用于网页抓取的最佳 Python 库
探索一系列用于网页抓取的强大 Python 库,包括用于 HTTP 请求、解析 HTML/XML 和自动浏览的库。
网络抓取已成为当今数据驱动世界中不可或缺的工具。Python 是最流行的抓取语言之一,拥有一个由强大的库和框架组成的庞大生态系统。在本文中,我们将探索用于网络抓取的最佳Python 库,每个库都提供独特的特性和功能来简化从网站提取数据的过程。
本文还将介绍最佳库和最佳实践,以确保高效和负责任的网络抓取。从尊重网站政策和处理率限制到解决常见挑战,我们将提供宝贵的见解,帮助您有效地驾驭网络抓取的世界。
Scrape-It.Cloud
让我们从 Scrape-It.Cloud 库开始,它提供了对用于抓取数据的API 的访问。该解决方案有几个优点。例如,我们通过中介来完成此操作,而不是直接从目标网站抓取数据。这保证了我们在抓取大量数据时不会被阻止,因此我们不需要代理。我们不必解决验证码问题,因为 API 会处理这个问题。此外,我们可以抓取静态页面和动态页面。
特征
借助 Scrape-It.Cloud 库,您可以通过简单的 API 调用轻松从任何站点提取有价值的数据。它解决了代理服务器、无头浏览器和验证码解决服务的问题。
通过指定正确的 URL,Scrape-It.Cloud 可以快速返回包含必要数据的 JSON。这使您可以专注于提取正确的数据,而不必担心数据被阻止。
此外,此 API 允许您从使用 React、AngularJS、Ajax、Vue.js 和其他流行库创建的动态页面中提取数据。
此外,如果您需要从 Google SERP 收集数据,您还可以将此 API 密钥用于serp api python库。
安装中
要安装该库,请运行以下命令:
pip install scrapeit-cloud
要使用该库,您还需要一个 API 密钥。您可以通过在网站上注册来获取它。此外,您还将获得一些免费积分来免费提出请求并探索图书馆的功能。
使用示例
对特定库的所有功能、特性和使用方法的详细描述值得单独撰写一篇文章。现在,我们将仅向您展示如何获取任何网页的 HTML 代码,无论您是否可以访问该网页、是否需要验证码解决方案以及页面内容是静态还是动态。
为此,只需指定您的 API 密钥和页面 URL。
from scrapeit_cloud import ScrapeitCloudClient
import json
client = ScrapeitCloudClient(api_key="YOUR-API-KEY")
response = client.scrape(params={"url": "https://example.com/"
}
)由于结果采用 JSON 格式,并且页面的内容存储在 属性 中["scrapingResult"]["content"],因此我们将使用它来提取所需的数据。
data = json.loads(response.text)
print(data["scrapingResult"]["content"])结果,检索到的页面的 HTML 代码将显示在屏幕上。
Requests 和 BeautifulSoup 组合
最简单和最流行的库之一是BeautifulSoup。但是,请记住,它是一个解析库,不具备自行发出请求的能力。因此,它通常与简单的请求库(如Requests、 http.client 或 cUrl )一起使用。
特征
这个库是为初学者设计的,非常容易使用。此外,它还拥有详细记录的说明和活跃的社区。
BeautifulSoup库(或 BS4)是专门为解析而设计的,这赋予了它广泛的功能。您可以使用 XPath 和 CSS 选择器来抓取网页。
由于其简单性和活跃的社区,在线提供了大量其使用示例。此外,如果您在使用过程中遇到困难,您可以获得帮助来解决您的问题。
安装中
如前所述,我们需要两个库来使用它。为了处理请求,我们将使用 Requests 库。好消息是它是预安装的,因此我们不需要单独安装它。但是,我们确实需要安装 BeautifulSoup 库才能使用它。为此,只需使用以下命令:
pip install beautifulsoup4安装完成后,您可以立即开始使用它。
使用示例
假设我们想要检索<h1>包含标头的标签的内容。为此,我们首先需要导入必要的库并发出请求以获取页面的内容:
import requests
from bs4 import BeautifulSoupdata = requests.get('https://example.com')为了处理页面,我们将使用 BS4 解析器:
