BERT数据处理,模型,预训练
代码来自李沐老师《动手学pytorch》
在数据处理时,首先执行以下代码
def load_data_wiki(batch_size, max_len):"""加载WikiText-2数据集"""num_workers = d2l.get_dataloader_workers()data_dir = d2l.download_extract('wikitext-2', 'wikitext-2')以上两句代码,不再说明paragraphs = _read_wiki(data_dir)train_set = _WikiTextDataset(paragraphs, max_len)train_iter = torch.utils.data.DataLoader(train_set, batch_size,shuffle=True)return train_iter, train_set.vocab
d2l.DATA_HUB['wikitext-2'] = ('https://s3.amazonaws.com/research.metamind.io/wikitext/''wikitext-2-v1.zip', '3c914d17d80b1459be871a5039ac23e752a53cbe')#@save
def _read_wiki(data_dir):file_name = os.path.join(data_dir, 'wiki.train.tokens')with open(file_name, 'r',encoding='utf-8') as f:lines = f.readlines()# 大写字母转换为小写字母 ,每行文本中包含两个句子,才进行处理,否则舍去文本paragraphs = [line.strip().lower().split(' . ')for line in lines if len(line.split(' . ')) >= 2]random.shuffle(paragraphs)return paragraphs
首先读取文本,每个文本必须包含两个以上句子(为了第二个预训练任务:判断两个句子,是否连续)。paragraphs 其中一部分结果如下所示
文本中包含了三个句子,每个’‘里面,代表一个句子
['common starlings are trapped for food in some mediterranean countries'
, 'the meat is tough and of low quality , so it is <unk> or made into <unk>'
, 'one recipe said it should be <unk> " until tender , however long that may be "'
, 'even when correctly prepared , it may still be seen as an acquired taste .']class _WikiTextDataset(torch.utils.data.Dataset):def __init__(self, paragraphs, max_len):'''每一个paragraph就是上面的包含多个句子的列表,将其进行分词处理。下面是一个分词的例子[['common', 'starlings', 'are', 'trapped', 'for', 'food', 'in', 'some', 'mediterranean', 'countries'], ['the', 'meat', 'is', 'tough', 'and', 'of', 'low', 'quality', ',', 'so', 'it', 'is', '<unk>', 'or', 'made', 'into', '<unk>'], ['one', 'recipe', 'said', 'it', 'should', 'be', '<unk>', '"', 'until', 'tender', ',', 'however', 'long', 'that', 'may', 'be', '"'], ['even', 'when', 'correctly', 'prepared', ',', 'it', 'may', 'still', 'be', 'seen', 'as', 'an', 'acquired', 'taste', '.']]'''paragraphs = [d2l.tokenize(paragraph, token='word') for paragraph in paragraphs]#将词提取处理,保存sentences = [sentence for paragraph in paragraphsfor sentence in paragraph]#形成一个词典,min_freq为词最少出现的次数,少于5次,则不保存进词典中self.vocab = d2l.Vocab(sentences, min_freq=5, reserved_tokens=['<pad>', '<mask>', '<cls>', '<sep>'])# 获取下一句子预测任务的数据examples = []for paragraph in paragraphs:examples.extend(_get_nsp_data_from_paragraph(paragraph, paragraphs, self.vocab, max_len))'''
