Oracle PL/SQL 类型(Type):索引表、嵌套表、变长数组、pipelined 管道
1、Oracle 新建员工表和部门表.sql。
集合类型
1、Oracle 集合是相同类型元素的组合,在集合中,使用唯一的下标来标识其中的每个元素,与 Java 的 List 很像。
2、常用集合方式:
| 类型 | 语法 | 下标 | 元素个数 | 初始值 | .extend | 能否存在DB中 |
|---|---|---|---|---|---|---|
| 索引表 | TYPE type_name IS TABLE OF element_type table_name type_name := type_name(); | 整数或字符 可以为负数 | 无限制 | 不用 | 不用 | 只能用在PLSQL中 |
| 嵌套表 | TYPE type_name IS TABLE OF element_type; table_name type_name := type_name(); | 只能为整数 | 无限制 | 用同名构造函数赋值 | 用 | 可以使用create type 创建, 存在数据库中 |
| 变长数组 | TYPE type_name IS VARRAY(n) OF element_type; varray_name type_name := type_name(); | 有限制 |
索引表:不需要初始化或者extend,且无个数限制,迄今为止最高效的集合类型,优先选择。唯一不足的一点是它只能用于PL/SQL而不能直接用于数据库。
嵌套表:如果需要使用10g,11g中的那些集合操作,则可以选择Nested table(嵌套表);
变长数组:需要限制集合元素个数时可以使用。
3、集合常用方法:集合方法是集合对象的内置函数,可以使用"."标记来调用。
| 方法 | 描述 |
|---|---|
| exists(n) | 索引处的元素是否存在, 返回TRUE|FALSE |
| count | 当前集合中的元素总个数 |
| limit | 集合元素索引的最大值 (索引表和嵌套表是不限个数的,所以返回null,变长数组返回定义时的最大索引 ) |
| first / last | 返回集合第一个/最后一个元素的下标 |
| prior / next | 当前元素的前一个 / 后一个元素 |
| extend | 增加元素,扩展集合的容量,不能用于索引表 x.extend 增加一个null元素 |
| trim | 从尾部删除, 被删元素不保留占位符,不能用于索引表。 x.trim 删除一个元素 |
| delete | 按索引删除集合元素, 被删元素保留占位符 delete 删除所有 |
索引表
| 语法 | TYPE type_name IS TABLE OF element_type INDEX BY index_type; table_name type_name; |
| 描述 | type_name:类型名称,自定义即可。 |
| element_type:集合中存放的元素类型,如 number、char、varchar2,也可以是整行记录 | |
| index_type:只能是整型或者字符串,可选值有:pls_integer, binary_integer or char | |
| table_name:索引表/集合变量名称,自定义即可。 |
示例一
declare--查询员工姓名cursor ename_cusor isselect ename from emp where rownum <= 100;--定义[索引表](元素类型为员工姓名)TYPE ename_type IS TABLE OF emp.ename%TYPE INDEX BY PLS_INTEGER;--定义索引表变量v_ename_index_table ename_type;--索引表定义为 index by pls_integer 时,需要一个整数变量做计数器下标v_idx number := 0;
begin--循环游标,将元素添加到索引表集合中for ename_row in ename_cusor loopv_idx := v_idx + 1;v_ename_index_table(v_idx) := ename_row.ename;end loop;--索引表集合for循环--引用不存在的元素会报错:ORA-01403: 未找到任何数据for i in v_ename_index_table.first .. v_ename_index_table.last LOOPdbms_output.put_line(i || ' ' || v_ename_index_table(i));end loop;
end;示例二
declare--查询员工信息cursor emp_cusor isselect t.* from emp t where rownum <= 100;--定义[索引表](元素类型为员工表整行记录)TYPE emp_type IS TABLE OF emp%ROWTYPE INDEX BY PLS_INTEGER;--定义集合变量v_emp_index_table emp_type;--索引表定义为 index by pls_integer 时,需要一个整数变量做计数器下标v_idx number := 0;
begin--循环游标,将元素添加到索引表集合中for emp_row in emp_cusor loopv_idx := v_idx + 1;v_emp_index_table(v_idx) := emp_row;end loop;--索引表集合for循环--引用不存在的元素会报错:ORA-01403: 未找到任何数据for i in v_emp_index_table.first .. v_emp_index_table.last LOOPdbms_output.put_line('empno=' || v_emp_index_table(i).empno ||' ename=' || v_emp_index_table(i).ename ||' comm=' || v_emp_index_table(i).comm);end loop;
end;嵌套表
| 语法 | TYPE type_name IS TABLE OF element_type; table_name type_name := type_name(); |
| 描述 | type_name:类型名称,自定义即可。 |
| element_type:集合中存放的元素类型,如 number、char、varchar2,也可以是整行记录 | |
| table_name:索引表/集合变量名称,自定义即可。 |
1、和索引表区别:
嵌套表没有 index of,其下标固定为整型;
必须使用和其同名的构造器对其初始化;
添加元素前,必须先使用.extend分配存储空间;
2、嵌套表的构造器函数() 与嵌套表类型完全同名,可以带参数也可以无参:
带参数初始化:table_name type_name := type_name(a,b,c,...);
不带参数初始化:table_name type_name := type_name();
示例一
