在Java中对XML的简单应用
- XML 数据传输格式
- 1 XML 概述
- 1.1 什么是 XML
- 1.2 XML 与 HTML 的主要差异
- 1.3 XML 不是对 HTML 的替代
- 2 XML 语法
- 2.1 基本语法
- 2.2 快速入门
- 2.3 组成部分
- 2.3.1 文档声明
- 格式
- 属性
- 2.3.2 指令(了解):结合CSS
- 2.3.3 元素
- 2.3.4 属性
- **XML 元素 vs. 属性**
- 2.3.5 文本
- **CDATA 区段(CDATA section)**
- 2.4 XML 约束
- 2.4.1 XML DTD (简单)
- DTD 的引入
- 2.4.2 XML Schema (复杂)
- Schema 的引入
- 3 XML 解析
- 3.1 什么是 解析 XML
- 3.1.1 操作 XML 文档
- 3.1.2 解析 XML 的方式
- 3.2 XML 常见的解析器
- 3.3 Jsoup
- 3.3.1 快速入门
- 3.3.2 对象的使用
- 3.3.2.1 Jsoup
- 3.3.2.2 Document
- 3.3.2.3 Element
- 3.3.2.4 Elements
- 3.3.2.5 Node
- 3.4 快捷查询方式
- 3.4.1 Selector 选择器
- 3.4.2 XPath 选择器
XML 数据传输格式
1 XML 概述
1.1 什么是 XML
- XML 指可扩展标记语言(EXtensible Markup Language)。
- XML 是一种很像HTML的标记语言。
- XML 的设计宗旨是传输数据,而不是显示数据。
- XML 标签没有被预定义。您需要自行定义标签。
- XML 被设计为具有自我描述性。
- XML 是 W3C 的推荐标准
1.2 XML 与 HTML 的主要差异
- XML 不是 HTML 的替代。
- XML 和 HTML 为不同的目的而设计:
- XML 被设计为传输和存储数据,其焦点是数据的内容。
- HTML 被设计用来显示数据,其焦点是数据的外观。
- HTML 旨在显示信息,而 XML 旨在传输信息。
**注意:**XML 不会做任何事情。XML 被设计用来结构化、存储以及传输信息。
1.3 XML 不是对 HTML 的替代
XML 是对 HTML 的补充。
XML 不会替代 HTML,理解这一点很重要。在大多数 web 应用程序中,XML 用于传输数据,而 HTML 用于格式化并显示数据。
对 XML 最好的描述是:XML 是独立于软件和硬件的信息传输工具。
2 XML 语法
2.1 基本语法
-
XML 文档的后缀名必须为
.xml -
XML 第一行必须定义为文档声明
<?xml version='1.0' ?> -
XML 文档有且仅有一个根元素
XML 文档必须有一个元素是所有其他元素的父元素。该元素称为根元素。
<root><child><subchild>.....</subchild></child> </root> -
XML 的属性值须加引号
在 XML 中,XML 的属性值须加引号。请研究下面的两个 XML 文档。第一个是错误的,第二个是正确的:
<!-- 这是错误的 --> <note date=08/08/2008> <to>George</to> <from>John</from> </note><!-- 这是正确的 --> <note date="08/08/2008"> <to>George</to> <from>John</from> </note> -
所有 XML 元素都须有关闭标签
在 XML 中,省略关闭标签是非法的。所有元素都必须有关闭标签:
<p>This is a paragraph</p> <p>This is another paragraph</p>**注意:**XML 声明没有关闭标签。这不是错误。声明不属于XML本身的组成部分。它不是 XML 元素,也不需要关闭标签。
-
XML 标签对大小写敏感
XML 元素使用 XML 标签进行定义。
XML 标签对大小写敏感。在 XML 中,标签
<Letter>与标签<letter>是不同的。必须使用相同的大小写来编写打开标签和关闭标签:
<Message>这是错误的。</message><message>这是正确的。</message> -
XML 必须正确地嵌套
在 XML 中,所有元素都必须彼此正确地嵌套:
<b><i>This text is bold and italic</i></b>在上例中,正确嵌套的意思是:由于
<i>元素是在<b>元素内打开的,那么它必须在<b>元素内关闭。 -
XML 会保留空格
在 XML 中,文档中的空格不会被删节。
2.2 快速入门
<?xml version='1.0' ?>
<users><user id='1'><name>zhangsan</name><age>23</age><gender>male</gender><br/></user><user id='2'><name>lisi</name><age>24</age><gender>female</gender></user>
</users>
2.3 组成部分
2.3.1 文档声明
格式
<?xml 属性列表 ?>
属性
- version:版本号 必须添加
- encoding:编码方式 告知解析引擎当前文档使用的字符集,默认值:ISO-8859-1
- standalone:是否独立
- 取值:
- yes: 不依赖其他文件
- no: 依赖其他文件
- 取值:
2.3.2 指令(了解):结合CSS
<?xml-stylesheet type="text/css" href="a.css" ?>
2.3.3 元素
XML 命名规则
XML 元素必须遵循以下命名规则:
- 名称可以含字母、数字以及其他的字符
- 名称不能以数字或者标点符号开始
- 名称不能以字符 “xml”(或者 XML、Xml)开始
- 名称不能包含空格
可使用任何名称,没有保留的字词。
2.3.4 属性
注意: id属性值唯一
XML 元素 vs. 属性
请看这些例子:
<person sex="female"><firstname>Anna</firstname><lastname>Smith</lastname>
</person> <person><sex>female</sex><firstname>Anna</firstname><lastname>Smith</lastname>
</person>
在第一个例子中,sex 是一个属性。在第二个例子中,sex 则是一个子元素。两个例子均可提供相同的信息。
没有什么规矩可以告诉我们什么时候该使用属性,而什么时候该使用子元素。我的经验是在 HTML 中,属性用起来很便利,但是在 XML 中,应该尽量避免使用属性。如果信息感觉起来很像数据,那么请使用子元素吧。
2.3.5 文本
CDATA 区段(CDATA section)
术语 CDATA 指的是不应由 XML 解析器进行解析的文本数据(Unparsed Character Data)。
在 XML 元素中,“<” 和 “&” 是非法的。
“<” 会产生错误,因为解析器会把该字符解释为新元素的开始。
“&” 也会产生错误,因为解析器会把该字符解释为字符实体的开始。
某些文本,比如 JavaScript 代码,包含大量 “<” 或 “&” 字符。为了避免错误,可以将脚本代码定义为 CDATA。
CDATA 部分中的所有内容都会被解析器忽略(原样展示)。
CDATA 部分由 <![CDATA[ 开始,由 ]]> 结束:
<![CDATA[function matchwo(a,b) {if (a < b && a < 0) then {return 1;}else {return 0;}}
]]>
在上面的例子中,解析器会忽略 CDATA 部分中的所有内容。
关于 CDATA 部分的注释:
-
CDATA 部分不能包含字符串
]]>。也不允许嵌套的 CDATA 部分。 -
标记 CDATA 部分结尾的
]]>不能包含空格或折行。
2.4 XML 约束
约束简单来说就是规定 XML 文档的书写规则
对约束的图解:
作为框架的使用者(程序员) 要求:
- 能够在 XML 中引入约束文档
- 能够简单的读懂约束文档
2.4.1 XML DTD (简单)
文档类型定义(DTD)可定义合法的XML文档构建模块。它使用一系列合法的元素来定义文档的结构。
DTD 可被成行地声明于 XML 文档中,也可作为一个外部引用。
DTD 的引入
内部DTD:将约束规则定义在XML文档中
外部DTD:将约束的规则定义在外部的DTD文件中
