ClickHouse(十九):Clickhouse SQL DDL操作-1

进入正文前,感谢宝子们订阅专题、点赞、评论、收藏!关注IT贫道,获取高质量博客内容!
🏡个人主页:含各种IT体系技术,IT贫道_Apache Doris,大数据OLAP体系技术栈,Kerberos安全认证-CSDN博客
📌订阅:拥抱独家专题,你的订阅将点燃我的创作热情!
👍点赞:赞同优秀创作,你的点赞是对我创作最大的认可!
⭐️ 收藏:收藏原创博文,让我们一起打造IT界的荣耀与辉煌!
✏️评论:留下心声墨迹,你的评论将是我努力改进的方向!
目录
1. 创建库
2. 查看数据库
3. 删除库
4. 创建表
5. 查看表
6. 查看表的定义
8. 删除表
9. 修改表
9.1 添加列
9.2 删除列
9.3 清空列
9.4 给列修改注释
9.5 修改列类型
10. 给表重命名
10.1 给表重命名语法
10.2 示例
DDL:Data Definition Language,数据库定义语言。在ClickHouse中,DDL语言中修改表结构仅支持Merge表引擎、Distributed表引擎及MergeTree家族的表引擎,SQL 中的库、表、字段严格区分大小写。
1. 创建库
- 创建库基础语法:
CREATE DATABASE [IF NOT EXISTS] db_name [ON CLUSTER cluster] [ENGINE = engine(...)]2. 查看数据库
- 查看数据库语法
SHOW DATABASES;3. 删除库
- 删除库基础语法:
DROP DATABASE [IF EXISTS] db [ON CLUSTER cluster]- 示例:
#创建库 test_dbnode1 :) create database if not exists test_db;CREATE DATABASE IF NOT EXISTS test_dbOk.0 rows in set. Elapsed: 0.007 sec.#删除库node1 :) drop database test_db;DROP DATABASE test_dbOk.0 rows in set. Elapsed: 0.003 sec.注意:在创建数据库时,在/var/lib/clickhouse/metadata/目录下会有对应的库目录和库.sql文件,库目录中会存入在当前库下建表的信息,xx.sql文件中存入的是建库的信息。如图:
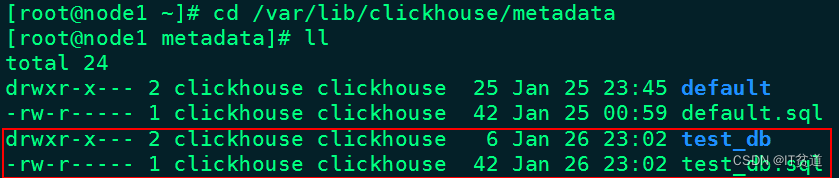
当删除数据库时,/var/lib/clickhouse/metadata/目录下对应的库目录和xx.sql文件也会被清空。
4. 创建表
创建表的基本语法:
#第一种CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster](name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],...) ENGINE = engine#第二种CREATE TABLE [IF NOT EXISTS] [db.]table_name AS [db2.]name2 [ENGINE = engine]#第三种CREATE TABLE [IF NOT EXISTS] [db.]table_name ENGINE = engine AS SELECT ...注意:以上普通第一种建表语句是直接创建表。第二种创建表方式可以创建一个与db2中name2一样结构的表,也可以指定表引擎,也可以不指定,不指定默认与db2中的name2表引擎一样,不会将表name2中的数据填充到对应的新表中。第三种方式可以指定引擎创建一个与Select 子句的结果相同结构的表,并将Select子句的结果填充它。
- 示例:
#第一种方式创建表node1 :) create table if not exists newdb.t1(:-] id UInt8 default 0 comment '编号',:-] name String default '无姓名' comment '姓名',:-] age UInt8 default 18 comment '年龄':-] )engine = TinyLog;CREATE TABLE IF NOT EXISTS newdb.t1(`id` UInt8 DEFAULT 0 COMMENT '编号',`name` String DEFAULT '无姓名' COMMENT '姓名',`age` UInt8 DEFAULT 18 COMMENT '年龄')ENGINE = TinyLogOk.0 rows in set. Elapsed: 0.004 sec.# 第二种方式创建表node1 :) create table if not exists t2 engine = Memory as newdb.t_tinylog;CREATE TABLE IF NOT EXISTS t2 AS newdb.t_tinylogENGINE = MemoryOk.0 rows in set. Elapsed: 0.006 sec.# 第三种方式创建表node1 :) create table if not exists t3 engine = Memory as select * from newdb.t_tinylog where id >2;CREATE TABLE IF NOT EXISTS t3ENGINE = Memory ASSELECT *FROM newdb.t_tinylogWHERE id > 2Ok.0 rows in set. Elapsed: 0.010 sec.#查询表t3数据node1 :) select * from t3;SELECT *FROM t3┌─id─┬─name─┬─age─┐│ 3 │ 王五 │ 20 │└────┴──────┴─────┘1 rows in set. Elapsed: 0.004 sec.5. 查看表
- 查看表语法:
SHOW TABLES;SHOW TABLES IN default;6. 查看表的定义
- 查看表定义语法:
SHOW CREATE TABLE XXX;- 示例:
#查看表定义node1 :) show create table t3;SHOW CREATE TABLE t3┌─statement─────────────────────────────────┐│ CREATE TABLE newdb.t3(`id` UInt8,`Name` String)ENGINE = TinyLog │└───────────────────────────────────────────┘1 rows in set. Elapsed: 0.002 sec.7. 查看表的字段
- 查看表定义语法:
DESC XXXX;- 示例:
#查看表t3的字段node1 :) desc t3;DESCRIBE TABLE t3┌─name─┬─type───┬─default_type─┬─...│ id │ UInt8 │ │ ...│ Name │ String │ │ ...└──────┴────────┴──────────────┴──...2 rows in set. Elapsed: 0.004 sec.8. 删除表
- 删除表的基本语法:
DROP [TEMPORARY] TABLE [IF EXISTS] [db.]name [ON CLUSTER cluster]- 示例:
#删除表node1 :) drop table t3;DROP TABLE t3Ok.0 rows in set. Elapsed: 0.003 sec.9. 修改表
- 修改表语法
ALTER TABLE [db].name [ON CLUSTER cluster] ADD|DROP|CLEAR|COMMENT|MODIFY COLUMN ...9.1 添加列
- 示例:
#使用default 库,创建表 test1,使用MergeTree引擎node1 :) use default;node1 :) create table test1(id UInt8,name String)engine = MergeTree() order by id partition by name;CREATE TABLE test1(`id` UInt8,`name` String,`loc` String)ENGINE = MergeTree()PARTITION BY locORDER BY idOk.0 rows in set. Elapsed: 0.005 sec.Ok.#查看表test1表结构node1 :) desc test1;DESCRIBE TABLE test1┌─name─┬─type───┬...│ id │ UInt8 │...│ name │ String │...│ loc │ String │...└──────┴────────┴...3 rows in set. Elapsed: 0.004 sec.#添加表字段node1 :) alter table test1 add column age UInt8;#查看表结构,添加字段成功node1 :) desc test1;DESCRIBE TABLE test1┌─name─┬─type───┬...│ id │ UInt8 │...│ name │ String │...│ loc │ String │...│ age │ UInt8 │...└─────┴─────┴...4 rows in set. Elapsed: 0.003 sec.9.2 删除列
- 示例:
#删除表test1中的name age字段node1 :) alter table test1 drop column age;#查看表 test1表结构node1 :) desc test1;DESCRIBE TABLE test1┌─name─┬─type───┬...│ id │ UInt8 │...│ name │ String │...│ loc │ String │...└──────┴────────┴...2 rows in set. Elapsed: 0.004 sec.9.3 清空列
注意,不能清空排序、主键、分区字段。
- 示例:
#向表 test1中插入以下几条数据node1 :) insert into table test1 values (1,'张三','北京'),(2,'李四','上海'),(3,'王五','北京');#查看表中的数据┌─id─┬─name─┬─loc──┐│ 1 │ 张三 │ 北京 ││ 3 │ 王五 │ 北京 │└────┴──────┴──────┘┌─id─┬─name─┬─loc──┐│ 2 │ 李四 │ 上海 │└────┴──────┴──────┘#清空 test1 name列在’北京’分区的值node1 :) alter table test1 clear column name in partition '北京';#查看表中的数据node1 :) select * from test1;┌─id─┬─name─┬─loc──┐│ 1 │ │ 北京 ││ 3 │ │ 北京 │└────┴──────┴──────┘┌─id─┬─name─┬─loc──┐│ 2 │ 李四 │ 上海 │└────┴──────┴──────┘#清空 test1 name 列下的值node1 :) alter table test1 clear column name;#查看表中的数据node1 :) select * from test1;┌─id─┬─name─┬─loc──┐│ 1 │ │ 北京 ││ 3 │ │ 北京 │└───┴────┴─────┘┌─id─┬─name─┬─loc──┐│ 2 │ │ 上海 │└───┴─────┴────┘9.4 给列修改注释
- 示例:
#修改表 test1 name 列的注释node1 :) alter table test1 comment column name '姓名';#查看表 test1描述┌─name─┬─type───┬─default_type─┬─default_expression─┬─comment─┬...│ id │ UInt8 │ │ │ │...│ name │ String │ │ │ 姓名 │...│ loc │ String │ │ │ │...└──────┴────────┴──────────────┴────────────────────┴─────────┴...-
9.5 修改列类型
- 示例:
#修改表 test1 name列类型为UInt8node1 :) alter table test1 modify column name UInt8#node1 :) desc test1;┌─name─┬─type───┬─default_type─┬─default_expression─┬─comment─┬│ id │ UInt8 │ │ │ ││ name │ UInt8 │ │ │ 姓名 ││ loc │ String │ │ │ │└──────┴────────┴──────────────┴────────────────────┴─────────┴10. 给表重命名
给表重新命名可以作用在任意的表引擎上。
10.1 给表重命名语法
RENAME TABLE [db11.]name11 TO [db12.]name12, [db21.]name21 TO [db22.]name22, ... [ON CLUSTER cluster]10.2 示例
#创建库 testdb1node1 :) create database testdb1;#创建库 testdb2node1 :) create database testdb2;#使用库testdb1,并创建表 t1node1 :) use testdb1;node1 :) create table t1 (id UInt8 ,name String) engine = MergeTree() order by id ;#将表 t1 重命名为test1node1 :) rename table t1 to test1;#将表test1 移动到testdb2库下,并重新命名为t2, testdb1 下没有表了node1 :) rename table testdb1.test1 to testdb2.t2;👨💻如需博文中的资料请私信博主。
相关文章:
ClickHouse(十九):Clickhouse SQL DDL操作-1
进入正文前,感谢宝子们订阅专题、点赞、评论、收藏!关注IT贫道,获取高质量博客内容! 🏡个人主页:含各种IT体系技术,IT贫道_Apache Doris,大数据OLAP体系技术栈,Kerberos安全认证-CSDN博客 &…...

