微服务08-多级缓存
1.什么是多级缓存
传统的缓存策略一般是请求到达Tomcat后,先查询Redis,如果未命中则查询数据库,如图:

存在下面的问题:
•请求要经过Tomcat处理,Tomcat的性能成为整个系统的瓶颈
•Redis缓存失效时,会对数据库产生冲击
多级缓存就是充分利用请求处理的每个环节,分别添加缓存,减轻Tomcat压力,提升服务性能:
- 浏览器访问静态资源时,优先读取浏览器本地缓存
- 访问非静态资源(ajax查询数据)时,访问服务端
- 请求到达Nginx后,优先读取Nginx本地缓存
- 如果Nginx本地缓存未命中,则去直接查询Redis(不经过Tomcat)
- 如果Redis查询未命中,则查询Tomcat
- 请求进入Tomcat后,优先查询JVM进程缓存
- 如果JVM进程缓存未命中,则查询数据库

在多级缓存架构中,Nginx内部需要编写本地缓存查询、Redis查询、Tomcat查询的业务逻辑,因此这样的nginx服务不再是一个反向代理服务器,而是一个编写业务的Web服务器了。
因此这样的业务Nginx服务也需要搭建集群来提高并发,再有专门的nginx服务来做反向代理,如图:
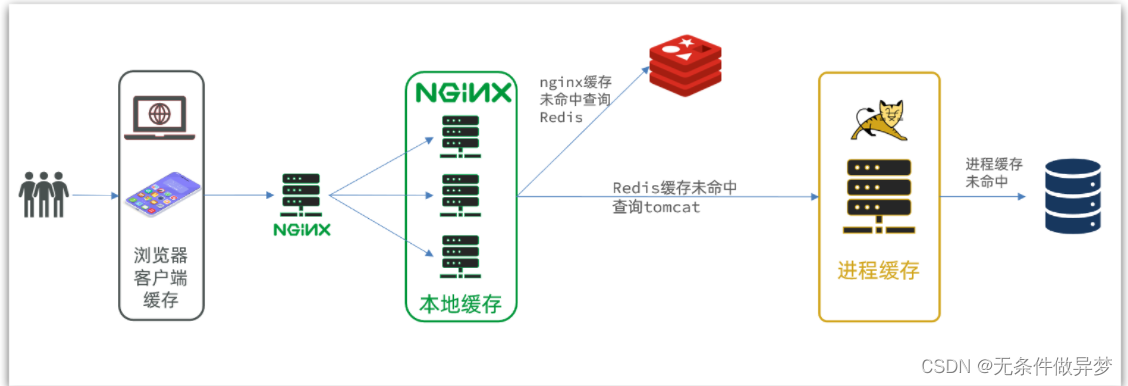
另外,我们的Tomcat服务将来也会部署为集群模式:
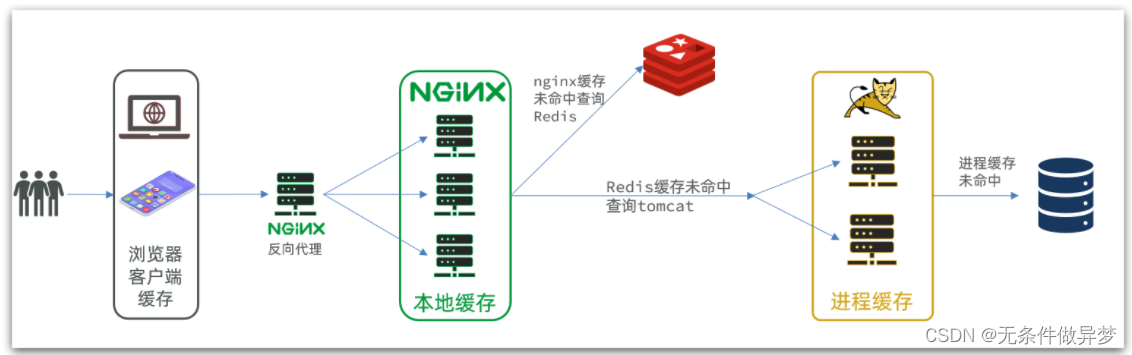
可见,多级缓存的关键有两个:
-
一个是在nginx中编写业务,实现nginx本地缓存、Redis、Tomcat的查询
-
另一个就是在Tomcat中实现JVM进程缓存
其中Nginx编程则会用到OpenResty框架结合Lua这样的语言。
2.JVM进程缓存
2.2.初识Caffeine
缓存在日常开发中启动至关重要的作用,由于是存储在内存中,数据的读取速度是非常快的,能大量减少对数据库的访问,减少数据库的压力。我们把缓存分为两类:
- 分布式缓存,例如Redis:
- 优点:存储容量更大、可靠性更好、可以在集群间共享
- 缺点:访问缓存有网络开销
- 场景:缓存数据量较大、可靠性要求较高、需要在集群间共享
- 进程本地缓存,例如HashMap、GuavaCache:
- 优点:读取本地内存,没有网络开销,速度更快
- 缺点:存储容量有限、可靠性较低、无法共享
- 场景:性能要求较高,缓存数据量较小
利用Caffeine框架来实现JVM进程缓存。
Caffeine是一个基于Java8开发的,提供了近乎最佳命中率的高性能的本地缓存库。目前Spring内部的缓存使用的就是Caffeine。GitHub地址:https://github.com/ben-manes/caffeine
缓存使用的基本API:
@Test
void testBasicOps() {// 构建cache对象Cache<String, String> cache = Caffeine.newBuilder().build();// 存数据cache.put("gf", "迪丽热巴");// 取数据String gf = cache.getIfPresent("gf");System.out.println("gf = " + gf);// 取数据,包含两个参数:// 参数一:缓存的key// 参数二:Lambda表达式,表达式参数就是缓存的key,方法体是查询数据库的逻辑// 优先根据key查询JVM缓存,如果未命中,则执行参数二的Lambda表达式String defaultGF = cache.get("defaultGF", key -> {// 根据key去数据库查询数据return "柳岩";});System.out.println("defaultGF = " + defaultGF);
}
Caffeine既然是缓存的一种,肯定需要有缓存的清除策略,不然的话内存总会有耗尽的时候。
Caffeine提供了三种缓存驱逐策略:
-
基于容量:设置缓存的数量上限
// 创建缓存对象 Cache<String, String> cache = Caffeine.newBuilder().maximumSize(1) // 设置缓存大小上限为 1.build(); -
基于时间:设置缓存的有效时间