declare--查询员工信息cursor emp_cusor isselect t.empno, t.ename, t.comm, t.sal from emp t where rownum <= 100;--定义[嵌套表](元素类型为员工表整行记录)TYPE emp_type IS TABLE OF emp%ROWTYPE;--定义集合变量, 并初始化嵌套表,使用和其同名的构造器对其初始化v_emp_index_table emp_type := emp_type();--集合元素下标(嵌套表下标只能是整数)v_idx number := 0;
begin--循环游标,将元素添加到索引表集合中for emp_row in emp_cusor loop--集合添加元素前,必须先调用它的extend方法给集合添加存储空间v_emp_index_table.extend;v_idx := v_idx + 1;v_emp_index_table(v_idx).empno := emp_row.empno;v_emp_index_table(v_idx).ename := emp_row.ename;v_emp_index_table(v_idx).comm := emp_row.comm;end loop;--索引表集合for循环for i in 1 .. v_emp_index_table.count LOOPdbms_output.put_line('empno=' || v_emp_index_table(i).empno ||' ename=' || v_emp_index_table(i).ename ||' comm=' || v_emp_index_table(i).comm);end loop;
end;自定义 split 函数
-- =============创建类型(Type)——>split_table_type=============
create or replace type split_table_type as table of varchar2(32676);
/
-- =============创建函数——> split=============
create or replace function split(p_str clob, p_sep varchar2 := ',')
-- 根据匹配给定的分隔符来拆分字符串,没有匹配时,返回空对象。--参数 p_str: 待分割的字符串。--参数 p_sep: 分隔符,不明确指定时,默认为逗号。--返回字符串(p_str)被指定字符(p_sep)分割后的嵌套表类型/集合。return split_table_type is--定义集合变量, 并初始化嵌套表,使用和其同名的构造器对其初始化v_split_table split_table_type := split_table_type();--集合元素下标(嵌套表下标只能是整数)v_idx number := 0;--分隔符找到的上一位置的索引v_sep_pre_idx number := 0;--分隔符找到的当前位置的索引v_sep_cur_idx number;
beginloopv_sep_cur_idx := instr(p_str, p_sep, v_sep_pre_idx + 1);if v_sep_cur_idx > 0 then--集合添加元素前,必须先调用它的extend方法给嵌套表(集合)添加存储空间v_split_table.extend;v_idx := v_idx + 1;--切割需要的目标元素(需要去掉分隔符本身),示例:split('7369=#=7521=#=7900=#=9000','=#=')if v_sep_pre_idx <= 0 then v_split_table(v_idx) := substr(p_str, v_sep_pre_idx, v_sep_cur_idx - 1);else v_split_table(v_idx) := substr(p_str, v_sep_pre_idx + length(p_sep), v_sep_cur_idx - (v_sep_pre_idx + length(p_sep)));end if;--将上一位置切换到当前位置v_sep_pre_idx := v_sep_cur_idx;elsif v_sep_pre_idx > 0 and v_sep_pre_idx + length(p_sep) <= length(p_str) then--处理最后一个分隔符到内容结尾的部分(比如 1##2##3,1##2##3##)v_split_table.extend;v_idx := v_idx + 1;v_split_table(v_idx) := substr(p_str, v_sep_pre_idx + length(p_sep), length(p_str));exit;elseexit;end if;end loop;return v_split_table;
end;
/
--==============调用示例--==============
--这样查询时,返回的原生的集合,可视化效果不明显
SELECT split('1,223,32,56565') FROM dual T;
--table 函数用于专门读取集合内容,列名默认为 column_value
select * from table(split('7369,7521,7900'));
select * from table(split(',7369,7521,,7900,'));
select * from table(split('7369,7521,7900','#'));
select * from table(split('','#'));--空结果
select * from table(split('#','#'));--返回一个null
select column_value as empno from table(split('7369=#=7521=#=7900=#=9000','=#='));
select column_value as empno from table(split('=#=7369=#=7521=#=7900=#=9000=#=','=#='));
select * from emp t where t.empno in (select * from table(split('7369,7521,7900')));
select * from emp t where t.empno in (select column_value as empno from table(split('7369,7521,7900')));存储函数返回多行多列结果集
1、存储过程,存储函数返回单个结果时比较容易处理,返回多行多列时,则需要借助其它一些知识点,比如引用游标,以及本文的 Type 类型。
-- =============创建类型(Type)对象,指定每一行的多列信息,相当于列。
create or replace type emp_qury_col_type is object
(empno NUMBER(4),ename VARCHAR2(10),job VARCHAR2(9),mgr NUMBER(4),hiredate TIMESTAMP(6),sal NUMBER(7, 2),comm NUMBER(7, 2),deptno NUMBER(2)
);
/
-- =============创建类型(Type)嵌套表,元素为上面的对象,相当于行。
create or replace type emp_qury_row_type is table of emp_qury_col_type;
/
