竞赛项目 深度学习验证码识别 - 机器视觉 python opencv
文章目录
- 0 前言
- 1 项目简介
- 2 验证码识别步骤
- 2.1 灰度处理&二值化
- 2.2 去除边框
- 2.3 图像降噪
- 2.4 字符切割
- 2.5 识别
- 3 基于tensorflow的验证码识别
- 3.1 数据集
- 3.2 基于tf的神经网络训练代码
- 4 最后
0 前言
🔥 优质竞赛项目系列,今天要分享的是
🚩 深度学习验证码识别 - 机器视觉 python opencv
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:3分
- 创新点:4分
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
1 项目简介
在python爬虫爬取某些网站的验证码的时候可能会遇到验证码识别的问题,现在的验证码大多分为四类:
-
1、计算验证码
-
2、滑块验证码
-
3、识图验证码
-
4、语音验证码
学长这李主要写的就是识图验证码,识别的是简单的验证码,要想让识别率更高,识别的更加准确就需要花很多的精力去训练自己的字体库。
2 验证码识别步骤
1、灰度处理
2、二值化
3、去除边框(如果有的话)
4、降噪
5、切割字符或者倾斜度矫正
6、训练字体库
7、识别
这6个步骤中前三个步骤是基本的,4或者5可根据实际情况选择是否需要,并不一定切割验证码,识别率就会上升很多有时候还会下降
这篇博客不涉及训练字体库的内容,请自行搜索。同样也不讲解基础的语法。
用到的几个主要的python库: Pillow(python图像处理库)、OpenCV(高级图像处理库)、pytesseract(识别库)
2.1 灰度处理&二值化
灰度处理,就是把彩色的验证码图片转为灰色的图片。
二值化,是将图片处理为只有黑白两色的图片,利于后面的图像处理和识别
在OpenCV中有现成的方法可以进行灰度处理和二值化,处理后的效果:

# 自适应阀值二值化
def _get_dynamic_binary_image(filedir, img_name):filename = './out_img/' + img_name.split('.')[0] + '-binary.jpg'img_name = filedir + '/' + img_nameprint('.....' + img_name)im = cv2.imread(img_name)im = cv2.cvtColor(im,cv2.COLOR_BGR2GRAY) #灰值化# 二值化th1 = cv2.adaptiveThreshold(im, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 21, 1)cv2.imwrite(filename,th1)return th1
2.2 去除边框
如果验证码有边框,那我们就需要去除边框,去除边框就是遍历像素点,找到四个边框上的所有点,把他们都改为白色,我这里边框是两个像素宽
注意:在用OpenCV时,图片的矩阵点是反的,就是长和宽是颠倒的
代码:
# 去除边框
def clear_border(img,img_name):filename = './out_img/' + img_name.split('.')[0] + '-clearBorder.jpg'h, w = img.shape[:2]for y in range(0, w):for x in range(0, h):if y < 2 or y > w - 2:img[x, y] = 255if x < 2 or x > h -2:img[x, y] = 255cv2.imwrite(filename,img)return img
效果

2.3 图像降噪
降噪是验证码处理中比较重要的一个步骤,我这里使用了点降噪和线降噪
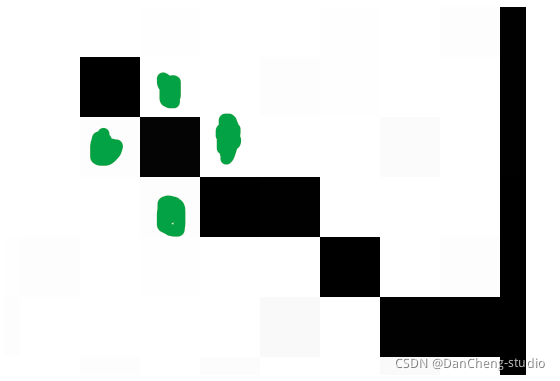
线降噪的思路就是检测这个点相邻的四个点(图中标出的绿色点),判断这四个点中是白点的个数,如果有两个以上的白色像素点,那么就认为这个点是白色的,从而去除整个干扰线,但是这种方法是有限度的,如果干扰线特别粗就没有办法去除,只能去除细的干扰线
# 干扰线降噪
def interference_line(img, img_name):filename = './out_img/' + img_name.split('.')[0] + '-interferenceline.jpg'h, w = img.shape[:2]# !!!opencv矩阵点是反的# img[1,2] 1:图片的高度,2:图片的宽度for y in range(1, w - 1):for x in range(1, h - 1):count = 0if img[x, y - 1] > 245:count = count + 1if img[x, y + 1] > 245:count = count + 1if img[x - 1, y] > 245:count = count + 1if img[x + 1, y] > 245:count = count + 1if count > 2:img[x, y] = 255cv2.imwrite(filename,img)return img
点降噪的思路和线降噪的差不多,只是会针对不同的位置检测的点不一样,注释写的很清楚了
# 点降噪
def interference_point(img,img_name, x = 0, y = 0):"""9邻域框,以当前点为中心的田字框,黑点个数:param x::param y::return:"""filename = './out_img/' + img_name.split('.')[0] + '-interferencePoint.jpg'# todo 判断图片的长宽度下限cur_pixel = img[x,y]# 当前像素点的值height,width = img.shape[:2]for y in range(0, width - 1):for x in range(0, height - 1):if y == 0: # 第一行if x == 0: # 左上顶点,4邻域# 中心点旁边3个点sum = int(cur_pixel) \+ int(img[x, y + 1]) \+ int(img[x + 1, y]) \+ int(img[x + 1, y + 1])if sum <= 2 * 245:img[x, y] = 0elif x == height - 1: # 右上顶点sum = int(cur_pixel) \+ int(img[x, y + 1]) \+ int(img[x - 1, y]) \+ int(img[x - 1, y + 1])if sum <= 2 * 245:img[x, y] = 0else: # 最上非顶点,6邻域sum = int(img[x - 1, y]) \+ int(img[x - 1, y + 1]) \+ int(cur_pixel) \+ int(img[x, y + 1]) \+ int(img[x + 1, y]) \+ int(img[x + 1, y + 1])if sum <= 3 * 245:img[x, y] = 0elif y == width - 1: # 最下面一行if x == 0: # 左下顶点# 中心点旁边3个点sum = int(cur_pixel) \+ int(img[x + 1, y]) \+ int(img[x + 1, y - 1]) \+ int(img[x, y - 1])if sum <= 2 * 245:img[x, y] = 0elif x == height - 1: # 右下顶点sum = int(cur_pixel) \+ int(img[x, y - 1]) \+ int(img[x - 1, y]) \+ int(img[x - 1, y - 1])if sum <= 2 * 245:img[x, y] = 0else: # 最下非顶点,6邻域sum = int(cur_pixel) \+ int(img[x - 1, y]) \+ int(img[x + 1, y]) \+ int(img[x, y - 1]) \+ int(img[x - 1, y - 1]) \+ int(img[x + 1, y - 1])if sum <= 3 * 245:img[x, y] = 0else: # y不在边界if x == 0: # 左边非顶点sum = int(img[x, y - 1]) \+ int(cur_pixel) \+ int(img[x, y + 1]) \+ int(img[x + 1, y - 1]) \+ int(img[x + 1, y]) \+ int(img[x + 1, y + 1])if sum <= 3 * 245:img[x, y] = 0elif x == height - 1: # 右边非顶点sum = int(img[x, y - 1]) \+ int(cur_pixel) \+ int(img[x, y + 1]) \+ int(img[x - 1, y - 1]) \+ int(img[x - 1, y]) \+ int(img[x - 1, y + 1])if sum <= 3 * 245:img[x, y] = 0else: # 具备9领域条件的sum = int(img[x - 1, y - 1]) \+ int(img[x - 1, y]) \+ int(img[x - 1, y + 1]) \+ int(img[x, y - 1]) \+ int(cur_pixel) \+ int(img[x, y + 1]) \+ int(img[x + 1, y - 1]) \+ int(img[x + 1, y]) \+ int(img[x + 1, y + 1])if sum <= 4 * 245:img[x, y] = 0cv2.imwrite(filename,img)return img
效果:

其实到了这一步,这些字符就可以识别了,没必要进行字符切割了,现在这三种类型的验证码识别率已经达到50%以上了
2.4 字符切割
字符切割通常用于验证码中有粘连的字符,粘连的字符不好识别,所以我们需要将粘连的字符切割为单个的字符,在进行识别
字符切割的思路就是找到一个黑色的点,然后在遍历与他相邻的黑色的点,直到遍历完所有的连接起来的黑色的点,找出这些点中的最高的点、最低的点、最右边的点、最左边的点,记录下这四个点,认为这是一个字符,然后在向后遍历点,直至找到黑色的点,继续以上的步骤。最后通过每个字符的四个点进行切割
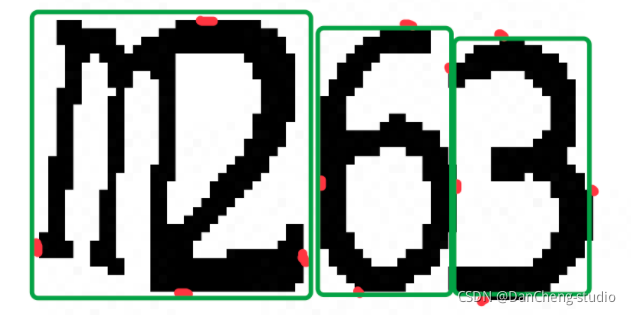
图中红色的点就是代码执行完后,标识出的每个字符的四个点,然后就会根据这四个点进行切割(图中画的有些误差,懂就好)
但是也可以看到,m2是粘连的,代码认为他是一个字符,所以我们需要对每个字符的宽度进行检测,如果他的宽度过宽,我们就认为他是两个粘连在一起的字符,并将它在从中间切割
确定每个字符的四个点代码:
def cfs(im,x_fd,y_fd):'''用队列和集合记录遍历过的像素坐标代替单纯递归以解决cfs访问过深问题'''# print('**********')xaxis=[]yaxis=[]visited =set()q = Queue()q.put((x_fd, y_fd))visited.add((x_fd, y_fd))offsets=[(1, 0), (0, 1), (-1, 0), (0, -1)]#四邻域while not q.empty():x,y=q.get()for xoffset,yoffset in offsets:x_neighbor,y_neighbor = x+xoffset,y+yoffsetif (x_neighbor,y_neighbor) in (visited):continue # 已经访问过了visited.add((x_neighbor, y_neighbor))try:if im[x_neighbor, y_neighbor] == 0:xaxis.append(x_neighbor)yaxis.append(y_neighbor)q.put((x_neighbor,y_neighbor))except IndexError:pass# print(xaxis)if (len(xaxis) == 0 | len(yaxis) == 0):xmax = x_fd + 1xmin = x_fdymax = y_fd + 1ymin = y_fdelse:xmax = max(xaxis)xmin = min(xaxis)ymax = max(yaxis)ymin = min(yaxis)#ymin,ymax=sort(yaxis)return ymax,ymin,xmax,xmindef detectFgPix(im,xmax):'''搜索区块起点'''h,w = im.shape[:2]for y_fd in range(xmax+1,w):for x_fd in range(h):if im[x_fd,y_fd] == 0:return x_fd,y_fddef CFS(im):'''切割字符位置'''zoneL=[]#各区块长度L列表zoneWB=[]#各区块的X轴[起始,终点]列表zoneHB=[]#各区块的Y轴[起始,终点]列表xmax=0#上一区块结束黑点横坐标,这里是初始化for i in range(10):try:x_fd,y_fd = detectFgPix(im,xmax)# print(y_fd,x_fd)xmax,xmin,ymax,ymin=cfs(im,x_fd,y_fd)L = xmax - xminH = ymax - yminzoneL.append(L)zoneWB.append([xmin,xmax])zoneHB.append([ymin,ymax])except TypeError:return zoneL,zoneWB,zoneHBreturn zoneL,zoneWB,zoneHB
切割粘连字符代码:
def cutting_img(im,im_position,img,xoffset = 1,yoffset = 1):filename = './out_img/' + img.split('.')[0]# 识别出的字符个数im_number = len(im_position[1])# 切割字符for i in range(im_number):im_start_X = im_position[1][i][0] - xoffsetim_end_X = im_position[1][i][1] + xoffsetim_start_Y = im_position[2][i][0] - yoffsetim_end_Y = im_position[2][i][1] + yoffsetcropped = im[im_start_Y:im_end_Y, im_start_X:im_end_X]cv2.imwrite(filename + '-cutting-' + str(i) + '.jpg',cropped)
效果:

2.5 识别
识别用的是typesseract库,主要识别一行字符和单个字符时的参数设置,识别中英文的参数设置,代码很简单就一行,我这里大多是filter文件的操作
# 识别验证码cutting_img_num = 0for file in os.listdir('./out_img'):str_img = ''if fnmatch(file, '%s-cutting-*.jpg' % img_name.split('.')[0]):cutting_img_num += 1for i in range(cutting_img_num):try:file = './out_img/%s-cutting-%s.jpg' % (img_name.split('.')[0], i)# 识别字符str_img = str_img + image_to_string(Image.open(file),lang = 'eng', config='-psm 10') #单个字符是10,一行文本是7except Exception as err:passprint('切图:%s' % cutting_img_num)print('识别为:%s' % str_img)
最后这种粘连字符的识别率是在30%左右,而且这种只是处理两个字符粘连,如果有两个以上的字符粘连还不能识别,但是根据字符宽度判别的话也不难,有兴趣的可以试一下
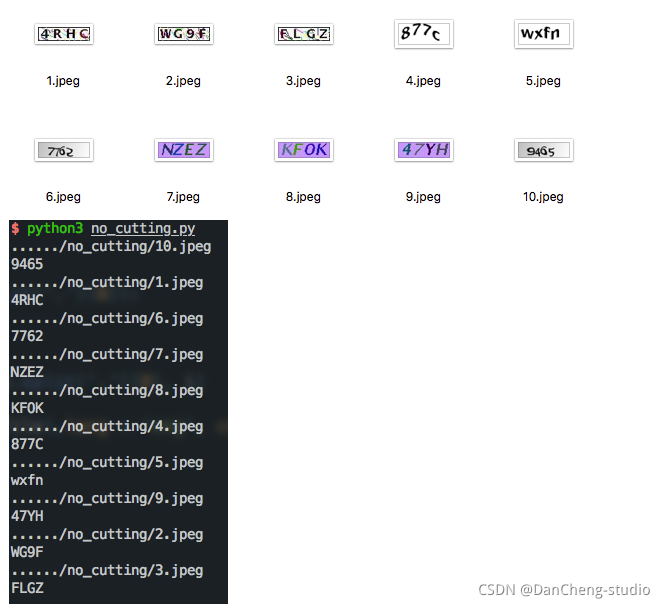
无需切割字符识别的效果:
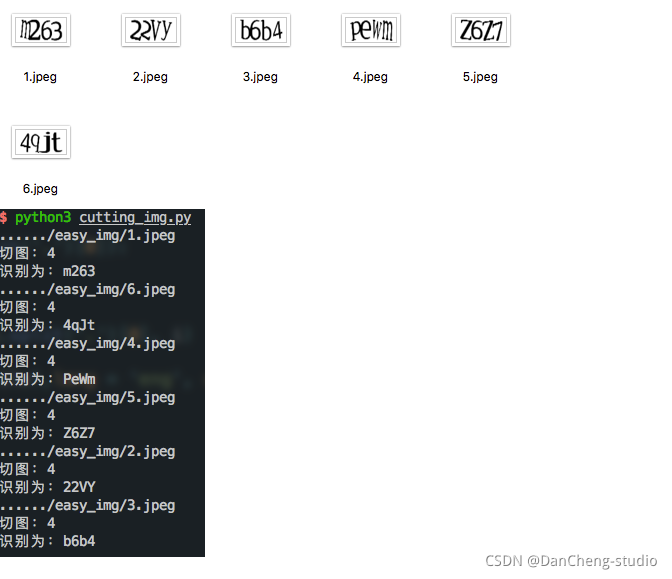
需要切割字符的识别效果:
3 基于tensorflow的验证码识别
-
python库: tensorflow, opencv, pandas, gpu机器。
-
训练集: 10w 图片, 200step左右开始收敛。
-
策略: 切分图片,训练单字母识别。预测时也是同样切分。(ps:不切分训练及识别,跑了一夜,没有收敛)
-
准确率: 在区分大小写的情况下,单字母识别率98%, 整体识别率75%+。
3.1 数据集