- 本地:`<!DOCTYPE 根标签名 SYSTEM "dtd文件的位置">`
- 网络:`<!DOCTYPE 根标签名 PUBLIC "dtd文件名字" "dtd文件的位置URL">`
2.4.2 XML Schema (复杂)
Schema 的引入
- 填写xml文档的根元素
- 引入xsi前缀
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" - 引入xsd文件命名空间
xsi:schemaLocation="http://www.itcast.cn/xml student.xsd" - 为每一个xsd约束声明一个前缀,作为标识
xmlns="http://www.itcast.cn/xml"
<students xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xmlns="http://www.itcast.cn/xml"xsi:schemaLocation="http://www.itcast.cn/xml student.xsd">
3 XML 解析
3.1 什么是 解析 XML
3.1.1 操作 XML 文档
3.1.2 解析 XML 的方式
DOM: 将标记语言文档一次性加载进内存,在内存中形成一颗DOM树。
- 优点:操作方便,可以对文档进行CRUD的所有操作
- 缺点:占内存
SAX: 逐行读取,基于事件驱动的。
- 优点:不占内存
- 缺点:只能读取,不能增删改
注意:DOM一般用于服务器端,SAX一般用于移动端
3.2 XML 常见的解析器
JAXP: sun公司提供的解析器,支持dom和sax两种方式。
DOM4j: DOM4j是一个开源的,基于Java的库来解析XML文档,它具有高度的灵活性,高性能和内存效率的API。
Jsoup: Jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
PULL: Android操作系统内置的解析器,sax方式的。
3.3 Jsoup
3.3.1 快速入门
步骤:
- 导入jar包 : jsoup-版本号.jar,JsoupXpath-版本号.jar
- 获取Document对象
- 获取对应的标签Element对象
- 获取数据
示例代码:
public static void main(String[] args) throws IOException {//获取Document对象,根据xml文档获取//获取student.xml的path路径String path = JsoupDemo01.class.getClassLoader().getResource("student.xml").getPath();//解析xml文档,加载文档进内存,获取dom树 --->documentDocument document = Jsoup.parse(new File(path), "utf-8");//获取元素对象Elements elements = document.getElementsByTag("name");//获取第一个name的element对象Element element = elements.get(0);//获取文本内容String name = element.text();System.out.println(name);}
3.3.2 对象的使用
3.3.2.1 Jsoup
Jsoup: 工具类,可以解析html或xml文档,返回Document
parse() 用法:
parse() 解析html或xml文档,返回Document
- parse(File in, String charsetName):解析xml或html文件的。
- parse(String html):解析xml或html字符串
- parse(URL url, int timeoutMillis):通过网络路径获取指定的html或xml的文档对象
示例代码:
public static void main(String[] args) throws IOException {//获取student.xml的path路径String path = JsoupDemo02.class.getClassLoader().getResource("student.xml").getPath();//解析xml文档,加载文档进内存,获取dom树 --->document/*Document document = Jsoup.parse(new File(path), "utf-8");System.out.println(document);*///parse(String html):解析html字符串String str = "<?xml version=\"1.0\" encoding=\"UTF-8\" ?>\n" +" <students>\n" +" \t<student number=\"heima_0001\">\n" +" \t\t<name>tom</name>\n" +" \t\t<age>16</age>\n" +" \t\t<sex>male</sex>\n" +" \t</student>\n" +"\t<student number=\"heima_0002\">\n" +"\t\t<name>claier</name>\n" +"\t\t<age>18</age>\n" +"\t\t<sex>female</sex>\n" +"\t</student>\n" +"\t\t \n" +" </students>";/*Document document = Jsoup.parse(str);System.out.println(document);*///parse(URL url,int timeoutMillis),通过网络路径获取指定的HTML的文档对象URL url = new URL("https://baike.baidu.com/item/jsoup/9012509?fr=aladdin");//代表网络中的一个资源网络Document document = Jsoup.parse(url, 10000);System.out.println(document);
}
3.3.2.2 Document
Document:文档对象。代表内存中的dom树
获取Element对象:
- getElementById(String id):根据id属性值获取唯一的element对象
- getElementsByTag(String tagName):根据标签名称获取元素对象集合
- getElementsByAttribute(String key):根据属性名称获取元素对象集合
- getElementsByAttributeValue(String key, String value):根据对应的属性名和属性值获取元素对象集合
示例代码:
public static void main(String[] args) throws IOException { //获取student.xml的path路径String path = JsoupDemo03.class.getClassLoader().getResource("student.xml").getPath();//获取document对象Document document = Jsoup.parse(new File(path), "utf-8");//获取元素对象 //1.获取所有的student对象Elements elements = document.getElementsByTag("student");
// System.out.println(elements);//2.获取属性名为id的元素对象们Elements elements1 = document.getElementsByAttribute("id");
// System.out.println(elements1);//3.获取number属相值为heima_0001的元素对象Elements elements2 = document.getElementsByAttributeValue("number", "heima_0001");
// System.out.println(elements2);//4.获取id属性值的元素Element element = document.getElementById("1");System.out.println(element);
}
3.3.2.3 Element
Element: 元素对象
-
