【从零开始学Kaggle竞赛】泰坦尼克之灾
目录
- 0.准备
- 1.问题分析
- 挑战
- 流程
- 数据集介绍
- 结果提交
- 2.代码实现
- 2.1 加载数据
- 2.1.1 加载训练数据
- 2.1.2 加载测试数据
- 2.2 数据分析
- 2.3 模型建立与预测
- 3.结果提交
0.准备
注册kaggle账号后,进入titanic竞赛界面
https://www.kaggle.com/competitions/titanic
进入后界面如下
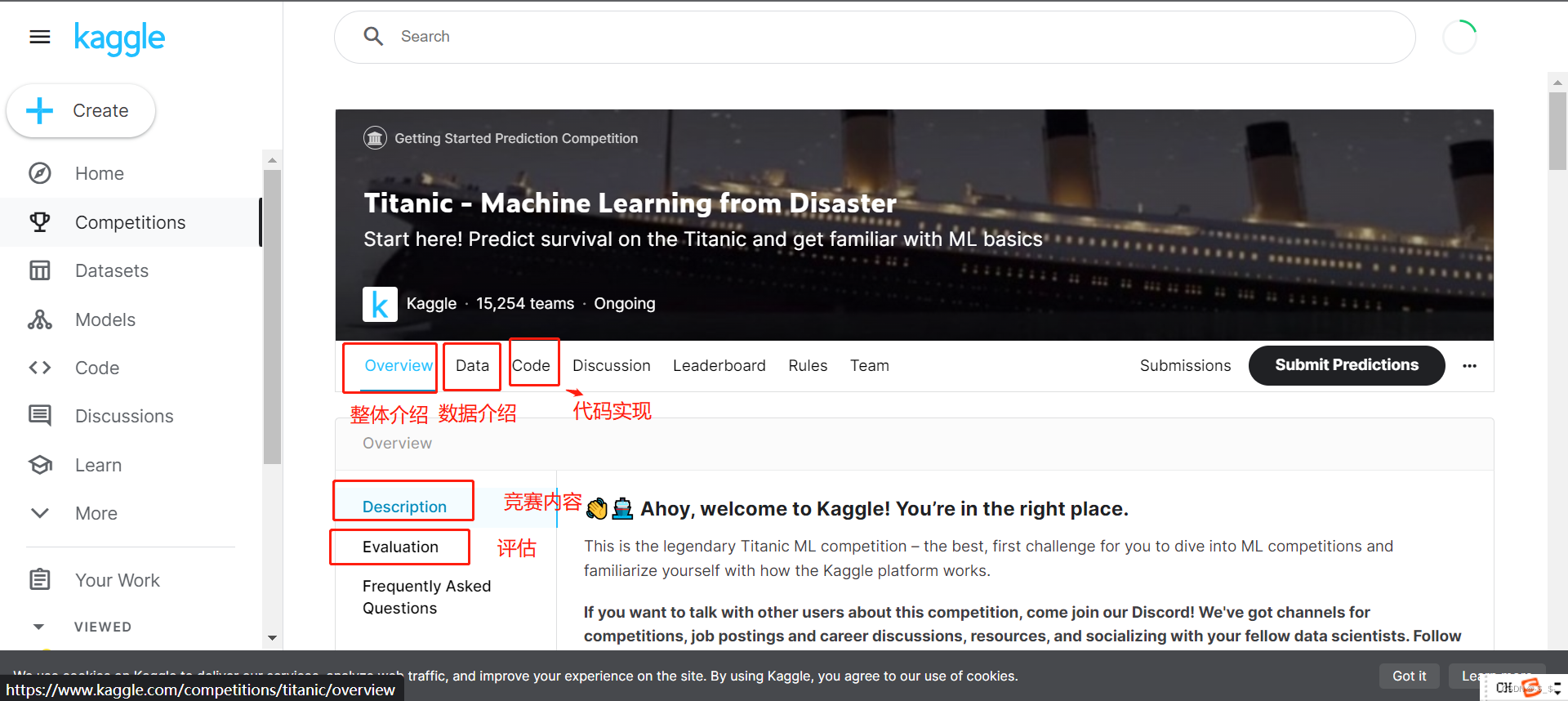
Overview部分为竞赛整体介绍,包括竞赛介绍以及结果评估。
Data部分为数据集介绍,介绍使用的数据集。
Code部分为提交的代码
1.问题分析
挑战
泰坦尼克号的沉没是历史上最臭名昭著的沉船事故之一。
1912 年 4 月 15 日,被公认为 "永不沉没 "的皇家邮轮泰坦尼克号在首航时撞上冰山沉没。不幸的是,由于没有足够的救生艇供船上所有人使用,2224 名乘客和船员中有 1502 人丧生。
虽然生还有一定的运气成分,但似乎有些群体比其他群体更有可能生还。
在这项挑战中,我们要求您建立一个预测模型来回答这个问题:"使用乘客数据(即姓名、年龄、性别、社会经济阶层等)来回答 "什么样的人更有可能幸存?
流程
- 参加竞赛
阅读挑战说明,接受竞赛规则并访问竞赛数据集。 - 开始工作
下载数据,在本地或 Kaggle Notebooks(我们的免设置、可定制的 Jupyter Notebooks 环境,配备免费 GPU)上构建模型,并生成预测文件。 - 提交
在 Kaggle 上以提交的形式上传您的预测,并获得准确率分数。 - 查看排行榜
在我们的排行榜上查看您的模型在其他 Kaggler 中的排名。 - 提高分数
查看讨论区,查找大量教程和其他竞争对手的见解。
数据集介绍
在本次竞赛中,您将获得两个类似的数据集,其中包括乘客信息,如姓名、年龄、性别、社会经济阶层等。一个数据集名为 train.csv,另一个名为 test.csv。
Train.csv将包含一个乘客子集(确切地说是891人)的详细信息,重要的是,它将揭示乘客是否幸存,也就是所谓的 “基本事实”。