数据集预处理
package com;
import java.awt.Color;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStream;
import java.util.Random;import org.patchca.color.ColorFactory;
import org.patchca.filter.predefined.CurvesRippleFilterFactory;
import org.patchca.filter.predefined.DiffuseRippleFilterFactory;
import org.patchca.filter.predefined.DoubleRippleFilterFactory;
import org.patchca.filter.predefined.MarbleRippleFilterFactory;
import org.patchca.filter.predefined.WobbleRippleFilterFactory;
import org.patchca.service.ConfigurableCaptchaService;
import org.patchca.utils.encoder.EncoderHelper;
import org.patchca.word.RandomWordFactory;public class CreatePatcha {private static Random random = new Random();private static ConfigurableCaptchaService cs = new ConfigurableCaptchaService();static {// cs.setColorFactory(new SingleColorFactory(new Color(25, 60, 170)));cs.setColorFactory(new ColorFactory() {@Overridepublic Color getColor(int x) {int[] c = new int[3];int i = random.nextInt(c.length);for (int fi = 0; fi < c.length; fi++) {if (fi == i) {c[fi] = random.nextInt(71);} else {c[fi] = random.nextInt(256);}}return new Color(c[0], c[1], c[2]);}});RandomWordFactory wf = new RandomWordFactory();
// wf.setCharacters("23456789abcdefghigklmnpqrstuvwxyzABCDEFGHIGKLMNPQRSTUVWXYZ");wf.setCharacters("0123456789abcdefghigklmnopqrstuvwxyzABCDEFGHIGKLMNOPQRSTUVWXYZ");wf.setMaxLength(4);wf.setMinLength(4);cs.setWordFactory(wf);}public static void main(String[] args) throws IOException {for (int i = 0; i < 100; i++) {switch (random.nextInt(5)) {case 0:cs.setFilterFactory(new CurvesRippleFilterFactory(cs.getColorFactory()));break;case 1:cs.setFilterFactory(new MarbleRippleFilterFactory());break;case 2:cs.setFilterFactory(new DoubleRippleFilterFactory());break;case 3:cs.setFilterFactory(new WobbleRippleFilterFactory());break;case 4:cs.setFilterFactory(new DiffuseRippleFilterFactory());break;}OutputStream out = new FileOutputStream(new File(i + ".png"));String token = EncoderHelper.getChallangeAndWriteImage(cs, "png",out);out.close();File f = new File(i+".png");f.renameTo(new File("checkdata/" + token +"_" + i+".png"));System.out.println(i+"验证码=" + token);}}
}
3.2 基于tf的神经网络训练代码
#coding:utf-8from gen_captcha import gen_captcha_text_and_imagefrom gen_captcha import numberfrom gen_captcha import alphabetfrom gen_captcha import ALPHABETimport numpy as npimport tensorflow as tfimport osos.environ["CUDA_VISIBLE_DEVICES"] = "0"text, image = gen_captcha_text_and_image()print("验证码图像channel:", image.shape) # (70, 160, 3)# 图像大小IMAGE_HEIGHT = 70IMAGE_WIDTH = 70MAX_CAPTCHA = len(text)print("验证码文本最长字符数", MAX_CAPTCHA) # 验证码最长4字符; 我全部固定为4,可以不固定. 如果验证码长度小于4,用'_'补齐# 把彩色图像转为灰度图像(色彩对识别验证码没有什么用)def convert2gray(img): if len(img.shape) > 2: gray = np.mean(img, -1) # 上面的转法较快,正规转法如下 # r, g, b = img[:,:,0], img[:,:,1], img[:,:,2] # gray = 0.2989 * r + 0.5870 * g + 0.1140 * b return gray else: return img"""cnn在图像大小是2的倍数时性能最高, 如果你用的图像大小不是2的倍数,可以在图像边缘补无用像素。np.pad(image【,((2,3),(2,2)), 'constant', constant_values=(255,)) # 在图像上补2行,下补3行,左补2行,右补2行"""# 文本转向量# char_set = number + alphabet + ALPHABET + ['_'] # 如果验证码长度小于4, '_'用来补齐char_set = number + alphabet + ALPHABET # 如果验证码长度小于4, '_'用来补齐CHAR_SET_LEN = len(char_set) #26*2+10+1=63def text2vec(text): text_len = len(text) if text_len > MAX_CAPTCHA: raise ValueError('验证码最长4个字符') vector = np.zeros(MAX_CAPTCHA*CHAR_SET_LEN) def char2pos(c): if c =='_': k = 62 return k k = ord(c)-48 if k > 9: k = ord(c) - 55 if k > 35: k = ord(c) - 61 if k > 61: raise ValueError('No Map') return k for