Apache Doris 入门教程27:BITMAP精准去重和HLL近似去重
BITMAP 精准去重
背景
Doris原有的Bitmap聚合函数设计比较通用,但对亿级别以上bitmap大基数的交并集计算性能较差。排查后端be的bitmap聚合函数逻辑,发现主要有两个原因。一是当bitmap基数较大时,如bitmap大小超过1g,网络/磁盘IO处理时间比较长;二是后端be实例在scan数据后全部传输到顶层节点进行求交和并运算,给顶层单节点带来压力,成为处理瓶颈。
解决思路是将bitmap列的值按照range划分,不同range的值存储在不同的分桶中,保证了不同分桶的bitmap值是正交的。当查询时,先分别对不同分桶中的正交bitmap进行聚合计算,然后顶层节点直接将聚合计算后的值合并汇总,并输出。如此会大大提高计算效率,解决了顶层单节点计算瓶颈问题。
使用指南
- 建表,增加hid列,表示bitmap列值id范围, 作为hash分桶列
- 使用场景
Create table
建表时需要使用聚合模型,数据类型是 bitmap , 聚合函数是 bitmap_union
CREATE TABLE `user_tag_bitmap` (`tag` bigint(20) NULL COMMENT "用户标签",`hid` smallint(6) NULL COMMENT "分桶id",`user_id` bitmap BITMAP_UNION NULL COMMENT ""
) ENGINE=OLAP
AGGREGATE KEY(`tag`, `hid`)
COMMENT "OLAP"
DISTRIBUTED BY HASH(`hid`) BUCKETS 3
表schema增加hid列,表示id范围, 作为hash分桶列。
注:hid数和BUCKETS要设置合理,hid数设置至少是BUCKETS的5倍以上,以使数据hash分桶尽量均衡
Data Load
LOAD LABEL user_tag_bitmap_test
(
DATA INFILE('hdfs://abc')
INTO TABLE user_tag_bitmap
COLUMNS TERMINATED BY ','
(tmp_tag, tmp_user_id)
SET (
tag = tmp_tag,
hid = ceil(tmp_user_id/5000000),
user_id = to_bitmap(tmp_user_id)
)
)
注意:5000000这个数不固定,可按需调整
...
数据格式:
11111111,1
11111112,2
11111113,3
11111114,4
...
注:第一列代表用户标签,由中文转换成数字
load数据时,对用户bitmap值range范围纵向切割,例如,用户id在1-5000000范围内的hid值相同,hid值相同的行会分配到一个分桶内,如此每个分桶内到的bitmap都是正交的。可以利用桶内bitmap值正交特性,进行交并集计算,计算结果会被shuffle至top节点聚合。
注:正交bitmap函数不能用在分区表,因为分区表分区内正交,分区之间的数据是无法保证正交的,则计算结果也是无法预估的。
bitmap_orthogonal_intersect
求bitmap交集函数
语法:
orthogonal_bitmap_intersect(bitmap_column, column_to_filter, filter_values)
参数:
第一个参数是Bitmap列,第二个参数是用来过滤的维度列,第三个参数是变长参数,含义是过滤维度列的不同取值
说明:
查询规划上聚合分2层,在第一层be节点(update、serialize)先按filter_values为key进行hash聚合,然后对所有key的bitmap求交集,结果序列化后发送至第二层be节点(merge、finalize),在第二层be节点对所有来源于第一层节点的bitmap值循环求并集
样例:
select BITMAP_COUNT(orthogonal_bitmap_intersect(user_id, tag, 13080800, 11110200)) from user_tag_bitmap where tag in (13080800, 11110200);
orthogonal_bitmap_intersect_count
求bitmap交集count函数,语法同原版intersect_count,但实现不同
语法:
orthogonal_bitmap_intersect_count(bitmap_column, column_to_filter, filter_values)
参数:
第一个参数是Bitmap列,第二个参数是用来过滤的维度列,第三个参数开始是变长参数,含义是过滤维度列的不同取值
说明:
查询规划聚合上分2层,在第一层be节点(update、serialize)先按filter_values为key进行hash聚合,然后对所有key的bitmap求交集,再对交集结果求count,count值序列化后发送至第二层be节点(merge、finalize),在第二层be节点对所有来源于第一层节点的count值循环求sum
orthogonal_bitmap_union_count
求bitmap并集count函数,语法同原版bitmap_union_count,但实现不同。
语法:
orthogonal_bitmap_union_count(bitmap_column)
参数:
参数类型是bitmap,是待求并集count的列
说明:
查询规划上分2层,在第一层be节点(update、serialize)对所有bitmap求并集,再对并集的结果bitmap求count,count值序列化后发送至第二层be节点(merge、finalize),在第二层be节点对所有来源于第一层节点的count值循环求sum
orthogonal_bitmap_expr_calculate
求表达式bitmap交并差集合计算函数。
语法:
orthogonal_bitmap_expr_calculate(bitmap_column, filter_column, input_string)
参数:
第一个参数是Bitmap列,第二个参数是用来过滤的维度列,即计算的key列,第三个参数是计算表达式字符串,含义是依据key列进行bitmap交并差集表达式计算