获取子元素对象:
- getElementById(String id): 根据id属性值获取唯一的element对象
- getElementsByTag(String tagName): 根据标签名称获取元素对象集合
- getElementsByAttribute(String key): 根据属性名称获取元素对象集合
- getElementsByAttributeValue(String key, String value): 根据对应的属性名和属性值获取元素对象集合
-
获取属性值:
- String attr(String key):根据属性名称获取属性值
-
获取文本内容:
-
String text(): 获取文本内容
-
String html(): 获取标签体的所有内容(包括字标签的字符串内容)
-
示例代码:
public static void main(String[] args) throws IOException { //获取student.xml的path路径String path = JsoupDemo04.class.getClassLoader().getResource("student.xml").getPath();//获取document对象Document document = Jsoup.parse(new File(path), "utf-8");//获取元素对象 //通过Document对象获取name标签,它是获取所有的name标签,本案例可以获取到两个Elements elements = document.getElementsByTag("name");System.out.println(elements.size());//通过Element对象或去子标签对象Element element_student = document.getElementsByTag("student").get(0);Elements ele_stu_name = element_student.getElementsByTag("name");System.out.println(ele_stu_name);System.out.println(ele_stu_name.size());//获取student对象的属性值String number = element_student.attr("number");System.out.println(number); System.out.println("--------------");//获取文本内容 //获取所有子标签的纯文本内容String text = ele_stu_name.text();System.out.println(text);//获取标签体的所有内容(包括子标签的标签和文本内容)String html = ele_stu_name.html(); System.out.println(html);
}
3.3.2.4 Elements
Elements: 元素Element对象的集合。
可以当作ArrayList<Element>来使用
3.3.2.5 Node
Node: Element 和 Document 的父类
3.4 快捷查询方式
3.4.1 Selector 选择器
使用方法:Elements select(String cssQuery)
语法:参考 Selector 类中定义的语法
示例代码:
public static void main(String[] args) throws IOException { //获取student.xml的path路径String path = JsoupDemo05.class.getClassLoader().getResource("student.xml").getPath();//获取document对象Document document = Jsoup.parse(new File(path), "utf-8");//获取元素对象//获取name标签Elements elements = document.select("name");System.out.println(elements); System.out.println("-------------");//查询id为1的元素Elements elements1 = document.select("#1");System.out.println(elements1); System.out.println("-------------");//获取student标签且number属性值为heima_0001的age子标签//获取student标签且number属性值为heima_0001Elements elements2 = document.select("student[number='heima_0001']");System.out.println(elements2);System.out.println("-------------");//获取student标签且number属性值为heima_0001的age子标签Elements elements3 = document.select("student[number='heima_0001'] age");System.out.println(elements3);
}
3.4.2 XPath 选择器
XPath 即为XML路径语言,它是一种用来确定XML(标准通用标记语言的子集)文档中某部分位置的语言
注意:
- 使用 Jsoup 的 Xpath 需要额外导入jar包
- 查询 W3Cshool 参考手册,使用 xpath 的语法完成查询
示例代码:
public static void main(String[] args) throws IOException, XpathSyntaxErrorException { //获取student.xml的path路径String path = JsoupDemo06.class.getClassLoader().getResource("student.xml").getPath();//获取document对象Document document = Jsoup.parse(new File(path), "utf-8");//根据document对象创建JXDocumentJXDocument jxDocument = new JXDocument(document);//结合xpath语法查询//查询所有的student标签List<JXNode> jxNodes = jxDocument.selN("//student");for (JXNode jxNode : jxNodes) {System.out.println(jxNode);} System.out.println("----------");//查询所有student标签下的name标签List<JXNode> jxNodes1 = jxDocument.selN("//student/name");for (JXNode jxNode : jxNodes1) {System.out.println(jxNode);} System.out.println("-----------");//查询student标签下带有id属性的name标签List<JXNode> jxNodes2 = jxDocument.selN("//student/name[@id]");for (JXNode jxNode : jxNodes2) {System.out.println(jxNode);} System.out.println("-------------");//查询student标签下带有id属性的name标签并且id属性值为1List<JXNode> jxNodes3 = jxDocument.selN("//student/name[@id='1']");for (JXNode jxNode : jxNodes3) {System.out.println(jxNode);}System.out.println("-------------");}
相关文章:
在Java中对XML的简单应用
XML 数据传输格式1 XML 概述1.1 什么是 XML1.2 XML 与 HTML 的主要差异1.3 XML 不是对 HTML 的替代 2 XML 语法2.1 基本语法2.2 快速入门2.3 组成部分2.3.1 文档声明格式属性 2.3.2 指令(了解):结合CSS2.3.3 元素2.3.4 属性**XML 元素 vs. 属…...