test.csv 数据集包含类似的信息,但不会披露每位乘客的 “基本事实”。您的任务就是预测这些结果。
利用您在 train.csv 数据中发现的模式,预测机上其他 418 名乘客(在 test.csv 中找到)是否幸存。
结果提交
-
目标
您的任务是预测泰坦尼克号沉没时是否有乘客幸存。
对于测试集中的每个变量,您必须预测其值为 0 或 1。 -
指标
您的分数是您正确预测乘客的百分比。这就是所谓的准确率。 -
提交文件格式
您应提交一个 csv 文件,其中包含 418 个条目和一行标题。如果您提交的文件中有额外的列(除乘客编号和存活人数外)或行,则会显示错误。
2.代码实现
首先选择Code,之后点击New Notebook
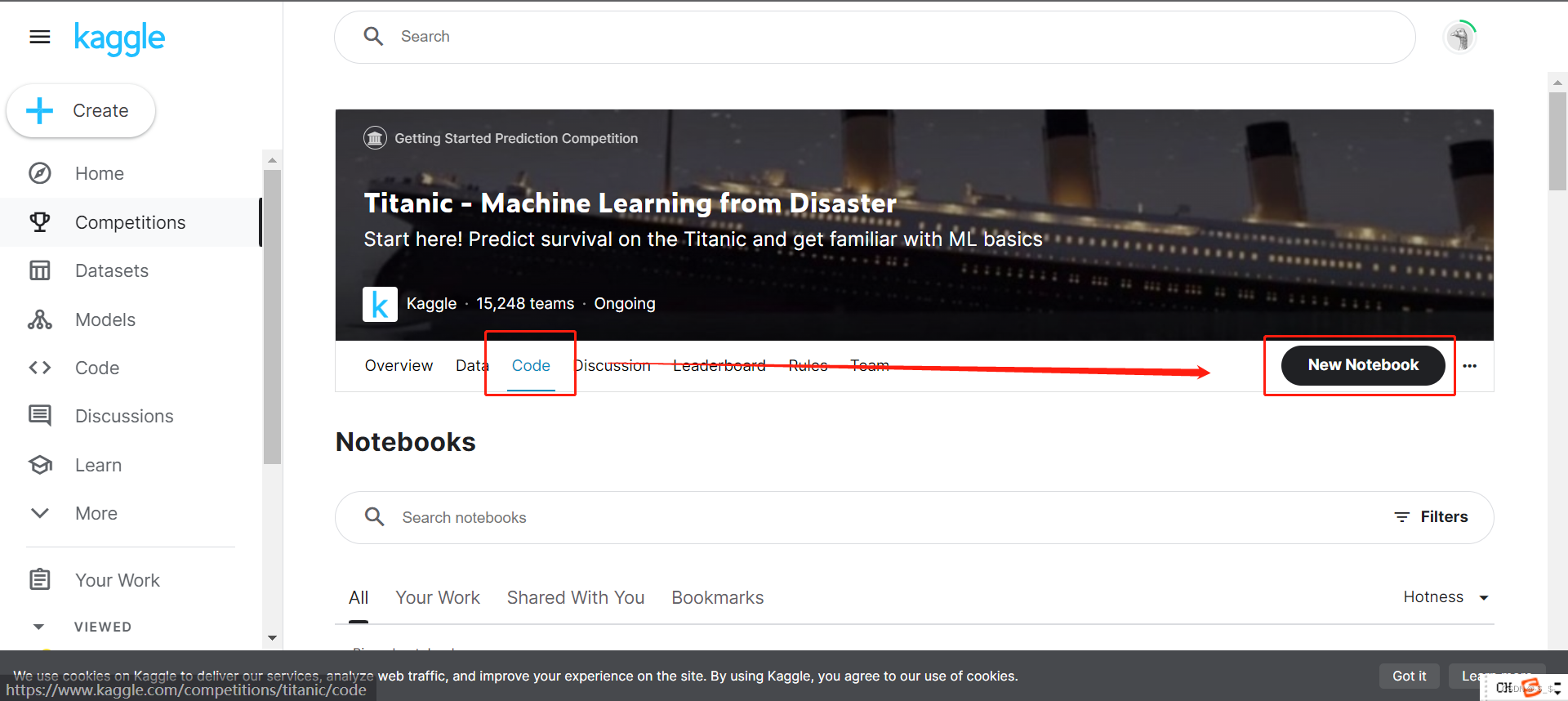
新建Notebook后,会出现如下界面
单击运行Notebook中的代码
查看运行结果
代码为
# This Python 3 environment comes with many helpful analytics libraries installed
# It is defined by the kaggle/python Docker image: https://github.com/kaggle/docker-python
# For example, here's several helpful packages to loadimport numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directoryimport os
for dirname, _, filenames in os.walk('/kaggle/input'):for filename in filenames:print(os.path.join(dirname, filename))# You can write up to 20GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using "Save & Run All"
