kafka基本概念及操作
kafka介绍
Kafka是最初由Linkedin公司开发,是一个分布式、支持分区的(partition)、多副本的 (replica),基于zookeeper协调的分布式消息系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景:比如基于hadoop的批处理系统、低延迟的实时系统、 Storm/Spark流式处理引擎,web/nginx日志、访问日志,消息服务等等,用scala语言编写,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。
1.使用场景
-
日志收集:可以用Kafka收集各种服务的log,通过kafka以统⼀接口服务的方式开放给各种consumer,例如hadoop、Hbase、Solr等。
-
消息系统:解耦和生产者和消费者、缓存消息等。
-
用户活动跟踪:Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、 搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时的监控分析,或者装载到hadoop、数据仓库中做离线分析和挖掘。
-
运营指标:Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告。
2.kafka基本概念

整个流程应该是:producer通过网络发送消息到Kafka集群,然后consumer 来进行消费,如下图:
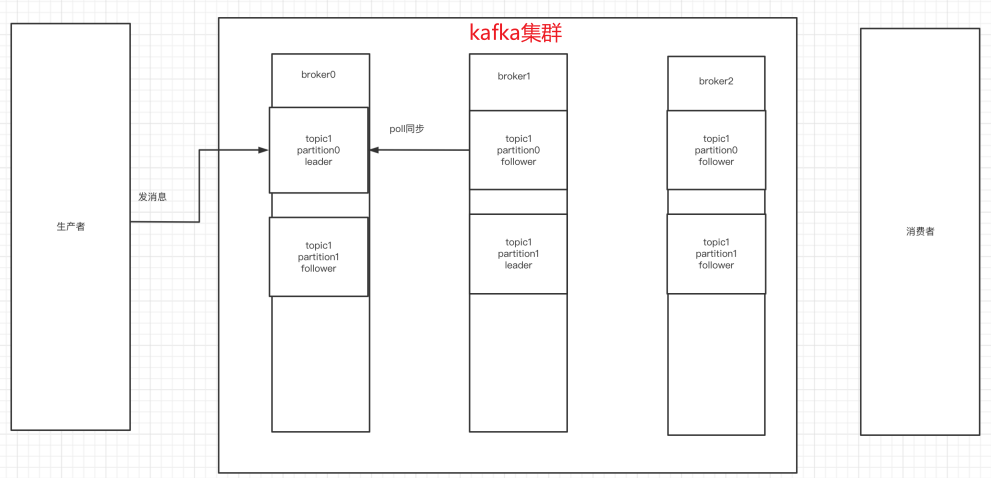
服务端(brokers)和客户端(producer、consumer)之间通信通过TCP协议来完成。
kafka基本使用
1.安装&关闭
以下所有操作全部基于kafka_2.13-3.0.1.tgz (3.0.1版本) 这个版本
配置文件server.properties(主要修改以下配置)
#broker.id属性在kafka集群中必须要是唯⼀
broker.id=0
listeners=PLAINTEXT://xx.xx.xx.xx(服务器内网IP地址):9092
advertised.listeners=PLAINTEXT://xx.xx.xx.xx(服务器对外IP地址):9092
#kafka的消息存储⽂件
log.dir=/usr/local/kafka/data/kafka-logs
#kafka连接zookeeper的地址
zookeeper.connect=192.168.65.60:2181
启动
./kafka-server-start.sh -daemon ../config/server.properties
验证
# 查看端口是否占用
netstat -ntlp
或者
进入到zk内查看是否有kafka的节点:/brokers/ids/0
./zkCli.sh

