大语言模型之一 Attention is all you need ---Transformer
大语言模型已经在很多领域大显身手,其应用包括只能写作、音乐创作、知识问答、聊天、客服、广告文案、论文、新闻、小说创作、润色、会议/文章摘要等等领域。在商业上模型即产品、服务即产品、插件即产品,任何形态的用户可触及的都可以是产品,商业付费一般都是会员制或者按次收费。当前大预言模型的核心结构是基于Transformer。
大模型之所以效果超出预期,一个很重要的原因是模型大到一定程度之后会发生质变,模型的记忆性和泛化性可以兼得。而Transformer可以令模型很大,大到在NLP领域模型可以发生质变,这使得应用得以井喷式出现在各个领域,但是也有一些问题存在需要进一步解决,这类大模型本质上是内容生成,生成的内容因符合如下三原则:
有用的(Helpful);
可信的(Honest);
无害的(Harmless)
仅仅基于Transformer框架的大预言模型(又称pretraining model)还不足以完全满足商业应用要求,业界的发展放到后续博客展开,本篇先谈谈大语言模型的核心架构Transformer。
Transformer 源于谷歌Brain 2017年针对机器翻译任务提出的,《Attention is all you need》论文详细解释了网络结构,在这个之前网络结构多采用RNN、CNN、LSTM、GRU等网络形式,这篇文章提出了一个新的核心结构-Transformer,其针对RNN网络在机器翻译上的弱点重新设计的结构,传统的Encoder-Decoder架构在建模过程中,下一个时刻的计算过程会依赖于上一个时刻的输出,而这种固有的属性就限制了传统的Encoder-Decoder模型就不能以并行的方式进行计算。
本文源码已托管到 github link地址
模型结构介绍
谷歌提出的Transformer也是包括Encoder和decoder两个部分,只是这两个部分核心是Attention结构,而非CNN、LSTM、GRU等这些结构。
对于Encoder,包含两层,一个self-attention层和一个前馈神经网络,self-attention能帮助当前节点不仅仅只关注当前的词,从而能获取到上下文的语义。Decoder也包含encoder提到的两层网络,但是在这两层中间还有一层attention层,帮助当前节点获取到当前需要关注的重点内容。
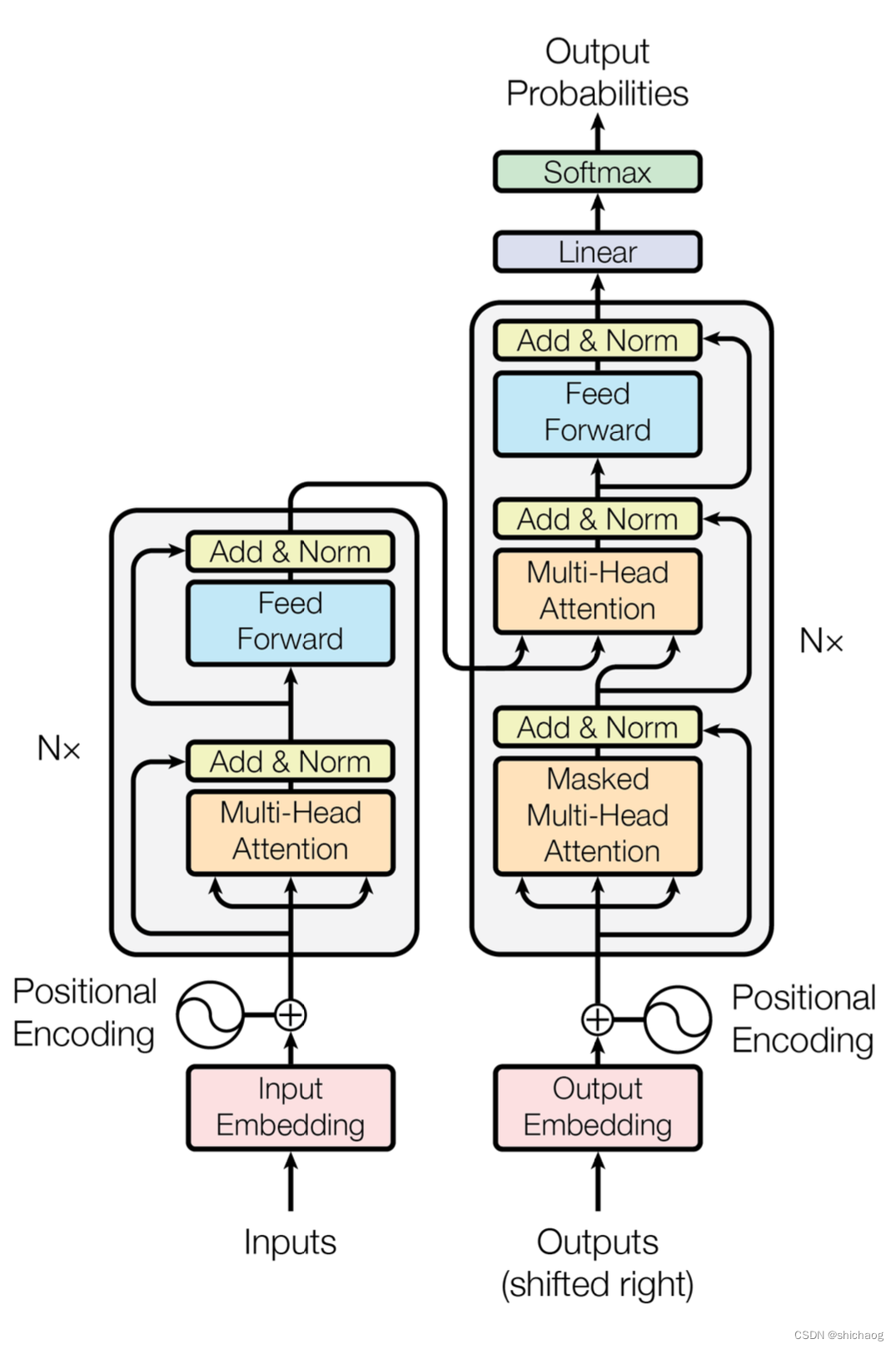
Transformer 模型架构
模型需要对输入的数据进行一个embedding操作(图中红色框框),Attention虽然可以提取出关注的信息,但是没有时序信息,而Position Encoding正是将时序信息转为位置信息来实现的,enmbedding结束之后加上位置编码,然后再输入到encoder层,self-attention处理完数据后把数据送给前馈神经网络(蓝色Feed Forward),前馈神经网络的计算可以并行,得到的输出会输入到下一个encoder。
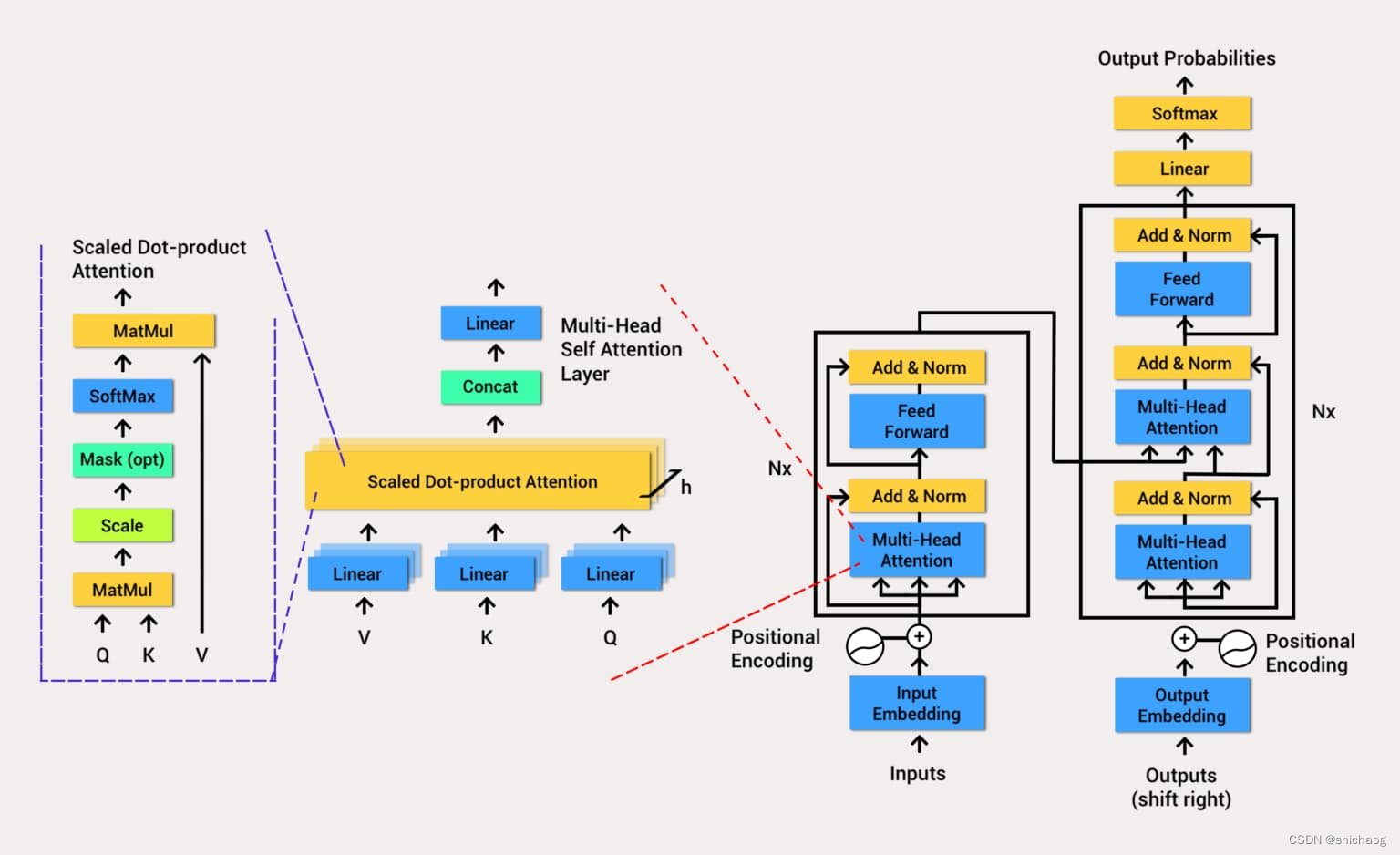
- Encoder 编码器
- Multi-Head Attention
- 多头自注意力机制,可以通过输入信息并行计算出查询-键-值(Query-Key-Value),来让后续的网络使用context来知道当前运算需要关注哪些信息。注意这里的计算QKV的矩阵也是网络参数的一部分,通过训练可以让网络的注意力更有效且集中。因为NLP领域都是时序上因果的,因而改进模型采用了因果多头自注意力模型。
- Add 残差连接
- 这里主要残差连接的主要作用是利用恒等映射来训练更深层的网络(输入和输出恒等),多头注意力和层归一化,前馈神经网络和层归一化,两部分均采用了残差连接。
- Norm 层归一化
- Layer Normalization 的作用是把神经网络中以样本维度为一层来进行归一化运算,以起到加快训练速度,加速收敛的作用。新的改进都是将Layer Normalization放在前面而非后面。
- Feed Forward 前馈神经网络
