自然语言处理: 第八章chatGPT的搭建
理论基础
Transformer 大模型家族可以分成三类, 至于三者的区别可以参考上一章:
- Encoder-only,
- Decoder-only, 只需要Pre_train
- Encoder-decoder , 可以在一些任务上无需进行fine_tune
必须要在下游任务进行微调比如Bert , Bart 。 T5 这种无需要微调就能完成一些任务 。最后GPT从3开始,只需要预训练就能适应很多任务。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EO295wD2-1692024764313)(image/09_chatGPT/1691416067253.png)]](https://img-blog.csdnimg.cn/d32c88e4e0964637babc5283f2a27c8f.png)
关于现在ChatgGPT的训练方法主要分为三步:
- Pre-Training, 这些就是从大量的文本中作问答的无监督的预训练,这个过程可以参考上一章内容,这一部分基本大家都一样,通过大量文本的无监督的学习,大模型就逐渐拥有了文本的理解能力,这种大模型由于参数超过一定数量级后(million级),就拥有了涌现能力(拥有few-shot 或者zero-shot的能力)。
- Instruction Tuning, SFT(supervised Fine-tuning)通过特定的指令调优,进行监督学习,使得生成的内容类似你问我答。
- Alignment, RLHF(Reinforcement Learning human feedback)经过人类的输入的强化学习从而得到更好的结果,生成的内容就更像对话
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nossRgZR-1692024764313)(image/09_chatGPT/1691589194128.png)]](https://img-blog.csdnimg.cn/6481111c21544e239c98eb16302cb355.png)
In - context Tuning(上下文调优)
由于预训练的文本不全是对话的数据集,所以为了让GPT更适合作为聊天机器人,所以利用对话内容作为数据,对GPT进行tuning,也就是给机器例子,从而让机器学会你的例子模板去回答。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IQdzJqQK-1692024764314)(image/09_chatGPT/1691589966907.png)]](https://img-blog.csdnimg.cn/f6d846f270a0433b89bbadf002a54ece.png)
下面的数据来自于Larger language models do in-context learning differently , 作者对in-context learning进行了研究,主要工作是对in-context learning的数据集给标记错误的lable后,再让不同大小的模型去学习这些错误的label,最后作者发现,其实in-context learning是有学习到知识的,而不是只是通过这些例子去学习到对话(或者激活某种任务的能力),从下面从左至右模型大小逐渐减少,可以看到这个在in-context learning的能力只有在大模型的基础上才能实现,具体可以参考上面这一篇论文。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ynhm1qIF-1692024764314)(image/08_ChatGPT/1691990780419.png)]](https://img-blog.csdnimg.cn/7c71befa3a7f4b3daf714bb7554115a9.png)
Instruction Tuning(指令调优)
通过添加一些明确的指令(Prompt)从而使得模型不仅仅会对话,而且能通过prompt暗示得到人类最想要的结果,这也是为什么prompt工程师诞生的原因。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oXqWTdQN-1692024764314)(image/09_chatGPT/1691590080891.png)]](https://img-blog.csdnimg.cn/d5eb5a871afd459ea3f5bc4198660229.png)