i, c in enumerate(text): idx = i * CHAR_SET_LEN + char2pos(c) vector[idx] = 1 return vector# 向量转回文本def vec2text(vec): char_pos = vec.nonzero()[0] text=[] for i, c in enumerate(char_pos): char_at_pos = i #c/63 char_idx = c % CHAR_SET_LEN if char_idx < 10: char_code = char_idx + ord('0') elif char_idx <36: char_code = char_idx - 10 + ord('A') elif char_idx < 62: char_code = char_idx- 36 + ord('a') elif char_idx == 62: char_code = ord('_') else: raise ValueError('error') text.append(chr(char_code)) return "".join(text)"""#向量(大小MAX_CAPTCHA*CHAR_SET_LEN)用0,1编码 每63个编码一个字符,这样顺利有,字符也有vec = text2vec("F5Sd")text = vec2text(vec)print(text) # F5Sdvec = text2vec("SFd5")text = vec2text(vec)print(text) # SFd5"""# 生成一个训练batchdef get_next_batch(batch_size=128, train = True): batch_x = np.zeros([batch_size, IMAGE_HEIGHT*IMAGE_WIDTH]) batch_y = np.zeros([batch_size, MAX_CAPTCHA*CHAR_SET_LEN]) # 有时生成图像大小不是(70, 160, 3) def wrap_gen_captcha_text_and_image(train): while True: text, image = gen_captcha_text_and_image(train) if image.shape == (70, 70, 3): return text, image for i in range(batch_size): text, image = wrap_gen_captcha_text_and_image(train) image = convert2gray(image) batch_x[i,:] = image.flatten() / 255 # (image.flatten()-128)/128 mean为0 batch_y[i,:] = text2vec(text) return batch_x, batch_y####################################################################X = tf.placeholder(tf.float32, [None, IMAGE_HEIGHT*IMAGE_WIDTH])Y = tf.placeholder(tf.float32, [None, MAX_CAPTCHA*CHAR_SET_LEN])keep_prob = tf.placeholder(tf.float32) # dropout# 定义CNNdef crack_captcha_cnn(w_alpha=0.01, b_alpha=0.1): x = tf.reshape(X, shape=[-1, IMAGE_HEIGHT, IMAGE_WIDTH, 1]) #w_c1_alpha = np.sqrt(2.0/(IMAGE_HEIGHT*IMAGE_WIDTH)) # #w_c2_alpha = np.sqrt(2.0/(3*3*32)) #w_c3_alpha = np.sqrt(2.0/(3*3*64)) #w_d1_alpha = np.sqrt(2.0/(8*32*64)) #out_alpha = np.sqrt(2.0/1024) # 3 conv layer w_c1 = tf.Variable(w_alpha*tf.random_normal([3, 3, 1, 32])) b_c1 = tf.Variable(b_alpha*tf.random_normal([32])) conv1 = tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(x, w_c1, strides=[1, 1, 1, 1], padding='SAME'), b_c1)) conv1 = tf.nn.max_pool(conv1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME') conv1 = tf.nn.dropout(conv1, keep_prob) w_c2 = tf.Variable(w_alpha*tf.random_normal([3, 3, 32, 64])) b_c2 = tf.Variable(b_alpha*tf.random_normal([64])) conv2 = tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(conv1, w_c2, strides=[1, 1, 1, 1], padding='SAME'), b_c2)) conv2 = tf.nn.max_pool(conv2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME') conv2 = tf.nn.dropout(conv2, keep_prob) w_c3 = tf.Variable(w_alpha*tf.random_normal([3, 3, 64, 64])) b_c3 = tf.Variable(b_alpha*tf.random_normal([64])) conv3 = tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(conv2, w_c3, strides=[1, 1, 1, 1], padding='SAME'), b_c3)) conv3 = tf.nn.max_pool(conv3, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME') conv3 = tf.nn.dropout(conv3, keep_prob) # Fully connected layer w_d = tf.Variable(w_alpha*tf.random_normal([9*9*64, 1024])) b_d = tf.Variable(b_alpha*tf.random_normal([1024])) dense = tf.reshape(conv3, [-1, w_d.get_shape().as_list()[0]]) dense = tf.nn.relu(tf.add(tf.matmul(dense, w_d), b_d)) dense = tf.nn.dropout(dense, keep_prob) w_out = tf.Variable(w_alpha*tf.random_normal([1024, MAX_CAPTCHA*CHAR_SET_LEN])) b_out = tf.Variable(b_alpha*tf.random_normal([MAX_CAPTCHA*CHAR_SET_LEN])) out = tf.add(tf.matmul(dense, w_out), b_out) #out = tf.nn.softmax(out) return out# 训练def train_crack_captcha_cnn(): output = crack_captcha_cnn() # loss #loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(output, Y)) with tf.device('/gpu:0'): loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=output, labels=Y)) # 最后一层用来分类的softmax和sigmoid有什么不同? # optimizer 为了加快训练 learning_rate应该开始大,然后慢慢衰 optimizer = tf.train.AdamOptimizer(learning_rate=0.001).minimize(loss) predict = tf.reshape(output, [-1, MAX_CAPTCHA, CHAR_SET_LEN]) max_idx_p = tf.argmax(predict, 2) max_idx_l = tf.argmax(tf.reshape(Y, [-1, MAX_CAPTCHA, CHAR_SET_LEN]), 2) correct_pred = tf.equal(max_idx_p, max_idx_l) accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32)) saver = tf.train.Saver() config = tf.ConfigProto(allow_soft_placement=True) config.gpu_options.allow_growth = True with tf.Session(config=config) as sess: sess.run(tf.global_variables_initializer()) step = 0 while True: batch_x, batch_y = get_next_batch(256) _, loss_ = sess.run([optimizer, loss], feed_dict={X: batch_x, Y: batch_y, keep_prob: 0.75}) # 每100 step计算一次准确率 if step % 100 == 0: batch_x_test, batch_y_test = get_next_batch(100, False) acc = sess.run(accuracy, feed_dict={X: batch_x_test, Y: batch_y_test, keep_prob: 1.}) print('step:%d,loss:%g' % (step, loss_)) print('step:%d,acc:%g'%(step, acc)) # 如果准确率大于50%,保存模型,完成训练 if acc > 0.98: saver.save(sess, "crack_capcha.model", global_step=step) break step += 1def crack_captcha(captcha_image): output = crack_captcha_cnn() saver = tf.train.Saver() with tf.Session() as sess: saver.restore(sess, tf.train.latest_checkpoint('.')) predict = tf.argmax(tf.reshape(output, [-1, MAX_CAPTCHA, CHAR_SET_LEN]), 2) text_list = sess.run(predict, feed_dict={X: [captcha_image], keep_prob: 1}) text = text_list[0].tolist() vector = np.zeros(MAX_CAPTCHA*CHAR_SET_LEN) i = 0 for n in text: vector[i*CHAR_SET_LEN + n] = 1 i += 1 return vec2text(vector)if __name__ == '__main__': #text, image = gen_captcha_text_and_image() #image = convert2gray(image) #image = image.flatten() / 255 #predict_text = crack_captcha(image) #print("正确: {} 预测: {}".format(text, predict_text)) train_crack_captcha_cnn()
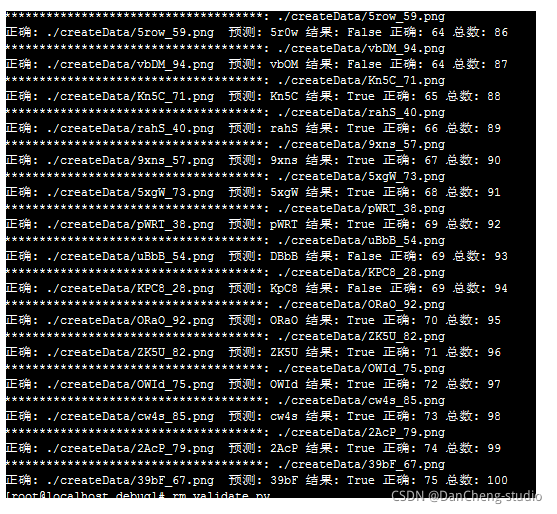
4 最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
相关文章:
竞赛项目 深度学习验证码识别 - 机器视觉 python opencv
文章目录 0 前言1 项目简介2 验证码识别步骤2.1 灰度处理&二值化2.2 去除边框2.3 图像降噪2.4 字符切割2.5 识别 3 基于tensorflow的验证码识别3.1 数据集3.2 基于tf的神经网络训练代码 4 最后 0 前言 🔥 优质竞赛项目系列,今天要分享的是 &#x…...
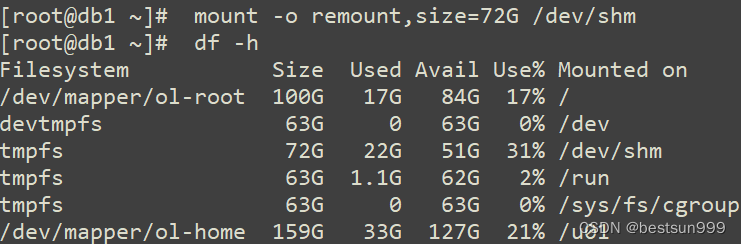
ORA-00845: MEMORY_TARGET not supported on this system
处理故障时,发现startup实例失败,报错ORA-00845: MEMORY_TARGET not supported on this system SYSorcl1> startup; ORA-00845: MEMORY_TARGET not supported on this system 查看alert日志,报错如下 Starting ORACLE instance (normal…...
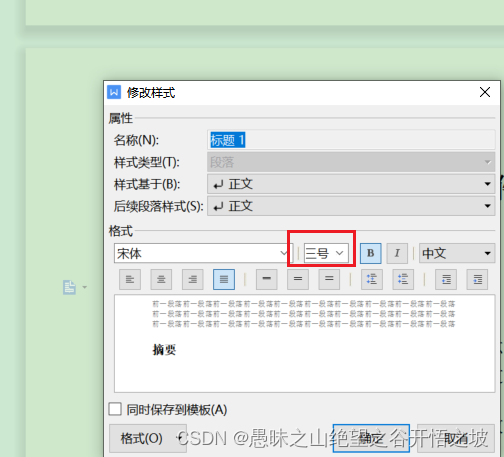
wps设置一键标题字体和大小
参考 wps设置一键标题字体和大小:https://www.kafan.cn/A/7v5le1op3g.html 统一一键设置...
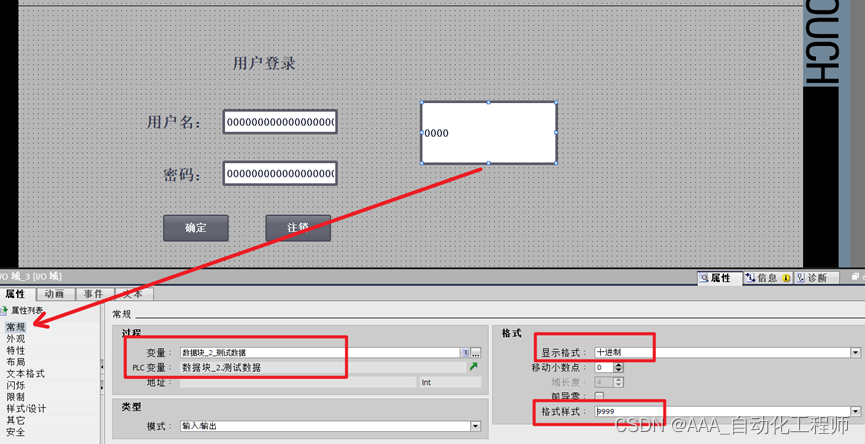
TIA博途WINCC_如何在IO域中保证输入数值只能为正数?
TIA博途WINCC_如何在IO域中保证输入数值只能为正数? 在某些情况下,输入的数值受到限制,本例就以输入的数值必须为正整数为例进行说明。 如下图所示,在PLC的全局DB块中添加一个测试变量,数据类型为Int(该数据类型的范围为-32768~+32767), 如下图所示,将该测试变量拖拽到…...
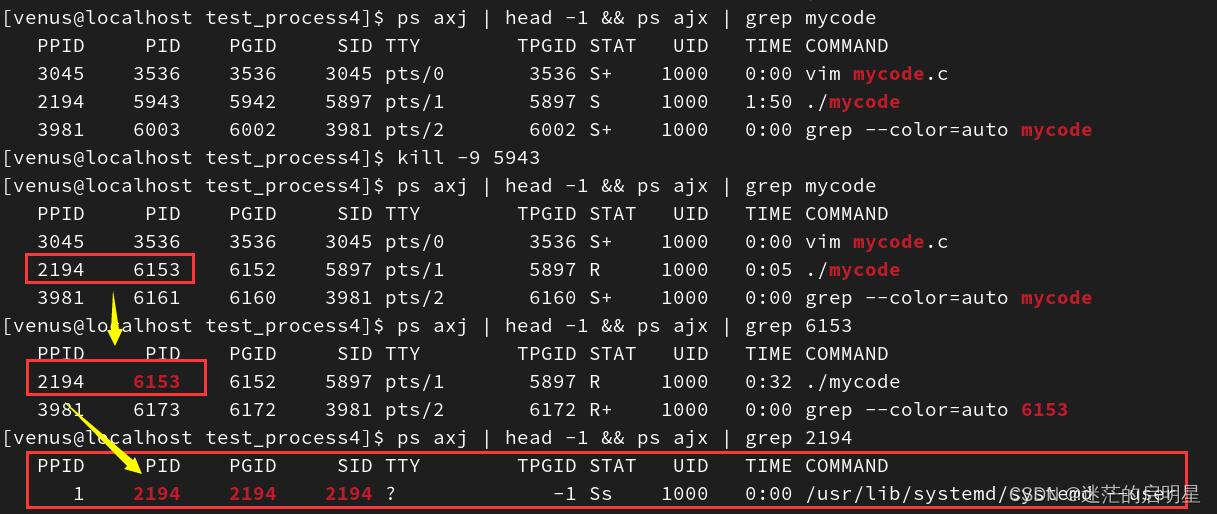
《Linux从练气到飞升》No.13 Linux进程状态
🕺作者: 主页 我的专栏C语言从0到1探秘C数据结构从0到1探秘Linux菜鸟刷题集 😘欢迎关注:👍点赞🙌收藏✍️留言 🏇码字不易,你的👍点赞🙌收藏❤️关注对我真的…...
安卓快速开发
1.环境搭建 Android Studio下载网页:https://developer.android.google.cn/studio/index.html 第一次新建工程需要等待很长时间,新建一个Empty Views Activity 项目,右上角选择要运行的机器,运行就安装上去了(打开USB调试)。 2…...
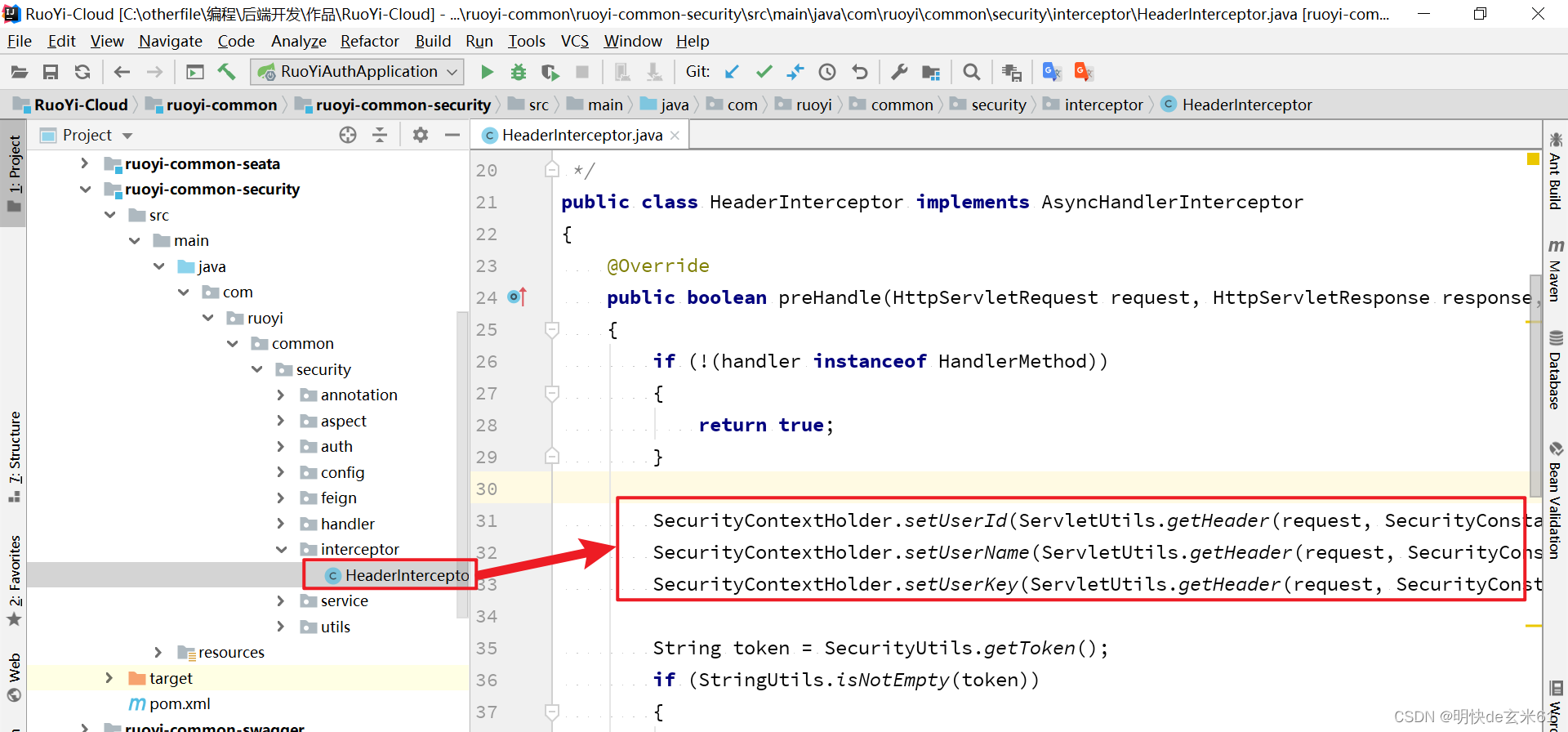
SpringCloud微服务之间如何进行用户信息传递(涉及:Gateway、OpenFeign组件)
目录 1、想达到的效果2、用户信息在微服务之间传递的两种途径3、用RuoYi-Cloud为例进行演示说明(1)网关将用户信息写在请求头中(2)业务微服务之间通过OpenFeign进行调用,并且将用户信息写在OpenFeign准备的请求头中&am…...

