关于HDFS
目录
一、HDFS概述
二、HDFS架构与工作机制
三、HDFS的Shell操作
四、Hdfs的API操作
一、HDFS概述
- HDFS:Hadoop Distributed File System;一种分布式文件管理系统,通过目录树定位文件。
- 使用场景:一次写入,多次读出,且不支持文件的修改。适用于数据分析,不适用于网盘应用;
- 优点:
- 高容错:多个副本,其中一个副本丢失,可以自动恢复;
- 适合处理大数据:数据规模大 & 文件规模大 & 可以构建于廉价机器上。
- 缺点:
- 不适合低延时数据访问;
- 无法高效的对大量小文件进行存储;
- 不支持并发写同一个文件,仅支持追加,不支持文件的随即修改。
二、HDFS架构与工作机制
- 官方文档
Apache Hadoop 3.3.4 – HDFS Architecture - 组成部分
- NameNode(NN):即Master,管理HDFS。
- Secondary NameNode(SNN):不是NN的热备份(热备份是指在程序还在运行的时候对数据进行备份)SNN对于NN的作用不同于平常的热备份的概念,SNN包含Fsimage和Edits,会定期合并Fsimage和Edits并推送给NN。
- DataNode(DN):即Slaver,执行NN下达的命令。
- Client:客户端,交互与访问。
- Block(hdfs文件块)
- Hadoop1.x中是64M,在Hadoop2.x-3.x中是128M;
- 块的大小既不能太大,也不能太小;(块大小的设置取决于磁盘传输的速率);
- NameNode和SecondaryNameNode的工作机制
- NameNode启动
- 第一次启动NN,需要创建命名空间镜像文件(fsimage)和编辑日志文件(edits)(如果NN不是第一次启动,直接加载fsimage文件和edits文件到内存);
- NN记录操作日志,滚动日志;
- NN在内存中对元数据进行修改操作。
- SecondaryNameNode工作过程
- SNN询问NN是否需要CheckPoint(是否需要合并fsimage和edits)。
- Secondary NameNode请求执行CheckPoint。
- NameNode滚动正在写的Edits日志。将滚动前的编辑日志和镜像文件拷贝到SNN,SNN加载编辑日志和镜像文件到内存进行合并,生成新的镜像文件fsimage.chkpoint。
- 拷贝fsimage.chkpoint到NameNode,NameNode将fsimage.chkpoint重新命名成fsimage。