关闭kafka
./kafka-server-stop.sh stop ../config/server.properties
2.创建topic
执行以下命令创建名为“test”的topic,这个topic只有⼀个partition,并且备份因子也设置为 1
./kafka-topics.sh --bootstrap-server kafkahost:9092 --create --topic test --partitions 1 --replication-factor 1-- 新版本的kafka,已经不需要依赖zookeeper来创建topic,新版的kafka创建topic指令如下:
./kafka-topics.sh --bootstrap-server 124.222.253.33:9092 --create --topic test --partitions 1 --replication-factor 1
3.查看kafka中所有的主题
./kafka-topics.sh --bootstrap-server kafkahost:9092 --list./kafka-topics.sh --bootstrap-server 124.222.253.33:9092 --list
4.发送消息
kafka自带了⼀个producer命令客户端,可以从本地文件中读取内容或者以命令行中直接输入内容,并将这些内容以消息的形式发送到kafka集群中。在默认情况下,每⼀个行会被当做成⼀个独立的消息。使用kafka的发送消息的客户端,指定发送到的kafka服务器地址和topic
把消息发送给broker中的某个topic,打开⼀个kafka发送消息的客户端,然后开始用客户端向kafka服务器发送消息
./kafka-console-producer.sh --bootstrap-server 124.222.253.33:9092 --topic test
5.消费消息
消费消息两种方式:
对于consumer,kafka同样也携带了⼀个命令行客户端,会将获取到内容在命令中进行输出,默认是消费最新的消息。 使用kafka的消费者消息的客户端,从指定kafka服务器的指定 topic中消费消息
-
从当前主题中的最后⼀条消息的offset(偏移量位置)+1开始消费
./kafka-console-consumer.sh --bootstrap-server 124.222.253.33:9092 --topic test -
从当前主题中的第⼀条消息开始消费