Linu学习笔记——常用命令
Linux 常用命令全拼: Linux 常用命令全拼 | 菜鸟教程 一、切换root用户 1.给root用户设置密码 sudo passwd root 2.输入密码,并确认密码 3.切换到root用户 su:Swith user(切换用户) su root 二、切换目录 目录结构:Linux 系…...
PLUS操作流程、应用与实践,多源不同分辨率数据的处理、ArcGIS的应用、PLUS模型的应用、InVEST模型的应用
PLUS模型是由中国地质大学(武汉)地理与信息工程学院高性能空间计算智能实验室开发,是一个基于栅格数据的可用于斑块尺度土地利用/土地覆盖(LULC)变化模拟的元胞自动机(CA)模型。PLUS模型集成了基于土地扩张分析的规则挖掘方法和基于多类型随机…...
item_review-获得淘宝商品评论
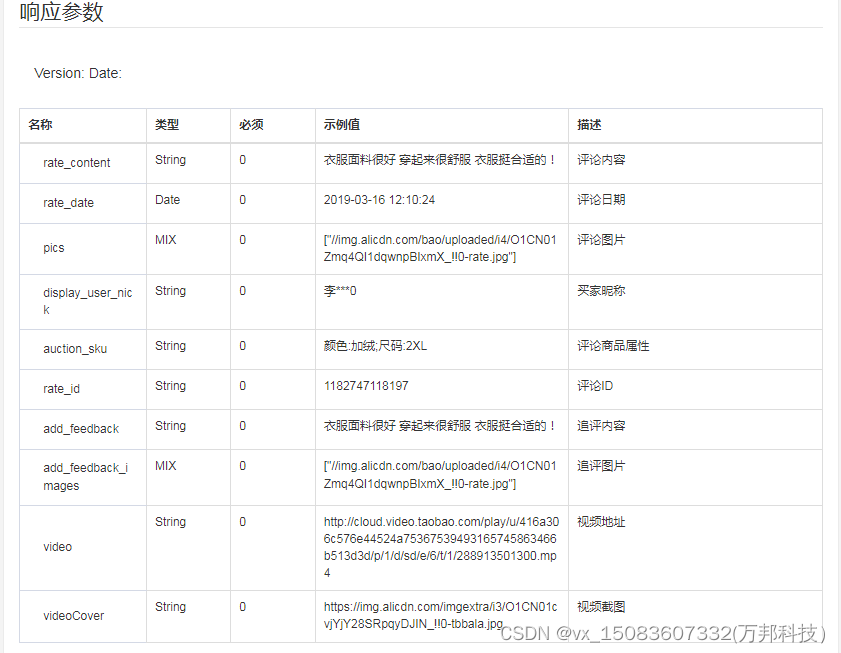
一、接口参数说明: item_review-获得淘宝商品评论,点击更多API调试,请移步注册API账号点击获取测试key和secret 公共参数 请求地址: https://api-gw.onebound.cn/taobao/item_review 名称类型必须描述keyString是调用key(点击获…...
如何读取文件夹内的诸多文件,并选择性的保留部分文件
