微服务04-elasticsearch
1、es概念
1.1 文档和字段
elasticsearch是面向**文档(Document)**存储的,可以是数据库中的一条商品数据,一个订单信息。文档数据会被序列化为json格式后存储在elasticsearch中:

而Json文档中往往包含很多的字段(Field),类似于数据库中的列。
1.2 索引和映射
索引(Index),就是相同类型的文档的集合。
例如:
- 所有用户文档,就可以组织在一起,称为用户的索引;
- 所有商品的文档,可以组织在一起,称为商品的索引;
- 所有订单的文档,可以组织在一起,称为订单的索引;

因此,我们可以把索引当做是数据库中的表。
数据库的表会有约束信息,用来定义表的结构、字段的名称、类型等信息。因此,索引库中就有映射(mapping),是索引中文档的字段约束信息,类似表的结构约束。
1.3 mysql与elasticsearch
| MySQL | Elasticsearch | 说明 |
|---|---|---|
| Table | Index | 索引(index),就是文档的集合,类似数据库的表(table) |
| Row | Document | 文档(Document),就是一条条的数据,类似数据库中的行(Row),文档都是JSON格式 |
| Column | Field | 字段(Field),就是JSON文档中的字段,类似数据库中的列(Column) |
| Schema | Mapping | Mapping(映射)是索引中文档的约束,例如字段类型约束。类似数据库的表结构(Schema) |
| SQL | DSL | DSL是elasticsearch提供的JSON风格的请求语句,用来操作elasticsearch,实现CRUD |
-
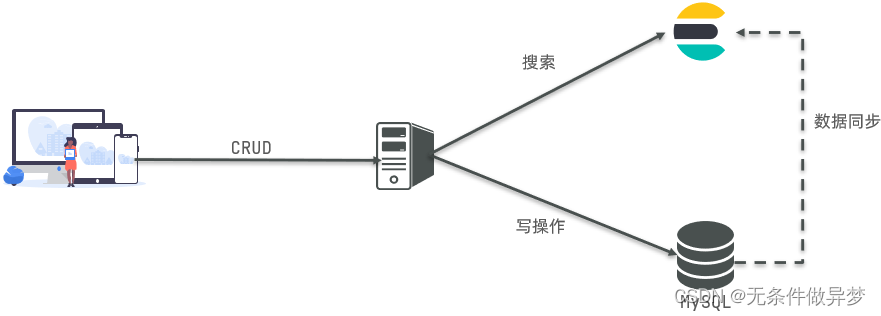
Mysql:擅长事务类型操作,可以确保数据的安全和一致性
-
Elasticsearch:擅长海量数据的搜索、分析、计算
在企业中,往往是两者结合使用:
- 对安全性要求较高的写操作,使用mysql实现
- 对查询性能要求较高的搜索需求,使用elasticsearch实现
- 两者再基于某种方式,实现数据的同步,保证一致性
2、索引库操作
索引库就类似数据库表,mapping映射就类似表的结构。
我们要向es中存储数据,必须先创建“库”和“表”。
2.1 mapping映射属性
mapping是对索引库中文档的约束,常见的mapping属性包括:
- type:字段数据类型,常见的简单类型有:
- 字符串:text(可分词的文本)、keyword(精确值,例如:品牌、国家、ip地址)
- 数值:long、integer、short、byte、double、float、
- 布尔:boolean
- 日期:date
- 对象:object
- index:是否创建索引,默认为true
- analyzer:使用哪种分词器
- properties:该字段的子字段
例如下面的json文档:
{"age": 21,"weight": 52.1,"isMarried": false,"info": "黑马程序员Java讲师","email": "zy@itcast.cn","score": [99.1, 99.5, 98.9],"name": {"firstName": "云","lastName": "赵"}
}
对应的每个字段映射(mapping):
- age:类型为 integer;参与搜索,因此需要index为true;无需分词器
- weight:类型为float;参与搜索,因此需要index为true;无需分词器
- isMarried:类型为boolean;参与搜索,因此需要index为true;无需分词器
- info:类型为字符串,需要分词,因此是text;参与搜索,因此需要index为true;分词器可以用ik_smart
- email:类型为字符串,但是不需要分词,因此是keyword;不参与搜索,因此需要index为false;无需分词器
- score:虽然是数组,但是我们只看元素的类型,类型为float;参与搜索,因此需要index为true;无需分词器
- name:类型为object,需要定义多个子属性
- name.firstName;类型为字符串,但是不需要分词,因此是keyword;参与搜索,因此需要index为true;无需分词器
- name.lastName;类型为字符串,但是不需要分词,因此是keyword;参与搜索,因此需要index为true;无需分词器
2.2 索引库的CRUD
这里我们统一使用Kibana编写DSL的方式来演示。
2.2.1 创建索引库和映射
基本语法:
- 请求方式:PUT
- 请求路径:/索引库名,可以自定义
- 请求参数:mapping映射
格式:
PUT /索引库名称
{"mappings": {"properties": {"字段名":{"type": "text","analyzer": "ik_smart"},"字段名2":{"type": "keyword","index": "false"},"字段名3":{"properties": {"子字段": {"type": "keyword"}}},// ...略}}
}
示例:
PUT /heima
{"mappings": {"properties": {"info":{"type": "text","analyzer": "ik_smart"},"email":{"type": "keyword","index": "falsae"},"name":{"properties": {"firstName": {"type": "keyword"}}},// ... 略}}
}
2.2.2 查询索引库
基本语法:
-
请求方式:GET
-
请求路径:/索引库名
-
请求参数:无
格式:
GET /索引库名
示例:

2.2.3.修改索引库
倒排索引结构虽然不复杂,但是一旦数据结构改变(比如改变了分词器),就需要重新创建倒排索引,这简直是灾难。因此索引库一旦创建,无法修改mapping。
虽然无法修改mapping中已有的字段,但是却允许添加新的字段到mapping中,因为不会对倒排索引产生影响。
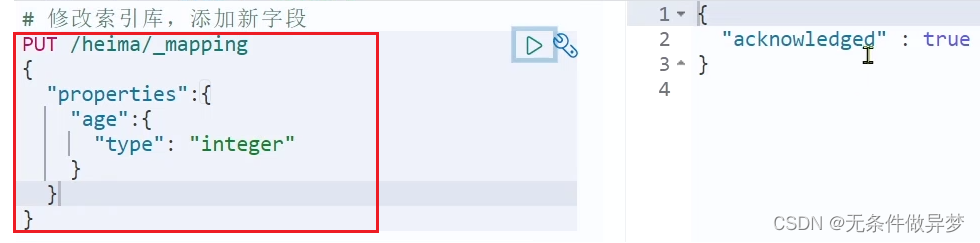
语法说明:
PUT /索引库名/_mapping
{"properties": {"新字段名":{"type": "integer"}}
}
示例:
2.2.4.删除索引库
语法:
-
请求方式:DELETE
-
请求路径:/索引库名
-
请求参数:无
格式:
DELETE /索引库名
在kibana中测试:
2.2.5 总结
索引库操作有哪些?
- 创建索引库:PUT /索引库名
- 查询索引库:GET /索引库名
- 删除索引库:DELETE /索引库名
- 添加字段:PUT /索引库名/_mapping
3、文档操作
3.1 新增文档
语法:
POST /索引库名/_doc/文档id
{"字段1": "值1","字段2": "值2","字段3": {"子属性1": "值3","子属性2": "值4"},// ...
}
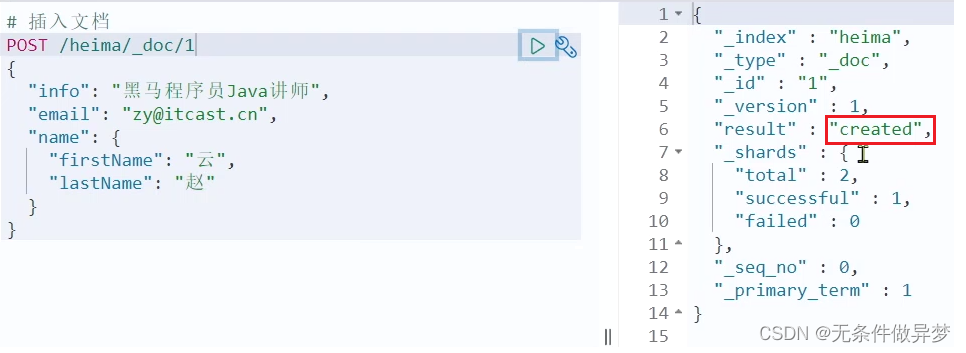
示例:
POST /heima/_doc/1
{"info": "黑马程序员Java讲师","email": "zy@itcast.cn","name": {"firstName": "云","lastName": "赵"}
}
响应:
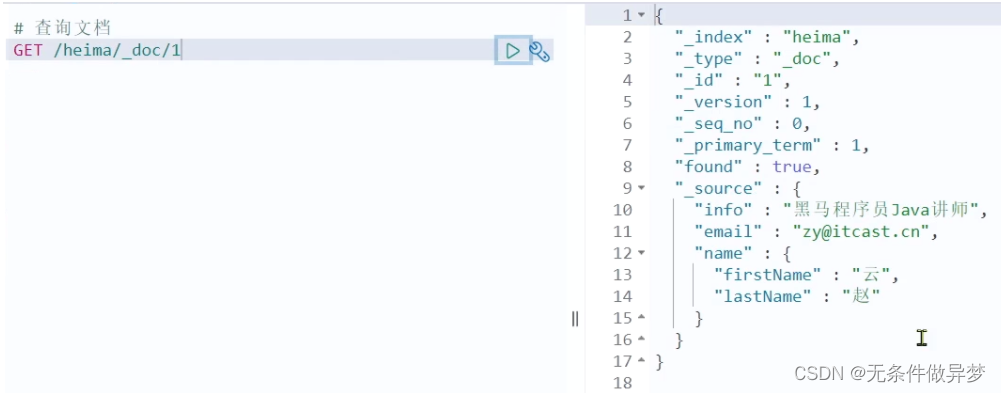
3.2 查询文档
根据rest风格,新增是post,查询应该是get,不过查询一般都需要条件,这里我们把文档id带上。
语法:
GET /{索引库名称}/_doc/{id}
通过kibana查看数据:
GET /heima/_doc/1
查看结果:
3.3.删除文档
删除使用DELETE请求,同样,需要根据id进行删除:
语法:
DELETE /{索引库名}/_doc/id值
示例:
# 根据id删除数据
DELETE /heima/_doc/1
结果:

3.4 修改文档
修改有两种方式:
- 全量修改:直接覆盖原来的文档
- 增量修改:修改文档中的部分字段
3.4.1 全量修改
全量修改是覆盖原来的文档,其本质是:
- 根据指定的id删除文档
- 新增一个相同id的文档
注意:如果根据id删除时,id不存在,第二步的新增也会执行,也就从修改变成了新增操作了。
语法:
PUT /{索引库名}/_doc/文档id
{"字段1": "值1","字段2": "值2",// ... 略
}示例:
PUT /heima/_doc/1
{"info": "黑马程序员高级Java讲师","email": "zy@itcast.cn","name": {"firstName": "云","lastName": "赵"}
}
3.4.2 增量修改
增量修改是只修改指定id匹配的文档中的部分字段。
语法:
POST /{索引库名}/_update/文档id
{"doc": {"字段名": "新的值",}
}
示例:
POST /heima/_update/1
{"doc": {"email": "ZhaoYun@itcast.cn"}
}
3.5 总结
文档操作有哪些?
- 创建文档:POST /{索引库名}/_doc/文档id { json文档 }
- 查询文档:GET /{索引库名}/_doc/文档id
- 删除文档:DELETE /{索引库名}/_doc/文档id
- 修改文档:
- 全量修改:PUT /{索引库名}/_doc/文档id { json文档 }
- 增量修改:POST /{索引库名}/_update/文档id { “doc”: {字段}}
4、RestAPI(※)
ES官方提供了各种不同语言的客户端,用来操作ES。这些客户端的本质就是组装DSL语句,通过http请求发送给ES。官方文档地址:https://www.elastic.co/guide/en/elasticsearch/client/index.html
其中的Java Rest Client又包括两种:
- Java Low Level Rest Client
- Java High Level Rest Client(※)
4.1.导入Demo工程
4.1.1 导入数据
数据结构如下:
CREATE TABLE `tb_hotel` (`id` bigint(20) NOT NULL COMMENT '酒店id',`name` varchar(255) NOT NULL COMMENT '酒店名称;例:7天酒店',`address` varchar(255) NOT NULL COMMENT '酒店地址;例:航头路',`price` int(10) NOT NULL COMMENT '酒店价格;例:329',`score` int(2) NOT NULL COMMENT '酒店评分;例:45,就是4.5分',`brand` varchar(32) NOT NULL COMMENT '酒店品牌;例:如家',`city` varchar(32) NOT NULL COMMENT '所在城市;例:上海',`star_name` varchar(16) DEFAULT NULL COMMENT '酒店星级,从低到高分别是:1星到5星,1钻到5钻',`business` varchar(255) DEFAULT NULL COMMENT '商圈;例:虹桥',`latitude` varchar(32) NOT NULL COMMENT '纬度;例:31.2497',`longitude` varchar(32) NOT NULL COMMENT '经度;例:120.3925',`pic` varchar(255) DEFAULT NULL COMMENT '酒店图片;例:/img/1.jpg',PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
4.1.2 导入项目
项目结构如图:

4.1.3 mapping映射分析
创建索引库,最关键的是mapping映射,而mapping映射要考虑的信息包括:
- 字段名
- 字段数据类型
- 是否参与搜索
- 是否需要分词
- 如果分词,分词器是什么?
其中:
- 字段名、字段数据类型,可以参考数据表结构的名称和类型
- 是否参与搜索要分析业务来判断,例如图片地址,就无需参与搜索
- 是否分词呢要看内容,内容如果是一个整体就无需分词,反之则要分词
- 分词器,我们可以统一使用ik_max_word
来看下酒店数据的索引库结构:
PUT /hotel
{"mappings": {"properties": {"id": {"type": "keyword"},"name":{"type": "text","analyzer": "ik_max_word","copy_to": "all"},"address":{"type": "keyword","index": false},"price":{"type": "integer"},"score":{"type": "integer"},"brand":{"type": "keyword","copy_to": "all"},"city":{"type": "keyword","copy_to": "all"},"starName":{"type": "keyword"},"business":{"type": "keyword"},"location":{"type": "geo_point"},"pic":{"type": "keyword","index": false},"all":{"type": "text","analyzer": "ik_max_word"}}}
}
几个特殊字段说明:
- location:地理坐标,里面包含精度、纬度
- all:一个组合字段,其目的是将多字段的值 利用copy_to合并,提供给用户搜索
地理坐标说明:

copy_to说明:

4.1.4 初始化RestClient
在elasticsearch提供的API中,与elasticsearch一切交互都封装在一个名为RestHighLevelClient的类中,必须先完成这个对象的初始化,建立与elasticsearch的连接。
分为三步:
1)引入es的RestHighLevelClient依赖:
<dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId>
</dependency>
2)因为SpringBoot默认的ES版本是7.6.2,所以我们需要覆盖默认的ES版本:
<properties><java.version>1.8</java.version><elasticsearch.version>7.12.1</elasticsearch.version>
</properties>
3)初始化RestHighLevelClient:
初始化的代码如下:
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(HttpHost.create("http://192.168.150.101:9200")
));
这里为了单元测试方便,我们创建一个测试类HotelIndexTest,然后将初始化的代码编写在@BeforeEach方法中:
package cn.itcast.hotel;import org.apache.http.HttpHost;
import org.elasticsearch.client.RestHighLevelClient;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;import java.io.IOException;public class HotelIndexTest {private RestHighLevelClient client;@BeforeEachvoid setUp() {this.client = new RestHighLevelClient(RestClient.builder(HttpHost.create("http://192.168.150.101:9200")));}@AfterEachvoid tearDown() throws IOException {this.client.close();}
}
4.2 创建索引库
4.2.1 代码解读
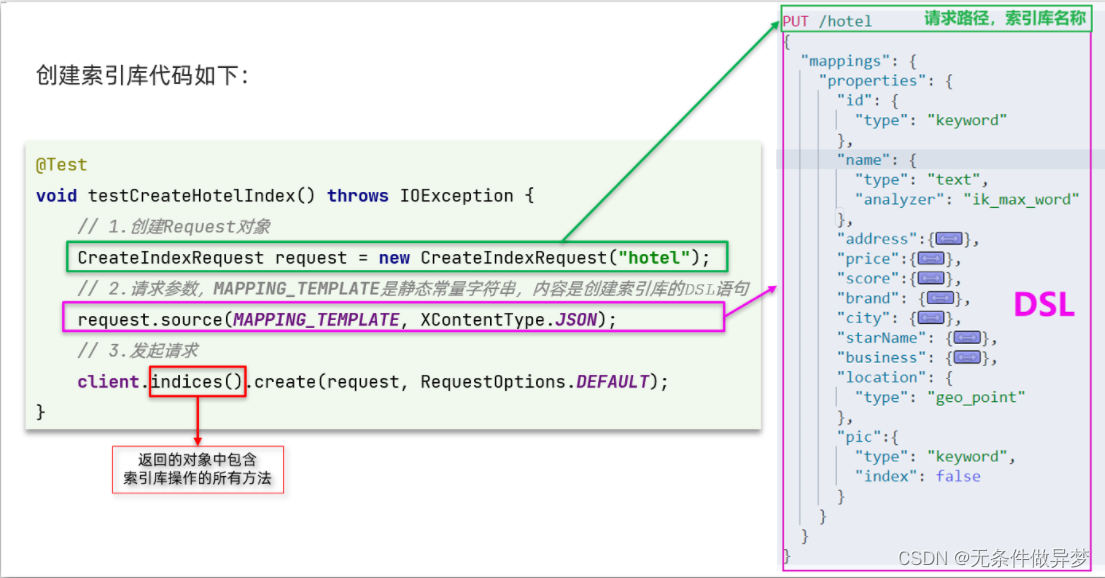
创建索引库的API如下:
代码分为三步:
- 1)创建Request对象。因为是创建索引库的操作,因此Request是CreateIndexRequest。
- 2)添加请求参数,其实就是DSL的JSON参数部分。因为json字符串很长,这里是定义了静态字符串常量MAPPING_TEMPLATE,让代码看起来更加优雅。
- 3)发送请求,client.indices()方法的返回值是IndicesClient类型,封装了所有与索引库操作有关的方法。
4.2.2 完整示例
在hotel-demo的cn.itcast.hotel.constants包下,创建一个类,定义mapping映射的JSON字符串常量:
package cn.itcast.hotel.constants;public class HotelConstants {public static final String MAPPING_TEMPLATE = "{\n" +" \"mappings\": {\n" +" \"properties\": {\n" +" \"id\": {\n" +" \"type\": \"keyword\"\n" +" },\n" +" \"name\":{\n" +" \"type\": \"text\",\n" +" \"analyzer\": \"ik_max_word\",\n" +" \"copy_to\": \"all\"\n" +" },\n" +" \"address\":{\n" +" \"type\": \"keyword\",\n" +" \"index\": false\n" +" },\n" +" \"price\":{\n" +" \"type\": \"integer\"\n" +" },\n" +" \"score\":{\n" +" \"type\": \"integer\"\n" +" },\n" +" \"brand\":{\n" +" \"type\": \"keyword\",\n" +" \"copy_to\": \"all\"\n" +" },\n" +" \"city\":{\n" +" \"type\": \"keyword\",\n" +" \"copy_to\": \"all\"\n" +" },\n" +" \"starName\":{\n" +" \"type\": \"keyword\"\n" +" },\n" +" \"business\":{\n" +" \"type\": \"keyword\"\n" +" },\n" +" \"location\":{\n" +" \"type\": \"geo_point\"\n" +" },\n" +" \"pic\":{\n" +" \"type\": \"keyword\",\n" +" \"index\": false\n" +" },\n" +" \"all\":{\n" +" \"type\": \"text\",\n" +" \"analyzer\": \"ik_max_word\"\n" +" }\n" +" }\n" +" }\n" +"}";
}
在hotel-demo中的HotelIndexTest测试类中,编写单元测试,实现创建索引:
@Test