# You can also write temporary files to /kaggle/temp/, but they won't be saved outside of the current session
结果应为
/kaggle/input/titanic/train.csv
/kaggle/input/titanic/test.csv
/kaggle/input/titanic/gender_submission.csv
2.1 加载数据
主要使用
pd.read_csv(filepath_or_buffer. sep=‘;’)
filepath_or_buffer 输入需要读取的csv文件路径
sep指定数据中列之间的分隔符,默认为逗号。
data.head():返回data的前几行数据,默认为前五行,需要前十行则data.head(10)
data.tail():返回data的后几行数据,默认为后五行,需要后十行则data.tail(10)
2.1.1 加载训练数据
代码
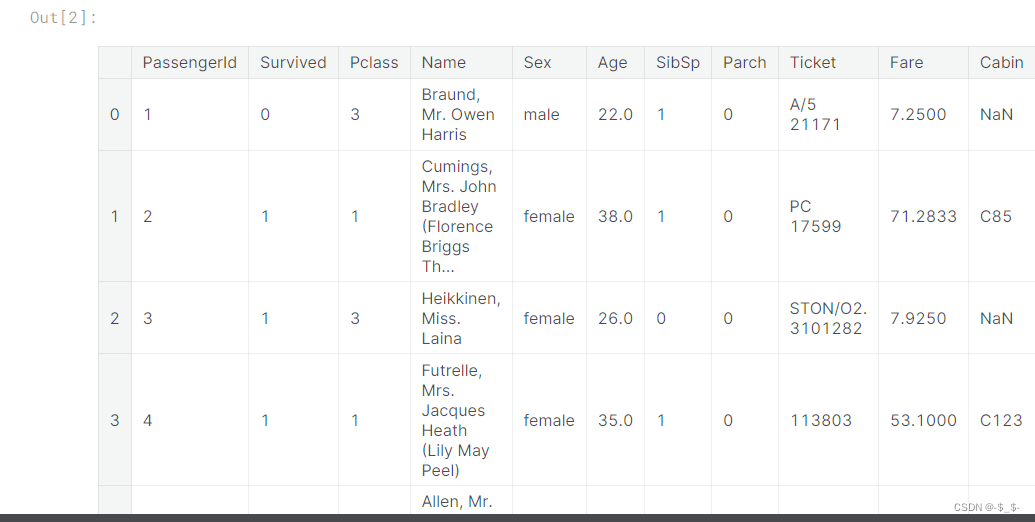
train_data = pd.read_csv("/kaggle/input/titanic/train.csv")
train_data.head()
输出结果
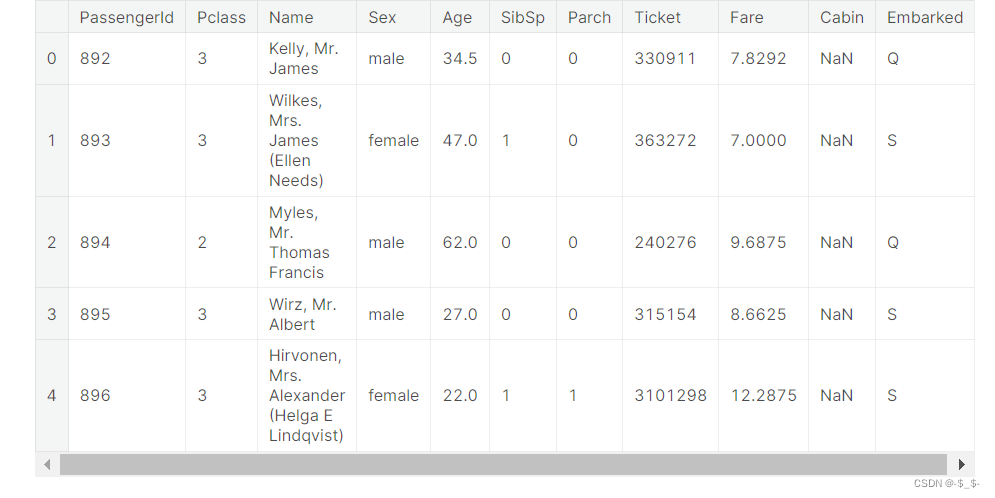
2.1.2 加载测试数据
代码
test_data = pd.read_csv("/kaggle/input/titanic/test.csv")
test_data.head()
结果
2.2 数据分析
记住我们的目标:我们希望在train.csv中找到规律,帮助我们预测test.csv中的乘客是否幸存。
当有这么多数据需要排序时,最初寻找规律可能会让人感到不知所措。所以,我们从简单开始。
请记住,gender_submission.csv中的样本提交文件假设所有女性乘客幸存(所有男性乘客死亡)。
这是一个合理的初步猜测吗?我们将检查这个猜测在数据中是否成立(在train.csv中)。
将下面的代码复制到新的代码单元格中。然后,运行单元格。
代码
(计算女性幸存率)