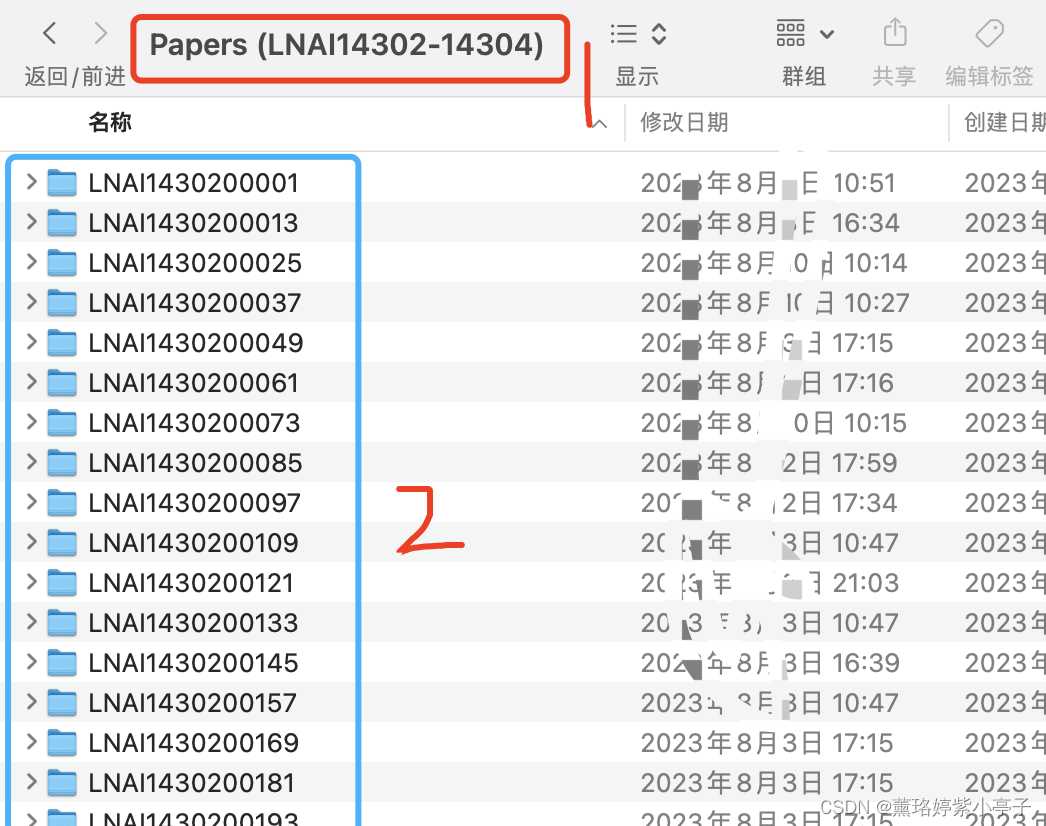
目录 问题描述: 问题解决: 问题描述: 当前有一个二级文件夹,第一层是文件夹名称是“Papers(LNAI14302-14304)",第二级文件夹目录名称如下图蓝色部分所示。第三层为存放的文件,如下下图所示,每一个文件中,均存放三个文件,分别为copyright.pdf, submission.pdf, s…...
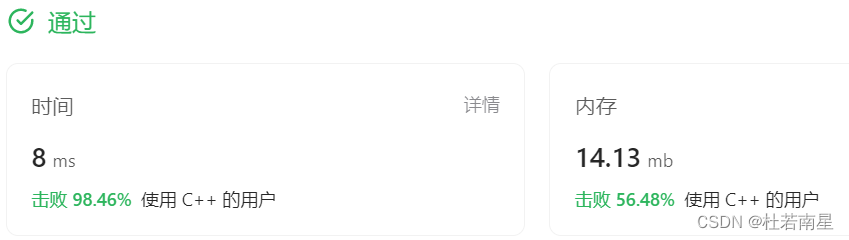
每天一道leetcode:1129. 颜色交替的最短路径(图论中等广度优先遍历)
今日份题目: 给定一个整数 n,即有向图中的节点数,其中节点标记为 0 到 n - 1。图中的每条边为红色或者蓝色,并且可能存在自环或平行边。 给定两个数组 redEdges 和 blueEdges,其中: redEdges[i] [ai, bi…...
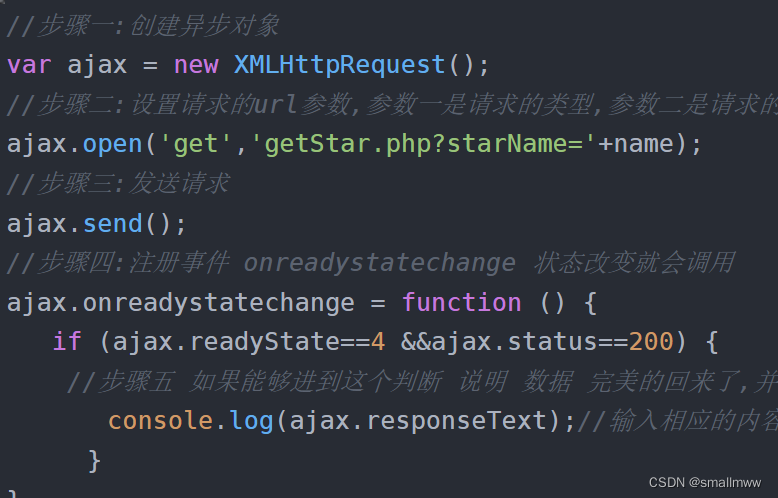
原生js发送ajax请求---ajax请求篇(一)
在原生js中我们使用的是XMLHttpRequest对象来发送ajax请求 主要步骤就是: 1.创建XMLHTTPRequest对象 2.使用open方法设置和服务器的交互信息 3.设置发送的数据,开始和服务器端交互 4.注册事件 5.更新界面 (1) get方式 //步骤一…...