./kafka-console-consumer.sh --bootstrap-server 124.222.253.33:9092 --from-beginning --topic test
6.消息的细节
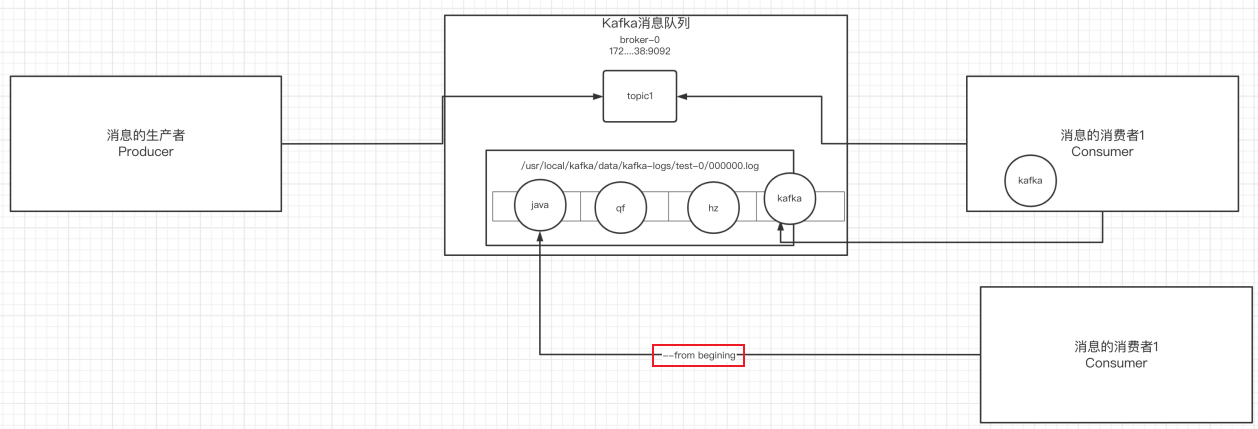
- 生产者将消息发送给broker,broker会将消息保存在本地的日志文件中
/usr/local/kafka/data/kafka-logs/主题-分区/00000000.log
- 消息的保存是有序的,通过offset偏移量来描述消息的有序性
- 消费者消费消息时可以通过offset来描述当前要消费的那条消息的位置
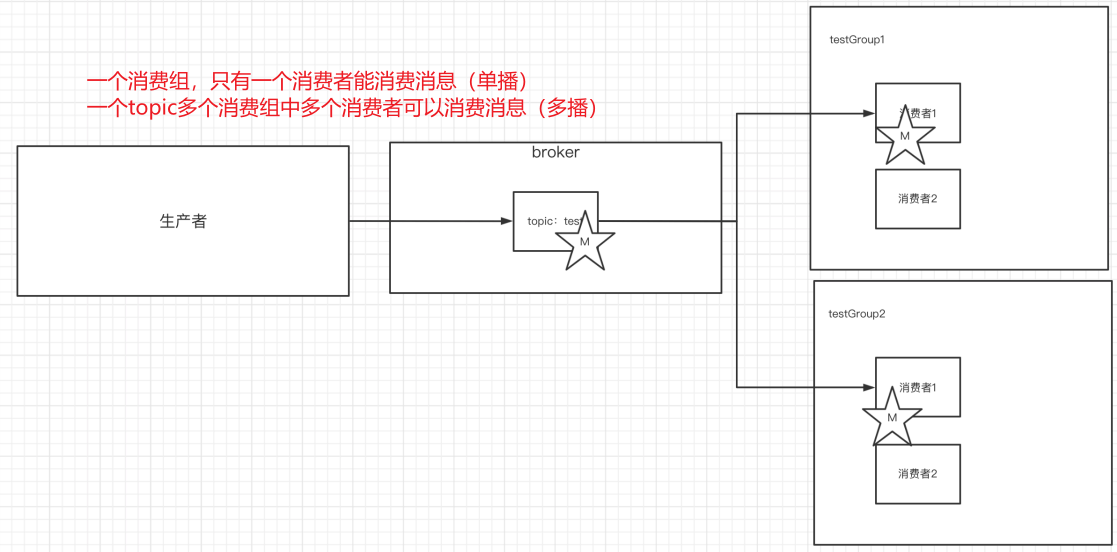
7.单播&多播消息
单播还是多播消息取决于topic有多少消费组
1)单播
如果多个消费者在同⼀个消费组,那么只有⼀个消费者可以收到订阅的topic中的消息。(同⼀个消费组中只能有⼀个消费者收到订阅topic中的消息。)
./kafka-console-consumer.sh --bootstrap-server 124.222.253.33:9092 --consumer-property group.id=testGroup --topic test
2)多播
不同的消费组订阅同⼀个topic,那么不同的消费组中只有⼀个消费者能收到消息。实际上也是多个消费组中的多个消费者收到了同⼀个消息。
./kafka-console-consumer.sh --bootstrap-server 124.222.253.33:9092 --consumer-property group.id=testGroup1 --topic test
./kafka-console-consumer.sh --bootstrap-server 124.222.253.33:9092 --consumer-property group.id=testGroup2 --topic test
3)区别
8.查看消费组详细信息
# 查看当前主题下有哪些消费组
./kafka-consumer-groups.sh --bootstrap-server 124.222.253.33:9092 --list# 查看消费组中的具体信息:⽐如当前偏移量、最后⼀条消息的偏移量、堆积的消息数量
./kafka-consumer-groups.sh --bootstrap-server 124.222.253.33:9092 --describe --group testGroup