women = train_data.loc[train_data.Sex == 'female']["Survived"]
rate_women = sum(women)/len(women)print("% of women who survived:", rate_women)
结果
% of women who survived: 0.7420382165605095
(计算男性幸存率)
men = train_data.loc[train_data.Sex == 'male']["Survived"]
rate_men = sum(men)/len(men)print("% of men who survived:", rate_men)
结果
% of men who survived: 0.18890814558058924
上面的代码计算了幸存的男性乘客(在火车.csv中)的百分比。
从中可以看出,船上几乎75%的女性幸存下来,而只有19%的男性活了下来。由于性别似乎是生存的有力指标,gender_submission.csv中的提交文件并不是一个糟糕的第一猜测!
但归根结底,这份基于性别的报告的预测只基于一个专栏。正如你所能想象的,通过考虑多列,我们可以发现更复杂的模式,这些模式可能会产生更明智的预测。由于同时考虑几个列是非常困难的(或者,同时考虑许多不同列中的所有可能模式需要很长时间),我们将使用机器学习来实现自动化。
2.3 模型建立与预测
我们将建立一个所谓的随机森林模型。该模型由几棵“树”组成(下图中有三棵树,但我们将构建100棵!),它们将单独考虑每位乘客的数据,并投票决定乘客是否幸存。然后,随机森林模型做出一个民主的决定:得票最多的结果获胜!
下面的代码单元在数据的四个不同列(“Pclass”、“Sex”、“SibSp”和“Parch”)中查找模式。它根据train.csv文件中的模式在随机森林模型中构建树,然后在test.csv中为乘客生成预测。该代码还将这些新预测保存在csv文件submission.csv中。
将此代码复制到您的笔记本中,并在新的代码格中运行。
