探索ES高可用:滴滴自研跨数据中心复制技术详解
Elasticsearch 是一个基于Lucene构建的开源、分布式、RESTful接口的全文搜索引擎,其每个字段均可被索引,且能够横向扩展至数以百计的服务器存储以及处理TB级的数据,其可以在极短的时间内存储、搜索和分析大量的数据。
滴滴ES发展至今,承接了公司绝大部分端上检索和日志场景,包括地图POI检索、订单检索、客服、内搜及把脉ELK场景等。
近几年围绕稳定性、成本、效率和数据安全这几个方向持续探索:
滴滴ES有很多在线P0级检索场景,为了提升集群稳定性,我们自研了跨数据中心复制能力,实现多机房数据写入强一致性,并配合管控平台让ES支持多活能力;
为了提升查询性能和解决查询毛刺问题,我们在7.6版本上原地升级支持JDK 17;
ES日志场景每天写入量在5PB-10PB量级,写入压力和业务成本压力大,为了提升ES的写入性能,我们让ES支持ZSTD压缩算法;
由于ES索引里包含很多敏感数据,我们又完善了ES的安全认证能力。
基于以上探索,我们总结了一定的经验,现分成4篇文章详细介绍。本篇文章介绍滴滴ES如何实现索引的跨数据中心复制从而保证索引的高可用。
滴滴跨数据中心复制能力 - Didi Cross Datacenter Replication,由滴滴自研,简称DCDR,它能够将数据从一个 Elasticsearch 集群原生复制到另一个 Elasticsearch 集群。如图所示,DCDR工作在索引模板或索引层面,采用主从索引设计模型,由Leader索引主动将数据push到Follower索引,从而保证了主从索引数据的强一致性。