- NameNode启动
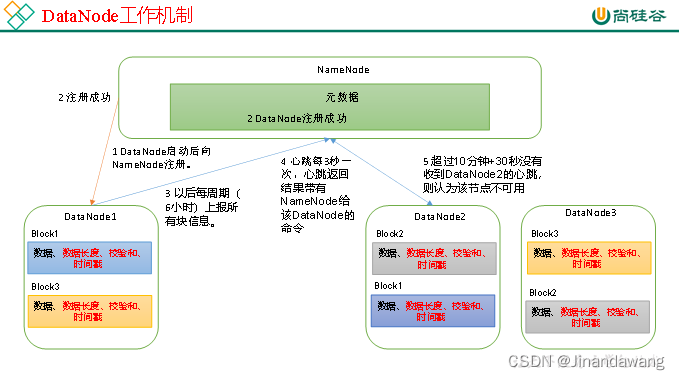
- DataNode的工作机制
- 一个数据块在DataNode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据(包括数据块的长度,块数据的校验和,以及时间戳)。
- DataNode启动后向NameNode注册,通过后,周期性(6小时)地向NameNode上报所有的块信息。
- 心跳是每3秒一次,心跳返回结果带有NameNode给该DataNode的命令如复制块数据到另一台机器,或删除某个数据块。如果超过10分钟没有收到某个DataNode的心跳,则认为该节点不可用。
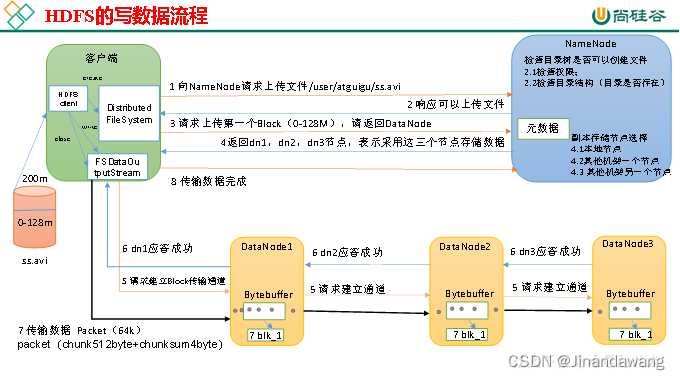
- HDFS的写流程
- 客户端通过Distributed FileSystem模块向NameNode请求上传文件,NameNode检查集群上目标文件是否已存在,父目录是否存在。
- NameNode返回是否可以上传。
- 客户端请求询问第一个 Block上传到哪几个DataNode服务器上。
- NameNode返回3个DataNode节点,分别为dn1、dn2、dn3。
- 客户端通过FSDataOutputStream模块请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成(Pipe管道机制)。
- dn1、dn2、dn3逐级应答客户端。
- 客户端开始往dn1上传第一个Block(先从磁盘读取数据放到一个本地内存缓存),以Packet为单位,dn1收到一个Packet就会传给dn2,dn2传给dn3;dn1每传一个packet,就会将其放入一个应答队列等待应答。
- 当一个Block传输完成之后,客户端再次请求NameNode上传第二个Block的服务器。(重复执行3-7步)。
- 传输完成后通知NameBode通知Client完成传输。
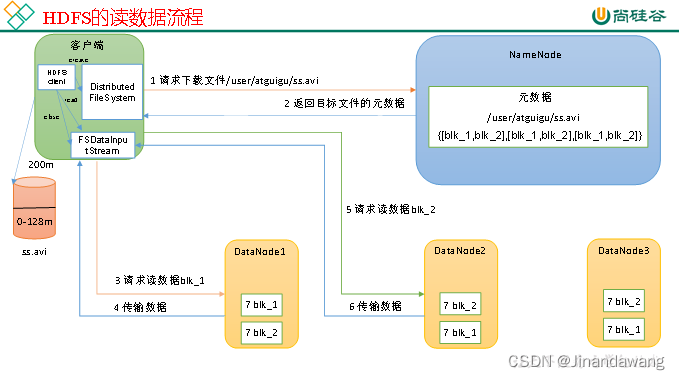
- HDFS的读流程
- 客户端通过DistributedFileSystem向NameNode请求下载文件,NameNode通过查询元数据,找到文件块所在的DataNode地址。
- 挑选一台DataNode(就近原则,然后随机)服务器,请求读取数据。
- DataNode开始传输数据给客户端(从磁盘里面读取数据输入流,以Packet为单位来做校验)。
- 客户端以Packet为单位接收,先在本地缓存,然后写入目标文件。
- 网络拓扑-节点距离计算 & 机架感知(副本位置的选择)
- 距离如图所示
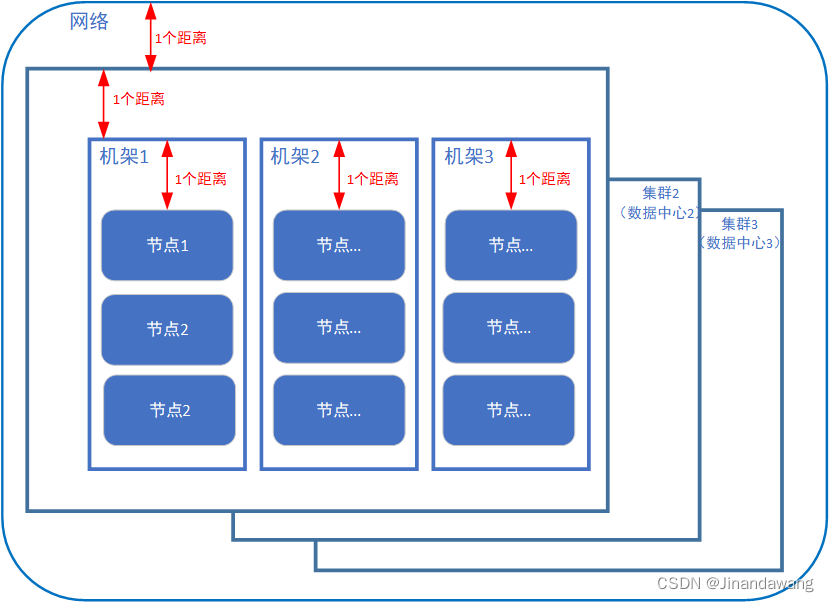
- 网络拓扑(将整个网络视为一个节点,各个大数据集群则是这整个网络节点的子节点,各个机架则分别是每个集群的子节点,每个实际节点又是机架节点的子节点。依次画出网络拓扑图并计算距离)
- 副本位置
- 第一个副本位于客户端所处的节点上,如果客户端不属于集群节点,则随机选择一个;
- 第二、三个副本位于另一个机架上的两个不同节点之上。
- 距离如图所示
- 数据完整性
- DataNode读取Block的时候,它会计算CheckSum,计算Block是否已经损坏;
- DataNode在文件创建后周期验证CheckSum;
三、HDFS的Shell操作
- hadoop fs 某指令 与 hdfs dfs 某指令 是一样的
- Hadoop hdfs的启动与关闭(以下是自定义脚本开启关闭hdfs)
#!/bin/bashif [ $# -lt 1 ] thenecho "No Args Input..."exit ; ficase $1 in "start")echo " =================== 启动 hadoop集群 ==================="echo " --------------- 启动 hdfs ---------------"ssh hadoop101 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh"echo " --------------- 启动 yarn ---------------"ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh"echo " --------------- 启动 historyserver ---------------"ssh hadoop101 "/opt/module/hadoop-3.1.3/bin/mapred --daemon start historyserver" ;; "stop")echo " =================== 关闭 hadoop集群 ==================="echo " --------------- 关闭 historyserver ---------------"ssh hadoop101 "/opt/module/hadoop-3.1.3/bin/mapred --daemon stop historyserver"echo " --------------- 关闭 yarn ---------------"ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh"echo " --------------- 关闭 hdfs ---------------"ssh hadoop101 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh" ;; *)echo "Input Args Error..." ;; esac - hdfs文件的上传下载
* 格式:hadoop fs -指令 [参数列表]上传: 1、本地"剪切"上传:hadoop fs -moveFromLocal ./localfile.txt /hdfs_dir 2、本地拷贝上传:hadoop fs -copyFromLocal ./localfile.txt /hdfs_dirhadoop fs -put ./localfile.txt /hdfs_dir (工作环境更倾向于用put) 3、追加(hdfs文件已存在)hadoop fs -appendToFile localfile.txt /hdfs_dir/hdfsfile.txt ======================================================================================= 下载: 1、hdfs拷贝至本地:hadoop fs -copyToLocal /hdfs_dir/hdfsfile.txt ./hadoop fs -get /hdfs_dir/hdfsfile.txt ./ (生产环境更倾向于用get) - 其他Hadoop shell指令(略)
四、Hdfs的API操作
- 在Windows下配置Hadoop的运行环境
- 添加Hadoop的Windows依赖文件夹至Windows下一个纯英文路径,配置HADOOP_HOME和Path环境变量(Hadoop的Windows依赖官网没有直接提供,需要自行下载,双击winutils.exe可以验证环境变量是否正常,报错可能是因为缺少微软运行库)
- 新建Idea Maven项目(配置阿里云maven镜像可以使下载的速度更快)
- 导入相应的依赖坐标(修改pom.xml - import changes)