def _get_nsp_data_from_paragraph(paragraph,paragraphs,vocab,max_len):nsp_data_from_paragraph=[]for i in range(len(paragraph)-1):_get_next_sentence函数传入的是相邻的句子a,b。函数中b会有一定概率替换为其他的句子tokens_a, tokens_b, is_next = _get_next_sentence(paragraph[i], paragraph[i + 1], paragraphs)句子长度大于bert限制的长度,则舍去。if len(tokens_a)+len(tokens_b)+3>max_len:continue#加上<cls>和<sep>,segments用于区token在哪个句子中tokens, segments = d2l.get_tokens_and_segments(tokens_a, tokens_b)nsp_data_from_paragraph.append((tokens, segments, is_next))return nsp_data_from_paragraphtoken和segments的例子: True表示两个句子相邻,False表示b被随机替换,a,b不相邻。(['<cls>', 'mushrooms', 'grow', '<unk>', 'or', 'in', '"', '<unk>', 'groups', '"', 'in', 'late', 'summer', 'and', 'throughout', 'autumn', ',', 'though', 'it', 'is', 'not', 'commonly', 'encountered', 'species', '<sep>', 'it','can', 'be', 'found', 'in', 'europe', ',', 'asia', 'and', 'north', 'america', '.', '<sep>'], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1,1, 1, 1, 1, 1], True),'''# 获取遮蔽语言模型任务的数据'''在这里我们会将句子中单词,替换为在词典中的索引。13意思为,句子的第13个词,进行了处理,可能不变,可能替换为其他词,可能替换为mask。在这里这个词没有替换。0与1区分两个句子,False代表两个句子不相邻。examples中的结果;([3, 2510, 31, 337, 9, 0, 6, 6891, 8, 11621, 6, 21, 11, 60, 3405, 14, 1542, 9546, 4, 2524,21, 185, 4421, 649, 38, 277, 2872, 13233, 4], [13], [60], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], False)'''examples = [(_get_mlm_data_from_tokens(tokens, self.vocab)+ (segments, is_next))for tokens, segments, is_next in examples]#_pad_bert_inputs对数据进行填充,all_mlm_weights中1为需要预测,0为填充# all_mlm_weights= tensor([1., 0., 0., 0., 0., 0., 0., 0., 0., 0.](self.all_token_ids, self.all_segments, self.valid_lens,self.all_pred_positions, self.all_mlm_weights,self.all_mlm_labels, self.nsp_labels) = _pad_bert_inputs(examples, max_len, self.vocab)def __getitem__(self, idx):return (self.all_token_ids[idx], self.all_segments[idx],self.valid_lens[idx], self.all_pred_positions[idx],self.all_mlm_weights[idx], self.all_mlm_labels[idx],self.nsp_labels[idx])def __len__(self):return len(self.all_token_ids)
上述已经将数据处理完,最后看一下处理后的例子:
将原来的句子列表填充1,一直到到大小为64
tensor([[ 3, 5, 0, 18306, 23, 11, 2659, 156, 5779, 382,1296, 110, 158, 22, 5, 1771, 496, 0, 3398, 2,5, 3496, 110, 5038, 179, 4, 16, 11, 19837, 6,58, 13, 5, 685, 7, 66, 156, 0, 3063, 77,3842, 19, 4, 1, 1, 1, 1, 1, 1, 1,1, 1, 1, 1, 1, 1, 1, 1, 1, 1,1, 1, 1, 1]])
segments用于区分两个句子,0为第一个句子中的词,1为第二个句子中的词,后面的0为填充
tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]])
valid_lens表示句子列表的有效长度
tensor([43.])
pred_positions需要预测的位置,0为填充
tensor([[19, 0, 0, 0, 0, 0, 0, 0, 0, 0]])
mlm_weights需要预测多少个词,0为填充
tensor([[1., 0., 0., 0., 0., 0., 0., 0., 0., 0.]])
预测位置的真实标签,0为填充
tensor([[22, 0, 0, 0, 0, 0, 0, 0, 0, 0]])
两句话是否相邻
tensor([0])
随后就是把处理好的数据,送入bert中。在 BERTEncoder 中,执行如下代码:
def forward(self, tokens, segments, valid_lens):# Shape of `X` remains unchanged in the following code snippet:# (batch size, max sequence length, `num_hiddens`)# 将token和segment分别进行embedding,X = self.token_embedding(tokens) + self.segment_embedding(segments)#加入位置编码X = X + self.pos_embedding.data[:, :X.shape[1], :]for blk in self.blks:X = blk(X, valid_lens)return X
将编码完后的数据,进行多头注意力和残差化
def forward(self, X, valid_lens):Y = self.addnorm1(X, self.attention(X, X, X, valid_lens))return self.addnorm2(Y, self.ffn(Y))
将结果返回到如下代码中:其中encoded_X .shape=torch.Size([1, 64, 128]),1代表批次大小为1,我们设置的每个批次只有行文本,每行文本由64个词组成,bert提取128维的向量来表示每个词。随后进行两个任务,一个是预测被掩盖的单词,另一个为判断两个句子是否为相邻。
def forward(self, tokens, segments, valid_lens=None, pred_positions=None):encoded_X = self.encoder(tokens, segments, valid_lens)if pred_positions is not None:mlm_Y_hat = self.mlm(encoded_X, pred_positions)else:mlm_Y_hat = None# The hidden layer of the MLP classifier for next sentence prediction.# 0 is the index of the '<cls>' tokennsp_Y_hat = self.nsp(self.hidden(encoded_X[:, 0, :]))return encoded_X, mlm_Y_hat, nsp_Y_hat
第一个任务为预测被mask的单词:
'''
例如:batch为1,X为1*64*128,其中num_pred_positions =10,batch_idx 会重复为[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],pred_positions为[ 3, 6, 10, 12, 15, 20, 0, 0, 0, 0],X[batch_idx, pred_positions]会将需要预测的向量取出。然后reshape为1*10*128的矩阵。最后连接一个mlp,经过规范化后接nn.Linear(num_hiddens, vocab_size)),会生成再vocab上的预测'''def forward(self, X, pred_positions):num_pred_positions = pred_positions.shape[1]pred_positions = pred_positions.reshape(-1)batch_size = X.shape[0]batch_idx = torch.arange(0, batch_size)# Suppose that `batch_size` = 2, `num_pred_positions` = 3, then# `batch_idx` is `torch.tensor([0, 0, 0, 1, 1, 1])`batch_idx = torch.repeat_interleave(batch_idx, num_pred_positions)masked_X = X[batch_idx, pred_positions]masked_X = masked_X.reshape((batch_size, num_pred_positions, -1))mlm_Y_hat = self.mlp(masked_X)return mlm_Y_hat
结束后,会返回到上层的代码中:
def forward(self, tokens, segments, valid_lens=None, pred_positions=None):encoded_X = self.encoder(tokens, segments, valid_lens)if pred_positions is not None:mlm_Y_hat = self.mlm(encoded_X, pred_positions)else:mlm_Y_hat = None# The hidden layer of the MLP classifier for next sentence prediction.# 0 is the index of the '<cls>' token判断句子是否连续,将<cls>的向量,放入mlp中,接一个nn.Linear(num_inputs, 2),最后变成一个二分类问题。nsp_Y_hat = self.nsp(self.hidden(encoded_X[:, 0, :]))return encoded_X, mlm_Y_hat, nsp_Y_hat
后面就是计算损失:
将mlm_Y_hat进行reshap,与mlm_Y求loss,最后需要乘mlm_weights_X,将填充的无用数据进行去除。mlm_l = loss(mlm_Y_hat.reshape(-1, vocab_size), mlm_Y.reshape(-1)) * mlm_weights_X.reshape(-1, 1)取平均lossmlm_l = mlm_l.sum() / (mlm_weights_X.sum() + 1e-8)nsp_l = loss(nsp_Y_hat, nsp_y)l = mlm_l + nsp_l
相关文章:

BERT数据处理,模型,预训练
代码来自李沐老师《动手学pytorch》 在数据处理时,首先执行以下代码 def load_data_wiki(batch_size, max_len):"""加载WikiText-2数据集"""num_workers d2l.get_dataloader_workers()data_dir d2l.download_extract(wikitext-2, w…...

Oracle将与Kubernetes合作推出DevOps解决方案!
导读Oracle想成为云计算领域的巨头,但它不是推出自己品牌的云DevOps软件,而是将与CoreOS在Kubernetes端展开合作。七年前,Oracle想要成为Linux领域的一家重量级公司。于是,Oracle主席拉里埃利森(Larry Ellison…...

微服务与Nacos概述-4
限流规则配置 每次服务重启后 之前配置的限流规则就会被清空因为是内存态的规则对象,所以就要用到Sentinel一个特性ReadableDataSource 获取文件、数据库或者配置中心是限流规则 依赖:spring-cloud-alibaba-sentinel-datasource 通过文件读取限流规则…...

Streamlit 讲解专栏(九):深入探索布局和容器
文章目录 1 前言2 st.sidebar - 在侧边栏增添交互元素2.1 将交互元素添加至侧边栏2.2 示例:在侧边栏添加选择框和单选按钮2.3 特殊元素的注意事项 3 st.columns - 并排布局多元素容器3.1 插入并排布局的容器3.2 嵌套限制 4 st.tabs - 以选项卡形式布局多元素容器4.1…...

使用cloud-int部署nginx
参考 azure创建虚拟机,创建虚拟机注意入站端口规则开放80端口,高级中使用自定义数据,初始化虚拟机,安装nginx 连接CLI,验证是否安装成功 访问虚拟机IP查看是否部署成功 参考文档: https://learn.microsoft.com/zh-cn…...
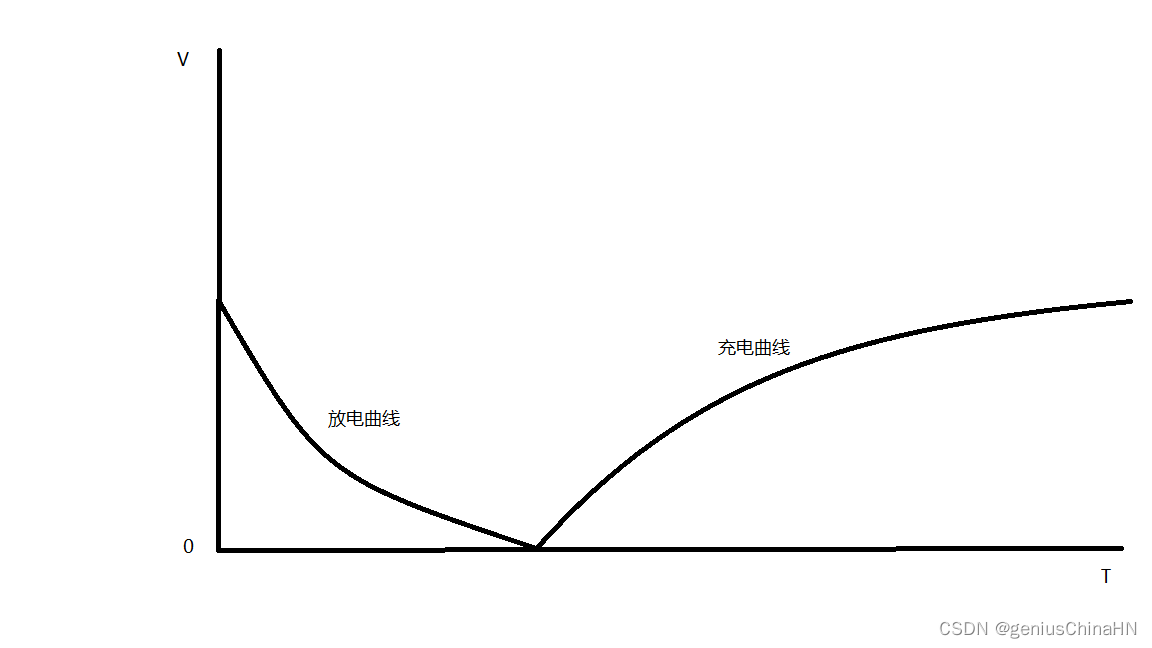
定量分析计算51单片机复位电路工作原理 怎么计算单片机复位电容和电阻大小
下面画出等效电路图 可以知道单片机内必然有一个电阻RX,为了简化分析,我们假设他是线性电阻(不带电容,电感的支路) 还有一个基础知识: 电容器的充电放电曲线: 还需要知道电容电压的变化是连续…...