- Currennt-offset:当前消费组的已消费偏移量(最后被消费的消息的偏移量)
- Log-end-offset:主题对应分区消息的结束偏移量(HW) 【消息总量,最后一条消息偏移量】
- Lag:当前消费组未消费的消息数(积压消息量)
Kafka中主题和分区的概念
1.主题
主题-topic在kafka中是⼀个逻辑的概念,kafka通过topic将消息进⾏分类。不同的topic会被订阅该topic的消费者消费。
但是有⼀个问题,如果说这个topic中的消息非常非常多,多到需要几T来存,因为消息是会被保存到log日志文件中的。为了解决单个文件过大的问题,kafka提出了Partition分区的概念。
2.分区
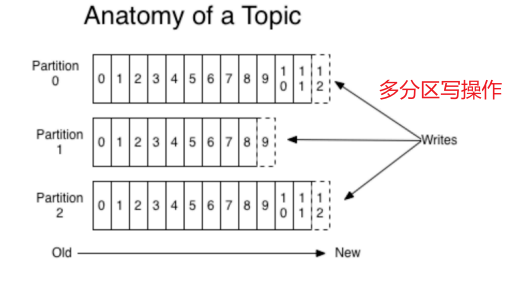
1)分区的概念
通过partition将⼀个topic中的消息分区来存储。
这样的好处有多个:
- 分区存储,可以解决统⼀存储文件过大的问题
- 提高了读写的吞吐量:读和写可以同时在多个分区中进行
2)创建多分区的主题
./kafka-topics.sh --bootstrap-server 124.222.253.33:9092 --create --topic test1 --partitions 2 --replication-factor 1
3.kafka中消息日志文件中保存的内容
-
00000.log: 这个文件中保存的就是消息
-
__consumer_offsets-49:
kafka内部自己创建了__consumer_offsets主题包含了50个分区。这个主题用来存放消费者消费某个主题的偏移量。因为每个消费者都会自己维护着消费的主题的偏移量,也就是说每个消费者会把消费的主题的偏移量自主上报给kafka中的默认主题:consumer_offsets。因此kafka为了提升这个主题的并发性,默认设置了50个分区(可以通过offsets.topic.num.partitions设置)。
- 提交到哪个分区:通过hash函数:hash(consumerGroupId) % __consumer_offsets 主题的分区数
- 提交到该主题中的内容是:key是consumerGroupId+topic+分区号,value就是当前offset的值
-
文件中保存的消息,默认保存7天。七天到后消息会被删除,最后就保留最新的那条数据。
Kafka集群操作
1.搭建kafka集群(三个broker)
- 创建三个server.properties文件
# 0 1 2
broker.id=2
# 9092 9093 9094
listeners=PLAINTEXT://xx.xx.xx.xx(服务器内网IP地址):9094
advertised.listeners=PLAINTEXT://xx.xx.xx.xx(服务器对外IP地址):9094
# kafka-logs kafka-logs-1 kafka-logs-2
log.dir=/usr/local/data/kafka-logs-2
- 通过命令来启动三台broker
./kafka-server-start.sh -daemon ../config/server.properties
./kafka-server-start.sh -daemon ../config/server1.properties
./kafka-server-start.sh -daemon ../config/server2.properties
- 校验是否启动成功
进入到zk中查看/brokers/ids中过是否有三个znode(0,1,2)
2.副本的概念
在创建主题时,除了指明了主题的分区数以外,还指明了副本数 replication-factor参数
如下主题,创建了两分区、三副本(副本对应集群中broker数量)
./kafka-topics.sh --bootstrap-server 124.222.253.33:9092 --create --topic my-replicated-topic --partitions 2 --replication-factor 3
副本是为了为主题中的分区创建多个备份,多个副本在kafka集群的多个broker中,会有⼀个副本作为leader,其他是follower。
查看topic情况:
# 查看topic情况
./kafka-topics.sh --describe --bootstrap-server 124.222.253.33:9092 --topic my-replicated-topic