void createHotelIndex() throws IOException {// 1.创建Request对象CreateIndexRequest request = new CreateIndexRequest("hotel");// 2.准备请求的参数:DSL语句request.source(MAPPING_TEMPLATE, XContentType.JSON);// 3.发送请求client.indices().create(request, RequestOptions.DEFAULT);
}
4.3 删除索引库
删除索引库的DSL语句非常简单:
DELETE /hotel
与创建索引库相比:
- 请求方式从PUT变为DELTE
- 请求路径不变
- 无请求参数
所以代码的差异,注意体现在Request对象上。依然是三步走:
- 1)创建Request对象。这次是DeleteIndexRequest对象
- 2)准备参数。这里是无参
- 3)发送请求。改用delete方法
在hotel-demo中的HotelIndexTest测试类中,编写单元测试,实现删除索引:
@Test
void testDeleteHotelIndex() throws IOException {// 1.创建Request对象DeleteIndexRequest request = new DeleteIndexRequest("hotel");// 2.发送请求client.indices().delete(request, RequestOptions.DEFAULT);
}
4.4 判断索引库是否存在
判断索引库是否存在,本质就是查询,对应的DSL是:
GET /hotel
因此与删除的Java代码流程是类似的。依然是三步走:
- 1)创建Request对象。这次是GetIndexRequest对象
- 2)准备参数。这里是无参
- 3)发送请求。改用exists方法
@Test
void testExistsHotelIndex() throws IOException {// 1.创建Request对象GetIndexRequest request = new GetIndexRequest("hotel");// 2.发送请求boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);// 3.输出System.err.println(exists ? "索引库已经存在!" : "索引库不存在!");
}
4.5 总结
JavaRestClient操作elasticsearch的流程基本类似。核心是client.indices()方法来获取索引库的操作对象。
索引库操作的基本步骤:
- 初始化RestHighLevelClient
- 创建XxxIndexRequest。XXX是Create、Get、Delete
- 准备DSL( Create时需要,其它是无参)
- 发送请求。调用RestHighLevelClient#indices().xxx()方法,xxx是create、exists、delete
5、RestClient操作文档(※)
为了与索引库操作分离,我们再次参加一个测试类,做两件事情:
- 初始化RestHighLevelClient
- 我们的酒店数据在数据库,需要利用IHotelService去查询,所以注入这个接口
package cn.itcast.hotel;import cn.itcast.hotel.pojo.Hotel;
import cn.itcast.hotel.service.IHotelService;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;import java.io.IOException;
import java.util.List;@SpringBootTest
public class HotelDocumentTest {@Autowiredprivate IHotelService hotelService;private RestHighLevelClient client;@BeforeEachvoid setUp() {this.client = new RestHighLevelClient(RestClient.builder(HttpHost.create("http://192.168.150.101:9200")));}@AfterEachvoid tearDown() throws IOException {this.client.close();}
}5.1 新增文档
我们要将数据库的酒店数据查询出来,写入elasticsearch中。
5.1.1 索引库实体类
数据库查询后的结果是一个Hotel类型的对象。结构如下:
@Data
@TableName("tb_hotel")
public class Hotel {@TableId(type = IdType.INPUT)private Long id;private String name;private String address;private Integer price;private Integer score;private String brand;private String city;private String starName;private String business;private String longitude;private String latitude;private String pic;
}
与我们的索引库结构存在差异:
- longitude和latitude需要合并为location
因此,我们需要定义一个新的类型,与索引库结构吻合:
package cn.itcast.hotel.pojo;import相关文章:
微服务04-elasticsearch
1、es概念 1.1 文档和字段 elasticsearch是面向**文档(Document)**存储的,可以是数据库中的一条商品数据,一个订单信息。文档数据会被序列化为json格式后存储在elasticsearch中: 而Json文档中往往包含很多的字段(Field),类似于数据库中的列。 1.2 索引和映射 索引(…...