<dependencies><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.1.3</version></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.12</version></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>1.7.30</version></dependency> </dependencies>
- 导入相应的依赖坐标(修改pom.xml - import changes)
-
- 日志添加(在项目的src/main/resources目录下,新建一个文件,命名为“log4j.properties”,在文件中填入)
log4j.rootLogger=INFO, stdout log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n log4j.appender.logfile=org.apache.log4j.FileAppender log4j.appender.logfile.File=target/spring.log log4j.appender.logfile.layout=org.apache.log4j.PatternLayout log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
- 日志添加(在项目的src/main/resources目录下,新建一个文件,命名为“log4j.properties”,在文件中填入)
- API编写代码(*重新理解API这个宽泛的概念)
- Java代码的大致逻辑:获取客户端对象 → 执行操作 → 关闭资源(Java标签的用法也可以了解一下,挺好用的)
package cn.hadoop.hdfs;import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.*; import org.junit.After; import org.junit.Before; import org.junit.Test;import java.io.IOException; import java.net.URI; import java.net.URISyntaxException; import java.sql.Array; import java.util.Arrays;public class HdfsClient {private URI uri;private Configuration conf;private String user = "hadoop"; //文件系统用于进行操作的用户名,这个用户名决定了操作的权限。private FileSystem fs;@Beforepublic void init() throws URISyntaxException, IOException, InterruptedException { //uri = new URI("hdfs://hadoop101:8020"); // 统一资源定位符:8020是NameNode内部通信端口conf = new Configuration(); //配置对象默认为空fs = FileSystem.get(uri, conf, user); //使用get()获取FileSystem实例}@Afterpublic void close() throws IOException {fs.close(); // 关闭FileSystem实例}@Test//创建目录public void testmkdir() throws URISyntaxException, IOException, InterruptedException {fs.mkdirs(new Path("/目录名")); //mkdirs()方法:创建一个新的目录}@Test//测试各个部分配置文件的优先级/** 代码内部的配置优先级 > 项目资源目录下的配置文件的优先级 > Linux上的配置文件 > 默认配置* */public void testPut() throws IOException, InterruptedException {conf.set("dfs.replication", "2"); //node level参数,指定每个block在集群上有几个备份(因为这个参数在hdfs-site.xml也有配置,所以可以用来比较这些参数之间的优先级)fs = FileSystem.get(uri, conf, user);fs.copyFromLocalFile(false, true, new Path("D:\\Edelweiss.txt"), new Path("hdfs://hadoop101/目录名称")); //hdfs文件路径开始的一部分是主机名}@Test//文件 下载public void testGet() throws IOException {fs.copyToLocalFile(false, new Path("/集群上的路径"), new Path("C:\\Users\\用户名\\Desktop"), false);}//删除delete、移动rename、更名rename等操作 略@Test//列出目录详细信息(也可以用于判断“路径类型”——文件或者目录)public void fileDetail() throws IOException {final RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"), true); //迭代器while (listFiles.hasNext()) {LocatedFileStatus fileStatus = listFiles.next(); //文件状态System.out.println("---------------" + fileStatus.getPath() + "---------------");System.out.println(fileStatus.getPermission());System.out.println(fileStatus.getBlockLocations());final BlockLocation[] blockLocations = fileStatus.getBlockLocations();System.out.println(Arrays.toString(blockLocations));}}@Testpublic void Test(){System.out.println("okk"+"\n");System.out.println("ookk"+"\\N");} } - 关于代码内部配置的优先级 > 项目资源目录下的配置文件的优先级 > Linux上的配置文件 > 默认配置。
- Java代码的大致逻辑:获取客户端对象 → 执行操作 → 关闭资源(Java标签的用法也可以了解一下,挺好用的)
- 遇见的报错:
- 不支持发行版本5:https://www.cnblogs.com/KennyWang0314/p/12268953.html 按图设置成与自己本地jdk匹配的版本就好了。之前maven是默认Java5,而我的本地是jdk11,无法生成Java5二进制文件。
相关文章:
关于HDFS
目录 一、HDFS概述 二、HDFS架构与工作机制 三、HDFS的Shell操作 四、Hdfs的API操作 一、HDFS概述 HDFS:Hadoop Distributed File System;一种分布式文件管理系统,通过目录树定位文件。使用场景:一次写入,多次读出…...