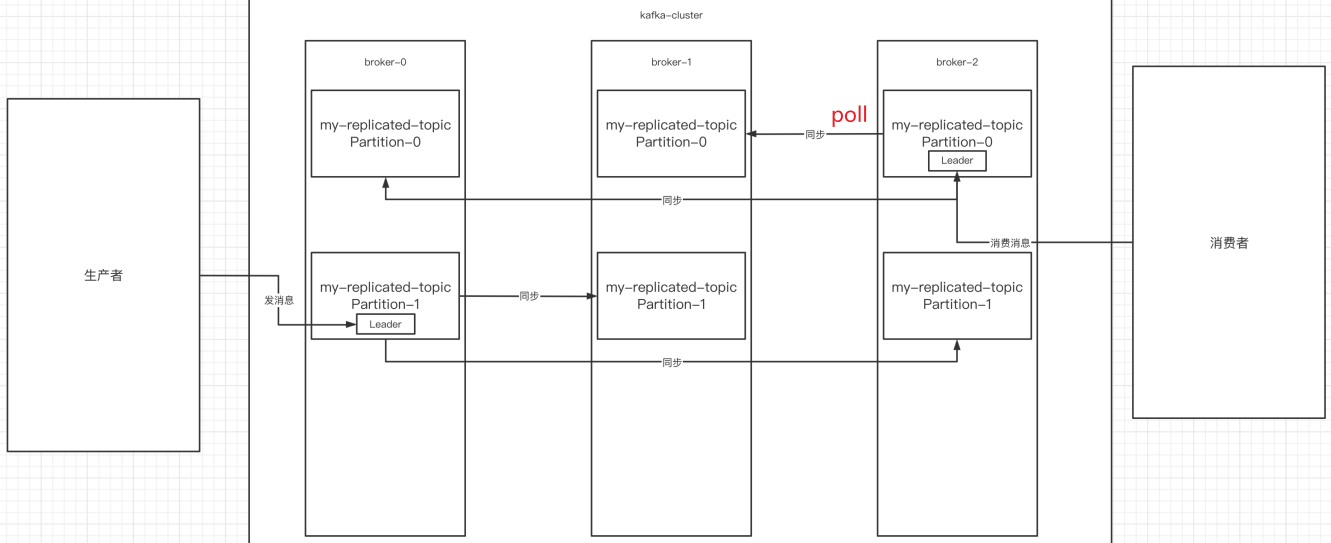
- leader:
kafka的写和读的操作,都发生在leader上。leader负责把数据同步给follower。当leader挂了,经过主从选举,从多个follower中选举产⽣⼀个新的leader(follower通过poll的方式来同步数据)
- follower:
接收leader的同步的数据,leader挂了,参与leader选举
- replicas:
当前副本存在的broker节点
- isr:
可以同步和已同步的broker节点会被存入到isr集合中。如果isr中的broker节点性能较差,会被踢出isr集合。
3.broker、主题、分区、副本
综上broker、主题、分区、副本概念已全部展示:
集群中有多个broker,创建主题时可以指明主题有多个分区(把消息拆分到不同的分区中存储),可以为分区创建多个副本,不同的副本存放在不同的broker⾥。
4.kafka集群消息的发送
./kafka-console-producer.sh --broker-list 124.222.253.33:9092,124.222.253.33:9093,124.222.253.33:9094 --topic my-replicated-topic
5.kafka集群消息的消费
1)普通消费
./kafka-console-consumer.sh --bootstrap-server 124.222.253.33:9092,124.222.253.33:9093,124.222.253.33:9094 --from-beginning --topic my-replicated-topic
2)指定消费组消费
./kafka-console-consumer.sh --bootstrap-server 124.222.253.33:9092,124.222.253.33:9093,124.222.253.33:9094 --from-beginning --consumer-property group.id=testGroup1 --topic my-replicated-topic
6.分区分消费组的集群消费中的细节
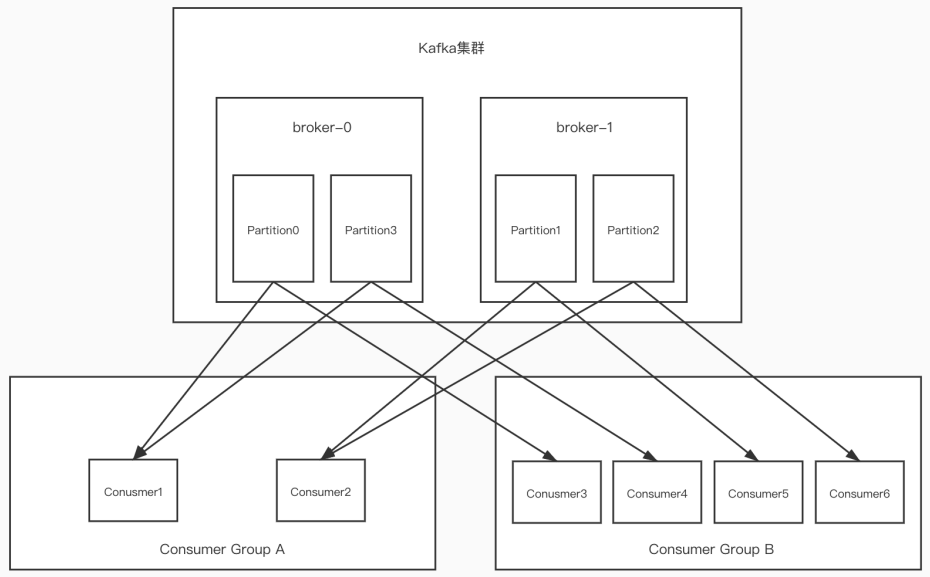
-
⼀个partition只能被⼀个消费组中的⼀个消费者消费,目的是为了保证消费的顺序性,但是多个partion的多个消费者消费的总的顺序性是得不到保证的,那怎么做到消费的总顺序性呢?(Kafka只在
partition的范围内保证消息消费的局部顺序性,不能在同⼀个topic中的多个partition中保证总的消费顺序性。 ⼀个消费者可以消费多个partition。) -
partition的数量决定了消费组中消费者的数量,
建议同⼀个消费组中消费者的数量不要超过partition的数量,否则多的消费者消费不到消息 -
如果消费者挂了,那么会触发rebalance机制,会让其他消费者来消费该分区
相关文章:
kafka基本概念及操作
kafka介绍 Kafka是最初由Linkedin公司开发,是一个分布式、支持分区的(partition)、多副本的 (replica),基于zookeeper协调的分布式消息系统,它的最大的特性就是可以实时的处理大量数据以满足各…...