soup = BeautifulSoup(data.text, "html.parser")现在,我们所要做的就是指定我们想要从页面中提取的确切数据:
text = soup.find_all('h1')最后,我们将获取到的数据显示在屏幕上:
print(text)正如我们所看到的,使用该库非常简单。然而,它确实有其局限性。例如,它无法抓取动态数据,因为它是一个与基本请求库而不是无头浏览器一起使用的解析库。
LXML
LXML是另一个流行的数据解析库,它不能单独用于抓取。由于它还需要一个库来发出请求,因此我们将使用我们已经知道的熟悉的 Requests 库。
特征
尽管它与以前的库相似,但它确实提供了一些附加功能。例如,它比 BS4 更擅长处理 XML 文档结构。虽然它还支持 HTML 文档,但如果您有更复杂的 XML 结构,该库将是更合适的选择。
安装中
如前所述,尽管需要请求库,但我们只需要安装 LXML 库,因为其他所需的组件已经预先安装。
要安装 LXML,请在命令提示符中输入以下命令:、
pip install lxml现在让我们继续看一下使用该库的示例。
使用示例
首先,就像上次一样,我们需要使用一个库来获取网页的 HTML 代码。这部分代码与前面的示例相同。
使用示例
与库示例不同,创建项目就像蜘蛛文件一样,是通过特殊命令完成的。必须在命令行中输入它。
首先,让我们创建一个新项目,在其中构建我们的抓取工具。使用以下命令:
scrapy startproject test_project
在我们继续创建蜘蛛之前,让我们看一下项目树的结构。
这里提到的文件是在创建新项目时自动生成的。这些文件中指定的任何设置都将应用于项目中的所有蜘蛛。您可以在“items.py”文件中定义公共类,在“pipelines.py”文件中指定项目启动时要执行的操作,并在“settings.py”文件中配置常规项目设置。
最佳实践和注意事项
为了使网络抓取更加高效,需要遵循一些规则。遵守这些规则有助于使您的抓取工具更加有效和道德,并减少您从中收集信息的服务的负载。
避免过多的请求
在网络抓取过程中,避免过多的请求对于防止被阻止并减少目标网站的负载非常重要。这就是为什么建议在最不繁忙的时间(例如晚上)从网站收集数据。这有助于降低资源过载并导致其故障的风险。
处理动态内容
在收集动态数据的过程中,有两种方法。您可以使用支持无头浏览器的库自行进行抓取。或者,您可以使用网络抓取 API,该 API 将为您处理收集动态数据的任务。
如果您有良好的编程技能和一个小项目,那么使用库编写自己的抓取工具可能会更好。但是,如果您是初学者或需要从多个页面收集数据,则网络抓取 API 会更好。在这种情况下,除了收集动态数据外,API 还将负责代理和解决验证码。
结论和要点
本文讨论了用于网页抓取的库和以下规则。总而言之,我们创建了一个表格并比较了我们涵盖的所有库。
下面的比较表重点介绍了用于网页抓取的 Python 库的一些关键功能:
| 图书馆 | 解析能力 | 高级功能 | JS渲染 | 使用方便 |
| Scrape-It.Cloud | HTML、XML、JavaScript | 自动抓取和分页 | 是的 | 简单的 |
| 请求和 BeautifulSoup 组合 | HTML、XML | 简单集成 | 不 | 简单的 |
| 请求和 LXML 组合 | HTML、XML | XPath 和 CSS 选择器支持 | 不 | 缓和 |
| 刮痧 | HTML、XML | 多个蜘蛛 | 不 | 缓和 |
| 硒 | HTML、XML、JavaScript | 动态内容处理 | 是(使用网络驱动程序) | 缓和 |
| 皮皮特师 | HTML、JavaScript | 使用无头 Chrome 或 Chromium 实现浏览器自动化 | 是的 | 缓和 |
总的来说,Python 是一种非常有用的数据收集编程语言。凭借其广泛的工具和用户友好的性质,它通常用于数据挖掘和分析。Python 可以轻松完成与从网站提取信息和处理数据相关的任务。
相关文章:
用于网页抓取的最佳 Python 库
探索一系列用于网页抓取的强大 Python 库,包括用于 HTTP 请求、解析 HTML/XML 和自动浏览的库。 网络抓取已成为当今数据驱动世界中不可或缺的工具。Python 是最流行的抓取语言之一,拥有一个由强大的库和框架组成的庞大生态系统。在本文中,我…...