小程序保留2位小数据,不四舍五入
方法1: parseInt toFixed /* * 保留2位小数,不四舍五入 * 5.992550 >5.99 , 2 > 2.00 * */ const toFixed2Decimal (value) > {return (parseInt(value*100)/100).toFixed(2) } console.log(587.67*100) console.log(toFixed2Decimal(587.67…...

【linux-nginx】nginx限流以及控制访问方法
一、限流 可以使用一些模块和指令来实现限流。以下是一些常用的方法: 使用 ngx_http_limit_req_module 模块:该模块可以限制每个客户端的请求速率。你可以在 Nginx 的配置文件中启用该模块,并使用 limit_req_zone 指令来定义限流规则。例如…...

菜单和内容滚动的联动原理及代码
之前写代码有个需求:左侧是一个菜单,右边是内容,点击左侧菜单右边内容滚动到对应位置,右边内容滚动到某位置时,左侧菜单也会选中对应的菜单项。UI如下:这是大多网站的移动端都会有的需求。 解决方案一&…...

Python爬虫:单线程、多线程、多进程
前言 在使用爬虫爬取数据的时候,当需要爬取的数据量比较大,且急需很快获取到数据的时候,可以考虑将单线程的爬虫写成多线程的爬虫。下面来学习一些它的基础知识和代码编写方法。 一、进程和线程 进程可以理解为是正在运行的程序的实例。进…...
超强的Everything,吊打系统自带文件搜索功能!
目录 一、软件简介 二、软件下载 三、软件说明 一、软件简介 Everything是一款由David OReilly开发的电脑搜索软件,它可以帮助用户快速找到电脑上的文件和文件夹。与其他搜索工具不同的是,Everything使用了一种非常快速和高效的搜索算法,…...

flink配置参数
flink-conf.yaml 基础配置 # jobManager 的IP地址jobmanager.rpc.address: localhost# JobManager 的端口号jobmanager.rpc.port: 6123# JobManager JVM heap 内存大小jobmanager.heap.size: 1024m# TaskManager JVM heap 内存大小taskmanager.heap.size: 1024m# 每个 TaskMan…...

学习Vue:安装Vue.js和设置开发环境
当您决定进入现代前端开发的世界,Vue.js 无疑是一个令人激动的选择。它以其简洁、灵活和高效的特点在开发者社区中备受赞誉。本文将为您详细介绍如何安装 Vue.js 并设置开发环境,让您能够迅速开始编写 Vue 应用程序。 步骤1:安装 Node.js 和 …...

