-单词拆分
leetcode原题链接:单词拆分 题目描述 给你一个字符串 s 和一个字符串列表 wordDict 作为字典。请你判断是否可以利用字典中出现的单词拼接出 s 。注意:不要求字典中出现的单词全部都使用,并且字典中的单词可以重复使用。 示例 1:…...

开源数据集分类汇总(医学,卫星,分割,分类,人脸,农业,姿势等)
本文汇总了医学图像、卫星图像、语义分割、自动驾驶、图像分类、人脸、农业、打架识别等多个方向的数据集资源,均附有下载链接。 该文章仅用于学习记录,禁止商业使用! 1.医学图像 疟疾细胞图像数据集 下载链接:http://suo.nz/2V…...

Linux:Firewalld防火墙
目录 绪论 1、firewalld配置模式 2、预定义服务:系统自带 3端口管理 绪论 firewalld 防火墙,包过滤防火墙,工作在网络层,centos7自带的默认的防火墙 作用是为了取代iptables 1、firewalld配置模式 运行时配置 永久配置 i…...

mysql死锁;锁表排查
概述 有时候提前终止了navicat执行线程,但是实际mysql还在执行这个线程, 需要通过mysql本身去终止. mysql:8.0 三板斧第一斧 捞点网上线程现成的执行命令 1.查询是否锁表 show OPEN TABLES where In_use > 0;2.查询进程(如果您有SUP…...
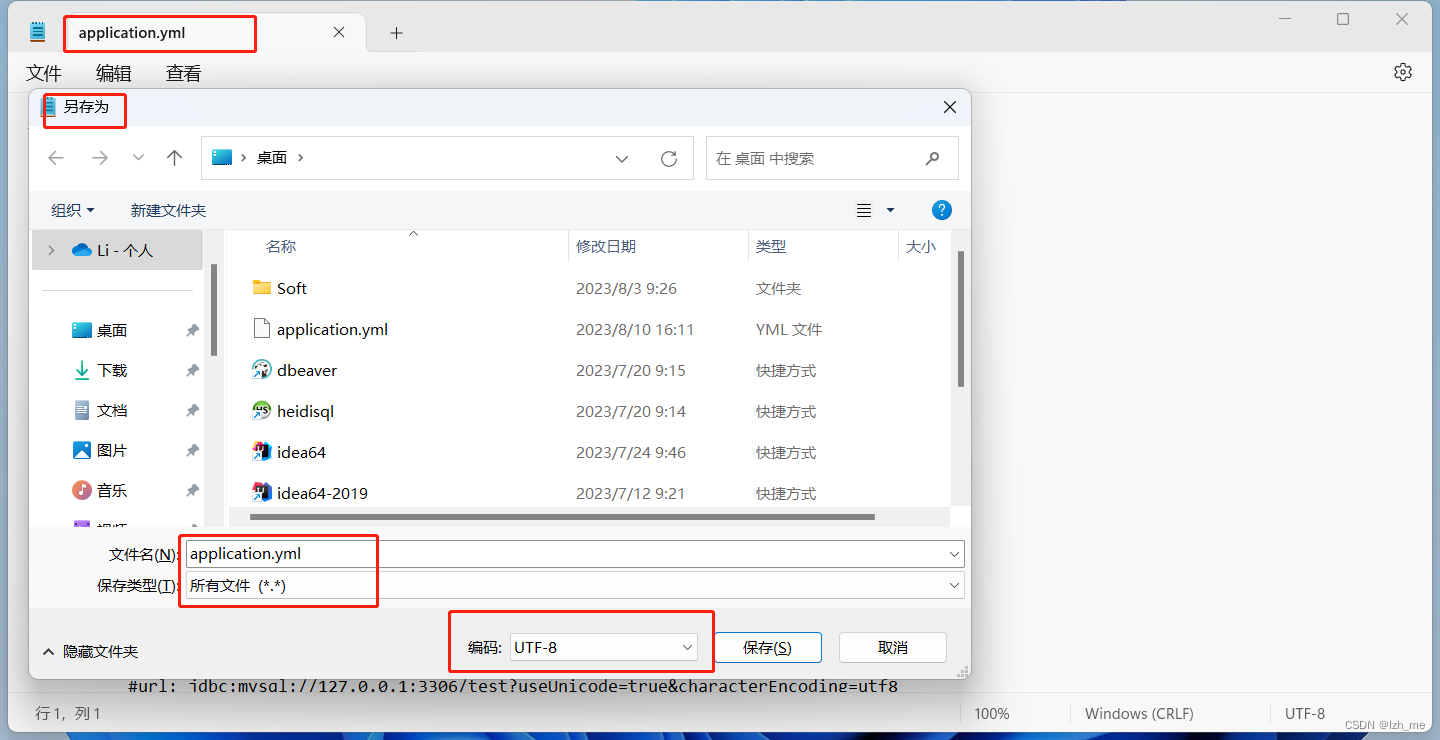
YAMLException: java.nio.charset.MalformedInputException: Input length = 1
springboot项目启动的时候提示这个错误:YAMLException: java.nio.charset.MalformedInputException: Input length 1 根据异常信息提示,是YAML文件有问题。 原因是yml配置文件的编码有问题。 需要修改项目的编码格式,一般统一为UTF-8。 或…...