【ARM 嵌入式 编译系列 2.1 -- GCC 编译参数学习】
文章目录 1.1 GCC 编译参数1.1.1 GCC arm-noe-eabi- 介绍1.1.1.1 ARM 和 Thumb 指令集区别1.1.2 GCC CFLAGS 介绍1.1.3 GCC LDFLAGS 介绍1.1.4 CXXFLAGS 介绍上篇文章:ARM 嵌入式 编译系列 2 – GCC 编译过程介绍 下篇文章:ARM 嵌入式 C 入门及渐进 3 – GCC attribute((weak…...

C++教程 - How to C++系列专栏第3篇
关于专栏 这个专栏是优质的C教程专栏,如果你还没看过第0篇,点击C教程 - How to C系列专栏第0篇去第0篇 本专栏一致使用操作系统:macOS Ventura,代码编辑器:CLion,C编译器:Clang 感谢一路相伴…...
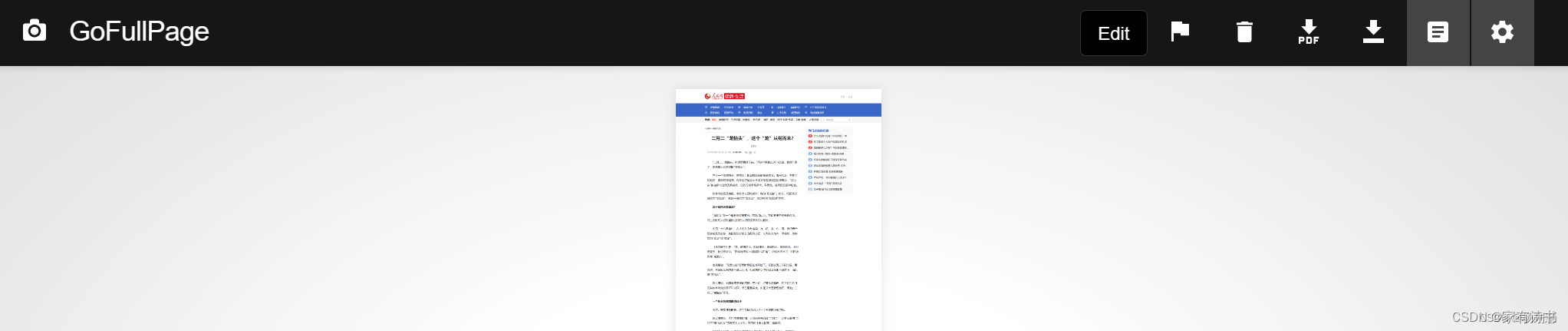
使用Edge和chrom扩展工具(GoFullPage)实现整页面截图或生成PDF文件
插件GoFullPage下载:点击免费下载 如果在浏览网页时,有需要整个页面截图或导出PDF文件的需求,这里分享一个Edge浏览器的扩展插件:GoFullPage。 这个工具可以一键实现页面从上到下滚动并截取。 一、打开“管理扩展”(…...