表达式支持的计算符:& 代表交集计算,| 代表并集计算,- 代表差集计算, ^ 代表异或计算,\ 代表转义字符
说明:
查询规划上聚合分2层,第一层be聚合节点计算包括init、update、serialize步骤,第二层be聚合节点计算包括merge、finalize步骤。在第一层be节点,init阶段解析input_string字符串,转换为后缀表达式(逆波兰式),解析出计算key值,并在map<key, bitmap>结构中初始化;update阶段,底层内核scan维度列(filter_column)数据后回调update函数,然后以计算key为单位对上一步的map结构中的bitmap进行聚合;serialize阶段,根据后缀表达式,解析出计算key列的bitmap,利用栈结构先进后出原则,进行bitmap交并差集合计算,然后对最终的结果bitmap序列化后发送至第二层聚合be节点。在第二层聚合be节点,对所有来源于第一层节点的bitmap值求并集,并返回最终bitmap结果
orthogonal_bitmap_expr_calculate_count
求表达式bitmap交并差集合计算count函数, 语法和参数同orthogonal_bitmap_expr_calculate。
语法:
orthogonal_bitmap_expr_calculate_count(bitmap_column, filter_column, input_string)
说明:
查询规划上聚合分2层,第一层be聚合节点计算包括init、update、serialize步骤,第二层be聚合节点计算包括merge、finalize步骤。在第一层be节点,init阶段解析input_string字符串,转换为后缀表达式(逆波兰式),解析出计算key值,并在map<key, bitmap>结构中初始化;update阶段,底层内核scan维度列(filter_column)数据后回调update函数,然后以计算key为单位对上一步的map结构中的bitmap进行聚合;serialize阶段,根据后缀表达式,解析出计算key列的bitmap,利用栈结构先进后出原则,进行bitmap交并差集合计算,然后对最终的结果bitmap的count值序列化后发送至第二层聚合be节点。在第二层聚合be节点,对所有来源于第一层节点的count值求加和,并返回最终count结果。
使用场景
符合对bitmap进行正交计算的场景,如在用户行为分析中,计算留存,漏斗,用户画像等。
人群圈选:
select orthogonal_bitmap_intersect_count(user_id, tag, 13080800, 11110200) from user_tag_bitmap where tag in (13080800, 11110200);注:13080800、11110200代表用户标签
计算user_id的去重值:
select orthogonal_bitmap_union_count(user_id) from user_tag_bitmap where tag in (13080800, 11110200);
bitmap交并差集合混合计算:
select orthogonal_bitmap_expr_calculate_count(user_id, tag, '(833736|999777)&(1308083|231207)&(1000|20000-30000)') from user_tag_bitmap where tag in (833736,999777,130808,231207,1000,20000,30000);
注:1000、20000、30000等整形tag,代表用户不同标签
select orthogonal_bitmap_expr_calculate_count(user_id, tag, '(A:a/b|B:2\\-4)&(C:1-D:12)&E:23') from user_str_tag_bitmap where tag in ('A:a/b', 'B:2-4', 'C:1', 'D:12', 'E:23');注:'A:a/b', 'B:2-4'等是字符串类型tag,代表用户不同标签, 其中'B:2-4'需要转义成'B:2\\-4'使用 HLL 近似去重
HLL 近似去重
在实际的业务场景中,随着业务数据量越来越大,对数据去重的压力也越来越大,当数据达到一定规模之后,使用精准去重的成本也越来越高,在业务可以接受的情况下,通过近似算法来实现快速去重降低计算压力是一个非常好的方式,本文主要介绍 Doris 提供的 HyperLogLog(简称 HLL)是一种近似去重算法。
HLL 的特点是具有非常优异的空间复杂度 O(mloglogn) , 时间复杂度为 O(n), 并且计算结果的误差可控制在 1%—2% 左右,误差与数据集大小以及所采用的哈希函数有关。
什么是 HyperLogLog
它是 LogLog 算法的升级版,作用是能够提供不精确的去重计数。其数学基础为伯努利试验。
假设硬币拥有正反两面,一次的上抛至落下,最终出现正反面的概率都是50%。一直抛硬币,直到它出现正面为止,我们记录为一次完整的试验。
那么对于多次的伯努利试验,假设这个多次为n次。就意味着出现了n次的正面。假设每次伯努利试验所经历了的抛掷次数为k。第一次伯努利试验,次数设为k1,以此类推,第n次对应的是kn。
其中,对于这n次伯努利试验中,必然会有一个最大的抛掷次数k,例如抛了12次才出现正面,那么称这个为k_max,代表抛了最多的次数。
伯努利试验容易得出有以下结论:
- n 次伯努利过程的投掷次数都不大于 k_max。
- n 次伯努利过程,至少有一次投掷次数等于 k_max
最终结合极大似然估算的方法,发现在n和k_max中存在估算关联:n = 2 ^ k_max。当我们只记录了k_max时,即可估算总共有多少条数据,也就是基数。
假设试验结果如下:
- 第1次试验: 抛了3次才出现正面,此时 k=3,n=1
- 第2次试验: 抛了2次才出现正面,此时 k=2,n=2
- 第3次试验: 抛了6次才出现正面,此时 k=6,n=3
- 第n次试验:抛了12次才出现正面,此时我们估算, n = 2^12
取上面例子中前三组试验,那么 k_max = 6,最终 n=3,我们放进估算公式中去,明显: 3 ≠ 2^6 。也即是说,当试验次数很小的时候,这种估算方法的误差是很大的。
