使用自己的数据利用pytorch搭建全连接神经网络进行回归预测
使用自己的数据利用pytorch搭建全连接神经网络进行回归预测
- 1、导入库
- 2、数据准备
- 3、数据拆分
- 4、数据标准化
- 5、数据转换
- 6、模型搭建
- 7、模型训练
- 8、模型预测
- 9、完整代码
1、导入库
引入必要的库,包括PyTorch、Pandas等。
import numpy as np
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, mean_absolute_error
from sklearn.datasets import fetch_california_housingimport torch
import torch.nn as nn
import torch.nn.functional as F
from torch.optim import SGD
import torch.utils.data as Data
import matplotlib.pyplot as plt
import seaborn as sns
2、数据准备
这里使用sklearn自带的加利福尼亚房价数据,首次运行会下载数据集,建议下载之后,处理成csv格式单独保存,再重新读取。
后续完整代码中,数据也是采用先下载,单独保存之后,再重新读取的方式。
# 导入数据
housedata = fetch_california_housing() # 首次运行会下载数据集
data_x, data_y = housedata.data, housedata.target # 读取数据和标签
data_df = pd.DataFrame(data=data_x, columns=housedata.feature_names) # 将数据处理成dataframe格式
data_df['target'] = data_y # 添加标签列
data_df.to_csv("california_housing.csv") # 将数据输出为CSV文件
housedata_df = pd.read_csv("california_housing.csv") # 重新读取数据
3、数据拆分
# 切分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(housedata[:, :-1], housedata[:, -1],test_size=0.3, random_state=42)
4、数据标准化
# 数据标准化处理
scale = StandardScaler()
x_train_std = scale.fit_transform(X_train)
x_test_std = scale.transform(X_test)
5、数据转换
# 将数据集转为张量
X_train_t = torch.from_numpy(x_train_std.astype(np.float32))
y_train_t = torch.from_numpy(y_train.astype(np.float32))
X_test_t = torch.from_numpy(x_test_std.astype(np.float32))
y_test_t = torch.from_numpy(y_test.astype(np.float32))# 将训练数据处理为数据加载器
train_data = Data.TensorDataset(X_train_t, y_train_t)
test_data = Data.TensorDataset(X_test_t, y_test_t)
train_loader = Data.DataLoader(dataset=train_data, batch_size=64, shuffle=True, num_workers=1)
6、模型搭建
# 搭建全连接神经网络回归
class FNN_Regression(nn.Module):def __init__(self):super(FNN_Regression, self).__init__()# 第一个隐含层self.hidden1 = nn.Linear(in_features=8, out_features=100, bias=True)# 第二个隐含层self.hidden2 = nn.Linear(100, 100)# 第三个隐含层self.hidden3 = nn.Linear(100, 50)# 回归预测层self.predict = nn.Linear(50, 1)# 定义网络前向传播路径def forward(self, x):x = F.relu(self.hidden1(x))x = F.relu(self.hidden2(x))x = F.relu(self.hidden3(x))output = self.predict(x)# 输出一个一维向量return output[:, 0]
7、模型训练
# 定义优化器
optimizer = torch.optim.SGD(testnet.parameters(), lr=0.01)
loss_func = nn.MSELoss() # 均方根误差损失函数
train_loss_all = []# 对模型迭代训练,总共epoch轮
for epoch in range(30):train_loss = 0train_num = 0# 对训练数据的加载器进行迭代计算for step, (b_x, b_y) in enumerate(train_loader):output = testnet(b_x) # MLP在训练batch上的输出loss = loss_func(output, b_y) # 均方根损失函数optimizer.zero_grad() # 每次迭代梯度初始化0loss.backward() # 反向传播,计算梯度optimizer.step() # 使用梯度进行优化train_loss += loss.item() * b_x.size(0)train_num += b_x.size(0)train_loss_all.append(train_loss / train_num)
8、模型预测
y_pre = testnet(X_test_t)
y_pre = y_pre.data.numpy()
mae = mean_absolute_error(y_test, y_pre)
print('在测试集上的绝对值误差为:', mae)
9、完整代码
# -*- coding: utf-8 -*-
# @Time : 2023/8/11 15:58
# @Author : huangjian
# @Email : huangjian013@126.com
# @File : FNN_demo.pyimport numpy as np
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, mean_absolute_error
from sklearn.datasets import fetch_california_housingimport torch
import torch.nn as nn
import torch.nn.functional as F