uniapp 微信小程序 订阅消息
第一步,需要先去小程序官方挑选一下订阅模板拿到模板id 订阅按钮在头部导航上,所以 <u-navbar :bgColor"bgColor"><view class"u-nav-slot" slot"left" click"goSubscribe"><image :src"g…...

JDK8日期时间工具类
此文章为笔记,为阅读其他文章的感受、补充、记录、练习、汇总,非原创,感谢每个知识分享者。 文章目录 1. 旧版日期时间的问题2. 新日期时间API介绍3. 日期时间的常见操作4. 日期时间的修改和比较5. 格式化和解析操作6. Instant类7. 计算日期…...
智汇云舟入选IDC《中国智慧城市数字孪生技术评估,2023》报告
8月7日,国际数据公司(IDC)发布了《中国智慧城市数字孪生技术评估,2023》报告。智汇云舟凭借在数字孪生领域的创新技术与产品,入选《2023中国数字孪生城市技术提供商图谱》。 报告通过公开征集的形式进行申报&am…...
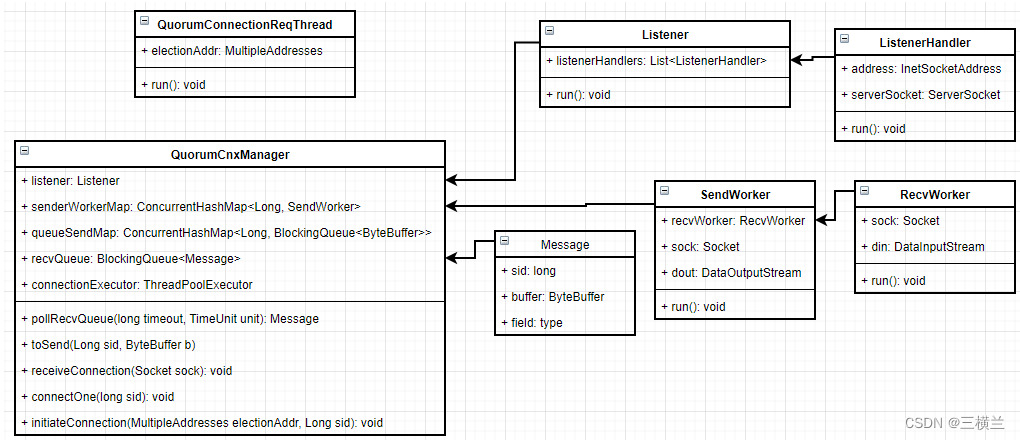
《Zookeeper》源码分析(九)之选举通信网络
在上一篇文章中讲到QuorumCnxManager,它负责zookeeper服务器在选举期间最底层的网络通信,整个网络涉及到的类如下: 整个网络建立的过程如下: 选举前创建好QuorumCnxManager实例,并在QuorumCnxManager构造函数中创建好…...

JVM——栈和堆概述,以及有什么区别?
方法栈 方法栈并不是某一个 JVM 的内存空间,而是我们描述方法被调用过程的一个逻辑概念。 在同一个线程内,T1()调用T2(): T1()先开始,T2()后开始;T2()先结束,T1()后结束。 堆和栈概述 从英文单词角度来…...
恒盛策略:沪指冲高回落跌0.26%,酿酒、汽车等板块走弱,燃气股拉升
10日早盘,两市股指盘中冲高回落,半日成交约4200亿元,北向资金净卖出超20亿元。 到午间收盘,沪指跌0.26%报3235.9点,深成指跌0.54%,创业板指跌0.28%;两市算计成交4202亿元,北向资金净…...
Mongodb 常用操作
// 查询 user_id 是否存在 db.getCollection("t_mongo_user").find({"user_id" : { $exists: true }}) // 查询 user_id 10 的记录 db.getCollection("t_mongo_user").find({"user_id" : 10}) // 排序 -1,按照 _id 倒…...
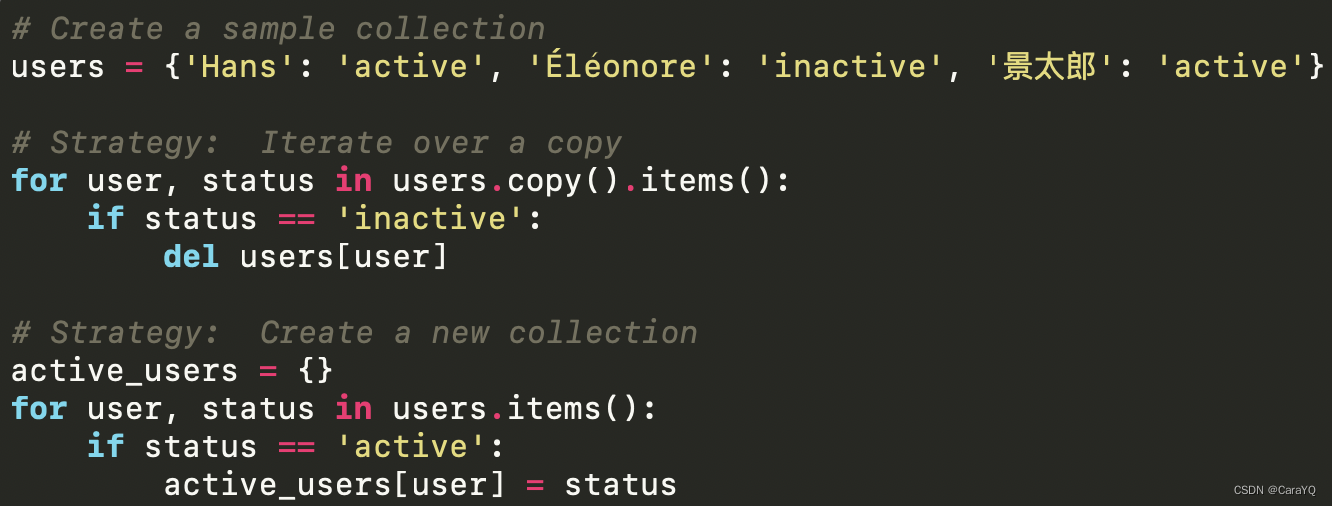
【python】-【】
文章目录 转义字符和原字符二进制与字符编码标识符和保留字变量的定义和使用变量字符串列表for 一、print会输出①数字②字符串(必须加引号)③含有运算符的表达式(例如 31 其中3,1是操作数,是运算符)&#…...

基于Elman神经网络的电力负荷预测
1 案例背景 1.1 Elman神经网络概述 根据神经网络运行过程中的信息流向,可将神经网络可分为前馈式和反馈式两种基本类型。前馈式网络通过引入隐藏层以及非线性转移函数可以实现复杂的非线性映射功能。但前馈式网络的输出仅由当前输人和权矩阵决定,而与网络先前的输出结果无关。…...