消息队列相关面试题
巩固基础,砥砺前行 。 只有不断重复,才能做到超越自己。 能坚持把简单的事情做到极致,也是不容易的。 面试题 项目上用过消息队列吗?用过哪些?当初选型基于什么考虑的呢? 面试官心理分析 第一࿰…...

33 | 美国总统数据分析
在这个数据分析项目中,利用Pandas等Python库对美国2020年7月22日至2020年8月20日期间的超过75万条捐赠数据进行了深入的探索和分析。通过这一分析,他们揭示了这段时间内美国选民对总统候选人的偏好和捐款情况。以下是对文章中的主要步骤和内容的进一步描述: 数据集处理: 作…...

每日一题之常见的排序算法
常见的排序算法 排序是最常用的算法,常见的排序算法有冒泡排序、选择排序、插入排序、快速排序、希尔排序和归并排序。除此之外,还有桶排序、堆排序、基数排序和计数排序。 1、冒泡排序 冒泡排序就是把小的元素往前放或大的元素往后放,比较…...
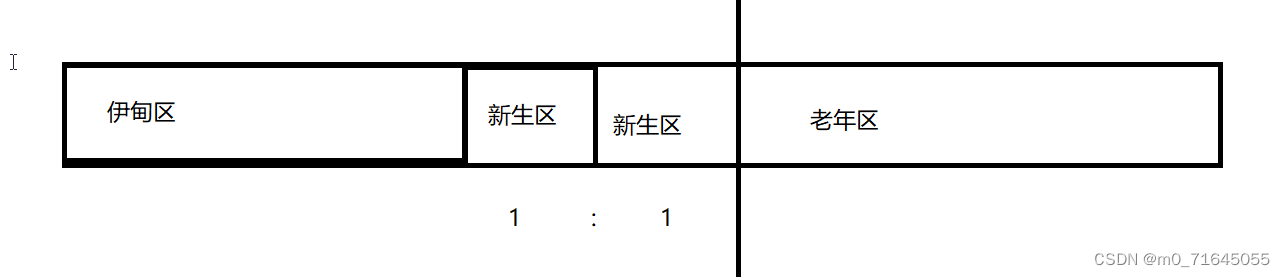
JVM 类加载和垃圾回收
JVM 1. 类加载1.1 类加载过程1.2 双亲委派模型 2. 垃圾回收机制2.1 死亡对象的判断算法2.2 垃圾回收算法 1. 类加载 1.1 类加载过程 对应一个类来说, 它的生命周期是这样的: 其中前 5 步是固定的顺序并且也是类加载的过程,其中中间的 3 步我们都属于连接…...