from torch.optim import SGD
import torch.utils.data as Data
from torchsummary import summary
from torchviz import make_dot
import matplotlib.pyplot as plt
import seaborn as sns# 搭建全连接神经网络回归
class FNN_Regression(nn.Module):def __init__(self):super(FNN_Regression, self).__init__()# 第一个隐含层self.hidden1 = nn.Linear(in_features=8, out_features=100, bias=True)# 第二个隐含层self.hidden2 = nn.Linear(100, 100)# 第三个隐含层self.hidden3 = nn.Linear(100, 50)# 回归预测层self.predict = nn.Linear(50, 1)# 定义网络前向传播路径def forward(self, x):x = F.relu(self.hidden1(x))x = F.relu(self.hidden2(x))x = F.relu(self.hidden3(x))output = self.predict(x)# 输出一个一维向量return output[:, 0]# 导入数据
housedata_df = pd.read_csv("california_housing.csv")
housedata = housedata_df.values
# 切分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(housedata[:, :-1], housedata[:, -1],test_size=0.3, random_state=42)# 数据标准化处理
scale = StandardScaler()
x_train_std = scale.fit_transform(X_train)
x_test_std = scale.transform(X_test)# 将训练数据转为数据表
datacor = np.corrcoef(housedata_df.values, rowvar=0)
datacor = pd.DataFrame(data=datacor, columns=housedata_df.columns, index=housedata_df.columns)
plt.figure(figsize=(8, 6))
ax = sns.heatmap(datacor, square=True, annot=True, fmt='.3f', linewidths=.5, cmap='YlGnBu',cbar_kws={'fraction': 0.046, 'pad': 0.03})
plt.show()# 将数据集转为张量
X_train_t = torch.from_numpy(x_train_std.astype(np.float32))
y_train_t = torch.from_numpy(y_train.astype(np.float32))
X_test_t = torch.from_numpy(x_test_std.astype(np.float32))
y_test_t = torch.from_numpy(y_test.astype(np.float32))# 将训练数据处理为数据加载器
train_data = Data.TensorDataset(X_train_t, y_train_t)
test_data = Data.TensorDataset(X_test_t, y_test_t)
train_loader = Data.DataLoader(dataset=train_data, batch_size=64, shuffle=True, num_workers=1)# 输出网络结构
testnet = FNN_Regression()
summary(testnet, input_size=(1, 8)) # 表示1个样本,每个样本有8个特征# 输出网络结构
testnet = FNN_Regression()
x = torch.randn(1, 8).requires_grad_(True)
y = testnet(x)
myMLP_vis = make_dot(y, params=dict(list(testnet.named_parameters()) + [('x', x)]))# 定义优化器
optimizer = torch.optim.SGD(testnet.parameters(), lr=0.01)
loss_func = nn.MSELoss() # 均方根误差损失函数
train_loss_all = []# 对模型迭代训练,总共epoch轮
for epoch in range(30):train_loss = 0train_num = 0# 对训练数据的加载器进行迭代计算for step, (b_x, b_y) in enumerate(train_loader):output = testnet(b_x) # MLP在训练batch上的输出loss = loss_func(output, b_y) # 均方根损失函数optimizer.zero_grad() # 每次迭代梯度初始化0loss.backward() # 反向传播,计算梯度optimizer.step() # 使用梯度进行优化train_loss += loss.item() * b_x.size(0)train_num += b_x.size(0)train_loss_all.append(train_loss / train_num)# 可视化训练损失函数的变换情况
plt.figure(figsize=(8, 6))
plt.plot(train_loss_all, 'ro-', label='Train loss')
plt.legend()
plt.grid()
plt.xlabel('epoch')
plt.ylabel('Loss')
plt.show()y_pre = testnet(X_test_t)
y_pre = y_pre.data.numpy()
mae = mean_absolute_error(y_test, y_pre)
print('在测试集上的绝对值误差为:', mae)# 可视化测试数据的拟合情况
index = np.argsort(y_test)
plt.figure(figsize=(8, 6))
plt.plot(np.arange(len(y_test)), y_test[index], 'r', label='Original Y')
plt.scatter(np.arange(len(y_pre)), y_pre[index], s=3, c='b', label='Prediction')
plt.legend(loc='upper left')
plt.grid()
plt.xlabel('Index')
plt.ylabel('Y')
plt.show()相关文章:

使用自己的数据利用pytorch搭建全连接神经网络进行回归预测
使用自己的数据利用pytorch搭建全连接神经网络进行回归预测 1、导入库2、数据准备3、数据拆分4、数据标准化5、数据转换6、模型搭建7、模型训练8、模型预测9、完整代码 1、导入库 引入必要的库,包括PyTorch、Pandas等。 import numpy as np import pandas as pd f…...

103.216.154.X服务器出现漏洞了有什么办法?
服务器出现漏洞是一种严重的安全风险,需要及时采取措施来应对。以下是一些常见的应对措施: 及时更新补丁:确保服务器上的操作系统、应用程序和软件都是最新版本,并及时应用相关的安全补丁,以修复已知的漏洞。 强化访问…...

数据结构:堆的实现(C实现)
个人主页 : 个人主页 个人专栏 : 《数据结构》 《C语言》 文章目录 一、堆二、实现思路1. 结构的定义2. 堆的构建 (HeapInit)3. 堆的销毁 (HeapDestroy)4. 堆的插入 (HeapPush)5. 堆的删除 (HeapPop)6. 取堆顶的数据 (HeapTop)7. 堆的数据个数 (HeapSize…...

数据分析两件套ClickHouse+Metabase(一)
ClickHouse篇 安装ClickHouse ClickHouse有中文文档, 安装简单 -> 文档 官方提供了四种包的安装方式, deb/rpm/tgz/docker, 自行选择适合自己操作系统的安装方式 这里我们选deb的方式, 其他方式看文档 sudo apt-get install -y apt-transport-https ca-certificates dirm…...

urllib爬虫模块
urllib爬取数据 import urllib.request as request# 定义url url "https://www.baidu.com" #模拟浏览器发起请求获取响应对象 response request.urlopen(url)""" read方法返回的是字节形式的二进制数据 二进制--》字符串 解码 decode( 编码的格式…...
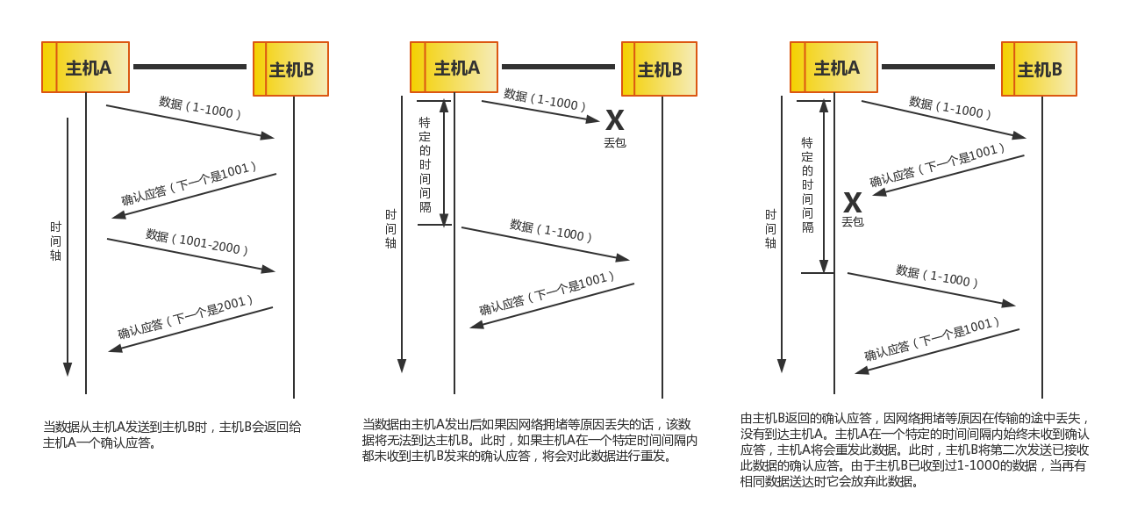
TCP消息传输可靠性保证
TCP链接与断开 -- 三次握手&四次挥手 三次握手 TCP 提供面向有连接的通信传输。面向有连接是指在数据通信开始之前先做好两端之间的准备工作。 所谓三次握手是指建立一个 TCP 连接时需要客户端和服务器端总共发送三个包以确认连接的建立。在socket编程中,这一…...