这三组试验,我们称为一轮的估算。如果只是进行一轮的话,当 n 足够大的时候,估算的误差率会相对减少,但仍然不够小。
Doris HLL 函数
HLL 是基于 HyperLogLog 算法的工程实现,用于保存 HyperLogLog 计算过程的中间结果,它只能作为表的 value 列类型、通过聚合来不断的减少数据量,以此
来实现加快查询的目的,基于它得到的是一个估算结果,误差大概在1%左右,hll 列是通过其它列或者导入数据里面的数据生成的,导入的时候通过 hll_hash 函数
来指定数据中哪一列用于生成 hll 列,它常用于替代 count distinct,通过结合 rollup 在业务上用于快速计算uv等
HLL_UNION_AGG(hll)
此函数为聚合函数,用于计算满足条件的所有数据的基数估算。
HLL_CARDINALITY(hll)
此函数用于计算单条hll列的基数估算
HLL_HASH(column_name)
生成HLL列类型,用于insert或导入的时候,导入的使用见相关说明
如何使用 Doris HLL
- 使用 HLL 去重的时候,需要在建表语句中将目标列类型设置成HLL,聚合函数设置成HLL_UNION
- HLL类型的列不能作为 Key 列使用
- 用户不需要指定长度及默认值,长度根据数据聚合程度系统内控制
创建一张含有 hll 列的表
create table test_hll(dt date,id int,name char(10),province char(10),os char(10),pv hll hll_union
)
Aggregate KEY (dt,id,name,province,os)
distributed by hash(id) buckets 10
PROPERTIES("replication_num" = "1","in_memory"="false"
);
导入数据
-
Stream load 导入
curl --location-trusted -u root: -H "label:label_test_hll_load" \-H "column_separator:," \-H "columns:dt,id,name,province,os, pv=hll_hash(id)" -T test_hll.csv http://fe_IP:8030/api/demo/test_hll/_stream_load示例数据如下(test_hll.csv):
2022-05-05,10001,测试01,北京,windows 2022-05-05,10002,测试01,北京,linux 2022-05-05,10003,测试01,北京,macos 2022-05-05,10004,测试01,河北,windows 2022-05-06,10001,测试01,上海,windows 2022-05-06,10002,测试01,上海,linux 2022-05-06,10003,测试01,江苏,macos 2022-05-06,10004,测试01,陕西,windows导入结果如下
# curl --location-trusted -u root: -H "label:label_test_hll_load" -H "column_separator:," -H "columns:dt,id,name,province,os, pv=hll_hash(id)" -T test_hll.csv http://127.0.0.1:8030/api/demo/test_hll/_stream_load{"TxnId": 693,"Label": "label_test_hll_load","TwoPhaseCommit": "false","Status": "Success","Message": "OK","NumberTotalRows": 8,"NumberLoadedRows": 8,"NumberFilteredRows": 0,"NumberUnselectedRows": 0,"LoadBytes": 320,"LoadTimeMs": 23,"BeginTxnTimeMs": 0,"StreamLoadPutTimeMs": 1,"ReadDataTimeMs": 0,"WriteDataTimeMs": 9,"CommitAndPublishTimeMs": 11 } -
Broker Load
LOAD LABEL demo.test_hlllabel(DATA INFILE("hdfs://hdfs_host:hdfs_port/user/doris_test_hll/data/input/file")INTO TABLE `test_hll`COLUMNS TERMINATED BY ","(dt,id,name,province,os)SET (pv = HLL_HASH(id)));
查询数据
HLL 列不允许直接查询原始值,只能通过 HLL 的聚合函数进行查询。
-
求总的PV
mysql> select HLL_UNION_AGG(pv) from test_hll; +---------------------+ | hll_union_agg(`pv`) | +---------------------+ | 4 | +---------------------+ 1 row in set (0.00 sec)等价于:
mysql> SELECT COUNT(DISTINCT pv) FROM test_hll; +----------------------+ | count(DISTINCT `pv`) | +----------------------+ | 4 | +----------------------+ 1 row in set (0.01 sec) -
求每一天的PV
mysql> select HLL_UNION_AGG(pv) from test_hll group by dt; +---------------------+ | hll_union_agg(`pv`) | +---------------------+ | 4 | | 4 | +---------------------+ 2 rows in set (0.01 sec)
相关文章:

Apache Doris 入门教程27:BITMAP精准去重和HLL近似去重
BITMAP 精准去重 背景 Doris原有的Bitmap聚合函数设计比较通用,但对亿级别以上bitmap大基数的交并集计算性能较差。排查后端be的bitmap聚合函数逻辑,发现主要有两个原因。一是当bitmap基数较大时,如bitmap大小超过1g,网络/磁盘…...

bug总结
bug总是意外的出现,对于语法问题导致的bug是容易排查的,对于逻辑的bug和环境的bug往往令人头疼。在这里,将这些收集起来。、 【1-8来自对博客认输了!这些Bug让我目瞪口呆!_电脑放青藏高原共振是真的?_Truda.的博客-C…...

DC电源模块的高转换率
BOSHIDA DC电源模块的高转换率 DC电源模块是将交流电转换为直流电供应设备使用的装置,是现代工业制造和电子产品中不可或缺的组件之一。高转换率是DC电源模块最重要的性能之一,它直接影响着电源的效率、功耗和发热等方面,因此也深受设计师的关…...

用于网页抓取的最佳 Python 库
探索一系列用于网页抓取的强大 Python 库,包括用于 HTTP 请求、解析 HTML/XML 和自动浏览的库。 网络抓取已成为当今数据驱动世界中不可或缺的工具。Python 是最流行的抓取语言之一,拥有一个由强大的库和框架组成的庞大生态系统。在本文中,我…...