C++ 多线程
C 多线程 多线程是多任务处理的一种特殊形式,多任务处理允许让电脑同时运行两个或两个以上的程序 一般情况下,两种类型的多任务处理:基于进程和基于线程 基于进程的多任务处理是程序的并发执行基于线程的多任务处理是同一程序的片段的并发…...
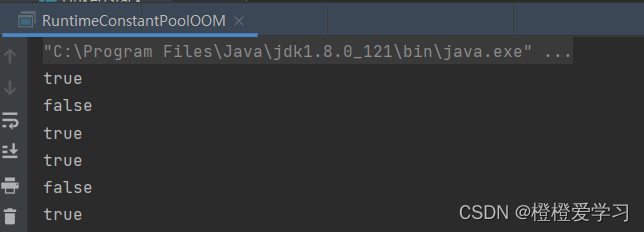
深入理解JVM之.intern()的用法
intern只在常量池里记录首次出现的实例引用 来看一段代码 public class RuntimeConstantPoolOOM {public static void main(String[] args) {String str1 new StringBuilder("计算机").append("软件").toString();System.out.println(str1.intern() st…...
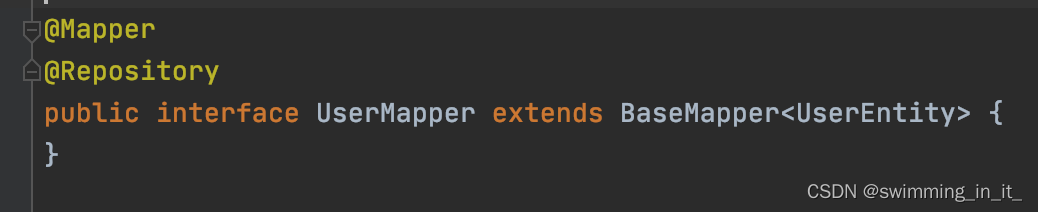
idea报“Could not autowire. No beans of ‘UserMapper‘ type found. ”错解决办法
原因和解决办法 1.原因 idea具有检测功能,接口不能直接创建bean的,需要用动态代理技术来解决。 2.解决办法 1.修改idea的配置 1.点击file,选择setting 2.搜索inspections,找到Spring 3.找到Spring子目录下的Springcore 4.在Springcore的子目录下…...
)
QEMU源码全解析35 —— Machine(5)
接前一篇文章:QEMU源码全解析34 —— Machine(4) 本文内容参考: 《趣谈Linux操作系统》 —— 刘超,极客时间 《QEMU/KVM》源码解析与应用 —— 李强,机械工业出版社 特此致谢! 上回书说到有3…...

SpringBoot对一个URL通过method(GET、POST、PUT、DELETE)实现增删改查操作
目录 1. rest风格基础2. 开启方法3. 实战练习 1. rest风格基础 我们都知道GET、POST、PUT、DELETE分别对应查、增、改、删除 虽然Postman这些工具可以直接发送GET、POST、PUT、DELETE请求。但是RequestMapping并不支持PUT和DELETE请求操作。需要我们手动开启 2. 开启方法 P…...

webpack 创建VUE项目
1、安装 node.js 下载地址:https://nodejs.org/en/ 下载完成以后点击安装,全部下一步即可 安装完成,输入命令验证 node -vnpm -v2.搭建VUE环境 输入命令,全局安装 npm install vue-cli -g安装完成后输入命令 查看 vue --ver…...

deepin 深度操作系统正式适配苹果 M1 芯片
导读近日消息,据深度操作系统官方消息,在已经发布的 deepin V23 beta 版本中,深度操作系统正式适配 Apple Mac mini M1 了。 官方表示,Mac mini M1 是苹果于 2020 年 11 月发布的迷你电脑主机,它搭载了最高 3.2GHz …...