异步回调中axios,ajax,promise,cors详解区分
Ajax、Promise和Axios之间的关系是,它们都是用于在Web应用程序中发送异步HTTP请求的JavaScript库,但它们有不同的实现方式和用法。 Ajax是一种旧的技术,使用XMLHttpRequest对象来向服务器发送异步请求并获取响应。它通常需要手动编写回调函数…...
IoTDB原理剖析
一、介绍 IoTDB(物联网数据库)是一体化收集、存储、管理与分析物联网时序数据的软件系统。 Apache IoTDB采用轻量式架构,具有高性能和丰富的功能。 IoTDB从存储上对时间序列进行排序,索引和chunk块存储,大大的提升时序…...
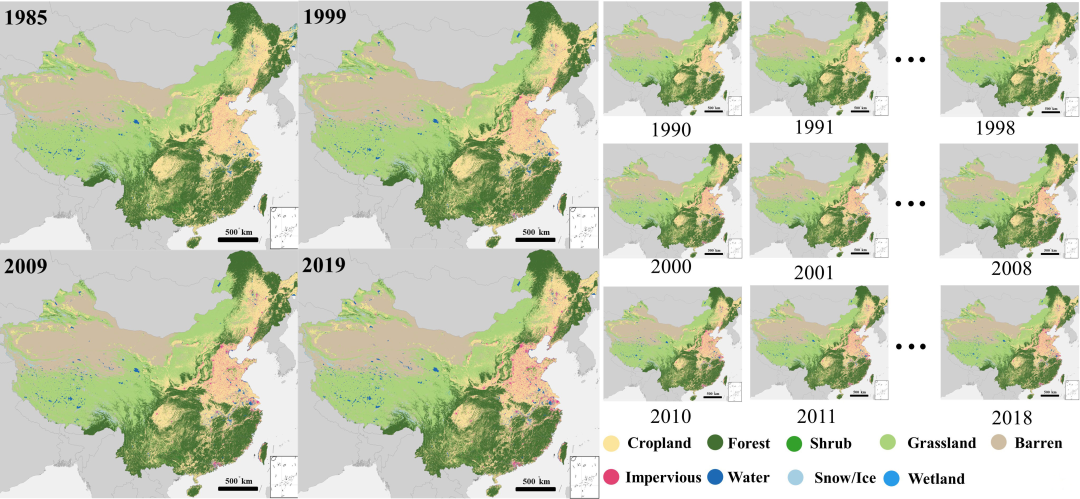
中国1990-2021连续30年土地利用数据CLCD介绍及下载
CLCD数据介绍 CLCD(China Land Cover Dataset)数据集由武汉大学黄昕老师公布,黄昕老师基于Google Earth Engine上335,709景Landsat数据,制作中国年度土地覆盖数据集(annual China Land Cover Dataset, CLCD),包含1985+1990—2020中国逐年土地覆盖信息。 为此,黄昕老师…...
Tubi 前端测试:迁移 Enzyme 到 React Testing Library
前端技术发展迅速,即便不说是日新月异,每年也都推出新框架和新技术。Tubi 的产品前端代码仓库始建于 2015 年,至今 8 年有余。可喜的是,多年来紧随 React 社区的发展,Tubi 绝大多数的基础框架选型都遵循了社区流行的最…...
Chrome
Chrome 简介下载 简介 Chrome 是由 Google 开发的一款流行的网络浏览器。它以其快速的性能、强大的功能和用户友好的界面而闻名,并且在全球范围内被广泛使用。Chrome 支持多种操作系统,包括 Windows、macOS、Linux 和移动平台。 Chrome官网: https://ww…...
零代码编程:用ChatGPT批量删除Excel文件中的行
文件夹中有上百个Excel文件,每个文件中都有如下所示的两行,要进行批量删除。 在ChatGPT中输入提示词: 你是一个Python编程专家,要完成一个处理Excel文件内容的任务,具体步骤如下: 打开F盘的文件夹&#x…...