代理技术在网络安全、爬虫和数据隐私中的多重应用
1. Socks5代理:灵活的数据中转 Socks5代理协议在网络通信中起着关键作用。与其他代理技术不同,Socks5代理不仅支持TCP连接,还能够处理UDP流量,使其在需要实时数据传输的场景中表现尤为出色。通过将请求和响应中转到代理服务器&am…...

Python 3 使用Hadoop 3之MapReduce总结
MapReduce 运行原理 MapReduce简介 MapReduce是一种分布式计算模型,由Google提出,主要用于搜索领域,解决海量数据的计算问题。 MapReduce分成两个部分:Map(映射)和Reduce(归纳)。…...
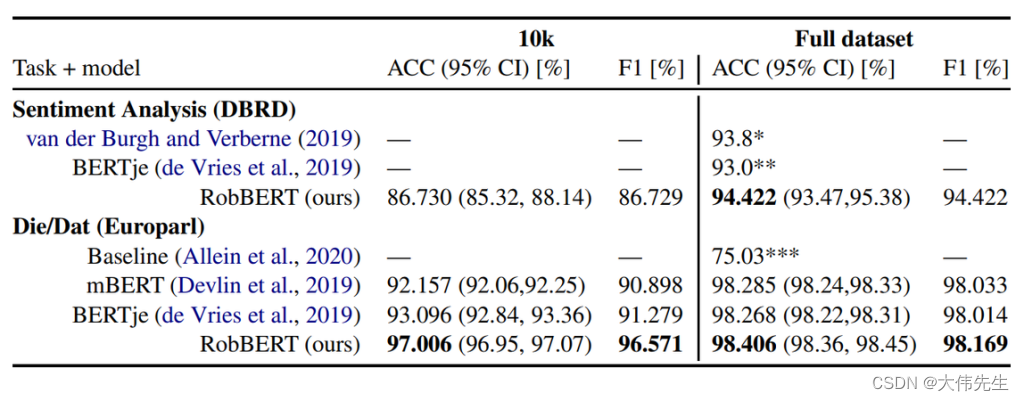
KU Leuven TU Berlin 推出“RobBERT”,一款荷兰索塔 BERT
荷兰语是大约24万人的第一语言,也是近5万人的第二语言,是继英语和德语之后第三大日耳曼语言。来自比利时鲁汶大学和柏林工业大学的一组研究人员最近推出了基于荷兰RoBERTa的语言模型RobBERT。 谷歌的BERT(来自Transformers的B idirectional …...

Postern中配置和使用Socks5代理指南
在Postern中配置和使用Socks5代理,可以为你的爬虫项目提供更灵活、更可靠的网络连接。本文将向你分享如何在Postern中配置和使用Socks5代理的方法,解决可能遇到的问题 配置和使用Socks5代理的步骤: 1.了解Socks代理:了解Socks5代…...

android 窗口级模糊实现方式
在Android上实现窗口级模糊效果有多种方法,下面列出了其中两种常用的实现方式: RenderScript模糊效果: 使用ScriptIntrinsicBlur类在RenderScript中实现模糊效果。创建一个RenderScript实例并将要模糊的图像传递给它。创建一个ScriptIntrinsi…...
面试热题(数组中的第K个最大元素)
给定整数数组 nums 和整数 k,请返回数组中第 k 个最大的元素。 请注意,你需要找的是数组排序后的第 k 个最大的元素,而不是第 k 个不同的元素。 输入: [3,2,1,5,6,4] 和 k 2 输出: 5提到数组中最大元素,我们往往想到就是先给数组…...

HTTP2协议介绍
前言 HTTP是现代互联网通信的基础协议之一,早在1991年,HTTP/0.9版本就诞生了,之后又陆续发布了HTTP/1.0和HTTP/1.1,为互联网应用提供了更高效和可靠的通信方式。 随着时间的推移,互联网的规模和复杂性不断扩大&#x…...

矩阵的转置
题目: 给你一个二维整数数组 matrix, 返回 matrix 的 转置矩阵 。 示例 1: 输入:matrix [[1,2,3],[4,5,6],[7,8,9]] 输出:[[1,4,7],[2,5,8],[3,6,9]]class Solution(object):def transpose(self, matrix):"&q…...

web集群学习:nginx+keepalived实现负载均衡高可用性
目录 项目架构 一,环境介绍 二,项目部署 在Web服务器上配置Web测试页面 nginx负载均衡配置 配置Nginx_Master 通过vrrp_script实现对集群资源的监控(1>通过killall命令探测服务运行状态) 通过vrrp_script实现对集群资源…...