DCDR跨数据中心复制能力图
DCDR在滴滴内部的主要生产应用如下:
灾难恢复(DR)/高可用性(HA):如果主集群发生故障,能够通过切换主从集群快速恢复,从而实现异地多活
索引迁移:索引可以在不同集群间迁移,保证集群间的数据均衡,同时实现索引在集群级别的分级保障
主从查询隔离:由于主从索引的强一致性保证,配合自研ES Admin管控平台,不同业务方可以查询不同的集群,避免相互之间的查询影响
背景及目标
原生的Elasticsearch提供了集群内部的高可用,能够保证集群内部的数据可靠性。但这种高可用无法满足对可靠性有进一步需求的用户。原生Elasticsearch主要有以下痛点:
对于数据中心级别故障无法实现快速恢复
数据在集群间搬迁成本很高,需借助外部工具来完成多个复杂操作
最初,滴滴内部应对跨数据中心的高可用,借助了外部同步平台将数据双写到不同集群来实现。该方式依赖较重,不支持历史数据同步,并且无法保证主从索引数据的强一致性。随着外部平台的收敛,双写的方式已经无法使用。ES 官方在6.7.0版本提供了跨集群数据复制功能,该功能需付费且只能保证主从索引数据的最终一致性。滴滴内部核心业务,如POI检索(滴滴APP上下车地点检索服务)、订单检索业务,都要求主从索引数据强一致性。
为解决上述问题,满足业务方诉求,滴滴ES团队决定自研跨数据中心复制能力,即上文的DCDR。
DCDR在设计时主要有以下几个目标:
保证主从数据的强一致性
保证高可用性,快速实现灾难恢复
实现不停机跨集群索引迁移
可靠的版本升级(Elasticsearch的Rolling upgrades和Full cluster restart upgrade方案都无法做到升级后回滚)
技术基础
DCDR功能支持将远程集群中的索引复制到本地集群,在复制过程中需要考虑两个重点:实时数据的同步、历史数据的同步。实时数据同步依赖ES写入机制,数据同步依赖ES副本恢复机制。因此,在介绍DCDR的方案设计以及实现细节之前,对这两个流程简单概述:
基本写入机制
ES写入是先写主分片,主分片写完后再将请求并行转发到副本,副本处理完再由主分片返回写入结果,具体流程如下:(注:本文中Si代表ES具体分片,P代表主分片,R代表副本)
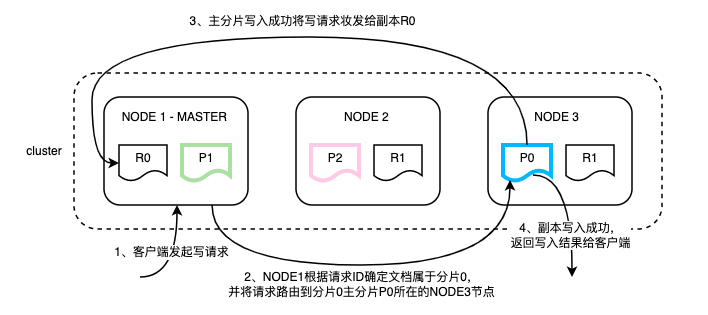
副本恢复流程
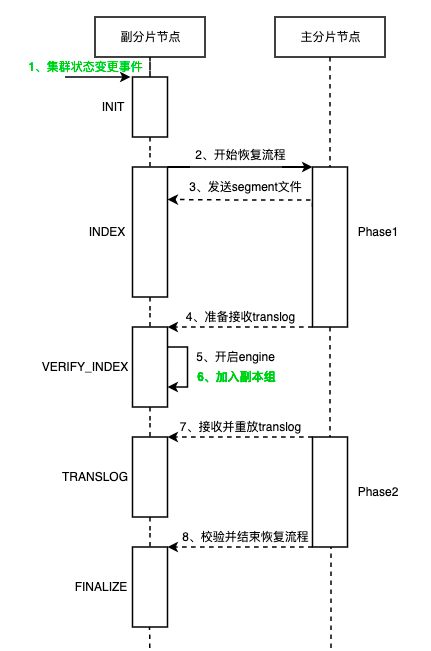
为了保证数据副本的一致性,副本的数据需要恢复到和主分片一致才能正常对外提供服务。ES的副本恢复是分片级别的,分为主分片恢复流程和副分片恢复流程。由于ES的副本恢复流程极为复杂,并且DCDR的数据恢复过程中仅与副分片恢复流程相关,因此这里只简单地介绍下副分片恢复流程。
副本recovery的目标是要将本地数据恢复到和主分片一致,主流程分为两个阶段:
阶段一是主分片给副本发送segment文件(存储的是已经落盘并解析后的具体数据)
阶段二是主分片向副本发送translog日志(未落盘的数据,类似mysql 的WAL Log),两阶段结束后副本的恢复流程就结束了
具体流程如下图:
方案设计
设计思想
DCDR的核心思想是将从索引对应分片看做主索引对应分片的一个远程副本来处理。如下图,从索引的shard0主分片,会被当做主索引shard0主分片的一个远程副本。