Labview控制APx(Audio Precision)进行测试测量(七)
处理集群控制子集 大多数用户不会想要设置所有的控制包括在一个大的控制集群,如水平和增益配置控制。例如,假设您只在 APx 中使用模拟不平衡输出连接器,而您想要做的就是控制发电机的电平和频率。在这种情况下,水平和增益配置集群…...
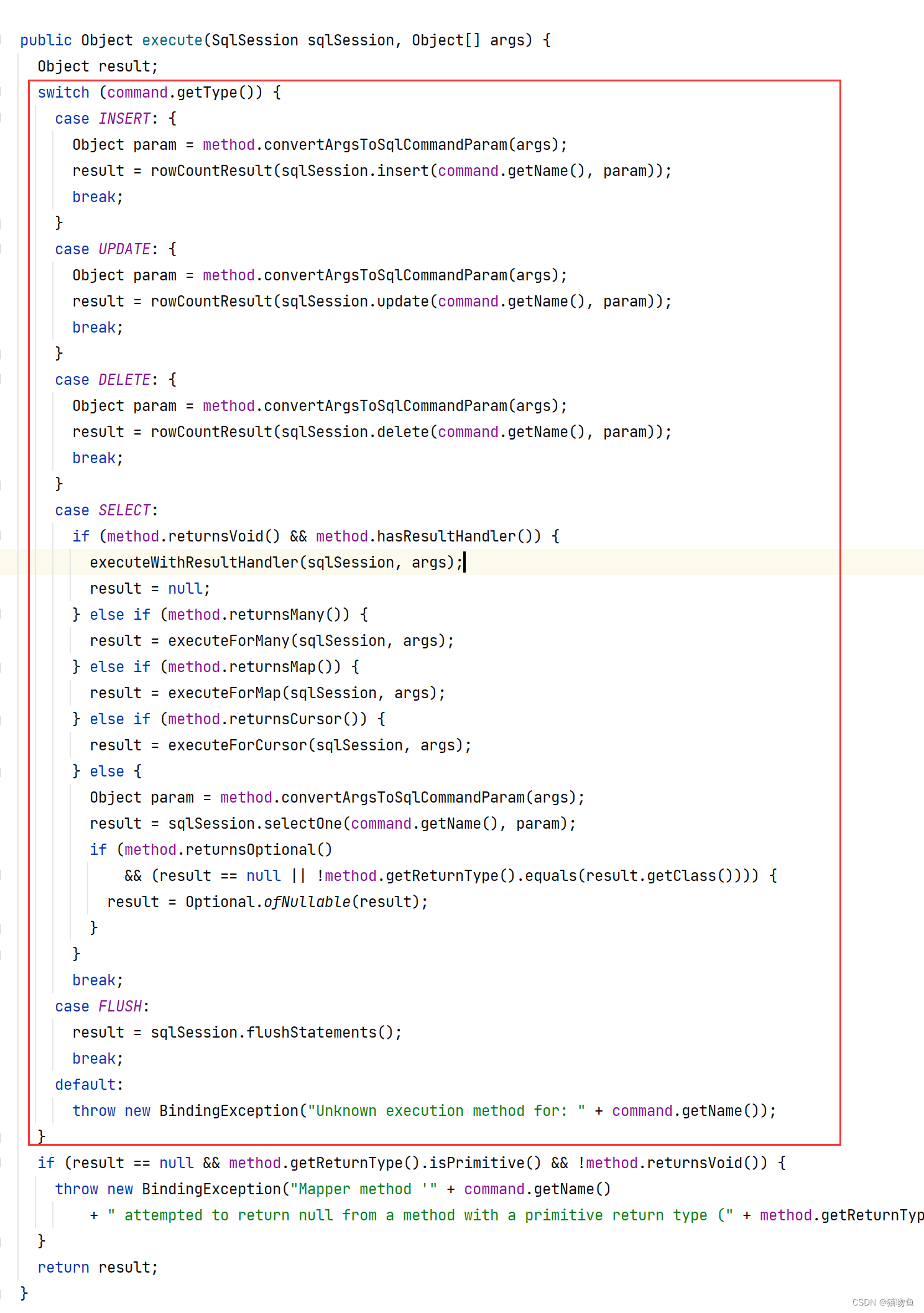
Mybatis 源码 ② :流程分析
文章目录 一、前言二、Mybatis 初始化1. AutoConfiguredMapperScannerRegistrar2. MapperScannerConfigurer3. ClassPathMapperScanner3.1 ClassPathMapperScanner#scan3.2 ClassPathMapperScanner#processBeanDefinitions 4. 总结 三、 Mapper Interface 的创建1. MapperFacto…...
Unity2D RPG开发笔记 P1 - Unity界面基础操作和知识
文章目录 工具选择简单快捷键Game 窗口分辨率检视器Transform 组件Sprite Renderer综合检视器 工具选择 按下 QWERTY 可以选择不同的工具进行 旋转、定位、缩放 简单快捷键 按下 Ctrl D 可以复制物体 Game 窗口分辨率 16:9 为最常见的分辨率 检视器 Transform 组件 物体在…...
Pixel Dream Workshop部署指南:多用户共享服务器下的资源隔离与并发优化
Pixel Dream Workshop部署指南:多用户共享服务器下的资源隔离与并发优化 1. 项目概述 像素幻梦 (Pixel Dream Workshop) 是一款基于 FLUX.1-dev 扩散模型构建的下一代像素艺术生成工具。它采用独特的16-bit像素工坊视觉设计,为创作者提供沉浸式的AI绘图…...