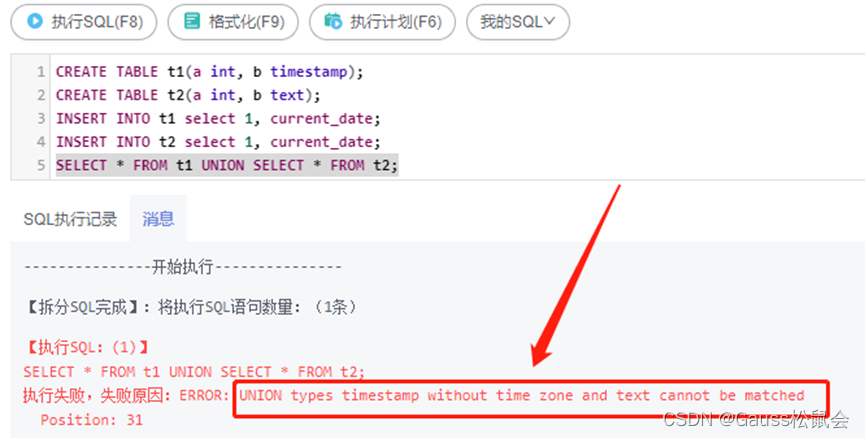
GaussDB数据库SQL系列-UNION UNION ALL
目录 一、前言 二、GaussDB UNION/UNION ALL 1、GaussDB UNION 操作符 2、语法定义 三、GaussDB实验示例 1、创建实验表 2、合并且除重(UNION) 3、合并不除重(UNION ALL) 4、合并带有WHERE子句SQL结果集(UNION ALL) 5、…...
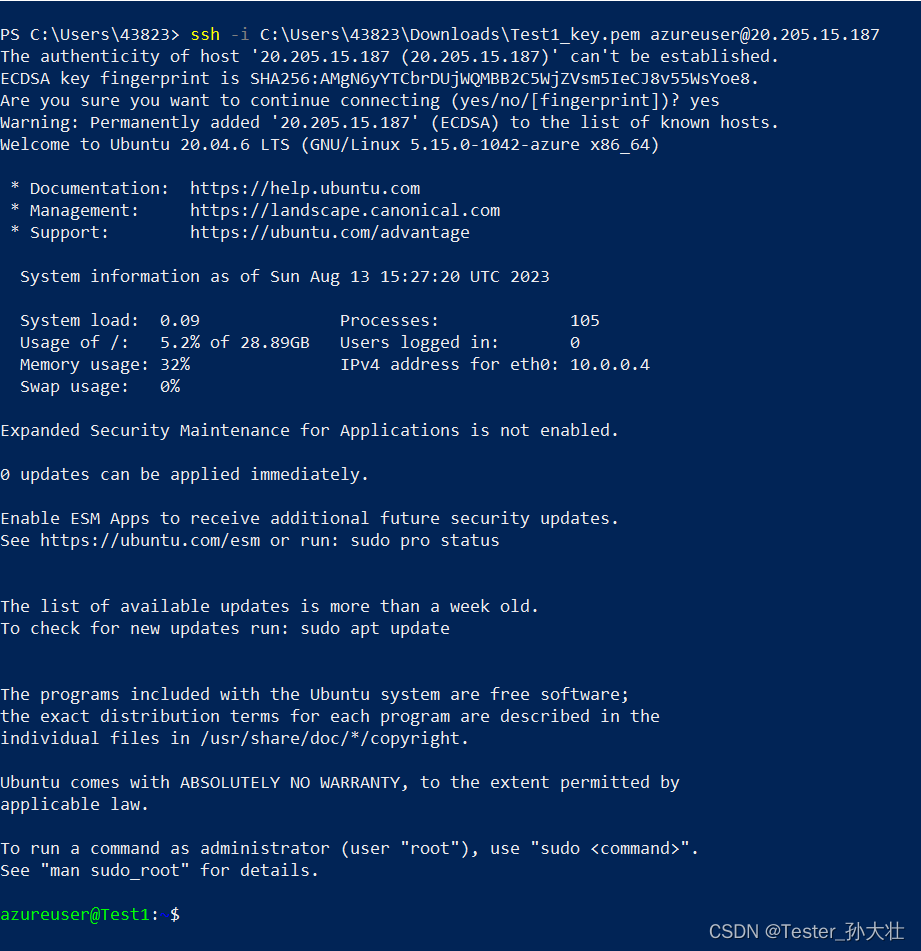
Azure创建第一个虚拟机
首先,登录到 Azure 门户 (https://portal.azure.com/)。在 Azure 门户右上角,点击“虚拟机”按钮,并点击创建,创建Azure虚拟机。 在虚拟机创建页面中,选择所需的基本配置,包括虚拟机名称、操作系统类型和版…...