分享个试卷去笔迹什么软件,几个步骤轻松擦除
试卷擦去笔迹是一项非常关键的技能,它可以帮助你更好地管理你的笔记和文件。不管是小伙伴们想重新测试试卷或者是将试卷输出为电子版,都可以实现的。在这篇文章中,我将分享一些方法和软件,帮助你更好地进行试卷擦除。有需要的小伙…...

ClickHouse(十八):Clickhouse Integration系列表引擎
进入正文前,感谢宝子们订阅专题、点赞、评论、收藏!关注IT贫道,获取高质量博客内容! 🏡个人主页:含各种IT体系技术,IT贫道_Apache Doris,大数据OLAP体系技术栈,Kerberos安全认证-CSDN博客 &…...

日常BUG——代码提交到了本地但是没有push,删除了本地分支如何恢复
😜作 者:是江迪呀✒️本文关键词:日常BUG、BUG、问题分析☀️每日 一言 :存在错误说明你在进步! 一、问题描述 代码在本地提交了,但是没有push到远程,然后删除了本地的分支。想要恢…...
Markdown语法
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 Markdown语法目录 前言1.标题2.文本样式3.列表四.图片5.链接6.目录7.代码片7.表格8.注脚9.注释10.自定义列表11.LaTeX数学公式12.插入甘特图13.插入UML图14.插入Merimaid流程…...

vue3表格,编辑案例
index.vue <script setup> import { onMounted, ref } from "vue"; import Edit from "./components/Edit.vue"; import axios from "axios";// TODO: 列表渲染 const list ref([]); const getList async () > {const res await ax…...
SQL Server Reporting Services 报错:报表服务器无法访问服务帐户的私钥
解决这个问题,有小伙伴提到可以使用命令 exec DeleteEncryptedContent 但这对这边的环境时行不通的,我在【服务账户】的配置和【数据库】的配置中到使用了域账户,试了几次都不行。改成使用内置账户就好了。具体原因还没扒拉(欢迎…...
QT报表Limereport v1.5.35编译及使用
1、编译说明 下载后QT CREATER中打开limereport.pro然后直接编译就可以了。编译后结果如下图: 一次编译可以得到库文件和DEMO执行程序。 2、使用说明 拷贝如下图编译后的lib目录到自己的工程目录中。 release版本的重新命名为librelease. PRO文件中配置 QT …...