Visual Studio 与QT ui文件
对.ui文件鼠标右键,然后单击 Open with…在弹出的窗口中,选中左侧的 Qt Designer,然后单击右侧的 Add 按钮,随后会弹出一个窗口,在 Program: 输入框中输入 Qt Designer 的路径,最后单击 OK找到 Qt Designer…...
竞赛项目 深度学习验证码识别 - 机器视觉 python opencv
文章目录 0 前言1 项目简介2 验证码识别步骤2.1 灰度处理&二值化2.2 去除边框2.3 图像降噪2.4 字符切割2.5 识别 3 基于tensorflow的验证码识别3.1 数据集3.2 基于tf的神经网络训练代码 4 最后 0 前言 🔥 优质竞赛项目系列,今天要分享的是 &#x…...
ORA-00845: MEMORY_TARGET not supported on this system
处理故障时,发现startup实例失败,报错ORA-00845: MEMORY_TARGET not supported on this system SYSorcl1> startup; ORA-00845: MEMORY_TARGET not supported on this system 查看alert日志,报错如下 Starting ORACLE instance (normal…...
wps设置一键标题字体和大小
参考 wps设置一键标题字体和大小:https://www.kafan.cn/A/7v5le1op3g.html 统一一键设置...
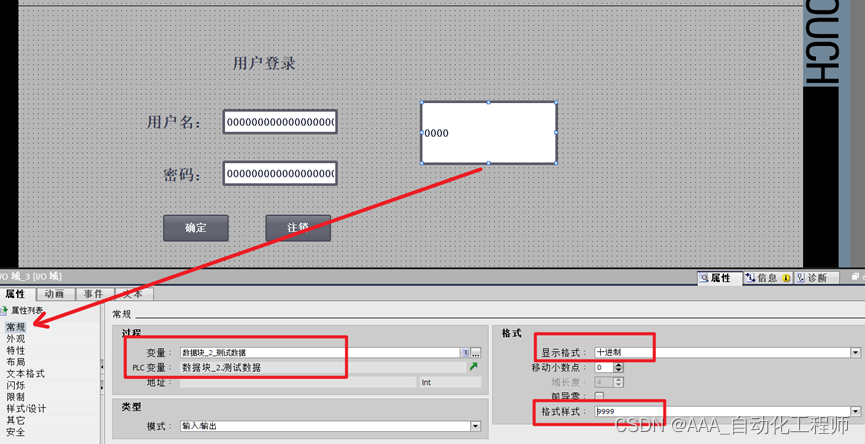
TIA博途WINCC_如何在IO域中保证输入数值只能为正数?