Scaling Instruction-Finetuned Language Models 在这篇文章中以PaLM为例验证了instruction tuning的有效性,如下图,可以看到随着instruction tuning的任务量增多,模型在不同任务的准确性也越来越好。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3WWFBIPf-1692024764315)(image/08_ChatGPT/1692007589972.png)]](https://img-blog.csdnimg.cn/19a3c4d55106499aa8ae62542bf5e020.png)
最近刷到了李宏毅老师教材,这里也解释了上文中in - context learning 和 instruction learning 的区别,对应的题目描述就是instruction , 而下面的例子就是in-content learning。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xGJgyeFJ-1692024764315)(image/08_ChatGPT/1691935401894.png)]](https://img-blog.csdnimg.cn/5371f10f7b014742a4a83810a02ffe73.png)
Alignment Training
在GPT -> instructGPT之后,为了让模型更像人类的行为,因此引入了对齐训练。OPENAI使用的是RLHF(Reinforcement Learning human feedback),简单的理解就是他在训练的时候引入了人类的打分机制,由于GPT生成模型其每次对于同样的问题回答都不一样,而人类根据GPT的回答进行打分,然后将这个分数去训练一个回归判分模型,训练完成之后这个打分模型能根据GPT的回答自动打分。拥有了这个打分模型之后,就可以在instructGPT模型不断生成答案,通过训练好的打分模型去打分,得到的分数再去优化instructGPT 使得优化后的GPT的得分越来越高。最后不断的重复这个过程最终可以使得GPT的回答与人类的回答对齐
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-J5G1MG7E-1692024764315)(image/09_chatGPT/1691590504242.png)]](https://img-blog.csdnimg.cn/efb684b78585445d8610657613cab76f.png)
- 通过大量的文本作预训练,使得GPT拥有涌现能力
- 通过SFT得到InstructionGPT,教会GPT拥有对话的能力,并且通过特殊的prompt得到对应的回答(对应下图step1)
- 创建强化学习的奖励模型(对应下图step2)
- 利用奖励模型,使用近端策略优化微调模型(PPO),可以参考这一篇知乎Proximal Policy Optimization (PPO) 算法理解:从策略梯度开始
(对应下图step3)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-imGHge9b-1692024764315)(image/09_chatGPT/1691594172958.png)]](https://img-blog.csdnimg.cn/d8d4b6574b3540d88df6c00fde65c3e2.png)
代码实现
SFT(Supervised Fine-tuning)
这里展示了一个简易代码,也就是在读取了做完无监督的预训练模型,利用一些加入了prompt的对话文本去作tuning,使得整个模型具备能根据prompt得到对应的贴合人类的回答,从而实现聊天机器人的功能
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JRxu1poG-1692024764316)(image/09_chatGPT/1691595292946.png)]](https://img-blog.csdnimg.cn/1b832dd5ac3e4ae98828a71399da4f98.png)
Reward-model
根据人为的打分去训练一个判分模型。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-myMs93wh-1692024764316)(image/09_chatGPT/1691595555964.png)]](https://img-blog.csdnimg.cn/e8524518a7914f409d48e85288c1517e.png)
PPO
利用step2训练好的打分模型,对经过SFT模型生成的答案进行打分,然后将这个分数的奖励进行最大化最终去优化整个instructGPT,不断的循环最终得到chatGPT
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MGauY2j6-1692024764316)(image/09_chatGPT/1691596150299.png)]](https://img-blog.csdnimg.cn/13b0af63b3ca4c4e92b00489764ece1e.png)