无需求文档,保障测试质量的可行性做法
这篇文章,内容是:无需求文档的情况下,作为一个测试人员,应该如何做 ,才能保障测试质量不出问题,以及如何不背锅 ? 001 没有需求文档3种可能情况 : 1、公司都没产品经理࿰…...

SpringBoot项目学习笔记
第一章 SpringBoot有哪些优点? Spring Boot作为Java开发的框架和工具集,具有许多优点,这些优点有助于简化开发过程并提高效率。以下是一些主要的优点: 简化配置: Spring Boot采用约定优于配置的原则,通过自…...

如何在Vue表单处理中实现表单字段的文件下载
Vue.js 是一种流行的JavaScript框架,用于构建用户界面。在Vue应用中,我们经常需要处理表单操作,其中一个常见需求是实现文件下载。以下介绍如何在Vue表单处理中实现表单字段的文件下载,大家共同交流。 一、使用HTML的a标签实现文…...

SSL证书DV和OV的区别?
SSL证书是在互联网通信中保护数据传输安全的一种加密工具。它能够确保客户端和服务器之间的通信得以加密,防止第三方窃听或篡改信息。在选择SSL证书时,常见的有DV证书和OV证书,它们在验证标准和信任级别上有所不同。那么SSL证书DV和OV的有哪些…...