create or replace function emp_qury_fun(pageNo in number := 1,pageSize in number := 20)--分页查询员工信息--参数 pageNo:查询的页码,从1开始,默认为1--参数 pageSize:每页的条数,默认为20--返回查询的集合——多行多列return emp_qury_row_type is--定义集合变量, 并初始化嵌套表,使用和其同名的构造器对其初始化v_emp_qury_row emp_qury_row_type := emp_qury_row_type();--集合元素下标(嵌套表下标只能是整数)v_idx number := 0;
begin--将查询的结果放入到嵌套表/集合中for row in (select t.empno, t.ename, t.job, t.mgr, t.hiredate, t.sal, t.comm, t.deptnofrom (select rownum r, t1.* from emp t1) t where t.r between ((pageNo - 1) * pageSize + 1) and pageNo * pageSize) loop--嵌套表集合添加元素前,必须先调用它的extend方法给嵌套表(集合)添加存储空间v_emp_qury_row.extend;v_idx := v_idx + 1;v_emp_qury_row(v_idx) := emp_qury_col_type(row.empno, row.ename, row.job, row.mgr, row.hiredate, row.sal, row.comm, row.deptno);end loop;return v_emp_qury_row;
end;
/
--==============调用示例(使用table函数将函数返回的嵌套表转换成查询可以使用的目的表)--==============
select T.* from table(emp_qury_fun(1,50)) T;
select T.* from table(emp_qury_fun(1,5)) T;
select T.* from table(emp_qury_fun(2,10)) T;
SELECT T.* FROM table(emp_qury_fun()) T; 变长数组
| 语法 | TYPE type_name IS VARRAY(size) OF element_type; varray_name type_name := type_name(); |
| 描述 | type_name:类型名称,自定义即可。 |
| size:表示数组的最大长度,一旦超过则报错:ORA-06532:下标超出限制 | |
| element_type:集合中存放的元素类型,如 number、char、varchar2,也可以是整行记录 | |
| varray_name:变长数组/集合变量名称,自定义即可。 |
示例一:
DECLARE--查询员工姓名CURSOR ename_cusor ISSELECT ename FROM emp WHERE ROWNUM <= 100;--定义[变长数组](元素类型为员工姓名)TYPE ename_type IS VARRAY(100) OF emp.ename%TYPE;---定义集合变量, 并使用和其同名的构造器对其初始化v_ename_array ename_type := ename_type();--集合元素下标(变长数组下标只能是整数)v_idx NUMBER := 0;
BEGIN--循环游标,将元素添加到索引表集合中FOR ename_row IN ename_cusor LOOPv_idx := v_idx + 1;--集合添加元素前,必须先调用它的extend方法给集合添加存储空间v_ename_array.EXTEND;v_ename_array(v_idx) := ename_row.ename;END LOOP;--索引表集合for循环--引用不存在的元素会报错:ORA-01403: 未找到任何数据FOR i IN v_ename_array.FIRST .. v_ename_array.LAST LOOPDBMS_OUTPUT.PUT_LINE(i || ' ' || v_ename_array(i));END LOOP;
END;
二维数组
1、Oracle 9i 开始,可以创建多层集合,相当于 Java 的二维数组。
declaretype varray_in is varray(6) of pls_integer; --内层集合,元素是整型,相当于列type varray_out is varray(4) of varray_in; --外层集合,元素是变成数组,相当于行,--定义变量,通过构造器函数初始化变长数组。v_varray_in varray_in := varray_in(1, 2, 3, 4, 5, 6);--外层集合赋值为内层集合v_varray_out varray_out := varray_out(v_varray_in);
begin--继续使用构造器赋值数据v_varray_out.extend;v_varray_out(2) := varray_in(5, 6, 7, 8, null, null);v_varray_out.extend;v_varray_out(3) := varray_in(9, 10, 11, 12, 13, null);--遍历二维数组for i in v_varray_out.first .. v_varray_out.last loopfor j in v_varray_in.first .. v_varray_in.last loopdbms_output.put_line('[' || i || '][' || j || ']= ' ||v_varray_out(i) (j));end loop;if i < v_varray_out.count thendbms_output.new_line();end if;end loop;
end;pipelined 管道
1、plsql 中使用 dbms_output 输出的信息,需要等服务器执行完成后,才能一次性返回给客户端。如果需要在客户端 实时 输出函数执行过程中的一些信息,在 Oracle9i 以后,可以使用管道函数。
2、管道函数为 并行执行。用关键字 pipelined 声明这是一个管道函数,返回值类型必须为集合,函数中 pipe row 语法被用来返回该集合的单个元素,可以以一个空的 return 语句提前结束。
示例1:
--自定义类型(嵌套表/集合),元素类型为字符串,最长38位
create or replace type uuid_table_type is table of varchar2(38);
/
--自定义函数
create or replace function uuid_fun(p_size number :=20)return uuid_table_type--生成指定个数的uuid值,小写。--参数 p_size:每次生成的个数,默认为 20个。--返回随机的uuid字符串,多行单列。pipelined is
begin
for i in 1 .. p_size loop--uuid转为小写,然后通过管道输出返回.pipe row(lower(sys_guid()));
end loop;
--经过测试,return 写不写效果都一样。