LeetCode 0088. 合并两个有序数组
【LetMeFly】88.合并两个有序数组:O(m 1) O(1)的做法 力扣题目链接:https://leetcode.cn/problems/merge-sorted-array/ 给你两个按 非递减顺序 排列的整数数组 nums1 和 nums2,另有两个整数 m 和 n ,分别表示 nums1 和 nums2…...

定义行业新标准?谷歌:折叠屏手机可承受20万次折叠
根据Patreon账户上的消息,Android专家Mishaal Rahman透露,谷歌计划推出新的硬件质量标准,以满足可折叠手机市场的需求。Android原始设备制造商(OEM)将需要完成谷歌提供的问卷调查,并提交样品设备进行严格审…...

在vscode中配置C/C++环境GCC on Linux
https://code.visualstudio.com/docs/cpp/config-linux 官方文档 准备工作 为了能够在vs code中编译运行C/C程序,需要下载: Visual Studio Code C扩展插件,cuda,,, 对于该扩展插件,打开vs c…...
后,可以删除源动态库文件,函数不会锁库文件)
windows执行完LoadLibrary()后,可以删除源动态库文件,函数不会锁库文件
windows执行完LoadLibrary()后,可以删除源动态库文件,函数不会锁库文件。 #include <iostream> #include <Windows.h>int main() {char path[MAX_PATH]{};GetCurrentDirectoryA(sizeof(path), path);HMODULE lib LoadLibraryA("testd…...
ios 知识
IOS 类文件.h和.m中interface的区别 大家都知道我们在创建类文件时会发现: #import <UIKit/UIKit.h>interface ViewController : UIViewControllerend和 #import "ViewController.h"interface ViewController ()end那么他们之间有何区别呢&#x…...

8 | 美国航班数据分析
"在现代快节奏的生活中,航空旅行已经成为人们出行的重要方式之一。然而,航班的准时性一直以来都是旅客和航空公司关注的焦点。无论是商务出差还是休闲度假,乘客们都希望能够在既定的时间内安全、准时地到达目的地。而对于航空公司而言,准点运营不仅关乎乘客体验,还涉…...
) 使用)
app.use(express.json()) 使用
Express内置的中间件 自 Express 4.16.0 版本开始,Express 内置了 3 个常用的中间件,极大的提高了 Express 项目的开发效率和体验 express.static 快速托管静态资源的内置中间件,例如: HTML 文件、图片、CSS 样式等(无…...
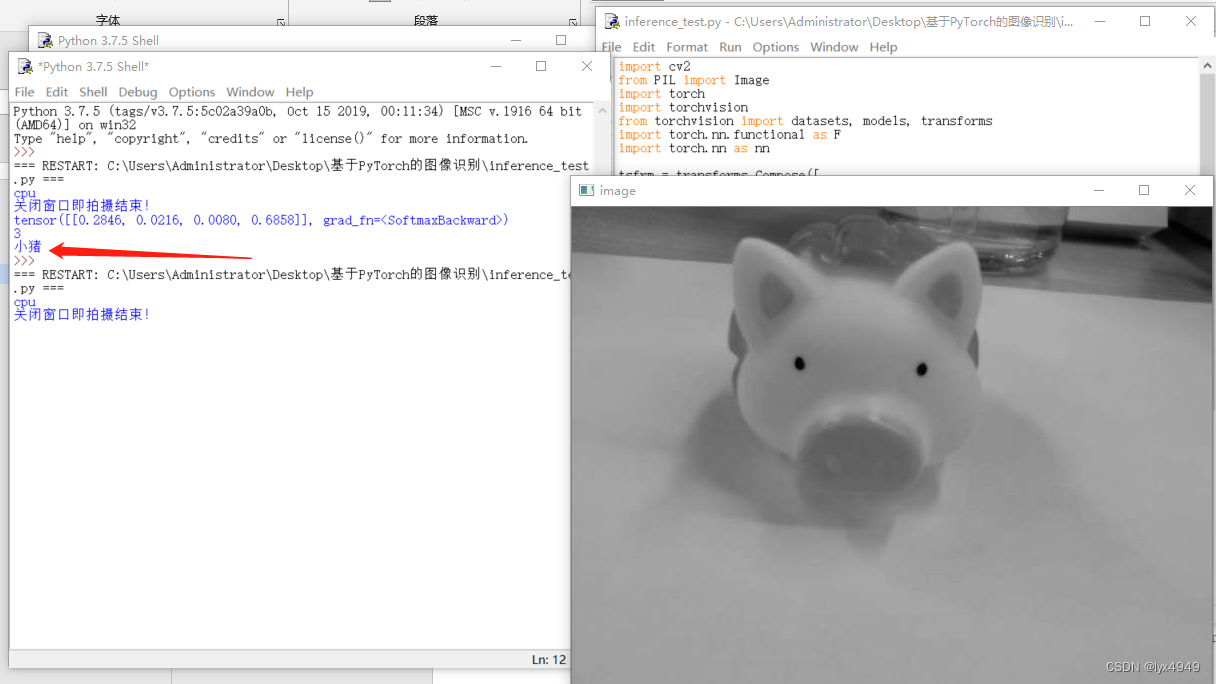
基于PyTorch的图像识别
前言 图像识别是计算机视觉领域的一个重要方向,具有广泛的应用场景,如医学影像诊断、智能驾驶、安防监控等。在本项目中,我们将使用PyTorch来开发一个基于卷积神经网络的图像识别模型,用来识别图像中的物体。下面是要识别的四种物…...
js合并数组对象(将数组中具有相同属性对象合并到一起,组成一个新的数组)
一、根据数组对象中某一key值,合并相同key值的字段,到同一个数组对象中,组成新的数组 1.原数组: var array [{ id: 1, name: Alice },{ id: 2, name: Bob },{ id: 1, age: 25 },{ id: 3, name: Charlie, age: 30 } ];2.合并后数…...