计算机竞赛 GRU的 电影评论情感分析 - python 深度学习 情感分类
1 前言 🔥学长分享优质竞赛项目,今天要分享的是 🚩 GRU的 电影评论情感分析 - python 深度学习 情感分类 🥇学长这里给一个题目综合评分(每项满分5分) 难度系数:3分工作量:3分创新点:4分 这…...
论文阅读 - Neutral bots probe political bias on social media
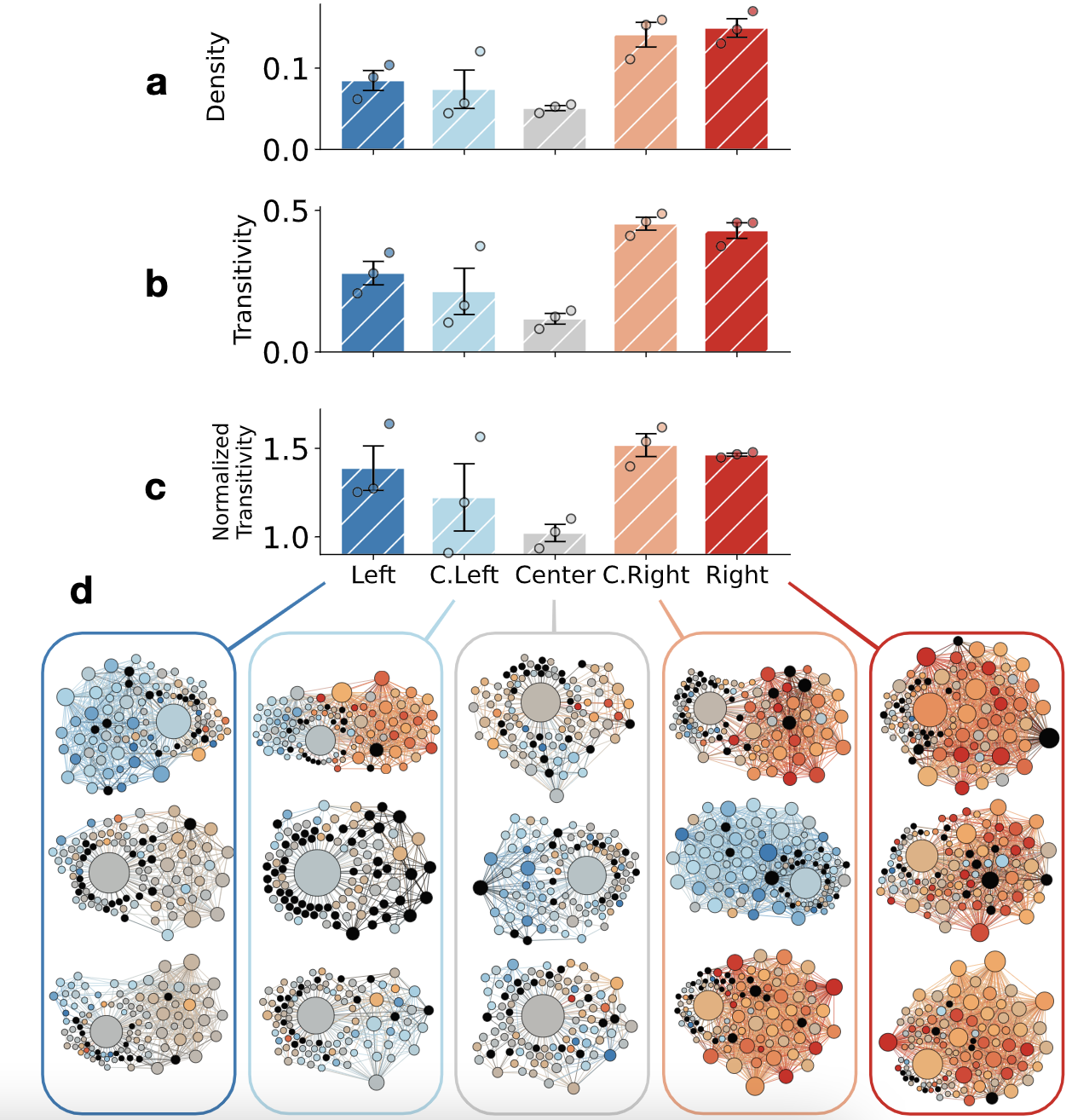
论文链接:Neutral bots probe political bias on social media | EndNote Click 试图遏制滥用行为和错误信息的社交媒体平台被指责存在政治偏见。我们部署中立的社交机器人,它们开始关注 Twitter 上的不同新闻源,并跟踪它们以探究平台机制与用…...
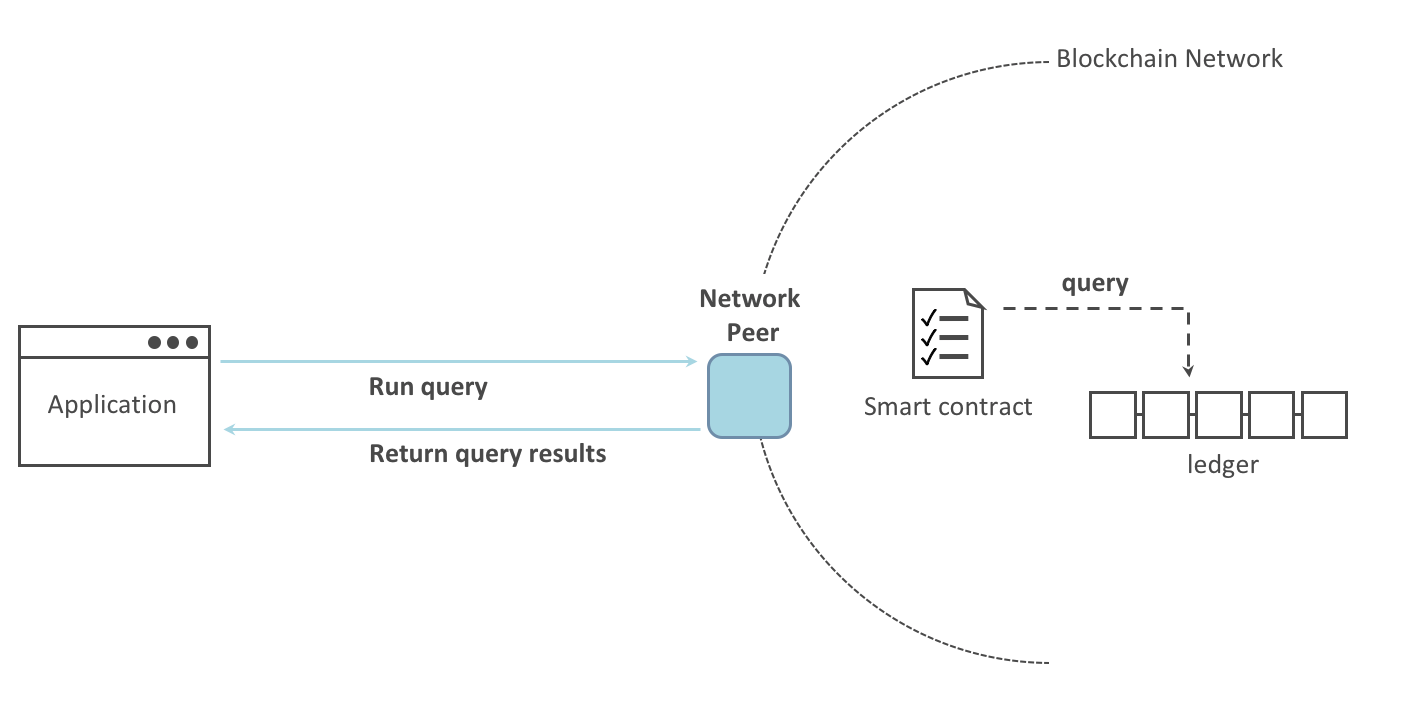
Fabric系列 - 知识点整理