互联网发展历程:从中继器口不够到集线器的引入
互联网的发展,就像一场不断演进的技术盛宴,每一步的变革都在推动着我们的世界向前。然而,在网络的早期,一项重要的技术问题曾困扰着人们:当中继器的接口数量不足时,如何连接更多的设备?这时&…...

vue+flask基于知识图谱的抑郁症问答系统
vueflask基于知识图谱的抑郁症问答系统 抑郁症已经成为当今社会刻不容缓需要解决的问题,抑郁症的危害主要有以下几种:1.可导致病人情绪低落:抑郁症的病人长期处于悲观的状态中,感觉不到快乐,总是高兴不起来。2.可导致工…...

操作格子---算法集
问题描述 有 n 个格子,从左到右放成一排,编号为 1-n。 共有 m 次操作,有 3 种操作类型: 1.修改一个格子的权值。 2.求连续一段格子权值和。 3.求连续一段格子的最大值。 对于每个 2、3 操作输出你所求出的结果。 输入格式 第一行 …...

科研绘图chapter1:绘图原则与配色基础
本系列会持续更新,主要参考datawhale的开源课程。详见: https://github.com/datawhalechina/paper-chart-tutorial 文章目录 1.1 科研论文配图的绘制基础1.2 科研论文配图的配色基础1.2.1 配色模式1.2.2 色环配色原则1.3 配色工具/网站 1.1 科研论文配图…...

Linux下grep通配容易混淆的地方
先上一张图: 我希望找到某个版本为8的一个libXXX.8XXX.so ,那么应该怎么写呢? 先看这种写法对不对: 是不是结果出乎你的意料之外? 那么我们来看一下规则: 这里的 "*" 表示匹配前一个字符的零个或多个 于是我们就不难理解了: lib*8*.so 表示 包…...

WebRTC音视频通话-WebRTC本地视频通话使用ossrs服务搭建
iOS开发-ossrs服务WebRTC本地视频通话服务搭建 之前开发中使用到了ossrs,这里记录一下ossrs支持的WebRTC本地服务搭建。 一、ossrs是什么? ossrs是什么呢? SRS(Simple Realtime Server)是一个简单高效的实时视频服务器,支持RTM…...

基于SpringBoot和Freemarker的页面静态化
页面静态化能够缓轻数据库的压力,还能提高页面的并发能力,但是网页静态化是比较适合大规模且相对变化不太频繁的数据。 页面静态化在实际应用中还是比较常见的,比如博客详情页、新闻网站或者文章类网站等等。这类数据变化不频繁比较适合静态…...

给软件增加license
搞计算机的,都知道软件license,版权,著作权等。在商业软件中,常用的模式是一年一付,或者五年一付,即软件的使用权不是无限年限的,在设计软件的时候,开发者就需要考虑这个问题。要实现这个功能&a…...

vue中实现订单支付倒计时
需求 创建订单后15分钟内进行支付,否则订单取消。 实现 思路: 获取当前时间和支付超时时间(在创建时间的基础上增加15分钟即为超时时间,倒计时多久根据自己的实际需求,这里为15分钟),支付超时…...

途乐证券-新手炒股快速入门教程?
随着互联网和金融商场的不断发展,越来越多的人开端重视股票商场。但是对于股市新手来说,怎么快速入门炒股成为了一个困扰他们的难题。以下从多个角度分析,提供一份新手炒股快速入门教程。 1. 了解根本概念 首要,股市新手需求了解…...

【冒泡排序及其优化】
冒泡排序及其优化 冒泡排序核心思想 冒泡排序的核⼼思想就是:两两相邻的元素进⾏⽐较 1题目举例 给出一个倒序数组:arr[10]{9,8,7,6,5,4,3,2,1,0} 请排序按小到大输出 1.1题目分析 这是一个完全倒序的数组,所以确定冒泡排序的趟数࿰…...