Redis 之 缓存预热 缓存雪崩 缓存击穿 缓存穿透
目录 一、缓存预热 1.1 缓存预热是什么? 1.2 解决方案: 二、缓存雪崩 2.1 缓存雪崩是什么?怎么发生的? 2.2 怎么解决 三、缓存穿透 3.1 是什么?怎么产生的呢? 3.2 解决方案 3.2.1、采用回写增强&a…...
:收集样本数据和编译)
Golang 程序性能优化利器 PGO 详解(二):收集样本数据和编译
在软件开发过程中,性能优化是不可或缺的一部分。无论是在Web服务、数据处理系统还是实时通信中,良好的性能都是至关重要的。Golang 从1.20版版本开始引入的 Profile Guided Optimization(PGO)机制能够帮助更好地优化 Go 程序的性能…...
《格斗之王AI》使用指南
目录 一、说明 二、步骤 1. 下载 2.配置环境 3.替换 4.测试 5.训练 一、说明 该项目是 针对B站UP主 林亦LYi 的作品 格斗之王!AI写出来的AI竟然这么强!的使用指南,目的是在帮助更多小白轻松入门,一起感受AI的魅力。 林亦LYi…...
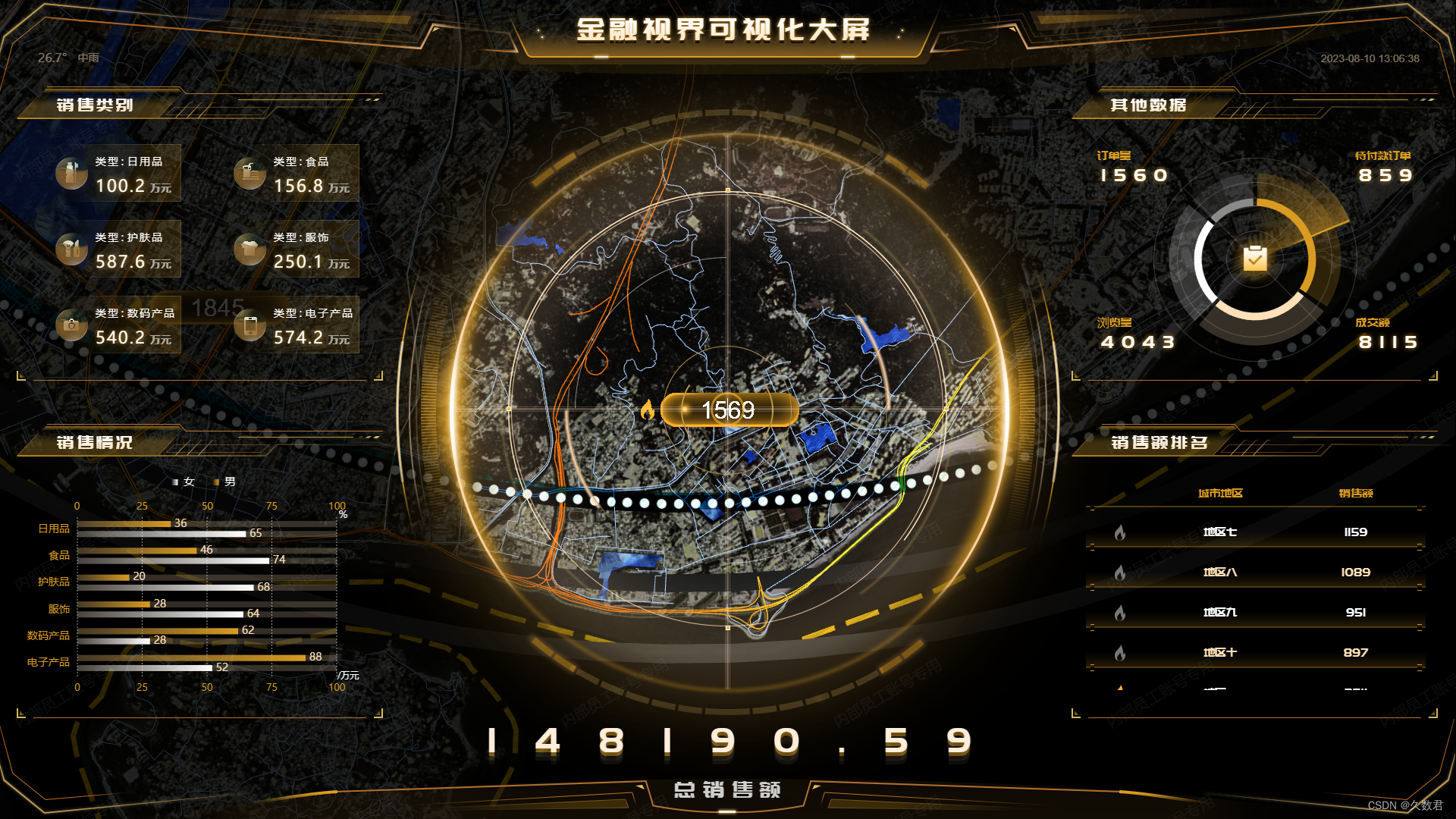
创新引领城市进化:人工智能和大数据塑造智慧城市新面貌