C++入门:类 对象
C 在 C 语言的基础上增加了面向对象编程,C 支持面向对象程序设计。类是 C 的核心特性,通常被称为用户定义的类型。类用于指定对象的形式,它包含了数据表示法和用于处理数据的方法。类中的数据和方法称为类的成员。函数在一个类中被称为类的成…...
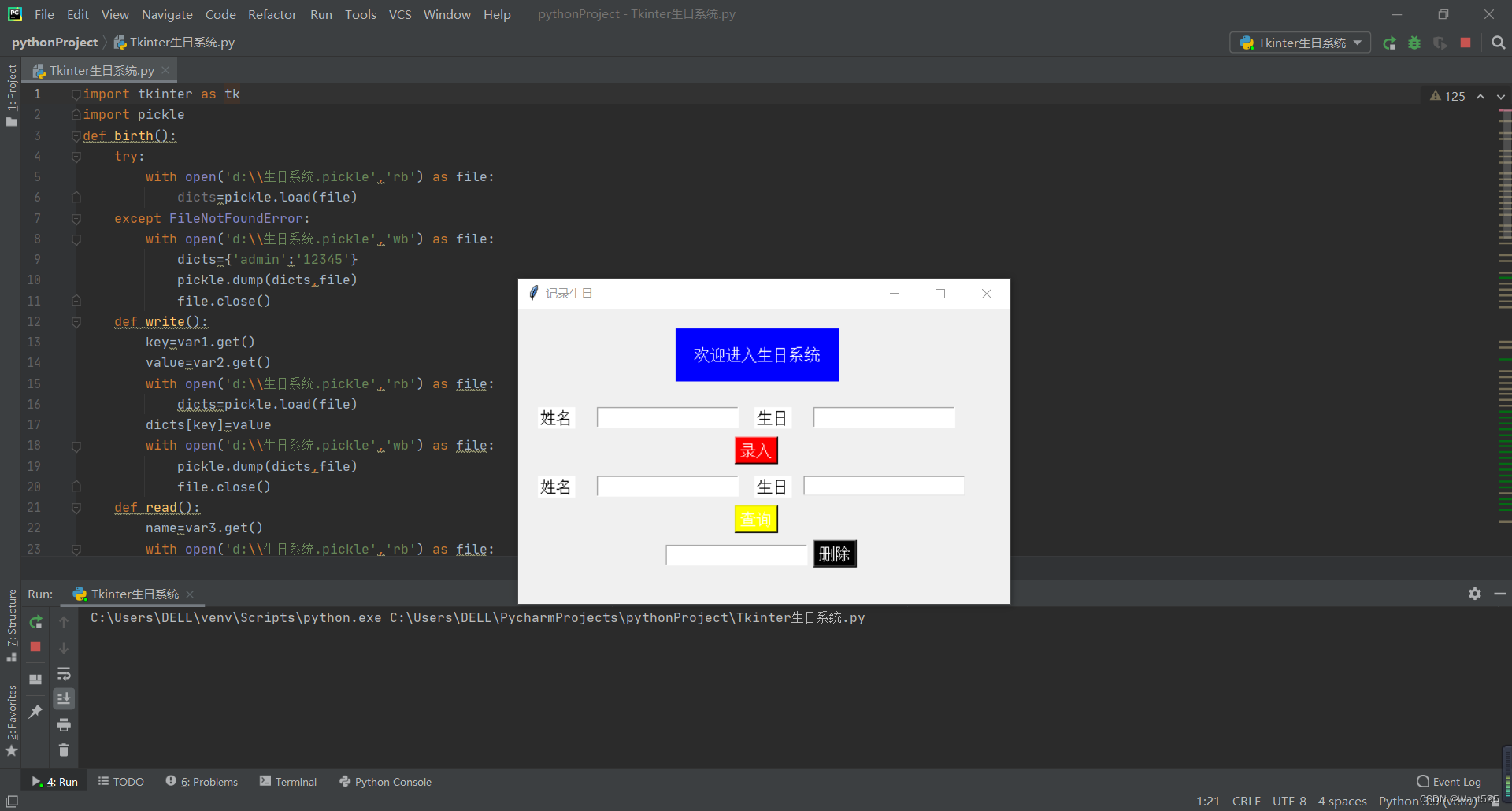
Python生日系统
#免费源码见文末公众号# 录入生日 def write():keyvar1.get()valuevar2.get()with open(d:\\生日系统.pickle,rb) as file:dictspickle.load(file)dicts[key]valuewith open(d:\\生日系统.pickle,wb) as file:pickle.dump(dicts,file)file.close() 查询生日 def read():namev…...