return;
end;
/
--==============调用示例--==============
select t.* from table(uuid_fun()) t;
select t.* from table(uuid_fun(100)) t; 示例2:dbms_output 输出日志不仅慢,而且手动缓冲区的大小限制,而采用管道则不仅快,而已不受大小限制。
--自定义类型(嵌套表/集合),元素类型为字符串
create or replace type emp_init_data_log_type is table of varchar2(32767);
/
--自定义函数
create or replace function emp_init_data_fun(p_empno_start number :=1,p_empno_end number :=5000)return emp_init_data_log_type--生成初始化员工表的 insert SQL语句--参数 p_empno_start:员工表主键开始的数值--参数 p_empno_end:员工表主键结束的数值pipelined isv_sql varchar2(2048);pragma autonomous_transaction;
begin
for i in p_empno_start .. p_empno_end loopv_sql := 'INSERT INTO EMP VALUES (' || i || ', ''SMITH' || i || ''', ''CLERK'', 7902,TO_DATE(''17-08-1980'', ''DD-MM-YYYY''), 100 + abs(mod(dbms_random.random,9999)) , NULL, 20);';--如果想在这里直接执行Insert语句,而在 SELECT 语句中调用该函数,则会报错:ORA-14551:无法在查询中执行DML操作--因为 SELECT 语句无法更改数据库的状态,一般来说,此时推荐创建为存储过程而不是存储函数。pipe row(v_sql);
end loop;
--经过测试,return 写不写效果都一样。
return;
end;
/
--==============调用示例--==============
select t.* from table(emp_init_data_fun(1,10)) t;
select t.* from table(emp_init_data_fun()) t;
自定义 split 函数
示例1:管道+Type(类型)实现其它语言中的 split 分割函数。
-- 创建类型(Type)——>split_table_type
create or replace type split_table_type as table of varchar2(32676);
/
-- 创建函数——> split
create or replace function split(p_list clob, p_sep varchar2 := ',' )
-- 根据匹配给定的分隔符来拆分字符串,没有匹配时,返回空对象。
--参数 p_list: 待分割的字符串。
--参数 p_sep: 分隔符,不明确指定时,默认为逗号。
--返回字符串(p_list)被指定字符(p_sep)分割后的表类型/集合。return split_table_typepipelined isv_idx pls_integer;--直接使用 number 类型也可以 v_list varchar2(32676) := p_list;
beginloop--获取分隔符所在的位置v_idx := instr(v_list, p_sep);if v_idx > 0 then--通过管道输出/返回截取的目标元素pipe row(substr(v_list, 1, v_idx - 1));--去掉截取过的内容,保留未截取的内容,用于下次循环继续截取v_list := substr(v_list, v_idx + length(p_sep));elsif v_list != p_list then--处理最后一个分隔符到内容结尾的部分(比如 1##2##3,1##2##3##)pipe row(v_list);exit;elseexit;end if;end loop;
end;
/
--==============调用示例--==============
--这样查询时,返回的原生的集合,可视化效果不明显
SELECT split('1,223,32,56565') FROM dual T;
--table 函数用于专门读取集合内容,列名默认为 column_value
select * from table(split('7369,7521,7900'));
select * from table(split(',7369,7521,,7900,'));
select * from table(split('7369,7521,7900','#'));
select * from table(split('','#'));--空结果
select * from table(split('#','#'));--返回一个null
select column_value as empno from table(split('7369=#=7521=#=7900=#=9000','=#='));
select column_value as empno from table(split('=#=7369=#=7521=#=7900=#=9000=#=','=#='));
select * from emp t where t.empno in (select * from table(split('7369,7521,7900')));
select * from emp t where t.empno in (select column_value as empno from table(split('7369,7521,7900')));相关文章:
:索引表、嵌套表、变长数组、pipelined 管道)
Oracle PL/SQL 类型(Type):索引表、嵌套表、变长数组、pipelined 管道
1、Oracle 新建员工表和部门表.sql。 集合类型 1、Oracle 集合是相同类型元素的组合,在集合中,使用唯一的下标来标识其中的每个元素,与 Java 的 List 很像。 2、常用集合方式: 类型语法下标元素个数初始值.extend能否存在DB中…...
Web 服务器 -【Tomcat】的简单学习
Tomcat1 简介1.1 什么是Web服务器 2 基本使用2.1 下载2.2 安装2.3 卸载2.4 启动2.5 关闭2.6 配置2.7 部署 3 Maven创建Web项目3.1 Web项目结构3.2 创建Maven Web项目 4 IDEA使用Tomcat4.1 集成本地Tomcat4.2 Tomcat Maven插件 Tomcat 1 简介 1.1 什么是Web服务器 Web服务器是…...
armbian使用1panel快速部署部署springBoot项目后端
文章目录 前言环境准备实现步骤第一步:Armbian安装1panel第二步:安装数据库第三步:查看数据库容器重要信息【重要】查看容器所在的网络查看容器连接地址 第四步:项目配置和打包第五步:构建项目镜像 前言 这里只是简单记录部署spr…...