异步回调中axios,ajax,promise,cors详解区分
Ajax、Promise和Axios之间的关系是,它们都是用于在Web应用程序中发送异步HTTP请求的JavaScript库,但它们有不同的实现方式和用法。 Ajax是一种旧的技术,使用XMLHttpRequest对象来向服务器发送异步请求并获取响应。它通常需要手动编写回调函数…...
IoTDB原理剖析
一、介绍 IoTDB(物联网数据库)是一体化收集、存储、管理与分析物联网时序数据的软件系统。 Apache IoTDB采用轻量式架构,具有高性能和丰富的功能。 IoTDB从存储上对时间序列进行排序,索引和chunk块存储,大大的提升时序…...
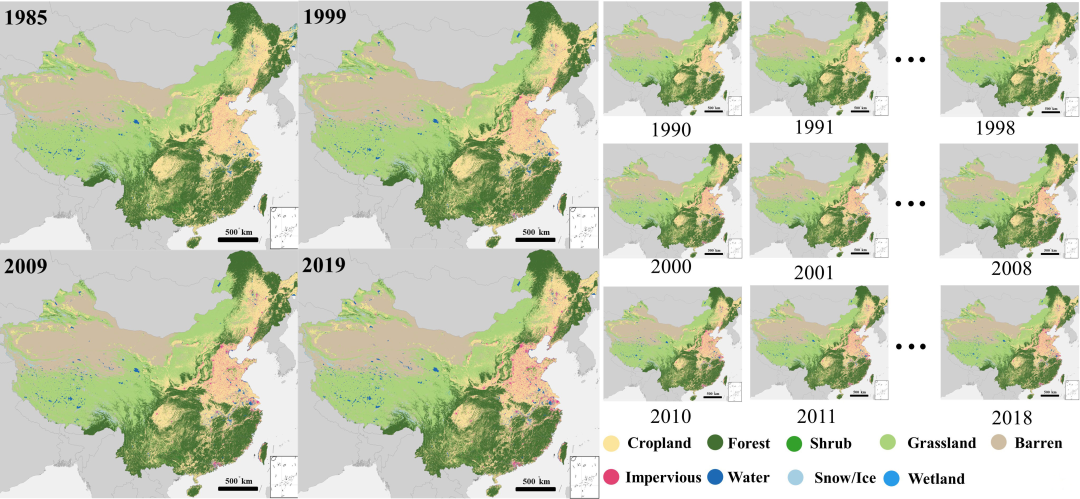
中国1990-2021连续30年土地利用数据CLCD介绍及下载
CLCD数据介绍 CLCD(China Land Cover Dataset)数据集由武汉大学黄昕老师公布,黄昕老师基于Google Earth Engine上335,709景Landsat数据,制作中国年度土地覆盖数据集(annual China Land Cover Dataset, CLCD),包含1985+1990—2020中国逐年土地覆盖信息。 为此,黄昕老师…...
Tubi 前端测试:迁移 Enzyme 到 React Testing Library
前端技术发展迅速,即便不说是日新月异,每年也都推出新框架和新技术。Tubi 的产品前端代码仓库始建于 2015 年,至今 8 年有余。可喜的是,多年来紧随 React 社区的发展,Tubi 绝大多数的基础框架选型都遵循了社区流行的最…...
Chrome