// 创建缓存对象 Cache<String, String> cache = Caffeine.newBuilder()// 设置缓存有效期为 10 秒,从最后一次写入开始计时 .expireAfterWrite(Duration.ofSeconds(10)) .build(); -
基于引用:设置缓存为软引用或弱引用,利用GC来回收缓存数据。性能较差,不建议使用。
注意:在默认情况下,当一个缓存元素过期的时候,Caffeine不会自动立即将其清理和驱逐。而是在一次读或写操作后,或者在空闲时间完成对失效数据的驱逐。
2.3.实现JVM进程缓存
2.3.1.需求
利用Caffeine实现下列需求:
- 给根据id查询商品的业务添加缓存,缓存未命中时查询数据库
- 给根据id查询商品库存的业务添加缓存,缓存未命中时查询数据库
- 缓存初始大小为100
- 缓存上限为10000
2.3.2.实现
首先,我们需要定义两个Caffeine的缓存对象,分别保存商品、库存的缓存数据。
在item-service的com.heima.item.config包下定义CaffeineConfig类:
package com.heima.item.config;import com.github.benmanes.caffeine.cache.Cache;
import com.github.benmanes.caffeine.cache.Caffeine;
import com.heima.item.pojo.Item;
import com.heima.item.pojo.ItemStock;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;@Configuration
public class CaffeineConfig {@Beanpublic Cache<Long, Item> itemCache(){return Caffeine.newBuilder().initialCapacity(100).maximumSize(10_000).build();}@Beanpublic Cache<Long, ItemStock> stockCache(){return Caffeine.newBuilder().initialCapacity(100).maximumSize(10_000).build();}
}
然后,修改item-service中的com.heima.item.web包下的ItemController类,添加缓存逻辑:
@RestController
@RequestMapping("item")
public class ItemController {@Autowiredprivate IItemService itemService;@Autowiredprivate IItemStockService stockService;@Autowiredprivate Cache<Long, Item> itemCache;@Autowiredprivate Cache<Long, ItemStock> stockCache;// ...其它略@GetMapping("/{id}")public Item findById(@PathVariable("id") Long id) {return itemCache.get(id, key -> itemService.query().ne("status", 3).eq("id", key).one());}@GetMapping("/stock/{id}")public ItemStock findStockById(@PathVariable("id") Long id) {return stockCache.get(id, key -> stockService.getById(key));}
}
3.Lua语法入门
Nginx编程需要用到Lua语言,因此我们必须先入门Lua的基本语法。
3.1.初识Lua
Lua 是一种轻量小巧的脚本语言,用标准C语言编写并以源代码形式开放, 其设计目的是为了嵌入应用程序中,从而为应用程序提供灵活的扩展和定制功能。官网:https://www.lua.org/
3.1.HelloWorld
CentOS7默认已经安装了Lua语言环境,所以可以直接运行Lua代码。
1)在Linux虚拟机的任意目录下,新建一个hello.lua文件