结果
这里展示的一个任务是在之前WiKi数据集上做完预训练之后得到的WikiGPT模型,这个模型已经具备一定的文本生成和理解能力了。再在Movie对白数据集进行的In-context tuning,使得其具有对话的能力,令其生成的内容更像对话,而不是生硬的文本。(PS: 如果想使得自己的模型进行prompt tuning, 目前比较常见的方法是利用特定的prompt 生成一段指令,然后将文本输入给GPT的API作生成回答,便可以快速得到一定量的问答数据,但是这样的话模型能力肯定是比GPT的能力低的,但是比自己找人生成对话数据成本更低时间更快,适用于小的垂直领域)
import torch
from GPT_Model_with_Decode import GPT
from CorpusLoader import MovieCorpus
from Utilities import read_data
from ModelTrainer import Trainer
import datetimedevice = "cuda" if torch.cuda.is_available() else "cpu"
# 加载 MovieCorpus 数据
dialog_corpus = MovieCorpus(read_data('cornell movie-dialogs corpus/processed_movie_lines.txt'))
chat_gpt = GPT(dialog_corpus).to(device)
chat_gpt.load_state_dict(torch.load('99_TrainedModel/WikiGPT_0.01_200_20230620_111344.pth'))
# chat_gpt.eval()# 微调 ChatGPT 模型
trainer = Trainer(chat_gpt, dialog_corpus, learning_rate=0.001, epochs=200)
trainer.train()# 保存微调后的模型
timestamp = datetime.datetime.now().strftime("%Y%m%d_%H%M%S") # 获取当前时戳
model_save_path = f'99_TrainedModel/miniChatGPT_{trainer.lr}_{trainer.epochs}_{timestamp}.pth'
torch.save(chat_gpt.state_dict(), model_save_path)# 测试微调后的模型
input_str = "how are you ?"
greedy_output = chat_gpt.decode(input_str, strategy='greedy', max_len=50)
beam_search_output = chat_gpt.decode(input_str, strategy='beam_search', max_len=50, beam_width=5, repetition_penalty=1.2)print("Input text:", input_str)
# print("Greedy search output:", greedy_output)
print("Beam search output:", beam_search_output)
如同上面代码,数据集采用的是电影对白的形式,一问一答。首先读取之前预训练好的WikiGPT,然后直接在MovieCorpus作训练就好了,因为数据的格式也是一问一答,所以代码与上一章的内容基本一致。这样训练好的之后的MiniGPT的文本生成能力就会更像人类的对话功能靠齐。
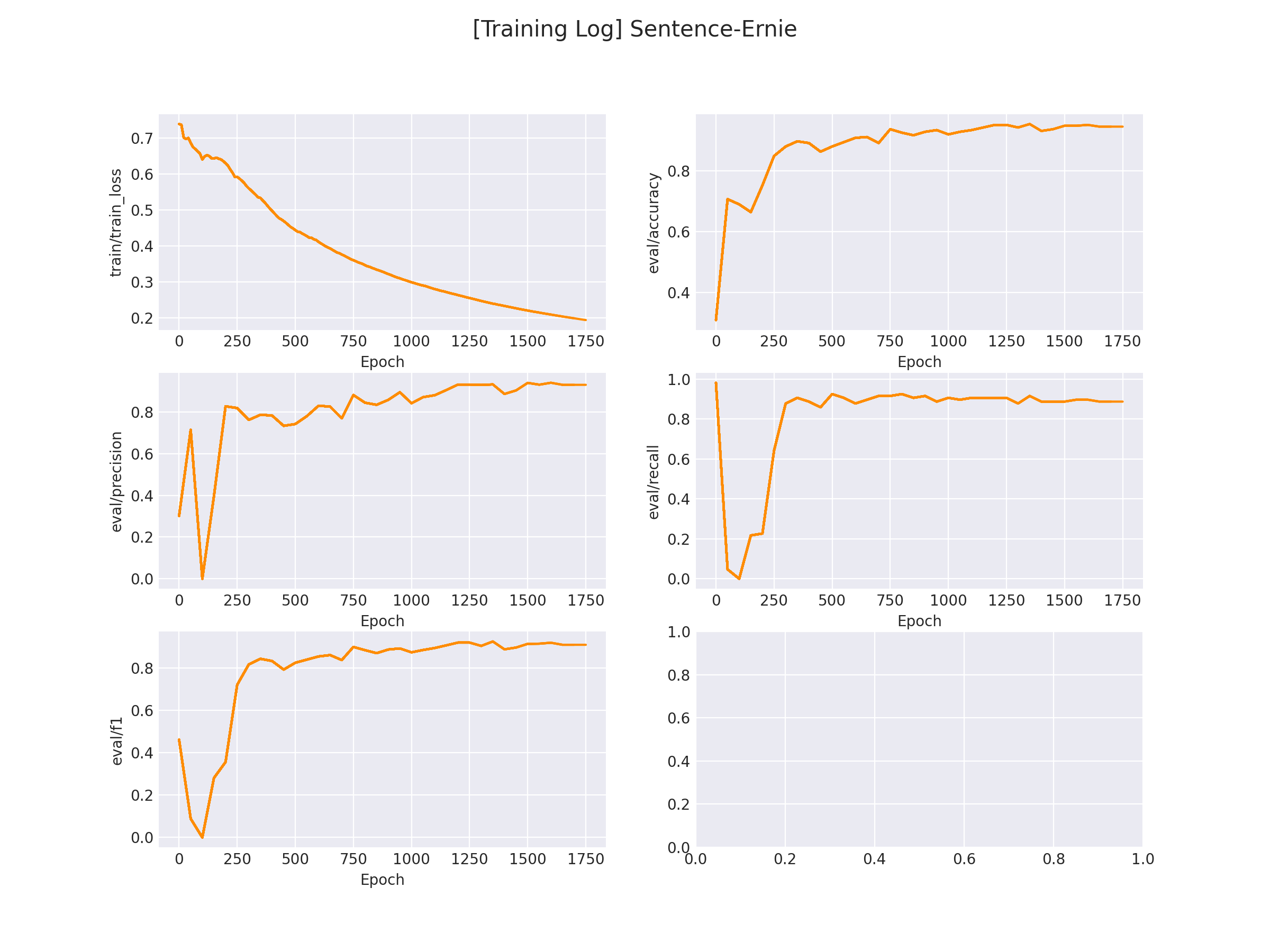
最终的效果如下:可以看到可能还是因为数据太小,或者训练的问题,整个生成的文本还是不能练成一句话,但是看上去也比较像对话了。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jeVigeG2-1692024764317)(image/09_chatGPT/1691658273867.png)]](https://img-blog.csdnimg.cn/6eadcb1c8cad4b65b781d2d4e1019f68.png)
相关文章:
自然语言处理: 第八章chatGPT的搭建
理论基础 Transformer 大模型家族可以分成三类, 至于三者的区别可以参考上一章: Encoder-only,Decoder-only, 只需要Pre_trainEncoder-decoder , 可以在一些任务上无需进行fine_tune 必须要在下游任务进行微调比如Bert , Bart 。 T5 这种无需要微调就能完成一些任…...