知识点 源码编译 主机编译 容器编译 手动部署(docker-compose) 单peer 多peer 中途加peer 多主机多peer 链码 语法, 接口 (go版) 命令行调用 ca server 在DApp中使用SDK调用 (js版) 部署的几个阶段 部署1排序和1节点, 1组织1通道 光部署能Dapp 带ca server (每个组织一个)…...
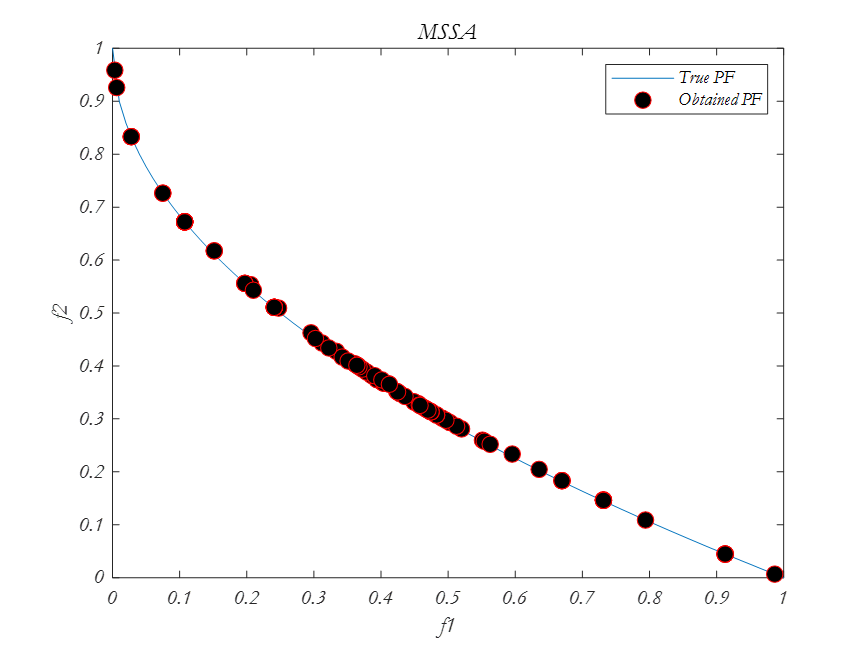
多目标优化算法之樽海鞘算法(MSSA)
樽海鞘算法的主要灵感是樽海鞘在海洋中航行和觅食时的群聚行为。相关文献表示,多目标优化之樽海鞘算法的结果表明,该算法可以逼近帕雷托最优解,收敛性和覆盖率高。 通过给SSA算法配备一个食物来源库来解决第一个问题。该存储库维护了到目前为…...
阿里云轻量应用服务器使用教程_创建配置_远程连接_网站上线
阿里云轻量应用服务器怎么使用?阿里云百科分享轻量应用服务器从选择创建、配置建站环境、轻量服务器应用服务器远程连接、开端口到网站上线全流程: 目录 阿里云轻量应用服务器使用教程 步骤一:购买一台轻量应用服务器 步骤二:…...