< CSDN周赛解析:第 28 期 >
CSDN周赛解析:第 27 期👉 第一题: 小Q的鲜榨柠檬汁> 题目解析> 解决方案👉 第二题: 三而竭> 解析> 解决方案> 拓展知识👉 第三题: 隧道逃生> 解析> 解决方案👉…...

【题外话】如何拯救小米11Pro这款工业垃圾
1 背景媳妇用小米11Pro手机,某日不慎摔落,幸好屏幕未碎,然而WiFi却怎样都无法打开,初以为是系统死机,几天依旧故障无法使用。现在的手机没有WiFi功能,就无法刷抖音、看视频,就是鸡肋了。后抽空去…...

Python中有哪些常用操作?这20个你都会吗
Python 是一个解释型语言,可读性与易用性让它越来越热门。 正如 Python 之禅中所述: 优美胜于丑陋,明了胜于晦涩。 在你的日常编码中,以下技巧可以给你带来意想不到的收获。 1、字符串反转 下面的代码片段,使用 P…...
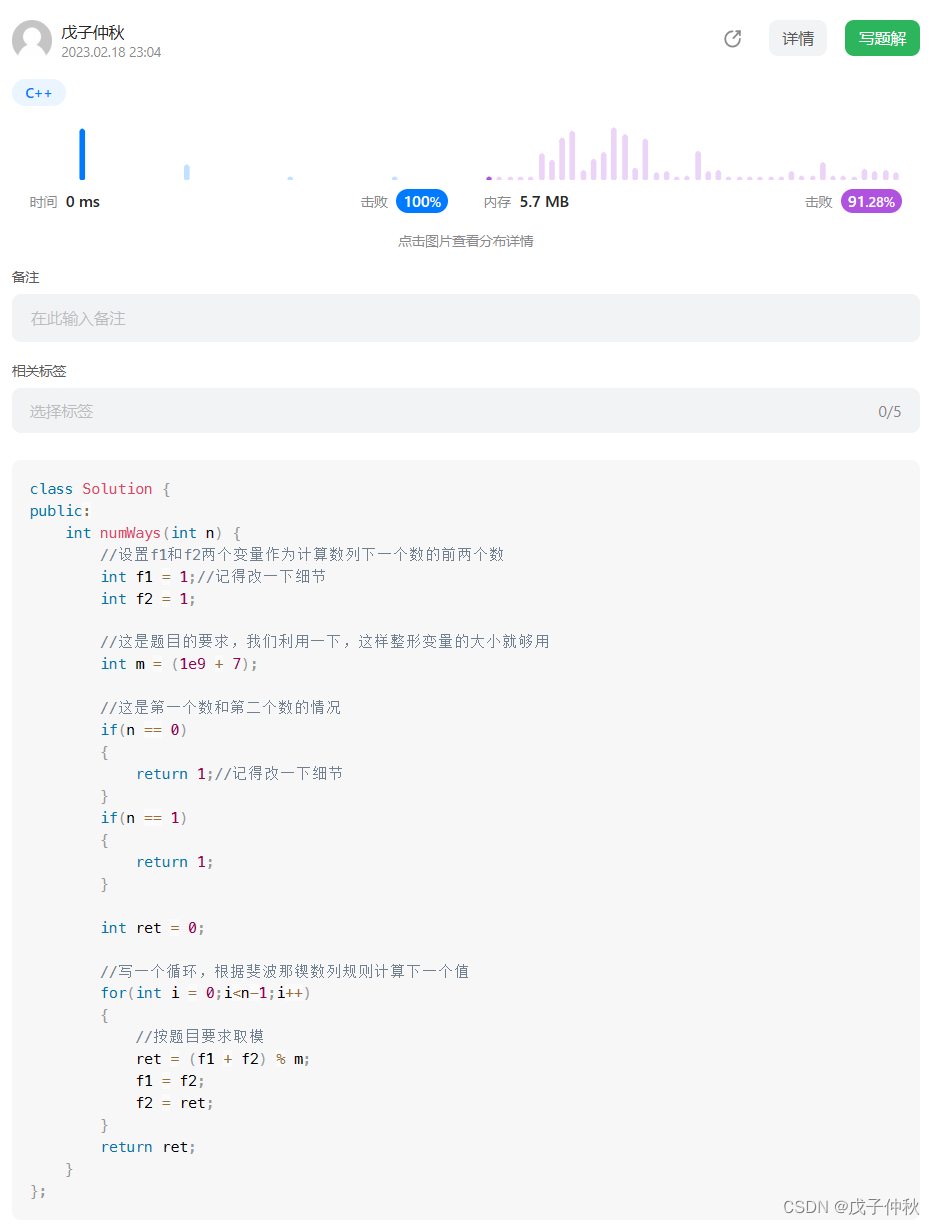
【LeetCode】剑指 Offer(4)
目录 写在前面: 题目:剑指 Offer 10- I. 斐波那契数列 - 力扣(Leetcode) 题目的接口: 解题思路: 代码: 过啦!!! 题目:剑指 Offer 10- II. …...
庄懂的TA笔记(十二)<>
庄懂的TA笔记(十二)<>一、作业展示,答疑:1、作业:2、答疑:二、作业示范,分析:1、文档分析:2、资源分析:3、资源优化:4、光…...
)
学分绩点(2023寒假每日一题 5)
北京大学对本科生的成绩施行平均学分绩点制(GPA)。 既将学生的实际考分根据不同的学科的不同学分按一定的公式进行计算。 公式如下: 实际成绩 绩点 90——100 4.0 85——89 3.7 82——84 3.3 78——81 3.0 75…...
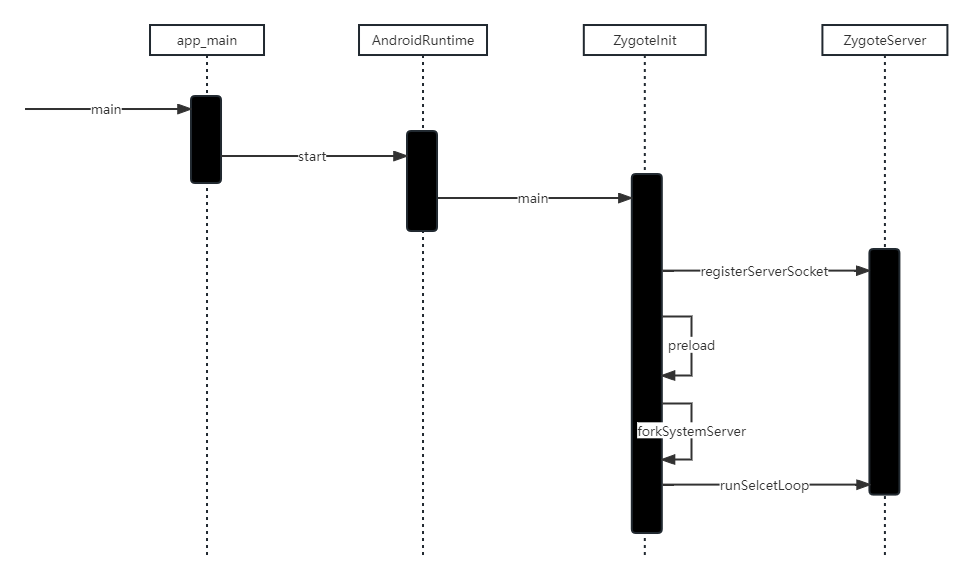
Framework学习之旅:Zygote进程