2)添加下面的内容
print("Hello World!")
3)运行

3.2.变量和循环
3.2.1.Lua的数据类型
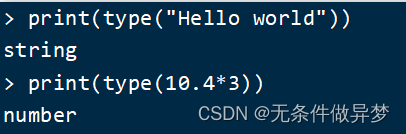
Lua中支持的常见数据类型包括:

另外,Lua提供了type()函数来判断一个变量的数据类型:
3.2.2.声明变量
Lua声明变量的时候无需指定数据类型,而是用local来声明变量为局部变量:
-- 声明字符串,可以用单引号或双引号,
local str = 'hello'
-- 字符串拼接可以使用 ..
local str2 = 'hello' .. 'world'
-- 声明数字
local num = 21
-- 声明布尔类型
local flag = true
Lua中的table类型既可以作为数组,又可以作为Java中的map来使用。数组就是特殊的table,key是数组角标而已:
-- 声明数组 ,key为角标的 table
local arr = {'java', 'python', 'lua'}
-- 声明table,类似java的map
local map = {name='Jack', age=21}
Lua中的数组角标是从1开始,访问的时候与Java中类似:
-- 访问数组,lua数组的角标从1开始
print(arr[1])
Lua中的table可以用key来访问:
-- 访问table
print(map['name'])
print(map.name)
3.2.3.循环
对于table,我们可以利用for循环来遍历。不过数组和普通table遍历略有差异。
遍历数组:
-- 声明数组 key为索引的 table
local arr = {'java', 'python', 'lua'}
-- 遍历数组
for index,value in ipairs(arr) doprint(index, value)
end
遍历普通table
-- 声明map,也就是table
local map = {name='Jack', age=21}
-- 遍历table
for key,value in pairs(map) doprint(key, value)
end
3.3.条件控制、函数
Lua中的条件控制和函数声明与Java类似。
3.3.1.函数
定义函数的语法:
相关文章:
微服务08-多级缓存
1.什么是多级缓存 传统的缓存策略一般是请求到达Tomcat后,先查询Redis,如果未命中则查询数据库,如图: 存在下面的问题: •请求要经过Tomcat处理,Tomcat的性能成为整个系统的瓶颈 •Redis缓存失效时,会对数据库产生冲击 多级缓存就是充分利用请求处理的每个环节,分…...