人工智能和大数据等前沿技术正以惊人的速度融入智慧城市的方方面面,为城市的发展注入了强大的智慧和活力。这些技术的应用不仅令城市管理更高效、居民生活更便捷,还为可持续发展和创新奠定了坚实的基础。 在智慧城市中,人工智能技术正成为城市…...
iOS开发-处理UIControl触摸事件TrackingWithEvent
IOS BUG记录 之 处理UIControl的点击事件。 UIControl的触摸事件的方法是beginTrackingWithTouch:withEvent:,continueTrackingWithTouch:withEvent:,endTrackingWithTouch:withEvent:,cancelTrackingWithEvent: ##下面简单的介绍一下 beg…...
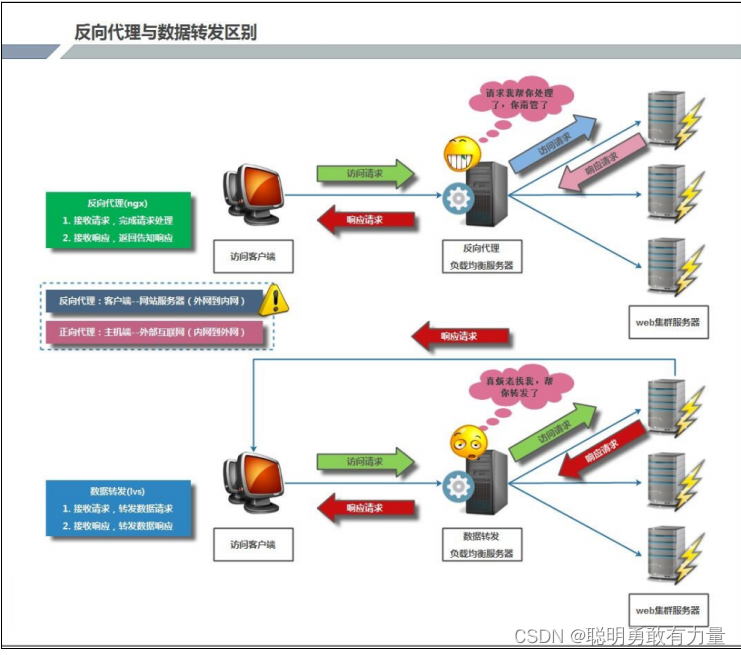
学无止境·运维高阶⑤(LVS-DR 群集 配置Nginx负载均衡)
LVS-DR 群集 && 配置Nginx负载均衡 一、LVS-DR 群集1、相关配置环境2、在RS上配置并启动脚本2.1相关脚本2.2 启动脚本,另一台RS同样步骤 3、LVS-DR模式配置脚本4、测试 二、Nginx负载均衡1、安装Nginx并关闭相应设置2、向主机 node2,node3 写入内…...