概述 在Android系统中,DVM(Dalvik 虚拟机和ART、应用程序进程以及运行系统的关键服务SystemServer进程都是由Zygote进程来创建的。通过fork(复制进程)的形式来创建应用程进程和SystemServer进程,由于Zygote进程在启动时会创建DVM…...
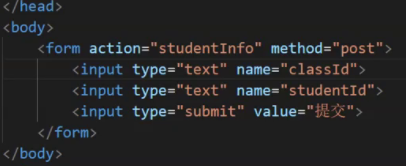
HTTP基础知识
关键字:一问一答用于和服务器交互什么是HTTPHTTP是个应用层协议,是HTTP客户端和HTTP服务器之间的交互数据格式。所以这里有个实例:在浏览网页的时候,浏览器会向服务器发送一个HTTP请求,告诉服务器我想访问什么..然后服…...
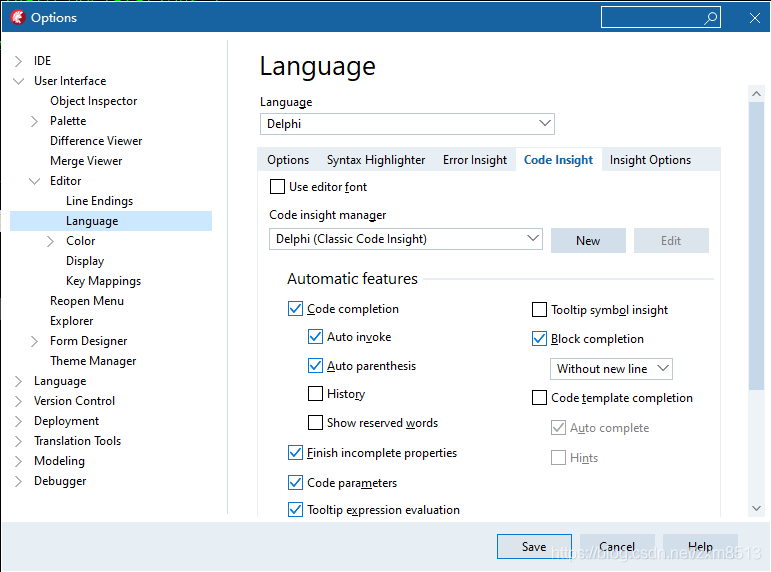
Delphi 10.4.2使用传统代码提示方案(auto complete)(转)
Delphi 10.4重点是实现了LSP,但现在最新的10.4.2还是不成熟,无法满足日常需要,不过没关系,可以设置为原有的方案,如下图:具体操作:Tools->Options->Editor->language->Code Insight…...
)
存储类别、链接与内存管理(三)
1、malloc函数详解 (1)函数声明 #include <stdlib.h> void* malloc(size_t size);malloc可以申请一定数量的空闲内存,这样的内存是匿名的,也就是malloc不会为其赋名,但是确实返回动态分配内存块的首元素地址&a…...
Java:Linux(CentOS)安装、配置及相关命令
目录一、VMware安装二、CentOS安装1、安装过程2、加载ISO2.1 桌面的设置三、VI/VIM编辑器1、一般模式2、编辑模式3、命令模式4、模式间转换四、网络配置和系统管理操作1、配置子网IP和网关2、配置虚拟机ip地址2.1 ifconfig 查询ip地址2.2 修改IP地址3、配置主机名3.1 hostname …...