Intel汇编和ATT汇编的区别?
一、前缀不同 在 Intel 语法中,没有寄存器前缀或立即前缀。 然而,在 AT&T 中,寄存器的前缀是“%”,而 immed 的前缀是“$”。 Intel 语法十六进制或二进制即时数据分别带有“h”和“b”后缀。 此外,如果第一个十六…...
MongoDB 备份与恢复
1.1 MongoDB的常用命令 mongoexport / mongoimport mongodump / mongorestore 有以上两组命令在备份与恢复中进行使用。 1.1.1 导出工具mongoexport Mongodb中的mongoexport工具可以把一个collection导出成JSON格式或CSV格式的文件。可以通过参数指定导出的数据项,…...
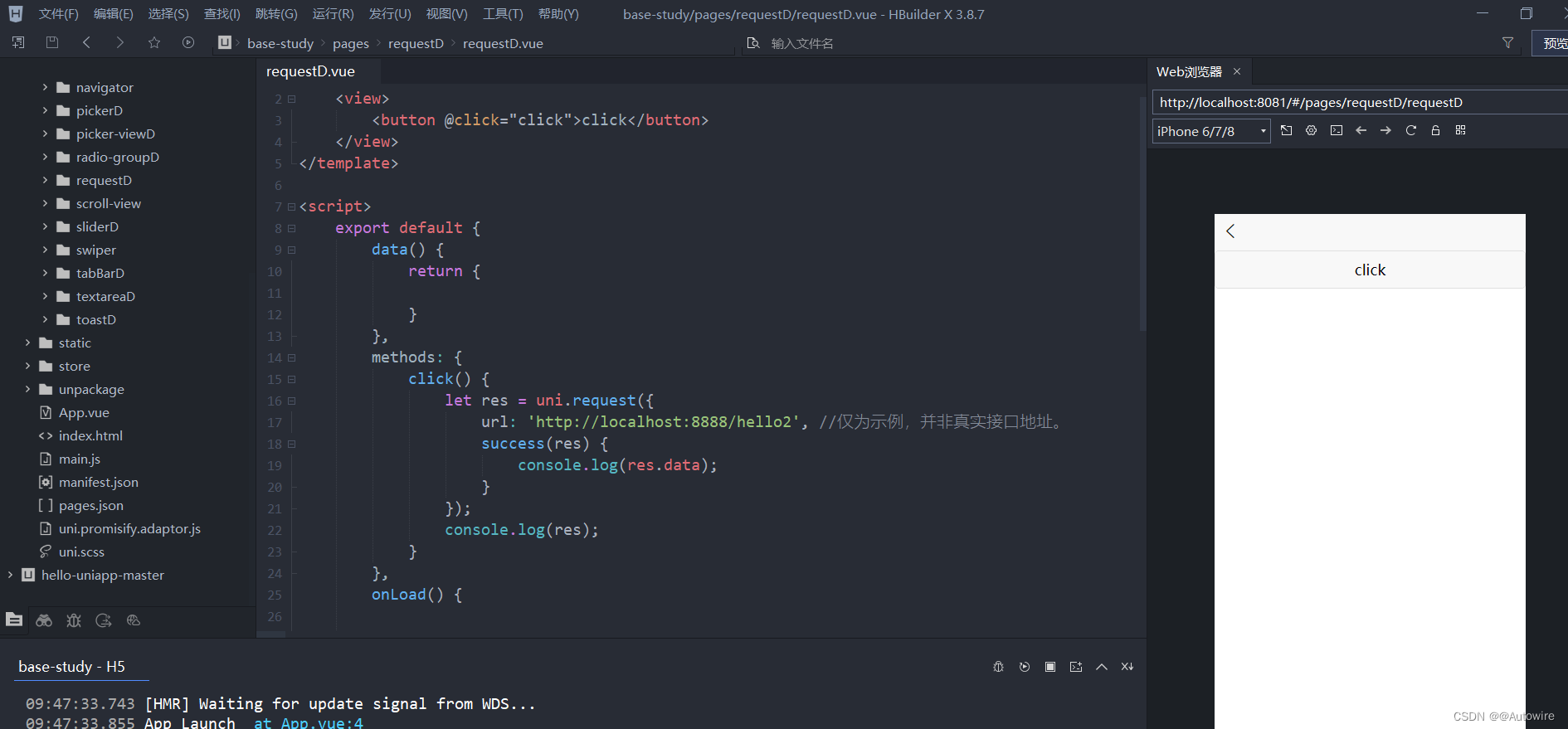
探讨uniapp的网络通信问题