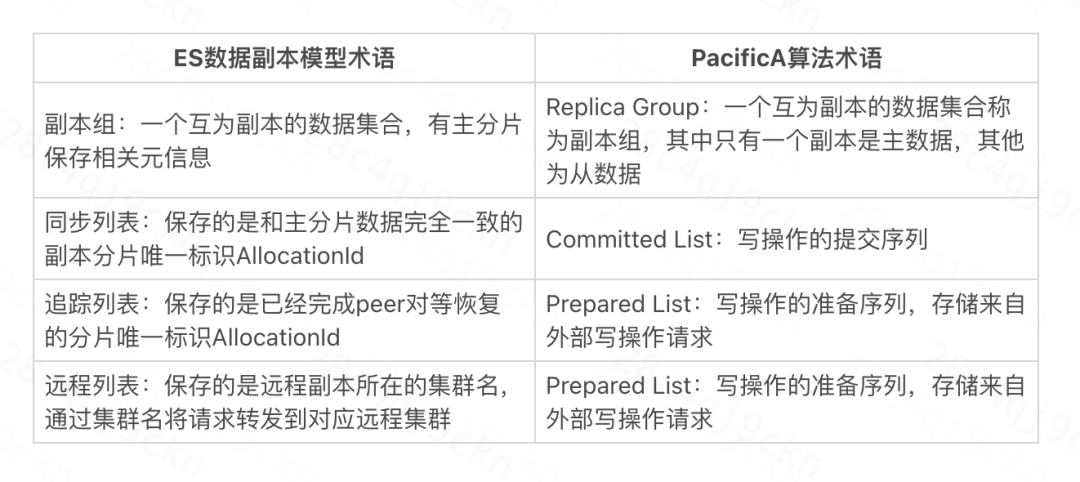
为了让大家更好地理解这个思路,简单介绍下远程副本:远程副本是由ES数据副本模型延伸而来,由主索引的主分片保存远程副本相关元数据,在实现上借鉴了微软的PacificA算法。该设计思想符合ES数据副本模型,能够极大程度地复用ES副本逻辑,降低开发难度,减少对开源ES内核的侵入。
以下是该算法的部分核心术语和ES数据副本模型的对应关系:
具体方案设计
DCDR是跨集群数据复制能力,实现该功能的第一步就是需要明确哪些索引模板或者索引需要进行数据的跨集群复制,也就是需要建立起DCDR链路。其次,DCDR的从索引作为一个远程副本,需要恢复到和主索引的数据一致才能正常提供服务,即历史数据恢复。从索引的数据恢复到和主索引一致,当主索引新增数据时,数据该如何写入从索引,即实时数据同步。经过以上环节,从索引就能够正常提供服务,那么如何保证数据的可靠性呢?这就涉及到了主从索引数据质量校验。
基于以上思考,整个DCDR的方案设计上分为四个主流程:

1、DCDR链路构建
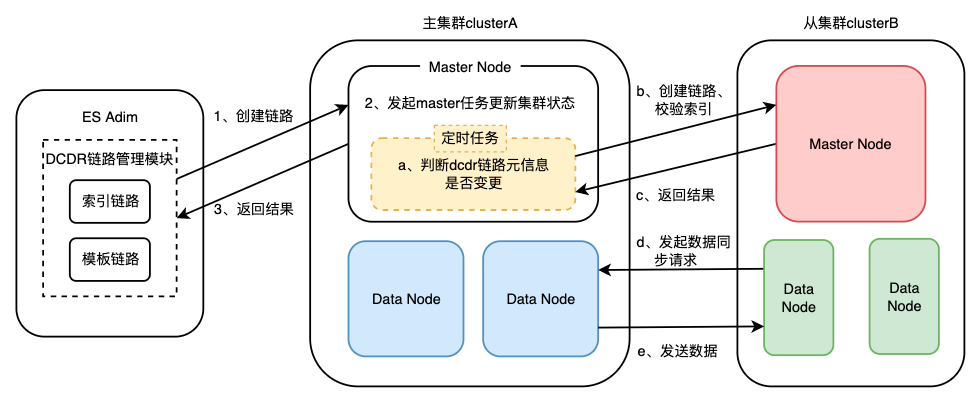
ES集群是基于集群状态驱动的,因此DCDR链路构建的本质就是改变集群状态,并在对应机器上应用新的集群状态。滴滴内部的ES使用方式是索引模板形式(一组拥有相同前缀的索引集合),因此在链路设计上需要支持模板链路和索引链路。DCDR链路集群元信息通过ES cluster state自定义metaData实现,链路拥有统一的命名规则,并且区分模板和索引,主要信息展示如下:
模板链路:
{"templates": {"templateA_to_ClusterA": {"name": "IndexA_to_ClusterA", // dcdr模板链路名"template": "templateA", // 索引模板名"replica_cluster": "ClusterA" // 从集群名称}}
}
索引链路:
{"Index_202206/Index_202206(ClusterA)": {"primary_index": "Index_202206", // 主索引名称"replica_index": "Index_202206", // 从索引名称"replica_cluster": "ClusterA", // 从集群名称"replication_state": true // 链路状态}
}ES集群对外提供了DCDR链路创建API,通过API将链路元信息更新到集群状态中,DCDR相关模块通过订阅集群状态变更事件,从而进入数据同步流程。如下图:
有个设计细节需要注意:
Q:主从索引名是一致的,那么主从索引的唯一标识UUID(集群建索引后自动生成的随机字符串)要怎么处理呢?
综合考虑开发难度和源码侵入问题,主从索引的索引名和UUID都保持一致
在从索引创建时透传主索引的UUID到从集群,从索引在创建索引时不再自动生成UUID,解决从索引创建UUID不一致问题
由于ES墓地会暂时保存被删除的索引,因此在从索引创建时扫描ES墓地并删除UUID相同的索引,解决从索引删除后无法重建问题
2、历史数据恢复
历史数据恢复方案在设计上借鉴了ES副本恢复策略。DCDR从索引的副本恢复同样是分片级别的,也需要进行segement和translog的复制环节。历史数据恢复发生的条件:
新建DCDR链路,从索引需要根据主索引进行历史数据恢复
从索引分片数据写入失败,主索引定时任务重建DCDR链路
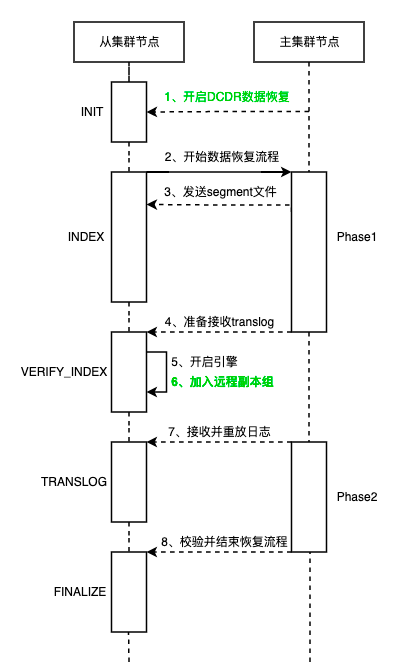
从索引作为远程副本在历史数据恢复方面和ES的副本恢复流程基本是一致的,主要区别(图中绿色标记)在于第1步的数据恢复触发条件,以及第6步加入的副本组不同。同时要注意以下设计细节:
Q:怎么触发历史数据的恢复?
ES的副本恢复是由集群状态变更事件驱动的,从索引的恢复是跨集群的,因此只能依靠主集群的RPC调用触发从集群的DCDR历史数据恢复。
Q:ES分片恢复是个很耗时的阶段,如何提高从索引的分片恢复效率,使得从索引能够快速提供服务?
从索引只需要恢复自身的主分片数据,之后DCDR从索引历史数据恢复结束,从索引就能正常接收主索引的写请求了。从索引自身的副本恢复依赖于从集群的ES副本机制即可。这样能够极大地降低DCDR链路历史数据恢复时间。
Q:从索引什么时候可以正常接收主索引的写请求呢?
ES副本会在主分片phase1结束,副本启动Engine后加入主分片副本组,开始接收主分片的写请求。从索引的恢复也是类似的,从索引的主分片作为主索引对应主分片的远程副本,也会在主索引主分片phase1结束后,自身Engine启动后,由主索引的对应主分片加入远程副本组,开始接收写请求。
远程副本组的实现是在ES的ReplicationGroup类中增加一个远程的prepared list。
Q:DCDR历史数据恢复过程中,主索引的主分片能否迁移?
分片搬迁是集群均衡的一种手段,由于DCDR的恢复是跨集群的,无法通过集群状态变更快速地感知到分片迁移并进行处理。因此,主分片不能迁移。在DCDR数据恢复过程中,会通过加锁的方式防止主分片迁移。
3、实时数据同步
实时数据同步指的是历史数据同步完成后,增量数据如何同步到从索引。根据前文的ES写入流程可知,ES写入是先写主分片,之后再将写请求同步转发到副本上。基于滴滴内部业务场景考虑,需要异地多活的业务数据写入量一般不大,远未达到ES的写入瓶颈,并且一些核心业务对数据一致性有强依赖。因此,DCDR在实时数据同步上采用主分片写入成功,将数据同步转发给副本以及远程副本这一方案。该方案牺牲一定的数据写入性能,从而保证了数据的强一致性。