MFC第二十九天 CView类的分支(以及其派生类的功能)、MFC六大关键技术
文章目录 CView类的分支CEditViewCHtmlViewMainFrm.h CMainFrame 类的接口CMainView .h CListCtrl与CListView的创建原理 CTreeViewCTreeCtrl类简介CTreeCtrl类的原理以及常用功能 MFC六大关键技术视图和带分割栏的框架开发与消息路由CLeftView.cppCRightView.hCRightView.cppC…...
自定义ErrorController)
SpringBoot复习:(37)自定义ErrorController
所有接口统一返回的数据格式 package cn.edu.tju.domain;public class MyResponse {private int code;private String message;private String exception;private String stack;public int getCode() {return code;}public void setCode(int code) {this.code code;}public S…...

Linux学习之防火墙概述
防火墙分类: 软件防火墙:常用于数据包的过滤,比如限制某些ip或者端口,进行某些数据的转发或者传送 硬件防火墙:防御地域攻击 软件防火墙的分类: 包过滤防火墙:控制比较宽泛,防御效果…...

Java + Spring Boot 操作 Kafka 完整学习指南
前置条件:ZooKeeper 集群 Kafka 集群已启动(3个ZK节点 3个Broker) Broker 地址:172.17.0.7:9092, 172.17.0.7:9093, 172.17.0.7:9094第一阶段:原生 Java API 操作 Kafka目的:理解底层原理,Spr…...

Unity资源归档:构建可信交付的四大技术支柱
1. 为什么“资源归档”不是打包,而是Unity项目生命周期的隐形分水岭在Unity项目做到中后期,你大概率会遇到这样几个信号:Build时间从3分钟涨到12分钟;AssetBundle生成脚本每次都要手动删旧包、清缓存、重设Variant;美术…...

DBSCAN与GMM串联:从盖亚天文大数据中自动发现恒星关联结构
1. 项目概述:当机器学习遇见星空在盖亚(Gaia)卫星释放出海量高精度天体测量数据之前,天文学家识别一个疏散星团的成员星,往往需要结合自行、视差、颜色-星等图(CMD)等多维信息,在复杂…...

工厂适合做跨境独立站吗?5个判断标准
工厂适合做跨境独立站吗?5个判断标准对很多制造企业来说,跨境电商独立站确实是一条值得认真考虑的出海路径。但它并不适合所有工厂一上来就重投入。要不要做独立站,关键不在于“别人都在做”,而在于产品是否适合、预算是否可控、团…...

从零开始手搓一个xv6内核页表:跟着6.S081源码一步步理解walk和mappages函数
从零构建xv6内核页表:深入解析walk与mappages的RISC-V实现在操作系统的核心机制中,虚拟内存管理始终是最具挑战性的部分之一。当我们打开MIT 6.S081课程的实验手册,面对"实现一个简化版页表"的任务时,许多学习者会陷入理…...

OpenClaw强势推出V2026.5.20版本地部署最新教程来啦!3分钟一键安装中文版可视化操作指南
凌晨两点,我刚把 OpenClaw 跑通。看着屏幕上终于亮起来的 WebChat 界面,心里那叫一个舒坦。说实话,之前装了几次都没成功,不是端口冲突就是 API Key 配置不对,折腾了大半天。后来静下心来把文档从头到尾看了一遍&#…...

OpenSSH用户枚举漏洞CVE-2018-15473深度解析与修复指南
1. 这个漏洞不是“能被爆破密码”,而是“连用户名都藏不住”OpenSSH用户枚举漏洞(CVE-2018-15473)在2018年7月被公开时,很多运维同学第一反应是:“哦,又是密码爆破相关?”——这个误解直接导致大…...

Claude Code 2026 全命令实战:6分钟开发完整坦克对战游戏
文章目录前言第一步:新建文件夹,然后输入一个单词第二步:/plan命令,比产品经理还贴心的规划师第三步:看着AI写代码,自己在旁边喝咖啡第四步:/rewind命令,程序员的后悔药第五步&#…...

DeepSeek-R1模型压缩到<380MB还能保持98.7%对话准确率?——边缘设备量化微调四步法首次公开
更多请点击: https://intelliparadigm.com 第一章:DeepSeek边缘设备部署 DeepSeek系列大模型在边缘侧的轻量化部署,正成为工业质检、智能安防与车载语音等低延迟场景的关键技术路径。其核心挑战在于平衡模型精度、推理吞吐与硬件资源约束——…...

终极指南:如何5步免费使用Cursor Pro破解工具实现永久免费AI编程
终极指南:如何5步免费使用Cursor Pro破解工具实现永久免费AI编程 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reache…...