uni-app 中有很多原生的 API,其中我们经常会用到的肯定有:uni.request(OBJECT) method 有效值 注意:method有效值必须大写,每个平台支持的method有效值不同,详细见下表。 success 返回参数说明 data 数据说明 最终…...
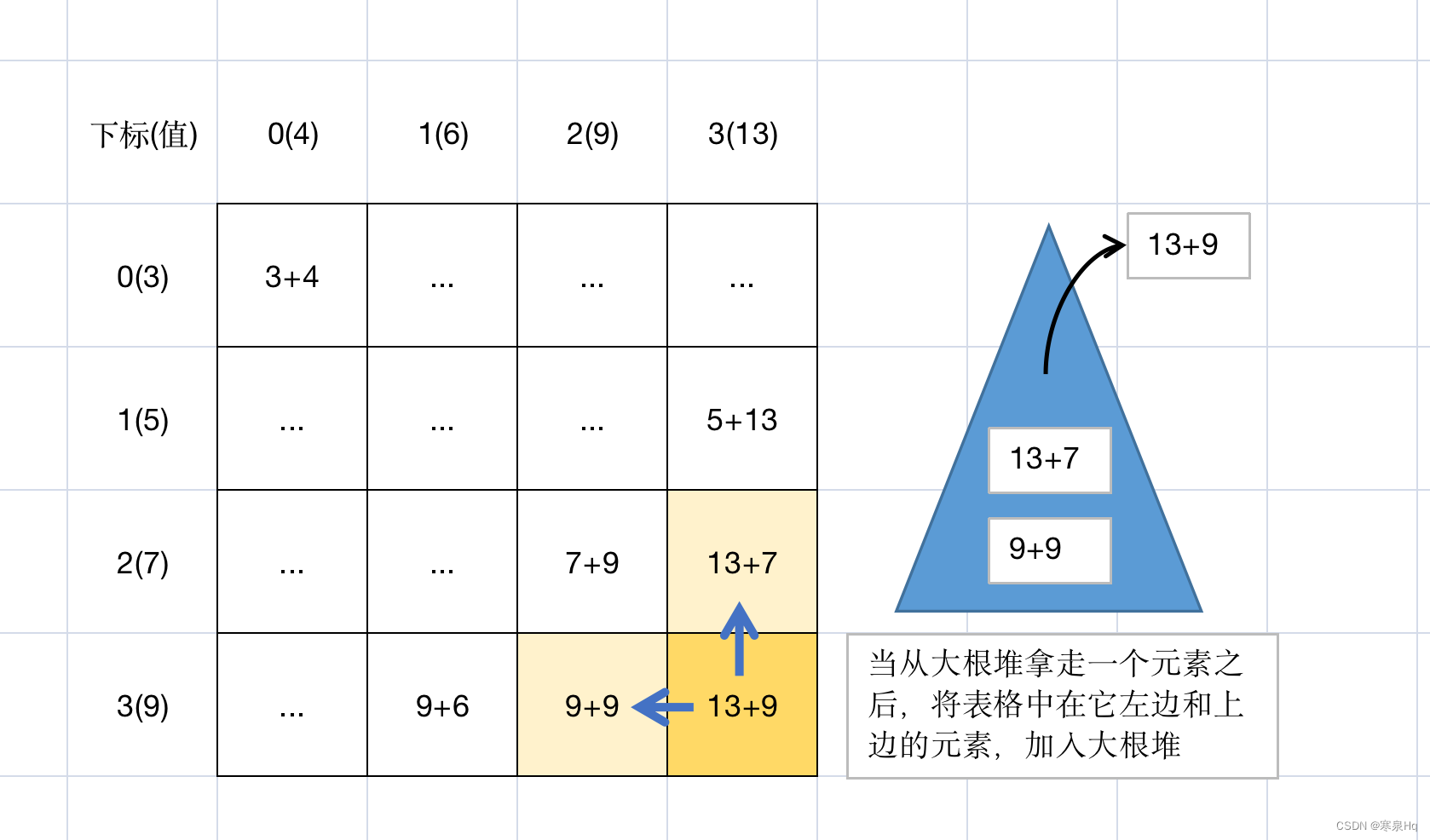
【左神算法刷题班】第18节:汉诺塔问题、岛屿问题、最大路径和问题
第18节 题目1:汉诺塔问题(变体) 体系学习班18节有讲暴力递归的汉诺塔原题。 给定一个数组arr,长度为N,arr中的值只有1,2,3三种 arr[i] 1,代表汉诺塔问题中,从上往下第…...
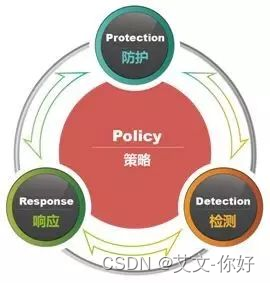
网络安全体系架构介绍
网络安全体系是一项复杂的系统工程,需要把安全组织体系、安全技术体系和安全管理体系等手段进行有机融合,构建一体化的整体安全屏障。针对网络安全防护,美国曾提出多个网络安全体系模型和架构,其中比较经典的包括PDRR模型、P2DR模…...