- 将通过了注意力层之后通过加权机制提取出的所关注信息,根据关注的信息在语义空间中做转换。
- 因此MLP将Multi-Head Attention得到的向量再投影到一个更大的空间(论文里将空间放大了4倍)在那个大空间里可以更方便地提取需要的信息(使用Relu激活函数),最后再投影回token向量原来的空间。
- Multi-Head Attention
- Decoder
- 和 Encoder基本一样,组成分为Masked Multi-Head Attention,Masked Encoder-Decoder Attention(这一层就是连接编码器和解码器的注意力层,后续由于GPT只用了编码器,因此删除了这一层。)和Feed Forward神经网络,三个部分的每一个部分,都有一个残差连接,后接一个Layer Normalization。下面介绍Decoder的Masked Self-Attention和Encoder-Decoder Attention两部分,
- Masked Multi-Head Attention
- Self-Attention的机制有一个问题,在训练过程中的完整标注数据都会暴露在 Decoder 中,这显然是不对的,我们需要对 Decoder 的输入进行一些处理,该处理被称为 Mask,将数据有选择的暴露给Decoder(在GPT中相当于遮住了后面的所有数据,由网络依次生成)。
- Multi-Head Attention
- Add 残差连接
- Norm 层归一化
- Feed Forward 前馈神经网络
- 线性层和Softmax
经过编码器和解码器最后是一层全连接层和SoftMax( 后面改进的大语言模型采用Gaussian Error Linear Units function)。线性层是一个简单的全连接的神经网络,它将解码器堆栈生成的向量投影到一个更大的向量,称为logits向量。Softmax层(Softmax 是用于多类分类问题的激活函数)将向量转换为概率(全部为正值,总和为1.0)。选择概率最高的单元,并生成与其关联的单词作为此时间步的输出。
模型Pytorch实现
红色部分input&output embedding。
class Embedder(nn.Module):def __init__(self, vocab_size, d_model):super().__init__()self.embed = nn.Embedding(vocab_size, d_model)def forward(self, x):#[123, 0, 23, 5] -> [[..512..], [...512...], ...]return self.embed(x)
位置编码
如下代码所示,其值会和上面的embedding相加后输入编解码模块。
class PositionalEncoder(nn.Module):def __init__(self, d_model: int, max_seq_len: int = 80):super().__init__()self.d_model = d_model#Create constant positional encoding matrixpos_matrix = torch.zeros(max_seq_len, d_model)# for pos in range(max_seq_len):# for i in range(0, d_model, 2):# pe_matrix[pos, i] = math.sin(pos/1000**(2*i/d_model))# pe_matrix[pos, i+1] = math.cos(pos/1000**(2*i/d_model))## pos_matrix = pe_matrix.unsqueeze(0) # Add one dimension for batch sizeden = torch.exp(-torch.arange(0, d_model, 2) * math.log(1000) / d_model)pos = torch.arange(0, max_seq_len).reshape(max_seq_len, 1)pos_matrix[:, 1::2] = torch.cos(pos * den)pos_matrix[:, 0::2] = torch.sin(pos * den)pos_matrix = pos_matrix.unsqueeze(0)self.register_buffer('pe', pos_matrix) #Register as persistent bufferdef forward(self, x):# x is a sentence after embedding with dim (batch, number of words, vector dimension)seq_len = x.size()[1]x = x + self.pe[:, :seq_len]return x
self-attention
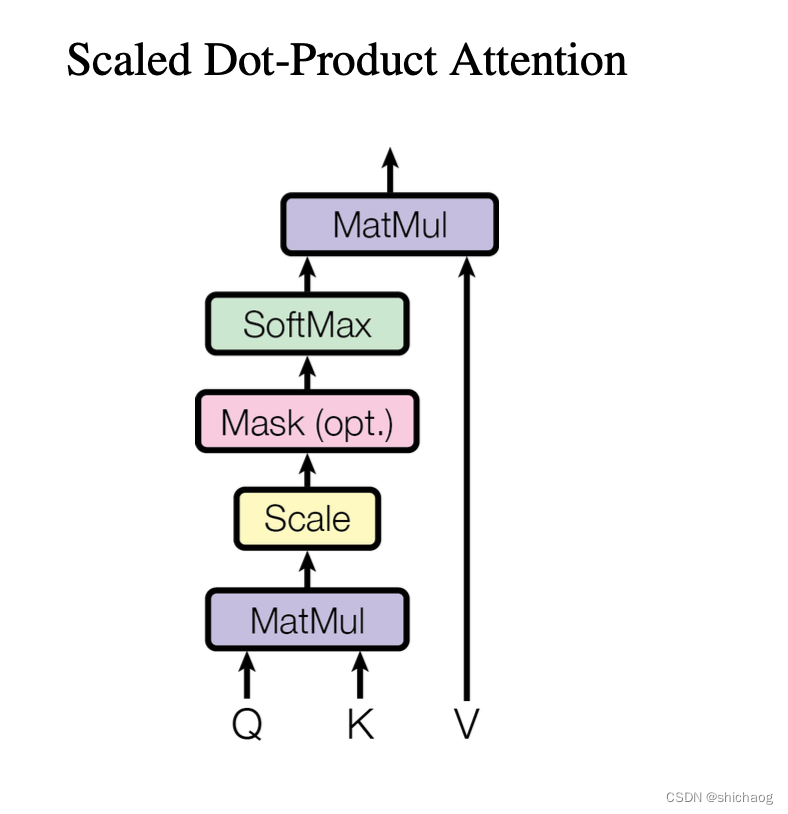
## Scaled Dot-Product Attention layer
def scaled_dot_product_attention(q, k, v, mask=None, dropout=None):# Shape of q and k are the same, both are (batch_size, seq_len, d_k)# Shape of v is (batch_size, seq_len, d_v)attention_scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(q.shape[-1]) # size (bath_size, seq_len, d_k)# Apply mask to scores# <pad>if mask is not None:attention_scores = attention_scores.masked_fill(mask == 0, value=-1e9)# Softmax along the last dimensionattention_weights = F.softmax(attention_scores, dim=-1)if dropout is not None:attention_weights = dropout(attention_weights)output = torch.matmul(attention_weights, v)return output
Multi-Head Attention layer
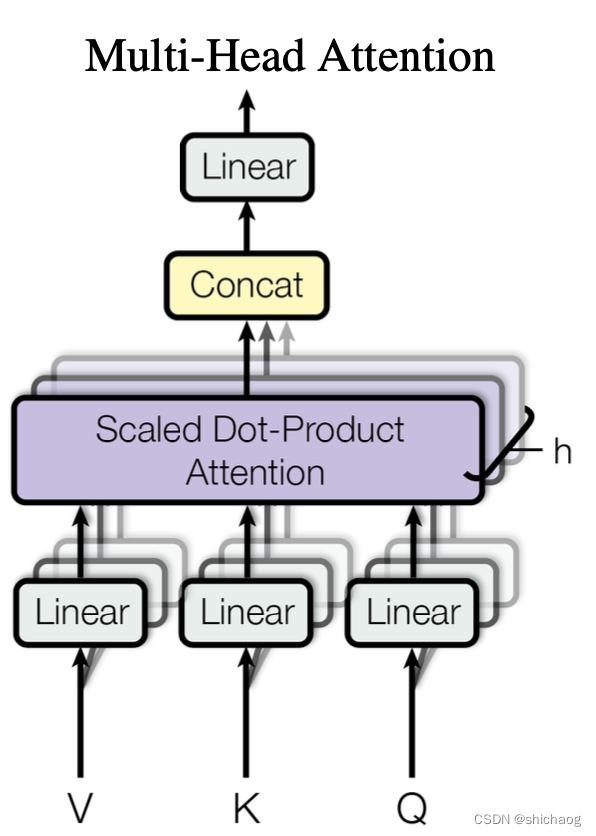
# Multi-Head Attention layer
class MultiHeadAttention(nn.Module):def __init__(self, n_heads, d_model, dropout=0.1):super().__init__()self.n_heads = n_headsself.d_model = d_modelself.d_k = self.d_v = d_model // n_heads# self attention linear layers#Linear layers for q, k, v vectors generation in different headsself.q_linear_layers = []self.k_linear_layers = []self.v_linear_layers = []for i in range(n_heads):self.q_linear_layers.append(nn.Linear(d_model, self.d_k))self.k_linear_layers.append(nn.Linear(d_model, self.d_k))self.v_linear_layers.append(nn.Linear(d_model, self.d_v))self.dropout = nn.Dropout(dropout)self.out = nn.Linear(n_heads*self.d_v, d_model)def forward(self, q, k, v, mask=None):multi_head_attention_outputs = []for q_linear, k_linear, v_linear in zip(self.q_linear_layers,self.k_linear_layers,self.v_linear_layers):new_q = q_linear(q) # size: (batch_size, seq_len, d_k)new_k = q_linear(k) # size: (batch_size, seq_len, d_k)new_v = q_linear(v) # size: (batch_size, seq_len, d_v)# Scaled Dot-Product attentionhead_v = scaled_dot_product_attention(new_q, new_k, new_v, mask, self.dropout) # (batch_size, seq_len,multi_head_attention_outputs.append(head_v)# Concat# import pdb; pdb.set_trace()concat = torch.cat(multi_head_attention_outputs, -1) # (batch_size, seq_len, n_heads*d_v)# Linear layer to recover to original shapoutput = self.out(concat) # (batch_size, seq_len, d_model)return output
翻译实例
这里github链接
以英语到法语的翻译实例展示Transformer这篇文章所述网络模型结构和其用法。Python安装版本信息如下:
Python 3.7.16
torch==2.0.1
torchdata==0.6.1
torchtext==0.15.2
spacy==3.6.0
numpy==1.25.2
pandas
times
portalocker==2.7.0
数据处理
分词和词映射为张量化的数字
使用torchtext提供的工具比较方便创建一个便于处理迭代的语音翻译模型的数据集,首先是从原始文本分词、构建词汇表以及标记为数字化张量。尽管torchtext提供了基本的英语分词支持,但是这里的翻译中除了英语还有法语,因而使用了分词python库Spacy。
首先是创建环境,接下来是下载英语和法语的分词器,因为这是一个很小的例子,因而使用新闻的spacy语言处理模型即可:
#python3 -m spacy download en_core_web_sm
#python3 -m spacy download fr_core_news_sm
如下图所示:
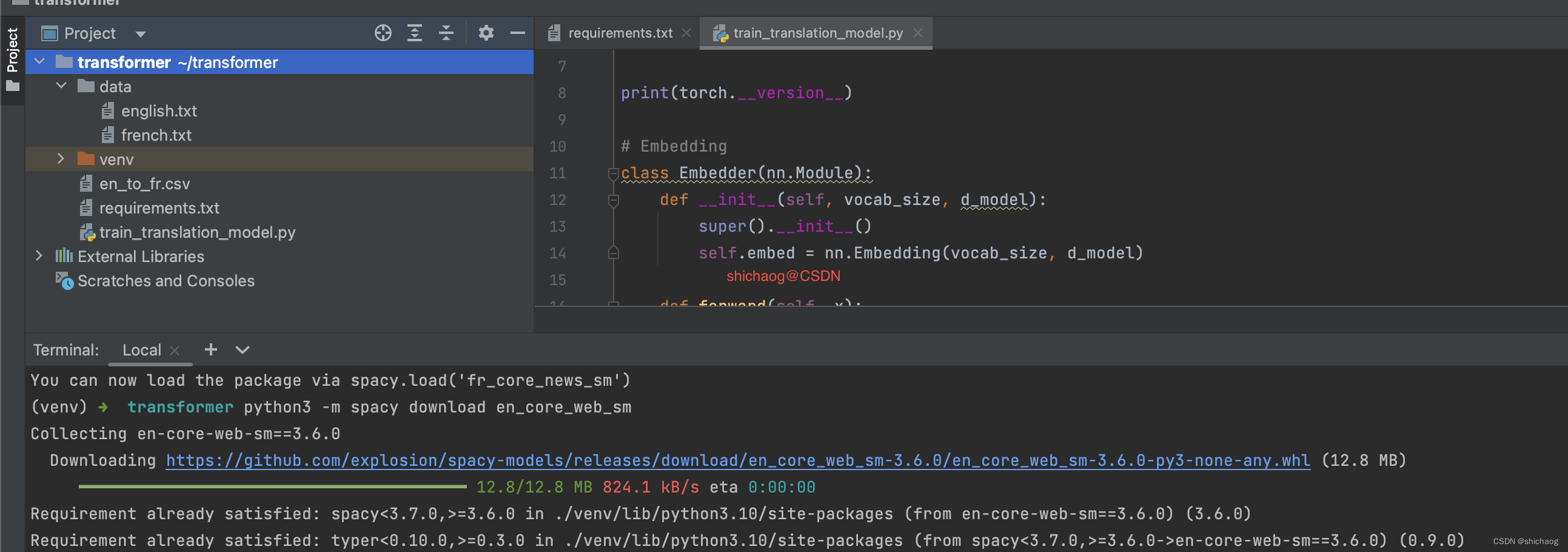
接下来是将数据进行分词,然后将词映射为张量化的数字
#Data processing
import spacy
from torchtext.data.utils import get_tokenizer
from collections import Counter
import io
from torchtext.vocab import vocabsrc_data_path = 'data/english.txt'
trg_data_path = 'data/french.txt'en_tokenizer = get_tokenizer('spacy', language='en_core_web_sm')