RabbitMQ之TTL+死信队列实现延迟队列
RabbitMQ是一个流行的消息队列系统,它提供了许多有用的功能,其中之一是TTL(Time To Live)和死信队列。这些功能可以用来实现延迟队列,让我们来看看如何使用它们。 首先,什么是TTL?TTL是消息的存…...
GrapeCity Documents for PDF (GcPdf) 6.2 Crack
GrapeCity PDF 文档 (GcPdf) 改进了对由 GcPdf 以外的软件生成的现有 PDF 文档的处理 在新的 v6.2 版本中,GcPdf 增强了 PDF 文档的加载和保存,并提供以下优势: GcPdf 现在可以加载和保存可能不严格符合 PDF 规范的 PDF 文档。GcPdf 现在将…...
)
【Sklearn】基于随机森林算法的数据分类预测(Excel可直接替换数据)
【Sklearn】基于随机森林算法的数据分类预测(Excel可直接替换数据) 1.模型原理1.1 模型原理1.2 数学模型2.模型参数3.文件结构4.Excel数据5.下载地址6.完整代码7.运行结果1.模型原理 随机森林(Random Forest)是一种集成学习方法,通过组合多个决策树来构建强大的分类或回归…...
问AI一个严肃的问题
chatgpt的问世再一次掀起了AI的浪潮,其实我一直在想,AI和人类的关系未来会怎样发展,我们未来会怎样和AI相处,AI真的会完全取代人类吗,带着这个问题,我问了下chatgpt,看一看它是怎么看待这个问题…...