Streamlit 讲解专栏(八):图像、音频与视频魔法
文章目录 1 前言2 st.image:嵌入图像内容2.1 图像展示与描述2.2 调整图像尺寸2.3 使用本地文件或URL 3 st.audio:嵌入音频内容3.1 播放音频文件3.2 生成音频数据播放 4 st.video:嵌入视频内容4.1 播放视频文件4.2 嵌入在线视频 5 结语&#x…...

python使用装饰器记录方法耗时
思路 python使用修饰器记录方法耗时,目的是每当方法执行完后,可以记录该方法耗时,而不需要在每个方法的执行前后,去创建一个临时变量,来记录耗时。 方式一(不推荐): 在每个方法的…...

JavaWeb课程学习--Day01
HTML 建立css文件: css使用方式: <span>...</span>无语意包裹标签 css中的三种选择器: 注意:播放视音频时要留出播放空间 盒子模型: 表格标签: 以上表格: 表单标签: 表…...

Spring Boot单元测试使用MockBean注解向Service注入Mock对象
1. 背景介绍 我们在测试时有一个Service,我们需要测试Service,但Service内部依赖ServiceA、ServiceB,此时我们希望Mock ServiceA,ServiceB 注入真实对象。 class Service {private ServiceA A;private ServiceB B;public int me…...

Java中使用instanceof判断对象类型
记录:470 场景:Java中使用instanceof判断对象类型。例如在解析JSON字符串转换为指定类型时,先判断类型,再定向转换。在List<Object>中遍历Object时,先判断类型,再定向转换。 版本:JDK 1…...
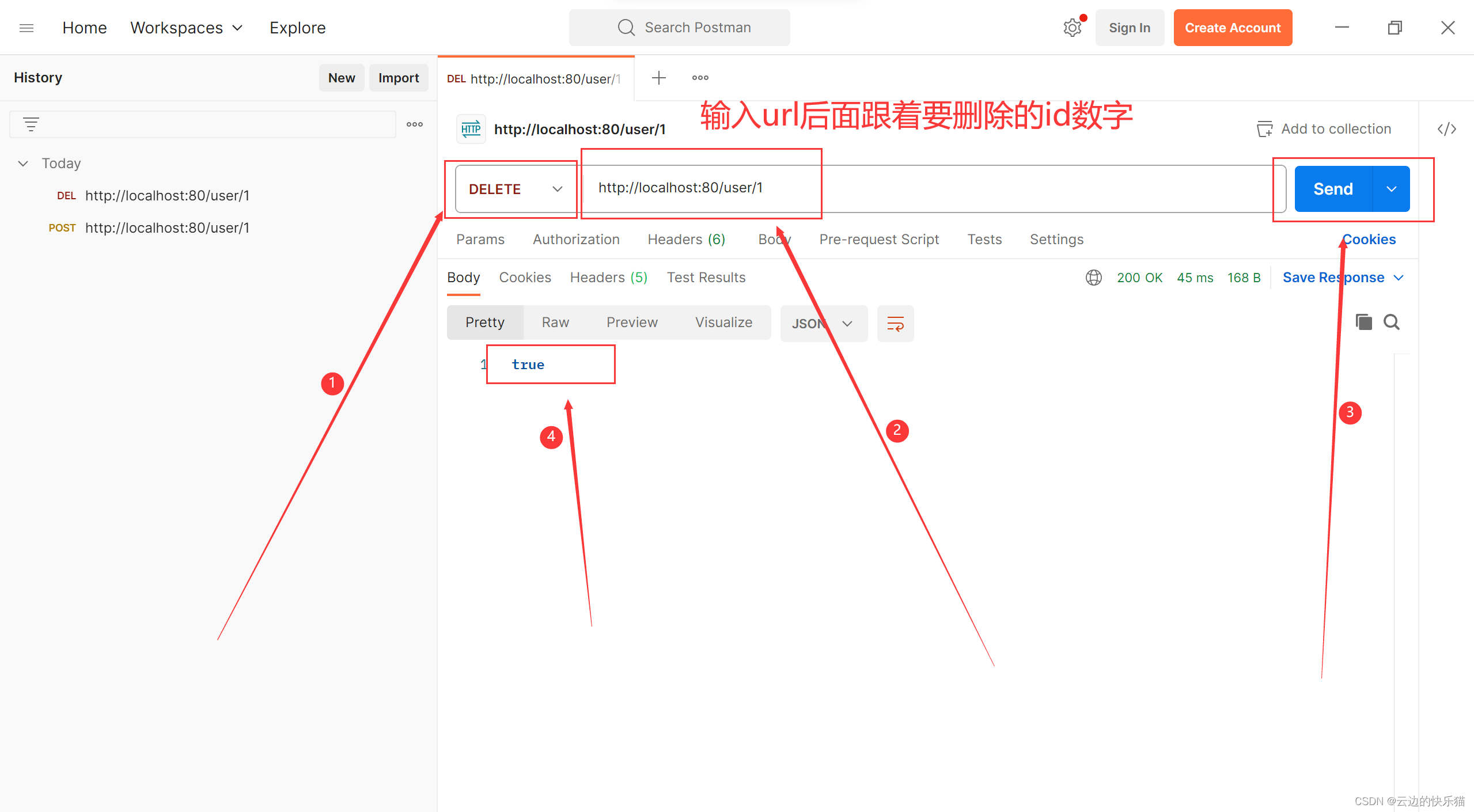
postman测试后端增删改查
目录 一、本文介绍 二、准备工作 (一)新建测试 (二)默认url路径查看方法 三、增删改查 (一)查询全部 (二)增加数据 (三)删除数据 (四&…...