Spring BeanPostProcessor 接口的作用和使用
BeanPostProcessor 接口是 Spring 框架中的一个扩展接口,用于在 Spring 容器实例化、配置和初始化 bean 的过程中提供自定义的扩展点。通过实现这个接口,您可以在 bean 实例创建的不同生命周期阶段插入自己的逻辑,从而实现对 bean 行为的定制…...

Nomic-Embed-Text-V2-MoE集成开发:在IntelliJ IDEA中配置Python模型调试环境
Nomic-Embed-Text-V2-MoE集成开发:在IntelliJ IDEA中配置Python模型调试环境 想试试那个挺火的Nomic-Embed-Text-V2-MoE模型,用它来搞点文本嵌入的应用,结果发现第一步就卡住了?代码在命令行里跑得磕磕绊绊,调试起来更…...
)
别再手动算反射率了!用Python一键搞定大疆P4M多光谱影像辐射定标(附完整代码)
用Python自动化处理大疆P4M多光谱影像:从DN值到反射率的一站式解决方案 多光谱影像分析在精准农业、环境监测等领域发挥着越来越重要的作用。大疆精灵4多光谱无人机(P4M)凭借其便携性和专业级的多光谱数据采集能力,已成为众多研究机构和企业的首选设备。…...

Typora沉浸式写作体验增强:集成Phi-4-mini-reasoning实现智能排版与校对
Typora沉浸式写作体验增强:集成Phi-4-mini-reasoning实现智能排版与校对 1. 写作痛点与解决方案 对于Markdown写作爱好者来说,Typora以其简洁优雅的界面和所见即所得的编辑体验赢得了大量忠实用户。但在实际写作过程中,我们常常会遇到一些影…...

告别抓包烦恼:在Mumu模拟器Android 12上配置Frida的保姆级避坑指南
告别抓包困境:Mumu模拟器Android 12环境Frida全流程实战手册 移动应用安全测试领域正面临一个关键转折点——随着主流应用逐步放弃对Android 9及以下版本的支持,测试人员不得不将工作环境升级到Android 10平台。Mumu模拟器提供的Android 12镜像成为当前最…...

无需代码!用圣女司幼幽-造相Z-Turbo轻松生成动漫女神图片
无需代码!用圣女司幼幽-造相Z-Turbo轻松生成动漫女神图片 1. 引言:零门槛AI绘画体验 想象一下,只需输入简单的文字描述,就能生成精美的动漫女神图片——这就是圣女司幼幽-造相Z-Turbo带来的神奇体验。这个基于Xinference部署的文…...

Qwen3-TTS-12Hz-1.7B-VoiceDesign效果展示:情感语音生成对比
Qwen3-TTS-12Hz-1.7B-VoiceDesign效果展示:情感语音生成对比 1. 引言 想象一下,你正在开发一个有声读物应用,需要为不同角色生成带有真实情感的语音。传统语音合成往往平淡无奇,缺乏情感变化,让听众难以沉浸其中。今…...

3个颠覆性技巧:用手柄打造你的跨平台B站娱乐中心
3个颠覆性技巧:用手柄打造你的跨平台B站娱乐中心 【免费下载链接】wiliwili 第三方B站客户端,目前可以运行在PC全平台、PSVita、PS4 、Xbox 和 Nintendo Switch上 项目地址: https://gitcode.com/GitHub_Trending/wi/wiliwili 你是否厌倦了手机小…...

网盘直链下载助手技术解析:基于JavaScript的多平台API集成方案
网盘直链下载助手技术解析:基于JavaScript的多平台API集成方案 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘…...

基于VC++的OBD2蓝牙诊断仪开发实战指南
1. 开发环境搭建与硬件准备 搞OBD2蓝牙诊断仪开发,首先得把家伙事儿备齐。我当年第一次折腾这个的时候,光找兼容的蓝牙模块就花了三天,这里把踩过的坑都给你总结好了。 开发主机建议用Windows 10/11系统,Visual Studio 2019或2022…...

ERNIE-4.5-0.3B-PT惊艳效果:方言理解与普通话转写生成能力
ERNIE-4.5-0.3B-PT惊艳效果:方言理解与普通话转写生成能力 1. 引言:当AI听懂你的家乡话 想象一下,你对着手机说了一句地道的家乡方言,屏幕上立刻出现了标准的普通话文字,还能用流畅的普通话回答你的问题。这听起来像…...