image has dependent child images
问题:很多none的镜像无法被删除 解决过程: 1、通过 docker image prune -f 提示可删除为 0 2、直接进行删除报错: docker rmi 8f5116cbc201Error response from daemon: conflict: unable to delete 8f5116cbc201 (cannot be forced) - im…...

Linux系统中基于NGINX的代理缓存配置指南
作为一名专业的爬虫程序员,你一定知道代理缓存在加速网站响应速度方面的重要性。而使用NGINX作为代理缓存服务器,能够极大地提高性能和效率。本文将为你分享Linux系统中基于NGINX的代理缓存配置指南,提供实用的解决方案,助你解决在…...
)
openCV项目开发实战--详细介绍如何改善夜间图像的照明(附python和C++源码)
文末附完整的代码实现下载链接 介绍 对于非摄影师来说,在光线不佳的条件下拍出好照片似乎很神奇。完成低光摄影需要技巧、经验和正确的设备的结合。在弱光下拍摄的图像缺乏色彩和独特的边缘。它们还遭受能见度差和深度未知的困扰。这些缺点使得此类图像不适合个人使用或图像处…...

rabbitmq的消息应答
消费者完成一个任务可能需要一段时间,如果其中一个消费者处理一个长的任务并仅只完成 了部分突然它挂掉了,会发生什么情况。RabbitMQ 一旦向消费者传递了一条消息,便立即将该消 息标记为删除。在这种情况下,突然有个消费者挂掉了…...
)
如何重置树莓派 Pico(重置外围设备失败)
有时候需要重置树莓派 Pico,一种方法是按住 Pico 上的“BOOTSEL”按钮再插入 USB;或者用按钮连接“RUN”和“GND”针脚,然后同时按下这个按钮和“BOOTSEL”按钮。这样就可以进入 USB 模式,这样从一定程度进行了重置。 但是这种方…...

LaWGPT基于中文法律知识的大语言模型_初步安装
准备代码,创建环境 # 下载代码 git clone gitgithub.com:pengxiao-song/LaWGPT.git cd LaWGPT# 创建环境 conda create -n lawgpt python3.10 -y conda activate lawgpt国内网络环境问题。你可以把requirements.txt里面的github.com替换成kgithub.com(这…...

一文学会sklearn中的交叉验证方法,cross_validate和KFlod实战案例
前言 在机器学习中,我们经常需要评估模型的性能。而为了准确评估模型的性能,我们需要使用一种有效的评估方法。五折交叉验证(5-fold cross-validation)就是其中一种常用的模型评估方法,用于评估机器学习模型的性能和泛…...

《面试1v1》ElasticSearch倒排索引
🍅 作者简介:王哥,CSDN2022博客总榜Top100🏆、博客专家💪 🍅 技术交流:定期更新Java硬核干货,不定期送书活动 🍅 王哥多年工作总结:Java学习路线总结…...
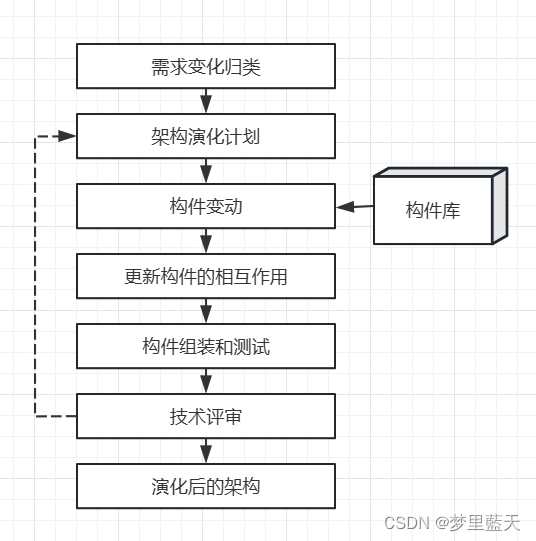
基于架构的软件开发方法
基于架构的软件开发方法 基于架构的软件开发方法是由架构驱动的,即指由构成体系结构的商业、质量和功能需求的组合驱动的。使用ABSD 方法,设计活动可以从项目总体功能框架明确就开始,这意味着需求抽取和分析还没有完成(甚至远远没有完成)&am…...
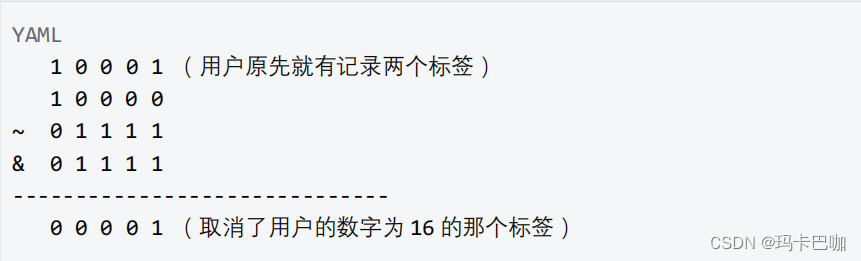
实战篇之基于二进制思想的用户标签系统(Mysql+SpringBoot)
一: 计算机中的二进制 计算机以二进制表示数据,以表示电路中的正反。在二进制下,一个位只有 0 和 1 。逢二进一 位。类似十进制下,一个位只有 0~9 。逢十进一位。 二: 进制常用运算 (位运算)…...