fr_tokenizer = get_tokenizer('spacy', language='fr_core_news_sm')def build_vocab(filepath, tokenizer):counter = Counter()with io.open(filepath, encoding="utf8") as f:for string_ in f:counter.update(tokenizer(string_))return vocab(counter, specials=['<unk>', '<pad>', '<bos>', '<eos>'])en_vocab = build_vocab(src_data_path, en_tokenizer)
fr_vocab = build_vocab(trg_data_path, fr_tokenizer)def data_process(src_path, trg_path):raw_en_iter = iter(io.open(src_path, encoding="utf8"))raw_fr_iter = iter(io.open(trg_path, encoding="utf8"))data = []for (raw_en, raw_fr) in zip (raw_en_iter, raw_fr_iter):en_tensor_ = torch.tensor([en_vocab[token] for token in en_tokenizer(raw_en)], dtype=torch.long)fr_tensor_ = torch.tensor([fr_vocab[token] for token in fr_tokenizer(raw_fr)], dtype= torch.long)data.append((en_tensor_, fr_tensor_))return datatrain_data = data_process(src_data_path, trg_data_path)
DataLoader
DataLoader是torch.utils.data提供的方法,其将数据集和采样器组合在一起,为给定的数据集提供可迭代的对象。DataLoader 支持单进程或多进程加载、自定义加载顺序和可选的自动批处理(合并)和内存固定的映射式和可迭代式数据集。
collate_fn(可选),它将样本列表合并以形成张量的小批量。在使用映射样式数据集的批量加载时使用。
#Train transformer
d_model= 512
n_heads = 8
N = 6
src_vocab_size = len(en_vocab.vocab)
trg_vocab_size = len(fr_vocab.vocab)BATH_SIZE = 32
PAD_IDX = en_vocab['<pad>']
BOS_IDX = en_vocab['<bos>']
EOS_IDX = en_vocab['<eos>']from torch.nn.utils.rnn import pad_sequence
from torch.utils.data import DataLoaderdef generate_batch(data_batch):en_batch, fr_batch = [], []for (en_item, fr_item) in data_batch:en_batch.append(torch.cat([torch.tensor([BOS_IDX]), en_item, torch.tensor([EOS_IDX])], dim=0))fr_batch.append(torch.cat([torch.tensor([BOS_IDX]), fr_item, torch.tensor([EOS_IDX])], dim=0))en_batch = pad_sequence(en_batch, padding_value=PAD_IDX)fr_batch = pad_sequence(fr_batch, padding_value=PAD_IDX)return en_batch, fr_batchtrain_iter = DataLoader(train_data, batch_size=BATH_SIZE, shuffle=True, collate_fn=generate_batch)
训练的输出如下:

相关文章:
大语言模型之一 Attention is all you need ---Transformer
大语言模型已经在很多领域大显身手,其应用包括只能写作、音乐创作、知识问答、聊天、客服、广告文案、论文、新闻、小说创作、润色、会议/文章摘要等等领域。在商业上模型即产品、服务即产品、插件即产品,任何形态的用户可触及的都可以是产品,…...

数字鸿沟,让气候脆弱者更脆弱
随着科技的飞速发展,数字化正在改变我们的生活方式和社会结构。然而,数字鸿沟(Digital Divide)这一长期存在的问题,却在某些方面加剧了社会的不平等现象。在此,我们将探讨数字鸿沟如何加剧了气候脆弱者的脆…...

Tomcat 部署优化
Tomcat Tomcat 开放源代码web应用服务器,是由java代码开发的 tomcat就是处理动态请求和基于java代码的页面开发 可以在html当中写入java代码,tomcat可以解析html页面当中的iava,执行动态请求 动态页面机制有问题:不对tomcat进行优…...
Django框架-使用celery(一):django使用celery的通用配置,不受版本影响
目录 一、依赖包情况 二、项目目录结构 2.1、怎么将django的应用创建到apps包 三、celery的配置 2.1、celery_task/celery.py 2.2、celery_task/async_task.py 2.3、celery_task/scheduler_task.py 2.4、utils/check_task.py 四、apps/user中配置相关处理视图 4.1、基本…...