阿里云国际版云服务器防火墙怎么设置呢?
入侵防御页面为您实时展示云防火墙拦截流量的源IP、目的IP、阻断应用、阻断来源和阻断事件详情等信息。本文介绍了入侵防御页面展示的信息和相关操作,下面和012一起来了解阿里云国际版云服务器防火墙设置: 前提条件 您需要先在防护配置页面,开…...
安装elasticsearch
一、docker安装elasticsearch 1、下载镜像 docker pull elasticsearch:6.5.4 2、启动容器 docker run -p 9200:9200 -p 9300:9300 --name elasticsearch \ -e "discovery.typesingle-node" \ -e "cluster.nameelasticsearch" \ -e "ES_JAVA_OPTS-Xm…...
)
【Sklearn】基于朴素贝叶斯算法的数据分类预测(Excel可直接替换数据)
【Sklearn】基于朴素贝叶斯算法的数据分类预测(Excel可直接替换数据) 1.模型原理2.模型参数3.文件结构4.Excel数据5.下载地址6.完整代码7.运行结果1.模型原理 模型原理: 朴素贝叶斯分类是基于贝叶斯定理的一种分类方法。它假设特征之间相互独立(朴素性),从而简化计算过…...

学习Vue:创建和使用组件
组件化开发是现代前端开发的一种重要方法,它可以将复杂的应用程序拆分成多个独立、可复用的组件。在Vue.js中,创建和使用组件非常简单,让我们一起来了解如何通过Vue.js实现组件化开发。 创建组件 在Vue.js中,您可以通过Vue.compo…...