根据源码,模拟实现 RabbitMQ - 通过 SQLite + MyBatis 设计数据库(2)
目录 一、数据库设计 1.1、数据库选择 1.2、环境配置 1.3、建库建表接口实现 1.4、封装数据库操作 1.5、针对 DataBaseManager 进行单元测试 一、数据库设计 1.1、数据库选择 MySQL 是我们最熟悉的数据库,但是这里我们选择使用 SQLite,原因如下&am…...

1、基于 CentOS 7 构建 LVS-DR 群集。 2、配置nginx负载均衡
一、基于CentOS7和、构建LVS-DR群集 准备四台虚拟机 ip作用192.168.27.150客户端192.168.27.151LVS192.168.27.152RS192.168.27.152RS 关闭防火墙 [rootlocalhost ~]# systemctl stop firewalld安装ifconfig yum install net-tools.x86_64 -y1、DS上 1.1 配置LVS虚拟IP …...

android 如何分析应用的内存(十七)——使用MAT查看Android堆
android 如何分析应用的内存(十七)——使用MAT查看Android堆 前一篇文章,介绍了使用Android profiler中的memory profiler来查看Android的堆情况。 如Android 堆中有哪些对象,这些对象的引用情况是什么样子的。 可是我们依然面临…...
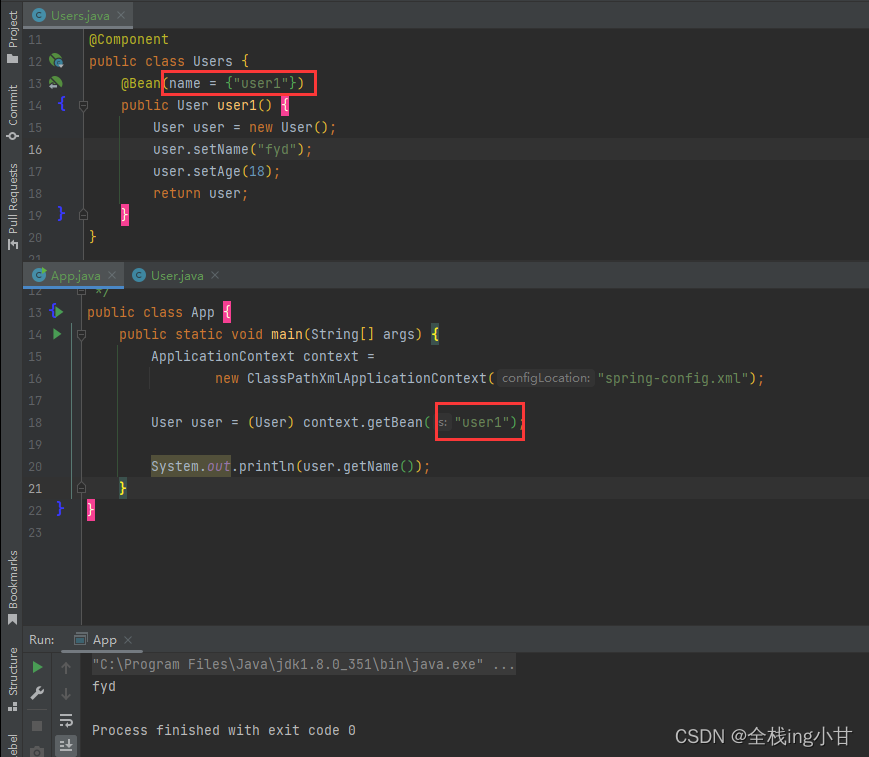
Spring 使用注解储存对象
文章目录 前言存储 Bean 对象五大注解五大注解示例配置包扫描路径读取bean的示例 方法注解 Bean Bean 命名规则重命名 Bean 前言 通过在 spring-config 中添加bean的注册内容,我们已经可以实现基本的Spring读取和存储对象的操作了,但在操作中我们发现读…...
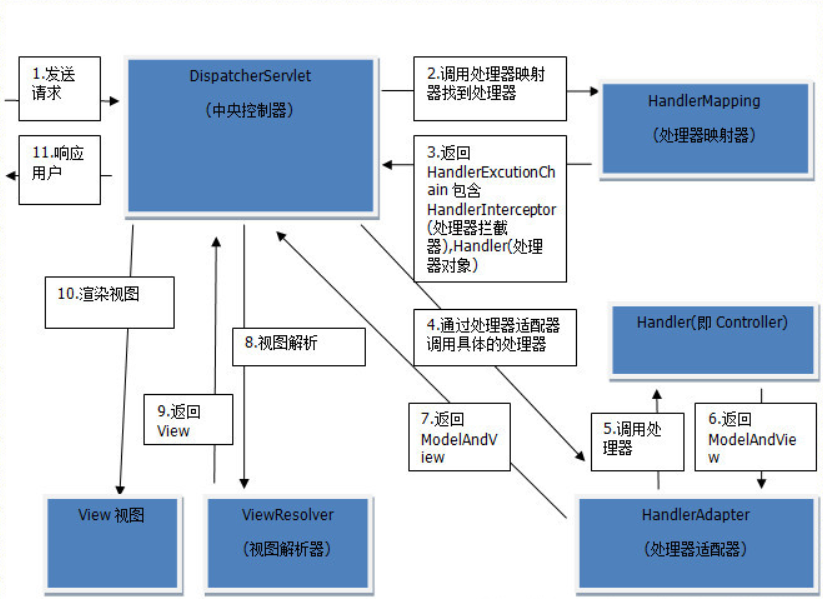
一、初始 Spring MVC
文章目录 一、回顾 MVC 模式二、初始 Spring MVC2.1 Spring MVC 核心组件2.1.1 前端控制器(DispatcherServlet)2.1.2 处理器映射器(HandlerMapping)2.1.3 处理器适配器(HandlerAdapter)2.1.3 后端控制器&am…...
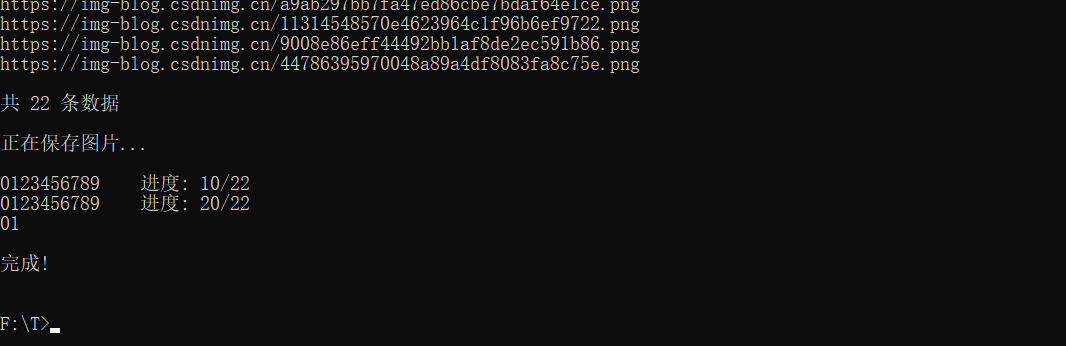
《爬虫》爬取页面图片并保存
爬虫 前言代码效果 简单的爬取图片 前言 这几天打算整理与迁移一下博客。因为 CSDN 的 Markdown 编辑器很好用 ,所以全部文章与相关图片都保存在 CSDN。而且 CSDN 支持一键导出自己的文章为 markdown 文件。但导出的文件中图片的连接依旧是 url 连接。为了方便将图…...