from sklearn.ensemble import RandomForestClassifiery = train_data["Survived"]features = ["Pclass", "Sex", "SibSp", "Parch"]
X = pd.get_dummies(train_data[features])
X_test = pd.get_dummies(test_data[features])model = RandomForestClassifier(n_estimators=100, max_depth=5, random_state=1)
model.fit(X, y)
predictions = model.predict(X_test)output = pd.DataFrame({'PassengerId': test_data.PassengerId, 'Survived': predictions})
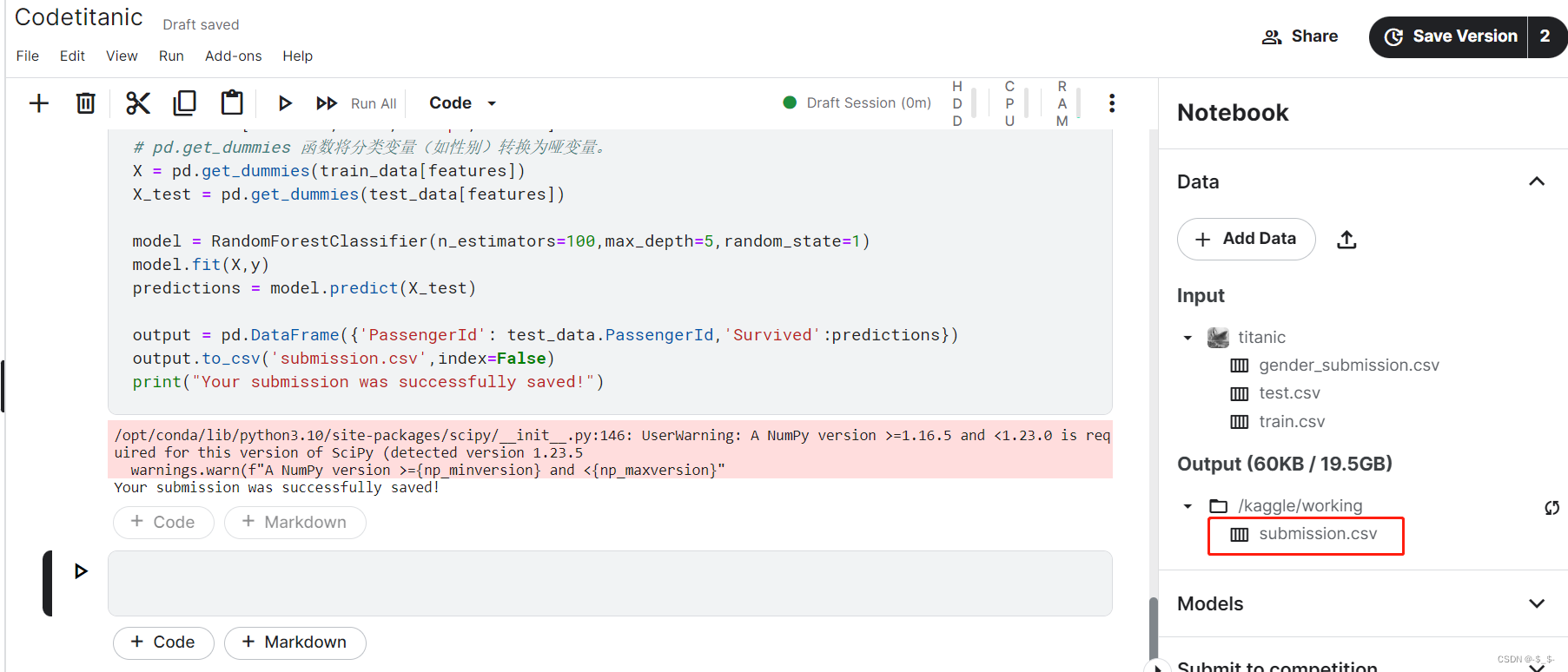
output.to_csv('submission.csv', index=False)
print("Your submission was successfully saved!")
运行结果
Your submission was successfully saved!
可以看到,在Outpu文件夹下生成了submission.csv
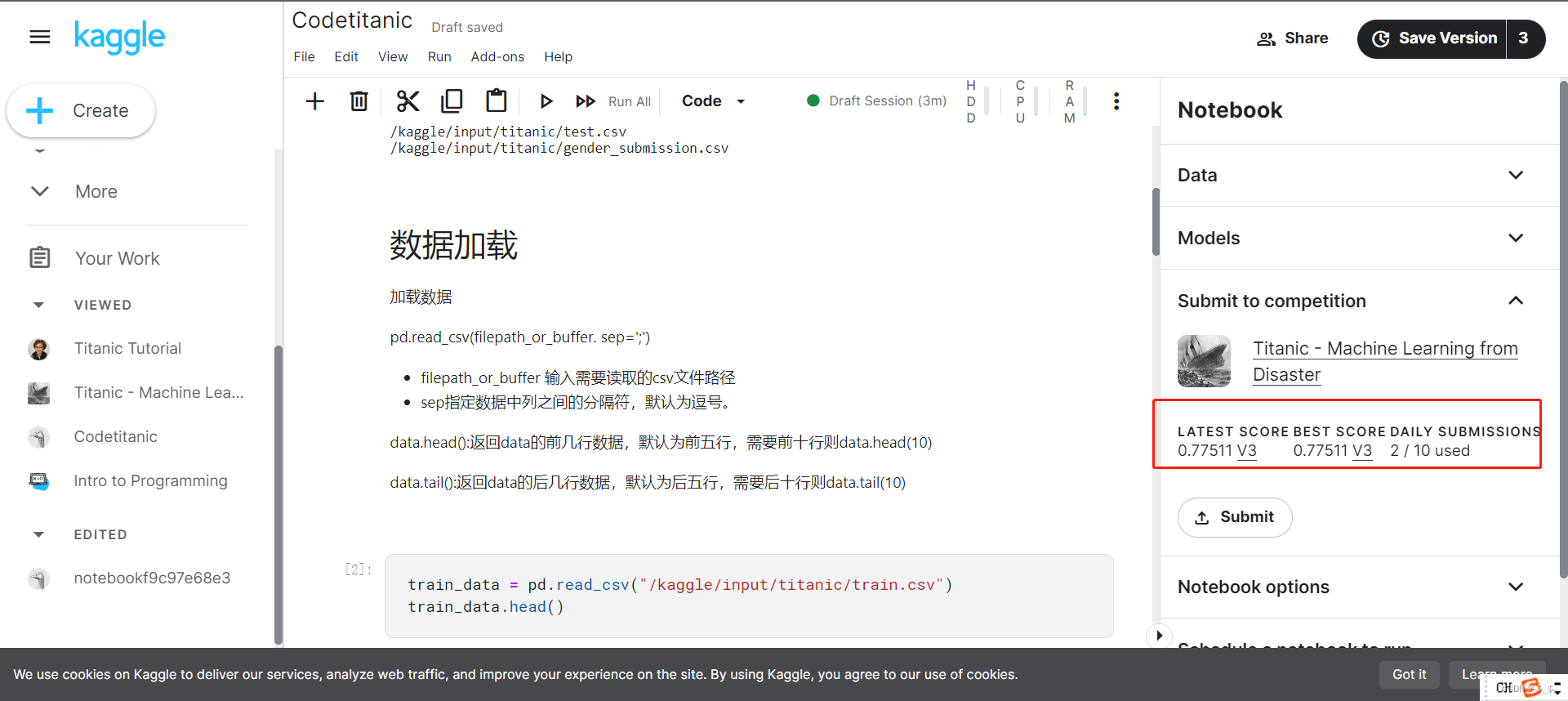
3.结果提交
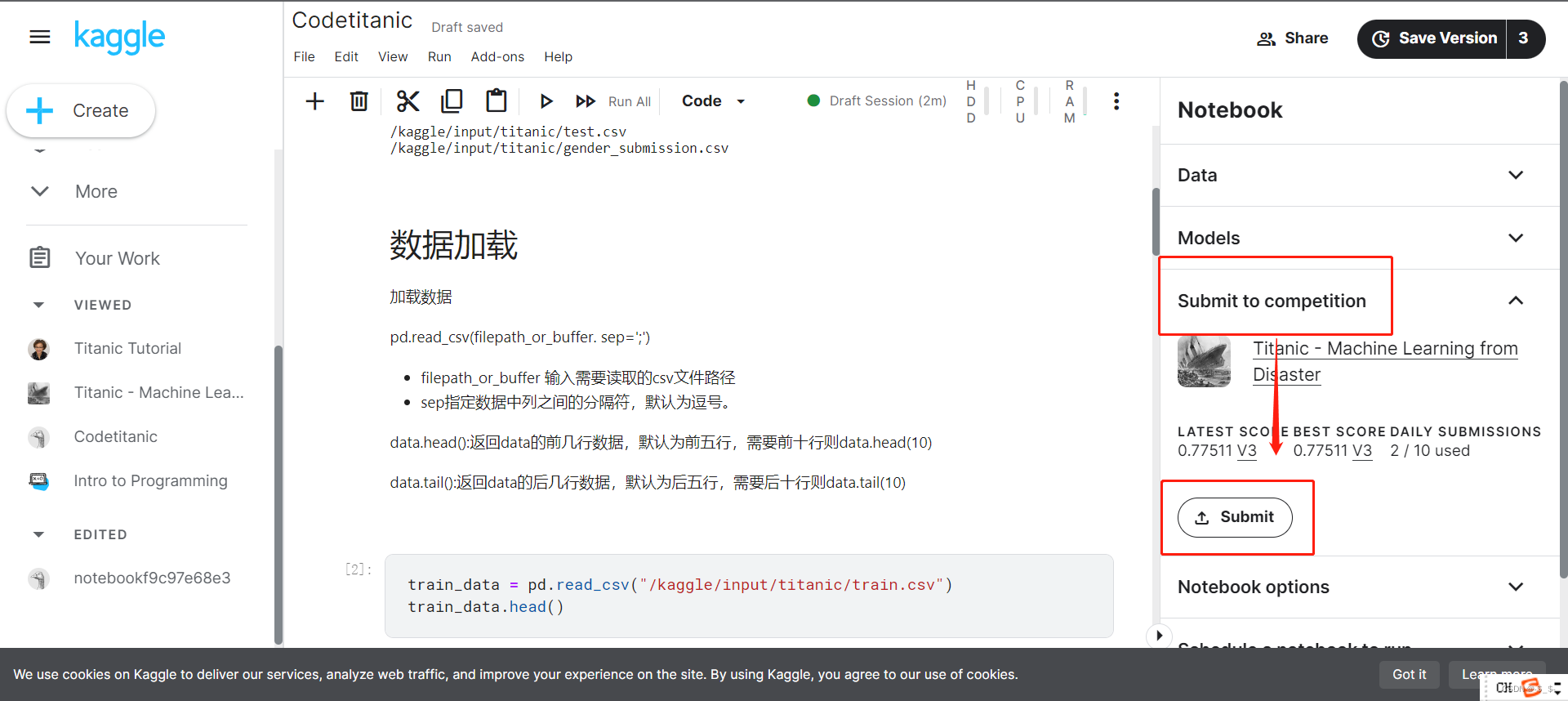
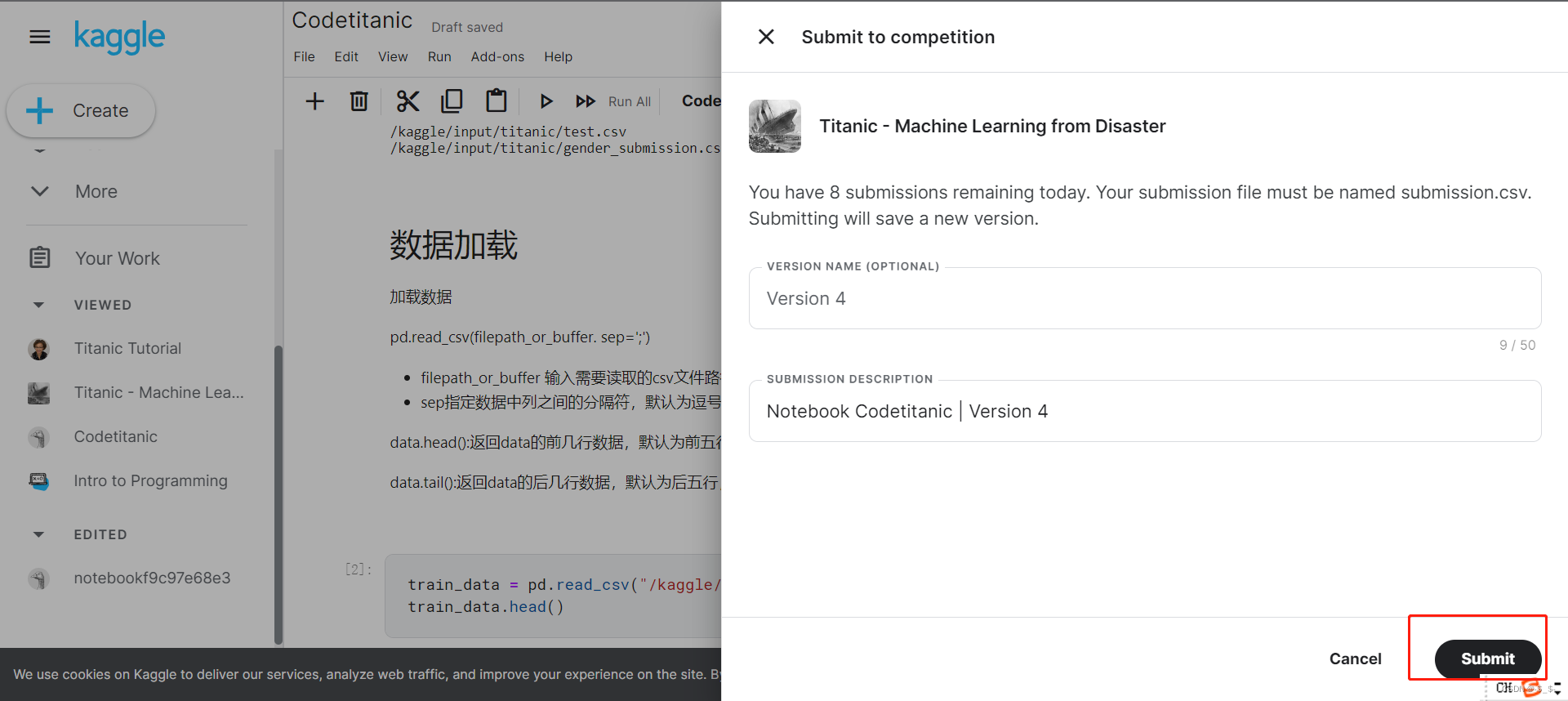
提交后在右边可看到最新提交的结果
相关文章:
【从零开始学Kaggle竞赛】泰坦尼克之灾
目录 0.准备1.问题分析挑战流程数据集介绍结果提交 2.代码实现2.1 加载数据2.1.1 加载训练数据2.1.2 加载测试数据 2.2 数据分析2.3 模型建立与预测 3.结果提交 0.准备 注册kaggle账号后,进入titanic竞赛界面 https://www.kaggle.com/competitions/titanic 进入后界…...