实时数据同步策略采用的是将写请求转发到远程副本实现的,仍然有许多细节需要考虑:
Q:远程副本写入失败怎么办?
ES副本写入失败的处理策略是将副本从同步副本组移除,并重新执行Recovery。远程副本写入失败的处理策略和ES副本写入失败处理策略类似,是将远程副本从主索引主分片的远程副本组中移除,主索引将不再转发写请求到从索引,由从索引的定时检查机制重新执行数据恢复流程。
Q:从索引的seq_num(每条请求递增的唯一ID,用来加快副本恢复流程的)如何保证主从一致?
从索引的分片采用了自定义的Engine,该Engine能够直接接收主索引传过来的seq_num,不再生成seq_num值。
Q:主从mapping如何保证一致?要更新mapping时怎么处理?
新建DCDR链路时会将主索引的mapping拷贝到从集群,并新建从索引,保证链路新建时主从索引的mapping是一致的。
DCDR的设计思想是远程副本策略,是将写请求直接转发给从索引。因此,后期如果出现需要更新mapping的字段,会由主从集群各自的master去执行master任务去更新mapping即可(主从master mapping更新处理策略一致)。
4、主从索引数据质量校验
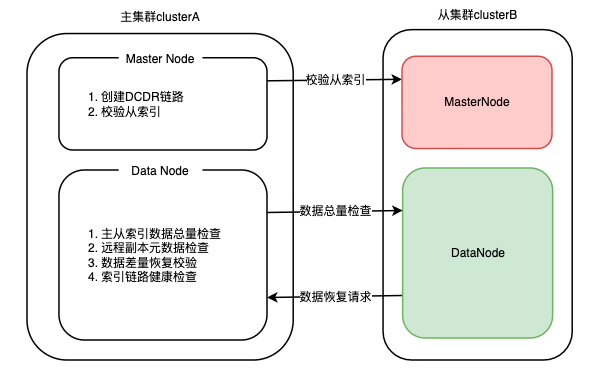
数据质量校验环节是从索引数据可靠性的保障。它会定时检查集群状态中的DCDR元信息是否和当前链路运行状态一致,根据结果对链路进行相应的操作。当主从索引数据差距过大或链路异常时,主集群会主动断开链路,并通知从索引进行差量数据恢复。ES集群中,MasterNode负责管控集群元数据,因此在设计校验任务时,主要用于链路元数据创建及检查从索引是否存在;DataNode负责数据存储,因此用于判断主从分片是否需要进行数据恢复。
5、其他
经过以上4个环节就能将数据从一个 Elasticsearch 集群原生复制到另一个 Elasticsearch 集群,搭配上主从切换策略,就能在保证数据强一致性的前提下实现跨集群高可用。对于不停机跨集群索引迁移这一目标,我们通过DCDR将数据同步到目的端集群,等待存量数据恢复完成,再进行一次主从切换。对于可靠的版本升级这一目标,我们通过DCDR复制待升级版本数据到备用集群,当版本升级异常时能够快速切换集群。
总结
目前滴滴ES共有6个DCDR从集群,建立的DCDR模板链路400+,DCDR索引链路2000+,涵盖了POI、dos_order、soda等滴滴核心业务。目前ES仍然存在查询毛刺、查询相互影响、分片恢复、写入性能等方面问题,后续我们会在这些方面重点发力,更好的助力业务发展。
相关文章:
探索ES高可用:滴滴自研跨数据中心复制技术详解
Elasticsearch 是一个基于Lucene构建的开源、分布式、RESTful接口的全文搜索引擎,其每个字段均可被索引,且能够横向扩展至数以百计的服务器存储以及处理TB级的数据,其可以在极短的时间内存储、搜索和分析大量的数据。 滴滴ES发展至今…...