【项目部署】JavaScript解析JSON解析报错Unexpected token xxx is not valid JSON
问题背景 这个报错发生在之前部署的一个前后端分离的项目中。后端使用的Spring Boot,前端使用的JavaScript,前后端交互使用Thymeleaf框架。 现象 项目组的另一个小伙伴说,突然有个页面打不开了,整个页面全空白。我F12打开浏览器…...
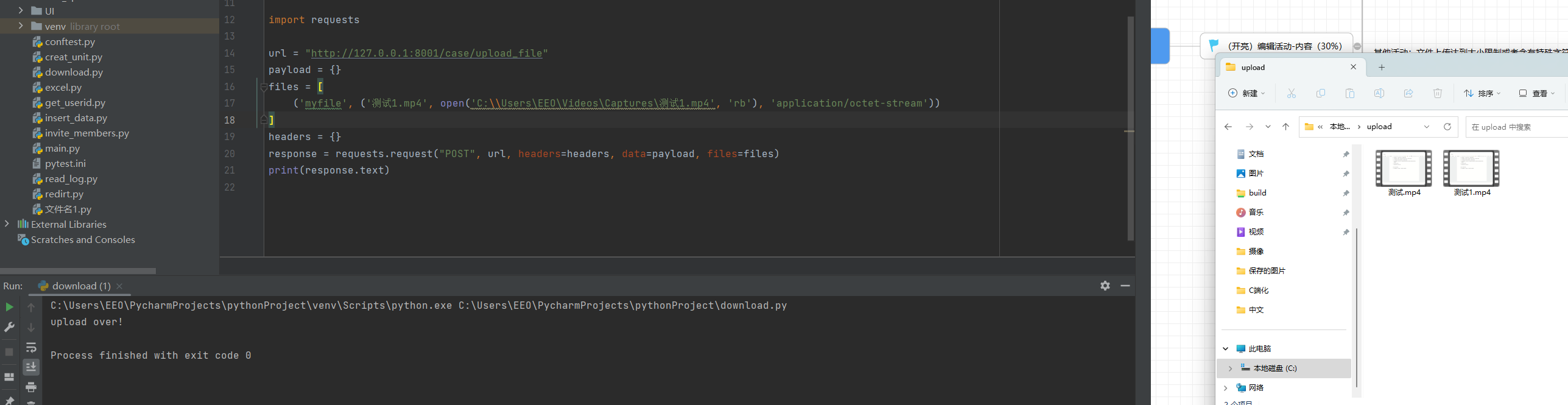
做接口测试如何上次文件
在日常工作中,经常有上传文件功能的测试场景,因此,本文介绍两种主流编写上传文件接口测试脚本的方法。 首先,要知道文件上传的一般原理:客户端根据文件路径读取文件内容,将文件内容转换成二进制文件流的格式…...