TIA博途WINCC_如何在IO域中保证输入数值只能为正数? 在某些情况下,输入的数值受到限制,本例就以输入的数值必须为正整数为例进行说明。 如下图所示,在PLC的全局DB块中添加一个测试变量,数据类型为Int(该数据类型的范围为-32768~+32767), 如下图所示,将该测试变量拖拽到…...
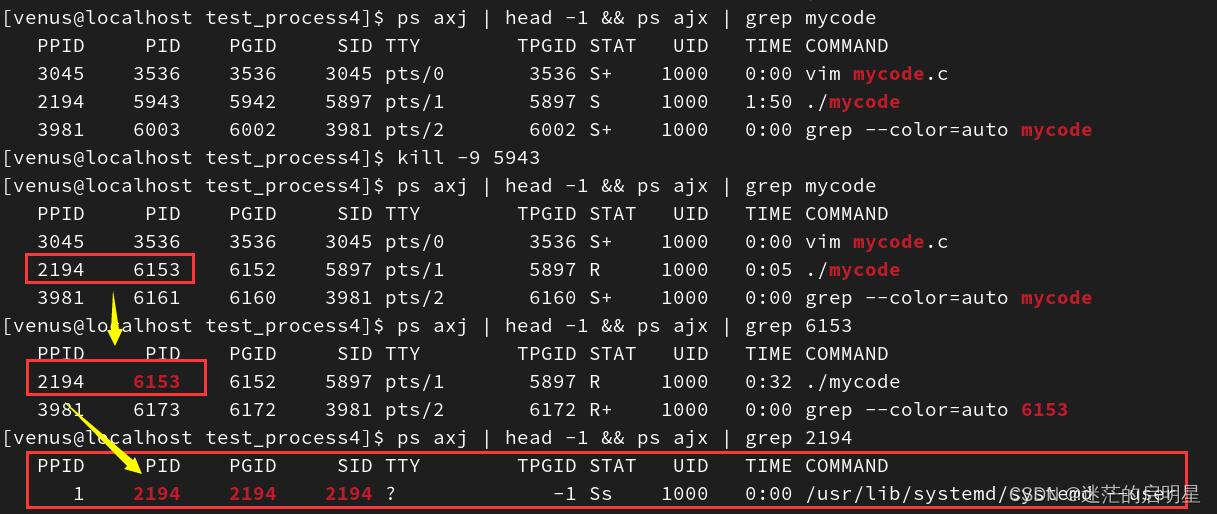
《Linux从练气到飞升》No.13 Linux进程状态
🕺作者: 主页 我的专栏C语言从0到1探秘C数据结构从0到1探秘Linux菜鸟刷题集 😘欢迎关注:👍点赞🙌收藏✍️留言 🏇码字不易,你的👍点赞🙌收藏❤️关注对我真的…...
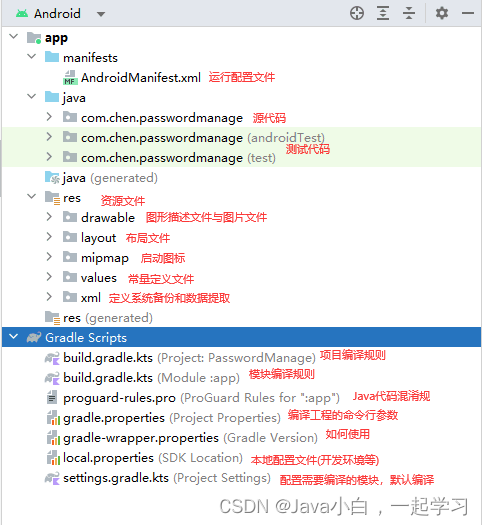
安卓快速开发
1.环境搭建 Android Studio下载网页:https://developer.android.google.cn/studio/index.html 第一次新建工程需要等待很长时间,新建一个Empty Views Activity 项目,右上角选择要运行的机器,运行就安装上去了(打开USB调试)。 2…...
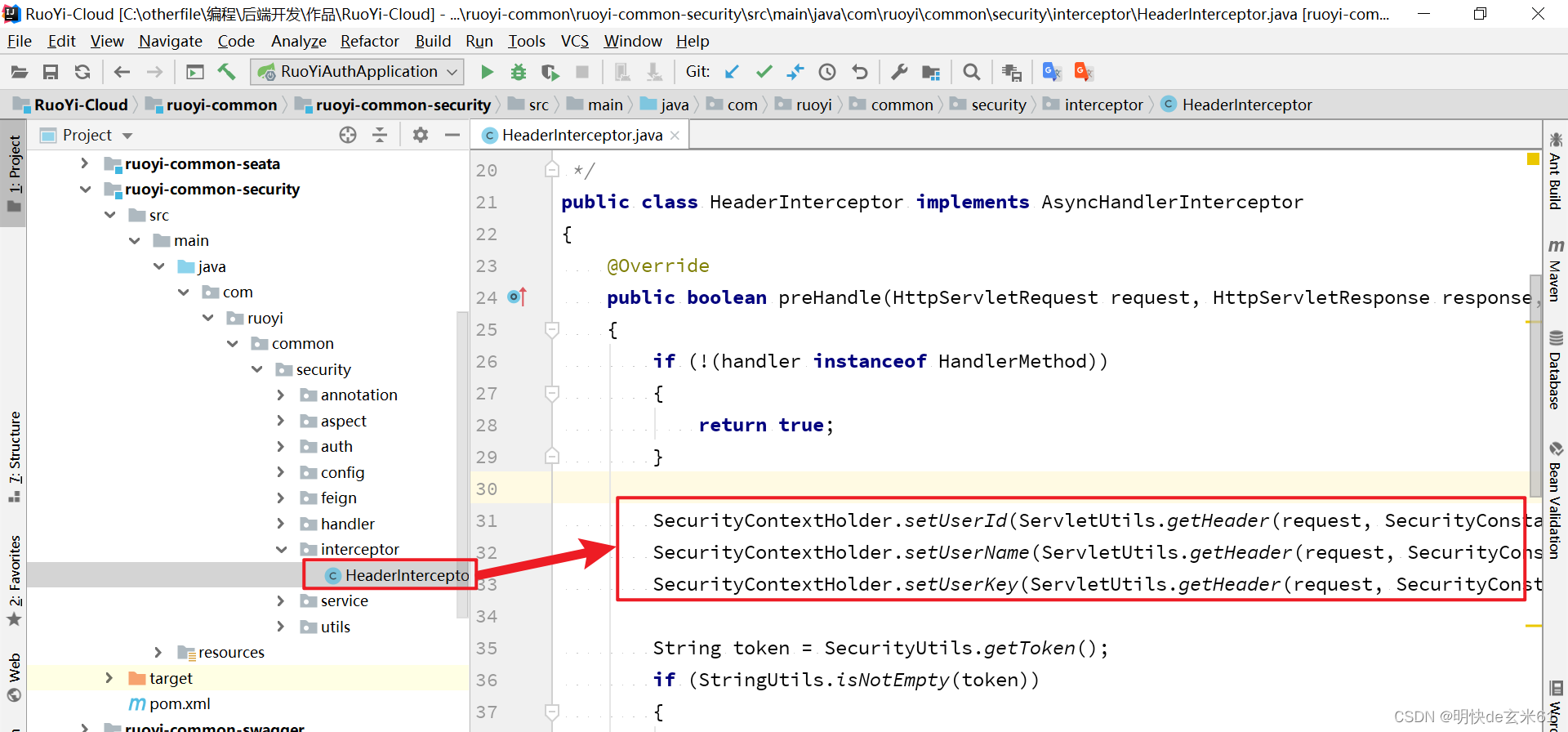
SpringCloud微服务之间如何进行用户信息传递(涉及:Gateway、OpenFeign组件)
目录 1、想达到的效果2、用户信息在微服务之间传递的两种途径3、用RuoYi-Cloud为例进行演示说明(1)网关将用户信息写在请求头中(2)业务微服务之间通过OpenFeign进行调用,并且将用户信息写在OpenFeign准备的请求头中&am…...