输出无重复的3位数和计算无人机飞行坐标
编程题总结 题目一:输出无重复的3位数 题目描述 从{1,2,3,4,5,6,7,8,9}中随机挑选不重复的5个数字作为输入数组‘selectedDigits’,能组成多少个互不相同且无重复数字的3位数?请编写程》序,从小到大顺序,以数组形式输出这些3位…...

muduo 29 异步日志
目录 Muduo双缓冲异步日志模型: 异步日志实现: 为什么要实现非阻塞的日志...

Qt 对象序列化/反序列化
阅读本文大概需要 3 分钟 背景 日常开发过程中,避免不了对象序列化和反序列化,如果你使用 Qt 进行开发,那么有一种方法实现起来非常简单和容易。 实现 我们知道 Qt 的元对象系统非常强大,基于此属性我们可以实现对象的序列化和…...
)
从零学算法(非官方题库)
输入两棵二叉树A和B,判断B是不是A的子结构。(约定空树不是任意一个树的子结构) B是A的子结构, 即 A中有出现和B相同的结构和节点值。 例如: 给定的树 A:3/ \4 5/ \1 2给定的树 B:4 / 1返回 true,因为 B 与 A 的一个子树拥有相…...

Java # JVM内存管理
一、运行时数据区域 程序计数器、Java虚拟机栈、本地方法栈、Java堆、方法区、运行时常量池、直接内存 二、HotSpot虚拟机对象 对象创建: 引用检查类加载检查分配内存空间:指针碰撞、空闲列表分配空间初始化对象信息设置(对象头内࿰…...