Java SPI机制详解-01
1. 概述 SPI(Service Provider Interface),是 Java 6 引入了一个内置功能,实现服务提供发现和加载机制,使之与特定接口的匹配。 SPI 机制的核心思想就是 解耦 ,将装配的控制权移到程序之外,这…...

由浅入深C系列六:C中实现字符串trim的功能
C中实现字符串trim的功能 简介设计思路代码实现运行效果 简介 一个项目中,需要用c语言实现对字符串中的字定字符进行过滤并从字符串的删除,查询了C语言的基本库,没有发现有这样的函数,于是发挥程序员的主观能力性,自力…...

博客网站添加复制转载提醒弹窗Html代码
网站如果是完全禁止右键(复制、另存为等)操作,对用户来说体验感会降低,但是又不希望自己的原创内容直接被copy,今天飞飞和你们分享几行复制转载提醒弹窗Html代码。 效果展示: 复制以下代码,将其…...

终极Windows驱动签名绕过指南:3步解决硬件兼容性问题
终极Windows驱动签名绕过指南:3步解决硬件兼容性问题 【免费下载链接】DSEFix Windows x64 Driver Signature Enforcement Overrider 项目地址: https://gitcode.com/gh_mirrors/ds/DSEFix DSEFix是一款专为Windows x64系统设计的驱动签名强制覆盖工具&#…...

macos简单配置openclaw焦
1 实用案例 1.1 表格样式生成 本示例用于生成包含富文本样式与单元格背景色的Word表格文档。 模板内容: 渲染代码: # python-docx-template/blob/master/tests/comments.py from docxtpl import DocxTemplate, RichText # data: python-docx-template/bl…...

掌握AI专著撰写技巧,借助工具,轻松打造高质量学术专著
学术专著创作困境与AI工具解决方案 许多学者在撰写学术专著时,常常面临着“有限的精力”与“无限的需求”之间的矛盾。写一本专著通常需要耗费3到5年,甚至更长的时间,而研究者在日常生活中还要兼顾教学、科研和学术交流等多重任务࿰…...

3步完成黑苹果配置工具:OpCore Simplify快速搭建macOS系统
3步完成黑苹果配置工具:OpCore Simplify快速搭建macOS系统 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 还在为复杂的OpenCore配置而烦恼…...

免费APK直装神器:告别模拟器,3分钟在Windows上畅玩安卓应用
免费APK直装神器:告别模拟器,3分钟在Windows上畅玩安卓应用 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 还在为安卓模拟器卡顿、臃肿而烦恼吗…...

Stable Yogi Leather-Dress-Collection企业案例:ACG品牌联名款服装概念图生成
Stable Yogi Leather-Dress-Collection企业案例:ACG品牌联名款服装概念图生成 想象一下,你是一家ACG(动画、漫画、游戏)潮牌的设计师。下个季度要和一部热门动漫IP联名,主题是“赛博朋克机车风”。老板要求你在三天内…...

Qt——Qt中的标准对话框
1.消息对话框是应用程序中最常见的界面元素消息对话框主要用于:为用户提示重要信息,强制用户进行操作选择2.文件对话框Open Mode——应用程序中需要用户打开一个外部的文件Save Mode——应用程序中需要将当前内容存储在用户指定的外部文件中Widget.h#ifn…...

改进的Yolo11算法 有效张点创新点 引入FocalModulation特征金字塔实现精度的提高
Yolo11 引入【FocalModulation】特征金字塔的实现步骤一、【FocalModulation】特征金字塔概述1.1 【FocalModulation】特征金字塔介绍 【FocalModulation】结构简介 以下为【FocalModulation】特征金字塔的核心处理过程和优势: 处理过程:分层上下文化处理…...

人工智能赋能软件开发:基于PyTorch 2.8的AI编程助手本地部署
人工智能赋能软件开发:基于PyTorch 2.8的AI编程助手本地部署 1. 为什么需要私有AI编程助手 想象一下这样的场景:凌晨两点,你正在赶一个紧急项目,遇到一个复杂的算法问题卡壳了。这时候如果有个懂行的搭档能随时提供建议该多好&a…...

三步搞定B站视频转文字:从链接到文字稿的智能转换方案
三步搞定B站视频转文字:从链接到文字稿的智能转换方案 【免费下载链接】bili2text Bilibili视频转文字,一步到位,输入链接即可使用 项目地址: https://gitcode.com/gh_mirrors/bi/bili2text 还在为观看B站视频时无法快速记录重点内容而…...