RabbitMQ之TTL+死信队列实现延迟队列
RabbitMQ是一个流行的消息队列系统,它提供了许多有用的功能,其中之一是TTL(Time To Live)和死信队列。这些功能可以用来实现延迟队列,让我们来看看如何使用它们。 首先,什么是TTL?TTL是消息的存…...
GrapeCity Documents for PDF (GcPdf) 6.2 Crack
GrapeCity PDF 文档 (GcPdf) 改进了对由 GcPdf 以外的软件生成的现有 PDF 文档的处理 在新的 v6.2 版本中,GcPdf 增强了 PDF 文档的加载和保存,并提供以下优势: GcPdf 现在可以加载和保存可能不严格符合 PDF 规范的 PDF 文档。GcPdf 现在将…...
)
【Sklearn】基于随机森林算法的数据分类预测(Excel可直接替换数据)
【Sklearn】基于随机森林算法的数据分类预测(Excel可直接替换数据) 1.模型原理1.1 模型原理1.2 数学模型2.模型参数3.文件结构4.Excel数据5.下载地址6.完整代码7.运行结果1.模型原理 随机森林(Random Forest)是一种集成学习方法,通过组合多个决策树来构建强大的分类或回归…...
问AI一个严肃的问题
chatgpt的问世再一次掀起了AI的浪潮,其实我一直在想,AI和人类的关系未来会怎样发展,我们未来会怎样和AI相处,AI真的会完全取代人类吗,带着这个问题,我问了下chatgpt,看一看它是怎么看待这个问题…...