【MongoDB基础】
目录 一、概述 1.概念 2.相关 2.1 实例 2.2 库 2.3 集合 2.4 文档 2.5 主键 3.特性 4,应用场景 二、安装 1.RPM安装 2.启动数据库 三、目录结构 1.rpm -ql mongodb-org-server 2.rpm -ql mongodb-org-shell 3.rpm -ql mongodb-org-tools 四、默…...
NLP文本匹配任务Text Matching [有监督训练]:PointWise(单塔)、DSSM(双塔)、Sentence BERT(双塔)项目实践
NLP文本匹配任务Text Matching [有监督训练]:PointWise(单塔)、DSSM(双塔)、Sentence BERT(双塔)项目实践 0 背景介绍以及相关概念 本项目对3种常用的文本匹配的方法进行实现:Poin…...

2023牛客第八场补题报告A H J K
2023牛客第八场补题报告A H J K A-Alive Fossils_2023牛客暑期多校训练营8 (nowcoder.com) 思路 统计字符串,取出现次数为t的。 代码 #include <bits/stdc.h> #define int long long #define endl \n #define IOS ios::sync_with_stdio(0), cin.tie(0), …...
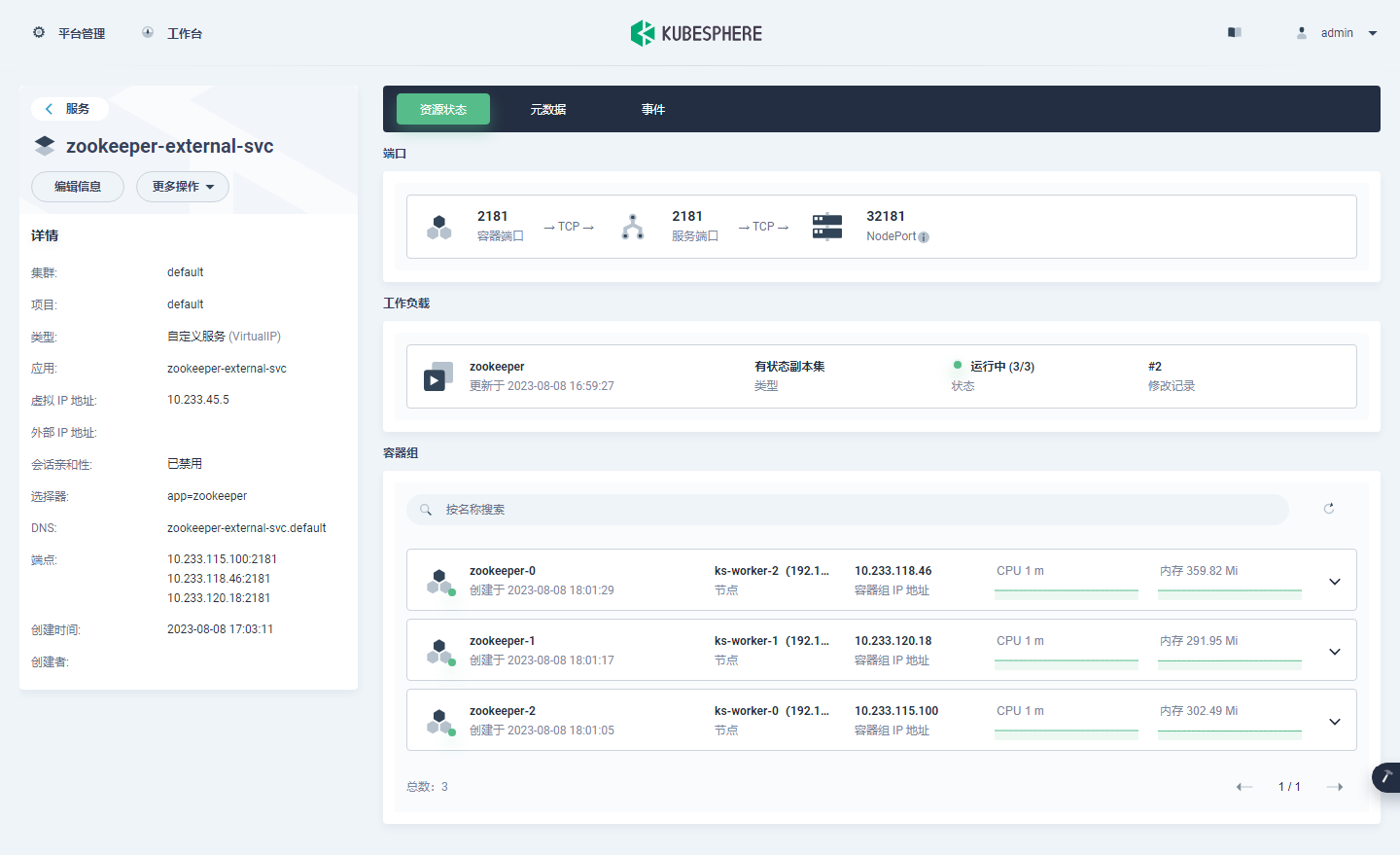
KubeSphere 部署 Zookeeper 实战教程
前言 知识点 定级:入门级如何利用 AI 助手辅助运维工作单节点 Zookeeper 安装部署集群模式 Zookeeper 安装部署开源应用选型思想 实战服务器配置(架构 1:1 复刻小规模生产环境,配置略有不同) 主机名IPCPU内存系统盘数据盘用途ks-master-0192.168.9.9…...

麦肯锡重磅发布2023年15项技术趋势,生成式AI首次入选,选对了就是风口
两位朋友在不同群里分享了同一份深度报告。 一位是LH美女,她在“AIGC时代”群里上传了这份文档,响应寥寥,可能是因为这些报告没有像八卦文那样容易带来冲击。 你看韩彬的这篇《金融妲己:基金公司女销售的瓜,一个比一个…...

【软件工程质量】代码质量管理平台Sonar
分析代码质量的工具有挺多的,比如:Alibaba Java Coding Guidelines plugin、QAPlug、SonarQube 等,平时用的比较多的事Alibaba Java Coding Guidelines plugin和sonarlint。 SonarQube 是一个用于管理源码质量的平台,帮助开发者…...