自监督学习的概念
Self-Supervised Learning (SSL)的主要思想是解决先验任务来学习特征提取器,在不使用标签的情况下生成有用的表示。 这里先验任务是指, 先使用原始数据和特征提取器来提取出 数据的有效表示. 对比方法(即对比学习, Contrastiv…...
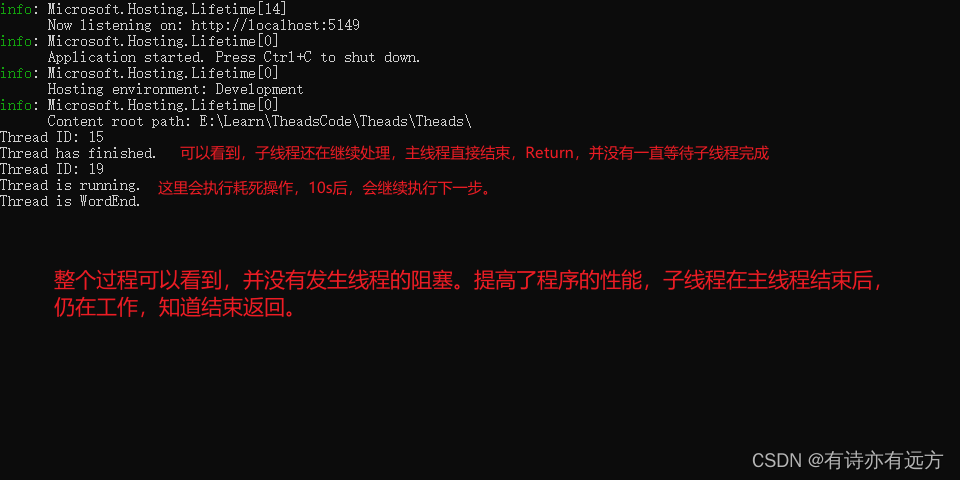
C#多线程开发详解
C#多线程开发详解 持续更新中。。。。。一、为什么要使用多线程开发1.提高性能2.响应性3.资源利用4.任务分解5.并行计算6.实时处理 二、多线程开发缺点1.竞态条件2.死锁和饥饿3.调试复杂性4.上下文切换开销5.线程安全性 三、多线程开发涉及的相关概念常用概念(1)lock(2)查看当前…...