指针---进阶篇(二)
指针---进阶篇(二) 前言一、函数指针1.抛砖引玉2.如何判断函数指针?(方法总结) 二、函数指针数组1.什么是函数指针数组?2.讲解函数指针数组3.模拟计算器:讲解函数指针数组 三、指向函数指针数组…...
Python实现SSA智能麻雀搜索算法优化循环神经网络分类模型(LSTM分类算法)项目实战
说明:这是一个机器学习实战项目(附带数据代码文档视频讲解),如需数据代码文档视频讲解可以直接到文章最后获取。 1.项目背景 麻雀搜索算法(Sparrow Search Algorithm, SSA)是一种新型的群智能优化算法,在2020年提出&a…...

【go语言基础】结构体struct
主要是敲代码,敲的过程中会慢慢体会。 1.概念 结构体是用户定义的类型,表示若干字段的集合,目的是将数据整合在一起。 简单的说,类似Java中的实体类。存储某个实体属性的集合。 2.结构体声明 注意:结构体名字&…...

显卡服务器适用于哪些场景
显卡(GPU)服务器,简单来说,GPU服务器是基于GPU的应用于视频编解码、深度学习、科学计算等多种场景的快速、 稳定、弹性的计算服务。那么壹基比小鑫告诉你显卡服务器主要的用途有哪一些。 一、运行手机模拟器 显卡服务器可支持…...

MySQL DML 数据操作
文章目录 1.插入记录INSERTREPLACE 2.删除记录3.修改记录4.备份还原数据参考文献 1.插入记录 INSERT 使用 INSERT INTO 语句可以向数据表中插入数据。INSET INTO 有三种形式。 INSET INTO tablename SELECT...INSET INTO tablename SET column1value1,column2value2...INSET…...

服务端与网络相关知识
1. http/https 协议 1.0 协议缺陷: ⽆法复⽤链接,完成即断开,重新慢启动和 TCP 3 次握⼿head of line blocking : 线头阻塞,导致请求之间互相影响 1.1 改进: ⻓连接(默认 keep-alive ),复⽤host 字段指定对应的虚拟站点新增功…...

一分钟上手Vue VueI18n Internationalization(i18n)多国语言系统开发、国际化、中英文语言切换!
这里以Vue2为例子 第一步:安装vue-i18n npm install vue-i18n8.26.5 第二步:在src下创建js文件夹,继续创建language文件夹 在language文件夹里面创建zh.js、en.js、index.js这仨文件 这仨文件代码分别如下: zh.js export de…...
stm32 cubemx can通讯(1)回环模式
文章目录 前言一、cubemx配置二、代码1.过滤器的配置(后续会介绍)2.main.c3.主循环 总结 前言 介绍使用stm32cubemx来配置can,本节讲解一个简答,不需要stm32的can和外部连接,直接可以用于验证的回环模式。 所谓回环模…...
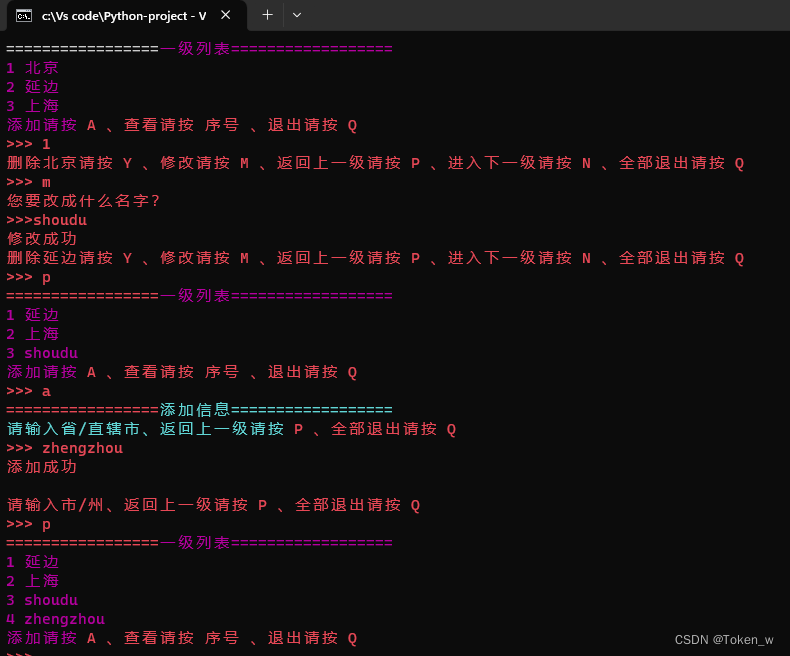
Python基础小项目
今天给大家写一期特别基础的Python小项目,欢迎大家支持,并给出自己的完善修改 (因为我写的都是很基础的,运行速率不是很好的 目录 1. 地铁票价题目程序源码运行截图 2. 购物车题目程序源码运行截图 3. 名片管理器题目程序源码运行…...