【EI/SCOPUS检索】第三届计算机视觉、应用与算法国际学术会议(CVAA 2023)
第三届计算机视觉、应用与算法国际学术会议(CVAA 2023) The 3rd International Conference on Computer Vision, Application and Algorithm 2023年第三届计算机视觉、应用与算法国际学术会议(CVAA 2023)主要围绕计算机视觉、计算机应用、计…...

crm客户管理系统的功能有哪些?
阅读本文,您可以了解:1、CRM客户管理系统的定义;2、CRM客户管理系统的功能。 CRM客户管理系统是一个工具或软件,能够帮助企业更好地与客户进行沟通、理解客户需求,以及有效地处理客户信息和互动。通俗地说,…...

leetcode 面试题 02.05 链表求和
⭐️ 题目描述 🌟 leetcode链接:面试题 02.05 链表求和 ps: 首先定义一个头尾指针 head 、tail,这里的 tail 是方便我们尾插,每次不需要遍历找尾,由于这些数是反向存在的,所以我们直接加起来若…...
培训报名小程序-用户注册
目录 1 创建数据源2 注册用户3 判断用户是否注册4 完整代码总结 我们的培训报名小程序,用户每次打开时都需要填写个人信息才可以报名,如果用户多次报名课程,每次都需要填写个人信息,比较麻烦。 本篇我们就优化一下功能,…...

java八股文之基本语法
目录 注释有几种形式 1.注释有几种形式 单行注释: 通常用于 解释 代码内某单行得作用 多行注释:通常用于接收某个方法得作用文档注释:通常用于生成 Java 开发文档。 标识符和关键字得区别 标识符:由字母,…...
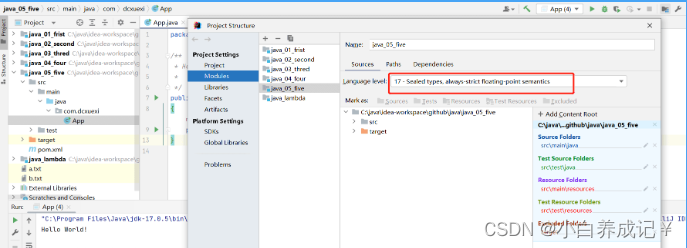
java不支持发行版本5
这篇文章主要给大家介绍了关于如何解决java错误:不支持发行版本5的相关资料,发行版本5是Java5,已经是十多年前的版本了,现在已经不再被支持,需要的朋友可以参考下 − 目录 问题描述:解决方法:永久解决方法:总结 问题描述: 在i…...
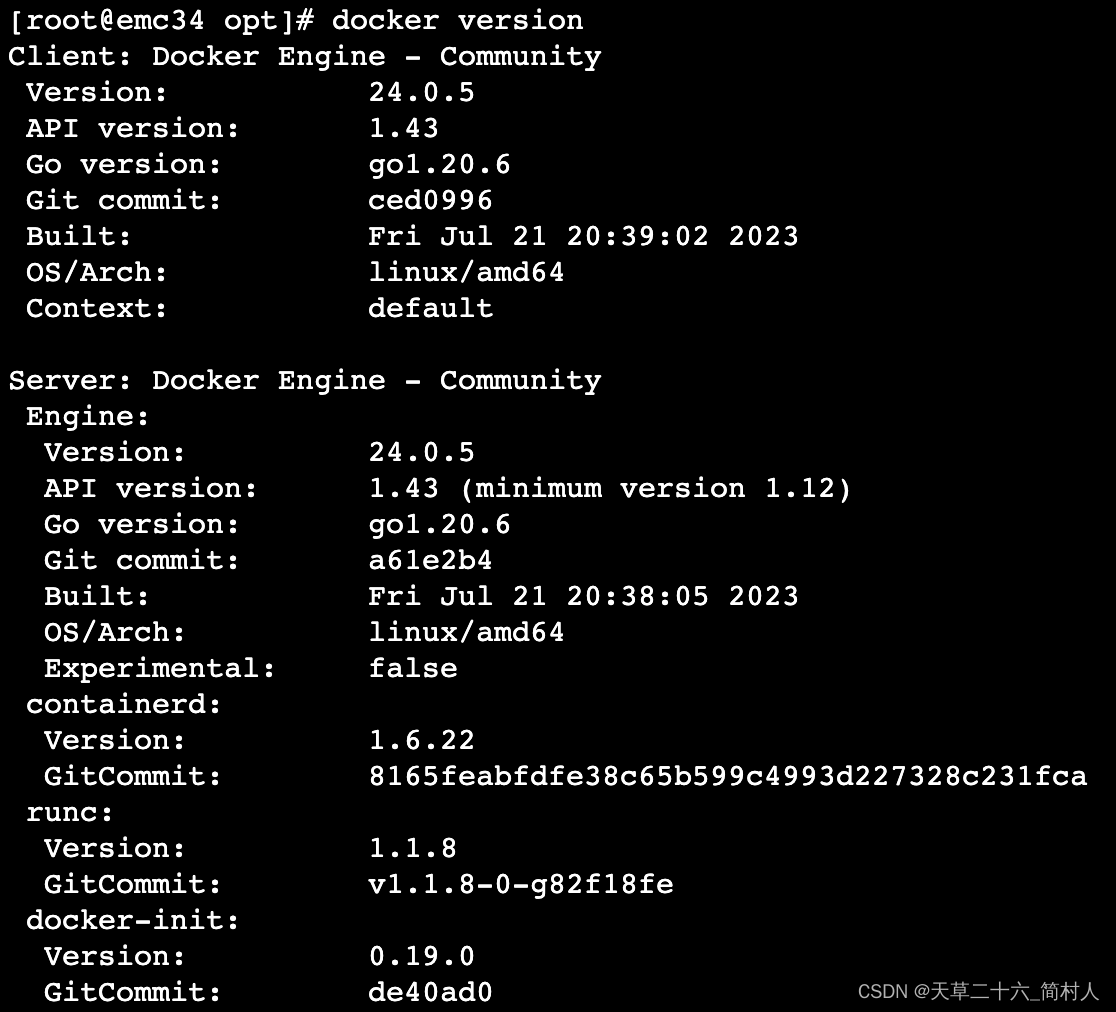
旧版本docker未及时更新,导致更新/etc/docker/daemon.json配置文件出现docker重启失败
一、背景 安装完docker和containerd之后,尝试重启docker的时候,报错如下: systemctl restart dockerJob for docker.service failed because the control process exited with error code. See “systemctl status docker.service” and “…...