Linux 基础篇(六)sudo和添加信任用户
一、sudo 1.是什么? 给被信任的普通用户授权,让被信任的普通用户能执行root用户才能执行的命令的一个命令。 2.为什么? 很多时候我们要在被信任的普通用户下执行一些root用户才能执行的命令,如 yum… 所以需要有一个命令能给普通用…...
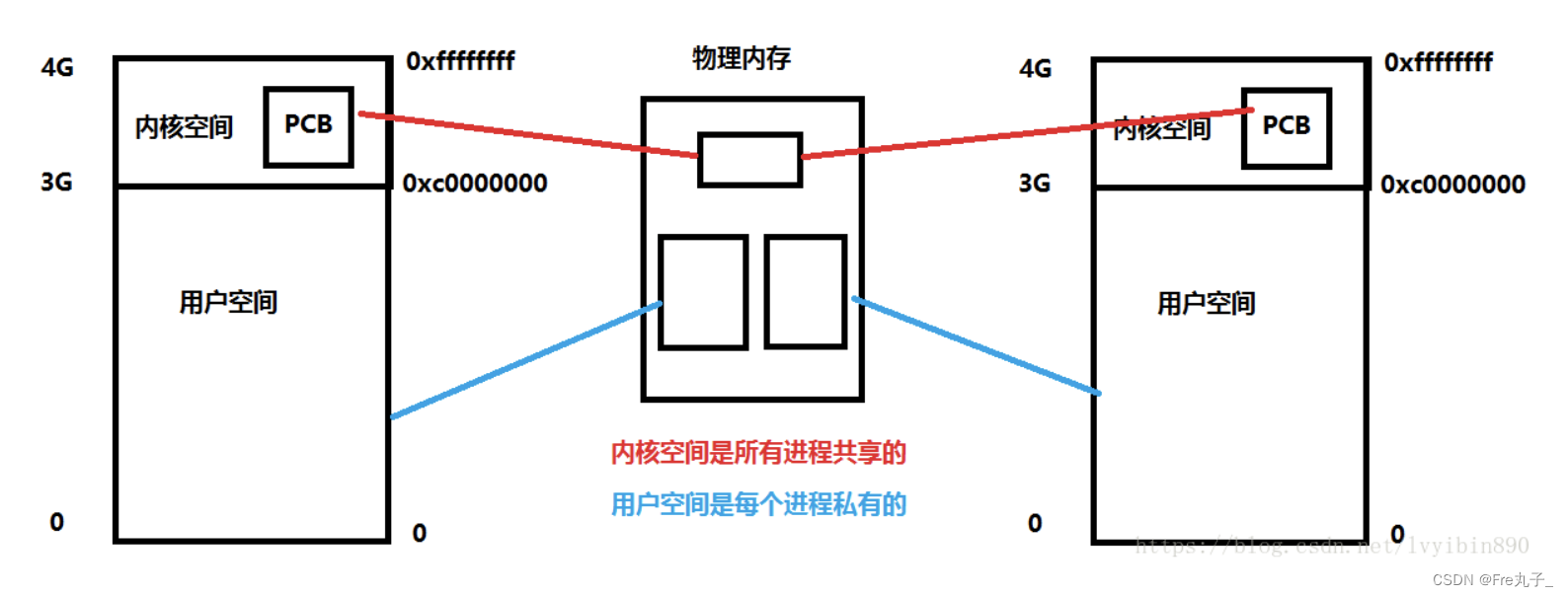
【Linux】程序地址空间
程序地址空间 首先引入地址空间的作用什么是地址空间为什么要有地址空间 首先引入地址空间的作用 1 #include <stdio.h>2 #include <unistd.h>3 #include <stdlib.h>4 int g_val 100;6 int main()7 {8 pid_t id fork();9 if(id 0)10 {11 int cn…...