JSP实训项目设计报告—MVC简易购物商城
JSP实训项目设计报告—MVC简易购物商城 文章目录 JSP实训项目设计报告—MVC简易购物商城设计目的设计要求设计思路系统要求单点登录模块商品展示模块购物车展示模块 概要设计Model层View层Controller层 详细设计Model层View层登录界面系统主界面 Controller层 系统运行效果项目…...

41、可靠传输——停等ARQ
前面两节内容我们学习了传输层的基本概况的一些知识,包括传输层在TCP/IP协议栈中负责的任务、传输层的两大协议,以及端口号、套接字等一些基本的概念。从这一节开始,我们将开启两大协议中TCP协议的学习。 但是,经过之前的学习&am…...

RK3568 cmake编译
一.简介 CMake是开源、跨平台的构建工具,可以让我们通过编写简单的配置文件去生成本地的Makefile,这个配置文件是独立于运行平台和编译器的,这样就不用亲自去编写Makefile了,而且配置文件可以直接拿到其它平台上使用,…...
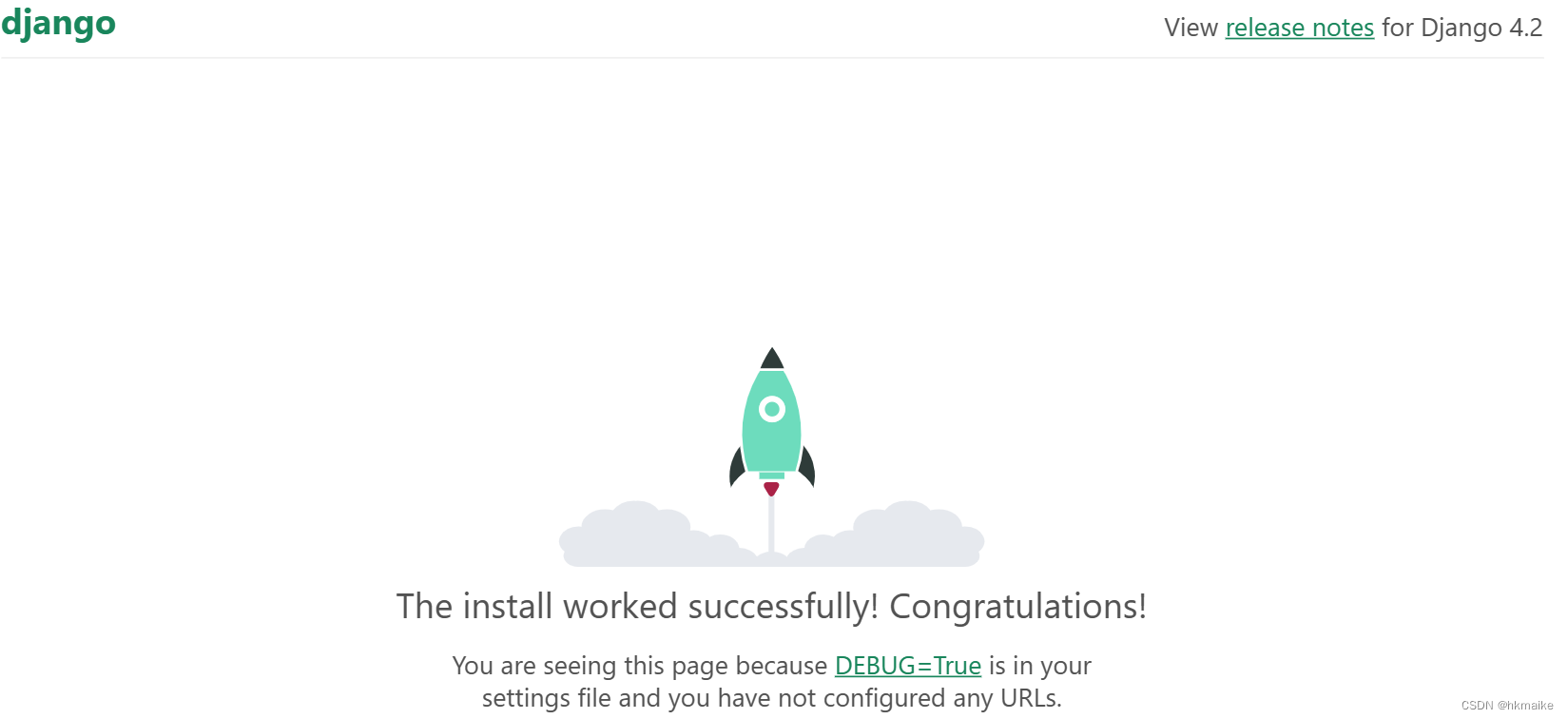
详细安装配置django
安装配置使用Django。 1,下载安装 django pip install django 2.创建设置项目 先进入要放置项目的文件夹下 2.1, 创建项目 django-admin startproject Api_project 2.2, 创建app命令 cd Api_project dir看一下是否有 manage.py 文件…...
HTTP之cookie基础学习
目录 Cookie 什么是Cookie Cookie分类 Cookie版本 Cookie工作原理 Cookie详解 创建cookie cookie编码 cookie过期时间选项 Cookie流程 Cookie使用 会话管理 个性化信息 记录用户的行为 Cookie属性 domain选项 path选项 secure选项 cookie…...

观察者模式和发布订阅模式
观察者模式与发布订阅模式的区别: 1、观察者模式中只有观察者和被观察者,发布订阅模式中有发布者、订阅者、调度中心 2、观察者模式是被观察者发生变化时自己通知观察者,发布订阅模式是通过调度中心来进行分布订阅操作 发布订阅模式 class …...

利用ViewModel和LiveData进行数据管理
利用ViewModel和LiveData进行数据管理 1. 引言 在当今移动应用开发的世界中,数据管理是一个至关重要的方面。随着应用的复杂性不断增加,需要有效地管理和维护应用中的数据。无论是从服务器获取数据、本地数据库存储还是用户界面的状态,数据…...
前后端分离------后端创建笔记(05)用户列表查询接口(下)
本文章转载于【SpringBootVue】全网最简单但实用的前后端分离项目实战笔记 - 前端_大菜007的博客-CSDN博客 仅用于学习和讨论,如有侵权请联系 源码:https://gitee.com/green_vegetables/x-admin-project.git 素材:https://pan.baidu.com/s/…...
浅谈GIS和三维GIS的区别?
GIS(地理信息系统)和三维GIS(3D地理信息系统)是地理信息领域的两个重要概念,它们在地理数据的处理和分析方面具有不同的特点和应用。可能很多人分不清二者的区别,本文就带大家简单了解一下二者的区别。 定义…...
ArcGIS Maps SDK for JavaScript系列之三:在Vue3中使用ArcGIS API加载三维地球
目录 SceneView类的常用属性SceneView类的常用方法vue3中使用SceneView类创建三维地球项目准备引入ArcGIS API创建Vue组件在OnMounted中调用初始化函数initArcGisMap创建Camera对象Camera的常用属性Camera的常用方法 要在Vue 3中使用ArcGIS API for JavaScript加载和展示三维地…...
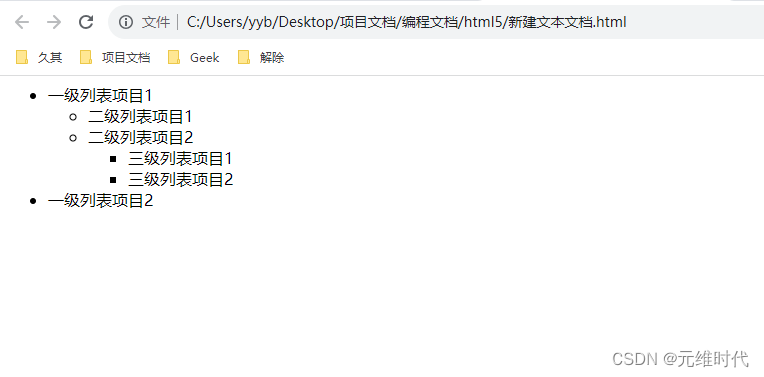
设计列表和超链接
在网页中,大部分信息都是列表结构,如菜单栏、图文列表、分类导航、新闻列表、栏目列表等。HTML5定义了一套列表标签,通过列表结构实现对网页信息的合理排版。另外,网页中还包含大量超链接,通过它实现网页、位置的跳转&…...