HTML 语言简介
1.概述 HTML 是网页使用的语言,定义了网页的结构和内容。浏览器访问网站,其实就是从服务器下载 HTML 代码,然后渲染出网页。 HTML 的全名是“超文本标记语言”(HyperText Markup Language),上个世纪90年代…...
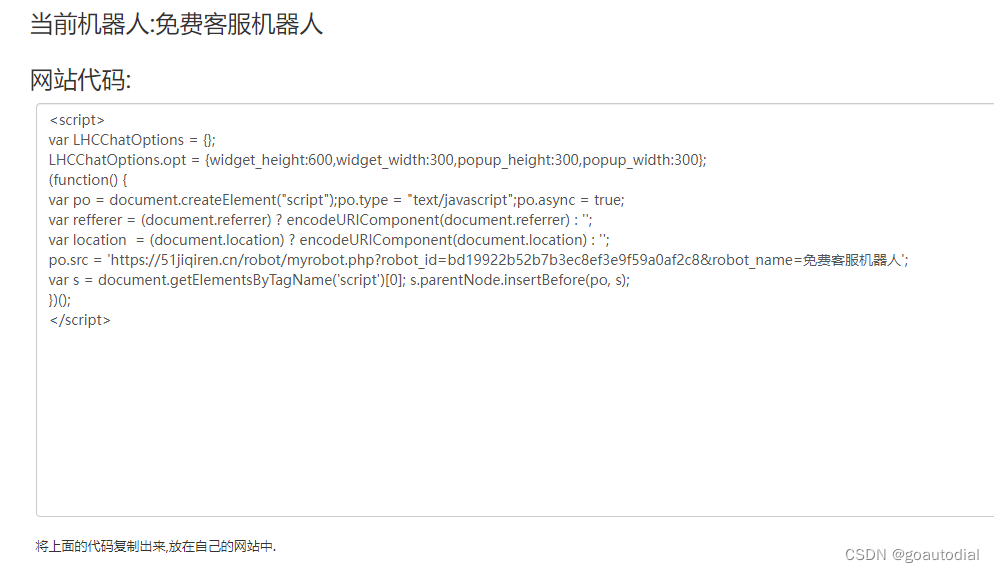
免费网站客服机器人来了(基于有限状态机),快来体验下
免费网站客服机器人来了,快来体验下 51jiqiren.cn 五分钟就可以完成一个简单的机器人. 懂json的同学可以自定义状态和状态跳转,完成复杂的业务流程. 更多功能还在开发中. 网站右下角点"联系客服"截图: 弹出来了: 后端管理界面: 有限状态机界面: 数据界面: 在网站…...