yolo视频识别 车辆速度估计识别 yolo11视频实时速度测量与测速估计
文章目录YOLOv11:视频实时速度测量与测速估计一、YOLOv11概述二、速度测量原理三、距离测量方法四、应用场景五、实践案例以下是关于使用YOLOv11进行视频实时速度测量与测速估计的介绍: YOLOv11:视频实时速度测量与测速估计 随着计算机视觉…...

【Lindy营销自动化工作流终极指南】:20年实战验证的7大反脆弱性设计原则,92%企业漏掉的关键衰减阈值
更多请点击: https://intelliparadigm.com 第一章:Lindy营销自动化工作流的基本范式与历史验证 Lindy效应指出,一个事物的预期剩余寿命与其当前年龄成正比——在营销自动化领域,Lindy范式体现为:经时间检验仍被广泛采…...

PS5 NOR Modifier深度解析:如何通过Windows工具修复PS5硬件故障与实现光驱版转数字版
PS5 NOR Modifier深度解析:如何通过Windows工具修复PS5硬件故障与实现光驱版转数字版 【免费下载链接】PS5NorModifier The PS5 Nor Modifier is an easy to use Windows based application to rewrite your PS5 NOR file. This can be useful if your NOR is corru…...

3步快速上手Whisper-WebUI:轻松实现语音转字幕的完整指南
3步快速上手Whisper-WebUI:轻松实现语音转字幕的完整指南 【免费下载链接】Whisper-WebUI A Web UI for easy subtitle using whisper model. 项目地址: https://gitcode.com/gh_mirrors/wh/Whisper-WebUI 还在为视频制作繁琐的字幕而烦恼吗?Whis…...

泰拉瑞亚地图编辑器:从像素画布到创意世界的蜕变之旅
泰拉瑞亚地图编辑器:从像素画布到创意世界的蜕变之旅 【免费下载链接】Terraria-Map-Editor TEdit - Terraria Map Editor - TEdit is a stand alone, open source map editor for Terraria. It lets you edit maps just like (almost) paint! It also lets you cha…...

C语言预处理指令全解析
第六章 预处理命令在c语言中,所有# 开头的指令,被称为预处理指令。gcc 编译预处理 所有的预处理指令,都要在这步处理完汇编编译连接#include包含头文件。 全局变量的声明,函数的声明, 自定义构造类型声明, …...

5分钟掌握m4s-converter:将B站缓存视频无损转换为MP4的终极指南
5分钟掌握m4s-converter:将B站缓存视频无损转换为MP4的终极指南 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾在B站缓存了…...

LeetCode 80 · 删除有序数组中的重复项 II:通用模板的威力
LeetCode 26 要求每个元素最多出现一次,这道题放宽到最多出现两次。看起来只是把 1 改成了 2,但这个"小改动"背后藏着一个通用的快慢指针模板——把 2 换成任意整数 m,代码几乎不用动。这就是模板的威力:改一个数字&…...

条件Shapley值:用shapr包实现更公平的模型可解释性
1. 项目概述与核心价值 如果你在数据科学或机器学习领域工作过一段时间,尤其是在需要向业务方或非技术团队解释模型决策的场景里,你肯定遇到过这样的困境:模型预测准确率很高,但当别人问“为什么这个客户的贷款申请被拒绝了&#…...

3大核心模块+5步实战:用RPFM彻底改变《全面战争》模组开发体验
3大核心模块5步实战:用RPFM彻底改变《全面战争》模组开发体验 【免费下载链接】rpfm Rusted PackFile Manager (RPFM) is a... reimplementation in Rust and Qt6 of PackFile Manager (PFM), one of the best modding tools for Total War Games. 项目地址: http…...