nvue语法与vue的部分区别
文章目录 1、仅支持flex布局2、字体样式3、高度问题 1、仅支持flex布局 仅支持flex布局。而且默认的是 flex-direction: column; 2、字体样式 字体的样式,必须要写在 text 标签内,才能生效 错误示例: <!-- 错误示例 --> <div cl…...

Java 开发工具 IntelliJ IDEA
1. IntelliJ IDEA 简介 IntelliJ IDEA 是一款出色的 Java 集成开发环境(IDE),提供了丰富的功能和工具,支持多种语言和框架的开发,如 Java、Kotlin、Scala、 Android、Spring、Hibernate 等。IntelliJ IDEA 专注于提高…...

将vsCode 打开的多个文件分行(栏)排列,实现全部显示,便于切换文件
目录 1. 前言 2. 设置VsCode 多文件分行(栏)排列显示 1. 前言 主流编程IDE几乎都有排列切换选择所要查看的文件功能,如下为Visual Studio 2022的该功能界面: 图 1 图 2 当在Visual Studio 2022打开很多文件时,可以按照图1、图2所示找到自…...
java中的同步工具类CountDownLatch
这篇文章主要讲解java中一个比较常用的同步工具类CountDownLatch,不管是在工作还是面试中都比较常见。我们将通过案例来进行讲解分析。 一、定义 CountDownLatch的作用很简单,就是一个或者一组线程在开始执行操作之前,必须要等到其他线程执…...

路由器和交换机的区别
交换机和路由器的区别 交换机实现局域网内点对点通信,路由器实现收集发散,相当于一个猎头实现的中介的功能 路由器属于网络层,可以处理TCP/IP协议,通过IP地址寻址;交换机属于中继层,通过MAC地址寻址(列表)…...
FreeRTOS(动态内存管理)
资料来源于硬件家园:资料汇总 - FreeRTOS实时操作系统课程(多任务管理) 目录 一、动态内存管理介绍 1、heap_1 2、heap_2 3、heap_3 4、heap_4 5、heap_5 二、动态内存总结与应用 1、heap_1 2、heap_4 3、heap_5 三、内存管理编程测试 1、heap_4 2、h…...

IntelliJ IDEA(简称Idea) 基本常用设置及Maven部署---详细介绍
一,Idea是什么? 前言: 众所周知,现在有许多编译工具,如eclipse,pathon, 今天所要学的Idea编译工具 Idea是JetBrains公司开发的一款强大的集成开发环境(IDE),主要用于Java…...

【LeetCode每日一题】——128.最长连续序列
文章目录 一【题目类别】二【题目难度】三【题目编号】四【题目描述】五【题目示例】六【题目提示】七【解题思路】八【时间频度】九【代码实现】十【提交结果】 一【题目类别】 哈希表 二【题目难度】 中等 三【题目编号】 128.最长连续序列 四【题目描述】 给定一个未…...
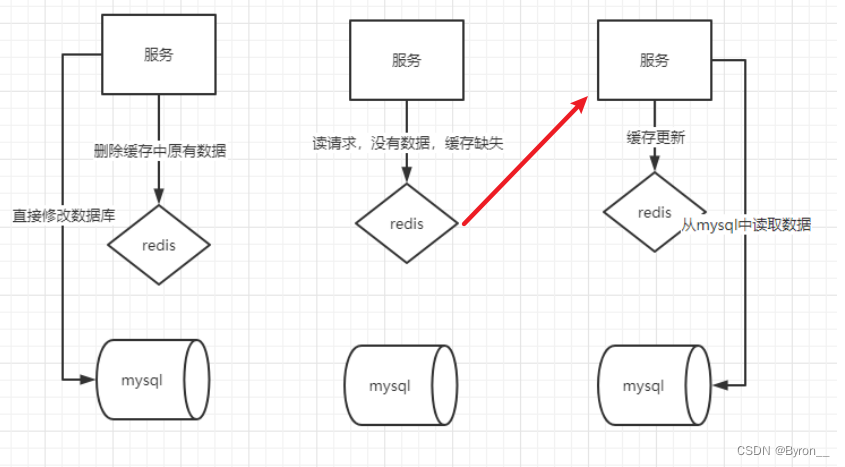
Redis_缓存1_缓存类型
14.redis缓存 14.1简介 穿透型缓存: 缓存与后端数据交互在一起,对服务端的调用隐藏细节。如果从缓存中可以读到数据,就直接返回,如果读不到,就到数据库中去读取,从数据库中读到数据,也是先更…...

模拟 枚举
分享牛客算法基础精选题单题目打卡!!! 目录 字符串的展开 多项式输出 机器翻译 : 铺地毯 : [NOIP2016]回文日期 字符串的展开 原题链接 : 字符串的展开 思路 : 模拟 代码 : #include<iostream> #include<cstring> #include<algorithm> using na…...
【实操】2023年npm组件库的创建发布流程
2022年的实践为基础,2023年我再建一个组件库【ZUI】。步骤回顾: 2022年的npm组件包的发布删除教程_npm i ant-design/pro-components 怎么删除_啥咕啦呛的博客-CSDN博客 1.在gitee上创建一个项目,相信你是会的 2.创建初始化项目,看吧&#…...

缓存设计的典型方案
缓存设计的典型方案 在使用缓存系统的时候,还需要考虑缓存设计的问题,重点在于缓存失效时的处理和如何更新缓存。 缓存失效是在使用缓存时不得不面对的问题。在业务开发中,缓存失效时由于找不到整个数据,一般会出于容错考虑&#…...