Python Opencv实践 - 在图像上绘制图形
import cv2 as cv import numpy as np import matplotlib.pyplot as pltimg cv.imread("../SampleImages/pomeranian.png") print(img.shape)plt.imshow(img[:,:,::-1])#画直线 #cv.line(img,start,end,color,thickness) #参考资料:https://blog.csdn.ne…...

管理者应该编码,但不是在工作时
管理者应该编码吗?这个问题似乎没有一个明确的答案。这场辩论有支持者也有反对者,每一方都有自己的论点。我最近在工作中编写了一个副业项目,这让我重新评估了我在这个问题上的立场。经历了这些之后,我可以说,我的立场已经从管理…...

深度学习常用的python库学习笔记
文章目录 数据分析四剑客Numpyndarray数组和标量之间的运算基本的索引和切片数学和统计方法线性代数 PandasMatplotlibPIL 数据分析四剑客 Numpy Numpy中文网 ndarray 数组和标量之间的运算 基本的索引和切片 数学和统计方法 线性代数 Pandas Pandas中文网 Matplotlib Mat…...

C语言属刷题训练【第八天】
文章目录 🪗1、如下程序的运行结果是( )💻2、若有定义: int a[2][3]; ,以下选项中对 a 数组元素正确引用的是( )🧿3、在下面的字符数组定义中,哪一个有语法错…...

阿里云PolarDB数据库倚天ARM架构详细介绍
阿里云云原生数据库PolarDB MySQL版推出倚天ARM架构,倚天ARM架构规格相比X86架构规格最高降价45%,PolarDB针对自研倚天芯片,从芯片到数据库内核全链路优化,助力企业降本增效。基于阿里云自研的倚天服务器,同时在数据库…...
pytest 编写规范
一、pytest 编写规范 1、介绍 pytest是一个非常成熟的全功能的Python测试框架,主要特点有以下几点: 1、简单灵活,容易上手,文档丰富;2、支持参数化,可以细粒度地控制要测试的测试用例;3、能够…...

Vue.use和vue.component的区别
Vue.use 注册全局插件vue.use时会将自动将开发者 vue构造函数传入插件,vue.use参数必须是function或者object,object中必须有install方法vue.use会自动判断当前插件时候已经被注册过了,防止重复注册 Vue.component 注册全局组件 为什么有了Vue.component还要用Vue.use呢 V…...

张驰咨询:提高企业竞争力,六西格玛设计公司(DFSS)在行动
六西格玛设计公司(DFSS)是一种专业从事六西格玛设计的企业,其主要作用是为客户提供高效的六西格玛设计服务,以帮助客户实现高品质、低成本和高效率的产品开发过程。六西格玛设计公司通常拥有一支专业的团队,具有丰富的六西格玛设计经验和技术…...

影响 40% 用户,Ubuntu 发行版被曝 2 个安全漏洞
导读近日消息,Wiz 的研究专家 S. Tzadik 和 S. Tamari 近日在 Ubuntu 系统中发现了 2 个安全漏洞,可以提升本地权限,预估影响 40% 的 Ubuntu 用户。 根据博文内容,汇总两个漏洞内容如下: 追踪编号:CVE-202…...

SpringCache的介绍和入门案例
文章目录 概述常用注解入门案例 概述 Spring Cache是Spring框架提供的一个缓存抽象层,用于在应用程序中实现缓存的功能。它通过在方法执行前检查缓存中是否已经存在所需数据,如果存在则直接返回缓存中的数据,如果不存在则执行方法体…...