badger的mainfest文件解读
1. mainfest文件的作用 mainfest文件是记录lsm tree中的各层tables表的创建删除记录的一个日志文件,主要的作用是badger数据库重启后,重新恢复内存中的各层tables表 2、内容结构 先是8个字节的魔数,魔数的结构如下 ----------------------…...

java导出excel浏览器下载,单线程VS多线程
java导出excel浏览器下载,单线程VS多线程 package com.mengyang.transactional.other.excelxssf; import com.mengyang.transactional.other.myselfExcel.ExcelUtils; import com.mengyang.transactional.pojo.ZhongXinDTO; import org.apache.poi.ss.usermodel.*…...

【rust/egui】(二)看看template的main函数:日志输出以及eframe run_native
说在前面 rust新手,egui没啥找到啥教程,这里自己记录下学习过程环境:windows11 22H2rust版本:rustc 1.71.1egui版本:0.22.0eframe版本:0.22.0上一篇:这里 开始 首先让我们看看main.rs中有些什么…...
Eigen在QT中的配置
Eigen简介 Eigen支持包括固定大小、任意大小的所有矩阵操作,甚至是稀疏矩阵;支持所有标准的数值类型,并且可以扩展为自定义的数值类型;支持多种矩阵分解及其几何特征的求解;它不支持的模块生态系统提供了许多专门的功能…...
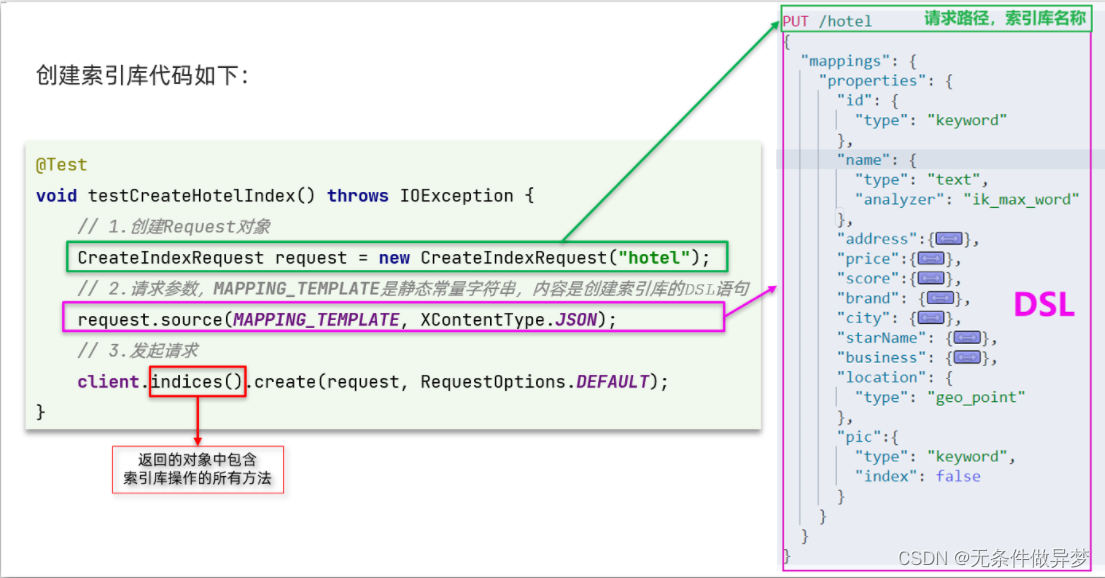
微服务04-elasticsearch
1、es概念 1.1 文档和字段 elasticsearch是面向**文档(Document)**存储的,可以是数据库中的一条商品数据,一个订单信息。文档数据会被序列化为json格式后存储在elasticsearch中: 而Json文档中往往包含很多的字段(Field),类似于数据库中的列。 1.2 索引和映射 索引(…...