Flowable流程的挂起与激活详解
1. 挂起与激活的定义及区别 在Flowable流程中,挂起是指将流程实例暂停,它将停止执行当前步骤并暂时中断流程的执行。相反,激活是指恢复被挂起的流程实例的执行,使其能够继续执行后续步骤。 区别在于挂起流程实例后,流…...

探索前端动画之CSS魔法
引言 在现代网页设计中,动画已经成为了吸引用户注意力、提升用户体验的重要手段之一。而在前端开发中,CSS动画是一种常见且强大的实现方式。本篇博客将带你深入探索前端动画中的CSS魔法,通过清晰的思路和完整的示例代码,帮助你掌…...

结肠“瑞士卷”制片法
在肠道病理研究中,如何完整保留小鼠结肠的全层结构、同时避免人为损伤,一直是实验操作的难点。本文分享一套改良版“瑞士卷”制片技术,无需剖开肠管、无需机械顶压,即可获得高质量的全结肠切片,特别适合炎症、隐窝异常…...

自动加字幕软件推荐:口播视频如何批量加字幕过
口播视频加字幕,为什么越做越累?一位知识类博主连续两周日更3条口播视频,每条12–18分钟,需手动校对字幕、拆分金句切片、补气口停顿、匹配背景音乐——最后一条视频发布时,字幕错漏率达17%,平台审核未过。…...

3分钟掌握抖音视频批量下载:解放双手的素材收集革命
3分钟掌握抖音视频批量下载:解放双手的素材收集革命 【免费下载链接】douyinhelper 抖音批量下载助手 项目地址: https://gitcode.com/gh_mirrors/do/douyinhelper 还在为一个个手动保存抖音视频而烦恼吗?想要高效收集创作者素材却苦于没有合适的…...

SHAP原理与特征贡献解析
SHAP(SHapley Additive exPlanations)是一种基于博弈论中Shapley值的模型解释方法,它为机器学习模型的预测提供了一种统一、理论完备的特征归因框架。其核心思想是将模型的预测值视为所有特征协同合作的“总收益”,然后公平地分配…...

密码学入门:区块链中的密码学原理
密码学入门:区块链中的密码学原理 大家好,我是欧阳瑞(Rich Own)。今天想和大家聊聊密码学这个重要话题。作为一个Web3探索者,密码学是区块链的基础。今天就来分享一下区块链中常用的密码学原理。 为什么密码学很重要&a…...

Charles弱网测试六维参数实战:从丢包率到DNS延迟的精准复现
1. 为什么弱网测试不能只靠“模拟3G”按钮点一下就完事做移动端或Web前端的同学,大概率都听过这句话:“上线前跑一遍Charles,切个2G网络测下加载。”——听起来很专业,实际一查日志,发现90%的团队连Charles的Throttlin…...

收藏2026版|大模型应用开发入门全攻略,小白程序员转行AI避坑学习指南
打算踏入大模型领域、转行AI赛道的新手与程序员,正式规划学习路径前,务必先吃透AI应用开发工程师的岗位定位与工作内容。清晰认知岗位核心价值,才能规避无效学习,精准找准发力方向。2026年大模型技术全面迈入商业化落地阶段&#…...

终极解决方案:彻底解决UE4SS DLL劫持导致的系统级应用程序启动错误
终极解决方案:彻底解决UE4SS DLL劫持导致的系统级应用程序启动错误 【免费下载链接】RE-UE4SS Injectable LUA scripting system, SDK generator, live property editor and other dumping utilities for UE4/5 games 项目地址: https://gitcode.com/gh_mirrors/r…...

通过用量看板清晰观测Taotoken的API调用成本与消耗
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过用量看板清晰观测Taotoken的API调用成本与消耗 对于将大模型能力集成到产品中的团队而言,API调用成本是项目预算与…...

如何免费解锁AMD Ryzen处理器隐藏性能?SMUDebugTool完整使用指南
如何免费解锁AMD Ryzen处理器隐藏性能?SMUDebugTool完整使用指南 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: …...