SQLAlchemy------更多查询
1 查询: filer:写条件 filter_by:等于的值
res = session.query(User).all() # 是个普通列表
print(type(res))
print(len(res))all()的结果就是列表,列表里面是对象
2 只查询某几个字段
# select name as xx,email from user;
res = session.query(User.name.label('xx'), User.email) #没有all(),打印是原生sql语句
#label是起别名3 filter传的是表达式,filter_by传的是参数
res = session.query(User).filter(User.name == "lqz").all()
res = session.query(User).filter(User.name != "lqz").all()
res = session.query(User).filter(User.name != "lqz", User.email == '3@qq.com').all() 5 取一个 all了后是list,list 没有first方法
res = session.query(User).first()
all()之后就不能.first()6查询所有,使用占位符(了解) :value :name
# select * from user where id <20 or name=lqz
res = session.query(User).filter(text("id<:value or name=:name"))
.params(value=20, name='lqz').all()7 自定义查询(了解)
from_statement 写纯原生sql
res=session.query(User).from_statement(text("SELECT * FROM users where email=:email"))
.params(email='3@qq.com').all()8 高级查询
1、and条件连接 ---------,就是and
res = session.query(User).
filter(User.id > 1, User.name == 'lqz099').all() # and条件2、between ------在什么之间
res = session.query(User).filter(User.id.between(1, 9), User.name == 'lqz099').all()
res = session.query(User).filter(User.id.between(1, 9)).all()3、in_ ----------是否是1,2,4
res = session.query(User).filter(User.id.in_([1,3,4])).all()
res = session.query(User).filter(User.email.in_(['3@qq.com','r@qq.com'])).all()4、 ~非,除。。外
res = session.query(User).filter(~User.id.in_([1,3,4])).all()
id不是1,或3,或4,的所有5. 二次筛选
res = session.query(User).filter(~User.id.in_(session.query(User.id).
filter_by(name='lqz'))).all()6、and or条件
from sqlalchemy import and_, or_# or_包裹的都是or条件,and_包裹的都是and条件
res = session.query(User).filter(and_(User.id >= 3, User.name == 'lqz099')).all() # and条件
res = session.query(User).filter(User.id < 3, User.name == 'lqz099').all() # 等同于上面
res = session.query(User).filter(or_(User.id < 2, User.name == 'eric')).all()
res = session.query(User).filter(or_(User.id < 2,and_(User.name == 'lqz099', User.id > 3),User.extra != ""))
7、通配符,以e开头,不以e开头
res = session.query(User).filter(User.email.like('%@%')).all()
# select user.id from user where user.name not like e%;
res = session.query(User.id).filter(~User.name.like('e%'))
res = session.query(User).filter(~User.name.like('e%')).all()8、分页
# 一页2条,查第5页
res = session.query(User)[2*5:2*5+2]9、排序,根据name降序排列(从大到小)
res = session.query(User).order_by(User.email.desc()).all()
res = session.query(Book).order_by(Book.price.desc()).all()
res = session.query(Book).order_by(Book.price.asc()).all()
# 第一个条件重复后,再按第二个条件升序排
res = session.query(User).order_by(User.name.desc(), User.id.asc())10、分组查询 5个聚合函数
from sqlalchemy.sql import func
# 分组后,只能拿分组字段和聚合函数字典,如果拿别的,是严格模式,会报错
res = session.query(User).group_by(User.extra) # 如果是严格模式,就报错
# 分组之后取最大id,id之和,最小id 和分组的字段
from sqlalchemy.sql import func
res = session.query(User.name,func.max(User.id),func.sum(User.id),func.min(User.id),func.avg(User.id)).group_by(User.name).all()
for item in res:print(item)# 分组后having
# select name,max(id),sum(id),min(id) from user group by user.name having id_max>2;from sqlalchemy.sql import func
res = session.query(User.name,func.max(User.id),func.sum(User.id),func.min(User.id)).group_by(User.name).having(func.max(User.id) > 2).all()print(res)连表查询
### 关联关系,基于连表的跨表查询
from models1 import Person,Hobby
# 链表操作
select * from person,hobby where person.hobby_id=hobby.id;
res = session.query(Person, Hobby).filter(Person.hobby_id == Hobby.id).all()# 自己连表查询
# join表,默认是inner join,自动按外键关联
# select * from Person inner join Hobby on Person.hobby_id=Hobby.id;
res = session.query(Person).join(Hobby).all()#isouter=True 外连,表示Person left join Favor,没有右连接,反过来即可
# select * from Person left join Hobby on Person.hobby_id=Hobby.id;
res = session.query(Person).join(Hobby, isouter=True).all()
# 没有right join,通过这个实现
res = session.query(Hobby).join(Person, isouter=True).all()# # 自己指定on条件(连表条件),第二个参数,支持on多个条件,用and_,同上
# select * from Person left join Hobby on Person.id=Hobby.id;
res = session.query(Person).join(Hobby, Person.hobby_id == Hobby.id, isouter=True) # sql本身有问题,只是给你讲, 自己指定链接字段
# 右链接
# print(res)# 多对多关系连表
# 多对多关系,基于链表的跨表查
# 多表链接
#方式一:直接连
#select * FROM boy, girl, boy2girl WHERE boy.id = boy2girl.boy_id AND girl.id = boy2girl.girl_id
res = session.query(Boy, Girl,Boy2Girl).filter(Boy.id == Boy2Girl.boy_id,Girl.id == Boy2Girl.girl_id)# 方式二:join连
# SELECT* FROM boy INNER JOIN boy2girl ON boy.id = boy2girl.boy_id INNER JOIN girl ON girl.id = boy2girl.girl_id WHERE boy.id >= %(id_1)s
res = session.query(Boy).join(Boy2Girl).join(Girl).filter(Boy.id>=2)
print(res)
相关文章:

SQLAlchemy------更多查询
1 查询: filer:写条件 filter_by:等于的值 res session.query(User).all() # 是个普通列表 print(type(res)) print(len(res)) all()的结果就是列表,列表里面是对象 2 只查询某几个字段 # select name as xx,email from user; res…...

13-数据结构-串以及KMP算法,next数组
串 目录 串 一、串: 二、串的存储结构: 三、模式匹配 1.简单模式匹配(BF算法) 2.KMP算法 2.1-next(j)数组手工求解 2.2-nextval(j)数组手工求解 一、串: 内容受…...

Stable Diffusion - 俯视 (from below) 拍摄的人物图像 LoRA 与配置
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://spike.blog.csdn.net/article/details/132192139 图像来自 哥特风格 LoRA 俯视 LoRA,提升视觉冲击力,核心配置 <lora:view_from_below:0.6>,(from below,…...
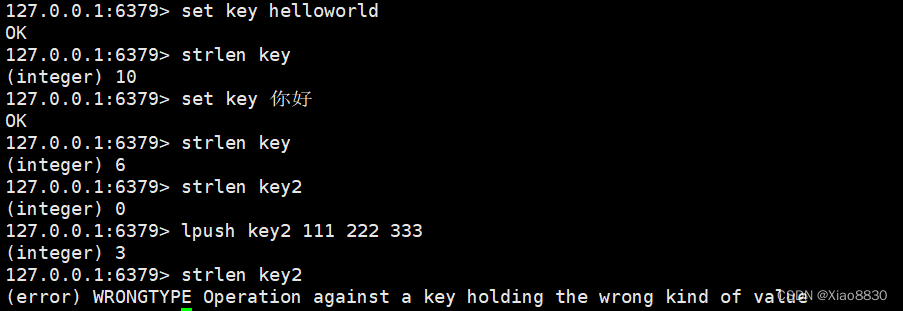
Redis——String类型详解
概述 Redis中的字符串直接按照二进制的数据存储,不会有任何的编码转换,因此存放什么样,取出来的时候就什么样。而MySQL默认的字符集是拉丁文,如果插入中文就会失败 Redis中的字符串类型不仅可以存放文本数据,还可以存…...
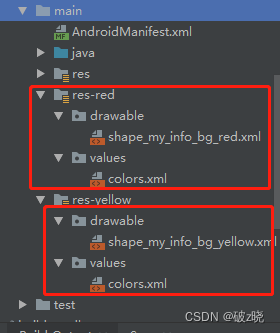
Android:换肤框架Android-Skin-Support
gihub地址:https://github.com/ximsfei/Android-skin-support 样例: 默认: 更换后: 一、引入依赖: // -- 换肤依赖implementation skin.support:skin-support:4.0.5// skin-supportimplementation skin.support:ski…...