rust包跨平台编译,macbook ,linux
在 MacBook 上编译 Rust 项目并生成 Linux 包需要一些步骤。以下是一般的步骤概述: 1. **安装所需工具:** 首先,确保您的 MacBook 上已经安装了所需的工具。您需要 Rust 编程语言的工具链以及一些用于交叉编译到 Linux 的工具。 - 安装 R…...
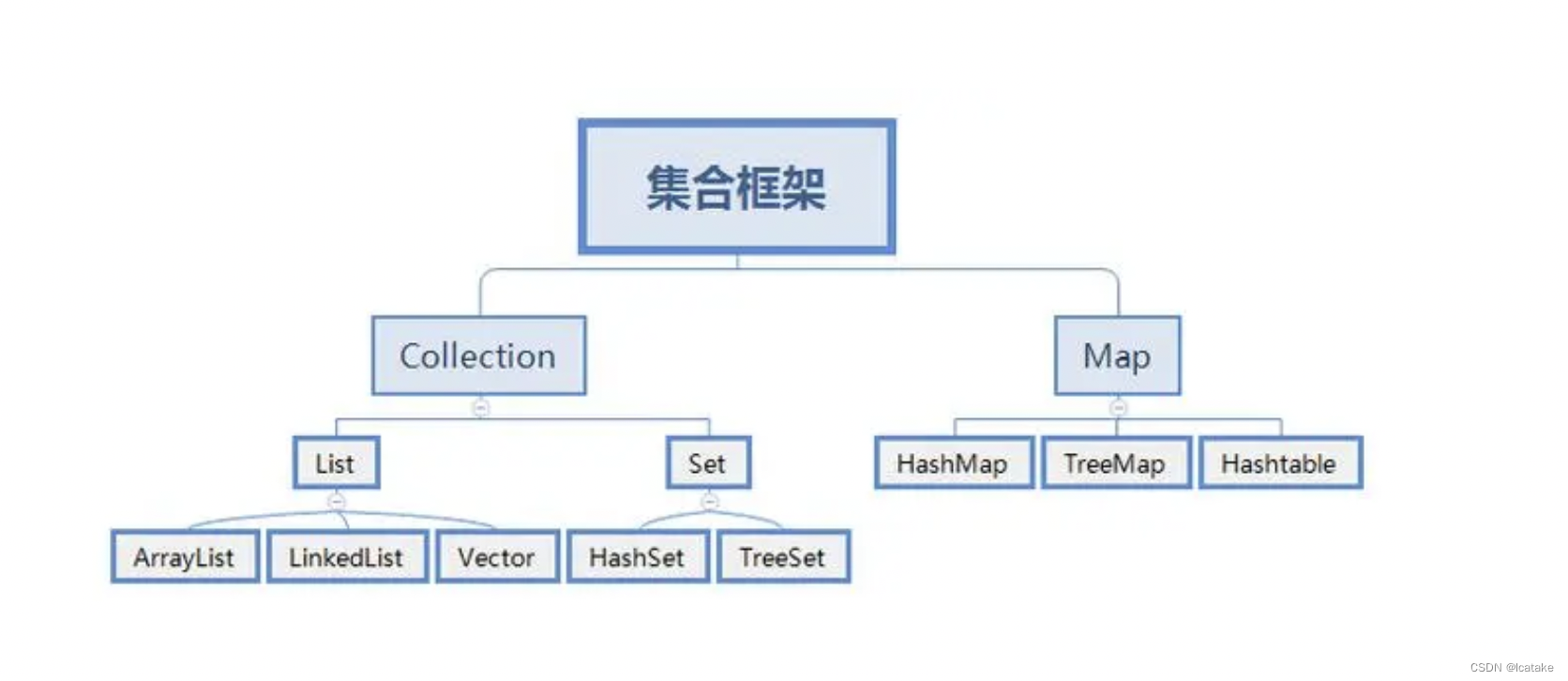
JAVA集合-List
// 数组的缺点:每次使用都需要指定长度,掉率低,操作麻烦 // // 【java集合体系】:分类:6个接口,1个工具类 // 6个接口: 单列 :Collection,(父接口) // …...
)
Python|OpenCV-绘制图形和添加文字的方法(2)
前言 本文是该专栏的第2篇,后面将持续分享OpenCV计算机视觉的干货知识,记得关注。 OpenCV作为一个强大的计算机视觉功能库,除了能解决图像处理和计算机视觉任务之外,它还有着非常丰富的图像绘制功能。可以说,不论是在计算机视觉任务中标记目标领域,还是在图像上绘制一些…...