大疆第二批笔试复盘
大疆笔试复盘(8-14) 笔试时候的状态和下来复盘的感觉完全不一样,笔试时脑子是懵的。 (1)输出无重复三位数 题目描述 从 { 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 } \left \{ 1,2,3,4,5,6,7,8,9 \right \...

【Linux】磁盘或内存 占用比较高要怎么排
当 Linux 磁盘空间满了时 请注意,在进行任何删除操作之前,请确保你知道哪些文件可以安全删除,并备份重要文件,以免意外丢失数据。当 Linux 磁盘空间满了时,可以按照以下步骤进行排查: 检查磁盘使用情况&…...
解决xss转义导致转码的问题
一、xss简介 人们经常将跨站脚本攻击(Cross Site Scripting)缩写为CSS,但这会与层叠样式表(Cascading Style Sheets,CSS)的缩写混淆。因此,有人将跨站脚本攻击缩写为XSS。跨站脚本攻击ÿ…...
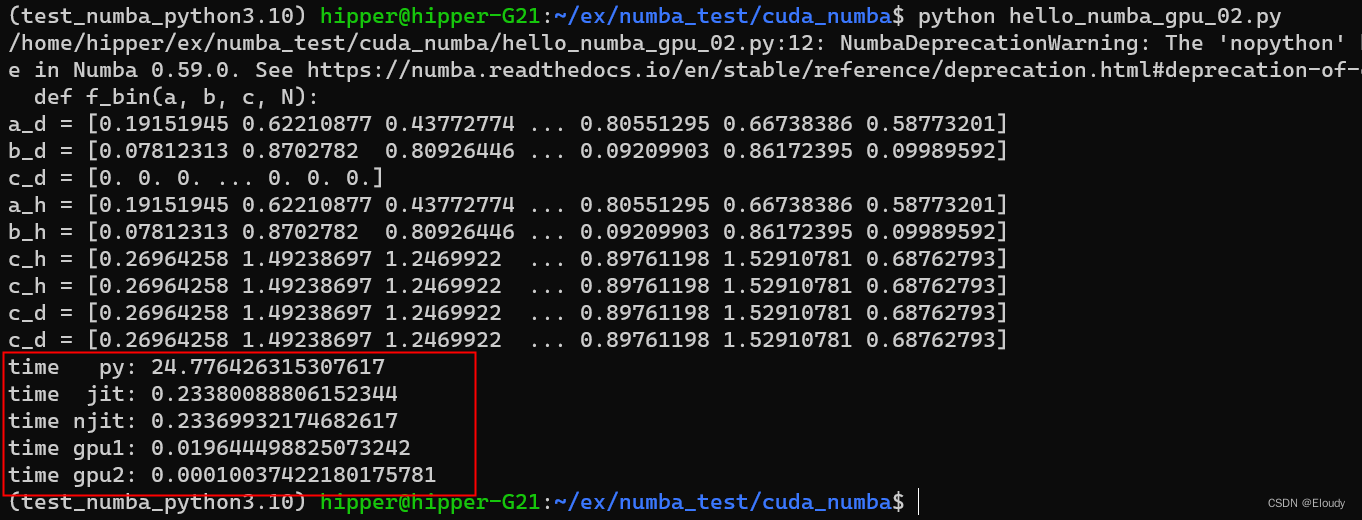
numba 入门示例
一维向量求和: C A B 在有nv 近几年gpu的ubuntu 机器上, 环境预备: conda create -name numba_cuda_python3.10 python3.10 conda activate numba_cuda_python3.10conda install numba conda install cudatoolkit conda install -c nvi…...

BUUCTF 还原大师 1
题目描述: 我们得到了一串神秘字符串:TASC?O3RJMV?WDJKX?ZM,问号部分是未知大写字母,为了确定这个神秘字符串,我们通过了其他途径获得了这个字串的32位MD5码。但是我们获得它的32位MD5码也是残缺不全,E903???4D…...

自定义hook之首页数据请求动作封装 hooks
本例子实现了自定义hook之首页数据请求动作封装 hooks,具体代码如下 export type OrganData {dis: Array<{ disease: string; id: number }>;is_delete: number;name: string;organ_id: number;parent_id: number;sort: number; }; export type SwiperData …...

2023上半年京东手机行业品牌销售排行榜(京东数据平台)
后疫情时代,不少行业都迎来消费复苏,我国智能手机市场在今年上半年也实现温和的复苏,手机市场的出货量回暖。 根据鲸参谋平台的数据显示,2023年上半年,京东平台上手机的销量为2830万,环比增长约4%…...
源码阅读笔记)
lodash之cloneDeep()源码阅读笔记
lodash之cloneDeep()源码阅读笔记 基本上都在写业务代码,没有机会写库,还是想了解一下lodash的库源码是怎么样的,平时用的最多的就是cloneDeep()方法了,终于有空详细看看其中的源码。 本文基于lodash5.0.0版本的源码进行阅读。 /…...

算法模版,今天开始背
二分查找算法 int left_bound(int[] nums, int target) {int left 0, right nums.length - 1;// 搜索区间为 [left, right]while (left < right) {int mid left (right - left) / 2;if (nums[mid] < target) {// 搜索区间变为 [mid1, right]left mid 1;} else if …...

新的 Python URL 解析漏洞可能导致命令执行攻击
Python URL 解析函数中的一个高严重性安全漏洞已被披露,该漏洞可绕过 blocklist 实现的域或协议过滤方法,导致任意文件读取和命令执行。 CERT 协调中心(CERT/CC)在周五的一份公告中说:当整个 URL 都以空白字符开头时&…...
)
react项目做的h5页面加载缓慢优化(3s优化到0.6s)
打包到生产环境时去掉SOURCEMAP 禁用生成 Source Map 是一种权衡,可以根据项目的实际需求和优化目标来决定是否禁用。如果您对调试需求不是特别强烈,可以考虑在生产构建中禁用 Source Map 以获取更好的性能。但如果需要保留调试能力,可以在生…...
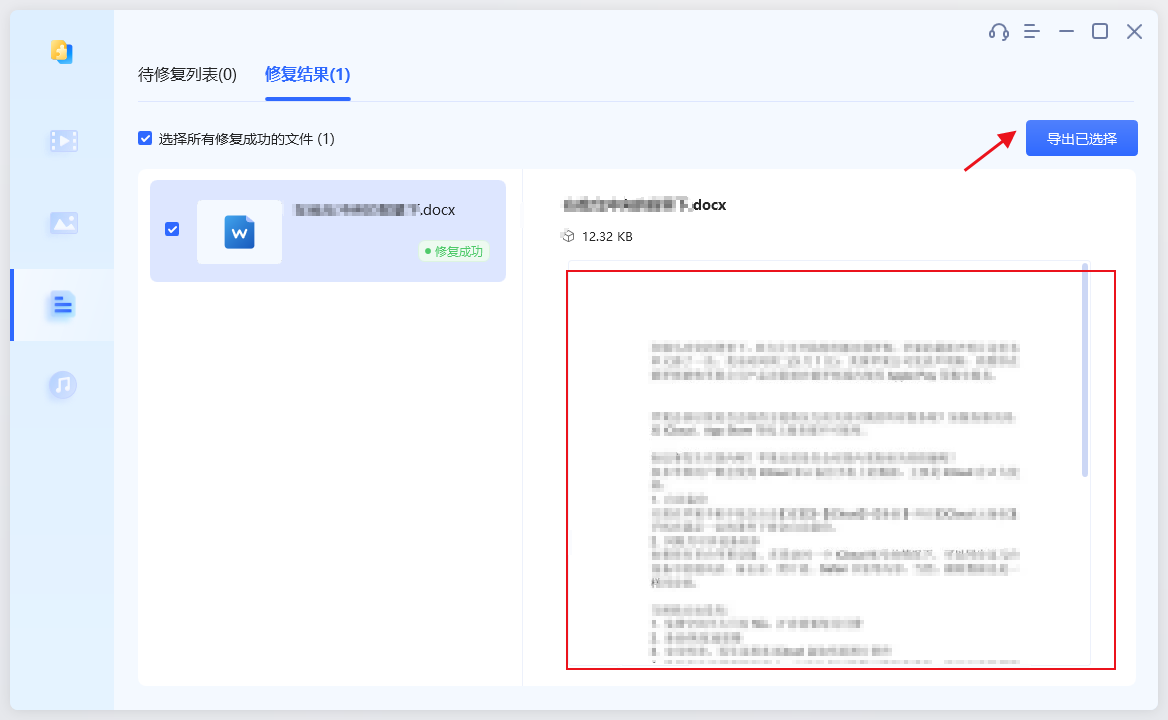
如何修复损坏的DOC和DOCX格式Word文件?
我们日常办公中,经常用到Word文档。但是有时会遇到word文件损坏、无法打开的情况。这时该怎么办?接着往下看,小编在这里就给大家带来最简单的Word文件修复方法! 很多时候DOC和DOCX Word文件会无缘无故的损坏无法打开,一…...