软件测试面试心得:四种公司、四种问题…
以下是我个人总结的一些经验: 传统开发模式:V模式,瀑布模式。传统开发模式往往循规蹈矩,从需求,概要设计,详细设计,开发,单元测试,集成测试,系统测…...
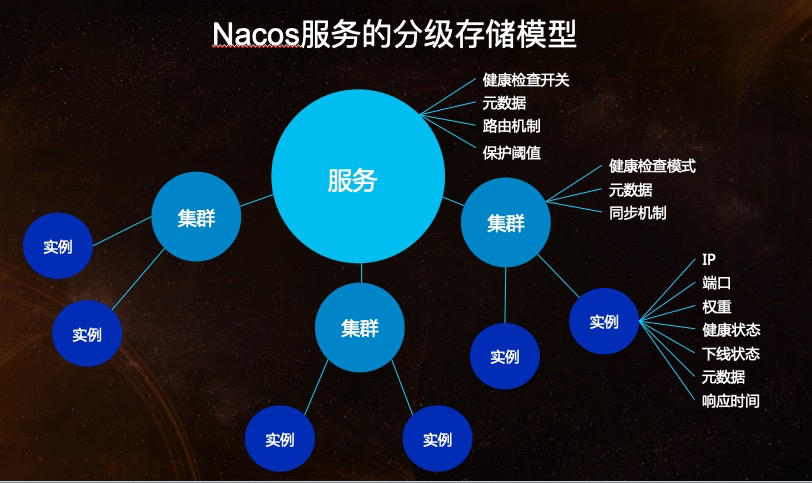
【探索SpringCloud】服务发现-Nacos使用
前言 在聊服务注册中心时,便提到了Nacos。这次便来认识一下。当然,这自然没有官方介绍那般详尽,权当是学习了解Nacos原理的一个过程吧。 Nacos简介 Nacos,全名:dynamic Naming And Configuration Service. 而这个名…...

soap通信2
首先,定义一个XSD(XML Schema Definition)来描述你的数据结构。在你的Maven项目的src/main/resources目录下,创建一个名为schemas的文件夹,并在其中创建一个名为scriptService.xsd的文件,内容如下ÿ…...

【MySQL】MySQL不走索引的情况分析
未建立索引 当数据表没有设计相关索引时,查询会扫描全表。 create table test_temp (test_id int auto_incrementprimary key,field_1 varchar(20) null,field_2 varchar(20) null,field_3 bigint null,create_date date null );expl…...
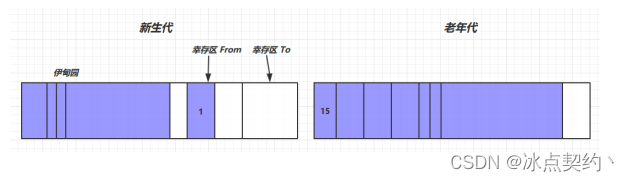
JVM垃圾回收篇-垃圾回收算法
JVM垃圾回收篇-垃圾回收算法 标记清除(Mark Sweep) 概念 collector指的就是垃圾收集器。 mutator是指除了垃圾收集器之外的部分,比如说我们的应用程序本身。 mutator的职责一般是NEW(分配内存)、READ(从内存中读取内容)、WRITE(将内容写入内…...

android APP内存优化
Android为每个应用分配多少内存 Android出厂后,java虚拟机对单个应用的最大内存分配就确定下来了,超出这个值就会OOM。这个属性值是定义在/system/build.prop文件中. 例如,如下参数 dalvik.vm.heapstartsize8m #起始分配内存 dalvik.vm.…...
mysql_docker主从复制_实战_binlog混合模式_天座著
步骤1:拉取镜像 docker pull mariadb:latest 步骤2.1:创建两个文件夹用于放置挂载mysql的my.cnf /tianzuomysqlconf/master /tianzuomysqlconf/slave mkdir /tianzuomysqlconf cd /tianzuomysqlconf mkdir master mkdir slave 步骤2.2:创…...

鸿蒙开发学习笔记1——真机运行hello world
问题背景 学习任何语言和框架的第一步,永远都是跑通熟悉的“hello world”,本文将介绍鸿蒙开发如何跑通“hello world”。 问题分析 一、构建第一个ArkTS应用(fa模型) 说明:请使用DevEco Studio V3.0.0.601 Beta1及…...

Java数组,简简单单信手沾来~
——数组,一组相同数据类型的数据 一.一维数组 1.数组的基本概念 1)数组用于存储多个同一数据类型的数据 2)数组是数据类型【引用类型】 3)数组的形式:数据类型 [] 4)数组的下标从0开始 5)数…...

认识SourceTree
一. SourceTree是什么 SourceTree是一款免费的Git和Mercurial版本控制系统,它可以帮助开发人员在一个友好的UI界面中管理代码,方便地进行版本控制和代码同步。支持创建、克隆、提交、push、pull 和合并等操作。 二. SourceTree的安装破解 1. 如果你还…...

python之列表推导式
列表推导式是一种简洁的方式来创建列表。它允许您通过在单个表达式中定义循环和条件逻辑,以一种更紧凑的方式生成新的列表。使用列表推导式可以使代码更简洁,易于阅读,并且通常比传统的迭代方法更快。 列表推导式的一般语法形式为:…...
selenium自动化测试之搭建测试环境
自动化测试环境: Python3.7Selenium3.141谷歌浏览器76.0/火狐浏览器 1、安装Python并配置环境变量。 下载并安装:配置环境变量:C:\Python37;C:\Python37\Scripts; 2、安装Pycharm开发工具。 下载地址: 注意下载:Co…...