Linux 操作系统原理 — 多任务优先级调度策略
目录 文章目录 目录多任务优先级调度策略User Process 调度策略配置调整 User Process 的优先级调整非实时进程的优先级调整实时进程优先级调整 User Process 的调度算法多任务优先级调度策略 在 Linux Kernel 中,Kernel Thread 作为唯一的调度实体,Kernel Scheduler(调度程…...

链表学习之找到两个链表相交的第一个节点
链表解题技巧 额外的数据结构(哈希表);快慢指针;虚拟头节点; 找到两个链表相交的第一个节点 给定两个链表,这两个链表可能有环,可能无环。判断这两个链表是否相交,相交则返回第一…...
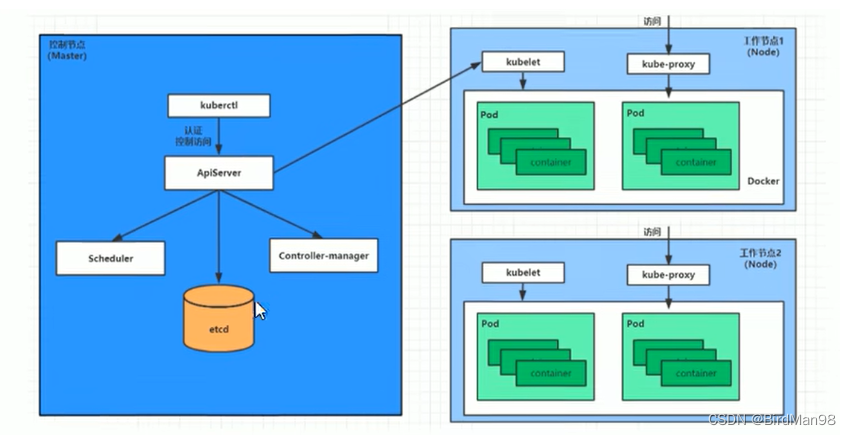
【Kubernetes】【十一】Pod详解 Pod的生命周期
Pod生命周期 我们一般将pod对象从创建至终的这段时间范围称为pod的生命周期,它主要包含下面的过程: pod创建过程 运行初始化容器(init container)过程 运行主容器(main container) 容器启动后钩子&#…...
)
Connext DDS录制服务 Recording Service(1)
1 序言 1.1 简介 RTI记录服务包括以下工具: •记录服务,一种RTI Connext DDS应用程序,用于记录主题和发现数据。记录服务记录数据更新以及时间戳,因此您可以查看或回放系统中随时间发生的数据更新。默认情况下,记录的数据存储在SQLite文件中。录制服务还具有一个API,用于…...

vTESTstudio - VT System CAPL Functions - VT2004(续2)
不要沮丧,不必惊慌,做努力爬的蜗牛或坚持飞的笨鸟,我们试着长大,一路跌跌撞撞,哪怕遍体鳞伤。vtsSetPWMVoltageLow - 设置PWM输出上的低电压功能:指定数字输出信号(尤其是PWM信号)输…...