Chrome 简介下载 简介 Chrome 是由 Google 开发的一款流行的网络浏览器。它以其快速的性能、强大的功能和用户友好的界面而闻名,并且在全球范围内被广泛使用。Chrome 支持多种操作系统,包括 Windows、macOS、Linux 和移动平台。 Chrome官网: https://ww…...
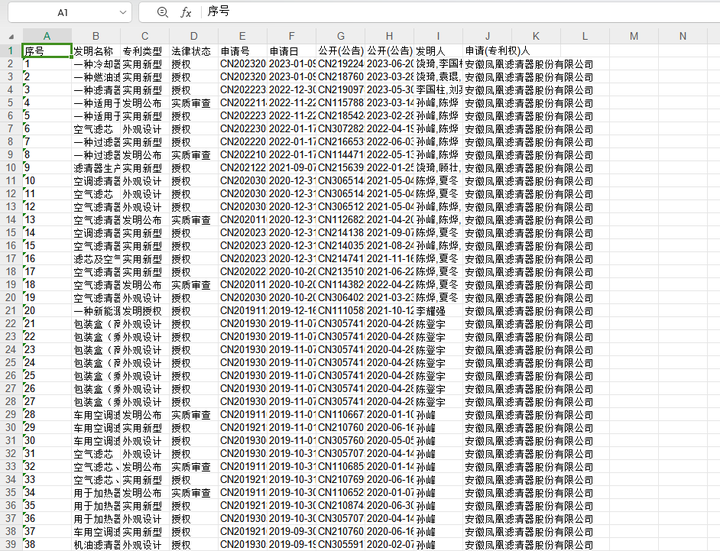
零代码编程:用ChatGPT批量删除Excel文件中的行
文件夹中有上百个Excel文件,每个文件中都有如下所示的两行,要进行批量删除。 在ChatGPT中输入提示词: 你是一个Python编程专家,要完成一个处理Excel文件内容的任务,具体步骤如下: 打开F盘的文件夹&#x…...
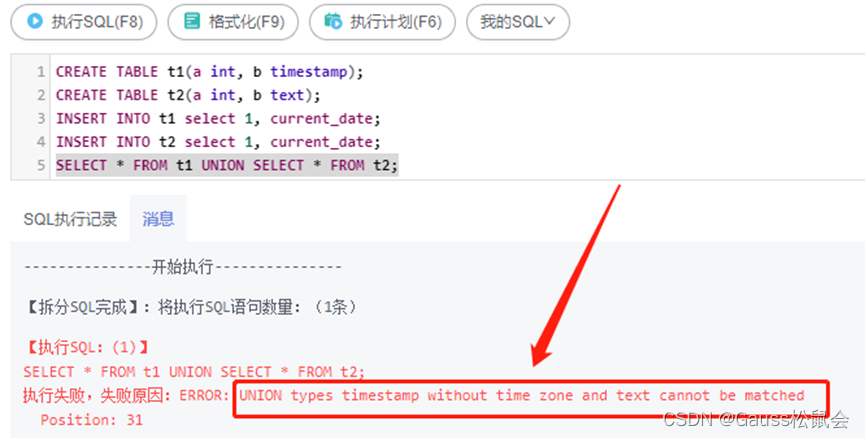
GaussDB数据库SQL系列-UNION UNION ALL
目录 一、前言 二、GaussDB UNION/UNION ALL 1、GaussDB UNION 操作符 2、语法定义 三、GaussDB实验示例 1、创建实验表 2、合并且除重(UNION) 3、合并不除重(UNION ALL) 4、合并带有WHERE子句SQL结果集(UNION ALL) 5、…...
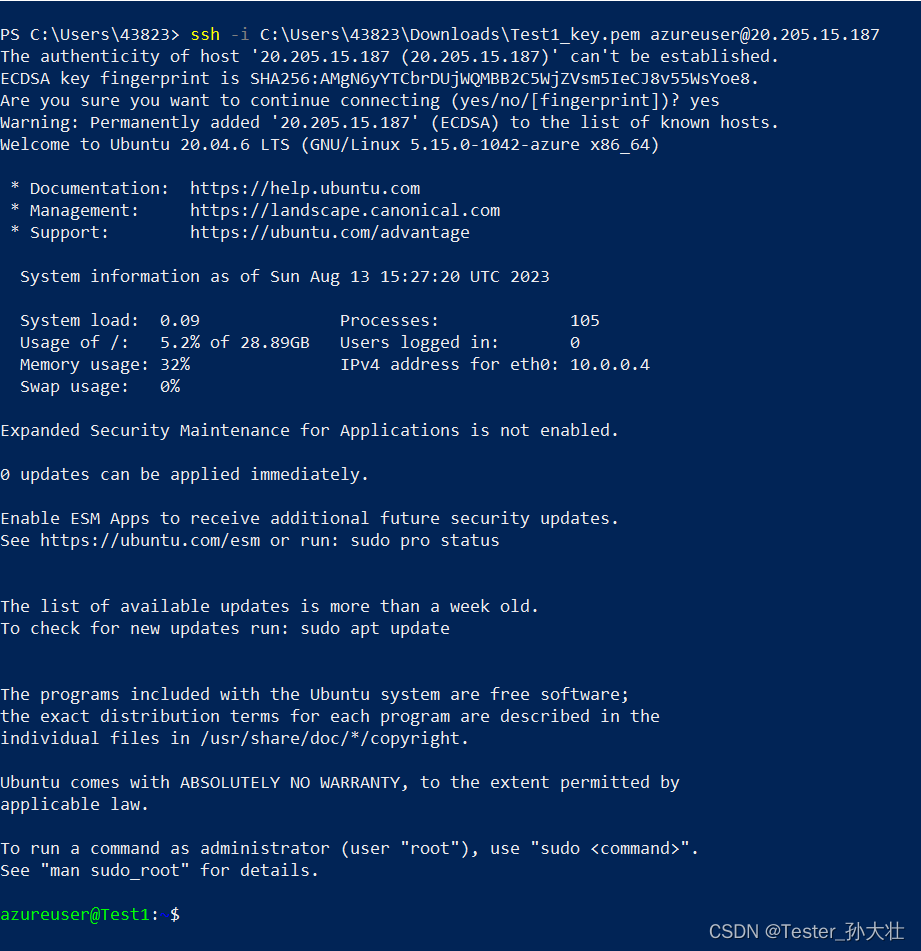
Azure创建第一个虚拟机
首先,登录到 Azure 门户 (https://portal.azure.com/)。在 Azure 门户右上角,点击“虚拟机”按钮,并点击创建,创建Azure虚拟机。 在虚拟机创建页面中,选择所需的基本配置,包括虚拟机名称、操作系统类型和版…...