UI设计师个人工作感悟5篇
UI设计师个人工作感悟一 工作一年了,结合我自身谈谈UI设计的重要性。现在主流的论坛建站程序有两种 Phpwind 和Discuz(Phpwind被阿里巴巴收购 Discuz被腾讯收购这两个论坛程序都是开源免费的),利用这两种程序我都分别建立过论坛,我第一次用的…...

Java堆、栈、内存的知识
在JAVA中,有六个不同的地方可以存储数据: 1.寄存器:最快的存储区, 由编译器根据需求进行分配,我们在程序中无法控制. 2. 栈:存放基本类型的变量数据和对象的引用,但对象本身不存放在栈中,而是存放在堆&…...

AX-MES生产制造管理系统-总览
前言说起 MES 就不得不说 ERP,但是 ERP 大家基本上都知道,MES 就不一定了,常见的 ERP 系统包括 SAP、金蝶、用友等,ERP的流程相对来说也比较统一;MES就不同了,基本上熟悉业务流程的软件公司都可以开发并实施…...

基于2D工程图几何特征与梯度提升模型的制造成本智能预测
1. 项目概述:从图纸到报价的智能革命在制造业,尤其是像汽车零部件这样的离散制造领域,报价速度直接决定了订单的生死。传统上,拿到一张新的2D工程图(DWG格式),成本工程师需要花上几天甚至几周时…...

基于Arduino与应变片传感器的高精度厨房电子秤DIY全攻略
1. 项目概述:用Arduino打造一台高精度厨房电子秤作为一个喜欢在厨房里折腾的硬件爱好者,我经常遇到需要精确称量食材的场合。市面上的电子秤要么精度不够,要么价格不菲,要么功能单一。于是,我萌生了自己动手做一台的想…...

别再盲跑了!手把手教你用Arduino Zero在IDE 2.0里设置断点单步调试
告别盲跑时代:Arduino Zero与IDE 2.0的源码级调试实战指南 当你的Arduino项目逻辑越来越复杂,仅靠串口打印调试就像在迷宫里摸黑前行——直到遇见Arduino Zero与IDE 2.0的调试组合。本文将揭示如何用这套工具实现 源码级精准调试 ,即使你手…...

从CTF题看RSA安全:为什么你的密钥不能‘共享素数’?
从CTF实战看RSA密钥安全:那些年我们踩过的坑 在网络安全竞赛和实际渗透测试中,RSA算法的错误实现方式往往成为突破的关键点。本文将通过典型CTF赛题案例,揭示五种常见RSA实现漏洞背后的数学原理和安全启示,帮助开发者在实际项目中…...

2026论文降AI怎么挑?亲测好用工具附免费降AI指南
“您的论文AIGC率为42%,超出学校30%的合格线,请修改后重新提交。”赶毕业论文的同学这段时间估计没少收到这样的提醒。2026年知网、万方、维普等主流平台的AI检测算法持续迭代,把AI生成内容改到符合学校要求,已经成了毕业生的刚需…...

WarcraftHelper:魔兽争霸III现代兼容性问题的终极解决方案指南
WarcraftHelper:魔兽争霸III现代兼容性问题的终极解决方案指南 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 魔兽争霸III作为经典即时战…...

3步快速部署:智能茅台抢购平台的终极自动化解决方案
3步快速部署:智能茅台抢购平台的终极自动化解决方案 【免费下载链接】campus-imaotai i茅台app自动预约,每日自动预约,支持docker一键部署(本项目不提供成品,使用的是已淘汰的算法) 项目地址: https://gi…...

从《王者荣耀》野怪巡逻到RTS单位集结:拆解Unity Navigation系统在实战中的4种高级用法
从《王者荣耀》野怪巡逻到RTS单位集结:拆解Unity Navigation系统在实战中的4种高级用法在MOBA游戏中,野怪沿着固定路线巡逻时突然转向追击玩家;RTS战场上,上百个单位向同一目标点移动却能保持整齐队形;潜行游戏中&…...

抖音批量下载助手:一键构建你的专属视频素材库
抖音批量下载助手:一键构建你的专属视频素材库 【免费下载链接】douyinhelper 抖音批量下载助手 项目地址: https://gitcode.com/gh_mirrors/do/douyinhelper 还在为手动保存抖音视频而烦恼吗?想要批量获取心仪创作者的精彩内容却无从下手&#x…...