模拟实现消息队列(以 RabbitMQ 为蓝本)
目录 1. 需求分析1.1 介绍一些核心概念核心概念1核心概念2 1.2 消息队列服务器(Broker Server)要提供的核心 API1.3 交换机类型1.3.1 类型介绍1.3.2 转发规则: 1.4 持久化1.5 关于网络通信1.5.1 客户端与服务器提供的对应方法1.5.2 客户端额外…...

WordPress更换域名后-后台无法进入,网站模版错乱,css失效,网页中图片不显示。完整解决方案(含宝塔设置)
我在实际解决问题时用到了 【简单暴力解决方案】的《方法一:修改wp-config.php》 和 【简单暴力-且特别粗暴-的解决方案】 更换域名时经常遇到的几个问题: 1、更换域名后,后台无法进入 2、更换域名后,网站模版错乱,css失效 3、更换域名后,网页中图片不显示 这是为什…...
)
无法正确识别车牌(Python、OpenCv、Tesseract)
我正在尝试识别车牌,但出现了错误,例如错误/未读取字符 以下是每个步骤的可视化: 从颜色阈值变形关闭获得遮罩 以绿色突出显示的车牌轮廓过滤器 将板轮廓粘贴到空白遮罩上 Tesseract OCR的预期结果 BP 1309 GD 但我得到的结果是 BP 1309…...

多自由度冗余空间机械臂位姿一体化规划与控制【附代码】
✨ 长期致力于空间机械臂、对偶四元数、位姿一体化、路径规划、跟踪控制研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)基于对偶四元数的冗余机械臂运…...

除了ulimit -c unlimited:深入理解Linux core dump机制与高级配置指南
深入Linux核心转储:从基础配置到生产环境实战指南当服务器上的关键应用突然崩溃时,系统管理员最需要的就是一份完整的"事故现场记录"。Linux的core dump机制正是为此而生,它能保存程序崩溃时的内存状态、寄存器值和调用堆栈&#x…...
)
ThinkPad开机报错0183/0253?别慌,手把手教你搞定EFI变量错误(附BIOS重置教程)
ThinkPad开机报错0183/0253?EFI变量错误全面解决方案当你按下ThinkPad的电源键,期待熟悉的开机画面时,屏幕上却突然跳出一串神秘代码——"0183: Bad CRC of Security Settings in EFI Variable"或"0253: EFI Variable Block D…...

学术写作创新突破!2026全流程AI论文工具精选指南
2026 年 AI 论文写作工具已进入全流程闭环 学术合规时代,千笔 AI(综合评分 99 分)中文学术场景标杆;Grammarly Academic与Elicit为英文论文写作首选;按需求匹配度 - 数据可信度 - 成本承受力三维模型选型,…...

网络配置工具类详解
CNet 网络配置工具类详解平台:仅支持 Linux,大量使用 ioctl 系统调用一、概述 CNet 是一个 纯静态方法的网络配置工具类,封装了 Linux 下常用的网络操作:功能类别涵盖内容IP 地址读取/设置本机 IP、子网掩码网关读取/添加/删除/设…...

巨量投放总结
巨量商务管理平台 : https://business.oceanengine.com 巨量广告投放平台: https://ad.oceanengine.com 商务管理平台 账户 广告组 计划 广告投放平台 层级关系: 广告组 -> 计划 -> 创意 对应FB: 系列 - > 广告组 -> 广告...

脉冲神经网络加速器设计与边缘计算优化
1. 脉冲神经网络加速器的设计挑战与突破在边缘计算领域,脉冲神经网络(SNN)正以其独特的生物启发特性引发新一轮技术变革。与传统人工神经网络(ANN)相比,SNN通过离散的脉冲信号传递信息,模拟生物神经元的工作机制,理论上可实现超低…...

yuzu模拟器完整指南:在电脑上畅玩Switch游戏的终极解决方案
yuzu模拟器完整指南:在电脑上畅玩Switch游戏的终极解决方案 【免费下载链接】yuzu 任天堂 Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/yu/yuzu 想在电脑上体验任天堂Switch游戏的魅力吗?yuzu模拟器正是你寻找的完美答案。作为…...

机器学习与深度学习在社交媒体心理健康检测中的权衡与选择
1. 项目概述:当AI遇见心灵,社交媒体心理健康检测的技术十字路口在社交媒体成为我们数字生活延伸的今天,海量的文本数据无意中记录着用户的情感波动与心理状态。作为一名长期混迹于数据科学和自然语言处理(NLP)一线的从…...

MeloTTS实战指南:解决多语言TTS部署中的核心挑战
MeloTTS实战指南:解决多语言TTS部署中的核心挑战 【免费下载链接】MeloTTS High-quality multi-lingual text-to-speech library by MyShell.ai. Support English, Spanish, French, Chinese, Japanese and Korean. 项目地址: https://gitcode.com/GitHub_Trendin…...