springboot 设置自定义启动banner背景图 教程
springboot banner Spring Boot中的banner是在应用程序启动时显示的一个ASCII艺术字符或文本。它被用来给用户展示一些关于应用程序的信息,例如名称、版本号或者公司标志等。 使用Spring Boot的默认设置,如果项目中有一个名为“banner.txt”的文件放置…...

Docker Desktop部署n8n避坑指南:从触发器到函数节点的完整调试心得
Docker Desktop部署n8n避坑指南:从触发器到函数节点的完整调试心得 作为一个刚接触n8n的开发者,我在实现一个简单的定时邮件提醒功能时踩了不少坑。这篇文章将分享我在Docker Desktop环境下部署n8n,并构建一个智能工作时间提醒工作流的完整过…...

LRC歌词制作终极指南:如何用歌词滚动姬轻松制作专业歌词
LRC歌词制作终极指南:如何用歌词滚动姬轻松制作专业歌词 【免费下载链接】lrc-maker 歌词滚动姬|可能是你所能见到的最好用的歌词制作工具 项目地址: https://gitcode.com/gh_mirrors/lr/lrc-maker 歌词滚动姬(LRC Maker)是…...

教育行业3D打印机怎么选?这家深耕校企合作的厂家值得关注
3D打印机的诞生最初主要适用于原型验证,后续伴随着技术的精进及市场需求的催化,3D打印技术的应用场景也由单一的原型验证走向教育、文创、航空航天、汽车等多种行业。其中3D打印技术在教育领域的应用,深度践行了产教融合,科教兴国…...

避开Cache和MMU:Trace32里A、NC、ANC三种访问类型到底该怎么选?
Trace32内存访问类型实战指南:A/NC/ANC在ARM调试中的精准选择 调试嵌入式系统时,最令人头疼的莫过于明明代码逻辑正确,却因为内存访问路径问题导致数据异常。上周我在调试一块Cortex-A72开发板时,就遇到了这样的困境:通…...

16.5【保姆级教程】C11对齐特性详解:比位填充更自然,底层开发必学
📢 关注博主不迷路!CSDN最细C11对齐特性教程来袭🔥 继位字段之后,解锁C语言底层内存控制新技能——C11对齐特性,比传统位填充字节更自然、更规范,吃透它,轻松搞定硬件相关开发难点,刚…...
Pixel Script Temple 目标检测辅助标注:基于YOLOv5预测结果生成可视化报告
Pixel Script Temple 目标检测辅助标注:基于YOLOv5预测结果生成可视化报告 1. 引言:当YOLOv5遇上可视化报告 在计算机视觉项目中,我们常常遇到这样的困境:YOLOv5模型跑完了,检测结果也出来了,但面对一堆枯…...

做泰国外贸生意,企业该如何预防合作骗局?
外贸企业防范泰国外贸骗局需做好尽职调查合同设计物流跟踪与风险监控,可借助泰国官方平台核验信息并通过催全球实地审验降低风险。外贸企业防范泰国外贸骗局,可从以下关键环节入手:前期尽职调查核实企业注册信息:通过泰国商业部商…...

2026年手机测控深度测评:优质服务商与推荐厂家全景解析
随着智能网联汽车技术的快速发展,手机控车作为人车交互的重要入口,已成为车企智能化升级的关键模块。本测评旨在通过对行业代表性企业的深度剖析,为采购方与合作伙伴提供客观、结构化的决策参考。本文基于公开资料、技术文档及行业逻辑推演&a…...

Flutter 三方库 get\_it + injectable 的鸿蒙化适配指南:实现优雅的依赖注入
Flutter 三方库 get_it injectable 的鸿蒙化适配指南:实现优雅的依赖注入 欢迎加入开源鸿蒙跨平台社区:https://openharmonycrossplatform.csdn.net 大家好呀!🌸 今天要和大家分享一个超级实用的Flutter开发技巧——如何将 get_i…...
、Chainlit端口映射与CORS配置)
Qwen3-0.6B-FP8部署教程:vLLM服务健康检查(llm.log)、Chainlit端口映射与CORS配置
Qwen3-0.6B-FP8部署教程:vLLM服务健康检查、Chainlit端口映射与CORS配置 1. 开篇:为什么你需要这篇教程? 如果你正在尝试部署一个轻量级的AI模型,比如Qwen3-0.6B-FP8,并且希望它能稳定运行,还能通过一个漂…...