从怀疑到真香!2026我日常办公离不开的这款在线文字转换器太好用了
刚入职那半年我踩过太多坑:一周三次新人培训,怕漏记知识点全程录音,下课手动整理1小时录音要熬3小时,知识点散得根本没法复习;部门周会做完记录,散会就要我出整理好的纪要,赶工赶得饭都吃不上&a…...

DISMTools企业部署:在组织中大规模应用的最佳实践
DISMTools企业部署:在组织中大规模应用的最佳实践 【免费下载链接】DISMTools The connected place for Windows system administration 项目地址: https://gitcode.com/GitHub_Trending/di/DISMTools DISMTools是一款专为Windows系统管理设计的连接平台&…...

OpenClaw 连接阿里云百炼图文教程
OpenClaw 连接阿里云百炼图文教程 前置准备 已安装并可以正常打开 OpenClaw Windows。 OpenClaw 顶部 Gateway 状态保持在线。 已准备好可正常登录的阿里云账号。 可以正常访问阿里云百炼登录地址:https://bailian.console.aliyun.com/cn-beijing#/home 建议提…...

echarts中heatmap鼠标滚动禁用缩放,向下滚动
配置如下效果如下...

AI开始替人办事后,最危险的不是模型不够强,而是它把旧资料当真了
AI开始替人办事后,最危险的不是模型不够强,而是它把旧资料当真了2026年真正值得重视的AI底层能力,是让模型知道该信谁 你有没有发现一个很扎心的变化。 以前我们用AI,最怕它不会。 现在我们用AI,最怕它太会了。 它能写…...
)
双系统Ubuntu磁盘告急?别重装!用GParted无损扩容保姆级教程(附U盘启动盘制作)
双系统Ubuntu磁盘告急?别重装!用GParted无损扩容保姆级教程(附U盘启动盘制作)当你在Windows和Ubuntu双系统环境下工作时,是否遇到过这样的窘境:当初安装时给Ubuntu分配的空间捉襟见肘,而Windows…...

当 AI Coding 进入复杂企业系统,为什么提效远没有宣传里那么美好 ?
以 Claude Code、Codex 为代表的自主编码智能体(Coding Agents),正在以惊人的速度席卷软件开发者生态。与此同时,类似“10 倍开发效率”“普通人也能随手构建软件”“程序员即将失业”的说法,也随处可见。这种不分场景…...

3分钟开启PC游戏分屏派对:NucleusCoop让单机游戏秒变多人同屏神器
3分钟开启PC游戏分屏派对:NucleusCoop让单机游戏秒变多人同屏神器 【免费下载链接】nucleuscoop Starts multiple instances of a game for split-screen multiplayer gaming! 项目地址: https://gitcode.com/gh_mirrors/nu/nucleuscoop 还在为热门PC游戏不支…...

DS4Windows终极指南:3步让PS手柄在PC上完美运行游戏
DS4Windows终极指南:3步让PS手柄在PC上完美运行游戏 【免费下载链接】DS4Windows Like those other ds4tools, but sexier 项目地址: https://gitcode.com/gh_mirrors/ds/DS4Windows 还在为PS手柄连接Windows电脑后无法识别而烦恼吗?🎮…...

LaTeX公式一键转Word:3步告别数学公式编辑烦恼
LaTeX公式一键转Word:3步告别数学公式编辑烦恼 【免费下载链接】LaTeX2Word-Equation Copy LaTeX Equations as Word Equations, a Chrome Extension 项目地址: https://gitcode.com/gh_mirrors/la/LaTeX2Word-Equation 还在为Word文档中的数学公式编辑而抓狂…...