告别复杂配置!用Ollama快速部署Llama-3.2-3B文本生成服务
告别复杂配置!用Ollama快速部署Llama-3.2-3B文本生成服务 还在为部署大语言模型而头疼吗?环境配置、依赖冲突、显存不足……这些繁琐的步骤常常让开发者望而却步。今天,我要分享一个极其简单的方法,让你在几分钟内就能拥有一个功…...

Linux V4L2核心子系统
一、drivers/media/v4l2-core 目录文件分析drivers/media/v4l2-core/ │ ├── 1. 字符设备核心模块 │ └── v4l2-dev.c # V4L2字符设备驱动核心 │ ├── video_device 注册/注销 │ ├── 申请主设备号(81) │ ├── 创建/dev…...
)
AI服务高并发低延迟落地难?揭秘3种经生产验证的AI原生后端设计模式(附Llama/Embedding/RAG实战拓扑图)
第一章:AI原生后端服务设计范式演进与核心挑战 2026奇点智能技术大会(https://ml-summit.org) 传统微服务架构在面对LLM推理调度、多模态流式响应、动态提示工程与实时上下文管理等需求时,暴露出显著的结构性失配。AI原生后端不再仅是“API封装层”&…...

【AI Token中转】2026年AI Token代理站搭建实战:技术架构与运营策略
2026年AI Token中转站搭建实战:技术架构与运营策略 上个月帮朋友搭了一个API中转站。折腾了一周,踩了几个坑,现在稳定跑了两个月。 这篇文章把整个过程和实际数据整理出来。包括技术选型、部署细节、运维经验,还有运营策略。 不讲…...
配置完整教程)
Windows 系统 Allure 环境变量(PATH)配置完整教程
🔑 前置准备 先确认你已经下载并解压了 Allure 工具,找到它的 bin 目录路径(比如 D:\tools\allure-2.30.0\bin,路径里绝对不能有中文、空格、特殊符号) 确认 bin 目录里有 allure.bat 和 allure.exe 这两个文件 已经安装好 Java 8+ 环境(java -version 能正常输出版本号…...
)
计及阴影遮挡效应的光伏阵列拓扑 PSO 重构优化研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
)
音视频AI工程化最后一公里(SITS2026原生框架实测报告:FFmpeg vs WebAssembly vs 原生Kernel Mode)
第一章:音视频AI工程化最后一公里的挑战与SITS2026原生框架定位 2026奇点智能技术大会(https://ml-summit.org) 在音视频AI大规模落地过程中,“最后一公里”并非指部署时长或物理距离,而是指模型能力与真实业务场景之间不可忽视的语义鸿沟—…...

BLE按键服务设计:轻量级只读GATT特征值实现
1. 项目概述ble-button是一个面向嵌入式 BLE(Bluetooth Low Energy)应用的轻量级服务模板,其核心目标是为物理按键、拨动开关、触摸感应等单比特输入设备提供标准化、可复用的蓝牙 GATT(Generic Attribute Profile)服务…...

MICROCHIP微芯 MIC2290YML-TR MLF8 DC-DC电源芯片
特性内置肖特基二极管输入电压2.5V至10V输出电压可调至34V开关电流超过500mA,1.2MHz PWM工作与陶瓷电容稳定 <1% 的线性和负载调节低输入和输出纹波 <1μA 关断电流欠压锁定输出过压保护过温保护2mm x 2mm 8引脚MLF封装结温范围-40℃至125℃...