LLM测试工程师必看,Claude E2E测试架构设计,从用例生成、黄金样本构建到回归基线告警闭环
更多请点击: https://codechina.net 第一章:LLM测试工程师必看,Claude E2E测试架构设计,从用例生成、黄金样本构建到回归基线告警闭环 核心架构概览 Claude端到端测试架构采用三层解耦设计:输入层(动态用…...

关于我第九次博客作业
(1)Flex布局核心概念一、Flex 是什么Flex 是 CSS3 一维弹性布局,专治元素对齐、自适应、空间分配问题,布局更高效灵活。二、两大核心角色1. 父容器(Flex容器)设置 display: flex 即为弹性父盒子,负责统一规定子元素排列…...

ESP32屏幕项目救星:用TFT_eSPI库的Touch_calibrate例程,5分钟搞定LittleVGL触摸校准
ESP32屏幕开发实战:5分钟完成LittleVGL触摸校准的高效方法论 当一块全新的ILI9341XPT2046电阻屏摆在你面前时,大多数开发者会迫不及待地跳进LittleVGL的配置深渊。但真正高效的硬件开发者知道,在编写任何图形界面代码之前,有一个关…...

COM3D2.MaidFiddler:实时内存编辑器与游戏模组开发的技术深度解析
COM3D2.MaidFiddler:实时内存编辑器与游戏模组开发的技术深度解析 【免费下载链接】COM3D2.MaidFiddler Maid Fiddler for COM3D2 -- a real-time value editor for COM3D2 项目地址: https://gitcode.com/gh_mirrors/co/COM3D2.MaidFiddler COM3D2.MaidFidd…...

用Playwright自动化测试工具,5分钟搞定网站短信验证码接口的批量测试
用Playwright实现短信验证码接口的自动化测试实战指南短信验证码作为现代Web应用的核心安全组件,其稳定性和防护能力直接影响用户体验和系统安全。根据2023年DevOps状态报告,超过60%的线上身份验证故障源于短信服务接口的异常。本文将带你用Playwright这…...

Arm Cortex-M的FP和MVE
Floating-point Support目前Arm architecture支持的floating-point extension版本是FPv5。FPv5提供了以下功能:单精度算术运算;可选的双精度算术运算;整数、双精度、单精度、和半精度格式之间的转换;用于浮点处理的寄存器…...

MiGPT终极教程:如何让小爱音箱秒变你的专属AI语音助手
MiGPT终极教程:如何让小爱音箱秒变你的专属AI语音助手 【免费下载链接】mi-gpt 🏠 将小爱音箱接入 ChatGPT 和豆包,改造成你的专属语音助手。 项目地址: https://gitcode.com/GitHub_Trending/mi/mi-gpt 还在为小爱音箱的"人工智…...

如何告别城通网盘龟速下载:三步获取高速直连的终极方案
如何告别城通网盘龟速下载:三步获取高速直连的终极方案 【免费下载链接】ctfileGet 获取城通网盘一次性直连地址 项目地址: https://gitcode.com/gh_mirrors/ct/ctfileGet 还在为城通网盘那令人抓狂的下载速度而苦恼吗?每次点击下载按钮后&#x…...

告别折腾!用DKMS一劳永逸管理你的水星MW310UH在Ubuntu 22.04上的驱动
告别折腾!用DKMS一劳永逸管理你的水星MW310UH在Ubuntu 22.04上的驱动每次内核更新后都要重新编译无线网卡驱动?这种重复劳动该终结了。对于使用水星MW310UH这类Realtek芯片设备的用户来说,DKMS(Dynamic Kernel Module Support&…...

工业控制系统安全:基于机器学习的数据融合异常检测实战
1. 项目概述与核心价值在工业控制系统(ICS)安全领域,我们面临着一个日益严峻的挑战:传统的“单点”防御策略越来越难以应对那些横跨网络层和物理过程层的复杂、隐蔽的攻击。想象一下,一个水处理厂的工程师,…...