SQL笔记
最近的工作对SQL的应用程度较高,而且写的sql类型基本没怎么涉及过,把用到的几个关键字记录下。 使用环境:达梦数据库 达梦数据库有个特点,他有一个叫模式的说法,在图形化工具里直接点击创建查询窗口,不用像…...

UHPC的疲劳计算——兼论ModelCode2010的适用性
文章目录 0. 背景1、结论及概述2、MC10对于SN曲线的调整(囊括NC、HPC、UHPC)2.1 疲劳失效曲面的构建2.2 新模型的验证 3、MC10对于疲劳设计强度的调整及其背后的原因4. 结语 0. 背景 今年年初,有一位用UHPC做混凝土塔筒的同行告诉我…...

关于elementui的input的autocomplete的使用
项目中需要实现搜索框搜索时能自动提示可选项的功能,elementui的input组件有已经封装好的el-autocomplete可以使用,但是在使用中发现一些问题,记录一下 基础使用 // html部分 <el-autocompletev-model"name":fetch-suggestion…...

即然利用反射机制可以破坏单例模式,有什么方法避免呢?
私有构造方法中添加防止多次实例化的逻辑:在单例类的私有构造方法中,可以添加逻辑来检查是否已经存在实例,如果存在则抛出异常或返回已有的实例。这样即使通过反射创建了新的实例,也能在构造方法中进行拦截。 使用枚举实现单例&a…...

如何快速释放微信空间:CleanMyWechat终极清理指南
如何快速释放微信空间:CleanMyWechat终极清理指南 【免费下载链接】CleanMyWechat 自动删除 PC 端微信缓存数据,包括从所有聊天中自动下载的大量文件、视频、图片等数据内容,解放你的空间。 项目地址: https://gitcode.com/gh_mirrors/cl/C…...

打造你的专属Minecraft体验:NightX Client深度解析与实用指南
打造你的专属Minecraft体验:NightX Client深度解析与实用指南 【免费下载链接】NightX-Client Minecraft Forge 1.8.9 hacked client, Based on LiquidBounce 项目地址: https://gitcode.com/gh_mirrors/ni/NightX-Client 你是否曾想过在Minecraft中拥有超越…...

告别VNC客户端!用noVNC在浏览器里远程操控CentOS桌面,附Xshell/Xftp联动技巧
浏览器原生远程桌面方案:noVNC与终端工具链的高效整合指南每次连接远程服务器都要切换多个客户端的日子该结束了。想象一下这样的场景:清晨的咖啡馆里,你只需打开浏览器就能直接访问CentOS的图形界面,同时在一个标签页里用Xshell执…...

告别网课低效循环:这款开源工具如何让学习时间减半
告别网课低效循环:这款开源工具如何让学习时间减半 【免费下载链接】mooc-assistant 慕课助手 浏览器插件(Chrome/Firefox/Opera) 项目地址: https://gitcode.com/gh_mirrors/mo/mooc-assistant 你是否曾在深夜对着电脑屏幕,一遍遍重复着相同的手…...

动力系统与机器学习融合:破解Sabra壳模型自相似爆破的非唯一性
1. 项目概述:当湍流奇点遇上动力系统与机器学习在流体动力学的世界里,有限时间奇点(Blowup)的形成一直是个迷人的谜题。想象一下,一个初始光滑的流体运动,在有限时间内,其速度或涡量等物理量突然…...

创新方案:DouZero_For_HappyDouDiZhu - AI智能斗地主实战指南
创新方案:DouZero_For_HappyDouDiZhu - AI智能斗地主实战指南 【免费下载链接】DouZero_For_HappyDouDiZhu 基于DouZero定制AI实战欢乐斗地主 项目地址: https://gitcode.com/gh_mirrors/do/DouZero_For_HappyDouDiZhu 你是否曾想过在斗地主游戏中拥有一个永…...

Hotkey Detective终极指南:3分钟定位Windows热键冲突的完整解决方案
Hotkey Detective终极指南:3分钟定位Windows热键冲突的完整解决方案 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective …...

3步掌握终极AMD Ryzen调试工具:免费解锁硬件深层控制
3步掌握终极AMD Ryzen调试工具:免费解锁硬件深层控制 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://git…...

色度下采样:揭秘那个让 4K 视频“飞“起来的隐形魔法
一、一个让我"开窍"的报纸印刷故事 我大学时学过一段时间平面设计,去一家报社实习,亲眼见识过报纸印刷的全过程。报社的印刷流程让我印象特别深刻——他们印彩色版面时,黑色文字部分的网点密度极高(每英寸 150 线以上&a…...

实时控制系统中VoU传输优化框架的设计与实践
1. 实时控制系统的网络传输挑战 在工业物联网和网络化控制系统中,传感器、控制器和执行器之间的实时数据传输质量直接影响整个系统的控制性能。传统控制系统通常假设通信链路是理想的——零延迟、无丢包且带宽无限。然而在实际无线多跳网络环境中,这种假…...