每天一个linux命令---awk
awk命令 1. 简介 awk是一种处理文本文件的语言,是一个强大的文本分析工具,grep、sed、awk并称为shell中文本处理的三剑客。 AWK 是一种处理文本文件的语言,是一个强大的文本分析工具。 之所以叫 AWK 是因为其取了三位创始人 Alfred Aho&am…...

Whisky完整指南:在macOS上运行Windows应用的终极解决方案
Whisky完整指南:在macOS上运行Windows应用的终极解决方案 【免费下载链接】Whisky A modern Wine wrapper for macOS built with SwiftUI 项目地址: https://gitcode.com/gh_mirrors/wh/Whisky 想要在Apple Silicon Mac上流畅运行Windows专属软件和游戏&…...

ROFL-Player:打破英雄联盟回放观看壁垒的革命性工具
ROFL-Player:打破英雄联盟回放观看壁垒的革命性工具 【免费下载链接】ROFL-Player (No longer supported) One stop shop utility for viewing League of Legends replays! 项目地址: https://gitcode.com/gh_mirrors/ro/ROFL-Player 你是否曾经因为游戏版本…...
)
别再只会用digitalWrite了!用Arduino UNO的PWM引脚玩转RGB呼吸灯(附完整代码)
Arduino PWM实战:从呼吸灯到RGB色彩控制的深度探索 引言:为什么我们需要PWM? 想象一下,你第一次接触Arduino时,可能从最简单的Blink程序开始——让LED灯以固定频率闪烁。这种简单的开关控制能满足基础需求,…...

在 Vue 2 与 Vue 3 中使用 markdown-it-vue 渲染 Markdown 和数学公式
markdown-it-vue 是一个功能强大的 Markdown 渲染 Vue 组件,它基于 markdown-it 解析引擎,集成了多种插件,开箱即用地支持GitHub风格的Markdown、代码高亮、图表(Mermaid, ECharts)、表情符号(emoji&#x…...

游戏后台记录器开发:从低开销捕获到硬件编码的工程实践
1. 项目概述:一个为游戏玩家设计的“后台记录器”如果你是一名资深游戏玩家,或者正在从事游戏相关的开发、测试、数据分析工作,那么你很可能遇到过这样的场景:在《艾尔登法环》里被某个Boss虐了上百次,却记不清每次失败…...

该不该现在买房?AI浪潮下,你的房贷是资产还是负债?
该不该现在买房?AI浪潮下,你的房贷是资产还是负债? 开篇:一个普通家庭的决策困境 深夜,东莞某小区的灯光次第熄灭。你刚刚哄睡一岁半的孩子,打开手机看到甲骨文最新一轮裁员的新闻,又瞥了一眼房…...

Laravel集成DeepSeek AI:官方SDK配置与实战指南
1. 项目概述与核心价值最近在折腾一个AI相关的Laravel项目,需要集成一个靠谱的文本生成模型。市面上大模型API不少,但要么贵,要么不稳定,要么就是国内访问延迟感人。直到我发现了deepseek-php/deepseek-laravel这个包,…...

Power Query处理月度报表,遇到数据有null怎么办?详解【标准】运算与自定义列的计算逻辑差异
Power Query空值处理实战:标准运算与自定义列的计算逻辑深度解析 财务总监Lisa盯着屏幕上满是错误标记的月度汇总报表,眉头紧锁。她刚刚用Power Query合并了六个部门的销售数据,却发现总金额列出现了大量意料之外的null值——这直接导致季度预…...

技术管理者最痛:如何让团队从“要我做”变成“我要做”?
在软件测试领域,技术管理者常常陷入一种无形的焦虑:测试用例的执行越来越像机械的流水线,回归测试变成了纯粹的体力劳动,而探索性测试和深度质量分析这些真正有价值的活动,却总是无人主动认领。你尝试过推行自动化覆盖…...

解锁B站高清与会员视频:基于you-get与EditThisCookie的自动化下载方案
1. 为什么需要you-get与EditThisCookie组合方案 每次在B站看到喜欢的视频想保存下来,你是不是也遇到过这样的烦恼?用普通下载工具要么画质模糊得像打了马赛克,要么遇到会员专属内容直接提示"无权限"。作为常年混迹技术社区的老司机…...