Redis 之 缓存预热 缓存雪崩 缓存击穿 缓存穿透
目录 一、缓存预热 1.1 缓存预热是什么? 1.2 解决方案: 二、缓存雪崩 2.1 缓存雪崩是什么?怎么发生的? 2.2 怎么解决 三、缓存穿透 3.1 是什么?怎么产生的呢? 3.2 解决方案 3.2.1、采用回写增强&a…...
:收集样本数据和编译)
Golang 程序性能优化利器 PGO 详解(二):收集样本数据和编译
在软件开发过程中,性能优化是不可或缺的一部分。无论是在Web服务、数据处理系统还是实时通信中,良好的性能都是至关重要的。Golang 从1.20版版本开始引入的 Profile Guided Optimization(PGO)机制能够帮助更好地优化 Go 程序的性能…...
《格斗之王AI》使用指南
目录 一、说明 二、步骤 1. 下载 2.配置环境 3.替换 4.测试 5.训练 一、说明 该项目是 针对B站UP主 林亦LYi 的作品 格斗之王!AI写出来的AI竟然这么强!的使用指南,目的是在帮助更多小白轻松入门,一起感受AI的魅力。 林亦LYi…...
创新引领城市进化:人工智能和大数据塑造智慧城市新面貌
人工智能和大数据等前沿技术正以惊人的速度融入智慧城市的方方面面,为城市的发展注入了强大的智慧和活力。这些技术的应用不仅令城市管理更高效、居民生活更便捷,还为可持续发展和创新奠定了坚实的基础。 在智慧城市中,人工智能技术正成为城市…...
iOS开发-处理UIControl触摸事件TrackingWithEvent
IOS BUG记录 之 处理UIControl的点击事件。 UIControl的触摸事件的方法是beginTrackingWithTouch:withEvent:,continueTrackingWithTouch:withEvent:,endTrackingWithTouch:withEvent:,cancelTrackingWithEvent: ##下面简单的介绍一下 beg…...
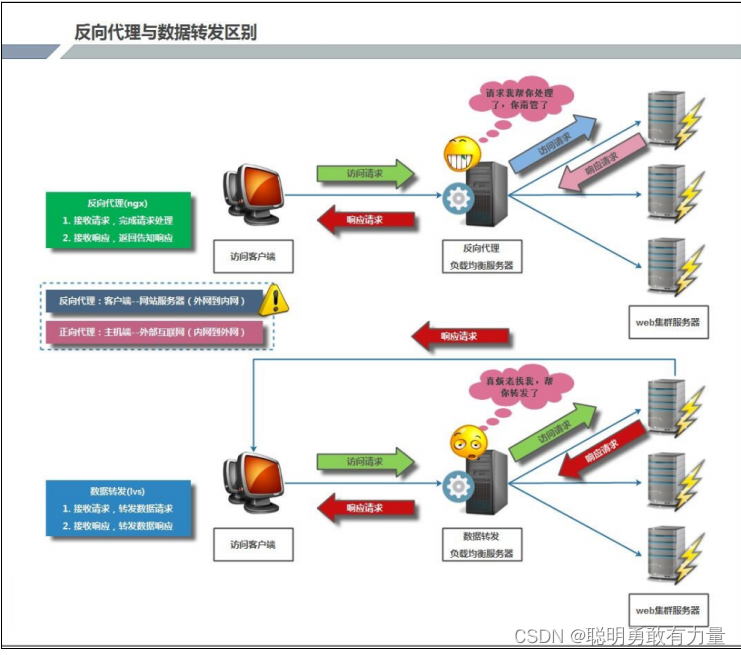
学无止境·运维高阶⑤(LVS-DR 群集 配置Nginx负载均衡)
LVS-DR 群集 && 配置Nginx负载均衡 一、LVS-DR 群集1、相关配置环境2、在RS上配置并启动脚本2.1相关脚本2.2 启动脚本,另一台RS同样步骤 3、LVS-DR模式配置脚本4、测试 二、Nginx负载均衡1、安装Nginx并关闭相应设置2、向主机 node2,node3 写入内…...