DeepSeek系统设计辅助效能断崖式下降的3个信号,第2个90%工程师至今未察觉!
更多请点击: https://kaifayun.com 第一章:DeepSeek系统设计辅助效能断崖式下降的3个信号,第2个90%工程师至今未察觉! 当 DeepSeek 的系统设计辅助能力突然变“笨”——接口建议频繁失准、上下文感知错乱、生成代码无法通过基础编…...

基于ESP32的AIS转WiFi转换器:实现NMEA 0183数据无线传输
1. 项目概述:从VHF-AIS接收器到iPad的无线桥梁作为一名经常在海上折腾电子设备的航海爱好者,我最近遇到了一个挺实际的需求:我的主力导航设备是iPad上的iSailor应用,它功能强大、界面友好,但有个“硬伤”——它需要通过…...

AI写的论文双率如何压到20%以下?这几款工具实测有效
毕业季、投稿季用AI写论文已经成为不少人的高效选择,但查重率飘红、AIGC疑似率超标两大问题,让很多人犯了难。2026年学术检测标准持续收紧,知网、维普及主流AIGC检测系统同步上线双检规则,两项指标均控制在20%以下才符合基本提交要…...

基于ESP32的智能电池充电器设计:多化学体系支持与模块化架构
1. 项目概述:打造一台全能的“电池医生”手头攒了一堆不同化学体系的电池,从航模用的4S锂聚合物电池,到应急灯里的12V铅酸电池,再到各种工具里的镍氢、锂离子电池,每次充电都得翻出好几个不同的充电器,桌面…...

碧蓝航线自动化脚本终极指南:3小时学会全自动游戏管理
碧蓝航线自动化脚本终极指南:3小时学会全自动游戏管理 【免费下载链接】AzurLaneAutoScript Azur Lane bot (CN/EN/JP/TW) 碧蓝航线脚本 | 无缝委托科研,全自动大世界 项目地址: https://gitcode.com/gh_mirrors/az/AzurLaneAutoScript 还在为碧蓝…...

基于雷达与光敏传感器的低功耗智能窗防设备设计与实现
1. 项目概述:一个基于雷达与光敏的智能窗防设备几年前,我因为一次短暂的出差,家里空置了几天,回来后就一直琢磨着怎么给家里的窗户加点“动静”。市面上的智能安防摄像头固然好,但要么需要复杂的布线,要么云…...

如何用HsMod解锁炉石传说60+项隐藏功能:终极优化指南
如何用HsMod解锁炉石传说60项隐藏功能:终极优化指南 【免费下载链接】HsMod Hearthstone Modification Based on BepInEx 项目地址: https://gitcode.com/GitHub_Trending/hs/HsMod HsMod是一款基于BepInEx开发的炉石传说功能增强插件,为玩家提供…...

基于Cynthion逆向USB协议,为DP100电源开发Linux控制软件
1. 项目概述:用Cynthion嗅探USB,为DP100电源打造Linux软件作为一名长期在Linux环境下折腾硬件和嵌入式开发的爱好者,我经常遇到一个头疼的问题:很多不错的桌面小设备,比如电源、示波器、逻辑分析仪,它们的官…...
P2P聊天程序)
基于C#实现(WinForm)P2P聊天程序
♻️ 资源 大小: 29.8MB ➡️ 资源下载:https://download.csdn.net/download/s1t16/87430269 p2p聊天程序 一、功能介绍 1.1 登录 用户凭用户名和密码登录系统,可以更换服务器 IP 和端口,以防网络不畅通,连接服务…...

基于晶体管逻辑的水箱自动控制器设计与实现
1. 项目概述:一个基于晶体管逻辑的自动水箱/湿度灌溉控制器 如果你也像我一样,曾经为家里的花园、阳台植物或者农村老家的储水塔手动开关水泵而烦恼,那么这个项目就是为你准备的。我设计并制作了一个完全自动化的水箱水位控制器,它…...