Flowable流程的挂起与激活详解
1. 挂起与激活的定义及区别 在Flowable流程中,挂起是指将流程实例暂停,它将停止执行当前步骤并暂时中断流程的执行。相反,激活是指恢复被挂起的流程实例的执行,使其能够继续执行后续步骤。 区别在于挂起流程实例后,流…...

探索前端动画之CSS魔法
引言 在现代网页设计中,动画已经成为了吸引用户注意力、提升用户体验的重要手段之一。而在前端开发中,CSS动画是一种常见且强大的实现方式。本篇博客将带你深入探索前端动画中的CSS魔法,通过清晰的思路和完整的示例代码,帮助你掌…...

Oracle数据库登录遇到密码临期问题
在oracle数据库中,如果设置了密码的有效期,则会出现密码临期提醒的问题,默认的密码有效期是180天,默认的密码提醒时间是15天(此处缺乏官方文档支撑),在密码临近过期时,如果登录 Orac…...
LVGL学习笔记 30 - List(列表)
目录 1. 添加文本 2. 添加按钮 3. 事件 4. 修改样式 4.1 背景色 4.2 改变项的颜色 列表是一个垂直布局的矩形,可以向其中添加按钮和文本。 lv_obj_t* list1 lv_list_create(lv_scr_act());lv_obj_set_size(list1, 180, 220);lv_obj_center(list1); 部件包含&…...

Ubuntu下mysql安装及远程连接支持配置
1.安装 下载mysql-server(必须加sudo) sudo apt update sudo apt install mysql-server 查看mysql的状态 sudo service mysql status 通过如下命令开启mysql sudo service mysql start 2.配置 第一次安装mysql后,为root设置一个密码 …...

自然语言处理: 第八章chatGPT的搭建
理论基础 Transformer 大模型家族可以分成三类, 至于三者的区别可以参考上一章: Encoder-only,Decoder-only, 只需要Pre_trainEncoder-decoder , 可以在一些任务上无需进行fine_tune 必须要在下游任务进行微调比如Bert , Bart 。 T5 这种无需要微调就能完成一些任…...

阿里云国际版云服务器防火墙怎么设置呢?
入侵防御页面为您实时展示云防火墙拦截流量的源IP、目的IP、阻断应用、阻断来源和阻断事件详情等信息。本文介绍了入侵防御页面展示的信息和相关操作,下面和012一起来了解阿里云国际版云服务器防火墙设置: 前提条件 您需要先在防护配置页面,开…...
安装elasticsearch
一、docker安装elasticsearch 1、下载镜像 docker pull elasticsearch:6.5.4 2、启动容器 docker run -p 9200:9200 -p 9300:9300 --name elasticsearch \ -e "discovery.typesingle-node" \ -e "cluster.nameelasticsearch" \ -e "ES_JAVA_OPTS-Xm…...
)
【Sklearn】基于朴素贝叶斯算法的数据分类预测(Excel可直接替换数据)
【Sklearn】基于朴素贝叶斯算法的数据分类预测(Excel可直接替换数据) 1.模型原理2.模型参数3.文件结构4.Excel数据5.下载地址6.完整代码7.运行结果1.模型原理 模型原理: 朴素贝叶斯分类是基于贝叶斯定理的一种分类方法。它假设特征之间相互独立(朴素性),从而简化计算过…...

四大桌面云品牌评测:从安全、体验到性价比
桌面云不再是大型企业的专属,它已成为各行各业实现数据安全、混合办公和IT降本增效的“标准配置”。经过对市场主流方案的全面评估,我们认为,深信服(Sangfor)aDesk桌面云因其在安全内生化、传输协议自研化、运维管理智…...
功能才是宝藏)
Unity Cinemachine相机系统深度使用:除了自动跟随,它的边界限制(Confiner)功能才是宝藏
Unity Cinemachine Confiner:解锁专业级镜头边界控制的实战指南在游戏开发中,镜头控制往往是被低估的艺术。许多开发者对Cinemachine的印象停留在"智能跟随相机"层面,却不知道它的Confiner功能能够彻底改变游戏镜头的专业度。想象一…...

如何永久备份微信聊天记录:3步完成数据导出的终极指南
如何永久备份微信聊天记录:3步完成数据导出的终极指南 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/WeCha…...

OpenPLC虚拟PLC:5分钟搭建开源工业控制器的完整指南
OpenPLC虚拟PLC:5分钟搭建开源工业控制器的完整指南 【免费下载链接】OpenPLC Software for the OpenPLC - an open source industrial controller 项目地址: https://gitcode.com/gh_mirrors/op/OpenPLC 想要零成本学习工业自动化?OpenPLC虚拟PL…...
)
DeepSeek熔断决策延迟超23ms?,基于eBPF实时观测的熔断器内核态性能瓶颈诊断指南(限内部技术圈流通)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek熔断降级方案 DeepSeek大模型服务在高并发、低质量请求或底层依赖异常时,需具备快速响应的熔断与降级能力,以保障系统整体可用性与资源稳定性。该方案基于响应延迟、错误…...

LeetCode 每日一题笔记 日期:2026.05.24 题目:1340. 跳跃游戏 V
LeetCode 每日一题笔记 0. 前言 日期:2026.05.24题目:1340. 跳跃游戏 V难度:困难标签:数组、动态规划、记忆化搜索、单调栈 1. 题目理解 问题描述: 给定一个整数数组 arr 和整数 d,从下标 i 出发࿰…...

《当下的力量》前三章深度解读:从思维奴隶到临在大师的觉醒之路
《当下的力量》前三章深度解读:从思维奴隶到临在大师的觉醒之路这是一本不能用大脑读的书,这是一本需要用生命去体验的书。——张德芬前言 在这个信息爆炸、节奏飞快的时代,我们似乎永远活在过去的遗憾和未来的焦虑中。我们的大脑像一台永不停…...

ncmdumpGUI:三步解锁网易云音乐NCM加密文件的完整指南
ncmdumpGUI:三步解锁网易云音乐NCM加密文件的完整指南 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI ncmdumpGUI 是一款专为Windows平台设计的开源…...

C51开发中枚举类型安全与防御性编程实践
1. C51开发中的枚举类型陷阱与防御性编程实践在嵌入式C开发领域,Keil C51编译器因其对8051架构的深度优化而广受欢迎。但就像我十年前第一次使用typedef enum时踩过的坑一样,许多开发者会惊讶地发现:编译器竟然允许将任意整数值赋给枚举变量&…...

用Godot 4.2的ShapePoints库,5分钟搞定游戏UI里的进度条、血条和技能图标
用Godot 4.2的ShapePoints库快速打造游戏UI组件在独立游戏开发中,UI设计往往是容易被忽视却至关重要的环节。传统做法需要美术资源支持,但当项目处于原型阶段或团队资源有限时,程序化生成UI元素就成为高效解决方案。Godot 4.2内置的ShapePoin…...