badger的mainfest文件解读
1. mainfest文件的作用 mainfest文件是记录lsm tree中的各层tables表的创建删除记录的一个日志文件,主要的作用是badger数据库重启后,重新恢复内存中的各层tables表 2、内容结构 先是8个字节的魔数,魔数的结构如下 ----------------------…...

java导出excel浏览器下载,单线程VS多线程
java导出excel浏览器下载,单线程VS多线程 package com.mengyang.transactional.other.excelxssf; import com.mengyang.transactional.other.myselfExcel.ExcelUtils; import com.mengyang.transactional.pojo.ZhongXinDTO; import org.apache.poi.ss.usermodel.*…...

Hunyuan-MT Pro智能助手:支持33语种的科研论文辅助翻译系统
Hunyuan-MT Pro智能助手:支持33语种的科研论文辅助翻译系统 1. 引言:科研翻译的新选择 作为一名经常需要阅读国际期刊的研究人员,你是否曾经为了一篇关键论文的翻译而头疼?那些专业的术语、复杂的句式,以及不同语言间…...

SDMatte开发环境搭建:Windows系统下Python与CUDA的配置详解
SDMatte开发环境搭建:Windows系统下Python与CUDA的配置详解 1. 准备工作:了解你的硬件和软件需求 在开始搭建SDMatte开发环境之前,我们需要先确认几个关键点。首先检查你的Windows电脑是否配备了NVIDIA显卡,这是使用CUDA加速的必…...

深入计算机网络:理解OFA-Image-Caption模型API调用的HTTP协议与网络延迟
深入计算机网络:理解OFA-Image-Caption模型API调用的HTTP协议与网络延迟 你是不是也遇到过这种情况?调用一个图像描述(Image Captioning)模型的API,比如OFA模型,明明服务器处理图片只需要几百毫秒…...

AI绘画神器FLUX.1-dev:Docker快速部署指南,开箱即用体验惊艳画质
AI绘画神器FLUX.1-dev:Docker快速部署指南,开箱即用体验惊艳画质 1. 引言:为什么选择FLUX.1-dev旗舰版? 如果你正在寻找一款能够生成影院级画质的AI绘画工具,FLUX.1-dev旗舰版绝对值得尝试。这个基于Docker的解决方案…...

SDMatte Web服务灾备方案:模型权重备份、配置快照、一键回滚流程
SDMatte Web服务灾备方案:模型权重备份、配置快照、一键回滚流程 1. 灾备方案概述 SDMatte作为一款专业级AI抠图服务,在生产环境中需要确保服务的高可用性和数据安全性。本文将详细介绍一套完整的灾备方案,涵盖模型权重备份、配置快照管理以…...

数据库开发云成本优化
数据库开发云成本优化:提升效率的关键策略 在云计算时代,数据库作为企业核心数据存储与处理的基石,其开发与运维成本直接影响整体业务效益。随着云服务的普及,如何优化数据库开发成本成为技术团队关注的焦点。本文将从多个角度探…...

EVA-02文本重建终端Python爬虫实战:自动化数据采集与智能处理
EVA-02文本重建终端Python爬虫实战:自动化数据采集与智能处理 1. 引言 你有没有遇到过这样的情况?需要从几十个网站上收集产品信息,手动复制粘贴到手软,好不容易整理成表格,却发现格式乱七八糟,关键信息还…...

数据库扩展方案设计
数据库扩展方案设计:应对海量数据挑战 随着数据量的爆炸式增长,传统单机数据库已无法满足高并发、高可用的业务需求。数据库扩展方案设计成为企业技术架构中的核心课题,它直接关系到系统的稳定性、性能和成本效益。本文将探讨几种关键的扩展…...

CTFHub文件上传靶场通关保姆级教程:从.htaccess到双写后缀的实战避坑
CTFHub文件上传靶场通关保姆级教程:从.htaccess到双写后缀的实战避坑 当你第一次接触CTF比赛中的文件上传漏洞挑战时,可能会被各种防御机制搞得晕头转向。别担心,这篇教程将带你一步步攻破CTFHub文件上传靶场的所有关卡,从最基础的…...

Qwen3-4B-Instruct-2507提示词编写技巧:如何让AI更懂你的需求
Qwen3-4B-Instruct-2507提示词编写技巧:如何让AI更懂你的需求 1. 为什么你的提示词总是不管用 你有没有遇到过这样的情况:你向AI模型提问,结果它要么答非所问,要么给你一堆没用的信息,要么干脆理解错了你的意思。你可…...