TypeScript 泛型的深入解析与基本使用
系列文章目录 文章目录 系列文章目录前言一、泛型的概念二、泛型函数三、泛型类四、泛型接口五、泛型约束总结 前言 泛型是TypeScript中的一个重要概念,它允许我们在定义函数、类或接口时使用参数化类型,增强了代码的灵活性和重用性。本文将深入探讨泛型…...
)
ROS Noetic实战:从bag包里‘抠’出雷达点云和IMU数据的保姆级教程(Ubuntu 20.04)
ROS Noetic实战:从bag包里提取雷达点云和IMU数据的完整指南(Ubuntu 20.04)在机器人开发中,ROS bag文件就像是一个装满珍贵数据的宝箱,而雷达点云和IMU数据则是其中最闪亮的宝石。作为一名长期与ROS打交道的开发者&…...

企业云盘签章技术方案:从数字签名原理到工程落地
背景 电子签章在企业云盘中的落地,不只是一个"上传盖章图片"的功能实现。本质上,它是一套涉及数字签名、PKI基础设施、文档完整性校验的综合性技术方案。本文从技术选型角度,说清楚企业云盘内置签章需要解决哪些问题、主流实现方案…...
)
从单体到事件驱动的生死跃迁:DeepSeek架构委员会认证的6阶段迁移路线图(含风险热力图与回滚触发阈值表)
更多请点击: https://codechina.net 第一章:从单体到事件驱动的生死跃迁:DeepSeek架构委员会认证的6阶段迁移路线图(含风险热力图与回滚触发阈值表) 向事件驱动架构(EDA)演进不是功能迭代&…...

正视孩童情绪波动,耐心陪伴平稳疏导
孩子的情绪就像夏天的天气,前一秒还晴空万里,后一秒可能就乌云密布。面对突如其来的哭闹、发脾气或者闷闷不乐,很多家长会急着“灭火”——要么讲道理,要么直接制止。但其实,情绪波动本身不是问题,它是孩子…...

【C++】零基础入门 · 第 5 节:函数基础
前面四节我们写的代码都集中在 main 函数里。随着程序变复杂,所有逻辑堆在一起会越来越难维护。函数就是用来解决这个问题的——它把一段代码「打包」起来,取个名字,需要的时候调用就行。 1. 为什么需要函数 假设你需要在程序的不同地方打印一行分隔线: cout << &…...

终极音乐解锁指南:3步让加密音乐在任何设备自由播放
终极音乐解锁指南:3步让加密音乐在任何设备自由播放 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址: https:/…...

音乐解锁工具终极指南:3分钟掌握加密音乐解密技巧
音乐解锁工具终极指南:3分钟掌握加密音乐解密技巧 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址: https://g…...

别再死记硬背了!用‘重复局面’这道CSP真题,带你彻底搞懂C++中map容器的使用场景与底层逻辑
从国际象棋到红黑树:用CSP真题解锁C map的底层力量 国际象棋大师卡斯帕罗夫曾说:"棋局如同程序,每一步都是对数据结构的选择。"当我们面对CSP考试中那道看似简单的"重复局面"题时,表面上是考察字符串处理能力…...

量子机器学习安全评估:Q-SafeML原理、实现与工程实践
1. 量子机器学习安全评估:为什么需要一套新方法?量子机器学习(QML)正在从理论走向实践,尤其是在药物发现、材料科学和金融建模等对精度和可靠性要求极高的领域。然而,一个核心挑战也随之而来:我…...

架构师的一天:开会、画图、背锅?真实工作大揭秘
架构师的一天:开会、画图、背锅?真实工作大揭秘 一、写在前面 很多程序员对架构师的工作充满好奇,也充满误解: “架构师是不是整天就画图?” “架构师不用写代码,太爽了吧?” “架构师就是开会的,多轻松” 今天我用一个架构师的一天,带你看看真实的架构师工作是什么…...