雅特力AT32 I2C实战:从零构建EEPROM存储系统
1. 硬件连接与基础配置 第一次玩AT32的I2C外设时,我对着开发板上的SCL和SDA引脚发呆了半天。后来发现,硬件连接其实就三个要点:上拉电阻、开漏输出、引脚复用。以AT32F403A开发板为例,I2C1的SCL(PB6)和SDA(PB7)需要配置为复用开漏…...
)
告别手动刷写!用CANoe CAPL脚本全自动搞定UDS Bootloader(附完整脚本框架)
构建汽车电子自动化测试框架:基于CAPL的UDS Bootloader全流程解决方案 在汽车电子开发领域,软件刷写效率直接影响到产品迭代速度和质量保障水平。传统手动操作不仅耗时费力,还容易因人为因素导致错误。本文将深入探讨如何利用CANoe的CAPL脚本…...

GoldHEN Cheats Manager:PS4游戏修改功能的一站式解决方案
GoldHEN Cheats Manager:PS4游戏修改功能的一站式解决方案 【免费下载链接】GoldHEN_Cheat_Manager GoldHEN Cheats Manager 项目地址: https://gitcode.com/gh_mirrors/go/GoldHEN_Cheat_Manager 在PlayStation 4的定制化游戏体验领域,GoldHEN C…...

一键构建25000+ASMR音频库:asmr-downloader高效下载与管理指南
一键构建25000ASMR音频库:asmr-downloader高效下载与管理指南 【免费下载链接】asmr-downloader A tool for download asmr media from asmr.one(Thanks for the asmr.one) 项目地址: https://gitcode.com/gh_mirrors/as/asmr-downloader 在数字化的放松体验…...

cv_unet_image-colorization多场景应用:婚纱照修复+新闻图片复原
cv_unet_image-colorization多场景应用:婚纱照修复新闻图片复原 1. 项目简介与核心原理 cv_unet_image-colorization 是一个基于深度学习技术的智能图像上色工具,它采用先进的UNet神经网络架构,专门用于将黑白照片转换为自然生动的彩色图像…...

FPGA PCIe设备上电配置时序实战解析:从规范到板卡设计的100ms挑战
1. PCIe设备上电配置的100ms生死时速 第一次调试FPGA PCIe板卡时,我盯着示波器上闪烁的波形百思不得其解——明明硬件连接正常,系统却始终检测不到设备。直到用逻辑分析仪捕获到PERST#信号与电源时序的关系,才恍然大悟:原来FPGA在…...

DoL-Lyra 汉化美化整合包:三分钟打造个性化游戏体验
DoL-Lyra 汉化美化整合包:三分钟打造个性化游戏体验 【免费下载链接】DOL-CHS-MODS Degrees of Lewdity 整合 项目地址: https://gitcode.com/gh_mirrors/do/DOL-CHS-MODS 还在为《Degrees of Lewdity》英文界面而烦恼吗?想要为游戏角色换上精美立…...

PyCharm中玩转Phi-4-mini-reasoning:插件开发与交互式Python调试
PyCharm中玩转Phi-4-mini-reasoning:插件开发与交互式Python调试 1. 引言:当PyCharm遇上Phi-4-mini-reasoning 作为Python开发者,PyCharm几乎是我们每天都要打交道的开发环境。而Phi-4-mini-reasoning作为一款轻量级推理模型,在…...
)
软考 系统架构设计师历年真题集萃(240)
接前一篇文章:软考 系统架构设计师历年真题集萃(239) 第472题 下面安全协议中,用来实现安全电子邮件的协议是( )。 A. IPSec B. L2TP C. PGP D.PPTP 正确答案:C。 所属知识点:系统安全分析与设计 -> 网络安全设计。 试题解析: PGP(Pretty Good Privacy),…...
)
Harmonyos在语文教学中应用-6. 口令指令执行器(对应:口语交际:我说你做)
6. 口令指令执行器(对应:口语交际:我说你做) 功能介绍: 辅助《我说你做》口语交际的工具。应用内置语音识别功能,当教师或同学发出指令(如“举起右手”、“摸摸耳朵”)时,系统识别语音并在屏幕上显示对应的动作图标或文字。这帮助学生听懂指令并做出反应,锻炼听力和…...